Sampling and annotation in the Middle English Grammar Project
Merja Stenroos (see publications), Department of Cultural Studies and Languages, University of Stavanger
The Middle English Grammar Project [1] is a research initiative that aims to produce a new descriptive account of the Middle English language (1100-1500), based on a corpus of localized texts. In the first instance, the focus will be on the 'transmission level', that is, orthography and phonology. The second phase will involve morphology.
No large-scale, authoritative reference grammar of Middle English has appeared since Jordan's Handbuch of 1929; this work, which deals with phonology only, was in itself the first volume of a projected larger work. Moreover, the field of Middle English language studies has changed irrevocably with the methodological insights published since the 1950s by the co-workers of the Linguistic Atlas of Late Mediaeval English (McIntosh, Samuels & Benskin 1986; henceforth LALME). These insights, of course, formed part of much larger developments within linguistics, with the rise of text- and use-based approaches as well as the concept of variability as a natural characteristic of language. With the arrival of easily accessible computer technology, making possible the systematic study of large amounts of data, including text corpora, the task facing a grammarian of Middle English has changed out of recognition. A new attempt at producing a reference grammar, taking into account these developments, is thus in order.
LALME itself contains a vast amount of linguistic data, collected from more than a thousand texts from the period 1300-1500 by means of a dialect questionnaire. The main purpose of the data collection was to build up a dialectal typology of texts, making possible their geographical localization relative to each other; in addition, the data provided material for a large number of dialect maps, giving a much more detailed picture of Middle English dialectal variation than had earlier been conceivable. The method is based on the insight that medieval scribes, when copying texts, often tended to translate them into their own preferred written forms. Such translation seems to be most consistent and predictable at the levels of orthography and morphology, making these levels of language the main focus of LALME.
The LALME data are designed to provide a view of regional dialectal variation, in the first instance for diagnostic and typological purposes. They were not in themselves intended to form a basis for a complete descriptive account of Middle English, even though they provide a very large amount of material towards such a task. In order to cover (at least in principle) the full range of features, the account will need to be based on a text corpus. This corpus should contain a very large number of texts in order to represent well the complex dialectal diversity of Middle English, and it should include information about extralinguistic factors such as date and localization.
The first task of the Middle English Grammar team is to produce such a corpus. The natural starting point for this is the framework of more than a thousand texts that were localized in LALME. A simple text corpus containing 3,000-word samples from all or most of these texts is the first practical goal of the project. A first version of this corpus (called MEG-C, or The Middle English Grammar Corpus), containing ca. 30% of the texts, will be released to the public by the end of 2007.
Secondly, the texts contained in the corpus need to be subjected to some form of lemmatization, linking the forms to headwords. The linguistic forms should also be linked to various kinds of contextual and text-specific information. This will make possible very powerful searches, relating variation pertaining to specific linguistic features to a range of variables such as genre, date and script, as well as to other linguistic features, contextual variables such as rhyme or word-initial position, and the like.
During the first phase of the project, the main task is thus to collect and organise a large amount of data, and, as a bonus, produce a corpus that will, it is hoped, be of use for other scholars as well. It is planned that the results of an initial analysis of the data will be published as three regional dialect surveys of Middle English, covering the Western, Northern and Eastern [2] areas respectively. These surveys will then form the basic source material for a reference grammar of Middle English.
The present paper describes the annotation of the corpus and discusses the choices made, both from the point of view of the aims and resources of the project and considering the wider application of the material. The annotation work is still in an early phase, and this paper cannot present ready results. Rather, it is meant to demonstrate the various choices involved in turning a large body of material into an annotated corpus, balancing research aims, available resources and scientific validity, with the specific aim to produce a Middle English Grammar.
The texts localized in LALME provide an excellent starting point for the enquiry, as they can be related to the geographical map. However, it should be admitted from the outset that they do not form a representative sample of all surviving Late Middle English texts, which also include a large number of texts in non-localizable language varieties, be they standardised, colourless or geographically mixed (for the concept of 'colourless language', cf. Samuels 1981 [1988: 86]). At a later stage they will need to be supplemented by other texts.
The main chronological scope of LALME is from the mid-fourteenth to the mid-fifteenth century, even though it includes a small number of earlier and later texts. The earlier period will be covered by the Linguistic Atlas of Early Middle English (= LAEME; Laing and Lass, under preparation), which will include a large annotated corpus as well as localizations and maps. Together, the two Atlases cover a period of 400 years (ca 1100-1500); this will eventually be the chronological scope of the present project.
Of the texts localized in LALME, those localized in Scotland are excluded from the present project, making the geographical scope England and Wales. The Scottish materials are not easily analysed as part of the continuum of medieval English dialects, and it is felt that a comprehensive description of medieval Scots should wait until the completion of the Linguistic Atlas of Older Scots (Williamson, under preparation).
The next question concerns the method of data collection. One option would have been to use a questionnaire supplementary to the LALME one, filling in the gaps in order to produce complete paradigms. Such an option would, however, have been unsatisfactory for at least three reasons. Firstly, there would inescapably have been problems of compatibility between the two sets of data. Secondly, we would still have been limited to a pre-defined set of linguistic features, with no way of supplementing the set other than a new round with another questionnaire. Thirdly, if new data had to be collected, it was felt highly desirable that it should be quantifiable; while manual counting is surely less cumbersome than it is sometimes made out to be, it nevertheless takes time and tends to introduce inaccuracies. A machine-readable corpus was clearly the answer.
Some years earlier, LAEME had also opted for a machine-readable corpus rather than a questionnaire approach. For this purpose, texts have been transcribed and tagged in their entirety or in large representative portions. This will provide nearly complete coverage of the localizable materials from this period, and clearly represents the ideal option: as complete a coverage as possible of as much material as possible. Such an approach did not seem necessary for the much more copious Late Middle English materials, at least with regard to the goals of our own project.
More than a thousand texts [3] are localized in LALME. These texts range in size from very short documents of around a hundred words to literary texts the size of a substantial novel. Transcribing and annotating the entire material would be a very large undertaking indeed. There is, however, no reason why such full coverage should be required for an overall description of Middle English. As the texts have already been analysed for internal consistency and localisation in LALME and/or LAEME, it should be perfectly feasible, for the present purpose, to base the description on a survey of representative samples, supplemented by a series of full-scale questionnaire-based studies of individual texts.
The size of the samples must naturally reflect the purpose for which they will be used. A survey of syntax would require much larger samples than a study of orthography, as the features studied involve larger structures and occur less densely. Most individual items of vocabulary also have a low density of occurrence, and thus most kinds of lexical study would require large samples. McIntosh (1973: 93) suggested that samples of 10,000 words would suffice for a study of Middle English word geography; the corpus he envisaged would have been based on samples of 500 texts, or approximately half the LALME material, making up ca. 4.5 million words overall.
However, the LALME localizations are not the best starting point anyway when it comes to syntactic and lexical studies: the translating scribe, upon which the LALME methodology is largely based, is assumed to be less likely to translate syntactic structures than spellings or morphemes, and scribal behaviour with regard to vocabulary is largely unpredictable (Benskin & Laing 1981: 94). Thus, the levels of language for which the present methodology is best suited are morphology, orthography and (indirectly) phonology. Most of the features to be studied — spellings, affixes, inflexions and closed-class words — occur fairly frequently and can be studied on the basis of relatively small samples.
The sample size for the Middle English Grammar Project Corpus has been defined as 3,000 words. This size has been felt to be the optimal one for balancing two crucial requirements: a) to be manageable in terms of resources and time and b) to produce sufficient attestations of a sufficient number of features.
In our experience, a 3,000-word sample takes 2-8 hours to transcribe, depending on the difficulty of the text and the proficiency, temperament and/or working methods of the transcriber. In addition, it will need to be proofread, checked against the manuscript and eventually entered onto a database. For a small research team, getting through the complete transcription process for a thousand texts is certainly the work of several years. Making the samples larger would entail either adding years to the overall project schedule or reducing the number of texts included.
The latter option has been considered by the project team. We have been using subcorpora of 15-300 texts for pilot studies of specific features (e.g. Smith 2000; Stenroos 2005, 2006). In Stenroos (2006), the present writer compiled a subcorpus of 164 texts, aiming at an approximately proportionate representation of the county and date distribution in LALME, for an orthographic study. This study involved highly frequent features (the letters thorn and yogh and their substitution sets in what might be called their prototypical functions) that were attested in all texts surveyed and plentiful in most of them. Still, the small number of texts severely restricted the validity of complex searches: for certain categories, the number of texts was simply too small for the results to have much significance.
As we wish to carry out searches involving several variables, a large total number of texts will be desirable. Naturally, the LALME corpus in itself does not constitute the kind of balanced sample possible in contemporary surveys, nor can such a sample be obtained from medieval materials: for some categories, there will simply be few texts available. Still, the LALME corpus does provide a fairly good spread with regard to most of the variables we are interested in, as may be seen from the provisional figures given in Table 1.
Table 1. The distribution of texts in relation to some key extralinguistic variables. The figures are based on a provisional classification that still needs much revision. Not all texts have yet been classified for each variable, and thus the total figures vary.
Genre: |
Document |
268 |
Religious prose |
249 |
Religious verse |
222 |
Secular verse |
126 |
Medica and treatises |
83 |
Secular narrative prose |
36 |
Letters |
27 |
Drama |
7 |
TOTAL |
1,018 |
Date (by half-century): |
13th century, second half |
19 |
14th century, first half |
34 |
14th century, second half |
79 |
15th century, first half |
442 |
15th century, second half |
228 |
16th century, first half |
13 |
TOTAL |
815 |
Region: |
East |
424 |
West |
369 |
North |
241 |
TOTAL |
1,034 |
Script: |
Anglicana |
227 |
Textura |
36 |
Secretary |
35 |
TOTAL |
298 |
The greatest discrepancies with regard to the distribution of texts are found in the Date category: the number of localizable texts surviving from the different half-centuries is very variable for historical reasons, something that cannot be helped. For the other categories, the spread is on the whole satisfactory: while some genres (such as drama) can only be badly represented, there are several large categories that allow for useful comparisons.
The pilot studies carried out so far suggest that the 3,000-word samples produce plentiful data for the study of a very wide range of features. Table 2 lists the attestations for fifteen linguistic features in a single text, consisting of poems by William Herebert (London, BL Add. 46919; LP 7410 in LALME). This text was chosen as an example because it is one of the few 3,000-word texts that has so far been annotated by the present writer. The total word count is 3,093.
Table 2. Attestations of fifteen linguistic features in a 3,000-word text (L7410; Poems of William Herebert, London, BL Add. 46919).
|
Feature |
No of attestations |
Attested forms |
1 |
PDE sh- |
45 |
45 sh |
2 |
PDE wh- |
51 |
51 wh |
3 |
PDE h- |
191 |
191 h- |
4 |
PDE ght |
82 |
60 ht, 14 th, 4 t, 3 tht, 1 3th |
5 |
OE eo: |
82 |
65 oe, 7 e, 6 y, 4 eo |
6 |
PDE f- |
57 |
26 v-, 21 u-, 10 f- |
7 |
PDE be- |
14 |
11 by, 3 bi |
8 |
PDE -ly |
15 |
4 lich, 4 liche, 4 lyche, 3 lych |
9 |
PDE I |
43 |
38 ich, 5 y |
10 |
PDE thou |
87 |
86 þou, 1 þu |
11 |
PDE she |
3 |
2 hoe, 1 a |
12 |
PDE us |
35 |
34 ous, 1 us |
13 |
PDE through |
6 |
5 þorou, 1 þorouh |
14 |
PDE up(-) |
8 |
8 op(-) |
15 |
OE ge- in past participle |
36 |
36 y- |
The first six features are orthographic ones; all these show comfortably high numbers of attestations, ranging from 45 to 191. The other, mainly morphological, features show a much more varied picture. For example, two common affixes, be- and -ly (features 7 and 8) show 14 and 15 attestations respectively; not large numbers, but enough to give an idea of the usage. The attested pronouns are highly dependent on text type: the present text, which consists of hymns addressed either to the Virgin or to Christ, contains a large number of first- and (especially) second-person pronouns and very few third-person pronouns; a narrative text would be likely to show the opposite proportions.
Even relatively frequent features may be missing from a sample, either accidentally or because they simply do not occur in a particular text type; this is, of course, more of a problem as regards grammatical or lexical features than orthography. When possible, we attempt to choose samples that combine narrative, dialogue and comment, in order to provide as full a range of grammatical forms as possible. Reflecting the present writer's interest in the history of personal pronouns, we also attempt to include parts of a narrative text that involve women as protagonists, thus eliciting feminine pronouns. However, given the large and varied material, such principles of selection cannot be applied in any strictly systematic way. Often, more practical considerations will have to take priority, such as the legibility of different parts of a manuscript or, quite simply, the availability of a particular part of a manuscript on a microfilm. Still, the large overall number of texts should assure a good coverage of most features of medium to high frequency.
It thus seems that the sample size of 3,000 words should be adequate for most of the searches we wish to carry out. It will, however, place limitations on our work. The corpus will allow us to describe the typical, dominant, frequent usage of each text, but it will miss out much of the minor variation. Occasional variant forms may give important suggestions about textual backgrounds, scribal habits and the like; for longer texts, such information will simply be lost in the sampling. The corpus will not be able to provide a full basis for the study of each individual text. It will also be of limited use for the study of features with a low density of occurrence.
On the other hand, cutting down substantially on the number of texts would restrict the use we can make of the corpus for quantitative analysis involving extralinguistic variables. This use, as far as we see it, is one of the most exciting possibilities of the present work. The coverage of a large number of texts is therefore important. For the equally crucial understanding of the dynamics of the individual texts, a parallel programme of studies of whole individual texts needs to accompany the corpus work.
The samples are in most cases first transcribed from microfilm or edition (facsimile or diplomatic edition); as far as feasible, these are then checked and corrected against the manuscript. All the transcriptions will be based at least on a good quality facsimile copy (never a printed edition alone), and the source of the transcription will always be given.
The transcriptions aim at reproducing the text at what might be called a rich diplomatic level, including the following features:
- folio or page references
- line division, initial large capitals and paragraphs
- rubrics/headings
- punctuation, using the full stop, semicolon, colon and slash for the following types of MS punctuation marks: dot, punctus elevatus (with or without a long top stroke) and virgule
- spelling, distinguishing between 31 letters including the sub-graphemic distinctions between <i/j> and <u/v>, but not other variant forms such as different forms of <r>, single and double compartment <a>, and so on
- capitalization
- abbreviations and some final flourishes/otiose strokes
- accents and dots over i's
An example of a transcribed text, illustrating most of these features, is provided. An image of the corresponding manuscript page may be viewed at http://www.bodley.ox.ac.uk/dept/scwmss/wmss/medieval/jpegs/lat/misc/c/1500/06600883.jpg
The transcription is carried out using only symbols belonging to the basic ASCII set. It has been felt important from the start that the texts should exist in a form that allows for easy conversion into virtually any electronic format. Thus, all 'ordinary' letters are typed in upper case (following the conventions of the LAEME project, compatibility with which has also been deemed an asset), while the special letters (þ [thorn], ð [eth],  [yogh], æ [ash] and [yogh], æ [ash] and  [wynn]) are typed as lower case letters (y, d, z, ae and w respectively). [wynn]) are typed as lower case letters (y, d, z, ae and w respectively).
Abbreviations are expanded in lower case, and aim at describing the visual form rather than giving an editorial interpretation: the aim is that each formally distinct abbreviation is consistently transcribed the same. Thus, a macron is always transcribed as a lower case nasal, whether or not this fits our intuitive feel of the linguistic meaning behind (except for cases where it represents a substantial part of a word rather than a single segment, as is typically the case in common proper nouns, e.g. ihesu). Similarly, a final flourish made without a pen lift is transcribed as a tilde, irrespective of what it 'stands for', including cases where it undoubtedly is to be interpreted as a nasal. The rationale behind this practice, which admittedly leads to some absurd 'readings', such as CUmMYG~ (rather than CUmMYnG), is to avoid making too many editorial choices at this stage, which might obscure the orthographic analysis for which we eventually wish to use the texts. For the published version of the corpus, it will be possible to convert the text into Unicode, so that the ASCII symbols used for flourishes and macrons can be turned into forms similar to their prototypical manuscript shape. It would be more time-consuming, but also perfectly manageable, to turn the symbols into editorial interpretations based on the likely 'intended' spellings, such as cummyng for CUmMYG~.
Many more features could be included in the transcription; ultimately, however, it is a question of balancing the ease and speed of transcription with the likely significance of the features, both for our own aims and for what we assume to be the aims of many potential users. Especially the last four features (e-h) listed above involve considerable problems of categorisation and definition: they bristle with fuzzy boundaries and questions of the type 'if this is included, then why not that?'. The system is not a perfect one, but rather the outcome of several pragmatic choices. For example, accents over <i> frequently determine readings of minim clusters and are included. Dots over <y>, on the other hand, may help to disambiguate <y> and <þ>, but in general add much less information for the interpretation of the text, and are not included in the transcription.
The treatment of final flourishes has been the most complicated question. We have taken as a starting point Parkes' (1979: xxx) statement that a transcription can afford neither to ignore final flourishes nor to treat them as abbreviations, but should simply record them as final flourishes, for example with an apostrophe. However, the problem then arises of the definition of a final flourish: at which point does a long end stroke become a flourish? Are cross bars over h's or double l's to be considered 'flourishes' even if they occur completely regularly, or are they part of the regular letter shape (figura)?
Such questions can often be answered in a fairly satisfactory way for an individual text; however, for the present purpose it is necessary to follow the same guidelines for every text. Recording everything that could possibly be described as a flourish seemed a hopeless task: some scripts [4] tend to involve something flourish-like in virtually every word, and many flourishes, especially of the cross bar type, seem to be best regarded as part of the figura. In the end, we have decided to record only such types of flourishes that form part of a continuum either with an abbreviation mark or with a final -e (that is, there are borderline cases that could plausibly be defined as either). This group includes flourishes on word-final minims as well as on <r>, <g>, <t> and <k>, as well as up-turned flourishes on <d>. It does not include such flourishes that only appear in late scripts and seem to be purely calligraphic, such as the 'horned e' or the downward stroke on <d>.
The transcribed text samples on their own will form a useful corpus for various kinds of study. However, for the detailed analysis of Middle English orthography and morphology, their usefulness has limitations that will be familiar to anyone working on a language with variable spelling. While current programs for text analysis may perform miracles, the scale of the variability of Middle English writing is bound to defeat machine recognition of words: the famous 510 spellings of through in LALME go far beyond predictable 'derived variants' (Benskin & Laing 1981: 77). However, even if it would be considered sufficient to simply collect most of the predictable forms, going beyond the individual word (or its initial or final letters) would still cause problems: for example, collecting data on particular sound categories, whether etymologically or synchronically defined, would be a laborious and, in the end, largely manual task.
The text therefore has to be subjected to some form of lemmatization. Each written form needs to be linked to some kind of reference point, so that different variants/reflexes of the same linguistic item can be retrieved and organised. Such variants should also be linked to the extralinguistic characteristics of the text in which they occur, so that they can be easily sorted according to variables such as date, genre and the like.
Irrespective of the format, annotating a corpus is a labour-intensive and time-consuming task; as misjudgments made at the outset may be irreversible later on, it is of crucial importance to be clear about the uses to which the material will eventually be put. The first point to note here is that we are not producing an annotated corpus primarily because we wish to produce a research tool for the academic community. The aim of the project is to write a description of Middle English; the corpus is our method of data collection for this purpose. This has clear implications for the choices made in corpus design and annotation.
Firstly, we need to be able to carry out precisely those searches that we wish to carry out, whether or not these are the ones of most interest to the majority of other scholars. Secondly, we wish to be able to complete the work within a reasonable timescale, in order to get to use the data: we are not producing the perfect corpus for future generations, but a workable corpus for our own use.
At the same time, it would clearly be an absurd waste of resources if the data collected and organised in a project of this scope would yield research materials only for a small group of scholars and for a single purpose. Therefore, it will be highly desirable to make the materials available for the public in a suitable format.
Annotating the corpus will take several years, and the annotated material will not be published until the first main studies based upon it have been completed. However, the transcribed texts will be made available as a plain text corpus from an early stage. This will, in the first instance, consist of the transcribed texts only, together with simple headers identifying the text and indicating source type (microfilm, manuscript) and transcriber.
Table 3. A simple header provided for each text in the plain text corpus (MEG-C).
| County |
Yorks NW |
| Code |
L0596 |
| MS reference |
London, BL Add. 25006 |
| Portion of MS |
fols 1r-10r |
| Text |
Lay Folks Catechism |
| Tranche |
fols 1r-3r and 6r-8v |
| Source type |
microfilm |
| Source description |
printout from Edinburgh collection |
| Transcribed by |
VJB 05/12/2006 |
| Checked by |
MRS 06/12/2006 |
| Checked ag. MS |
-- |
At the moment of writing, ca. six hundred texts have been transcribed, and the transcriptions are in the process of being proofread and checked against the manuscript. A first version of MEG-C, consisting of approximately one third of the total material, will be made available as an open-access web publication by the end of 2007. The remainder of the texts will then be added over the next two years.
The main challenge ahead will be to annotate the corpus in order to make possible the searches we wish to carry out. This will be done by entering the text into an Access database, in which each word is analysed into spelling units and linked with corresponding headwords, fields giving grammatical and contextual information, as well as with the extralinguistic information relating to the entire text.
The possibility of producing an XML-tagged corpus has been considered as an alternative. However, the relational database offers some important practical advantages for the present project: in short, it is likely to save much time and resources. The initial design [5] for the Access database is largely completed, much work has already been done on test databases, and the expertise [6] required for finalizing the design is available. In addition, most team members are familiar with Access, but not with XML. Finally, a relational database requires very little training for entering data, a consideration that is crucial, as this will allow postgraduate students and assistants to contribute to the work.
In the database, each linguistic form will be linked to two main kinds of information: some fields will relate specifically to each form entered, and some will relate to an entire text. These two kinds of information will be entered into separate tables, WordTable and TextTable. The tables are described below under 5.2 and 5.3 respectively.
A database is essentially an electronic card file system; unlike a tagging system, it requires us to define one single linguistic unit — word, morpheme, letter — as the basis of entry. The structure of the table containing the linguistic forms, and the kinds of information to be entered, will thus depend very heavily on the questions we wish to be able to ask and answer in the end.
Most importantly, we should be able to trace linguistic units below the word level — segments and morphemes — through their historical development. This aim makes the present work different from that involved in annotating most corpora. While contemporary corpus linguistics has traditionally focussed on areas such as syntax, discourse analysis, genre studies and the like, our main focus, at least to begin with, is on structures at or below the word level.
The annotation should make it possible to search for specific spellings in different contexts: initial h-, word-final -th, spellings representing reflexes of OE /a:/. This can (as far as we can see) only be done by including the following two features:
- headwords that represent solidly definable reference points in earlier and later periods, perhaps also in ME
- a breakdown of the word into smaller, searchable elements
In addition, the database will need to contain contextual information relating to each linguistic form: its manuscript context, rhyming/alliterative usage and so on.
The single most important part of the annotation is what may be called the lemmatization proper: defining the identity of each linguistic form by linking it to a reference point. The reference point should be based on an authoritative, stable source such as a major dictionary. Preferably, the lemmatization should also include a way of distinguishing between homographs among the reference forms.
In order to be able to trace the history of linguistic forms and to capture as many of them as possible in searches, we need reference points going both back and forward in time. For the present-day reference point, the obvious source is the Oxford English Dictionary. For all words recorded after 1800, it will be straightforward to use the OED headword as a PDE lemma. Words that became obsolete before 1800 pose a problem, however: their most recent headwords may not conform to the usual PDE spelling conventions, and might obscure searches based on PDE orthography. This can be solved by adding an extra field which labels the forms as either current or obsolete.
The PDE headword alone will permit a wide range of searches. Among other things, it should make possible a systematic comparison of PDE and ME spelling conventions; it should also make it possible, through the interpretation of written forms, to elicit information about phonological changes and spoken dialectal patterns in the late- and post-medieval periods. However, another reference point back in time is needed in order to trace etymological patterns, study the earlier linguistic developments and simply to define words that may have become obsolete at an early stage.
Defining the etymology of a linguistic form requires two pieces of information. Firstly, the immediate source language (OE, OF, ON, L) is defined in a separate field. Words with obscure etymologies are entered as 'ME'. For Old English words, the headword is that found in the Anglo-Saxon Dictionary by Bosworth and Toller (Bosworth 1898); for all other etymologies, the headword is the first cited form of the source language given in the OED entry.
These two lemmas — a PDE one and an etymological one — should between them define by far most of the linguistic forms entered. There still remains the question of short-lived words that neither go back to OE nor survive up to PDE times. For a maximal power of identification, it might be argued that the database should also include a ME reference point, perhaps based on the Middle English Dictionary (henceforth MED). There are, however, problems involved here. A third reference point (combined with the spelling unit analysis described below) would add a considerable amount of extra time to the process of entering data into the database; the gain would therefore need to be substantial in order to justify the effort [7].
The MED certainly fills the condition of being an authoritative, stable source; it is also the only source for specifically ME headwords that aims to provide a full coverage of the lexis. At the same time, being based on a naturally variable orthography, the headwords do not lend themselves easily to systematic searches: a search for all ME headwords including the vowel digraph <ay> would not capture forms that are recorded with <ai>, <ei> or <ey>, and would be of limited use. One solution might be to include all spelling variants given; this would greatly add to the work load. Alternatively, it would be possible to make general decisions about the spelling variants to be chosen (e.g. only entering variants with <ay> for all words that contain the same vowel). However, this would impose an artificial 'ME standard' on the material and would also make the data entry a much more demanding and specialised task, requiring much memorization of choices. Neither alternative is desirable. On the whole, while the MED is a vitally important reference work for the project, it seems that the benefits of adding MED headwords are unlikely to justify the added effort of entering them.
The headwords will, then, simply consist of an OED one and an etymological one, requiring the use of only two works of reference: the OED (online) and the Bosworth-Toller dictionary of Old English. The former headword will, in addition, need to be marked as "current" or "obsolete", making it possible to limit searches based on PDE spelling conventions to PDE headwords only.
Finally, there is the question of disambiguating homographs among the headwords. It would be possible to add a field including the OED identity tags (noun 1, noun 2 etc); however, this would, again, make the headword entry a much more cumbersome one, making it necessary to look up every single everyday PDE word. The record will, however, include a field providing a simple grammatical label. For this purpose, we use a set of grammatical tags based on the UCREL CLAWS tag set but slightly modified to suit Middle English grammatical categories. Together with the combination of etymological and OED headwords, this should provide a powerful enough system of disambiguation for our purposes; it will always be possible to check the context for any remaining ambiguities.
In the first trial database designed for the project, the text was entered letter for letter, with one record for each letter. This was not only extremely time-consuming, but produced very large numbers of records with much redundancy. The individual word is, without doubt, the ideal candidate for the basic unit of entry: it links directly to headwords, grammatical labels and such, and makes word counts easy within the database itself. It also makes (relatively) fast entering possible.
For the present purpose, however, the single word has to be analysable into smaller elements, which must be retrievable by searches. Marking morphological boundaries would help somewhat: at least, the word MIS|HAP would not be returned in a search for *SH*. However, there is still the problem of organizing the data returned by the search. There appears to be no entirely straightforward way to deal with 5,000 unsorted words that somewhere contain a spelling mostly corresponding to modern SH. While complex queries will make possible a rough sorting, the final analysis needs to be checked manually; from the point of view of yield and work involved, a questionnaire survey would probably have been more efficient.
The solution would seem to be to include several fields in each record that allow for the analysis of each individual word into smaller units. Bound morphemes, of which there are a limited number, will count as single units. For free morphemes, the analysis will be based on "spelling units", a concept modelled on Venezky's (1970) analysis of Present-day English spelling.
A spelling unit, in short, is a segment or a succession of segments of the same type (vowel or consonant) contained within the same morpheme. In other words, it can consist of a single vowel, a vowel digraph or (rarely) trigraph, a single consonant or a consonant cluster. The main difference between these units and Venezky's "relational units" is that the latter only include di- and trigraphs whose functions cannot be predicted from their constituents, such as <ch>, <th> and <aw> (Venezky 1970: 51, 54). The spelling units, as defined here, include any successive groups of vowels or consonants, even if they cross a syllable boundary. This allows for a much more mechanical application, something that is essential if a group of several co-workers are to produce a reasonably uniform analysis. There will still be problems of interpretation: it is not always self-evident what is a vowel and what is a consonant, and morpheme boundaries may also be difficult to determine; however, such problems should be considerably smaller than those involved in determining ME syllable boundaries [8].
A potential problem here will be the number of necessary spelling unit fields within a record. However, English simplex words hardly ever consist of more than three alternating consonant and vowel units, and most are limited to two. Only compound words are likely to produce longer stretches. In order to limit the number of fields per record, and to make the overall analysis simpler, it will make sense to define the unit of entry as the free morpheme, combined with all those bound morphemes that are directly attached to it. In other words, simplex words and derivatives [9] make up one record each, while compounds are divided into their constituent free morphemes. An additional field will then define the record as containing either a simplex or the first, second or third element of a compound word.
Defining compound words in a ME text is, of course, not straightforward (as it is not in PDE, for that matter). Entering one free morpheme per record will, in fact, provide a more flexible analysis than would a system based on lexical items. Identifying free morphemes is a largely (if not completely) mechanical process. The definitions about compoundness or otherwise, placed in the separate field, are transparently interpretative, and may easily be changed.
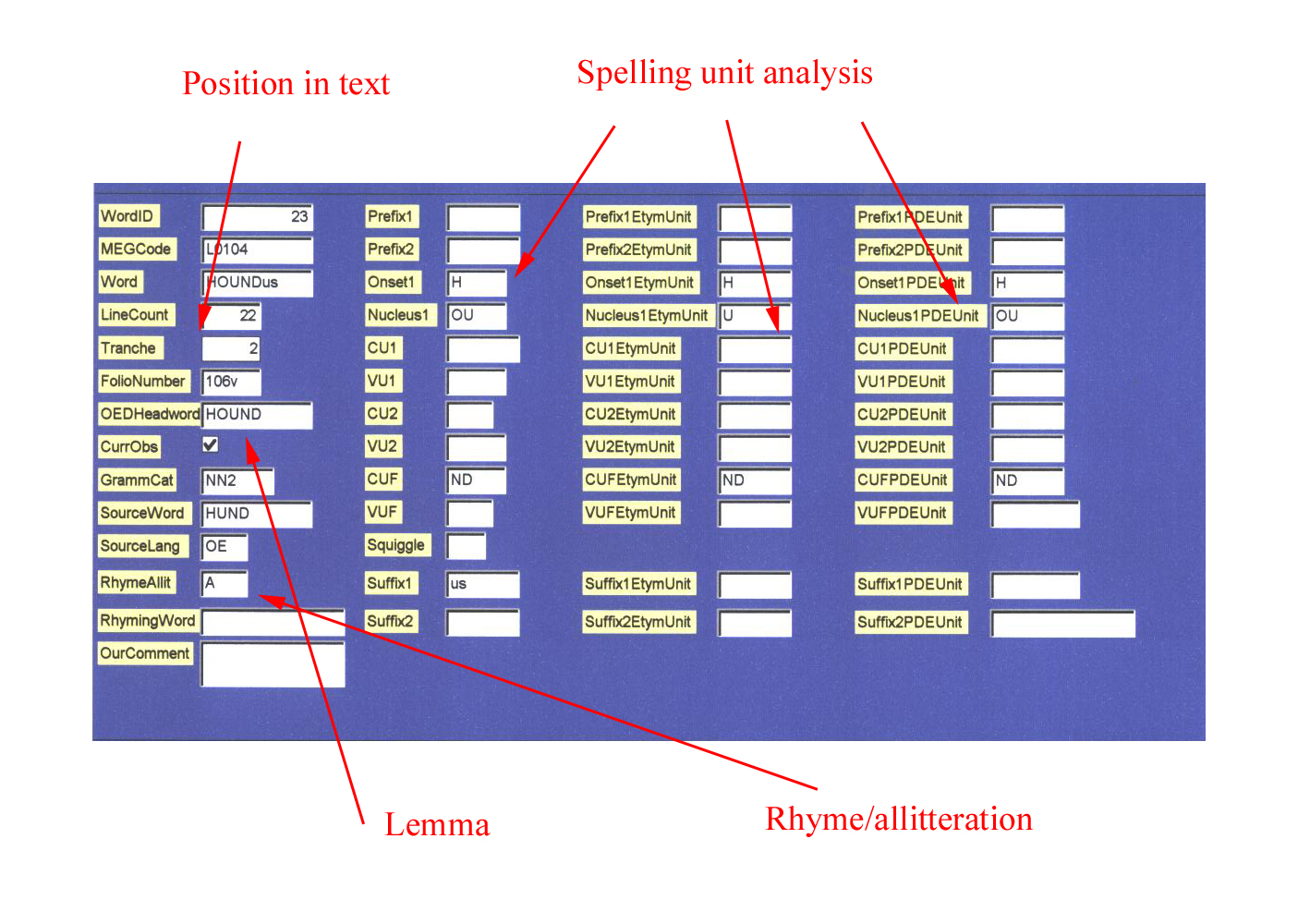
The fields recording the linguistic forms will thus be arranged as follows. The written form of a non-compound word will be entered into a keyword field, and the spelling units and bound morphemes will then be entered into the appropriate fields within the same record. The fields include designated fields for prefixes and suffixes and for initial, medial and final elements. The initial elements are labelled Onset1 and Nucleus1. For the rest of the word, syllable structure cannot be taken for granted; thus, medial consonant and vowel units are simply numbered and final ones are marked as final. Taking three PDE words as an illustration, the entries might look like this:
| Word | BRIGHT | BEHEADED | EFFORTLESSLY |
|---|
| Prefix1 | | BE | |
|---|
| Prefix2 | | | |
|---|
| Onset1 | BR | H | |
|---|
| Nucleus1 | I | EA | E |
|---|
| CU1 | | | FF |
|---|
| VU1 | | | O |
|---|
| CU2 | | | |
|---|
| VU2 | | | |
|---|
| CUFinal | GHT | D | RT |
|---|
| VUFinal | | | |
|---|
| Suffix1 | | ED | LESS |
|---|
| Suffix2 | | | LY |
|---|
It may be noted that the structure suggested here would not quite accommodate ANTIDISESTABLISHMENTARIANISM; however, it will be easy to add another field should that become necessary.
When the corresponding units are entered for each headword as well, it should be possible to carry out very specific searches this way, limiting the search to the reflex of a particular sound in a particular context.
If all the spelling units should be entered by hand, this would make the database extremely slow and cumbersome to produce. The crucial feature here will be a prompt function that memorizes and reproduces the analysis from the latest identical form entered. Such a prompt function will also be used to suggest headwords.
Apart from the fields relating to the linguistic form itself, each record will contain information relating to textual and manuscript context. Rhyming or alliterative position will be marked by entering R, A or N ("zero value") into a specific field. The record will also include a field for folio number and for a running line count starting from the beginning of the text sample. Several other fields recording information about manuscript context are conceivable; however, the descriptive detail will need to be balanced up against the work involved.
The complete structure of the WordTable is illustrated in Figure 1.
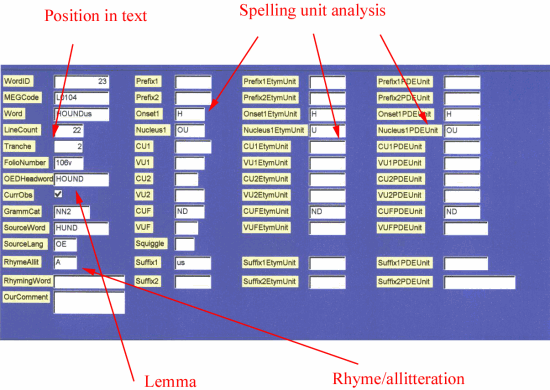
Figure 1. Structure of the WordTable.
A substantial amount of information will be linked to each text sample. This information falls into three groups: a) identifying the text, b) relating to the transcription of the text and c) searchable extralinguistic information. The following fields fall under these categories:
- MEGCode
MSRef
ScribalText
- MEGSample
SourceType
Source
TranscrBy
CheckedBy
CheckedMS
- Text
Genre
County
Region
Date
DateType
Script
Scribe
AddInfo
This structure is illustrated in Figure 2.

Figure 2. Structure of the TextTable.
The first three fields identify the text. Each text is given a MEG code number, consisting of the Atlas (LALME or LAEME) code number made into a four-digit number by adding initial zeros as required, and prefixed with a letter indicating the sub-corpus (L for LALME and E for LAEME). When, in the future, texts other than the Atlas ones are added to the corpus, they can be provided with different prefixes. Thus, the text on which Linguistic Profile 104 was based in LALME will appear as L0104. Where a composite profile in LALME has been split into separate scribal texts, these are identified by the letters a,b,c, etc., e.g. L7151b. Under MSRef, the repository reference and shelfmark of the manuscript are given in a slightly abbreviated form. Finally, the ScribalText field indicates which part of the manuscript is defined as the scribal text relating to the MEGCode. This will most often be identical to the Linguistic Profile definition in LALME; however, as composite profiles in LALME have been divided up for the present project, some of the scribal texts will be more narrowly defined here.
The MEGSample and SourceType fields will indicate the folio and line references of the transcribed sample, and note whether the transcription is based on the original manuscript or on a reproduction. The Source field will define precisely which reproduction (if any) has been used, e.g. a printout from a microfilm housed at the Edinburgh University Library. The TranscrBy, CheckedBy and CheckedMS record the team members responsible for each step in the transcription process.
The remaining nine fields record different kinds of extralinguistic information, and make possible the variationist approach we hope to pursue in the final analysis. While standard sociolinguistic variables such as age, sex and social class are difficult or impossible to retrieve for medieval texts, other variables are more readily available. The Text field contains a title or description of the text, entered in a conventional form, making it possible to search for all versions of the same literary text. The Genre field makes use of a classification of ME genres/text types defined especially for the purposes of the present project. At an earlier stage, it was felt that using a model based on existing diachronic studies, such as the Helsinki Corpus, would be useful; however, the first attempts at categorization showed clearly that, in order to make sense, the list of categories must take as a starting point the present corpus itself.
The County field is self-explanatory. At an earlier stage, it was planned to include more specific geographical localizations, such as the Ordnance Survey grid references used in LALME. However, it is felt that very precise localizations are best handled by a format other than the database, and should be left to any future electronic version of LALME. For the present purpose, the County labels, together with the Region field, will provide a basic geographic searchability; large counties will in addition be divided into sub-divisions.
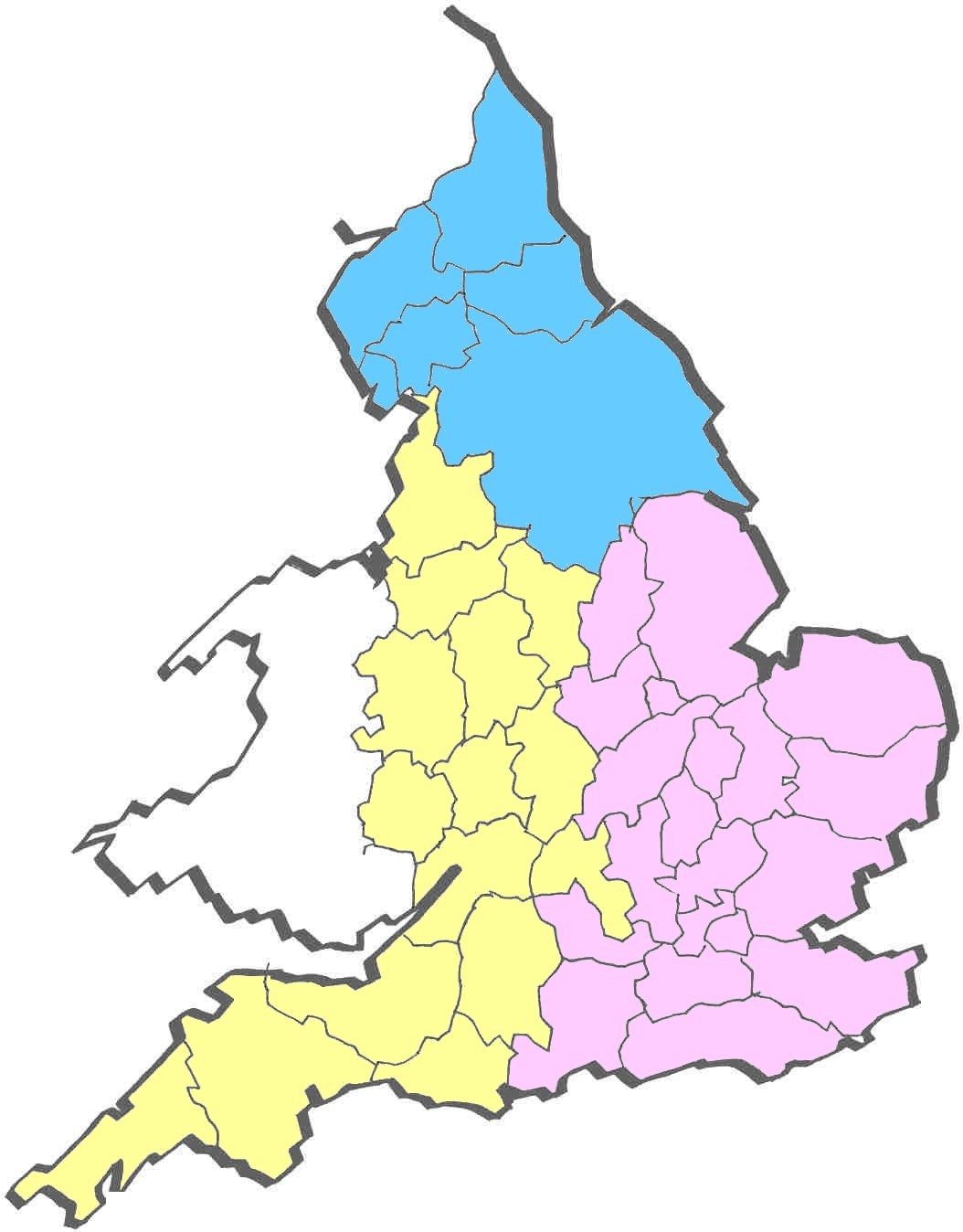
The Region field provides a division of England into three main regions: the North, West and East. In addition, the West and East will be divided into sub-divisions, corresponding approximately to North-Midland, South-Midland and South.
Medieval texts may be either 'dated' or 'datable' (Parkes 1983: 116): that is, the manuscript itself may contain a note of its date (as documents often do) or it may be possible to infer the date from its contents; alternatively, it may be datable on palaeographic grounds. The Date for each text, based on what is judged to be the most trustworthy source available, is entered by half- or quarter-century in the format 14a2 (the second half of the first half, i.e. the second quarter, of the fourteenth century). Another field, Date type, will record the kind of dating involved.
The Script field identifies the script type, according to a very simple classification. This recognizes three main script types: textura, anglicana and secretary, as well as distinguishing between formal and cursive variants of a script and recording mixture between types. Finally, an AddInfo field will record any relevant information about the text; the most useful kind of information to be added here will involve scribal behaviour and textual history, e.g. 'translated from a Northern exemplar' or 'autograph'.
Other text-specific fields would be possible, and some may still be added. However, the set here listed should make possible a wide range of searches of considerable complexity. It has been tried out in pilot studies, both using data derived from LALME (Stenroos 2004) and eliciting such data from the existing plain text corpus as can be retrieved by means of a concordance (Stenroos 2005 and 2006). For the features studied so far — the letters thorn and yogh and their substitution sets, and the third-person plural pronouns — the most important variation has related to the variables County, Date and Genre, the main genre division being that between documents and non-documents. All three studies suggested a general trend whereby innovative forms characteristic for the 'Chancery Standard' (or Type IV, cf. Samuels 1963 [1989: 71]), such as <th> and the their, them type pronoun forms, spread much faster in documents than in other kinds of texts. Further searches, involving many more linguistic features and a larger number of texts, made possible by the annotated corpus, should be able to put this finding to the test, as well as uncover other patterns that so far remain hidden.
The WordTable and TextTable will be linked to each other by the MEGCode field. The WordTable will almost certainly need to be subdivided in order to accommodate all the data: the most natural division will be regional, so that the material for the Western, Northern and Eastern regions will be entered into three different WordTables, all linked to the TextTable.
This basic design will be sufficient for the project's own purposes. However, for the purpose of eventual publication, the user-friendliness of the database could be greatly developed by adding further tables. These could include lists of recorded forms for each lemma, more detailed information about manuscript repositories, and so on. Such features are, however, still at a very early planning stage.
Producing the entire annotated corpus will take some years. The Western part is scheduled to be finished by 2010, at which time the Northern one should also be well under way.
The raw data cannot, of course, be converted directly into a Middle English Grammar. Before the Grammar can be written, the data will need to be subjected to a thorough analysis, little of which can reasonably be included in the textbook(s) that are viewed as the final product. Working towards a Grammar, we will need to combine quantitative analyses of data with a discussion of the relationship between written and spoken systems: as we wish to make inferences about spoken forms based on the written data, we need to problematize and make transparent the theoretical basis upon which these inferences are made.
As noted in the Introduction, it is planned that this intermediate work will take the form of large-scale regional studies. These will then provide a basis for the synthesizing work on the Grammar, together with the findings of other recent surveys, such as those carried out by Kristensson (1967-). A series of studies of individual areas has formed part of the project work from the start; continuing from the seminal work by Margaret Laing on Lincolnshire (Laing 1978), PhD theses linked to the project have so far dealt with the dialect materials of Herefordshire, Essex and the West Country. At the moment, studies of Yorkshire and Durham materials are ongoing at Stavanger. These studies form an important complement to the Corpus, as they provide detailed studies of texts in their entirety. Apart from supplementary data, they provide the detailed micro-level understanding of texts and scribes that is of fundamental importance for the study of real language, and that is easy to lose sight of in a Corpus survey. Finally, they will allow us to test and evaluate the representativeness of the Corpus.
Once all the Atlas texts have been entered, it will be possible to continue enlarging the Corpus by adding specific groups of texts. Groups of particular interest might include texts representing non-regional usages such as the 'Central Midland Standard' and the 'Chancery Standard' (Types I and IV in Samuels 1963 [1989: 67, 71]), as well as textual traditions such as Piers Plowman and the Canterbury Tales. Such groups would not include hundreds of texts, and would provide excellent opportunities for PhD-theses in the future. Supplemented in such ways, the annotated corpus here described should provide a very powerful means indeed to uncover patterns of linguistic variation in ME.
The project is closely related to LAEME, and there will be some overlap between the areas covered; however, the concrete aims of the two projects are clearly different. This is, we assume, also true of any future electronic version of LALME. The present project does not focus on detailed geographical localizations, but rather attempts to bring in a range of other variables besides geography. The use of relatively small samples that may be subjected to a detailed analysis also differs from the Atlas methodologies, which cover whole texts or substantial parts of them. Finally, the aims of the present project differ from the Atlas aims: while the Atlas work needs to focus on the diagnostic, taking into account the untypical and rare, in order to create the typologies upon which the localizations are based, our main goal is to produce a description of Middle English based on the typical and the frequent. In short, the present project is intended as an undertaking that is complementary to the Atlases, and it is hoped that both lines of work will benefit each other.
It is also hoped that both the plain text corpus and, in due course, the annotated corpus will be of use for a much broader group of scholars than those directly involved in the project. Broadening the latter group would also be an advantage. At least from the present viewpoint, there is a seemingly unending row of interesting tasks that lie ahead. While none of us can carry out all of them, every step will, it is hoped, take us a little bit further in our understanding of the glorious materials available for an empirical study of ME.
[1]
The Middle English Grammar Project has been ongoing since 1998 at the Universities of Glasgow (UK) and Stavanger (Norway). For the moment, much of the research activity is concentrated in Stavanger, where the project is funded by the Norwegian Research Council in 2006-2010. The Stavanger project team in the Autumn 2007 consists of Vibeke Bratland, Martti Mäkinen, Merja Stenroos and Nedelina Naydenova. We cooperate with Jeremy Smith (University of Glasgow) and Simon Horobin (Magdalen College, Oxford). More information about the project is available at the Stavanger website, http://www.uis.no/category.php?categoryID=3678.
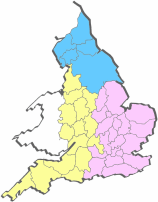 [2] The material is divided into three regional groups: the West, the North and the East. This reflects the original division of labour with regard to transcription (as we started with non-Northern texts, the Eastern ones were to be transcribed at Glasgow and the Western ones at Stavanger). The division is felt to be a useful one, as it breaks up the material into more manageable portions, and it is retained in the plans to publish the research results initially in the form of three regional surveys. [2] The material is divided into three regional groups: the West, the North and the East. This reflects the original division of labour with regard to transcription (as we started with non-Northern texts, the Eastern ones were to be transcribed at Glasgow and the Western ones at Stavanger). The division is felt to be a useful one, as it breaks up the material into more manageable portions, and it is retained in the plans to publish the research results initially in the form of three regional surveys.
The texts are unevenly distributed across the country, with some areas having a denser coverage than others; however, most parts of the country are reasonably well covered. It is only the partly Celtic areas in the West and far Southwest that, understandably, are nearly blank (see LALME I: 568).
[3] The number of LALME texts included in MEG-C will almost certainly be different from the number of Linguistic Profiles in LALME. On the one hand, we split up all those profiles that consist of multiple contributions, such as 'three hands in the same language' or 'two manuscripts in similar language' — while these could be treated together for the purposes of dialect typology, for descriptive purposes they need to be kept apart to avoid mixing (even slightly) different systems. This splitting process will raise the overall number of texts. On the other hand, we will not be able to get hold of every single LALME text: some texts will be impossible to trace or difficult to access, and we can only hope to include the majority of them.
[4] The distinction between script types is an important one for the study of Middle English orthography (for a demonstration of this, see e.g. Benskin 1982: 21-25). Our classification is based on that of Parkes (1979). We distinguish between three main types of script: Textura, Anglicana and Secretary; for the two latter types, we also distinguish between formal and cursive styles. The following mixed types are also recognized: Bastard Anglicana, Bastard Secretary and a mixture of Anglicana and Secretary. Only a small part of the material has so far been classified, and the details of classification are still work in progress.
The following links to digital images provided by the Bodleian Library, Oxford, provide examples of the three main script types:
[5] Both the classification of linguistic units and the range of database fields have undergone much modification from the test databases developed in the first period of project work in the late 1990s; much important work was at that stage carried out by Dr Simon Horobin. Cf. Black et al. (2002) for a description of a much earlier model. This paper was originally given in 1999-. A partial description of a later test version is given in Stenroos (2004).
The practices of corpus compilation and the database design described in sections 3 and 5 respectively have benefited greatly from discussions with and input from my co-worker, Martti Mäkinen.
[6] We are fortunate to have close contact with the team of the Historical Thesaurus of English (University of Glasgow), who have been very generous in lending their expertise when it comes to database design.
[7] Looking up entries in the MED is likely to take more time than dealing with the other two sources. The OED entries for many common words are so self-evident that they do not need to be checked (we will not need to look up man, is, old or house if they are unambiguous in the text). The OE headwords, on the other hand, are more formally predictable than the ME ones, and thus tend to be easier to find.
[8] The question of Middle English syllable boundaries is an extremely complex one. Important changes took place during this time, largely connected to the loss of final unstressed vowels. To take a simple example, the syllabic analysis of the word appearing in the written form time will be very different depending on whether we assume a final vowel to be pronounced or not. To define syllable boundaries is therefore not something that can be done before analysing the data as a whole; instead, the spelling units need to be defined in as transparent a way as possible, that involves no linguistic analysis beyond the identification of vowels and consonants.
[9] Attaching bound morphemes to the adjacent free morpheme may end up with some semantically rather illogical analyses, such as OTHER + WORLDLY, to take a present-day example; however, as such words are relatively rare, and the present analysis is mainly intended for the study of units below word level, the advantages would seem to weigh up for this.
OED = Oxford English Dictionary (online), http://www.oed.com/
MED = Middle English Dictionary, http://ets.umdl.umich.edu/m/med/
MEG = Middle English Grammar Project, http://www.uis.no/category.php?categoryID=3678
HC = Helsinki Corpus of English Texts, http://www.helsinki.fi/varieng/CoRD/corpora/HelsinkiCorpus/
Historical Thesaurus of English, http://www.gla.ac.uk/schools/critical/research/fundedresearchprojects/historicalthesaurusofenglish/
Bodleian Library, University of Oxford: Western manuscripts to ca. 1500, http://www.bodley.ox.ac.uk/dept/scwmss/wmss/medieval/browse.htm
University Centre for Computer Corpus Research on Language (UCREL), University of Lancaster, http://ucrel.lancs.ac.uk/
UCREL CLAWS tag set, http://ucrel.lancs.ac.uk/claws5tags.html
Edinburgh Atlases Project: A Linguistic Atlas of Early Middle English (M. Laing and R. Lass) and A Linguistic Atlas of Older Scots (K. Williamson), University of Edinburgh, http://www.amc.lel.ed.ac.uk/?page_id=19
Ordnance Survey website, https://www.ordnancesurvey.co.uk/resources/maps-and-geographic-resources/the-national-grid.html
Benskin, Michael. 1982. "The letters <þ> and <y> in later Middle English, and some related matters". Journal of the Society of Archivists 7: 13-30.
Benskin, Michael & Margaret Laing. 1981. "Translations and Mischsprachen in Middle English manuscripts". So Meny People Longages and Tonges: Philological Essays in Scots and Mediaeval English Presented to Angus McIntosh, ed. by Michael Benskin & M. L. Samuels, 55-106. Edinburgh: Middle English Dialect Project.
Black, Merja, Simon Horobin & Jeremy J. Smith. 2002. "Towards a new history of Middle English spelling". Middle English from Tongue to Text, ed. by Peter J. Lucas & Angela M. Lucas, 9-20. Frankfurt am Main: Peter Lang.
Bosworth, Joseph. 1898. An Anglo-Saxon Dictionary. Edited and enlarged by T. Northcote Toller. Oxford: Clarendon.
Jordan, Richard. 1968. Handbuch der mittelenglischen Grammatik: Lautlehre, 3. Auflage. Heidelberg: Carl Winter / Universitätsverlag (first published 1929).
Kristensson, Gillis. 1967-. A Survey of Middle English Dialects 1290-1350. Lund: Gleerup / University Press.
Kurath, Hans, Sherman M. Kuhn & John Reidy (eds.). 1952-. Middle English Dictionary. Ann Arbor: University of Michigan Press.
Laing, Margaret. 1978. Studies in the Dialect Material of Mediaeval Lincolnshire. PhD thesis. University of Edinburgh.
Laing, Margaret. 1993. Catalogue of Sources for a Linguistic Atlas of Early Medieval English. Camridge: Brewer.
McIntosh, Angus. 1973. "Word geography in the lexicography of mediaeval English". Annals of the New York Academy of Sciences, 211: 55-66. Reprinted 1989 in: Middle English Dialectology: Essays on some Principles and Problems, ed. by Margaret Laing, 86-97. Aberdeen: University Press.
McIntosh, Angus, M. L. Samuels & Michael Benskin, with Margaret Laing & Keith Williamson 1986. A Linguistic Atlas of Late Mediaeval English. 4 vols. Aberdeen: University Press.
Parkes, Malcolm B. 1979. English Cursive Book Hands 1250-1500. London: Scolar Press.
Parkes, Malcolm B. 1983. "On the presumed date and possible origin of the manuscript of the 'Ormulum': Oxford, Bodleian Library, MS. Junius 1". Five Hundred Years of Words and Sounds: A Festschrift for Eric Dobson, ed. by E. G. Stanley and Douglas Gray, 115-127. Cambridge: Brewer.
Samuels, M. L. 1963. "Some applications of Middle English dialectology". English Studies, 44: 81-94. Reprinted 1989 in Middle English Dialectology: Essays on some Principles and Problems, ed. by Margaret Laing, 64-80. Aberdeen : University Press.
Samuels, M. L. 1981. "Spelling and dialect in the late and post-Middle English periods". So Meny People Longages and Tonges: Philologial Essays in Scots and Mediaeval English Presented to Angus McIntosh, ed. by Michael Benskin & M.L. Samuels, 43-54. Edinburgh: Middle English Dialect Project. Reproduced 1981 in The English of Chaucer and his Contemporaries, ed. by Jeremy J. Smith, 86-95. Aberdeen: University Press.
Smith, Jeremy J. 2000. "The letters s and z in South-Eastern Middle English". Neuphilologische Mitteilungen 101: 403-413.
Stenroos, Merja. 2004. "Regional dialects and spelling conventions in Late Middle English: Searches for (th) in the LALME data". Methods and Data in English Historical Dialectology, ed. by Marina Dossena & Roger Lass, 257-285. Bern: Peter Lang.
Stenroos, Merja. 2005. "The spread of they, their and them in English: The Late Middle English evidence". Naked Wordes in Englissh, ed. by Marcin Krygier & Liliana Sikorska, 67-96. Frankfurt am Main: Peter Lang.
Stenroos, Merja. 2006. "A Middle English mess of fricative spellings: Some thoughts on thorn, yogh and their rivals". To Make his Englissh Sweete upon his Tonge, ed. by Marcin Krygier & Liliana Sikorska, 9-35. Frankfurt am Main: Peter Lang.
Venezky, Richard L. 1970. The Structure of English Orthography. The Hague/Paris: Mouton. |
|


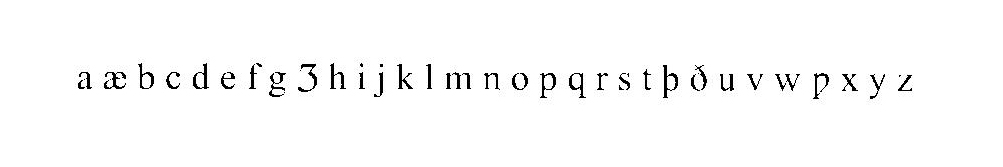{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}