Coreferenced corpora for information structure research
Erwin R. Komen
Centre for Language Studies, Radboud University Nijmegen and SIL-International
Abstract
Research in the area of information structure requires texts that are not only annotated syntactically, but have also been enriched with coreference information, from which the information status of constituents can be derived. This paper describes two computer programs that facilitate building a corpus of such enriched texts: "Cesax", which can be used to semi-automatically add coreferential information, and "CorpusStudio", which facilitates corpus research projects on enriched texts. The applicability of these two tools for information structure research is illustrated by a set of queries that look for prepositional phrases that introduce a new referent in a text. The proportion of PPs that do this grows from 54% in Old English to over 75% in late Modern English, the length distribution of the coreferential chains they introduce remains roughly the same throughout, and the proportion of those that introduce protagonist-like participants, being no more than 8% at any time, rises from Old English to Middle English, after which it gradually decreases again.
1. Introduction
English word order and the usage of constructions such as left dislocation, clefts etc, are not only contingent upon syntactic rules, but also depend on information ordering rules (Los 2009, Los and Komen 2012). Authors and speakers combine these rules to provide syntactically valid constructions signaling pragmatic notions such as topic and focus. Readers and hearers understand these signals to the extent that they discern which constituent bears focus and which refers to a topic.
In order to understand if and how the information ordering rules themselves (e.g. “newest last”) have changed during the history of English and how the interplay with syntactic rules has changed, the existing English historical corpora need to be enriched. The parsed English corpora already contain syntax information, but they don’t have information from which their informational status (new, given etc) can be readily derived. I argue that the informational status of a constituent in a syntactically parsed text can be derived by supplying coreferential information: the constituent’s referential status (such as “new” or “inferred”), and its antecedent (if it has one).
This paper describes how existing parsed corpora can be enriched with coreference annotation (section 2), and how these enriched corpora can be queried (section 3). Enriching the existing corpora involves the computer program “Cesax” (Komen 2011), while querying can effectively be done using “CorpusStudio” (Komen 2009). [1]
2. Enriching texts with referential information
The history of the English language is represented by several corpora that have been syntactically annotated. These syntactically parsed English corpora are listed in section 6. The parsed corpora are made available in a “bracketed labeling” format, where the hierarchy of constituents translates into embedding between brackets, and the constituent types are defined by a label that is attached to the opening brackets (Marcus et al. 1993).
The enrichment to these existing corpora should contain two vital elements for each noun phrase (and possibly for other syntactic categories): (a) referential status and (b) antecedent information. The referential status indicates whether a constituent has an antecedent, and if so, in what relation it stands to this antecedent. The antecedent information tells us where this antecedent is located.
I suggest tackling the coreference resolution in two steps: (i) convert the existing corpora to xml, and then resolve coreference semi-automatically. Section 2.1 describes the first step in the process of making coreferenced corpora, which consists of transforming the existing bracketed labeling format into an xml format that closely complies with the TEI-P5 standard (TEI Consortium 2009). This format allows supplying constituents with referential links as well as with features, such as the referential status. The set of referential statuses is discussed in section 2.2. Adding the coreference information can be done semi-automatically using the program “Cesax”, as shown in section 2.3.
2.1 From bracketed labeling to xml
The existing bracketed labeling format used for the parsed English corpora encodes the syntactic category of a constituent (e.g: NP, PP, IP) as well as the function this constituent has within the hierarchical structure, as for instance (1).
| (1) |
Penn-Helsinki-York Treebank example |
| (IP-MAT (CONJ But) |
|
(NP-SBJ (PRO$ my)(N Partner)) |
|
(VBD went) |
|
(PP (P to)(NP (D the)(N Monastery))) |
|
(. ,)) |
The label NP-SBJ, for example, indicates a noun phrase that has the syntactic function of “subject” in a clause, and the label IP-MAT refers to a matrix (main) clause. Word categories are found in end nodes, and their labels are sometimes combined with number information, so the label N is a singular noun, while NS is a plural noun. The labels in the bracketed labeling format, then, facilitate annotating features (such as the function of a constituent) by separating these with hyphens.
2.1.1 Enhancing bracketed labeling
The principle of feature annotation is straightforward for the annotator, but querying constituents that are equipped with multiple features may become difficult, unless a method is used by which feature types can be readily distinguished. Let us briefly consider one possible method. We could decide to not only add feature values to constituent labels, but also feature names. So if we were to have a subject noun phrase with a referential status of “Identity” (the types are explained further in 2.2), then the label of the noun phrase could be something like: NP-SBJ-CREF:IDT.
If we were to add more features, such as animacy (human versus non-human) and person/gender/number, we may end up with a label: NP-SBJ-CREF:IDT-AN:H-PGN:3ms.
It would still be possible to query texts containing these kinds of labels with an engine like “CorpusSearch” (Randall et al. 2005). Consider the query to look for subject noun phrases with a referential status of “Identity” that are 3rd person masculine singular in (2).
| (2) |
CorpusSearch2 query example |
| 1 |
query: |
(IP-MAT iDoms NP-SBJ*) AND |
| 2 |
|
(NP-SBJ* HasLabel *CREF:IDT*) AND |
| 3 |
|
(NP-SBJ* HasLabel *PGN:3ms*) |
One complication in the approach above is that of encoding and querying referential pointers. Each constituent can not only take features, but also a reference to another constituent. In order to facilitate such a referential system, we would need to equip each constituent with a unique identifier, such as NP-SBJ-ID:101. The constituent with this identifier could then be referred to from another constituent by using its identification number, for example: NP-OB1-ID:124-REF:101. Querying these kinds of references using CorpusSearch, however, will become a difficult task.
In view of the difficulties mentioned above, the approach advocated in this paper is that of (a) converting the bracketed labeling corpora to an xml format, (b) adding coreference information to the xml corpora, (c) facilitating querying these xml corpora in a user-friendly way, (d) allowing the resulting xml corpora to be converted to a bracketed labeling format for those who would like to search them using CorpusSearch, and (e) using as much as possible existing open standards. This last point has the added advantage that it is not us who have to take the burden of developing query engines and maintaining them.
2.1.2 The psdx tag set for parsed English corpora
The xml format to which the parsed English corpora are converted will be referred to as the “psdx” format, since files in this format carry the .psdx extension. [2] The psdx tag set is a subset of a standard called the “Text Encoding Initiative P-5”. The particular subset used for psdx is discussed in section 19.3 of the P5 guidelines, and is built around the idea of “embedded trees”. The main elements of the tags that are used to encode the hierarchical phrase structure of the parsed corpora are shown in (3).
| (3) |
Main elements of the TEI-P5 embedded tree tag set |
|
<eLeaf> |
An end-node containing one text element (a word or punctuation mark). |
|
<eTree> |
A hierarchical element from the phrase-structure. An <eTree> may contain one <eLeaf> or one or more <eTree> elements. |
|
<forest> |
This typically is a line in a text, and may contain one or more <eTree> elements. |
|
<forestGrp> |
A collection of <forest> elements constituing one text groups together in a <forestGrp> element. |
Each text contains one <forestGrp> tag, which has one <forest> child for each line in the text. These <forest> tags contain a hierarchical structure of <eTree> elements, which indicate the phrase structure of this sentence, as for example in Figure 1.
The actual words and punctuation marks of the sentence are found in the <eLeaf> elements. The <forest>, <eTree> and <eLeaf> tags themselves contain a limited number of attributes in order to facilitate querying them. Each <forest> element, for instance, contains identifiers Location and TextId which contain information similar to that in the ID label of the bracketed labeling format.
Each <eTree> contains a numerical identifier attribute, which serves to facilitate the coreference information we want to add. The psdx format allows an unlimited number of features, divided into feature sets, to be added, as illustrated in (4).
| (4) |
Coreference information in the psdx format |
| <fs type="coref"> |
|
<f name="RefType" value="Identity" /> |
|
<f name="IPdist" value="20" /> |
| </fs> |
| <ref target="321"> |
| <fs type="NP"> |
|
<f name="GrRole" value="Oblique" /> |
|
<f name="PGN" value="3s" /> |
|
<f name="NPtype" value="QuantNP" /> |
| </fs> |
The tags used for feature sets <fs>, features <f> and references <ref> are all taken from the TEI-P5 tag set. The example in (4) contains two feature sets: one for the coreference information, and one for noun phrase information. The coreference information notes the type of link to the antecedent in the feature called RefType, and it contains a distance measure to the antecedent in IPdist. The <ref> tag gives us value of the antecedent’s Id field.
2.2 Referential status
The status of the information represented by constituents may, at first glance, be divided into “new” and “old” (Chafe, 1976). Constituents that are “new” do not have an antecedent, while those that are “old” do. Instead of such a binary division, several proposals have been made for finer-grained distinctions, such as Prince’s (1981) taxonomy of given and new, which distinguishes 7 statuses, Ariel’s (1994, 1999) “accessibility marking hierarchy”, distinguishing over 13 statuses, and the “givenness hierarchy” introduced by Gundel, Hedberg and Zacharsky (2004), comprising 5 cognitive statuses.
I argue that only a limited set of 5 statuses, which I refer to as the “Pentaset”, is sufficient to serve as primitives from which finer-grained distinctions can be made (Los and Komen forthcoming). The text in (5) serves as an example that will be used to explain the Pentaset, which consists of the following members: “Identity”, “Inferred”, “Assumed”, “Inert”, and “New”. [3]
| (5) |
a. |
[np I] am the second son of [np a family of eight], - six sons and two daughters, - |
|
b. |
and was born on December 6, 1824, at [np Plymouth], where [np my] father and mother were on a visit after one of [np his voyages to India]. |
|
c. |
My father was one of three sons of Captain J. Fayrer: |
|
d. |
[np the eldest] was the Rev. Joseph Fayrer, rector of St Teath, Cornwall; |
|
e. |
the third, Edward, a midshipman in [np the navy], was drowned when H. M. S. Defence foundered, with all hands, in a gale of [np wind] in the Baltic in 1811. |
|
f. |
My mother was the only daughter of a Lancashire gentleman named Wilkinson: |
|
g. |
she was descended on the female side from John Copeland, who took David, King of Scots, prisoner at [np the battle of Neville's Cross]. [fayrer-1900:7-13] |
The first constituent I in (5a) is discourse-new but addressee-old information, which receives the category of “Assumed” in the Pentaset. Other constituents with the same category are, for instance, Plymouth in (5b), the navy in (5e) and the battle of Neville’s Cross in (5g).
The status of a family of eight is not only new to the discourse, but also to the addressee, for which reason it receives the category of “New” in the Pentaset.
The personal pronoun my has an antecedent in the discourse (the pronoun I in the first line), and the entity referred to by the current constituent and its antecedent completely coincide, so that they receive the Pentaset category of “Identity”.
The constituent the eldest in line (5d) refers back to three sons of Captain J. Fayrer in (5c), but the entities are not identical—they stand in a part-whole relationship. This relationship as well as other bridging inferences receive the Pentaset category of “Inferred”.
There is one final Pentaset category called “Inert”, and the noun phrase wind in (5e) is an example of it. This wind really is an attribute to gale, so that, as attribute, it cannot refer to something, nor can it be referred to. In other words: such noun phrases are inert to the whole process of referencing.
The information status of a noun phrase like his voyages to India in (5b) would be “New” as far as the Pentaset is concerned, since the information is both new to the addressee as well as to the discourse. A finer-grained system, such as the “taxonomy of given and new”, would assign it the “Brand-new anchored” status. However, this finer-grained distinction is derivable from the available syntactic information and the Pentaset statuses. The status of “Brand-new anchored” can be assigned to any constituent that (a) has the Pentaset category of “New”, and (b) contains at least one syntactic child with the Pentaset status of “Identity”. In the current example the pronoun his has the status of “Identity”, since its antecedent is my father, and the entity referred to by his and my father is identical.
2.3 Coreferencing with "Cesax"
The task of coreference resolution consists of determining the referential status of each noun phrase, and the exact antecedent if the noun phrase has one. There are three principally different attempts at coreference resolution: manual, automatic and semi-automatic.
The computer program “Cesac”, the predecessor of “Cesax”, provided a user-friendly platform to resolve coreference manually (Komen 2009a). The manual task, however, is very time consuming, and error-prone. The kappa measurements of inter-rater agreement were in fact very low. [4]
The task of coreference resolution has received continuing attention within the realm of computational linguistics. Hobbs’ (1978) algorithm, for instance, reports an accuracy of 88% for finding the correct antecedents for 3rd person anaphoric pronouns, while the Resolution of Anaphora Procedure (RAP) provided by Lappin and Leass (1994) report 86% accuracy. Both algorithms not only assume the presence of syntactic information, but also of morphological. The most crucial bit of morphological information is that of the person/gender/number (PGN) of each constituent. This information allows restricting the set of possible antecedents drastically. More recent stochastically oriented algorithms reach an accuracy of 80% without having syntactic or morphological information (Kehler et al. 2004, Soon et al. 2001).
Our task distinguishes itself from the purposes for which fully automatic algorithms are being used. Fully automatic algorithms are aimed at analyzing large datasets and are usually part of a larger task, such as text summarization or categorization (Mitkov et al. 2007). The purpose for the coreference resolution we are doing is linguistic analysis. We do not want to do more work than necessary, but we do want to reach as high accuracy as possible. This is why we advocate a semi-automatic approach, which is described and evaluated in the next sections.
2.3.1 Semi-automatic coreference resolution with "Cesax"
The semi-automatic algorithm implemented in the computer program “Cesax” tries to resolve as much as possible automatically, but when it is in doubt or recognizes a suspicious situation, it asks for the user-input. The algorithm’s steps are shown in (6), and each of the steps will be explained below.
| (6) |
Semi-automatic coreference resolution |
|
a. |
Add features such as: noun phrase type, grammatical role and person/gender/number (automatic). |
|
b. |
Resolve local coreference (automatic). [5] |
|
c. |
Mark particular noun phrases as “New”, others as “Inert” (automatic). |
|
d. |
Determine the “winner antecedent”: the most likely candidate antecedent of the current noun phrase based on a ranked set of constraints (automatic). |
|
e. |
If the combination <source, winner antecedent> belongs to a “suspicious situation”, then consult the user, if not, automatically make the link. |
|
f. |
Allow the user to check the links that have been made automatically (manual). |
Once the user has loaded a text into “Cesax”, the program starts in (6a) by adding several kinds of features that are crucial to resolving coreference, such as the person, gender and number. Only then does the algorithm start processing the text line by line and clause by clause. When it encounters a noun phrase, it first, as in (6b), checks if there is any indication of a strictly local coherence (such local coreferences can be determined from the bracketed labels). Then in (6c) it checks if the noun phrase is “Inert” or “New” (see 2.2). If this is the case, it can not have an antecedent, so that no antecedent will have to be found for it.
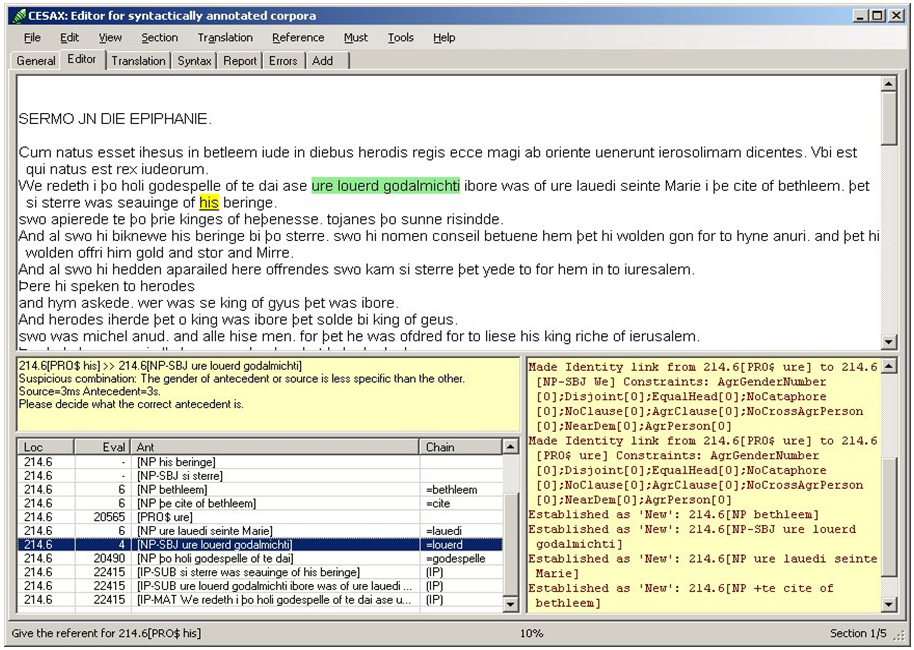
Those noun phrases that pass through step (6c) are the ones that could, in principle, have an antecedent. The step in (6d) is where potential antecedents for such a noun phrase are evaluated. A pool of potential antecedents is kept up to date constantly, and when there is a noun phrase that may have an antecedent, all pairs of <noun phrase, potential antecedent> are evaluated against a ranked set of constraints. This results in an evaluation number for each pair, where the lowest number has the highest likelihood of being the correct antecedent. As soon as a winner has been found in step (6d), the pair <noun phrase, winner antecedent> is evaluated against a list of suspicious situations. If there is a suspicious situation, then the user is presented with the most likely antecedent candidate, as well as an explanation of the suspicious situation, such as illustrated in Figure 2.
“Cesax” suggests that the possessive pronoun his (in yellow) has the antecedent ure louerd godalmichti (in green). The reason this constituent is suggested is the fact that it has the lowest evaluation value (the value “Eval” in the lower left pane is “4”). The suspicious situation is described for the user in the middle-left pane as: “The gender of antecedent or source is less specific than the other. Source=3ms Antecedent=3s”. The problem, apparently, is that we do know the gender of the pronoun his: it is masculine. But the automatic gender resolution process that is executed prior to the coreference resolution task has not been able to determine the gender of the noun phrase “ure lourd godalmichti” with more accuracy than “3rd person singular”, since gender information is not encoded in the parsed English corpora. If the user is satisfied with the suggestion made by “Cesax”, the choice can be confirmed. If not, the user can select the correct antecedent from the list in the lower-left pane.
If there is no suspicious situation found in step (6e), then the most likely link is made automatically. (Cesax’s own and the user’s decisions are all available in the lower-right pane.)
The final step in (6f) allows a user to double check all the automatically made links after the whole text is parsed through “Cesax”.
2.3.2 Performance of “Cesax”
The performance of “Cesax” has been measured on the text named “long-1866”, which is taken from the PPCMBE corpus (Kroch et al. 2010). The text consists of three chapters from a history book entitled "The decline of the Roman empire" written by George Long. It contains 3083 noun phrases.
About 54% of the noun phrases were processed automatically by the algorithm, while the user was consulted for the remaining 46% of the cases. The user agreed with about 40% of the suggestions in this last 46%, choosing other options for the remaining 60% of the situations where consultation was deemed necessary by “Cesax”. About 5% of the 54% of the noun phrases that had been processed automatically were found to be erroneous, so that the total success rate of the algorithm (the number of correctly automatically resolved coreference situations and the number of correctly made suggestions) becomes 72%.
This performance may seem poor from the point of view of fully automatic coreference resolution algorithms, which can reach 80% accuracy even without prior knowledge. The problem with the fully-automatic algorithms, however, is that we do not know off-hand where errors occur, so that were we to use a fully-automatic algorithm, we would have to manually check 100% of the references made.
The semi-automatic resolution process has reduced the manual task considerably. We can be reasonably confident that the automatic part (which amounted to 54% in the “Long” text) is done well, and we can agree with many of the suggestions “Cesax” makes to us.
2.4 Coreferential chains
The coreference resolution performed with “Cesax” gives us access to coreferential chains: ordered sets of noun phrases that refer to the same mental entity. The concept of coreferential chains can be illustrated from the sample text in (7).
| (7) |
a. |
[sbj Johni] entered the room where [hisi daughterj] watched television. |
|
b. |
[sbj Hei] looked around, |
|
c. |
and [sbj 0i] saw hisi daughterj, [sbj whoj] sat on the couch. |
|
d. |
[sbj Shej] looked up, |
|
e. |
and [sbj 0j] made a face at himi, |
|
f. |
while [sbj hei] passed by. |
|
g. |
[sbj Shej]’d had a rough day at school. |
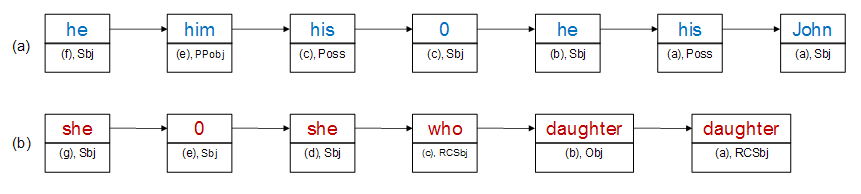
The coreferential chain of “John” runs backwards from line (7f) until line (7a), as shown in Figure 3, while that of “his daughter” runs from line (7g) until line (7a).
All the elements on chain (a) refer to the same person, called “John”, while all the elements on chain (b) refer to “his daughter”. Coreferential chains are present in the psdx files that have undergone coreference resolution, since each of the constituents on a coreferential chain receives the unique identification number of that chain as one of its features.
Each element on a coreferential chain contains a combination of referential status information and syntactic information, such as: person/gender/number, the text of the referring expression (e.g: “he”), its grammatical role (e.g: “argument”), the type of the noun phrase (e.g: “pronoun”), and the status of its relation with its antecedent (e.g. “new”, “identity” etc.).
The coreferential chains offer a new research area, allowing us to combine syntactic and referential status information of individual participants in a text. We could, for instance, determine how many times a participant is the subject, how long chains of participants can be, how many different participants are present during the ‘life-span’ of, say, a major protagonist and so forth. The coreferential chains certainly offer information that can be used to calculate the quantitative discourse measures introduced by Givón (1992), but they offer such a rich resource of information, that their usability may well be extended through future studies.
3. Querying coreferenced corpora
While corpus research can presently be done using web-based tools, such research has severe limitations. Querying texts over the internet is usually possible on the word level and the part-of-speech level, but not on a syntactic level. There are special programs allowing off-line syntactic searches in historical English texts, but these programs are often command-line oriented, and researchers often directly invoke queries using Window’s command prompt. Such methods are error-prone, and can lead to unrepeatable or irretrievable results.
Corpus research programs from the “Tiger” complex (TigerSearch, TigerGraphViewer) have a graphical interface, but only work with xml files coded in a particular format (Brants et al. 2002). While it would be possible to convert the existing corpora into the tiger format, there are additional problems with the available tools. None of them facilitate handling a comprehensive corpus research project such as will be described in section 3.1, which comprises a series of queries, executed in a particular order, and which makes use of particular input files.
The program “CorpusStudio” addresses the problems above. It is a stand-alone program that functions as a user-friendly environment to query the existing parsed English corpora as well as the coreferenced English corpora discussed in section 2. [6] We will first walk through a brief introduction into the functionality of the “CorpusStudio” program (3.1), and then proceed to see how coreference information can be employed in “CorpusStudio” (3.2).
3.1 Working with “CorpusStudio”
“CorpusStudio” is aimed at providing a graphical interface between the corpus researcher (not only the senior researcher, but also students) and the available search engines. Defining queries and maintaining them with the Window’s shell based programs is possible, but requires advanced computer skills from the researcher as well as a lot of discipline in archiving the queries properly. “CorpusStudio” requires much less computer skills and greatly reduces the researcher’s discipline, since it stores the crucial information belonging to one project in one file (the corpus research project file, as discussed in 3.1.1). This should help avoid making mistakes and may therefore lead to a higher repeatability in getting results.
3.1.1 Corpus research projects
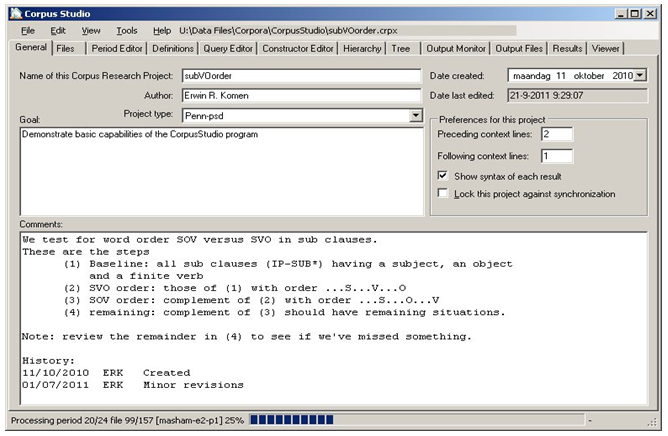
A “Corpus research project file” is an xml file containing all information for one particular corpus research project, as illustrated in Figure 4.
The “General” tab page in “CorpusStudio” allows defining meta information for a corpus research project, such as its creation date, the name of the author, the overall goal of the project, and comments, which could, for instance, outline the procedure followed in the project in more detail. Figure 4 shows the meta-information of a project where we determine the word order (SVO versus SOV) in subclauses in all the parsed English corpora.
Corpus research projects can be set to automatically synchronize their information with the computer at work and at home, but if this is undesirable, as when one wants to archive a project for later retrieval, projects can be “locked”.
3.1.2 Defining queries
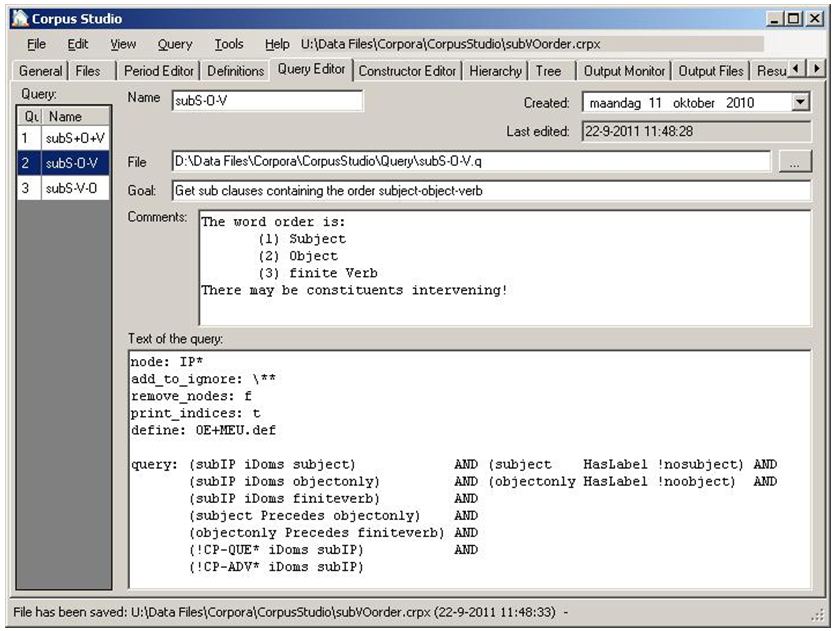
“CorpusStudio” has a query editor where queries either for CorpusSearch2 or for Xquery can be defined, as shown in Figure 5.
The query editor does not only allow one to define the text of the query, but meta-information such as creation date, the query’s main goal, and any comments can also be added. The queries are part of the corpus research project file they are included in, but a copy of each query is maintained in a user-definable directory.
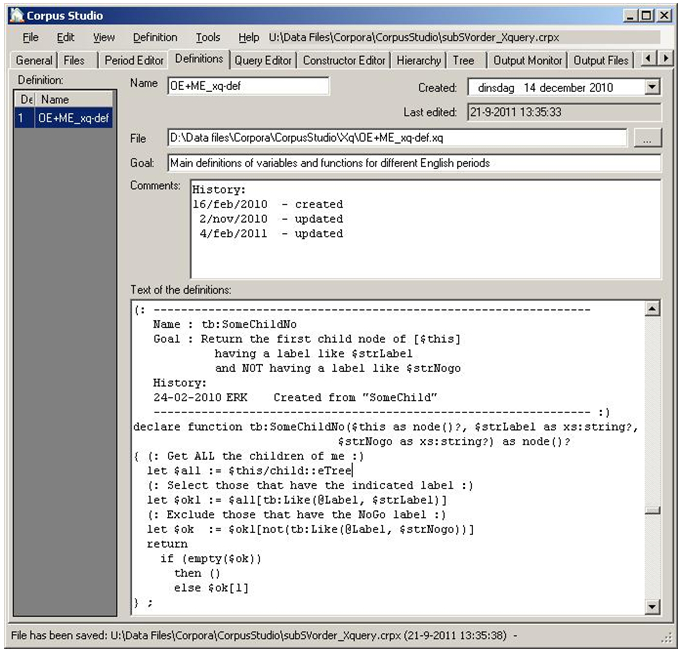
It is often helpful to use pre-defined shortcuts that, for instance, define which constituent labels should be regarded as those of a finite verb (finite verbs could consist of past tense verbs labelled VBD, present tense verbs VBP, past tense forms of be, which are labelled BED, present tense forms of be labelled BEP etc.) An entry in a definition file could state that the shortcut “finiteverb” means “VBP|VBD|BED|BEP”. [7] “CorpusStudio” facilitates working with definitions, since it provides the user with a “Definitions editor” on the Definitions tab page, as illustrated in Figure 6. [8]
Definitions allow one to re-use templates for all the labels referring to a “subject” or a “finiteverb” for instance. The Xquery functions that can be defined on the Definitions tab page for the xml based corpus research projects are essential to the linguist’s working with xml corpora. “CorpusStudio” comes with several pre-defined Xquery functions that are “hard-wired” within the program. These functions are described in the online user manual (Komen 2009b).
3.1.3 Combining queries
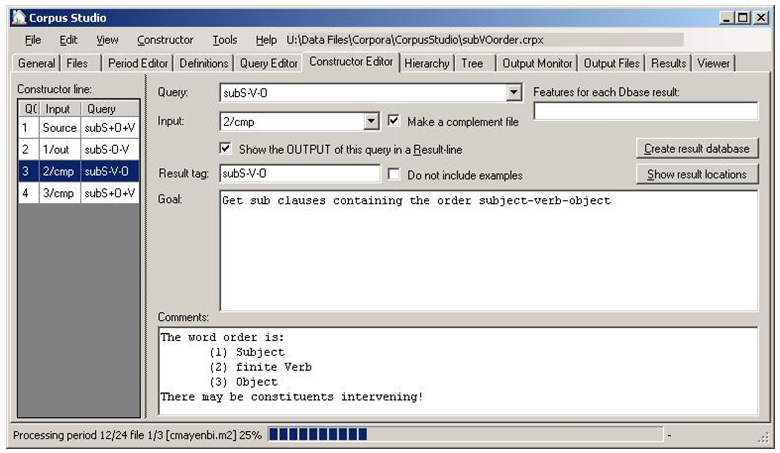
“CorpusStudio” allows combining queries in the required order with the “Constructor editor”, as shown in Figure 7.
The constructor editor in Figure 7 shows that the project starts with query subS+O+V in line 1, which takes its input from the “source”—those are all the input files defined on the “Files” tab page. The second line takes the output of the first line as its input, executing query subS-O-V (this query is actually shown in Figure 5). The third line, which is the one shown in Figure 7, executes the query subS-V-O and takes its input from the complement of the second line. (The complement contains all the <forest> elements that do not comply with the conditions specified in the query.) The Constructor Editor, then, allows one to define queries hierarchically.
Once the queries of a research project and the order in which queries have to be executed have been specified, query execution can take place. “CorpusStudio” optimizes query execution in a number of ways, and queries are executed in the order shown in (8).
| (8) |
Query execution order |
|
a. |
Period (such as Old English, Middle English, or parts of these) |
|
b. |
Text |
|
c. |
Sentence (Xquery only) |
|
d. |
Query line (as defined in the constructor editor) |
The order of query execution forces all different queries to be executed right with the first line in the text that is being queried (for Xquery processing) or with the first text (for CorpusSearch2 processing). This means that if there is an error in one of the queries, the query engine (Xquery or CorpusSearch2) will detect this error very quickly.
3.1.4 Research project results
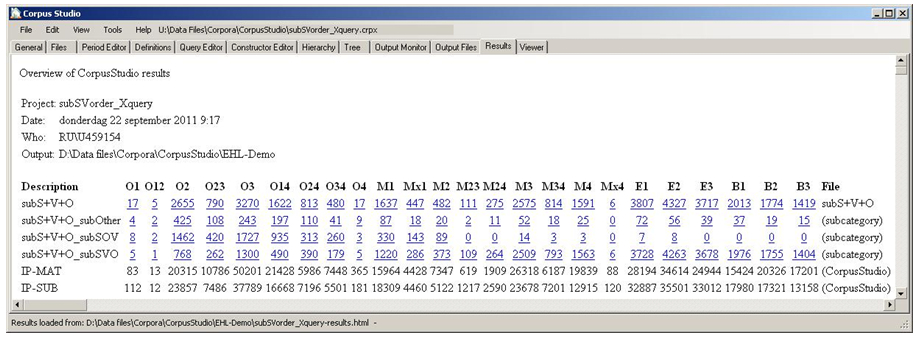
The results of a corpus research project such as the one used in our example here, that of determining the SOV versus SVO word orders in different English time periods, are presented to us in several different ways. One form is that of an html file, which is created separately, and shown from within “CorpusStudio” on the Results tab page, as illustrated in Figure 8 .
The results give us some meta-information, such as the name of the corpus research project, the date and time of execution and the username of the one executing the project.
The results then come with a table offering a summary of the output of the different queries, which is broken up in the subperiods that have been specified in the “Period Editor” (see the manual). Old English, for instance, is divided into sub periods O1, O12, ... O4. The numbers in each cell (e.g. “17” in column “O1” of row “subS+V+O”) represent the number of instances that adhere to the query of that particular line. Normalization of frequencies is left to the user, who can decide to define a query that supplies a baseline or use the numbers of main clauses (“IP-MAT”) and subclauses (“IP-SUB”) supplied by “CorpusStudio”, if that is helpful.
What we see for our example-project is a steady decrease of the SOV word order, and this word order vanishes by the M23 time period. The SVO word order in sub clauses starts out as relatively small in early Old English, but reaches a break-even point with the SOV word order somewhere towards the end of Old English.
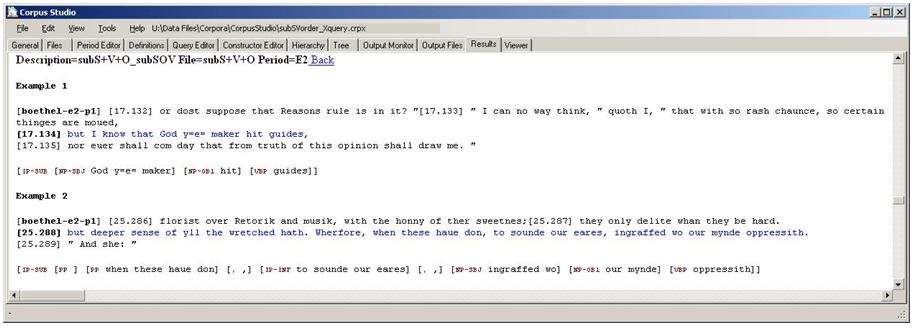
The results do not only give the summary table as shown in Figure 8 , but they also allow “jumping” to individual examples by clicking on a cell in the table. If we were to click, for instance, on the number “8” which indicates the number of sentences with SOV word order in the sub clause in the period E2, we end up on the part of the results page shown in Figure 9.
The individual results are numbered, they come with a preceding and following context, and they can be set to come with a syntactic breakdown of the sentence that was found. The example 1 in Figure 9 , for instance, shows that it has found the sentence “but I know that God your maker hit guides” as an example of the subSOV query from the E2 (2nd part of early Modern English) time period, and then it gives a syntactic breakdown of the result, as repeated in (9).
| (9) |
[IP-SUB [NP-SBJ God the maker] [NP-OB1 hit] [VBP guides]] |
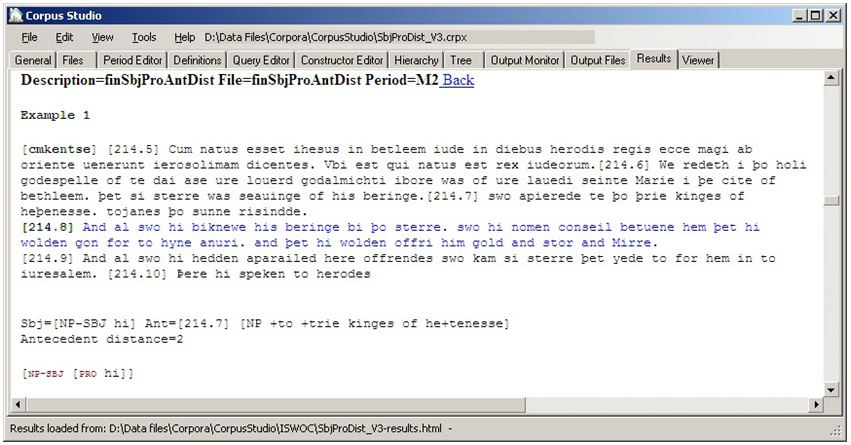
The corpus research projects working with Xquery allow each example to be accompanied with user-definable additional information. Consider, for instance, the results of an Xquery project that finds subject pronouns together with their antecedents, as in Figure 10.
The query, which will not be discussed in detail here, looks for subject pronouns that have an antecedent, and then gets the distance to that antecedent. The example result above shows that the Middle English subject pronoun hi ‘they’ has been found, and the additional information, which has been defined by the user in this particular corpus research project, not only shows the subject pronoun itself, but also the location of the antecedent (line [214.7]), the antecedent’s noun phrase þo þrie kinges of heþenesse ‘the three heathen kings’, and the distance to the antecedent (Antecedent distance=2).
3.2 Querying coreferenced corpora
We have seen that “CorpusStudio” allows us great flexibility in defining functions, queries and query execution order. This section shows how we can put all of that to work in order to query coreferenced corpora.
Suppose we have a set of coreferenced texts and we set ourselves a task that combines syntactic information with referential status. Our task will be to look at main clauses that contain: (a) a subject, (b) a finite verb, and (c) a prepositional phrase. What we want to know is whether the proportion of PPs containing “New” information has changed significantly over time. Are PPs used to express new information more or not?
We will use a query for this task that employs “CorpusStudio”’s subcategorization feature. The query, matS+V+PP, retrieves all the main clauses with the correct content: a subject, a finite verb and a PP that contains at least one NP. It then determines the referential status of this last NP, and divides the results accordingly. The code of this query is shown in (10).
| (10) |
Query matS+V+PP |
| 1 |
for $adjunct in //eTree[tb:Like(@Label, $_anypp)] |
| 2 |
|
(: Get the usual [search] value: the parent matrix IP :) |
| 3 |
|
let $search := $adjunct/parent::eTree[tb:Like(@Label, $_matrixIP)] |
| 4 |
|
|
| 5 |
|
(: Find the subject of this IP and the finite verb :) |
| 6 |
|
let $sbj := tb:SomeChildNo($search, $_subject, $_nosubject) |
| 7 |
|
let $vb := tb:SomeChild($search, $_finiteverb) |
| 8 |
|
|
| 9 |
|
(: Get the (first) NP object of the PP, and its reftype :) |
| 10 |
|
let $obj := tb:PPobjectOrNP($adjunct) |
| 11 |
|
let $ref := ru:feature($obj, 'RefType') |
| 12 |
|
let $cat := if (tb:Like($ref, 'New|Inferred|Assumed')) then 'new' |
| 13 |
|
else if (tb:Like($ref, 'Identity')) then 'old' |
| 14 |
|
else 'other' |
| 15 |
|
|
| 16 |
where ( exists($sbj) and |
| 17 |
exists($vb) and |
| 18 |
exists($obj) |
| 19 |
) |
| 20 |
return ru:back($adjunct, '', $cat) |
Line (10.1) starts by selecting prepositional phrases, which are characterized by having an <eTree> element whose @Label attribute matches one of those defined by the variable $_anypp. [9] The prepositional phrase that is selected is assigned to the variable $adjunct. [10] We would like to limit our search to main clauses with their direct child-constituents, which is why line (10.3) checks if the parent constituent of $adjunct is a constituent with a main clause label as defined in the variable $_matrixIP. [11] Having obtained the main clause variable $search, we can now look for the subject $sbj in line (10.5) and the finite verb $vb in line (10.7).
Line (10.10) obtains a variable $obj, which contains the noun phrase governed by the PP node $adjunct that we are currently treating. The noun phrase $obj is the main object of our attention in this query, and we want to know the referential status of this NP. We retrieve its referential status in line (10.11) through the built-in ru:feature function (see the online manual), which gives us the value of the grandchild <f> feature node with feature name RefType. Lines (10.12-14) derive the value of the subcategorization variable $cat, which can be new, old or other, depending on the particular referential category found for the noun phrase $obj.
The where clause in lines (10.16-18) makes sure that we only proceed if we have actually found a main clause (in $search) that contains a subject (in $sbj), a verb (in $vb) and PP object (in $obj), without any specification as to the order in which these occur.
The last line of the query in (10.20) uses the built-in ru:back function, which makes sure that, if all the conditions have been met, we return a <forest> node as a result (this typically is one line in the text we are processing, see 2.1.2). These returned <forest> nodes are then used by “CorpusStudio” to count the number of results and to show the user where the results are located. The call to ru:back in line (10.20) also contains the subcategorization variable $cat, which makes “CorpusStudio” not only give us a row in the summary table with the number of PPs that meet all the conditions of (10), but it will make three additional rows, which give us the number of referentially new, old and other PPs. (This is comparable with the matS+V+O row in in Figure 8 , which are followed by three subcategorization rows.)
Several lines in the query make use of functions such as tb:SomeChild and tb:SOmeChildNo—these are defined in the “Definitions” section of the “CorpusStudio” project. We will briefly have a look at one function to see how this feature of Xquery works.
| (11) |
Function tb:SomeChild |
| 1 |
(: ----------------------------------------------------------------------------- |
| 2 |
|
Name : tb:SomeChild |
| 3 |
|
Goal : Return the first child node of [$this] having a label like $strLabel |
| 4 |
|
History: |
| 5 |
|
24-02-2010 ERK Created |
| 6 |
|
------------------------------------------------------------------------------ :) |
| 7 |
declare function tb:SomeChild($this as node()*, $strLabel as xs:string?) as node()? |
| 8 |
{ |
| 9 |
|
(: Get ALL the children of me :) |
| 10 |
|
let $all := $this/child::eTree |
| 11 |
|
(: Select those that have the indicated label :) |
| 12 |
|
let $ok := $all[tb:Like(@Label, $strLabel)] |
| 13 |
|
return |
| 14 |
|
if (empty($ok)) |
| 15 |
|
then () |
| 16 |
|
else $ok[1] |
| 17 |
} ; |
The function tb:SomeChild as shown in (11) starts with a declare line where the input arguments and the output type are defined. Line (11.10) gets all the direct <eTree> children of the input node $this, and line (11.12) selects those of the children that have a @Label attribute like the $strLabel argument supplied by the calling function. The function finishes in lines (11.13-16) by returning either “nothing” if we have not found a child fulfilling the conditions, or else the first child that fulfills the conditions.
When the query in (10) is executed, we get the number of PPs that are new, old and other according to the referential status division made in (10.12-14). Table 1 gives the numerial results, as divided over all the subperiods where the enriched corpus texts are from.
| Result |
O3 |
O14 |
M1 |
M2 |
M3 |
E1 |
E2 |
E3 |
B1 |
B3 |
| matS+V+PPnew |
103 |
50 |
61 |
36 |
44 |
45 |
64 |
60 |
131 |
282 |
| matS+V+PPold |
91 |
39 |
28 |
43 |
13 |
31 |
42 |
19 |
65 |
68 |
Table 1. Prepositional phrases in main clauses found by query (10)
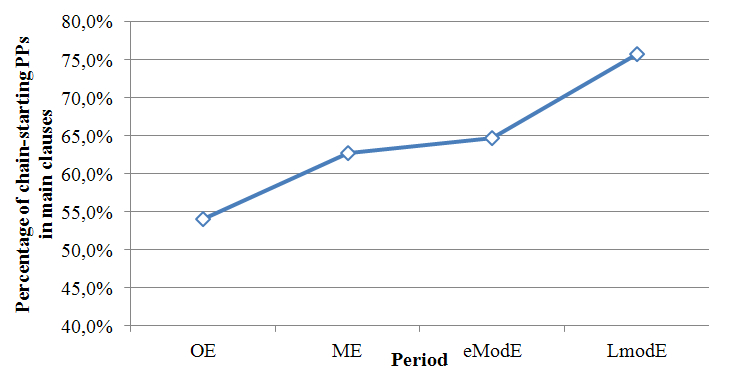
The number of occurrences is limited, but if we combine the results into the four main periods (Old English, Middle English, early Modern English and late Modern English), then we get a good idea of what is going on. Figure 11 shows the result of combining the subperiods into larger periods (O3 and O14 are both part of OE). [12]
What we see graphically in Figure 11, and quantitatively in Table 1, is that the PPs in main clauses are increasingly new to the definition in (10.12). The question arises what kind of newness this is. The referential statuses that form the category new as in (10.12) are: “New”, “Inferred” and “Assumed”. These are the referential statuses a constituent has that can potentially start off a coreferential chain. Those with referential status “New” are new to the addressee as well as to the discourse. Those with status “Inferred” infer a new participant from an existing one, and those with category “Assumed” refer to an addressee-known entity. NPs in all three categories can be referred to subsequently, and are therefore the constituents that can lie at the basis of coreferential chains.
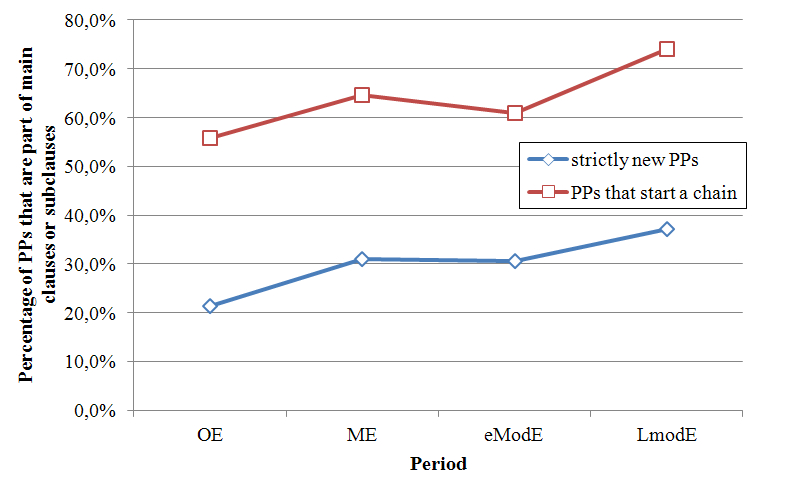
There are, as usually is the case in corpus research, several questions coming up from the discussion so far. If the PPs from query (10) and Figure 11 have such a “wide” definition of newness, we would like to know how PPs that are new in a stricter sense behave. A follow-up experiment, a variation to the query in (10), selects PPs in main clauses and subordinate ones, and calculates the percentage of new PPs according to two definitions: (a) those that start off a coreferential chain (defined as in 10.12), and (b) those that are new in a strict sense: they have referential category “New”, and do not even have an anchor. [13] The results of this experiment are shown in Figure 12.
What we can conclude from the tendencies in Figure 12 is that even strictly new PPs gradually increase from just over 20% in OE to almost 40% in LmodE. This means that PPs are increasingly being used as a vehicle to contain unestablished information instead of established information. We also see that the picture for all finite clauses as in Figure 12 does not greatly differ from the picture we obtained for just the main clauses as in Figure 11.
We would now like to know what kind of coreferential chains are started by PPs, and this is where the Xquery capabilities as facilitated by “CorpusStudio” have to be used to an even fuller extent than sofar. We have two questions about the nature of these chains. The first question concerns the length distribution of the chains being started by PPs. The experiment that is needed to get the distribution of the lengths of the chains formed by PPs in main and subordinate clauses is shown fully in (12).
| (12) |
Query finS+V+Ppchain |
| 1 |
1 for $adjunct in //eTree[tb:Like(@Label, $_anypp)] |
| 2 |
|
(: Get the usual [search] value: the parent matrix IP :) |
| 3 |
|
let $search := $adjunct/parent::eTree[tb:Like(@Label, $_finiteIP)] |
| 4 |
|
|
| 5 |
|
(: Find the subject of this IP and the finite verb :) |
| 6 |
|
let $sbj := tb:SomeChildNo($search, $_subject, $_nosubject) |
| 7 |
|
let $vb := tb:SomeChild($search, $_finiteverb) |
| 8 |
|
|
| 9 |
|
(: Get the (first) NP object of the PP, and its reftype :) |
| 10 |
|
let $obj := tb:PPobjectOrNP($adjunct) |
| 11 |
|
let $ref := ru:feature($obj, 'RefType') |
| 12 |
|
|
| 13 |
|
(: Filter out the Inert and NewVar ones :) |
| 14 |
|
let $ok := tb:Like($ref, 'New|Inferred|Assumed') |
| 15 |
|
|
| 16 |
|
(: Get the distribution of the chainlength :) |
| 17 |
|
let $distri := ru:distri(ru:chlen($obj, 'following'), 'finNewPP') |
| 18 |
|
| 19 |
where ( exists($sbj) and |
| 20 |
|
exists($vb) and |
| 21 |
|
exists($obj) and |
| 22 |
|
$ok and |
| 23 |
|
$distri |
| 24 |
) |
| 25 |
return ru:back($adjunct) |
Line (12.14) in the query makes sure we only get PPs that can potentially start off a chain. The distribution of the chain is then taken care of by two built-in functions in line (12.17). The function ru:chlen obtains the length of the chain starting at the PP’s noun phrase. This function “walks” the coreferential chain in order to find the chain length. The ru:distri function is one of the built-in statistical functions. It keeps track of the chain lengths and, after running the query through all the texts, gives a logarithmically scaled distribution of these lengths. The results of this query are in Table 2.
| length range |
OE |
ME |
eModE |
LmodE |
| 1 |
88,7% |
83,0% |
82,4% |
88,6% |
| 2 |
5,4% |
9,0% |
10,2% |
6,4% |
| 3-4 |
3,2% |
4,9% |
3,7% |
3,7% |
| 5-8 |
0,9% |
1,4% |
2,6% |
0,9% |
| 9-16 |
1,8% |
1,7% |
0,9% |
0,5% |
| 17-32 |
0,0% |
0,0% |
0,3% |
0,0% |
Table 2. Length distribution of chains started out by main clause and subclause PPs
The distribution of the lengths of the chains as shown in Table 2 tells us that there are no big changes going on. So, even though the PPs increasingly are being used to start off chains of participants, the distribution of the lengths in these chains does not change dramatically. The numbers in OE and LmodE are quite comparable, in fact.
The last question we would like to be answered also concerns the difference in chains started by PPs. We want to know whether the number of such chain-starting PPs that contain at least one subject constituent changes. The presence of a subject constituent on a chain is a rough indication that the chain belongs to a participant of some importance, since it is typically the subject that can function as agent of an action. [14]
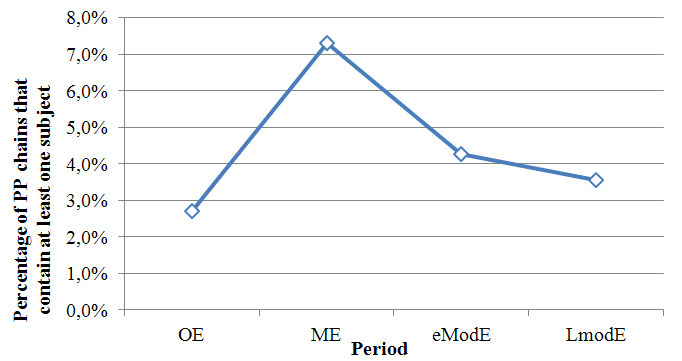
The way to measure the presence of a subject on a coreferential chain is to use an Xquery function that “walks” the chain: it transitions from one constituent to the next by using a built-in function like ru:chnext. As it does so, it checks if the constituent it ends up in is a subject or not. Walking a chain in this way can be done by using a “recursive” Xquery function: one that keeps invoking itself until specified conditions are met. While using such functions is quite technical, the fact that Xquery allows one to do so is very practical for our purposes, and it demonstrates nicely how we can make use of the coreferential chains that have been derived through the texts we have enriched in “Cesax”.
The results in Figure 13 show that the percentage of PP-initiated chains with at least one subject is small overall, ranging from 3% in OE to 7% in ME. The largest change is, in fact, the transition from OE to ME, and after that the percentage gradually decreases into LmodE to reach a level that only marginally differs from OE.
We may conclude, then, that PPs are gradually being used more often to point to strictly new information, they are also gradually being used more often to start-off coreferential chains, but the length distribution of these chains does not change dramatically, and their usage to point to relatively more important participants remains marginal.
The examples in this section illustrate how “CorpusStudio” is able to combine syntactic and referential information to yield results in the area of diachronic information structure research. What “CorpusStudio” needs in order to do this, is combine two pieces of information: (a) the syntactic information that already is available in the parsed English corpora, and (b) the referential enrichments to these parsed corpora. This, then, illustrates that the combination of “Cesax” and “CorpusStudio” allows us to find answers to research questions that are involved in the interaction between syntax and information structure.
4. Conclusions
In order to investigate research questions involving both the syntax as well as the information ordering rules, we need to have corpora that contain syntactic as well as referential information. The computer program “Cesax” allows enriching existing parsed English with coreferential information, which tells us which constituent has which other constituent as antecedent, and it also tells us what the referential status of each noun phrase is. The program does this in a semi-automatic way, saving us a lot of manual labor.
Once syntactically parsed texts are enriched with “Cesax”, we yield texts in the psdx format (an xml format where the hierarchical structure of bracketed labeling from the Treebanks has been replaced by a hierarchical structure of embedded tree tags), which contain referential information.
The computer program “CorpusStudio” provides a user-friendly interface to define corpus research projects. It not only facilitates querying the existing treebank files using the CorpusSearch2 engine, but also supports querying the psdx files using the open standard Xquery language. The combination of the two tools, “Cesax” and “CorpusStudio”, has been demonstrated to work on the texts that have been enriched. As more enriched texts become available, we expect that the accuracy and significance of the current research work will increase.
5. Acknowledgements
I would like to acknowledge the support of the Netherlands Organization for Scientific Research (NWO), grant 360-70-370.
Notes
[1] Both programs can be used freely and installed from http://erwinkomen.ruhosting.nl/software. They can only run on computers with the Windows XP/Vista/7 operating system. The author of this paper is the developer of both programs.
[2] As the name indicates, the format is the xml form of the format of the text files with the bracketed labelling format used for the English parsed corpora, which have the .psd extension.
[3] The textual examples in this paper are taken from the parsed English corpora (see section 6) and referred to by their filename followed by the line number they occur in.
[4] The interrater agreement of the OE text “Apollonius” resulted in values for Cohen’s kappa ranging from .198 (slight agreement) to .629 (substantial agreement).
[5] Local coreference is already coded in the syntactically annotated treebanks for several coindexation situations, such as between a wh-word and its trace in a relative or subordinate clause (e.g: whati I have ti to add shall be with reference to both [brightland-1711:17]).
[6] CorpusStudio supports working with syntactically annotated Penn-Treebank corpora using the CorpusSearch2 engine (Randall et al., 2005). It also facilitates searching xml coded Treebank corpora using the Xquery language (Boag et al., 2010). Texts that have been enriched with coreference information come to us in the psdx format (an xml variant discussed in section 2.12.1.2). The embedded tree format that the psdx format uses is particularly well suited for work with Xquery.
[7] The actual definition of a finiteverb is much more complex, and can be found on the files that support working with CorpusStudio.
[8] The definition editor allows for the definition of constants such as used in CorpusSearch2. Corpus research projects that make use of Xquery can have user-definable functions in the definition editor.
[9] This variable is defined in the “Definitions” section of the corpus project as a shortcut for nodes with the label PP as well as those with the label PP-*. The latter ones are PPs with a further (often functional) specification, and include, for instance, PP-LFD (a PP that occurs in a left-dislocated position).
[10] As a matter of convention, we use the $_ prefix for globally defined variables and the simple $ prefix for variables that are defined inside the Xquery function where they are being used.
[11] The variable $_matrixIP is a shortcut for nodes with a label like IP-MAT, IP-MAT-SPE etc.
[12] The subperiod “O14” means that we have an Old English manuscript from the 4th (final) subperiod of OE, but the original could have been from any time within OE, starting with O1.
[13] An example of an anchored NP is his voyages to India in (5b), which as an NP is referentially “New”, but links to an existing participant through the “anchor” pronoun his. Anchored NPs are not as new as unanchored ones.
[14] A more advanced study would have to take into account the kind of action (mirrored in the kind of verb) that the participant belonging to the PP-started chain takes. While the measure we take here is, therefore, but a very rough estimate, it is nevertheless important, since it illustrates the capabilities of intelligently “walking” the coreferential chains that CorpusStudio supports.
The syntactically parsed English corpora that are currently being enriched are listed below, where the name of the corpus provides a link to the CoRD database:
YCOE: the York-Toronto-Helsinki Parsed Corpus of Old English Prose, which contains approximately 1.5 million words, divided over 100 texts (Taylor et al., 2003). Old English was around from 450 until 1150 A.D, but the earliest manuscripts are from the 9th century.
PPCME2: the Penn-Helsinki Parsed Corpus of Middle English, second edition (Kroch and Taylor, 2000). This corpus contains about 1.2 million words, which are divided over 55 text samples, and it covers a period from 1150 to 1500.
PPCEME: the Penn-Helsinki Parsed Corpus of Early Modern English (Kroch et al., 2004). It contains about 1.7 million words, which are divided over 448 text samples. The period it covers runs from 1500 to 1710.
PPCMBE: the Penn Parsed Corpus of Modern British English (Kroch et al., 2010). This corpus contains about 950.000 words, which are divided over 101 text samples, covering the period from 1700 until 1914.
Programs
Komen, Erwin R. 2009. CorpusStudio Nijmegen: Radboud University Nijmegen, http://erwinkomen.ruhosting.nl/software/CorpusStudio. Download the manual as a PDF: http://erwinkomen.ruhosting.nl/software/CorpusStudio/CrpStu_Manual.pdf
Komen, Erwin R. 2011. Cesax: coreference editor for syntactically annotated XML corpora Nijmegen, Netherlands: Radboud University Nijmegen, http://erwinkomen.ruhosting.nl/software/Cesax.
References
Ariel, Mira. 1994. “Interpreting anaphoric expressions: a cognitive versus pragmatic approach”. Journal of Linguistics 30: 3–42.
Ariel, Mira. 1999. Accessing noun-phrase antecedents. London & New York: Routledge.
Boag, Scott, Don Chamberlin, Mary F. Fernández, Daniela Florescu, Jonathan Robie, & Jérôme Siméon. 2010. XQuery 1.0: An XML Query Language (Second Edition): W3C Recommendation. http://www.w3.org/XML/Query/#specs.
Brants, Sabrin, Stefanie Dipper, Silvia Hansen, Wolfgang Lezius, & George Smith. 2002. “The Tiger treebank”. Proceedings of the Workshop on Treebanks and Linguistic Theories, Sozopol: http://www.coli.uni-saarland.de/publikationen/softcopies/Brants:2002:TT.pdf.
Chafe, Wallace L. 1976. “Givenness, contrastiveness, definiteness, subjects, topics and point of view”. Subject and topic, ed. by Charles N. Li, 25–56. New York: Academic Press.
Givón, Talmy. 1992. “The grammar of referential coherence as mental processing instructions”. Linguistics 30: 5–55.
Gundel, Jeanette K., Nancy Hedberg, & Ron Zacharski. 2004. “Demonstrative pronouns in natural discourse”. In Fifth Discourse Anaphora and Anaphora Resolution Colloquium (DAARC-2004). São Miguel, Portugal.
Hobbs, Jerry R. 1978. “Resolving pronoun references”. Lingua 44: 311–338.
Kehler, Andrew, Douglas Appelt, Lara Taylor, & Aleksandr Simma. 2004. “The (non)utility of predicate-argument frequencies for pronoun interpretation”. Paper presented at HLT/NAACL, Boston, Mass.
Komen, Erwin R. 2009a. “CESAC: Coreference Editor for Syntactically Annotated Corpora”. 7th York-Newcastle-Holland Symposium on the History of English Syntax (SHES7), 8. Nijmegen, CLS/Department English Language and Culture: Radboud University.
Komen, Erwin R. 2009b. Corpus Studio manual Nijmegen: Radboud University Nijmegen. http://erwinkomen.ruhosting.nl/software/CorpusStudio/CrpStu_Manual.pdf.
Kroch, Anthony, Beatrice Santorini, & Ariel Diertani. 2004. Penn-Helsinki Parsed Corpus of Early Modern English. http://www.ling.upenn.edu/hist-corpora/PPCEME-RELEASE-2/index.html.
Kroch, Anthony, Beatrice Santorini, and Ariel Diertani. 2010. Penn Parsed Corpus of Modern British English. http://www.ling.upenn.edu/hist-corpora/PPCMBE-RELEASE-1/index.html.
Kroch, Anthony, & Ann Taylor. 2000. Penn-Helsinki Parsed Corpus of Middle English, second edition. http://www.ling.upenn.edu/hist-corpora/PPCME2-RELEASE-3/.
Lappin, Shalom, & Herbert J. Leass. 1994. “An algorithm for pronominal anaphora resolution”. Computational Linguistics 20: 535–561.
Los, Bettelou. 2009. “The consequences of the loss of verb-second in English: information structure and syntax in interaction”. English Language and Linguistics 13: 97–125.
Los, Bettelou, & Erwin R. Komen. 2012. “Clefts as resolution strategies after the loss of a multifunctional first position”. The Oxford Handbook of the History of English, ed. by Terttu Nevalainen & Elizabeth Closs Traugott, 884–898. New York: Oxford University Press.
Los, Bettelou, & Erwin R. Komen. (forthcoming). “The Pentaset: annotating information state primitives”. Dialogue and Discourse.
Marcus, Mitchell, B. Santorini, & Mary Ann Marcinkiewicz. 1993. “Building a large annotated corpus of English: the Penn treebank”. Computational Linguistics 19.
Mitkov, Ruslan, Richard Evans, Constantin Orasan, Le An Ha, & Viktor Pekar. 2007. “Anaphora Resolution: To What Extent Does It Help NLP Applications?”. Paper presented at Anaphora: Analysis, Algorithms and Applications, Berlin.
Prince, Ellen. 1981. “Toward a taxonomy of given-new information”. Radical Pragmatics, ed. by P. Cole, 223–255. New York: Academic Press.
Randall, Beth, Ann Taylor, & Anthony Kroch. 2005. CorpusSearch 2. http://corpussearch.sourceforge.net/credits.html.
Soon, Wee Meng, Hwee Tou Ng, & Daniel Chung Yong Lim. 2001. “A machine learning approach to coreference resolution of noun phrases”. Computational Linguistics 27: 521–544.
Taylor, Ann, Athony Warner, Susan Pintzuk, & Frank Beths. 2003. The York-Toronto-Helsinki Parsed Corpus of Old English Prose. http://www-users.york.ac.uk/~lang22/YCOE/YcoeHome.htm.
TEI Consortium, eds. 2009. TEI P5: Guidelines for electronic text encoding and exchange. Oxford, Providence, Charlottesville, Nancy. http://www.tei-c.org/Guidelines/P5/.
|