
Studies in Variation, Contacts and Change in English
Studies in Variation, Contacts and Change in English
Terttu Nevalainen
Research Unit for Variation, Contacts and Change in English, University of Helsinki
The future? Come back to the past. (Caption in an olive-oil advertisement)
The S-shaped curve is typically used to model the diffusion of linguistic change across time. This paper looks at the degree to which the model applies to empirical real-time data of some time-depth. An S-shaped curve is commonly attested in the quantitative studies discussed, but it is not the only pattern that emerges from systematic analyses. To put the model and its descriptive adequacy into perspective, I consider both typical cases and exceptions to them, notably change reversals. I also draw attention to the level of analytic detail that has a major role to play in empirical research into processes of language change and their outcomes. [1]
The diffusion of language change across time is commonly presented as an S-shaped curve. Going back to sociological research on the diffusion of innovations across populations, this model has also been adopted by sociolinguists to describe the spread of linguistic innovations (e.g. Blythe & Croft 2012; Denison 2003; Labov 1994; Kroch 1989). It refers to a process with a slow beginning when only a few speakers use the incoming form or pattern, followed by a middle stage when it is gaining ground rapidly among the speakers, and a slower final phase in which the vast majority have adopted it.
In this study I discuss data from successive time periods as material for historical trend studies in order to be able to evaluate the degree to which the progress and outcome of linguistic change can be captured by the S-curve model. The issues to be addressed include the completion of an ongoing change and the shape and composition of the S-curve at various levels of analytic depth. I will concentrate on data from earlier times, but the basic trajectories of change that stand out have been attested in more recent sociolinguistic processes as well (e.g. Labov, Rosenfelder & Fruehwald 2013).
After introducing the concept of an S-curve in more detail in section 2, I will move on in section 3 to discuss the patterns that have been observed in real-time empirical studies, i.e., regular S-curves, inverted S-curves, and potentially continuous U-shaped curves. Section 4 considers the depth of the linguistic analysis carried out and its sociolinguistic and diachronic dimensions as factors affecting the descriptive adequacy of the S-curve model. My conclusions on its heuristic value in section 5 are moderately optimistic, not forgetting, however, that ongoing individual changes are susceptible to varying linguistic and social circumstances and hence liable to fluctuate and even reverse.
The S-curve model has come to be associated with the diffusion of innovations among populations in various fields of scholarship and science. Analysing hundreds of related studies, the sociologist Everett Rogers (cf. Rogers 2003) has presented the principles of the model shown in Figure 1. It suggests two ways of approaching the process of diffusion, looking at successive groups of people adopting the new idea or technology (i.e. innovators, early adopters, early majority, late majority and laggards) and at the increasing use of the innovation (its market share) over time, which eventually reaches a saturation point when the laggards join in. The first curve, shown in blue in Figure 1, forms a bell curve and the second, the yellow one, constitutes an S-curve.
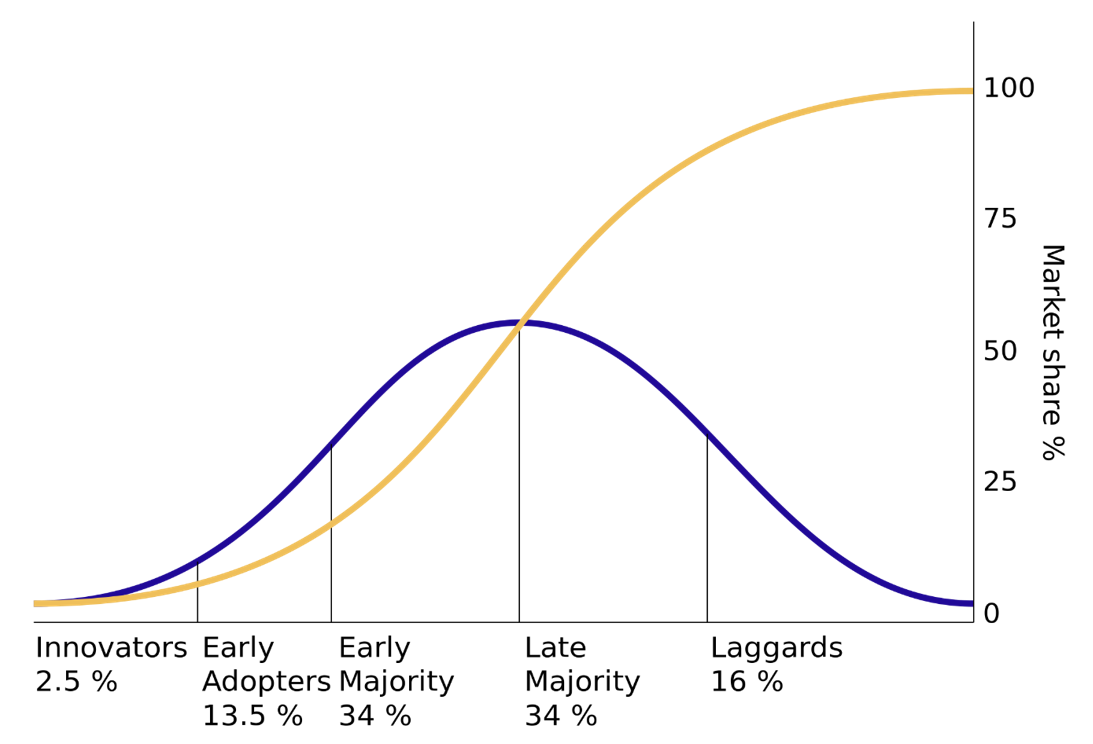
Figure 1. The diffusion of innovations according to Rogers (2003). Successive groups of people adopting an innovation are shown in blue and the increasing market share of the innovation is shown in yellow (Source: Wikimedia commons). [2]
In linguistics, the S-curve has been adopted at least from the early 1950s on to model the diffusion of linguistic change (Denison 2003: 54). [3] In variationist sociolinguistics, the S-curve model is used to describe the progressively changing frequencies of variant forms of a linguistic variable, i.e. alternative ways of saying the same thing. Analysing the process of one form being replaced by another, Labov (1994: 65–66) suggests that the logistic S-curve models the frequency of contact between users of the older and the newer form and the subsequent adoption of the newer form. At first, the users of the older form are rarely exposed to the newer one, and only a little transfer takes place. The rate of change and amount of contact between speakers are greatest at midpoint. In the final stages there is only a slight pressure to change and the rate of change falls as the number of speech events where the shift could occur diminishes (Labov 1994: 66). In the final stages there are often particular linguistic environments that resist change.
Analysing linguistic variation in general, Kretzschmar (2009) approaches variant expressions in terms of their frequency distributions and finds that, at any given time, they follow the power law curve (an “A-curve”), based on Zipf’s law. [4] He accounts for the ways in which speakers perceive the different frequencies of features (variant forms) as follows:
[T]he most frequent variants are perceived as “normal”, less frequent variants are perceived as “different”, and since particular variants are more or less frequent among different groups of people or types of discourse, the variants come to mark identity of the groups or types by means of these perceptions. (Kretzschmar 2009: 4)
Kretzschmar and Stenroos (2012) studied spelling variation in Late Middle English texts, tracking the alternative variants in order of frequency. They found that the variants patterned, as expected, along the power law curve in any given variety, but the dominant forms varied greatly between regions and periods. Like Labov (1994: 66), they observed that when a change was under way and a particular form moved up in frequency rank over time, “the distributional patterns of both the A-curve and the S-curve predict that there is a larger relative change in the middle of the curves” (Kretzschmar & Stenroos 2012: 119).
One of the concerns that Denison (2003) has with the S-curve model is its deterministic nature: when a change is under way, it is predicted to eventually reach completion. Theoretically speaking, no such determinism is warranted in that change need not be completed: after an initial progress of the new form, variation between the old and the new form can stabilize and persist in the population. He therefore suggests that:
It is probably the case that complete or near-complete S-curves are outnumbered by changes which show just part of the S-curve, whether the part-curves result from the impossibility of obtaining numerical evidence or from disruption or reversal of a change. (Denison 2003: 63–64)
Raumolin-Brunberg (2002) considers some potential instances of stable variation in the history of English, citing cases such as the (ING) variable, multiple negation and affixal and nonaffixal negation. [5] Her conclusion is that although stable variation could be claimed to have existed for a long time in cases such as these, the linguistic variables can only be established at a highly abstract level and the diachronic continuity of sociolinguistic variation may be difficult to document in quantitative terms (Raumolin-Brunberg 2002: 113). This latter point, also made by Denison, relates to the historical sociolinguist’s “bad-data problem” and may not as such serve as evidence against the diffusion of linguistic change along an S-curve model of change (but neither does lack of evidence allow us to assume such diffusion).
My work in Nevalainen (2006a, 2006b) explores the history of some potentially stable features in empirical terms by analysing what Chambers (1995: 242) has called “vernacular universals”, features that “appear to be primitives of vernacular dialects in the sense that they recur ubiquitously all over the world”. Chambers singles out negative concord and “default singulars” (the use of was instead of were with plural subjects) as typical instances of such features. However, diachronically they do not share a common, unbroken past but rather display different origins and variable time depths. Although the history of was/were variation, for example, may look like a case of relatively stable variation when a set of multigenre corpora are analysed, it reveals a more sharply declining trend in various linguistic contexts and different social groups in a socially stratified single-genre corpus. [6] I will return to this issue of depth of analysis in section 4.
In this section I outline the major patterns of diffusion of language change that have emerged in empirical work on real-time language change. Besides the possibility of stable variation, the basic options come in three kinds: regular S-curves, their reversals (inverted S-curves), and potentially repetitive U-shaped curves, this third alternative being a modification of the second. The studies to be discussed do not relate the absolute frequencies of the exponents of different processes to each other, as these can be expected to vary from low to high text frequency following Zipf’s Law and depending on issues like genre or register variation (Biber 1995; Kretzschmar & Stenroos 2012: 119). Rather, the studies reconstruct linguistic variables, the alternative forms and constructions from which the language user needs to select one to express, say, a given grammatical function.
Although there is a good deal of empirical variation, an S-shaped curve is detectable in many processes of linguistic change: this is to varying extents the case in as many as twelve out of the fourteen cases studied in Nevalainen and Raumolin-Brunberg (2003), which range from morpheme replacements (e.g. of ‑th by ‑s in the third person singular present indicative) to abstract structural patterns (e.g. the loss of negative concord). The diachronic profiles of these processes, and the S-curves they project, vary in several respects, testifying to the complexity of the trajectories of actual linguistic changes (e.g. completed/not completed) and the rate at which a certain variant is gaining ground across the language community (in a few decades/many centuries). Processes may also vary with respect to their regional directionality (e.g. from south to north, from north to south) and social origins (from higher/middle/lower socio-economic classes).
The case illustrated in Figure 2 is typical in that it diagrams the diffusion of an incoming feature, the subject form you, which replaces the traditional form ye (ye go > you go) at the aggregate level of the language community as represented by the Corpus of Early English Correspondence (CEEC). The change is very rapid and takes less than a century to run its course (Nevalainen & Raumolin-Brunberg 2003: 218, Table 1).
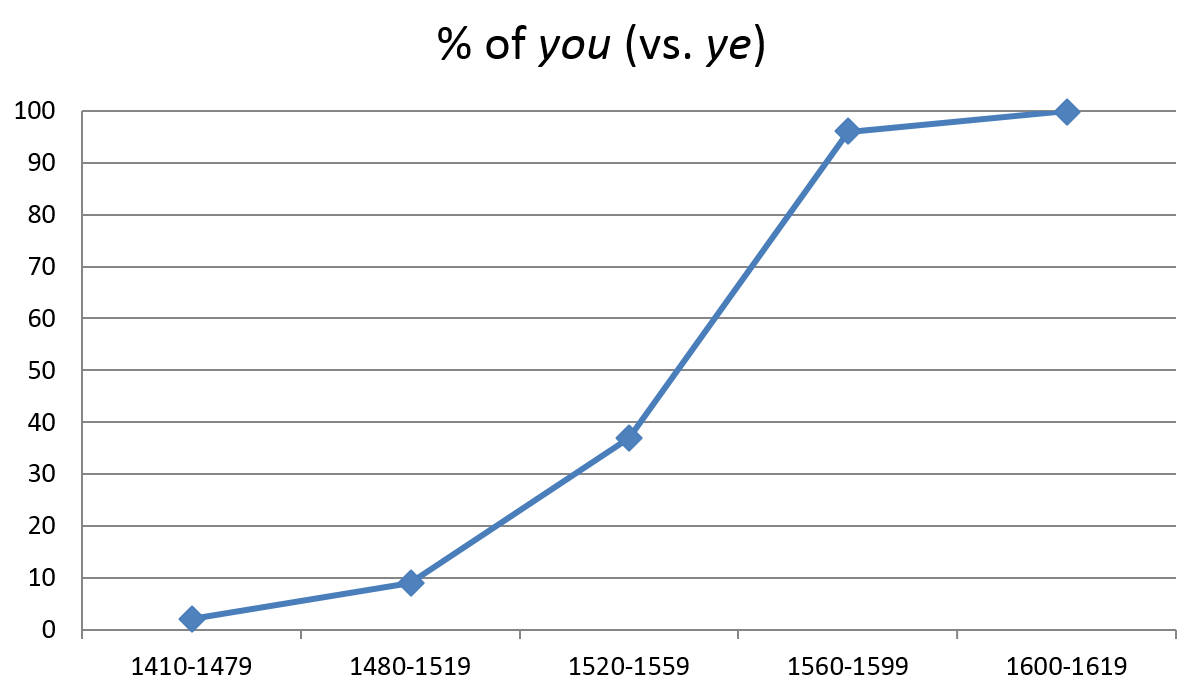
Figure 2. Rapid change reaching completion: the subject form you (CEEC).
At the level of analytic detail plotted in Figure 2, this change serves as a good illustration of the process of linguistic change in real time from inception to completion. It provides researchers with baseline information that they can use to analyse the process in its various phases and to trace its social and regional diffusion over time in more detail. The bulk of the process is statistically significant from subperiod to subperiod even at more detailed sociolinguistic levels of analysis, as shown, for example, by Hinneburg et al. (2007: 146–147), who compared different methods of significance testing and calculated Bayesian estimates for the probability of the subject you for males and females and for different regions in the CEEC data.
Although cases that progress along an S-curve are in the majority among those studied using the CEEC, there are also notable exceptions. A case in point is the history of periphrastic do, the use of the “dummy” auxiliary do in affirmative statements, which picked up in the course of the 16th century, only to reverse its course in the early 17th century. Figure 3 shows this trajectory, which forms an inverted S-curve over time (based on Table 8, Nevalainen & Raumolin-Brunberg 2003: 220, drawn from Nurmi 1999). Similar findings with a somewhat earlier peak are reported by Ellegård (1953), who used a mixed set of genres as his primary data.
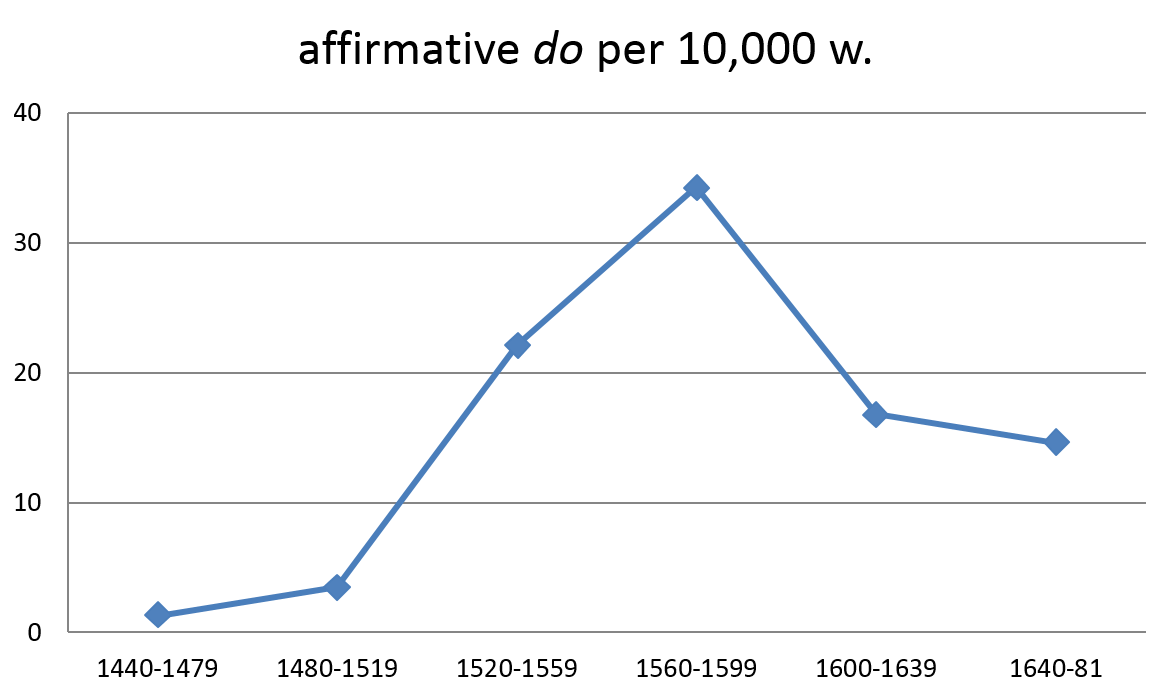
Figure 3. Change reversal: affirmative do (CEEC).
Another, somewhat later reversal of an initially successful diffusion of a construction is shown in Figure 4. It traces the rise and subsequent decline of the agreement pattern you was of the subject pronoun you and the past tense form of be in the 18th-century extension of the CEEC (based on Table 1 in Laitinen 2009: 206). A similar rising–falling trajectory could be found in the diffusion of you was in corpora such as ARCHER (A Representative Corpus of Historical English Registers). [7]
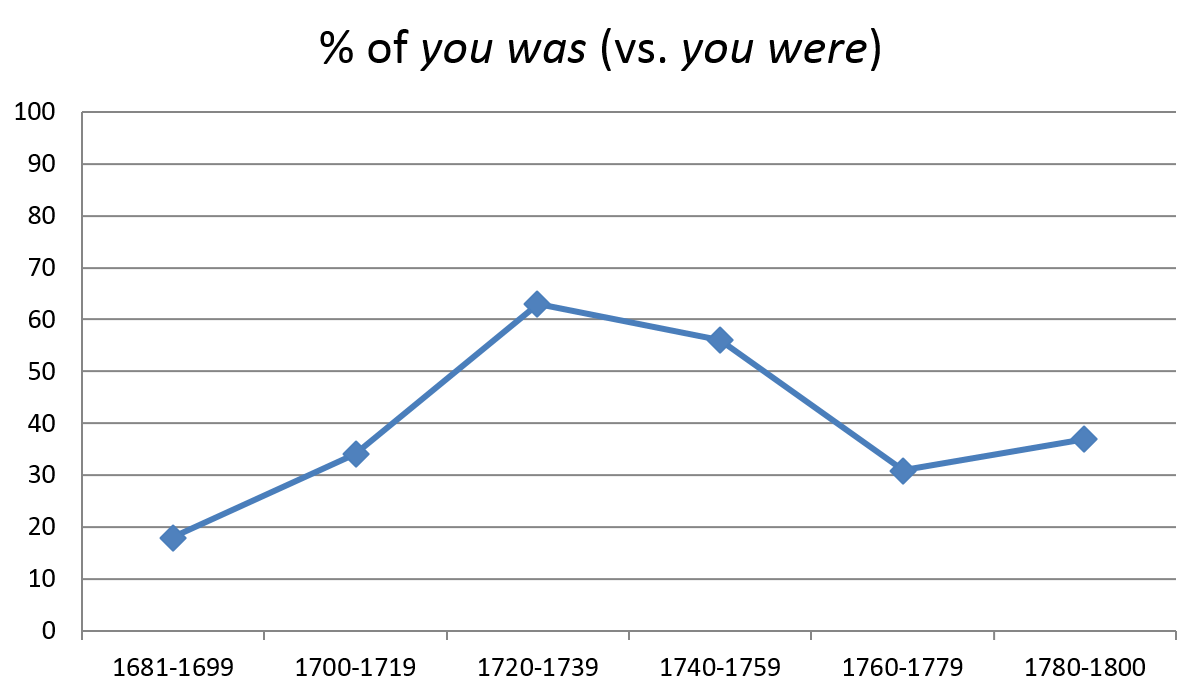
Figure 4. Change reversal: you was (CEEC, 18th century).
If the outcome is expected (with the benefit of hindsight, for example), the diffusion of linguistic change along an S-shaped curve does not necessarily call for an explanation, but a change reversal normally does. Although similar in their overall shape, different social factors have been suggested to account for the two processes of diffusion in Figures 3 and 4: dialect contact with Scots in the case of do, and the influence of 18th-century normative grammar in that of you was. Analysing the regional spread of periphrastic do in affirmative statements in ten-year periods, Nurmi (1999: 179–181) comes to the conclusion that the accession of James I of England (and VI of Scotland) to the English throne and the arrival of his court in London had an impact on linguistic usage, bringing to a halt the rise of periphrastic do in affirmative statements, which was infrequent in Older Scots at the time. Laitinen (2009: 215) in turn made the point that 18th-century prescriptive grammarians ruled out you was as ungrammatical because you was considered a plural form that required a plural verb. You was reversing its course in the late 18th century would therefore be a good candidate for normative grammar impacting on the course of an ongoing language change.
In Figure 4 we can see a small upward turn in the last period, 1780–1800, which may be simple data fluctuation but could also make you was a less good specimen of a change reversal than affirmative do in Figure 3. After all, you was continues to be found in many present-day varieties of English, including both traditional and high-contact L1 varieties such as Scottish English and Welsh English, respectively (Kortmann & Lunkenheimer 2013, feature 180). The overall frequency of the incoming pattern you was in Figure 4 remains relatively high even in the last subperiod but one, at about 30 per cent of the cases. Looking at the figure in this light, an alternative explanation to decline might be to argue in favour of a repetitive U-shaped curve. The notion was put forward by Buchstaller (2006: 19) in her study of the quotative go. She writes:
The important feature in this hypothetical diachronic scenario I have proffered here, though, is that the variable (e.g. go, labialized fricatives, centralized diphthongs, ...) persists latently in the linguistic repertoire of the community, does not fully die out and can therefore potentially be picked up as a fashion again. This effectively means that variants are being actively recycled by the speech community. (Buchstaller 2006: 19)
This interpretation gains some support from the information in Figure 5 provided by the Google Books Corpus of British English. [8] Presenting the normalized frequency of you was per 1,000 words by ten-year intervals from the 1760s to the 2000s, the figure shows fluctuation of the same kind as Figure 4, a fall and a subsequent rise in the frequency of you was in the late 18th century. Since Google Books does not represent a balanced corpus, findings such as these would obviously require further confirmation. [9]

Figure 5. Fluctuation of you was (Google Books Corpus, British English).
However, there is evidence for a kindred phenomenon that Lass (1990: 80) calls exaptation, meaning “the opportunistic co-optation of a feature whose origin is unrelated or only marginally related to its later use”. This formulation is looser than Buchstaller’s repetitive U-curve and implies the reuse of the feature in a different sense or function. Items undergoing grammaticalization, for example, would qualify as instances of exaptation in Lass’s sense. Although there are lexical items such as some intensifying adverbs that may arguably be revived in different communities over time, reuse in the same function appears to be harder to come by in one and the same community in real-time. [10]
On the other hand, some data fluctuation from one period to the next is not unexpected in historical corpora, which inevitably reflect issues like genre evolution and register variation (e.g. Nevalainen 2013). Periodic fluctuation may also arise from corpus composition and size, and the way in which the linguistic variable has been reconstructed. Based on the ARCHER corpus, Figure 6 shows the distribution of a set of verbs that are undergoing regularization in their past tense and past participle forms over three hundred years (redrawn from data in Schlüter 2013: 129). The trend line marks the general decline in irregular forms but, unlike the graph may suggest, no recycling need be involved.
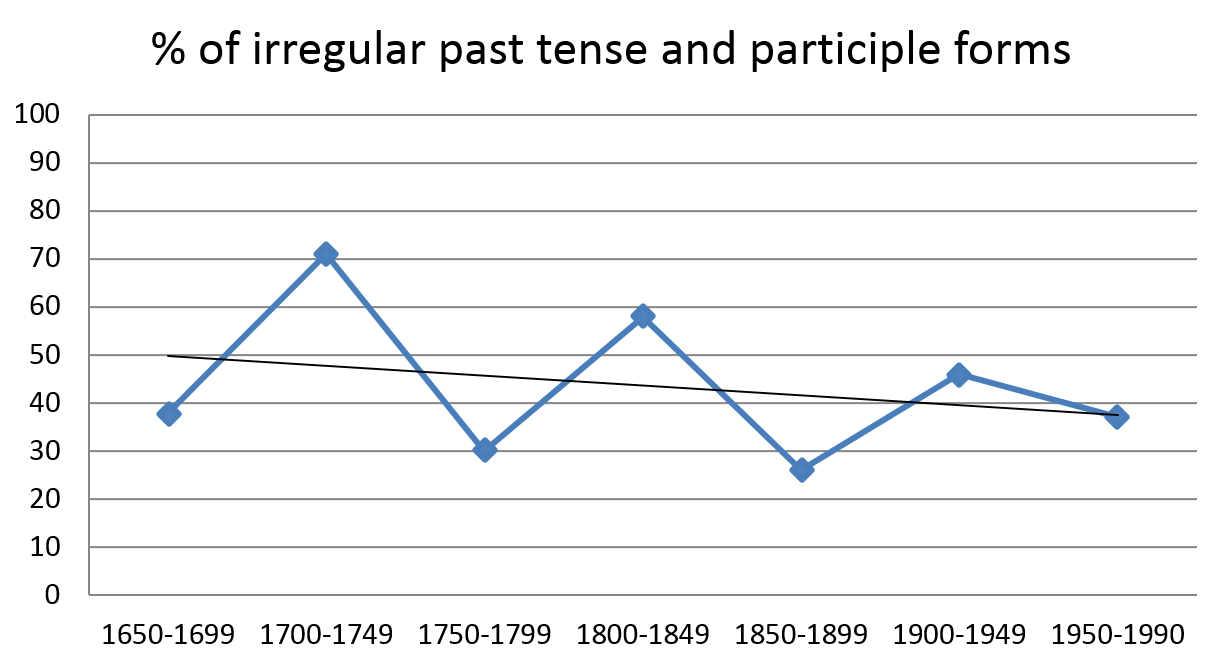
Figure 6. Relative frequency of the irregular past tense and past participle forms of burn, dream, kneel, leap and learn in ARCHER.
As Schlüter notes, two things essentially contribute to this zigzag pattern: the different rates at which the individual verbs undergo this change and the low frequencies of their pooled period totals (varying between 21 and 35 instances per period). The much larger database of drama records that Schlüter (2013: 130) uses to make the point reveals vastly different verb-specific developments over time. What on the surface may look like a repetitive U-curve can hence arise from various circumstances, the low frequency of the phenomenon studied being one of them.
In historical studies the S-curve pattern tends to be viewed as a model of language change at the top level of analysis (cf. Denison 2003). This is also how I have approached it in section 3. There are of course a number of empirical, methodological and theoretical decisions that the researcher can take which may alter the degree to which this pattern captures the process of change. In this section I move on to consider certain analytic choices that impact on the outcome of diachronic studies and may be reflected on the adequacy of the S-curve model to account for them.
The complexity of language change can be approached at various levels of linguistic detail and in data sources of varying heterogeneity. For example, what in one set of sources may look like stable variation may prove to be a case of change in progress in another. To illustrate the point, let us consider subject–verb non-concord with the past tense form of be and plural notional subjects in existential sentences (there was people in the room vs. there were people in the room). Figure 7 plots the data discussed in Martínez-Insua and Pérez-Guerra (2006: 196), drawn from four multi-genre written-language corpora (Helsinki Corpus of English Texts, ARCHER, the Lancaster-Oslo/Bergen Corpus of British English and the British National Corpus). [11] The results indicate low overall frequency, below ten per cent, and relative stability of there was over an extended period of time.
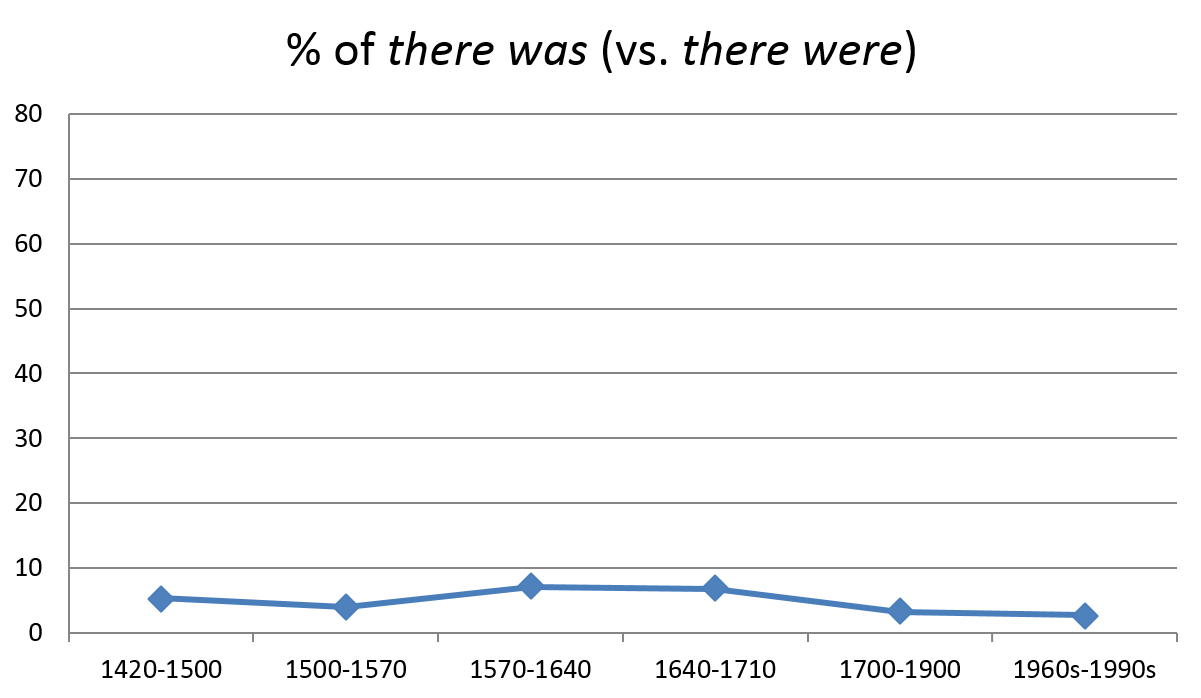
Figure 7. Singular agreement with plural notional subjects in there-existentials (multiple corpora).
As Figure 7 suggests, singular agreement has a long history in existentials with plural notional subjects in English. My earlier work indicates that it was particularly common in the north of England in the 16th century in data retrieved from the Corpus of Early English Correspondence (Nevalainen 2006b). Based on this single-genre corpus, data from Nevalainen (2009: 93) can be used to show that a change in progress rather than stable variation was typical of there-existentials in personal and private writings in the 18th century. As we can see from Figure 8, both the past and present forms of the construction displayed a decline in singular non-concord, the past later than the present. [12] Examples (1) to (4) illustrate these concord options in both tenses.
| (1) | There are two little things I should have a Curiosity to see. (CEEC, 1746? T JBROWN 104) |
| (2) | … and there is two children dead, one before I received the things and one since. (CEEC, 1759 T JKENTING 54) |
| (3) | The perjured priest read prayers att his own church, of Sunday morning, where there were such members of the mobb, that those near him kisst his hand. (CEEC, 1710 FO ACLAVERING 77) |
| (4) | … and tell her I was last night at St Jeames, and yt ther was but a few dancers. (CEEC, 1699? FN A2HATTON 241) |
Figure 8 shows how grammatical variation of this kind can be a factor contributing to the overall decline of non-concord to varying degrees over time. Analysing the process in aggregate terms without distinguishing the tense would overlook the different stages that past and present tense forms were at between 1680 and 1800. Figure 8 also makes the more general point that the S-curve model can be applied to capture a systematic process of change at varying depths of data level, not just at the top level of analysis. Compiled on sociolinguistic principles, corpora such as the CEEC make it possible, for example, to query the degree to which the S-curve model can be extended to variation based on a range of social variables.
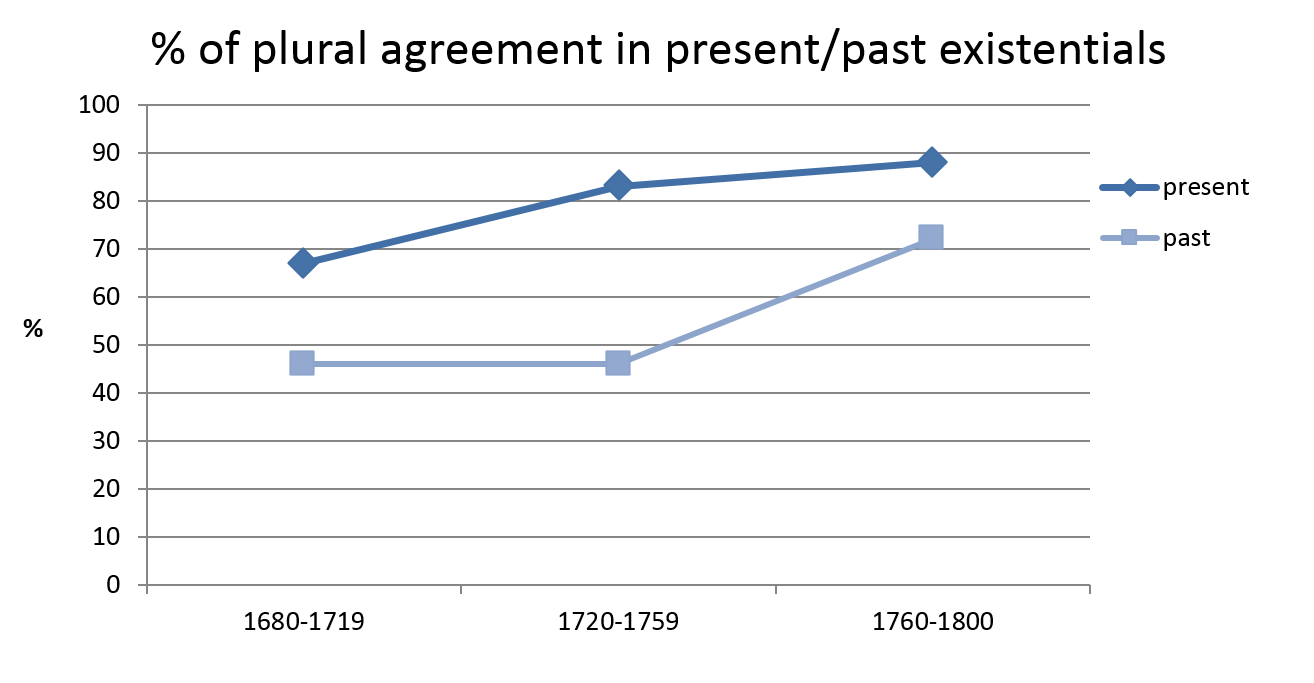
Figure 8. Percentages of plural agreement of be in there-existentials with plural notional subjects according to tense (CEEC, 18th century).
Figure 9 (based on Nevalainen 2009: 93) combines the data on tense variation in Figure 8 with information on the writer’s gender. Displaying four distinct S-shaped curves, it shows that aggregate figures would conceal the varying rates at which plural agreement gained ground in existentials with plural notional subjects not only in different linguistic environments but also across groups of language users. [13] As Figure 9 indicates, the 18th-century decline of non-concord was led by male rather than female writers. Subject–verb non-concord was heavily stigmatized by 18th-century normative grammars, and women rarely had the same educational opportunities as men at the time (Nevalainen 2006b: 9–94, 100; cf. you was in 3.2).
Variationist sociolinguistic studies have time and again shown that language change is usually led by women but that, in changes from above the level of social awareness, gender differences also correlate with differences in education and exposure to formal written language. The gender difference found in Figure 9 may hence be partly a reflection of register variation. Non-concord in there-existentials is common in everyday speech even today, giving Chambers (2004; 1995: 242–243) good cause to include these “default singulars” in his inventory of English “vernacular universals”.
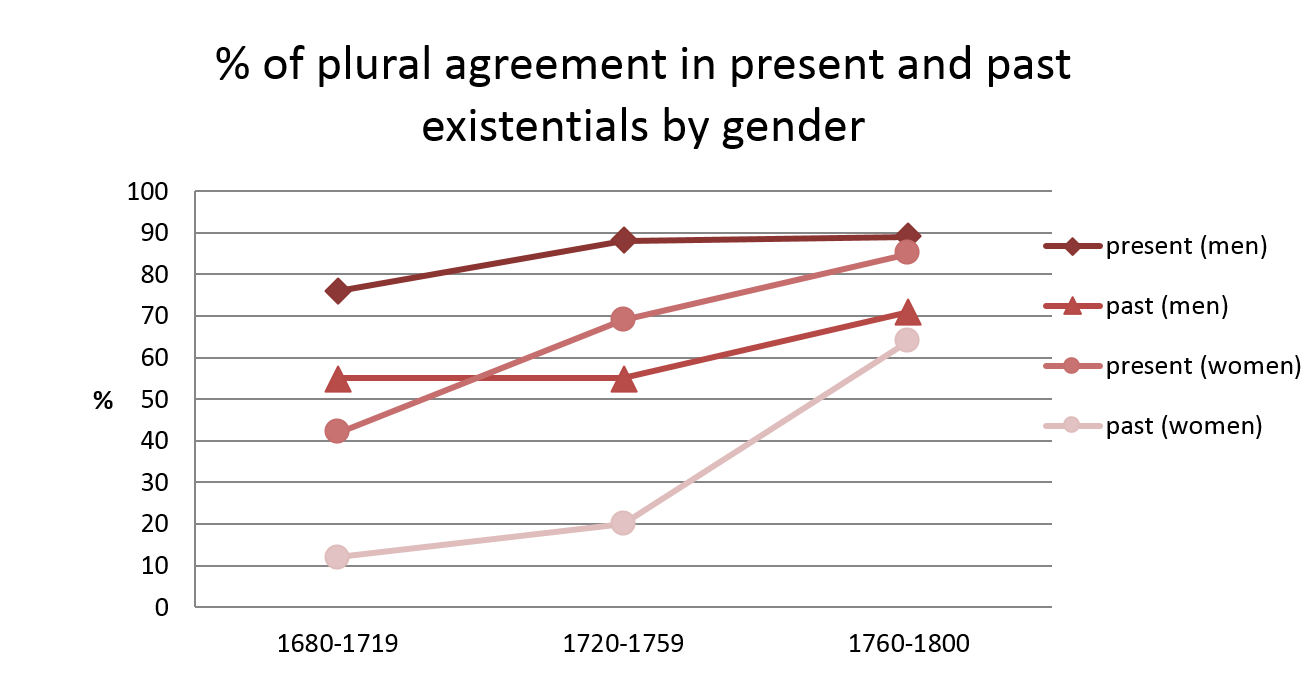
Figure 9. Percentages of plural agreement in there-existentials with plural notional subjects in the present and in the past according to gender (CEEC, 18th century).
The S-curve model readily accommodates the findings presented in Figures 8 and 9. Observations such as these support the case put forward by Aitchison (2013: 96) that an S-curve can consist of a series of overlapping S-curves, completed at different rates in different environments. Discussing the loss of the final /n/ in French in words like an (‘year’) and the transition of word-initial voiced stops into voiceless ones in the Shuang-Feng dialect of Chinese, Aitchison (2013: 95–96) concludes that “many S-curves are themselves composed of smaller S-curves. Each little S-curve covers one particular linguistic environment”. In French the change progressed by the vowel and in Chinese from tone to tone. Looking at socially indexed distributions of two alterative expressions, such as those in Figure 9, we could add that the S-curve pattern can also be demonstrated for user-based variation in real-time historical data. That the pattern is expected in apparent-time sociolinguistic studies of language variation and change is, of course, well established (see e.g. Tagliamonte, this volume).
As an empirical tool to measure the progress of linguistic change, the S-curve pattern is usually constructed following the periodization adopted by the compilers of a given text corpus. Although this superimposed periodization provides a quick way of assessing processes of change within a certain time frame, it may not do justice to the vastly different time courses of changes in progress. Based on dated letters, a corpus such as the CEEC offers a range of options for periodization. In Nevalainen and Raumolin-Brunberg (2003) we collected our linguistic data using 20-year periods, which could then be combined into forty-year periods and further analysed in stages, depending on the time course of a particular change (Nevalainen, Raumolin-Brunberg & Mannila 2011). Figure 10 shows how the suffix -s diffuses and replaces -th in the third-person singular present indicative (the sun riseth > the sun rises) in the CEEC material between 1410 and 1680 (based on Table 7 in Nevalainen & Raumolin-Brunberg 2003: 220). After a small rise and a subsequent fall in the 15th century due to varietal fluctuation in the corpus, the bulk of the 16th- and 17th-century data follows an S-curve pattern, the process reaching completion towards the end of the 17th century.
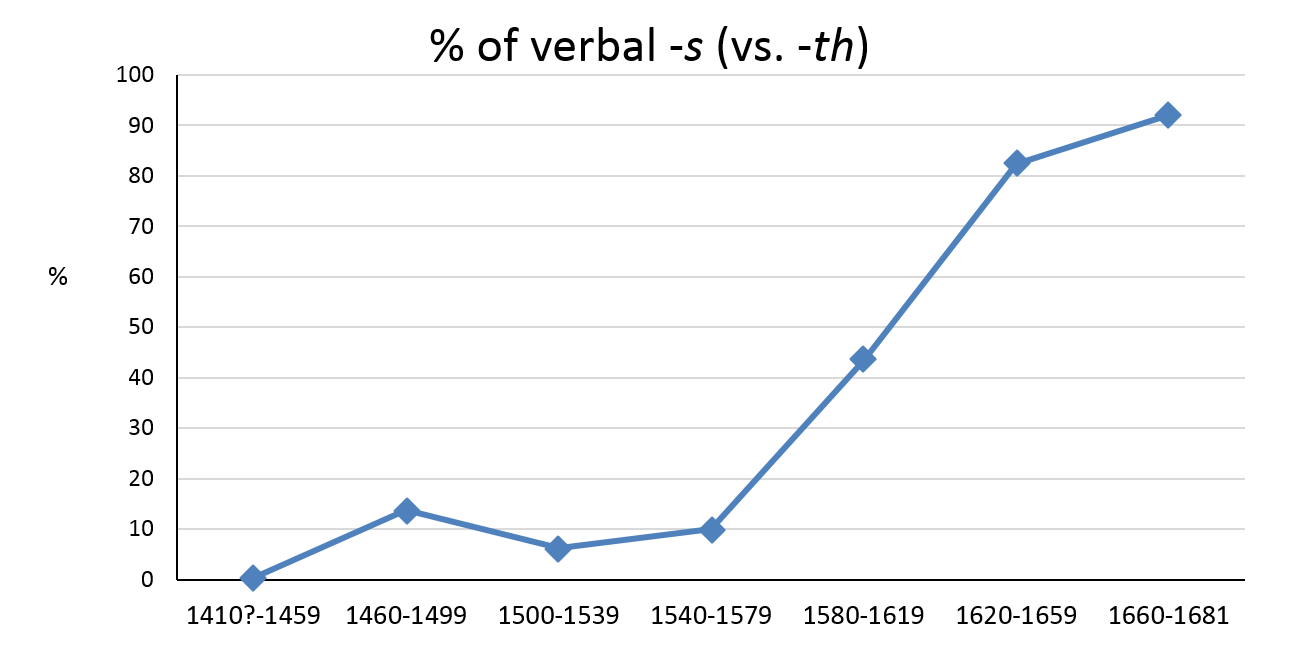
Figure 10. Percentage of -s (vs. -th) in third-person singular present indicative (CEEC).
An alternative approach to the periodization of a change in progress is offered by Gries and Hilpert (2010), who abandoned predefined periods and developed an algorithm to map linguistic data into successive, statistically significant stretches of time. One of their reasons for including time as an explanatory variable was that it would allow the researcher to examine the ways in which the other variables studied interact with time.
To establish the temporal stages of the transition of verbal -(e)th to -(e)s, Gries and Hilpert (2010: 299–301, 2012: 142–143) applied a method of bottom-up clustering to the data provided by the Parsed Corpus of Early English Correspondence (PCEEC). [14] The clustering algorithm they used (Variability-based Neighbor Clustering, VNC) merges or separates temporally adjacent files on the basis of their similarity. The first application of the method yielded nine periods (Table 1), which reflect the S-curve pattern shown in Figure 10 to the extent that they even pick up the small rise in the use of verbal -s in 1479–1482. However, this solution also includes two one-year periods, 1509 and 1544, which are likely to reflect idiolectal usage differences. Incidentally, this is also the case with the three-year period shown in Table 1, which is dominated by an individual, a merchant who systematically uses the originally northern suffix -(e)s.
| Period 1 | Period 2 | Period 3 | Period 4 | Period 5 | Period 6 | Period 7 | Period 8 | Period 9 |
|---|---|---|---|---|---|---|---|---|
| 1417–1478 | 1479–1482 | 1483–1508 | 1509 | 1510–1543 | 1544 | 1545–1609 | 1610–1648 | 1649–1681 |
| (61 years) | (3 years) | (25 years) | (1 year) | (33 years) | (1 year) | (64 years) | (38 years) | (32 years) |
Table 1. Algorithmically defined periods for verbal -s; nine-period solution (PCEEC; based on Gries & Hilpert 2012: 143).
As one-year periods are not meaningful with a change that takes over two centuries to run its course, they were removed as outliers from the second application of the algorithm, shown here in Table 2. However, the third period now covers the stretch of time from 1483 to 1609, altogether 124 years (leaving out 1509 and 1544), which comprises the bulk of the S-curve in Figure 10. Although it may pattern systematically with the other linguistic features analysed, this extra-long period fails to capture the diffusion of the incoming form in the language community and the S-shaped patterns repeated with all major sociolinguistic variables studied in Nevalainen and Raumolin-Brunberg (2003). One may conclude that, despite the two rogue one-year periods, Table 1 may in fact capture the progression of the change along an S-shaped curve better than the more summative five-period solution in Table 2.
| Period 1 | Period 2 | Period 3 | Period 4 | Period 5 |
|---|---|---|---|---|
| 1417–1478 | 1479–1482 | 1483–1609 (excluding 1509 and 1544) |
1610–1647 | 1648–1681 |
| (61 years) | (3 years) | (124 years) | (37 years) | (33 years) |
Table 2. Algorithmically defined periods for verbal -s; five-period solution (PCEEC; based on Gries & Hilpert 2010: 302).
Approximations to an S-shaped curve can also be looked for in idiolects by using longitudinal data to trace potential life-span changes. This question is related to the much-debated issue of language change in adulthood (e.g. Gerstenberg & Voeste 2015). To test the hypothesis of lifespan change and to compare individuals and their participation in a change in progress, the history of verbal -s was examined using the CEEC data. The hundred years from 1570 to 1670 were divided into ten-year periods, and ten (near-)contemporaries whose correspondence has been preserved from several decades were included in the study (Raumolin-Brunberg 2005; Nevalainen & Raumolin-Brunberg 2012).
Figure 11 (based on Raumolin-Brunberg 2005: 50–51, Appendix 1) shows the variety of patterns that emerged, ranging from rather stable usage, both progressive (Chamberlain) and conservative (Hastings), to change reversal in mid-course (Gawdy). However, the most common pattern was that of an approximate S-shaped curve or a part of it, which was witnessed in seven cases out of the ten studied. The variable patterns may be partly accounted for by analysing the individual letter writers’ backgrounds, including age, education, domicile and mobility, as well as their relationship with the letter recipients. [15]
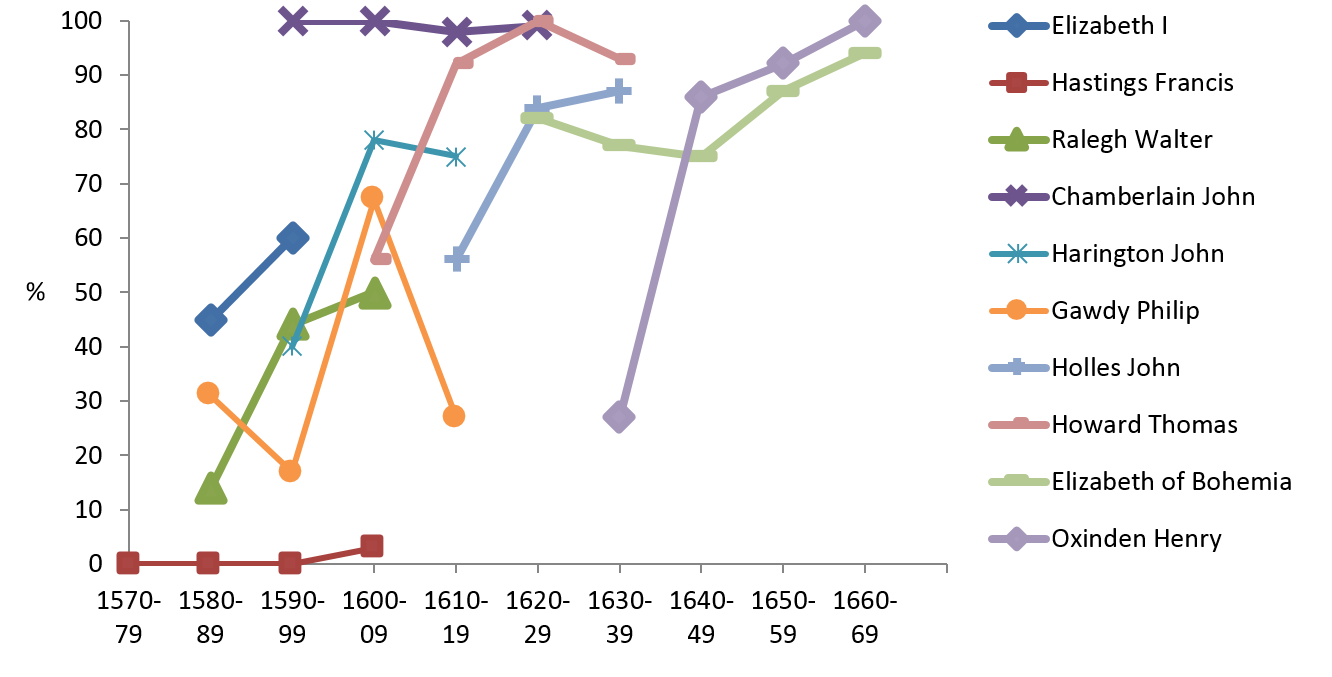
Figure 11. Percentage of -s (vs. -th) in ten idiolects, 1570–1669 (CEEC, Supplement).
On the basis of the 39 processes of change that they reviewed, Blythe & Croft (2012: 281) conclude that when a change in progress is robust enough, its trajectory displays an S-shaped curve “despite the variation in the behavior of individual words, speakers, texts, geographical regions, or social classes over the trajectory of the change”. Real-time S-curves hence provide an important heuristic: they can serve as a baseline against which individual, register and community variation can be identified and measured.
Looking at the diffusion of linguistic change across written and spoken registers, Krug (2000: 196–198) makes similar observations on the descriptive adequacy of the S-curve model. He notes that although the graphs drawn on the basis of actual changes in natural language will rarely be neat S-curves, the model describes individual changes more accurately than some other abstract models suggested in the literature.
The data I have discussed show that trajectories of grammatical changes often also display S-shaped patterns at finer levels of analysis, both sociolinguistic and grammatical, testifying to the descriptive adequacy of the model. Given enough data, it is even possible to describe lifespan changes in terms of an S-shaped curve or identify individual leaders of linguistic changes (Nevalainen, Raumolin-Brunberg & Mannila 2011). These frequency distributions of incoming features of course cannot be automatically interpreted as changes in the grammar of the language community, only in that of the given subgroup or individual.
Although historical linguists have few advantages in comparison with their colleagues who work with the present, the benefit of hindsight is one of them. Analysing language variation in real time makes it possible to observe actual trajectories of change. The S-curve pattern is one that has stood the test of time well enough to merit its current status as a fitting abstraction in describing the unfolding of the process of language change over time, at least in light of the variationist sociolinguistic work done so far.
[1] My work on this study was funded by an Academy of Finland professorship grant, which is hereby gratefully acknowledged. I would also like to thank the two anonymous reviewers and the volume editor for their useful comments on the draft version of this paper.
I use the term “descriptive adequacy” of the S-curve model in comparing this abstract pattern with those that emerge from actual language data. For a similar use of the term, see e.g. Krug (2000: 157, 169, 196, 250). [Go back up]
[2] Figure by Everett Rogers [Public domain], via Wikimedia Commons. [Go back up]
[3] In current quantitative linguistics its various applications are known by different names, including Piotrowski’s Law (Leopold 2005). For an earlier sociolinguistic discussion, see Cooper (1982). [Go back up]
[4] See also Kretzschmar (2015: 83–85). [Go back up]
[5] On (IN/ING) see, for example, Hazen (2006), and on affixal and nonaffixal negation, Tottie (1980). [Go back up]
[6] Trudgill (2008) considers the issue from the broader perspective of s/r variation of the past tense of be in Germanic dialects and suggests that present-day dialectal variation is due to variety-specific analogical levelling. [Go back up]
[7] Laitinen (2009: 205). See further ARCHER (A Representative Corpus of Historical English Registers). [Go back up]
[8] This corpus, created by Mark Davies, consists of 34 billion words (n-grams). See the link to the Google Books Corpus in the Sources section. [Go back up]
[9] By comparison, the British National Corpus (BNC) yields the normalized frequency of 7.19 instances of you was per million words for fiction genres (69 different texts), 24.29 instances for the context-governed part of spoken texts (72 different texts), and 41.33 for the demographically sampled part (69 different texts; BNCweb). These average frequencies are higher for present-day spoken varieties of British English than those for writing even during the heyday of the construction in the (admittedly highly mixed) written sources the Google Books Corpus consists of. [Go back up]
[10] For reuse of so, see Tagliamonte & Roberts (2005). [Go back up]
[11] For details of these corpora, see the Corpus Resource Database (CoRD). [Go back up]
[12] The use of singular is declined significantly from 33 to 12 per cent of the cases (N = 489; chi-square test, p < .001), and that of singular was from 54 to 28 per cent (N = 142, p < .01). [Go back up]
[13] The drop in the use of singular is was significant for both genders (N = 117 for women, and N = 372 for men; chi-square test, p < .001), as was the decline in women’s use of singular was (N = 48); the decline in men’s use did not reach the conventional 5%-level of significance (N = 94). [Go back up]
[14] It is noteworthy that the corpora used in Figure 10 (CEEC and its Supplement) and Gries and Hilpert’s (2010) Tables 1 and 2 (PCEEC) are not fully identical. Due to copyright restrictions, all the original CEEC data could not be included in the tagged and parsed version of the corpus. See the details of the CEEC corpora on CoRD. [Go back up]
[15] Although the absolute numbers per subperiod remain relatively low in many cases, they project quite consistent individual profiles. These results encourage further research into the patterning of individual variation over time. [Go back up]
ARCHER-3.2. A Representative Corpus of Historical English Registers version 3.2. 1990–1993/2002/2007/2010/2013/2016. Originally compiled under the supervision of Douglas Biber and Edward Finegan at Northern Arizona University and University of Southern California; modified and expanded by subsequent members of a consortium of universities. Current member universities are Bamberg, Freiburg, Heidelberg, Helsinki, Lancaster, Leicester, Manchester, Michigan, Northern Arizona, Santiago de Compostela, Southern California, Trier, Uppsala, Zurich. Examples of usage taken from ARCHER were obtained under the terms of the ARCHER User Agreement. http://www.alc.manchester.ac.uk/linguistics-and-english-language/research/projects/archer/
BNC = The British National Corpus. Distributed by Oxford University Computing Services on behalf of the BNC Consortium. http://www.natcorp.ox.ac.uk/. BNCweb (CQP edition, version 4.1). 2008. http://corpora.lancs.ac.uk/BNCweb/
CEEC = Corpus of Early English Correspondence. 1998. Compiled by Terttu Nevalainen, Helena Raumolin-Brunberg, Jukka Keränen, Minna Nevala, Arja Nurmi & Minna Palander-Collin. Helsinki: Department of English, University of Helsinki. http://www.helsinki.fi/varieng/CoRD/corpora/CEEC/index.html
Corpus Research Database (CoRD): http://www.helsinki.fi/varieng/CoRD/corpora/index.html
Google Books Corpus: Davies, Mark. 2011–. Google Books (British English) Corpus (34 billion words, 1810-2009). Available online at http://googlebooks.byu.edu/x.asp
PCEEC = Parsed Corpus of Early English Correspondence. 2006. Annotated by Ann Taylor, Arja Nurmi, Anthony Warner, Susan Pintzuk & Terttu Nevalainen. Compiled by the CEEC Project Team. University of York & University of Helsinki. Distributed through the Oxford Text Archive. http://ota.ox.ac.uk/desc/2510
Figure by Rogers on Wikimedia Commons: https://commons.wikimedia.org/wiki/File:Diffusion_of_ideas.svg
Aitchison, Jean. 2013 [1981]. Language Change: Progress or Decay? 4th edn. Cambridge: Cambridge University Press.
Biber, Douglas. 1995. Dimensions of Register Variation. Cambridge: Cambridge University Press.
Buchstaller, Isabelle. 2006. “Diagnostics of age-graded linguistic behaviour: The case of the quotative system”. Journal of Sociolinguistics10: 3–30.
Blythe, R.A. & William Croft. 2012. “S-curves and the mechanisms of propagation in language change”. Language 88(2): 269–304.
Chambers, J.K. 1995. Sociolinguistic Theory. Oxford: Blackwell.
Chambers, J.K. 2004. “Dynamic typology and vernacular universals”. Dialectology Meets Typology: Dialect Grammar from a Cross-Linguistic Perspective, ed. by Bernd Kortmann, 128–145. Berlin & New York: Mouton de Gruyter.
Cooper, Robert L. 1982. “A framework for the study of language spread”. Language Spread: Studies in Diffusion and Social Change, ed. by Robert L. Cooper, 5–36. Bloomington: Indiana University Press & Washington D.C. Center for Applied Linguistics.
Denison, David. 2003. “Log(ist)ic and simplistic S-curves”. Motives for Language Change, ed. by Raymond Hickey, 54–70. Cambridge: Cambridge University Press.
Ellegård, Alvar. 1953. The Auxiliary ‘Do’: The Establishment and Regulation of its Use in English (Gothenburg Studies in English 2). Stockholm: Almqvist & Wiksell.
Gerstenberg, Annette & Anja Voeste, eds. 2015. Language Development: The Lifespan Perspective (IMPACT: Studies in Language and Society 37). Amsterdam & Philadelphia: John Benjamins.
Gries, Stefan Th. & Martin Hilpert. 2010. “Modeling diachronic change in the third person singular: A multifactorial, verb- and author-specific exploratory approach”. English Language and Linguistics 14(3): 293–320. doi:10.1017/S1360674310000092
Gries, Stefan Th. & Martin Hilpert. 2012. “Variability-based neighbor clustering: A bottom-up approach to periodization in historical linguistics”. The Oxford Handbook of the History of English, ed. by Terttu Nevalainen & Elizabeth Closs Traugott, 134–144. Oxford & New York: Oxford University Press.
Hazen, Kirk. 2006. “IN/ING variable”. Encyclopedia of Language & Linguistics, Vol. 5, ed. by Keith Brown, 581–584. 2nd edn. Oxford: Elsevier.
Hinneburg, Alexander, Heikki Mannila, Samuli Kaislaniemi, Terttu Nevalainen & Helena Raumolin-Brunberg. 2007. “How to handle small samples: Bootstrap and Bayesian methods in the analysis of linguistic change”. Literary and Linguistic Computing 22: 137–150. doi:10.1093/llc/fqm006
Kortmann, Bernd & Kerstin Lunkenheimer, eds. 2013. The Electronic World Atlas of Varieties of English. Leipzig: Max Planck Institute for Evolutionary Anthropology. http://ewave-atlas.org
Kretzschmar, William A., Jr. 2009. The Linguistics of Speech. Cambridge: Cambridge University Press.
Kretzschmar, William A., Jr. 2015. Language and Complex Systems. Cambridge: Cambridge University Press.
Kretzschmar, William A., Jr., & Merja Stenroos. 2012. “Evidence from surveys and atlases in the history of the English language”. The Oxford Handbook of the History of English, ed. by Terttu Nevalainen & Elizabeth Closs Traugott, 111–122. Oxford & New York: Oxford University Press.
Kroch, Anthony. 1989. “Reflexes of grammar in patterns of language change”. Language Variation and Change 1: 199–244.
Krug, Manfred. 2000. Emerging English Modals: A Corpus-Based Study of Grammaticalization (Topics in English Linguistics 32). Berlin/New York: Mouton de Gruyter.
Labov, William. 1994. Principles of Linguistic Change. Volume 1: Internal Factors. Oxford, UK & Cambridge, USA: Blackwell.
Labov, William, Ingrid Rosenfelder & Josef Fruehwald. 2013. “One hundred years of sound change in Philadelphia: Linear incrementation, reversal, and reanalysis”. Language 89(1): 30–65.
Laitinen, Mikko. 2009. “Singular you was/were variation and English normative grammars in the eighteenth century”. The Language of Daily Life in England (1400–1800), ed. by Arja Nurmi, Minna Nevala & Minna Palander-Collin, 199–217. Amsterdam: Benjamins.
Lass, Roger. 1990. “How to do things with junk: Exaptation in language evolution”. Journal of Linguistics 26: 79–102.
Leopold, Edda. 2005. “Das Piotrowski-Gesetz”. Quantitative Linguistik/Quantitative Linguistics: Ein internationales Handbuch/An International Handbook, ed. by Reinhard Köhler, Gabriel Altmann & Rajmund G. Piotrowski, 627–633. Berlin: Walter de Gruyter.
Martínez-Insua, Ana E. & Javier Pérez-Guerra. 2006. “‘There’s Bjørg’: On there-sentences in the recent history of English”. ‘These Things I Write vnto thee ...’ Essays in Honour of Bjørg Bækken, ed. by Leiv Egil Breivik, Sandra Halverson & Kari E. Haugland, 189–211. Oslo: Novus Press.
Nevalainen, Terttu. 2006a. “Negative concord as an English ‘vernacular universal’: Social history and linguistic typology”. Journal of English Linguistics 34(3):257–278.
Nevalainen, Terttu. 2006b. “Vernacular universals? The case of plural was in Early Modern English”. Types of Variation: Diachronic, Dialectal and Typological Interfaces (Studies in Language Companion Series 76), ed. by Terttu Nevalainen, Juhani Klemola & Mikko Laitinen, 351–369. Amsterdam & Philadelphia: John Benjamins.
Nevalainen, Terttu. 2009. “Number agreement in existential constructions: A sociolinguistic study of 18th-century English”. Vernacular Universals and Language Contact, ed. by Markku Filppula, Juhani Klemola & Heli Paulasto, 80–102. New York & London: Routledge.
Nevalainen, Terttu. 2013. “English historical corpora in transition: From new tools to legacy corpora?” New Methods in Historical Corpora (Corpus Linguistics and Interdisciplinary Perspectives on Language 3), ed. by Paul Bennett, Martin Durrell, Silke Scheible & Richard J. Whitt, 37–53. Tübingen: Gunter Narr.
Nevalainen, Terttu & Helena Raumolin-Brunberg. 2003. Historical Sociolinguistics: Language Change in Tudor and Stuart England. London: Longman.
Nevalainen, Terttu & Helena Raumolin-Brunberg. 2012. “Historical sociolinguistics: Origins, motivations and paradigms”. The Handbook of Historical Sociolinguistics, ed. by Juan Manuel Hernández-Campoy & Juan Camilo Conde-Silvestre, 22–40. Malden, MA: Blackwell.
Nevalainen, Terttu, Helena Raumolin-Brunberg & Heikki Mannila. 2011. “The diffusion of language change in real time: Progressive and conservative individuals and the time depth of change”. Language Variation and Change 23(1): 1–43. doi:10.1017/S0954394510000207
Nurmi, Arja. 1999. A Social History of Periphrastic do (Mémoires de la Société Néophilologique de Helsinki 56). Helsinki: Société Néophilologique.
Raumolin-Brunberg, Helena. 2002. “Stable variation and historical linguistics”. Variation Past and Present (Mémoires de la Société Néophilologique de Helsinki LXI), ed. by Helena Raumolin-Brunberg, Minna Nevala, Arja Nurmi & Matti Rissanen, 101–116. Helsinki: Société Néophilologique.
Raumolin-Brunberg, Helena. 2005. “Language change in adulthood: Historical letters as evidence”. European Journal of English Studies 9(1): 37–51.
Rogers, Everett M. 2003. Diffusion of Innovations. 5th edn. New York: Simon & Schuster.
Schlüter, Julia. 2013. “Using historical literature databases as corpora”. Research Methods in Language Variation and Change, ed. by Manfred Krug & Julia Schlüter, 119–135. Cambridge: Cambridge University Press.
Tagliamonte, Sali A. & Chris Roberts. 2005. “So weird; so cool; so innovative: The use of intensifiers in the television series Friends”. American Speech 80(3): 280–300.
Tottie, Gunnel. 1980. “Affixal and non-affixal negation in English: Two systems in almost complementary distribution”. Studia Linguistica 34(2): 101–123. doi:10.1111/j.1467-9582.1980.tb00310.x
Trudgill, Peter. 2008. “English dialect ‘default singulars’, was versus were, Verner’s Law, and Germanic dialects”. Journal of English Linguistics 36: 341–353.

University of Helsinki
{kind=link}