The Chemnitz Corpus of Specialised and Popular Academic English *
Josef Schmied, Chemnitz University of Technology, Germany
The Chemnitz Corpus of Specialised and Popular ACademic English (SPACE) is a parallel corpus, although it contains neither texts in several languages (all texts are in English) nor from different times (all texts were published after 2000) nor from different genres (if academic writing can be considered one genre). Still, it can be used to compare academic English from different academic disciplines as well as for different readerships. The defining criterion for our new Chemnitz SPACE Corpus is that the texts included are represented in pairs, where more or less the same content is explicitly referred to in scholarly articles (as part of the specialised expert-to-expert communication of a specific discipline) and in the derived popular versions (as part of the broader journalist-to-layperson communication in general academia). The new corpus will be a useful basis for many theoretical and applied research questions, as it allows us, for instance, to compare linguistic complexity on different levels, lexical, semantic and syntactic. In each case, we might assume that (usually professional) journalists might have simplified the original academic article to adapt the same form for the less specialised reader without losing too much content.
This contribution introduces the rationale behind the SPACE Corpus, its context and set-up, and it illustrates its usefulness in analysing complex phenomena across texts and domains in several small case studies.
Since English is the international Lingua Franca in research institutions all over the world today, this new "variety" has attracted special attention in linguistic research. Unfortunately, the term "English for Academic Purposes" (EAP) that has been used as a cover term for many recent discussions (cf. Hyland 2006) is applied to very dissimilar types of discourse on different levels at universities: It covers the basic writing skills of first-year language students, the academic teaching of scientists and the learning of their students and the scholarly exchanges between scientists in conferences. Most importantly, it covers specialist journals as well as the popular or non-specialist versions of scientific findings produced by science journalists. The transmission of academic knowledge obviously includes clearly different communicative perspectives and problems: Thus we distinguish between "basic EAP" on the students' level and "advanced EAP" on the scientists' level. Even on this "advanced EAP" level we find a specialised (or intra-disciplinary) academic discourse between specialists in the same field and a more general (or inter-disciplinary) academic discourse between scientists and the general academic public in popular science journals (like the Scientific American or the New Scientist). The writers in those journals are either scientists with a special journalistic talent or, more often, science journalists, who contribute to the public understanding of science in an age when specialisation seems to become linearly more and more "special". Usually, science writers in this sense have a specialised academic background as well as a writing background, so that they can transfer information from specialised to popular academic style. Although in many cases this transfer may be done intuitively, this raises the question of how linguists, and in particular empirical corpus-linguists, can analyse differences between these academic styles and thus contribute towards the understanding of science as transmitted via academic discourse. Perhaps they can verify old intuitions or make everyone aware of more style features than "meet the eye". Since academic texts are becoming more and more available in electronic form, the task of the corpus compiler has become easier but a thorough investigation still requires careful planning and sampling, detailed quantitative and qualitative analysis and cautious contextualised interpretation.
For many years, research into academic English has been based on genres (like conference presentations, review articles or research articles; cf. Swales 1990 and 2004) and in many discussions research articles have been considered central to the spread of scientific knowledge, esp. in the natural sciences. Research articles (learned articles, scientific articles, journal articles, articles in learned journals, etc.) have also been seen in contrast to popular or popular-scientific articles (e.g. Gläser 1990:67). In corpus-linguistics, the genre approach has been followed particularly by the Brown and LOB corpus compilers (Hofland/Johansson 1982). Both corpora contained a text-type of "Learned and scientific writings" with 80 texts (out of 500), with a wide stratification from natural science to medicine, social/behavioural sciences, political science/law/education, from humanities to technology and engineering. Similarly, the British National Corpus (BNC) contains texts from the domains Applied Science, Arts, Natural/Pure Science and Social Science; these comprise more than half of the informative texts and are twice as many as all imaginative texts (Aston/Burnard 1998:29). These parts of the BNC and the LOB Corpus can serve as reference corpora for the specialised parts of the SPACE Corpus.
In the following project (cf. also Schmied 2006 and Haase fc.), we want to present a quantitative and qualitative comparison of expert-to-expert communication in some restricted academic fields and expert-to-general-academic or expert-to-academic learner communication, using texts that report more or less the same content. We call these texts specialist vs. popular academic discourse and we can only deal with differences in form, not in content (as far as simplification of surface forms can be done without changing the meaning). We also restrict our analysis to corpus-linguistic methodologies, partly parallel to the analyses that are commonly applied to the spoken academic genres of MICASE (Michigan Corpus of Academic Spoken English). We do not include any teaching aspects (cf. Paltridge 2004), but the qualitative and quantitative analyses can at least be seen as a starting point for further discussions.
Our starting-point for text selection were texts in popular science journals, in which the non-specialist versions refer explicitly to their source materials in two specialist on-line publications: We juxtapose academic online data-bases like ArXiv and publications in the Proceedings of the National Academy of Sciences (PNAS) with their popular academic adaptations in journals like New Scientist - and possibly later the even more popular reflections in national and international English newspapers.
The New Scientist has been considered as a leading international interdisciplinary journal for a long time (cf. Gläser 1990). It contains many short articles that make current specialist research results available to the non-specialist "academic layperson"; the articles are sometimes presented by specific science editors, sometimes by an anonymous member of the scientific writers' team.
The Proceedings make specialist research available to the general public because the research is generally funded by public agencies, but articles are usually in a highly specialized style, because they are written by the researchers themselves. Similarly, ArXiv articles are not produced by mediators but by the researchers directly, since Open Access publishing is the fastest way for them to spread their results. However, ArXiv research is often more topical because researchers intend to secure a certain claim on research findings for themselves quickly before colleagues intervene in their field, whereas Proceedings articles report on on-going, publicly funded research.
So far the data has been collected by retrieving New Scientist texts and following up all the references and downloading all the corresponding articles in ArXiv and Proceedings (from 2000 to 2005). The first selection showed that the New Scientist has a strong bias towards the fashionable disciplines astrophysics and genetics or cell biology, so the question was whether the selection should be a sample of the publishers' preferences or whether there should be a stratification according to academic disciplines and subdisciplines. Since it proved often difficult for us as non-specialists to classify the articles clearly, we finally opted for the traditional big disciplines physics, biology and medicine in the first place and only add a tentative sub-categorisation into molecular biology, cell biology, biochemistry, anthropology, ecology/evolution, to name only the most frequent, that could be compared qualitatively later. This might, for instance, reveal whether anthropology or ecology show less specialisation in their publications. These considerations lead to the following stratified distribution of SPACE texts at the time of writing [1]:
Table 1. Text distribution in the Chemnitz Corpus of Specialised and Popular ACademic English (SPACE) to date.
|
discipline |
type |
physics |
bio |
med |
total |
popular |
60 |
60 |
40 |
160 |
specialised |
65 |
60 |
40 |
165 |
total |
125 |
120 |
80 |
325 |
Interestingly, there are more specialised texts than popular texts in physics since one popular text referred to four and another one to three related scholarly articles in ArXiv.
These texts were not only stored in a raw form in a data-base, but they were automatically POS-tagged using the Treetagger and the Penn Treebank tagset as well as CLAWS 7, which are standard input for further analyses. For the semantic lexical analysis, we use our own complexity analyser called ComplexAna, which uses WordNet entries [2] to calculate semantic parameters. The number of tokens and words and the number of sentences are used to calculate the mean number of words in a sentence. The number of nouns is counted and a stop list can be used to exclude the most frequent and empty function words. The remaining words are checked in WordNet; words not included there are considered subject-specific technical terms. Of the words contained in WordNet a degree of semantic specification can be calculated depending on their vertical position in the WordNet ontology. Finally, a value score for degree of semantic complexity of the overall text is calculated, which is flexible because the number of variables included and their coefficients can be changed and thus fine-tuned (see Image 1). At this stage of the project, we are still experimenting to see whether the "felt difficulty" as perceived by human analysers and the "calculated difficulty" as proposed by ComplexAna are similar (see 3.1 below).
The complete corpus will be made available (as far as copyright issues permit) to interested researchers on a WWW portal, which will allow simple searches that produce KWIC (key-word in context) concordances as well as crosstabulations that show distributions according to the main sampling parameters of text-type (i.e. specialised vs. popular) across the three disciplines.
The data-base allows us to venture some hypotheses, which we will try to verify or falsify. Of course, the sentence parameters would suggest that higher figures for all types of complexity can be found in the specialised/expert texts than in the popular/journalistic texts. This applies to mean sentence and word length, to the number of commas in the texts and in a single sentence. Similarly, the calculated score of semantic difficulty should be higher in expert texts than in popular texts. This applies to unknown words and the specific specification of the nouns (all compared to WordNet).
Other hypotheses based on differences between disciplines or the years between 2001 and 2005 seem generally too bold at the moment, although really topical debates (like the one on climate change) could certainly produce special results.
The following case studies illustrate some of the analyses that will be possible on the basis of the new SPACE Corpus. The examples demonstrate that not only simple searches based on surface phenomena are possible, but also very complex analyses that look deep into the lexical and grammatical set-up of the corpus texts. We have chosen three case studies: a comparison of two individual parallel texts, a comparison of lexicons in related specialised and popular texts, and an analysis of complexity features in a sub-corpus, 40 parallel medical texts. Since the corpus compilation is not completed, the results are only sketched in a few keywords and the validity and reliability of the results are not discussed in detail, because the main purpose of the case studies is to demonstrate the usefulness of the new corpus and related tools for the type of research questions raised.
The following figure shows the user interface of ComplexAna, which was developed specifically for the analysis of our specialist and non-specialist academic texts (Image 1). After researchers have chosen an input file (by clicking on "Browse"), they can watch the processing, which takes between 10 and 60 seconds, depending on the length and difficulty of the text. The input files for ComplexAna should (and do in the examples below) not contain the scholarly references or bibliographies, since they would influence some of the parameters used below (like the number of commas and the proper names would rank a text with many publications listed as more complex than it actually is).
In the top right-hand corner, a few options like the choice of types instead of tokens for the analysis and the use of a stop list can be selected as well as a record command, so that the results do not only appear on screen, but are also transferred directly to an Excel file for further processing. The results can be influenced by the choice and weighting of the coefficients, so that the variables calculated can be given a high or low score or they can be excluded from the calculation. Our experiments, which are still largely based on intuition, so far show that the settings emphasise or deemphasise differences, but the settings cannot change the relative order of the texts in the complexity sequence.
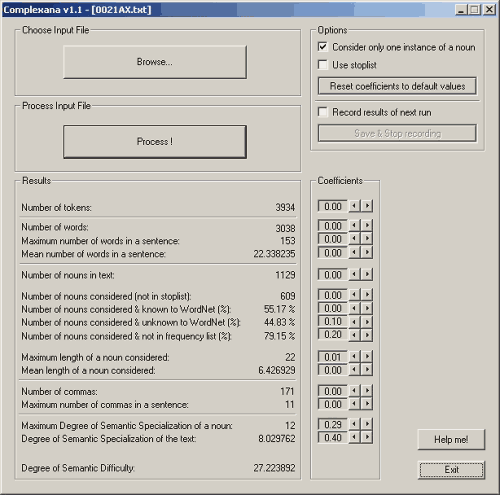
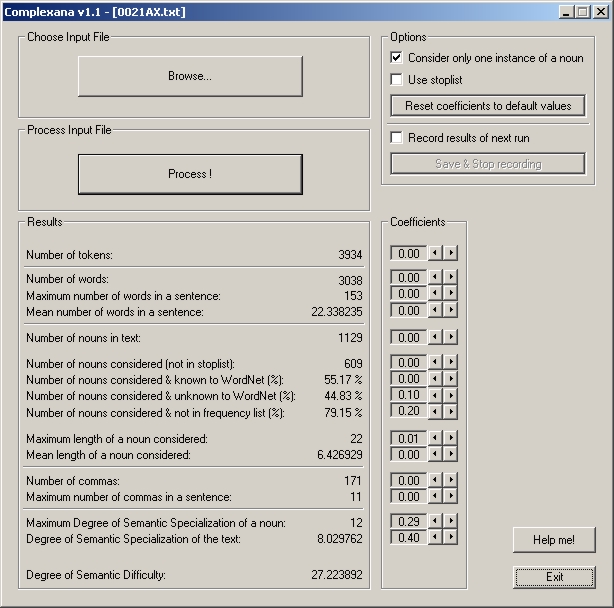
Image 1. The ComplexAna interface with figures for a specialist text (0021AX). (Click to enlarge)
The figures included show the results for the difficult scientific text from ArXiv, which can only be sketched in this context:
- The number of words in the text (tokens) is almost 4000, but there are only about 3000 different words (types). The maximum number of words per sentence is 153; the average is over 22. These variables are not included in the calculation of semantic difficulty below.
- The number of nouns in the text according to our POS tagging is 1129, whereas the number of nouns not included in the stop list of most common words is 609. A high proportion of these words could not be found in WordNet (almost 45 %) and are not included in the standard frequency list (79 %). The last figures are included in the calculation of semantic complexity below.
- The maximum length of a considered noun is 22 letters, which is remarkably high, but the variable is only weighted in the calculation with a relatively low coefficient (0.01). The mean length is almost 605, but this figure is not included in the calculation of semantic complexity.
- The maximum degree of semantic specification of a noun (according to WordNet) in this text is 12; the degree of semantic specification of the text is over 8, which is remarkably high. Both variables are weighted in the calculation with a relatively high coefficient.
- The two syntactic variables, the number of commas, 171 in this case, and the maximum number of commas in the sentence, 11 in this text, are both comparatively high - but not included in the calculation of semantic complexity.
- Overall, this text reached a score of over 27, which is one of the highest among ArXiv texts and among all specialist texts (only Proceedings text 47 had almost 28). In contrast to this, the lowest degree for the specialist texts calculated is 19 (an ArXiv text). The range for the non-specialist texts in the New Scientist was between 16.4 and 22.65.
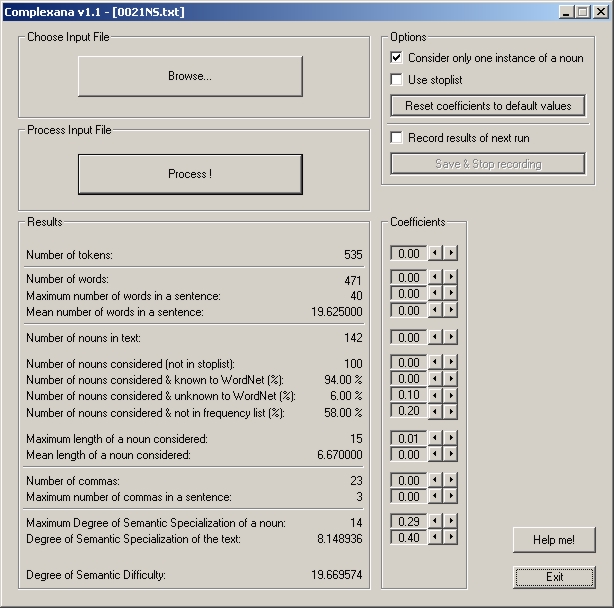
Image 2 shows again the ComplexAna Interface with the results for a non-specialist New Scientist text (0021NS) with low scores compared to the parallel specialist text above (Image 1).
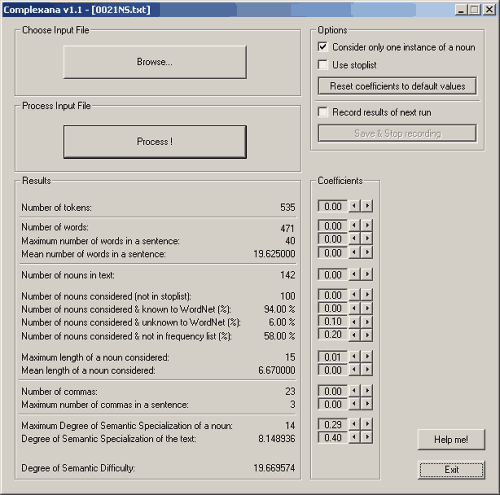
Image 2. The ComplexAna interface with figures for a non-specialist text (0021NS). (Click to enlarge)
This procedure was carried out for a subsection of the texts in the SPACE Corpus so far. The means and some standard deviation for the text types New Scientist for the popular version and ArXiv and Proceedings for specialist versions can be seen in Table 2. Four groups of texts are distinguished: 46 ArXiv texts and their corresponding New Scientist texts and 61 Proceedings texts and their equivalents. All figures here show expected results: The popular versions show lower figures of complexity than the specialist versions. Interestingly, Proceedings texts show clearly higher figures for all syntactic and semantic complexity variables than ArXiv texts, because they also include more variation (as can be seen in the standard deviations). New Scientist texts show relative uniformity in means and standard deviations. Whether the aggregated means are useful remains to be seen.
Table 2. Measuring semantic, syntactic and lexical complexity of specialist and non-specialist academic texts.
source: |
AX |
NS01
-46 |
PNAS |
NS47
-107 |
NS all |
AX+
PNAS |
all |
semantic |
|
|
|
|
|
|
|
mean sem. complexity |
23.61 |
19.11 |
26.28 |
19.79 |
19.50 |
25.06 |
22.37 |
SD sem. complexity |
2.12 |
1.26 |
1.28 |
1.24 |
1.25 |
2.17 |
3.31 |
max. sem. complexity |
27.8 |
21.81 |
28 |
22.64 |
22.64 |
28 |
28 |
sem. specialisation |
8.08 |
8.09 |
8.19 |
8.26 |
8.19 |
8.14 |
8.16 |
syntactic |
|
|
|
|
|
|
|
max. noun length |
24.17 |
22.83 |
39.58 |
17.38 |
19.72 |
32.55 |
26.34 |
mean noun length |
6.54 |
6.89 |
6.82 |
6.78 |
6.83 |
6.69 |
6.76 |
commas in text |
191 |
42 |
463 |
28 |
34 |
339 |
191 |
max. commas/sentence |
11 |
4 |
23 |
3 |
3 |
18 |
11 |
lexical |
|
|
|
|
|
|
|
mean length |
3113 |
812 |
4359 |
500 |
634 |
3790 |
2262 |
mean % vocab. unknown |
30.05 |
12.03 |
34.59 |
10.94 |
11.41 |
32.52 |
22.30 |
SD vocab. unknown |
7.49 |
3.85 |
5.38 |
3.34 |
3.59 |
6.87 |
11.92 |
Sources: AX = arXiv, NS = New Scientist, PNAS = Proceedings of the National Academy of Science
Generally, our parameters of semantic, syntactic and lexical complexity correspond nicely. The general hypotheses have been confirmed, e.g. non-specialist texts are syntactically less complex (i.e. they contain fewer words per sentence and fewer commas) and non-specialist texts include fewer unknown nouns (i.e. those not included in WordNet) and more general nouns (i.e. those higher in the WordNet hierarchy).
A few special results deserve a brief comment:
Our complexity score is a valid indicator, although it only allows relative comparisons, since the actual figures are arbitrary, due to of the coefficient weighting. The mean complexity is clearly reduced in the non-specialist texts, although it is slightly higher for the New Scientist texts derived from the Proceedings articles than the others; more complex originals have left their mark. Thus most results of our preliminary analyses confirm standard hypotheses; it is, however, surprising that the mean word length is lower for ArXiv texts than for their New Scientist equivalents.
Generally, the number of unknown words is a valid indicator of complex vocabulary, the mean of commas and the commas per sentence is a rough indicator of complex syntax. However, commas may be used to separate coordinated noun phrases as well as to structure clauses, not only to co- or subordinate clauses. The former usages may actually improve the readability of texts and simplify texts, the latter make them more complex. Thus a more detailed investigation of commas on the basis of the available POS tagging seems desirable.
Since in some corpus-linguistic analyses, the individual texts seem to disappear too soon behind figures, the following three analyses demonstrate that a comparison of complexity can be carried out on several levels, from the most concrete text level to the more abstract domain level.
Averages may blur interesting differences in real language, thus a few text examples can complement the quantitative comparison. This qualitative comparison also illustrates some interesting strategies in transferring content from specialist to non-specialist discourse and the tagging mentioned.
Text 1a is the beginning of a non-specialist astrophysics text (0035NS). Both parts consist of two sentences, which are not very long and consist mainly of general and general academic words, even informal talk.
CARBON and oxygen are streaming outwards in the atmosphere of a planet 150 light years away. It's the first time anyone has observed these elements in a planet outside the solar system.
The planet, which orbits a star called HD 209458 in the constellation Pegasus, has been nicknamed Osiris, after the Egyptian god of the underworld. It is a Jupiter-like gas giant and orbits very close to its star, whipping around it every 3.5 days.
Text 1a. Introductory lines from a non-specialist astrophysics text (0035NS).
Text 1b is the corresponding specialist astrophysics text (0035AX), which is rather complex, having a score of 27.24. It includes more complex noun phrases, compounds like absorption depth or heavy postmodification like determination of the planet's radius and mass. The specialist texts typically include figures and references to publications in brackets, which makes the complex syntax difficult to process. However, there are also clear parallels: both texts use oxygen and carbon as well as gas giant.
The absorption depths in Oi and Cii show that oxygen and carbon are present in the extended upper atmosphere of HD209458b. ...
The extrasolar planet HD209458b is the first one for which repeated transits across the stellar disk have been observed (1.5% absorption; Henry et al. 2000; Charbonneau et al. 2000). Together with radial velocity measurements (Mazeh et al. 2000), this has led to a determination of the planet's radius and mass, confirming that it is a gas giant.
Text 1b. Part of the abstract and introductory lines from the corresponding specialist astrophysics text (0035AX).
Of course, longer texts could be compared as well; sometimes it is not easy to see the equivalents so clearly, because the semantics may be lexicalized in less specialised vocabulary (hence our measurement using WordNet). Usually the subjective impressions of complexity are confirmed by the objective data-processing.
From individual features in texts, we move to aggregate parameters in texts. The following Table 3 juxtaposes three parameters, number of nouns, number of nouns not in stoplist and percentage of nouns in WordNet, for corresponding texts from ArXiv and New Scientist one below the other. In each case, the popular texts are shorter and a larger proportion of nouns can be found in WordNet, i.e. over 80 % of the nouns are part of general English and less than 20 % are specialised lexemes. There is only one exception, 0009AX, where the specialised text is unusually short and thus more similar to a popular text than usual.
Table 3. A comparison of the lexicon of related specialised and popular texts.
Specialised Texts |
|
Popular Texts |
text |
# N |
# N in WordNet (%) |
|
text |
# N |
# N in WordNet (%) |
0001AX |
1996 |
66,13 |
|
0001NS |
137 |
90,8 |
0002AX |
1391 |
62,27 |
|
0002NS |
595 |
87,27 |
0003AX |
1200 |
65,77 |
|
0003NS |
655 |
91,33 |
0005AX |
454 |
56,47 |
|
0005NS |
650 |
84,42 |
0007AX |
153 |
74,04 |
|
0007NS |
432 |
86,88 |
0008AX |
1546 |
67,29 |
|
0008NS |
130 |
87,5 |
0009AX |
148 |
82,57 |
|
0009NS |
118 |
86,3 |
0010AX |
203 |
73,48 |
|
0010NS |
97 |
86,57 |
0011AX |
141 |
73,4 |
|
0011NS |
46 |
82,86 |
0012AX |
2220 |
65,79 |
|
0012NS |
467 |
84,05 |
Similar figures and proportions can be found when other parameters are compared between the popular and the specialised texts.
Here, we do not consider individual features, nor individual texts. But we look at all simple complexity features in one academic discipline, medicine, and we only compare averages and differences. The averages in Table 4 are based on 40 texts from the popular journal and 40 from the specialised part. In almost every variable, the ComplexAna values (see 3.1 above) show the higher complexity of the medical specialised (MEDspec) section compared to the medical popular (MEDpop) section. Of course, the proportion of words known to WordNet must be higher to indicate lower complexity. When we compare the differences in the calculated differences between the parallel versions (Δ spec-pop) we clearly see that there are only two unusual values: Surprisingly, the mean number of words in a sentence is higher in the popular than in the specialised section and the degree of semantic specification of the entire text is slightly higher for popular than specialised texts. This may be because the relatively small number of nouns make the few really specialised ones stand out even more. Such figures can be taken as an interesting starting point for more detailed comparisons.
Table 4. A comparison of complexity in specialised vs. popular medical texts based on ComplexAna.
COMPLEXITY features |
Ø MEDspec |
Ø MEDpop |
Ø MED |
Δ spec-pop |
Number of Tokens |
7099,350 |
496,400 |
3797,875 |
6602,950 |
Number of Words |
5431,350 |
426,250 |
2928,800 |
5005,100 |
Maximum number of words in a sentence |
138,525 |
59,750 |
99,138 |
78,775 |
Mean number of words in a sentence |
20,486 |
23,058 |
21,772 |
-2,573 |
Number of nouns in text |
2566,375 |
157,925 |
1362,150 |
2408,450 |
nouns considered (not in stoplist) |
865,900 |
96,200 |
481,050 |
769,700 |
nouns known to WordNet (%) |
66,169 |
86,555 |
76,362 |
-20,386 |
nouns unknown to WordNet (%) |
33,832 |
13,446 |
23,639 |
20,386 |
nouns not in frequency list (%) |
72,742 |
55,876 |
64,309 |
16,866 |
Maximum length of a considered noun |
33,400 |
17,825 |
25,613 |
15,575 |
Mean length of a considered noun |
7,131 |
6,732 |
6,932 |
0,399 |
Number of commas |
445,525 |
21,875 |
233,700 |
423,650 |
Maximum number of commas in sentence |
23,675 |
3,725 |
13,700 |
19,950 |
Maximum Semantic Specialization of noun |
15,275 |
13,675 |
14,475 |
1,600 |
Degree of Semantic Specialization of text |
8,341 |
8,376 |
8,358 |
-0,035 |
Degree of Semantic Difficulty |
26,031 |
20,014 |
23,023 |
6,017 |
These illustrative case studies clearly demonstrate that many more studies are possible. We are planning to compare the frequency and type of hedges (on the basis of the research tradition started by Lakoff 1972) in the SPACE texts, since one could assume that journalistic writing is more expressive than scholarly writing; thus our hypothesis could be that popular article writers leave out the small words that indicate hedging in many ways, modal verbs (like might), modal adverbs (like perhaps), and determiners (like a few). Similarly, author involvement and author commitment are an important issue in objective sciences. How the various surface features are presented by the researchers themselves in the specialised texts and by the information management specialist in the popular texts depends on multi-faceted genre conventions and personal attitudes. Naturally, the SPACE texts can not only be compared with each other, but also with parallel texts in other corpora. Brown/LOB and the BNC have been mentioned above, other comparable corpora like the historical dimensions of the two American and British reference corpora are equally possible (cf. Mair/Leech 2006).
Finally, the analyser tools could also be expanded to include cohesion phenomena from sentence adverbs, especially with a causative dimension (like consequently), to standard scientific chunks (like These data suggest). The POS tagging available already is a good input for such a quantitative add-on tool.
This brief survey only sketches the potential for a stratified new comparative corpus like SPACE. We have developed a structured research data-base that can be used for qualitative and quantitative comparisons and that is very flexible. This could be expanded in the future because several dimensions that seem important in academic writing have not been developed fully: everyone interested in C.P. Snow's "two cultures" may want to calculate whether natural and social sciences are really different in their publication conventions or which science cultures display greater proximity (e.g. whether medical writing is closer to physics, biology, or psychology). The even more popular representation of science texts in daily or weekly newspapers could add a section that may be further explored. This is only a beginning.
* I wish to thank my collaborators in this on-going project, Christoph Haase, Peggy Hoinka and Stefanie Kirste for many interesting discussions.
[1] We are just adding another domain to the SPACE Corpus, psychology, which will add another 60 texts bringing the total number of words in the corpus to over 1 million. However, the specialised equivalents in the New Scientist articles are not taken from one or two archived sources, but from various renowned international journals we had access to. Whether this diversity brings more variation in our linguistic variables only the more detailed analysis will show.
[2] WordNet has to date over 207,000 word-sense pairs, 128,321 monosemous and 27,006 polysemous words with 78,695 senses (http://wordnet.princeton.edu/man/wnstats.7WN.html, as of 14/06/07). This means that words that cannot be found must really be part of specialist vocabulary.
Primary sources:
Other WWW sources:
Aston, Guy & Lou Burnard. 1998. The BNC Handbook: Exploring the British National Corpus with SARA. Edinburgh: Edinburgh U.P.
Gläser, Rosemarie. 1990. Fachtextsorten im Englischen. (= Forum für Fachsprachen-Forschung, 13). Tübingen: Narr.
Haase, Christoph. Forthcoming. "Corpora and Academic English: Compilation, Analysis, and Teaching". In ReCall 19(3) (2007), Special Issue on Incorporating Corpora in Language Learning and Teaching.
Hyland, Ken. 2006. English for Academic Purposes: an Advanced Resource Book. New York: Routledge.
Hofland, Knut & Stig Johansson. 1982. Word Frequencies in British and American English. London: Longman.
Lakoff, George. 1972. "Hedges: A Study in Meaning Criteria and the Logic of Fuzzy Concepts". Proceedings of the Chicago Linguistics Society 8: 183-228.
Mair, Christian & Geoffrey Leech. 2006. "Current Changes in English Syntax". The Handbook of English Linguistics, ed. by Bas Aarts & April McMahon, 318-342. Malden, Oxford & Carlton: Blackwell.
Paltridge, Brian. 2004. "Academic writing". Language Teaching 37: 87-105.
Schmied, Josef. 2006. "Specialist vs. Non-Specialist Academic Discourse: Measuring complexity in lexicon and syntax". In Discourse and Interaction 2. Brno Seminar on Linguistic Studies in English: Proceedings, ed. by R. Povolná & O. Dontcheva Navratilová, 143-152. Brno: Masaryk University.
Swales, John M. 1990. Genre Analysis. English in Academic and Research Settings. Cambridge: Cambridge University Press.
Swales, John M. 2004. Research Genres. Exploration and Application. Cambridge: Cambridge University Press.
|
|