Two Staffordshires: real and linguistic space in the study of Late Middle English dialects
Merja Stenroos
Kjetil V. Thengs
University of Stavanger
Abstract
The purpose of this paper is to problematize the kinds of geographical distribution shown in Middle English dialect maps. It presents two sets of dialect maps of the late medieval county of Staffordshire, based on different approaches to medieval dialect geography. The first set is based on a corpus of local documents, organized according to the geographical provenance of the texts. The other one, based on the Middle English Grammar Corpus (MEG-C), represents the kind of maps published in the Linguistic Atlas of Late Mediaeval English or LALME, where the texts are localized on linguistic grounds. In the terminology of Williamson (2000: 119–120), the two sets of maps represent “geographical space” and “linguistic space” respectively; accordingly, the localizations on each kind of map mean quite different things and should be kept distinct. The paper compares the distributions shown in the two sets of maps and discusses their implications for the study of linguistic variation in Middle English. It is not suggested that one kind of map is “better” than the other; rather, they are complementary in the sense that they answer very different research questions.
1. Introduction [1]
This paper presents a comparison between two different sets of Middle English dialect maps. The first is based on the geographical provenances of documentary texts for which local connections may be established. The second represents the kind of map produced in the Linguistic Atlas of Late Mediaeval English (henceforth LALME), which is based on localizations on linguistic grounds, using the “fit-technique” developed by McIntosh (1956, 1963; see 2 below). The maps are based on two text corpora, the Middle English Local Documents corpus (MELD) and the Middle English Grammar Corpus (MEG-C), both of which are being compiled at Stavanger.
For the purpose of this study, we have focussed on the material in each corpus that relates to the pre-1974 county of Staffordshire. For this material, the time span is approximately 1375–1515. We have carried out a small dialect survey, collecting data for 30 orthographic or morphological features in the Staffordshire parts of the corpora; the findings for ten of these features are presented on dialect maps and discussed in section 4.
This study forms part of ongoing work on two related projects: a PhD thesis studying the local documentary materials of the Northwest Midlands (Thengs, under preparation) and a larger project dealing with the language and geography of late-medieval English local documents; both these projects together contribute to MELD. [2] Staffordshire was chosen as the geographical focus of this paper, as it formed the starting point of Thengs’ project and most of the materials had already been identified and transcribed. The Staffordshire subcorpus of MELD used for the present study consists of 38 local documents and has been compiled by Thengs. [3] The maps based on this corpus are compared to ones based on the Staffordshire part of the Middle English Grammar Corpus (MEG-C), which contains all the 32 texts (whole or in samples) that were mapped in Staffordshire in LALME.
Both corpora are geographically organized and the data can be plotted on maps. However, they are based on very different approaches to geographical variation: in MELD, the localizations represent the actual geographical locations where the texts were produced, while in MEG-C, they form part of a reconstructed dialect continuum and do not necessarily reflect any physical connection with a particular location. These two kinds of map represent two different kinds of space: in a very real sense, they relate to two Staffordshires. In the first case, the patterns on the map relate to real or geographical space; in the second, to typological or linguistic space (see section 2).
This means that the maps also relate to different research questions, and the implications that may be drawn from them are very different. The second kind of map has largely dominated Middle English dialect studies over the last decades; while its importance is in no way called into question here, it is suggested that the first kind might be more useful for some of the questions that we wish to ask about linguistic variation in the late medieval period.
2. Localizing Middle English texts: real space vs linguistic space
Williamson (2000: 119–120) distinguishes between four kinds of space in which linguistic data may be represented on maps: “real”, “geographical”, “reticular” and “linguistic”. He defines “real space” as the space where speakers (or writers) are located in the real world, while “geographical space” is the representation of real space on the map. It is these two kinds of space that are involved in the production of a map of local documents, and it is to them that all modern dialect surveys relate. In human geography, these kinds of space have provided the starting point from which other, more abstract but socially salient spaces have been derived, such as social space and perceived space (on the application of these concepts to linguistic variation, see Britain 2003: 604; Muysken 2008: 4).
In Middle English, localizations in real or geographical space are unavailable for a large part of the material: the provenance of most surviving manuscripts is unknown, as are the geographical backgrounds of most scribes. At the same time, the texts contain much linguistic variation, which is assumed to be to a large extent geographically conditioned. The written variation in Middle English presumably related to other variables as well; however, the focus has until recently largely been on geography (cf. Kretzschmar and Stenroos 2012).
This focus, together with the availability of much interesting material of unknown provenance, have led scholars to develop alternative approaches to geographical variation. Over the last half century, the study of dialectal variation in Middle English has increasingly dealt with localizations in “linguistic space”, based on linguistic similarities, rather than in real space.
The method of localization on linguistic grounds known as the “fit-technique” was developed by McIntosh in the mid-twentieth century (McIntosh 1956, 1963; cf. also Benskin 1991a), with the aim to solve the problem of mapping Middle English linguistic variation. It was used to create the framework of more than 1,000 texts, localized in relation to each other and to “anchor texts” with known provenance, contained in LALME. The localizations are purely typological and reflect similarities of language; in Williamson’s terminology, they are localized in linguistic space. This is an abstract network of relationships, which may then be projected onto a geographical map using the “anchor texts” as connecting points between the two spaces. This is done by means of reticular space: a grid on which the anchor points have their relative places on the geographical map, and the other texts are distributed between them according to their degrees of similarity.
The fit-technique is based on the model of an unbroken dialect continuum. A localizable text is one that can be fitted among the already localized texts without disturbing the continuum, and then itself becomes part of the framework for fitting more texts. To be transferable to a geographical map, the continuum has to include at least some texts with a known geographical provenance, which provide points of connection with “real space”; however, these “anchor texts” cannot be random examples of local documents, but also need to be selected so that they form part of the continuum. [4]
The localizations thus do not provide any direct evidence of the physical provenance of the text. [5] This point is made clearly in LALME and is in no way a shortcoming of the method: its purpose is to reconstruct a dialect continuum, not to provide evidence about text production. The maps based on the fit-technique answer questions such as “where would this text belong in an ideal dialect continuum?” and “which texts are dialectally most similar to each other?” The LALME map of Staffordshire, accordingly, shows those local documents that have been deemed to form the best evidence for the Staffordshire dialect, together with those texts that are most similar in dialect to them, wherever they were produced.
This methodology has had an enormous impact on ME dialectology, to the extent that the linguistically based localizations have generally come to be seen as more “real” or relevant than geographical provenance: as one of the plenary speakers at the Corpus Festival expressed this view, it is the “dialect” rather than the provenance that matters (Kytö 2011).
On the other hand, if we are interested in the social and historical context of Middle English linguistic variation, including text production, we might like to ask a very different question relating to geography, viz. “what was actually produced in a given place?”. Rather than asking which texts represent the “same dialect” on linguistic grounds, we could simply ask what kinds of written language were produced at a given geographical location.
This question will be a crucial one if we wish to study the sociolinguistic realities of the period; however, it needs a different kind of corpus. The corpus should only include texts for which the provenance may be established, and they should not be selected on the basis of their language. This means that the data derived from the corpus, when mapped, will almost certainly not represent a regular continuum: real-life data do not tend to pattern in such a way, but rather cluster and overlap (cf. Kretzschmar 2009: 130, 142–145). Instead, the maps are likely to reflect the messiness of the real world: scribes and exemplars travelling and scribes being trained in institutionalized or supralocalized varieties of written English. [6] However, even though the patterns may be complex, we would not expect them to be random: as with present-day dialect surveys, we may assume that local variants will turn out to be the most frequent overall. Even if the surviving documents from a particular town may contain different kinds of language, the majority may be assumed to represent the writing practices of scribes in that area. How far these also represent a distinctive local dialect, localizable as part of a dialect continuum, may, then, be a research question. Such a corpus allows us to study the range of forms actually used in a particular area, and could thus throw light on the dynamics of changing conventions and the processes of supralocalization.
A Corpus of Middle English Local Documents (MELD), now being compiled at Stavanger, is designed to be such a corpus. It will contain documentary texts for which the provenance may be reasonably certainly established on non-linguistic grounds. The Northwest Midland part of the corpus (ca 250 texts) has already been compiled and work on the rest of the country will begin in 2012. The Corpus is designed to complement the Middle English Grammar corpus (MEG-C), which is based on the LALME localizations, and make possible the kind of research outlined above. [7] The study presented in this paper is a first attempt to compare the distributions of data in these two corpora, located in geographical and linguistic space respectively.
3. The corpora
3. 1.The Staffordshire Local Documents corpus
The Staffordshire part of MELD has been compiled as part of an ongoing PhD project (Thengs: under preparation), which deals with the late medieval dialect materials of the Northwest Midlands (Staffordshire, Shropshire and Cheshire with immediate surroundings). The texts included in this project span a time range from the late fourteenth to the early sixteenth century, and consist of what LALME (I: 40) terms “documentary texts”:
By “documents” we mean legal instruments, administrative writings, and personal letters: the type of material that is calendared by historians, likely to be of known date and local origins.
Documentary texts are usually relatively short, containing between 100 and 1,000 words. Because they often have a limited and repetitive vocabulary, they have sometimes been found less useful as dialect evidence than longer texts (see e.g. LALME I: 10); as they are also less readily available for study (most are unedited and have to be sought out in the archives), it is not surprising that they have not been studied to the same extent as the literary manuscripts. At the same time, the repetitive nature of the language means that documents may provide plentiful evidence for a limited number of very frequent items; documents also survive in very large numbers, so that the overall corpus may be large even though individual texts are short. Most importantly, however, documents constitute the main body of evidence that may be precisely localised on non-linguistic grounds:
Most of these [documents] can be expected to contain indications of their local origins, and in general they can be trusted to attest a form of the written language, if not precisely of the stated place, then of somewhere near to it (LALME I: 9)
Not all legal documents give equally good evidence of their provenance. In order to distinguish between the different types of non-linguistic information used for their localisation, the material has been divided into a Primary and a Secondary category.
Some documents state directly where they were written, and are precisely dated. This information is commonly given in a formulaic clause such as the following (Birmingham Archives, 277108):
|
3eue at west bromwich Jn þe feste of þe Purificaciun of oure lady Jn the regnyge of oure kynge harre þe sixte aftur þe conquest þe xviij |
|
‘Given at West Bromwich in the feast of the Purification of Our Lady, in the 18th year of the reign of our King Henry VI after the conquest’ |
Such clauses usually appear at the beginning or end of the document. Sometimes the date is given at the beginning and the provenance at the end. Thus, one of the Staffordshire documents (Göttingen UL Cod. MS Jurid. 822/1/10) begins as follows:
|
This bille indented and mayde þe xiiij day of May þe 3ere of þe Reynie of kyng Edwarde þe forte aftur þe conquest þe viij 3er |
|
‘This bill indented and made the 14th day of May in the 8th year of the reign of King Edward IV after the conquest’ |
The same document ends with
|
3evun att Blor þo day and the 3ere aboueseyd |
|
‘Given at Blore on the day and year abovesaid’ |
As long as there is no reason to assume that the document is a later copy, this kind of statement may be taken as good evidence of origin, and documents that contain this type of provenance clauses constitute the Primary category of the corpus.
In other documents, which lack a provenance clause, the place of origin can sometimes be deduced with a relatively large degree of certainty on the basis of places and people referred to in the text; such documents form the Secondary category of the corpus. Here, the interpretation of the evidence will need to take into account the kind of documents involved. For example, a lease of land between two parties within the same township or parish is relatively clear evidence of the place of origin, as are marriage agreements and enfeoffments involving only local people and places. A list of witnesses from the same village is also good evidence of a local connection.
Documents involving people or places from different towns or counties are more difficult to place, and, unless there are compelling reasons for why one place of origin would be more likely than the other, such documents have been left out of the corpus. The same applies to petitions to the crown or the church, which frequently seem to have been written by clerks with central government connections. On the other hand, local petitions, by people from a certain location to the bailiffs or lords of the same place, have been included.
Many manorial registers and cartularies fall into the same category as petitions to the national governing bodies; these are often government copies of original documents, and may not be trusted to be in the same language as the original. Bishops’ or priors’ registers are a different matter, as these appear to have been written locally, and might serve as local linguistic evidence, especially as far as local land registers are concerned. It should be noted, however, that all types of registers may contain copies of original legal documents written in a different place. Accordingly, one has to consider each text in a given register separately, rather than drawing general conclusions as to what kinds of registers may or may not be used as local evidence. In fact, close scrutiny of all documents is required in order to establish whether they may be considered to represent a specific geographical location.
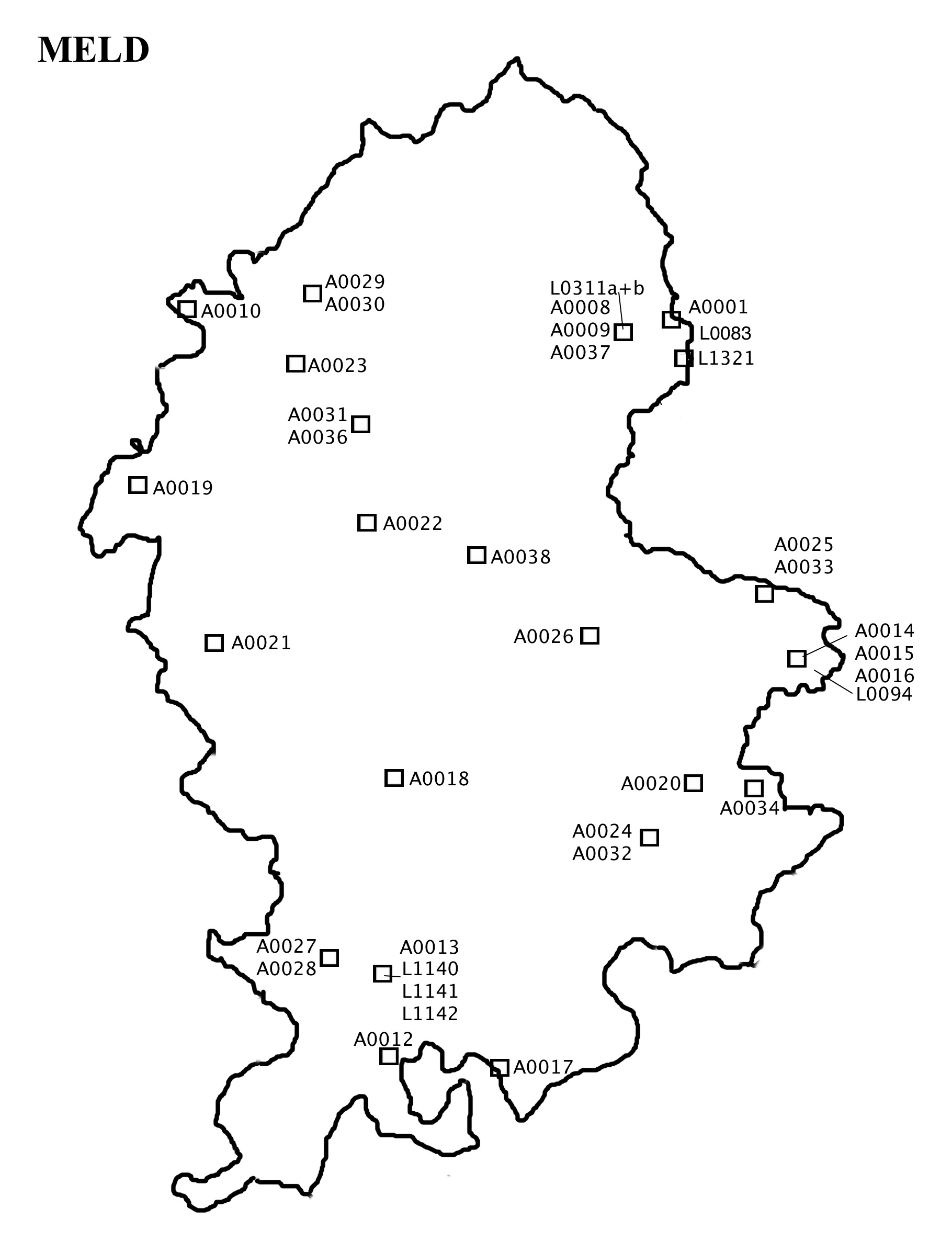
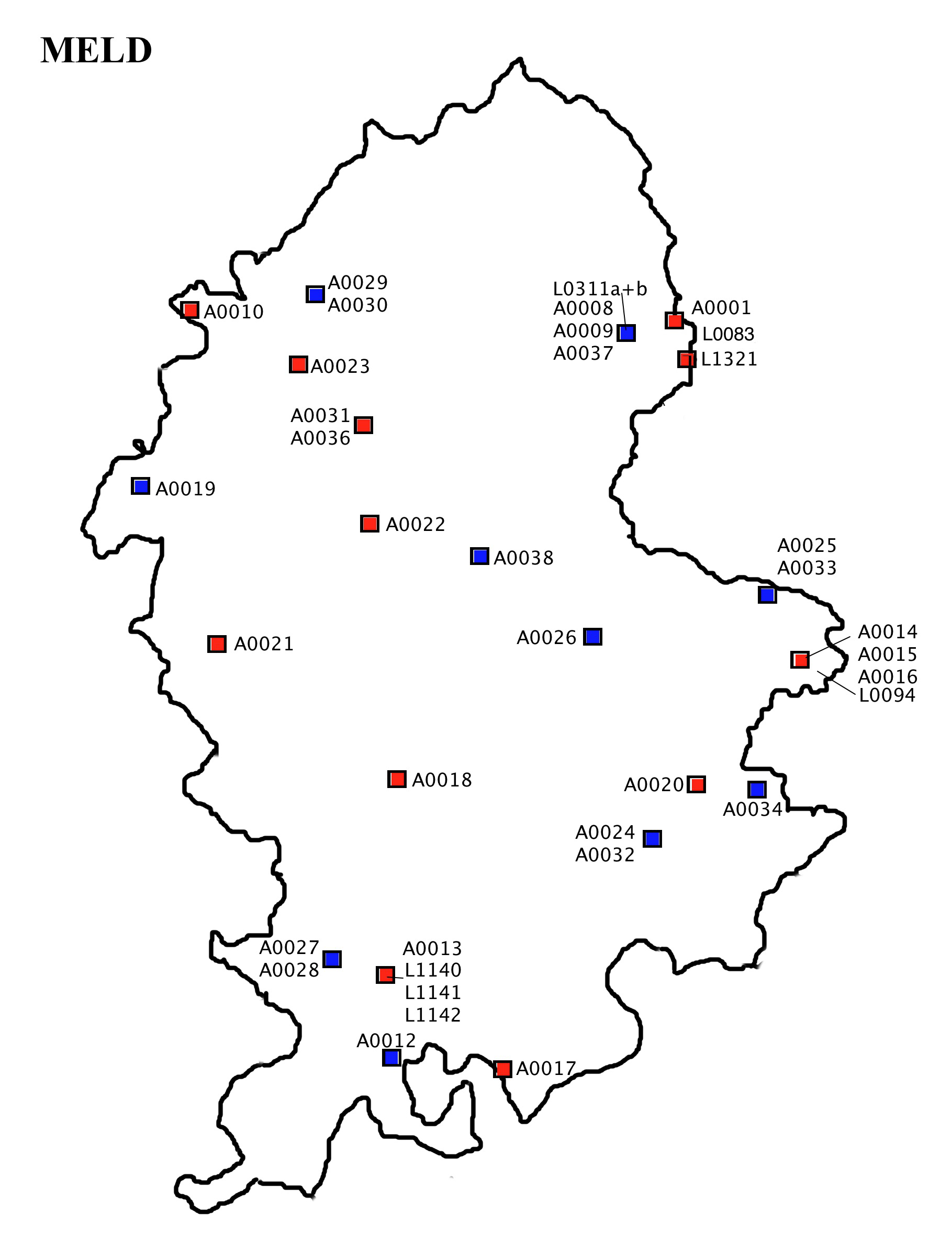
The Staffordshire part of the MELD corpus that was used in the present study consists of 15 transcribed texts in the Primary and 23 in the Secondary category; this makes up a total of 38 texts, containing 21,878 words (see Map 1 and the Staffordshire MELD Corpus list in the appendix). Eight of these were also used in LALME. The Primary texts are spread across the whole county, and are complemented very well by the texts of the Secondary category, which both fill in empty spaces on the map and add data to places that also contain Primary texts (see Map 2). The date of the texts spans more or less evenly from 1400 to 1515; however, approximately half of the texts are from the latter part of the reign of Henry VI, that is, from about 1440–1460.
The texts are referred to with the four-digit codes used in the Middle English Scribal Texts programme. For texts mapped in LALME, the code consists of the LALME LP code prefixed with L and with the number of zeros required to make up four digits; LP 83 thus becomes L0083. The local documents that were not included in LALME have the prefix A followed by four digits.
3.2. The Middle English Grammar Corpus (MEG-C)
The Middle English Grammar Corpus (MEG-C) contains transcriptions of the texts mapped in LALME; longer texts are included in 3,000-word samples and shorter texts entire. The current online version (2011.1), on which the present study is based, contains 410 texts; this is slightly less than half the eventual projected number (ca 1,000).
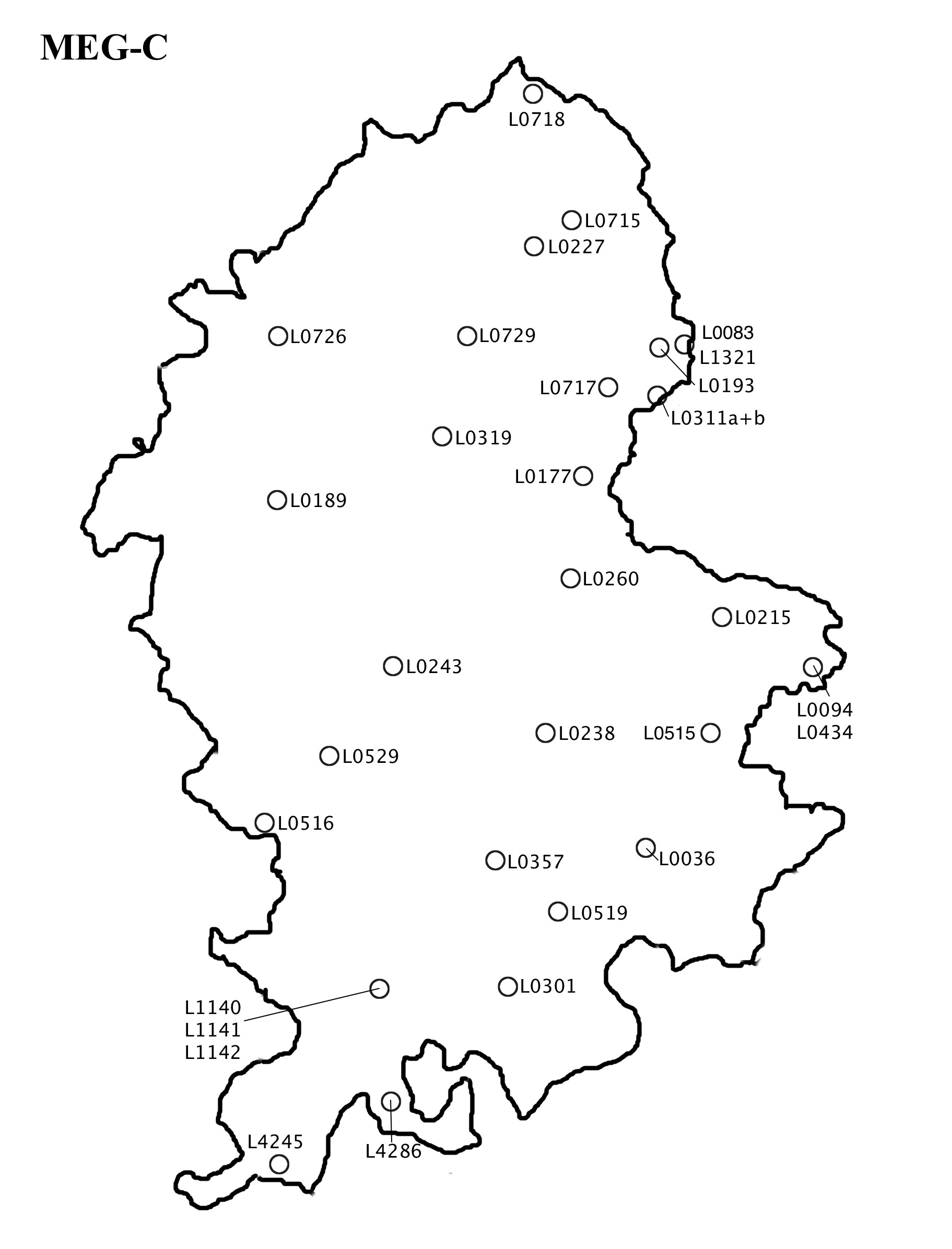
The Staffordshire part has been completed and contains all the texts mapped in LALME; this makes up altogether 32 texts from about 1375 to 1500 (see Map 3 and the Staffordshire part of the Middle English Grammar Corpus list in the appendix). These include nine documents, seven religious verse texts (including copies of the Prick of Conscience and the poems of John Audelay) and fifteen prose texts of various genres, including sermons, medica, grammatica and the Prose Brut. Most of the texts are, again, from the middle of the fifteenth century. The latest texts are from the end of the fifteenth century, making the chronological range of this corpus slightly shorter than that of the MELD one; any comparison between the two corpora should therefore take into account the slightly longer timespan of the MELD corpus, even if the late texts are few. The corpus contains altogether 68,733 words.
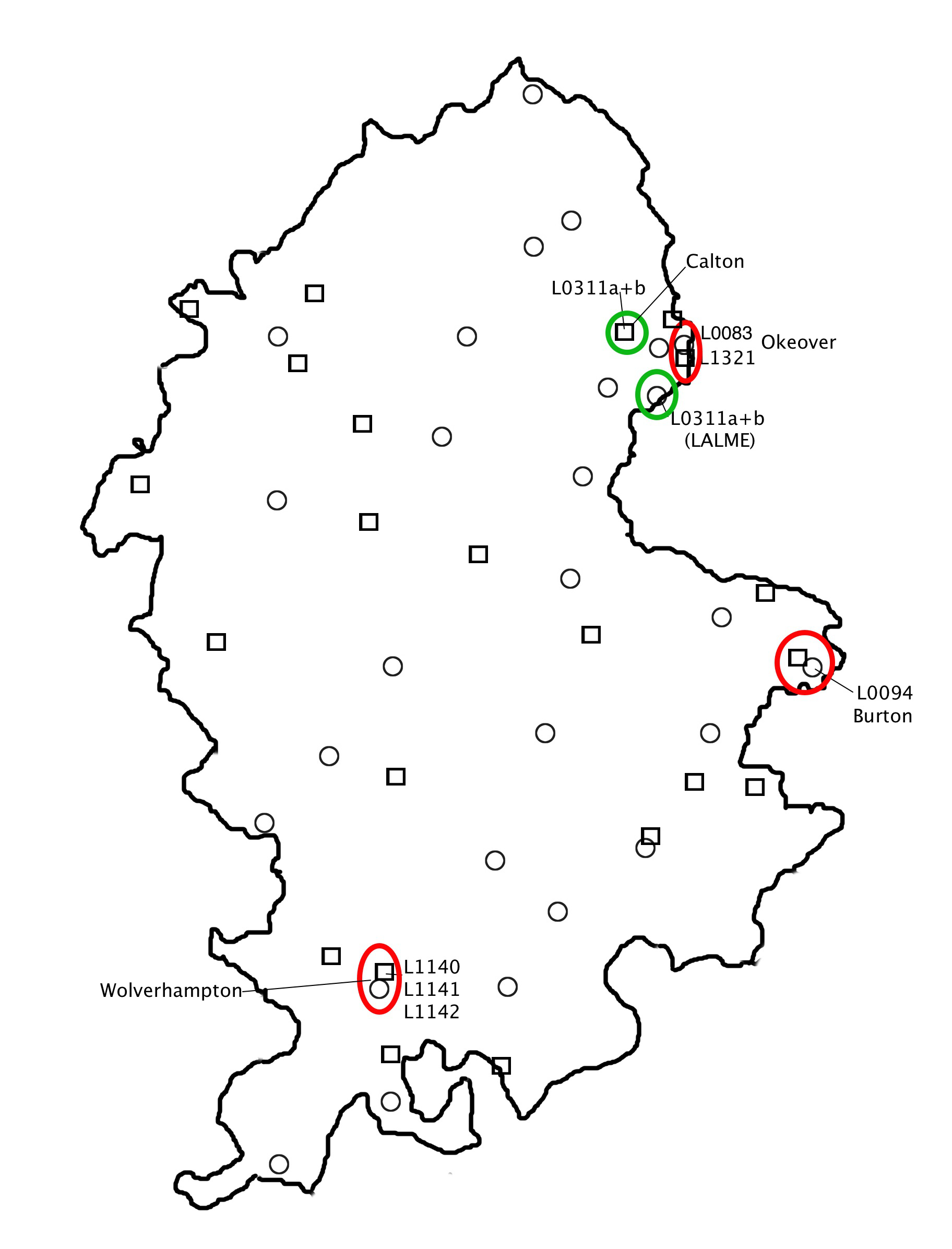
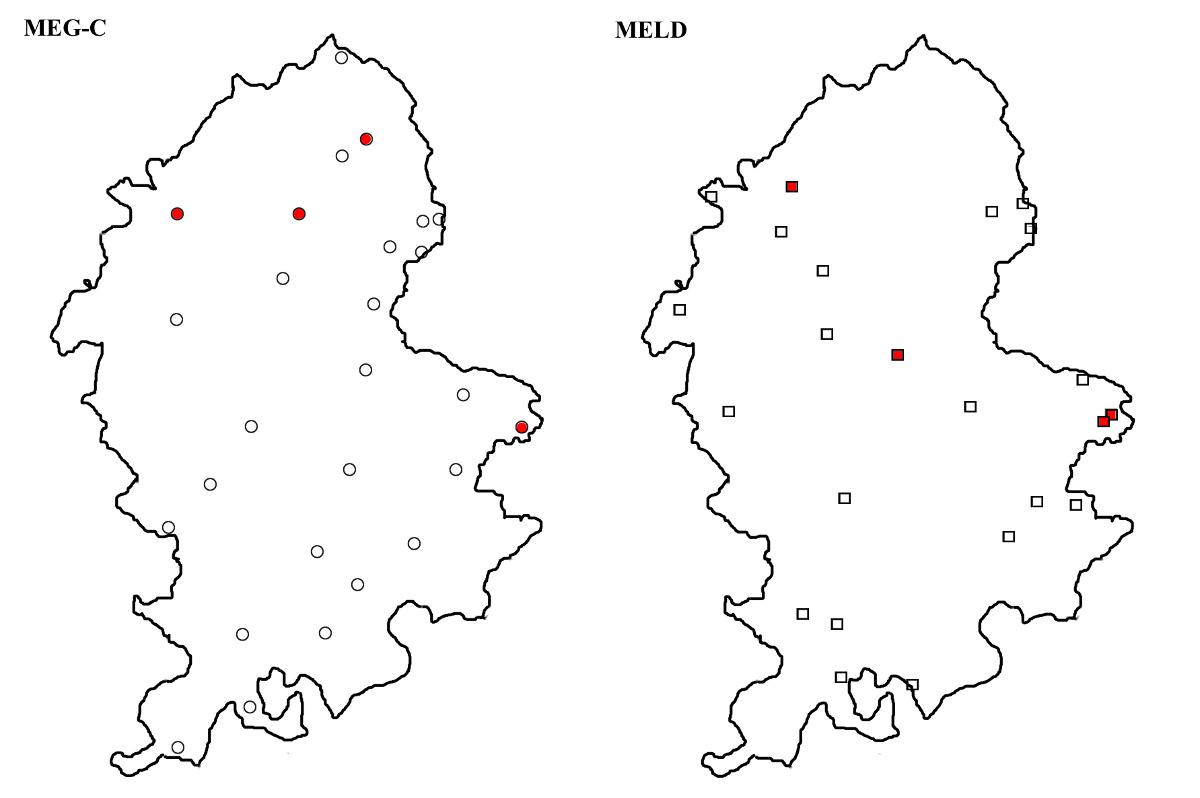
The texts are spread fairly evenly across the county in the typological matrix, but there are few texts along the western border. The documents, most of which were presumably used as anchor texts (Map 4), are clustered around three places: two in the Okeover area in the North East, two in Burton-upon-Trent, somewhat further South, and three in Wolverhampton in South Staffordshire. It should be said, however, that some of the other prose and verse texts may also be used as anchors on the basis of extralinguistic evidence; for Staffordshire one such text is L0036 (Cambridge, Trinity College 383 (R.3.8)), which is believed to be in the hand of a Lichfield scribe (McIntosh 1963: 6–7) (see Map 5). A good example of the difference between geographical and linguistic space can be seen in the placement of L0311a and L0311b in LALME and in the MELD corpus respectively (see Map 4). In LALME, the localisation is several miles south-east of Calton, which appears to be the place of origin of the two texts. The other documents with a localising clause that were used in LALME have been mapped in the place indicated by the clause, and thus seem to have been used as anchor texts.
All the assumed Staffordshire anchors are situated along the Southern and Eastern border. This means, in effect, that they are not very useful for mapping the remaining texts in Staffordshire, whose even spread can only be explained by linguistic comparison with anchor texts in the neighbouring counties. The nearest points of reference to the West follow a line through the middle of Shropshire, from Ludlow in the South via Shrewsbury to Hinton near Whitchurch in the North, continuing North-West into Cheshire, through Nantwich and Middlewich to Peover (see Map 6). In other words, the large expanse between all these anchor points is void of texts with any physical connection to the map. The even spread of the documents in the MELD corpus throughout the area thus makes for an interesting comparison with the typological matrix of LALME.
3.3. Methodology
Both corpora were transcribed using the MEG-C conventions, as described in the MEG-C Manual. As noted in 3.2., the longer texts in MEG-C are transcribed in samples of 3,000 words; none of the MELD texts exceed this word count and accordingly all are included whole. The two corpora are so far of uneven size: the Staffordshire part of MEG-C, which contains many long non-documentary texts, is more than three times the size of MELD in terms of overall word count. However, the absolute number of tokens collected from the two corpora varies greatly from item to item: while ‘any’ provides relatively equal amounts of data in both corpora (140 tokens in MEG-C and 106 in MELD), the number of tokens for ‘it’ is almost nine times higher in MEG-C. Conversely, the item ‘land’ yields almost three times as many tokens in MELD as compared to MEG-C, which makes it eight times more frequent in relative terms (see Table 1).
|
MEG-C |
MELD |
| ANY |
140 (2.03) |
106 (4.85) |
| IT |
837 (12.18) |
95 (4.34) |
| GOOD |
217 (3.16) |
25 (1.14) |
| THEM |
474 (6.90) |
84 (3.84) |
| LAND |
70 (1.02) |
189 (8.64) |
| THE |
2832 (41.20) |
1950 (89.13) |
| THIS |
525 (7.64) |
75 (3.43) |
| THAT |
1957 (28.47) |
371 (16.96) |
| SHALL |
386 (5.62) |
160 (7.31) |
| OTHER |
207 (3.01) |
106 (4.85) |
Table 1. The total numbers of tokens collected from each of the two corpora for the items presented in the maps. Normalized figures (attestations per 1,000 words) are provided in brackets.
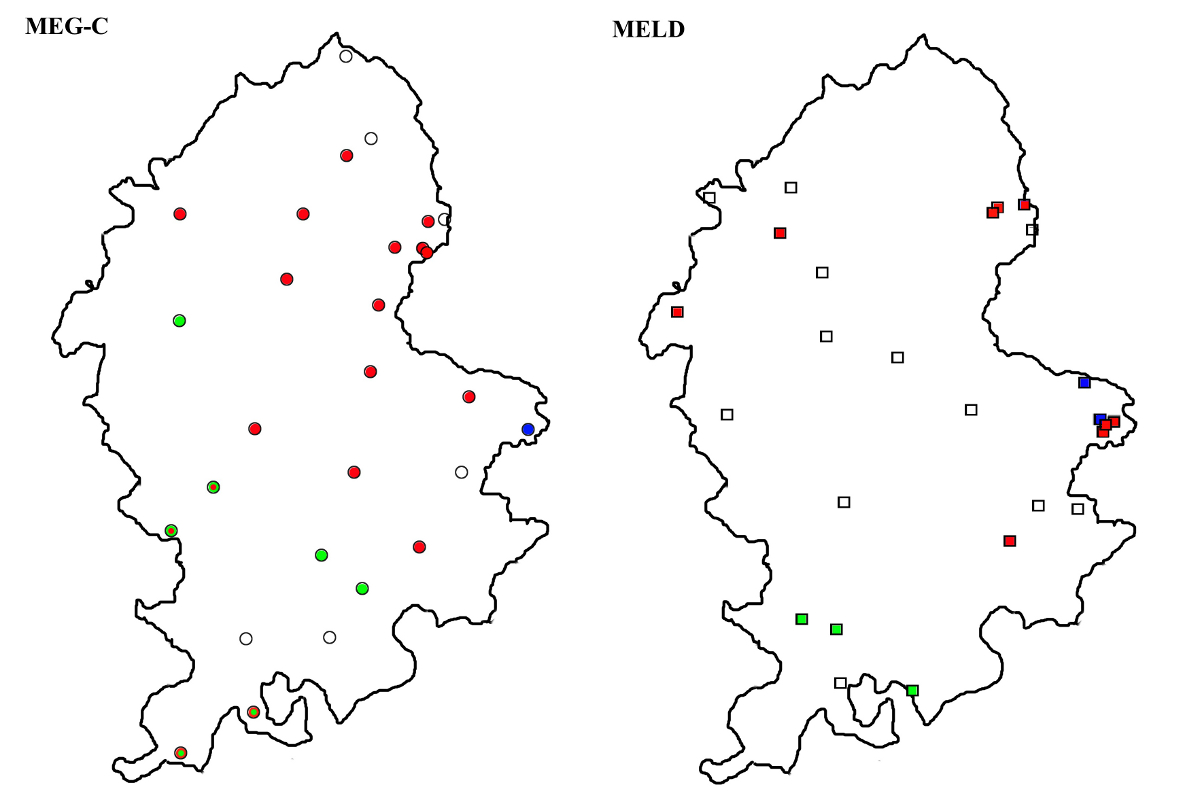
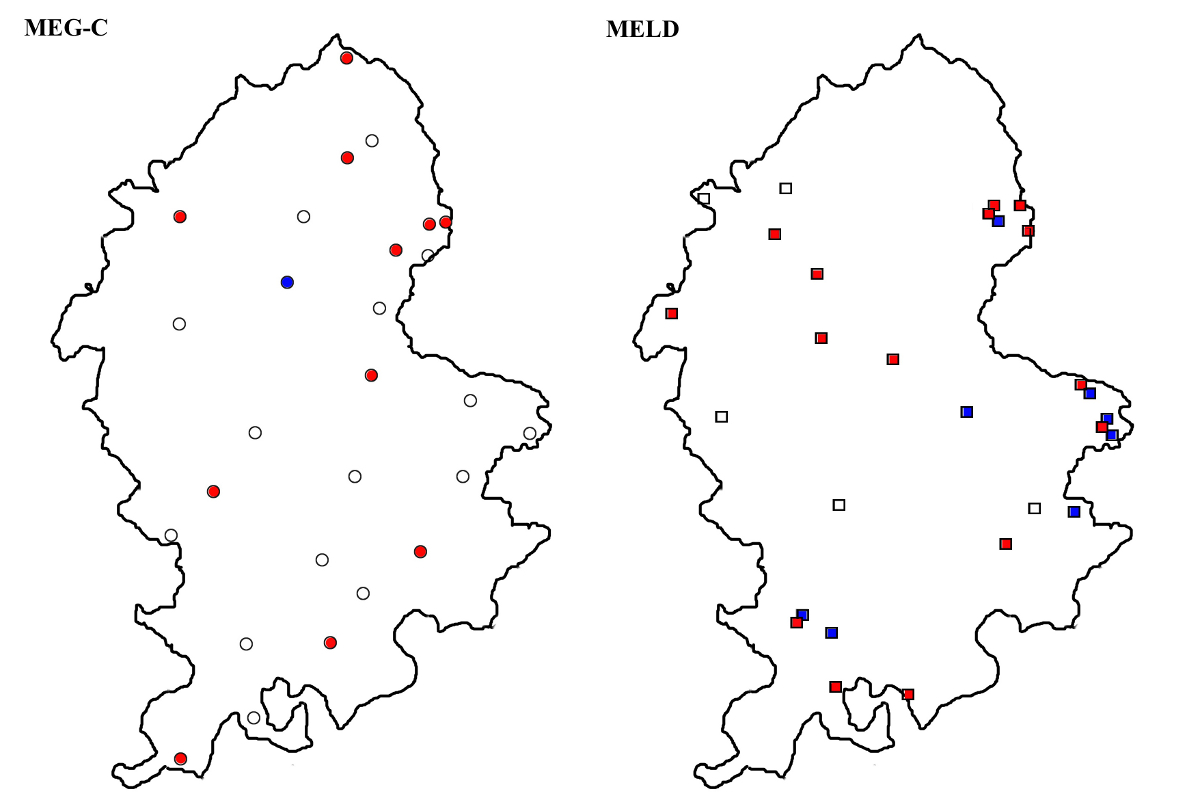
Most of the mapped features show relatively little variation within each text, and where there is variation, there is mostly a very clear majority form. The coloured dots on the dialect maps represent either such clear majority forms, or forms with no variants; in the few cases where there is no clear majority form, the variation is indicated by using two colours (see e.g. Map 7).
The linguistic items for study were chosen on three main grounds. Firstly, they should be reasonably frequent in both corpora. Secondly, there should be reason to assume that they would show variation in the Staffordshire material. As this was also a criterion for the LALME questionnaire, it made sense to include some of the items on the basis of the LALME maps, such as ‘any’, ‘did’, ‘each’ and ‘it’. Thirdly, at least some items should provide systematic information about orthographic or morphological categories. The data were collected with a concordancer, AntConc 3.2.1w; as this involved sorting forms alphabetically, initial elements were particularly suitable for collection. We decided to study the spelling of the initial fricatives corresponding to Present-Day English <sh>, <th> and <wh>. The following 30 items were initially included in the study:
‘after’, ‘any’, ‘but’, ‘did’, ‘each’, ‘either’, ‘give’, ‘good’, ‘have’, ‘if’, ‘it’, ‘land’, ‘man’, ‘many’, ‘much’, ‘other’, ‘shall’, ‘she’, ‘should’, ‘such’, ‘that’, ‘the’, ‘them’, ‘this’, ‘what’, ‘whether’, ‘where’, ‘which’, ‘whether’, ‘whither’
Only simplex forms were collected, leaving out compound forms such as goodman. The data were imported to an Access database together with several categories of extralinguistic information about the texts, including subcorpus, text code, localization, date and script. Some items turned out to be very unevenly distributed within each corpus: both ‘man’ and ‘she’ appeared in too few texts in the MELD corpus to be useful for the study. Others, such as ‘which’, provided large quantities of data, but the variation was highly complex and could only be expected to show patterns over a much broader geographical range. The findings for the following ten items will be presented in what follows: ‘any’, ‘good’, ‘it’, ‘land’, ‘other’, ‘shall’, ‘that’, ‘the’, ‘them’ and ‘this’.
4. Presentation and discussion of the findings
4.1. Similar distributions: ‘any’, ‘it’ and ‘good’
The items ‘any’, ‘it’ and ‘good’ were chosen because their distributions in other studies suggested that they might show variation in the Staffordshire material. The LALME distributions of forms of ‘any’ and ‘it’ show clearly patterned variation in this area, while the distribution of gud type forms of ‘good’ seems to be to some extent conditioned by genre in northern materials (Jensen 2010; Stenroos and Thengs, under preparation).
In the LALME maps for ‘any’ (LALME I: 329, Maps 97–99) the distribution of the ony type (all spellings with <o>, including oni, onie) shows a concentration in the Central and East Midlands and scattered occurrences elsewhere, while the eny type shows an almost complementary distribution, with a concentration in the Southwest Midlands and the South and scattered occurrences in the Northwest Midlands. The any type occurs everywhere on the LALME map, except for the Gloucestershire area, which has eny. The form ony was identified by Samuels (1963 [1989: 67]) as one of the typical features of his “Type 1” or “Central Midland Standard”, the set of writing conventions used in the majority of Wycliffite texts of the late fourteenth and fifteenth centuries, although not by any means confined to them.
Map 7 shows the distribution of the any, ony and eny forms in the present material, in the MEG-C and MELD corpora respectively. On the MEG-C map, any appears as the main form, with eny in the south and west, either as a dominant form or in variation with any; only one text (L0094), in the far east, shows ony. The MELD distribution does not give any information about the middle of the country, but it also shows any as the main form, with eny appearing in the south. The one MEG-C text showing ony, L0094, forms part of the MELD material as well; in addition, another text from the same area, A0033, shows ony. On the whole, both maps seem to show largely the same picture, even though the relatively small number of texts and tokens means that the similarities could be fortuitous.
The variants of ‘it’ with and without initial <h>, the hit and it types, show a fairly clear geographical patterning in LALME (I: 310–311, Maps 24, 25). While the <h>-less forms occur in all parts of the country, they are clearly less common in the West Midland area; the forms with initial <h>, on the other hand, are largely restricted to the southern and western half of England. Map 8 shows that the forms with <h> are solidly in the majority in both corpora; both show it/yt as the sole or dominant form only in two and three texts respectively, all in the eastern part of the county.
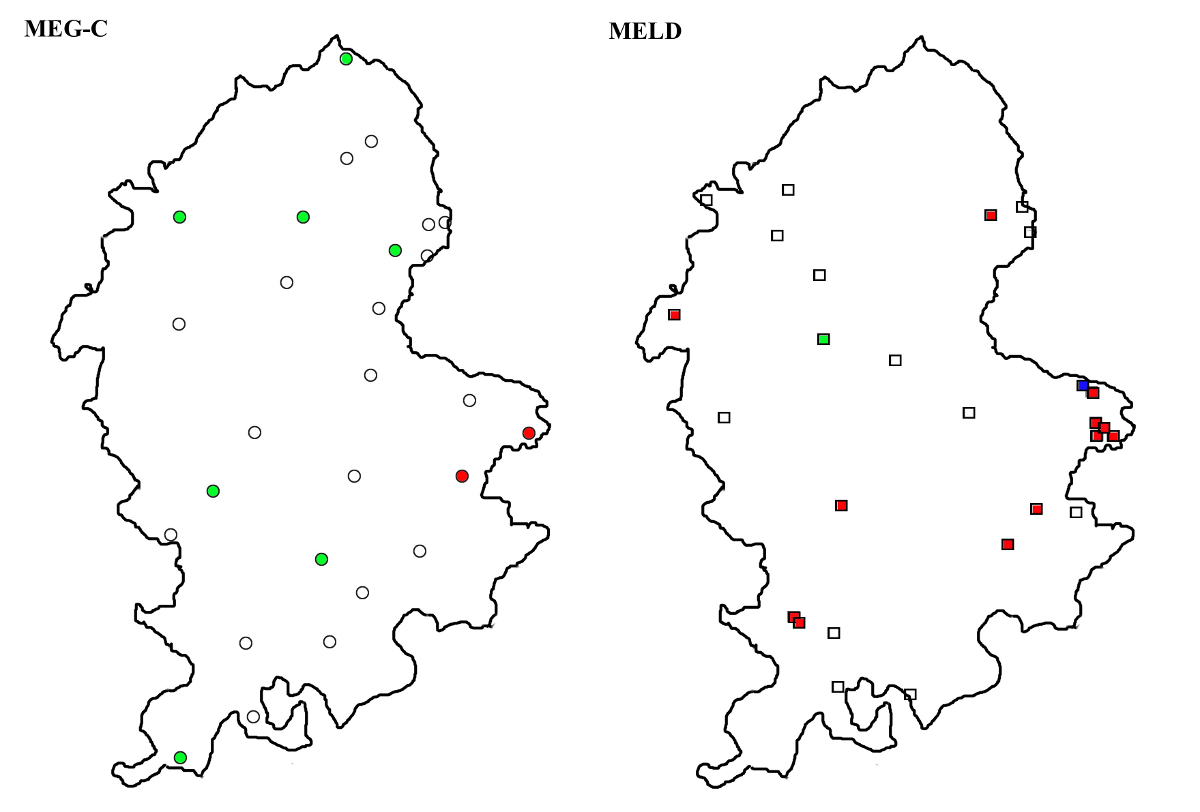
The LALME map for ‘good’ spelt with <u>, the gud type, shows a focal area of distribution limited to northern England, with a scattering of texts through the southern part but with no occurrences in Staffordshire. However, the form occurs more than occasionally in the present material, with altogether 37 occurrences in seven texts. While these figures are still small, they were included in the study, as the gud type seems to show an interesting genre-based pattern in the northern materials: in Jensen (2010), it was shown that gud type forms were almost completely restricted to documentary texts in the Yorkshire West Riding material, a finding that has also been corroborated by a study of the northern documentary texts in MEG-C (Stenroos and Thengs, under preparation).
Map 9 shows the distribution of the gud type forms. All the seven texts in which they occur (four in each corpus, with L0094 shared by both corpora) are localized in the northern and eastern parts of Staffordshire. While this area lies clearly to the south of the LALME focal area, its MELD distribution suggests that the forms might perhaps be related to the northern spelling convention, rather than representing the kind of southern <u> spellings that Britton (2002: 225) suggests may have had independent reasons such as “compound shortening”. Unlike the Yorkshire material studied by Jensen, however, the present material does not suggest any specific association of the gud forms with documentary texts; the three texts in the MEG-C corpus that show the gud type as a dominant form with several occurrences (L0715, L0726 and L0729) are all non-documentary texts. A total of seven texts, is, of course, too little for drawing any conclusions; however, in conjunction with the previous two maps, it adds to a general picture of similarity between the two Staffordshires.
4.2. A difference of chronology: ‘them’
The forms of ‘them’ with initial th-, spelt <th>, <þ> or <y>, seem to have spread to the southern half of England only relatively late in the medieval period. The LALME maps (I: 317, Maps 51, 52) show a fairly clear dividing line, running diagonally close to the old Danelaw boundary, with h-forms occurring only to the south of this line and th-forms being mainly concentrated to the north. Black (1998) showed that, in the texts localized in Herefordshire in LALME, th- forms were extremely rare and only occurred in texts that were very late or had external connections.
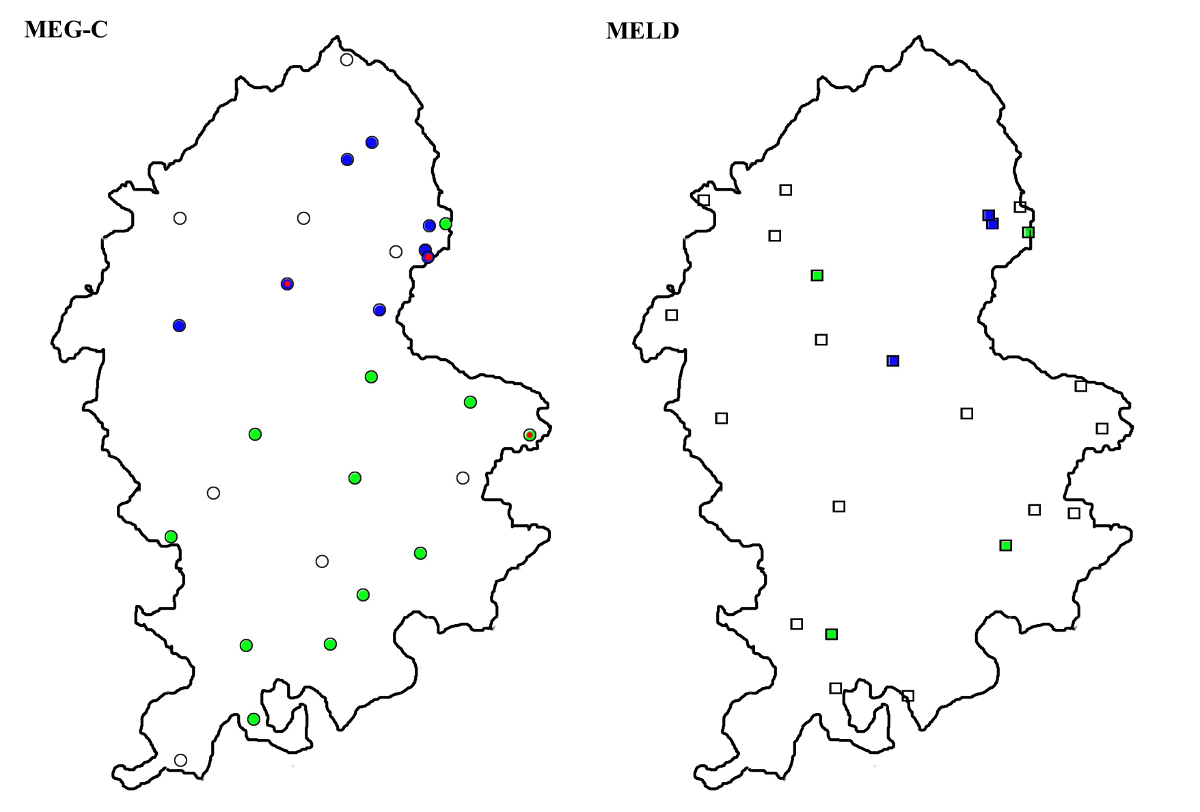
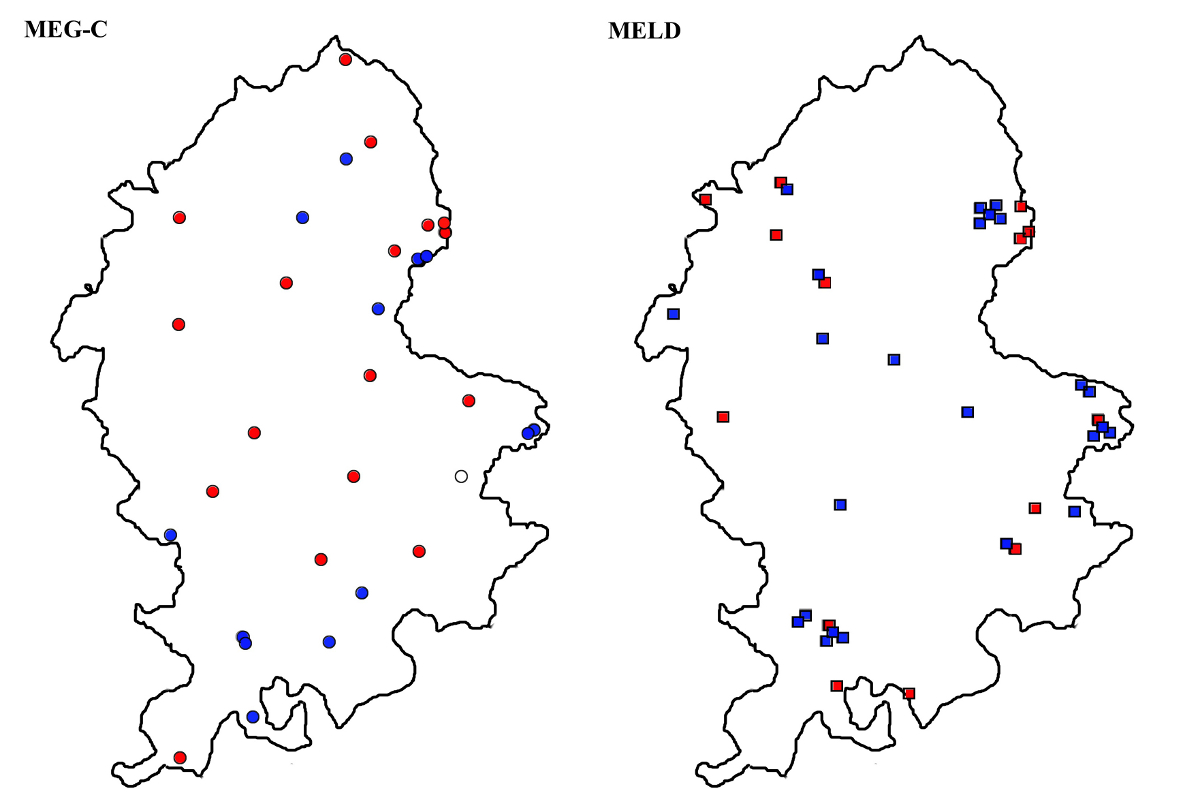
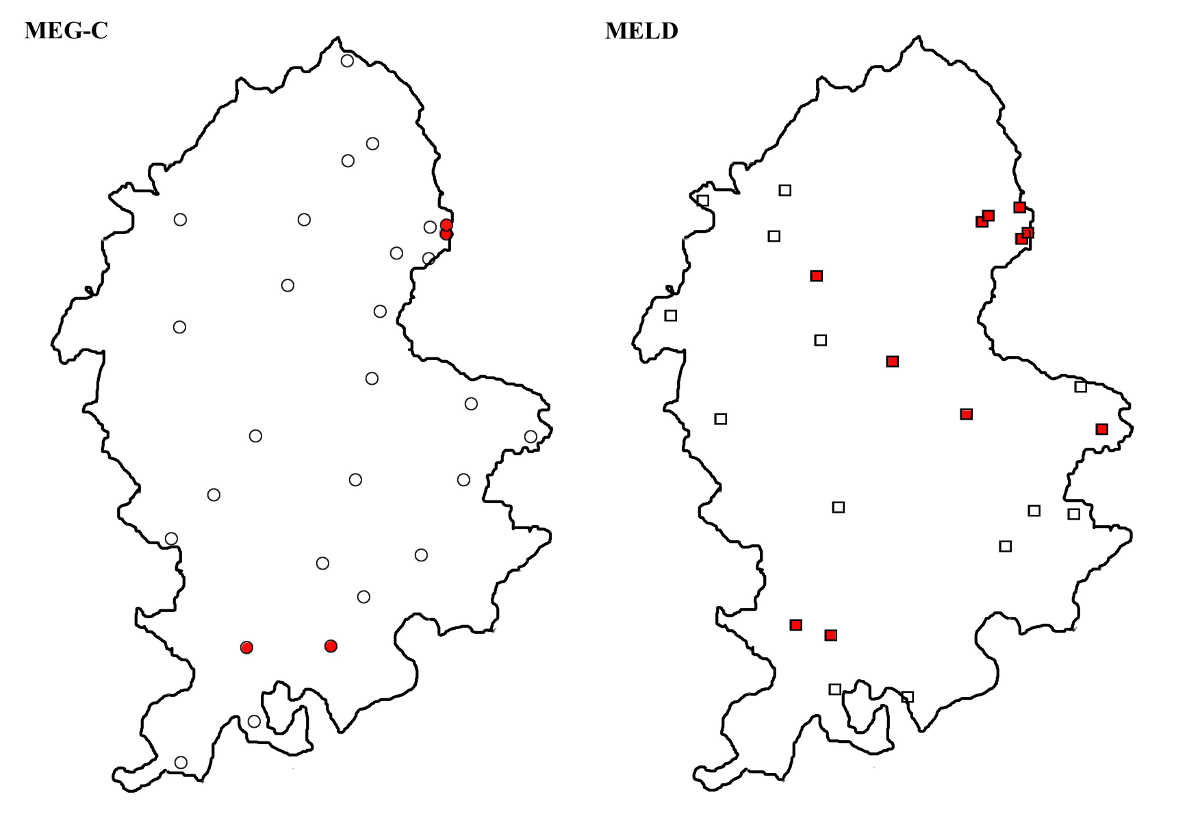
Map 10 shows the distribution of the different variants of ‘them’, including h- forms with medial <e> and <o> (the hem and hom types respectively) as well as th-forms. At first sight, the maps seem to show a significant difference between the two corpora, with the local documents showing a large number of occurrences of the th- forms, hardly evidenced in the MEG-C corpus. However, the difference in this case turns out to be mainly one of chronology. If the material is delimited to the first half of the period studied, viz. 1375–1450, neither map shows th-spellings as a dominant or sole form; in fact they only occur as minor variants in two MEG-C texts (Map 11). As dominant forms, they only appear in the latter period, viz. 1450–1515, for which the coverage of the MEG-C corpus is fairly scanty; while the th- forms appear to be much more common on the MELD map, it should be noted that a few of the texts on this map are slightly later than the latest MEG-C ones (Map 12). The appearance of th- forms is accompanied by a disappearance of the hom type, which is virtually absent from the post-1450 data; in fact, the only text in which it appears is A0033, a document dated 1451.
4.3. Genre differences: th- and sh-
The selection of items was meant to elicit systematic information as well as including individual, highly variable items such as ‘any’ and ‘it’. For this purpose, spellings corresponding to initial fricatives were collected. The variation between forms of <þ> that are distinct from or identical with <y> has shown itself to be an interesting example of purely orthographic variation that patterns geographically (cf. Benskin 1982; Stenroos 2004); in the present material, texts that distinguish between the forms are much more common; however, <y> spellings occur in both corpora, with a northern distribution reminiscent of that of gud ‘good’.
For the present purpose, however, the distribution of <th> spellings, as opposed to <þ/y>, is of particular interest. Map 13 shows the distribution of the and þe/ye variants of ‘the’. The map does not suggest a shared pattern; if anything, the two distributions seem to be reversed, with the <þ/y> forms dominant in the central Staffordshire area in MEG-C and the <th> forms in MELD.
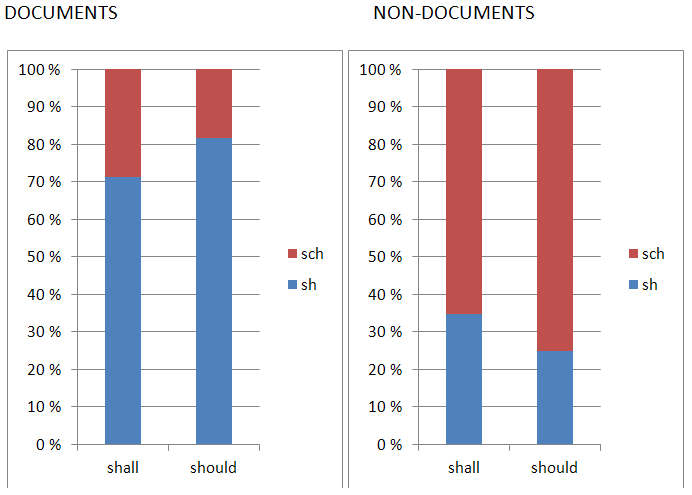
The major difference here turns out to be between documents and non-documents. Figure 1, based on the data for ‘the’, ‘that’ and ‘this’, shows that the overwhelming majority of documents has <th> as the dominant or sole form, while non-documentary texts most commonly have <þ> or <y>. The first consonantal elements of ‘shall’ and ‘should’ show a very similar distribution with regard to genre (Figure 2); here, spellings with <sh> dominate in the documentary texts, while <sch> dominates in other texts. Again, the maps show no clear patterns (Map 14).
4.4. More or less supralocal? ‘land’ and ‘other’
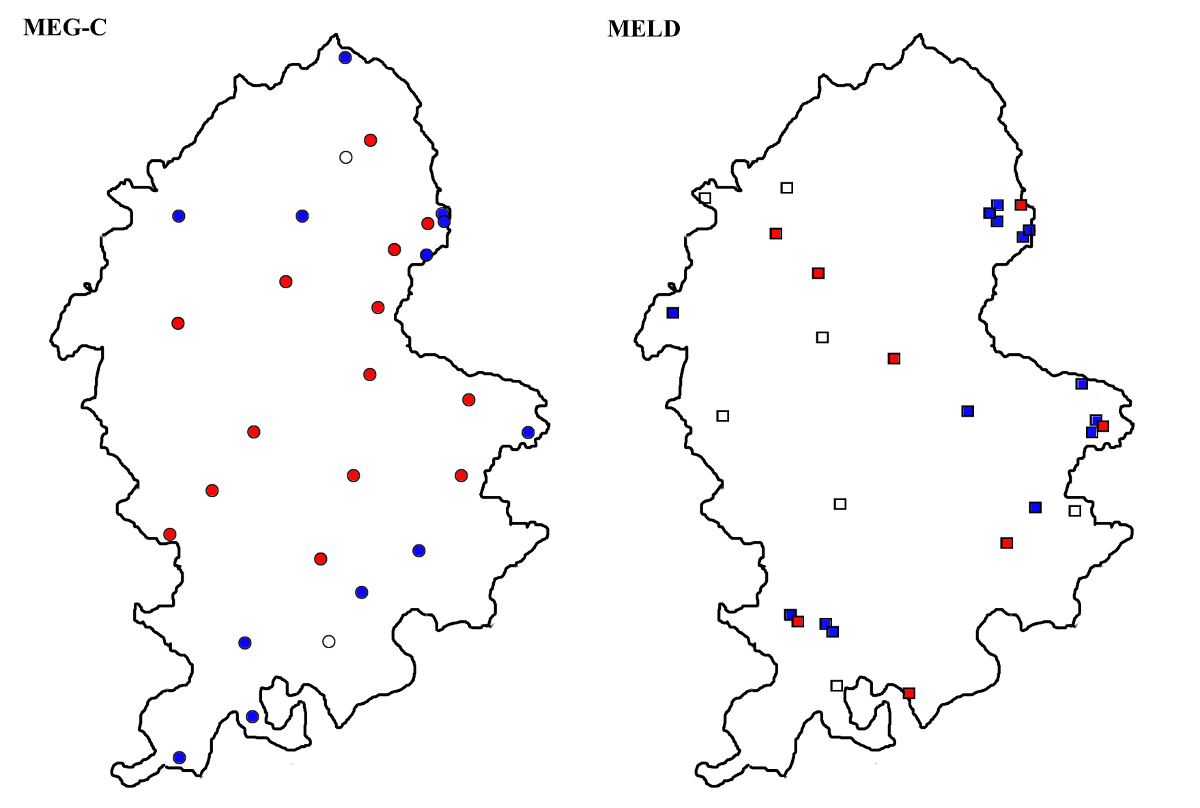
It might be expected that the local documents would show a higher frequency of supralocal forms at the expense of markedly western ones. There are at least two reasons to expect this: firstly, the local documents have not been selected for their dialect features, and, secondly, the supralocalization (or “standardisation”) of written English has been thought to take place particularly early in legal documents (Benskin 1992, Rissanen 2000). At first sight, the maps for ‘them’ seemed to suggest such a tendency; however, the pattern turned out to be one of diachronic change rather than a difference between the corpora. However, in the case of ‘land’, we seem to get the expected kind of pattern. Map 15 shows the distribution of variants of ‘land’ spelt with <o> or <a>. Both maps show the lond type; however, only the MELD map shows a large number of texts with dominant or sole land. There does not seem to be a diachronic lag here, as for them.
On the other hand, the reverse pattern occurs as well. As Map 16 shows, spellings of ‘other’ with medial <d> are much more common in MELD; in the MEG-C material they are only found in four texts, also legal documents. The oder type is not a particularly western form, but neither does it represent supralocal usage; in LALME, it seems to appear in clusters, including one in the London area. For some reason, like gud ‘good’ in the northern texts, it seems to be a favoured form in the local documents; it clearly forms part of the written usage of late medieval Staffordshire.
5. Conclusions
Many of the maps show a close resemblance between the two Staffordshires. This is not surprising, since the LALME compilers based their localizations on local documents. It was also expected that the MELD maps would tend to show a higher proportion of non-western forms, as texts showing supralocal usage would generally have been excluded from LALME. Some of the maps, indeed, show such a pattern; however, sometimes the opposite is the case, and the local documents show more marked forms. While much more work is needed here, it seems clear that the local documents do not necessarily show a unidirectional march towards “standardisation”. Neither do they show a particularly “chaotic” picture compared to the MEG-C distributions.
The drawback of using only local document material is, of course, that the individual texts are short; for most features, the MEG-C maps are based on rather more robust numbers of occurrences. On the other hand, even if the individual documents tend to be short, the overall number of available documents is large, and many have never been studied before. For MELD, it should be possible to provide good coverage for most parts of the country. A larger corpus will also make possible studies that deal more specifically with frequencies than has been possible here, and that will be able to focus on more narrowly delimited periods of time.
However, even if the MELD maps are based on smaller numbers, the distributions shown in them have very different implications compared to the MEG-C ones. The latter show patterns in linguistic space: forms that belong to the reconstructed, “ideal” dialect of Staffordshire. The MELD maps, instead, show us what was actually written in Staffordshire: to paraphrase William Kretzschmar (2009: 74–82), “who wrote what where”. They relate directly to the historical context and the manuscript reality: for example, they show that the scribes who produced documents in Staffordshire had fairly commonly the habit of spelling ‘other’ with a medial <d>, something that could be significant in the light of other information about scribal networks and text production.
Finally, the maps for ‘them’, ‘the’ and ‘shall’ show clearly that geographical variation should not be studied in isolation. Geographical space has perhaps always been the most important variable with regard to spoken language; however, there are at least two major problems in the categorization of late Middle English dialects along a purely geographical continuum. Firstly, in linguistic variation we are dealing with social space rather than with strictly euclidean geography: changes are disseminated along networks of contact, not through the empty countryside. Secondly, the role of geography is less obvious in the written mode, which more easily transcends the limitations of space and time, and is also more likely to reflect formal schooling. It is generally agreed that, by the sixteenth century, geography is no longer a major variable in relation to written English (cf. Benskin 1992: 71–72, Samuels 1981 [1988]: 86); it must therefore be assumed that other parameters are strongly present also in fifteenth-century written variation.
Identifying the parameters of variation is perhaps the most central task in the study of late- and post-medieval English. If we wish to consider the full range of extant material, rather than the group of texts that may be localized using the fit-technique, the variation will be extremely complex and difficult to unravel. To approach this complexity in an orderly way, it would seem to make sense to relate the data strictly to those extralinguistic parameters that are available, such as the actual provenance of documentary texts.
Notes
[1] We would like to give our profound thanks to Michael Benskin and William Kretzschmar for help and inspiration that has been crucial for this work; this does not, of course, imply that they would agree with all the arguments presented here, and we are solely responsible for all mistakes. The maps for this paper were produced by Anne Liv V. Halvorsen, who has also given us valuable feedback.
[2] This project, “The language and geography of Middle English documentary texts” has recently been granted funding, jointly by the Research Council of Norway and the University of Stavanger, for the period 2012–2016.
[3] The total number of texts in the Staffordshire corpus has subsequently risen to 54.
[4] LALME does not list the “anchor texts” (cf. Benskin 1991b: 220–21). A partial list is, however, provided in Laing (1991: 28).
[5] The LALME Introduction (LALME I: 23) suggests that the localizations generally tell us “where the scribe of a manuscript learnt to write”; however, as we have little information about the school background of most medieval scribes, this would be difficult to verify.
[6] The term “supralocalization” is here preferred to the traditional but misleading “standardisation”, following the practice of Nevalainen and Raumolin-Brunberg (cf. Nevalainen 2006: 117, Nevalainen and Raumolin-Brunberg 2003: 157–161).
[7] MELD and MEG-C both form part of a long-term research programme at the University of Stavanger, Norway: the Middle English Scribal Texts programme (MEST) [www.uis.no/research-and-phd-studies/research-areas/history-languages-and-literature/the-middle-english-scribal-texts-programme/]
Sources
The Middle English Grammar Corpus (MEG-C), version 2011.1, http://www.uis.no/research/humanities/the-middle-english-scribal-texts-programme/meg-c/
A Corpus of Middle English Documentary Texts, under preparation, University of Stavanger http://www.uis.no/research/humanities/the-middle-english-scribal-texts-programme/meld/
Stenroos, Merja and Martti Mäkinen, 2011. “MEG-C Corpus Manual, version 2011.1”. The Middle English Grammar Corpus, compiled by M. Stenroos, M. Mäkinen, S. Horobin and J. J. Smith, University of Stavanger. http://www.uis.no/getfile.php/Forskning/Kultur/MEG/Corpus_manual_%202011_1.pdf
References
Benskin, Michael. 1982. “The letters <þ> and <y> in later Middle English, and some related matters”. Journal of the Society of Archivists 7: 13–30.
Benskin, Michael. 1991a. “The fit-technique explained”. Regionalism in Late Medieval Manuscripts and Texts, ed. by Felicity Riddy, 9–26. Cambridge: D.S. Brewer.
Benskin, Michael. 1991b. “In Reply to Dr Burton”. Leeds Studies in English n.s. 22: 209–62.
Benskin, Michael. 1992. “Some new perspectives on the origins of standard written English”. Dialect and Standard Language in the English, Dutch, German and Norwegian Language Areas, ed. by J.A. van Leuvensteijn & J.B. Berns, 71–105. Amsterdam: Royal Netherlands Academy of Arts and Sciences, North-Holland.
Black, Merja. 1998. “Studies in the dialect materials of medieval Herefordshire”. PhD thesis, University of Glasgow.
Britain, David. 2003. “Space and spatial diffusion”. Handbook of Language Variation and Change, ed. by J. K. Chambers, P.Trudgill & N. Schilling-Estes, 603–637. Oxford: Blackwell.
Britton, Derek. 2002. “Northern fronting and the north Lincolnshire merger of the reflexes of ME /u:/ and ME /o:/”. Language Sciences 24: 221–229.
Jensen, Vibeke. 2010. Studies in the Medieval Dialect Materials of the West Riding of Yorkshire. PhD thesis, University of Stavanger.
Kretzschmar, William A. 2009. The Linguistics of Speech. Cambridge: Cambridge University Press.
Kretzschmar, William A. & Merja Stenroos. 2012. “Evidence from surveys and atlases in the history of the English language”. The Oxford Handbook of the History of English, ed. by T. Nevalainen & E. Traugott, 111–122. New York & Oxford: Oxford University Press.
Kytö, Merja. 2011. “In charted and uncharted territories: Exploring geographical variation in English historical corpora”. Plenary paper delivered at the Helsinki Corpus Festival, University of Helsinki,1 October 2011.
Laing, Margaret. 1991. “Anchor texts and literary manuscripts in early Middle English”. Regionalism in Late Medieval Manuscripts and Texts, ed. by Felicity Riddy, 27–52. Cambridge: D.S. Brewer.
LALME = McIntosh, Angus, Michael L. Samuels & Michael Benskin. 1986. A Linguistic Atlas of Late Mediaeval English. 4 vols. Aberdeen: Aberdeen University Press.
McIntosh, Angus. 1956. “The analysis of written Middle English”. Transactions of the Philological Society 55(1): 26–55.
McIntosh, Angus. 1963. “A new approach to Middle English dialectology”. English Studies 44: 1–11.
Muysken, Pieter. 2008. “Introduction”. From Linguistic Areas to Areal Linguistics, ed. by Pieter Muysken, 1–23. Amsterdam: John Benjamins.
Nevalainen, Terttu. 2006. “Fourteenth-century English in a diachronic perspective”. The Beginnings of Standardization, ed. by U. Schaefer, 117–132. Frankfurt am Main: Peter Lang.
Nevalainen, Terttu & Helena Raumolin-Brunberg. 2003. Historical Sociolinguistics: Language Change in Tudor and Stuart England. London: Longman.
Rissanen, Matti. 2000. “Standardisation and the language of early statutes”. The Development of Standard English, 1300–1800, ed. by L. Wright, 117–130. Cambridge: Cambridge University Press.
Samuels, Michael L. 1963. “Some applications of Middle English dialectology”. English Studies 44: 81–94. Reprinted in 1989. Middle English Dialectology: Essays on some Principles and Problems, ed. by M. Laing, 64–80. Aberdeen: University Press.
Samuels, Michael L. 1981. “Spelling and dialect in the late and post-Middle English periods”. So Meny People Longages and Tonges: Philological Essays in Scots and Mediaeval English Presented to Angus McIntosh, ed. by M. Benskin & M.L. Samuels, 43–54. Edinburgh: Middle English Dialect Project. Reprinted in 1988. The English of Chaucer and his Contemporaries, ed. by J.J. Smith, 86–95. Aberdeen: University Press.
Stenroos, Merja. 2004. “Regional dialects and spelling conventions in Late Middle English: searches for (th) in the LALME data”. Methods and data in English historical dialectology, ed. by M. Dossena & R. Lass. Bern: Peter Lang. 257–285.
Stenroos, Merja & Kjetil V. Thengs. In preparation. “The orthography of northern documents: a preliminary study”.
Thengs, Kjetil V. In preparation. English Medieval Documents of the North-West Midlands: A Study in the Language of a Real Space Text Corpus. PhD thesis.
Williamson, Keith. 2000. “Changing spaces: linguistic relationships and the dialect continuum”. Placing Middle English in Context, ed. by I. Taavitsainen et al., 141–179. Berlin: Mouton.
Appendix 1
The Staffordshire part of the Middle English Grammar Corpus (MEG-C)
| L0036 |
Cambridge, Trinity College 383 (R.3.8) |
| L0083 |
Derbyshire RO, Matlock: D231 M/F 15 |
| L0094 |
Göttingen UL: Cod. MS Jurid. 822/1/9 |
| L0177 |
Oxford, Bodleian Laud Misc. 286. Hand C, fols 5vb.17-34vb |
| L0189 |
Oxford, Bodleian Douce 302. Hand A, fols 1r-34va |
| L0193 |
Oxford, Bodleian Gough eccl.top.4. Hand A (first contrib). beg - fol. 97v |
| L0215 |
Dublin, Trinity Coll 155 (C.5.7) Hand A. pp 1-18, 21-90, 109-135 |
| L0227 |
Oxford, Bodleian Rawlinson B.166 |
| L0238 |
London, BL Lansdowne 348 |
| L0243 |
Oxford, Bodleian Ashmole 41 Part I |
| L0260 |
Oxford, Bodleian Laud Misc. 286. Hand B, fols 2va.7-5vb.16 |
| L0301 |
London, BL Cotton Nero C xii, fol. 155r-v |
| L0311a |
London, PRO: C 1/6/318 |
| L0311b |
London, PRO: C 1/6/321 |
| L0319 |
Aberystwyth, National Library of Wales, Peniarth 395 D |
| L0357 |
Oxford, Bodleian Ashmole 1438, part II. Hand L, fols 67-80, 83 - end. |
| L0434 |
London, PRO: C 1/9/378 |
| L0515 |
Oxford, Bodleian Douce 103, part C. Hand A of English, fols 53r-58 |
| L0516 |
Cambridge, Trinity College 1285 (O.5.4), fols 1-7 |
| L0519 |
Manchester University, John Rylands Library Eng. MS 50, pp. 1-104 |
| L0529 |
Oxford, Bodleian Hatton 96, fols 162r-165r, 169r-174r.19 |
| L0715 |
London, BL Arundel 272. Hand B, fols 36r-end |
| L0717 |
Oxford, Bodleian Gough eccl.top.4. Hand B, fols 98r-103r.14 |
| L0718 |
London, BL Sloane 3160. Hand O, fols 153r-160r.18 |
| L0726 |
Oxford, Bodleian Bodley 123. Hand D, fols 86v-97v |
| L0729 |
London, BL Sloane 3160. Hand P, fols 160r-165v |
| L1140 |
Göttingen UL: Cod. MS Jurid. 822/1/5 |
| L1141 |
Göttingen UL: Cod. MS Jurid. 822/1/3 |
| L1142 |
Göttingen UL: Cod. MS Jurid. 822/1/7 |
| L1321 |
Derbyshire RO, Matlock: D231 M/E 9 |
| L4245 |
Oxford, Bodleian Greaves 57 |
| L4286 |
Oxford, Bodleian Lyell 30 |
Appendix 2
The Staffordshire MELD Corpus (preliminary version)
| Primary corpus: |
| A0001 |
Göttingen UL: Cod. MS Jurid. 822/1/10 |
| A0010 |
Derbyshire RO, Matlock: D231 M/E 210 |
| A0017 |
Birmingham Archives: 277108 |
| A0018 |
Shropshire Archives: 6000/2372 |
| A0020 |
Shakespeare Centre Library and Arch.: Wheeler Papers, vol. I, no. 41 |
| A0021 |
Staffordshire RO, Stafford: D 593/B/7/2 |
| A0022 |
Staffordshire RO, Stafford: D(W) 0/7/24 |
| A0023 |
Staffordshire RO, Stafford: D 593/B/1/6/1E/14 |
| A0031 |
Staffordshire RO, Stafford: D 593/B/1/23/2/14 |
| A0032 |
Lichfield RO: D 126/5/17 (fols 4r-8r) |
| L0083 |
Derbyshire RO, Matlock: D231 M/F 15 |
| L0094 |
Göttingen UL: Cod. MS Jurid. 822/1/9 |
| L1140 |
Göttingen UL: Cod. MS Jurid. 822/1/5 |
| L1141 |
Göttingen UL: Cod. MS Jurid. 822/1/3 |
| L1321 |
Derbyshire RO, Matlock: D231 M/E 9 |
| Secondary corpus: |
| A0008 |
Derbyshire RO, Matlock: D231 M/T 325 |
| A0009 |
Derbyshire RO, Matlock: D231 M/E 5116 |
| A0012 |
Oxford, University College 97 (pastedown at the end) |
| A0013 |
Tokyo, Takamiya 27 |
| A0014 |
Nottingham UL: Mi.DC.7. Fols 12v, 14v, 20r-21r, 26r-27v. Hand A |
| A0015 |
Nottingham UL: Mi.DC.7. Fol. 35v. Hand B |
| A0016 |
Nottingham UL: Mi.DC.7. Fols 36v-37v. Hand C |
| A0019 |
Keele UL: C 482 |
| A0024 |
Lichfield RO: D 77/1 (Lichfield Gild Register, fol. 15v) |
| A0025 |
London, College of Arms: Arundel 59 Tutbury Abbey, fols 2r-v |
| A0026 |
Staffordshire RO, Stafford: D(W) 1721/3/18/8 |
| A0027 |
Staffordshire RO, Stafford: D 593/A/2/16/11 |
| A0028 |
Staffordshire RO, Stafford: D 593/A/2/16/12 |
| A0029 |
Staffordshire RO, Stafford: D 1229/1/3/5 |
| A0030 |
Staffordshire RO, Stafford: D 1229/1/3/6 |
| A0033 |
Staffordshire RO, Stafford: D 641/5/T/20/11 |
| A0034 |
London PRO: C 1/9/304B |
| A0036 |
Staffordshire RO, Stafford: D 593/B/1/23/2/16 verso |
| A0037 |
Göttingen UL: Cod. MS Jurid. 822/1/11 |
| A0038 |
Göttingen UL: Cod. MS Jurid. 822/1/4 |
| L0311a |
London, PRO: C 1/6/318 |
| L0311b |
London, PRO: C 1/6/321 |
| L1142 |
Göttingen UL: Cod. MS Jurid. 822/1/7 |
|
|