This paper introduces the Helsinki Archive of Regional English Speech (HARES) and the protocols the HARES team chose for its compilation. Transcribing rural speech and compiling it into a fully functional archive or corpus is riddled with problems and pitfalls that must be acknowledged during corpus compilation (see e.g. Beal et al. 2007). In this paper, I will comment on the problem of content description, previously visited in my unpublished Master's Thesis (Ahava 2010a). The question is whether or not transcriptions combined with a versatile enough annotation schema (XML with TEI specifications in the case of HARES) can solve the paradoxical problem of using text to describe speech. This problem is persistent especially when grammaticality of the transcribed utterance is under scrutiny. Thus I will also introduce an intermediate variant in the past BE paradigm of Cambridgeshire dialect speakers (Ahava 2010a, see also Richards 2010) and illustrate how it characterises the problem of content description, which people doing transcription work and spoken language corpus compilation must resolve. [1]
1. Introduction
These are interesting times for rural language studies. With the supply and ease of use of digital media, we can approach language data with research questions and methods that would have been difficult to imagine, let alone to come by, a little more than two decades ago. In the realm of textual linguistics, we have projects such as the digitised English Dialect Dictionary (EDD; see Markus 2008), which makes accessible one of the most revered publications in dialectology and rural studies. Projects such as BBC Voices and the Newcastle Electronic Corpus of Tyneside English (NECTE, see Beal et al. 2007 and Beal & Corrigan in this volume) have brought about an increased respect for linguistic diversity and variation both across and within speech communities. Beyond the audio-textual interfaces of BBC Voices and NECTE, it is now also possible to include video stream, images, hypertext and even GPS data in corpora, language archives and published articles. These technological advances have helped bridge the gap between concepts and contexts, the latter having received increased importance in language studies over the recent years (e.g. Carter & Adolphs 2008). Indeed, in certain cases it is impossible to compile a corpus without encoding contextual metadata. XML-annotated corpora rely more and more on the specifications authored by the Text Encoding Initiative (TEI), and these guidelines require that specific elements of extra information are included in every corpus file.
However, giant leaps in the realm of innovation come at a price. Even if the methodology is sound, and this is not always the case as I argue in this paper, new technology is spearheaded at the expense of some fundamental concepts which deserve re-evaluation but are brushed aside due to their self-evident nature. One such concept, rooted in the methodology of transcription, is encapsulated by Halliday (2002: 21): "spoken language is not meant to be written down, and any visual representation distorts it in some way or other". As transcriptions remain the most viable way to approach data, at least in traditional spoken language research, this problem of content description must be addressed during corpus compilation and in any subsequent research on the data.
Another problem, the problem of content analysis, is the misalignment of spoken and written language when it comes to questions of grammaticality or functionality. Approaching spoken language data with pre-established categories (Haspelmath 2007), most often firmly rooted in the grammar of Standard English, obscures any attempt to formulate an elegant description of the phenomena found within. As I argue in this paper, this problem can be partly overcome by choosing an approach that balances between apriorism and insights derived directly from the data. It should also be noted that refining linguistic theory to solve the problem of content analysis cannot be separated from the methodological re-evaluation that the problem of content description requires. Thus the two problems are intertwined, and all stages of data collection, description and analysis must involve problem solving on both fronts.
This paper is a partial rewrite of my Master's Thesis (Ahava 2010a). Here the main focus is on the Helsinki Archive of Regional English Speech (HARES, see Section 3) and the ways in which we approached the problem of description. HARES is a collection of audio-recorded rural speech, collected in the 1970s and 1980s. This paper illustrates how the first HARES module, the Cambridgeshire sampler (HARES-CAM), was compiled and how the problem of content description was tackled during the process (see Section 4). I will introduce the problem of content description in more detail in the next section, after which I will give an example of a situation where the problem persists (the intermediate past BE variant). The secondary purpose of this paper is to act as a roadmap for (spoken) language corpus compilers (see Ahava 2010b). The protocol I illustrate later in this paper contains a detailed description of the annotation schema we adopted for HARES compilation. Working with TEI specifications allowed us to simultaneously highlight the uniqueness of the material while situating it within the larger sphere of digital research materials.
2. Tools and methods of spoken language corpus compilation
The heterogeneity of languages, dialects, speech communities and even the idiosyncratic varieties of each individual speaker is reflected in the lack of a standardised protocol for spoken language transcription (e.g. Moore 1999) and, in some cases, the compilation of a corpus. The situation is mirrored by the seemingly endless amount of different research questions the data must be subjected to answer. Whether the data are intended to shed light on the lexicon of the speakers (e.g. the Survey of English Dialects (SED) and the EDD), syntactic and vernacular idiosyncrasies in general (e.g. HARES and NECTE) or linguistic diversity on a global scale (e.g. Linguistic Atlas Projects and the International Corpus of English), encoding the data is first and foremost reliant on the compilers' own subjective demands. However, this situation should perhaps remain unremedied. Having a standardised annotation protocol (XML) allows the compilers to rely on their own judgement in compilation matters, as long as the data are encoded according to guidelines that are versatile enough to allow for a multitude of different approaches to the data, while at the same time being standardised enough to make data conversion, comparison and extraction easy across and within individual corpora.
Naturally, the relationship between transcription and annotation protocols is, at best, strained and relies on the presence of or ease of access to the primary data (audio, in this case). Verifiability of data shifts the responsibility of data interpretation from the transcriber to the end user (e.g. Miller & Weinert 1998: 12). In situations where the corpus has been compiled according to the principle of having the primary data at hand, it becomes, of course, absolutely necessary to actually include the audio in the corpus. Otherwise we end up facing the concern that Svartvik (1992: 10) has articulated as follows:
The greatest risk of all, however, is the distance that may arise between the end user of a standard corpus and the primary textual material - a danger that is particularly imminent in the case of impromptu speech which has been recorded and orthographically transcribed by others than the user and where the actual audio-recording is not readily available or properly consulted.
If the audio data are included in the end product, what is left is to choose an annotation protocol that does not hamper data interpretation and situates the data within the larger framework of other projects that employ the same annotation schemata. The fact that XML constructs with TEI specifications are emerging as some sort of "world standards" (Kretzschmar et al. 2006: 195) for encoding digital collections of language permits the corpus compilers and end users to ask research questions that in the case of the HARES data, for example, would not have been possible to ask during data collection (see Section 3.1). Thus advances in the methodology of spoken language research and the development of tools in the field reveal new paths for the research to take. The opposite is also possible, where more and more ambitious research questions guide the methodology:
A particular challenge for current research is therefore to integrate the computer-enabled power of corpus linguistic methods with the theories and practices of multimodal communication research - in other words, to provide computerised analyses of key patterns of meaning and to establish norms and regularities for these patterns. (Adolphs & Carter 2007: 135)
Finally, the question remains just how much context can we include with the data? Bloomfield problematised human interaction by stating that "[t]he situations which prompt people to utter speech, include every object and happening in the universe" (1933: 74). Trying to keep up with the fluctuations of human interaction and to draw conclusions that might extend beyond the scope of the data at hand are challenges that technology and theory have yet to conquer. An example from rural language studies would be the difficulty of defining just what is considered vernacular. According to Labov, the vernacular is something that emerges when the speaker is comfortable with his or her surroundings and when attention is diverted away from his or her speech (1972: 209). However, the vernacular that is hypothesised to emerge when constraints of the Observer's Paradox are eliminated is still only an abstraction and situated spatially and temporally in that particular speech situation.
There is also the matter of shared background knowledge between speakers in interaction, which defies satisfactory analysis. What conclusions can be derived from audio recordings, video clips and other products of technology if some contextual information is always situated in the confines of the speakers' minds? This is the great challenge of context evaluation in research within and beyond the field of spoken language studies.
2.1 The problem of description
The crux of the matter is this: because printed media are the main channels of information diffusion, all other data types are subservient to the development of tools, methods and theories in the realm of written language. Having a PLAY button in the pages of a printed journal article is hardly cost-efficient to realise with current technology. Similarly, coming up with any means of content description for spoken language data other than category labels such as 'word', 'noun' or 'uh', for example, is difficult and would require a paradigm shift in the study of language. We have, therefore, accepted transcriptions as the main medium of data description in studies of spoken language (cf. Moore 1999, Halliday 2002, Adolphs & Carter 2007). Optimally, a transcription assigns a text label to an event contained within an utterance of the speaker. This event should be clearly identifiable as belonging to a certain lexical category, being detailed enough to situate itself comfortably within the morphophonological boundaries of the lexeme while being vague enough to allow for some elbow room in the form of idiosyncratic and dialectal variation. Thus we can type, optimally again, anything for anythin', anythang and even anythink, but not for only thing.
The problem is, of course, that 'optimally' occurs rarely in the kind of language present in HARES. Indeed, 'optimally' would be a word most often associated with spoken language representations that are closer to Standard English and not the kind of rural speech that is omnipresent in the dialects of HARES informants. Rural speech is not only rich with archaisms and linguistic oddities that would be difficult to situate in any Standard English grammar book, but it is also inextricable from the cultural context it occurs in. In the example (1) below, the Devonshire informant switches to a broad form of his dialect to illustrate the peculiarities of the vernacular.
(1)
w- when us <pause/> when us thinks back about the things <pause/> what us used to do before there was these here <pause/> newfangled tractors like I'm sitting on now <pause/> but years ago when <pause/> everything had to be done with horses walking along behind them all the time
Crafting a grammatical description of what goes on in example (1) is daunting. The speaker switches to what he considers a broad form of the Devon dialect, exemplified by his use of us where the first person pronoun I would be expected. Even though an inventory of the features of this informant's dialect would be relatively straightforward to compile, assigning functional values to phenomena such as the pronoun substitution above would require further research to identify whether the variation is lexical or grammatical (cf. Trudgill 2008). Furthermore, since this is the informant's own perception of what the Devonshire dialect sounds like, an elegant description would require further discussion with the informant himself, which would, in turn, require an appraisal of the dangers of elicitation (Ihalainen 1981).
Example (2) shows a characteristic case of resilience to interviewer input. The interviewer provides the Standard English structure in her question (go to Cambridge), but the informant rejects this in favour of the structure he acknowledges as more familiar (go Cambridge). This means that speakers uphold a strong psychological allegiance to the idiosyncratic ways in which they use their own language. Thus, to analyse (2) as an example of a speaker 'dropping' the proposition is possibly a faulty approach, because this type of non-expression of the preposition might simply be a feature of the speaker's idiosyncratic variety of speech. Indeed, the speaker might not be aware that, from a grammatical point of view, anything is missing (see the Cambridgeshire Dialect Grammar).
I am not arguing that description of rural language is impossible. It simply requires more than the casual juxtaposing of Standard English orthography and grammar with what one hears on the audio track. As I will present in the next section, the danger of misrepresenting the data by overt abstraction simply because one does not listen with enough scrutiny is real. Relying too much on pre-established categories blunts the edge of linguistic description very much in the same way as treating linguistic heterogeneity as a "tolerable imprecision of performance" (Weinreich, Labov and Herzog 1968: 121) undermines the empiricist's agenda.
The elusive notion of abstraction and to what extent it should be applied when dealing with empirical data is at the heart of the problem of description. Labelling a sample of spoken language with arbitrary and abstract labels such as 'word' or 'phrase' is controversial but commonplace. Abstraction as a law rather than exception has long traditions in the history of the discipline, but it was especially Chomsky's (1965) legitimisation of idealisation that came as a relief to the scholarly community in his wake. With the powerful agenda of the generativist school of thought, it was not surprising that mainstream linguistics proceeded to "ignore variation that challenged this idealization" (Adger & Trousdale 2007: 262). Though Chomsky advocated the abolition of all discovery methods (1957: 56), his universalist approach to language was, perhaps, healthier than the kind of puritan descriptivism exemplified by e.g. Boas (Haspelmath 2007: 122). Today, we are wiser and recognise that the most realistic approach would be somewhere in the middle of the cline between empiricism and universalism. However, it is still necessary to spell out explicitly what the level of abstraction is that transcribers, for example, have adopted in their work.
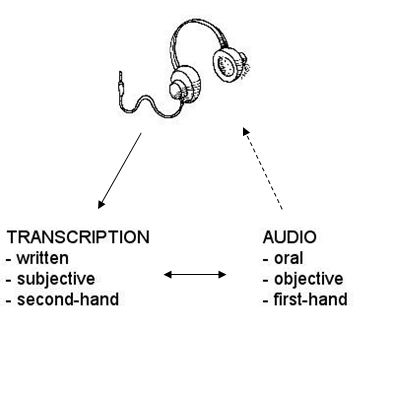
Indeed, the fact remains that transcriptions are often simply subtitles. They exclude far more than they include. Even though it is possible to invent markup that would include prosody and other contextual information, any given speech situation involves shared knowledge, implicit references, minute visual cues and background information that are all difficult to describe, never mind transcribe (Ahava 2010a: 8). The distance from the primary data that transcriptions impose upon the transcriber and the analyst forces the latter to work in the order illustrated by Figure 1. Even though the audio is present, direct, a priori consultation is rare thanks to the textual interface of the query and search application. Furthermore, transcriptions are, in essence, subjective interpretations made by the transcriber. They are his or her own research (cf. Ochs 1979) and should be treated as such. Add into this mixture the problems with describing rural speech and desperation is ready to set in.
Figure 1. Compiling and using spoken language corpora. [4]
Problems with transcribing (rural) speech have been addressed many times before (e.g. Preston 2000, Beal et al. 2007, Tagliamonte 2007, Carruthers 2008), and the general consensus seems to be that while transcriptions are admittedly a 'necessary evil', there are ways to overcome the problem of description at least to a certain degree. With HARES, we abided by the following rules of thumb:
1. Treat audio as the primary data 2. Translate what you hear to Standard English orthography 3. Annotate all irregularities with metadata
I will explain how these rules have affected HARES compilation in Section 4, but their immediate effect on the description and subsequent analysis of a specific linguistic phenomenon is introduced in the next section.
2.2 That wa lovely dairy we had
As an example of how difficult transcription sometimes is and how much it is affected by the transcriber's own intuition, a special feature of the Cambridgeshire dialect is presented here. The past BE paradigm is one of the most researched items in dialectological studies and features in an impressive amount of literature (see Ahava 2010a for a summary). Traditionally, the focus has been on the two most salient members in the paradigm, was and were, and their distribution among the speakers of one or more speech communities. However, HARES data from Cambridgeshire show that some of the speakers utilise a neutral form of the past BE verb across all contexts. This structure can be heard in the following audio segment.
(3)
well we'd always got some <pause/> in the dairy cos that wa lovely dairy we had
This structure can be best described as an intermediate variant. [5] It is not an allophonic realisation of was or were (Ahava 2010a, Richards 2010) nor is it clearly distinguishable as an allomorph of either one. Because it is highly frequent in all contexts among certain speakers, it fits into the mould of those dialect features that would require re-evaluation in terms of grammaticality and orthography. Approaching this variant with pre-established categories in mind would require that the researcher assign the variant to either was or were, depending on what his or her research aim is. If one were to respect the rules and structures of Standard English, the variant would be transcribed as was, as it has a singular subject. However, Cambridgeshire is rife with levelling to were (Vasko 2010, see also Trudgill 2008), and the variant could be considered a phonetically derived form of were (Richards 2010). In this case, it would be transcribed accordingly. However, a quick listen to the speaker reveals that even he is not consistent with his use of past BE.
(4)
and I think that was four and a half mile to bike up the Lode bank up to Upware
In (4), that occurs clearly with was, and in (5), the speaker uses that with were, even though the interviewer provides the Standard English grammatical structure in the question ("that was a lot of money then"). Admittedly, in the last example the verb is in stressed position in the utterance and thus not directly comparable to the other two examples. However, the important fact is that the speaker uses it and thus displays allegiance to the non-standard structure which is embedded in his own personal grammar.
Examples (6-8) provide evidence from another speaker in Cambridgeshire. As with cam09, she is inconsistent with her use of past BE, using was in (7), were in (8) and the intermediate variant in (6), all with singular subjects. Note that in (8) the verb occurs again in stressed position, but I argue that it is a useful example of how dialect speakers regularly defy the rules dictated by Standard English grammar and how the non-standard structure is firmly embedded in the grammar of the speaker. Looking for unstressed were is problematic, as it only occurs with an audible /r/ release in pre-vocalic position. Here, I believe, we find some overlap with the intermediate variant and were because whether we categorise this rhoticised variant as unstressed were or a rhoticised version of the intermediate variant boils down to our point-of-view. If one wishes to solidify the distinction between the variants in the paradigm, this rhoticity should be analysed in further research. In this paper, I am satisfied to accept that this type of overlap is typical of the fuzziness that exists within the paradigm.
How, then, to describe, transcribe and analyse the intermediate variant if even the speakers themselves are inconsistent in its use? Reverting to was or were with insufficient evidence would take away from the charm of this new entry into the paradigm. Richards' and my data concur that the frequency of the intermediate variant should establish its salience as a distinctive variant in the past BE paradigm of the speakers studied (see Table 1). However, as our studies are restricted in time and space to the speakers we looked at, it might be too early to make changes in grammar books. What we have done is identify an underlying process in the paradigm, one which may prove to be significant if more data are included in the analysis. Nevertheless, our findings are conclusive, and thus any studies done on the past BE use of these speakers are potentially falsifiable if they do not take into account the possible existence of this new variant.
Table 1. Frequency data gathered from Richards (2010) and Ahava (2010a).
Data set
Intermediate past BE % in affirmative contexts
cam02
66
cam04
49
cam09
32
cam10
74
Richards
65
What needs to be done is a careful survey of the phenomenon. This would require a hypothesis that is both intuitive and data-driven, a methodology that combines quantitative and qualitative tools and, finally, an appraisal of the results that simultaneously highlights the unique quality of the phenomenon while confessing that it is delimited in time and space to the utterances available on the analysed speaker. This is what was done by Ahava (2010a) and Richards (2010). Their findings illustrate the emergence of the intermediate variant in two separate speech communities. Even though a lot of research remains to be done on the subject, reducing the intermediate variant to an allomorphic relationship with its two more famous siblings, was and were, is, as found by Richards and myself, erroneous. [6]
After preliminary research is done, steps can be taken to ensure that the variant is described in a manner that acknowledges its uniqueness. As explained in the previous section, we relied on three main principles during HARES compilation. Bearing these in mind, the new variant can be orthographically represented and annotated so that it does not make browsing the corpus an arduous task and so that it does not disappear into the vast amount of utterances within the archive. Here are the principles reiterated with a review of their implications on the intermediate variant and its transcription and annotation into the corpus:
1. Treat audio as the primary data – Even though this is more an ideological than a concrete step in the protocol, it is, in many ways, the most important guideline. Treating the audio as the primary data means that we, as corpus compilers, shift the responsibility of interpretation and judgement to the corpus user. Since the audio is readily available, there is no reason for corpus users to accept our interpretations (the transcriptions) as perfect representations of what is said, but they can formulate their own hypotheses. In terms of the intermediate variant, this means that we only have to make the variant known to the user, after which he or she can look for it, annotate it, extract it and research it in any way he or she chooses to, regardless of what we have done before.
2. Translate what you hear to Standard English orthography – This is perhaps more controversial but still necessary. Traditionally, corpora of rural speech needed to be transcribed in more detail because audio was not available to the users (see Section 3.1). The use of 'eye-dialect' was commonplace (see e.g. Peitsara 2006) as were various methods of describing dialectal peculiarities. However, I argue that the more the audio is integrated into the corpus the more obsolete these special transcription measures become. Be that as it may, the intermediate variant is not readily translatable to Standard English orthography, as explained above. It would require a new lexical entry altogether. Introducing such a newcomer into Standard English orthography would be a rash decision mainly because the event has no precedent. It is simply too bold to usher in a new past BE verb as long as research on the topic is still ongoing and indecisive. In HARES compilation, we transcribed the intermediate variant according to what Standard English grammar would require. Thus "that wa lovely dairy we had" became "that was lovely dairy we had".
3. Annotate all irregularities with metadata – However, we do need to highlight the special quality of the new variant somehow. This is where annotation comes into play. Using XML code, we can introduce a tag that gives specific information about its content without upsetting the data at all. Thus, we would transcribe what we hear as "that was lovely dairy we had", but we would also introduce a special <w id="INT"> was </w> tag around the past BE verb, indicating that what we hear is the intermediate variant. This is a simple albeit partial solution to the problem of content description, which permits us to avoid the difficult problem of giving a fool-proof description of the data by using multiple levels of annotation (orthography and metadata).
The method above, in short, is our solution to the problem of description. However, it is not complete and must be reinforced with a thorough manual, extensive research and the readiness to accept that the method might not be the most sophisticated one. In the following section, these problems and insights will be inspected with more scrutiny and across the entire process of HARES compilation.
3. Helsinki Archive of Regional English Speech (HARES)
HARES is a collection of audio-recorded speech collected in England in the 1970s and 1980s. The fieldworkers were Finnish graduate and post-graduate students from the University of Helsinki. The project began as an effort to append the Survey of English Dialects (SED) with data for syntactic study (see Section 3.1). Because syntactic studies require longer stretches of speech than what could be elicitated with questionnaires and wordlists, HARES data were collected in informal interviews between one or more interviewers and one or more informants.
To encourage the informants to speak, they were given free reign over topics of conversation. Even though the interviewer led the interview with leading questions, he or she did not, in general, stop or redirect the conversation if the informant sidetracked. This meant that the conversations developed naturally, and the speakers were perhaps more comfortable than if confronted with more direct approaches. This also meant that elicitation of any structures that the interviewer found interesting was difficult. In order to diminish the effect of the Observer's Paradox, it was necessary to avoid elicitation (Labov 1972: 209). The fieldworkers went so far as to mask their true research interests in linguistic study by introducing themselves as history aficionados and students of local culture.
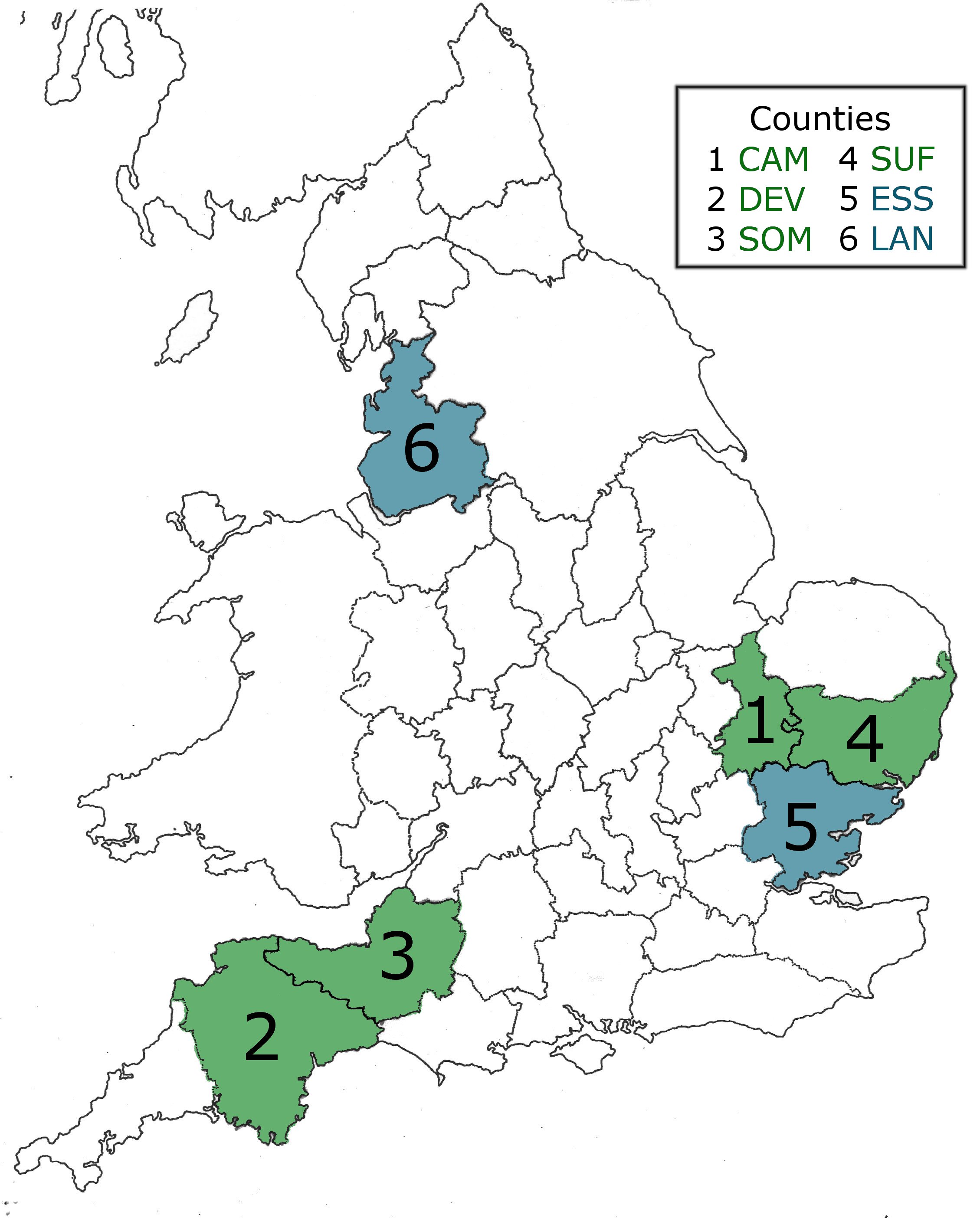
All in all, HARES consists of circa 211 hours of recorded material. Data come from seven counties: Cambridgeshire, Devonshire, Essex, Isle of Ely, Lancashire, Somerset and Suffolk (see Figure 2).
Due to the enormity of the project, HARES has been compiled in modules. At the end of 2010, the first module, the Cambridgeshire sampler (HARES-CAM; see Section 3.2), has been completed and released for academic use by the Research Unit for Variation, Contacts and Change in English (VARIENG). All subsequent sections in this paper and references to compilation have to do with HARES-CAM, but the protocols will be same for the future modules, too.
The next sections will introduce HARES and the sampler in more detail, together with the compilation protocol we adopted to minimise the effect of the problem of description on the data.
3.1 Brief history
When discussing HARES history, it is important to understand that HARES and the first corpus of the dialect project, the Helsinki Corpus of British English Dialects (HD), are both only interpretative devices intended to make best use of the audio by whatever technological means have been available during corpus compilation. The interview recordings are the heart and soul of the data, which means that if the end user is not satisfied with the methodological approach taken by HD or HARES, he or she can approach the data directly and craft new ways to interpret the audio.
Our understanding of the technology which enables us to make the most out of the audio and our apprehension of the research climate which permits us to burrow further and deeper into the data mirror the aspirations and the original motivation of the research team that began working on the project in the early 1970s. The Helsinki Dialect Syntax Group, as it was called, comprised of the project leader, Professor Tauno F. Mustanoja, and a group of Finnish postgraduate students eager to uncover patterns of morphosyntactic variation in the speech of rural inhabitants of England (Vasko 2005: 38-39). The project was originally intended to supplement SED, which was one of the largest dialect projects of the 20th century but one that focused exclusively on phonological and lexical phenomena (see e.g. Orton 1962).
In order to uncover patterns of syntactic variation, the fieldworkers needed to familiarise themselves with the informal interview method, which was a major departure from, for example, SED and EDD, which had gathered data by using questionnaires and wordlists. The problem was that these "direct elicitation methods" (Ihalainen 1981: 27) were seen as potentially harmful to the collection and analysis of natural language. The interview method, on the other hand, was all about avoiding direct elicitation. A top priority among the fieldworkers was to induce a relaxed atmosphere during the recordings, so that the informants would feel comfortable enough to not pay attention to distractions such as the presence of a microphone, a tape recorder and an interviewer, who was most often a stranger to the informants.
The fieldworkers gathered data from seven regions of England: Cambridgeshire, Devon, Essex, Isle of Ely, Lancashire, Somerset and Suffolk [8]. The informants were mostly 'typical' dialect speakers (cf. Chambers & Trudgill 1980: 33), i.e. elderly, rural, minimally educated males. However, female informants were selected as informants especially in the Cambridgeshire and Isle of Ely data, marking a departure from the aforementioned informant selection criterion which was common in other dialect projects of the time (Vasko 2005: 45-48).
In the early 1980s, the dialect data were computerised as orthographic transcriptions to be included in the otherwise diachronic Helsinki Corpus of English Texts (HC) as the dialectal, synchronic part. The dialectal part was later labelled the Helsinki Corpus of British English Dialects. During this stage of the project, the orthographic transcription protocol was idiosyncratic and tailored according to each transcriber's own research interest. As HD was developed further, the transcription protocol remained largely the same. A main concern was that since the interviews were contained on reel-to-reel tapes, it was impossible to include audio data in the corpus and thus the transcription protocol had to include orthography that highlighted the dialectal structures. Even though the HD transcription protocol was later standardised to some extent (Vasko 2005: 58), it was still very much biased towards a more faithful representation of the non-standard structures and the hapax legomena heard in the recordings.
HARES, then, was developed with a new and more transparent approach to the data in mind. Because the original reel-to-reel tapes were digitised, it was now possible to include the primary data in the corpus and, consequently, to create a more transparent transcription protocol. However, with the integration of audio technology and a more standardised orthography came a new problem: how to combine the audio and the transcriptions into a functional corpus? The answer was provided by XML. Even though XML and other markup languages had been for long used in the annotation of digital data, it is the introduction of the Text Encoding Initiative (TEI) guidelines into (spoken) language corpus compilation which truly opens up a world of possibilities for the corpus compiler (e.g. Allen et al. 2007, Carruthers 2008). TEI is a consortium which develops guidelines for annotating and encoding digital data. TEI provides customisable XML schemata in modules which can be combined to create the best protocol for each project (see Section 4.2 for a description of how TEI guidelines were put to use in HARES).
With a standardised and transparent orthographic transcription protocol and with a flexible and extensible annotation schema, I argue that HARES is currently the best way to interpret the audio data. Being able to negotiate such idiosyncratic structures as the intermediate past BE variant into a corpus is a major achievement in the development of an archive that is both easy to use but powerful enough to fuel even the most ambitious research aims. Another perk with using XML with TEI guidelines is the extensibility of the schemata. TEI guidelines are being constantly developed and the consortium boasts a large support network of developers. With each new update to the guidelines, projects such as HARES can be optimised even further to pose new questions on and provide new insights to the original, unique data content.
3.2 The Cambridgeshire sampler of HARES
The sampler is an 18-hour-long collection of audio from Cambridgeshire. The sampler consists of:
20 audio files – the interviews themselves (see Table 2)
20 XML files – transcriptions encoded in XML (see Section 4.2)
20 TXT files – transcriptions minimally annotated for use as a plain text corpus (see Section 4.3)
Table 2. Audio files in the Cambridgeshire sampler. [9]
Audio file
Length (hh:mm:ss)
Size (KB)
cam01.mp3
00:49:08
46 067
cam02.mp3
00:40:03
37 550
cam03.mp3
00:54:07
50 741
cam04.mp3
00:36:33
34 266
cam05.mp3
01:01:26
57 600
cam06.mp3
01:32:22
86 609
cam07.mp3
00:54:35
51 188
cam08.mp3
01:34:59
89 054
cam09.mp3
00:47:41
44 715
cam10.mp3
00:51:50
48 598
cam11.mp3
00:46:53
43 963
cam12.mp3
00:47:29
44 521
cam13.mp3
00:46:52
43 947
cam14.mp3
00:22:17
20 892
cam15.mp3
01:16:32
71 753
cam16.mp3
01:14:00
69 384
cam17.mp3
00:35:12
33 003
cam18.mp3
00:47:23
44 438
cam19.mp3
01:34:35
88 685
cam20.mp3
00:46:43
43 805
TOTAL
18:40:40
1 050 824
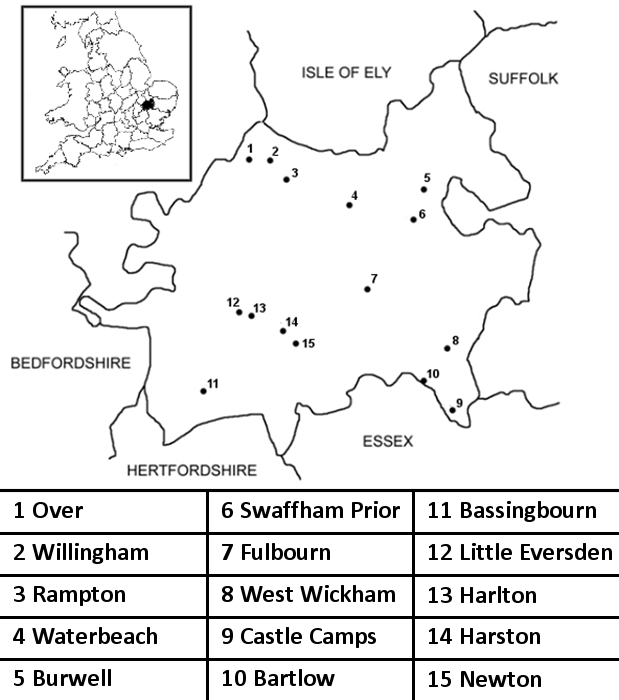
The interviews were conducted in 15 villages around the area (see Figure 3). The interviews were generally 45 minutes in length, but there are exceptions. Most of the informants are typical HARES informants: elderly, minimally educated men in rural professions. However, Anna-Liisa Vasko, the Cambridgeshire fieldworker, also interviewed women during her fieldwork (see Vasko 2005) and two of these interviews are included in the sampler. Villages were selected from around the county, and they represent a fairly good geographical distribution of the region. Willingham is represented with five interviews, mainly because Vasko resided in Willingham during her stay in the county and thus familiarised herself with the locals better.
Figure 3. Villages in the Cambridgeshire sampler. [10]
The sampler provides a unique insight into the lives and times of the informants, with stories from as early as the mid-19th century. Even though the archive began as a strictly linguistic venture, with modern technology coupled with a heightened interest in local culture and history the archive and the sampler can be used to cater to a wide variety of research interests. Indeed, the multiple uses of the archive have had a direct consequence on the compilation protocols we chose. As I illustrate in the next section, transcription and annotation protocols were deliberately tailored to support the thematic content of the interviews as well as the linguistic data.
4. Compiling the Cambridgeshire sampler
The sampler was compiled for two main reasons:
1. To supplement the Cambridgeshire Dialect Grammar (CDG).
2. To create, use and review a set of protocols for transcribing, annotating and maintaining spoken language data in a corpus.
CDG is a grammatical account of the Cambridgeshire data. It contains hundreds of examples of the informants' speech and gives a detailed description of the utterances. HARES-CAM supplements Vasko's work by aligning the examples with their audio counterparts in the digitised interview files. Having the audio paired with the text examples will give readers and users of CDG a chance to listen to the primary data for which the grammatical description was crafted in the first place.
Using CDG as a motivation for sampler compilation meant that informant and locality selection criteria for the sampler were largely dependent on the informants sampled in CDG. Nevertheless, the sampler is fairly representative, with villages from all around the county and with only Willingham (four interviews), Rampton (three interviews) and Waterbeach (two interviews) represented more than once. We included cam16 in the sampler, even though it was not referred to in CDG. However, the interview has a female informant as the interviewee and was included in order to increase the representativeness of the corpus.
The second reason (2) was the guiding thought behind the sampler, and it enabled us to create a roadmap for future HARES work. We considered it especially important that transcription and annotation work should require an inherently critical approach. Because we were translating what we heard to Standard English orthography, questioning and double-guessing our own decisions during compilation resulted in numerous passes over the audio by all members of the HARES team. Even though this slowed the process down, we consider this part of the protocol most important because it highlights both the uneven quality of the audio data and the way how we all hear things a little bit differently. It is surprising how even the segments that the native English speakers in the HARES team found crystal clear upon the first pass of the audio could be disputed, modified and completely altered by the time the segment had been listened to by all the members. This critical approach should be extended to all work on spoken language transcription, not just rural speech. Nothing benefits transcription work more than cumulative interpretation of the primary data.
4.1 Transcribing the audio
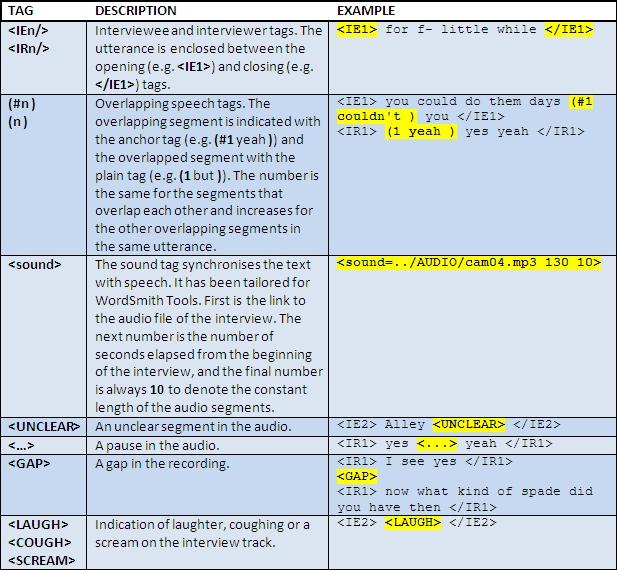
We approached the digitised audio with the questions: how do we transcribe the audio so that it would be possible to align the text and the speech in the corpus, and how do we keep the archive modular, so that new tiers of data could be appended to it in the future? In this, we turned to NECTE (see e.g. Beal et al. 2007), which had partially answered these difficult questions for us. Using XML with TEI P5 guidelines provided a versatile tag set for the transcription of oral data, and it is possible to add new tiers of data at a later stage without having to disturb any of the original content.
For the actual transcription work, we used Transcriber, a freeware utility for transcribing digitised audio recordings. With Transcriber, it was simple to segment the audio, to indicate who is speaking in any given utterance and to extract the transcription as a Transcriber XML file. Early on we decided against pause-to-pause or utterance-to-utterance segmentation because doing so would have required far more time and resources than we had available. Like NECTE, we decided to anchor the audio to the text in segments of constant length. NECTE had chosen 20 seconds as their segment length; we decided to go for 10-second-long intervals. Even though this meant that more often than not the anchor is contained within an utterance, sometimes even within a word [11], we saved a lot of time and resources.
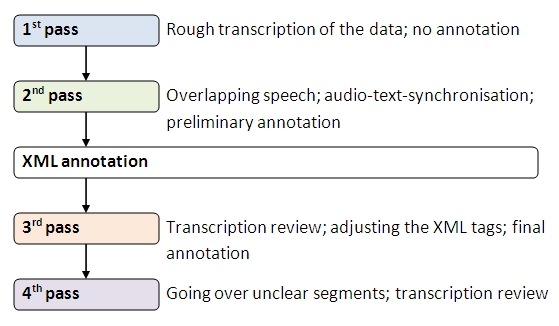
Our method is illustrated in Figure 4. Transcription involved many passes over the audio, with the last pass being the very last thing we did before declaring corpus work finished. Naturally, every time someone listens to the audio, whether for transcription review or research purposes, the number of passes is increased by one. We accept the fact that the transcriptions are not complete. Needless to say, there are still countless segments which could easily be disputed and modified. We accept this as a quality of the primary data, not as a quality of the people who did the transcription work. Rural speech is difficult to decipher, and as presented in the previous section not all of the 'clear' cases are without controversy, either. The informants speak through their pipes and false teeth, frequently walk around the room, talk over each other and completely forget that there is a microphone present. Even though these aspects of the interview were necessary to ensure the emergence of everyday speech (Vasko 2005: 40-42), they make some of the utterances difficult to understand [12].
Figure 4. HARES transcription method.
The transcription protocol we chose for HARES follows Standard English orthography. However, in some cases we needed to create a new spelling for an utterance (e.g. een't, cos), and in some cases we needed to go back in history to archaisms that have since disappeared from the language (e.g. agin). Each case which deviates from Standard English either by spelling or by use is documented in the manual (Ahava 2010b). We took exception to Standard English writing rules by omitting punctuation (commas, full stops, exclamation and question marks, hyphens) and reducing capitalisation to only proper nouns (no sentence-initial capitalisation). Punctuation is not a feature of spoken language, and since establishing the boundaries of a sentence in spoken language is notoriously difficult (see e.g. Vasko 2005: 55-56), we decided to drop out all markers that would normally indicate where a sentence begins and ends. Commas were left out because the pause tags are far more suitable ways of indicating pauses in the utterances, and we left hyphens out in compound words because of their visual clutter. Hyphens are retained in false starts (e.g. w- we), but in these cases they receive a special <seg/> annotation in XML:
(9)
had to go and feed them before <pause/> <seg type="truncation"> fo- </seg> <seg type="truncation"> w- </seg> come to work <pause/> <anchor xml:id="cam13hares0240"/> five o'clock in the morning
On a final note, transcription was and is an arduous process, where the person working on the audio file is forced to pass judgement on what abstract label to pin on an utterance heard in the audio file. The casual offhandedness in which these decisions are made during the transcription process would be harshly criticised in any methodology review, but with transcriptions we have learned to accept the difficulties associated with the work. Nevertheless, for the work to be duly recognised as the transcriber's own interpretation, it is crucial that the protocol is examined in the documentation, which can then be reviewed by other users of the transcriptions. Nothing is more detrimental to the spoken language cause than a poorly made transcription, based on bad judgement and lack of protocols, which takes on a life of its own and spoils any research referring to it.
4.2 Annotating the XML corpus
To avoid inconsiderate 'transcription worship' it is possible to mask the harmful effects of transcriber judgement by using metadata which introduce new levels of interpretation. Instead of using only the orthographic level, with XML one can link the audio to the orthography and even add, for example, POS-tags and phonetic information to the content. By using all the available levels in analysis, the researcher can draw the most sophisticated conclusions from the data. XML, or eXtensible Markup Language, is quickly becoming the tried-and-true way to annotate large bodies of language in linguistic research (e.g. Kretzschmar et al. 2006). The multiple uses and infinite customisability of XML combined with a logical syntax and consistent requirements of well-formedness make it the obvious choice for an annotation schema in spoken language corpora.
HARES uses TEI specifications for encoding its data. TEI has specific guidelines for transcription of speech and for language corpora, which meant that we had a schema ready to use for HARES annotation. Because we transcribed the audio with Transcriber, which has its own native XML output, the first thing we did was convert the Transcriber tags to the (roughly) equivalent tags in the TEI specifications. This was relatively straightforward, and we used simple Microsoft Word macros to do the work for us. After that it was a question of manually going over each utterance in order to assign unique IDs and cross-references to the XML elements.
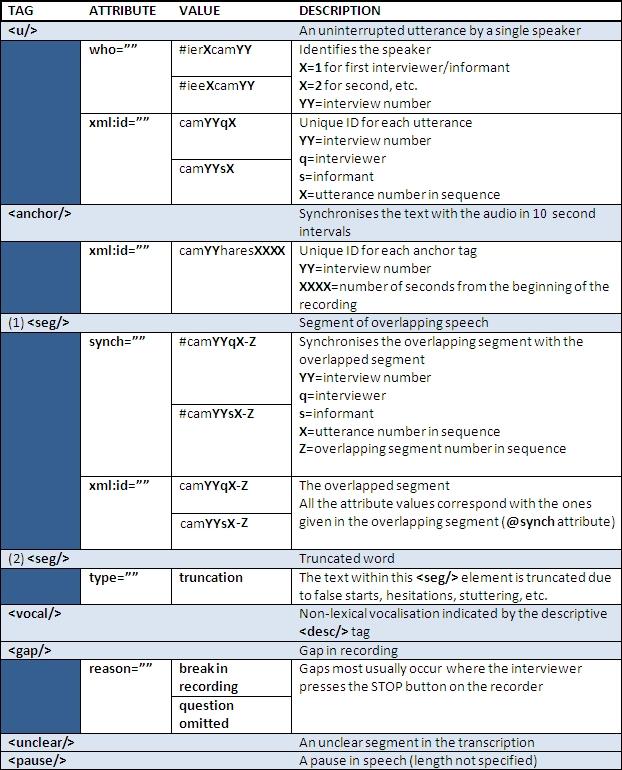
We chose a fairly limited number of tags for HARES content annotation (see Figure 5). This is partly because we wanted to focus on the orthographic level and partly because we wanted to keep the content clean and readable. We divided the XML corpus into a master file and 20 interview files because we didn't want to confine the entire corpus to a single XML file. The master file contains the header of the corpus (see Figure 6) and links to each individual interview. The interview files begin with a header (see Figure 7) followed by the body with all the interview content.
The tags we adopted for HARES content description provide the bare minimum that we considered necessary for the annotation of spoken utterances. Because the original motivation of the dialect project (see Section 3.1) was the study of dialect syntax, we opted to choose the body tags with this goal in mind. We have left out, at this point, thematic annotation (topics of conversation, dialect words, etc.), phonetic transcription and POS-tags. Extensibility of the markup language means that these other levels of annotation can be added at a later stage and then linked together with all the other tiers.
Overcoming the problem of content description is another motivation for choosing these specific tags. Appending the content with metadata such as indication of who is speaking is a step closer towards transparency of description. With the exception of the truncation tag (see above), each tag describes a quality of the audio, not the transcription. Events such as utterances, pauses, laughs and coughs are all features of the primary data. The more we ground the transcriptions in the source material, the more redundant the textual approach becomes. Finally, anchoring the transcriptions to the audio makes the connection between a HARES tag and the corresponding audio event concrete. This is the ultimate purpose of content metadata, and with new tiers of annotation it is possible to go even further and maybe, at some point, abolish the use of written, word-for-word transcriptions altogether.
Figure 6. HARES XML master file.
The master file contains, again, the bare minimum that a TEI corpus header requires. Most of the tags refer back to the manual (Ahava 2010b). We wanted to keep the master file short and simple because the manual contains all the necessary information (and more) that the corpus user might be interested in. We also wanted to elevate the status of the manual beyond its traditional use as an introductory guide to the product. After the header, the master file contains links to all 20 interview files. These links actually embed the external interview files into the master file. The end result is the same as if we would have included the interview files as raw text within the master file. We opted against doing this because having the interview files separate makes it easier to browse and query them.
Figure 7. HARES XML interview header.
Even though the manual contains far more detail on the interviews as well, we decided to include more than just references back to the manual in the interview headers. Thus they contain information about the recording itself, the setting of the interview and any people present during the recording. Each participant is assigned a unique ID (e.g. iee1cam04), which is then used in each subsequent utterance tag that contains speech by the person. We decided to include the basic information on every person in the header because this cross-referencing between the header and subsequent utterances makes it easier to follow the interview.
The HARES-CAM XML corpus has been validated and checked that it obeys TEI specifications. It should work in any corpus browser that takes XML files as its input. However, full functionality of the XML schema might need a corpus browser specifically tailored for HARES. The synchronisation of audio and text by using the <anchor/> tags is idiomatic to HARES and NECTE. Thus existing XML browsers might not understand the syntax and would have a hard time adjusting to the technical requirements of how to realise the audio-text-synchronisation. Naturally, the XML files can be used in other software such as AntConc or WordSmith, both which include the option of discarding tags from searches. If one wishes to discard the XML tags from searches, it logically follows that the XML corpus is not being used up to its full potential. However, we acknowledge the fact that XML-literate corpus browsers which understand the requirements of spoken language annotation are few and far between [14].
4.3 Annotating the TXT corpus
To enhance HARES use, especially while a suitable XML browser is still waiting to be compiled, we converted the XML files to plain text format. We developed a unique annotation schema for the TXT corpus, so that all vital metadata that were present in the XML corpus could be observed in this format as well. Since there are no well-formedness restrictions on the annotation schema that we created, the plain text corpus comprises solely of the twenty interview files and two tag files for WordSmith Tools. Each interview is preceded by a header (see Figure 8), and all but one of the body tags have their equivalents in the XML corpus (see Figure 9). The purpose of the TXT corpus is to provide quick access to HARES especially for those who have a hard time following XML syntax. The tags are inconsequential and exist solely for the purpose of structure. Thus they can be discarded from searches without hesitation. The only tag with a special function is the <sound/> tag (see below).
Figure 8. HARES TXT interview header.
The TXT corpus interview header contains the same information as the XML header (see Figure 7). The header can also be used for cross-reference purposes, as the tag identifying the speaker (e.g. <IE1>) is identical to the utterance tag later in the body. The header tags and their content are:
<CAMxx> - Interview ID (xx=01-20)
<R> - Recorded by
<L> - Location of interview
<D> - Date of interview
<T> - Length of interview
<IRx> - Interviewer ID (x=interviewer number, N=name, X=sex)
<IEx> - Interviewee ID (x=interviewee number, N=name, X=sex, A=age group, H=place of residence, O=occupation, E=left school at)
Figure 9. HARES TXT body tags.
The TXT corpus body tags exist solely to provide structure for the transcription. With the exception of the <seg type="truncation"/>> tag, all the XML corpus tags have an equivalent in the TXT corpus. We decided to omit the truncation tag from the TXT corpus because it has no function other than to make explicit the hyphenated segment in the text. While this might be important in an XML-capable browser, there is hardly any need for such explicit description in the TXT corpus, where the presence of the hyphen (e.g. w- when) is indication enough of hesitation or a false start.
The <sound> tag was created so that it could be associated with the media playback functionality of WordSmith Tools (see Ahava 2010b for instructions). With the media tag and WordSmith Tools, it is now possible to use the corpus in the way that we intended: you can listen to the audio while browsing and querying the corpus, facilitating data verifiability and corpus usage in general.
5. Discussion and closing comments
The goal of this paper was two-fold: Firstly, it was intended to shed light on the problem of content description. The very idea of transforming speech to text is controversial but the practice is commonplace and often beyond reproach. Even though it is arguable that every key press that a person does during the transcription process should require extensive research, justification and verification before the textual label is accepted as a suitable representation of the sounds on the recording, the consensus leans towards accepting the level of abstraction that transcription requires as given. This is why the pile of research that debates whether or not the textual should represent the oral is slim indeed.
In this paper, I take a stance on content description of spoken language and argue that in some cases it is truly problematic. The intermediate past BE variant is one such case. The variant does not deserve the casual shrug that most of its companions on a recording of impromptu speech receive. On the contrary, the variant has been established by two separate research papers (Ahava 2010a and Richards 2010), and thus a re-evaluation of the past BE verb paradigm and even previous research of the paradigm should be called for. What is concerning is that the intermediate variant is just one minuscule drop in an ocean of variation. If only one structure has the ability to unhinge a well-founded verb paradigm and the seemingly exhausted research thereof, one can only wonder what the same level of scrutiny would do to the rest of the analysis.
The second goal of this paper was to provide a roadmap for the compilation of an archive of rural speech. HARES was conceived and compiled because it is a privilege to share the unique recordings of equally unique speakers to the academic and general public. This is the reason why HARES data were not restricted to only those researchers who had direct access to them, and this is the reason why HARES has been annotated as transparently and with as much room for extension as possible. We, the HARES team, consider it of paramount importance that the data be restricted in as few ways as possible. Transcriptions are already a nuisance, and they effectively filter out a lot of room for interpretation and analysis, no matter how intricately the primary audio data are involved in the mix. However, with XML and TEI specifications we can decrease the importance of the transcriptions and place a new emphasis on the primary data and all the analyses that have not yet been made. HARES annotation schemata render the transcriptions into the very thing that they have only ever been: an interpretation, our interpretation, of the audio. The end users are welcome to make their own interpretations of the data by using the annotation schema to its fullest and maybe even making one of their own.
Notes
[1] I am grateful for the help of Professor Terttu Nevalainen and Professor Joan Beal, whose relevant comments resulted in many changes to the draft.
[2] When referring to interviews in HARES that have not been transcribed or included in a finished module, the format is (initials_of_speaker-locality-region-hares). For example, (c-tiverton-devon-hares) would refer to the informant whose name is C and who resides in Tiverton, Devon.
[3] HARES informants are referred to according to instructions in the HARES CoRD entry: (interviewID-hares). For example: (cam13-hares).
[5] The term 'intermediate variant' is originally from Richards (2010: 63), who described them as occurring "in between the two standard productions, both in terms of perception…and production".
[6] Naturally, if the intermediate variant is established as a distinctive variant in the past BE paradigm, it should receive a new descriptive name, as 'intermediate variant' already implies an allomorphic relationship with was and were.
[7] Note that the counties included in the archive are according to pre-1974 borders. Also, Cambridgeshire and Isle of Ely are treated as separate regions in the archive, even though politically they were conjoined into one county in 1965.
[8] The Essex and Lancashire data were collected in urban areas of the counties by Riitta Kerman in the late 1980s, which means that they are not directly comparable to the rural recordings from the 1970s. Nevertheless, they were included in HD and will probably be included in HARES as well.
[11] Note that if the anchor occurred in the middle of a spoken segment, we moved it to the beginning of the segment. Thus not all the anchors are exactly 10 seconds apart.
[12] All corrections to the data can be directed to the HARES team (see Ahava 2010b for contact details).
[13] Modified from the Quick Start Guide & Reference Sheet included in the sampler. These tags are explained in greater detail in the sampler manual (Ahava 2010b).
Adger, David & Graeme Trousdale. 2007. "Variation in English syntax: theoretical implications". English Language and Linguistics 11(2): 261-278.
Adolphs, Svenja & Ronald Carter. 2007. "Beyond the word. New challenges in analysing corpora of spoken English". European Journal of English Studies 11(2): 133-146.
Ahava, Simo. 2010a. Intermediate Past BE: A Paradigm Reshaped With Data Drawn From HARES. MA thesis, University of Helsinki. 20 Oct. 2010. http://urn.fi/URN:NBN:fi-fe201006212088.
Allen, W. H., J. C. Beal, K. P. Corrigan, W. Maguire & H. L. Moisl. 2007. "A Linguistic 'Time-Capsule': The Newcastle Electronic Corpus of Tyneside English". Creating and Digitising Language Corpora, Vol. 2: Diachronic Databases, ed. by Joan C. Beal, Karen P. Corrigan and Hermann L. Moisl, 16-48. Basingstoke: Palgrave Macmillan.
Beal, Joan C., Karen P. Corrigan, Nicholas Smith & Paul Rayson. 2007. "Writing the Vernacular: Transcribing and Tagging the Newcastle Electronic Corpus of Tyneside English (NECTE)". Annotating Variation and Change (Studies in Variation, Contacts and Change 1), ed. by Anneli Meurman-Solin & Arja Nurmi. 20 Oct. 2010. http://www.helsinki.fi/varieng/series/volumes/01/beal_et_al/.
Beal, Joan C. & Karen P. Corrigan. 2011. "Inferring Syntactic Variation and Change from the Newcastle Electronic Corpus of Tyneside English (NECTE) and the Corpus of Sheffield Usage (CSU)". This volume.
Bloomfield, Leonard. 1933. Language. New York, N.Y.: Henry Holt.
Carruthers, Janice. 2008. "Annotating an oral corpus using the Text Encoding Initiative. Methodology, problems, solutions". Journal of French Language Studies 18(1): 103-119.
Carter, Ronald & Svenja Adolphs. 2008. "Linking the verbal and visual: new directions for corpus linguistics". Language and Computers 64: 275-291.
Chambers, J. K. and Peter Trudgill. 1980. Dialectology. Cambridge: Cambridge University Press.
Chomsky, Noam. 1957. Syntactic Structures. The Hague: Mouton.
Chomsky, Noam. 1965. Aspects of the Theory of Syntax. Cambridge, Mass.: The MIT Press.
Halliday, M. A. K. 2002. "The spoken language corpus: a foundation for grammatical theory". Language and Computers 49: 11-38.
Haspelmath, Martin. 2007. "Pre-established categories don't exist. Consequences for language description and typology". Linguistic Typology 11(1): 119-132.
Ihalainen, Ossi. 1981. "A note on eliciting data in dialectology: The case of periphrastic 'do'". Neuphilologische Mitteilungen 82(1): 25-27.
Kretzschmar, William A. Jr., Jean Anderson, Joan C. Beal, Karen P. Corrigan, Lisa Lena Opas-Hänninen & Bartlomiej Plichta. 2006. "Collaboration on Corpora for Regional and Social Analysis". Journal of English Linguistics 34(3): 172-205.
Markus, Mannfred. 2008. "Wright's English Dialect Dictionary computerised: towards a new source of information". Towards Multimedia in Corpus Studies (Studies in Variation, Contacts and Change 2), ed. by Päivi Pahta, Irma Taavitsainen, Terttu Nevalainen & Jukka Tyrkkö. 20 Oct. 2010. http://www.helsinki.fi/varieng/series/volumes/02/markus/.
Miller, Jim and Regina Weinert. 1998. Spontaneous Spoken Language: Syntax and Discourse. Oxford: Clarendon Press.
Moore, Kathleen. 1999. "Linguistic Airbrushing in Oral History". Writing in Nonstandard English, ed. by Irma Taavitsainen, Gunnel Melchers & Päivi Pahta, 347-360. Amsterdam & Philadelphia: John Benjamins.
Ochs, Elinor. 1979. "Transcription as theory". Developmental pragmatics, ed. by E. Ochs & B. Schieffelin, 43-72. New York, N.Y.: Academic Press.
Orton, Harold. 1962. Survey of English Dialects. A: Introduction. Leeds: E. J. Arnold and Son.
Peitsara, Kirsti. 2006. Manual to the Dialectal Part of the Helsinki Corpus of British English Dialects. Department of English, University of Helsinki.
Preston, Dennis R. 2000. "Mowr and mowr bayud spellin: Confessions of a sociolinguist". Journal of Sociolinguistics 4(4): 615-621.
Richards, Hazel. 2010. "Preterite be: a new perspective?" English World-Wide 31(1): 62-81.
Svartvik, Jan. 1992. "Corpus linguistics comes of age". Directions in Corpus Linguistics. Proceedings of Nobel Symposium 82. Stockholm, 4-8 August 1991, ed. by Jan Svartvik, 7-13. Berlin: Mouton de Gruyter.
Tagliamonte, Sali A. 2007. "Representing real language: Consistency, trade-offs and thinking ahead!" Creating and Digitising Language Corpora, Volume 1: Synchronic Corpora, ed. by Joan C. Beal, Karen P. Corrigan & Hermann L. Moisl, 205-240. Basingstoke: Palgrave Macmillan.
Trudgill, Peter. 2008. "English Dialect 'Default Singulars,' Was versus Were, Verner's Law, and Germanic Dialects". Journal of English Linguistics 36(4): 341-353.
Vasko, Anna-Liisa. 2005. Up Cambridge. Prepositional locative expressions in dialect speech: A corpus-based study of the Cambridgeshire dialect. Helsinki: Société Néophilologique.
Vasko, Anna-Liisa. 2010. "Past Tense Be: old and new variants". University of Bamberg Studies in English Linguistics 54: 289-298.
Weinreich, Uriel, William Labov and Marvin Herzog. 1968. "Empirical foundations for a theory of language change". Directions for historical linguistics, ed. by W. Lehmann & Y. Malkiel, 95-188. Austin, Tex.: University of Texas Press.