Society is increasingly dependent on digital information. Much of this is available online free of charge but metadata is at a premium. This has encouraged the emergence of a new online phenomenon known as social (or collaborative) tagging. The predominant social tagging site is Delicious, which allows users to assign keywords (or ‘tags’) to their bookmarks (favourite web pages) to describe their content. These tags are then shared with other users, who can search the collection by tag. However, many of the linguistic problems which exist in traditional keyword search remain. Most research on tagging to date has been conducted by information scientists, but this paper describes new work which is examining social tagging from a corpus linguistic perspective. Our discussion compares the new, text-external aboutness indicators offered by social tagging with text-internal aboutness indicators. We illustrate how we are using this multi-layered approach to aboutness both to make better sense of the existing social tagging and to suggest guidelines for better tagging practice. Our work aims to reconcile the worlds of formal textual analysis and intuition.
1. Background
Traditionally, top-down hierarchical structures have been used to classify documents in large collections. Taxonomic classification, such as the Dewey Decimal system used in libraries, can be carried out only by trained experts and relies upon controlled vocabularies. Early web navigational aids, such as the Yahoo! Directory[1], attempted to mirror such hierarchical structures, employing editors to categorise web pages. Page authors were encouraged to aid indexing by including a hidden ‘keywords’ meta-tag at the top of each page to list words describing its content (see section 6.1). However, this system was open to abuse through deliberate inclusion of words not reflecting the content in order to improve search ranking, and keywords are now largely ignored by search engines such as Google, which dominate the market. Nevertheless, the top-down approach to web classification has continued to dominate in recent years and is particularly evident in the focus on ‘ontologies’ within the Semantic Web movement.
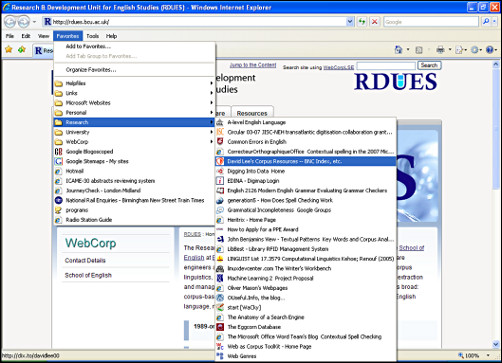
The main limitation of hierarchical structures is that they require expert human input and, thus, are not scalable to the vast, rapidly growing web. Society is increasingly dependent on digital information, much of which is available online free of charge, but metadata is at a premium. This has encouraged the recent emergence of an alternative, ‘bottom-up’ mechanism on the web in the form of social (or collaborative) tagging. The predominant social tagging site, with over 5 million users, is Delicious, which allows users to assign keywords (or ‘tags’) to their favourite web pages to describe the content of the pages. Before Delicious existed, the standard way to store one’s favourite web pages (also known as ‘bookmarks’) was to save links to them in a web browser, as shown in Figure 1 using Microsoft Internet Explorer. In this particular example, the user has grouped some of the favourites/bookmarks into named folders representing categories.
Delicious is conceptually similar but it saves favourites to the web, making them accessible to the user from any computer. An important distinction is that Delicious allows users to share tagged favourites with other people and, thus, tag profiles are built up collaboratively for individual web pages and sites (see Figure 2). At the time of writing, Delicious users had tagged over 150 million web pages. When Delicious was first created in 2003, the focus was very much on the tagging of Computing web sites, reflecting its initial technically-advanced usership. This focus has widened to non-technical web sites as the user base has grown.
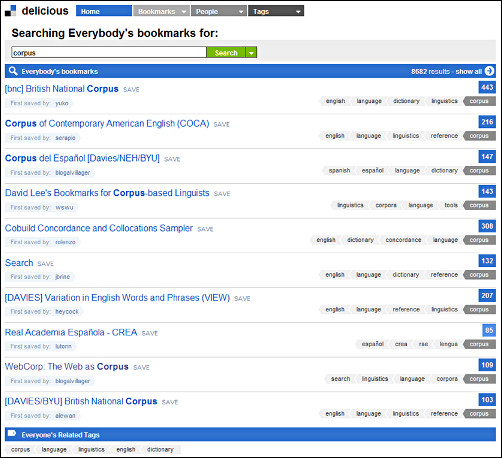
A major advantage of social tagging sites such as Delicious is that the tag profiles are searchable. Figure 3 shows the results of a search for the tag corpus in Delicious, which returns a variety of corpus-related web pages. These include the homepage of the British National Corpus (BNC), which has been tagged by 443 people with the words english, language, dictionary and linguistics, as well as corpus.
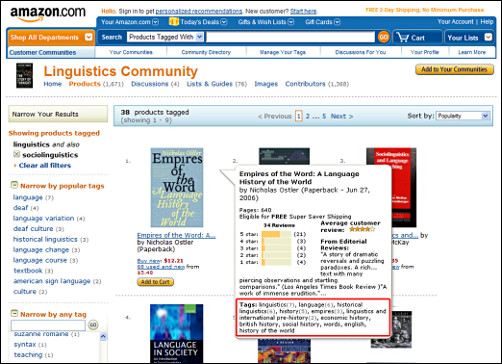
Delicious is an example of a so-called ‘Web 2.0’ site: the next-generation, collaborative web where passive readers become active participants. Web 2.0 encompasses wiki-based sites, which allow users to collaborate on production of texts (Wikipedia being most famous example), and popular social networking sites such as Facebook and Twitter. Apart from Delicious, other social tagging sites include Flickr (for the tagging and sharing of photographs); CiteULike, Connotea and BibSonomy (for academic references) and YouTube (for videos). In fact, tagging features have begun to appear on established websites such as Amazon, as shown in Figure 4 where items for sale have been tagged by members of a Linguistics community.
Social tagging is seen by some as a first practical step toward a Semantic Web (e.g. Xu et al. 2006). However, most research on tagging to date has been conducted by information scientists, who tend to look at tags and user behaviour in isolation from the tagged texts themselves.
The Research & Development Unit for English Studies (RDUES) team has been viewing developments on the web from a linguistic perspective for the past decade, as we have refined and developed our WebCorp system (Kehoe & Renouf 2002; Renouf 2003; Kehoe & Gee 2007). Through this work, we have become familiar with the structure of the web, and with some of its limitations for linguistic analysis.
It is clear to us that social tagging has the potential to provide a new perspective on textual ‘aboutness’ (see section 5) but also that there are several linguistic hurdles to be overcome. In this paper, we present the first steps in our plan to harness the power of tagging as new measure of textual aboutness.
2. Social tagging: an example
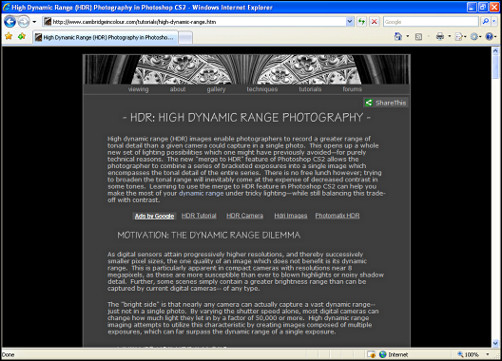
We illustrate our discussion in this paper with an example of a web page which has been assigned 332 unique tags by 2,938 Delicious users [2]. The page in question is a photographic tutorial on the specific topic of High Dynamic Range (HDR) Photography: a technique for producing more life-like digital photographs using the Adobe Photoshop application (see Figure 5). This tutorial contains 3,199 tokens (999 types) on a single HTML web page. In our previous work on the WebCorp Linguist’s Search Engine (Kehoe & Gee 2007), we discovered that only 3.73% of HTML pages contained more than 2000 tokens, so the HDR tutorial is relatively long in web terms.
2.1 Delicious representation of tagging data
On the Delicious website, it is possible to list the tags assigned to a particular text by each user and the tags most frequently assigned to that text overall. It is also possible to view a graphical representation of the tagging data in the form of a ‘tag cloud’ (Figure 6), where the most commonly assigned tags are presented in the largest typeface. Note that in Delicious tags can be single words only – phrases are not permitted.
Figure 6. Delicious ‘tag cloud’ for HDR tutorial.
Our aim in the following sections is to compare the tag data from Delicious with a variety of text-internal aboutness indicators in order to determine how useful tags are as a guide to textual aboutness. Drawing upon our previous work on web search, our particular focus is on tags as an aboutness indicator which can assist users attempting to find texts on a particular topic on the web.
3. First stage comparison: word list versus tag list
Our first, rather basic, comparison sees us adopt the ‘bag of words’ approach to compare the words in the text with the words used by Delicious users to tag the text. Table 1 shows the top words in each list, with the words which appear in both lists underlined. The word list, on the left, was produced using the Word List tool in WebCorp Live[3], with the stopword filter switched on to exclude high frequency grammatical words. The tag list, on the right, was extracted from the Delicious web site using a tool we have developed for this purpose.
Table 1. Most frequent non-stopwords in text (left) vs. most frequent tags assigned to text in Delicious (right).
Word List
Freq
Tag List
Freq
hdr
43
photography
1558
image
42
photoshop
1373
contrast
30
hdr
1320
tonal
24
tutorial
916
range
22
photo
456
images
20
howto
439
local
18
tutorials
373
brightness
17
art
146
dynamic
17
photos
124
light
12
digital
99
photoshop
12
camera
98
bits
11
graphics
96
exposure
11
reference
92
example
11
design
86
method
11
tips
80
exposures
10
images
57
detail
9
software
52
global
9
guide
52
mapping
9
tools
50
tones
9
dynamic
41
curve
9
article
38
file
8
color
38
histogram
8
image
37
cs2
7
diy
34
point
7
range
32
digital
7
hdri
30
16-bit
7
flickr
29
single
7
technique
28
files
7
cool
24
This simple comparison reveals some overlap between the words in the text and the words used to tag the text and there are, in fact, 35 words which appear in both the full word list and the full tag list [4]. However, the most frequently used tag, photography, is not found at the top of the word list as it only appears twice in the text. In fact, there are 246 words unique to the tag list, i.e. they do not appear in the text itself. This constitutes 75% of the tags used, and in the following section we outline our initial classification of these.
3.1 Classification of tags which do not appear in the text itself
Our initial classification of the 246 words unique to the tag list contains nine categories:
evaluative words (e.g. fantastic, useful, nifty, cool): These are non-topic words which are of little use for information retrieval purposes. The very fact that a Delicious user has tagged a text at all shows that s/he values it in some way, but the exact tag used offers little extra information. Note that there are some circumstances where a tag such as cool may be a topic word (relating to weather, the town Cool in California, the Cool computer programming language, etc. [5]) but these circumstances are limited.
non-English words (e.g. bildbehandling, fotografía): Although the text under analysis is written in (American) English, the web is, of course, multilingual and Delicious users tag English texts in their own native languages. These non-English tags are undoubtedly helpful to other Delicious users who speak the same language as the original tagger.
phrases deliberately conjoined (e.g. creativeendeavors, digital-photography, digital_photography): Since it is not possible to use phrases as tags in Delicious [6], some users have devised creative solutions, writing phrases as solid or hyphenated compounds or using other separator characters such as underscores. Some other users may well have intended to tag the text with a phrase separated by a space (e.g. digital photography) but Delicious would treat this as two separate tags.
attempts to categorise (e.g. articles, recreation, hobbies): Some users have attempted to categorise the example text according to genre or domain. This may be influenced by the ‘categorised folder’ system used by some users to organise sites in their web browser’s ‘Favourites’ or ‘Bookmarks’ list (Figure 1).
attempts to build topic hierarchy (e.g. photoshop/howto, .tutorial.photoshop): Some Delicious users go beyond the single word domain/genre categorisation, and are apparently attempting to build topic hierarchies reminiscent of traditional taxonomies and the Yahoo Directory. The ‘levels’ of the hierarchy are often separated by dots or slashes and this may reflect the initial dominance on social tagging sites of ‘technical’ users familiar with computing notation (where slashes are used to separate folder, or directory, names in a path and dots are used in object-oriented programming).
Mnemonics (toread, readmelater, !toread, todo): ‘Signpost’ tags such as toread appear to be firmly established in the tagging lexicon. For our purposes, such tags are of little interest in themselves but they do capture the dichotomy between tagging for personal benefit and tagging for the collective benefit of the community which is inherent in so-called ‘social’ tagging and which must be considered in any analysis of tag data.
meta-data (e.g.English):This category includes tags which do not describe the topic, domain or genre of the text but provide some basic meta-level information.
Typos (e.g. photograpy): As in any system requiring human input, there are some typographical errors.
(syno)nyms (e.g. art, pictures, high-definition, lessons, tips, software): We note several instances where a tag does not itself appear in the text but where the tag is semantically related to one or more words in the text. In most cases the semantic relation is synonymy (e.g. tag: pictures, text: photographs) but there are also instances of hyponymy (tag: software, text: photoshop) and other semantic relations.
In fact, these categories are interrelated; for instance, the hyponym example in (ix) could be classified as a categorisation (iv) or hierarchical relationship (v). However, what is clear from our initial analysis is that there are many problems with the use of collectively-assigned tags as a retrieval aid which have been noted by information scientists analysing social tagging but which are already familiar to linguists in other contexts. We discuss some of these below.
4. Social tagging: the linguistic problems
The problems with social tagging have been combined under the heading ‘vocabulary divergence’ (Xu et al. 2006; Chi & Mytkowicz 2008) – the fact that different users select different tags for the same concept – and include:
semantic specificity (terms selected at different levels on the semantic hierarchy, e.g.: Siamese, cat, animal)
Some authors have referred to the tag sets built up through the actions of the users of social tagging sites as ‘folksonomies’ (e.g. Angeletou et al. 2007; Van Damme et al. 2007). This term is rather misleading in that it implies that the controlled vocabularies, hierarchical structures and overall indexing rigour of traditional taxonomies are also found in these ‘folk taxonomies’. We have already indicated that this is not the case and, in the following section, we look in more detail at the tags associated with our example text by different Delicious users. We also outline some of the approaches other researchers have adopted to handle vocabulary divergence in social tagging.
4.1 Vocabulary divergence in action
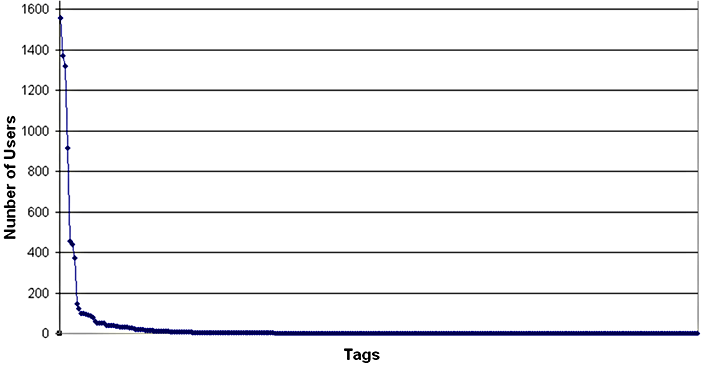
It is possible to examine vocabulary divergence in detail by plotting tag usage on a graph. Figure 7 shows the number of Delicious users who assigned each of the 332 tags to the HDR Tutorial text, with the tags plotted in descending frequency order.
Figure 7. Tag graph for ‘HDR’ example (2883 users, 332 tags).
This graph illustrates that the 6 most frequent tags are used by between 400 and 1600 people, corresponding with the data in Table 1. However, the vast majority of tags, in the so-called ‘long tail’ of the graph, are used only once, i.e. by a single person. We see parallels here with the structure of the lexicon in general, with the very high frequency (grammatical) words at the top and, as predicted by Zipf’s Law (Zipf 1935), a long tail of hapax legomena at the other end of the scale. In her 1987 study of a 7.3 million word corpus, Renouf found that 52% of types appeared once only (Renouf 1987). More recent work on larger corpora has corroborated these findings by showing that 40% to 60% of types appear once only (Kornai 2008: 72). Some researchers have seen the kind of vocabulary divergence exemplified in Figure 7 as a problem and have attempted to standardise vocabulary at the tagging stage by developing systems to suggest tags to users based upon tags already assigned by other users (e.g. Xu et al. 2006). The aim in much of this work is to combine related tags into a single canonical form, yet it is clear that vocabulary divergence can actually increase recall: users in the ‘long tail’ of Figure 7 are in the minority but retaining their tags, and not merging them with more common terms, allows other users with a similar mindset to find the page in question. In fact, research using Information Theory has shown that tags are becoming less useful as navigational aids: as the size of the document collection and number of users increases, any single tag references too many documents to be considered useful in search (Chi & Mytkowicz 2008). This reinforces the belief that the merging or condensing of tags into one canonical form is not the best solution.
The development of semantically-aware ‘tagging assistant’ software has the potential to improve recall and precision in tag search, and to increase awareness amongst the users who assign tags of what makes a linguistically useful tag and how best to combine multiple tags to clarify meaning. However, the systems developed to date are somewhat linguistically naïve, e.g. in using character bi-grams to identify similar tags (Xu et al. 2006). The SemKey system (Marchetti et al. 2007) asks users to specify the semantics of their tags by adding one of the labels ‘hasAsTopic’, ‘hasAsKind’ (i.e. genre) or ‘myOpinionIs’. Although this assists in disambiguating and classifying tags to an extent, it builds upon a limited view of the relation between tag and text (3 kinds only) and increases interaction cost for users.
Conversely, SparTag.us (Hong et al. 2008) aims to reduce interaction cost by allowing the user to click on a paragraph in a document and assign tags to it either by typing or by clicking on a word in the paragraph to use as a tag. However, this approach may actually reduce tag diversity by encouraging users to choose words directly from the text as tags. The authors’ comment that ‘when a word is going to be used as a tag … there is a good chance it derives from the content itself’ overlooks the fact that this ‘derivation’ may extend beyond direct lifting to paraphrase by synonymy, evaluation, categorisation, etc. (see section 3.1).
There is a growing body of work which attempts to apply semantic relations from external ontologies to social tagging. For instance, Van Damme et al. (2007) use Wikipedia to identify homonyms in a list of tags and WordNet to map synonyms. However, it is not clear how one can ever know what a tag means in context by focussing on external resources and not considering the text to which the tag is applied. In fact, Angeletou et al. (2007) show that few of the tags used in Delicious actually appear in online ontologies as these ontologies cover a limited number of textual domains, contain mainly English nouns, and are not up to date with the latest terms.
5. Returning to the text
5.1 The notion of aboutness
The previous section highlighted some of the approaches taken by non-linguists to the linguistic problems which arise when texts are socially tagged for aboutness on a large scale. What these approaches have in common is that they adopt a text-external approach, relying on generalisations at the expense of an analysis of the linguistic features of individual texts.
The issue of aboutness has long been central to information science and underpins all information retrieval (IR) systems, including web search engines. The goal of an IR system is to determine how related a document is, in terms of its aboutness, to a user-specified ‘query’ (in practice, often a single search word). Over the past two decades, many such systems have strayed from text-level analyses to adopt a mathematical approach, the Latent Semantic Analysis/Indexing (LSA or LSI) technique (Deerwester et al. 1990) being one of the most widely adopted in recent years. In their 2000 study of ‘Aboutness from a commonsense perspective’, Bruza et al. (2000) review this shift in emphasis in the treatment of aboutness by information scientists, yet their proposed ‘commonsense perspective’ is based entirely on propositional logic and does not consider aboutness at text level.
This has not always been the case in information science. Early studies by Hutchins (1977; 1978) suggested that the indexing of documents in libraries could be improved by considering the linguistic organisation of texts, in particular through analysis of the theme-rheme system and the respective roles of given and new information. Hutchins outlines standard library classification procedures, whereby indexers ‘are able to state what a document is “about” by formulating an expression which “summarizes” the content [through] … the selection of “key” words or phrases from the text’ (Hutchins 1978: 1).
Hutchins’ work follows Van Dijk (1972) in viewing text at two levels: the sentence-by-sentence, or microstructure, level and the global, text-ordering macrostructure level. Another author who follows Van Dijk in his use of these terms is Phillips, in his work on lexical macrostructure (1985; 1989). Phillips’ model for the study of aboutness as a ‘knowledge-free analysis of text at the level of orthographic substance … on the scale of the whole text’ (1989: 69) is one which influences our work in the following sections.
5.2 Key words
Moving beyond the simple comparison of word lists, perhaps the most commonly used aboutness measure in corpus linguistics is the concept of ‘key words’, popularised by the WordSmith Tools software package (Scott 1996). This is the same concept described by Hutchins, in the context of library indexing, who refers to (manually extracted) key words as ‘expressions which are “significant” indicators of content and which together sum up the message of the document’ (Hutchins 1978: 2). In WordSmith, key words are ‘those whose frequency is unusually high in comparison with some norm … The aim is to find out which words characterise the text you're most interested in’ (Scott 2009).
Adopting a similar procedure, we used our WebCorpLSE software to compare the HDR tutorial with a large master corpus of web texts, using the log-likelihood statistic (Dunning 1993). Our master, or reference, corpus contains 4.3 billion tokens of text downloaded from the web by WebCorpLSE [7] (see Kehoe & Gee 2007). Table 2 shows the top 30 key words for the HDR text, where the numerical columns from left to right are word frequency in the HDR text, word frequency in web corpus, frequency per million words in HDR text, frequency per million words in web corpus, and log-likelihood score. The words at the top of this list are the words most typical of the HDR text – those which are ‘overused’ in the HDR text when compared with the large web corpus.
Table 2. Log-likelihood comparison of HDR text with 4.3 billion word web reference corpus – top 30 key words.
Word
HDR Freq
Web Freq
HDR
Per Mil
Web Per Mil
L-L
HDR
43
2604
23102.31
1.07
753.59
tonal
24
3826
13201.32
1.57
385.53
image
42
452323
23102.31
186.00
321.72
contrast
30
169762
16501.65
69.81
268.18
brightness
17
20102
9350.94
8.27
205.07
dynamic
17
103387
9350.94
42.51
149.53
images
20
265813
11001.10
109.30
144.86
Photoshop
12
15569
6600.66
6.40
142.53
range
22
593338
12101.21
243.98
128.66
CS2
7
1186
3850.39
0.49
111.60
exposures
10
22579
5500.55
9.28
107.71
histogram
8
5248
4400.44
2.16
105.92
GND
7
4253
3850.39
1.75
93.75
tones
9
31784
4950.50
13.07
88.91
bits
11
124385
6050.61
51.15
83.20
mapping
9
54474
4950.50
22.40
79.25
local
18
1084374
9900.99
445.90
77.23
curve
9
67284
4950.50
27.67
75.47
exposure
11
196768
6050.61
80.91
73.21
LDR
4
625
2200.22
0.26
64.42
detail
9
201603
4950.50
82.90
55.91
method
11
570353
6050.61
234.53
50.36
light
12
775021
6600.66
318.69
49.90
adaptation
6
48936
3300.33
20.12
49.27
doorway
5
19334
2750.28
7.95
48.49
tutorial
5
22999
2750.28
9.46
46.76
darker
5
27066
2750.28
11.13
45.14
regions
7
170273
3850.39
70.02
42.36
gamma
4
10364
2200.22
4.26
41.99
digital
7
237527
3850.39
97.67
37.80
Scott (2009) classifies key words into three types: i) proper nouns; ii) ‘high frequency words like because or shall or already’; iii) ‘key words that human beings would recognise … [which] give a good indication of the text’s “aboutness”’. We ran our log-likelihood calculation in WebCorpLSE with a stopword filter switched on, so we do not see high frequency words in the key words output. Most of the words in Table 2 belong in Scott’s third category of recognisable aboutness words. Perhaps unsurprisingly, these are words which relate to photography in general, and to digital photography in particular. The abbreviation HDR appears as the top key word and two of its components, dynamic and range, also appear near the top of the list (the other component high appears much lower, at rank 464) [8]. Of course, the words high, dynamic and range are all polysemous, and this highlights a limitation of single word key word analysis: high, dynamic and range in isolation are not good aboutness words for this text, whereas the phrase ‘high dynamic range’, or the abbreviation HDR, are more useful. This is related to the limitations imposed by single word tags in Delicious.
Apart from Photoshop, we do not find examples of Scott’s first category, proper nouns, in Table 2 or, indeed, lower down the log-likelihood output. This may well be a reflection of the type of text analysed. Newspaper articles, a staple of key word analyses, are usually ‘about’ a particular event, involving particular places, organisations and people. In corpus stylistic studies of literary texts, where key word analyses are increasingly used, the characters are central to the aboutness. Our example text, however, is a tutorial on a particular technique, which does not involve any named person (even the name of the author is not included on the page), any location, or any product other than Photoshop (the name of the software manufacturer, Adobe, is not mentioned).
Text type also plays a role in the choice of reference corpus for key word analysis. By using a large web corpus rather than a standard reference corpus such as the BNC, we ensured that words did not appear as key in our HDR text simply by virtue of the fact that they refer to new technology which has appeared since the BNC was compiled. The first version of Photoshop was released in 1990 and there are, in fact, 8 occurrences of the word in the BNC. However, the fact that Photoshop occurs 12 times in our relatively short example text would have up-weighted its keyness massively had we used the BNC as a reference corpus. As it stands, Photoshop occurs 15,569 in our web reference corpus yet is still recognised as key in our example text.
Notwithstanding the requirement for careful selection of a reference corpus, key words are a useful indicator of textual aboutness and, indeed, Amazon has begun to adopt a similar automated procedure to determine the aboutness of books in its online catalogue. The methodology for extracting ‘Statistically Improbable Phrases’ (SIPs), as described on the Amazon website, is highly reminiscent of the key words technique and is, in effect, an automated version of the library indexing system described by Hutchins (1978):
“SIPs” are the most distinctive phrases in the text of books in the Search Inside program. To identify SIPs, our computers scan the text of all books in the Search Inside program. If they find a phrase that occurs a large number of times in a particular book relative to all Search Inside books, that phrase is a SIP in that book.
SIPs are not necessarily improbable within a particular book, but they are improbable relative to all books in Search Inside. For example, most SIPs for a book on taxes are tax related. But because we display SIPs in order of their improbability score, the first SIPs will be on tax topics that this book mentions more often than other tax books. For works of fiction, SIPs tend to be distinctive word combinations that often hint at important plot elements. [9] (our emphasis)
5.3 Core topic-bearing sentences
In previous research projects, the RDUES team has applied the concept of lexical cohesion (Hoey 1991) to document summarisation (Collier & Renouf 1995) and the detection of similar documents (in the SHARES Project: Banerjee 2005). Both of these applications require the extraction of core aboutness from texts and are thus intrinsically related to the IR goal of matching documents to user queries (cf. Hutchins 1977 on the summarisation approach to library indexing).
Lexical cohesion examines patterns of repetition across a text. Hoey’s model draws upon Phillips’ (1985; 1989) work on lexical macrostructure, going beyond the ‘obvious claim … that chapters with shared content will also share vocabulary’ (in effect, the key words approach) to the ‘novel claim … that this vocabulary is tightly organized in terms of collocation … [allowing] the identification of topic opening and topic closing and of the text’s general pattern of organization’ (Hoey 1991: 24). In the lexical cohesion model, ‘links’ are formed when a word is repeated between sentences and a ‘bond’ is formed when the number of links passes a set threshold. Linking words are less trivial markers of aboutness than first-level key words, as textual position is taken into account and the flow of argument is traced. This technique goes beyond the simple ‘bag of words’ approach by up-weighting the key content-bearing sentences. As Hutchins states:
On the whole, the more often a particular item or a particular linkage is mentioned in a text the more characteristic is that item or linkage of the text's content. In general the more frequently occurring participants and activities will tend to constitute elements of the macro-structure. (Hutchins 1977: 12)
Figure 8 shows the beginning of the HDR text with the inter-sentence linking words highlighted. The lexical cohesion model proposed by Hoey (1991) was based not solely on verbatim repetition but allowed grammatical variants, synonyms (together with other ‘nyms’ such as hyponyms and even antonyms), and instantial repetition (co-reference). Our implementation in the SHARES project used stemming as a heuristic for full lemmatisation, and added additional weighting based on word frequency and sentence length. However, we found that allowing sense relations and instantial repetition added too much noise to a fully-automated system, without bringing a significant improvement to the results for our specific task.
Highdynamicrange (HDR) images enable photographers to record a greater range of tonal detail than a given camera could capture in a single photo.
This opens up a whole new set of lighting possibilities which one might have previously avoided for purely technical reasons.
The new "merge to HDR" feature of PhotoshopCS2 allows the photographer to combine a series of bracketedexposures into a single image which encompasses the tonal detail of the entire series.
There is no free lunch however; trying to broaden the tonalrange will inevitably come at the expense of decreased contrast in some tones.
Learning to use the merge to HDRfeature in PhotoshopCS2 can help you make the most of your dynamicrange under tricky lighting while still balancing this trade-off with contrast.
As digitalsensors attain progressively higherresolutions, and thereby successively smaller pixel sizes, the one quality of an image which does not benefit is its dynamicrange.
This is particularly apparent in compact cameras with resolutions near 8 megapixels, as these are more susceptible than ever to blown highlights or noisy shadow detail.
Further, some scenes simply contain a greaterbrightness range than can be captured by current digitalcameras-- of any type.
The "bright side" is that nearly any camera can actually capture a vast dynamicrange-- just not in a single photo.
By varying the shutterspeed alone, most digitalcameras can change how much light they let in by a factor of 50,000 or more.
Highdynamicrangeimaging attempts to utilize this characteristic by creatingimagescomposed of multiple exposures, which can far surpass the dynamicrange of a single exposure.
I would suggest only using HDRimages when the scene's brightnessdistribution can no longer be easily blended using a graduatedneutraldensity (GND) filter.
This is because GNDfilters extend dynamicrange while still maintaining localcontrast.
Scenes which are ideally suited for GNDfilters are those with simple lighting geometries, such as the linearblend from dark to light encountered commonly in landscape photography (corresponding to the relatively dark land transitioning into brightsky).
In contrast, a scene whose brightnessdistribution is no longer easily blended using a GNDfilter is the doorway scene shown below.
Figure 8. Lexical linking words (bold type) in first section of HDR text. (Excerpt reproduced with permission.)
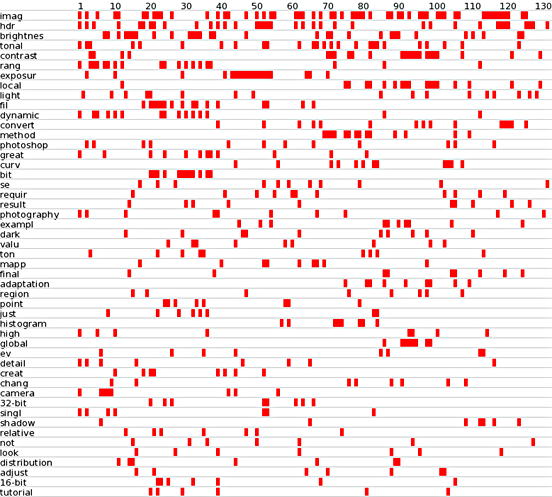
Figure 9 gives a clearer indication of the core linking words and their position in the HDR text. The numbers running across the top show sentences and each block represents the appearance of the corresponding (stemmed) word in that sentence. From this we can see, for instance, that whereas words beginning with imag (image, images, imaging) are fairly evenly distributed throughout the text, the discussion of exposur(e/es) is focussed in one section (sentences 40–55). Furthermore, there is a long section (sentences 15–70) where contrast disappears, only to return later in the text.
Similar patterns have been noted in other work on word distributions in text. Church (2000) showed that content (aboutness) words tend to occur in bursts. This observation must be taken into consideration in any study of aboutness operating at document level, combining the micro-level internal aboutness indicators from the different sections of the document. In the use of social tags as an aboutness indicator, the issue is even more significant given the variation in status of the specific object being tagged. Delicious users are free to assign tags to a website as a whole or to individual pages on that website. For example, a user may tag the root, or homepage, level of the BBC News site or tag a particular article on the BBC News site on a very specific topic. At the same time, other users, encouraged by tagging assistants like SparTag.us (Hong et al. 2008), may be assigning tags to individual paragraphs in an individual article.
Our tagging example in this paper has been at specific article rather than general website level, but both kinds of tag assignment are treated in exactly the same way by Delicious. This adds a level of complexity to the analysis of tags which few authors writing on social tagging appear to have considered.
6. Text-external aboutness indicators
6.1 The author perspective: keywords meta-tag
In his study of lexical macrostructure, Phillips (1985) compared the findings of his analysis of a text with the description of its structure provided by its authors in their preface. He found that the authors’ ‘fairly sophisticated view of the text … conceived of as simultaneously integrated and modular’ was ‘entirely compatible’ with his macrostructural evidence (1985: 67-68). However, this comparison was only made possible by the fact that the text under consideration was an Electronics textbook, broken down into distinct chapters, with an overall introduction describing the content and role of each chapter. For shorter and less formal texts, such an explicit statement of the author’s intention is not available and one must look for other indicators.
As mentioned in section 1, in the early days of web search, authors were encouraged to include a ‘keywords’ meta-tag in the header section of their web pages to describe the aboutness of the pages. Such meta-tags are invisible to the reader but can be used for manual or automated indexing. They are analogous to the ‘keywords’ data given on the first page of academic papers in certain journals (not to be confused with the ‘key words’ extracted by WordSmith Tools). The author of the HDR tutorial specified the following information:
high dynamic range, HDR, Photoshop CS2, CS3, CS4[10]
As a description of the content of the page, this short list of keywords does not offer much and, whilst the author’s chosen title ‘High Dynamic Range (HDR) Photography in Photoshop’ adds slightly more information, it is clear from this example why search engine developers were forced to devise more intelligent methods for indexing web content.
6.2 The peer perspective: Google PageRank
One such method is the Google PageRank algorithm, described in embryonic form by Brin and Page (1998). In simple terms, PageRank associates keywords with a web page based upon the words used to link to that page from other pages, written by other authors. Pages with large numbers of incoming links receive a higher rank, with extra weighting based on the PageRank of the linking pages themselves. In this way, the method goes beyond the author’s view of a text, taking into account other web authors’ views on its aboutness.
WebCorpLSE and associated multi-terabyte corpora allow us to replicate the Google PageRank approach, albeit on a smaller scale, in order to examine the words used to link to our HDR tutorial page from other web pages. These are the words which appear in ‘anchor text’: the clickable, usually underlined and blue, hyperlinks used to weave the web together. In some instances, anchor text offers little extra information with regard to aboutness; e.g. where other web authors have linked to the HDR tutorial using anchor text containing only its web address (URL) or its title as specified by its author (‘High Dynamic Range (HDR) Photography in Photoshop’). In other cases, the word here is the only word in the anchor text, e.g.:
Cambridgeincolour.com has written a detailed example on how to create HDR images from your photos, and can be viewed here. [11]
In this case, it would have been good practice for the author to have used the whole descriptive phrase ‘a detailed example on how to create HDR images from your photos’ as the anchor text (hyperlink) rather than the word here, although the use of the latter kind of link is common on the web. [12]
Nevertheless, some useful phrases do arise from our analysis of anchor text: ‘How to Take Great Digital Photos in Poor Light’, ‘tutorial on creating HDR Photographs’, ‘Create HDR images in Photoshop CS2’. Our small-scale trial does indicate that, on a larger scale, a PageRank-style analysis could present further possible aboutness indicators.
In fact, there are some parallels between the Google PageRank system and social tagging in that both rely on the views of a community to decide what each web page is about and also which web pages are most ‘relevant’ or important. These parallels have led to the suggestion of a ‘FolkRank’ mechanism (Hotho et al. 2006) which uses social tagging data for web indexing and search. We consider the community level in more detail in the following section.
6.3 The reader perspective
In his early work on library indexing, Hutchins explains the role of the indexer as follows:
Every reader interprets a text according to his own knowledge and environment; every reader has his own idea of what ‘topic’ may be. The indexer’s task is to take as broad a view as possible of what others may ‘read into’ a text. (Hutchins 1977: 2)
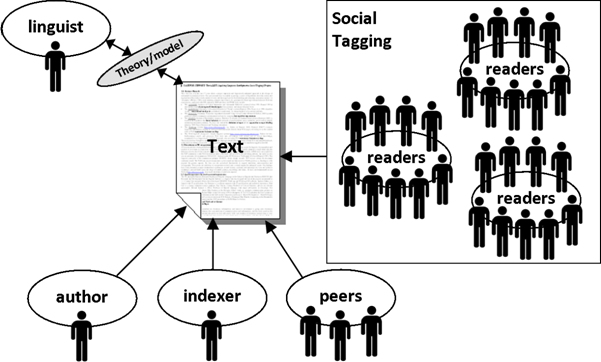
Phillips rejects this intuitive judgement of textual aboutness and instead attempts to derive an aboutness measure solely from the text itself. In doing so, he concludes that the notion of lexical macrostructure ‘provides a vital clue to the reader’s understanding of what the text is about’ (Phillips 1985: 69). Though they adopt very different techniques, both Hutchins and Phillips are attempting to infer what the reader’s interpretation of aboutness may be. These approaches are illustrated in Figure 10.
Figure 10. Perspectives on textual aboutness.
Hutchins is in the traditional ‘indexer’ role in this diagram, determining the aboutness of the text by skim reading it. Phillips is in the ‘linguist’ role, determining aboutness by viewing the text in light of a particular theory or model of language use. Practitioners of the key words approach also occupy this role, where the chosen reference corpus acts as a model of ‘normal’ language use against which the aboutness of a text can be judged. A further perspective in Figure 10 is that of the author’s peers, as exemplified in section 6.2 with reference to the Google PageRank approach.
As we have illustrated in this paper, social tagging offers access to the reader’s view of aboutness in a way which was previously possible only on a small scale through elicitation experiments. The indexer’s role is no longer to adopt ‘as broad a view as possible of what others may “read into” a text’ (Hutchins 1977: 2) but is instead to make sense of the jumble of tags surrounding a text, extract those most indicative of textual aboutness and attempt to find consensus. The indexer can ensure that the view is as broad as possible by considering the views of a whole social tagging community but also by considering the views of different communities, as indicated by the three separate groups of readers in Figure 10. The discussion in this paper has focussed on the social tags assigned to a single text on a single tagging site, but we have also begun to examine tagging behaviour across tagging sites, or across communities. Whilst space does not permit a full discussion, we touch upon a few main points here.
The various social tagging sites focus on the tagging of different kinds of resources, with Delicious and Simpy for general bookmarks and CiteULike, BibSonomy and Connotea for academic references. For this reason, it is not common, we have observed, to find a resource which has been tagged on all five of the sites. However, the previously cited paper on the early architecture of Google (Brin & Page 1998) is one such example. The readership of this academic paper has widened to a more general one as Google itself has become ubiquitous. Table 3 shows the number of users tagging the online version of the paper and the number of tags assigned on each of the five sites [13].
Table 3. Tags assigned to Google paper on five different social tagging sites.
It is clear that more in-depth cross-repository linguistic analysis is required to gain insight into the perspectives on aboutness offered by different user communities. One hurdle to overcome is the fact that there is often variation in the specific entity being tagged within and across tagging sites. For example, the Brin and Page paper appears at four or more different web addresses and is tagged in Delicious as a separate entity for each. The duplicate and similar document detection algorithms we have developed for WebCorpLSE (Kehoe & Gee 2007) will be useful in such cases.
7. From key words to key tags
A new technique we have adopted is to compare the tags assigned to an individual web page in Delicious with those assigned to all web pages in Delicious. Our approach is designed to find the ‘key’ tags assigned to each page, building on the concept of key words. Key tags are those tags from the social tagging lexicon which best describe the content of a particular web page; they are the tags which make a web page ‘stand out from the crowd’ in retrieval terms.
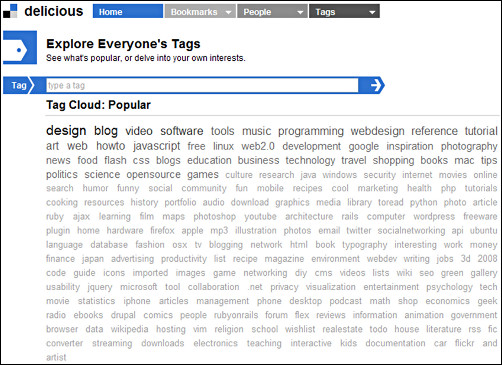
It is possible in Delicious to view the most popular tags on the whole site (Figure 11), although this list is limited to the top 199 tags and it is not possible using the Delicious interface to view a list of all assigned tags. However, if we are to carry out a key words style analysis of the tags assigned to a web page, we require the full tagging lexicon for comparison, or at least an approximation of it beyond the top 199 tags.
We have addressed this by conducting a crawl of the Delicious site using our WebCorpLSE software. We started by downloading the list of most popular tags (the tag list – Figure 11) and using this to ‘seed’ our crawl. Delicious allows users to view the frequency of individual tags and a list of web pages which have been assigned a specific tag (the bookmark list – as shown in Figure 3 for the tag corpus). Alongside each bookmark in Figure 3 are the other tags which have been assigned to it (english, language, dictionary and linguistics in the first case). Our procedure takes each tag in the tag list in turn, downloading the bookmark list for that tag and extracting the tag’s frequency. It then extracts all other tags listed on the bookmark list and adds these to the queue of tags to be downloaded. Using this recursive approach, we can continue to download tags until no new ones are found. As the term implies, this crawling procedure adopts a slow and steady pace and is therefore rather time consuming, taking a month to download data for 1 million tags. For the experiment described in this paper, we used a sample of 100,000 tags.
Table 4 presents the results of a log-likelihood comparison of the tags assigned to the HDR text with the tags in our Delicious sample. An important point to note here is that the Delicious ‘frequency’ is actually the number of pages assigned a particular tag in the Delicious sample rather than the number of times the tag is used in the sample. For example, the tag Photoshop has been assigned to 1,689,018 pages but what we do not know is how many times each of these pages has been assigned that tag by Delicious users. Our figures are therefore an approximation, but we feel that they provide a useful starting point for an evaluation of key tags. This limitation is, in fact, identical to that which arises when linguists attempt to use Google to extract word frequencies from the web, where Google ‘hit’ counts give the number of pages containing a word rather than the total web frequency of the word.
The above caveat notwithstanding, Table 4 offers some interesting results. This output down-weights tags which are assigned frequently to the HDR text but are also assigned frequently throughout Delicious: photos, graphics, art, images, tips and, in particular, reference (one of the top ten tags in Figure 11). It also down-weights mid-frequency tags in the HDR list which are highly frequent in the general tagging lexicon (toread, cool). On this evidence, none of these tags would be an ideal search term for finding the needle that is the HDR text in the Delicious haystack.
The Table 4 output up-weights tags such as hdr, hdri[15], dynamic and range, which are not particularly frequent in Delicious as a whole but which are assigned to the HDR text relatively frequently. These are the most useful tags in information retrieval terms. An interesting comparison can be made between the tags exposure and 3d. The former is assigned to the HDR text less often than the latter (5 times versus 14) but the latter is over eighty times more frequent in the wider Delicious lexicon. As a result, the key tags analysis ranks 3d in position 213 for the HDR text, amongst tags assigned only once.
Table 4. Log-likelihood comparison of HDR tags with tags in Delicious sample.
Tag
HDR Freq
Del Freq
L-L
1
hdr
1320
66081
16738.74
2
photoshop
1373
1689018
8686.82
3
photography
1558
3510240
8013.21
4
tutorial
916
4069916
3518.87
5
photo
456
1512268
2005.27
6
tutorials
373
1901077
1336.80
7
howto
439
3631099
1184.03
8
digital
99
441958
379.43
9
camera
92
354130
378.42
10
hdri
32
4958
334.00
11
dynamic
41
33902
291.54
12
range
30
7485
284.68
13
photos
124
1367540
271.88
14
cs2
15
2521
154.13
15
technique
28
56062
150.44
16
graphics
96
1585783
146.46
17
high
24
39765
137.82
18
guide
52
568098
114.86
19
art
146
4241294
104.88
20
techniques
19
53588
89.47
21
projects
29
250108
76.05
22
color
38
487576
73.57
23
image
38
507644
71.02
24
images
52
1047614
63.53
25
fotografie
13
53524
51.81
26
fotografia
21
199486
51.49
27
effect
11
42744
45.05
28
tips
80
2659813
44.50
29
exposure
5
8316
28.68
30
pictures
20
361079
27.75
31
retouching
6
23483
24.49
…
147
toread
30
1122057
12.82
…
154
reference
98
5403142
10.46
…
159
cool
34
1509718
8.98
…
211
gfx
1
8250
2.98
212
panoramic
1
7107
2.97
213
3d
14
673372
2.79
214
primer
1
12281
2.70
8. Summary
In this paper, we have explored the new perspective offered by social tagging on the established problem of determining textual aboutness. This problem, which was once the domain of librarians and information scientists, has become increasingly pressing as textual holdings have grown to web scale and their audience has widened accordingly. Specialists in a variety of fields have begun to examine the aboutness issues in social tagging, and this paper has described what is, to the best of our knowledge, the first attempt to apply corpus linguistic methods. Our approach is a multi-layered one, which considers text-derived aboutness indicators and attempts to reconcile these with the author’s perspective, as expressed in document meta-data and, in particular, with the perspective of readers, as expressed through social tagging by various online communities.
One of our longer term aims is to encourage better tagging practice in these communities, through the production of a guide to best practice and an automated software assistant to determine the ‘utility’, or usefulness, of a tag. In introducing the concept of ‘key’ tags, we have illustrated one way in which this might be achieved.
We feel that further linguistic insight will be vital, as online textual holdings continue to increase in size, to ensure that social tagging sites continue to function effectively and that the power of social tagging as a window to the views of large numbers of readers can be harnessed effectively.
Notes
[1] The name Yahoo! was apparently chosen as an acronym of ‘Yet Another Hierarchical Officious Oracle’ (http://archive.is/puqz).
[12] It would, in theory, be possible to adopt a collocation-style approach and take the words in close proximity to the ‘here’ hyperlink as indicative of its aboutness. This is, in fact, the approach taken by Google and other search engines for the indexing of images and other non-textual content.
[13] The other sites have fewer users than Delicious. The figure for Delicious is the number of tags assigned to the URL listed under Brin and Page (1998) in the References section of this paper, but see the caveat about multiple URLs. The two figures in each column for BibSonomy are for ‘Bookmarks’ and ‘Publications’, which are separate categories on that site. Phrasal tags are allowed in Connotea.
[14] Search Engine Optimisation – optimising web pages to ensure optimal ranking in search engines such as Google.
[15] An alternative acronym, not used in our example text itself, standing for High Dynamic Range Imaging.
Angeletou, Sofia, Marta Sabou, Lucia Specia & Enrico Motta. 2007. “Bridging the gap between folksonomies and the semantic web: An experience report”. Bridging the Gap between Semantic Web and Web 2.0, ed. by Bettina Hoser & Andreas Hotho. http://www.kde.cs.uni-kassel.de/ws/eswc2007/proc/ProceedingsSemnet07.pdf.
Bruza, Peter D., Dawei W. Song & Kam Fai Wong. 2000. “Aboutness from a commonsense perspective”. Journal of the American Society for Information Science 51: 1090-1105.
Chi, Ed H. & Todd Mytkowicz. 2008. “Understanding the efficiency of social tagging systems using information theory” Proceedings of the nineteenth ACM Conference on Hypertext and Hypermedia, 81-88. New York: ACM.
Church, Kenneth W. 2000. “Empirical estimates of adaptation: The chance of two noriegas is closer to p/2 than p2”. Proceedings of the 18th Conference on Computational Linguistics, Volume 1 (COLING '00), 180-186. Stroudsburg, Penn.: ACM.
Collier, Alex & Antoinette Renouf. 1995. “A system of automatic textual abridgement”. Proceedings of AI95, 15th International Conference, Language Engineering, Montpellier, June 27-30 1995, 395-407.
Deerwester, Scott, Susan T. Dumais, George W. Furnas, Thomas K. Landauer & Richard Harshman. 1990. “Indexing by Latent Semantic Analysis”. Journal of the American Society for Information Science 41(6): 391-407.
Dunning, Ted. 1993. “Accurate methods for the statistics of surprise and coincidence”. Computational Linguistics, 19(1): 61-74.
Hoey, Michael. 1991. Patterns of Lexis in Text. Oxford: OUP.
Hong, Lichan, Ed H. Chi, Raluca Budiu, Peter Pirolli & Les Nelson. 2008. “SparTag.us: A low cost tagging system for foraging of web content”. AVI 2008 The International Conference on Advanced Visual Interfaces, 65-72. New York: ACM.
Hotho, Andreas, Robert Jäschke, Christoph Schmitz & Gerd Stumme. 2006. “Information retrieval in folksonomies: Search and ranking”. The Semantic Web: Research and Applications, ed. by York Sure & John Domingue, 411-426. Berlin/Heidelberg: Springer.
Kehoe, Andrew & Matt Gee. 2007. “New corpora from the web: Making web text more ‘text-like’”. Towards Multimedia in Corpus Studies (= Studies in Variation, Contacts and Change in English, 2), ed. by Päivi Pahta, Irma Taavitsainen, Terttu Nevalainen & Jukka Tyrkkö. University of Helsinki. http://www.helsinki.fi/varieng/series/volumes/02/kehoe_gee/.
Marchetti, Andrea, Maurizio Tesconi, Francesco Ronzano, Marco Rosella & Salvatore Minutoli. 2007. “SemKey: A semantic collaborative tagging system”. Proceedings of WWW2007, Banff, Canada. http://www2007.org/workshops/paper_45.pdf.
Phillips, Martin. 1985. Aspects of Text Structure:An Investigation of the Lexical Organization of Text. Amsterdam: North-Holland.
Phillips, Martin. 1989. Lexical Structure of Text, Discourse Analysis Monograph no. 12, English Language Research, University of Birmingham.
Renouf, Antoinette. 1987. “Lexical resolution”. Corpus Linguistics and Beyond: Proceedings of the Seventh International Conference on English Language Research on Computerized Corpora, ed. by Willem Meijs, 121-131. Amsterdam: Rodopi.
Renouf, Antoinette. 2003. “WebCorp: Providing a renewable data source for corpus linguists”. Extending the scope of corpus-based research: new applications, new challenges, ed. by Sylviane Granger & Stephanie Petch-Tyson, 38-53. Amsterdam: Rodopi.
Van Damme, Céline, Martin Hepp & Katharina Siorpaes. 2007. “FolksOntology: An integrated approach for turning folksonomies into ontologies”. Bridging the Gap between Semantic Web and Web 2.0, ed. by Bettina Hoser & Andreas Hotho. http://www.kde.cs.uni-kassel.de/ws/eswc2007/proc/ProceedingsSemnet07.pdf.
Van Dijk, Teun A. 1972. Some Aspects of Text Grammars. The Hague: Mouton.
Xu Zhichen, Yun Fu, Jianchang Mao & Difu Su. 2006. “Towards the Semantic Web: Collaborative tag suggestions”. Proceedings of WWW 2006. Edinburgh. http://www.ibiblio.org/www_tagging/2006/13.pdf.
Zipf, George K. 1935. The Psychobiology of Language. Boston: Houghton Mifflin.