This article presents examples from an image-linked Middle English research corpus with an alternative set of tags and description elements for spelling and spelling-related variation. It is argued that inclusion of these additional description elements is useful in order to examine spelling variation. The term spelling is used to indicate orthographic variation on a graphemic, lexical and morphosyntactic level. Spelling variation includes: abbreviations, scribal variation, additions, narrow and broad script, multi-level writing, cancellations, on-the-fly corrections and multiple corrections. Spelling-related features are any related manuscript properties (such as layout and preservation) that may influence spelling. Spelling-related variables included are: material and background variation, script type and size, line spacing, decorations, layout, deterioration, glossing and punctuation. The examples are taken from the Wycliffe Spelling Corpus (WSC), which is currently being compiled at Technical University Berlin. It combines text editions and original manuscript images from texts by writers associated with the English religious reformer John Wycliffe during the second half of the 14th century. While several of the variables are already integrated and tagged as parts of existing corpora, the proposed sets of tags and description elements allow optimization of corpora for both qualitative and quantitative orthographic research. The integration of the original manuscript images also facilitates further differentiation by referring back to the original and will be useful for research in related fields such as verb morphology or syntax.
1. Spelling research and Middle English corpora
1.1 Spelling in Middle English
The lack of a standard orthography in Middle English (ME) manuscripts is one of the key problems for researchers who compile and analyze corpora from that time period. Spelling varied widely throughout the period, reflecting the unofficial status of English in contrast to the official languages Latin and Norman French. Spelling habits were influenced by a variety of sociolinguistic factors, from regional influence or pragmatic aspects to individual preference. Moreover, spelling was spectacularly inconsistent even within documents written by the same scribe. Even at sentence level, spelling of the same word could vary (see figure 5 for two variant spellings of liȝt and lyȝt in the same sentence). In recent years several attempts have been made to integrate spelling features and tags as part of corpus samples, for example in the context of the Middle English Grammar Corpus (MEG-C) and various special-purpose corpora like the Middle English Medical Texts (MEMT) edited by Taavitsainen, Pahta & Mäkinen (2005). However, spelling is frequently seen as a secondary issue in corpora, and the frequent limitation to samples rather than full transcripts makes quantitative spelling analysis difficult, since word frequencies cannot be reliably determined and even the extraction of qualitative samples is difficult due to the manifold spellings that have to be considered. One reason is, of course, that auto-taggers do not work on a non-standardized text. In addition, existing tagsets are, for the most part, designed to primarily provide grammatical or semantic information. In this respect, spelling variation is a hindrance, rather than a research focus, leading to the standardization of spelling during transfer to electronic format. Even if the transcription preserve spelling differences, not all such variation can be preserved within the confined of a standard typeset; thus, even a careful transcription would be inadequate to answer various spelling issues. Norman Blake remarks that "we are increasingly realizing that things on the ground [i.e. in the manuscripts] are rather more complicated than had first seemed true" (Blake 2000: 91). From the perspective of a spelling researcher, what is needed are tags or feature categories that specifically documents spelling variation on various levels.
1.2 Other spelling-annotated Middle English corpora
Various compilers have, of course, dealt with this problem before. Manfred Markus (in Taavitsainen et al. 2000: 181) has commented on the general practice of normalization which – out of fashion for almost 80 years – has gained a considerable following with computer and corpus linguists. The main argument against documenting variation, apart from the amount of time it would take, was (and still is) the lack of a tagset that fully reflects the level of variation on a graphemic and subgraphemic level in Middle English manuscripts. In the 1980s and 1990s, with much less powerful computers, it was a fully understandable decision not to attempt a corpus compilation that included a detailed transcription or documentation of spelling variation. I am not talking about the usual spelling variation, which could be tagged under their modern lexical equivalent easily enough, like the dozens of spellings of through, but about the many variables on a morphosyntactic and orthographical level that are so idiosyncratic that even a trained paleographer cannot consistently transcribe them, such as the various stages of verb-particle combination ranging from prefixation over separable prefixes with variable distance to hyphenated or fully separate prefixes (for a further description see Diemer 2012). This is in contrast to Early Modern English, where it is much more feasible to research spelling due to lower variation (cf. for example Baron 2009). As for Middle English, the Helsinki Corpus, for example, preserves the partly standardized spelling found in printed sources, as do most other corpora. Leaving aside the problems of reliability of early transcription processes and the possible introduction of new mistakes (which, for the Helsinki Corpus, has recently been addressed in its revised XML edition presented in 2011), this eliminates most variation on the word level and even those variants partly preserved in footnotes as part of the printed editions (for example in Forshall & Madden's 1850 parallel edition of the Wycliffite Bible). The Innsbruck Computer Archive of Middle English Texts (ICAMET), another mainstay of research, keeps the various spellings found in the basic editions, but it rarely goes back to the manuscripts. The Penn-Helsinki Parsed Corpus of Middle English (Kroch 2010), the largest resource currently at our disposal, deals with the spelling problem at various levels. Regarding syntactical variation, the corpus contains a general definition of when words are treated as unitary, i.e. split or joint, such as inasmuch or withoutforth. As for the central question of separable prefixes, they assert: that "[b]ecause it is not reliably possible, we do not distinguish between separable and inseparable prefixes when they precede the verb. All verbal prefixes are treated as part of the verb. By contrast, separable prefixes that follow the verb are tagged RP." (PPCME Manual). Otherwise, it pragmatically tags along word borders, sometimes adding internal tags, for example in noun compounds like evil-doer or gentleman. As for lexical variation, PPCME groups lexical items irrespective of their many individual spellings, while additionally performing some standardization.
The Middle English Grammar Corpus (MEG-C), an ongoing project at the University of Stavanger does provide a "rich diplomatic level" (Stenroos & Mäkinen 2011) transcription of 410 short texts and samples of longer texts dated between 1325 and 1500, mostly from manuscripts or facsimiles, or from a text edition checked against a facsimile. Thus, it not only illustrates variety on a word level, but also numerous other features, such as sub-graphemic distinctions, capitalization, abbreviations, punctuation, word and line division, initials and corrections. While generally keeping to the standard of the Linguistic Atlas of Early Middle English, it introduces several transcription conventions (though not tags) accounting for these variants, e.g. ** for initials, ~ for "squiggles" (ibid.) and # for line divisions. The selection process allows for variation between scribes, since, according to the manual, different scribes' production is usually treated as different text. There are also tags for text-based features like erasures (<rbd></rbd>) and additions (<add></add>). In this respect, the MEG-C projects illustrates many of the features also proposed in this paper. The main issue from the perspective of spelling research is the reliance on relatively short excerpts of longer texts, which, from a quantitative perspective, may not reflect variation adequately. Previous studies of spelling variation in Wycliffite texts on a graphemic level seem to indicate that spelling is not a uniformly discrete feature that can be sampled reliably, thus necessitating large samples and, inasmuch as possible, the inclusion of full manuscript sources (for the respective corpus-based studies of spelling in Wycliffite texts and the spelling of verb-particle combinations see Diemer 1998 and 2008). However, it would of course be useful to examine some of the variables presented in this article in the context of the existing MEG-C corpus, with a perspective of integrating the most salient features.
In summary, although spelling is a feature that is gaining more and more interest, no ME corpora have yet been compiled with a view toward primarily analyzing spelling variation. The lack of a specific spelling corpus has a variety of reasons. Mostly it is due to the available print editions of ME texts. In addition to general layout problems that make automatic scanning difficult, spelling is often standardized in the earlier printed editions, variants from different manuscripts are often listed without quantifying them, and not all surviving manuscripts are included. The text editions by the Early English Text Society (EETS), for example, provide much detail on variant spellings, but the guidelines for editors clearly state that
"[c]itation of variants should be reserved for substantive variation only. […]. Variants which are merely orthographical are normally excluded." (EETS Guidelines 2011: 15).
This does not seem a useful basis for quantitative spelling research. Of course, the amount of work that close transcription from manuscripts takes is the main reason why most corpora understandably do not use originals on a large scale. Perhaps this explains why only a small selection of spelling variants from the print editions were integrated during the compilation of existing ME corpora. The Corpus of Middle English Prose and Verse, for example, only selects one of the two columns from the 1850 edition (which is already heavily standardized), thus removing 50% of the full text. An integration of the original manuscripts of The Wycliffe Bible (or, at a minimum, the full text editions) seems therefore a precondition for a quantitative analysis on spelling. In addition, a spelling-tagged version that structures spelling patterns further could be useful in order to illustrate and quantify variation.
1.3 The Wycliffe Spelling Corpus (WSC): a case for the integration of manuscripts
The examples in chapter 2 serve to illustrate several types of spelling variation in manuscripts. They are taken from the Wycliffe Spelling Corpus (WSC), currently being compiled at Berlin Technical University by combining the 1998 Wycliffe Corpus (Diemer 1998), consisting of texts attributed to the English religious reformer John Wycliffe and his followers and written at the end of the fourteenth century, with manuscript images. A detailed study of spelling in the 1998 Wycliffe Corpus is provided in Diemer (1998) and summarized in the following:
The rationale behind the original Wycliffe corpus project was to identify and examine spelling variation down to the level of individual scribes and to quantify the level of standardization by counting spelling variants according to the Linguistic Atlas of Late Medieval English (McIntosh et al. 1986) scheme, which uses a list of 251 items to distinguish dialectal variants. Over 240 manuscripts survive of the main Wycliffite work, as Anne Hudson observes (Hudson 1997: 164), an astonishing number in view of the vagaries of time and the comparative rarity of written texts before the introduction of the printing press. Preliminary research on text editions of the main Bible manuscripts demonstrated the unusual uniformity of spelling (in comparison to other contemporary manuscripts) in Wycliffite texts, which was interpreted as an intentional attempt to set a spelling standard independent of scribes and authors. A parallel text edition of the Wycliffite Bible from 1850 by Josiah Forshall and Frederick Madden and other print texts with the addition of excerpts from the original manuscripts, held by the Bodleian Libraries in Oxford, were used as basis for a detailed discussion of the Wycliffite attempt to set a spelling standard by means of a 5 million word research corpus composed of various print texts and manuscript original sources:
MSS Bodley 959, Christ Church 145, as transcribed by Conrad Lindberg (1959-73).
The Wycliffe Bible in several MSS as edited by Forshall and Madden (1850)
Lollard texts by various compilers (Arnold 1871, Matthew 1880, Winn 1929, Gradon 1988, Hudson 1978, 1990, 1993)
Facsimiles of MS Bodley 959, MS Bodley 227, MS Bodley 665, MS Douce 369, MS Fairfax 2, MS Laud misc. 182, MS Laud misc. 361, MS Junius 29 (for comparison with print texts)
A detailed discussion of the analysis and its results is not necessary in this context. In short, it was possible to show that the Wycliffite texts possess a statistically significant uniformity of spelling in regard to the questionnaire. The results of this analysis essentially confirm an intentional attempt to set a spelling standard. This incipient standardization can be interpreted as intentional. It facilitated the spread of these texts after the peasant revolts of the 1380s before the suppression by authorities. If Wycliffe's proto-reformation had not failed, the Midland-based dialect of the Lollard Bible translations might have become the English spelling standard. Even so, Wycliffite spelling conventions were remarkably close to the later Chancery standard, as Diemer (1998) illustrates. This 1998 study, which essentially comments on spelling variation in lexis, also shows that a standardized computer corpus for spelling needs access to at least some (and better all) of the original manuscripts in order to discover and quantify inconsistencies in transcription which may influence a lexical spelling analysis. At that time, technical constraints prevented the seamless integration of manuscripts as integral part of a corpus, which led to extremely time-consuming compilation and analysis phases (the corpus described here took several years to compile). Thus, the documents existed parallel to the text version, making time-consuming manual comparisons necessary. But even with today's vastly more powerful computer infrastructure, the integration of manuscripts is still problematic, both for general technical and specific spelling-related reasons. The term spelling is used here and in the following to indicate orthographic variation on a graphemic, lexical and morphosyntactic level. Spelling-related features are any related manuscript properties (such as layout and preservation) that may influence spelling.
2. Spelling and spelling-related variation in manuscripts
2.1 General issues
There are several issues to consider when integrating manuscripts as part of a corpus: (1) access, (2) material, (3) conversion, (4) integration and (5) documentation. How these issues are handled may have a significant impact on the spelling varieties that are documented as part of the compiled corpus.
(1)
Access: Most importantly, access to the originals remains limited and costly. Most manuscripts remain offline, although more and more are made available through various initiatives, for example as part of library websites, the Internet Archive or other online data initiatives such as the Digital Scriptorium. Even then, longer and more obscure manuscripts rarely form a part of such collections. Thus, research still has to be done in person, on-site more often than not, often on the original manuscript. Since even after the access to the original, researchers might have to revisit issues, it is (or should be) common practice to obtain reproductions for later reference and for inclusion as part of a spelling corpus.
(2)
Material: Some manuscripts can no longer be accessed in the original due to massive deterioration. Depending on the level of preservation, microfilms or, worse, paper copies have to be used for research, which adds to the difficulties in discerning spelling issues, especially those below a lexical level and influenced by variation in the writing materials, the document surface or the degree of preservation. Very often, only the highest-quality photographic reproductions are suitable for spelling research. Since these are expensive to obtain (reflecting the considerable effort involved on the part of the libraries holding the originals), there is also a financial hurdle to integrating full manuscripts. Once these reproduction are made (and reproduction permission have been obtained), integrating them as part of a corpus would thus allow other researchers to access and use them. However, the use agreements by copyright holders often do not allow this, a problem that still prevents public access to the WSC.
(3)
Conversion: Automatic scanning of hand-written Middle English documents is (and will remain for quite some time) a fool's errand. There is too much variation on all levels, from material to spelling, to trust even the most advanced automatic character recognition techniques. This only leaves manual transcription and tagging in order to obtain a machine-readable result. In this conversion process, it is essential to keep the research focus of the intended corpus in mind, since otherwise variation may get lost. For example, a researcher interested in the influence of the writing material on the writing process would need information on material and surface of the manuscript to be included, while a lexical researcher would not need such a level of detail. Thus, even a manual transcription process does not provide enough data for specialized research. It is reasonable to preserve access to high-quality reproductions of the originals in order to allow later integration of these and other issues.
(4)
Integration: Once high-quality reproductions of manuscripts have been obtained, they can be used to check transcription quality and to discover and describe additional variation, if necessary. However, just providing a link to the image file in question, while desirable as a standard feature of spelling corpora, does not facilitate research much. Rather, the manuscripts should be linked to the corpus in such a way that switching between different versions, original, tagged and text, is possible without, every time, having to laboriously search the words, passages or folios in question. This paper proposes a parallel corpus that links these different layers at word level, as described in chapter 4. Thus, several types of spelling variation below the lexical level can be illustrated in addition to the more traditional features, for which a text version might be enough.
(5)
Documentation: The integration of the original manuscripts resulted in the discovery of numerous spelling variables below the lexical level. Since the text version does not contain these and the manuscript version only shows the individual examples, an additional text version tagged for spelling is needed as part of the spelling corpus. This separate layer allows comparison and quantification of variables in the context of both general and more specific research. Chapter 2.2 will give examples for such features, based on examples from the WSC. The tagset for documentation of these variables is then described in chapter 3.
2.2 Examples for spelling and spelling-related features
There are several spelling and spelling-related features that should be included as part of corpora in a suitable form wherever possible. These concern (1) punctuation and abbreviations, (2) interlinear elements and layout, (3) corrections and (4) writing medium. For further examples of variation found in these categories see Diemer (2012).
(1) Punctuation and abbreviations
Punctuation: Since punctuation can vary considerably in manuscripts, diachronically, between regions, scriptoria, scribes or even in a single text, computer corpora tend to use the remaining modern equivalents for various groups of symbols that can be counted in this category. However, the much more varied inventory of medieval scribes is of considerable importance for lexical analysis, as the symbols are also used to separate words and even parts of words.
Figure 1. Punctuation in two versions of Genesis, MS Douce 370, fol. 5v and MS Fairfax 2, fol. 3r (Bodleian Library, University of Oxford 2012)
Figure 1 shows two parallel versions of Genesis. While the first version, MS Douce 370, uses a colon after firmament (at the end of the second line), the second, MS Fairfax 2, does not have any punctuation (in the middle of the second line), which might hint at a closer semantic connection. The MS Fairfax version also exhibits capitalization after the virgule (or slash) at the end of the first line, indicating a syntactic closure. Since there are far too many varieties of punctuation to create manageable different tags for all and then use them consistently in the manual tagging process, the tagset in chapter 3 distinguishes just six varieties apart from hyphenation (which is not separately tagged). By setting punctuation apart from the text level, spelling research would be greatly facilitated.
Abbreviations: Abbreviations are ubiquitous in Middle English manuscripts, but rather more variable and idiosyncratic in previous Latin scribal practice. They indicate parts of words that were so obvious and standard that they could be left for the readers to supply – the importance for spelling in the area of participle endings is obvious. Another interesting interpretation for the use of abbreviations is the indication of potential developmental loss or the level of care and speed with which the document was written. Figure 2, for example, shows multiple instances for abbreviations in MS Bodley 959, such as with, in, the and several more, which (in connection with other factors discussed below) points to a dynamic writing process in what may be a very early 'working copy', possibly an original translation.
Figure 2. Abbreviations in MS Bodley 959, fol. 1r (Bodleian Library, University of Oxford 2012)
There are different ways in which existing corpora account for abbreviations, but it is still common practice to expand them to full lexical items (sometimes in square brackets or the like), thus precluding further analysis. By tagging all abbreviated features with a blanket tag, it will be possible to quantify, for example, the loss of endings. At this time, available resources do not permit a further distinction of abbreviation types. Admittedly, one could argue that the type of abbreviation should be further distinguished based on scribal conventions – in the existing corpus this would need to be done manually, before detailed research on, for example, the weakening of final vowels or the clipping and blending of lexical items could be performed. In fact, the proposed blanket tag should just be considered as a first step to a more detailed investigation of this variable.
(2) Interlinear elements and layout: Elements in this category are line breaks and continuations, line and word spacing, page layout, script type, initials and decorations, glossing, additions and multi-level writing
Line breaks and continuations: Due to the rigid layout of most manuscripts, line breaks may or may not follow word boundaries. It is common practice to stop words in the middle and continue in the next line. Sometimes a break in a word is indicated by a hyphen or other symbol, often not. Especially early text editions join word components that are stranded, and many corpora do not indicate line breaks in the middle of words (or at all). However, the position of the break is not fully arbitrary – breaks tend to be made after syllables or lexemes, which gives us information about word morphology. Since affixes tended to be less firmly connected, they often end up stranded in separate line without an indication of word continuation, which allows the study of morphosyntactic cohesion. Thus, tags for line breaks are essential for the study of spelling, morphology and syntax. Figures 3 to 5 show several instances of line breaks inside words, illustrating various line-wrapping strategies.
Figure 3. Line breaks in MS Douce 370, fol. 5v: dyuy-did (lines 2 and 3), ma-ad (lines 4 and 5) (Bodleian Library, University of Oxford 2012)
Figure 4. Line breaks in MS Douce 370, fol. 5v: vola-tilis (lines 1 and 2), ha=uyng (lines 2 and 3) (Bodleian Library, University of Oxford 2012)
Figure 5. Line break in MS Fairfax 2, fol. 3v: de udide (Bodleian Library, University of Oxford 2012)
Line and word spacing: Longer texts frequently exhibit changes in line spacing, especially if the text is not marked by an auxiliary grid. Variation in line or word spacing may indicate early drafts or versions with fewer formal restrictions. In these circumstances, a widening distance between lines points to a higher writing speed, often accompanied by more mistakes, abbreviations and corrections. Very narrow lines are often accompanied by an increased use of abbreviations and reductions in mean word length (which influences spelling but also grammar and content). The example in figure 6 shows both types of variation.
Figure 6. Line and word spacing in MS Douce 370, fol. 5v, together with a tagged transcript version from the WSC. (Bodleian Library, University of Oxford 2012)
Page layout: The layout of Middle English manuscripts varies; most larger formats have two columns. As mentioned above, narrow columns entail more line breaks or continuations as well as changes in word length, use of abbreviations and even syntax. Examples for double-column layouts can be seen in figures 7 and 8, an example for single-column layout in figure 9.
Script type and initials: Script type, size and use of initials can give useful information about a manuscript as well as its content. The first paragraph in figure 7, for example, shows clear variation in script size compared to the left column, as well as a decorated initial spanning six lines. The initial prompts the introduction of abbreviations in the first column (generacioŭ) and the removal of intra-word spaces (ofthe). Adding this type of information can help investigating scribal identity and care of production (which correlates with frequency of mistakes).
Figure 7. Script size variation and decorated initial in MS Laud misc. 361, fol. lv, together with a tagged transcript version of column 1 from the WSC. (Bodleian Library, University of Oxford 2012)
Decorations: Illuminations and decorations in manuscripts usually indicate prestigious and expensive documents. Usually, illuminated texts are finished or established versions and exhibit less variation. Figure 8 shows the decorative border in MS Bodley 665, with the Book of Generations, a part of the Wycliffite Bible.
Glossing and additions: Glosses are commonly transcribed in text-based Middle English corpora. Although these single lexical items are not essential for spelling purposes, the addition of the image layer and a separate tag (rather than a footnote like in many older texts) will allow the investigation of their exact position in relation to the text, which might be important for a content based analysis. Additions are similar to glosses, but tend to contain text-related information rather than comments, for example notes on translation, word class, etymology and other issues that are useful for spelling and lexical research. In contrast to glosses, they often refer to single words (for example adding the categories 'name', or 'tre[e]' to indicate that this is mentioned in the text). The addition of the manuscript layer and a separate tag allows for a quantitative and qualitative analysis, though not necessarily spelling-related. Figures 9 and 10 show examples for glossing and addition.
Figure 9. Glossing in MS Laud 182, fol. 5v (Bodleian Library, University of Oxford 2012)
Figure 10. Additions in MS Douce 370, fol. 6r (Bodleian Library, University of Oxford 2012)
Multi-level writing: The term is used for words, including abbreviations, that are corrected or amended in superscript above the regular line. This feature is quite common in longer manuscripts and may be interpreted as a considered addition indicating a conscious revision process. An example of multi-level writing is given in Figure 11. The scribe writes the phrase the maistris of the stu, and then continues, only to return and add dies on top of stu in order to complete the term studies.
Figure 11. Multi-level writing in MS Bodley 959, fol. 1r: the maistris of the studies (Bodleian Library, University of Oxford 2012)
(3) Corrections: This category considers cancellation, on-the-fly corrections, and multiple corrections
Crossing out and expunctions: Usually in medieval manuscripts, spelling mistakes were dealt with by scraping off the ink and writing the corrected word in the space of the previous one. This deletion process is extremely difficult to detect, as it tends to get lost in any reproduction of the manuscript, even high-resolution photographs. Thus, there is as yet no way to consistently tag it beyond manual analysis of the original manuscripts on-site. Two other possibilities commonly used were cancellations by crossing out and expunction of words. The former, a very crude method, is extremely rare in the manuscripts that form part of the WSC, which is not surprising in view of the high prestige and value of written texts. Thus, it constitutes a last resort. Nevertheless, there are some astonishing examples, as in figure 12 which shows the crossing out of the word after an initial (though for aesthetic reasons the initial is retained).
Figure 12. Crossing out in MS Junius 29, fol. 13v. (Bodleian Library, University of Oxford 2012)
Cancellations can also alternatively or additionally be marked by points beneath the word (expunction), as in figure 13. This usually points to the existence of a separate correcting process.
Figure 13. Expunction and subsequent crossing in MS Laud misc 361, fol. lv (Bodleian Library, University of Oxford 2012)
It should be added that the basis for this taxonomy and interpretation of cancellations is the situation found in Wycliffite texts, which were shown to be unusually consistent in terms of spelling and correction policy (Diemer 1998). In other manuscripts the use of cancellations may be (and often is) less consistent. In any case, cancellations should be tagged separately, since they may provide valuable information about attitudes concerning spelling, They could document, for example, a possible consistent scriptorium policy and establish a chronology of corrections vs. original versions, thus permitting the construction of a copying history of the various text versions.
On-the-fly corrections: There are other types of corrections that occur frequently in early versions and texts that are less elaborately illustrated. One form that is familiar to all manual writers (alas, fewer and fewer) is the 'on-the-fly' correction (the term is introduced in Diemer 2012). In contrast to the two techniques described above, these are made immediately after the word has been written, for example by inserting letters that have been left out or changing letters into different ones. This does not have quite as negative a consequence as crossing out, but it leaves a noticeable trace. There is quite a high frequency of this type, especially in the earlier Wycliffite texts, and like today a possible interpretation would be an ongoing composition or translation process rather than a copying. In addition, these corrections are of fundamental importance for spelling analysis, because they can show, as Norman Blake comments, "incipient standards developed around a monastic foundation" (Blake 1992: 21). The fact of correction presupposes the awareness of a standard in the context of the tradition of the respective scriptorium. It is essential to include this type of information in a spelling computer corpus as a tag and to provide a link to the document itself. Figures 14 and 15 show examples for on-the-fly corrections.
Figure 14. Insertion of the letter m into the word hiself, MS Bodley 959, fol. 1r (Bodleian Library, University of Oxford 2012)
Figure 15. Correction in MS Bodley 959, fol. 1r: not gra(s)ping (Bodleian Library, University of Oxford 2012)
Multiple corrections: One of the 'work-in-progress' documents of the Wycliffite Bible translation is MS Bodley 959, from which several examples have been presented in this article, and which was carefully transcribed from the original by Conrad Lindberg (1961–1994) in standard text format. Studies on its lexis and dialect by Lindberg and Samuels (1969), respectively, establish its important position in the translation process. But accessing the original manuscript also yields interesting results beyond the lexical level. Most importantly, MS Bodley 959 is a useful source for multiple corrections. These happen when earlier additions are later corrected. This type of additions indicates that the document is a working copy, possibly the original translation basis in the case of the Wycliffe Bible. Figure 16 shows the alternation of various possibilities, starting with the phrase "oth thinges", then adding "oth(r) thinges" and finally "oth(r) (mennys) thinges".
Figure 16. Multiple corrections in MS Bodley 959, fol. 1r (Bodleian Library, University of Oxford 2012)
(4) Writing medium: Material background and deterioration
Material and background: Figure 17 shows a part of MS Bodley 296, one of the Wycliffe Bible manuscripts. It illustrates how the surface of the writing material, vellum, can vary. The dark areas visible are remains of skin, ridges and contractions resulting from the manufacturing process and even holes predating the writing process. This has significant consequences for the writing process: since the dark areas have to be avoided when writing, page formatting is adjusted, influencing line breaks and the use of abbreviations. Since the writing surface is uneven and the retention of ink on some areas substandard, the writing quality varies considerably, and the number of mistakes may increase, as illustrated in figure 19. Early print editions usually contain quite a number of transcription errors even on the lexical level as a result. The variable background is also one of the problems that prevent automatic character recognition.
Figure 18. Variation in writing quality in MS Laud 361, fol. lv (Bodleian Library, University of Oxford 2012)
Deterioration: Parchment is very durable, and scholars work with Old English manuscripts that have retained their original quality after more than 1000 years. However, many texts are in poorer condition. Figure 18 shows a part of a Wycliffite manuscript that suffered repeated damage, rendering it very difficult to use for research purposes. The copying process resulted in a copy which is barely adequate for manual transcription. However, most existing corpora only comment on the preservation status when marking unreadable lexical items. Additional, paragraph-based information on the condition of a manuscript could explain discrepancies on a lexical or punctuation level that may have been lost due to deterioration, as figure 19 shows.
The examples above should serve to illustrate why integrating the original manuscript is useful, and how the added integration of specific tags and description elements can give useful information on more specific spelling habits.
3. Proposed tags and description elements for spelling variation
Is it really necessary to create still more tags or description elements in addition to those already in existence? The answer, unfortunately, is yes. It would be much more convenient to adapt and, at need, to extend those description elements already existing in a standard typeset in accordance with the guidelines for electronic text encoding and interchange (TEI) in its latest P5 version (Burnard & Bauman 2012). In fact, TEI manuscript description tags provide an abundance of useful information categories:
the manuscript description element (metadata about the text, such as an identifier or content element, but also <condition> and <layout>)
phrase-level elements (e.g. <catchwords>, <material>, <watermark>, <dimensions>)
None of those, however, refer to spelling in the stricter sense. Although it might be possible to integrate information on line spacing and glossing as part of the <dimensions> and <catch-words> categories, I would argue that a consistent spelling analysis needs separate elements.
Nothing prevents the integration as part of an future extended TEI description set, and this should be seen as a desirable outcome of this proposal. In fact, regarding layout, decorations and script, which were identified above as one possible influence on spelling habits, the respective TEI description elements such as <layout>, <decoDesk> or <handDesc> are perfectly adequate. TEI also provides an <additions> tag, which should be sufficient to include the (SPADD) and (SPGLO) categories proposed below. In the meantime and until TEI integration can be achieved, the proposed tagset needs to be distinct in order to avoid confusion with existing tags or description elements and to facilitate integration into existing corpora and adaptation of other separate spelling tags. The proposed solution thus is a temporary addition to existing tagging categories, including image link tags. Via an XML-based hypertext interface, the various layers of research-related can be displayed and, at need, integrated as part of the transcript. A disadvantage of this method is, of course, that the text, particularly the linked manuscript pictures, will not be searchable as part of a standardized computer archive without some rework. On the other hand, the integration of additional data is comparatively easy and allows adaptation of supplementary levels as needed. In addition, non-text formats are not as difficult to handle or convert any more. Thanks to XML as a cross-platform standard it is easier to use the full range of fonts, for example, and still produce a document that is machine-readable in a wide range of environments. All in all, the advantages of adapting XML format far outweigh the disadvantages, which is why this approach is proposed for a spelling research corpus.
Based on the examples detailed in chapter 2, there are several groups of features to be taken into account beyond variation on a lexical level, both general and specific: (1) punctuation and abbreviations, (2) interlinear elements and layout, (3) corrections and (4) manuscript features. The proposed tags and description elements are described in tables 1 to 4.
Punctuation and abbreviations
Punctus (various types)
(SPPUN .), (SPPUN ∙)
Colon (:)
(SPPUN :)
Et (&)
(SPPUN and)
Virgule, solidus or slash (/ |)
(SPPUN /)
Dash ‒
(SPPUN ‒)
Hyphen
no tag (indicated in text)
Abbreviations
(SPABR)
Table 1. Proposed tags for punctuation and abbreviations
Interlinear elements and layout
Line breaks
(SPLBR)
Line spacing (paragraph description element)
(analogous to TEI <dimensions> element
specifications)
(SPLSN) narrow
no tag: standard
(SPLSB) broad
Continuation from previous line
(SPLIN)
Initials
(SPINI)
Glossing
(SPGLO)
Additions
(SPADD)
Multi-level writing
(SPMUL)
Distance (paragraph description element)
(analogous to TEI <dimensions> element
specifications)
Very narrow (SPSP1)
Narrow (SPSP2)
Normal: no tag
Wide (SPSP3)
Table 2. Proposed tags and description elements for interlinear elements and layout
Corrections
Crossing out
(SPCRO)
Expunctions
(SPXPN)
On-the-fly corrections
(SPCOR)
Multiple corrections
(SPMCO)
Table 3. Proposed tags for corrections
Manuscript features
Influence of writing material
(SPBGR)
Condition of manuscript
(preservation degree)
Good or average preservation: no tag
(SPLCN) section in bad condition
(SPNOR) section not readable
Table 4. Proposed description elements for manuscript features
Obviously more features will be integrated and description elements will be modified as the research on spelling in the corpus continues. The system proposed above allows for sufficient flexibility to introduce additional tags and spelling features as warranted. The format should make the integration of other partly spelling-tagged corpora (or the integration of parts of the corpus into other databases) comparatively straightforward. The proposed tagset is, of course, specifically non-proprietary and free to use in a research context.
4. Layout of the Middle English spelling research corpus
The interface, which is currently being implemented and only functional as a demonstration version, is intended to facilitate navigation and optimize corpus access particularly for spelling researchers. It uses a browser-based dynamic hypertext basis, with integrated dynamic elements for focusing and three main levels, or layers: (1) untagged text, (2) manuscript, (3) spelling-tagged version. The following demonstration is an example using a manuscript page from MS Bodley 959, the Wycliffe Bible. Navigation is through a minimum of control elements, aimed at facilitating a touch interface. In addition to navigating between levels in full-page view, users can also switch between levels for single words and sentences. Thus, different layers can be displayed in various areas of the manuscript, allowing a customized research version that can be saved separately, combining manuscript, text and tagged elements. The navigation elements and the lavers are described below.
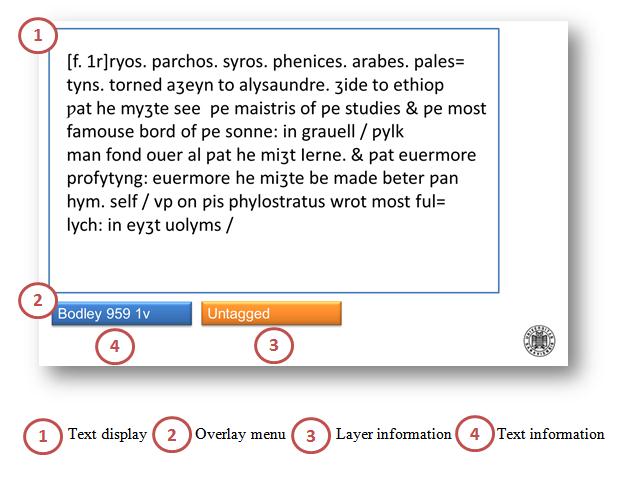
Navigation elements: The corpus uses a full-screen display with an overlay menu, as seen in figure 20. Apart from document name, scrolling bars and search window, no additional information is displayed. The main philosophy behind this design is the facilitation of direct text access and the minimization of non-essential information.
Figure 20. Navigational elements
(1)
Text display: The text is displayed in full-screen format without additional navigation aids except scrolling bars. Tapping (or clicking) on a word will change the display type for that word: double-tapping changes the display type for the sentence or line (depending on text type)
(2)
Overlay menu: The menu is displayed by double-tapping (or clicking) the lower part of the screen. It allows access to layer and text information, as well as access to additional options, most importantly screenshot, help and save functions and a return to the main corpus screen
(3)
Layer information: The layer information icon allows access to the three full layers described below, alternating the layers upon tapping (or clicking).
(4)
Text information: The default icon displays the manuscript with folio information and provides access to further manuscript information as well as a search function. Further options that are still worked on include a touch-controlled split screen to facilitate a side-by-side comparison of layers and export tools for screenshots and concordances.
Layer (1) Untagged Text: This layer (see figure 21) displays the full, transcribed text without any tags. The organization is as close as possible to the original manuscript layout, displaying line breaks, empty lines, columns, punctuation and glosses. Any tags will be avoided here in order to facilitate reading.
Figure 21. Spelling corpus, untagged text layer, transcribed from MS Bodley 959, fol. 1r
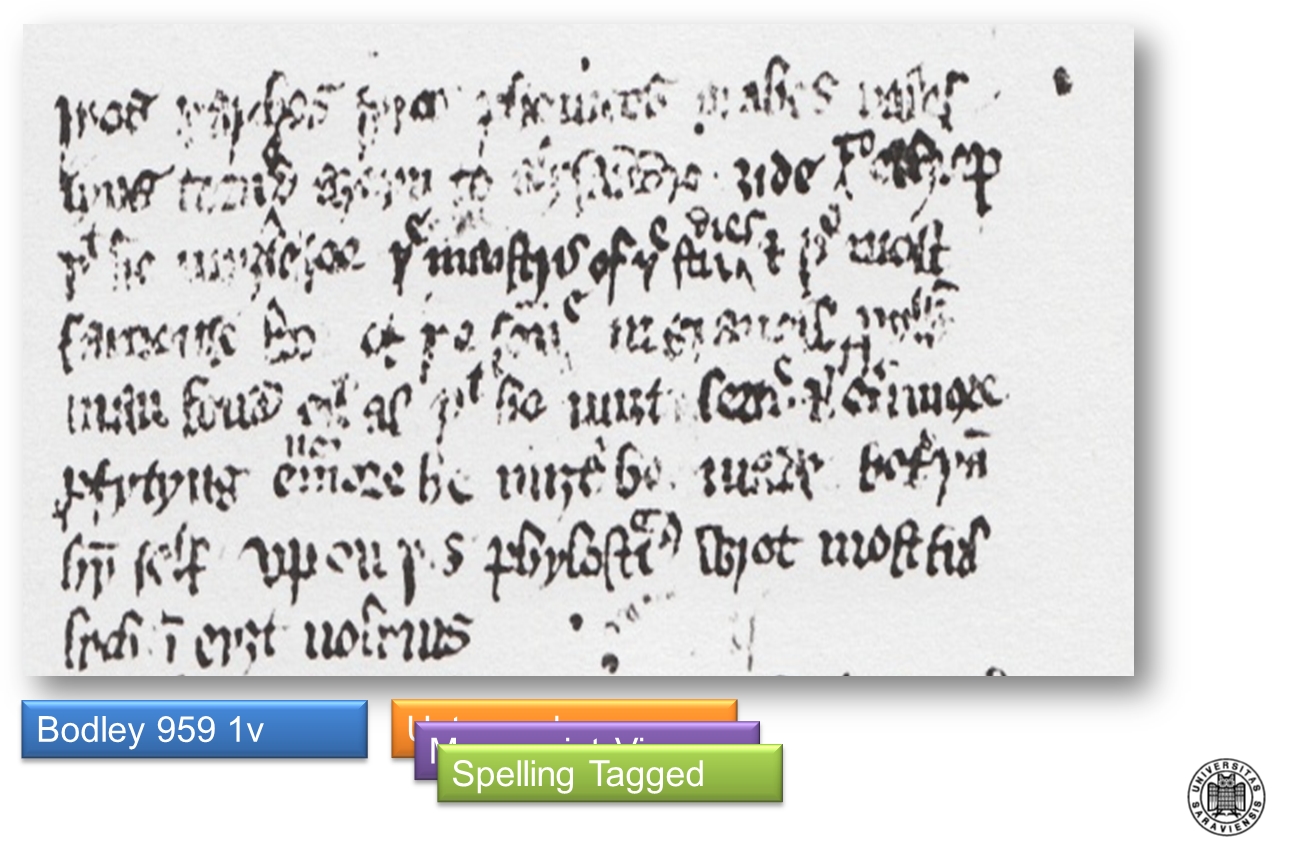
Layer (2) Manuscript: This layer (see figure 22) shows the original manuscript in the format provided for researchers by the copyright holder (usually photographs or photocopies). It is dynamically linked to the text layer and adjusts to display the same passage. An adjustment of this layer will also adjust the other two layers, so switching between layers will always display the same text.
Figure 22. Spelling corpus, manuscript layer, detail from MS Bodley 959, fol. 1r (Bodleian Library, University of Oxford 2012)
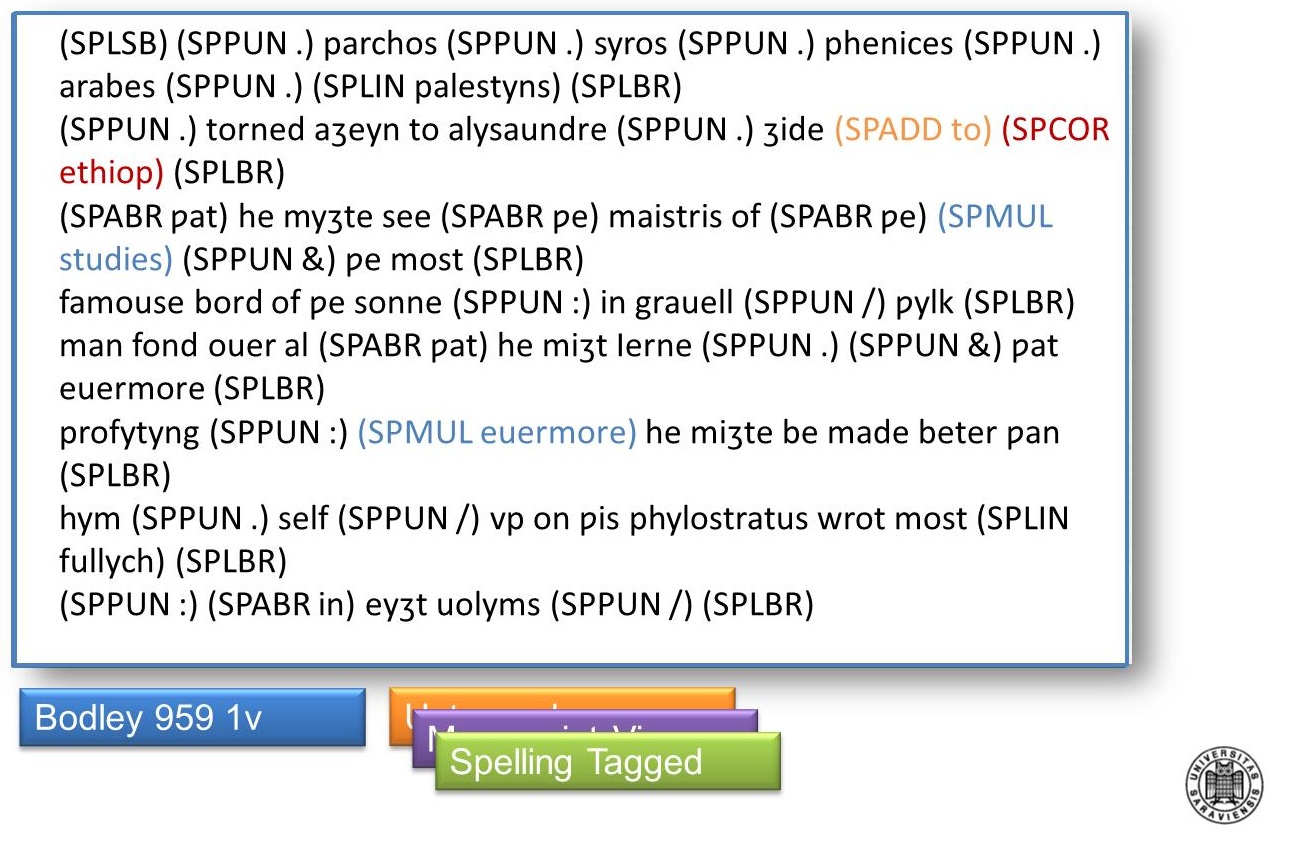
Layer (3) Spelling-tagged version: This layer uses the spelling tags described above, color-coded for better orientation to display relevant spelling features. An example is given in figure 23.
Figure 23. Spelling corpus, tagged text layer, transcribed and annotated from MS Bodley 959, fol. 1r
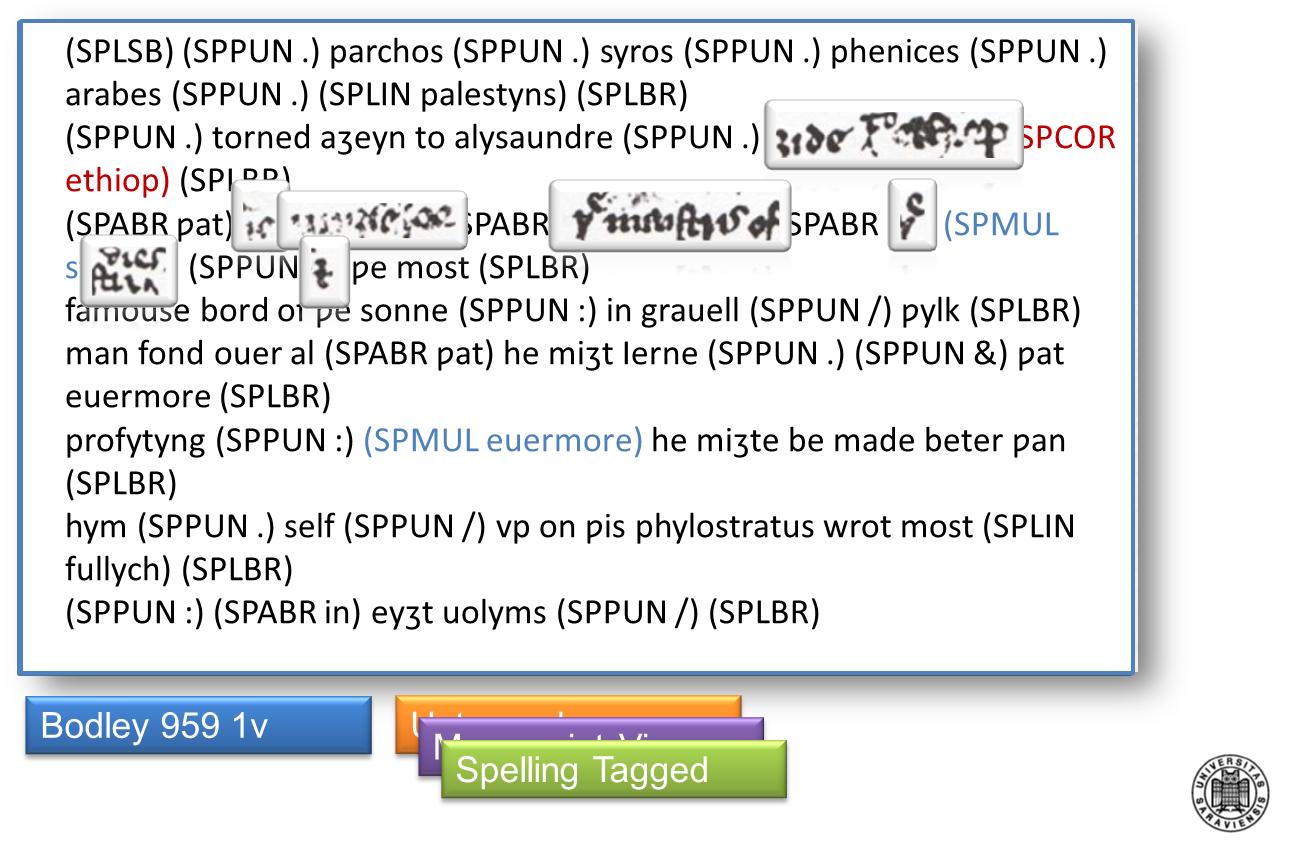
It is also possible to switch between the three layers on a word or sentence level, which allows, for example, the display of the manuscript image instead of the tagged word or the word in the text version. The intuitive interface thus allows easy access and comparison of all layers, as shown in figure 24.
Figure 24. Spelling corpus, tagged text with manuscript layer details, transcribed from MS Bodley 959, fol. 1r (Bodleian Library, University of Oxford 2012)
As shown above, corrections can be analyzed from the original manuscript by just clicking on the tag. The traditional plotting and listing views available with other corpus tools are thus complemented by the manuscript view which enables researchers to compare features of the manuscript with the transcription and the tagged version. This can lead to new insights into grammar and spelling issues. Figure 25, for example, shows that the scribe of this manuscript implemented both lexical and grammatical corrections. The scribe was possibly the main translator of the project, John Purvey, as surmised in Lindberg's 1994 study of the earlier version of the Wycliffite Bible. The corrections documented here give further evidence to this theory.
Figure 25. Examples for lexical and grammatical corrections in MS Bodley 959, fol. 1r
The tagging of glossing and additions allows researchers to see, at a glance, that the content of the text has been reconsidered, indicating a paragraph of special importance, as in figure 26. Obviously, where corrections, glossing and additions occur together, the content is most difficult or controversial (instead of it being just a long day in the scriptorium, as it were).
Figure 26. Glossing and additions in a transcribed and tagged version of MS Bodley 959, fol. 1r
The occurrence of several instances of multi-level writing in figure 27 may indicate that these emendations are not just spelling errors, since they were not made on the fly. Furthermore, they all concern the perspective of the translator and author, indicating original authorship.
Figure 27. Multi-level writing in a transcribed and tagged version of MS Bodley 959, fol. 1r
5. Conclusion
The corpus is not finished, and the interface presented here is still a preliminary test version. The integration of manuscripts entails numerous problems, first and foremost of a pecuniary nature, as the acquisition of the rights for the integration of photographs clearly represents a major source of income for the respective libraries, in this case particularly the Bodleian Libraries in Oxford. The first in a series of image-linked and tagged WSC manuscripts will be finalized and accessible by June 2013. However, the examples above should suffice to demonstrate that an ideal corpus for spelling research of Middle English texts should include the full text, separate for each manuscript, and tagged for spelling variation, with attached individual imagery of scans for manuscripts. The tags and description elements were created with the aim to establish suitable, platform-independent designations for the features discussed in chapter 2. They can be combined and modified easily to fit into any existing set of grammar- or lexis-oriented tags or description elements. In addition to spelling research, this type of corpus will also be useful for other areas of research such as lexical analysis, syntax, scribal identification, correction and censorship issues.
References
Baron, Alistair, Paul Rayson & Dawn Archer. 2009. “The extent of spelling variation in Early Modern English”. ICAME 30. Lancaster University, UK.
Blake, Norman F., ed. 1992. The Cambridge History of the English Language, vol. II: 1066–1476. Cambridge: Cambridge University Press.
Blake, Norman F. 2000. “Dialect, normalization and corpus-linguistic methodology: Introduction”. Placing Middle English in Context (=Topics in English Linguistics, 35), ed. by Irma Taavitsainen, Terttu Nevalainen, Päivi Pahta & Matti Rissanen. New York: Mouton.
Burnard, Lou & Syd Bauman, eds. 2012. TEI P5: Guidelines for electronic text encoding and interchange. Text Encoding Initiative Consortium. Charlottesville, Virginia. Version 2.1.0. 20 June 2012. http://www.tei-c.org/release/doc/tei-p5-doc/en/Guidelines.pdf.
Diemer, Stefan. 1998. John Wycliffe und seine Rolle bei der Entwicklung der englischen Rechtschreibung und des Wortschatzes. [Sprachwelten 12]. Frankfurt: Peter Lang.
Diemer, Stefan. 2006. “The polysemy of over in Late Middle English verb-particle combinations”. Information Distribution in English Grammar and Discourse and Other Topics in Linguistics, ed. by See-Young Cho & Erich Steiner, 51–97. Frankfurt am Main: Peter Lang.
Diemer, Stefan. 2008. Die Entwicklung des englischen Verbverbandes – eine korpusbasierte Untersuchung. Berlin: Technical University Berlin.
Diemer, Stefan. 2012. “Spelling variation in Middle English manuscripts: The case for an integrated corpus approach”. Middle and Modern English Corpus Linguistics: A Multi-dimensional Approach (SCL 50), ed. by Manfred Markus, Yoko Iyeiri, Reinhard Heuberger & Emil Chamson, 31–45. Amsterdam: Benjamins.
Forshall, Josiah & Madden, Frederick. 1850. The Holy Bible, in the Earliest English Versions, made from the Latin Vulgate by John Wycliffe and his Followers. Oxford: Oxford University Press.
Fristedt, Sven. 1953. The Wycliffe Bible: Part 1, The principal problems connected with Forshall and Madden’s edition. Stockholm: Almqvist & Wiksell.
Hiltunen, Risto. 1983. The Decline of the Prefixes and the Beginnings of the English Phrasal Verb: The Evidence from Some Old and Early Middle English Texts. Turku: Turun Yliopisto.
Hudson, Anne, ed. 1997. Selections from English Wycliffite Writings. Toronto: University of Toronto Press.
Lindberg, Conrad, ed. 1994. MS Bodley 959: Genesis-Baruch 3.20 in the Earlier Version of the Wycliffite Bible (Acta Universitatis Stockholmiensis vols. 6, 8, 9, 13, 20, 29, 81). Stockholm: Almqvist & Wiksell.
Markus, Manfred. 2000. “Normalizing the word-forms in Ayenbite of Inwyt”. Placing Middle English in Context (=Topics in English Linguistics, 35), ed. by Irma Taavitsainen, Terttu Nevalainen, Päivi Pahta & Matti Rissanen, 181–198. New York: Mouton.
McIntosh, Angus, Samuels, Michael Louis & Michael Benskin. 1986. A Linguistic Atlas of Late Medieval English. Aberdeen: Aberdeen University Press.
Samuels, M. L. 1969. ‘The dialects of MS Bodley 959’. Appendix 1 (329–339) of C. Lindberg ed., MS Bodley 959. Genesis - Baruch 3.20 in the Earlier Version of the Wycliffite Bible. Volume 5: Ecclesiasticus 48.6 - Baruch 3.20. Stockholm: Almqvist & Wiksell.
MS. Bodley 959: Genesis-Baruch 3.20 in the Earlier Version of the Wycliffite