Modularity and localisation of the neural systems of speech, gesture and cognition
Tom Campbell *, Helsinki Collegium for Advanced Studies, University of Helsinki
By way of introduction to this section of the volume, to understand Fodorian modularity, the brain, by analogy, can be compared to a stack-up hi-fi system, within which each modular component serves a different function. In this volume, Petri Ylikoski comments upon how mental processes may be decomposable into such functionally separate modules, though also argues such modules are not necessarily localisable.
Evidence from auditory investigations of non-human and human primate brains is supportive of neurally distinct processing of 1) where an auditory onset comes from and 2) what that sound is. However, an auxiliary assumption appears unavoidable: a diffuse process, which cannot be localised, subsequently integrates what and where information within the brain. In this volume, Natalya Sukhova extends these concepts of what and where streams in a manner which can be related to the processing of both speech and gesture within the brain.
Further, neuroimaging evidence also indicates that during the perception of speech sound, a functionally distinct anatomically localisable system is activated, which determines how sound is processed. Whilst the what system is arguably activated by all sounds, this how system is activated only when the brain has learned to perceive that sound as speech. This how stream implicates the left posterior superior temporal sulcus and projects to frontal areas classically involved in language production, in a manner that can be related to a speech module. In the hi-fi analogy, for a record on the what system to play as speech rather than non-speech, the amplifier of the how system needs to be on.
Chomsky considers speech as a manifestation of the human mind, the roots of which reside within innate knowledge in the form of modules and mental representations (Chomsky 1984, 1995). The learning of a specific language occurs by the tuning of the Universal Grammar to the specific features of the language environment. Chomskian modules thus are assumed to be innate representations of the rules of language, with which a child hypothesises about the structure of the language and learns by checking these hypotheses against perceptual data. Accordingly, Chomskian modules are assumed to be representational.
The focus of this volume, however, is not about Chomskian modularity but Fodorian modularity. Fodorian modularity assumes that modules are not representational, but rather are mechanisms characterised by their function rather than their propositional content (Fodor 1983).
By way of introduction, consider the elucidation of Fodorian modules as described by Ellis and Young's (1988) analogy of the brain to an old stack-up hi-fi system, within which each modular component serves a different function. These stack-up systems consisted of separate and separable record decks, cassette decks, amplifiers, headphones and separate and separable speakers. When there was a malfunction in such a stack-up system, it was easy to trace the fault, if the malfunction was limited to just one part of the hi-fi system and the other components remain operative. So if the cassette that you were playing did not sound as good as usual, you might try playing a record instead to determine if the problem was with the cassette deck or the amplifier or later. If neither cassette nor record played well, then you might try listening through headphones instead of speakers to identify if the problem was with the speakers or the amplifier.
The human brain is also susceptible to malfunction, as can occur following a cerebrovascular accident, when the damage can spare certain functions. In an analogous way to when a cassette deck fails and the record deck's function remains intact, a prosopagnosic patient can have a deficit in recognising human faces, whilst having intact object recognition. One instance of such a prosopagnosic was a farmer who could not recognise his wife, yet could recognise his cows. Conversely, an agnosic patient can have a deficit in object recognition, whilst still having intact face recognition. Like the function of the record deck and the cassette player, the brain mechanisms associated with face recognition and object recognition are accordingly functionally speaking "modular" at some level (for a review of the aphasia literature, see Ellis & Young 1988).
The advantage of the old stack-up hi-fi systems was that when a new better record deck came on the market, then it was easy to disconnect the old record deck from the amplifier and replace the old deck with the new record deck. The modular design of such a system thus permits the rapid improvement of the performance of the hi-fi without substantial reorganisation of the rest of the wiring to the other components. Similarly, the sudden development of functional modules, such as a better speech module (Lieberman & Mattingly 1985) as could be brought about by a genetic change, might permit new activities that could immediately improve the chances of survival (e.g., speech). The possibility for such sudden developments of new modules may accord with punctuated equilibrium accounts of human evolution.
However, one of the many differences between a stack-up hi-fi system and the human brain is the readiness with which the functional modules can be localised. Two patients with lesions at different anatomical loci may have the same functional problem, e.g., prosopagnosia. Possibilities include that pathways or "streams" of brain areas are associated with a given function, and that damage to multiple points in that stream may be critical in disrupting that function. Alternatively, the brain process associated with the intact function may not be localisable and instead be connected to a diffuse process. In this volume, Ylikoski addresses these issues.
Also within this volume, Sukhova's article offers a cognitive perspective upon the interaction between gestural movements and the units of speech. Central to this perspective is the concept of a speech act, an act which a speaker performs when making an utterance. That is, the meaning of words depends upon their function with respect to the speaker, the listener and their situation. Thus words alone do not have a simple fixed meaning. Speech acts have an intended function. By way of example, the speech act of asking someone to mow the lawn, whilst having a slightly different function, is just as much an act as the action of mowing the lawn. Whether the listener performs the act intended by the speaker and mows the lawn or not depends on the speaker, the listener and their situation. Gestures, from pointing to smiling, can supplement such a spoken speech act in a manner that is not completely semantically redundant with the spoken speech act, yet that large numbers of people can communicate through sign offers a case that gestures can also serve as speech acts in their own right. Sukhova's perspective thus aligns with a view that gesture is communication.
Sukhova's perspective assumes that the perception of spoken and gestural speech acts is the converse of the production of those acts. Accordingly, perception passes through the same stages as production, yet in reverse. If this assumption is made, the more readily-observed linguistic data upon the production of spoken and gestural speech acts could offer insights into the less readily-observed process of the perception of speech acts.
Sukhova's functional analysis identifies four planes that seem to be necessarily stage-like phases in the production of an utterance:
- Plane of orientation upon which develops the motive to speak that develops into an idea, which, in turn, results in an internal or external utterance. Accordingly, upon this plane, the aim of the utterance is set. This aim is derived from this motive and forms the meaning of the internal or external utterance, the speech act, as can be constituted by either speech or gestural units.
- Plane of utterance upon which the symbolic representation of either speech or gesture is activated. It is postulated that whilst on a deep representational level speech and gesture are two sides of the same coin, meanings of speech units are transmitted via linguistic formats independently from gestural units, which are transmitted directly. The channels of transmission are independent and arguably implicate distinct neural systems.
- Plane of realisation upon which the transmitted representations are then realised as speech signals and gestural movements.
- Plane of control upon which the realised utterance is compared with the model of the utterance and corrected as necessary.
The reported data centre upon the analysis of monologue speech acts with an onus upon prosodio-kinetic complexes, which consist of a sequence of gestural movements coupled with the prosodic nucleus of an utterance. Sukhova tested the hypothesis that prosodio-kinetic complexes are instigated from the outset, upon the plane of orientation. The methodology involved the classification of utterances of two different forms of speech act with different intended functions (i.e., different aims upon the plane of utterance were classified):
- Statements that render new information available to the listener.
- Statement-estimations that express the speaker's attitude toward a state-of-affairs (people, situation, action, event), whilst also conveying new information about that state-of-affairs.
The proportion of these two kinds of utterances was identified that were accompanied by movements of different parts of the body. It appears from the data that there was a greater proportion of statements that were accompanied by hand movements, whilst there was a greater proportion of statement estimations that were accompanied by body movements. The point is that the gestures used varied with the class of utterance. Accordingly, the data are consistent with the hypothesis that the inter-relation of gestural and verbal parts of an utterance starts when the aim of that utterance is set up. That is, gestural and verbal aspects of an utterance become related when the intended function of that speech act is set up. This inter-relation may be regarded as occurring from the outset, upon the earliest plane, the plane of orientation.
However, Sukhova's article argues that upon the second plane, the plane of utterance, the activation of representation of the utterance runs a separate independent course for speech and gestural units. This independent course is interpreted in terms of the framework offered by Bobrova and Bobrov (2005), who seem to adopt the two pathway "what and where" doctrine of the visual cortex. That is, bilaterally a ventral stream runs from the primary visual cortex to the temporal lobe - the what system, which is assumed to mediate form vision - whilst a dorsal stream runs to the parietal cortex, which has been assumed to mediate spatial vision and is thus termed the where system (see Figure 1; for a review, see Mishkin, Ungeleider & Macko 1983; for an alternative perspective, see Zeki 1993:186-196). However, Sukhova's framework assumes that the what and where systems in the left and right hemispheres have different functional specialisations.
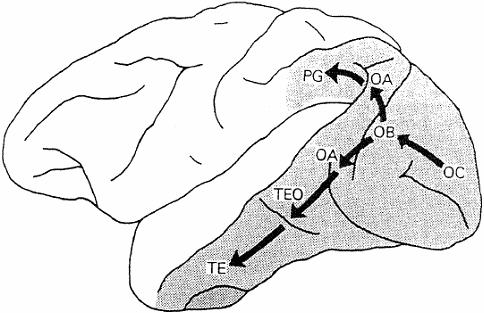
Figure 1. The postulated "two pathway organisation of the visual cortex". Adapted from Mishkin et al. (1983). Both pathways begin in primary visual cortex (area OC), diverging within prestriate cortex (areas OB and OA), and then project either ventrally into the inferior temporal cortex (areas TEO and TE) or dorsally into the inferior parietal cortex (area PG). The ventral what pathway is imputed to subserve object vision. The dorsal where pathway is assumed to be involved in spatial vision.
That is, in the right hemisphere, the activation of a neuronal population within the what stream transmits information about visual form, which codes the primitives of an image. Subsequently, within the where stream a visual image is derived from those primitives coded in the what system. By contrast, in the left hemisphere, the activation of a neuronal population within the what stream transmits information about an abstract rather than a primitive description of the visual image, whereas within the where system, a visual scene is derived from the abstract images coded in the what system.
Thus a "mechanism of frames" is assumed to operate in the where system of both hemispheres. This mechanism sets a constituent that is coded in the what system into that constituent's context which imbues the constituent with an additional meaning within frames coded in the where system. In the visual domain, the constituents are visual primitives in the right hemisphere; visual images in the left hemisphere. However, Sukhova's framework develops that of Bobrova and Bobrov's with further respect to the representation of speech and gestural units by extending the concept of hemispheric specialisation of what and where systems to linguistic and motor domains. Accordingly, in the linguistic domain, the constituents are elements of words in the right hemisphere; truncated codes of words in the left hemisphere. Similarly, in the motor domain, the constituents are precise parameters of movements in the right hemisphere; successive movements in the left hemisphere.
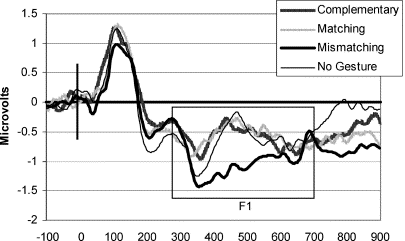
Figure 2. A principal component of the auditory ERP to a speech sound reflecting, primarily, a negativity from 324 to 648 ms (N400) at bilateral sites situated over the temporal lobe. When a preceding gesture was incongruent with the meaning of speech sound, the mismatching condition produced a larger negativity to the speech sound than the matching condition, but this mismatching condition did not differ significantly from the complementary and no gesture conditions. The content of the preceding gesture thus influences the brain's electrical N400 response to speech, which is typically considered to be related to semantic processing.
Sukhova's framework offers the view that the transmission of speech and gestural units from some deep representation is more rapid and directly realised for gesture. Evidence marshaled in favor of such a position is that when volunteers see a hand gesture reflecting either the tallness or thinness of a glass this influences the auditory event-related potential (ERP) to a subsequent speech sound, "tall" or "thin" which indexes the brain's electrical response to that speech sound (Kelly, Kravitz, & Hopkins 2004, see Figure 2). This auditory ERP is influenced by gesture in a manner which could be related to the neural processing of the gesture. Such data offer compelling evidence for the influence of gesture on brain processes in response to speech sound, which could be related to some confluence of information during the processing of perceived speech and gestures. Such a confluence would be commensurate with the assumption that the processing of speech and gesture are not entirely independent systems upon the plane of utterance. However, that a preceding gesture such as an incongruent hand movement towards a tall glass influences aspects of the generation of the ERP to a subsequent speech sound would seem not in itself to support the position that the transmission of gesture during the perception of an utterance is more direct than that of speech. Alone this ERP evidence would seem not to stand as evidence for the more direct nature of the realisation of gesture than speech.
An assumption that remains open to question is that of perceptual reversal, which takes Sukhova's framework a long way in terms of the framework's applicability in the investigation of the production of prosodio-kinetic complexes. That is, the perception of spoken and gestural speech acts is the converse of the production of those acts and thus the perception of speech acts may be understood by investigating the production of such acts. Such a perceptual reversal assumption seems somewhat reminiscent of Lieberman and Mattingly's (1985) abstract motor theory of speech perception whereby the intended rather than observed speech gestures form the substrate of speech perception, which is perceived directly via a speech module with a knowledge of the mappings between the intended articulatory gestures and their acoustic and visual consequences (and vice versa).
Arguments against such a perceptual reversal assumption, as embodied by such a module within the abstract motor theory, include that the assumption of this speech module is a mere restatement of the problem of how we perceive speech. The assumption of such a module is simply saying "what needs to be done" in speech perception rather than saying "how what needs to be done is done". On the other hand, the central mechanisms of 1) perceived and 2) produced speech have been associated with increases in cerebral bloodflow in anatomically distinct regions (Price, Wise, Warburton, Moore, Howard et al. 1996). Price et al.'s investigation has also shown that these regions interact with one another during speech perception, production and verbal repetition. Recent fMRI evidence from the audio-visual speech perception literature has indicated that the classical speech production area, under certain conditions can become activated during the perception of speech (Ojanen, Möttönen, Pekkola, Jääskeläinen, Joensuu et al. 2005). It seems then that, although anatomically distinct from one another the brain processes associated with speech perception and production are also linked. This connection of these processes could be related to the perception-production link postulated by the abstract motor theory. Indeed, an intriguing empirical question remains whether neuroimaging investigations could reveal an association of such brain processes to perception-production link in the case of gesture. Such investigations seem necessary given the assumed direct realisation of gesture and the tacit assumption of direct perception (reversed direct realisation) of gesture with Sukhova's framework.
This framework represents an advance on a restatement of the problem, as cast in theories such as the abstract motor theory. That is, some of the representational-algorithmic details of the processes of the production of an utterance are specified upon the plane of utterance. These representational-algorithmic details can be related to the parcellation of different forms of neural codings of information within different what and where systems in the two hemispheres. Such a framework is indeed testable with neuroimaging methods during the perception of gestural and speech units.
Support for the validity of the what and where distinction in the context of spoken language derives from electrophysiological investigations of response selectivity of single neurons within the lateral belt regions of the superior temporal gyrus in macaque monkeys (Rauschecker & Tian 2000), a region of non-primary auditory cortex that encircles the primary auditory cortex (for a review, see Hall, Hart, & Johnsrude 2003). Macaques were presented with monkey calls and control sounds with different meanings from different locations. Greatest spatial selectivity of neurons was found in the caudolateral area of the lateral belt, whilst greatest selectivity for different monkey calls was found in the anterolateral area of the lateral belt, indicative of the splitting of the processing of what and where information into separate streams at the level of the belt of the non-primary auditory cortex. Whilst homologies of auditory cortical regions in macaques with those in humans remain to be identified (Hall, Hart, & Johnsrude 2003), Rauschecker & Tian suggest that this anterior region of belt is the precursor to Wernike's area that is classically associated with speech perception and understanding in humans and may be construed as part of a what stream that is distinct from a where stream.
Corroborative neuroimaging evidence includes that from investigations of the processing of tones in humans (Anurova 2005). There is an early divergence in the cortical systems that separately process the location and pitch of sound during the time range of about 100 ms post-stimulus onset within where and what systems in the brain. This N1m response to tones is typically generated by dipolar sources localisable within the vicinity of the auditory cortices (Campbell & Neuvonen 2007). In an immediate memory task, this N1m response has been shown to peak earlier when the brain is attending to the location rather than the pitch of sounds (Anurova, Artchakov, Korvenoja, Ilmoniemi, Aronen et al. 2003, 2005; Anurova 2005) in a manner that differs in anatomical locus when the tone is a cue (Anurova et al. 2003) rather than a probe (Anurova et al. 2005). This reduction in the N1m peak latency for attended locations relative to attended pitch is arguably of evolutionary significance. One critical function of spatial audition of sound location could be that of an early warning mechanism. Accordingly, that early warning system directs subsequent attentional and visual processing to where the onset of the source of the sound is. In turn, what the content of that sound is may be processed and acted upon, should the onset of that source pose a threat to life.
However, at a later stage in processing of a sound, which can be related to immediate memory for sounds, this decomposition of function arguably is not a watertight compartmentalisation of processing into particular brain structures. Rather, despite an early divergence of what and where streams, as reflected by N1m peak latencies, findings from the late slow wave to cues indicate a subsequent convergence of the processing of what and where information within a distributed network of brain areas (Anurova et al. 2003, Anurova 2005). That is, the late slow wave is affected by memory load to cue tones in a manner that goes unaffected by whether volunteers are attending to pitch or location. The generator mechanism of this late slow wave, in this case, seems to be functionally relevant to memory load, yet remains much more difficult to localise than the dipolar sources of N1m. An auxiliary assumption - commensurate with Ylikoski's arguments that some functionally distinct processes cannot be distinctly localised - thus appears unavoidable on the basis of these data. That is, this memory-load related process, which generates that late slow wave of the auditory ERP and subsequently integrates information from the what and where streams, needs to be assumed to be diffuse. This diffuse process is implicated in the formation of a more abstract coding of this what and where information within the brain that can be related to an abstract code of auditory objects.
Different regions of left superior temporal cortices are differentially sensitive to non-speech and speech including sentences and single words (for reviews see Scott 2005, Scott & Johnsrude 2003). For humans, in addition to the what and where systems present in all primates, Scott (2005) also postulates a posterior how stream, which can operate in an articulatory-gestural domain and projects from a posterior part of the left superior temporal sulcus to the frontal speech production regions such as Broca's area. This assumption of a how system could further the applicability of the inclusion of what and where systems upon Sukhova's plane-of-utterance to neuroimaging investigations of how the brain processes gestural units. The theoretical utility of such a system in relation to the analysis of gestural units, such as posture within human communication, remains to be determined.
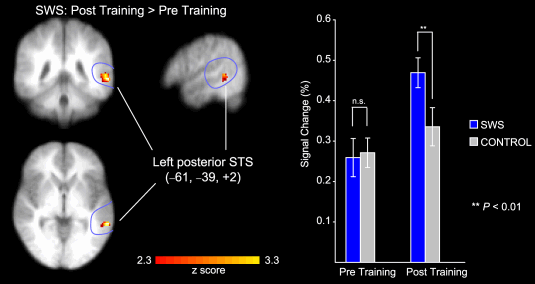
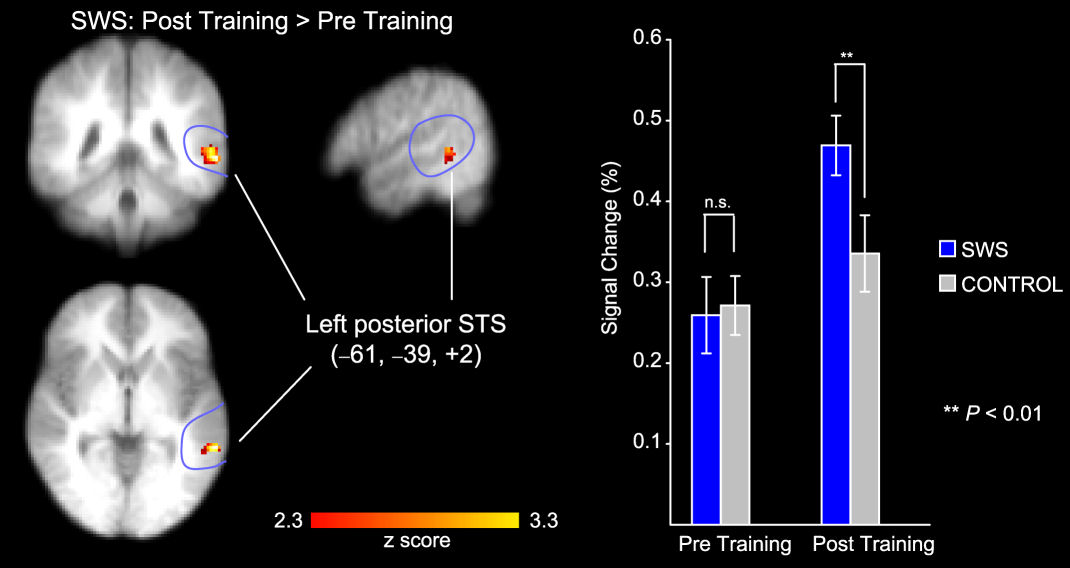
Figure 3. Speech-specific activation in the left posterior Superior Temporal Sulcus (STSp). Activation was increased in the post-training relative to the pre-training session for the Sine-Wave-Synthesised (SWS) stimuli (left panel). Mean changes in signal from the left STSp for SWS and control stimuli in the pre- and post-training sessions are also depicted (right panel). From Möttönen (2006).
A training investigation supports the view that the left posterior superior temporal sulcus plays a causal role in the processing of attended sound as linguistic material (Möttönen, Calvert, Jääskeläinen, Matthews, Thesen et al. 2006), which could be imputed to play a role within this how system (Scott 2005). Sine-wave-synthesised speech consists of modulated speech sounds that are composed from three sinusoids, which follow the dynamics of the lowest formants and can be perceived as speech or non-speech, Remez, Rubin, Pisoni, & Carrell (1981). The capacity to perceive sine-wave-synthesised speech as speech varies from person to person and may be trained. Möttönen et al. (2006) investigated cerebral blood flow with fMRI during the presentation of sounds, before and after training. When individuals learned to perceive sine-wave-synthesised speech as speech, there was an increase in activation of the left posterior superior temporal sulcus in response to the sine-wave-synthesised speech when perceived as speech after training (Figure 3, left panel). A control stimulus was used that resembled a rasping, rattling or shushing sound, as was derived from spectrally rotated vo-coded versions of the speech sound. The response of the left posterior superior temporal sulcus to this control stimulus sound did not exhibit such a marked increase in activation following training (Figure 3, right panel) as did the sine-wave-synthesised speech.
Möttönen et al.'s (2006) data are particularly compelling evidence of a causal relation of the training of the mental process of speech perception with an increase in cerebral blood flow within a localisable neural system. If there is a speech module (Lieberman & Mattingly 1985), then some neurophysiological processes operating within the posterior superior temporal sulcus can be related to this module and may indeed be one localisable component of a broader how stream (Scott 2005) that projects to frontal language production regions.
However, even the co-determination of mental and brain processes by the effects of training does not necessarily prove a causal relation of those mental and brain processes. Arguments for some form of psychophysical parallelism concerning these changes in mental and brain processes still cannot be excluded by such neuroimaging findings. Such arguments aside, changes in the brain process measured - apparently produced by training - could still be mere correlates of another brain process that is causally related to learning. Perhaps a different way of training the how stream would rather better establish this brain system as causally related to the perception of speech acts. As the left posterior superior temporal sulcus is activated during the comprehension of sign language (MacSweeney, Campbell, Woll, Giampietro, David et al. 2004) then consider the possibility that training in sign language were to increase activation of the left posterior superior temporal sulcus when signs are understood as language. Such a result would further support the case for a causal relation between the mental process of perceiving stimuli - whether speech or gesture - as language and an increased activation of the how system during the perception of language.
Worthy of consideration within Möttönen et al.'s (2006) data is the absence of the activation of the what system as would be manifest by the enhanced activity in the anterior part of the left superior temporal sulcus and gyrus during speech perception. A first interpretation is that the what system requires sounds to be processed as meaningful for this system to be activated. All auditory stimuli in Möttönen et al.'s investigations were digital manipulations of meaningless pseudowords. Accordingly, there was no activation of the what stream. However, a second alternative interpretation offered by Möttönen et al. (2006) is that whilst implicated in speech perception, the what system is only concerned with the acoustic properties of speech sounds and only the how stream implicating the posterior superior temporal sulcus is influenced by whether that sound is processed as speech or not. It remains an empirical question to decide between the two interpretations of the apparent lack of additional activation of the what system when the how system is activated. This second favored interpretation may be more readily reconciled with the assumption that the what stream may also process not only complex sounds but also tonal non-speech sounds (Anurova 2005).
Within the stack-up hi-fi analogy, this how system could be regarded as an amplifier. Metaphorically speaking, for a record to be played upon the record deck, the what system needs to switched on. However, for the record to play as speech rather than non-speech, the amplifier - the how system - also needs to be switched on.
The posterior superior temporal sulcus would thus seem to be a localisable aspect of this how stream, some aspects of which are localisable as a module that is anatomically and functionally distinct from the what and where streams implicated in auditory speech processing. Our understanding of the how system could benefit from neuroimaging investigations of the role of gesture and sign language in human communication. In particular, training investigations involving neuroimaging could serve as one promising way to better establish causal connections between the relevant mental and brain systems, which may, at least in part, be localisable.
The interdisciplinary interaction within this volume represents a new step towards an understanding of how brain processes could be related to the processing of language. This increased openness of linguistics and philosophy towards data from neuroimaging investigations is encouraging, and, indeed, such data-intensive research is often best inspired by abstract questions. Read on, as it is hoped that our understanding of this landscape will become more interesting when we jointly mount our mountains.
* Correspondence:
Tom Campbell
Helsinki Collegium for Advanced Studies
P.O. Box 4
FIN-00014 University of Helsinki
Finland
tel. +358415409764
fax. +358919124509
e-mail: tom.campbell@helsinki.fi
Anurova, Irina. 2005. Processing of Spatial and Nonspatial Auditory Information in the Human Brain. Ph.D. dissertation, Department of Physiology, Institute of Biomedicine, Faculty of Medicine, University of Helsinki, Finland. http://urn.fi/URN:ISBN:952-10-2480-1
Anurova, Irina, Dennis Artchakov, Antti Korvenoja, Risto J. Ilmoniemi, Hannu J. Aronen & Synnöve Carlson. 2003. "Differences between auditory evoked responses recorded during spatial and nonspatial working memory tasks". NeuroImage 20(2): 1181-1192. doi:10.1016/S1053-8119(03)00353-7
Anurova, Irina, Dennis Artchakov, Antti Korvenoja, Risto J. Ilmoniemi, Hannu J. Aronen & Synnöve Carlson. 2005. "Cortical generators of slow evoked responses elicited by spatial and nonspatial auditory working memory tasks". Clinical Neurophysiology 116(7): 1644-1654. doi:10.1016/j.clinph.2005.02.029
Bobrova, E.V. & A. Bobrov. 2005. "Neurophysiological aspects of language birth: Vertical posture and explosion". Paper presented at Imatra International Summer Institute for Semiotics and Structural Studies.
Campbell, Tom A. & Tuomas Neuvonen. 2007. "Adaptation of neuromagnetic N1 without shifts in dipolar orientation". NeuroReport 18(4): 377-380. doi:10.1097/WNR.0b013e32801b3ce8
Chomsky, Noam. 1984. Modular Approaches to the Study of the Mind. San Diego: San Diego State University Press.
Chomsky, Noam. 1995. The Minimalist Program. Cambridge, Mass.: MIT Press.
Ellis, Andrew W. & Andrew W. Young. 1988. Human Cognitive Neuropsychology. Hove, England: Lawrence Erlbaum Associates.
Fodor, Jerry A. 1983. Modularity of Mind: An Essay on Faculty Psychology. Cambridge, Mass.: MIT Press.
Hall, Deborah A., Heledd C. Hart & Ingrid S. Johnsrude. 2003. "Relationships between human auditory cortical structure and function". Audiology & Neuro-Otology 8: 1-18. doi:10.1159/000067894
Kelly, Spencer D., Corinne Kravitz & Michael Hopkins. 2004. "Neural correlates of bimodal speech and gesture comprehension". Brain and Language 89(1): 253-260. doi:10.1016/S0093-934X(03)00335-3
Lieberman, Alvin & Ignatius G. Mattingly. 1985. "The motor theory of speech perception revised". Cognition 21(1): 1-36. doi:10.1016/0010-0277(85)90021-6
MacSweeney, Mairéad, Ruth Campbell, Bencie Woll, Vincent Giampietro, Anthony S. David, Philip K. McGuire, Gemma A. Calvert & Michael J. Brammer. 2004. "Dissociating linguistic and nonlinguistic gestural communication in the brain". NeuroImage 22(4): 1605-1618. doi:10.1016/j.neuroimage.2004.03.015
Mishkin, Mortimer, Leslie G. Ungerleider & Kathleen A. Macko. 1983. "Object vision and spatial vision: Two cortical pathways". Trends in Neurosciences 6: 414-417. doi:10.1016/0166-2236(83)90190-X
Möttönen, Riikka. 2006. "Speech-specific auditory processing". Paper presented at Cognitive Neuroscience: Short-term, long-term and linguistic information processing, Brain Awareness Week, Helsinki Collegium for Advanced Studies, University of Helsinki, Finland, 13th-16th March, 2006.
Möttönen, Riikka, Gemma A. Calvert, Iiro P. Jääskeläinen, Paul M. Matthews, Thomas Thesen, Jyrki Tuomainen & Mikko Sams. 2006. "Perceiving identical sounds as speech or non-speech modulates activity in the left posterior superior temporal sulcus". NeuroImage 30(2): 563-569. doi:10.1016/j.neuroimage.2005.10.002
Ojanen, Ville, Riikka Möttönen, Johanna Pekkola, Iiro P. Jääskeläinen, Raimo Joensuu, Taina Autti & Mikko Sams. 2005. "Processing of audiovisual speech in Broca's area". NeuroImage 25(2): 333-338. doi:10.1016/j.neuroimage.2004.12.001
Price, Cathy J., Richard J.S. Wise, Elizabeth A. Warburton, Caroline J. Moore, David Howard, Karalyn Patterson, Richard J. Frackowiak & Karl J. Friston. 1996. "Hearing and saying: The functional neuro-anatomy of auditory word processing". Brain 119(3): 919-931. doi:10.1093/brain/119.3.919
Rauschecker, Josef P. & Biao Tian. 2000. "Mechanisms and streams for processing of 'what' and 'where' in auditory cortex". Proceedings of the National Academy of Sciences of the United States of America 97: 11800-11806. http://www.pnas.org/content/97/22/11800.abstract
Remez, Robert E., Philip E. Rubin, David B. Pisoni & Thomas D. Carrell. 1981. "Speech perception without traditional speech cues". Science 212: 947-949. doi:10.1126/science.7233191
Scott, Sophie K. 2005. "Auditory processing: Speech, space and auditory objects". Current Opinion in Neurobiology 15(2): 197-201. doi:10.1016/j.conb.2005.03.009
Scott, Sophie K. & Ingrid S. Johnsrude. 2003. "The neuroanatomical and functional organization of speech perception". Trends in Neurosciences 26(2): 100-107. doi:10.1016/S0166-2236(02)00037-1
Sukhova, Natalya V. 2009. "Cognitive interaction of verbal and nonverbal signs (prosodio-kinetic complexes)". Approaches to Language and Cognition (= Studies in Variation, Contacts and Change in English, 3), ed. by Heli Tissari. Helsinki: VARIENG. http://www.helsinki.fi/varieng/series/volumes/03/sukhova/
Ylikoski, Petri. 2009. "The heuristic of decomposition and localization". Approaches to Language and Cognition (= Studies in Variation, Contacts and Change in English, 3), ed. by Heli Tissari. Helsinki: VARIENG. http://www.helsinki.fi/varieng/series/volumes/03/ylikoski/
Zeki, Semir. 1993. A Vision of the Brain. Oxford, England: Blackwell Scientific Publications.
|