Why is it full of funny characters?
Converting the BNC into XML
Ylva Berglund Prytz,
Research Technologies Service, Oxford University Computing Services, University of Oxford
1. Introduction
'Why is it full of funny characters?' is a question that the BNC team has heard several times. Usually the question is raised by someone who has tried to open one of the files in the British National Corpus with a text editor, finding that the text they see is full of codes <in brackets>. The answer to the question usually contains an explanation of the fact that the corpus contains not only texts but also information about the texts, coded in this particular way, and that the availability of this annotation is one of the features of the corpus that makes the resource so valuable. The BNC annotation offers information about the texts in the corpus, such as the source, date of publication, or the setting in which they were recorded. It also provides information about the author/speaker, the target audience, and type of publication in which the original text was published. In addition to the information on text level, BNC texts contain mark-up that identifies paragraphs, headings, sentence-like elements and words, and linguistic information is provided for each individual word. The annotation makes it possible to automatically identify particular kinds of texts or words, or easily retrieve instances of an item in a text with certain characteristics. Admittedly, the codes used also make the texts difficult to read without special tools, and that is one of the reasons why it was decided to convert the BNC from its original SGML format into XML, as further described below.
2. Introduction to the BNC
When the British National Corpus (BNC) was first released, it was the largest corpus of contemporary English that was generally available. Although larger corpora have been produced since, the BNC still occupies a unique position thanks to its composition, and wide-spread use.
The BNC consists of over 4,000 different texts with around 100 million words in total. The first edition was released in 1995, with a second, revised edition being made available world-wide in 2001 (BNC World). One of the factors making the corpus so valuable is the way it was compiled. As described in the BNC Reference Guide, the compilation of the corpus was carefully planned and followed guidelines drawn up at the beginning of the project. These guidelines did not only specify the amount of text to be sampled from different sources, but also how these sources were to be identified and how the sampling was to take place. For the fiction component, for example, lists of books in print, bestseller lists, library lending statistics and literary prizes were considered to establish not only what was produced (written) but also what was received (read). Similar approaches were taken for other genres in order to create a corpus which would reflect the British English language of the time.
The BNC contains about 10 million words of spoken, orthographically transcribed data. Although the proportion of spoken material (10%) may seem small, the spoken component was nevertheless many times larger than previously available resources (for example the London-Lund Corpus, 0.5 million words). A novel approach was adopted for the gathering of the spontaneous conversation material: a number of demographically representative "respondents" were recruited and asked to record their conversations over a set period of time. To this demographically sampled collection was added other spoken material from a range of text types within four contextually based categories: educational, business, public/institutional, and leisure. The spoken corpus material was orthographically transcribed.
The design of the corpus is described in more detail in the BNC Reference Guide. Information about the creation of the corpus (permissions clearance; collection, encoding, linguistic annotation, and storage and documentation of texts) is also available on the BNC website.
2.1 More than texts
In addition to the written and spoken texts as such, the BNC also contains significant amounts of descriptive or bibliographic data particular to each text. This metadata includes details about author, target audience, recording date, domain and much more. Descriptions of typographical features (page breaks, headings) and information specific to spoken data (such as non-verbal events, voice quality) have been recorded in the texts, and grammatical information (part-of-speech) is available for each word.
It is soon obvious to anyone who tries to record a large amount of information about a text that this is not always straightforward. It is important to ensure not only that the information is available, but also that the texts themselves can be distinguished from the additional information (as recommended by Geoffrey Leech (2005), for example in Developing Linguistic Corpora: A Guide to Good Practice (see chapter 2, section 4). The BNC was created at the time when the Text Encoding Initiative (TEI) was preparing the release of its first Guidelines. Since the two projects were closely related, aiming to make encoded text widely usable, it was natural to choose a mark-up and encoding scheme for the corpus in line with the TEI recommendations. The first two versions of the BNC were marked-up using a version of Standard Generalized Mark-Up Language (SGML). The start of a typical written text could look like this:
<text complete=Y decls='CN000 HN001 QN000 SN000'>
<div1 complete=Y org=SEQ>
<head type=MAIN>
<s n=001>
<w NP0>CAMRA <w NN1>FACT <w NN1>SHEET
<w AT0>No <w CRD>1 </head>
<head r=it type=SUB>
<s n=002><w AVQ>How <w NN1>beer <w VBZ>is
<w AJ0-VVN>brewed </head>
<p><s n=003>
<w NN1>Beer <w VVZ>seems <w DT0>such
<w AT0>a <w AJ0>simple <w NN1>drink <w CJT>that
<w PNP>we <w VVB>tend <w TO0>to <w VVI>take
<w PNP>it <w CJS-PRP>for <w VVD-VVN>granted
<c PUN>.
The actual text content of the passage reads as follows:
CAMRA FACT SHEET No 1
How beer is brewed
Beer seems such a simple drink that we tend to take it for granted.
The text is interspersed with the mark-up, provided in tags. Each tag is enclosed in brackets (< >), which makes it easy to distinguish automatically. The <w> marks the beginning of a word (as defined in the corpus), <c> is used for marking punctuation, and <s> denotes the beginning of a sentence (or sentence-like element, as defined in the corpus reference guide). Other elements, such as headings (<head>) and larger divisions of text (<div>), are surrounded by two tags, marking the start and end of the element.
Information about the corpus as a whole and information that is shared by all the texts is contained in the corpus header. Information specific to a particular text is contained in the text header, while the text itself is contained in the body. The corpus thus consists of a corpus header and a number of corpus texts (4,000+), each with a text header (with information about the text) and a body (the text itself).
More information about the BNC mark-up conventions is available in BNC User Reference Guide and is also discussed by Burnard (2002).
2.2 Format issues
One reason for originally selecting SGML was that it was the emerging standard at that time (for example Connolly 1995). Among the benefits of using SGML is that it allows different kinds of annotation in a text (part-of-speech, extra-linguistic, meta-data), which was needed for the BNC. It is also easy to automatically distinguish mark-up from text, which fulfils one of the criteria for corpus annotation recommended by Leech (2005, chapter 2, section 4). The fact that SGML allowed minimization was an important factor. By only marking the beginning of certain high-frequency elements (such as the word), for example, the size of the corpus was kept down. Being forced to add an end tag to each word in the corpus would increase its size with 400.000.000 characters (the equivalent of adding the characters '</w>' after each of the 100 million words). This was a relevant consideration for the creators, who were constructing the corpus at a time when a personal computer might have 50 Mb of disk space and the amount of disk space needed to install the corpus was only found on central servers (and sometimes not even there). Another major factor influencing the choice of mark-up format was that the corpus was to be usable on a wide variety of platforms and with different kinds of tools. As it was expected that a selection of tools would become available to use with SGML material, that was a further reason for choosing that format.
It soon turned out, however, that this last calculation failed to come true. On the contrary, very few tools for handling SGML texts of the scope found in the BNC have materialised and become generally available. The BNC was distributed with a custom-made search and retrieval tool (SARA). Although this tool could be used for many tasks, it did not suit all users, and was often subject of criticism. Some alternative interfaces were developed, for example BNCweb and the Shogakukan interface, but these were not generally available and could not easily be installed on a local desktop. Corpus users in possession of the necessary skills and computer power could write their own scripts or programs for retrieving information from the corpus. As it happened, however, it was not the language engineers and NLP researchers who turned out to be the main users of the corpus. Linguists, teachers and students soon became a prominent user group, and one which did not necessarily have the inclination, equipment, or skill to write their own programs. Many users also wanted to study the corpus texts in detail by reading them or longer extracts of them. This turned out to be difficult, due to the mark-up in the text. A common complaint by people opening a BNC text in a non-SGML aware program, such as a text editor, was that the text was 'full of funny characters' and impossible to read. Thus, despite the conscious effort by the creators to make the corpus a portable resource that did not require the use of specialist tools, many users felt they could not benefit from the resource because of the format.
2.3 A suggested solution
To overcome some of the problems users had encountered with the corpus, it was suggested that the BNC be converted to a different format. When the opportunity arose, the obvious choice was to convert it to XML (Extensible Markup Language), a text format derived from SGML. XML was originally designed for large-scale electronic publishing but is now increasingly used for exchange of data in different contexts, not least on the Web (see World Wide Web Consortium website). XML shares most of the features of SGML which had made the format so suitable for the corpus in the first place. The fact that using XML mark-up would increase the corpus size (in disk space required, not number of words), was no longer an issue, since the space required by the new version would be but a fraction of what is customarily available on a modern PC anyway. As converting documents from SGML to XML can be relatively simple to do, this was a further benefit (see TEI Task Force on SGML to XML Migration).
A strong influence for choosing XML was also that this is an emerging standard, recommended for use with electronic text material not only by the World Wide Web consortium (W3C) and the TEI. The intention has always been to make the BNC usable with a wide range of tools, not to lock it into one particular software product. Considering the changes in the digital world that have taken place since the BNC was first created, converting the corpus to XML seemed an obvious step in that direction. In addition to the benefits gained by the conversion to the new format, issuing a new edition would also offer an opportunity to correct known errors and inconsistencies in the corpus.
3. Introduction to XML
XML is a standard that is widely used and widely described both online and in print. The following section will offer a brief introduction to XML. The W3C website is recommended for a more thorough presentation and further information.
A feature of XML, which is shared with SGML and HTML (another sub-set of SGML, usually used for web pages), is that the encoded information is provided in the shape of tags, enclosed in brackets (< >).
-
A part of text surrounded by tags marking beginning and end is called an element: <tag>element</tag>.
-
An element can contain other elements: <a><b>…</b><b>…</b></a>.
-
Each element can have attributes, defining the element in some way:
<head type="MAIN">a main heading</head>
<head type="SUB">a sub-heading</head>
In the BNC, attributes can be numbers (such as sentence numbers), tags (such as part-of-speech tags) or descriptions of non-verbal events that are part of a spoken text, to mention but a few options.
In XML, names of elements and attributes are arbitrary. That means that anyone who produces an XML document can choose their own names for all elements. Although the benefit of this is that you can opt for names that are meaningful to you or suit your particular project, there are obvious drawbacks as well. If one producer uses <s> to mark a sentence and someone else uses <s> to mark a pause, this causes confusion and makes comparison more difficult. One way to avoid confusion among users of XML documents is to use a recommended standard for naming elements and attributes. The BNC uses the recommendations drawn up by the Text Encoding Initiative (TEI), which suggest what tags to use and how to use them. The TEI recommendations are carefully documented and explained, and can be applied to a range of different types of texts. TEI allows a certain degree of flexibility, and the choices made for the BNC XML edition are described further in the mark-up conventions in the Reference Guide for the British National Corpus (XML Edition). The complete TEI guidelines, together with additional information material, is available at the TEI website.
4. Conversion
The conversion of the BNC from SGML into XML format was easy and fairly automatic. [1] The conversion of the corpus into the new format also offered an opportunity to make some minor changes to fix known errors and inconsistencies. No new texts were added to the corpus, but some duplicated texts were removed. The part-of-speech tagging is the same as in BNC World, but additional linguistic information is now available. This is further described below.
Table 1. Converting the BNC.
Unchanged |
With changes |
same texts as BNC World |
minus duplicates |
same POS tagging |
extended with lemmata and simpler tagset |
no proofing, re-editing, or re-parsing... |
text categorisation errors corrected |
|
tokenisation/segmentation errors corrected |
|
multi-word tokens eliminated |
|
non-linguistic and paralinguistic descriptions standardised |
The changes that were made to the corpus can be divided into three main categories:
-
changes of the formatting (such as replacing the SGML tags with XML ones, identifying and correcting SGML tagging errors. Changes to the header are also included here);
-
changes to the texts themselves (known errors and inconsistencies, including tokenisation and segmentation errors);
-
changes to the linguistic information (addition of lemma information, additional word class annotation, changes to annotation of multiword units).
The last category, changes to the linguistic information, will facilitate new types of queries and uses and can be assumed to be of particular interest to linguists using the corpus. The addition of lemma information, additional word class annotation, and changes to the annotation of multiword units will therefore be described in more detail below.
4.1 Making the mark-up consistent
Although the initial idea was to simply convert the texts into the new format, the more tractable mark-up revealed a number of areas that needed further attention. Work was undertaken in order to make the mark-up more consistent, for example by limiting the range of descriptive attribute values that was used to describe non-verbal events and vocal descriptions. The list below illustrates some of the terms used to describe that the speaker breathes audibly:
Table 2. Simplifying the mark-up.
What used to be: | became: |
|---|
<vocal desc="big breath"/> | |
<vocal desc="breathing out suddenly"/> | |
<vocal desc="drawing in breath"/> | |
<vocal desc="exhales"/> | |
<vocal desc="indrawn breath"/> | |
<vocal desc="inhales"/> | <vocal desc="breath"/> |
<vocal desc="intake of breath"/> | |
<vocal desc="sharp intake of breath"/> | |
<vocal desc="takes a deep breath"/> | |
<vocal desc="takes breath"/> | |
The use of different tags in the mark-up suggests that there was a difference in the event, and that the choice of term is a valuable source of information. However, it is not known on what basis the different terms were chosen or to what degree the opportunity to mirror an event by a creative use of terms was used by different transcribers. That means that although the individual terms may be informative, they also falsely suggest that 'indrawn breath' and 'intake of breath' are different from 'takes breath' and 'inhales', which cannot be verified. It was, therefore, decided that the list of terms used should be simplified. With a smaller set of terms, retrieving all instances of a phenomenon, such as the speaker taking a breath, is also facilitated considerably. Similar simplification was done on the <shift desc>, <event desc>, and <vocal desc> elements.
Some tags that were rarely or inconsistently used were removed, such as <hi>, <poem>, and <caption>. Once again, it was argued that although some information is arguably lost, removing the infrequent, inconsistently used instances of these tags made the material as a whole more reliable and useful. Work was also performed on rationalising text structures by removing empty divisions and redundant pointers. Some errors in sentence and word boundary identification were corrected. In order to facilitate comparison and cross-reference with earlier versions of the corpus, the original numbering of the sentences was kept. Where an empty element was removed, the preceding and following sentences kept their sentence numbers, resulting in a gap in the numeric sequence of the sentences.
4.2 Lemma information
In the previous version of the BNC (BNC World), lemma information could only be retrieved when making a query in SARA. It means that is was possible to find all forms of the verb sing, for example, when making a Word query, even though that information was not explicitly coded in the running text. If you were reading the texts, or searching them with a different program however, you would not find this information.
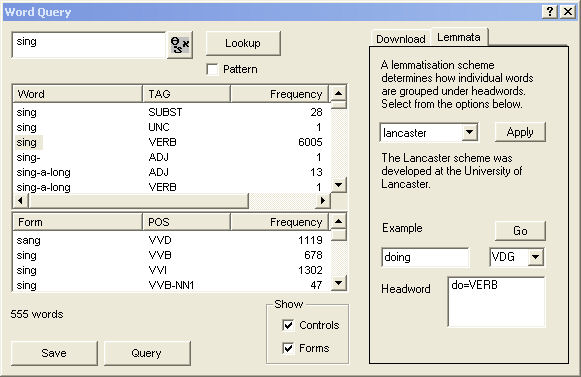
Figure 1. Word Query illustrating
lemma information available to users of BNC World with SARA.

Figure 2. Concordances illustrating lemma information available to users of BNC World with SARA.
In BNC XML Edition, the lemma information has been added to the corpus texts. As the information is now coded for each running word, it can be retrieved whenever accessing the texts and not only when searching the corpus with one particular tool.
Below is an example from the corpus, showing how the lemma annotation (hw="lemma") and the realisation of the lemma are given (for ease of reading, all other word-level annotation has been removed in this example).
...
<w hw="they">they </w>
<w hw="be">'re </w>
<w hw="with">with </w>
<w hw="they">their </w>
<w hw="owner">owners </w> … [BNC A17: 263]
The BNC lemmas were derived automatically using manually-defined rules. The basis was a number of morphological rules which take into account the part-of-speech tagging. These simple POS-sensitive suffix stripping rules were combined with a word list of common exceptions (code and a set of rules files kindly supplied by Paul Rayson, UCREL). The result was a set of head-words or lemmas. As the process was automatic and not post-edited, it is not always accurate, and errors can be found, not least for foreign or unusual words. More information about the lemmatization can be found the BNC Reference Guide, section 6.6.4.7.
4.3 Multiword units
In the first two versions of the BNC, multiword units were treated as a special entity. The definition for these multiword units given in the tagging manual is: 'multiple-word combinations which function as one wordclass — for example, a complex preposition, an adverbial, or a foreign expression naturalised into English as a compound noun' (Leech & Smith 2000).
Some examples are: ad nauseam, according to, all right. A list of all the multiword units and their tags is available on the BNC homepage.
As these multiword units were tagged as one word, this meant that the words in the unit could not easily be identified as separate units. A search for 'spite', for example, would not retrieve instances used in the multiword sequence 'in spite of'. Through the feedback offered by people, prominently John Sinclair, it became obvious that although many recognize the usefulness of being able to identify these multiword units, they would also like to be able to find the individual items forming the multiword. It was therefore decided to revise the BNC multiword tagging and break out the individual components. The original identification of multiwords has not been lost, however — the new word-tags have been added inside the multiword element, as illustrated in this example (for ease of reading, all other word-level annotation has been removed in this example):
The original <w PRP>in spite of has become
<mw type="PRP">
<w type="AVP">in </w>
<w type="NN1">spite </w>
<w type="PRF">of </w>
</mw>
The preposition in spite of is identifiable through the multiword tag <mw type="PRP"> … </mw>. The multiword unit has the wordclass tag PRP (preposition). Inside the mw-tag are found the three words in spite of, with their individual wordclass tags.
The word class tags for the words inside the mw-tag have been assigned automatically, which means that each multiword unit is always analysed in the same way. No attempt has been made to manually disambiguate any possible variants.
4.4 Simplified word-class tags
Considerable time and effort has gone into the analysis and annotation of the BNC texts where part-of-speech is concerned. The process, including the reasoning for many of the decisions that had to be made, is described in detail in the Manual to accompany The British National Corpus (Version 2) with Improved Word-class Tagging (Leech & Smith 2000).
The BNC Basic tagset, known as the C5 tagset, contains 61 tags. There are tags for singular and plural nouns as well as for proper nouns and common nouns. The tagset contains several tags for different kinds of pronouns and prepositions, and there are 25 tags for verbs. The detailed information made available through the word-class tags offers an excellent tool for examining the corpus — it is possible to easily identify only reflexive pronouns, for example, or all instances of the past participle form of lexical verbs. However, it also means that certain tasks may become unnecessarily complicated. To find all pronouns, for example, the user has to look for four different tags (PNI, PNP, PNX, and PNQ for indefinite, personal, reflexive and wh-pronoun respectively). The advanced tagging was also felt to be confusing for less proficient users, such as younger learners or students with limited knowledge of linguistics. By introducing an additional tagset, it has been possible to include a simplified version of the wordclass tagging. The simplified POS-tagset used for the BNC only distinguishes between ten wordclasses (and one punctuation tag).
The simplified tags have been assigned solely on the basis of the C5 tags, and the mapping is illustrated in the table:
Table 3. Simple POS-tags and their corresponding C5 tags.
| POS value |
significance |
combines |
| ADJ |
adjective |
AJ0, AJC, AJS, CRD, DT0, ORD |
| ADV |
adverb |
AV0, AVP, AVQ, XX0 |
| ART |
article |
AT0 |
| CONJ |
conjunction |
CJC, CJS, CJT |
| INTERJ |
interjection |
ITJ |
| PREP |
preposition |
PRF, PRP, TO0 |
| PRON |
pronoun |
DPS, DTQ, EX0, PNI, PNP, PNQ, PNX |
| STOP |
punctuation |
POS, PUL, PUN, PUQ, PUR |
| SUBST |
substantive |
NN0, NN1, NN2, NP0, ONE, ZZ0, NN1-NP0, NP0-NN1 |
| UNC |
unclassified, uncertain, or non-lexical word |
UNC, AJ0-AV0, AV0-AJ0, AJ0-NN1, NN1-AJ0, AJ0-VVD, VVD-AJ0, AJ0-VVG, VVG-AJ0, AJ0-VVN, VVN-AJ0, AVP-PRP, PRP-AVP, AVQ-CJS, CJS-AVQ, CJS-PRP, PRP-CJS, CJT-DT0, DT0-CJT, CRD-PNI, PNI-CRD, NN1-VVB, VVB-NN1, NN1-VVG, VVG-NN1, NN2-VVZ, VVZ-NN2 |
| VERB |
verb |
VBB, VBD, VBG, VBI, VBN, VBZ, VDB, VDD, VDG, VDI, VDN, VDZ, VHB, VHD, VHG, VHI, VHN, VHZ, VM0, VVB, VVD, VVG, VVI, VVN, VVZ, VVD-VVN, VVN-VVD |
This means that it is now possible to query the corpus for 'any verb following any noun' (search for two simple tags) or to retrieve all instances of 'any adjective preceding a proper noun' (search for the simple adjective tag followed by the C5 tag for proper noun).
The following example illustrates the format of the simplified tag (for ease of reading, all other word-level annotation has been removed in this example):
<w pos="PREP">In </w>
<w pos="SUBST">spite </w>
<w pos="PREP">of </w>
<w pos="ADJ">this </w>
<w pos="PRON">nothing </w>
<w pos="ADJ">vital </w>
<w pos="VERB">is </w>
<w pos="ADJ">broken </w>
<w pos="PRON">I </w>
<w pos="VERB">hope </w> (BNC ANF 1612)
5. Bringing it all together
In the preceding sections, each instance of the mark-up has been dealt with in isolation. What happens when it is all brought together?
Even to an untrained eye, it is immediately obvious that the XML tagging hardly is simpler than the SGML one. Compare these two extracts — each from the same part of the corpus (A0A 1-3).
SGML
<head type=MAIN>
<s n=001>
<w NP0>CAMRA <w NN1>FACT <w NN1>SHEET
<w AT0>No <w CRD>1 </head>
<head r=it type=SUB>
<s n=002><w AVQ>How <w NN1>beer <w VBZ>is <w AJ0-VVN>brewed </head>
<p><s n=003><w NN1>Beer <w VVZ>seems <w DT0>such <w AT0>a <w AJ0>simple <w NN1>drink <w CJT>that <w PNP>we <w VVB>tend <w TO0>to <w VVI>take<w PNP>it <w CJS-PRP>for <w VVD-VVN>granted<c PUN>.
XML
<head type="MAIN">
<s n="1"><w c5="NP0" hw="camra" pos="SUBST">CAMRA </w><w c5="NN1" hw="fact" pos="SUBST">FACT </w><w c5="NN1" hw="sheet" pos="SUBST">SHEET </w><w c5="NN1" hw="no" pos="SUBST">No </w><w c5="CRD" hw="1" pos="ADJ">1</w></s></head><head rend="it" type="SUB">
<s n="2"><w c5="AVQ" hw="how" pos="ADV">How </w><w c5="NN1" hw="beer" pos="SUBST">beer </w><w c5="VBZ" hw="be" pos="VERB">is </w><w c5="VVN" hw="brew" pos="VERB">brewed</w></s></head><p>
<s n="3"><w c5="NN1" hw="beer" pos="SUBST">Beer </w><w c5="VVZ" hw="seem" pos="VERB">seems </w><w c5="DT0" hw="such" pos="ADJ">such </w><w c5="AT0" hw="a" pos="ART">a </w><w c5="AJ0" hw="simple" pos="ADJ">simple </w><w c5="NN1-VVB" hw="drink" pos="SUBST">drink </w><w c5="CJT" hw="that" pos="CONJ">that </w><w c5="PNP" hw="we" pos="PRON">we </w><w c5="VVB" hw="tend" pos="VERB">tend </w><w c5="TO0" hw="to" pos="PREP">to </w><w c5="VVI" hw="take" pos="VERB">take </w><w c5="PNP" hw="it" pos="PRON">it </w><w c5="PRP" hw="for" pos="PREP">for </w><w c5="VVN" hw="grant" pos="VERB">granted</w><c c5="PUN">.</c></s>
The new XML version is not only much longer but also, if possible, even more difficult to read with all the tags. Has it then been worth the effort to convert the corpus?
The answer is yes. The text as such may seem more difficult to tackle, but since it is in well-formed XML, help is at hand. By opening a text in a simple web browser (such as Mozilla Firefox or Internet Explorer), the layout is changed and the text is more easily readable. Try this link to see what the beginning of text A0A would look like. Note that the first part is the text metadata, followed further down by the actual text.
Displaying the elements one on each row (as in the web browser example above) helps to some degree, but reading a whole text like that is nevertheless daunting to most of us. It is, however, possible to easily change the way the text is displayed in the browser by using a style sheet, also called CSS (cascading style sheet). A style-sheet is a set of instructions detailing how different elements are to be displayed. Such instructions could not only define what tags to show and which to hide but also say that all sentences should be displayed beginning on a new line, that all verbs should be rendered in red and that anything spoken by a woman should appear in bold font, to mention but a few possibilities.
By adding a single line of code to the very beginning of a corpus text, the Web browser is instructed to display the text in a certain way, which is coded in a separate document (a number of such display option documents are distributed with the corpus). The examples below illustrate some different options:
6. Xaira
It was illustrated above how the texts can be read in an ordinary Web browser. Those who, for example, wish to find a particular phrase spoken by women or compare how a word is used in newspapers and academic prose, will probably find, though, that they need other tools, tools that can retrieve information from the headers (for example about text characteristics, speaker information, publication type, etc) while searching for words or phrases in the texts. Although the new edition of the corpus can be used with any XML-aware tool, it is still the case that the availability of tools suitable for use with large corpora in XML format is limited. The BNC XML is therefore distributed with such a tool. Xaira is based on the SARA program originally designed for use with the BNC. The program has been developed in response to feedback from the corpus linguistics community, and now offers improved performance and a range of new features. The new features will allow the user
-
to search on the part-of-speech tag without specifying a lexical item (for example, find 'any verb', 'all singular nouns', etc.)
-
to use an improved collocation feature (find patterns with any or unspecified lexical items, lemmas, and part-of-speech tags)
-
to display distribution of search term across different types of texts (graphically and numerically)
-
to restrict their search to a part of the corpus defined by existing or user-defined text categories (genre, written/spoken, year of publication, target audience, etc.)
Of course, it is only because the information is available in the corpus that the program can retrieve it. Xaira uses a complex set of indexes for its searches. If someone were to add more annotation to the corpus, or choose their own XML-tags, or if they wanted to search other corpora, they could still use Xaira assuming they index their texts first.
7. Summing up
The new edition of the BNC is in many respects not dissimilar to previous versions, and that is one of the advantages. The features that made the BNC useful for and used by so many are still present in BNC XML edition. Users still benefit from the careful design plan, the unique spoken component, the valuable part-of-speech annotation, and the detailed metadata, amongst other things. The conversion to XML has meant that the corpus is easier to exploit, not only with the Xaira tool but also by those using other tools and alternative approaches. The fact that the BNC now conforms to the standard increasingly used not only for text encoding and web publishing, means that it is more portable and more easily used in a number of contexts. The work on the corpus texts, to remove duplicates and improve the consistency of the mark-up is a further improvement. This is not to say that the corpus and its mark-up now is flawlessly perfect. Errors and inconsistencies still exist, in the texts as such (for example duplicated parts of texts), in the metadata (information missing about some aspects of a text), with regard to the linguistic information and doubtlessly in other areas as well. Work is under way to identify these and offering solutions to the problems they may cause. Making a corpus that is perfect in every respect, without any errors or inconsistencies and with no scope for improvement in any area may be a dream, but hardly one that will come true. This is not only due to lack of resources and funding but also because we are dealing with natural language which in its very nature is full of variation, inconsistencies, and deviations from the norms. With access to a large, carefully compiled corpus in a useful format, we can explore the language and learn more about its structure, variation and use.
Notes
[1] The technical work was performed by Tony Dodd and Lou Burnard, with assistance and advice from many BNC users and beta-testers worldwide.
Sources
The British National Corpus, version 3 (BNC XML Edition). 2007. Distributed by Oxford University Computing Services on behalf of the BNC Consortium. http://www.natcorp.ox.ac.uk/
- Aston, Guy & Lou Burnard. 1998. The BNC Handbook: Exploring the British National Corpus with SARA. (Edinburgh Textbooks in Empirical Kinguistics). Edinburgh: Edinburgh University Press.
- Burnard, Lou. 1995. Users Reference Guide for the British National Corpus Version 1.0. Oxford: British National Corpus Consortium, Oxford University Computing Services.
- Burnard, Lou. 2000. Reference Guide for the British National Corpus (World Edition). Humanities Computing Unit, Oxford University Computing Services. http://www.natcorp.ox.ac.uk/docs/URG/.
- Burnard, Lou. 2007. Reference Guide for the British National Corpus (XML Edition). British National Corpus Consortium, Research Technologies Service, Oxford University Computing Services. http://www.natcorp.ox.ac.uk/docs/URG/.
- Leech, Geoffrey & Nicholas Smith. 2000. Manual to Accompany The British National Corpus (Version 2) with Improved Word-class Tagging. UCREL, Lancaster University. http://www.natcorp.ox.ac.uk/docs/bnc2postag_manual.htm.
- Reference Guide for the British National Corpus (XML Edition), http://www.natcorp.ox.ac.uk/docs/URG/
- The design of the corpus, http://www.natcorp.ox.ac.uk/docs/URG/BNCdes.html
- The creation of the corpus, http://www.natcorp.ox.ac.uk/corpus/creating.xml
- Mark-up conventions, http://www.natcorp.ox.ac.uk/docs/URG/cdifbase.html#cdifsgml
- List of multiword units and their tags, http://www.natcorp.ox.ac.uk/docs/multiwd.htm
- C5 Tagset, http://www.natcorp.ox.ac.uk/docs/bnc2guide.htm#tagset
BNCweb. Developed by Hans Martin Lehmann, Sebastian Hoffmann and Peter Schneider at the University of Zurich. http://corpora.lancs.ac.uk/BNCweb//
The London-Lund Corpus of Spoken English. Greenbaum, Sidney & Jan Svartvik. http://clu.uni.no/icame/manuals/LONDLUND/INDEX.HTM.
SGML Aware Retrieval Application (SARA). Developed by Tony Dodd for the British National Corpus project. http://www.natcorp.ox.ac.uk/archive/sara/index.xml
Shogakukan Corpus Network. Japanese interface to the BNC. http://scnweb.jkn21.com/BNC2/
Text Encoding Initiative (TEI), http://www.tei-c.org/index.xml
UCREL University Centre for Computer Corpus Research on Language, Lancaster University, http://ucrel.lancs.ac.uk/
World Wide Web consortium, http://www.w3.org/
Xaira: XML Aware Indexing and Retrieval Architecture. Developed by Lou Burnard and Tony Dodd, Research Technologies Service, Oxford University Computing Services. http://projects.oucs.ox.ac.uk/xaira/
References
Burnage, Gavin & Dominic Dunlop. 1992. "Encoding the British National Corpus". English Language Corpora: Design, Analysis and Exploitation, ed. by Jan M. G. Aarts, 79-95. Amsterdam: Rodopi.
Burnard, Lou. 1995. "The Text Encoding Initiative". Spoken English on Computer: Transcription, Mark-up and Application, ed. by Geoffrey Leech, Greg Myers & Jenny Thomas, 69-81. Harlow: Longman Group Limited.
Burnard, Lou. 1999. "Using SGML for linguistic analysis: The case of the BNC". Markup Languages Theory and Practice 1: 31-51.
Burnard, Lou. 2002. "Where did we go wrong? A retrospective look at the British National Corpus". Teaching and Learning by Doing Corpus Analysis, ed. by Bernhard Kettemann & Georg Marko, 51-71. Amsterdam: Rodopi. Version available at http://users.ox.ac.uk/~lou/wip/silfitalk.html.
Clark, James. 1997. "Comparison of SGML and XML". World Wide Web Consortium Note 15-December-1997. https://www.w3.org/TR/NOTE-sgml-xml-971215/.
Connolly, Dan. 1995. "Overview of SGML resources". http://www.w3.org/MarkUp/SGML/.
Edwards, J. A. 1995. "Principles and alternative systems in the transcription, coding and mark-up of spoken discourse". Spoken English on Computer: Transcription, Mark-up and Application, ed. by Geoffrey Leech, Greg Myers & Jenny Thomas, 19-34. Harlow: Longman Group Limited.
Extensible Markup Language (XML). 2007. World Wide Web Consortium. http://www.w3.org/XML/.
Fligelstone, Steve, Mike Pacey & Paul Rayson. 1997. "How to generalize the task of annotation". Corpus Annotation: Linguistic Information from Computer Text Corpora, ed. by Roger Garside, Geoffrey Leech & Antony McEnery, 122-136. London: Longman.
Garside, Roger, Geoffrey Leech & Anthony McEnery. 1997. Corpus Annotation: Linguistic Information from Computer Text Corpora. London: Longman.
Lee, David Y. W. 2001. "Genres, registers, text types and styles: Clarifying the concepts and navigating a path through the BNC Jungle". Language Learning and Technology 5: 37-72. http://llt.msu.edu/vol5num3/lee/default.html.
Leech, Geoffrey, Roger Garside & Michael Bryant. 1994. "CLAWS4: The tagging of the British National Corpus". Proceedings of the 15th International Conference on Computational Linguistics (COLING 94). Kyoto, Japan, 622-628. http://ucrel.lancs.ac.uk/papers/coling.html.
Leech, Geoffrey. 1995. "A brief users' guide to the grammatical tagging of the British National Corpus". http://www.natcorp.ox.ac.uk/docs/gramtag.html.
Leech, Geoffrey. 1997. "Introducing corpus annotation". Corpus Annotation: Linguistic Information from Computer Text Corpora, ed. by Roger Garside, Geoffrey Leech & Anthony McEnery, 1-18. London: Longman.
Leech, Geoffrey. 2005. "Adding linguistic annotation". Developing Linguistic Corpora: A Guide to Good Practice, ed. by Martin Wynne, 17-29. Oxford: Oxbow Books. http://www.ahds.ac.uk/creating/guides/linguistic-corpora/index.htm.
Sperberg-McQueen, C. M. & Lou Burnard. 1994. Guidelines for Electronic Text Encoding and Interchange (TEI P3). Oxford, Virginia, Brown: Text Encoding Initiative.
Sperberg-McQueen, C. M. & Lou Burnard. 2007. TEI Guidelines, P5. Oxford, Virginia, Brown: Text Encoding Initiative. http://www.tei-c.org/Guidelines/P5/.
|
|
