The automatic syntactic analysis of natural language texts has made impressive progess. But when applied to historical linguistic texts, parser performance drops considerably. We first report parsing performance on several time periods in the Archer corpus. Second, we implement and evalutate a variety of adaptations to historical texts. We address spelling issues, adapt local grammar rules, and conduct an analysis of errors. Parser performance increases due to our adaptations. This pilot study also tests a number of more global extensions to address freer word order and different punctuation in earlier texts. We give an outlook on possible applications.
1. Introduction
The automatic syntactic analysis of natural language texts, typically known as parsing, has made impressive progess in the past few years. A number of fast and robust parsers with reasonable accuracy for Present Day English texts exist now, for example Collins (1999), Nivre (2006) and Schneider (2008).
Typically, parsers are trained on the Penn Treebank (Marcus et al. 1993), which consists of sentences from the Wall Street Journal (WSJ), and applied to held-out texts from the same corpus. The genre of WSJ is mainly news and finance. The accuracy of parsers declines significantly when they are applied to genres that differ from the training domain. For example, Gildea (2001) has trained a parser on the Penn Treebank, and measured its performance when applied to a subsection of the Brown corpus which primarily contains fiction texts. He showed that performance on the Brown subsection is about 5% lower than on the in-domain WSJ texts. While precision on WSJ was 86.6%, precision on Brown was only 81.0% percent. Also recall decreases: recall on WSJ was 86.1%, recall on Brown 80.3%. These figures illustrate why adaptation to other genres has become an important research topic. For example, in the CoNLL shared task on dependency parsing (Nivre et al. 2007), subtasks were included on the adaptation of parsers to chemical research texts and to child language.
When applied to historical linguistic texts, parser performance also drops considerably. Arguably, texts from 400 years ago are much more different from PDE texts than genre variation within PDE texts, for example between news and fiction, as tested by Gildea (2001). We first report parsing performance on several time periods in the Archer corpus (Biber et al. 1994). Second, we suggest, implement and evalutate a variety of adaptations to historical texts. We perform an analysis of errors which on the one hand allows us to improve the parser, and on the other hand shows characteristics of the language of the investigated periods. To improve the performance, we address spelling issues, adapt the grammar rules and test extensions to the parsing algorithm. We show that parser performance increases due to our adaptations.
The paper is structured as follows. In section 2, we give a brief introduction to the dependency grammar parser that we have used. In section 3, we address spelling variation and show that spelling normalisation improves parsing. In section 4, we describe the performance of the parser on a random subset of the Archer corpus, and give an overview of the problems encountered. In section 5, we do an analysis of the errors. In section 6, we describe the improvements that we have made to the parser. In section 7, we give an example of possible diachronic applications of using a parser for the description of historical differences.
2. The Pro3Gres Parser
We have used the dependency parser Pro3Gres (Schneider 2008) for our experiments. Dependency Grammar goes back to Tesnière (1959) and is used by many parsers (e.g. Tapanainen and Järvinen 1997, Nivre 2006). Pro3Gres uses a hand-written grammar which models linguistic competence, and statistical disambiguation which models performance. The parser learns the performance statistics from the Penn Treebank. The performance model measures attachment probabilities for a dependency relation (R), given the lexical heads of the governor (a) and the dependent (b).
p(R|a,b) = f(R,a,b) / f(∑R,a,b)
Using a hand-written grammar allows us to adapt the grammar, for example to do linguistic experiments or to adapt it to genres, varieties and diachronic stages of English for which little or no training material exists. The parser outputs intuitive dependency relations. A subset of possible relations is given in Table 1.
RELATION
LABEL
EXAMPLE
verb–subject
subj
he sleeps
verb–direct object
obj
sees it
verb–second object
obj2
gave (her) kisses
verb–adjunct
adj
ate yesterday
verb–subord. clause
sentobj
saw (they) came
verb–pred. adjective
predadj
is ready
verb–prep. phrase
pobj
slept in bed
noun–prep. phrase
modpp
draft of paper
noun–participle
modpart
report written
verb–complementizer
compl
to eat apples
noun–preposition
prep
to the house
Table 1. Important dependency relations that are output by Pro3Gres
The parser uses tagging and chunking as pre-processing step. Tagging, and by consequence also chunking is affected by spelling variants that are different from the PDE training corpus. Let us look at an example sentence from the 17th century part of the Archer corpus.
(1)
My Love to my wife, whom I easilie beleife the finest yong woman in your country.
This sentence is tagged as follows by the C&C tagger, which we use in our pipeline. We use the Penn Treebank tagset.
There are three words that are spelled differently from present day English: easilie, beleife and yong. They are unkown to the tagger. Unknown words do not necessarily get incorrect part-of-speech tags. While the tagger can assign the correct tag (JJ=adjective) to the unknown word yong, as the context between a superlative adjective (JJS) and singular noun (NN) is not very ambiguous, the fact that pronouns (I_PRP) are typically followed by a verb triggers the incorrect tag VBP (verb, present tense) to be assigned to the unknown word easilie. Word endings of unknown words are typically also considered by taggers. Many verbs end in -e, a tendency which supports finding the (almost) correct tag for beleife, but which in the case of easilie also contributes to assigning a wrong tag. The tag VB, which is given to the word beleife, signifies verb base form, whilw we actually have a present tense form (VBP) here. Some tagging errors lead to chunking and or parsing errors, some are inconsequential. Most parsers are robust enough to attach a subject to a verb base form (which strictly speaking is syntactically not possible), as this is a relatively frequent tagging error, also in present day English. As a consequence, the correct parse could still be found, so this tagging error (beleife_VB) is inconsequential. But the error of assigning a verb tag to easilie has the immediate consequence that the parser attaches the pronoun I_PRP to this verb.
We discuss a possible solution to the spelling variant problem in the following section.
3. Normalizing Spelling Variation
Spelling in the earlier Archer texts was different from PDE and not fully standardized. Applying standard taggers to them produces many tagging errors, many of which are due to spelling differences. A solution to this problem can be to map the original spelling to its PDE counterpart, for which a number of tools are available. We have used VARD (Baron & Rayson 2008). We will henceforth refer to the process of replacing historical spellings by their PDE counterparts in the text as normalisation.
Intuitively, tagging and consequently also chunking and parsing, improve from mapping the original spelling to the same spelling as used in the tagger and parser training resource. The statistical performance disambiguation, which uses lexical heads, should equally profit. As the normalisation process also makes errors, the assumption that performance will improve cannot be taken for granted. Concerning tagging accuracy, this assumption has been tested in Rayson et al. (2007). They report an increase of about 3% (from 82% to 85% accuracy) on Shakespeare texts. As an upper bound, when tests are manually normalized, they report 89% accuracy.
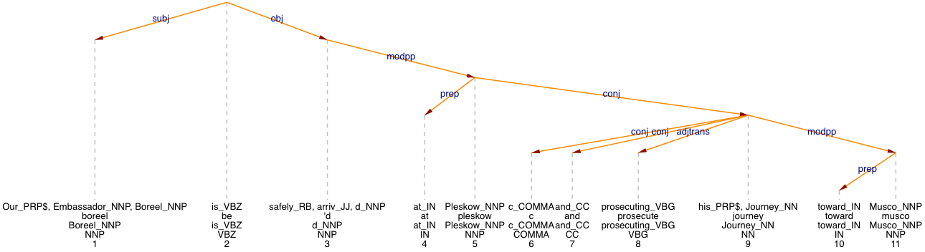
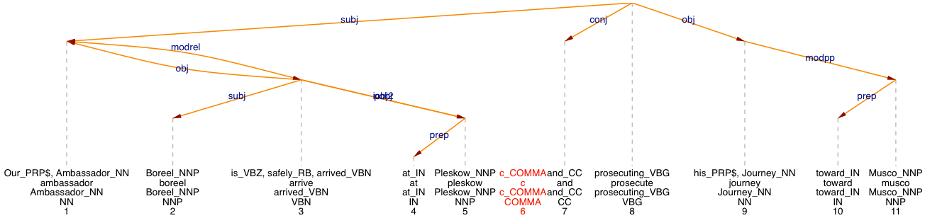
Concerning parsing, the assumption that normalisation improves the performance has, to our knowledge, not been confirmed. We have thus tested it by selecting 100 random sentences from the 17th century (1600–1699) part of the Archer corpus and evaluated by comparing the parser output. In the automatic conversion mode, at a 50% threshold (see VARD for details), 131 normalisations are made in these 100 sentences. In the normalised text, 16 of the 100 sentences receive a syntactic analysis which differs from the original. 12 of these 16 sentences get a normalised syntactic analysis that is better than the original analysis, 1 sentence gets a worse analysis. 3 sentences correct some errors, but introduce new errors instead. An example of a sentence in the latter class is given in figure 1 (original spelling) and figure 2 (using normalized spelling). The past participle in its original spelling arriv'd is split into two words by the tokenizer, the second word 'd is tagged as a proper name, which leads to an analysis in which 'd is an object of is. After spelling normalisation, the verb chunk is safely arrived is recognized correctly. But the NP our Ambassador Boorel is not recognized as a single noun chunk. Therefore, preference is given to an incorrect relative clause analysis. Parsing with the normalised spelling thus also introduces a new error here. The object attachment prosecute journey is also better in the normalised version, but this does not affect the classification: correcting some errors while introducing new errors.
Since the normalized data leads to considerably fewer errors, we use normalised texts except for the 20th century (where there is no need to normalise) for the rest of our experiments.
4. Performance on the Archer Corpus
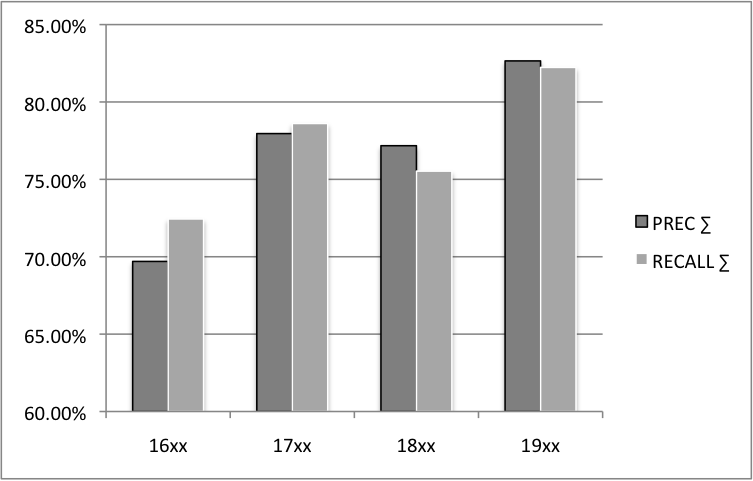
We have conducted an evaluation of the performance on Archer as follows. We have selected 25 random sentences from each century (16xx, 17xx, 18xx, 19xx) leading to a total of 100 sentences. We have manually annotated them and then compared to the parser output on the following relations: subject (subj), object (obj), PP-attachment (modpp and pobj) and subordinated clauses (sentobj). We report precision and recall by century in figure 3. Precision measures how many syntactic relations that the parser delivers are also contained in the manual annotation (or in simpler words, how correct the parser output is). Recall measures how many of the relations that are given in the gold standard are also assigned by the system (or in simpler words, how complete the parser output is).
(Near-) PDE texts (19xx) achieve above 80% precision and recall, which is similar to the performance of Pro3Gres on other PDE texts (Schneider 2008, Haverinen 2008, Lehmann and Schneider 2009). There is a clear trend towards lower performance, the further one moves into the past, although 18xx is potentially an outlier. In 16xx, precision and recall are about 70%, which indicates an increase in errors by about a third compared to PDE. This could also indicate that every third parsing error is caused by language changes in 16xx, and thus gives a rough measure of the linguistic distance from the training century.
Figure 3. Precision and recall by century
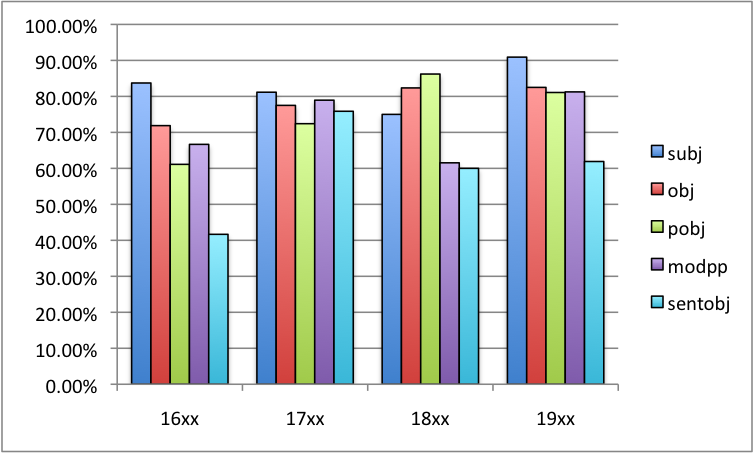
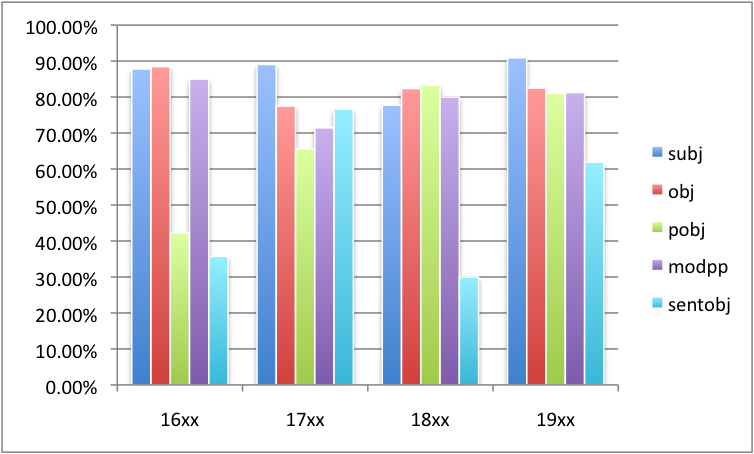
Figure 4 reports precision broken down by relation, figure 5 shows recall by relation. Only subordinate clauses (sentobj) are below 80% precision on PDE, subject precision stays relatively high in all periods.
Figure 4. Precision, broken down by relation
Figure 5. Recall, broken down by relation
As counts are low for some relations, there is considerable fluctuation. The table of absolute counts of 16xx and 18xx is given in Table 2, giving an impression of the data sparseness. This sparseness can account for the extremely low sentobj recall on 18xx. The low recall is due to the fact that there were many saith and doth in 18xx, which were not normalised to says and does, respectively, by VARD. Therefore, they always got mistagged as noun.
16xx
is
should
%
18xx
is
should
%
PRECISION
PRECISION
subj
36
43
83.7%
subj
21
28
75.0%
obj
23
32
71.9%
obj
12
16
75.0%
pobj
11
18
61.1%
pobj
26
31
83.9%
modpp
17
27
63.0%
modpp
8
12
66.7%
sentobj
5
12
41.6%
sentobj
3
6
50.0%
∑
92
132
69.7%
∑
70
93
75.3%
RECALL
RECALL
subj
36
41
87.8%
subj
21
27
77.8%
obj
23
26
88.4%
obj
12
17
70.6%
pobj
11
26
42.3%
pobj
26
30
86.7%
modpp
17
20
85.0%
modpp
8
10
80.0%
sentobj
5
14
35.7%
sentobj
3
10
30.0%
∑
92
127
72.4%
∑
70
94
74.5%
Table 2. Absolute counts on 16xx and 18xx
A first inspection of the errors in the early texts suggests that there are more complex conjunctions, many extremely long sentences (both leading to a considerable loss in the performance of sentobj), and freer constituent order. To get an impression, we give an example sentence from 16xx:
(2)
butt she was well built, a fair ship, of a good burden, and had mounted in her forty pieces of brass cannon, two of them demi cannon, and she was well manned, and of good force and strength for war: she was a good sailor, and would turn and tack about well; she held 100 persons of Whitelocke ’s followers, and most of his baggage, besides her own mariners, about 200.
This sentence shows the following difficulties for the automatic parser:
Genitive of quality / quality of-PP: of a good burden , of good force
X-bar violation, freer word order: mounted [in her] forty pieces
Ellipsis: two of them demi cannon
Conjunctions: was well manned , and of good force and strength for war (adjective/participle and complex PP in coordination)
Appositions: besides her own mariners , about 200
We take a closer look at typical parsing errors in the following section.
5. Error Analysis
We now give an analysis of selected errors that we encountered in the 100 random sentences. We proceed by century.
5.1 Errors in 16xx
Sentence (2) illustrates many of the parser errors in 16xx. For example, the quality of-PP has lower probability than an apposition analysis, which is thus returned as the most likely analysis. This error arises from PDE lexical preferences which are unsuitable for application to 17th century material.
The X-bar violation mounted [in her] forty pieces causes the chunker to do overchunking; [in her forty pieces] is returned as a single noun chunk. Other chunking errors are also found. For example in the phrase The states [are here reinforcing] their guards the chunker does underchunking and returns two verb chunks ([are] here [reinforcing]). This chunking error is caused by the fact that in PDE, the adjective here very rarely appears inside verb chunks.
A further frequent source of parsing errors stem from tagging errors. In The cabins wherein_NN Whitelocke was , were of an handsome make_VBP the unknown relative pronoun wherein is tagged as noun, the noun make is mistagged as verb.
Further difficulties arise from the frequent very long sentences, which partly explains generally low performance of sentobj. An example of such a sentence is:
(3)
that, for his part, he had done nothing but sigh for her ever since she came; and that all the white beauties he had seen, never charmed him so absolutely as this fine creature had done; and that no man of any nation, ever beheld her, that did not fall in love with her; and that she had all the slaves perpetually at her feet; and the whole Country resounded with the fame of Clemene, “For so,” said he, “we have Christened her”.
In sentences of this type, it is also difficult for human annotators to determine clausal relations.
5.2 Errors in 17xx
In the 18th century random sentences, we have encountered the following parsing errors.
A crossing relative pronoun dependency (indicated by indeces) could not be found by the parser in the following sentence:
(4)
It might be perhaps as easy to persuade a man_1 to dance who_1 had lost the use of his limbs, ...
Crossing dependencies also exist in PDE, but they are relatively rare.
A further source of problems is illustrated by the following sentence. The word but is not known as an adverb in the parser grammar:
(5)
He is such an Itinerant, to speak that I have but little of his company.
Similarly, lest is not known as a complementizer in the parser grammar:
(6)
A like policy inspired him with the thought of inviting Frederic ’s champion into his castle, lest he should be informed of Isabella’s flight ...
Tagging errors are again frequent. In the following sentence, the unknown word thee is tagged as verb in one case and as noun in another case.
(7)
To thee_VB , and thee_NN alone, do I confess my weakness.
5.3 Errors in 18xx
As mentioned in section 4, an important source of errors in 18xx is the relative frequency of saith and doth, which seem to cluster in our random sentences. This can happen due to low counts.
(8)
She doth_VBZ nothing but laugh at and make light of the afflicted children, and saith_NN there be no witches.
doth is actually tagged correctly, but the morphological analyzer delivers the incorrect lemma doth.
Possible solutions to some of these errors are now addressed in section 6.
6. Adaptations to the Parser for historical English
6.1 Specific improvements
In order to tackle some of the errors reported in section 5, we have extended the grammar by a number of specific local adaptations. We have added rules addressing but and lest to the grammar, thus correcting the analyses for sentences (5) and (6). However, we have decided not to deal with tagging and chunking issues here, as the parser uses off-the-shelf taggers and chunkers. The problems caused by doth and saith could easily be solved by adapting VARD. We will address these issues in future research.
Each of these small changes has lead to a small improvement in general performance, but many types of errors cannot be addressed by local grammar adaptations. Bigger generalisations, for example relaxing word-order constraints to adapt to the freer word order which we have observed, seem more appropriate. We have therefore tried several more global improvements, which we present in the following subsection.
6.2 Bigger generalisations
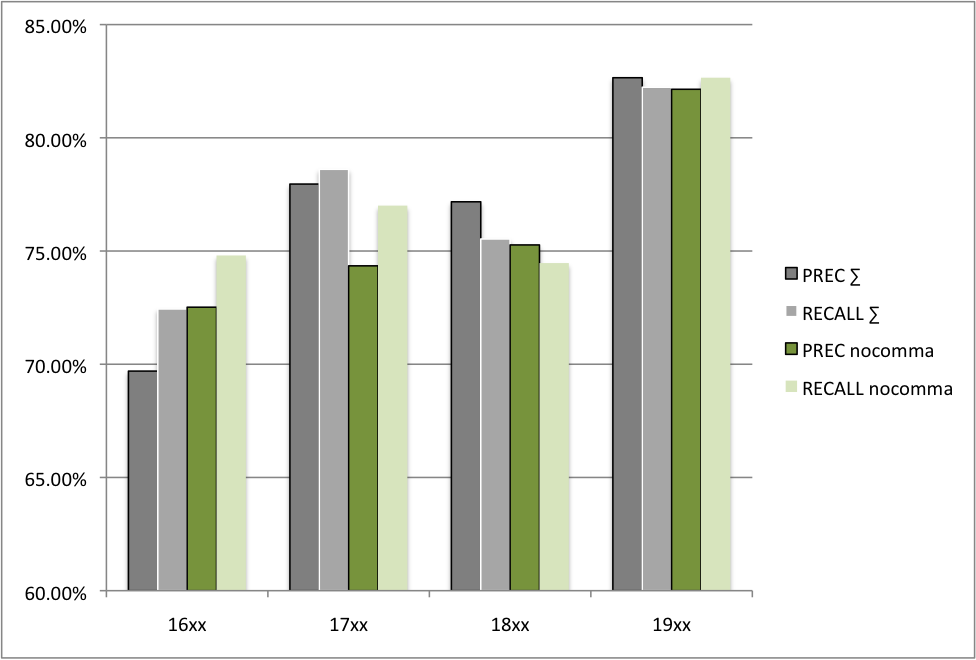
We have noticed that sentences in historical texts are often extremely long, and that punctuation seems to be used differently (see e.g. sentence (3)). Full stops are rarer, and commas often appear in different places than in PDE. For example, the difficulty with the quality of-PP in sentence (2), which gets analysed as an apposition, partly stems from the comma: PDE of-PPs are typically not separated by commas, while appositions are. As an experiment, we have removed all commas from the text. In order to make a fair comparison, for the experiments in this subsection we have used a version of the parser without the extensions described in section 6.1. Performance differences are given in figure 6. The figure shows that there is a considerable improvement in 16xx, but not in the textual samples for the other centuries. There is also too much fluctuation to discern a clear trend. The improvement in 16xx but not later could either be due to the fact that log sentences and irregular comma uses are particularly prevalent there, but it could equally be a sparse data problem caused by the small evaluation corpus.
Figure 6. Performance when removing commas. Original system in grey, after removing commas in green.
As noticed above, word order is not as fixed as in PDE. Relaxing word-order constraints to adapt to the freer word order could lead to a better performance. Fronted PPs are a frequent example of freer word order in historical or poetic English. In the following sentence, the PP in the morning is fronted.
(9)
…and went well to bed, where she took as good rest and sleep, as ever before, but in the morning, when she awakened, and attempted to turn herself in her bed, was not able…
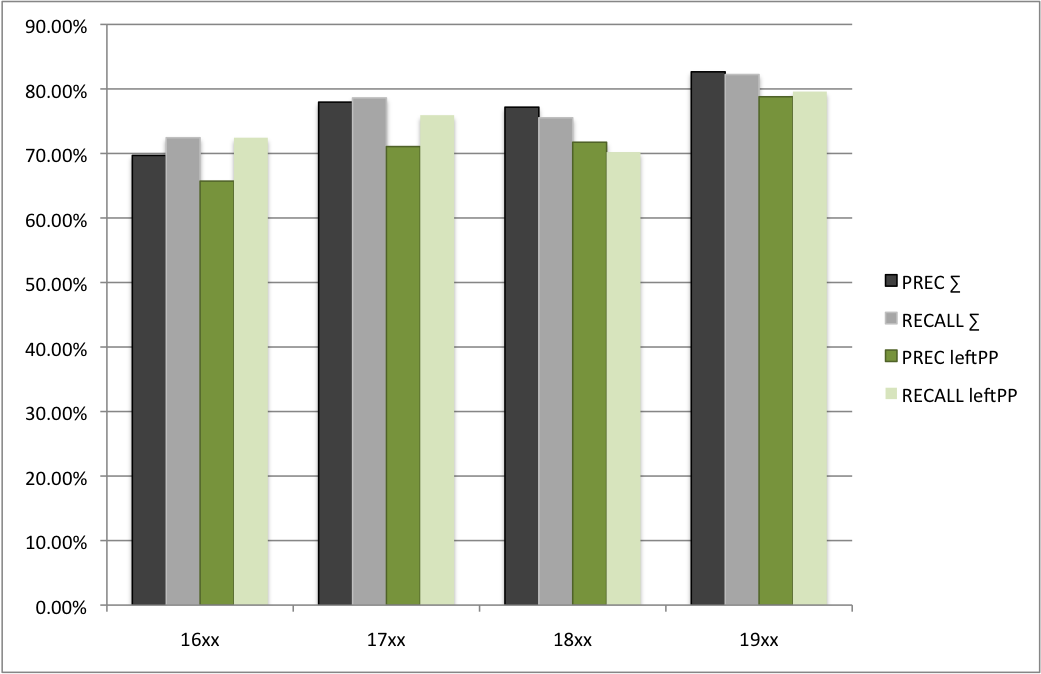
In the original parser grammar, fronted PPs are only allowed sentence-initially in order to curb overgeneration. If we relax this constraint and generally allow PPs to be fronted (i.e. allowing verbs to attach PPs that appear before them), this leads to the results given in figure 7. We see that performance generally decreases. In particular, precision decreases, which indicates overgeneration: many PPs that should attach to a preceding verb are now attached to a subsequent verb.
Figure 7. Performance when generally allowing fronted PPs
We have also tested versions that make semantic restrictions: only temporal and manner-PPs are allowed to be fronted. While this partly recovers precision, recall is more affected.
7. Application to Descriptive Linguistics
In this section, we give an outlook on a possible application to descriptive linguistics: the investigation of diachronic differences. From a quantitative perspective, frequency differences in certain features (i.e. the signal which the parser reports), indicate differences in language use. We are assuming that the increasing error rate on older texts does not introduce a significant skew. From a qualitative perspective, an analysis of errors as we have given in section 5 provides detailed insights into diachronic developments.
The question whether the parser signal can be used is addressed by Schneider and Hundt (2009). This study investigates the use of the same syntactic parser as used here on English varieties, particularly on New Englishes. The paper investigates if the parser signal reliably describes linguistic differences, and if non-standard varieties lead to increased parser breakdowns, as the parser has not been trained to non-standard varieties. It is concluded that the signal can be usefully exploited in a partly corpus-driven approach to the description of New Englishes, that the reported statistical differences in the use of constructions indicate differences in language use. Concerning parser breakdowns, hardly any connection between parser breakdowns and non-standard variety is reported. We will briefly report on parser breakdowns in the Archer corpus and then show an example of a signal difference.
English texts that date from several centuries back are potentially more different from standard English than New English texts, we have therefore measured parser-breakdowns on historical texts. Pro3Gres is a robust parser, it always reports some results, but if sentences are ungrammatical or not modelled in the grammar or are very long, it often returns several fragments instead of a single analysis spanning the entire sentence. The fragments are connected with an ad-hoc relation with the label bridge. We measure the frequency of the bridge relation as percentage per all relations. Measuring fragmentation per sentence would add a skew towards longer sentences, as longer sentences are far more likely to break. The frequency of the bridge relation on a random subset is given in Table 3. While fragmentation is clearly lowest on the training century (19xx), there is no increase towards older texts: 16xx to 18xx are at the same level. In other words: the parser has more difficulties with all older texts than with PDE.
Fragmentation
16xx
17xx
18xx
19xx
# bridge
204
242
224
129
∑ rels
3738
4231
3503
3508
% bridge
5.46%
5.72%
6.36%
3.68%
Table 3. Parse fragmentation by century
When measuring signal differences we have noticed that for most features there are no signal differences. For example, if one measures frequencies of relation types, no clear differences are visible. Language change typically occurs at lexical level and at the interface between lexis and grammar. As an example, we compare the frequency of the most frequent prepositions in 16xx to the overall frequency of this preposition in Table 4.
prep in a PP
16xx
∑ Archer
Reduction
of
130
54517
1.09
in
62
28109
1.01
to
48
19397
1.13
with
37
13140
1.29
by
20
8659
1.05
for
19
10590
0.82
at
19
9374
0.93
as
17
4786
1.62
from
16
7665
0.95
upon
10
2259
2.02
∑
441
201229
1
Table 4. Reductions in frequency of the most frequent 16xx prepositions
The preposition for has increased slightly since the 17th century, as has decreased slightly, and upon has become much rarer. The counts do not represent surface word occurrences (e.g., to is often an infinite particle), but the frequency of these words as preposition in the parsed data.
8. Conclusions
We have shown that spelling normalisation has a big impact, in particular that the use of the spelling normalisation tool VARD leads to improved parser performance.
Performance on texts with normalised text, using the unadapted parser, increases from about 70% in the 17th century (16xx) to 80% in the 20th century (19xx). The parser makes about a third more errors on 17th century texts than on the (near-) PDE text for which the competence grammar was written and on which the performance disambiguation was trained.
Further progress has been reported by several local grammar adaptations for specific lexemes. These are easy to make and slightly improve general performance.
In order to address more global changes in historical linguistics, such as freer word order in older texts, we have conducted experiments on removing grammatical constraints. Removing constraints, however, comes at the cost of detrimental side-effects, which introduced more errors than they were able to correct.
An analysis of the errors that occurred in our evaluation set has shown that many difficulties in historical texts from as early as the 17th century, for example freer word order and crossing dependencies, are the same as in PDE texts. But they are more frequent in earlier data, and less restricted to e.g. poetic and emphatic use.
We have given an outlook on using the parser as a tool for the description of language change: Some differences are in the signal (i.e. analysed correctly), and some differences are in the errors: parser errors offer a different, partly systematically wrong perspective on the data. While the parser has more difficulties to parse texts from before 1900, no trend towards further difficulties with even older texts could be measured.
Adapting parsers to historical texts is a new research task at an early stage. In our pilot study, we have not addressed tagging, chunking or VARD retraining issues, which we will tackle in future research.
Baron, Alistair & Paul Rayson. 2008. “VARD 2: A tool for dealing with spelling variation in historical corpora”. Proceedings of the Postgraduate Conference in Corpus Linguistics, Aston University, Birmingham, 22 May 2008. http://acorn.aston.ac.uk/conf_proceedings.html
Biber, Douglas, Edward Finegan & Dwight Atkinson. 1994. “ARCHER and its challenges: Compiling and exploring A Representative Corpus of Historical English Registers”. Creating and using English language corpora, Papers from the 14th International Conference on English Language Research on Computerized Corpora, Zurich 1993, ed. by Udo Fries, Peter Schneider & Gunnel Tottie, 1–13. Amsterdam: Rodopi.
Gildea, Daniel. 2001. “Corpus variation and parser performance”. Proceedings of the 2001 Conference on Empirical Methods in Natural Language Processing (EMNLP), 167–202, Pittsburgh, PA. http://www.aclweb.org/anthology-new/W/W01/W01-0521.pdf
Haverinen, Katri, Filip Ginter, Sampo Pyysalo & Tapio Salakoski. 2008. “Accurate conversion of dependency parses: targeting the Stanford scheme”. Proceedings of Third International Symposium on Semantic Mining in Biomedicine (SMBM 2008), Turku, Finland, 2008. http://mars.cs.utu.fi/smbm2008/?q=proceedings
Lehmann, Hans Martin, & Gerold Schneider. 2009. “Parser-Based Analysis of Syntax-Lexis Interaction”. Corpora: Pragmatics and Discourse. Papers from the 29th International conference on English language research on computerized corpora (ICAME 29), Ascona, Switzerland, 14–18 May 2008 (Language and computers 68), ed. by Andreas H. Jucker, Daniel Schreier & Marianne Hundt, 477–502. Amsterdam: Rodopi.
Marcus, M., B. Santorini, & M. Marcinkiewicz. 1993. “Building a large annotated corpus of English: the Penn Treebank”. Computational Linguistics, 19(2): 313–330. http://www.aclweb.org/anthology-new/J/J93/J93-2004.pdf
Nivre, Joakim. 2006. Inductive Dependency Parsing. Text, Speech and Language Technology 34. Springer, Dordrecht, The Netherlands.
Nivre, Joakim, Johan Hall, Sandra Kübler, Ryan McDonald, Jens Nilsson, Sebastian Riedel & Deniz Yuret. 2007. "The CoNLL 2007 shared task on dependency parsing". Proceedings of the CoNLL Shared Task Session of EMNLP-CoNLL 2007, 915–932. http://www.aclweb.org/anthology-new/D/D07/D07-1096.pdf
Pawley, Andrew & Frances Hodgetts Syder. 1983. "Two Puzzles for Linguistic Theory: Native-like selection and native-like fluency". Language and Communication, ed. by J. C. Richards & R. W. Schmidt, 191–226. London: Longman.
Rayson, Paul, Dawn Archer, Alistair Baron, Jonathan Culpeper & Nicholas Smith. 2007. "Tagging the Bard: Evaluating the accuracy of a modern POS tagger on Early Modern English corpora". Proceedings of Corpus Linguistics 2007, July 27–30, University of Birmingham, UK. http://ucrel.lancs.ac.uk/people/paul/publications/RaysonEtAl_CL2007.pdf
Schneider, Gerold. 2008. Hybrid Long-Distance Functional Dependency Parsing. Doctoral Thesis, Institute of Computational Linguistics, University of Zurich. http://dx.doi.org/10.5167/uzh-7188
Schneider, Gerold & Marianne Hundt. 2009. “Using a parser as a heuristic tool for the description of New Englishes.” Proceedings of the Fifth Corpus Linguistics Conference, Liverpool 20–23 July 2009. http://ucrel.lancs.ac.uk/publications/cl2009/
Tapanainen, Pasi & Timo Järvinen. 1997. "A non-projective dependency parser". Proceedings of the 5th Conference on Applied Natural Language Processing, 64–71. Association for Computational Linguistics.