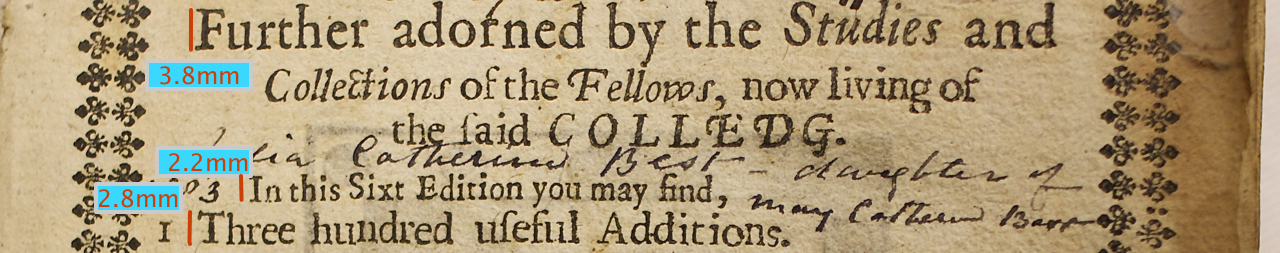The Culpeper Project: Digital editing of title-pages
Jukka Tyrkkö, University of Tampere
Ville Marttila, University of Helsinki
Carla Suhr, University of Turku
Abstract
With a few notable exceptions, traditional corpus linguistic methods have focused on linguistic rather than peritextual features, while the enterprise of digital editing has paid more attention to the latter. Over the last decade, the rising prominence of the field of digital humanities has served to bring together these two disciplines by means of common annotation schemata and, more crucially still, has fostered a renewed sense that a comprehensive understanding of the primary source is useful to both linguists and archivists. Today, by means of careful digital editing, many contextual and co-textual features of the artefact can be recorded in a searchable and quantifiable format along with the text itself.
This article presents a TEI XML-based system of peritextual annotation developed by the authors as part of the Gatekeepers of Knowledge project. In addition to discussing the annotation model in some detail, we present some of the first findings of a pilot study on the title-pages of books by the seventeenth-century medical author Nicholas Culpeper. The pilot project will demonstrate the usefulness of the system of annotation and the preliminary findings will support the observation made in earlier scholarship that Culpeper’s main publishers can be effectively divided into two competing branches.
1. Introduction
Nicholas Culpeper (1616–1654) was arguably the most prominent medical writer in seventeenth-century London. A ‘gentleman student of physick and astrology’, as the title-pages of his books frequently styled him, Culpeper practiced medicine as an apothecary and astro-physician, but found lasting fame during the last five years of his short life as an author and translator. His career as an author started auspiciously as the author of the London Dispensatory (1649), the unlicensed translation of the Pharmacopoeia Londinensis, the official medicine book of the Royal College of Physicians. Thereafter, Culpeper wrote and translated a number of best-selling titles, and became a marketing phenomenon, with more than 230 entries in the English Short Title Catalogue (henceforth ESTC) bearing the name Nicholas Culpeper. His name became a byword for printing medicine for the masses and, by so doing, fighting the Latinate establishment.
Culpeper’s personal history and publishing history have already been extensively and expertly studied by several scholars, perhaps most notably by Jonathan Sanderson (1999), Mary Rhinelander McCarl (1996) and Elisabeth Lane Furdell (2002 and/or 2004), aspects of his story can also be studied from the perspective of more general book history as an early example of how a best-selling brand was created in seventeenth-century London. Although Culpeper was no doubt a forceful and exciting personality, it is clear that he owes his fame to a handful of printers, who saw the opportunity to sell medical books on a previously unseen scale by capitalizing on a recognisable and appealing name. Accordingly, this chapter will focus on the commercial branding of Nicholas Culpeper, and take as a case study the most conspicuous instrument of book advertising, the title-page. Proceeding from the well-established notions that the seventeenth-century title-page was largely the domain of the bookseller and printer, and that its main use was as a vehicle for advancing sales, we take a systematic look at the title-pages of Culpeper’s books – books both written or translated by him, as well as those attributed to him – and try to uncover the role of individual printers and printing houses in creating this best-selling brand.
1.1 Research questions
The starting point to this study has been established in previous scholarship. According to Rhinelander McCarl (1996), Culpeper publishing can be seen as forming two different strands, one emphasizing his medical work, the other exploiting Culpeper’s name in any way possible. The main personality in the former group, later referred to as Strand A, was Culpeper’s friend and major publisher Peter Cole, who can be credited with the initial creation of his success, and John Streater who took over after Culpeper’s main titles after Cole’s death. The latter group, Strand B, is most prominently represented by Nathaniel Brookes and Obdahiah Blagrave, as well as a host of minor publishers. Our objective was to examine the paratextual practices of these two groups of printers and to established the extent to which they, on the one hand, strived to make use of features common to the best-selling brand and, on the other, exhibited idiosyncratic printing-house styles. To a lesser extent, we are also concerned with the notion of the title-page as a form of advertisement, and will consequently offer some comments and observations on the prominent visual characteristics of the title-pages.
The methodological focus of this article is on the digital editing of early modern books, both in terms of the methods of editing itself and of extracting useful data from digital editions. To that end, we discuss the annotation of the structural and visual features of title-pages in XML, using a scheme based on the P5 version of the Text Encoding Initiative’s Guidelines for Electronic Text Encoding and Interchange (hereafter referred to as the TEI Guidelines), and introduce a methodology for annotating the physical dimensions and visual layout of the page in a way that combines expedience with accuracy. The approach we took owes much to corpus linguistic methodology, particular when it comes to the analysis of annotated data. In an effort to quantify the peritextual features of the title-pages, various quantitative and qualitative features were extracted from the descriptive annotation using XSLT transformations and tabulated into a database, on which further quantitative analysis could be carried out.
2. The historical context: the man and the brand
The early modern period witnessed the emergence of printing as the new dominant medium of knowledge dissemination. This not only meant that written texts became available to a wider audience in a volume previously unimagined, but also that an entirely new commercial industry was created. Printers and publishers, who in the early days of printing came from the ranks of goldsmiths and other skilled craftsmen, soon formed into new communities of practice with established rules and a new identity as purveyors of literature and culture (Tyrkkö, forthcoming). Early book professionals were quick to grasp the rules of the new game, and innovations like the title-page, the printing of advertising leaflets and trading in stock image plates soon became established as common practices. Importantly for the present discussion, the development of the printed medium was driven by the commercial interests of publishers and printers, not of the authors. In 1557, when London booksellers organized as a chartered livery company, the Worshipful Company of Stationers, the focus was on protecting the trade and in establishing internal rules of copyright and fair-trading, such as maintaining the Stationers’ Register. The rights to books, such as they were, were the rights of publishers. While this is not to say that prominent authorities did not get a word in at all – in the medical field, for example, some master surgeons and notable physicians would even self-publish important titles – it is important to bear in mind that decisions about the advertising and publicizing of books was the domain of the publisher. The obvious bestsellers, to use a modern term, were religious titles and devotional books as well as calendars and other commonplace books, but none of these foregrounded the author in any particularly salient way. It would take well over a hundred years before printing had reached a point where it is reasonably talk about contemporary authors as being bestselling literary personas. This paper focuses on one such character, Nicholas Culpeper, with particular reference to the role printing and marketing played in turning him from a rather unremarkable apothecary to a best-selling author whose books have remained in print for nearly 350 years.
2.1 Nicholas Culpeper
Nicholas Culpeper was born in 1616. The son of the Reverend Nicholas Culpeper, he was brought up by his mother at the house of his grandfather, William Attersole, because his father died before he was born. He was sent up to Cambridge at 16 to read for the Church, but he abandoned his studies following the death of his fiancée, and was subsequently disinherited for letting down his family’s expectations. Culpeper then moved to London and took up an apprenticeship with Francis Drake, an apothecary in London. In the medical hierarchy of the time, apothecaries served the functions of both chemists and general practitioners, often serving as de facto providers of primary medical care for the poor. A protestant and a Leveller, Culpeper felt that basic instruction in preventive medicine and the treatment of common ailments ought to be made available to everyone, and he soon set to work writing medical books for the benefit of his customers. Once freed, Culpeper established himself in the Spittle-fields, where he is known to have had his own shop by 1640 (Furdell 2004: 43). This put the deeply religious young apothecary in daily contact with the large segment of society who had no direct access to other medical care. During the Civil War, he served Cromwell’s army as a surgeon, training himself for the job. Culpeper started writing and translating medical books toward the end of the 1640s. Although his entire output is characterized by sometimes rambling preliminaries devoted to social causes and religious themes, there are conflicting views about the extent to which Culpeper really advocated the dissemination of medical knowledge to the masses. Some scholars like Hill (1972: 240) believe that Culpeper was hopeful of transforming medicine by doing to medical Latin what the protestant movement had done to Latinate religion, that is, to make knowledge available to everyone regardless of background or ability to read Latin. On the other hand, others like Wear (2000: 61) argue that Culpeper did not intend indiscriminate dissemination of medical knowledge to laymen, but rather only to non-Latinate practitioners of medicine. Regardless of the truth about Culpeper’s moral convictions, another, more prosaic reason most likely spurred Culpeper to embark on a career as a medical author. His health was declining, likely as a result of being wounded in the shoulder during the war, and he suffered from tuberculosis. He wanted to make provisions for his wife and children after his death, and from 1649 onward he wrote and translated at an unremitting pace.
Culpeper’s very first foray into medical writing brought him lasting fame – or infamy. As a fearless advocate of writing for the poor, Culpeper translated the Pharmacopeia Londinensis, the official handbook of medicaments approved by the Royal College of Physicians. Because it was written in Latin, the handbook was effectively restricted to the well-educated and wealthy. This not only excluded the poor, but also the majority of apothecaries and surgeons, who at the time were not educated at universities and could not, as a rule, read Latin. Culpeper’s decision to translate the book went against every principle of the College which fought fervently against charlatans and unlicensed practitioners, and the publishing of medical knowledge in the vernacular. The ownership of the copy of Pharmacopoeia Londinensis and the behind-the-scenes dealings involving it are discussed in detail by Sanderson, who notes that Culpeper started the translation work in 1647 in anticipation of a new, revised version of the Latin Pharmacopoeia which was being planned by the College (Sanderson 1999: 74). The first scandalous translation was published with the title Physical Directory, or a Translation of the London Dispensatory in 1649. Printed by Peter Cole, it was to be the first of many Culpeper titles printed by Cole (see 2.1). A steady stream of titles followed: A Directory for Midwives (1651), Semeiotica Uranica (1651), Galen’s Art of Physick (1652), English Physitian (1652), Compleat Herbal (1653) and Pharmacopoeia Londinensis (1653, Image 2). Most of the major books would continue to be published for decades. In addition to these, several minor astrological works also appeared to considerably less fanfare.
Although Culpeper is largely remembered today as a single author, he did collaborate fairly closely with at least two physicians. The first of them was Abdiah Cole, a possible relation of Peter Cole, Culpeper’s printer. There is not enough evidence at this time to know this for certain, but we do know that Abdiah Cole worked with Culpeper on several translations and later, after Culpeper’s death, prepared many of the posthumous manuscripts for publication by Peter Cole. The second collaborator was the physician William Rowland, who worked with Culpeper and Cole on the translation of Lazare Rivière’s The Practice of Physick (1655). Years later, Rowland claimed in the paratext of his translation of Schröder’s The Compleat Chymical Dispensatory (1669) that he, in fact, was the true translator of all works ascribed jointly to Culpeper and Cole. [1] Rowland’s name and likeness appears in a four-portrait frontispiece of the first edition of The Practice of Physick along with Rivière’s, Culpeper’s and Abdiah Cole’s, but his name was removed from subsequent editions, shortened to R.W. in the second edition and removed entirely from the third edition.
One the most interesting aspects of the Culpeper story concerns the way the author’s name continued to flourish as a commercial entity long after his death in 1654 at the age of only 38. For the first ten years after Culpeper’s death, Peter Cole carried on publishing Culpeper’s titles with the blessing and cooperation of his widow Alice. In 1655, Alice Culpeper wrote that her husband left behind 79 unfinished manuscripts, both books and translations. Cole would eventually print seventeen of these. Although posthumous printing was hardly uncommon on a smaller scale, it is of note that in Culpeper’s case the vast majority of the titles associated with him were posthumous, and the number of titles attributed to his name without any actual link came to be particularly noteworthy. The 1659 octavo edition of Pharmacopoeia Londinensis includes, among the several pages of advertisements set in small type, a list of “thirty four books of Nich. Culpeper, Gent. Student in Physick and Astrologie, formerly published”, as well as titles translated by Culpeper such as Dr Johnston’s Practice of Physick. There is no clear consensus about how many titles Culpeper actually left behind, and the question is made even more complicated by the fact that Culpeper not only wrote but also translated medical books. For Culpeper’s possible role as the lexicographer behind the glossary in Rivière’s The Practice of Physick (1655) and the subsequent stand-alone dictionary A Physical Dictionary (1657) (see Tyrkkö 2012).
2.2 A brand is created
So how did an apothecary like Nicholas Culpeper become such a lasting figure in medical writing, when most of his contemporaries have disappeared into virtual oblivion? Does it all come down to his personal initiative and the daring he showed in publishing what others did not? The evidence suggests otherwise. Although there is no denying Culpeper’s productivity, much of the enduring success that Culpeper’s books came to enjoy can be attributed to his principal publisher Peter Cole and the other printers who subsequently contributed to Culpeper’s creation as a marketing phenomenon.
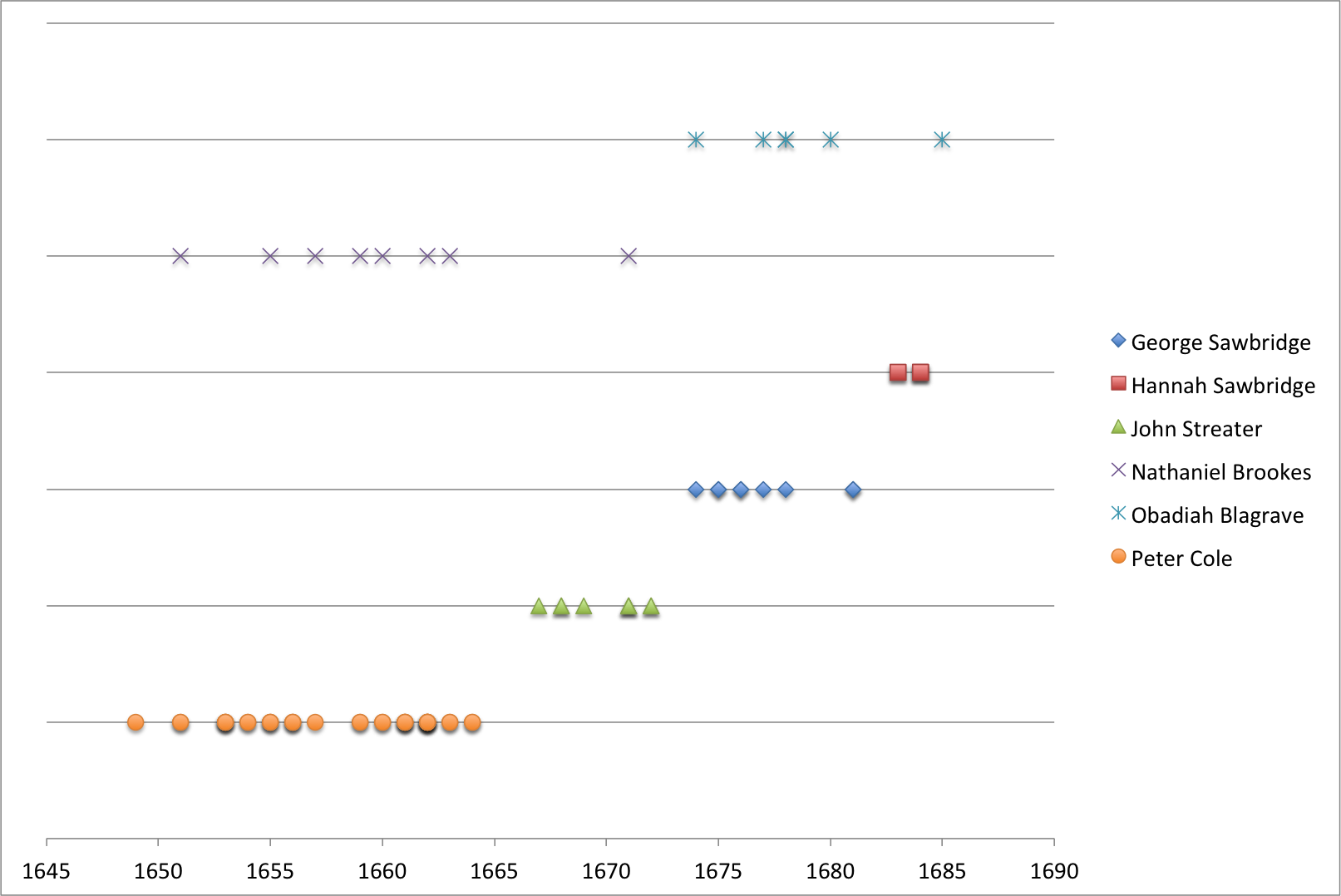
Born in 1613, Peter Cole started his career as an apprentice to a London stationer. After winning his freedom, he soon extended his activities to printing and before too long became a controversial figure in the London printing scene. He was one of the favourite printers of the puritan movement, an association that saw him involved in the production and sale of seditious books and frequently landed him in trouble with the authorities. According to Furdell (2004: 772), the objectives of puritan publishing not only agreed with Cole’s personal views, but the business coming his way from the puritan movement also made him a wealthy man. Cole maintained two printing houses, one in Leadenhall, the other in Cornhill near the Royal Exchange. Of the two, the former was Cole’s main shop, the latter largely devoted to medical works and especially Culpeper’s books (see Furdell 2002: 42). Although the principle connection between the two men was established through shared puritan beliefs, there is no doubt that Culpeper could not have found a better marketing man, and Furdell suggests that Cole’s support of Culpeper was in part motivated by financial backing from the Society of Apothecaries (2004: 43). Within a few years, Cole established a distinct literary persona for Culpeper, complete with full-page frontispiece portraits and a distinct styling as “Gentleman Student of Physick”, a nod toward his gentrified background. The attractive 1653 edition of Pharmacopeia Londinendis carries a striking frontispiece of a handsome young man dressed in apothecaries’ robes. His family crest, another constant feature of the Culpeper myth, is displayed in the top left-hand corner. Although there is nothing particularly unusual about a frontispiece portrait perse, they were usually reserved for masters of the College of Physicians and the Company of Barber-Surgeons as well as for effigies of ancient or foreign authorities. Men of Culpeper’s relatively mediocre official status did not merit the investment of a portrait – and yet, that is what Cole did. Cole’s practice of printing Culpeper’s books with a frontispiece was a costly enterprise as each was prepared separately, and it is clear that the objective was to establish an identifiable and marketable character, a brand. As Kuitert (2007) notes, the same principle of marketing through exploitations of the author’s persona would later see the appearance of biographical notes and photographs of authors emerge in books during the late nineteenth century. The success of Cole’s venture can be seen in the way such portraiture became an established part of Culpeper-printing, to the extent that many printers after Cole also adopted the habit when printing Culpeper’s books. There is no doubt the frontispiece became a hallmark feature.
As noted by Rhinelander McCarl (1996), other booksellers, most importantly Nathaniel Brookes and Obadiah Blagrave, soon moved in to capitalize on the Culpeper name. Seeing an opening for exploitating a name that sold well, Brookes and Blagrave started to attribute new titles to Culpeper, titles that had nothing whatsoever to do with him. As Shevlin (1999: 51–52) notes, alluding to George Whither’s The Scholars Purgatory (1625), unprincipled publishers would “assign titles that bore no relationship to the texts they labeled, alter the author’s name or title or both to generate greater interest and devise new titles and printing new title-pages to resurrect old texts”. Another typical practice was to add new content to previously published editions and to advertise the fact, but to leave out the fact that the new content was not written by the original author. Image 3 shows the title-page of Culpeper’s Last Legacy (1657), printed by Nathaniel Brookes.
Alice Culpeper’s preface to Two Books of Physick, viz. Medicaments for the Poor, or Physick for the Common People (1656), a translation from Latin by her late husband, makes it clear that Brookes’s forthcoming Culpeper’s Last Legacy is a forgery. Brookes’ retaliated by including a preface allegedly written by Nicholas Culpeper to his wife. Addressed by the fake Culpeper to “his consort”, the preface essentially advertises the other volumes also printed by Brookes (Image 4). According to Furdell, several of the titles printed by Brookes are indeed known to be false, either in part or full (2004: 44).
Image 4. Nathaniel Brookes’ forged preface from Culpeper to his wife. Photography by Jukka Tyrkkö at Wellcome Trust Library, London, and used with kind permission of the Wellcome Trust.
Another examples of a blatant attempt to make money with the name of the late apothecary was Blagrave’s supplement or enlargement to Mr. Nich. Culpeppers English physitian (1677). Printed by Obadiah Blagrace, the title of the book actually alludes to a Mr. Joseph Blagrave, given on the title-page as a “student in physick and astrology” in ironic reference to Culpeper’s typical title. The book claims to include medicinal plants that Culpeper omitted from his book, as well as those of which Culpeper’s knowledge was “deficient”.
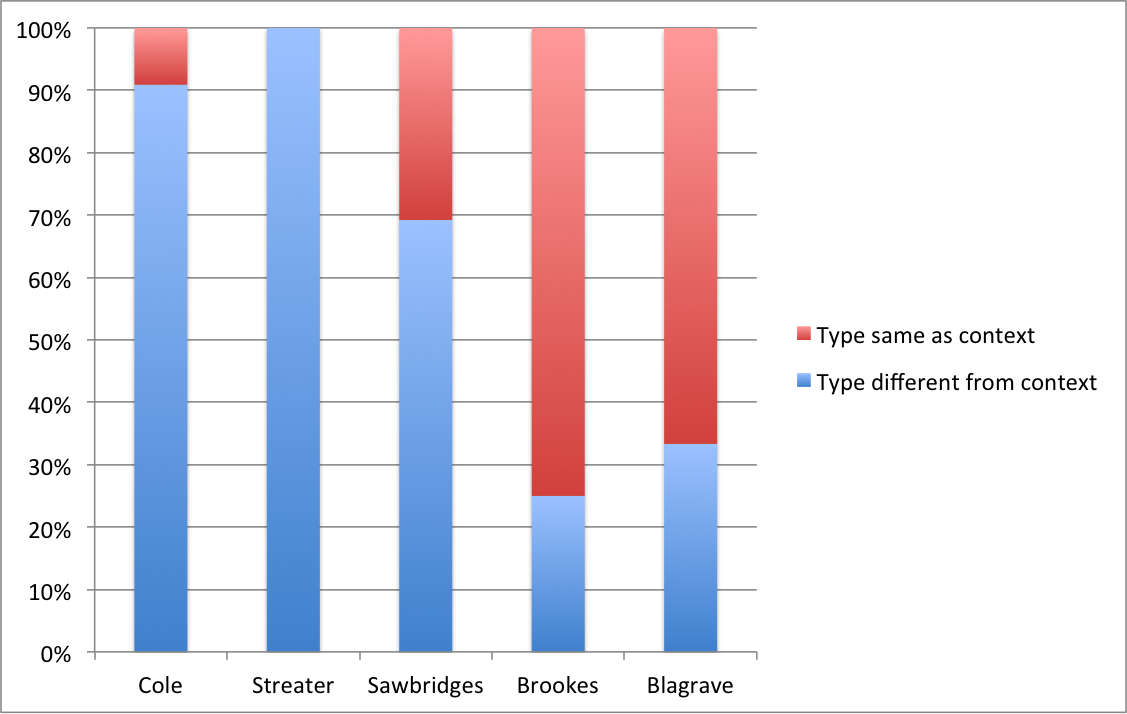
As Brayman Hackell notes, it was quite common practice for new printers to replicate the typography of earlier editions, and both Brookes and Blagrave astutely realized that good marketing was half the game (2005: 96–100). Although typographical copying was partly motivated by the wish to save the printer time and effort – creating an effective layout for a new title-page could take a considerable time – there can be little doubt that in some cases at least marketing also played a substantial role. When a well-known book had come to be known as having a particular appearance, it only made sense for the new printer to make his edition similar to the previous one – and, given the lack of effective copyright legislation, this was an avenue open to enterprising printers.
Peter Cole committed suicide in 1665, nine years after Culpeper’s passing (see Furdell 2004). Culpeper’s titles were passed to Cole’s colleague and long-time partner, the printer John Streater (see Furdell 2002: 43). Like Cole, Streater printed controversial books and pamphlets, among them medical titles. Streater printed several editions of Pharmacopoeia Londinensis and Directory for Midwives,as well as books translated by Culpeper such as Bartholonius Anatomy and A sure guide, or, The best and nearest way to physick and chyrurgery. After Streater’s printing interests moved from medicine to the law, George Sawbridge acquired control of the main Culpeper titles in 1669. George Sawbridge the elder was a prominent printer and bookseller specializing in medical works. His titles also include several dictionaries, such as the first and second editions of Blount’s Glossographia (1656 and 1661) and the fourth (1671) revised edition of Bullokar’s English Expositor. Sawbridge mostly followed the layout and typography established by Cole during Culpeper’s lifetime, but also introduced certain new elements, as discussed in section 5. He printed Culpeper’s books for a little more than ten years, and after he died in 1681, his widow Hannah Sawbridge carried on running the company for five more years, continuing to print the same titles her husband did.
Culpeper’s titles continued to be printed after 1686, but the volume began to wane slowly. Various smaller publishers such as Thomas Hawkins, Awnsham Churchill and John Churchill, Richard Bentley, J. Phillips, Henry Rhodes and John Taylor printed single copies of earlier titles, but none was capable of recapturing the early excitement for Culpeper’s books. Much of what had made Culpeper such a refreshing and revolutionary character began to be seen as commonplace, and his medical views, based on Paracelsian principles tempered with Galenic influences, came to be seen as old-fashioned. Nonetheless, some of Culpeper’s titles remained popular among the general public and remained in sporadic print for centuries.
3. Paratext, digital editing and corpora
The concept of paratext was introduced by Gérard Genette in his 1987 work Seuils (translated in 1997 as Paratexts: Thresholds of Interpretation) to account for the fact that published texts are “rarely presented in an unadorned state, unreinforced and unaccompanied by a certain number of verbal or other productions” (Genette 1997: 1), but rather accompanied by a framework of various textual and non-textual elements that guide the reader’s approach to the text and her reception of it. While Genette defined an entire ontological system for discussing the full set of layered features surrounding written texts, the focus in this article is on what Genette terms the publisher’s peritext. This part of the paratextual apparatus encompasses all those paratextual elements that are “the direct and principal (but not exclusive) responsibility of the publisher (or perhaps, to be more abstract but also more exact, of the publishing house)”, including not only textual elements like the title-page, indices and other referential devices, but also the physical peritext, the features that “constitute the book’s material realization”, such as the selection of type, typesetting, layout and the choice of paper (Genette 1997: 33–34).
3.1 Paratext in corpora
The conventional approach to text editing for corpus linguistic purposes has been to record the linguistic content, that is, words and punctuation, of the text, and to discard, in most cases, all paratextual and, almost invariably, all peritextual features. The reasons behind this practice have been many and varied. Early corpora predating structured markup languages like SGML and XML often exclude paratextual elements out of the desire to ensure that nothing but “the texts themselves” is included in the corpus and that the textual samples accurately reflect the text type assigned to the corpus text. Even in structurally annotated corpora, where the paratext could be assigned a different text type, it is often valued only for its informational content and summarized as metadata. In the case of omitting the physical paratext (layout, typeface, etc.), it is usually a question of either priorities, when the visual features of the text are not considered linguistically interesting or important enough to warrant the (perceived) additional effort and complication required for encoding them, or of technical limitations, when the encoding system adopted for the corpus (often from legacy corpora) does not allow these kinds of features to be conveniently annotated. Both of these impulses tend to be reinforced by the common perception — or rather, misconception — that corpus linguists have no use for this kind of annotation in their analysis; for a laudable example to the contrary, see Claridge (this volume). Part of the problem has been, and to some extent remains to this day, that while tools and data management systems capable of making use of XML annotation are permeating almost every area of our digital lives, the corpus linguistic community is still largely using tools that either cannot cope with XML or, at best, manage to ignore it. It goes without saying that XML annotation, as well as other similar mark-up, are more accessible to corpus linguists capable of writing their own search scripts, but at present that is hardly the majority.
Of the paratextual elements defined by Genette, the ones that have traditionally been given the most attention in the context of corpora and corpus linguistics are the ones making up the core bibliographic metadata, i.e. the name of the author, date of publication and the possible title of the text. This information is usually encoded in some form or another in the corpus metadata and it serves as the principal means of identifying a text. However, considering that the actual way these elements are presented on the title-page can often provide clues about their relative statii and the advertising strategy of the printer or publisher, they – like all of the information on the title-page – should ideally be included in the corpus in the original form and context, whether they are included in the biographical metadata or not.
The same goes for the rest of the textual paratext, particularly in the preliminaries or front matter: prefaces, dedicatory epistles, the author’s or publisher’s addresses to the reader, tables of contents and indices are routinely omitted from corpora. In terms of corpus linguistic analysis this might be a sound decision, but in terms of evaluating and contextualizing the corpus texts this is extremely problematic. Given that paratexts provides important information about the author’s and publisher’s intentions, the intended audience of the text, and other contextual facts, it seems clear that using a text as a source of language data without access to the context provided by the prefatory materials can potentially lead to misguided evaluations of the evidence found in the corpus text. For an example of how contextual metadata can be included in a traditional corpus, see Taavitsainen and Pahta (this volume). In extract corpora which only contains samples of each text, this approach is somewhat understandable—although a more useful practice would be to include a separate sample of at least the most important paratextual components, for example of any prefatory essays or letters. Although it may seem that there is little point in including in linguistic corpora structural components such as indices and tables of content, one might argue that even they can provide meaningful information about contemporary ways of classifying and organizing knowledge and about the words and concepts that were perceived to be central to the text. Furthermore, knowledge of this kind can aid the corpus linguist both in the formulation of corpus queries and in the interpretation of results. Prefaces, in particular, supply information that is vital to interpreting the functions, intended audiences and features of texts. In the case of Nicholas Culpeper, one example of this is the preface to the English translation of the London Dispensatory, where Culpeper postulates a very different—in fact almost diametrically opposed—target audience and function than the preface of the original Latin version of the Pharmacopœia Londinensis, which is also included in Culpeper’s translation. In such cases it is naturally important not only to include these paratextual elements, but also to provide them with the necessary metadata to identify their differing authors and textual histories.
The case of the physical paratext is somewhat different. Many early corpora, such as the Helsinki Corpus of English Texts, already made some efforts at so-called pseudo-facsimile editing, that is, the systematic representation of peritextual features using the standard set of alphanumeric characters available on a typewriter, but were seriously handicapped by having to represent all the characters unavailable in the ASCII system using combinations of characters (see Rissanen and Tyrkkö, this volume) Over the last three decades, the rapid development of computational technology has rendered many of the earlier challenges of basic text representation moot. In particular, the ASCII system of 128 characters has been replaced by the much more extensive Unicode standard and the UTF-8 character encoding, that are currently capable of encoding all of the characters used in not only a huge number of modern languages, but also of many historical language variants. Although Unicode and UTF-8 have expanded our options for representing various character systems in documents and are supported by all modern operating systems (as well as being implemented by technologies like XML, Java and Microsoft’s .NET Framework), it has not entirely obliterated the problem of different, competing character encodings. Various older standards like ISO-8859-1 and Windows-1252 are still used by some corpora and software, and other differences in encoding practice, such as the use of different end-of-line markers in Windows and Unix-based systems (e.g. Mac OS X and Linux) can also cause problems. Regular users and even “ordinary working linguists” are often unaware of the system their software uses, and word processors and corpus tools frequently run into problems when encoding systems are changed without the user realising it. The unfortunate results can range from the misrepresentation of characters to omitted otherwise erroneous search results, making this a major issue that is far too rarely discussed in literature.
It goes without saying that character encoding is only one aspect of peritextual annotation. Examined without presumptions, any page of printed or indeed manuscript text comes with a wide array of different semiotic features, all of which could conceivably be of importance to a given research question. In addition to the text itself and the orthographic and typographic features thereof, a page may include margins and marginal notes, borders, decorations, images, tables, diagrams, handwritten notes, etc. Each of these elements can in turn be analyzed as carrying with it a variety of more specific features such as colour, method and quality of production, thematic content, and so on.
Fortunately, development has also taken place in the standardized annotation of text structure and metadata. The growing need to create documents that can be correctly read and manipulated across multiple operating systems and software solutions has led to the emergence of annotation standards that transcend the constraints of the immediate computational environment. Today, most major file formats – including those used in Microsoft Office products – make use of some variation of XML or eXtensible Markup Language. When it comes to digital editing, however, the major difference is that the scholarly editor will usually wish to be aware of the annotation underlying the visible text in order to make sure it is fit for the task and, when necessary, to adapt it to the requirements of the present research project. One of the major benefits of standardization in this field has, admittedly in a somewhat circular fashion, been the increased awareness of the benefits of standards-compliant annotation. Researchers, like other information professionals, are more aware than ever of the need to follow well-documented standards not only for the purpose of keeping the present annotation system transparent, but also to ensure further usefulness by future researchers. One of the major benefits of adopting a widely-used and fundamentally flexible system of mark-up such as XML is that it allows for a layered approach to annotation, where levels or types of annotation can be added without affecting the underlying basic textual level at all (for a thorough discussion, see Monella 2008 or Honkapohja, Marttila and Kaislaniemi 2009).
From the perspective of corpus linguistic and philological research, the basic requirement for useful digital editing must be that all the features included in the edition are also searchable. There is little added value to be gained from an annotation system which presents changes in text type or layout which cannot be quantified or further annotated, and there is even less value in systems that do not represent such information in a systematic fashion. As argued by Meurman-Solin 2013 (this volume, section 4.3), the taxonomization of features in corpora ought to be systematic, not only for clarity of analysis but also, importantly, because it will then lend itself to quantification. When it comes to applying a systematic descriptive system to corpus annotation, the options available to the digital editor can be roughly divided into two: either to develop a new system or to follow an established standard. The latter option must be considered preferable for several reasons, even if it requires work in adapting the standard to the needs of the present project (which any well-defined standard should allow for). Established standards have the benefit of being, at least in their principles, familiar to a reasonably large group of users, and of being well-documented. This latter point is important not only for more universal accessibility in human terms, but also for the ease of conversion and automatic manipulation. If no established standard is available, to be appropriated and adapted, if necessary, for the purposes of a more specialized corpus project, the next best option is to develop a new one in analogy of some suitable existing standard, using similar logic and general solutions. This will make it possible (and possibly even trivial) to interface the new system with an established standard, and in cases where that established standard is being actively developed, to incorporate the new system into the standard.
3.2 The title-page
The paratext is an instrument for the author and his accomplices to instruct the potential reader in not only using the book but also in finding it in the first place. This marketing function of paratext — which was mainly in the interest of the publisher and the bookseller — is most saliently captured in early modern printed books in the form of the title-page, which served as the initial point of contact between the book and the prospective buyer. As Eisenstein (1993: 73) points out, the regular use of title-pages has been frequently recognised by book historians as the single most significant new feature of printed books in comparison to manuscripts. According to Smith (2000: 16) the title-page was a direct response to the needs of protecting unbound copies and of advertising unsold copies in the shop. The importance of the title-page as an advertising device is reflected in the fact that the title-page was not just the first thing the buyer saw of the book itself— books in the Early Modern period were commonly sold in an unbound state—but extra copies of them were frequently printed to be displayed at booksellers’ shops to inform customers of new or important works available for sale (Voss 2003: 102; Bland 2010: 66). As Bland (2010) notes, at first the most important items in the title-page were the title and the publisher, with the author’s name and the printer being less important and often given in brief, if at all. Then, as the decades went by, title-pages slowly came to provide not only all the information that used to be included in the colophon, but often a much greater volume of bibliographic information about the publication history and contents of the book. According to Shevlin (1999) the title-page gradually turned into a form of contract in the sense that it stated what was in the book and what had been added since the previous editions. As such, the title-page framed the text and gave it context or, as Sherman (2007: 69) writes, the title-page serves as “paratext [that] marks out a preliminary space where readers are brought to the edge of the text, invited to enter it, and given important information about it — its title and genre, its author and the circumstances of its composition, its relationship to other texts and the appropriate methods for digesting or applying it” (see also McLean 1991). The contributions of McConchie and Ratia in this volume exemplify the importance of the printed title-page to the historical linguist and philologist; for discussion of similar features in manuscripts, see Meurman-Solin, and Sairio and Nevala (this volume).
The first printed books of the fifteenth century, which were designed to look just like the manuscripts they were reproducing, did not yet include what we call a title-page. The reader had to search for the title at the end of the volume, in the colophon, along with the name of the printer and the date of the printing (Genette 1997: 64). The title-page, introduced in the early sixteenth century, was both a descendant of the medieval colophon and “the ancestor of the whole modern publisher’s peritext” (Genette 1997: 33). The typography and layout of the title-page was almost entirely within the realm of the printer or, to be more precise, the compositor, and the use and arrangement of type was governed by a variety of factors ranging from availability to aesthetic concerns. It is important to be reminded of the material context in which the early modern printing house operated. The choice of using a particular type face or, let us not forget, a type of a different size, was not simply a matter of selecting one from a drop-down menu of a word-processor, but rather required that the font, or set of type, was already available in-house or, failing that, was available to borrow or buy. As will be shown in section 5, the average number of different types used on a single title-page was eight or nine. Similarly, as Bland (2010: 118) notes, the characteristics of the specific hand-press used in a printing house affected the appearance of the final product, sometimes forcing the compositor to change wordings or spellings to fit the text on the page in a pleasing way.
Early modern title-pages could also contain illustrations ranging from mere ornamental flourishes to a full-fledged frontispiece, “a more or less monumental portico entrance” (Genette 1997: 33). By the seventeenth century, when Culpeper’s texts first saw print, title-pages had lost much of their ornamentation while “the frontispiece took refuge on the left-hand page facing the title-page” (Genette 1997: 33). The author’s name was not among the first paratextual elements imposed by the invention of printing, and the medieval anonymity of the author was by no means a rare practice even in the early modern period (Genette 1997: 37). While publishers had already realized the value of an author’s name as a selling point by the mid-seventeenth century, the use of Culpeper’s name surpassed anything that had been seen before, certainly in medical publishing. While the use of onymity – a term coined by Genette (1997: 39) to signify the modern-day default case where the author’s legal name appears in the paratext, as opposed to anonymity or pseudonymity – to promote texts by authors who had already acquired themselves a reputation was not a new idea as such, Culpeper’s publishers started doing this very early on in his short career, without practically any prior qualifications on his part. Genette (1997: 39) has described these kinds of “promotional practices that somewhat anticipate glory by mimicking its effects” as a form of “magical thinking”: “act as if it were so, and you’ll make it happen”.
In addition to serving a commercial function as an advertisement for the text, the author’s name can also be seen to vouchsafe the content of the text, in essence to guarantee a reputable origin for the information contained within:
The author’s name fulfills a contractual function whose importance varies greatly depending on genre: slight or nonexistent in fiction, it is much greater in all kinds of referential writing, where the credibility of the testimony, or its transmission, rests largely on the identity of the witness or the person reporting it. (Genette 1997: 41)
Especially on the title-page, the author’s name was often accompanied by various titles, honorifics and epithets, some formal and others made up by the printer to encourage sales. These credentials served both to enhance the advertising value of the author and – especially in the case of official medical licenses – to establish the author as a legitimate source of medical information. Although there were few legal controls over the use of scholarly titles in the early modern period, the presence of the College of Physicians in London did discourage the misuse of the title of “doctor”, and thus unqualified practitioners like Culpeper had to resort to other strategies. In Culpeper’s case this involved coming up with and consistently maintaining the rather notable style of “Gentleman Student of Physick”, a recognisable moniker that came to be associated with his person. We must not forget that a big part of Culpeper’s early appeal was in his persona as a rogue or a man of the people, the apothecary who revealed the secrets of the College of Physicians to the everyman. At the same time, the title of a “gentleman” and the persistent use of the family crest in the frontispiece added a certain prestige of its own and elevated Culpeper above the average apothecary. Notably, decades later some posthumous editions of Culpeper’s books afford him the title of “doctor”. Sometimes the reason was that the printer wanted to add some extra prestige to Culpeper as an author or authority, but on occasion this may have been an honest mistake considering how Culpeper had become a widely-acknowledged medical authority by that time.
4. Editing the Culpeper corpus
The books studies in the pilot project were initially identified using the English Short Title Catalogue, and the initial list was then pruned to discard unavailable copies and mistakes in the ESTC. We included books that fulfilled all of the following criteria:
- Printed between 1649 and 1700
- Bearing the name Culpeper on the title-page, regardless of its semantic role
- A physical copy of the book was available for examination at the British Library, Wellcome Trust Library, or Cambridge University Library.
The final list of titles included 95 items. The title-pages were keyed-in and annotated using Early English Books Online (EEBO) facsimiles (see Section 3) as a starting point whenever possible. The transcriptions were then compared against original copies at the British Library, Wellcome Trust Library and Cambridge University Library, as appropriate, and measurements were taken of the dimensions of the page, of all the different types used, and of all other visual features such as extra spaces and decorative elements. Twenty texts were entirely keyed-in from original copies. Because the transcription work was carried out by all three members of the project, the transcriptions were later proofread and the XML code verified in an effort to unify the annotation.
It is worth noting here that when it comes to taking measurements, the otherwise superbly useful EEBO facsimiles have to be approached with some caution. Our initial plan was simply to measure the overall dimensions of the title-page from the physical copy and then to carry out further measurements from the facsimile image, but this proved less than ideal. Although digital photography is a wonderful tool for book historians and linguists working on early data, there are numerous problems associated with getting sufficiently accurate images. Firstly, although a ruler is often provided for scale on the first image of a facsimile file, this is not consistent. Secondly, we encountered at least one instance where, compared to the original, the EEBO photograph had clearly been compressed horizontally, making the image unreliable for measurements. While of the problems with facsimile images are negligible for most purposes, when the measurements are taken at the accuracy on one fifth of a millimetre, as we did here, even slight changes in the angle of the camera or distance between camera and page can have considerable impact on the findings.
4.1 Editing and annotating the visual features of title-pages
Our approach in editing the Culpeper title-pages was to start with a faithful representation of the text and a wide variety of the visual features on the page an sich without assigning them any interpretative encoding based on preconceived notions of significance. Even this kind of annotation – which could be called descriptive – can of course never fully escape subjectivity and already presupposes some kind of a theory of the text. In this respect it could be considered parallel to the transcription of the textual characters into digital form, which involves a similar process of observation and classification. Because we are interested in examining the relationship between printing house practices and the text printed, and because we want to make it possible – at some point in the future – to extend the analysis to minute details of the material aspects of printing, we opted to err on the side of excessively fine granularity in measuring and recording the phenomena, since it is easy to automatically convert data from fine to more coarse distinctions, but impossible to do the converse. In addition to this descriptive layer of annotation, we also wanted to analyse and record the functional structure of the text. This kind of imposition of preconceived semantic and ontological categories onto the text – e.g., labelling some stretch of text as a title or a subtitle – results in a layer of annotation which could be characterized as analytical. The superimposition of these two different layers of annotation onto the same textual base allows us to examine and analyse their interrelationships. While this kind of analysis is always involved in interpreting a text, annotating it not only makes it explicit and allows others to replicate or refute our results and interpretations, it also allows us to use quantitative corpus methods on a wider range of textual features than a plain-text corpus. And in being explicitly identified as our interpretation, the annotation can always be ignored if new, compelling evidence emerges to challenge it. In addition to the visual and functional structure of the title-pages, our specific needs required the annotation of specific kinds of semantic information, traditionally referred to as named entities. This included all dates, place names and personal names occurring on the title-page, which were annotated with their normalized forms and in the case of personal names also the professional role played by that person in the production of the book.
4.2 TEI Guidelines for Electronic Text Encoding and Interchange
The guidelines developed and published by the Text Encoding Initiative (henceforth TEI) provide a rich ecosystem of mark-up for the digital representation of texts. A brief introduction to and an explanation of the basic rationale of the TEI Guidelines can be found on the TEI website, as well as the latest version of the TEI Guidelines in various formats. For practical purposes, the TEI guidelines can be thought of as a widely accepted, though not yet a universally followed, set of best practices for digital editing. It is worth noting that while the TEI Guidelines are currently expressed using XML, they are not intrinsically tied to any given mark-up language. The TEI guidelines do not refer explicitly to XML encoding, even if they are most commonly associated with that particular schema. At its core, the TEI Guidelines define a general semiotic system for describing documents and systematically representing the components of which texts are composed and of their relations to one another.
The full TEI Guidelines cover a very wide range of different text and document types. The unique elements and attributes provide a highly sophisticated semiosphere of descriptors, which can be adapted to the specific needs of an editing project. The main challenge is therefore very rarely that there would be a need to create an entirely new system of annotation, or even add elements to the ones defined by the Guidelines, but rather what features of the Guidelines to use and to what degree of detail. Consequently, digital editors usually find themselves making choices between alternative encodings allowed by the Guidelines and ensuring that they follow the semantic and ontological model established by the Guidelines. This latter point is of particular importance, because there are frequently alternative ways of annotating specific features and the misuse of established elements will lead to confusion, potentially false results and ultimately the lack of cross-usability.
4.3 The Gatekeepers model
The main purpose of the present project was to explore the digital editing of visual features on title-pages and, by extension, in early printed books using the TEI XML model. It is worth noting at the very beginning that strict adherence to the TEI Guidelines does not always come without challenges when it comes to the annotation of text structure. One of the standard features of the Guidelines is to provide the nesting rules for each element, that is, to give lists of specific individual XML elements that may be placed within other elements and the elements within which they, in turn, may be placed. These are occasionally at odds with the needs of the digital editor, requiring the use of semantically empty segment elements and other means with which the perceived structure on the page can be represented.
Although our needs at this stage did not require a full TEI header for each title-page file, we recorded details of the source text in the <encodingDesc> element. Within the element, we use <projectDesc> to provide a brief reference to the project, <samplingDecl> to explain the sampling principle followed, <editorialDecl> to describe the editorial policies, and <revisionDesc> to provide a step-by-step description of the revision process including the date and a brief description of the specific work done. This makes it possible to track to progress of the project and, potentially at least, to identify systematic human errors made during the transcription process. The following is an example of the <revisionDesc>, from the 1695 edition of the English Physician Enlarged:
The descriptive model was based on the TEI P5 guidelines, focusing on the most visually significant features of the title-page. As always, a balanced was to be struck between the desire to include all features to the fullest extent possible, and the expediency of designing a descriptive model which allows the analysis desired but does not become exceedingly difficult to implement. In addition to the transcription of the textual content and the annotation of the basic textual structure of the title page, the following paratextual elements were recorded for each title page:
- Size of text area (to a millimeter)
- Type family (roman, italic, small capitals, swash)
- Type size (to one fifth of a millimeter)
- Border (none, line, double line, ornamental)
- Delimiter line (length)
- Extra horizontal and vertical spaces (beyond)
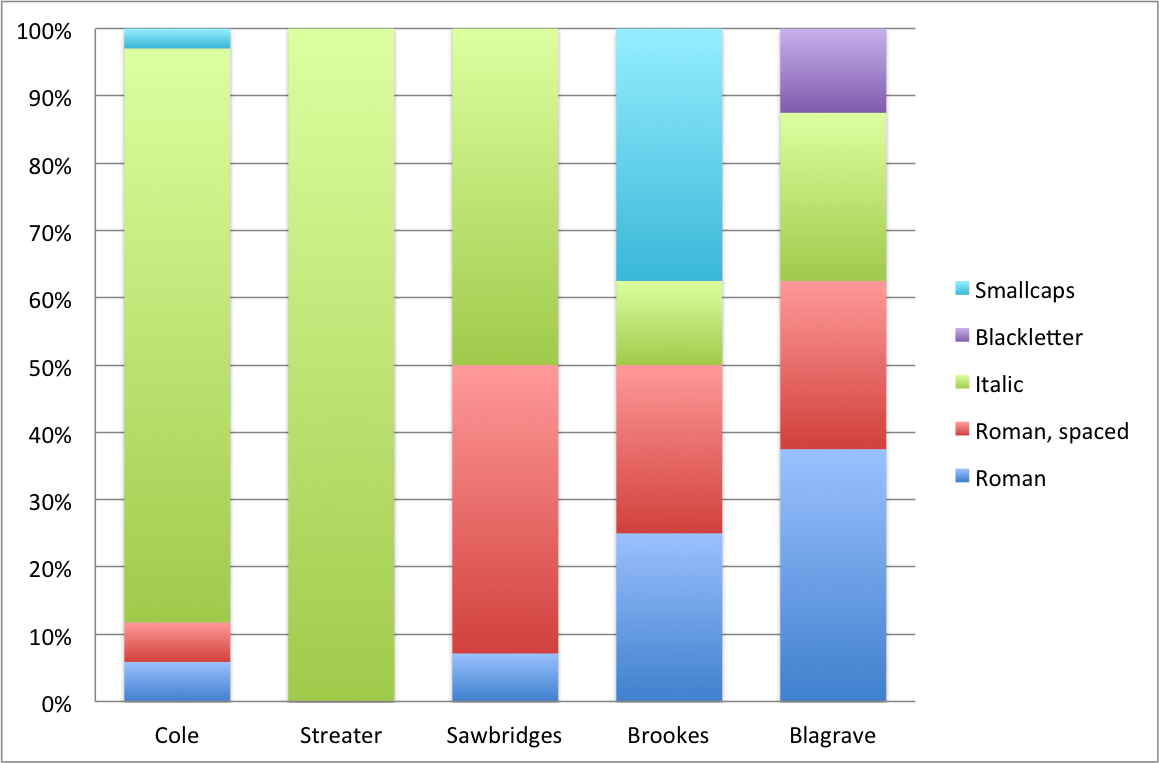
Notably, several of the features were simplified in the taxonomy as taking one of a restricted set of discreet values. For example, the decision to analyse the use of type by assigning to each character on the page with attribute values for “family” and “size” has the effect of allowing us to idenfity repeated use of the same typeface, but not of font. We use “typeface” in reference to the impression left by a particular font, while “font’ in turn is used in reference to a specific casting of a particular typeface. Our annotation method does not give direct access to information about fonts, although by cross-referencing a printer and a particular type may give reasonable initial evidence that the same font is in use. Borders were simplified in the annotation system by dividing them into four types, the last of which covers all ornamental borders without making further distinctions between floral, geometric, etc.
When all the layers of annotation are accumulated together, the end result is a detailed yet relatively concise and simple representation of the linguistic, text-structural and visual content of the title-page in a structured format that allows full corpus-linguistic queries. Notably, the annotation described here can be used for various alternative or complementary purposes, ranging from the creation of a pseudo-facsimile rendition to in-depth analysis of interactions between linguistics and non-linguistic elements (see McConchie, this volume). Image 6 presents the title-page of the 1654 edition of Pharmacopoeia Londinensis, followed by the full Gatekeepers transcription of the same page.
The XML file corresponding with image 6 is given below. Note the cascading use of attributes which saves the effort of having to annotate the typographic features of each line of text separately. For details of the annotation system not discussed here, please consult the guidelines.
<titlePage rend="align(center) type(roman) size(2.8) border(pattern)">
<docTitle>
<titlePart type="main" rend="size(5.0)">
<lb/>Pharmacopœia Londinenſis;
</titlePart>
<titlePart type="alt" rend="size(2.4)">
<lb/><hi rend="spaced">OR THE</hi>
<lb/><hi rend="size(3.8)">LONDON DISPENSATORY</hi>
</titlePart>
<titlePart type="desc">
<lb/><seg rend="size(3.8)">Further adorned by the <hi rend="type(italic)">Studies</hi> and</seg>
<lb/><hi rend="type(italic)">Collections</hi> of the <hi rend="type(italic)">Fellows</hi>, now living of
<lb/>the ſaid <hi rend="type(italic) spaced">COLLEDG</hi>.
</titlePart>
</docTitle>
<lb/><space dim="vertical" unit="mm" quantity="2"/>
<argument rend="align(just)">
<list>
<lb/><space dim="horizontal" unit="mm" quantity="7"/><head rend="size(2.2)">In this Sixt Edition you may find,</head>
<item>
<lb/>1 <space dim="horizontal" unit="mm" quantity="1"/>Three hundred uſeful Additions.
</item>
<item>
<lb/>2 <space dim="horizontal" unit="mm" quantity="1"/>All the Notes that were in the Margent are brought
<lb/><space dim="horizontal" unit="mm" quantity="5"/>into the Book between two ſuch Crotchets as
<lb/><space dim="horizontal" unit="mm" quantity="5"/>theſe [<space dim="horizontal" unit="mm" quantity="2"/> ]
</item>
<item>
<lb/>3 <space dim="horizontal" unit="mm" quantity="1"/>On the top of the pages of this Impreſſion is printed
<lb/><space dim="horizontal" unit="mm" quantity="5"/><hi rend="type(italic)">The ſixt Edition, Much Enlarged</hi>.
</item>
<item>
<lb/>4 <space dim="horizontal" unit="mm" quantity="1"/>The Vertues, Qualities, and Properties of every
<lb/><space dim="horizontal" unit="mm" quantity="5"/><hi rend="type(italic)">Simple</hi>.
</item>
<item>
<lb/>5 <space dim="horizontal" unit="mm" quantity="1"/>The Vertues and Uſe of the <hi rend="type(italic)">Compounds</hi>.
</item>
<item>
<lb/>6 <space dim="horizontal" unit="mm" quantity="1"/>Cautions in giving al Medicines that are dangerous.
</item>
<item>
<lb/>7 <space dim="horizontal" unit="mm" quantity="1"/>All the Medicines that were in the <hi rend="type(italic)">Old Latin Diſ-
<lb/><space dim="horizontal" unit="mm" quantity="5"/>penſatory</hi>, and are left out in the <hi rend="type(italic)">New Latin</hi> one,
<lb/><space dim="horizontal" unit="mm" quantity="5"/>are printed in this Sixt Impreſſion in Engliſh, with
<lb/><space dim="horizontal" unit="mm" quantity="5"/>their Vertues.
</item>
<item>
<lb/>8 <space dim="horizontal" unit="mm" quantity="1"/>A <hi rend="type(italic)">Key to <hi rend="type(roman)">
<persName role="authority" ref="#galen">Galen</persName>’s</hi> Method of Phyſick</hi>, containing
<lb/><space dim="horizontal" unit="mm" quantity="5"/>thirty three Chapters.
</item>
<item>
<lb/>9 <space dim="horizontal" unit="mm" quantity="1"/>In every Page two Columns.
</item>
<item>
<lb/>10 <space dim="horizontal" unit="mm" quantity="1"/>In this Impreſſion, the Latin name of every one of
<lb/><space dim="horizontal" unit="mm" quantity="5"/>the Compounds is printed, and in what page of the
<lb/><space dim="horizontal" unit="mm" quantity="5"/>New Folio Latin Book they are to be found.
</item>
</list>
</argument>
<lb/><graphic width="80mm" url="hori_line.svg"/>
<byline rend="size(2.2)">
<lb/><seg rend="size(2.8)">By <persName role="author" ref="#nicholas_culpeper" rend="type(italic)">Nich. Culpeper</persName>
Gent. Student in Phyſick and</seg>
<lb/>Aſtrology ; living in <placeName ref="#spittle_field">Spittle-fields</placeName>, neer
<placeName ref="#london" rend="type(italic) size(2.0)">London</placeName>.
</byline>
<lb/><graphic width="81mm" url="hori_line.svg"/>
<docImprint rend="size(2.2)">
<lb/><placeName ref="#london" rend="type(italic) size(2.0)">London</placeName>: Printed by
<persName role="printer seller" ref="#peter_cole" rend="type(italic) size(2.0)">Peter Cole</persName> in
<placeName ref="#leadenhall" rend="type(italic) size(2.0)">Leaden-Hall</placeName>, and are to be ſold
<lb/>at his Shop at the ſign of the Printing-Preſs in <placeName ref="#cornhill">Cornhil</placeName>,
<lb/>neer the <placeName ref="#royal_exchange">Royal Exchange</placeName>. <docDate when="1654" rend="spaced">1654</docDate>.
</docImprint>
</titlePage>
If desired, the XML file can be transformed into HTML. With the proper style sheet, the HTML version can serve as a rather accurate approximation of the visual features of the original image (Image 7).
In the following we give some more details of the most important parts of the annotation model. The full guidelines of our internal editing guidelines for the Culpeper-project are available for download, as well as the Culpeper title-page corpus in its entirety as a zip file. The corpus is made available under Creative Commons Non-commercial license, and we request that anyone using the corpus credits the source as:
Marttila, Ville, Carla Suhr and Jukka Tyrkkö. 2012. Culpeper title-page corpus. Released June 20, 2013 under Creative Commons non-commercial license. <http://www.helsinki.fi/varieng/domains/gatekeepers>
4.3.1 Annotation of visual features
The most time-consuming part of the editing process was the recording of physical measurements. The work was mainly carried out in March 2012 when the project members conducted a library visit to the British Library, Wellcome Trust Library and Cambridge University Library, in addition to which certain measurements were taken later from facsimile images from Early English Books Online (EEBO). In these cases we had measured the exact page dimensions from original copies at the libraries and could therefore scale the facsimile images accurately. The facsimile images were also used for checking and correcting some of the earlier measurement. It is worth noting here that extreme care must be taken when using facsimiles for this type of measuring. Although the general quality of EEBO photography is good, we encountered at least one case where the facsimile photograph had been scaled without maintaining the original aspect ratio, leading to an inaccurate height-to-width ratio in the photograph.
The measurements were taken using a jeweller’s loop and a ruler grid printed in high quality on a clear transparent film, the latter produced by us. These tools allowed us to reach a precision of one fifth of a millimetre, which we deemed sufficient for the type of analysis we were interested in and which was sufficient for distinguishing between text printed using type from two different fonts while coarse enough to avoid spurious distinctions between slightly varying impressions from type from the same font.
The basic unit of visual layout is the typographic line of text. Lines were annotated using the <lb> or line break element for the horizontal aspect of layout, we use a key-value pair on the @rend attribute of each structural element to indicate the alignment of the lines contained by it with regard to the title block as either ‘left’, ‘right’, ‘centered’ or ‘justified’. Making use of the inheritance principle of XML, we did not need to do this for all the elements, but rather we define a default value for these key-value pairs for the whole page and then replaced them on a case-by-case basis as necessary for the representation of any deviations from this basic lineation and alignment scheme. <Seg> elements were used when blocks of text within a structural element were aligned differently from the rest of the parent element. Our decision was to annotate all visually significant spaces, or spaces that did not fall within the natural layout of the title-page on terms of normal line or word spacing. Graphical elements such as horizontal divider lines and borders were also annotated following a similar method.
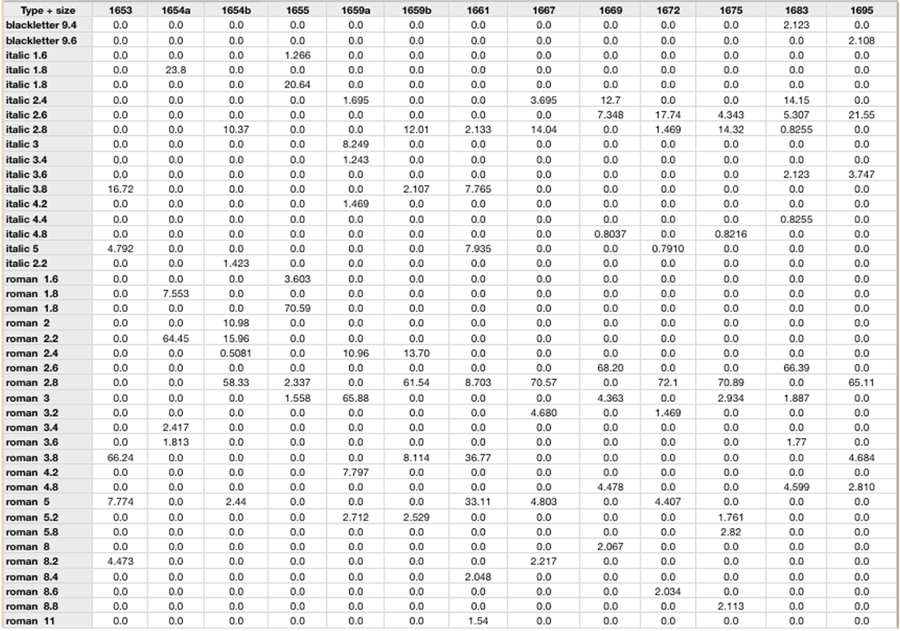
The most significant visual aspect of the page in terms of the kinds of questions we were interested in was typography. As with spaces, we used key-value pairs on the @rend attributes of relevant structural elements to annotate the size and type family used, and the size of the type. The latter was measured as the height of the average capital letter, which we measured from the baseline of the impression to the ascender line, taking several measurement from the same type set for verification (see Image 8).
The multiple measurements not only ensure that slight variances are averaged out, but also that slight human differences in taking the measurements are more or less alleviated. For example, when the level of precision is one fifth of a millimeter, the difference between ascender height and cap line is often less than the minimum threshold of measurement. This approach was preferred over the arguably more established X-height, or the height of the character x as measured between the baseline and the mean line, because the main focus was on the visual prominence of the type and the relationship between the mean line and the ascender is not in any way fixed. By measuring to the ascender, we thus get a more accurate sense of the visual impact of the type in question.
As with the horizontal alignment, these key-value pairs are considered inheritable, and thus we only need to annotate the default type family and size on the <titlePage> element and for its subordinate text-structural elements, and then indicate separately those bits deviate from these default values by using <seg> and <hi> elements. A difference was made between the two on the basis of whether or not the text in question appeared as a segment with no apparent function or as a saliently highlighted element. Note that the annotation is entirely independent from the actual type or type size used: on a page consisting entirely of italic type, a word printed in roman would serve as a highlight.
Because type family and size are indicated by separate key-value pairs and are independent of each other, there is again no need to repeat information in the encoding, but still preserve a record of the type family and size of every character on the page. Naturally, using an annotation system that makes use of inheritable values will require both awareness of the system and a measure of technical know-how on the part of the end-user. Should the scholar using the digital edition not understand the principles followed, they could inadvertently read misinterpret the values.
At the final stage of the transcription process, the typographic information was collated into the <layoutDesc> element (Image 9). This saves considerable time in the long run, because basic typographic data such as the quantities of specific types can be accessed simply by querying the <measure> elements under <layoutDesc> instead of having to search the entire XML tree each time.
The annotation model also accommodates more infrequent features such as the use of brackets or diagrams. These were occasionally used in early modern books for various purposes ranging from knowledge trees to the linking of similar topics. On title-pages, brackets were most frequently used when indicating that a number of authors collaborated on a book or, less frequently, that certain sections of the contents share features. The XML annotation of these visual features can quickly become extremely complicated and consequently very difficult to query effectively.
4.3.2 Annotation of structural and semantic metadata
Along with the annotation of physical features on the page, we also annotated some metadata concerning the content. This metadata fell into two categories: identifiers and role attributes. Identifier attributes (@xml:id) are used in XML to supply unique values to unique occurrences of particular elements such as person or places names, which may then be used for cross-referencing between documents or documents and databases.
The following excerpt from the <byline> element of Example X demonstrates the use of @xml:id in practice:
By <persName role="author" ref="#nicholas_culpeper" rend="type(italic)">Nich. Culpeper</persName> Gent. Student in Phyſick and</seg>
<lb/>Aſtrology ; living in <placeName ref="#spittle_field">Spittle-fields</placeName>, neer <placeName ref="#london" rend="type(italic) size(2.0)">London</placeName>.
The excerpt features three proper names: Nicholas Culpeper, Spittle-fields, and London. The first is annotated using the <persName> element, the latter two using <placeName>. The @ref attribute is used within the elements to link the instance to a unique person or place, which allows us to correctly identify, for example, all occurrences of the name Nicholas Culpeper in the corpus without the need to come up with complicated queries to catch all variant spellings and formulations. The systematic use of the @xml:id attribute for person and place names will also allow us to link these items to a relational database, which we are still in the process of populating with biographical and historical information drawn from a variety of sources like the ESTC, the BBTI and the Registers of the Stationer’s Company. This will allow us to create a fully-featured TEI XML edition in the near future. Our annotation of personal names did not go further than the <persName>, but TEI gives a number of more fine-grained levels such as <surname>, <forename> and <addname>, the last used for indicating a nickname or alias. For example, in the case of Culpeper, the common form given by printers to his first name, “Nich.”, could arguably be interpreted as a nickname and thus annotated with the <addname> element.
In the case of place names, it was at once evident that several different levels of specificity would be needed. In the example above, both London and the borough of Spittle-fields are given unique @ref-attribute values. In many cases the name of the printers’ or stationers’ place of business is also given on the title-page, such as “at the sign of the Rolling-Press for Pictures”. These names could arguably be annotated either as place-names elements or by using another element such as <residence>, which is used in TEI to descrive a person’s current or past place of residence. We chose to use place names for all geographic descriptions without going into more detail at that time.
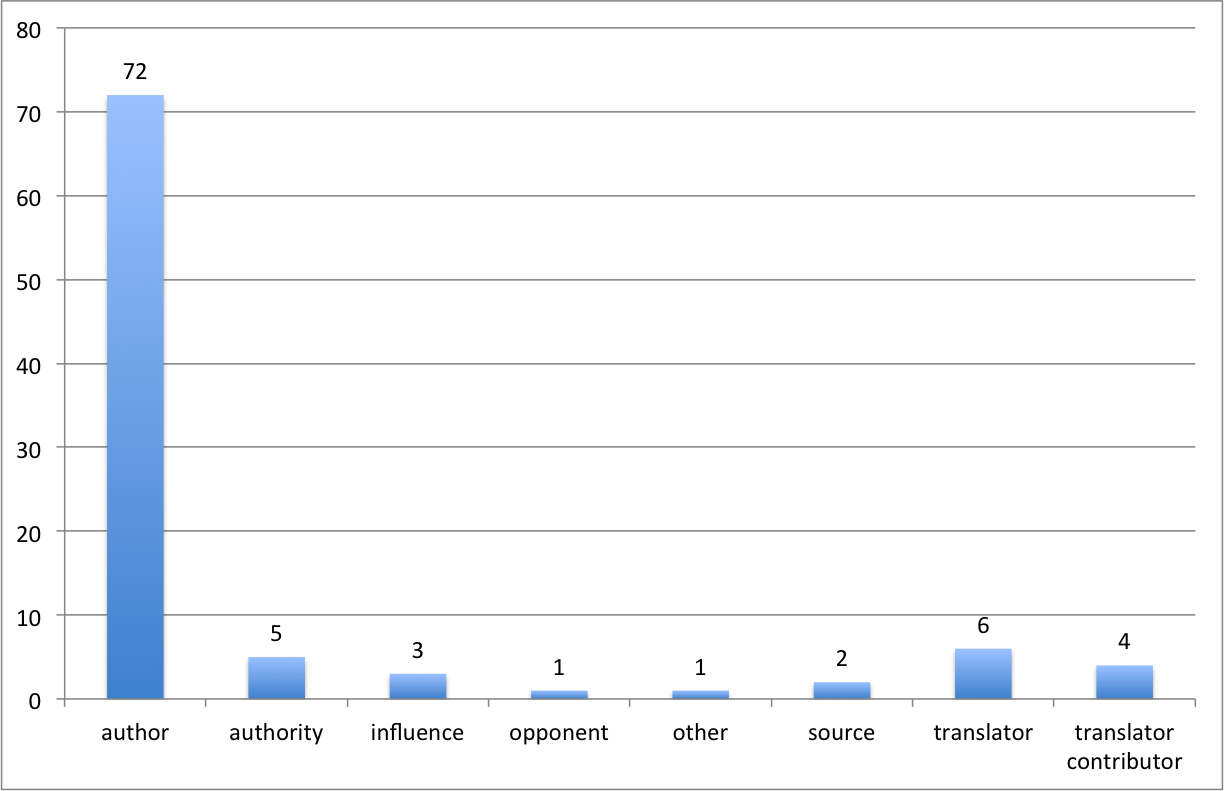
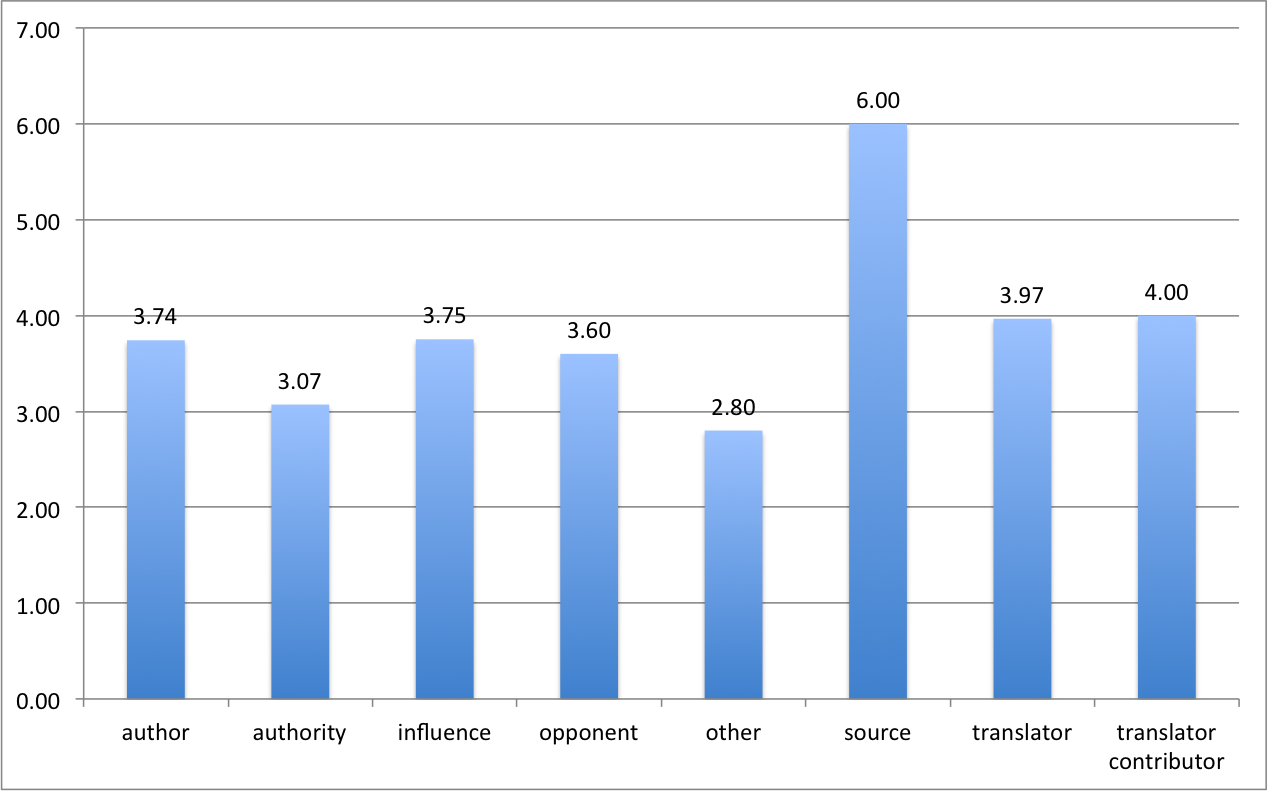
Because the focus of our project was specifically on examining the marketing aspects of Nicholas Culpeper, it was also deemed necessary to introduce searchable metadata about the role given on the title-page to Culpeper’s name. By including the semantic roles, we were able to analyse whether a relationship could be found between the way someone’s name was highlighted on the page and their perceived role. It is important at this point to make explicit that here the annotation process shifted, by necessity, to include analytical rather than purely descriptive information. On the basis of analysis by the project members, we used the @role attribute to classify persons appearing on the title-pages according to their stated or inferred function following a taxonomy based on the source material (see Table 1 and section 5). Note, however, that because the analytical data is given as an attribute of the personal name element, a researcher who does not wish to use the taxonomy can simply ignore the attribute.
| Role |
Description |
| Author |
The author of the text; in case of multiple authors, each is given as author |
| Authority |
A person referred to on the title-page as a medical authority |
| Translator |
Culpeper is named as the translator; only when given explicitly as such |
| Influence |
Culpeper is named an influence on the author, though the author may not have had any contact with Culpeper personally |
| Opponent |
Culpeper is named as a scholarly opponent to the author |
| Source |
Culpeper is given as a source of knowledge |
Table 1. Semantic roles of person’s mentioned on title-pages.
5. Analysis
To operationalise our research questions concerning printing-house styles and the prominence of Culpeper’s name on the title-page, we focused on a small selection of the most prominent features on the title-page and turned them into corpus queries which produced quantifiable data based on the paratextual annotation. To examine how printers used the title-page as a form of advertisement, we first looked at the length of the title-page contrasting successive editions of the same book with one another. Next, the visual prominence of Culpeper’s name was examined by proportional analysis contrasting the type size and family with the mean type size and family on the same page. We did not take into consideration the use of extra spacing in this study, though that data is available in the corpus. Finally, printing house styles were examined in terms of the use of different typefaces, the latter consisting of both the type family and the size of the type, as measured from the impression.
As discussed in Sections 2 and 3, the printers involved in producing Culpeper books from 1649 to roughly 1675 can be divided roughly into two main groups (Table 2). In the analysis, we define the two main groups as Strands A and B, and treat the others as an undifferentiated group of less consequence who will not be discussed in this pilot study.
| Strand A |
Strand B |
| Peter Cole |
Nathaniel Brookes |
| John Streater |
Obadiah Blagrave |
| George Sawbridge |
|
| Hannah Sawbridge |
|
Table 2. Main lines of Culpeper publishing
Image 10 gives the timelines of the editions included in this study, showing the successive line from Peter Cole to John Streater and then to George and Hannah Sawbridge. At the top of the figure, we see a similar succession from Nathaniel Brookes to Obadiah Blagrave.
5.1 Length of the title-page
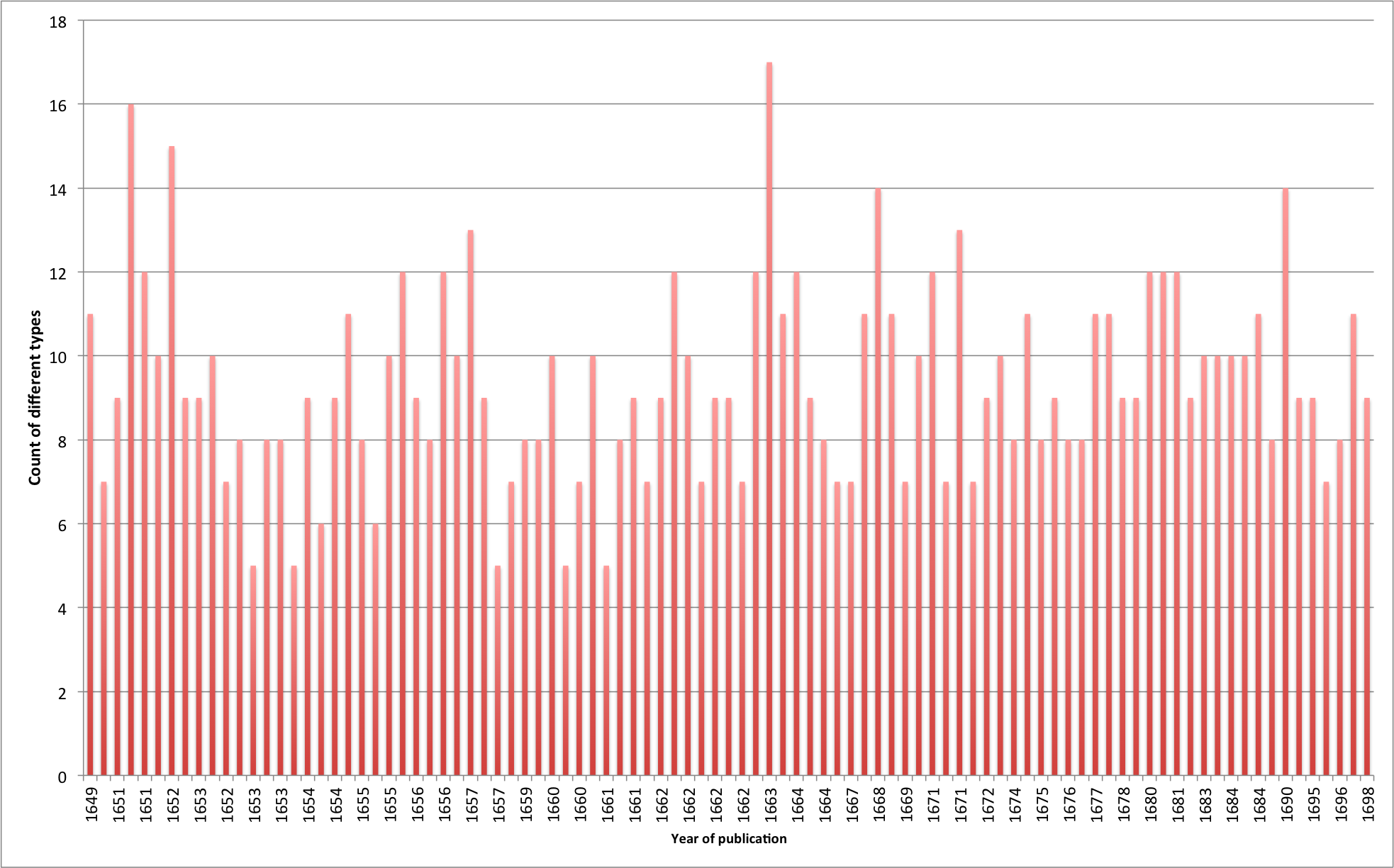
The length of the title-page in characters is a basic metric which can be extracted from any standard corpus with little effort. Nevertheless, the quantity of text on a page is a valuable and visually salient feature, and doubly so of a title-page, where history shows that fashions have gone from one extreme to another. The longer “laundry list” style of title-page was in fashion from the late sixteenth century to the early eighteenth century. During the late seventeenth century when Culpeper’s books came out, the title-pages of medical books commonly gave a sprawling title and an extensive list of contents, as well as other content such as epigraphs. Title-page thus tended to be on the long side, and it was not uncommon for publishers to add more and more content as new editions were printed. Because our analysis was focused on a relatively small number of printers over no more than 50 years, we might expect that the evidence of such practices might be relatively modest.
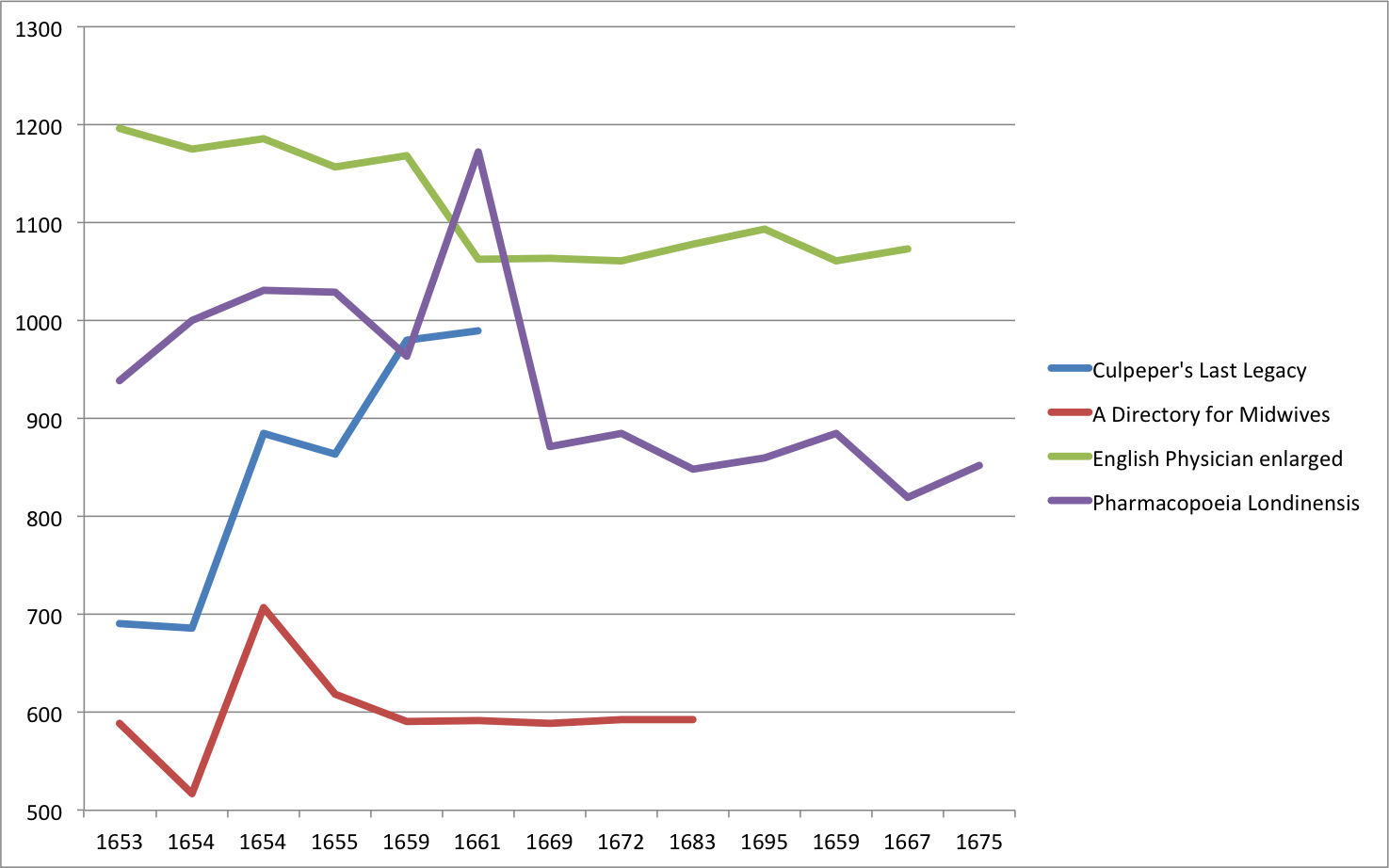
Image 11 gives the length of the title-page measured in characters. Four titles are included, representing books with more four or more editions. The overall impression is that if anything, the title-pages get shorter over the years, perhaps in testament both to Culpeper’s strong prominence which made it unnecessary to make claims about new content and to the generally honest nature of the printers.
The only notable exception is Culpeper’s Last Legacy, a hotly contested title that saw editions printed by Streater, Brookes, Blagrave and later Robert Hartford. The editions by Brookes, Blagrave and most likely Hartford are considered pirated copies, and it is quite remarkable to note how those editions are the only ones to show a dramatic increase of content on the title-page.
5.2 Culpeper’s name on the title-page
Next, the emphasis the printers put on the name Culpeper in advertising the books was evaluated by comparing the size and type family used for printing the name Culpeper against the mean size and type used on the respective page. This approach relates directly to the analytical principle of polarisation discussed by Meurman-Solin 2013 (this volume, section 4.2), where variant forms of any linguistics or here, peritextual features, are considered in relation to the baseline. In terms of philological background, this line of inquiry was inspired by the notion generally held among book historians that the Early Modern printer’s interest in aesthetics often outweighed both logical structure and basic semantics, with the result that the most prominent words on the title-page were often function words such as articles, prepositions and the like (see, e.g., Tschichold 2001: 116). Could this have been the case with Culpeper’s book, given the enormous sales potential of the apothecary’s name?
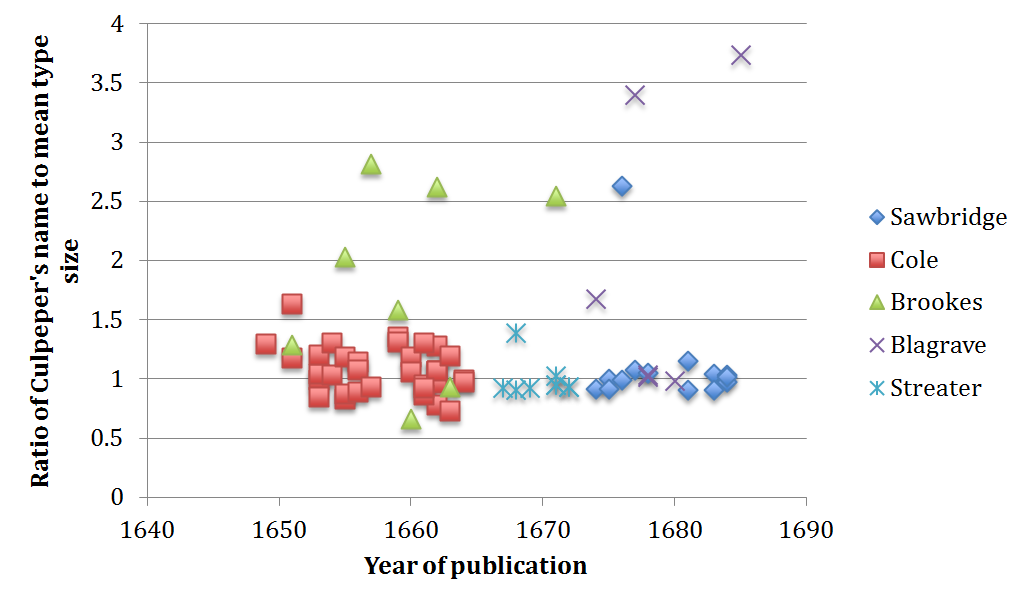
The average type size on a title-page is 3.11mm (standard deviation 0.82mm) and the average size of the main title is 6.84mm (standard deviation 2.30mm). By contrast, Culpeper’s name is printed, on average, 3.74mm (standard deviation 1.75mm). Thus, on average, Culpeper’s name is printed in a slightly larger type than the main text, but considerably smaller than the main title. The average ratio of Culpepers name to mean type is 1.20 and of the main title to mean type 2.19.
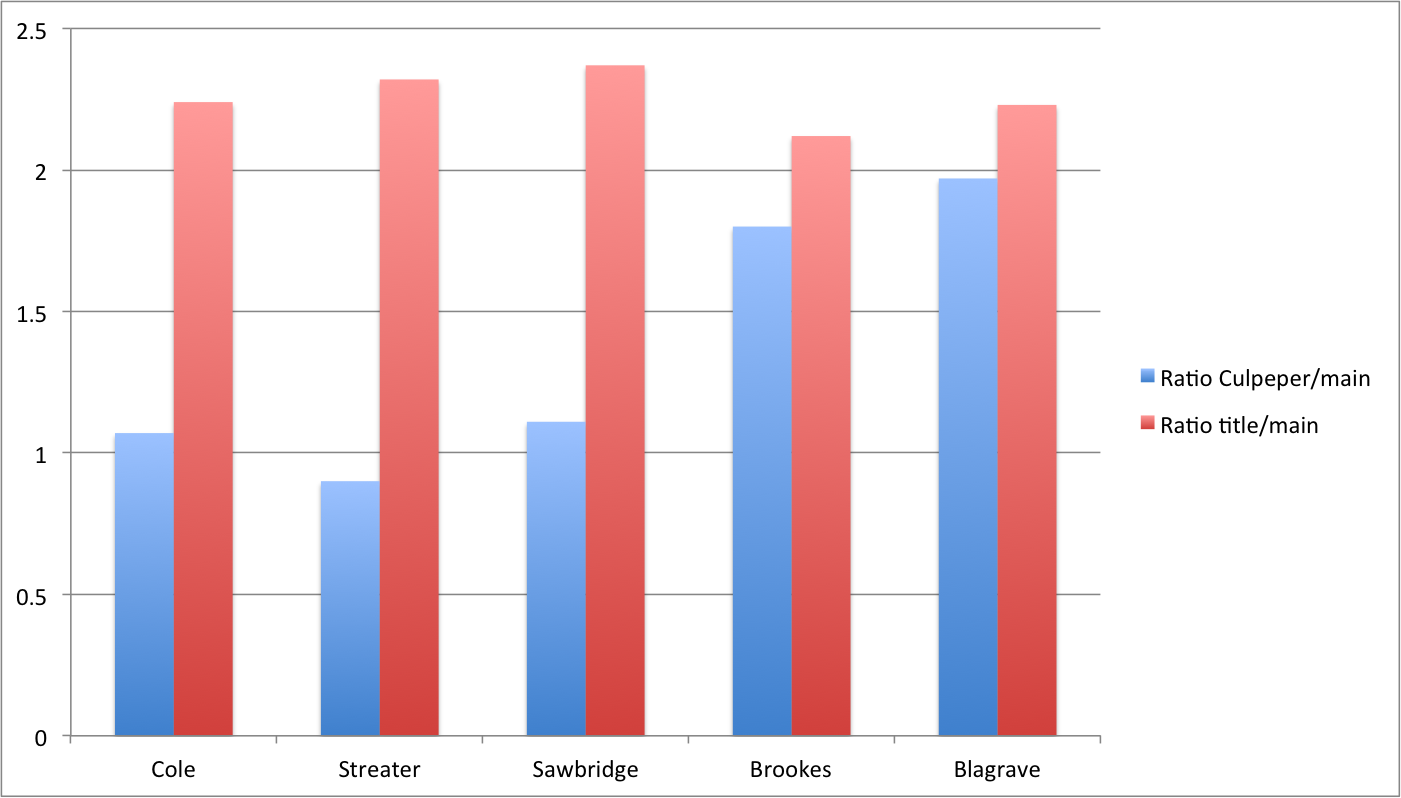
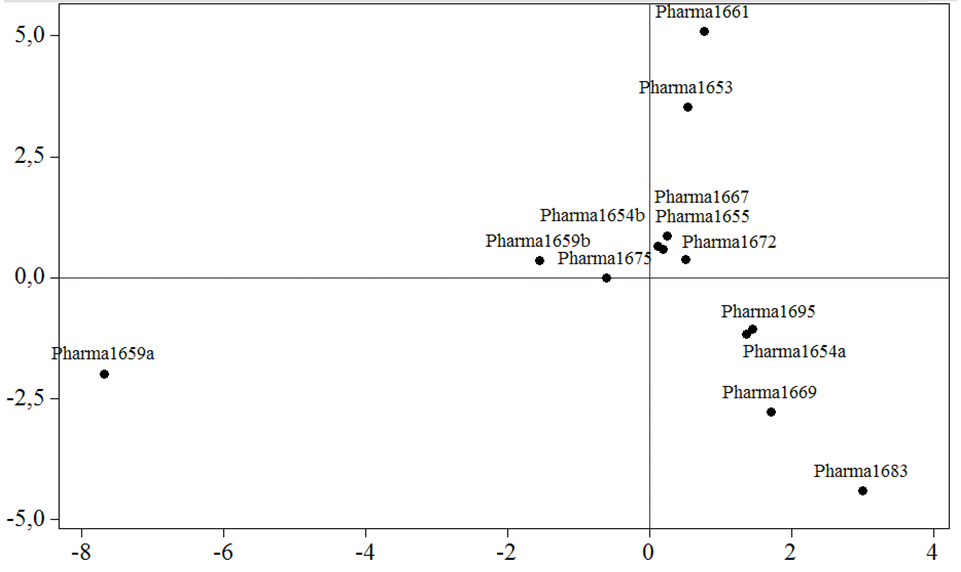
However, if we plot the data on a timeline (Image 12), the evidence shows that printers of Strand A — Cole, Streater and the Sawbridges — printed Culpeper’s name in a relatively conservative size with an average ratio of 1.06. Going by individual printing house, Cole’s average is 1.07, Streater’s 0.98 and the Sawbridges’ 1.11. The only real outlier with a ratio of 2.63 was produced, curiously enough, by Streater, in his 1676 edition of Culpeper’s Directory for Midwives. This was a complete departure from the Sawbridges’ normally very stable house style. By contrast, printers of Strand B, Brookes and Blagrave, tended to emphasize the author’s name considerably more. Brookes’ ratio is 1.8, while Blagrave’s is 1.97.
What does this tell us? Although the evidence must be considered tentative given the small sample size, these early results suggest that printers of a more unscrupulous character, that is, printers who deliberately fabricated new titles under the name of Culpeper, appeared to put more emphasis on Culpeper’s name. In fact, it even appears that in an effort to foreground Culpeper’s bestselling name, Strand B printers opted to downplay the actual title. If we look at the relationship between main title and mean type size, the ratio for Cole is 2.24, for Streater 2.32 and for the Sawbridges 2.37. By contrast, Brookes’ ratio is 2.12 and Blagrave’s 2.23. If we compare the two ratios, we find compelling evidence of two very different strategies of visual presentation (Image 13).
Image 14 gives the proportions of different type families used for printing Culpeper’s name, by printing house. The figure makes it immediately apparent that while Cole and Streater predominantly preferred italic type, the Sawbridges introduced the spaced roman as a preferred form for emphasis. Brookes and Blagrave, by contrast, used Roman type and downplayed italic.
Another way of highlighting text besides the size of type is of course by selecting a type that stands out from its context. Here, surprisingly, Strand B printers turn out to be much more conservative. Brookes and Blagrave use the same type as the surrounding text in 70% of the cases (Image 15). This, of course, partly explains why the same printers used a larger type size: if the type does not stand out because of form, it needs to be emphasized in another way.
Finally, the relationship between Culpeper’s semantic role and the size of type is also of interest because it has the potential of revealing contemporary attitudes to authorship and authority. Although Culpeper is predominantly given as the author, he also appears in several other roles (Image 16):
When we look at the mean type size of Culpeper’s name in these different roles, it emerges that no great differences can be observed (Image 16). There is a slight tendency to emphasize Culpeper as a source or translator, but the dataset is too small to draw any firm conclusions. This line of inquiry, however, seems very fruitful for future research, particularly as the database grows diachronically and allows the analysis of developments over longer timelines.
5.3 Metrics for printing house styles and typographic profiles of title-pages
The number of different types — i.e., combinations of type family and size — on a page can be looked at as a salient indicator of a printer’s desire to attract attention and show his wares, so to speak. Contrary to what one might expect, minor printers often used a greater number of different types on the same page. Arguably, the effect they sought was to catch the eye and to demonstrate quality by proxy of abundance, while more firmly established printers paid more heed to quality of composition.
To begin with a general view, we find that the median number of different types, that is, of combinations of type face and size, on a Culpeper title-page was 9 with an average of 9.34 and standard deviation of 2.34. Likewise, we know that the predominant typeface in the title-pages is roman type. The median for roman is 622, for italics 206 and for both blackletter and small caps 0. Blackletter is found on only 12 title-pages out of 95, small caps on 22.
Image 18 gives the number of types as a bar chart. There were no title-pages with less than 5 types, while the most extreme case, The compleat midvvife’s practice enlarged (1663) by Nathaniel Brookes, features 17 different types (see Image 18).
When it comes to the less common type families of blackletter and small caps, we can see clearly see that blackletter only appears on the title-pages from around 1670 (Image 17). A closer look reveals that blackletter is used by John Streater, George Sawbridge and by the smaller printing house of the Churchill’s. Considering that blackletter was a relatively rare type to use in the latter half of the seventeenth century, one may ask why several printers would opt to use it here. The answer most likely lies, once again, in marketing. In England, blackletter had come to signify writing for the masses, and the choice of type is thus no accident: the printers wanted to emphasize Culpeper’s credentials as a champion of the people, and for the contemporaries the use of blackletter was a transparent and clear signal to that effect (see McKerrow 1927: 297).
The quantitative approach to analysing the use of type also allows us to compile the data as a type profile matrix, as seen in Table 3. Each font, or type of a different size, is given a row in the matrix, while the texts under examination are placed in columns. This method holds considerable promise for the future, because it opens up the possibility of tracing the ownership and use of fonts across a timeline as well as of following up on new trends in publishing. A similar method could be used to track the use of specific images or of image motifs, the use of additional spacing, and so on. The resulting datasets will also make it possible to examine relationships between printing houses, for example by highlighting the sharing of fonts, and give us a long diachronic view of how peritextual styles developed and changed.
Table 3 illustrates the variety of types used by a handful of printers. The table gives the relative frequencies, in percentages, of each type by family and size, on the title-pages of thirteen editions of Pharmacopoeia Londinensis from 1653 to 1695. The table shows that 43 different sets of type are used in the thirteen editions.
This type of quantitative data can be analysed using multivariate methods that allow us to find similarities between title-pages on the basis of type distribution. Image 18 illustrates the potential of this type of analysis by means of principal component analysis, presented as a two-dimensional plot. The visualisation makes it apparent that the 1659a edition, printed by Peter Cole, differs markedly from all the other editions, sharing only very few fonts with any of the other editions. It is impossible to know why that happened, but we may conjecture that the one or more of the necessary fonts were in other use at the time. However, the actual imprint is in fact quite similar to the other editions printed by Cole, which suggests that Cole went to great lengths to recreate the same look using a completely different set of types.
This visualisation also illustrates the challenges of this method, because if one were to view the statistically dissimilar covers of 1659a and 1659b side-by-side, it would be immediately apparent that the pages are in fact quite similar to the naked eye. It would be possible to quantify the proportional distributions on the page without reference to the actual type sizes, thereby producing a metric that would show the two texts examined here as similar rather than dissimilar.
6. Conclusions
The first results of this pilot study into Culpeper’s title-pages can be interpreted as supporting the results of earlier scholarship on the major trends involving Culpeper’s works. The typographic evidence suggests clear differences between the two major strands of printing, but also raises new and evocative question concerning the motivations behind the printers’ decisions. In particular, we were intrigued to realize the almost symmetrical opposition between the two groups practices when it came to emphasizing Culpeper’s name: while members of Strand A preferred to highlight the author’s name by switching type, Strand B accomplished the same goal by keeping to the same type but switching to a larger size font. This observations underlines the importance of taking a broad look at the data, for had only one of the two variables, type size or type form, been examined alone, any conclusions drawn on their basis would have been misguided. The findings concerning printing house styles were also of interest, particularly as they suggest that printers succeeding to the same titles appear to have picked up the general style of the previous editions with only minor modifications based on house style, such as the use of blackletter by Streater and Sawbridge.
More than anything else, this pilot study served as an exploratory look into the feasibility of applying TEI XML annotation, at a relatively high level of detail, to the study of paratextual features of early modern books. The process taught us plenty, and we hope that the admittedly superficial discussion here, supplemented with our annotation guidelines and the corpus itself, can convey some of the lessons we learned. It goes without saying that the same principles would apply to the editing of manuscripts as well, as long as the necessary adjustments were observed.
It is clear that digitally annotated editions open up an entirely new world of analytical possibilities when it comes to bibliographic and paratextual features. Most importantly, descriptive annotation of the kind practiced here does not impose preconceived theoretical notion on the end-user, but rather simply turns the elements on the page into searchable and quantifiable format (see Meurman-Solin, this volume). While this inevitably implies a certain basic agreement on what the basic structural elements are – for example, a shared understanding of what a title is – and how the elements are measured, among other things, the model foregoes the problems associated with annotation schemes that explicitly associate features of the text with specific functions. An example of the latter would be to annotate all text printed in italics as <foreign>, simply on the assumption that that was the predominant use of that particular type family.
An important aspect of any project of digital transcription concerns the pragmatics of actually following the design of the annotation scheme, however well thought out it may be. In particular, this involves careful consideration of the labor required and the clarity of the guidelines followed. When it comes to labor, projects must consider the learning curve of not just getting to grips with the basics of the annotation model, such as XML, but also the particulars of the specific scheme used. As the number of elements and attributes increases, so does the complexity of using them in a systematic and consistent manner — particularly if the project has multiple transcribers, which is usually the case. Depending on the type of text and topic, the transcription work may require expertise in various issues ranging from identifying textual elements to recognizing quotes, names and semantic roles, just to name a few. Learning these may take time, depending on the previous experience of the transcribers, and will in every case require a well-written, comprehensive and clear set of guidelines. New computer-aided systems of digital transcriptions are currently being developed that would combine optical character recognition with automatic identification of major structural elements, and with luck these will be available to researchers before too long.
The potential benefits to diachronic studies of printing-house practices and features of early printed books of careful XML annotation of paratextual features are considerable. This small-scale study of some one hundred title-pages already demonstrated that the various features of the styles of individual printing-houses can be identified and that searchable data on typographic features allows us to evaluate the visual impact of specific textual content on the basis of measurements and type changes. This latter line of inquiry could naturally be improved considerably by working together with experts in psycholinguistics and cognitive sciences. The tracking of commercial and social communities of practice is also made possible by the careful annotation of types and illustrations, with the potential of uncovering previously unknown dynamics.
Notes
[1] S.v. “Cole, Abdiah”, Oxford Dictionary of National Biography
Sources
Culpeper title-page corpus. Download as a .zip file.
EEBO = Early English Books Online. Chadwyck-Healey. http://eebo.chadwyck.com/
Marttila, Ville. Transcription and Annotation Guidelines for the Gatekeepers of Knowledge Project, Version 0.5. Download the PDF
TEI = Text Encoding Initiative. TEI Consortium. http://www.tei-c.org/Guidelines/P5/
References
Culpeper corpus references
Anonymous. 1652. Black Munday turn’d white. London. Shelfmark British Library 718.e.20.(2.)
Anonymous. 1653. Mercurius anglicus. London. Shelfmark Wellcome Library EPB/B 36505/B
Anonymous. 1661. The rationall physitian’s library. London. Shelfmark British Library 773.m.10.(1.)
Bartholin, Thomas. 1663. Bartholinus anatomy. London. Shelfmark Cambridge University Library Keynes O.3.5.
Bartholin, Thomas. 1668. Bartholinus anatomy. London. Shelfmark British Library 780.i.46
Blagrave, Joseph. 1674. Blagrave’s supplement or enlargement to Mr. London. Shelfmark British Library 546.c.18
Chamberlayne, Thomas. 1663. The compleat midvvife’s practice enlarged. London. Shelfmark British Library 1177.b.7
Chamberlayne, Thomas. 1680. The complete midvvife’s practice enlarged. London. Shelfmark British Library 1608/4426.(1.-4.)
Chamberlayne, Thomas. 1680. The complete midvvife’s practice enlarged. London. Shelfmark Wellcome Library EPB/B 18555/B/1
Chamberlayne, Thomas. 1698. The compleat midwife’s practice enlarged. London. Shelfmark British Library 778.b.44
Cole, Abdiah, Nicholas Platter, Nicholas Culpeper. 1662. A golden practice of physick. London. Shelfmark Wellcome Library [shelfmark]
Culpeper, Nicholas and Peter Cole. 1653. The English physitian enlarged. London. Shelfmark Wellcome Library [shelfmark]
Culpeper, Nicholas. 1649. A physicall directory. London. Shelfmark Wellcome Library 19294/B/1
Culpeper, Nicholas. 1651. A directory for midvvives. London. Shelfmark Wellcome Library 19311/A
Culpeper, Nicholas. 1651. A physical directory. London. Shelfmark British Library 7510.g.10
Culpeper, Nicholas. 1651. Semeiotica uranica. London. Shelfmark British Library E.1360.(2.)
Culpeper, Nicholas. 1652. A directory for midwives. London. Shelfmark British Library C.194.a.449
Culpeper, Nicholas. 1652. Catastrophe magnatum. London. Shelfmark British Library 8610.c.23
Culpeper, Nicholas. 1652. The English physician or an astrologo-physical discourse of the vulgar herbs of this nation. London. Shelfmark British Library 1606/2070
Culpeper, Nicholas. 1652. The English physitian. London. Shelfmark British Library 774.a.34.
Culpeper, Nicholas. 1653. Pharmacopoeia Londinensis. London. Shelfmark Cambridge University Library Acton.b.53.9
Culpeper, Nicholas. 1654. Pharmacopoeia Londinensis. London. Shelfmark British Library 777.a.10
Culpeper, Nicholas. 1654. Pharmacopoeia Londinensis. London. Shelfmark Wellcome Library 19298/B
Culpeper, Nicholas. 1655. Culpeper’s astrologicall judgment of diseases from the decumbiture of the sick much enlarged. London. Shelfmark Cambridge University Library Hunter.d.65.4.
Culpeper, Nicholas. 1655. Pharmacopoeia Londinensis. London. Shelfmark Wellcome Library 19299/B
Culpeper, Nicholas. 1655. The English physitian enlarged. London. Shelfmark Wellcome Library 19321/B
Culpeper, Nicholas. 1656. A directory for midwives. London. Shelfmark British Library 1175.a.10
Culpeper, Nicholas. 1656. Mr. London. Shelfmark British Library 1032.a.9
Culpeper, Nicholas. 1656. The English physitian enlarged. London. Shelfmark Wellcome Library 19322/B
Culpeper, Nicholas. 1657. Culpeper’s last legacy. London. Shelfmark Wellcome Library 19385/A
Culpeper, Nicholas. 1657. Mr. Culpepper’s Treatise of aurum potabile. London. Shelfmark Wellcome Library 1538/A
Culpeper, Nicholas. 1659. Culpeper’s school of physick. London. Shelfmark Wellcome Library 19393/A/1
Culpeper, Nicholas. 1659. Pharmacopoeia Londinensis. London. Shelfmark British Library 1488.f.43
Culpeper, Nicholas. 1659. Pharmacopœia Londinensis. London. Shelfmark Wellcome Library 19300/B/1
Culpeper, Nicholas. 1661. Pharmacopoeia Londinensis. London. Shelfmark British Library 7509.g.15
Culpeper, Nicholas. 1661. The English physitian enlarged. London. Shelfmark Wellcome Library [shelfmark]
Culpeper, Nicholas. 1662. Culpeper’s last legacy. London. Shelfmark British Library 1507/366
Culpeper, Nicholas. 1662. The English physitian enlarged. London. Shelfmark Wellcome Library 19324/B
Culpeper, Nicholas. 1663. Two treatises. London. Shelfmark British Library 783.b.38
Culpeper, Nicholas. 1667. Pharmacopoia Londinensis. London. Shelfmark British Library 777.b.3
Culpeper, Nicholas. 1668. Culpeper’s last legacy. London. Shelfmark Wellcome Library 57246/A
Culpeper, Nicholas. 1669. Pharmacopoeia Londinensis. London. Shelfmark Cambridge University Library Keynes.T.4.9
Culpeper, Nicholas. 1671. A directory for midwives. London. Shelfmark Wellcome Library 65234/A
Culpeper, Nicholas. 1671. Culpeper’s last legacy. London. Shelfmark British Library Cup.407.a.113
Culpeper, Nicholas. 1672. Pharmacopoeia Londinensis. London. Shelfmark British Library RB.23.a.7335
Culpeper, Nicholas. 1672. Two treatises. London. Shelfmark British Library C.194.a.1203
Culpeper, Nicholas. 1674. The English physitian enlarged. London. Shelfmark British Library 1607/190
Culpeper, Nicholas. 1675. A directory for midwives. London. Shelfmark British Library RB.23.a.19466(1)
Culpeper, Nicholas. 1675. Pharmacopoia Londinensis. London. Shelfmark British Library 1488.aa.34
Culpeper, Nicholas. 1676. Culpeper’s Directory for midwives. London. Shelfmark British Library RB.23.a.19466(2)
Culpeper, Nicholas. 1676. The English physitian enlarged. London. Shelfmark British Library 1607/206
Culpeper, Nicholas. 1677. Culpeper’s last legacy. London. Shelfmark Cambridge University Library Keynes.P.3.18
Culpeper, Nicholas. 1678. Culpeper’s school of physick. London. Shelfmark British Library 544.d.32.
Culpeper, Nicholas. 1678. Culpeper’s school of physick. London. Shelfmark Wellcome Library 19394/A
Culpeper, Nicholas. 1681. A directory for midwives. London. Shelfmark Wellcome Library 57232/A
Culpeper, Nicholas. 1681. The English physitian enlarged. London. Shelfmark British Library 1607/203
Culpeper, Nicholas. 1683. Pharmacopoeia Londinensis. London. Shelfmark Wellcome Library EPB/A 19307/B/1
Culpeper, Nicholas. 1683. The English physitian enlarged. London. Shelfmark British Library 7510.d.1.
Culpeper, Nicholas. 1684. A directory for midwives. London. Shelfmark British Library Cup.363.a.22
Culpeper, Nicholas. 1684. The English physitian enlarged. London. Shelfmark British Library 1608/5801
Culpeper, Nicholas. 1684. The English physitian enlarged. London. Shelfmark Wellcome Library 19329/B
Culpeper, Nicholas. 1685. Culpeper’s last legacy. London. Shelfmark British Library 1166.b.14
Culpeper, Nicholas. 1690. Physical receipts. London. Shelfmark British Library 1038.d.28.(1.)
Culpeper, Nicholas. 1693. A directory for midwives. London. Shelfmark British Library 1175.b.29
Culpeper, Nicholas. 1695. Pharmacopoeia Londinensis. London. Shelfmark British Library 1490.d.45
Culpeper, Nicholas. 1695. The English physitian enlarged. London. Shelfmark British Library 546.c.21
Culpeper, Nicholas. 1696. Culpeper’s school of physick. London. Shelfmark Wellcome Library 19397/A
Culpeper, Nicholas. 1698. The English physician enlarged. London. Shelfmark Wellcome Library 19331/B
Culpeper, Nicholas. 1700. A directory for midwives. London. Shelfmark Wellcome Library 19314/A
Galen. 1653. Galens art of physick. London. Shelfmark Wellcome Library 23859/A
Galen. 1662. Galen’s art of physick. London. Shelfmark Wellcome Library 23860/A
Galen. 1671. Galen’s Art of physick. London. Shelfmark British Library C.194.a.396
Godbury, John. 1652. Philastrogus knavery epitomized. London. Shelfmark British Library E.659.(16.)
Jonstonus, Joannes. 1657. The idea of practical physick in twelve books. London. Shelfmark Wellcome Library EPB/C 30632/C
Mackaile, Matthew. 1664. Moffet-well. London. Shelfmark British Library 1171.e.43
Patrlicus, Simeon. 1654. A new method of physick. London. Shelfmark Wellcome Library 39945/A
Platter, Felix. 1664. Platerus golden practice of physick. London. Shelfmark Wellcome Library Suppl. C 60297/C
Prevost, Jean. 1656. Medicaments for the poor. London. Shelfmark British Library [shelfmark]
Prevost, Jean. 1664. Medicaments for the poor. London. Shelfmark Wellcome Library 57515/A
Riolan, Jean. 1671. A sure guide. London. Shelfmark Wellcome Library 44082/C
Rivière, Lazare. 1655. The practice of physick. London. Shelfmark Wellcome Library 44145/C
Rivière, Lazare. 1662. Two treatises the first of pulses. London. Shelfmark Wellcome Library 22432/A
Rivière, Lazare. 1668. The practice of physick in seventeen several books wherein is plainly set forth the nature. London. Shelfmark Cambridge University Library Path.b.169
Rivière, Lazare. 1678. The practice of physick. London. Shelfmark Wellcome Library 44151/c/1
Sennert, Daniel. 1660. Thirteen books of natural philosophy. London. Shelfmark Wellcome Library 47807/e/1
Sennert, Daniel. 1660. Two treatises. London. Shelfmark Wellcome Library 773.m.10(5)
Sennert, Daniel. 1661. [T]hirteen books of natural philosophy. London. Shelfmark British Library 773.m.10(2)
Sennert, Daniel. 1662. Chymistry made easie and useful. London. Shelfmark British Library 7580.a.49.(2.)
Sennert, Daniel. 1662. The sixth book of Practical physick. London. Shelfmark British Library 7580.a.49.(3.)
Sennert, Daniel. 1664. Practical physick. London. Shelfmark British Library 7580.a.49
Vesling, Johann. 1653. The anatomy of the body of man. London. Shelfmark British Library 548.k.11
Vesling, Johann. 1677. The anatomy of the body of man. London. Shelfmark British Library C.184.c.2
von Rodach, George Fedro. 1656. Culpepers physical and chymicall way of curing the most difficult and incurable diseases. London. Shelfmark British Library 1036.a.19
Wecker, Johann Jacob. 1660. Arts master-piece. London. Shelfmark Cambridge University Library E.2124(3)
Wecker, Johann Jacob. 1660. Cosmeticks. London. Shelfmark British Library E.2140(3)
Primary references
Blount, Thomas. 1656. Glossographia. London.
Blount, Thomas. 1661. Glossographia. London.
Bullokar, John. 1671. English Expositor. London.
Schöder, Johann. 1669. The Compleat Chymical Dispensatory. London.
Whither, George. 1625. The Scholars Purgatory. London.
Secondary references
Bland, Mark. 2010. A Guide to Early Printed Books and Manuscripts. Hong Kong: Wiley Blackwell.
Brayman Hackell, Heidi. 2005. Reading Material in Early Modern England: Print, Gender, and Literacy. Cambridge: Cambridge University Press.
Eisenstein, Elizabeth L. 1993 [1983]. The Printing Revolution in Early Modern Europe. Cambridge: Cambridge University Press.
Furdell, Elizabeth Lane. 2002. Publishing and Medicine in Early Modern England. Rochester: University of Rochester Press.
Furdell, Elizabeth Lane. 2004. “‘Reported to be Distracted’: The suicide of Puritan entrepreneur Peter Cole”. The Historian 66(4): 772–792.
Gaskell, Philip. 1974. A New Introduction to Bibliography. Oxford: Oxford University Press.
Genette, Gerard. 1997. Paratexts: Thresholds of Interpretation. Cambridge: Cambridge University Press.
Hill, Christopher. 1972. The World Turned Upside Down: Radical ideas during the English Revolution. New York: Viking Press.
Honkapohja, Alpo, Samuli Kaislaniemi & Ville Marttila. 2009. “Digital Editions for Corpus Linguistics: Representing manuscript reality in electronic corpora”. Corpora: Pragmatics and Discourse. Papers from the 29th International Conference on English Language Research on Computerized Corpora (ICAME 29), ed. by Andreas Jucker, Daniel Schreier & Marianne Hundt, 451–475. Amsterdam: Rodopi.
Kuitert, Lisa. 2007. “The exploitation of fame – a book-historical approach”. Quarendo 37: 175–177.
McKerrow, R.B. 1927. An Introduction to Bibliography for Literary Students. Second edition. Oxford: Oxford University Press.
McLean, Marie. 1991. “Pretexts and paratexts: The art of the peripheral”. New Literary History 22(2): 273–279.
Monella, Paolo. 2008. “Towards a digital model to edit the different paratextuality levels within a textual tradition”. Digital Medievalist 4. www.digitalmedievalist.org/journal/4/monella/
Raven, James. 2007. The Business of Books: Booksellers and The English Book Trade. New Haven: Yale University Press
Rhinelander McCarl, Mary. 1996. “Publishing the works of Nicholas Culpeper, astrological herbalist and translator of Latin medical works in seventeenth-century London”. Canadian Bulletin of Medical History / Bulletin canadien d’histoire de la médecine 13(2): 225–276.
Sanderson, Jonathan. 1999. “Medical secrets and the book trade: Ownership of the copy of the College of Physicians’ Pharmacopoeia (1618–1650)”. The Human Face of The Book Trade, ed. by Peter Isaac & Barry McKay, 65–80. Delaware: Oak Knoll Press.
Sherman, William. 2007. “On the threshold: Architecture, paratext and early print culture”. Agent of Change: Print Culture Studies after Elizabeth L. Eisenstein, ed. by Sabrina Alcorn, Eric N. Lindquist & Eleanor F. Shevlin, 67–81. Amherst: University of Massachusetts Press.
Shevlin, Eleanor F. 1999. “’To Reconcile Book and Title, and Make ’em Kin to One Another’: The evolution of the title”s contractual functions”. Book History 2(1): 42–77.
Smith, Margaret M. 2000. The Title-Page: Its Early Development 1460–1510. London: Oak Knoll Press.
TEI Consortium. 2012. TEI P5: Guidelines for Electronic Text Encoding and Interchange, ed. by Lou Burnard & Syd Bauman. Version 2.2.0. Charlottesville, VA: Text Encoding Initiative Consortium. http://www.tei-c.org/release/doc/tei-p5-doc/en/html/
Tschichold, Jan. 2001. “The principles of the new typography”. Texts on Type: Critical Writings on Typography, ed. by Steven Heller & Philip B. Meggs, 115–128. New York: Allworth Press.
Tyrkkö, Jukka. 2012. “A Physical Dictionary (1657): The first English medical dictionary. Reprint”. Ashgate Critical Essays on Early English Lexicographers. Vol. 4. The Seventeenth Century, ed. by John Considine. Ashgate.
Tyrkkö, Jukka. Forthcoming. “Printing houses as communities of practice: Orthography in early modern medical books”. Communities of Practice in the History of English, ed. by Joanna Kopazcyk & Andreas Jucker. Amsterdam: John Benjamins.
Voss, Paul J. 2003. “Printing conventions and the Early Modern play”. Medieval and Renaissance Drama in England, Volume 15, ed. by John Pitcher, Robert Lindsey & Susan Cerasano, 98–116. New Jersey: Fairleigh Dickinson University Press.
Wear, Andrew. 1996. “Religious belief and medicine in Early Modern England”. The Task of Healing: Medicine, Religion, and Gender in England and the Netherlands, 1450–1800, ed. by Marland Hilary & Margaret Pelling, 145–169. Rotterdam: Erasmus.
Wear, Andrew. 2000. Knowledge and Practice in Medicine, 1550–1680. Cambridge: Cambridge University Press
Webster, Charles. 1975. The Great Instauration: Science, Medicine and Reform, 1626–1660. New York: Holmes and Meier.
West, Anthony James. 2003. The Shakespeare First Folio: A New Worldwide Census of First Folios. Oxford: Oxford University Press.
|