
Studies in Variation, Contacts and Change in English
Studies in Variation, Contacts and Change in English
Hilde Hasselgård
Department of Literature, Area Studies and European Languages, University of Oslo
This study investigates the use of the colligational framework ‘the N1 of the N2’ in novice academic English. The material comes from the English literature discipline in the Norwegian component of the VESPA corpus (Varieties of English for Specific Purposes dAtabase) and the BAWE corpus (British Academic Written English). The research questions concern the frequency, distribution, lexical realizations and meaning of the colligation in L1 and L2 novice academic English. Although the L2 users were expected to underuse the colligation due to cross-linguistic differences between English and Norwegian as well as the fact that phrasal complexity requires a high level of proficiency, the frequency of the pattern was found to be relatively similar between the two corpora. The second noun in the colligation shows more discipline-specificity than the first. The colligation has a high degree of variability in both corpora: the most recurrent lexical pattern is that in which the N1 represents a part and the N2 a literary work, as in the end of the novel. However, there were qualitative differences between the two datasets, the most important of which concerned cases in which the N1 is a nominalization. These were used more in L1 than in L2 along with support nouns, while the learners used the pattern with partitive and possessive meaning slightly more than the native speakers.
This paper examines complex noun phrases in novice academic English through the lens of the colligational framework ‘the N1 of the N2’, as in the nature of the essays. The novices in question are university students of English literature in the UK and Norway writing English as a first and a second language, respectively. The term ‘colligational framework’ is an adaptation of Renouf and Sinclair’s (1991) term ‘collocational framework’: it refers to a sequence of grammatical words with empty slots whose part of speech is specified (Hasselgård 2016), and thus involves the regular co-occurrence of grammatical as well as lexical choices (Sinclair 2004: 32). [1] The realizations of this particular colligation will be complex noun phrases involving a noun-modifying prepositional phrase. In addition to being a complexity feature typical of academic written English (Biber & Gray 2016), noun phrases have been described as “a yardstick of syntactic complexity across the variables of development, genre, modality, and cross-linguistic variation” (Ravid & Berman 2010: 6). It is therefore of great interest to study the use of the colligation ‘the N1 of the N2’ in novice academic writing.
Hunston (2008) argues for the usefulness of taking “small words” as the starting point of linguistic investigations. For the present study, the following assertions are notable:
…in a specialised corpus, such as a corpus comprising texts from a given academic discipline, pattern-based sequences of ‘lexical item’ + preposition + ‘lexical item’ can be identified, and sometimes longer semantic sequences are identified. Those longer sequences in particular identify the phraseology of a discipline and reveal its workings. (2008: 293)
The aim of the present study is to find out how advanced Norwegian learners of English use the colligation ‘the N1 of the N2’ in their academic texts compared to native speakers. The research questions concern the frequency, distribution, lexicalization and meaning of the colligation in L1 and L2 novice academic English: How frequent and widespread is it among both writer groups? What nouns are involved? As illustrated in examples (1)–(4), the colligation can involve a range of meaning relations between the N1 and the N2, such as possession (1), nominalization + object (2), N1 is part of N2 (3) and N1 is a feature/aspect of N2 (4); see further Section 3.3. [2] An important part of the study will be to survey the meanings expressed by the two writer groups when they use the colligation.
| (1) | This layering of images characterises the poetry of the Modernists… (BAWE) |
| (2) | Others include the rejection of the possibility of any absolute truth… (BAWE) |
| (3) | In the beginning of the book we find an apt example of this… (VESPA) |
| (4) | According to Andrew, adaptation is to interpret the meaning of the original text… (VESPA) |
Apart from the fact that complex noun phrases in general are a well-known point of difficulty for language learners (Parkinson & Musgrave 2014), Norwegian learners of English may be expected to have trouble with some uses of this particular colligation due to differences between English and Norwegian. For example, Norwegian lacks a preposition similar to of, although the pattern of definite noun + preposition + definite noun is common in Norwegian too. However, Hasselgård (2016) found that more than half of English “the N1 of the N2” sequences in the fiction part of the English-Norwegian Parallel Corpus (ENPC) corresponded to other construction types in Norwegian, such as compound nouns, s-genitives and noun simplexes (see further Section 3). Thus, although the form of the colligation may be familiar to the learners, its distribution and full range of meanings may not be. In other words, the colligation can be expected to be difficult for learners on account of cross-linguistic differences and linguistic complexity as well as academic register. It is also conceivable that even native speakers of English struggle with complexity features of the academic register, so it is important to note that the native speaker material is not to be taken as a norm for how the colligation should be used. [3] As Staples et al. (2016: 152) point out: “even L1 writers must develop the use of the phrasal complexity styles found in specialist academic writing”.
The rest of the paper is organized as follows: Section 2 outlines some relevant previous research in the field, and Section 3 introduces the material, the method of exploring it, and the classificatory framework. Section 4 presents the analysis itself, focusing on lexical bundles, lexical realization and recurrence of the N1 and the N2 in the colligation and the meaning relations between the two nouns connected by of. Section 5 gives a summary of findings and offers some concluding remarks.
Sequences that instantiate the framework ‘the N1 of the N2’ are complex noun phrases, traditionally taken to consist of a head noun (N1) plus a postmodifier (of the N2). According to Biber et al. (1999: 606), prepositional phrases are the most frequent type of noun postmodifier, and of these, 60-65% are introduced by of (Biber et al. 1999: 635). Lexical bundles with the pattern ‘noun phrase with postmodifier fragment’ are found to be characteristic of academic prose (Biber et al. 1999: 996), and a list of four-word bundles of this type contains numerous instances of the colligation ‘the N1 of the N2’, such as the end of the, the beginning of the, the nature of the (Biber et al. 1999: 1014 f).
Biber and Gray (2016) discuss noun phrases in terms of phrasal complexity in contrast to clausal complexity (see also Staples et al. 2018). The general drive behind the increased phrasal complexity in academic prose is “economy of expression” (Biber & Gray 2016: 207). The complexity of noun phrases can be “ranked along a cline of compression” as follows (going from least to most compressed): NP modified by finite relative clause < NP modified by non-finite relative clause < NP modified by post-modifier phrase < NP modified by pre-modifier phrase (Biber & Gray 2016). The colligation ‘the N1 of the N2’ thus represents a high degree of phrasal complexity and semantic compression. Staples et al. (2018), investigating the development of grammatical complexity in academic writing in the BAWE corpus, find that phrasal complexity – including of-genitives and nominalizations – increases with level of academic study (Biber & Gray 2016: 162). The increased use of nominalizations is, however, much clearer than that of of-phrases (Biber & Gray 2016: 163, 169), also when the broad discipline Arts and Humanities (which includes English literature, cf. Nesi & Gardner 2012: 8) is studied separately (Staples et al. 2018: 166).
Though frequent, of is not a “typical” preposition; in particular it generally does not introduce PPs with an adjunct function (Sinclair 1991; Owen 2007). According to Sinclair (1991: 83), “it may ultimately be considered distracting to regard of as a preposition at all”. On the other hand, of is highly multifunctional in terms of the meaning relationships it expresses between nouns preceding and following it. Sinclair argues that an “N of N” sequence is not necessarily one of head noun followed by a postmodifier, since the second noun seems to be most salient. Hence, of can preface the second noun as a (semantic) headword in phrases such as this kind of problem, the bottle of port (1991: 85), an issue also discussed by Keizer (2007).
The meaning relations expressed by of in the N of N sequence can to some extent be linked to the meaning of the N1 according to Sinclair (1991: 87 ff). The N1 can be a “focus noun”, specifying some part of the N2 (which is regarded as the head noun), e.g. the edge of the teeth. The focus can also be on a “specialized part”, e.g. the depths of the oceans, the horns of the bull, or on “a component, aspect, or attribute”, e.g. the sound of his feet, the study of geography. Alternatively, the N1 can be a “support noun”, often reduced in meaning and “offering some kind of support to N2, rather than just specifying some relevant aspect of N2” (Sinclair 1991: 89), e.g. the notion of machine intelligence, many examples of local authorities. In addition, if the N1 is a nominalization, the relationship between N1 and N2 is propositional, e.g. the description of the lady (Sinclair 1991: 91 f).
Keizer (2007) focuses mainly on the structural properties of noun phrases with of, distinguishing the following construction types: head-modifier, head-complement, partitive, head-qualifier and of-appositions (2007: 83). The N1 is invariably viewed as the head of the phrase, in contrast to Sinclair (1991). In terms of meaning, the first two construction types express “possession” in a broad sense which includes ownership, kinship and body parts and is extended to non-human possessors, e.g. the mosaics of Venice, the problems of the world (Keizer 2007: 63). A particular group of nouns in the N1 position are called “relational” (Keizer 2007: 64): these include kinship terms (the son of Aron), body parts, and “nouns which denote parts of (physical or abstract) features of entities”, such as size, middle, feature, nature (Keizer 2007). Relational nouns may also occur in head-qualifier expressions where the N2 qualifies the denotation of the N1, as in a book of comics (Keizer 2007: 71). Finally, partitive constructions with of typically denote a member of a set, as in the first of a few questions (Keizer 2007: 65, 73), while in appositional of-phrases the N2 is more or less coreferential with the N1 (the job of foreign minister); see also Quirk et al. (1985: 1284). Since Keizer’s starting point is structural rather than semantic/functional, it is difficult to map his categories onto Sinclair’s (1991) framework. However, Keizer’s relational nouns overlap with both focus nouns and support nouns. The present study uses an adapted version of Sinclair’s framework for the classification of the N1 of the N2 constructions; see further Section 3.3.
The concept of ‘collocational framework’ was introduced by Renouf and Sinclair (1991). Defining their framework as “a discontinuous sequence of two words, positioned at one word remove from each other” (1991: 128), they investigate the intermediate collocate in a number of frameworks, two of which involve complex noun phrases with of (‘a + ? + of’ and ‘an + ? + of). They conclude that the frameworks based on grammatical words provide a sensible way of presenting and explaining language patterning (Renouf and Sinclair 1991: 143).
More recent studies of a similar kind include Römer (2010), Gray and Biber (2013) and Garner (2016), who investigate recurrent discontinuous word sequences with one empty slot in academic English using the terms ‘p[hrase]-frames’ / ‘lexical frames’ (see footnote 1). Gray and Biber (2013) also compare academic prose to conversation and the recurrence of lexical frames to that of n-grams (i.e. discontinuous and continuous word sequences). One finding is that there are “many fewer continuous sequences than frames” once recurrence and dispersion are taken into account (Gray and Biber 2013: 115). In general, academic prose displays more variability in the realization of lexical frames than conversation (Gray and Biber 2013: 125). Interestingly, however, the frame the * of the emerges as the most frequent one in both academic prose and conversation (Gray and Biber 2013: 124); see also Lu et al. (2018: 80). Garner (2016: 48) finds the same p-frame to be frequent across proficiency levels in his corpus of learner English (by German learners). There is more variability at higher proficiency levels, meaning in practice that the nouns end and middle account for an increasingly smaller proportion of the nouns used in the variable slot (Garner 2016).
As already mentioned, the term ‘colligational framework’ was first used in a contrastive study of English and Norwegian (Hasselgård 2016), which examined the English colligation ‘the N1 of the N2’ and its Norwegian correspondences in a corpus of fiction. The majority of instances of the English colligation were found to have divergent correspondences in Norwegian, even when congruent correspondences were available, i.e. two definite nouns linked by a preposition. Many of the divergent correspondences avoid the heavy postmodification often found in the English expressions. [4] Variation in congruence/divergence was associated with individual lexemes occurring as N1 and N2 as well as the meaning relations between them. These findings gave rise to the hypothesis that Norwegian users of English might use the colligation ‘the N2 of the N2’ differently from native speakers.
The investigation is based on material from two corpora of novice academic English, one representing first-language (L1) users of English and the other advanced learners of English (L2). The L1 corpus is the British Academic Written English Corpus (BAWE), and the learner corpus is the Norwegian component of the Varieties of English for Specific Purposes dAtabase (VESPA). Both corpora represent disciplinary academic texts by university students writing in their respective fields of specialization (Nesi & Gardner 2012; Paquot et al. 2013). The selected texts belong to the discipline of English literature and were written by students with English and Norwegian, respectively, as their first language. All the texts meeting these criteria were included. The composition of the material is as shown in Table 1.
| Corpus | Words | Texts | Mean text length | Median text length | Range |
|---|---|---|---|---|---|
| BAWE | 221,551 | 94 | 2312 | 2239 | 4438 |
| VESPA | 151,200 | 68 | 2224 | 2069 | 5541 |
Table 1. The corpora used for the present study.
Both corpora have functional mark-up (Ebeling & Heuboeck 2007) to exclude e.g. block quotes and reference lists from the corpus searches when using WordSmith (Scott 2012), hence ensuring as far as possible that the hits represent the students’ own usage. The corpora are not PoS tagged, so the search string was simply ‘the * of the *’, which allows premodification of the N2 in the output but not of the N1 (e.g. the end of the eighteenth century, but not the contradictory ideologies of the day). The concordance lines were scrutinized manually to remove irrelevant hits, e.g. from quotes and titles that had escaped the functional mark-up and cases where the search string yielded something other than a complex noun phrase with the structure ‘the N1 of the N2’.
The methodological framework is that of Contrastive Interlanguage Analysis (Granger 1996, 2015). I compare an interlanguage variety of English to a native reference variety, with a view to identifying similarities and differences. As Granger (2015: 11) argues, the gap in proficiency between advanced learners and native speakers is narrow “and L1-L2 comparisons are very powerful heuristic tools to circumscribe it”. Moreover, the study draws on the Integrated Contrastive Model (Granger 1996; Gilquin 2000/2001) in looking to cross-linguistic differences between the learners’ first and second language in order to explain differences between L1 and L2 usage of the colligation. For this, I rely on my previous study of ‘the N1 of the N2’ and its Norwegian correspondences (Hasselgård 2016).
Following Renouf and Sinclair (1991: 136) I have used the N1 as a point of departure for classifying the meanings represented by ‘the N1 of the N2’. The classification draws on frameworks found in previous descriptions, e.g. Sinclair (1991), Keizer (2007) and Groom (2007: 84 ff). The meaning relations were classified into the following descriptive categories (which might also be seen as semantic sequences; cf. Hunston 2008; Groom 2007):
The list is not exhaustive; it is corpus-driven in the sense that it reflects the semantic sequences that were found repeatedly in the material. [5] It may be noted that the partitive category includes body parts and locative relationships (e.g. the middle of the forest). N1s denoting quantity, e.g. the majority of the animals are included as ‘feature of N2’ because they were not frequent enough in this material to merit their own category.
Several of the categories listed above might arguably be grouped under “possession” in Keizer’s (2007) wide sense, i.e. the top four on the list, and possibly also nominalization (2007: 62). The category of “support noun” has been borrowed from Sinclair (1991). His category of “focus noun”, however, has not been applied; instances of this type have been included in the partitive relation. There is admittedly also some overlap between the categories. Particularly “nominalization”, which is identified on the basis of the form of the N1, may overlap with other categories, which are identified purely on the basis of meaning. However, the nominalized form of the N1 signals that the N1 and the N2 are propositionally related (Renouf & Sinclair 1991: 136). That is, when the N1 is a nominalized verb, the relation is typically Verb-Object (the transformation of the camp), less typically Verb-Subject (the response of the authorities); when the N1 is a nominalized adjective, it typically corresponds to a Predicative-Subject relation: the brutality of the conflict. Importantly, however, each example was assigned to only one category; hence NPs with nominalized N1s, for example, were categorized as nominalizations even if they might have semantic similarities with other categories.
Contrary to expectation, the colligation ‘the N1 of the N2’ is only slightly (and not significantly) less frequent in L2 than in L1: 313 vs. 335 per 100,000 words, as shown in Table 2. It occurs in close to 96% of the texts in both corpora, with a median frequency per text of 7 in BAWE and 6 in VESPA. Both corpora have two outliers containing 22 and 27 instances in BAWE and 22 and 24 in VESPA. [6] The frequency and distribution of the colligation is thus surprisingly similar across learners and native speakers.
| BAWE | VESPA | |
|---|---|---|
| Raw frequency | 743 | 473 |
| Frequency per 100,000 words | 335.4 | 312.8 |
| % of texts | 95.7 | 95.5 |
| Min. - max. per text | 0-27 | 0-24 |
| Median | 7 | 6 |
Interquartile range |
7 (4-11) | 7 (3-10) |
Table 2. Frequency and distribution of ‘the N1 of the N2’.
The following subsections will take a more qualitative look at the colligation in the two corpora, considering issues of lexical recurrence and semantic relations between the two nouns connected by of.
The most frequently occurring lexical realizations of ‘the N1 of the N2’ can be characterized as lexical bundles, i.e. as uninterrupted recurrent sequences of words that commonly go together in natural discourse (Biber et al. 1999: 990, 993). Nouns modified by of-phrases have been found to constitute a highly frequent structural type of lexical bundles in academic prose (Biber et al. 1999: 1014 f.); see also Römer (2010: 105). To identify lexical bundles in my material of ‘the N1 of the N2’ colligations, I set the cut-off point for recurrence to 4 in BAWE and 3 in VESPA (corresponding to about two per 100,000 words), with the additional requirement that the bundle should occur in at least three texts (cf. Biber et al. 1999: 992). [7] The bundles that fulfil these criteria are given in Table 3.
| BAWE (L1) | # | norm. | VESPA (L2) | # | norm. |
|---|---|---|---|---|---|
| the rest of the poem | 9 | 4.1 | the end of the novel | 9 | 6.0 |
| the end of the poem | 6 | 2.7 | the beginning of the novel | 5 | 3.3 |
| the use of the word | 5 | 2.3 | the beginning of the book | 4 | 2.6 |
| the end of the novel | 4 | 1.8 | the end of the book | 4 | 2.6 |
| the structure of the poem | 4 | 1.8 | the ending of the novel | 3 | 2.0 |
Table 3. The most frequent lexical bundles (raw and normalized frequencies).
The low numbers in Table 3 show that there is little recurrence in the colligation as a whole, and there are no particular bundles that boost the use of the colligation. [8] These results agree with Gray and Biber’s (2013: 115) observation that “not all highly frequent discontinuous frames may be associated with a highly frequent continuous sequence”. However, it may be noted that all the bundles reflect the discipline of literary studies, although they do not constitute technical terms or theory-specific turns of phrase. Most can be generalized as “the part of the literary work” as shown in (5). There is slightly more variation in BAWE than in VESPA in that two of the N1s refer to something other than a part of a literary work (use and structure); see example (6).
| (5) | Towards the end of the novel we learn that Cal chooses to live as male… (VESPA) |
| (6) | It is an important observation that it was during the Renaissance that the use of the word 'self' as a prefix first arises. (BAWE) |
This section takes a closer look at the nouns occurring as N1 and N2 in the colligation. The overall type and token frequencies are displayed in Table 4. It can be observed that there is slightly more recurrence in BAWE than in VESPA in both N1 and N2 position, as indicated by the type-token ratios; however, this may be an effect of the larger size of the BAWE material (see Tables 1 and 2) and hence need not reflect any difference between L1 and L2 usage. More interestingly, VESPA has less recurrence in N1 than in N2 position, while in BAWE the type-token ratio is similar for N1 and N2.
| BAWE (L1) | VESPA (L2) | |||
|---|---|---|---|---|
| N1 | N2 | N1 | N2 | |
| Word types | 359 | 357 | 287 | 255 |
| Word tokens | 743 | 743 | 473 | 473 |
| Type-token ratio | 48.32 | 48.11 | 60.68 | 54.49 |
Table 4. Word types and tokens in N1 and N2 position.
It may be noted that the colligations in the present study have much less recurrence in N1, but more in N2, than in Hasselgård (2016), which was based on fiction. This indicates that the colligation is sensitive to register (as seen also in Biber et al. 1999 and in Gray & Biber 2013) in terms of both frequency and content. The most recurrent nouns (lemmas) in N1 and N2 position – excluding those occurring in only one text – are listed in Tables 5 and 6. The nouns that occur in both corpora have been highlighted in bold.
| BAWE (L1) | VESPA (L2) | ||||
|---|---|---|---|---|---|
| N1 | # | norm. freq. | N1 | # | norm. freq. |
| end | 42 | 19.0 | end | 28 | 18.5 |
| use | 30 | 13.5 | beginning | 17 | 11.2 |
| beginning | 18 | 8.1 | rest | 12 | 7.9 |
| rest | 16 | 7.2 | life | 7 | 4.6 |
| repetition | 15 | 6.8 | rise | 7 | 4.6 |
| importance | 13 | 5.9 | action | 6 | 4.0 |
| image | 12 | 5.4 | ending | 6 | 4.0 |
| nature | 10 | 4.5 | eyes | 5 | 3.3 |
| role | 10 | 4.5 | idea | 5 | 3.3 |
| structure | 10 | 4.5 | land | 5 | 3.3 |
| context | 9 | 4.1 | |||
| mind | 9 | 4.1 | |||
Table 5. The most frequent lemmas in N1 position (min. 4 per 100,000 words or top 10; min. 2 texts).
As Table 5 shows, more words occur above four times per 100,000 words in BAWE than in VESPA. Most of the N1s in both corpora are general in meaning, i.e. they are not specific to the discipline of literary studies. The three shared N1s in Table 5 also occur in the lexical bundles reported in Table 3, i.e. they refer to a part of a literary work. The top N1, end, is equally frequent in both corpora, but frequencies drop more sharply in VESPA. The high frequency of end may be expected from the generally high frequency of the lexical bundle the end of the (Biber et al. 1999: 999, 1012). It may be noted that ending in VESPA is used in much the same way as end, as illustrated by (7).
| (7) | The scenes presented in the ending of the film are a composite of several scenes provided in the novel… (VESPA) |
The second-most frequent N1 in BAWE, use, is found as N1 in VESPA, but only three times, and thus below the cut-off point for inclusion in Table 5. Three of the most frequent N1s in BAWE are nominalizations (use, repetition, importance), while in VESPA only rise is a nominalization; see further Section 4.3.2. The BAWE list also contains more abstract nouns than the VESPA one. [9]
Turning to the recurrent nouns in N2 position, we find that they reflect the academic discipline to a much greater extent than the N1s in the colligation. That is, they point to the type of text studied (novel, poem, story) or the content of such texts (character, word), as detailed in Table 6.
| BAWE (L1) | VESPA (L2) | ||||
|---|---|---|---|---|---|
| N2 | # | norm. freq. | N2 | # | norm. freq. |
| poem | 55 | 24.8 | novel | 37 | 24.5 |
| play | 20 | 9.0 | character | 16 | 10.6 |
| novel | 18 | 8.1 | book | 14 | 9.3 |
| character | 17 | 6.3 | century | 11 | 7.3 |
| line | 14 | 6.3 | story | 11 | 7.3 |
| story | 14 | 6.3 | Houyhnhnms | 10 | 6.6 |
| text | 14 | 5.9 | world | 10 | 6.6 |
| word | 13 | 5.0 | film | 9 | 6.0 |
| scene | 11 | 5.0 | woman | 8 | 5.3 |
| bible | 9 | 4.1 | house | 7 | 4.6 |
| world | 9 | 4.1 | poem | 7 | 4.6 |
| swede | 7 | 4.6 | |||
| coffee-house | 6 | 4.0 | |||
| people | 6 | 4.0 | |||
| ##s | 6 | 4.0 | |||
Table 6. The most frequent lemmas in N2 position (min. 4 per 100,000 words; min. 2 texts).
Table 6 indicates that the most frequent N2s, in contrast to N1s, are slightly more recurrent in VESPA than in BAWE. The VESPA list reflects some specific literary works which are set texts in the courses for which the assignments were written, e.g. Houyhnhnms, Swede, and coffee-house. There are also more general vocabulary words in the VESPA list, particularly woman, house, people and ##s, where the # refers to a number, e.g. the 1960s. General words are also found as N2 in BAWE, but below the set frequency threshold for Table 6; for instance woman occurs eight times. In contrast, the most frequent N2s in Hasselgård (2016) referred to physical objects, places and times, e.g. house, road, room, table, night, day. The more discipline-specific nature of the N2s in the present study support Sinclair’s (1991) view that the semantic head of the ‘N of N’ construction is typically the second noun; the N1 is subordinate. The next section takes a closer look at the meaning relations between the first and second noun involved in the colligation.
The meaning relations outlined above are unevenly distributed in the material. Frequencies are shown in Table 7, where the meaning categories have been listed in descending order of their frequency in BAWE. However, the ranks in BAWE and VESPA are not identical, and we may note particularly that the partitive relation is more frequent than ‘N1 is a feature of N2’ in VESPA. [10] Patterns in which the N1 is caused by N2 (example 8) or where N1 contains N2 (example 9) are much less frequent in VESPA than in BAWE, while N1s denoting a person are more frequent in VESPA (example 10).
| BAWE | VESPA | |||||
|---|---|---|---|---|---|---|
| N | norm. freq. | % | N | norm. freq. | % | |
| Nominalization | 241 | 108.8 | 32.4 | 139 | 91.9 | 29.4 |
| Feature of N2 | 144 | 65.0 | 19.4 | 74 | 48.9 | 15.6 |
| Partitive | 110 | 49.6 | 14.8 | 95 | 62.8 | 20.1 |
| Possessive | 90 | 40.6 | 12.1 | 75 | 49.6 | 15.9 |
| Support | 79 | 35.7 | 10.6 | 41 | 27.1 | 8.7 |
| Caused by N2 | 28 | 12.6 | 3.8 | 6 | 4.0 | 1.3 |
| Contains N2 | 16 | 7.2 | 2.2 | 1 | 0.7 | 0.2 |
| Temporal | 16 | 7.2 | 2.2 | 13 | 8.6 | 2.7 |
| Person | 13 | 5.9 | 1.7 | 20 | 13.2 | 4.2 |
| Other | 6 | 2.7 | 0.8 | 9 | 6.0 | 1.9 |
| 743 | 100 | 473 | 100 | |||
Table 7. Frequency and distribution of meaning relations between N1 and N2.
| (8) | It obliges him to consider the consequences of the atrocities he is forced to commit. (BAWE) |
| (9) | … it is important to consider the context of the Victorian period that Moore was writing in. (BAWE) |
| (10) | …and that will in almost every case clash with the views of some of the readers of the book. (VESPA) |
Figure 1 shows the percentages of texts in both corpora that contain instances of the five most frequent meaning relations between N1 and N2. The differences in dispersion resemble those between the percentages in Table 7: nominalization, feature and support are more frequent and widely distributed in BAWE, and partitive and possessive are more frequent and (slightly) more widespread in VESPA. While 84% of the BAWE texts contain at least one instance of ‘the N1 of the N2’ with a nominalized N1, no meaning category is represented in more than 66% of the VESPA texts. Only these five meaning categories are sufficiently numerous and widely distributed to be suitable for further exploration, as presented in Sections 4.3.2–4.3.7.
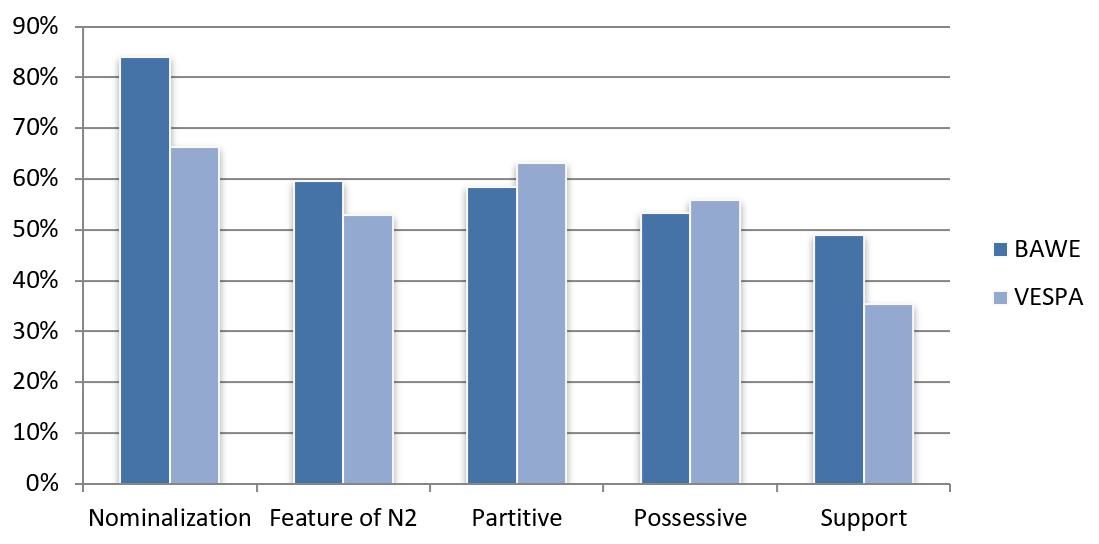
Figure 1. Percentages of texts containing the most frequent meaning relations between N1 and N2.
Nominalized N1s occur frequently in the colligation ‘the N1 of the N2’ in both BAWE and VESPA. A noun has been considered a nominalization if it “reconstru[es] a process or quality as a kind of entity” (Halliday 1998[2004]: 66), but still retains a semantic feature of process or quality, such that nominalization + of-phrase can be “unpacked” (Halliday 1998[2004]: 73) as a clausal structure (e.g. the use of the term : sb used the term; the death of the author : the author died; the simplicity of the title : the title is simple). As Table 7 and Figure 1 show, nominalization is more frequent and widely distributed in L1, occurring in 79 out of 94 texts in BAWE (84%) and in 45 out of 68 texts in VESPA (66%). Frequencies per text vary from 0 to 15 in BAWE (median frequency = 2) and from 0 to 10 in VESPA (median frequency = 1). Few N1s are very recurrent. Table 8 shows those that occur at least 4 times in BAWE and 3 times in VESPA, and in at least two texts. Shared lemmas have been highlighted.
| BAWE (n=241) | VESPA (n=139) | ||
|---|---|---|---|
| use | 30 | rise | 7 |
| repetition | 14 | importance | 3 |
| importance | 13 | reading | 3 |
| death | 8 | survival | 3 |
| complexity | 5 | use | 3 |
| loss | 4 | work | 3 |
| manipulation | 4 | ||
| simplicity | 4 | ||
Table 8. Recurrent nominalized N1s in BAWE and VESPA.
Most of the nominalizations (tokens) come from verbs (72% in BAWE and 70% in VESPA), as illustrated in example (11); the rest are from adjectives, as in (12).
| (11) | The conversion of the stone pit into a garden is testament to the enduring spirit of this bucolic pastoral world … (BAWE) |
| (12) | One loses the richness of the narrative and the story and the complexity of the characters. (VESPA) |
There is less recurrence in N2 position, particularly in VESPA, where only six words occur more than twice (ancients, coffee-house, story, whale, woman, character) and none above four times. Most of them reflect specific literary texts, while the BAWE ones seem less dependent on the assignment. The most recurrent N2s in BAWE are word (11 tokens), story (7 tokens) and poem (5 tokens), while seven more occur four times (bible, character, fricative, individual, mind, phrase, world). These N2s do not reveal any clear patterns, but some refer to the texts, or part of the texts, that the students are discussing. Character and story recur as N2 after nominalized N1s in both corpora, as illustrated by (13).
| (13) | In 'Eveline' the entirety of the story is presented as a stream of consciousness. (BAWE) |
The great diversity of nouns used in the colligation suggests that the degree of automatic co-selection is low, with the possible exception of the use of N2 in BAWE.
The ‘feature’ relationship between N1 and N2 may be regarded as a more abstract type of possession, though with non-animate possessors, cf. Keizer (2007). The pattern is more frequent and widespread in BAWE than in VESPA, as shown in Table 7 and Figure 1. Frequencies per text vary between 0 and 8 in BAWE and between 0 and 5 in VESPA. Very few N1s occur above the cut-off points used for recurrence in this section (4 in BAWE and 3 in VESPA). In BAWE, the following nouns recur: structure (10), meaning (7), function (5), tone (5), light (4), pace (4) and rhythm (4). In VESPA only horrors occurs three times (and in two texts). Most of the recurrent N1s in BAWE refer to typical attributes/features of texts, and hence can be said to be discipline-specific. VESPA contains many of the same (type of) N1s in this category, albeit below the frequency threshold.
In contrast, the N2s in this pattern show more recurrence. In BAWE, poem occurs 29 times as N2 and the following nouns between 4 and 6 times: novel, text, story, word. Similarly, in VESPA, the following nouns occur 3-5 times: novel, poem, story, world, epic. Hence, within the disciplinary discourse of literary analysis, the N2 in the meaning relation ‘N1 is a feature of N2’ typically refers to the literary work under scrutiny. Typical examples are given in (14) and (15).
| (14) | His compulsion to own her and control her is even noticeable through the structure of the poem. (BAWE) |
| (15) | Thus Austen has in the first sentence established the theme of the novel. (VESPA) |
Another frequent meaning relation between the N1 and the N2 is the partitive one. It is more widespread in VESPA than in BAWE, occurring in 63% of VESPA texts and 58.5% of BAWE texts. Frequencies per text vary between 0 and 7 in VESPA and between 0 and 6 in BAWE. The most frequent N1s are displayed in Table 9.
| BAWE (n=110) | VESPA (n=95) | ||
|---|---|---|---|
| end | 42 | end | 26 |
| beginning | 18 | beginning | 17 |
| rest | 16 | rest | 12 |
| start | 5 | ending | 6 |
| conclusion | 3 | eye(s) | 6 |
| hand | 3 | part(s) | 4 |
| heart | 3 | focus | 3 |
| members | 3 | ||
Table 9. The most frequent N1s in the partitive pattern ‘N1 is part of N2’.
The top three N1s in the partitive pattern are shared between the two corpora. As noted above (Sections 4.1 and 4.2), these nouns typically occur with an N2 that denotes a literary work; see examples (5) and (7) above. Some of the slightly less recurrent N1s in Table 9 refer to body parts, although it may be noted that heart, hand(s) and eye(s) all tend to have non-literal meaning; see (16) and (17).
| (16) | Humanism was a movement that lay at the heart of the fifteenth century Renaissance in Italy. (BAWE) |
| (17) | Dr. Philobosian, being a medical professional, must in the eyes of the reader be trusted to present an educated opinion… (VESPA) |
Almost all the N2s occurring at least 4 times in the partitive construction in BAWE refer to the work analysed, i.e. poem (19 times), novel, line, play, film, scene and verse. The only exception is century, which occurs five times. In VESPA we find novel, book, film and century between 6 and 23 times (and none between 3 and 5 times). Thus, the partitive meaning relation arguably produces the most recurrent lexical patterns of the colligation ‘the N1 of the N2’, with the “the part of the literary work” and the beginning/end/turn of the century being the most productive instantiations.
The meaning relationship representing the of-genitive is relatively frequent in the material, but entails very little recurrence of either N1 or N2. There are 118 realizations of this possessive meaning relation in BAWE; the N1 in nine of these is mind, and the following nouns occur 4-5 times: life, voice, consciousness, work. among the 75 of-genitives in VESPA, the following N1s occur between 3 and 6 times (in descending order of frequency): action, land, life, story, mind, name. The N2 position similarly offers much variability and little recurrence. The most frequent N2 (lemma) in both corpora is character (10 in BAWE and 9 in VESPA). The second most frequent N2s in BAWE are poet and reader (6 tokens each), while in VESPA we find Houyhnhnms 7 times, evidently reflecting an assignment on J. Swift’s Gulliver’s Travels. Example (18) illustrates the most frequent N1 related to the most frequent N2 in BAWE, while (19) shows the most frequent N1 in the possessive meaning relation in VESPA.
| (18) | The reader is plunged into the mind of the character and the feel of uncertainty… (BAWE) |
| (19) | … where Jerry Levov shows his true feelings towards the actions of the Swede… (VESPA) |
As most of the N1s as well as the N2s in this category occur only once or twice, we may conclude that the colligations expressing possessive meaning are to a great extent composed on the basis of open choice rather than as chunks.
Support nouns are less numerous and widespread than the other meaning relations discussed so far, especially in VESPA. However, there seems to be a limited number of nouns filling the role of support noun. BAWE has 79 occurrences of support nouns, of which the most frequent (N>3) are image (12), nature (10), role (9), idea (5), theme (5), concept (4), and figure (4). Very few nouns are recurrent in N2 position, and only one (woman)occurs as often as four times. An example is given in (20). We see a similar selection of N1s, but even less recurrence in VESPA. The Norwegian writers use the following N1s at least three times: idea (5), context (4), nature (4), course (3) and role (3). Only the word novel, with five occurrences, is used more than twice in N2 position, see (21).
| (20) | The figure of the "other woman" is also a medium of expressing sexuality now that she represents the latter and, also, immorality. (BAWE) |
| (21) | …same development that Huck has gone through during the course of the novel. (VESPA) |
This section has shown that there are few quantitative differences between learners and native speakers in their use of the colligation ‘the N1 of the N2’ even though previous studies have found that the pattern increases with proficiency (Garner 2016: 48) and with study level (Staples et al. 2018: 166). However, there are qualitative differences between the two writer groups in their use the colligation, especially regarding the meaning relations between the N1 and the N2. Of the five meaning relations that were frequent enough to provide a basis for comparison, nominalization, ‘feature of N1’ and support nouns were more frequent and widespread in BAWE, while partitive and possessive meanings were more frequent and slightly more widespread in VESPA. The greatest frequency difference between the corpora was found with nominalizations. Staples et al. (2018: 166) show that the use of nominalization increases significantly with study level in BAWE, which makes it a developmental feature. Study levels have not been distinguished in this investigation, but since both corpora contain texts from both BA and MA students, it is unlikely that this factor should account for the difference in use of nominalization between L1 and L2 users of English. It may be noted that Hasselgård (2016: 67) found that ‘the N1 of the N2’ constructions had more than twice as many divergent as congruent correspondences in Norwegian, i.e. most of them corresponded to a Norwegian expression other than two definite nouns connected by a preposition. [11] Thus, at this point the Norwegian learners seem to be faced with a cross-linguistic difference as well as the abstraction and semantic compression inherent in a nominalization postmodified by an of-phrase.
Interestingly, the two meaning relations that are more frequent in VESPA than in BAWE were also the two that had the highest percentage of congruent Norwegian correspondences according to Hasselgård (2016: 68 f.). [12] Thus, both the partitive and the possessive relations between N1 and N2 are familiar to Norwegian learners from their mother tongue. It may be noted that both writer groups had the highest degree of recurrence in both N1 and N2 position within the partitive relation, where the most typical realizations were the end/beginning/rest (etc.) of the novel/poem/film/play (etc.). Hence, this was the category of instantiations that most closely reflects the idiom principle (Sinclair 1991: 109 ff). The pattern ‘N1 is a feature of N2’ resembled the partitive pattern in that discipline-specific nouns showed up in N2 position. However, ‘feature’ N1s were much less recurrent than N1s in partitive constructions.
Contrary to expectation, the frequencies and distribution of the colligational framework ‘the N1 of the N2’ are relatively similar between the learners and the native speakers. Hence, to the extent that there are cross-linguistic differences between the learners’ first and second language in this area the writers in VESPA prove to be proficient enough to use the colligation almost as frequently as their native peers. There are both similarities and differences between the two corpora regarding the nouns used as N1 and N2 in the colligation. Most of the recurrent lexical bundles comprising the whole colligation denote “the part of the literary work”, especially in VESPA (L2). In general, the most recurrent N1s are relatively general in meaning, and in both groups the discipline-specific nouns show up predominantly as N2. BAWE has been found to have more recurrence in both N1 and (particularly) N2 position than VESPA. This might suggest that the learners are using the colligation more on an “open-choice” basis while the native speakers are using it more on the basis of the idiom principle. However, this point requires further study.
The study of meaning relations between the N1 and the N2 in the framework revealed qualitative differences between the two groups, in particular in the extent to which they use nominalizations in the N1. Nominalized constructions are both more frequent and more widespread in BAWE, as evidenced already in the study of lexical bundles, where the use of the word came up in BAWE, while all the bundles in VESPA conveyed a partitive meaning. The other non-partitive bundle in BAWE, the structure of the poem reflects another meaning category that is more frequent and widespread in L1, namely N1 is a feature of N2.
The present study points to several avenues of further work. Above all, it would be interesting to compare the material examined here to expert writing within the same field, i.e. published articles in literary studies, to see if the novices are using the colligation in what may be termed the “target” fashion of the discipline. Furthermore, it would be worthwhile to investigate other, related collocational and colligational frameworks across the L1/L2 dimension, e.g. those discussed in Renouf and Sinclair (1991), N1-preposition-N2 (with prepositions other than of) as well as other features of phrasal complexity, including more extensive noun phrases than those examined here.
At a methodological level, the study has demonstrated the feasibility of using a colligational framework as the starting point for a comparison between two writer groups. Hunston (2008: 293) points out that “[w]hereas lexical words are a good place to find the subject matter of the discipline, grammar words function to find its epistemology”. Investigating second-language academic writing from the point of view of grammatical words can thus give information on the extent to which the learners have acquired the epistemology as well as the phraseology of their academic discipline.
[1] A similar concept has been studied under the names of ‘phrase frame’/‘p-frame’, e.g. Römer (2010), Garner (2016) and Lu et al. (2018), and ‘lexical frame’ Gray & Biber (2013). However, p-frames contain only one variable slot (e.g. Römer 2010: 102), while the colligation examined in the present study contains two. [Go back up]
[2] Here and elsewhere the relevant noun phrases have been highlighted; otherwise the examples are rendered as they occur in their respective corpora, including any infelicities. [Go back up]
[3] A future study might include a corpus of published academic papers to find out how close the novices are to target usage within the same academic discipline. [Go back up]
[4] For definitions of congruence/divergence, see Johansson (2007: 25). [Go back up]
[5] Hasselgård (2016) additionally contained the categories “locative”, “body part” and “ordinal”. The reason for the difference is that these categories were much more frequent in the fictional material for the 2016 study and/or they constituted interesting points of comparison with their Norwegian correspondences. [Go back up]
[6] Most of the texts that do not contain ‘the N1 of the N2’ (3 of 4 in BAWE and 2 of 3 in VESPA) are well below the mean text length. The two outliers in each corpus are well above. The material does not, however, point to any systematic relationship between text length and number of occurrences of the colligation. [Go back up]
[7] Strictly speaking, the realizations of a specific colligation are not lexical bundles, since contrary to Biber et al.’s definition, they have a predefined structural status. However, for the present purposes, I will refer to recurrent realizations of ‘the N1 of the N2’ as lexical bundles; see also Gray & Biber (2013: 114). [Go back up]
[8] The type-token ratios for the complete pattern, calculated with WordSmith, are 85.7 for BAWE (683 types, 743 tokens) and 88.3 for VESPA (418 types, 473 tokens). [Go back up]
[9] Apart from end, beginning, rest, the lists differ remarkably from the list of recurrent N1s occurring in the pattern in fiction (Hasselgård 2016), where most of the N1s were locative (end, rest, back, edge, side, centre, top, middle, bottom). [Go back up]
[10] The distribution of patterns in the material as a whole differs significantly between the corpora: χ2 = 26.22, p<0.001 (http://corpora.lancs.ac.uk/sigtest/). [Go back up]
[11] Hasselgård (2016) was based on fictional material, and hence is not directly comparable with the academic register investigated here. However, it is likely that the cross-linguistic differences uncovered will extend to other registers as well. [Go back up]
[12] The meanings ‘N1 is a feature of N2’, and support nouns, were both rare in Hasselgård (2016), but particularly ‘N1 is a feature of N2’ had a clear majority of divergent correspondences in Norwegian (Hasselgård 2016: 67). [Go back up]
BAWE = British Academic Written English Corpus. http://www.coventry.ac.uk/research/research-directories/current-projects/2015/british-academic-written-english-corpus-bawe/
VESPA = Varieties of English for Specific Purposes dAtabase. https://uclouvain.be/en/research-institutes/ilc/cecl/vespa.html, https://www.hf.uio.no/ilos/english/services/knowledge-resources/vespa/
Biber, Douglas & Bethany Gray. 2016. Grammatical Complexity in Academic English. Linguistic Change in Writing. Cambridge: Cambridge University Press.
Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad & Edward Finegan. 1999. Longman Grammar of Spoken and Written English. London: Longman.
Ebeling, Signe Oksefjell & Alois Heuboeck. 2007. “Encoding document information in a corpus of student writing: The British Academic Written English corpus”. Corpora 2(2): 241–256. doi:10.3366/cor.2007.2.2.241
Garner, James R. 2016. “A phrase-frame approach to investigating phraseology in learner writing across proficiency levels”. International Journal of Learner Corpus Research 2(1): 31–68. doi:10.1075/ijlcr.2.1.02gar
Gilquin, Gaëtanelle. 2000/2001. “The integrated contrastive model: Spicing up your data”. Languages in Contrast 3(1): 95–123. doi:10.1075/lic.3.1.05gil
Granger, Sylviane. 2015. “Contrastive interlanguage analysis: A reappraisal”. International Journal of Learner Corpus Research 1(1): 7–24. doi: 10.1075/ijlcr.1.1.01gra
Groom, Nicholas. 2007. Phraseology and Epistemology in Humanities Writing. Ph.D. dissertation, University of Birmingham. https://ethos.bl.uk/OrderDetails.do?uin=uk.bl.ethos.536571
Granger, Sylviane. 1996. “From CA to CIA and back: An integrated approach to computerized bilingual and learner corpora”. Languages in Contrast. Papers from a Symposium on Text-based Cross-linguistic Studies, Lund 4–5 March 1994, ed. by Karin Aijmer, Bengt Altenberg & Matts Johansson, 37–51. Lund: Lund University Press.
Gray, Bethany & Douglas Biber. 2013. “Lexical frames in academic prose and conversation”. International Journal of Corpus Linguistics 18(1): 109–135. doi:10.1075/ijcl.18.1.08gra
Halliday, M.A.K. 1998 [2004]. “Things and relations: Regrammaticizing experience as technical knowledge”. Reading Science: Critical and Functional Perspectives on Discourses of Science, ed. by James R. Martin & Robert Veel. London: Routledge. Reprinted in M.A.K. Halliday, The Language of Science, 49–101. London: Continuum.
Hasselgård, Hilde. 2016. “The way of the world: The colligational framework ‘the N1 of the N2’ and its Norwegian correspondences”. Nordic Journal of English Studies 15(3): 55–79. http://ojs.ub.gu.se/ojs/index.php/njes/article/view/3589
Hunston, Susan. 2008. “Starting with the small words. Patterns, lexis and semantic sequences”. International Journal of Corpus Linguistics 13(3): 271–295. doi:10.1075/ijcl.13.3.03hun
Johansson, Stig. 2007. Seeing through Multilingual Corpora. On the Use of Corpora in Contrastive Studies. Amsterdam & Philadelphia: Benjamins.
Keizer, Evelyn. 2007. The English Noun Phrase. The Nature of Linguistic Categorization. Cambridge: Cambridge University Press.
Lu, Xiaofei, Jungwan Yoon & Olesya Kisselev. 2018. “A phrase-frame list for social science research article introductions”. Journal of English for Academic Purposes 36: 76–85. doi:10.1016/j.jeap.2018.09.004
Nesi, Hilary & Sheena Gardner. 2012. Genres across the Disciplines. Student Writing in Higher Education. Cambridge: Cambridge University Press.
Owen, Charles. 2007. “Notes on the ofness of of – Sinclair and grammar”. International Journal of Corpus Linguistics 12(2): 201–222. doi:10.1075/ijcl.12.2.07owe
Paquot, Magali, Hilde Hasselgård & Signe Oksefjell Ebeling. 2013. “Writer/reader visibility in learner writing across genres: A comparison of the French and Norwegian components of the ICLE and VESPA learner corpora”. Twenty Years of Learner Corpus Research: Looking back, Moving ahead, ed. by Sylviane Granger, Gaëtanelle Gilquin & Fanny Meunier, 377–387. Louvain: Presses Universitaires de Louvain.
Parkinson, Jean & Jill Musgrave. 2014. “Development of noun phrase complexity in the writing of English for Academic Purposes students”. Journal of English for Academic Purposes 14: 48–59. doi:10.1016/j.jeap.2013.12.001
Quirk, Randolph, Sidney Greenbaum, Geoffrey Leech & Jan Svartvik. 1985. A Comprehensive Grammar of the English Language. London: Longman.
Ravid, Dorit D. & Ruth A. Berman. 2010. “Developing noun phrase complexity at school age: A text-embedded cross-linguistic analysis.” First Language 30(1): 3–26.
Renouf, Antoinette & John McH. Sinclair. 1991. “Collocational frameworks in English”. English Corpus Linguistics: Studies in Honour of Jan Svartvik, ed. by Karin Aijmer & Bengt Altenberg, 128–144. London: Longman.
Römer, Ute. 2010. “Establishing the phraseological profile of a text type. The construction of meaning in academic book reviews”. English Text Construction 3(1): 95–119. doi:10.1075/etc.3.1.06rom
Scott, Mike. 2012. WordSmith Tools (version 6). Stroud: Lexical Analysis Software.
Sinclair, John. 1991. Corpus, Concordance, Collocation. Oxford: Oxford University Press.
Sinclair, John. 2004. Trust the Text. Language, Corpus and Discourse. Abingdon: Routledge.
Staples, Shelley, Jesse Egbert, Douglas Biber & Bethany Gray. 2016. “Academic writing development at the university level: Phrasal and clausal complexity across level of study, discipline, and genre”. Written Communication 33(2): 149–183. doi:10.1177/0741088316631527
