As the case may be: A corpus-based approach to pronoun case variation in subject predicative complements in British and American English
Georg Maier
Universität Hamburg
Abstract
The distribution of pronoun case forms in Present-Day English has been the subject of a lively linguistic debate. There are variable contexts which seem to permit a choice between the use of subjective and objective pronoun forms. This paper provides a survey of the distribution of British and American English pronoun case forms in two of these variable contexts, i.e. simple subject predicatives and subject predicatives also functioning as focus of it-clefts. Based on data from the British National Corpus and the Corpus of Contemporary American English, this study tests longstanding hypotheses on the distribution of pronoun case forms and also sheds more light on the mechanisms determining the choice of pronoun case forms in variable contexts. First, the analysis of the data shows that it is not only the position of the pronoun relative to the finite verb but also its function which may influence its form. Additionally, it is demonstrated that the mode of discourse may significantly influence the choice of a pronoun form in some contexts but not in others. Furthermore, this study also reveals significant cross-varietal differences in the distribution of pronoun case forms and emphasises the need for larger cross-varietal databases in order to analyse infrequent morphosyntactic phenomena quantitatively.
1. Introduction
The “right use” of pronominal case forms has been deemed “one of the knottiest points in English grammar” (Jespersen 1933: 132). The reason for this “knottinesss” is the fact that in English there are contexts which permit a choice between the subjective and the objective pronoun form. Prominent examples of these variable contexts include the following: [1]
| Construction Type |
Example |
| It-clefts |
It is she/her who is to blame |
| It be sentences |
Who is it? – It is I/me |
| Coordinated NPs in Subject Positions |
Jane and I/me will get married |
| Coordinated NPs in Object Positions |
This matter has to stay between you and I/me |
| PR-NP constructions |
We/Us Irish are a musical people |
| Than-comparatives |
Mary is bigger than he/him |
Table 1. Variable contexts of pronoun case distribution in Modern English
This variability leads, on the one hand, to some uncertainty among speakers regarding the choice of the ‘correct’ pronoun case form, which can be easily observed on the English World Wide Web.
| (1) |
Unfortunately, someone has to say it and this time it is me (or I): INTERNATIONAL GRAND SLAM TENNIS IS THE MOST BORING SPORT EVER DEVISED BY THE WIT OF MAN, WOMAN OR DOG. [2] |
At the same time, this variability in the distribution of pronoun case forms has triggered a lively linguistic debate (e.g. Angermeyer & Singler 2003; Erdmann 1978; Hudson 1995; Kjellmer 1986; Quinn 2005, 2009; Parker, Riley & Meyer 1988; Shorrocks 1992; Sobin 1997). Despite the considerable amount of scholarly attention that the variability of pronoun case forms has received in the past, there have been rather few corpus-based studies addressing these issues (e.g. Angermeyer & Singler 2003; Biber et al. 1999, Erdmann 1978, Quinn 2009). This is particularly true for the first two constructions presented in Table 1, which are the main focus of this paper. In both of these variable contexts, it serves as the subject of a clause which is then followed by a form of the copula be. [3] Furthermore, in either context, the personal pronoun form functions as a subject predicative complement of the clause. In the first sentence in Table 1, however, the pronoun also serves as the focus of a cleft construction. We distinguish between these two types of subjective predicatives by adopting Quinn’s terminology (2005) in referring to simple subject predicatives as it be sentences and to those also serving as focal-pronouns as it-clefts.Although the issue of pronoun case distribution and variation in both focal pronoun position of it-cleftsand it be sentences is addressed in most English grammar books (e.g. Biber et al. 1999; Greenbaum 1996; Jespersen 1933; Quirk et al. 1985; Huddleston & Pullum 2002), there appear to be only a few corpus-based studies trying to quantify the distribution and variation in these two contexts.
In view of this shortcoming, this study sets out to provide an overview of the pronoun case distribution in it-clefts and it be sentences, as observed in both the British National Corpus (henceforth BNC) and the 400 million word version of the Corpus of Contemporary American English (henceforth COCA). [4] In addition, this study aims to investigate the following hypotheses, which are discussed in detail in section 3: First, we assess whether the syntactic function of a pronoun, as well as its position, has influence on the distribution of pronoun forms. Given the rigid SVO order in Present-Day English, it is very difficult to distinguish between the syntactic function and the position of a pronoun in a clause. However, when comparing the distribution of pronoun case forms in it-clefts to that of it be sentences, it should be possible to assess whether the syntactic function influences the distribution of pronoun forms, since in both contexts – it be sentences and it-clefts – the pronouns occupy the same syntactic position but differ with regard to their syntactic function. Furthermore, we will test to what extent the degree of formality or mode of discourse influences the distribution of pronoun case forms in it be sentences and it-clefts in the two corpora analysed. Finally, we try to assess whether there are cross-varietal differences between British and American English in the distribution of pronoun forms in these two contexts or not.
We start our study, however, with a brief survey of the previous research (cf. section 2) before introducing and motivating the underlying hypotheses (cf. section 3). Next, the database of this study is introduced (cf. section 4) before we present the results of this study (cf. section 5). Finally, a discussion of the findings is provided in section 6.
2. Previous research
Despite the loss of a more elaborate case morphology, much of the formal syntactic literature still postulates a healthy case system for Present-Day English. Although morphological case is realized mainly on personal pronouns, this is considered evidence of the fact that subjects of finite clauses are assigned nominative case, objects of verbs and prepositions receive objective case, and possessive noun phrases are marked with genitive case (e.g. Chomsky 1993; Haegeman & Guéron 1999: 143–144; McCreight 1988: 5–10; Quinn 2005: 26–64). The most important difference between these formal approaches lies in the relative importance they attribute to certain syntactic configurations involved in case assignment (e.g. Chomsky 1995; Kiparsky 1997; Wunderlich 1997; Quinn 2005: 26–64 for an overview).
The assumption that the distribution of pronominal case forms is subject to underlying case mechanisms has, however, met with a lot of opposition, even within the formalist framework (e.g. Emonds 1985: 220). Alternatively, the position of the pronoun form in a clause has been considered the decisive factor in determining the distribution of the different pronoun forms (e.g. Burridge 2004: 1118; Emonds 1976, 1985; Hudson 1995). A good example to illustrate this “positionalist” approach is Quirk et al. (1985: 337). In their account – especially with regard to informal varieties of English – the clause is divided into “subject territory”, i.e. the preverbal subject position immediately preceding the finite verb (cf. 2), and “object territory”, i.e. all noun-phrase positions apart from that immediately preceding the verb (cf. 3).
| (2) |
Pronoun forms in “subject territory” |
|
a. |
She is a nice lady. |
|
b. |
They have just bought a new house. |
| (3) |
Pronoun forms in “object territory” |
|
a. |
It is him. |
|
b. |
Me and Jodie are a couple. |
|
c. |
Who is it? – Me. |
|
d. |
Jane is more intelligent than him. |
By making this distinction, this approach is able to explain the use of objective pronouns in many variable contexts, including coordinated noun phrases in subject position and it be sentences (Quirk et al. 1985: 337–338). Interestingly, although this approach has recently found many supporters, it has a very long history. As early as the late 17th century, Cooper noted in his Grammatica linguae Anglicanae: “I, thou, he, she, we, ye, they, verbis anteponuntur, me, thee, him, her, us, you, them, postponuntur verbis & præpositionibus” (1685 [1968]: 121).
Another influential approach accounting for pronoun case distribution, which also has a long scholarly tradition, focuses more on the distinction of different classes of pronoun forms than on delimiting certain areas in which they are supposed to occur:
“The real difference between ‘I’ and ‘me’ is that ‘I’ is an inseparable prefix used to form finite verbs, while ‘me’ is an independent or absolute pronoun, which can be used without a verb to follow. These distinctions are carried out in vulgar English as strictly as in French, where the distinction between ‘je’ and the absolute ‘moi’ is rigidly enforced” (Sweet 1875: 495)
Hence, the proponents of this approach tend to distinguish between “weak” and “strong” pronouns similar to those classes in Romance languages (e.g. Harris 1981; Quinn 2005). French, in particular, with its set of clitic subject pronouns je, tu, il, and ils, the possible application range of which is also severely confined, serves as a reference for this model, as has become obvious from the citation above. In English, the class of so-called “weak” pronouns is made up of the subjective forms I, he, she, we, and they, whereas the class of the so-called “strong” pronouns consists of the objective forms me, him, her, us, and them. The reason why the latter set is called “strong” is that these forms can appear in much more contexts than their “weak” counterparts (cf. 4–7 ). The latter are, according to this approach, also more or less confined to the position of uncoordinated subject immediately preceding the finite verb. Thus, it can be concluded that this approach makes very similar predictions with regard to the distribution of pronoun forms as the “positionalist” approach does (e.g. Harris 1981; Quinn 2005; Shorrocks 1992).
| (4) |
“Weak” pronoun context in French |
|
Je ferme la porte. |
| (5) |
“Strong” pronoun form in French |
|
C’est moi qui ferme la porte. |
| (6) |
“Weak” Pronoun context in English |
|
I close the door. |
| (7) |
“Strong” pronoun form in English |
|
It is me who closes the door. |
Interestingly, this approach – like the “positionalist” approach – is also not restricted to a particular linguistic tradition but has sympathisers in different linguistic frameworks (e.g. Quinn 2005; Sweet 1875; Shorrocks 1992).
Although doubts have been cast on the impact of the syntactic function as an influential factor in determining the distribution of pronoun case forms (Burridge 2004: 1118), there are other studies identifying the syntactic function of the pronoun as an important variable (Angermeyer & Singler 2003: 197–198; Erdmann 1978). Erdmann, for example, agrees with some of the “positionalists” mentioned above (e.g. Emonds 1985; Hudson 1995) in that he rejects the labelling of the two sets of pronouns in Present-Day English as “nominative” and “accusative”. However, after analysing his corpus of 40 British novels, Erdmann comes to the conclusion that the distribution of pronoun case forms is also determined by the syntactic function of the pronoun in the sentence: If the personal pronoun is used in object position, it is more likely to surface as an objective form. If, however, the personal pronoun occurs in a subject complement position, it can vary between subjective and objective form (Erdmann 1978: 78–79). Hence, he concludes that the “pronominal system has changed from a morphologically determined to a syntactically determined” system (Erdmann 1978: 79).
Another factor which has been acknowledged as influencing pronoun case distribution by most accounts is the degree of formality of the text/speech in which a certain pronoun form occurs. Most accounts agree that informal situations favour the use of objective pronouns, whereas a high degree of formality encourages the use of subjective pronoun forms (e.g. Biber et.al 1999; Erdmann 1978: 72; Quirk et al. 1985: 337–338; Shorrocks 1992: 436; Sobin 1997: 418–419; Sweet 1875: 495). Furthermore, it is believed that the higher degree of formality associated with subjective forms and their putatively higher degree of politeness are, in combination with the prescriptive bias in favour of the subjective forms, accountable for so-called hypercorrect uses of pronoun forms. These hypercorrections are instances of subjective forms, particularly in coordinated object noun phrases such as in between you and I, in which the objective forms are the norm (Angermeyer & Singler 2003: 177; Huddleston & Pullum 2002: 463; Sobin 1997: 338; Quirk et al. 1985: 338).
In addition to these potential variables, Angermeyer & Singler (2003) identify a whole range of other factors that may influence the choice of a pronoun form in a variable context. In their discussion of coordinate noun phrases, they identify the speaker’s sex, age, and degree of education as social factors potentially influencing the choice of pronoun forms. Furthermore, factors such as length or syntactic complexity, animacy, number, familiarity, and degree of focus also seem to influence the choice of pronoun forms in certain contexts (Angermeyer & Singler 2003: 197). Although their study was restricted to coordinate noun phrases, it seems likely that at least some of these factors are also relevant for the choice of pronoun forms in the other contexts summarised in Table 1 .
In view of these sociolinguistic factors influencing pronoun case distribution and due to the variability of pronoun case assignment in many contexts in general, it is likely that different varieties of English also exhibit different distributional patterns. This is particularly true when taking into consideration the massive scope of variation in case marking across different varieties of English (e.g. Britain 2007, Kortmann et al. 2004; Trudgill & Chambers 1991). In fact, some scholars consider the scope of variation of pronoun case assignment in certain domains to be so extensive “that any pan- or polylectal approach seems fraught with difficulties, if not foredoomed to failure “(Shorrocks 1992: 441–442). Hence, it is likely that cross-varietal differences can also be observed in the domains discussed in this study, i.e. it clefts and it be sentences. Unfortunately, there have not been many quantitative studies examining distributional differences in pronoun case assignment across varieties of English (e.g. Siemund et al. 2009; Quinn 2009). One of the few quantitative analyses of these phenomena is offered by Biber et al. (1999: 335–336). Their analysis, however, only distinguishes between different registers and persons, and makes no distinction between American and British English. Furthermore, their distributional analysis of pronoun case forms is rather vague, since they state approximate frequency values rather than specifying concrete percentages (Biber et al. 1999: 336). Erdmann’s (1978) study provides exact numbers but only focuses on British English. This scarcity of quantitative analyses of constructions exhibiting pronoun case variation in general and of it-clefts and it be sentences in particular is also due to the low frequency of these constructions in available corpora, which means that huge amounts of data are required in order to obtain a sufficient number of pronoun tokens to quantify these phenomena. Most corpora representing regional varieties of English are relatively small as compared to big national corpora such as the BNC or the COCA, and hence the cross-varietal analysis of variable contexts of pronoun case variation is actually very difficult (cf. Quinn 2009: 41).
In sum, linguistic theory has put forward a substantial number of different accounts and potential variables to explain the variation in pronoun case assignment that is observable in Present-Day English. In the following sections, the aim of this article is to test some of the most influential ones in order to shed light on the issue of pronoun case distribution in the domains of it be sentences and it-clefts. The following section outlines in detail those hypotheses that are tested in the present contribution.
3. Hypotheses
The aim of this study is not only to provide a survey of the distribution of pronoun case forms in it-clefts and it be sentences as observed in the BNC and in the COCA, but also to test the following hypotheses:
| Position-versus-function-hypothesis: |
|
If it is true that the distribution of pronoun case is, for the most part, determined by position rather than function, than we should observe no, or no significant differences, between the pronoun case distribution in it-clefts and it be sentences (cf. Biber et al. 1999: 335; Burridge 2004: 1118; Emonds 1976, 1985; Hudson 1995). |
|
If, however, the function of the pronoun also plays a role in the distribution of pronoun case forms, we should observe significant differences in the distribution of forms between it-clefts and it be sentences (cf. Erdmann 1978). |
The way in which this hypothesis is motivated can be explained as follows: As discussed in section 2, many current accounts attribute a great deal, if not the lion’s share, of influence on the distribution of pronoun case forms to the position of the pronoun form relative to the verb – regardless of whether their proponents subscribe to a “positionalist“ or a “weak versus strong” pronoun class approach (e.g. Biber et al. 1999: 335; Burridge 2004: 1118; Emonds 1976; Harris 1981; Hudson 1995; Quinn 2005). That the position of the pronoun does indeed have a strong influence on the distribution of pronoun forms is, in principle, unchallenged. Due to the rigid SVO order in English, this strong influence is more or less inevitable, and it is difficult to separate the pronoun’s function from its position. However, Erdmann’s functionalist approach puts forward the hypothesis that the pronoun’s syntactic function also influences its form, especially in those contexts which exhibit variation in terms of pronoun case forms (1978). This, in turn, has been challenged by Harris (1981), who states in a direct response to Erdmann’s article that:
“[…] the ultimate distribution of I/me seems likely to be directly parallel to that of je/moi in French, the former being restricted to clitic positions within finite verb phrases and the latter used elsewhere (Harris 1981: 20).
Furthermore, Erdmann has also been challenged by “positionalists” who acknowledge a “general trend in English towards case selection [being] dictated by position rather than function” (Burridge 2004: 1118). Despite the fact that the function of a pronoun form is closely intertwined with its position in a clause because of the rigid SVO order and the difficulty in distinguishing between function and position, the putative influence of the pronoun’s function with regard to its distribution should be borne out by the data for the following reasons: In both it be and it-cleft contexts, the pronoun forms serve as subject predicatives and occupy exactly the same position in the clause. If we adopt a very strict interpretation of either the “positionalist” or the “weak versus strong pronoun” account, we expect to predominantly observe objective pronouns in both contexts simply because the pronoun form occurs in postverbal position, which is, depending on the respective account, either “object territory” or a “strong” pronoun context. From a functionalist point of view, however, the pronouns in it-clefts are not merely subject predicatives but may fulfil a double function or – put differently – may have a “Janus-like status” (Quirk et al. 1985: 338). In their function as focal pronouns of it-clefts, the personal pronouns are not only the subject complements of the main clause, but may additionally be the head of the subordinate clause when they are coreferential with the subject of the following dependent clause, as in (8). Hence, in these sentences where the personal pronoun has this double function of both complement of the matrix clause and subject of the subordinate clause, the pronoun forms are functionally different from their counterparts in it be sentences. In the data used for this study, this is the case for 90% of the British it-clefts taken from the BNC, i.e. 729 of 810 instances, and for 92.03% of the American data obtained from the COCA, i.e. 1159 of 1292 it-clefts. Examples of it-clefts in which the clefted pronoun form is coreferential with an object of the following relative clause are given in (9).
| (8) |
It-cleft in which the pronoun form is coreferential with the subject of the dependent clause [5] |
|
a. |
Well it took him What? What about Maisy? Some people say it was him that wrote it. Oh! Mm. What’s is that Emily again? (BNC/KDM/S_conv) |
|
b. |
Witch, witch, the tower warder’s laughter or perhaps it is she who makes the sound, uneven breath the rachet whisper of that laugh. (COCA/1997/FIC/ FantasySciFi) |
| (9) |
It-cleft in which the pronoun form is coreferential with an object of the dependent clause |
|
a. |
In the same instant someone had leapt for the window. It was he whom Matthew had brought down in a flying tackle. (BNC/ J54 / W_fict_prose) |
|
b. |
I was beginning to think I’d been stood up, but maybe it was her you saw. A few minutes ago, you say?” (COCA/2002/FIC/BkJuv:ManCliff) |
If this functional difference between the pronoun forms in it-clefts and it be sentences plays an additional role in the distribution of pronoun forms, as suggested by Erdmann (1978), this should be indicated in the data. Moreover, if there are distributional differences, they can be attributed to the function of the pronoun rather than to its position or its membership in a certain pronoun class, since both the “positionalist” and the “weak versus strong” pronoun account would predict basically the same distribution for it be and it-cleft contexts.
Second, with the help of the data, we try to assess to what extent the degree of formality, or more precisely the mode of discourse, actually influences the distribution of pronoun forms.
| Formality-hypothesis: |
|
If the mode of discourse has an influence on the selection of the different pronoun forms, and in particular, if informal language favours objective pronoun forms, we should observe a higher proportion of objective forms in the spoken data than we do in the written data on the basis that, on average, spoken data is less formal than written (e.g. Biber et.al 1999; Erdmann 1978: 72; Quirk et al. 1985: 337–338) |
|
If, however, informal language does not favour the use of objective pronouns, we should not observe a higher proportion of objective pronouns in the spoken data of the corpora than we do in the written data. |
As stated in section 2, most accounts of pronoun case variation agree that the use of objective pronouns is preferred in informal situations, whereas a high degree of formality encourages the use of subjective pronoun forms (e.g. Biber et al. 1999; Erdmann 1978: 72; Quirk et al. 1985: 337–338; Shorrocks 1992: 436). We will look at the spoken and written data for both it be sentences and it-clefts separately in each corpus in order to assess whether or not this variable influences the distribution of pronoun case forms.
Next we test whether there are cross-varietal differences in the distribution of pronoun case forms in it-clefts and it be sentences. While Quinn (2009) could not find cross-varietal differences in it be sentences and it-clefts, Siemund et al. (2009) attested regional differences in the distribution of pronoun case forms in it be sentences and it-clefts for British, Australian, South African, Irish, and Indian Englishes. It will be interesting to see whether there are also cross-varietal differences between the two corpora at hand and hence between British and American English.
| Cross-varietal-differences-hypothesis |
|
If there are differences in terms of pronoun case assignment between British and American English, they should be borne out by the data and we should observe significant differences between the different corpora. |
|
If there are, however, no differences between the analysed varieties, there should not be any statistically significant differences between the two analysed corpora in the distribution of pronoun case forms. |
The testing of this hypothesis might be affected, however, by the differences in corpus design between the BNC and the COCA, which will be discussed in section 4. Nevertheless, given the size of the corpora, if there are salient differences between the varieties represented by the corpora, they may still be reflected in the data.
4. The data used for this study
The present study is based on results obtained from the online versions of the British National Corpus (BNC) and the Corpus of Contemporary American English (COCA), both of which are freely accessible at Mark Davies’ website through Brigham Young University. [6] Although both corpora are large-scale representations of major varieties of English, it should be noted that the corpora are not entirely comparable, because they exhibit differences in their composition, the most important of which are now briefly discussed.
When compared to the BNC, the COCA is more than four times larger than the BNC and contains proportionally twice as much spoken data. In addition, there are also noteworthy qualitative differences between these two corpora:
A first importance difference concerns the collection period of the data in these two corpora. While the data of the COCA currently represents the period from 1990–2011 and is being continuously expanded, the BNC data is, on average, older, consisting of data from 1960–1994. Although these different periods represented by both corpora may suggest at first glance that both corpora actually represent different generations of speakers and or writers and are hardly comparable at all, a closer look at the BNC data reveals that no spoken BNC data was collected before 1991 and the vast majority of the BNC texts, i.e. 93 percent, are taken from the period between 1985–1994 (Burnard 2007; Leech, Rayson & Wilson 2001: 1). Thus, the intersection of the data in both corpora in terms of their age is – despite all differences – still considerable.
As far as the spoken data of these corpora are concerned, it has to be noted that the COCA data consists of unscripted conversations transcribed from TV and radio shows. [7] The BNC, however, represents a much wider spectrum of spoken data, since it not only comprises what is called “context-governed” data, such as transcripts of meetings, debates, seminars and radio programmes, which is indeed very similar to the spoken data of the COCA, but also contains a large share of what is called a “demographic component”. This demographic component consists of informal conversations recorded by and from a socially-stratified sample of informants who are distinguished according to several social parameters such as sex, age-group, geographic region, and social class, and it accounts for more than four million words (Aston & Burnard 1998: 31–33). Hence, the BNC represents a much more diversified spectrum of spoken sub-genres than the COCA. [8]
There are, however, also qualitative differences in the written data of these two large-scale corpora. Whereas the written data of the COCA is rather evenly distributed across the genres “fiction”, “popular magazines”, “newspapers”, and “academic” texts, the spectrum of the written BNC data is, again, much broader, as it also includes a wide range of other texts such as brochures, manuals, leaflets, advertisements, and letters in order to fulfil the corpus’ major aim, i.e. providing “a microcosm of British English in its entirety” (Burnard 2007). [9]
These differences must be borne in mind when further analysing data from these two corpora. Despite these differences, the two corpora still seem to be the best means to uncover intra-, and perhaps even inter-varietal, differences in pronoun case distribution between British and American English, because contexts in which pronoun case variation typically occur are rather infrequent. This is particularly true for it-clefts and it be sentences, as recent and ongoing research has demonstrated: In the ICE family, for example, these constructions are so scarce that it is impossible to draw substantial conclusions based on the results obtained from these databases (Quinn 2009; Siemund et al. 2009). [10] However, with the help of these two large-scale corpora, it should be possible to obtain a sufficient number of instances to assess the distribution of pronoun case forms in it-clefts and it be sentences for these two varieties. Given the sheer amount of data, cross-varietal differences may appear, if these differences are salient enough even though the compositions of the corpora are different.
One last important remark regarding the use of the COCA data in this study concerns the date of data compilation. Since the COCA is a dynamic corpus that is continuously being enlarged, it is important to note that the data compilation for this study took place on 23 July 2010. This means that the study is not based on the currently available 425-million-word version of this corpus but on the slightly older 400-million-word version of the COCA. However, the version used for this study still yields considerably more data points than any other available corpus, and hence forms a suitable data source for this study.
Following Biber et al. (1999: 335–336, 1134), all instances of it + is/was/’s + I/me/he/him/she/her/we/us/they/them occurring in both BNC and COCA were analysed, which yielded all potential instances of it be sentences and it-clefts with a case-sensitive focal pronoun. In order to obtain only the clear instances of it be sentences and it-clefts, all ambiguous constructions and those irrelevant for this study were excluded from further analysis. Constructions excluded from this study constitute the following:
First of all, those constructions were eliminated that exhibited the respective search string – it followed by one of the forms of be mentioned above and complemented by a case-sensitive pronoun form, but in which the constituents were not part of the same clause.
| (10) |
Search string split in different clauses |
|
a. |
Whatever it is I’ll need a lot of prayer. (BNC/CC8/W_misc) |
|
b. |
Even as it is he’s mad at me for leaving the thing unfinished. (COCA/1992/FIC/BkSF:LostBoys) |
Secondly, sentences were excluded in which it was not possible to decide whether the search string really represented an it-cleft or it be sentence, or whether the search string could be interpreted as something else. Examples for this category of ambiguous cases include the following.
| (11) |
Ambiguous cases |
|
a. |
So, it’s they - they usually ask people to pose for them and everything, but then they couldn’t, that’s because their cameras are freezing, they’re not that fast. (COCA/2010/SPOK/NPR_TellMore) |
|
b. |
I can’t see It’s it’s I I Right. Okay. I I I’ll I’ll check that Can you? (BNC/FUK/S_meeting) |
In addition, instances in which the pronoun forms were used as either demonstrative or possessive pronouns were also excluded from further analysis.
| (12) |
Demonstrative use of pronouns |
|
a. |
It’s them damn calories, though. (COCA/1993/FIC/SouthwestRev) |
|
b. |
We got a whole teacher got a whole lot of letters for some piece all about collecting cans for getting and it was them letters (BNC/HVB/S_interview_oral_history) |
| (13) |
Possessive use of pronouns |
|
a. |
It is me final ambition to top meself. (COCA/1998/MAG Forbes) |
|
b. |
But er, I didn’t believe in, well it was me dad’s pigs of course, but I was there at the time as well like, you know. (BNC/G4R/S_interview_oral_history) |
Also not considered were constructions which, although they are relevant in the discussion of pronoun case variation in English, are not clear instances of either it be sentences or it-clefts (e.g. Huddleston & Pullum 2002: 458–467; Quinn 2005). On the one hand, examples of this category include sentences in which the pronoun form is followed by a noun phrase. In these instances, it is normally the 1st person plural pronoun form which is modified by an integrated dependent in the NP structure. This modifier is usually semantically restrictive in that it limits the denotation of the nominal head and typically provides identifying information (Huddleston & Pullum 2002: 447).
| (14) |
Pronoun-NP constructions |
|
a. |
So who else could it be? Well, maybe it’s us guitarists! (BNC/C9M/W_pop_lore) |
|
b. |
Then use us John, use our strength, it’s us four now, a tribe of warriors, everything we have comes (COCA/1991/FIC Mov:Doors) |
On the other hand, this category includes constructions in which the pronoun form is followed by a gerund participle and may act as its subject (Huddleston & Pullum 2002: 1190–1193.)
| (15) |
Pronoun + –ing form |
|
a. |
He said he’s now become the wind and he can go anywhere and everywhere he wants at any time. He said when I see the wind moving the leaves, it is him waving to me and I should smile his gorilla smile when that happens. (COCA/2006/ SPOK/NPR_Saturday) |
|
b. |
He thinks it’s us trying to come on like Einstein. (BNC/CD6/W_pop_lore) |
|
c. |
Foster, whose own career started at the tender age of 3, discovered 9-year-old Adam in a New York classroom: “It was him wanting to be something that drew me,” she says. (BNC/ED3/W_pop_lore) |
Although sentences such as (15a) are semantically similar to it-clefts, these gerund constructions are difficult to analyse. This is due to the fact that it is very often not clear whether the personal pronoun form is to be construed as the complement of it and be which is then followed by a non-finite clause or whether the pronoun case form belongs rather to the following gerund constituting a part of the non-finite clause which, as a whole, functions as the complement to it and the form of be. In the latter case, the situation is complicated further by the fact that the personal pronouns do not typically alternate between subjective and objective forms, but instead between possessive and objective forms where the non-finite clause functions as a complement. Only in adjuncts can pronoun forms alternate between subjective and objective forms in such gerundial non-finite clauses. In (15c), for example, it is possible to replace the objective pronoun with a possessive pronoun, whereas the replacement of the objective form by a subjective form would be unexpected (Huddleston & Pullum 2002: 460; 1192–1193). In view of this unclear and ambiguous situation, these sentences were excluded from further analysis.
Instances in which the pronoun form following it and a form of be potentially serve as the subject of other non-finite constructions, such as those in (16), were likewise eliminated from further processing of the data. In these cases, it is also not clear whether the personal pronoun form is to be construed as the complement of it and be which is then followed by a non-finite clause, or whether the pronoun case form serves as the subject of the following non-finite clause, which in its entirety functions as the complement to it and the form of be.
| (16) |
Pronoun succeeded by other non-finite constructions |
|
Clinton should do the honorable thing for his party and his country and resign as it is him, and him alone, responsible for the current division of this country. (COCA/1998/NEWS/SanFrancisco) |
Although the sentences in (17) have a finite verb form, they are still in a way incomplete because we observe zero relative markers in subject positions. These sentences are so-called ‘contact clauses’ (e.g. Filppula 2004).
| (17) |
Pronoun forms in contact clauses |
|
a. |
Are you wishing it was I had rolled under in the waves, not me you are, for doing as you ordered? Are you wishing it was I had rolled under in the waves, not your father’s grandson, because he (BNC/APW/W_fict_prose) |
|
b. |
Whether it was her did it or a stranger that abducted Caylee and did it, you still think, “Gosh if we had had custody, this wouldn’t have happened. Please don’t let this be my grandchild that’s dead. (COCA/2009/SPOK/CNN_Velez) |
The reason for the exclusion of the contact clauses in (17) is, like the cases in (15) and (16), the potential ambiguity resulting from the lacking relativiser. Due to the missing relative pronoun, it is often not clear whether the personal pronoun form following it and the form of be in these sentences can indeed be considered the focal pronoun of an it-cleft or whether it should be analysed as the subject of the following clause (cf. Huddleston & Pullum 2002: 1055).
Moreover, all instances of sentences which are ambiguous between the pronoun-NP constructions (cf. (14)) and the demonstrative use of personal pronoun forms (cf. (12)) on the one hand and it-clefts on the other hand had to be excluded as well.
| (18) |
Ambiguous it-clefts |
|
a. |
It was them aliens that’s got the admiral spooked. That’s why. (COCA/2005/FIC/Analog) |
|
b. |
Again it is we anthropologists who create “community” and talk about “social development” but what if we, too, are part of the dominant ideology? (BNC/BMP/W_ac_humanities_arts) |
Similar to the constructions just mentioned, it-clefts and it be sentences with coordinated pronouns were excluded from further analysis of the data. This is due to the fact that coordinated noun phrases also represent a context that is sensitive to pronoun case variation (e.g. Angermeyer & Singler 2003; Biber et al. 1999: 337; Quirk et al. 1985: 338). Therefore, in instances of it-clefts or it be sentences with coordinated noun phrases, it is not clear whether the selection of one pronominal case form over the other can be attributed solely to its occurrence in an it-cleft, it be sentence, or the coordination, or to an interplay of these factors.
| (19) |
Coordinated pronouns in it-clefts |
|
a. |
The plaintiff may be urgently in need of the money. It is he or she who will be incurring additional expenses as a result of the accident and whose earning power may have been impaired. (BNC/GVH/W_ac_polit_law_edu) |
|
b. |
It was him and his side that vilified the Florida court by saying that, because they were nominated by Democrats, they have to be liberals and they have to side with Gore. (COCA/2000/SPOK/CNN_Talkback) |
| (20) |
Coordinated pronouns in it be sentences |
|
a. |
Until then, it’s he and his wife and other family members. (COCA/2003/NEWS/Houston) |
|
b. |
Me and your mother not your mother and I. It’s me and your mother. Well that was, the other day? told him about (BNC/KCF/S_conv) |
Additionally, the exclusion of coordinated pronouns in it-clefts and it be sentences from the analysed data sample seems justified considering the fact that certain pronoun-pronoun combinations, particularly those involving us and them seem to have an idiom-like status, since these coordinations may be used to contrast certain groups or persons with others, such as ordinary citizens with the authorities. [11] Due to this idiomatic status, it is unclear whether these constructions admit pronoun case variation to the same extent as uncoordinated pronouns do (e.g. Angermeyer & Singler 2003: 196, Erdmann 1978: 70). Hence, they were not considered further.
| (21) |
Idiom-like coordinated pronouns |
|
a. |
I’ll tell you, I’m -- I’m locked on them. And it’s them or us (COCA/1997/SPOK/CBS_Sixty) |
|
b. |
Who’s Using who’s All the West End News. A Bunch of Fives Interference Song It’s TV Newstime -- It’s us and them (BNC/B38/W_misc) |
The same is true for pronouns that are contrasted with the help of certain prepositions, such as against and versus. They, too, seem to have idiom-like status and are also used to contrast certain groups of people. [12] Consequently, they were also eliminated from the subsequent analysis.
| (22) |
Idiom-like prepositional constructions |
|
a. |
“What had excited him was the message --;” it’s us against them. That gave me a charge that we could take back to our members (BNC/EG0/W_non_ac_soc_science) |
|
b. |
The fact that there’s so much news all the time, 24-seven, you know, running non-stop, that the only context for understanding a story line is to make it all black and white. It’s us vs. them. It’s the Democrats vs. Republicans and so everything gets turned into sort of verbal mud wrestling. (COCA/2001/SPOK/NPR_FreshAir) |
Negative coordinations such as those in (23a) and (23b) were also excluded from further investigation. This is because these constructions, although negative, can still be considered coordinations (e.g. Huddleston & Pullum 2002: 1313). Hence, other factors, like those outlined above, may influence the choice of a certain pronominal case form in these constructions.
| (23) |
Negative coordinations |
|
a. |
Ashcroft served as a range rider, and many Navajos believed that it was he, not Washington, who directed the slaughter. (COCA/1998/ACAD/AmerIndianQ) |
|
b. |
It was they, not we, who threw down the challenge. It was they again, not we, who invited the judgment of the electorate. (BNC/HRJ/W_non_ac_polit_law_edu) |
Furthermore, instances in which the pronoun form in the search string is modified by an adnominal self-form were likewise omitted. The reason for this omission is the fact that the addition of a self-form may, as in coordinations, influence the choice of a pronoun form, since self-forms favour a subjective form for an antecedent, regardless of their position in the sentence (Jespersen & Haislund 1949: 225; Quinn 2005: 299). Moreover, self-forms may occur only because their insertion helps to avoid the difficulty of choosing between the objective and the subjective pronoun forms in certain variable contexts (Harris 1981: 18; Hernández 2002: 269). Therefore, it seems justified to exclude these instances from further analysis.
| (24) |
Pronouns with adnominal self-intensifier |
|
a. |
Liza did not know how she got back to her billet, only that she had bicycled so fast and furiously that, as she flung herself on her bed, she thought, grimly, that if anyone had reason to miscarry at that juncture it was she herself. (BNC/CDE/W_fict_prose) |
|
b. |
Ajib decided that such riches should belong to someone who appreciated them, and that was himself. To take his older self’s wealth would not be stealing, he reasoned, because it was he himself who would receive it. (COCA/2007/FIC/FantasySciFi) |
Finally, instances which were clear doublets or repetitions of earlier hits were excluded as well.
The remaining data were subsequently coded according to a number of criteria. The first criterion which was taken into consideration was the mode of discourse, distinguishing between spoken and written data. In a second step, we made a distinction between subjective and objective case forms. As subjective forms, we classified the pronoun forms I, he, she, we, and they, and as objective forms we classified me, him, her, us, and them. Furthermore, we distinguished between singular and plural pronouns and between third person forms and non-third person forms. We also distinguished different varieties of English. The COCA data were coded as US, whereas the BNC data were coded as GB. Finally, we also made a distinction between the individual pronoun forms (I vs. me vs. he vs. him vs. she. vs. her. vs. we vs. us vs. they vs. them). All this coding was done in order to obtain the distribution of pronoun case forms in it-clefts and it be sentences in the BNC and the COCA and to test the hypotheses introduced in section 3.
5. Results
The following sections represent the findings for the quantitative analysis of the corpus data, and provide an overview of the pronoun case forms attested in both corpora. The presentation of the quantitative results is divided into two distinct subsections. The first subsection provides the analysis of the distribution of pronoun case forms after it and a form of be in the BNC, while the second subsection shows the same for the pronoun forms attested in the COCA.
5.1 Pronoun case distribution in the British National Corpus
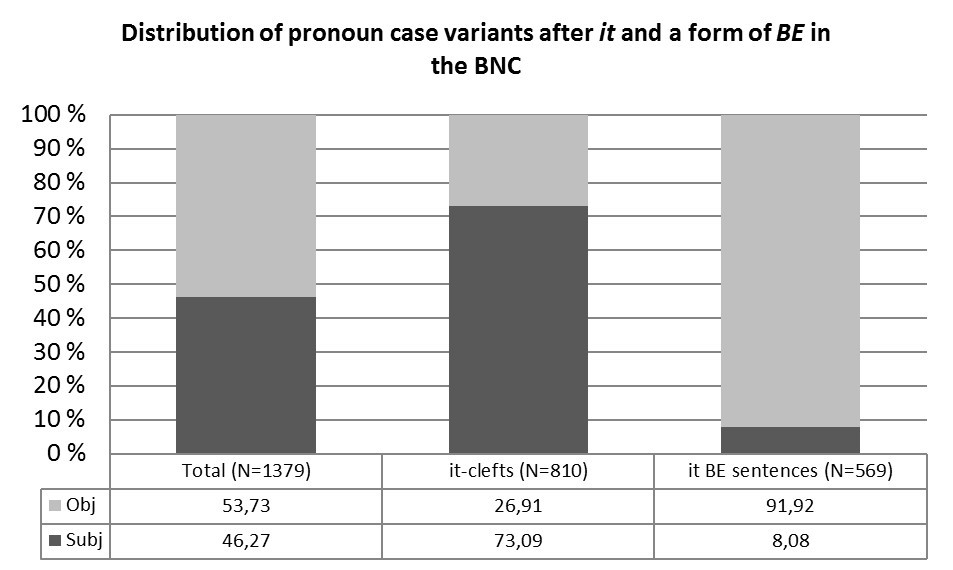
After eliminating all irrelevant constructions (cf. section 4), the data sample of the BNC consists of 1379 instances of pronouns that follow it and a form of be, i.e. is, was and ’s.
As can be seen in Figure 1, generalising over both contexts – it-clefts and it be sentences – the proportion of objective pronouns slightly surpasses the proportion of subjective pronouns. Objective pronouns account for 53.73% of all forms, whereas the subjective forms account for the remaining 46.27% of all instances. However, if we take the clause type in which the pronoun forms surface into consideration, we observe even more marked differences in the distribution of pronoun case forms. A subjective pronoun case form is used in more than 73% of all it-clefts, but the share of subjective pronoun case forms in it be sentences only accounts for 8,08% of all instances. Using a chi-square test, we notice that these differences are not only very highly significant statistically (χ2= 568.04, df= 1, p<0.001, φ= 0.64), but also seem to imply that the distribution of post-verbal pronominal case forms is highly dependent on the function of the pronoun and its syntactic context.
If we take a further variable into consideration, namely the mode of discourse, we obtain the following results represented in Figure 2.
This figure yields not only remarkable results, but also offers a more fine-grained picture of the distribution of pronoun case forms in the analysed contexts. In the domain of it be sentences, there are no statistically significant differences between the written and spoken data when analysed by means of a chi-square test (χ2= 1.66, df= 1, p>0.05, φ= 0.05). In both subcomponents, the objective pronouns in this construction amount to roughly 90% of all tokens. When considering the it-cleft data, however, we get a very different picture. In this domain, there is a clear and highly significant statistical difference between the written and spoken data (χ2= 127.41, df=1, p<0.001, φ= 0.40). In fact, the distribution of pronoun case forms appears to be nearly complementary between the spoken and the written data: In the spoken component, we observe a share of objective forms of more than 80% and a share of about 20% of subjective forms, whereas we find more or less the opposite pattern for the written component. Thus, we can state that the mode of discourse seems to influence the distribution of pronoun case forms in the domain of it-clefts but not in the domain of it be sentences in British English.
5.2 Pronoun case distribution in the Corpus of Contemporary American English
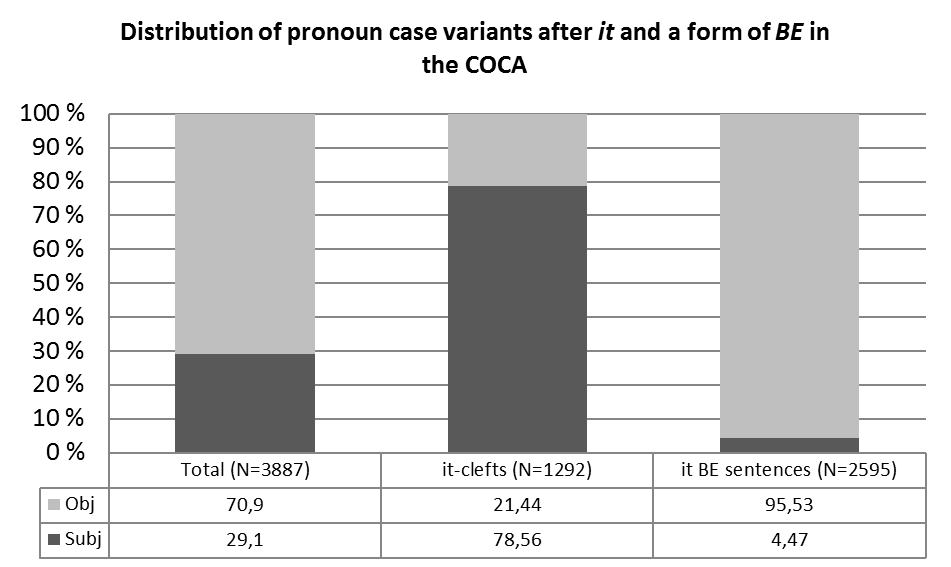
After eliminating all irrelevant constructions in the COCA data (cf. section 4), the remaining sample from this corpus consists of 3887 relevant constructions for further analysis.
As Figure 3 illustrates, there are marked differences between the COCA data and the data from the BNC. Generalising over both contexts, we notice that the overall proportion of objective pronouns amounts to 70.9% of all forms, whereas the subjective forms only have a share of 29.1%. When compared to the BNC data, this high share of objective forms can, however, be partly attributed to the relatively low number of it-clefts with a case-sensitive focal pronoun in the COCA data. While we observe a ratio of roughly 8.1 it-clefts per million words for the BNC data, the ratio for the COCA data only amounts to roughly 3.2 it-clefts per million words. [13] By contrast, the ratios of it be sentences between the corpora are more similar. In the BNC, we detect a ratio of about 5.7 it be sentences per million words, as compared to a ratio of 6.5 it be sentences per million words in the COCA. Looking again at the distribution of the pronoun case forms between the different functions, i.e. distinguishing between mere subject predicatives in it be sentences and focal pronouns in it-clefts, we again observe marked differences. For it-clefts, we find a 21.44% share of objective forms and a 78.56% share of subjective forms, whereas we detect a 95.53% share of objective forms for it be sentences as compared to a 4.47% proportion of subjective forms. These distributional differences between it-clefts and it be sentences are, of course, very highly significant (χ2= 2295.06, df= 1, p<0.001, φ= 0.77).
If we now take into consideration the mode of discourse as a further variable, i.e. the distinction between spoken and written data, pronoun case is distributed in the following manner.
As was the case with the BNC data, the inclusion of the mode of discourse variable again offers a more fine-grained view. In the domain of it be sentences, we detect only minimal differences in terms of pronoun case distribution between the written and the spoken subsets of the corpus. In both subcomponents, the share of objective pronouns in this construction lies between 95% and 96%. Hence, it is not surprising that these differences are not statistically significant (χ2= 0.24, df= 1, p>0.05, φ= 0.01).
However, the it-cleft data once again depict a strikingly different picture. Although the data is not quite as complementarily distributed as in the BNC, the distribution of the pronominal case forms is still marked by a very highly significant difference between the written and spoken components of the corpus (χ2= 16.50, df= 1, p<0.001, φ= 0.11). For the written data, the share of it-clefts with subjective focal pronoun amounts to 80.14% while the objective forms account for the remaining 19.86%. Remarkably, the share of subjective focal-pronouns is still 64.93% compared to 35.07% objective forms in the spoken data. This high share of subjective forms in the spoken data may, however, be due partly to the corpus composition, because the COCA’s spoken data are more formal than that of the BNC, as was explained in section 4.
If we compare the findings obtained for the two corpora, we obtain the following results: In the domain of the it be sentences, it should suffice to compare the written subsets of the two corpora with each other. This is because we have found no statistically significant difference between either the written and the spoken component in the BNC or the written and the spoken component in the COCA. Taking the written BNC data as the reference value, we can say that there are significant differences between the written BNC and the written COCA data, because the COCA favours objective pronoun forms in it be sentences even more than the BNC data does (χ2= 5.03, df= 1, p<0.05, φ= 0.04). Although the difference between the American data and the British data is ‘only’ significant at the 5% level, and the effect-size (φ= 0.04) indicates only a weak correlation, it is still significant. When comparing the it-cleft data with each other and taking again the written BNC data as reference, we again find interesting results. First of all, there are no significant differences between the written it-cleft data of the BNC and that of the COCA (χ2= 0.54, df= 1, p>0.05, φ= 0.02). If we contrast the written BNC data with the spoken subsets of both corpora we obtain highly significant results: Comparing the written BNC it-cleft data to the spoken BNC data and applying a chi-square test, we achieve the following results: χ2= 127.41, df= 1, p<0.001, φ= 0.40. When we test the differences between the written BNC it-cleft data and the spoken COCA data by applying a chi-square test, the following results are obtained: χ2= 12.08, df= 1, p<0.001, φ= 0.12. Although it might seem counterintuitive to compare the written BNC data with the spoken COCA data, this method can be justified by the fact that there was no statistically significant difference between the written BNC and the written COCA data, so this comparison seems plausible. In sum, we can state that the COCA data differs from the BNC data with regard to both the overall frequency and the distribution of pronoun forms for both constructions. As far as the it be sentences are concerned, we determined that they occur more frequently in COCA than in the BNC: 6.5 times per million words in the COCA as compared to 5.7 it per million words in the BNC. With regard to the pronoun form distribution in it be sentences, we noted that the share of subjective forms is even lower than in the BNC data. For the it-cleft data, however, we observed that the share of subjective forms is higher, particularly in the spoken data, which may be attributed partly to the differences in the data composition. In terms of frequency, we can state that it-clefts are considerably less frequent in the COCA data than in the BNC.
6. Discussion
With regard to the Position-versus-function-hypothesis, the results clearly corroborate Erdmann (1978) in that they indicate that the function of the pronoun in the clause seems to additionally determine, or at least co-determine, the distribution of its form: If the additional focus function of the pronoun in it-clefts played no role in the choice of the pronoun forms, we would not expect to see such remarkable differences in the distribution of pronoun case forms between it be sentences and it-clefts as we do here. Although the clefted constituent can, of course, also be coreferential with an object of the following relative clause, as discussed in section 3, in 90% of the BNC it-clefts and more than 92% of the COCA it-clefts, the clefted personal pronoun is coreferential with the subject of the following clause. The fact that the clefted pronoun may be coreferential with the subject of the dependent clause seems clearly to promote the use of subjective pronoun forms. Thus, this double function or “Janus-like status”, as Quirk et al. (1985: 338) call it, of the personal pronoun in an it-cleft seems to influence heavily the choice of pronoun case forms. In light of these results, it seems far too early to postulate that the position of the pronoun is the sole determinant of the pronoun form in a given context (e.g. Burridge 2004: 1118). Furthermore, predictions about a supposedly telic development of pronoun case distribution have to be re-evaluated. Proponents of the classification of pronoun forms in “weak” and “strong” classes predict that the English pronoun system will eventually resemble the one found in French or other Romance languages (e.g. Harris 1981: 18–19; Quinn 2005: 383). In a similar fashion, positionalists predict the eventual victory of position over function as the sole determining factor (e.g. Burridge 2004; Collins & Peters 2004: 605), and some accounts even suggest the total loss of the subjective/objective distinction in favour of a retention or, depending on the perspective, emergence of one common case serving all functions, which will most likely be the objective case (Wales 1996: 107). However, there are no detailed diachronic studies that corroborate these claims. If we now compare the results of the present study to Erdmann’s results, which are based on corpus data consisting of about 40 British novels from 1930 to 1970 and, hence, are about 40 to 60 years older than the present British data, at least a very crude diachronic comparison should be possible. Erdmann reports a 90.41% share of objective forms (N= 66) and a 9.59% share of subjective forms (N= 7) for it be sentences. Comparing these numbers to the written data of the BNC, we do not observe statistically significant differences between Erdmann’s results and the findings of this study (χ2= 0.51, df= 1, p>0.05, φ= 0.03). For it-clefts, Erdmann reports an 83.19% proportion (N= 99) of subjective forms and a 16.81% (N= 20) proportion of objective forms. Again, comparing these results to the written BNC data, we also do not observe any statistically relevant differences (χ2= 1.24, df= 1, p>0.05, φ= 0.04). Hence, we can state that if pronoun case distribution is still subject to ongoing language change, the data indicate that this change has been rather slow in British English, at least with regard to it-clefts and it be sentences for the last 40 or 50 years. In view of these results, it can be concluded that the use of subjective pronoun forms in both “object territory” and “strong” pronoun contexts is quite stable both in it-clefts and it be sentences, although at a considerably lower rate for the latter than for the former.
As far as the Formality-hypothesis is concerned, the data demonstrate that the mode of discourse, or the degree of formality, has a certain influence on the distribution of pronoun case forms in it-clefts. The subjective pronoun forms are clearly favoured in the written components of both corpora, whereas the likelihood of occurrence of objective forms is higher in the spoken data of both corpora. How great the likelihood actually is for observing an objective case form as focal pronoun in the spoken component depends, however, on the respective corpus. In the BNC, the share of objective pronoun forms in the spoken component was much higher than in the COCA, which could be partly attributed to the more formal spoken data of the COCA. As far as it be sentences are concerned, there are no statistically significant differences between the spoken and the written data either in the BNC or in the COCA. Hence, it seems that style or formality is not a decisive factor in determining the distribution of pronoun case forms in it be sentences. In this domain, objective forms are indeed “nearly universal” (Biber et al. 1999: 336). However, there are still noteworthy proportions using subjective forms in both corpora. Thus, future research might focus on these exceptions to find out which factors motivate the choice of a subjective form in these contexts in order to shed more light on the factors motivating pronoun case distribution in it be sentences. That there are marked differences between the written and the spoken data in the domain of it-clefts but not it be sentences may also be due to the frequent double function of the personal pronoun as complement of the matrix clause on the one hand and subject of the subordinate clause on the other. Due to the increased amount of planning time needed to produce an utterance in the written mode of discourse the speaker/writer may become more aware of this “clash” between complement function and subject coreference, and thus may favour the subjective form in the written mode (Quirk et al. 1985: 338).
From a cross-varietal perspective, this study has revealed striking differences between the British and American data. First of all, the differences with regard to the relative frequency of the analysed constructions are very remarkable. While the rate of occurrence of it be sentences is quite similar in both corpora, ranging from 5.9 instances per million words in the BNC to 6.5 occurrences per million words in the COCA, the frequency of it-clefts is strikingly different. According to the corpus data, it-clefts are 2.5 times more common in British English than in American English, with a rate of occurrences of about 3.2 it-clefts per million words in the COCA as compared to approximately 8.1 it-clefts per million words in the BNC. This seems to be a robust cross-varietal difference, since the differences between the corpora do not seem to be sufficient to account for these differences. Biber et al. (1999: 961–963) showed that it-clefts are common in all registers and are actually most frequent in academic texts. Thus, the differences in the composition of the corpora should not result in such marked differences if there were no cross-varietal differences in the frequency of use.
Furthermore, it is remarkable to note that the share of objective pronoun forms in it be sentences is significantly higher in the COCA data than in the BNC data. Although the effect size of this difference is rather small (χ2= 5.03, df= 1, p<0.05, φ= 0.04), and although it is ‘only’ significant at the 0.05 level of significance, this finding is remarkable, bearing in mind that some accounts assume a “general trend in English towards case selection [being] dictated by position rather than function” (Burridge 2004: 112).
In the domain of it-clefts, we do not observe significant differences between the written components of the BNC and the COCA. However, the high proportion of subjective forms in the spoken it-cleft data of the COCA, which amounts to 64.93% is strikingly different from the results obtained from the BNC, in which the share of spoken it-clefts with a subjective focal pronoun amounts to only 18.42%. Although this high share of subjective forms in the COCA could be argued to derive from the more formal character of its spoken data as compared to that of the BNC (cf. section 5.1), it seems implausible that this should be the sole reason for these differences. Hence, also bearing in mind the differences observed for the it be sentences, we can conclude that there are indeed cross-varietal differences observable in the distribution of pronoun forms in variable contexts of pronoun case assignment, since we observe different distributions not only for different constructions, but also for different modes of discourse.
Moreover, this study has also corroborated earlier accounts in showing that variable contexts of pronoun case assignment are low frequency phenomena, which makes it difficult to analyse these phenomena quantitatively (e.g. Quinn 2009). With the rates of occurrence for the analysed phenomena ranging from 3.2 and 8.1 instances per million words, it becomes obvious that most existing corpora are simply too small to allow for quantitative analyses. This is particularly true for corpora representing varieties of English such as the individual components of the International Corpus of English (ICE). Consequently, cross-varietal analyses of these phenomena remain a challenge for corpus linguistics in view of the limited databases available thus far. Hence, this study also clarifies the need for bigger cross-varietal databases in order to uncover all syntactic, pragmatic, and semantic factors underlying the distributional differences of standard and non-standard morphosyntactic features in general (cf. Kortmann 2006: 603), and the distribution of pronoun case forms in particular (cf. Maier 2012).
7. Conclusion
The purpose of this paper was not only to offer a survey of the distribution of pronoun case forms in two variable contexts, i.e. it-clefts and it be sentences in the BNC and the COCA, but also to test potential variables with regard to their actual influence on the choice of pronoun case forms in the analysed contexts. In contrast to the expectations of much of the recent linguistic literature, the syntactic function of the pronoun still seems to play an important role in some contexts when it comes to choosing between the subjective and the objective pronoun forms, as both our results and the discussion of the findings have shown. Hence, this study has once more underlined the need for large-scale quantitative studies not only in inter- and intra-varietal studies but also for linguistic theory formation in general. Furthermore, our results have demonstrated that the difference between spoken and written data seems to affect the choice of pronoun case forms in some contexts but not in others: Whereas, in the context of it be sentences, the preference for the objective form was nearly universal, regardless of the mode of discourse, the it-cleft data exhibited a pronounced sensitivity to the distinction between spoken and written data. With regard to cross-varietal differences in the distribution of pronoun case forms, our results have illustrated that differences between varieties of English in the distribution of pronoun case forms in variable contexts exist, but also how much data is actually needed in order to discover these differences. Hence, this study has also shown the need for bigger cross-varietal data bases in order to analyse and quantify also rather infrequent syntactic phenomena and uncover all of the underlying factors determining their distribution.
Notes
[1] Although there is a lot of discussion about the appropriateness of terminology (cf. Huddleston & Pullum 2002: 456), we will adopt Quirk’s et al. (1985) terminology in the following, which seems to be widely acknowledged.
[2] www.smh.com.au/articles/2003/01/24/1042911550577.html, accessed 15 July, 2008.
[3] Although it might appear counterintuitive to attribute subject status to it in both it be sentences and it-clefts, it actually fulfills seven of the eight criteria for subjecthood proposed by Huddleston & Pullum (2002: 235–244). The reason the eighth criterion, case, is not met is that it is not applicable. Furthermore, general reference grammars of English clearly identify these constructions as (subject) predicative complements (Biber et al. 1999: 335–336; Huddleston & Pullum 2002: 251–252).
[4] The data was collected in the summer of 2010, when the Corpus of Contemporary American English consisted of 400 million words. This has to be mentioned as this corpus is constantly being expanded.
[5] Please note that no editorial changes were made in the corpus examples, besides the removal of superfluous spacing.
[6] http://corpus.byu.edu/, accessed 11 July, 2010.
[7] Cf. http://corpus.byu.edu/coca/compare-bnc.asp, accessed 21 Oct 2011.
[8] Cf. http://corpus.byu.edu/coca/compare-bnc.asp, accessed 21 Oct 2011.
[9] Cf. http://www.natcorp.ox.ac.uk/docs/URG/BNCdes.html, accessed 21 Oct 2011 and http://corpus.byu.edu/coca/compare-bnc.asp , accessed 21 Oct 2011.
[10] Cf. http://ice-corpora.net/ice/index.htm, accessed 3 December 2011[archive.org].
[11] Cf: (us, pron., n., and adj. OED Online. November 2010. Oxford University Press. http://www.oed.com/view/Entry/220627?redirectedFrom=us%20and%20them, accessed 3 December, 2010.
[12] Cf: (us, pron., n., and adj. OED Online. November 2010. Oxford University Press. http://www.oed.com/view/Entry/220627?redirectedFrom=us%20and%20them, accessed 3 December, 2010.
[13] Note that the normalised frequencies of it-clefts and it be sentences per million words are based on the idealised token counts of 100 million words for the BNC and 400 million words for the COCA. The author is of course aware that the actual token counts differ from these idealised numbers. However, as it was not possible to retrieve the exact token count of the 400 million word COCA afterward (Davies 2011, p.c.), this approach offers at least a crude approximation to the per-million-word frequencies of the analysed constructions. Furthermore, even if the numbers were slightly different, they would probably not diminish the vast frequency differences in the domain of it-clefts between the two corpora.
Sources
Davies, Mark. 2008– The Corpus of Contemporary American English: 425 million words, 1990–present. Available online at http://corpus.byu.edu/coca/, accessed 23 July 2010.
Davies, Mark. 2004–. BYU-BNC. (Based on the British National Corpus from Oxford University Press). Available online at http://corpus.byu.edu/bnc/, accessed 22 July 2010.
Mark Davies’ Homepage at Brigham Young University. http://davies-linguistics.byu.edu/personal/, accessed 23 July 2010.
Oxford English Dictionary Online. http://www.oed.com/, accessed 3 December 2010.
References
Angermeyer, Philipp S. & John Victor Singler. 2003. “The Case for Politeness: Pronoun Variation in Co-ordinate NPs in Object Position”. Language Variation and Change 15, 171–209.
Aston, Guy & Lou Burnard. 1998. The BNC Handbook: Exploring the British National Corpus with Sara. Edinburgh: Edinburgh University Press.
Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad & Edward Finegan. 1999. Longman Grammar of Spoken and Written English. Harlow: Pearson Education.
Britain, David, ed. 2007. Language in the British Isles. Cambridge: Cambridge University Press.
Burnard, Lou. 2007. “BNC User Reference Guide”. University of Oxford. http://www.natcorp.ox.ac.uk/docs/URG/BNCdes.html
Burridge, Kate. 2004. “Synopsis: morphological and syntactic variation in the Pacific and Australasia.” In Kortmann et al. (eds.), 1116–1131.
Chomsky, Noam. 1993. “A Minimalist Program for Linguistic Theory”. The view from Building 20: Essays in Linguistics in Honor of Sylvain Bromberger (Current Studies in Linguistics 24), ed. By Ken Hale & Samuel J. Keyser, 1–52. Cambridge, Mass: MIT Press.
Chomsky, Noam. 1995. “Chapter 4: Categories and Transformations”. The Minimalist Program (Current Studies in Linguistics 28), 291–392. Cambridge, Mass: MIT Press.
Collins, Peter & Pam Peters. 2004. “Australian English: morphology and syntax”. In Kortmann et al. (eds.), 593–610.
Cooper, Christopher. 1685 [1968]. Grammatica Linguae Anglicanae (English Linguistics 1500–1800. A Collection of Facsimile Reprints 86), ed. by R. Alston. Menston: Scolar Press Limited.
Emonds, Joseph. 1976. A transformational approach to English syntax. New York: Academic Press.
Emonds, Joseph. 1985. A unified theory of syntactic categories. Dordrecht: Foris.
Erdmann, Peter. 1978. “It’s I, It’s Me: A Case for Syntax”. Studia Anglica Posnaniensia 10: 67–80.
Filppula, Markku. 2004. “Irish English: morphology and syntax”. In Kortmann et al. (eds.), 73–101.
Greenbaum, Sidney. 1996. The Oxford English Grammar. Oxford: Oxford University Press.
Haegeman, Liliane & Jacqueline Guéron. 1999. English Grammar. A Generative Perspective. Oxford & Malden: Blackwell.
Harris, Martin. 1981. “It’s I, It’s Me: Further Reflections”. Studia Anglica Posnaniensia 13: 17–20.
Hernández, Nuria. 2002. “A Context Hierarchy of Untriggered self-Forms in English”. Zeitschrift für Anglistik und Amerikanistik (ZAA) 50(3): 269–284.
Huddleston, Rodney & Geoffrey Pullum. 2002. The Cambridge Grammar of the English Language. Cambridge: Cambridge University Press.
Hudson, Richard. 1995. “Does English Really Have Case?”. Journal of Linguistics 31: 375–392.
Jespersen, Otto. 1933. Essentials of English Grammar. London: Allen and Unwin.
Jespersen, Otto & Niels Haislund. 1949. A Modern English Grammar on Historical Principles. Part VII: Syntax. Copenhagen: Ejnar Munksgaard.
Kiparsky, Paul. 1997. “The Rise of Positional Licensing”. Parameters of Morphosyntactic Change, ed. by Ans van Kemenade & Nigel Vincent, 89–146. Cambridge: Cambridge University Press.
Kjellmer, Göran. 1986. “‘Us Anglos Are a Cut above the Field’: On Objective Pronouns in Nominative contexts”. English Studies: A Journal of English Language and Literature 67: 445–449.
Kortmann, Bernd. 2006. “Syntactic variation in English: A global perspective”. Handbook of English Linguistics, ed. by Bas Aarts. & April McMahon, 603–624. Oxford: Blackwell.
Kortmann, Bernd, Kate Burridge, Rajend Mesthrie, Edgar Schneider & Clive Upton, eds. 2004. A Handbook of Varieties of English. Volume 1: Phonology, Volume 2: Morphology and Syntax. Berlin & New York: Mouton de Gruyter.
Leech, Geoffrey, Paul Rayson & Andrew Wilson. 2001. Word Frequencies in Written and Spoken English – Based on the British National Corpus. Harlow: Longman.
McCreight, Katherine. 1988. Multiple Case Assignments. PhD thesis, MIT. http://www.ai.mit.edu/projects/dm/theses/young88.pdf
Maier, Georg. 2012. The Distribution of Pronoun Case Forms in Subject Predicative Complements in Varieties of English. A Corpus- and Web-Based Study of Pronoun Case Variation. Ph.D. dissertation, University of Hamburg.
Parker, Frank, Kathryn Riley, & Charles Meyer. 1988. “Case Assignment and the Ordering of Constituents in Coordinate Constructions”. American Speech 63: 214–233.
Quinn, Heidi. 2005. The Distribution of Pronoun Case Forms in English. Amsterdam: Benjamins.
Quinn, Heidi. 2009. “Pronoun forms”. Comparative Studies in Australian and New Zealand grammar and beyond, ed. by Pam Peters, Peter Collins & Adam Smith, 31–47. Amsterdam: John Benjamins.
Quirk, Randolph, Sidney Greenbaum, Geoffrey Leech & Jan Svartvik. 1985. A Comprehensive Grammar of the English Language. London: Longman.
Shorrocks, Graham. 1992. “Case Assignment in simple and coordinate constructions in Present-day English”. American Speech 67(4): 432–444.
Siemund, Peter, Georg Maier & Martin Schweinberger. 2009. “Towards a more fine-grained analysis of the areal distributions of non-standard features of English”. Language Contacts meet English Dialects. Studies in Honour of Markku Filppula, ed. by Esa Penttilä & Heli Paulasto, 19–45. Cambridge Scholars Publishing: Cambridge.
Sobin, Nicholas. 1997. “Agreement, Default Rules, and Grammatical Viruses”. Linguistic Inquiry 28: 318–343.
Sweet, Henry. 1875. “Words, logic and grammar”. Transactions of the Philological Society. 470–503.
Trudgill, Peter & J. K. Chambers, eds. 1991. Dialects of English. Studies in grammatical variation. London & New York: Longman.
Wales, Katie. 1996. Personal Pronouns in Present-Day English. Cambridge: Cambridge University Press.
Wunderlich, Dieter. 1997. “Cause and the Structure of Verbs”. Linguistic Inquiry 28: 577–628.
|
|