The Corpora of Early English Correspondence (CEEC400)
Minna Nevala, English Philology, Department of Modern Languages, University of Helsinki
Arja Nurmi, School of Language, Translation and Literary Studies, University of Tampere
Abstract
The Corpus of Early English Correspondence started as one 2.6-million-word corpus and has over the past two decades developed into a corpus family covering 400 years of English letters from the beginning of the fifteenth century to the end of the eighteenth. CEEC400, as the current version is called, contains 5.2 million words of personal correspondence written by Englishmen and Englishwomen from all the literate social ranks. The corpus has been designed to be as socially representative as possible, and variables taken into account in compilation included writer’s gender, social status, and geographic origin, as well as the relationship between writer and recipient. While based on edited letter collections, the compilation team has endeavoured to discover reliable editions presenting the language of the original manuscripts in as authentic a way as possible. The corpora are accompanied by a sender and recipient database, which contains information about the social backgrounds of the informants as well as a letter database recording details of each letter. Some of this is also coded into the corpora (e.g., relationship between writer and recipient). A part of the corpus (PCEEC) has been linguistically annotated and released for the use of the wider scholarly community.
The research carried out using the corpus started with the basic question: is it possible to apply the methods of present-day sociolinguistics to historical data? Once this question was answered in the affirmative, the scope of research questions could be widened. Within the compilation team approaches have ranged from stratificational and interactive sociolinguistics to socio-pragmatics, but the corpus has also provided suitable material for more linguistically focused studies by scholars around the world.
1. Brief description of the corpora
The Corpus of Early English Correspondence (CEEC) is a single genre corpus which has been compiled to facilitate sociolinguistic research into the history of English. The CEEC family of corpora currently covers personal letters from four hundred years between 1400 and 1800, and consists of six daughter corpora. The original corpus, which spans the decades from 1410 to 1680, was completed in 1998, and its sampler version (CEECS) was made publicly available the same year. Based on the original, the Parsed Corpus of Early English Correspondence (PCEEC) was released in 2006, and provides users with linguistic annotation both at the part-of-speech and at the syntactic level. The eighteenth-century Corpus of Early English Correspondence Extension (CEECE) and the Corpus of Early English Correspondence Supplement (CEECSU) covering gaps in the original CEEC rounded out the diachronic coverage of the corpus family, and there are plans underway of adding linguistic annotation to these parts of the corpus as well. In 2012, the Standardised-spelling Corpora of Early English Correspondence (SCEEC) were added to allow for a wider range of corpus-based methods, including keyword and cluster analysis. The ultimate aim of the compilers is to combine these sub-corpora into one structured whole, which will amount to over 5 million running words (the compilers are listed on the CEEC homepage, see the entry in Sources for the link). The attendant sender/recipient and letter databases are nearing completion, as some data is still being checked against recent sources. This combined version of the corpus family has already been in in-house use by the compilation team, and is known as CEEC400. There are plans of releasing a version of CEEC400 to the wider scholarly community, but due to difficulties in gaining permissions from copyright holders only a limited version seems likely to be released widely, while the rest will be available on-site.
The material for the corpus goes back to different parts of England, but priority was given to three distinct regions, which contributed about half of the letters. These regions are London (the City and Southwark), East Anglia and the North (counties north of Lincolnshire). The important role of the language of the rapidly growing capital was self-evident, and the North was considered equally significant as it was known to have been the site of origin of many medieval changes. East Anglia was chosen for the good availability of data, in particular for the continuity provided by two very large collections of Norfolk correspondence, the Paston letters from the fifteenth century and the Bacon letters from the sixteenth; in the eighteenth century Norfolk material is considerably scarcer. A fourth region, ‘the Court’, is also identified in the corpus. The idea of a separate region for the Court came about when a category was needed for correspondents who worked for the central administration of the country or stayed at court in various capacities. Furthermore, while the royal court was often situated at Westminster, this was not always the case. A separation between ordinary Londoners and courtiers seemed a valid distinction, and is supported by research results.
The letters included in the corpora range from private (e.g., love letters) to official (royal letters and administrative letters), but the emphasis is on the private end of the continuum. There are also some business letters between trading partners or merchants and clients. Many letters can be described as containing ‘mixed’ topics: the wool trade was a family business, so details of buying and selling are included in a letter to brother or wife along with family matters and local gossip. Similarly, gentry families will write about managing the family estate, the shopping list for the one visiting London, and the births and marriages of neighbours in one and the same letter. Even administrative letters between men who know each other well will include details of the writer’s and recipient’s (and their family members’) health and general circumstances.
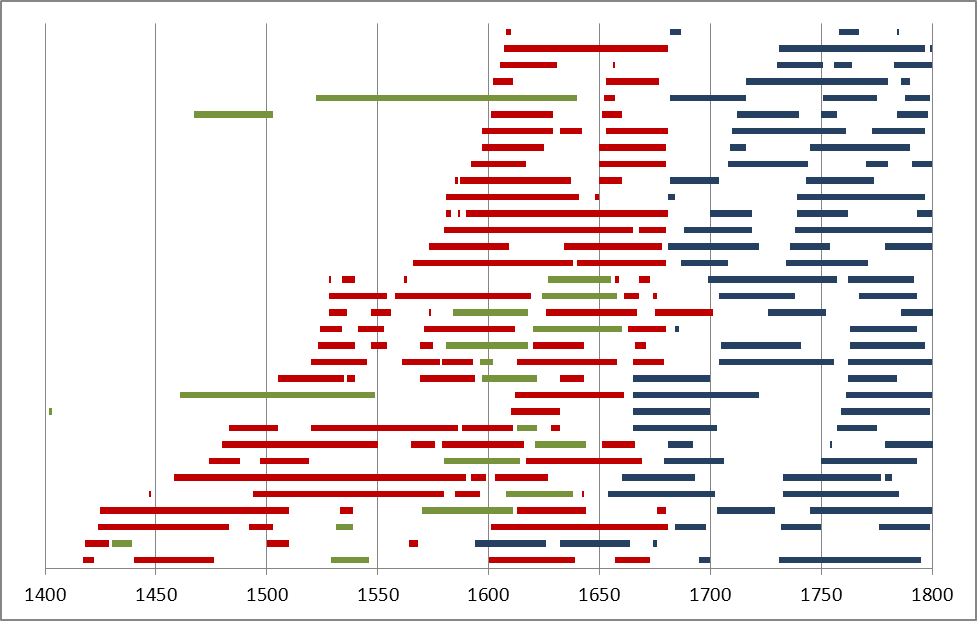
Figure 1 illustrates the temporal coverage of the various parts of CEEC400 over time. It shows clearly the poor availability of data from the earlier time periods, particularly the fifteenth century, but also some unexplainable gaps, such as the one in the first half of the eighteenth century. (For more details on the collections shown here, see the appendix in Nurmi, Nevala & Palander-Collin eds. 2009.) [1]
The CEEC corpora are distributed on a non-commercial basis for research purposes. The already published parts of the corpus, CEECS and the PCEEC, are available through the Oxford Text Archive (OTA). The International Computer Archive of Modern and Medieval English (ICAME) has also included CEECS in its corpus CD-ROM together with other corpora, which is available for a small fee. There are plans of including CEECS (and possibly PCEEC) in the CLARINO distribution service along with other corpora previously distributed through ICAME. This would make them available to all registered users under the aegis of the CLARIN project. The manuals are available in an electronic format. The corpora can be used with the standard tools, such as the Wordsmith (developed by Mike Scott), Corpus Presenter (Hickey 2003) and AntConc (developed by Laurence Anthony), as well as the older software packages the WordCruncher (see Kytö 1996: 65–67), and TACT (developed by Ian Lancashire and his colleagues). The tagged and parsed version, PCEEC, can be employed to its fullest potential with the search engine called CorpusSearch, developed for the purpose at the University of Pennsylvania; it is also possible to apply the before-mentioned corpus tools for simpler searches.
The CEEC corpora have provided data for a variety of studies approaching historical sociolinguistics, and the compilation team continues to test new approaches. While the initial plan was to study the feasibility of historical stratificational sociolinguistics in general, the corpus has proved its value as a source for interactional sociolinguistics and socio-pragmatics as well – and, to a smaller extent, network studies. Latest research by the compiler team members embark further into discourse studies by combining the socio-cultural approach and the building of social identity (SoReaL and DYLAPS).
There are three major volumes of studies by the members of the compiler team: the first one outlining the starting points of the project (Nevalainen & Raumolin-Brunberg 1996) and the second one, benefiting from the decade and half of preceding research, looking at further avenues of investigation, focusing particularly on individuals’ roles in language change and interactional sociolinguistics and socio-pragmatics (Nurmi, Nevala & Palander-Collin 2009). The third one, (Nevalainen, Palander-Collin & Säily, in preparation) will focus on eighteenth-century changes and their connections to prescriptivism. In a more focused study, Nevalainen & Raumolin-Brunberg (2003) provide an overview of the field of historical stratificational sociolinguistics made feasible by the existence of the corpus; in that volume they trace the social embedding of several changes over the course of the fifteenth, sixteenth and seventeenth centuries and evaluate the validity of social variables. Four doctoral dissertations based on CEEC, Grammaticalization and Social Embedding: I think and methinks in Middle and Early Modern English (Palander-Collin 1999), A Social History of Periphrastic do (Nurmi 1999), Address in Early English Correspondence: Its Forms and Socio-Pragmatic Functions (Nevala 2004) and Agreement Patterns in English: Diachronic Corpus Studies on Common-number Pronouns (Laitinen 2007) illustrate the versatility of the corpus. Particularly Nevala’s thesis applies the socio-pragmatic framework. In addition to the volumes mentioned, CEEC has provided data for nearly one hundred publications. Many of these are by the compilation team (see Sources for the bibliography of research), but there are also numerous studies by scholars from all over the world (see e.g., Agrafojo Blanco 2004, Allen 2008, Bromhead 2009, Carroll 2007, González Díaz 2003, Gries & Hilpert 2010, Koivisto-Alanko & Tissari 2006, Nishimura 2004, Peitsara 2006, Rissanen 2008, Sönmez 2005, and Tissari 2008). CEEC has offered material for analyses of previously studied grammatical changes like the periphrastic do as well as research on grammaticalization and politeness in a socio-pragmatic framework. It has also shown itself suited to the study of multilingual practices in the history of English (see e.g. Nurmi & Pahta 2004, 2012). The sampler version CEECS has found its way to the hands of many historical linguists, who have often used it as one linguistic source among many, and the Parsed Corpus of Early English Correspondence (PCEEC) is providing material for more sophisticated studies of historical syntax.
2. Assessment
2.1. Aim of the corpus project
The Corpus of Early English Correspondence (CEEC) was compiled within the ‘Sociolinguistics and Language History’ research project, which was funded by the Academy of Finland and the University of Helsinki in 1993–1997. After that date, the researchers withparticipating in with this project formed the core of the ‘Historical Sociolinguistics’ team in the Research Unit for Variation (Contacts) and Change in English (VARIENG) at the University of Helsinki, in 2000–2005 and 2006–2011.
The original aim of the research project was to test the applicability of sociolinguistic methods to historical data, work which could not be carried out without a corpus designed specifically for this purpose. The team initially identified the following five requirements for the data to be used: (1) the size of the corpus should be sufficient for research on morphological variation and change, (2) information on the social background of the writers and their audiences should be readily accessible, (3) the language used should represent private writing and relate closely to the spoken idiom, (4) there ought to be easy access to the material, which should be available or made easily available in a computerized form, and (5) the corpus should cover a period of time long enough for diachronic comparisons (Nevalainen & Raumolin-Brunberg 1996: 39). The chronological range from Late Middle to Early Modern English was chosen in view of the team’s research interests and experience.
The team decided to focus on personal letters, because they fulfil the requirements better than most other text types. Correspondence is available from the 1410s onwards, the amount of data increasing with time. Moreover, the people who wrote and received letters are relatively easy to identify. Previous research has shown that the language of correspondence often resembles spoken registers more closely than most other types of writing (see e.g., Biber 1995).
In retrospect, the original five requirements have kept their validity during almost twenty years of project work. The linguistic phenomena to be studied have been expanded to areas other than morphology, such as syntax, pragmatic phraseology, and grammaticalized lexemes. Only the initial chronological range has been extended to allow for tracing further trajectories of changes studied.
2.2. Relevance of the corpora
CEEC has turned out to be a balanced corpus with as full a social and quantitative coverage as can be recovered from edited collections of early English letters. Also, its size can be described as comprehensive, particularly considering the long diachrony of 400 years of single-genre material. Using already published editions has brought on some difficulties, since most of the CEEC material has been under copyright restrictions. The current regulations in the European Union protect copyright until 70 years have elapsed from the death of the copyright holder. Most of the editions were published in the twentieth century and the editors, or the publishers in some cases, consequently still held the copyrights in the 1990s. The original compilation work was carried out without attention to possible problems in copyright issues, since it was known that the corpus could be used as private research material without restrictions. However, copyright clearance would have been needed for the release for general use. Despite these problems, the corpus team has been able to publish the CEEC Sampler, a corpus of 450,000 words, which contains copyright-free collections, as well as PCEEC, where publishers gracefully granted copyright clearance for the vast majority of collections in CEEC. CEECS has a relatively even chronological coverage of the full CEEC period c. 1410–1680, and is especially suited to studies of high-frequency phenomena. PCEEC is distributed in three formats: plain text, part-of-speech tagged and syntactically annotated, and adds depth to the social coverage of the time-period, as well as allowing for linguistically more complex research questions.
The CEEC corpora are as representative as possible of the literate social ranks of England in the time span covered. Over the years, as members of the compilation team have wished to study new research topics, the corpus has been correspondingly extended. For Helena Raumolin-Brunberg’s study of language change in individuals, for example, more letters for specific informants whose correspondence was available for an extended period of time were needed, and these were included in the Corpus of Early English Correspondence Supplement (see e.g., Raumolin-Brunberg 2009 for the results of the study). Similarly, the desire to follow changes into the eighteenth century prompted the creation of the Corpus of Early English Correspondence Extension.
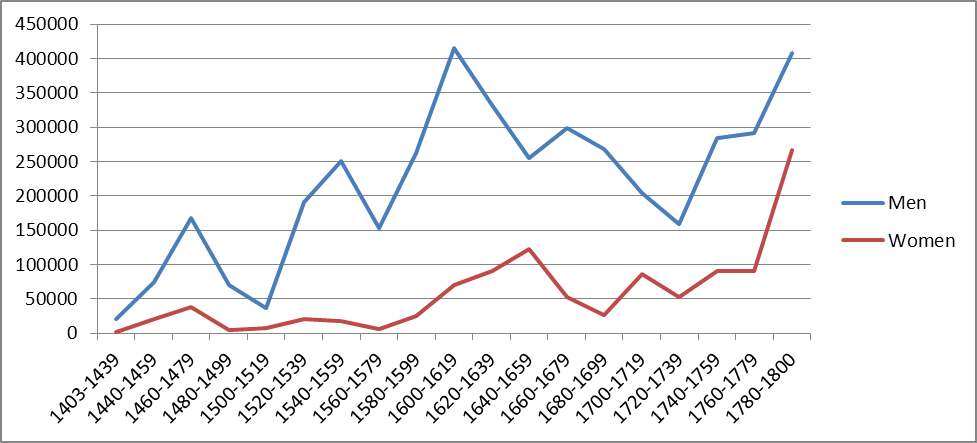
The social coverage of the corpora is uneven despite our best efforts. Gender is discussed here as an example, but what is said regarding it very much goes for the lower social strata as well. Because of the poor literacy rates of women and lower ranks of society, the availability of data has not been even. Figure 2 shows the amount of text in words from male and female writers in CEEC400. The amount of data available from female writers is at all times considerably lower than that of men, and it is only in the last two decades of the eighteenth century that the gap seems to be closing. Besides differences in educational opportunities, also editorial interest has influenced the availability of letters. For a long time only the letters of famous men were considered worthy of editing, and the existing correspondence of family members is noted upon but not included in the edition. An increasing interest in social history and gender studies has improved the situation, but there are still many unedited treasures in archives. The importance of gender as a social variable connected to linguistic change has been shown in many studies, most recently in Säily et al. (2011).
In many cases the individual informants included in the corpus have provided only small samples of data, in some cases only one or two letters. With increasingly sophisticated statistical methods (developed for example under the aegis of the DAMMOC project) however, it is possible to arrive at significant results based on even relatively small samples (see e.g., Hinneburg et al. 2007). The linguistic practices of individual letter writers are more and more the focus of study: whether regarding the position of writers on the linguistically progressive–conservative continuum (Nevalainen et al. 2011) or the social positioning of an individual (Palander-Collin 2009).
CEEC400 is relatively large in size when compared to general-purpose corpora covering the same time period (the Helsinki Corpus and ARCHER). The CEEC corpus family also has the advantage of not being divided into sub-periods: the coverage aims to be even across the centuries, which allows individual scholars to select suitable slices at any point covered (see e.g., Gries & Hilpert 2010). On the one hand, the range of register variation is narrower than that of multi-genre corpora, but on the other hand the coverage of informal and intimate registers is more extensive.
2.3. Quality and authenticity of data
The CEEC corpus family is mainly based on published editions of correspondence. The quality of editions naturally varies. Some, especially nineteenth-century, editions are somewhat unreliable and do not provide sufficient information about editorial principles or the background of writers, while others are aimed at a non-linguistic readership and normalise many details of interest for linguists, such as abbreviations, superscripts, spelling variation and the like. The corpus compilation team has worked to overcome these obstacles through a variety of means. These include editing some letters from manuscript, whether from scratch (like the GawdyL collection by Minna Nevala; for a sample see Nevala 2004b) or re-editing a poorly edited selection of letters (e.g., Keränen 1998). [2] Editions were also checked against original manuscripts, and poor quality editions were subsequently abandoned. Finally, in the rare cases when a new edition has been published this has been taken advantage of. So, in the case of the Plumpton correspondence, the old Stapleton edition (1839) was used for the text in CEEC and its published versions, while corrections to identification of writers and dates were included from the Kirby edition (1996). The latter was eventually digitised as part of CEECSU, and is in in-house use instead of the earlier Stapleton one.
Since the corpora are intended to portray the linguistic practices of identifiable individuals, the authenticity of letters is a vital concern. At the very early stages of corpus compilation a four-tiered authenticity scale was created, separating autograph letters by a person with sufficient background data from autograph letters by relatively unknown people, and making a further distinction between copied and/or secretarial letters and cases where authenticity was doubtful (see e.g. Nevalainen & Raumolin-Brunberg 1996: 43 or the General introduction to CEEC on CoRD). Many of the latter received a new authenticity code based on the work of the compilation team in archives, checking manuscripts and comparing hands across them. (On the linguistic variation between autograph and secretarial letters, see Nevalainen 2002.)
The corpora are suited to many different research approaches besides the strictly sociolinguistic, but there are limitations because of their compilation method. The CEEC corpora cannot provide reliable evidence for the study of e.g., orthography, punctuation or, visual prosody (see Meurman-Solin in this volume). These features are inadequately represented in most printed editions, and the corpus format and annotation further fade out features relevant to this kind of approach, which is most reliably carried out through perusal of the original manuscripts themselves – or, increasingly, through high-quality digital images.
2.4. Language-external variables and their coding
As the main purpose of the corpora was to present a socially representative sample of the English population, this criterion trumped some of the other ones. Particularly in the case of women and lower social ranks, secretarial letters from editions with less than optimal editorial principles were included; in the supplement even some editions using modernised spelling have been accepted, but these are marked with a specific authenticity code.
The background data on the corpora informants has not been distributed along with the published corpora (CEECS and PCEEC), since much of it is interpretation and would lead to problematic results if used unquestioningly. PCEEC contains some additional data compared to CEECS; this information is of the more easily verifiable factual kind (year of birth, relationship to recipient). There are no plans to publish the database in its entirety. For in-house use, a database tool called CEECer was programmed by a group of computer science students at the University of Helsinki. CEECer allows for searches taking advantage of all the social parameters in the sender and recipient database.
The corpora have fulfilled the purpose they were compiled for and provided avenues for further research. Not only has the work of the compilation team shown the plausibility and importance of stratificational sociolinguistics with historical stages of English, but also other approaches, particularly those of interactional sociolinguistics and socio-pragmatics have proved to be successfully carried out with the help of the CEEC corpora. Nurmi, Nevala & Palander-Collin (2009) gives a sampling of these approaches with an up-to-date description of the corpora, and Nevalainen, Palander-Collin & Säily (in preparation) will provide more insight.
3. New initiatives and the future of the corpora
While the CEEC corpus family is complete as is, there are also plans to extend it to the nineteenth century. This is a project carried out by Professor Liselotte Anderwald at the University of Kiel. She and her team are following the principles and annotation conventions of the original CEEC corpora, and are in the process of compiling a corpus which will allow the study of sociolinguistic variables in connection with language variation and change in the nineteenth century. In addition, because distributing the full corpus seems unfeasible because of copyright constraints, there are plans of building a network of corpus compilation. Others digitising early letters, for example, the Glasgow team who have edited the letters of Bess of Hardwick have opted for the route of publishing their data freely online. This is obviously not an option for the CEEC data in its entirety, but for academic access the published parts may soon be available through the CLARIN interface.
Spelling normalisation is yet another avenue currently being explored by the CEEC team. The VARD2 tool has been applied to the corpus data from the sixteenth century onwards, and extending the standardisation to earlier data is also in the works. The standardisation has been carried out with the purpose of being better able to make use of corpus-linguistic methods such as keyword analysis. These techniques are more appropriately used with data that has consistent spelling, since the orthographical irregularities of particularly the earlier centuries will obscure patterns that could otherwise be seen emerging. This work is particularly valuable for the “Language and Identity: Variation and Change in Patterns of Interaction in the History of English” project launched by Minna Palander-Collin, Minna Nevala, and Anni Sairio, but will benefit other corpus users as well. [3]
As the corpus has been expanded, particularly the eighteenth-century extension has raised new questions. While allowing a range of new approaches particularly in the study of interaction and networks, it has also proved problematic. Some research (e.g., Säily 2011) seems to suggest that the eighteenth century is different from the previous parts of the corpus. Whether this is a real difference in linguistic change and socio-cultural history or an accident of corpus sampling remains to be seen as the work on the CEEC corpora continues.
The CEEC team has been a pioneer of quantitative research using early letters, but the idea has found many followers in the field of historical sociolinguistics. In a recent volume (Dossena & Del Lungo Camiciotti 2012), letters from a variety of languages (including Dutch, Finnish, German and Portuguese) are studied, and while many scholars have started from unpublished manuscripts rather than edited collections, there are certain commonalities with their work and that of the CEEC team. There is, however, no corresponding corpus representing any other language or variety to our knowledge. Even with the help of smaller, systematically collected data sets, through the work of more and more scholars, studying the past stages of an ever greater variety of languages, we will be able to recognise the linguistic features typical of letters regardless of language, as well as see the particularities of each separate language.
Notes
[1] Many of these gaps may be due to editorial preferences: while letters written during the seventeenth century have still been seen as evidence of ‘how people lived’, editors of the eighteenth century correspondence collections seem more focused on ‘extraordinary individuals’. The gap in the first half of the eighteenth century may well be due to such a preference, and, as the scholarly paradigm of what is interesting changes, more editions of ‘ordinary people’s’ correspondence may also be published from the eighteenth century.
[2] Letters from the Gawdy Correspondence (1600?–1639?). Edited from British Library manuscripts by Minna Nevala.
[3] The project currently continues under the name of the Dynamics of Change in Language Practices and Social Meaning 1700–1900 (DYLAPS), funded by the Academy of Finland for 2012–2016.
Sources
AntConc: http://www.laurenceanthony.net/software/antconc/
ARCHER = A Representative Corpus of Historical English Registers. http://www.llc.manchester.ac.uk/research/projects/archer/
CLARIN = Common Language Resources and Technology Infrastructure: http://www.clarin.eu/
CLARINO = Common Language Resources and Technology Infrastructure Norway: http://clarin.b.uib.no/
Corpora of Early English Correspondence, CoRD entry: http://www.helsinki.fi/varieng/CoRD/corpora/CEEC/index.html
Corpora of Early English Correspondence, General introduction: http://www.helsinki.fi/varieng/CoRD/corpora/CEEC/generalintro.html
Corpora of Early English Correspondence, Bibliography of Research at CoRD: http://www.helsinki.fi/varieng/CoRD/corpora/CEEC/bibliography.html
Corpus of Early English Correspondence Extension (CEECE), CoRD entry: http://www.helsinki.fi/varieng/CoRD/corpora/CEEC/ceece.html
Corpus of Early English Correspondence Sampler (CEECS), CoRD entry: http://www.helsinki.fi/varieng/CoRD/corpora/CEEC/ceecs.html
Corpus of Early English Correspondence Supplement (CEECSU), CoRD entry: http://www.helsinki.fi/varieng/CoRD/corpora/CEEC/ceecsu.html
CorpusPresenter: http://www.uni-due.de/CP/
CorpusSearch: http://corpussearch.sourceforge.net/
DAMMOC: http://tauchi.cs.uta.fi/virg/projects.html
Dynamics of Change in Language Practices and Social Meaning 1700–1900, homepage: http://blogs.helsinki.fi/languagedynamics
Helsinki Corpus, CoRD entry: http://www.helsinki.fi/varieng/CoRD/corpora/HelsinkiCorpus/index.html
International Computer Archive of Modern and Medieval English (ICAME, http://clu.uni.no/icame/)
Oxford Text Archive (OTA, http://ota.ahds.ac.uk).
Parsed Corpus of Early English Correspondence (PCEEC), CoRD entry: http://www.helsinki.fi/varieng/CoRD/corpora/CEEC/pceec.html
Socio-cultural Reality and Language Practices in Late Modern England, homepage: http://www.helsinki.fi/varieng/soreal/index.htm
Standardised-spelling Corpora of Early English Correspondence (SCEEC), CoRD entry: http://www.helsinki.fi/varieng/CoRD/corpora/CEEC/standardized.html
Text Analysis Computing Tools (TACT): http://projects.chass.utoronto.ca/tact/
The Letters of Bess of Hardwick Project (Alison Wiggins, Anke Timmerman, Graham Williams, Imogen Marcus, Felicity Maxwell). School of English & Scottish Language & Literature, University of Glasgow. http://www.bessofhardwick.org/home.jsp
VARD2: http://www.comp.lancs.ac.uk/~barona/vard2/
WordCruncher: http://wordcruncher.byu.edu/wordcruncher/default.htm
WordSmith: http://www.lexically.net/wordsmith/
References
Agrafojo Blanco, Héctor. 2004. “The rise of modal meanings in Early Modern English: The case of the semi-auxiliary verb BE supposed to”. ‘Good my lord, vouchsafe me a word with you’: Yearbook of the Spanish and Portuguese Society for English Renaissance Studies, SEDERI XIV, ed. by Luciano García García, Jesús López-Peláez Casellas, Eugenio Olivares Merino & Alejandro Alcaraz Sintes, 189–198. Jaén: Universidad de Jaén.
Allen, Cynthia L. 2008. Genitives in Early English: Typology and Evidence. Oxford: Oxford University Press.
Biber, Douglas. 1995. Dimensions of Register Variation: A Cross-linguistic Comparison. New York: Cambridge University Press.
Bromhead, Helen. 2009. The Reign of Truth and Faith. Epistemic Expressions in 16th and 17th Century English (Topics in English Linguistics 62). Berlin: Mouton de Gruyter.
Carroll, Ruth. 2007. “Lists in letters: NP-lists and general extenders in early English correspondence”. Bells Chiming from the Past: Cultural and Linguistic Studies on Early English, ed. by Isabel Moskowich-Spiegel & Begoña Crespo-García, 37–54. Amsterdam & New York: Rodopi.
Dossena, Marina & Gabriella Del Lungo Camiciotti, eds. 2012. Letter Writing in Late Modern Europe (Pragmatics & Beyond New Series 218). Amsterdam & Philadelphia: John Benjamins.
González Díaz, Victorina. 2003. “Adjective comparison in Renaissance English”. ‘Nothing but Papers My Lord’: Studies in Early Modern English Language and Literature, SEDERI XIII, ed. by Jorge L. Bueno Alonso, Jorge Figueroa Dorrego, Dolores González Álvarez, Javier Pérez Guerra & Martín Urdiales Shaw, 87–100. Vigo: Universidade de Vigo, Servicio de Publicacíons.
Gries, Stefan Th. & Martin Hilpert. 2010. “Modeling diachronic change in the third person singular: A multifactorial, verb- and author-specific exploratory approach”. English Language and Linguistics 14(3): 293–320.
Hinneburg, Alexander, Heikki Mannila, Samuli Kaislaniemi, Terttu Nevalainen & Helena Raumolin-Brunberg. 2007. “How to handle small samples: Bootstrap and Bayesian methods in the analysis of linguistic change”. Literary and Linguistic Computing 22: 137–150.
Keränen, Jukka. 1998. “Forgeries and one-eyed bulls: Editorial questions in corpus work”. Neuphilologische Mitteilungen 10(2): 217–226.
Kirby, Joan, ed. 1996. The Plumpton Letters and Papers (Camden Fifth Series 8). Cambridge: Cambridge University Press for the Royal Historical Society.
Koivisto-Alanko, Päivi & Heli Tissari. 2006. “Sense and sensibility: Rational thought versus emotion in metaphorical language”. Corpus-Based Approaches to Metaphor and Metonymy (Trends in Linguistics 171), ed. by Anatol Stefanowitsch & Stefan Th. Gries, 191–213. Berlin: Mouton de Gruyter.
Kytö, Merja, comp. 1996. Manual to the Diachronic Part of The Helsinki Corpus of English Texts: Coding Conventions and Lists of Source Texts. Helsinki: Department of English. http://clu.uni.no/icame/manuals/
Laitinen, Mikko. 2007. Agreement Patterns in English: Diachronic Corpus Studies on Common-Number Pronouns (Mémoires de la Société Néophilologique de Helsinki 71). Helsinki: Société Néophilologique.
Nevala, Minna. 2004a. Address in Early English Correspondence: Its Forms and Socio-Pragmatic Functions (Mémoires de la Société Néophilologique de Helsinki 64). Helsinki: Société Néophilologique.
Nevala, Minna. 2004b. “A commentary on Lettice Gawdy’s letter to her father Sir Robert Knollys, 1620”. Reading Early Modern Women: An Anthology of Printed Texts and Manuscripts, 1500–1700, ed. by Helen Ostovich & Elizabeth Sauer, 208–210. London: Routledge.
Nevalainen, Terttu. 2002. “What’s in a royal letter? Linguistic variation in the correspondence of King Henry VIII”. Of Dyuersitie & Chaunge of Langage: Essays Presented to Manfred Görlach on the Occasion of his 65th Birthday (Anglistische Forschungen 308), ed. by Katja Lentz & Ruth Möhlig, 169–179. Heidelberg: Universitätsverlag C. Winter.
Nevalainen, Terttu, Minna Palander-Collin & Tanja Säily, eds. In preparation. Linguistic Change in Its Social Contexts in Eighteenth-Century English.
Nevalainen, Terttu & Helena Raumolin-Brunberg. 1996. “The Corpus of Early English Correspondence”. In Nevalainen & Raumolin-Brunberg (eds.), 39–54.
Nevalainen, Terttu & Helena Raumolin-Brunberg. 2003. Historical Sociolinguistics: Language Change in Tudor and Stuart England (Longman Linguistics Library). London: Longman.
Nevalainen, Terttu & Helena Raumolin-Brunberg, eds. 1996. Sociolinguistics and Language History: Studies Based on The Corpus of Early English Correspondence (Language and Computers 15). Amsterdam & Atlanta: Rodopi.
Nevalainen, Terttu, Helena Raumolin-Brunberg & Heikki Mannila. 2011. “The diffusion of language change in real time: Progressive and conservative individuals and the time depth of change”. Language Variation and Change 23: 1–43.
Nishimura, Hideo. 2004. “Degree adverbs in the Corpus of Early English Correspondence Sampler”. English Corpus Linguistics in Japan (Language and Computers: Studies in Practical Linguistics 38), ed. by Toshio Saito, Junsaku Nakamura & Shunji Yamazaki, 183–193. Amsterdam & New York: Rodopi.
Nurmi, Arja. 1999. A Social History of Periphrastic DO (Mémoires de la Société Néophilologique de Helsinki 56). Helsinki: Société Néophilologique.
Nurmi, Arja, Minna Nevala & Minna Palander-Collin, eds. 2009. The Language of Daily Life in England (1400–1800) (Pragmatics and Beyond New Series 183). Amsterdam: Benjamins.
Nurmi, Arja & Päivi Pahta. 2004. “Social stratification and patterns of code-switching in Early English letters”. Multilingua 23(4): 417–456.
Nurmi, Arja & Päivi Pahta. 2012. “Multilingual practices in women’s English correspondence”. Language Mixing and Code-Switching in Writing: Approaches to Mixed-Language Written Discourse, ed. by Mark Sebba, Shahrzad Mahootian & Carla Jonsson, 44–67. London: Routledge.
Palander-Collin, Minna. 1999. Grammaticalization and Social Embedding: I THINK and METHINKS in Middle and Early Modern English (Mémoires de la Société Néophilologique de Helsinki 55). Helsinki: Société Néophilologique.
Palander-Collin, Minna. 2009. “Patterns of interaction: Self-mention and addressee inclusion in the letters of Nathaniel Bacon and his correspondents”. In Nurmi et al. (eds.), 53–74.
Peitsara, Kirsti. 2006. “MAN-compounds in English”. Selected Proceedings of the 2005 Symposium on New Approaches in English Historical Lexis (HEL-LEX), ed. by Roderick W. McConchie, Olga Timofeeva, Heli Tissari & Tanja Säily, 113–122. Somerville, MA: Cascadilla Proceedings Project. http://www.lingref.com/cpp/hel-lex/2005/abstract1352.html
Raumolin-Brunberg, Helena. 2009. “Lifespan changes in the language of three early modern gentlemen”. In Nurmi et al. (eds.), 165–196.
Rissanen, Matti. 2008. “From ‘quickly’ to ‘fairly’: On the history of rather”. English Language and Linguistics 12(2): 345–359.
Säily, Tanja. 2011. “Sociolinguistic variation in morphological productivity in 18th-century English”. Corpus Linguistics and Linguistic Theory 7(1): 119–141.
Säily, Tanja, Terttu Nevalainen & Harri Siirtola. 2011. “Variation in noun and pronoun frequencies in a sociohistorical corpus of English”. Literary and Linguistic Computing 26(2): 167–188.
Sönmez, Margaret. 2005. “A study of request markers in English family letters from 1623 to 1660”. European Journal of English Studies 9(1): 9–19.
Stapleton, Thomas, ed. 1839/1968. Plumpton Correspondence: A Series of Letters, Chiefly Domestick, Written in the Reigns of Edward IV. Richard III. Henry VII and Henry VIII (Camden Original Series 4). New York: AMS Press.
Tissari, Heli. 2008. “A look at respect: Investigating metonymies in Early Modern English”. English Historical Linguistics 2006. Volume II: Lexical and Semantical Change. Selected Papers from the Fourteenth International Conference on English Historical Linguistics (ICEHL 14), Bergamo, 21–25 August 2006, ed. by Richard Dury, Maurizio Gotti & Marina Dossena, 139–157. Amsterdam: John Benjamins.
|