Employing and elaborating annotation for the study of modality
Arja Nurmi, Research Unit for Variation, Contacts and Change in English, University of Helsinki
This paper discusses the possibilities and limitations of corpus annotation in recognising and further analysing complex linguistic features, using modality as an example. While linguistic annotation facilitates the retrieval of many different types of linguistic elements, the multifaceted nature of a feature like modality is still a hurdle in computer-assisted research. This leads in many cases to somewhat arbitrary limitations being placed on the studied expressions: only a predefined list of items is retrieved, for example, or merely a small selection of texts is used as data where instances are identified by reading.
A further obstacle in the study of modality is the difficulty of automatically assigning meaning-labels — however broad — on the instances retrieved. The more advances are made in the annotation-assisted retrieval of modal expressions in corpora, the more need for some level of semantic categorisation would seem to arise, since the manual assignation of semantic labels to thousands, if not tens of thousands, of examples is not practical.
I will begin by defining what I mean by modality in section 2, and continue with a discussion of retrieving expressions of modality with the help of existing annotation schemes, such as part-of-speech tagging, syntactic parsing and semantic labelling in section 3. Section 4 will focus on the elaboration of modal meaning, with a discussion of the applicability of existing semantic and pragmatic tagging in the process. Section 5 will provide the conclusions.
Any description of modality falls into two parts: firstly, an account of the various linguistic means of expressing modal meaning is needed; and secondly, the range of modal meaning needs to be depicted in all its variety. While modal auxiliaries are the most stereotypical instances of modality in English, there is in fact a much wider range of linguistic elements which can be regarded as expressing modal meaning. These are further described in section 2.1.
When it comes to modal meaning, it is most commonly analysed in such terms as epistemic and deontic. There are, however, not only more fine-grained models of description, but also other dimensions of modality. The ways of analysing modal meaning are discussed in section 2.2.
The definition of modality employed in this paper is the widest one possible, agreeing with, for example, Huddleston & Pullum (2002: 172). They define modality as a category of meaning which, in the verbal system, is grammaticalised by mood. In their usage mood comprises modal auxiliaries and the contrast between indicative and subjunctive. Expressions of modality are not limited to the verbal system, however. There are other linguistic means of expressing modal meaning. Facchinetti, Krug & Palmer (2003: vi), for example, list modal auxiliaries and lexical verbs, as well as nouns, adjectives, adverbs, idioms, particles, mood and prosody in speech.
Facchinetti et al. (2003) use the term "mood" to cover the remnants of the subjunctive in English, but not the modal auxiliaries. This illustrates well one of the difficulties of discussing modality: there is a lack of agreement on the scope and definition of the phenomenon. Since this paper aims to chart the principles for annotating modality, I find it useful to use as wide a definition as possible. Huddleston & Pullum's description is broad enough to form a good basis for such a discussion, although any annotation scheme would most usefully be informed by a wider range of research (for a further discussion of modality, see e.g. Perkins 1983). On the other hand, it would be impractical to go into too thorough a description of the phenomenon when discussing general principles rather than a detailed plan. All in all, a comprehensive description seems a desirable goal in realising modal annotation, since even if a large variety of expressions were labelled as modal by an annotation scheme, it would still be possible for researchers to limit their corpus searches to a subset.
In looking at individual expressions of modality, Huddleston & Pullum (2002: 173-175) give a list of various linguistic means. Modal auxiliaries are the traditional starting point, as they are the means by which Present-day English most clearly encodes modality (see example (1)).
(1)
It could be suggested that this is one determining factor in whether teachers are able to effect and sustain change. (BNC H88 1831)
Huddleston & Pullum apply the title lexical modals to items expressing meanings similar to those of the modal auxiliaries. These include much of the list in Facchinetti et al. (2003) quoted above: adjectives, verbs and nouns (see examples 2-4). Next to modal auxiliaries, this is probably the most frequently occurring group, both as a means of expressing modality and as an object of research.
(2)
It is possible to suggest that the two poets resemble one another. (BNC A05 723)
(3)
They are permitted no naturalistic embellishment, but given that choice the stylisation should be taken further. (BNC A4E 158)
(4)
And I do not give you permission to fling yourself at her feet, grab her hands and weep into her palms. (BNC A0L 3327)
Next on Huddleston & Pullum's list is past tense, where preterite (5) can express irrealis, and therefore can function as part of the field of modality. Verb inflection in other ways (or the lack of it) is listed separately, and the group includes the plain form (i.e. infinitive); see example (6).
(5) If you did that again you would be fired. (Huddleston & Pullum 2002: 174)
(6) He's the one to do the job. (Huddleston & Pullum 2002: 174)
Clause type is included as one possible expression of modality, since imperatives (7) function as directives (encoding deontic modality), while interrogatives (8) imply epistemic meanings.
(7) All that escapes from me is a pathetic plea, "Talk to me". (BNC BMF 1179)
(8) Are there any complications with shingles? (BNC A0J 991)
Huddleston & Pullum include under the heading of subordination instances such as I think he is ill and I know he is ill, which both have an epistemic marker as the main clause and the actual proposition in the subordinate clause. Finally, parentheticals are listed as a separate group, although they include what Huddleston & Pullum call 'lexical modals' (e.g. think), which often appear in combination with subordination as well.
While the above description is probably by no means exhaustive, it does give a good picture of the difficulty of identifying expressions of modality in corpora for the purposes of retrieval, particularly as some expressions are not merely lexical or syntactic. It should also be noted that, because research on modality has been so heavily focussed on modal auxiliaries, our descriptions of other linguistic means are lacking in detail.
In analysing the different meanings associated with them, the varying expressions of modality fall into fuzzy categories, with some instances being more prototypical and others merely borderline cases. The different dimensions of modality have been described in various ways, but for the sake of simplicity I am here, too, following Huddleston & Pullum (2002: 175-180). The three dimensions of modality they list are strength, kind and degree. In previous research these terms have been given various meanings, so that degree of modality, for example, has been used for what Huddleston & Pullum term strength (see e.g. Vihla 1999). Whatever a descriptive model ends up calling these dimensions, they do seem to be three aspects relevant for a discussion of modal meaning.
The three dimensions of modality are illustrated by Figure 1, which depicts the three-dimensional space envisaged by this model of description. Any given expression of modality will have a value on each of the three axes: kind (epistemic to deontic), strength and degree (the latter two both on a scale from weak to strong).
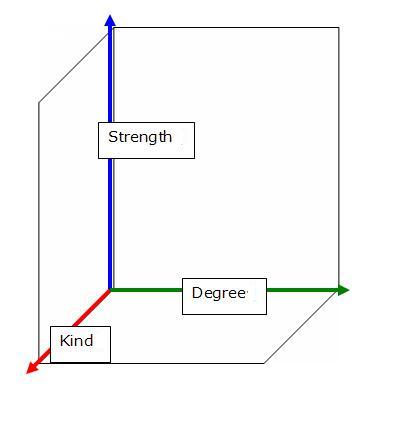
Figure 1. Dimensions of modality.
Under strength Huddleston & Pullum (2002: 175-177) group both the speaker's strength of commitment to the truth value of a proposition and the pragmatic strength of an utterance, where, for example, a semantically strong modal may be weakened in its context, becoming a polite offer. Their description allows for strong (9), medium (10) and weak (11) expressions of modality on this dimension.
(9) It must be some kind of joke. (BNC A3T 324)
(10) It should be somewhere near here. (BNC A0R 1742)
(11)
it may be some conscious or subconscious nutritional knowledge at work. (BNC CB8 474)
Kind of modality is the dimension much of previous research has focussed on. Therefore, it is also the area of modal research where differing descriptions abound. The two most frequently recognised categories are epistemic (12) and deontic (13) modality, although most researchers include the dynamic (14) category as well.
(12) You must be joking . (BNC ABX 3597)
(13) You may go now. (BNC FSJ 534)
(14) details are easily gained if you can speak and read French. (BNC ECG 550)
These categories are often subdivided further into, for example, possibility, inference and necessity for epistemic; volition, necessity, prediction and possibility for deontic; and ability, possibility, prediction, necessity and habit for dynamic (see e.g. Gotti et al. 2002). Furthermore, since much research on modality in English has focussed on modal auxiliaries, other classifications of modality, perhaps informed by cross-linguistic thinking, may be needed when looking at a wider range of modal expressions (see e.g. Nokkonen 2006). For a comprehensive discussion of kinds of modality see also e.g. Palmer (1979: 17-40), Coates (1983: 10-21) and Vihla (1999: 17-35).
The third dimension of modality described by Huddleston & Pullum (2002) is degree, where they discuss the problem of identifying modal meaning clearly. A modal element may be difficult to recognise because it does not necessarily change the meaning of an expression greatly, if at all. This is another example of the fuzziness of modal categories, with some instances being more prototypical, others falling on the outskirts of the group. Examples (15a) and (15b) are from Huddleston & Pullum, the first one unmodalised, the second expressing low degree modality.
(15a) She is one year old tomorrow. (Huddleston & Pullum 2002: 179)
(15b) She will be one year old tomorrow. (Huddleston & Pullum 2002: 179)
Like strength of modality, degree of modality can also be expressed on a scale from strong to weak.
Since modality is expressed through such varied means, it is no surprise that there is no general agreement on how to annotate it in a corpus, particularly as many scholars disagree on what exactly constitutes modality in the first place. Many linguistic items express modality only as one aspect of their range of meaning, and therefore a simple list of modal items is not helpful. For example, I think often appears in an epistemic function, as in (16). It can, however, also be used in a purely unmodal sense, referring to the cognitive act, as in (17).
(16) He is referring to his parents, I think. (BNC: A05 327)
(17)
When I think of the hours of weeding it saves, it appears nothing but beautiful to me. (BNC: A5N 93)
Any annotation of modality would need to be able to differentiate between these two uses of I think. Obviously, I think on its own without an object would more likely to be epistemic, while I think with the of-preposition phrase will probably more commonly express the unmodal meaning. However, not every case is this clear-cut, and a great deal of research would have to go into recognising patterns of usage in order to formulate them into rules for annotation software.
Despite these problems, existing annotation schemes can be used to recognise many more expressions of modality than are actually coded as such. In the following, I will suggest some applications of existing schemes for the retrieval of a variety of constructions.
3.1 Part-of-speech tagging
Modal auxiliaries are the most unambiguous category expressing modality, although even there the status of various semi-modals or marginal modals complicates the issue. Most POS-tagging systems have a separate tag for modal auxiliaries. Since modal auxiliaries are not inflected in any way, recognising them is easy based on a simple lexicon. On the other hand, such unvarying lexical items are easily retrieved from an unannotated corpus as well.
Different annotators have delineated the group of modal auxiliaries slightly differently. The British National Corpus (BNC) was annotated using CLAWS, and the tag VM0 was assigned to '[m]odal auxiliary verb (e.g. will, would, can, could, 'll, 'd )' (Leech & Smith 2000). Examples in the manual show that used to and let's (as one item) are also given the modal tag. Under the heading of 'Catenative or semi-auxiliary verbs' it also appears that while these verbs are not given a special tag as a category, some are tagged as modal auxiliaries (ought to in the example given in the manual).
On the other hand, expressions of modality that are recognised in many descriptions of English (see e.g. Huddleston & Pullum 2002: 206; Quirk et al. 1985: 137), such as be to in example (18) are tagged as regular verbs and therefore can not be retrieved with the help of tags.
(18) The money is_VBZ to_TO0 go in a penalty box kept by Grandmother; (BNC B10 1892)
This state of affairs is by no means peculiar to the BNC alone, but is rather consistent all through different annotation schemes.
When looking for ways to retrieve some other expressions of modality with the help of POS-tagging, various tag sets are at times helpful. Imperatives, for example, are in some cases indicated with a specific tag or group of tags. This goes, for example, for some historical corpora of English, such as the PCEEC, PPCEME and PPCME. Note that here in addition to the tag for verbs in the imperative (19), BE, DO and have have their individual imperative tags (20-22).
(19)
Seke_VBI not_NEG the_D name_N without_P the_D thing_N ,_. (PCEEC Wyatt: Thomas Wyatt 1537, 42) [1]
(20)
be_BEI moderat_ADJ in_P atinge_VAG peie_N crust_N (PCEEC PastonK: Katherine Paston 1578, 89)
(21)
I_PRO say_VBP '_' doe_DOI it_PRO or_CONJ do_DOI it_PRO not_NEG '_' ,_, or_CONJ what_WPRO ever_ADV else_ADJ you_PRO think_VBP fitt_ADJ ;_. (PCEEC Petty: William Petty 1677, 42)
(22)
Good_ADJ cosen_N have_HVI me_PRO hartely_ADV commendid_VAN to_P my_PRO$ good_ADJ cosen_N Wyndam_NPR (PCEEC Bacon: Jane Tuttoft 1580, II,125)
Depending on the tag sets used in annotating individual corpora, it may be possible to retrieve, or facilitate the retrieval of even more modal expressions with the help of POS-tagging. So, for example in the case of I think mentioned above, it would be possible to look for instances of I think that are not followed by a preposition, with the expectation that this would rule out its use as a private verb and leave in the epistemic usage. With the help of parsed corpora this process would, of course, be even more reliable (see section 3.2). However, as much help as POS-tagging can provide in the identification of modal items, there are still a great many expressions not retrievable with the help of this means, and the particular complementation patterns of individual items would have to be known more clearly before attempting the retrieval of items similar to I think, for example.
3.2. Parsing
Parsed corpora bring some added value to POS-tagged corpora in the search for modality. Identifying and retrieving modal auxiliaries is in no way different, although parsing does open avenues for the further classification and analysis of examples (see Section 4).
In the case of clause types and subordination, parsed corpora can be used to identify interrogatives, as well as subordination, although in the latter case a great deal of work will still be needed to weed out the relevant examples. Figure 2 shows how interrogatives appear in the Fuzzy Tree Fragments in the mark-up of ICE-GB. In the blue box on the top left, the defining features of the analysed parsing unit are listed: main clause, interrogative, intransitive, present tense.
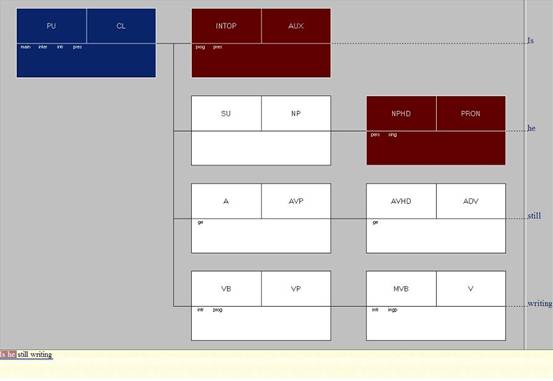
Figure 2. Interrogative structure in ICE-GB.
Similarly, the parsed historical corpora of English allow for searching questions with the help of word order information, i.e. looking for subjects following their verbs.
(23)
((CP-QUE ( META (NP (CODE <font>) (NPR D. ) (NPR Rat) (CODE </font>)))
(IP-SUB (BEP Is)
(NP-SBJ (PRO he))
(ADJP (ADJ worthy)
(NP (Q any) (ADJR better)))
(, ,)
(NP-VOC (N sir)))) (ID STEVENSO-E1-H,66.490))
((CP-QUE (WADVP-1 (WADV how))
(IP-SUB (ADVP *T*-1)
(DOP do)
(NP-SBJ (PRO ye))
(VB (VB iudge) (CONJ and) (VB deame)))
(. ?)) (ID STEVENSO-E1-H,66.491))
(PPCEME E1 COMEDY STEVENSON 66) [2]
Depending on the annotation scheme, more ways for retrieving expressions of modality from parsed corpora could be conceived. Most of them are likely to produce a high degree of false hits along with the desired instances, but even this may in some cases be preferable to sifting through large collections of data without the means of ruling out at least some of the garbage. In the process of charting out the limits of modality, trying to identify the particularities of modal expressions as opposed to those not expressing modality, a degree of false positives would most likely be even helpful in the initial stages of research, as an aid for recognising typical patterns for modality.
3.3. Semantic annotation
The existing semantic tag sets seem to concentrate largely on lexical words and their meanings (see e.g. Segond et al 1997), although the approaches to tagging e.g. temporal expressions (see e.g. Schilder & Habel 2001) can be seen as more complex adaptations of this. Applying semantic tags to a wholly different kind of semantic phenomenon such as modality would require some reworking and rethinking of existing methods, since the process would start from a very different set of priorities. There are basic principles, however, which could be adapted to an annotation of modality.
There are also tag sets which take some account of modality. The USAS category system (Archer, Wilson & Rayson 2002) has modals mentioned among its semantic fields, but the analysis is not detailed. The description of category A7 is quite general:
A7 Definite (+ modals)
Abstract terms of modality (possibility, necessity, certainty, etc.)
PROTOTYPICAL EXAMPLES: ACHIEVABLE (+), ARGUABLE (-), CAN (+), CERTAINTY (+), CIRCUMSTANTIAL (-), CONCEIVABLE, CONVINCE, CONCLUSIVE (+++), CONTENTIOUS (-), DEFINITE (+++)
DON'T STAND AN EARTHLY (---), BY ALL MEANS (+), DITHER ABOUT (-),
GOOD CHANCE (+++), GREY AREA (-), HIT AND MISS (-), IN LIMBO (-),
MADE CERTAIN (+), MAY AS WELL (+), NO UNCERTAIN TERMS (+)
(Archer, Wilson & Rayson 2002: 6)
While this USAS category refers to expressing shades of epistemic modality, none of the examples is unambiguously deontic, and some (such as contentious) could be categorised as stance adverbials rather than epistemic modals. [3] In addition, other USAS categories appear to catch some shades of modal meaning, such as A8 (Seem/appear), which seems to include some epistemic expressions as well. Deontic modality is found in, for example, categories S6 (Obligation and necessity) and S7 (Power relationship, with subcategories such as S7.4 Permission). S6 does not overtly mention modality in its description, but has must and ought as prototypical examples, and S7 includes lexical modals such as allow and authorized. Furthermore, T1.1.3 (Time: General: Future) lists will as prototypical. There may well be other categories suited for catching modal expressions, but, as the above description shows, the categorisation has not been designed with research on such complex categories in mind.
With the help of USAS tagging it would certainly be possible to retrieve a great many lexical expressions of modality from an annotated corpus, and the scheme has some built-in options suitable for elaborating the description of any given instance (see section 4). Unfortunately, for the moment the availability of semantically annotated corpora is still quite limited.
The preceding examples show that, while there is no consistent means of retrieving expressions of modality from corpora with the help of existing annotation schemes, there are many ways in which various levels of linguistic annotation can be of use in tracing the trails of modal expressions. While, for example, prosodic annotation was not discussed here, it could be used to retrieve questions through intonation patterns.
Identifying and retrieving varying expressions of modality is an enormous enough task in itself, but a further requirement for a useful annotation of modality would be the elaboration on the modal meaning of each expression. This elaboration should ideally take place on all the three dimensions of strength, kind and degree described in section 2.2. Assigning values to individual instances on all these levels is likely to be quite problematic, however.
For instance, the classification of the kinds of modality into deontic, epistemic and possibly dynamic is not necessarily an exercise in assigning a value on a linear scale. These types of modality can perhaps more fruitfully be regarded as overlapping fields, with ambiguous border-line cases (see e.g. Coates 1983). It can also be argued that existing descriptions of modality are too reliant on the meanings of modal auxiliaries, and that a wider perspective, possibly cross-linguistically aware, would be useful in creating an annotation scheme for modality. A further obstacle is the necessity of annotating many different levels of language from individual words to clause and sentence types.
When pondering the existing schemes of annotation, the USAS, in addition to assigning epistemic and deontic modality to different categories, seems to have elements suited for further elaborating the different strengths of modality. If we take a closer look at USAS category A7, we can see that some range of elaboration already exists. Items classified as belonging to category A7 receive a tag noting this membership: A for 'General and abstract terms', 7 for the subcategory 'Definite (+ modals)'. The items included are optionally further analysed on a scale of plus and minus symbols 'to indicate a positive or negative position on a semantic scale' (Archer, Wilson & Rayson 2002). Thus in the entry repeated below degrees of certainty receive one or more plus signs while degrees of uncertainty receive one or more minus signs:
A7 Definite (+ modals)
Abstract terms of modality (possibility, necessity, certainty, etc.)
PROTOTYPICAL EXAMPLES: ACHIEVABLE (+), ARGUABLE (-), CAN (+), CERTAINTY (+), CIRCUMSTANTIAL (-), CONCEIVABLE, CONVINCE, CONCLUSIVE (+++), CONTENTIOUS (-), DEFINITE (+++)
DON'T STAND AN EARTHLY (---), BY ALL MEANS (+), DITHER ABOUT (-),
GOOD CHANCE (+++), GREY AREA (-), HIT AND MISS (-), IN LIMBO (-),
MADE CERTAIN (+), MAY AS WELL (+), NO UNCERTAIN TERMS (+)
(Archer, Wilson & Rayson 2002: 6)
This assignation of positions on the semantic scale seems to be related to the strength of modality but, as it exists, does not seem to relate directly to this dimension as described in this paper. In category S6, for example, must, which is usually regarded as one of the strongest modal expressions, only receives one plus sign.
Another take on the scalarity of epistemic modality is presented by non-linguists in the National Security Estimate summary (reproduced by the New York Times; see also commentary in Language Log), giving a seven-step range of certainty from 'remote' to 'almost certain', and including the middle value of 'even chance'. Developing an annotation scheme along this model seems quite feasible, since the meaning of each step is clearly explained.
One possibility of developing a scalar model for the strength of deontic modality would be making use of the type of pragmatic annotation implemented in the Sociopragmatic Corpus. [4] This model could make use of speaker and hearer roles, and the concomitant power relationships, for example, to estimate the strength of obligation in any given exchange. After all, modality is clearly linked to speaker relationships and issues of power and solidarity.
A corpus annotated with speaker/writer and interlocutor/recipient/audience coding, would probably allow for some automatic assignation of the strength of deontic modality. It is quite likely, after all, that the stronger expressions of modality would be found in situations where the speaker/writer is in a position of authority with regard to the hearer/recipient/audience, while a more equal relationship would most likely give rise to a different range of expressions (see Nurmi & Palander-Collin forthcoming, for some results on the use of modal auxiliaries in eighteenth-century correspondence).
The difficulty of automatically annotating different genres of text with this type of fine-grained information should of course be recognised. It may well be that this particular model would only be useful in the case of direct two-party communication, such as dialogues or correspondence (see also Palander-Collin, this volume). But a socio-pragmatic annotation would probably form a useful basis for creating a scale of strength for deontic modality, and would probably also be useful in training a modal tagger for other materials.
There are also other methods which would be useful in recognising the different positions of modals on the dimensions of kind and strength. Corpus-based descriptions, such as Coates (1983) and Nokkonen (2006), provide much information on the co-occurrence of, for example, particular subject and main verb types as well as intonation patterns with specific meanings and strengths of particular modal expressions. While most work has been carried out, once again, with modal auxiliaries, some tendencies could probably be generalised to lexical modals as well.
The degree of modality seems to be the dimension where there is no detailed research available. Yet, if as wide a range of modal expressions as possible were to be annotated, it would be useful to be able to sort examples on this dimension as well. It should also be noted that degree of modality is not necessarily relevant only for the less studied modal items, but is in fact a central aspect of the most common modal auxiliary in English, will, with its range of meaning from 'pure future' (usually only weakly modal) to fairly strongly deontic. How this dimension should be defined in terms of annotation, or how existing linguistic annotation schemes could be adapted to assist in the process is the subject of some further study.
The ideal annotation scheme for modality would contain the possibility of combining the three dimensions of kind, strength and degree of modality, and allowing several values for each dimension, as well as a possibility for ambiguity tagging. One way of approaching this dilemma would be the path of scalar annotation (see e.g. Meurman-Solin, this volume). The varying descriptions of modal meanings, with dimensions differently defined and weighted, would seem to benefit from a scalar approach to annotation, with more detailed levels available to researchers wishing to avail themselves of such.
In practice, this could mean that fairly broad categories of, for example, kind of modality would be applied, and these would be further detailed on the next level of the annotation scheme. There could be a top-level category for epistemic, with lower level categories such as possibility, inference and necessity available if required. There might also be double membership of categories for instances which are not easily definable in terms of any one category. In the case of will, for example, the sense of futurity is most often present, even if some other meaning is more evident.
This paper has discussed some of the problems associated with the annotation of modality. The problems can be seen existing on two separate levels. On the one hand, annotation capable of assisting in the retrieval of modal expressions other than modal auxiliaries is badly needed for any large-scale study of modality. On the other hand, semantic annotation elaborating on the different semantic dimensions of the kind, strength and degree of modality would be of great assistance in further analysing any large amounts of data most likely produced through more efficient and wide-ranging retrieval methods. Scalar thinking would seem to be a prerequisite of a successful annotation scheme.
The requirements of an annotation scheme assisting in the identification and analysis of modal expressions are such that no short-term realisation can be envisaged, but this does not prevent us from taking better advantage of existing schemes in modality research. The problems of a semantic category expressed through a wide range of linguistic means are different from those encountered by earlier annotation systems, but the work carried out in creating them makes a solid basis for further elaborations.
The research reported here was funded by the Academy of Finland.
[1] In references to the Parsed Corpus of Early English Correspondence (PCEEC), the name of the letter collection, name of the writer, year of writing and page number in the letter collection are given. For a list of collections see e.g. Nurmi 1999, Palander-Collin 1999, Nevalainen & Raumolin-Brunberg 2003 or Nevala 2004.
[2] In references to the Penn-Helsinki Parsed Corpus of Early Modern English (PPCEME) the period of the Helsinki Corpus, the text type category, the text identifier and page number of the edition are given. For details on any text, see Kytö (comp.) 1996.
[3] I am using Biber et al.'s (1999) descriptions of adverbial meaning, and the division into circumstance, stance and linking adverbials.
[4] See also Palander-Collin (this volume) for a discussion of the Sociopragmatic Corpus.
British National Corpus (BNC). http://www.natcorp.ox.ac.uk/
Helsinki Corpus (HC). http://www.helsinki.fi/varieng/CoRD/corpora/HelsinkiCorpus/
International Corpus of English (ICE-GB). http://www.ucl.ac.uk/english-usage/projects/ice-gb/ Parsed Corpus of Early English Correspondence (PCEEC) 2006. Annotated by Ann Taylor, Arja Nurmi, Anthony Warner, Susan Pintzuk, and Terttu Nevalainen. Compiled by Terttu Nevalainen, Helena Raumolin-Brunberg, Jukka Keränen, Minna Nevala, Arja Nurmi and Minna Palander-Collin. York: University of York and Helsinki: University of Helsinki. Distributed through the Oxford Text Archive.
http://www-users.york.ac.uk/~lang22/PCEEC-manual/corpus_description/
Penn-Helsinki Parsed Corpus of Middle English (PPCEME). Kroch, Anthony, Beatrice Santorini, and Lauren Delfs. 2004. https://www.ling.upenn.edu/hist-corpora/PPCEME-RELEASE-3/index.html
Penn-Helsinki Parsed Corpus of Middle English, second edition (PPCME-2). Kroch, Anthony, and Ann Taylor. 2000. https://www.ling.upenn.edu/hist-corpora/PPCME2-RELEASE-4/index.html
University Centre for Computer Corpus Research on Language, http://ucrel.lancs.ac.uk/
• CLAWS part-of-speech tagger. http://ucrel.lancs.ac.uk/claws/
• UCREL Semantic Analysis System (USAS). http://ucrel.lancs.ac.uk/usas/
Archer, Dawn & Jonathan Culpeper. 2003. "Sociopragmatic annotation: New directions and possibilities in historical corpus linguistics". Corpus Linguistics by the Lune: A Festschrift for Geoffrey Leech, ed. by Geoffrey N. Leech, Paul Rayson, Anthony McEnery & Andrew Wilson, 37-58. Frankfurt am Main: Peter Lang.
Archer, Dawn, Andrew Wilson & Paul Rayson. 2002. "Introduction to the USAS category system". http://ucrel.lancs.ac.uk/usas/usas%20guide.pdf
Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad & Edward Finegan (1999). Longman Grammar of Spoken and Written English. London: Longman.
Coates, Jennifer. 1983. The Semantics of the Modal Auxiliaries. London: Croom Helm.
Facchinetti, Roberta, Manfred Krug & Frank Palmer (eds.). 2003. Modality in Contemporary English. (Topics in English Linguistics 44). Berlin & New York: Mouton de Gruyter.
Gotti, Maurizio, Marina Dossena, Richard Dury, Roberta Facchinetti & Maria Lima. 2002. Variation in Central Modals. A Repertoire of Forms and Types of Usage in Middle English and Early Modern English. (Linguistic Insights, Studies in Language and Communication 4). Bern: Peter Lang.
Huddleston, Rodney & Geoffrey K. Pullum. 2002. The Cambridge Grammar of the English Language. Cambridge: Cambridge University Press.
Kytö, Merja (comp.). 1996. Manual to the Diachronic Part of the Helsinki Corpus of English Texts: Coding Conventions and Lists of Source Texts, 3rd edition. Department of English, University of Helsinki. http://clu.uni.no/icame/manuals/
Leech, Geoffrey & Nicholas Smith. 2000. BNC2 POS-tagging Manual. Guidelines to Wordclass Tagging. http://www.natcorp.ox.ac.uk/docs/bnc2guide.htm
Meurman-Solin, Anneli. 2007. "Annotating variational space over time" . Annotating Variation and Change, ed. by Anneli Meurman-Solin & Arja Nurmi. (Studies in Variation, Contacts and Change in English 1). Helsinki: VARIENG. http://www.helsinki.fi/varieng/series/volumes/01/meurman-solin/
Mindt, Dieter. 1995. An Empirical Grammar of the English Verb. Modal Verbs. Berlin: Cornelsen.
National Security Estimate. 2007. "Iran: Nuclear intentions and capabilities". National Intelligence Council. Published by the New York Times at http://graphics8.nytimes.com/packages/pdf/international/20071203_release.pdf. Accessed 4 December 2007.
Nevala, Minna. 2004. Address in Early English Correspondence. Its Forms and Socio-pragmatic Functions . (Mémoires de la Société Néophilologique de Helsinki 64). Helsinki: Société Néophilologique.
Nevalainen, Terttu & Helena Raumolin-Brunberg. 2003. Historical Sociolinguistics. London: Longman.
Nokkonen, Soili. 2006. "The semantic variation of NEED TO in four recent British English corpora". International Journal of Corpus Linguistics 11(1): 29-71.
Nurmi, Arja. 1999. A Social History of Periphrastic DO. (Mémoires de la Société Néophilologique de Helsinki 56). Helsinki: Société Néophilologique.
Nurmi, Arja. 2003. "The role of gender in the use of must in Early Modern English". Extending the Scope of Corpus-based Research: New Applications, New Challenges, ed. by Sylviane Granger & Stephanie Petch-Tyson, 111-120. (Language and Computers: Studies in Practical Linguistics 48). Amsterdam & Atlanta: Rodopi.
Nurmi, Arja & Minna Palander-Collin. forthcoming. "Letters as a text type: Interaction in writing". Paper presented at a workshop 'Towards a handbook on Late Modern English letter writing' organized at the ICEHL-14, Bergamo, Italy 21.-25.8.2006.
Palander-Collin, Minna. 1999. Grammaticalization and Social Embedding: I THINK and METHINKS in Middle and Early Modern English. (Mémoires de la Société Néophilologique 55.) Helsinki: Société Néophilologique.
Palander-Collin, Minna. 2007. "What kind of corpus annotation is needed in sociopragmatic research?" Annotating Variation and Change, ed. by Anneli Meurman-Solin & Arja Nurmi. (Studies in Variation, Contacts and Change in English 1). Helsinki: VARIENG. http://www.helsinki.fi/varieng/series/volumes/01/palander-collin/
Palmer, F. R. 1979. Modality and the English Modals. (Longman Linguistics Library). London & New York: Longman.
Partee, Barbara. 2007. "Modal semantics in National Intelligence Estimate". Language Log December 4 2007. http://itre.cis.upenn.edu/~myl/languagelog/archives/005179.html
Perkins, Michael R. 1983. Modal Expressions in English. London: Frances Pinter.
Quirk, Randolph, Sidney Greenbaum, Geoffrey Leech & Jan Svartvik. 1985. A Comprehensive Grammar of the English Language. London & New York: Longman.
Segond, Frédérique, Anne Schiller, Gregory Grefenstette & Jean-Pierre Chanod. 1997. "An experiment in semantic tagging using Hidden Markov Model tagging". Proceedings of the Workshop on Automatic Information Extraction and Building of Lexical Semantic Resources (ACL/EACL 1997) , 78-81. http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=1790F95DE27D134297A7071675AFD0D8?doi=10.1.1.11.5155&rep=rep1&type=pdf
Schilder, Frank & Christopher Habel. 2001. "From temporal expressions to temporal information: Semantic tagging of news messages". Annual Meeting of the ACL: Proceedings of the workshop on Temporal and spatial information processing 13: 1-8.
Vihla, Minna. 1999. Medical Writing. Modality in Focus. (Language and Computers: Studies in Practical Linguistics 28). Amsterdam: Rodopi. |
