Taxonomisation of features of visual prosody
Anneli Meurman-Solin
Research Unit for Variation, Contacts and Change in English (VARIENG), University of Helsinki
Abstract
The study suggests that we require an annotation theory and an annotation language for a wider range of features of texts than those traditionally annotated in digital corpora. The focus is on observations the writer made in the long process of editing digitally and annotating original manuscripts of Scottish letters dating from 1500–1715. While, for example, the identification of linguistically significant features of visual prosody is a challenge as such, a valid reconstruction of their variational space in synchrony and diachrony and the creation of a variationist taxonomy for annotating them is an exercise in which corpus linguists do not yet have a lot of experience. Such simplistic dichotomies as the polarisation between “default” and “marked” reflect the tendency to let frequency or distinctiveness influence the annotation language; yet concepts such as these are too crude to be theoretically valid or pragmatically useful. After discussing options such as taxonomies based on statistical salience or prototype theory, the study argues for three taxonomisation principles in the annotation of paratextual features: the parameter values are purely descriptive; they are dynamic in the sense that the values are sensitive to variation and change even over a long time-span; and the values contain information provided by cross-disciplinary research. Thus, the theoretical validity of a taxonomy is questionable if description and interpretation are intermingled in one way or another; no feature can be assumed to be a permanent member of a particular category, switching category being a well-documented phenomenon; variables depicting the continuum of wider contexts relevant in the history and production circumstances of a particular text permit a valid interpretation of the findings. In taxonomies of this kind, the annotation system is based on ordering the descriptive components into strings of properties. A system like this faithfully records the inherent potential for variation and change within each component and also reflects patterns of interrelatedness between components.
1. Introduction
This study draws on my experience as the compiler, editor, digitiser, and annotator of the Corpus of Scottish Correspondence (CSC), 1500–1715. While Meurman-Solin 2013a, Meurman-Solin 2013b, and Nevala & Sairio 2013 provide numerous illustrations of letter manuscripts digitised for the CSC and the CEEC family of corpora, concentrating on visual prosody and layout features, this chapter discusses what kind of variation has been observed in these features and especially how that variation could be converted into transparent taxonomies which permit both the use of a coherent and consistent annotation language and the retrieval of all the information coded into that annotation. Some of the ideas presented here have functioned as guidelines in the annotation of the CSC data. However, since most of the principles and practices discussed here have not yet been applied to corpus data I have been involved in compiling, the main goal of this chapter is to join the ongoing discussion concerning the challenging issue of how to categorise fuzzy and inherently variable features in annotating historical manuscript texts. While Meurman-Solin 2007a, Meurman-Solin 2007b, and the Manual of the Corpus of Scottish Correspondence describe the annotation of linguistic features in the CSC, this chapter chiefly examines problems related to the annotation of visual prosody.
A useful general context for the matters discussed in this chapter is provided by issues related to the question:
- What is a text?
- A physical object which
- is written on varying types of materials applying varying types of style sheets …
- is copied, printed, consumed, and distributed …
- is written in response to another text/textual item …
- may undergo damage … appear in a number of versions…
- borrows features from another text/textual item, a number of other texts/textual items, or a particular tradition of writing …
- has visually observable features usually not included in later versions such as their printed editions …
- has numerous other features often ignored in digital versions of a text/textual item for varying (usually unspecified) reasons.
- Language
It is possible to claim that, in regarding texts as specimens of language use, we tend to marginalise features which we label as “non-linguistic” and therefore consider them less significant in the process of ensuring the authenticity of data. However, I propose that we refer to these features by using the concept of “indirectly linguistic” in order to stress that many of them provide information which is not only useful and important but often also indispensable for producing a correct linguistic analysis (see, e.g., Meurman-Solin 2007c and Meurman-Solin 2012).
- We require an annotation theory and an annotation language for a wider range of features of texts than those traditionally annotated in digital corpora.
2. Theory vs. pragmatic considerations in corpus annotation
Annotation systems applied to recently compiled corpora may use practices chiefly selected by the criterion of being widely used and/or standardised. In other words, in annotating a text, the tendency is to impose conventionalised category labels on data in order to be user-friendly, to ensure that data retrieval is technically successful, and to achieve comparability between data sources, for example.
Yet, every annotator has made observations such as the following:
- Variation in the original text can rarely be represented fully in the digital text, not only because of the limited number of searchable symbols available on the keyboard but also for a number of other reasons, most importantly, the problem of what can be considered distinctive variants of a particular feature. Therefore, it has seemed unavoidable not to simplify the observed complexity of variation by resorting to taxonomies of prototypical categories (e.g., the use of <,> and </> for numerous different shapes of ‘commas’; see section 4.2 in Meurman-Solin 2013a). In fact, it has become a general practice in recent corpus-based research to use the simplified versions of texts as data exclusively, since consulting the original manuscript or an early printed work is possible only in corpora in which the digital images of the original texts are available. A general practice of this kind has made it easy for the users to forget the fact that the degree of complexity in the original text is reduced considerably in the digital text. I refer to the simplified versions of texts as representing “streamlined variation”.
- Beside reducing complexity, annotation rarely succeeds in reflecting the inherently scalar nature of numerous features. Annotators work within the long tradition of resorting to compartmentalisation by applying tags naming discrete categories to scalar phenomena.
- The conclusion is that, in the present era of corpus annotation, we are still more concerned about the pragmatics of the exercise than about how annotation can be seamlessly related to the increased level of sophistication in our theoretical thinking, our understanding of linguistic variation and change in particular. In the present context, it is appropriate to stress that, in addition to problems caused by our relatively vaguely defined theoretical approach, we are creating another set of problems by marginalising particular properties of historical texts.
3. Visual prosody
3.1 The concept of visual prosody
As described in more detail in Meurman-Solin 2013a, section 3, the concept of visual prosody has been selected to stress the following points:
The use of the term “prosody”, even though it is a well-established term, primarily in phonetics, a completely different field of linguistics, invites us to read epistolary prose keeping in mind the following features:
| (a) |
Letters represent an interactive genre; the fact that letters are dialogic means that, in order to understand the writer’s intention, it is often necessary to read them similarly to how we “read” the prosodic features of a piece of conversation for linguistic analysis. Complicating the analysis is the fact that addressee-orientedness may be expressed either explicitly or implicitly, so that, for example, an indirectly dialogic expression has the function of a suggestion, request, or assurance, or the addressee is approached directly by using lexical phrases such as ‘let me remind you’, ‘let me ask you’, and ‘let me assure you’ (Meurman-Solin 2012).
I would like to stress that while the methodological approach of conversation analysis provides useful tools for interpreting text and discourse structure in an interactive prose text, I do not think we can appeal to resemblance to the spoken idiom in describing writing styles, not even in the case of private letters between socially equal correspondents. |
| (b) |
The writers’ linguistic and stylistic literacy varies in epistolary prose more than in many other genres. Idiosyncratic grammars of prose in letters, especially written by inexperienced and less trained writers, may not be identifiable if the syntax is assumed to reflect conventionalised grammars of written prose or practices of standardised language use. |
Instead, a range of complementary types of reading is usually required. For example:
- a reading attentive to the writer’s style in forming and sequencing utterances (e.g., utterance length, relations between utterances, discourse types in successive utterances, the use of discourse type indicators, etc.),
- a reading attentive to information structure. For example, the syntactic and information-structural properties of a sequence of utterances may be explicit as a result of the use of a particular connective in the utterance boundary (see Lenker 2010, Lenker 2011, Meurman-Solin 2011, Meurman-Solin 2012, and Meurman-Solin 2013a).
Cf. a reading based on punctuation or capitalisation, which is often impossible in the CSC data because of lack of systematicity in the application of punctuation marks or upper-case characters. See Meurman-Solin 2013a, section 4.2.
The attribute “visual” in the term “visual prosody” usefully provides a distinctive profile for features which are visually observable in the original manuscript. In my experience, many of these visually observable manuscript features are usually not considered (strictly) linguistic data and are therefore omitted in both printed editions and the digital transcriptions of historical documents.
Moreover, in editions in which there is some information about visual features, they may have been annotated in a way which does not allow the retrieval of this information. Even more importantly, the annotation system may not permit searches by queries which would provide information about visual features as explicitly related to particular linguistic features in a particular manuscript.
The general claim here is that features of visual prosody contain relevant information for linguistic analysis. This information may be indispensable for the analysis of syntactic and discourse structure in particular.
There are problems related to annotating features of visual prosody which are scalar by nature or realised by variants which relate to one another in a complex way. Complex relations refer here to cases in which a range of variants comprises both those which should be viewed as representing discrete sub-categories, even though further study may be required for defining their presumably varying functions (e.g., slightly varying shapes of the virgule) and those which are visually different but usually share the same function (e.g., variants of a particular upper-case character in utterance boundaries) but may frequently also have some other function (e.g., nouns with initial capitals of varying shapes). See Meurman-Solin 2013a for illustrations.
The main challenge in annotating visual prosody is how to taxonomise, that is, how to translate a large degree of variation into retrievable variant types without losing information which is relevant from the perspective of the perceived range of research topics. This is of course true of any process of imposing more or less discrete category labels on scalar phenomena, but, in language use reflecting a relatively low degree of standardisation such as that of less trained and inexperienced writers of letters, lack of a systematic relation between a variant form and function causes further problems for annotation (see section 4.1).
Even when the annotator’s experience increases and she becomes aware of the range of variation a particular visually-indicated prosodic feature represents, the taxonomy of parameter values will remain subjective. In other words, the system will always reflect the annotator’s subjective assessment of what elements of a feature can be considered to justify a distinctive sub-category and how the various sub-categories are related to one another. For example, the annotator will have to decide how much variation she allows for categorising a particular space between words or clauses as “default”, what she considers “ambiguous”, and what she interprets as “marked”.
3.2 Features of visual prosody
In the creation of the CSC annotation system, the following visually observable features were paid attention to. Features in red (insertion, punctuation, spacing, marked character shape, paragraph structure) are particularly relevant in the present context, since their annotation requires the creation of a theory-based taxonomy. In contrast, features in purple (page number, line-break, change of hand, cancellation, correction) can be described by providing information about such facts as line-breaks or page number, whereas those in orange (physical condition, position of text, script type, idiosyncratic features) permit either a taxonomy-based annotation facilitating digital retrieval or a descriptive account containing information the details of which – instead of being retrievable digitally – function as a commentary.
- physical condition (e.g., torn margin or damage by damp)
- page number
- line-break
- position of text (in margin, before or after the body of the letter)
- change of hand
- script type
- idiosyncratic features of a particular hand
- insertion; cancellation; correction
- punctuation
- spacing
- marked character shape
- paragraph structure
It is obvious that a much wider range of features could be included when the principles and practices of annotating visual prosody, especially tools for retrieving this information, develop further. [1]
Seeing that the items in purple (page number, line-break, change of hand, cancellation, correction) require no further discussion in this context, let us first look at features in orange (physical condition, position of text, script type, idiosyncratic features) which permit taxonomisation but are usually viewed as requiring a description rather than just a symbol (such as a backward slash (<\>) to indicate line-break) or numeric information (e.g., f1v, f1r, f2v, etc. to indicate page number and side), or can be described by a simple system of pairs of parameter values (e.g., hand 1> … <hand 1, hand 2>…<hand2) or explicit information about what has been cancelled (e.g., word-final <t> cancelled) or a replacement (e.g., <et> replaced by <it>).
Physical condition can be defined in terms of a polarisation between “damaged” and “fully legible”, this level of generalisation being scarcely useful for the corpus user. In my view, information about damage, for example, should be explicitly related to a particular detail (e.g., a particular character is unclear or illegible because of an ink blot, or the margin is torn, so that the text in the rest of the line is missing). In the CSC, information of this kind is provided in comments put in curly brackets:
| ‘heartly’ |
| ha??rtlie {<ink blot} = the third character covered by an ink blot |
| hai?rtlie {<damaged} = the third character unclear because of damage |
| hairtl??? \ {<torn} = the right margin is torn, so that the rest of the word is missing |
| {torn} a full word or several words are missing because the manuscript is torn |
Information about the position of text in the margin or before or after the body of the letter can be purely descriptive. However, if the research question is about the type of information provided in the margin (e.g., indicating that the adjacent text contains an enumeration or adds a piece of more specific information), a taxonomy can be created on the basis of functions such as “enumerative”, numbering a list in the text, “summative”, naming themes, “complementary”, adding information, or “intertextual”, providing a reference to another text or naming a source, etc. The investigation of a research question concerning the positioning of terms of address or the place and time of writing in letters would require a more detailed annotation system, based on the measured position (a) on the writing material and (b) with regard to the body of the text (see Meurman-Solin 2013b and Nevala & Sairio 2013).
In the CSC, script type is indicated to distinguish between “secretary”, “italic”, and “other”, seeing the linguistically most relevant differences have been recorded between “secretary” and “non-secretary” (e.g., the different frequencies of contracted word-forms and differences in the punctuation system; see also section 4.3). A much more detailed investigation of the history of Scottish hand-writing would be required for a reliable taxonomisation of script types (see Simpson 1975).
A particularly challenging task is to develop digital tools for annotating the idiosyncratic features of a particular hand. In my opinion, a comparison of digital images of character shapes would be an ideal tool for developing a valid taxonomy. Whether a venture of this kind is sufficiently cost-efficient is worth exploring, but detailed inventories would provide important evidence for dispelling ambiguity in areas in which the reading of particular character shapes now remains doubtful. Moreover, inventories consisting of digital images could be a rich data source for producing comprehensive histories of handwriting, functioning as handbooks for researchers and students alike. Such a data source would provide further evidence of the conditioning of sociolinguistically relevant variables in the evolution of linguistic and stylistic literacy).
The annotation of change of hand is useful for (i) identifying autograph as against non-autograph passages (see example 00 in Meurman-Solin 2013a) and (ii) other functions of script type change:
- Handwriting and change of hand provide evidence for investigating authorship.
- However, even though relatively rare in epistolary prose, change of hand may also be related to a particular linguistic feature such as marking direct speech, a quotation, or a formulaic expression.
The discussion in the succeeding sections chiefly draws on observations related to the taxonomisation of variant realisations of insertions, punctuation marks, spacing, character shapes, and paragraphs. The variational space of these features can be defined briefly as follows. Insertion type can be defined with reference to its position (e.g., in the body of the text; in the margin; after the signature (see Meurman-Solin 2013b, section 5)), and its contents (e.g., a structurally or syntactically relevant word or morpheme, a clarification or additional information, a conventionalised discourse move indicator (see Meurman-Solin 2013b, section 5)). The investigation of punctuation, spacing, and marked character shapes would benefit from this method of comparing digital images of variant realisations, since this is the only way of dealing with large quantities of these data types. In the CSC data, for example, a semi-colon is used in a number of functions (for an example of its use, see Meurman-Solin 2013a, example 10); another punctuation mark the variational space of which is difficult to define is the virgule, with its various shapes and positions. In fact, valid taxonomies for the annotation of these features are hardly possible without a corpus consisting of their digital images. Variational space in the evolution of paragraph structure should be defined by regarding punctuation marks and their hierarchies as one end of the continuum and by tracing the development from chunks of text indented in various ways to paragraphs with first-line indenture, with an optional space; for example, an extra line between chunks of text (see Meurman-Solin 2013b).
- Overall, the validity of taxonomies in an annotation system varies depending on feature type. Quite straightforward taxonomies can be created for insertions, corrections and cancellations as well as features of layout. It may be a somewhat more challenging task to identify marked character shapes, for example, differences between the extended shapes of lower-case characters and the varying shapes of upper-case characters. However, the annotation of these features is of course essential in the identification of sentence and clause boundaries in texts which do not indicate them by capitalisation and/or punctuation.
- This brief summary of problems related to visual prosody types shows that their taxonomisation for annotation requires advances in two areas: firstly, in the case of a number of features, variation can only be taxonomised by compiling corpora of digital images of the variants; secondly, it is necessary to formulate theoretically sound models for converting inherent variation into retrievable categories. The latter challenge will be discussed in the remaining sections of this chapter.
4. Principles of taxonomisation
4.1 Dimensions of variation
Let us investigate a range of dimensions available for the annotator for creating a taxonomy. Why does it make sense to provide purely descriptive information in the annotation of “indirectly linguistic” features? In sections 4.2–4.4, I will discuss what implications the application of such intentionally quite different taxonomisation principles as polarisation, frequency, and membership of a particular discourse or text community (Meurman-Solin 2004) have in the annotation of visual features of digitised manuscripts.
Polarisation (4.2) is related to the well-established tradition in linguistics in which variants are described with reference to a perceived norm or the outcome of a process of standardisation, being positioned on the cline “Default” versus “Marked” in a taxonomy-oriented system.
Frequency (4.3) is generally assumed to give statistically significant evidence of patterns of variation and change, even though factors conditioning frequency may not be fully understood. Consequently, a taxonomy may be structured according to the relative frequencies of variants or be based on the most frequent variants exclusively.
The concepts of discourse community and text community (4.4) evoke the overlapping variational spaces comprising the idiolectal, grouplectal, and community-wide parameters, and co-textual, contextual, genre-specific and intertextual dimensions. [2]
Thus, to create an annotation theory, the core questions the annotator will have to answer can be formulated with reference to how she conceptualises the relations between default – marked, statistically salient, idiolectal – grouplectal – community-wide, and cotextual – contextual – genre-specific – intertextual.
- Whether the annotation system reflects frequency or distinctiveness, for example, has major implications for the annotation theory applied to the data. The following sections aim to provide food for thought in the process of defining these relations and deciding which definitions lead to a theoretically coherent and transparent annotation system.
4.2 Polarisation as the basis of categorisation
In historical linguistics we frequently explore unknown territories in the sense that numerous texts we use as data have not been previously described either in terms of their history, consumption, visual properties, or their language. Yet, since we tend to assume that polarisation is a universally valid categorisation principle, we insist on the legitimacy of contrastive category labels, which typically reflect the more or less clearly perceived standard or norm as contrasted with what differs from such a standard or norm. I will illustrate polarisation as the basis of taxonomisation by the dimension default versus marked.
In examining the present annotation practices critically, perhaps one of our immediate observations is that annotation tends to be based on a taxonomy in which a particular feature, or set of features, is (usually, tacitly) defined as “default”, while other features are (usually, arbitrarily) considered “marked”. Only the latter are then given parameter values, which allow their retrieval in a corpus search. This practice has consequences of the following kind:
Firstly, the fact that “default” features are usually left unannotated makes it impossible for the corpus user to produce a statistically valid analysis of the proportion of “marked” features in the data.
Secondly, while it is perhaps relatively easy to identify systematically occurring practices in texts written by educated writers and representing a well-established genre tradition (on the established practices of layout in early printed texts, see Marttila, Suhr, and Tyrkkö in this volume), it is certainly quite difficult to taxonomise idiosyncrasies in a wide variety of private letters by writers representing varying degrees of linguistic and stylistic literacy. Thus, the classification into “default” and “marked” features is valid only to the extent that it can be based on a thorough knowledge of a particular text, its history, related texts, and a particular genre tradition.
Thirdly, since features of visual prosody are an under-researched area of study, decisions are made relying on the relevance of comparing practices with those in modern texts, rather than on the basis of research which draws on a wide range of contemporary texts representing the same or a similar genre or text tradition. For example, in examining spacing, the modern reader of a manuscript text may interpret spaces similar to those in present-day hand-written texts as “default” and those that are different from present-day practices as “marked”.
In my experience, the polarisation between “default” and “marked” is too crude to be theoretically valid or pragmatically useful. At least the corpus annotator should determine what criteria have been applied to the classification of features into these two categories. A better option is to define these concepts by describing the variational space of each in the annotated data and by stating explicitly what principles have been applied to their sub-categorisation, prototype theory, the relative frequency of use, or rules of conventionalised or standardised grammatical practice, for example. The schema of the resulting taxonomy probably represents the following type:
| Category A |
Default |
| Category B |
| Marked 1 |
| Marked 2 |
| Marked 3 |
| Marked 4 |
| Marked 5 |
The “Default” category, if defined and illustrated carefully, does not necessarily require sub-categorisation. However, in the case of most features, the “Marked” category is certainly more useful when divided into types according to the distinctive observed properties. As regards the visually observable properties, the taxonomisation tools can be tailored on the basis of information about space, position, size, and colour, for example, taking into account that some of these properties will tend to co-occur (e.g., a particular character shape marked by space and size or a particular virgule marked by position and colour, exemplified by variation from rather light and indeterminate strokes to those in ink as dark as the words in the text). In creating these taxonomisation tools, it is necessary to take into account the fact that a further dimension of the annotation language is created by these interrelations between properties, for example, spacing and marked character shapes being interrelated in varying ways.
4.3 Frequency as the basis of taxonomisation
Frequency is generally assumed to give statistically significant evidence of patterns of variation and change (even for a grammar of language use), despite factors conditioning frequency not being fully understood. In corpus linguistics, using frequency as the guiding principle of taxonomisation seems a legitimate methodological option. However, since annotation usually takes place hand in hand with the compilation of a corpus, i.e., before information about frequencies in the whole corpus is available, such a principle is not necessarily applicable in practice. Moreover, while frequency may provide relevant information in areas such as punctuation and capitalisation, for example, by suggesting the degree of systematicity, this purely quantitative information provides only partially relevant answers to the conditioning of idiolectal or grouplectal language use, language norms, and the co-textual, contextual and intertextual properties (see section 4.4).
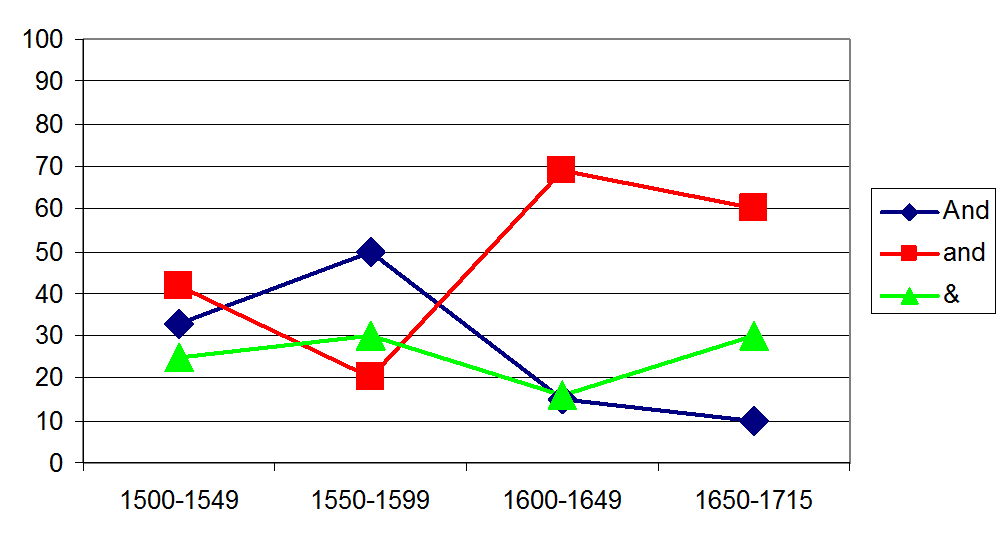
Figure 1 (cf. Table 1 in Meurman-Solin 2012) illustrates a standard way of providing a statistical account based on the relative proportion of the variant forms occurring in a particular function:
An account of this kind gives no indication of variant shapes of upper-case <A>, nor is there information about marked spacing in utterance boundaries in which this particular utterance-initial connective and has been attested (for more information, see Meurman-Solin 2012 and Meurman-Solin 2013a). The present chapter suggests that instances of and should be annotated by providing information about marked character shapes, spacing, and the presence or absence of an immediately preceding punctuation mark.
There are different stages in the annotator’s work in the relatively long process of annotating a corpus, the recording of evidence for depicting the variational space of a feature being cumulative by nature. Let us examine how she learns to consider particular criteria appropriate as a result of her preliminary investigation of the data. In general, the criteria defined for distinguishing between variant realisations of any of the features of visual prosody listed in section 3.2 are based on an investigation of variants in an idiolect (represented either by just a single letter or numerous letters by the same informant) and those occurring in contemporary hands. In other words, in the actual annotation process, the annotator begins by observing variation in a particular idiolect. After having analysed the recorded variants according to similarities and differences, she then classifies the variants into sub-categories, which she sees as forming (at least the first version of) a taxonomy. She then investigates contemporary hands, unavoidably keeping in mind the idiolect-based taxonomy, at the same time trying to verify whether the taxonomy is grouplectally valid. At the next stage, the annotator proceeds by asking whether the suggested taxonomy is also universally valid in a particular script type.
The problems in creating a frequency-based taxonomy are caused by the nature of the annotation procedure as described above. These problems can be summarised as follows:
- Especially at the early stages of annotating a database, there is no information available for the annotator about the frequencies of particular features of visual prosody.
- Therefore, it is not possible for the annotator to create a frequency-based taxonomy in which the statistically most salient features of visual prosody are subjected to annotation by tag, comment, or description (see section section 3.2).
In reporting on features of visual prosody, it is often difficult to achieve statistical validity. As a result of changes in which script type or types prevail in a particular time-period, comparing the features of visual prosody over a long time-span drawing on data in a diachronic corpus is not a straightforward exercise. This is because a preliminary analysis suggests that the range and realisations of features of visual prosody are different in different script types, time-periods, and, tentatively, in different communicative settings and text communities as well. The CSC is unevenly representative by the criterion of script type because of a widespread preference for secretary hand in sixteenth-century formal letters written by members of the higher ranks and professionals and the much earlier adoption of italic among circles close to the royal court.
Moreover, script type and particular features of visual prosody are interrelated in various ways. For example, since there is a correlation between the use of secretary and contracted forms, the statistical validity of a diachronic account of these forms is decreased if it is not carefully related to the quite different general frequency of secretary in different letter types, even different communicative settings, in different time-periods. In other words, as a result of change in script type over time, comparison of some features of visual prosody in a diachronic corpus is not feasible.
Comparison is also complicated by the fact that there are relatively few letters by women in secretary hand, female literacy increasing only when other script types have taken over. Therefore, in the analysis of the majority of features, developments over time can only be traced by first examining the various informant categories separately; for example, by regarding male and female members of the nobility and gentry using secretary as separate categories.
- Linguists like to talk about statistical salience. Thus, in creating annotation principles, we may feel tempted to annotate statistically salient features. In my work, I have become aware of the fallacy of statistical salience, and would therefore like to suggest that frequency should be considered an independent variable, which should not be taken into account in creating criteria for taxonomisation.
4.4 Variables related to discourse community and text community in taxonomisation
As described in section 4.3, the annotator usually starts by carefully investigating features of visual prosody in a particular idiolect or grouplect in order to identify those that occur sufficiently frequently to suggest a pattern, to permit the identification of a practice. She then decides to annotate those relatively frequently and systematically occurring features which, in her view, may have relevance in the linguistic analysis.
However, an annotation taxonomy of this kind may only function as a tool for data retrieval and may not be a valid framework for presenting and discussing the findings. In other words, categories created for a taxonomy are not directly applicable to analysing language use and the role of visual prosody in texts from the perspective of variation and change.
This section concentrates on visual features in discourse and text structure, the analysis of which usually requires knowledge about a wide range of variational spaces from idiosyncrasies in an idiolect and practices within varying sizes and shapes of discourse and text communities (Meurman-Solin 2004: 28–29; Meurman-Solin 2007b) to relations between texts.
Thus, an annotation system is valid to the extent that it succeeds in providing information about non-linguistic features which play a role in both purely linguistic and discourse and textual analysis. The question is how to choose the best practice between annotating a text as a separate entity and annotating a text taking intertextual relations into account. A successful annotation process for striking a balance between the two may consist of the following stages:
- A good understanding of the data being annotated.
- A good understanding of the immediate context of the data set; the immediately relevant context can be defined with reference to similar contemporary texts.
- A good understanding of the continuum of wider contexts relevant in the history and production circumstances of a particular data set. Each of the wider contexts can be defined by a particular genre tradition in a particular time, space, and socio-cultural milieu. The even wider contexts involve the influence of printing, channels of distributing texts, consumption of printed works, linguistic and stylistic literacy, the influence of manuals, models and conventions, evolution of particular prose styles, intertextual links, etc.
Besides technical details, generally accepted as essential, corpus manuals should contain a detailed description of how the annotator sees the functions and relations that the annotated texts have in their immediate and wider geographical, social, and cultural context and how this analysis is reflected in the annotation system.
5. Concluding remarks
In principle, variation is widely accepted as an inherent feature of language use by linguists. However, this awareness has not always been translated into principles and practices of annotation applied to corpus data. We still confidently believe it is possible for us to distinguish prototypical properties from those assumed to have a marginal significance in the variational space of a particular feature. For the annotation of linguistic features, I have created a system in which properties in the variational space of a particular feature are indicated by means of a string of co-ordinates in its tag (link: slide Annotating linguistic features by strings of co-ordinates in the tag and Meurman-Solin 2007a).
A system based on co-ordinates would also be possible in the annotation of features of visual prosody, with properties providing information about space, position, size, and colour, for example, being indicated in co-ordinate strings of tags (see section 4.2).
The main conclusion is that annotation principles and practices should not use such attributes as “marked” or “prototypical” because these provide an interpretation rather than a description of the data. However, a property can be described with reference to shape and size, its position in the layout of a text, its use as an indicator of an utterance boundary or co-occurrence with other such indicators, and its appearance in a visually salient conventionalized formula, for example, but such descriptive information does not suggest a category. Instead, each descriptive property is one of the co-ordinates in a string of properties. In other words, each feature is annotated by providing a description of a carefully stratified system of variables.
Prototypes do not exist over time, space, communicative setting, and social milieu, for example. The tracing of evolution over time is possible only by producing a synchronic description of practices in each text and then by relating these synchronic pictures to one another, either by focusing on each co-ordinate separately or by examining relations within and between the internally heterogeneous property strings.
Since, in principle, an annotation system is only valid for the investigation of the database it was created for, comparability between annotation systems remains a problem. Overall, every annotation system reflects its creator’s theoretical and methodological approach; in other words, no annotation system can be claimed to be generally valid. However, we can improve the general applicability of annotation systems by making them as transparent as possible.
Categories created for an annotation taxonomy are not directly applicable to analysing language use. In other words, an annotation taxonomy only functions as a tool in data retrieval and thus may not be a valid framework for presenting and discussing the findings. Corpus users will have to study the principles and practices of each annotation system in order to understand completely the criteria applied to the taxonomies created for a particular feature or set of features. Before drawing any conclusions, they should also make sure that there is no contradiction between the annotation taxonomies and their research hypothesis and their theoretical and methodological approach.
One of the goals for further innovative work is the creation of taxonomies using optical tools for measuring text in space, drawing on digital images of texts.
Notes
[1] Contracted forms and variants with elements in superscript could also be regarded as features of visual prosody, but, in the CSC, they have been digitised as variant word-forms and will appear as such in the item and form lists created by the software available on the CSC site. These variant word-forms are never treated as instances of full words.
[2] A further important dimension applicable to taxonomisation is the cline form – function. At one end of such a cline we would position interchangeable variant forms with no functional difference, at the other the functionally distinctive ones. However, a taxonomisation principle of this kind is not acceptable in the annotation of data which has not been researched in detail with regard to functions of particular variants. Since the research into the visual properties of the CSC letters has only just started, an annotation system based on co-ordinates on the form – function cline is not discussed here.
Sources
CEEC = Corpus of Early English Correspondence. 1998. Compiled by Terttu Nevalainen, Helena Raumolin-Brunberg, Jukka Keränen, Minna Nevala, Arja Nurmi & Minna Palander-Collin at the Department of English, University of Helsinki. http://www.helsinki.fi/varieng/CoRD/corpora/CEEC/
CSC = Corpus of Scottish Correspondence 1500–1715. 2007. Second edition. Compiled by Anneli Meurman-Solin. Helsinki: VARIENG. http://www.helsinki.fi/varieng/CoRD/corpora/CSC/
Meurman-Solin, Anneli. 2007. Manual to the Corpus of Scottish Correspondence (CSC). With auxiliary databases containing information about the letters and their writers and addressees. Helsinki: VARIENG. http://www.helsinki.fi/varieng/csc/manual/
References
Lenker, Ursula. 2010. Argument and Rhetoric: Adverbial Connectors in the History of English (Topics in English Linguistics 64). Berlin & New York: Mouton de Gruyter .
Lenker, Ursula. 2011. “A focus on adverbial connectors: Connecting, partitioning and focusing attention in the history of English”. Connectives in Synchrony and Diachrony in European Languages (Studies in Variation, Contacts and Change in English 8), ed. by Anneli Meurman-Solin & Ursula Lenker. Helsinki: Research Unit for Variation, Contacts, and Change in English. http://www.helsinki.fi/varieng/series/volumes/08/lenker/
Meurman-Solin, Anneli. 2004. “Data and methods in Scottish historical linguistics”. The History of English and the Dynamics of Power, ed. by Ermanno Barisone, Maria Luisa Maggioni & Paola Tornaghi, 25–42. Alessandria: Edizioni dell’Orso.
Meurman-Solin, Anneli. 2007a. “Annotating variational space over time”. Annotating Variation and Change (Studies in Variation, Contacts and Change in English 1), ed. by Anneli Meurman-Solin & Arja Nurmi. Helsinki: Research Unit for Variation, Contacts and Change in English. http://www.helsinki.fi/varieng/series/volumes/01/meurman-solin/
Meurman-Solin, Anneli. 2007b. “The manuscript-based diachronic Corpus of Scottish Correspondence”. Creating and Digitizing Language Corpora, Vol. 2: Diachronic Databases, ed. by Joan C. Beal, Karen P. Corrigan & Hermann L. Moisl, 127–147. Basingstoke: Palgrave Macmillan.
Meurman-Solin, Anneli. 2007c. “Relatives as sentence-level connectives”. Connectives in the History of English (Current Issues in Linguistic Theory 283), ed. by Ursula Lenker & Anneli Meurman-Solin, 255–87. Amsterdam: Benjamins.
Meurman-Solin, Anneli. 2011. “Utterance-initial connective elements in early Scottish epistolary prose”. Connectives in Synchrony and Diachrony in European Languages (Studies in Variation, Contacts and Change in English 8), ed. by Anneli Meurman-Solin & Ursula Lenker. Helsinki: Research Unit for Variation, Contacts and Change in English. http://www.helsinki.fi/varieng/series/volumes/08/meurman-solin/
Meurman-Solin, Anneli. 2012. “The connectives and, for, but, and only as clause and discourse type indicators in 16th- and 17th-century epistolary prose”. Information Structure and Syntactic Change in the History of English (Oxford Studies in the History of English 2), ed. by Anneli Meurman-Solin, María José López-Couso & Bettelou Los, 164–196. New York: Oxford University Press.
Meurman-Solin, Anneli. 2013a. “Visual prosody in manuscripts of letters in the study of syntax and discourse”. Principles and Practices for the Digital Editing and Annotation of Diachronic Data, ed. by Anneli Meurman-Solin & Jukka Tyrkkö. (Studies in Variation, Contacts and Change in English 14). Helsinki: Research Unit for Variation, Contacts, and Change in English. http://www.helsinki.fi/varieng/journal/volumes/14/meurman-solin_a/
Meurman-Solin, Anneli. 2013b. “Features of layout in sixteenth- and seventeenth-century Scottish letters”. Principles and Practices for the Digital Editing and Annotation of Diachronic Data (Studies in Variation, Contacts and Change in English 14), ed. by Anneli Meurman-Solin & Jukka Tyrkkö. Helsinki: Research Unit for Variation, Contacts and Change in English. http://www.helsinki.fi/varieng/journal/volumes/14/meurman-solin_b/
Nevala, Minna & Anni Sairio. 2013. “Social dimensions of layout in eighteenth-century letters and letter-writing manuals”. Principles and Practices for the Digital Editing and Annotation of Diachronic Data (Studies in Variation, Contacts and Change in English 14), ed. by Anneli Meurman-Solin & Jukka Tyrkkö. Helsinki: Research Unit for Variation, Contacts and Change in English. http://www.helsinki.fi/varieng/journal/volumes/14/sairio_nevala/
Simpson, G. 1975. Scottish Handwriting 1150–1650. Edinburgh: Bratton.
|
|