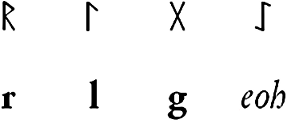Coin epigraphy and early Old English variation: Explorations in the Corpus of Early Medieval Coin Finds
Philip Shaw,
School of English,
University of Leicester
Abstract
This piece provides an introduction to the potential uses as a linguistic corpus of two important interlinked databases of coins hosted and maintained by the Fitzwilliam Museum, Cambridge. These databases provide a valuable way to search and assemble data not present in the Dictionary of Old English Corpus, as well as allowing easy cross-referencing of this linguistic data with other information about the coins, such as their find sites. As the databases are designed primarily with numismatic study in mind, however, linguists need to be aware of the ways in which transcription protocols may differ from those they might themselves adopt. The possibilities for using XML to mark-up linguistic transcriptions of Anglo-Saxon coin inscriptions are briefly discussed, before turning to three brief case studies conducted using the Fitzwilliam's databases. The first of these discusses evidence for devoicing of final /d/ in Old English, comparing data from coin inscriptions against personal name forms in Libri Vitae. The second considers the variety of forms of the name of the Northumbrian moneyer Cuthheard, considering the possibility that practical considerations involved with the administration of a currency may prompt experimentation with varying spellings. The final case study considers the evidence provided by early Anglo-Saxon coin inscriptions for vowel epenthesis in Old English, a feature that also appears sporadically in early manuscript sources.
1. Introduction
It is customary to think that our corpus of Old English is closed – that, barring some extraordinary discovery of a new manuscript or fragment, we have all the linguistic data we are ever going to have. But one area of the corpus has, in fact, grown over the last few decades, and continues to grow. This is, moreover, an area of the corpus that does not even feature in the Dictionary of Old English Corpus that has become so indispensable to Anglo-Saxonists in recent years: the coin inscriptions of Anglo-Saxon England. While coin inscriptions do not form part of the major corpora, however, a large sample of them is available via publicly-accessible databases. The Fitzwilliam Museum in Cambridge provides two interlinked databases that allow easy access to details of Anglo-Saxon coin inscriptions – and the possibilities and problems of using these databases as linguistic corpora form the principal subject of this paper. The first part of the paper discusses some of the basic issues that arise when using these databases to study Old English language, while the second part presents a brief study of some of the linguistic features apparent in early Northumbrian coins recorded in the databases.
2. The Early Medieval Corpus of Coin Finds and Sylloge of Coins of the British Isles
The Fitzwilliam Museum's databases are the Leverhulme-funded Corpus of Early Medieval Coin Finds and a database drawn from the printed Sylloge of Coins of the British Isles. The former collects together data on single finds of coins in the British Isles, including coins minted elsewhere, while the latter covers coins minted in the British Isles, wherever they are now held. By combining the two databases, good coverage of the extant Anglo-Saxon coinages can be achieved, and this is facilitated by the ability to search both databases from a single form at http://www.fitzmuseum.cam.ac.uk/coins/emc/emc_search.php. It should be noted, however, that the printed volumes of the Sylloge of Coins of the British Isles remain an indispensable resource, and the database as at 15 January 2011 does not yet include data from volume 52 onwards (coverage of earlier volumes is complete, with the exceptions of 28 and 41, which are index volumes, 3, which covers pre-medieval coins, and 31, 38, 43, 44, 46 and 49, all of which cover post-medieval material). The databases contain numerous searchable fields, including data of interest to the numismatist such as the weight, die axis and silver or gold content of the coins, as well as information on findspot, place of minting, ruler, moneyer, and, of course, the inscriptions on the coin. The search form also allows searches to be narrowed by date, kingdom, ruler, mint and findspot.
Clearly these databases offer a wealth of information that can be used in historical studies of various kinds. Our concern here, however, is specifically with how they can be used to assemble evidence for Old English language. Fran Colman has studied later Anglo-Saxon coin inscriptions extensively (see, for instance, Colman 1989 and Colman 1990; a fuller list of Colman's work in this area is given in Shaw 2008: 105 n. 5): this piece will therefore focus on using the databases to explore the linguistic evidence provided by earlier inscriptions, concentrating on coins produced in or before the early ninth century. For these purposes, the key fields in the database are those that record data about personal names, which represent the main source of linguistic data on eighth century coins (in later Anglo-Saxon England, mint-names become more common, providing data on place-names). The fields for ruler and moneyer record the names commonly used by historians today, allowing us an easy way to find the coins produced by a particular king or moneyer. This can be useful if we are concerned with variation in the representations of an individual's name. Perhaps more frequently, however, we might wish to find all the instances of a particular sequence of graphs. For this purpose, we would have recourse to the inscription fields, which record the inscription on the obverse (heads side) of the coin and on the reverse (tails side). The following is an example record from the database:
EMC number 2004.0197 (Ref: Reported)
State: Kent (616-825), Ruler: anon. (early penny) (675-750)
Type: Series C: Metcalf R1 (705-710)
Mint and moneyer unknown.
Weight: 1.11g. Die axis: 90.
Findspot: Pampisford, Cambridgeshire, England (TL 4948)
Obv. epa (runic, outwardly and retrograde)
Source: Coin Register 2005, no. 69
Image source: Actual coin (300 pixels, 300 dpi)
This record also includes images of the obverse and the reverse of the coin (reproduced as Figure 1, below), although some of the records do not. The fields recording the inscriptions are labelled 'Obv.' for obverse and 'Rev.' for reverse. In this case, only the obverse bears an inscription, the name Epa in runic characters. As the database relies on plain text transcriptions, the runes have here been transliterated, and a note in parentheses within the field provides the information that the inscription is runic. Where the inscription is in roman characters, there is often no other information within the field, which is ideal for the linguist who may be interested in searching these database fields for particular linguistic forms. However, it will be immediately apparent that searches on these fields may sometimes produce hits caused by notes, such as this note on the characters employed in the inscription. Such notes often provide vital information about the form of an inscription, or peculiarities of its arrangement, but one must be careful to sift results to identify any false positives from within annotations: relying on overall numbers of hits without checking the individual records is inadvisable. There are, then, three important issues to consider in collecting linguistic data from the database's inscription fields:
- Presence of additional notes.
- Transcription of minuscule and majuscule letter forms.
- Treatment of runes.
The first of these issues is, as noted above, not unduly problematic as long as one's analysis of results is thorough. The transcription of minuscule and majuscule letter forms in the inscription fields can be checked against the coin images in the database, where these are available. For many linguistic purposes, it does not matter what forms of letters are used, but there may well be interesting work to be done on the mixing of minuscule and majuscule forms in some coinages, and the relationship between the development of manuscript hands and the letterforms employed in coin inscriptions. The third issue is more complex, and raises problems in the interpretation of epigraphic data. There are occasionally problems with the transcription protocols adopted in the Corpus of Early Medieval Coin Finds as it stands, with, for instance, the runic character wynn transcribed at times by <p> (e.g. 2008.0096, 2004.0055), at times by <þ> (e.g. 2002.0267, 2002.0270), and at other times by <w> (e.g. 2008.0098, 1984.0210). These basic inconsistencies can easily be remedied, but the difficulties encountered by the database's compilers in arriving at consistent transcription protocols for these characters point towards the wider problems presented by any attempt to create searchable transcriptions of coin epigraphy for the purpose of linguistic study.
In printed discussions of epigraphic data, it is conventional to transcribe roman inscriptions in majuscules (e.g. DE LVNDONIA) and runic inscriptions in bold minuscules (e.g. pada; on which, see Blackburn 1991: 145). This allows for the possibility of indicating inscriptions in which both roman and runic characters are used by mixing these two conventions. While this works well in print, however, it is not helpful in creating an electronic corpus where we might wish to search for a runic character rather than its roman equivalent, or vice versa. This sort of searching requires that characters are tagged as runic or roman, and this could be one way in which the Corpus of Early Medieval Coin Finds and Sylloge of Coins of the British Isles databases could usefully be developed to enable more efficient searching for linguistic forms. Yet such a development is not as simple as creating tags for two distinct categories of character: there are cases where a character could be read as runic or roman. In some cases, runic and roman characters are similar in form: for instance, runic r and roman R. In the case of coin epigraphy, characters are frequently reversed either horizontally or vertically, creating difficulties in deciding whether a character constitutes Roman L or runic l. The problems worsen, moreover, with runic characters that appear similar to roman characters but represent entirely different sounds: for instance, runic g can appear indistinguishable from roman X, and, as Blackburn (1991: 164) has pointed out, confusion of the rune 'eoh' (in this case representing /x/) with roman N has obscured important evidence for the usage of a relatively rare rune.
These difficulties can be addressed by careful examination of the images in the database, where these are available, but methods for searching databases in the vast majority of cases rely on textual data. For the study of the inscriptions as linguistic evidence, therefore, it would be helpful to devise a system for transcription that can express degrees of uncertainty about identification of characters, or ambiguity as to whether a character is runic or roman. At the same time, thought should perhaps be given to marking the directions in which inscriptions run. Coin inscriptions can consist of a single, clockwise sequence of graphs, as we are used to, or they can be arranged in other ways: for instance, in separate clockwise and anti-clockwise halves (for a fuller discussion of the range of possibilities in evidence, see Anderson & Colman 2004: 36-39). This can also lead to uncertainties about the precise sequence in which characters should be read, an issue that clearly has relevance to linguistic studies.
These issues could usefully be addressed by transcribing coin inscriptions using an XML format similar to that set out in the EpiDoc Guidelines (Anderson et al 2007). The possibility of creating a set of guidelines specifically for coin inscriptions was discussed at a meeting in 2006 (Digital Coins Network. Notice of meeting), but I am not aware of a set of guidelines having been published as a result of this meeting. However, the EpiDoc Guidelines themselves already indicate ways of addressing many of the issues raised above.
Since the EpiDoc Guidelines were devised with classical epigraphy in mind, they do not define tags for handling runic characters. However, The Unicode Standard, Version 5.1.0 defines a fairly wide range of runic characters (The Unicode Consortium: 475-477). This could provide one way of handling runic characters, but editors of runic texts usually transcribe into roman equivalents. Where EpiDoc originally developed attributes within tags to indicate special characters, but these characters have subsequently been added to Unicode, EpiDoc has tended to recommend using the Unicode characters rather than attributes. [1] While tag attributes might offer one way of representing runes, use of the appropriate Unicode characters may actually be preferable, and need not prevent the translation of these characters into the traditional roman equivalents for display to users. The potential difficulties of ambiguous forms noted above do, of course, require informed judgements to be made by individual scholars based on examination of the coins themselves, or, failing that, good quality images of them; but a transcription protocol that can indicate such issues in a principled way has the benefit of allowing scholars to identify clearly and readily the difficulties which they must address.
Unlike runic characters, uncertainties in readings are a common feature of classical inscriptions, just as they are in Anglo-Saxon coin inscriptions. EpiDoc therefore defines an 'apparatus component' that allows a series of alternative readings for a character to be recorded. [2] The <unclear> tag that is used to enclose characters where a clear reading cannot be determined has a 'reason' attribute that can be set to 'execution' to indicate cases where the inscription was executed in a way that creates uncertainty. This could allow for uncertainties created by roman/runic ambiguity, and the use of an 'apparatus component' would allow for the various possible readings to be set out. The EpiDoc format also allows for reversed characters with the 'rend' attribute, whose value can be set to 'reversed'. [3] This could be extended by the definition of an additional value 'inverted', to allow for upside-down characters. The 'rend' attribute can also be used in indicating script direction, and the EpiDoc documentation explicitly notes that 'other values of the rend attribute can be created in the case of texts written vertically, in a circle or spiral, or otherwise unusually'. [4]
This is not the place for a full exploration of how a corpus of Anglo-Saxon coin inscriptions for linguistic purposes might be assembled, and there are issues beyond the efficient and easily searchable representation of the inscriptions themselves. It might also, for instance, be useful to tag individual name elements, insofar as these can be unproblematically identified, to allow easy searching for a specific name element in all its spellings. Clearly, the Corpus of Early Medieval Coin Finds and Sylloge of Coins of the British Isles databases provide access for linguists to a wealth of material that is eminently worthy of study. The evidence assembled by these resources could also form the basis of a corpus of numismatic material tailored to use in linguistic studies: a corpus that would need to tackle the various issues discussed above. We will turn now to a brief case study of some of the linguistic features apparent in early Northumbrian coinage, as a demonstration of some of the potential of this material for further work.
3. Linguistic features in Northumbrian coin epigraphy
3.1 Devoicing of /d/ in Old English
Campbell (1959: § 450) claims that devoicing of stops was not a common feature of Old English, but according to Hogg (1992: 7.65), final stops (including syllable-final stops) are devoiced occasionally in several Old English dialects, with Northumbrian and Early West Saxon particularly prone to devoicing in unstressed syllables. The Lindisfarne Gospels glosses have -et, -at in weak past participle endings, usually after dental stem endings, and Hogg (1992: 7.65-7.66) takes this to be the first glimmerings of the Scots past participle ending -it. Nevertheless, he accepts that all of these manifestations of devoicing appear only 'sporadically' (Hogg 1992: 7.65). Eadberht of Northumbria's coinage, however, seems to suggest devoicing of /d/ in the prototheme Ead- (Shaw 2008: 105). Personal names, of course, can display phonological developments that differ from those of ordinary words (see, for instance, the discussions in Colman 1989 and Colman 1990). It is therefore worth considering the evidence for devoicing in personal names in particular as a context for understanding Eadberht's apparent devoicing.
The evidence assembled by Gerchow (1988: 378-379) from Anglo-Saxon libri vitae shows that <t> is used for the /d/ of Ead- in the forms Ætfled, Eatferð, Eatfrith, Eatcume, Eatdegn, Eatðegn, Eatdryd and Eatðryð. Names such as Eadbald, Eadberht, Eadburh, Eadgar, Eadgiefu, Eadmund and Eadweard, on the other hand, do not appear with <t> spellings in Gerchow's (1988: 377-379) data. This strongly suggests that devoicing of /d/ is occurring in these names as a process of assimilation of /d/ to the following unvoiced consonants /f, k, ?/ (with /?/ variously represented by <d> and <ð>).
However, an extra complexity arises when we consider the monothematic names listed by Gerchow as derived from Ead-. These are Aetti, Eata, Eota and Utta, alongside Eada, Eadu, Eda, Euda, Oda, Odda, Odo and Uda (Gerchow 1988: 377). Clearly there can be no question of assimilation to a following unvoiced consonant in these names. How, then, can we account for this data? One possibility is that some of these names do not, in fact, derive from Ead-. The monothematic names can be etymologically more problematic than the dithematic names, and we would probably be unwise to attempt to relate them all to elements used in forming dithematic names (Colman 1990: 68). On the other hand, there is evidence that at least some monothematic names were hypocoristic forms of dithematic names: the best-known example is King Sæberht of the East Saxons, whose sons, according to Bede (Historia Ecclesiastica, book 2, chapter 5), called him Saba (Plummer 1896: 1.91). It is possible that Old English speakers did not simply clip names or add endings in order to create hypocoristic names, but also altered the sounds of the original names, just as Modern English speakers do in forms such as Shaz for Sharon, Bess for Elizabeth and Kate for Catherine. Such alterations can consist of the replacement of a voiced stop by its unvoiced equivalent, or vice versa, as in Paddy for Patrick (though this may be a product of interchange between Irish or Hiberno-English phonology and the phonology of southern British English) and Humpy for Humbert. Perhaps, then, we should not be surprised to find evidence of such patterns in Old English.
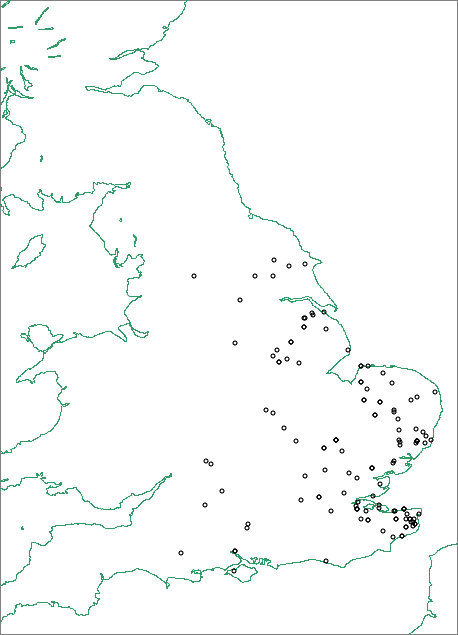
This makes sense of the data from libri vitae, perhaps, but it leaves us none the wiser about the apparent devoicing in inscriptions on the coinage of Eadberht of Northumbria. The deuterotheme -berht begins with a voiced sound, and we should not therefore expect devoicing through assimilation, as in the names discussed above. We might, therefore, argue that Eadberht's coinage provides evidence for a variety of Old English in which general devoicing of final stops occurred, although little trace of such a variety survives in later Old English. Or we could consider the possibility of influence from Continental orthography. Devoicing of stops appears to have been much more common in Old High German, and it is possible that Frankish orthographic practice was important in the early development of Old English roman orthography. However, while it is not implausible that seventh-century Kentish coin inscriptions might show strong Frankish influence (Shaw 2008: 99-100), it seems less likely that a strong influence would appear in Eadberht's coinage in the eighth century. When we plot single finds of Merovingian coins in England, moreover, we find that they are mainly distributed south of the Humber, particularly in Kent and the area of East Anglia and the Wash:
Given this distribution of single finds of Merovingian coins, it seems unlikely that they would have played a major role as direct models for Northumbian coin epigraphy. While the eastern parts of Southumbria show some considerable concentrations of such coins, suggesting that they may have been fairly readily available as models for coinages in these areas, Northumbria is notably lacking in finds. The possibility remains of more indirect paths of influence, but on the whole it seems more likely that Northumbrian coin epigraphy was not heavily influenced by Frankish models. This suggests that we may wish to explain the EOT spellings of Ead in terms of variation within the Northumbrian dialect of Old English.
There is another individual's name from eighth-century Northumbrian coinages that also shows an alternation between D and T spellings. The moneyer Cuthheard, who is thought to have operated in Northumbria during the reigns of Æthelred I (774–778, 790–796), Eardwulf (796–806), Ælfwald II (806–808) and Eanred (810–840), frequently spells his name with a final T rather than D. As with Eadberht, the form with T lacks the phonological environment we would expect for devoicing, but a closer examination of the issues bearing Cuthheard's name suggests a way of interpreting such variations.
3.2 The moneyer Cuthheard
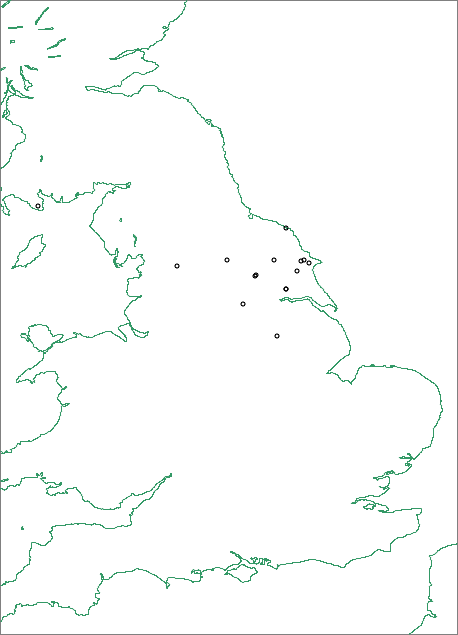
The Corpus of Early Medieval Coin Finds lists 23 single finds of coins of Cuthheard, with a more or less even distribution between T and D spellings. The distribution of spellings seems, moreover, to correlate with the production of coins under different monarchs, with only T spellings occurring in the coinage of Ælfwald II, while D spellings are restricted to the coinages of Æthelred I and Eanred. Eardwulf is unusual in having a mixture, with one instance of a T spelling and two instances of D spellings. If we accept that we are dealing with a single individual named Cuthheard, then this initially appears to indicate two changes of spelling of his name: we begin with D spellings under Æthelred, with a transitional mixture under Eardwulf leading to T spellings exclusively under Ælfwald, with a switch back to D spellings under Eanred. We should note, however, that while the deuterotheme of his name is spelt HEART (often with the A inverted) or HEARD prior to Eanred's coinage, it is HARD in the two instances of Eanred's coinage bearing his name. In other words, we see a progression from reign to reign: HEARD > HEARD/HEART > HEART > HARD. We might seek to explain this in various ways. One possibility is that we are actually dealing with more than one individual with the same name, and that different spellings were deliberately adopted to differentiate them. Or perhaps we have different individuals whose pronunciations of their names differed slightly. Another possible explanation would be that the coins were produced in different centres, and hence reflected different local varieties. A distribution mapping of the single finds, however, suggests that they were all centred on the same area of southern Northumbria.
This distribution does not support a hypothesis of production in different centres. It also seems unlikely that there were two or three different men called Cuthheard acting as moneyers for different Northumbrian kings across the end of the eighth and beginning of the ninth century. The correlation between different spellings of moneyers' names and different rulers suggests, rather, that a single moneyer's name was varied as part of a strategy for differentiating the coinages of the different rulers involved (for a possible purpose for such differencing, see the discussion of 'privy marks' below). This may also account for the fact that the <h> of heard usually appears in minuscule form in instances of the name spelt with T (see Corpus of Early Medieval Coin Finds 1977.0127, 1983.0124, 1983.0125, 1983.0126, 1997.6002, 1997.8199, 1997.8200, 2001.0110, 2001.0162), but in majuscule form in instances spelt with D (see Corpus of Early Medieval Coin Finds 1986.0313, 1986.5015, 1995.6001, 1997.0411, 2001.0029, 2001.0249, 2001.0528, 2006.0324, 2008.0483). The question that this raises, however, is how such deliberate variation would be generated.
In the case of the letter <h>, variation between minuscule and majuscule forms offers a simple way to differentiate inscriptions without doing violence to the representation of sounds. Switching between <ea> and <a> spellings, and between <t> and <d> spellings, on the other hand, would seem to indicate slight variation in pronunciations. It is possible, of course, that it was simply felt that phonetic accuracy was less important than creating the desired differentiation, but I would argue that the variation is not entirely divorced from regular phonological patterns. The use of <t> for <d> in Eadberht and Cuthheard is occurring in phonological contexts where we do not expect it to occur, but we have seen in the data from the libri vitae that such variations do occur in certain phonological contexts. Those who produced the inscriptions on Eadberht's coinage and on the Cuthheard coins were, perhaps, generating spelling variants on the basis of existing, phonologically motivated variations.
The variation between <ea> and <a> in Cuthheard is a bit more complicated to account for. A number of scholars have treated this variation in the deuterotheme -heard as the result of breaking and retraction effects in different dialects. Northumbrian texts, and some early Mercian texts, exhibit retraction of /æ/ to /a/ in stressed syllables before /r/ followed by a consonant, when the following consonant, or the consonant preceding the /æ/ is labial (Campbell 1959: § 144; Hogg 1992: 5.29). However, the deuterotheme -hard does not fulfil these conditions: neither /h/ nor /d/ is a labial consonant, and as this is a deuterotheme, not a prototheme, the stress environment may not allow for such a development. Pirie (1996: 47) criticises Smart (1987: 246) for claiming that 'the -heard variant' in Cuthheard's name is West Saxon, arguing that 'the use of EA rather than just A may have been dependent on some northern factor'. This is somewhat unfair, as Smart does not in fact claim that this is a West Saxonism, but merely notes, quite rightly, that -heard is the West Saxon form. On the other hand, Smart also claims that the form CVDHARD shows an Anglian failure of breaking, but, as we shall see, this is not a satisfactory explanation of the data. The account given by van Els (1972: 184-185) also seeks to place these forms within the context of breaking and retraction as they occur in stressed syllables.
The standard grammars, on the other hand, explain -hard forms as the result of retraction (in all dialects) in an unstressed syllable, on the basis that deuterothemes of uninflected personal name forms lack stress: Cúðhe?ard (Campbell 1959: § 338; Hogg 1992: 6.7). The -heard forms can then be explained by reference to the inflected forms of such names, where the deuterotheme carries a secondary stress: Cúðhèarde?s (Campbell 1959: § 338; Hogg 1992: 6.7 n. 1). The presence of -heard in uninflected forms is perhaps the result of analogy with the inflected forms, or the influence of the adjective heard on the name element (Campbell 1959: § 338 n. 1; Hogg 1992: 6.7 n. 1). This account treats dithematic personal names as equivalent to compound words in which the second element is obscured (Hogg 1992: 2.90), and is supported, in the case of the element heard, by the fact that as a prototheme it appears only once in the form hard- in the Prosopography of Anglo-Saxon England (see 'Hardleih 1'), but several times in the form heard- (see 'Heardberht 1', 'Heardberht 3', 'Heardberht 4', 'Hærdred 1', 'Heardred 1', 'Heardred 2' and 'Heardred 3').
The fact that these spellings – <t> for <d> and <ea> for <a> – reflect variations that appear in particular phonological environments, even though these forms lack the necessary environments themselves, suggests the possibility of analogy, but analogy motivated by conscious cultivation of spelling variation. In the case of Cuthheard, the different forms of his name, as discussed above, appear to be related to the coinages of different kings, suggesting a deliberate use of different spellings of the moneyer's name as a way of differencing the coins. Booth (1987: 67-8) has suggested that variations in the representation of Æthelred I of Northumbria's (774-778 and 790-796) name and title may represent 'privy marks' – that is, small differences in spelling, presentation, and so on, that make it harder for forgers to keep up with the forms of the coinage, and easy for those with the relevant knowledge to distinguish genuine coins from fakes. Cuthheard's differencing may well have just such a practical purpose. This in itself provides a motivation for Cuthheard to look for alternative ways of representing his name, and in doing so, he might very well make a deliberate decision to use the graphy that represents the vowel sound of the inflected forms in representing the uninflected form. We may not, then, be looking simply at a regular process of analogy whereby variation is levelled out – quite the reverse, we may have evidence here for a deliberate manipulation of existing variation in order to create differencing spellings.
It is harder to be sure why Eadberht's name appears in two different forms on his coinage. Shaw (2008: 104) suggested that the EOT- spellings may have been earlier issues, reflecting the south Northumbrian dialect of the area in which the coins were minted, while the EAD- spellings may belong to later issues influenced by north Northumbrian conventions for spelling Old English personal names – conventions that may owe much to the orthographic practice of Bede in his Historia Ecclesiastica Gentis Anglorum. In light of the foregoing discussion, we might want also to consider the possibility that the difference is not chronological (though the influence of Bede's forms, or northern Northumbrian forms more generally, may still have been involved), but reflects a similar process of appropriation of alternative forms. In this case, the alternative form is derived not from oblique forms of the name Eadberht itself, but from other names with the prototheme Ead- in which a deuterotheme with an initial unvoiced consonant creates the phonological conditions (a following unvoiced consonant) for devoicing of the /d/ of Ead-.
3.3 Evidence of informal speech patterns? Epenthesis in the name element beorht
A slightly different kind of variation seems to be evidenced in the spellings of the deuterotheme beorht on Eadberht's coinage. The forms -berht- and -bereht- both occur, suggesting that an epenthetic vowel could develop in the consonant cluster /rx/ in Eadberht's name. Such epenthesis is not unknown from other evidence. Hogg (1992: 6.35-37) treats vowel epenthesis in r/l consonant clusters dialect by dialect, noting early examples in Northumbrian and Mercian, but claiming a restriction to Northumbrian in later texts, while also noting 'a scattering of forms' in late West Saxon (6.37). The implication appears to be that epenthesis of this sort is dialectally distributed, but, given the occasional examples in late West Saxon texts, it seems possible that this was a feature of most Old English dialects, although one that was perhaps mainly a feature of informal, spoken language, rarely appearing in texts. [6] Schulte (2006: 122-125) argues that signs of vowel epenthesis in runic inscriptions are 'a hallmark of rapid speech' (123), although in discussing his theoretical framework of a lento-allegro continuum of speech styles he notes that in allegro styles 'the crucial factor is carelessness rather than speed' (120). I would suggest that the evidence Schulte presents – and the evidence from coin inscriptions under discussion here – may reflect informal forms rather than those produced quickly (allowing, of course, that speedy articulation and informal styles may often go together). Indeed, the apparent distribution Hogg describes may simply reflect our main textual sources for forms produced outside the formal context provided by late West Saxon: the early records of Old English are largely Mercian and Northumbrian, together with some Kentish charters, with West Saxon later providing a formal, written form of the language, often termed a Schriftsprache, that might be produced by scribes from most if not all areas of England (Hogg 1992: 1.10). We therefore see epenthesis mainly in Mercian and Northumbrian in the early records, because these records themselves consist for the most part of texts in those dialects. Later, the West Saxon Schriftsprache tends not to record epenthesis, but the records of later Northumbrian in the Lindisfarne and Rushworth gospel glosses represent textual production in a local form, rather than following the Schriftsprache, and we might therefore expect them to record more features reflecting informal speech styles. It is also to be expected that such features occasionally surface in later West Saxon texts, just as other informal features such as reduction of inflexional endings (e.g. dative plural -an < -um; see Campbell 1959: § 572) occur sporadically in such texts. We should, then, be cautious in considering the evidence for a dialectal distribution of epenthesis of this sort: it remains possible that it was an informal feature of most Old English dialects.
The possibility of occasional epenthesis in speech in most areas of England clearly does not translate into frequent representation of the phenomenon in writing. When we consider the textual evidence presented by Hogg alongside the evidence of coin epigraphy, however, it becomes clear that there was a particularly strong tendency to represent epenthetic vowels in southern areas of Northumbria. In the later Northumbrian examples noted by Hogg (1992: 6.36), the Northumbrian section of the Rushworth Gospels gloss provides a large proportion of the examples compared to more northerly texts such as the Lindisfarne Gospels gloss and the gloss to the Durham Ritual. There is also some evidence from the early manuscripts of Bede's Historia Ecclesiastica of a particularly south Northumbrian tendency to represent epenthetic vowels: van Els (1972: 212-3) argues that the form bericthun, twice used in the Kassel manuscript (Kassel, Landesbibliothek, MS. 4o Theol. 2) of the Historia Ecclesiastica for the Abbot of Beverley (while Beorhthun of Sussex appears in the form bercthuno), can best be explained by 'a personal relationship' between Abbot Beorhthun and the scribe. This scribe, van Els (1972: 213) suggests, may have worked or been trained at Beverley. This could therefore demonstrate a particular tendency to represent epenthetic vowels in writing in this foundation in southern Northumbria.
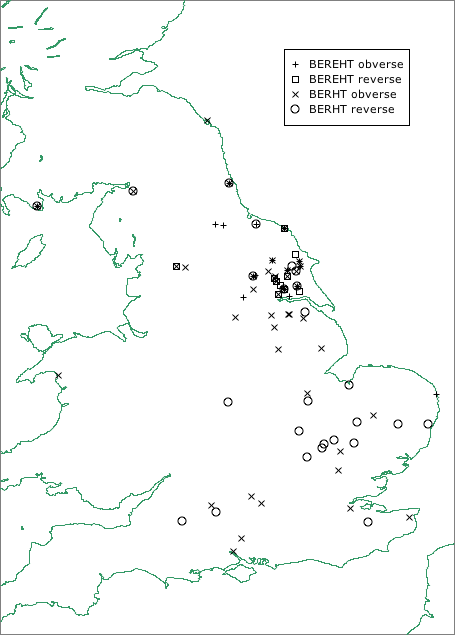
The evidence of coin inscriptions allows us to add to this picture. The representation in writing of epenthetic vowels in r/l consonant clusters is particularly common in Northumbrian coin inscriptions. For instance, Corpus of Early Medieval Coin Finds 2008.0086, a coin attributed to Ælfwald I of Northumbria, has an obverse inscription given in the database as +ALEFDLAL, but the accompanying image looks to me as though it reads +ALEFVALD, with ALEF read clockwise from the cross, and VALD read anti-clockwise. Corpus of Early Medieval Coin Finds 2008.0088 is a coin of Alchred of Northumbria (765-774) with an obverse inscription +ALUHREd. Eadberht of Northumbria, discussed above, appears in the forms EOTBEREhTVS, EOTBERHTVS, EADBEREhTVS, EADBERhTVS (Pirie 1996: 26). Indeed, the numbers of coins that show epenthetic vowel spellings in the name element beorht are sufficient to allow us to plot distribution maps: the Corpus of Early Medieval Coin Finds plots the results of searches for berht and bereht in obverse and reverse inscriptions as follows. The distribution of coins with the bereht form clearly suggests the production and dissemination of these coins (which are all Northumbrian issues) in southern Northumbria.
4. Conclusions
The implications of this argument for studies of Old English phonology and dialect are worth bearing in mind. Historical linguists tend to work with the basic assumption that Anglo-Saxons wrote more or less phonemically, but that factors such as analogy, scribal transmission or the use of a Schriftsprache can interfere with the data. In these cases, however, it seems that writing was undertaken which deliberately departed from the phonemic principle, for practical purposes associated with the use to which the writing was being put. But this conscious variation of forms is not random, as one might be led to expect when Booth (1987: 68) talks of 'slight misspellings' (but to be fair to Booth, his concern is not with the language of the inscriptions per se). The writers who produce this variation draw on existing resources in the language. Whether the same is true of moneyers' names outside Northumbria is an issue that might repay further research. It is of interest to remark, however, that deliberate variation in a king's name, as in the case of Eadberht, may well have been avoided in cases where a moneyer's name could be employed instead. Bibire (1998: 166), discussing Southumbrian coinages, notes that kings' and archbishops' names were less prone to variation that moneyers' names, but attributes this to standardisation of obverse production.
The use of patterns from other names is particularly interesting, as it demonstrates a conscious engagement with the individual elements of dithematic personal names. In eighth-century Northumbria, it seems, speakers were perfectly capable of identifying the name element Ead- even in names where they might have felt its pronunciation better represented by the sequence Eat-. Similarly, in some varieties of English, the final consonant of the element foot in football underwent assimilation to the initial consonant of ball some time ago, as Geoffrey Willans's (1939a and 1939b) forms foopbal and foopball in his Molesworth columns for Punch attest, [7] but no one today is unaware that the foop- of football is the same word as foot, and they are unlikely to be reliant on the standard spelling alone for this knowledge. Indeed, most individuals who pronounce the word in this way would probably be surprised to discover that they do. In the case of eighth-century Northumbria, however, it seems that such variations – variations that we, with our standardised spelling system, may tend not to notice – were creatively employed by the producers of coin inscriptions in order to suit the specific needs of creating identifiable yet differing versions of a single name for different coin issues. [8]
Notes
[1] See, for instance, the treatment of acrophonic numerals: http://www.stoa.org/epidoc/gl/5/acrophonic.html.
[2] http://www.stoa.org/epidoc/gl/5/unclear.html.
[3] http://www.stoa.org/epidoc/gl/5/reversedletters.html.
[4] http://www.stoa.org/epidoc/gl/5/directionoftext.html.
[5] The Corpus of Early Medieval Coin Finds database can generate maps from users' searches, against which the maps of the present article can be compared; Maps 1–3 were plotted using the grid reference data that appears in individual records in the database.
[6] Hogg's (1992: 6.35) three examples of vowel epenthesis in two early Kentish charters (two of which stem from Sawyer 19 rather than its later derivative Sawyer 21, as Hogg claims) might also contribute to the evidence for this phenomenon across most dialects. However, Chaplais (1965-1969: 538-539) has argued on palaeographical grounds – as well as on the basis of the spellings showing vowel epenthesis – that Sawyer 19 shows Northumbrian influence, quite possibly from a Northumbrian scribe. A non-Kentish scribe has also been suspected for the other charter Hogg cites, Sawyer 293: Stevenson (1959: 203 n. 1) argues that the forms Alahhere and Walahhere are 'unmistakably Old High German' and the product, in his view, of a Frankish scribe. Stevenson (1959: 203 n. 1) supports his argument with the claim that <a> as a spelling for an epenthetic vowel does not occur elsewhere in Old English, but in fact this spelling, though rare, does occur elsewhere (Hogg 1992: 6.35). The possibility remains, then, that vowel epenthesis may have featured in Kentish varieties of Old English.
[7] As far as the present author is aware, the earliest Molesworth columns are those cited here, from August and December 1939. Barber gives tempence for tenpence as an example of this sort of assimilation in both the original 1964 edition of The Story of Language (Barber 1964: 64) and in the 1972 revised edition (Barber 1972: 60). When he came to revise the text again for its 1993 re-publication as The English Language: A Historical Introduction, he replaced this with foopball for football as his example of this sort of process (Barber 1993: 44).
[8] The author wishes to thank Martin Allen of The Fitzwilliam Museum for his assistance in identifying and providing the image of Figure 1.
Sources
Primary sources:
Corpus of Early Medieval Coin Finds & Sylloge of Coins of the British Isles databases. 16 Mar. 2009. http://www.fitzmuseum.cam.ac.uk/dept/coins/emc/.
Healey, Antonette di Paolo (ed.). 2004. The Dictionary of Old English Corpus in Electronic Form. 16 Mar. 2009. http://tapor.library.utoronto.ca/doecorpus/.
Plummer, Carolus, ed. 1896. Venerabilis Baedae Historiam Ecclesiasticam Gentis Anglorum, Historiam Abbatum, Epistolam ad Ecgberctum una cum Historia Abbatum Auctore Anonymo. 2 vols. Oxford: Clarendon Press. Available online at http://www.archive.org/details/venerabilisbaed02plumgoog (vol. 1), http://www.archive.org/details/venerabilisbaed01plumgoog (vol. 2).
Prosopography of Anglo-Saxon England. 16 Mar. 2009. http://www.pase.ac.uk.
Willans, Geoffrey. 1939a. "My Sumer Diary, by Nigel Molesworth". Punch 197.5131 (August 9): 152-153.
Willans, Geoffrey. 1939b. "My Diary of the War, by Nigel Molesworth". Punch 197.5152 (December 27): 698-699.
WWW sources:
Anderson, Lisa et al. 2007. "EpiDoc: Guidelines for Structured Markup of Epigraphic Texts in TEI". Release r-5. 15 Mar. 2009. http://www.stoa.org/epidoc/gl/5/.
Digital Coins Network. Notice of meeting. 16 Mar. 2009. http://insaph.kcl.ac.uk/project/calendar/numisdoc.html.
Kelly, S. E. 1999. The Electronic Sawyer. An Online Version of the Revised Edition of Sawyer's 'Anglo-Saxon Charters'. 18 Mar. 2009. https://www.trin.cam.ac.uk/users/sdk13/chartwww/eSawyer.99/eSawyer2.html [Cited by Sawyer number.] [link no longer available, see http://www.esawyer.org.uk/browse/sawyercat.html]
The Unicode Consortium. 2007. The Unicode Standard, Version 5.1.0, defined by: The Unicode Standard. Version 5.0, as amended by Unicode 5.1.0. Boston, Mass.: Addison-Wesley. 16 Mar. 2009. http://www.unicode.org/versions/Unicode5.1.0/.
References
Anderson, John & Fran Colman. 2004. "Non-Rectilinear Name-Forms in Old English and the Media of Language". An International Master of Syntax and Semantics: Papers Presented to Aimo Seppänen on the Occasion of his 75th Birthday. (=Gothenburg Studies in English, 88.), ed. by Gunnar Bergh, Jennifer Herriman & Mats Mobärg, 31-42. Gothenburg: Acta Universitatis Gothoburgensis.
Barber, Charles. 1964 [1967]. The Story of Language. London: Pan.
Barber, C. L. 1972. The Story of Language. Revised edition. London: Pan.
Barber, Charles. 1993 [1997]. The English Language: A Historical Introduction. Cambridge: Cambridge University Press.
Bibire, Paul. 1998. "Moneyers' Names on Ninth-Century Southumbrian Coins: Philological Approaches to Some Historical Questions". Kings, Currency and Alliances: History and Coinage of Southern England in the Ninth Century. (=Studies in Anglo-Saxon History, 9.), ed. by Mark A. S. Blackburn and David N. Dumville, 155-166. Woodbridge: Boydell.
Blackburn, Mark. 1991. "A Survey of Anglo-Saxon and Frisian Coins with Runic Inscriptions". Old English Runes and their Continental Background. (=Anglistische Forschungen, 217.), ed. by Alfred Bammesberger, 137-189. Heidelberg: Winter.
Booth, James. 1987. "Coinage and Northumbrian History: c.790-c.810". In Metcalf (ed.), 57-89.
Campbell, A. 1959 [1997]. Old English Grammar. Oxford: Clarendon Press.
Chaplais, Pierre. 1965-1969. "Who Introduced Charters into England? The Case for Augustine". Journal of the Society of Archivists 3: 526-542.
Colman, Fran. 1989. "Neutralization: On Characterizing Distinctions between Old English Proper Names and Common Nouns". Leeds Studies in English n.s. 20: 249-270.
Colman, Fran. 1990. "Numismatics, Names and Neutralisations". Transactions of the Philological Society 88: 59-96.
Gerchow, Jan. 1988. Die Gedenküberlieferung der Angelsachsen. (=Arbeiten zur Frühmittelalterforschung, 20.) Berlin: de Gruyter.
Hogg, Richard M. 1992. A Grammar of Old English. Volume 1: Phonology. Oxford: Blackwell.
Metcalf, D. M., ed. 1987. Coinage in Ninth-Century Northumbria: The Tenth Oxford Symposium on Coinage and Monetary History. (=BAR British Series, 180.) Oxford: B.A.R.
Pirie, Elizabeth J. E. 1996. Coins of the Kingdom of Northumbria, c. 700-867 in the Yorkshire Collections. Llanfyllin: Galata Print
Schulte, Michael. 2006. "Oral Traces in Runic Epigraphy: Evidence from Older and Younger Inscriptions". Journal of Germanic Linguistics 18: 117-151.
Shaw, Philip. 2008. "Orthographic Standardization and Seventh- and Eighth-Century Coin Inscriptions". Two Decades of Discovery (=Studies in Early Medieval Coinage, 1.), ed. by Tony Abramson, 97-112. Woodbridge: Boydell.
Smart, Veronica. 1987. "The Personal Names on the Pre-Viking Northumbrian Coinages". In Metcalf (ed.), 245-255.
Stevenson, William Henry, ed. 1959 [1998]. Asser's Life of King Alfred. Together with the Annals of Saint Neots Erroneously Ascribed to Asser, new impression. Oxford: Clarendon Press.
van Els, T. J. M. 1972. The Kassel Manuscript of Bede's 'Historia Ecclesiastica Gentis Anglorum' and its Old English Material. Assen: Van Gorcum.
|
|