The Helsinki Corpus of English Texts (HC)
Matti Rissanen, University of Helsinki
Jukka Tyrkkö, University of Tampere
Abstract
The compilation of the Helsinki Corpus of English Texts (HC) was initiated in the early 1980s and the corpus was completed and publicly distributed in 1991. Its size is c. 1.5 million words, and it covers the periods from Early Old English to the end of Early Modern English, i.e., to the beginning of the eighteenth century. The Corpus is structured chronologically and by sociolinguistic, dialectal and genre-based parameters. After two decades, it is still used in various parts of the world as a “diagnostic” corpus giving useful indications of the first thousand years of the development of the English language. The results given by the Helsinki Corpus can be easily supplemented from other larger and/or more focused historical corpora compiled in Helsinki and elsewhere.
1. General description of the Helsinki Corpus
The Helsinki Corpus of English Texts was the first English long-time-span diachronic corpus. Its size is c. 1.5 million words, and it covers a thousand years of English texts, from the eighth to the beginning of the eighteenth century. The corpus includes more than four hundred samples of continuous text varying from 2000 to 20,000 words, both short texts and extracts from longer ones. It is divided into three sections: Old, Middle, and Early Modern English. Each section consists of three or four sub-periods of 70, 80, or 100 years. The length of the Old English sub-periods and the two first Middle English sub-periods is 100 years, from mid-century to mid-century. The third Middle English sub-period covers 70 years, from 1350 to 1420, and the fourth 80 years, from 1420 to 1500. In this way, all the early manuscripts of Chaucer’s writings could be included in the third sub-period, without disproportionally truncating the fourth sub-period, which gives valuable information on the initial stages of development of the Southern Standard. The size of the periods and sub-periods is not equal because the number and quality of available texts varies considerably between the sub-periods. The text samples are mainly transcribed from printed editions. The compilers did, however, get permission from the Dictionary of Old English project to use their early machine-readable transcripts of Old English texts as the basis for the Old English part of the corpus. These samples were proofread and a number of corrections made in the course of the compilation of the Helsinki Corpus.
At the beginning of each text sample there is a set of parameter codes giving information on the date, author, dialect, genre and other relevant features of the text. No grammatical or syntactic coding is included. There are, however, later versions of the corpus including this kind of coding.
To ensure the representativeness of the selected corpus texts, three external factors affecting the choice of variant forms were taken into consideration: (1) Regional variation, i.e. dialects; (2) Sociolinguistic variation, including the author’s gender, age, social background and education; (3) Genre variation, i.e. texts of different types written for different purposes, etc.
Dialects are observed only in the Old and Middle English sections. In the Early Modern English section, all texts represent the Southern Standard. The parameters giving sociolinguistic information become relevant in the late Middle and Early Modern English subsections. The genre or text type distribution of the samples is noted in all parts of the corpus although even this variation becomes richer and more relevant in later sections. The genres are grouped under six major “prototypical” text categories, which run from Old to Modern English contributing to the genre continuity from period to period. Samples of Bible translations from the tenth century to the King James Bible (1611) and of five English versions of Boethius’ De Consolatione Philosophiae from Old English to the late seventeenth century are included. Texts giving information on forms and constructions typical of spoken language include Late Middle English and Early Modern English drama and private letters and Early Modern English sermons, trial records and the dialogue in fictitious anecdotes and jests.
The Helsinki Corpus can be ordered from the Oxford Text Archive. An introduction to the Corpus, with a number of studies by the compilers, can be found in Rissanen et al. 1993. Two volumes of articles by the compilers, testing the usefulness of the Helsinki Corpus,were published in the 1997 (Rissanen et al. 1997a, 1997b).
2. Assessment
The idea for the compilation of the The Helsinki Corpus of English Texts (originally The Diachronic Part of the Helsinki Corpus of English Texts) saw daylight in the early 1980s. A group of scholars and postgraduate students at the English Department of the University of Helsinki got together to discuss the possibilities for combining their expertise in the history of English with new but rapidly developing computer technology. As a result of this brain-storm, they decided to create a historical English corpus inspired by the model offered by the Brown and Lancaster-Oslo/Bergen corpora of present-day American and British English. The project was funded by the University of Helsinki and by the Academy of Finland, and the corpus was completed and publicly distributed in 1991.
As mentioned above, the Helsinki Corpus was the first long-diachrony corpus of English. The compilers’ aim was to produce a fairly loosely structured corpus consisting of both complete short texts and extracts from longer ones, with special attention paid to the description of each text sample applying a number of parameters. This last principle introduced a real innovation in corpus compilation; it reflects the basic tenets of the variationist approach to language change. Later corpora of the “HC family” – and many historical corpora created elsewhere – apply the parameter model in one way or another. These parameters define, among other features, the date, dialect and genre of the text, the gender, age, and social status of the author, and his or her relationship to the receiver(s) of the text. The level of formality of the texts and their relationship to spoken language are marked, as these aspects are of particular importance in the study of the long-diachrony development of English.
A number of practical solutions had to be found. In the decisions made, the representativeness of the text collection and the accuracy of the transcripts were of course dominant. However, a number of compromises were inevitable; otherwise the 1.5 million-word corpus would never have been completed with the resources available. As mentioned above, the compilers were fortunate to get access to the Toronto Dictionary of Old English Project transcripts for the Old English texts, but the Middle and Early Modern English texts were taken from the best printed editions available. The attitudes of the publishers of these editions were most positive and important for the success of the project: copyrights were readily given with no demands of remuneration.
One problem of transferring the text into machine-readable form was of course how to cope with the special characters and other markings of the edition from which the text was taken. In the 1980s when the corpus project began, the only practical solution was to use ASCII coding. Special characters were marked with two symbols: +a for æ; +t for þ; +d for ð, +g for ȝ, etc. It seems, however, that solutions of this kind do not decisively weaken the usefulness of HC even today – the +combinations can be easily changed to corresponding characters.
The length of the text samples varies as it made sense to include shortish texts in their entirety; even the extracts taken from longer texts vary in length, from c. 2,000 to c. 20,000 words, as some texts were regarded as particularly relevant from the point of view of the development of the English language. Owing to the wider variety of genres, the Early Modern English text samples tend to be shorter than the Old and Middle English ones.
After two decades, the Helsinki Corpus is still in use in hundreds of English departments all over the world, and the number of articles on the history of English based on this corpus must amount to thousands. It has also offered a model for “second-generation” corpora resulting from projects in Helsinki and elsewhere. A new annotated version of the Helsinki Corpus is completed. Most importantly, the Helsinki Corpus can be used as a “diagnostic corpus” which, thanks to its structure and variation-based annotation, gives easy access to initial information on the occurrences and frequencies of a number of orthographic, morphological, syntactic and lexical details in the first thousand-year period of the development of English. The selection of genres, based on extra-linguistic factors, allows the comparison between texts with different relationships to spoken expression, and texts including a large amount of dialogue encourage even historical discourse research. All this information can easily be supplemented by richer data from larger and/or more focused corpora. Reference to additional corpus material is particularly important in comparisons based on occurrences derived by an individual genre, dialect, or sociolinguistic group: only in this way can the problem of the decreasing number of examples be avoided (cf. the “mystery of vanishing reliability” in Rissanen 1989). Important focused corpora compiled in Helsinki are, for instance, the CEEC family of early correspondence, the MEMT family of scientific texts, and the historical Scottish corpora , HCOS and CSC (see this volume). Of genre-based corpora compiled outside Helsinki, The Corpus of English Dialogues (CED) and The Lampeter Corpus of Early Modern English Tracts (LC) are particularly useful. Information on these and other historical English corpora can be found in CoRD and Rissanen (2012).
The first problem in compiling the Old English part of the Helsinki Corpus was the uneven chronological distribution of extant texts. Yet, keeping the earliest texts and the texts of the transition period after the Norman Conquest separate from the “creative” time from the late ninth to early eleventh century is vital for finding information on the developments in Old English, which even show trends of standardisation. For this reason the sub-periods OE2 (850–950) and OE3 (950–1050) are more extensive than the sub-periods OE1 (–850) and OE4 (1050–1150). The texts are located into sub-periods on the basis of the date of the manuscript used. We found it most important, however, to also code the approximate date of the original text, if known. It is only to be expected that the codemark “X”, for “unknown” is frequently used both in reference to the date of the original text and to its author.
Another crucial question in deciding on the Old English text selection was dialect distribution. If the number of extant texts representing each Old English dialect had been taken as the criterion for inclusion, this part of the Helsinki Corpus would have given the impression that almost all people in Anglo-Saxon England spoke the West-Saxon dialect. This is of course eminently untrue; for this reason, for the better or worse, Anglian and Kentish texts are over-represented. As a result of this decision, we could even say that the Helsinki Corpus gives a truer picture of the dialect situation in Anglo-Saxon England than a corpus including all extant texts would do, although even this picture may be far from the actual state of dialect use in the Old English period.
It was also important to code verse texts as opposite to prose texts as they represent not only different genres of writing but also different traditions of oral and written expression. Old English poetical texts give us a glimpse in the ways of expression dating from the pre-literary stage of the language. Similarly, from the point of view of the earliest development of English, the coding of religious vs. secular texts, and, in particular, texts based on Latin original vs. texts of vernacular origin is essential.
The number and length of the texts in the four sub-periods of Middle English texts also varies, for the same reason as in Old English. The number of extant English texts written between 1150 and 1350 is relatively small; after 1350, there is an explosion of available text material. The time difference between the original text and the extant manuscript is particularly interesting in ME1 (1150–1250), as many of the texts are later copies of Old English versions and thus give us information on the development of the language in the transition period after the Norman Conquest.
The coding of dialects is more accurate than in Old English as the information given in the Linguistic Atlas of Late Medieval English was available. It is a pity that the excellent Linguistic Atlas of Early Middle English material and coding was not available at the time of the compilation of the Helsinki Corpus.
Sociolinguistic coding of the author and the relationship between the writer and receiver become important in fifteenth-century private correspondence, notably in the letters written by the Pastons (see also the description of CEEC). Genre definitions gain in relevance in late fourteenth-century and fifteenth-century texts. With the reintroduction of English in all genres of writing, the number of official documents (statutes, appeals, wills, etc.) increased radically. The same can be said of literary texts (Chaucer and his contemporaries) and various kinds of translations from French and Latin. The vernacularisation of scientific texts is notable. The structured Middle English part of the Helsinki Corpus thus gives us insights into the origins and earliest steps of development of the Southern Standard. The corpus also gives ample information on the genres of special importance in the introduction of French loan-words.
2.3 Early Modern English
The art of printing meant of course an enormous increase in the amount of material available for corpus compilers. For this reason, the texts selected for the Early Modern English part of the Helsinki Corpus give a richer and more many-sided picture of the language of the period than those included in the Old and Middle English parts. Some new genres could be added and the amount of available text material representing, for instance, private correspondence and drama made the selection both easy and difficult. The comparison of the first (1500–1570) and last (1640–1710) Early Modern sub-corpora underlines the rapid development from the early sixteenth-century English, still showing some Middle English characteristics, to the written English of the end of the seventeenth century – a language form approaching the present-day stage of the language.
2.4 Small and beautiful?
Structured multi-purpose or focused corpora, with carefully selected text material and parameter code systems, such as the Helsinki Corpus, have been described as “small and beautiful”. It is obvious that the Helsinki Corpus only represents a very narrow slice of the linguistic reality of the periods covered by its text selection. But the fact that it has been in frequent – and enthusiastic – use by historical linguists for two decades indicates that it is still regarded as a gate to the path leading to the beginnings and early development of the English language. In most cases the picture given by its 1.5 million words can and should be supplemented from other larger, more focused and more sophisticated historical corpora, but surprisingly often the results derived from the Helsinki Corpus are confirmed, rather than contradicted, by searches from other corpora.
One of the great advantages of “small and beautiful” corpora is that the parameter system describing the character of each text sample encourages and almost compels the user to enter into a detailed variation-based analysis of the quantitative results, with due attention paid to sociolinguistic, geographical and genre-based extra-linguistic factors. Giving simple statistics of the occurrences of various forms and expressions of the linguistic feature studied is not a sufficient result in corpus-based research: “research begins where counting ends” has been the slogan of the Helsinki team since the birth of the Helsinki Corpus. This attitude also underlines the fact that the use of evidence given by historical corpora is only “legitimate” if the student has sufficient mastery of the language form of the period or periods from which the examples are taken (cf. “the philologist’s dilemma”, Rissanen 1989).
This does not, however, mean that very large corpora, consisting of tens or even hundreds of millions of words, would be useless. Quite obviously they represent a larger slice of linguistic reality than the “small and beautiful” corpora. But the variation-based study of language development should, whenever possible, begin with the description and analysis of individual examples and observations on the joint influence of extra-linguistic factors and intralinguistic trends in time and only after that move to the massive evidence offered by giant corpora.
3. Helsinki Corpus XML edition
The discipline of corpus linguistics has advanced by leaps and bounds over the twenty years since the Helsinki Corpus was released. Consequently, while the compilation principles of the Helsinki Corpus are as sound today as they were back then, the tools and methods scholars use to query corpora have developed significantly. Corpus mark-up, comprising both meta- and paratextual mark-up and linguistic annotation, has been firmly established in current methodology, but there has been a distinct lack of common effort to establish a universal mark-up system within the discipline of corpus linguistics. With the notable exception of basic part-of-speech tagging, which has benefited from the standardizing effect of popular tools, corpora have been mostly annotated using systems created by individual compilers. While this reflects to some degree the divergent nature of the data, it is worth noting that efforts toward a unified descriptive model have been ongoing elsewhere since the late 1980’s. For example, the Text Encoding Initiative (henceforth TEI), a prime example of a non-profit collaborative effort in the humanities, has been issuing guidelines to facilitate digital editing and data transfer since 1993. Although especially the early years of TEI benefited from contributions by several corpus linguists, the actual use of TEI for corpus annotation has been less that prevalent. As a result, corpora have been annotated using a very wide variety of mark-up systems, of which many of the older ones have become antiquated and incompatible with modern practices.
As the years went by, this state of affairs was also becoming more and more apparent when it came to the Helsinki Corpus. The Helsinki Corpus was traditionally accessed using Word Cruncher, a venerable piece of software dating back to the DOS era, and as linguists were increasingly turning to more modern software, they were finding it difficult to work with the annotation in HC. Part of the problem was that few corpus tools allow much flexibility when it comes to the handling of annotation. In the typical case, the tool has room for a single type of annotation, and the options only include the ability to either ignore the tags or to include them in searches. [1] It is worth mentioning in this context that the popularity of the Helsinki Corpus prompted many subsequent corpora to follow the HC model of annotation or organization. For example, the Helsinki Corpus of Older Scots and the first two sub-corpora of the Corpus of Early English Medical Writing offer an essentially similar model of markup. Many of the descriptive parameters used in HC are likewise frequently seen in English historical corpus linguistics, and the timeline division has been adopted by numerous researchers, even for studies that make use of entirely different corpora.
3.1 The conversion project
The conversion of the Helsinki Corpus was carried out in-house by a fairly large team of experts comprising members of the original Helsinki Corpus team as well as more junior members of the research unit. The project was initiated in the autumn of 2010 and completed a year later in 2011, in time for a conference organized by VARIENG in celebration of the 20th anniversary of the Helsinki Corpus. A more detailed description of the project and a list of its members is available in the Corpus Resource Database, but we will focus here on some aspects of the project that may hold more universal interest. For detailed information about TEI XML, please read the TEI P5 Guidelines.
When the decision was made to produce an updated version of the Helsinki Corpus, the team agreed on two major points very quickly. Firstly, the new version would preserve every piece of information from the original corpus. Any research carried out using the first version could be reproduced using the new version. Secondly, the decision was made that the new version would be in XML, a universal standard of mark-up that provides the best possible guarantee of longevity in today’s fast-changing digital landscape. Indeed, it is of paramount importance to recognize that the key to digital durability is not in the details of any one system of mark-up, but rather in its potential for later conversion. The more widely a system of mark-up is used, the more likely it is that there will be automatic and semi-automatic conversions methods to new formats that do not even exist yet but we know will come. To that same end, the importance of valid and rules-compliant mark-up cannot be overestimated. For human readers scanning a digital text, slight variations and oversights in annotation are merely a distraction, but for automatic software dealing with the same text, a missing tag or two inadvertently overlapping elements can spell disaster. This not only affects the way a corpus can be used, but equally the conversion of a corpus from one format to another. Valid mark-up can be transformed into another system with a conversion script, but even the slightest deviation from the standard means that workload is increased manifold as everything has to be manually checked and verified. When it comes to research, in the worst case scenario a mark-up problem may mean that some relevant findings are not retrieved correctly and that conclusion may be drawn based on entirely faulty data.
In addition to making the decision to use XML mark-up, the team made the further decision to follow the latest TEI guidelines. The decision was a profound one as it meant a commitment not only to a system of markup but also to its underlying ontology and to a strictly defined schema of data organization. While the conversion of the markup used to indicate surface features such as special characters from the HC to XML is essentially trivial, the wholesale adoption of TEI P5 resulted in the need to do a considerable amount of rethinking.
The original Helsinki Corpus came in two formats: as separate text files or as a single file, at the time considered so large that only mainframe computers could handle it. The XML version comes as a single file, with a teiHeader giving general data that pertains to the entire corpus and further teiHeaders for each individual text. The general teiHeader gives information on the XML file itself, its creators, availability and sources. Encoding information is given next, with detailed notes on all the practices followed including the taxonomies of each descriptive parameter. Finally, a revision description provides a chronological account of changes made to the XML file. The individual text headers give bibliographic and descriptive metadata. The former provides bibliographic source used for the digital edition in a <bibl> element as well as data from the original <Q, <A and <N parameters, or text identifies, author and name of text, respectively. The <bibl> element was used for essentially reproducing the bibliographic data from the original Helsinki Corpus, while the separate <biblStruct> element was used to render that same information (and more) in a structured and thus fully searchable format.
The annotation model used in the Helsinki Corpus bears a resemblance to XML, but not to an extent that would have allowed full conversion to XML using a single conversion script. The COCOA format, short for “Word COunt and COncordance on Atlas”, was originally developed as a file format for an eponymous text processing software developed in the late 1970s. The format was widely used in the 1980s and into the early 1990s. Each line corresponds with one piece of information, as indicated by the first letter that follows the opening bracket. The HC header thus included 20 items of descriptive parameters, in addition to which bibliographic data was provided in a separate, uncategorized entry. The following example gives the two headers, illustrating the difference in the level of detail:
Example 1. Original Helsinki Corpus header
<Q E3 XX CORP EOXINDEN>
<N LET TO MOTHERINLAW>
<A OXINDEN ELIZABETH>
<C E3>
<O 1640-1710>
<M X>
<K X>
<D ENGLISH>
<V PROSE>
<T LET PRIV>
<G X>
<F X>
<W WRITTEN>
<X FEMALE>
<Y 20-40>
<H HIGH>
<U X>
<E INT UP>
<J INTERACTIVE>
<I INFORMAL>
<Z X>
Example 2. Helsinki Corpus TEI XML header
<teiHeader>
<fileDesc>
<titleStmt>
<title key="E3 XX CORP EOXINDEN" ref="#eoxinden.let_to_motherinlaw" n="LET TO MOTHERINLAW">Letters (to her mother-in-law)</title>
<author key="OXINDEN ELIZABETH" ref="#oxinden_elizabeth"><forename>Elizabeth</forename> <surname>Oxinden</surname></author>
<editor role="compiler" ref="#HC_EME_compilers"/>
</titleStmt>
<extent>
<measure quantity="1865" unit="words"/>
<idno type="file">CEPRIV3</idno>
</extent>
<publicationStmt>
<p>Published as a part of the <title ref="#HC_XML">Helsinki Corpus TEI XML Edition</title>.</p>
</publicationStmt>
<sourceDesc>
<biblStruct>
<monogr>
<title level="m">The Oxinden and Peyton Letters, 1642–1670. Being the Correspondence of Henry Oxinden of Barham, Sir Thomas Peyton of Knowlton and Their Circle</title>
<editor>D. Gardiner</editor>
<imprint>
<pubPlace n="1">London</pubPlace>
<publisher n="1">The Sheldon Press</publisher>
<pubPlace n="2">New York</pubPlace>
<publisher n="2">The Macmillan Company</publisher>
<date when="1937">1937</date>
</imprint>
<biblScope n="196">pp. 308.1–310.6 (196)</biblScope>
<biblScope n="204">pp. 320.22–322.27 (204)</biblScope>
<biblScope n="209">pp. 331.16–333.35 (209)</biblScope>
</monogr>
</biblStruct>
</sourceDesc>
</fileDesc>
<profileDesc>
<creation>
<date type="original" from="1641" to="1710">1640–1710</date>
<date type="manuscript" from="1500" to="1710">1500–1710</date>
</creation>
<langUsage>
<language ident="en">Early Modern English</language>
</langUsage>
<textClass xml:id="eoxinden_classification" default="true">
<catRef n="O" scheme="#periods" target="#E3"/>
<catRef n="M" scheme="#periods" target="#EX"/>
<catRef n="K" scheme="#contemporaneity" target="#unknown"/>
<catRef n="D" scheme="#dialect" target="#ENGLISH"/>
<catRef n="V" scheme="#form" target="#prose"/>
<catRef n="T" scheme="#texttype" target="#let.priv"/>
<catRef n="G" scheme="#foreign_orig" target="#x.orig"/>
<catRef n="F" scheme="#foreign_lang" target="#NA"/>
<catRef n="W" scheme="#spoken" target="#written"/>
<catRef n="X" scheme="#author_sex" target="#female"/>
<catRef n="Y" scheme="#author_age" target="#age_20-40"/>
<catRef n="H" scheme="#social_rank" target="#rank_high"/>
<catRef n="U" scheme="#audience" target="#aud_x"/>
<catRef n="E" scheme="#part_rel" target="#int.up"/>
<catRef n="J" scheme="#interaction" target="#interactive"/>
<catRef n="I" scheme="#setting" target="#informal"/>
<catRef n="Z" scheme="#proto" target="#x.proto"/>
</textClass>
</profileDesc>
</teiHeader>
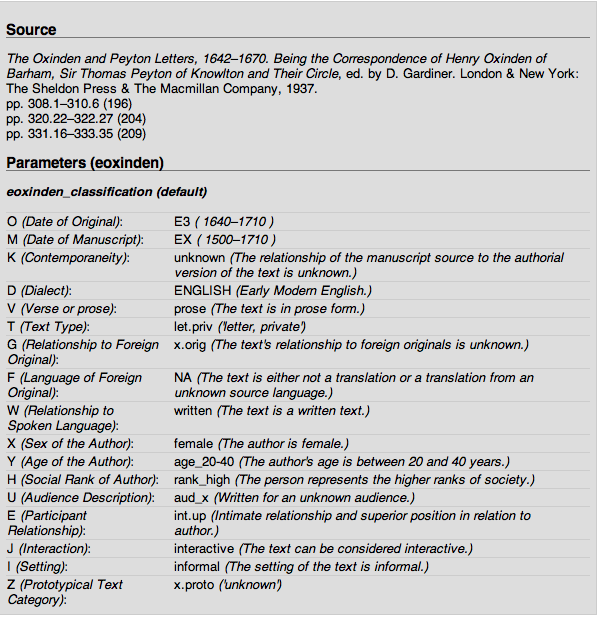
For convenience, the XML header can be easily transformed into more readable formats (Illustration 1). The next example shows how the previous header is presented in the XML Helsinki Corpus Browser. [2] Note how both the names and values of parameter have been supplied with explanatory information to make the description accessible.
Space does not permit a detailed discussion of the entire conversion process, but instead we will focus on two of the major conceptual challenges that the team faced and which, in the end, came to inform the entire process.
One of the first issues the team faced was the structural division of the original corpus into 242 files. On closer inspection, these files do not consistently represent individual source texts as many of them include extracts from more than one source. Each of these structural units, which conceptually amount to texts in the corpus linguistic sense, had their own headers. The original set of files thus comprise of files that represent only a single sample and others which include several. Also, some files included pseudo-headers in the middle of the text. These did not stand for an entirely new sample, but rather for a section in the source text that for one reason or another required separate parameter information: for example, a new letter in a correspondence collection. Finally, the original corpus made use of one more layer of structural data, a <sample> code that could span several subdivisions or be found within one. In the new version, each separate source text was considered a <text> element and <div> elements, annotated for @type as either subdivisions or samples, were used to indicate the original pseudo-headers and samples, respectively. As a result, the number of texts went from 242 to 432 while the textual content of the corpus remains identical to the original.
Another main challenge was that the TEI guidelines require strict adherence to a predefined semantic rules. This not only means that specific elements are to be used to mark well-defined entities, but also their interrelationships. Some of the guidelines are of course universal to XML, such as the rule that elements cannot overlap. In TEI, the possible relationships between elements are also controlled and explicitly defined in the guidelines for each element. For example, the element <titlePage> may only contain one or more of the following ten text structure elements: <argument>, <byline>, <docAuthor>, <docDate>, <docEdition>, <docImprint>, <docTitle>, <epigraph>, <imprimatur> and <titlePart>. Consequently, supposing we had a hypothetical title page that includes a cast list for a play, the <castList> element could not be placed directly under <titlePage>, but would have to be included within either a <epigraph> or <titlePart> element, both of which are allowed to include <castList>. In the course of the conversion project, equivalent TEI nomenclature had to be found for all the annotation in the original corpus and the taxonomies of parameter values had to be translated into TEI-compliant formats. Thus, for example, <date> elements were added to supplement time period data. For example, the original corpus gave the time periods of Aelfric's Lives of Saints as two tags, one for the original and the other for the manuscript:
<O 950-1050>
<M 950-1050>
In HC XML, this information is preserved, but the <creation> element within <fileDesc> also gives the data in a searchable format:
<date type="original" from="0951" to="1050">950–1050</date>
<date type="manuscript" from="0951" to="1050">950–1050</date>
Note that the <date> element is used for giving the datings of both the original and the manuscript, the difference being indicated with the @type attribute. The value of the element is given as in the original corpus, but the start and end dates are also given explicitly as attribute values.
3.2 Legacy information and errata
One of the many strengths of the TEI guidelines is the robust approach taken to the preservation of information both about the source text and the process by which the digital edition was created. In traditional corpus linguistic projects, this data is frequently not included in the digital file at all, but is instead given in a separate manual — if at all. In particular, information about the editing process is usually almost never given. The Helsinki Corpus included more information of this kind than most early historical corpora, but the creation of the new version provided the opportunity to introduce improvements here as well. As already mentioned, the <teiHeader> included in the root of the top-level <teiCorpus> gives detailed information on the entire process, making it possible to go back in time and identify individuals who worked on specific parts of the corpus.
The new version also gave the team the opportunity to make corrections. In the twenty years since the Helsinki Corpus was released, two entire folders full of errata had been collected and some of these had been published as errata sheets on CoRD. Athough everyone welcomed the opportunity to make these corrections to the corpus, it was, in light of the fact that hundreds of studies have been conducted using the original corpus, of paramount importance that all the data in the original corpus would also continue to be available, even if corrections were made. Altogether 558 revisions were annotated into the corpus. The following example shows an example of editorial correction. The original HC corpus gave the word form “haye” and this information is retained as a <sic> element within the <choice> element. The @resp attribute is used to indicate the source, in this case the original Middle English team. The second item within the <choice> element is the element <corr>, which indicates that the word form is in fact “haue”. The source of the information, this time the conversion team, is again given.
She hath do wryte the pris of her <lb/>colte vnder her fote she wolde that I shold <choice><sic resp="#HC_ME_compilers">haye</sic><corr resp="#HC_XML_errata_corrections">haue</corr></choice> redde it / but I <lb/>can not one lettre / whiche me sore repenteth /
Example 3. Errata in the XML code from Caxton’s The History of Reynard the Fox, p. 59
In addition to editorial intervention by the original or conversion team, the Helsinki Corpus also includes, when known, information about decisions made by the editors of source editions.
4. Concluding words
Along with providing an overview of the Helsinki Corpus, this article hopefully also gives a sense of the progressive nature of corpus compiling and digital editing. Few corpus projects span twenty years and it has been highly educational for all involved to observe the life cycle of a single corpus from the beginning of historical corpus linguistics to the present day, when corpora are widely used in our discipline. Both the original corpus and the XML version were created by large teams of scholars that discussed, debated and reconsidered all aspects of the corpus from text selection to annotation. This iterative process has been, to our mind at least, part of the reason the corpus has had such longevity.
The strength of a small corpus is in its quality, with any ill-considered decisions of text selection or editing having far-reaching consequences. The process of compiling and now converting the Helsinki Corpus has demonstrated the need to document all practices with great care and to make all the mark-up as transparent and consistent as possible. Corpus linguistic research is often quantitative in nature and it is perhaps unavoidable that the scholar may at times experience a slight sense of detachment from the individual texts in favour of the corpus, or part thereof, as a whole. However, our work on the Helsinki Corpus reminds us time and again that familiarity with, and appreciation of, the individual primary sources can be vital to the evaluation and correct interpretation of the findings that corpora yield. In our experience, corpora are at their best when they give detailed and considered metadata on all the sources, and when that metadata is provided in a searchable and quantifiable format along with the text itself. We hope that this approach will maintain the value of the early Helsinki Corpus and its structured and annotated versions and successors even in decades to come.
Notes
[1] Tools that allow for a wider range of mark-up include WordSmith Tools by Mike Scott and Corpus Presenter by Raymond Hickey.
[2] The browser was developed by Henri Kauhanen and distributed along with the corpus at the Helsinki Corpus Festival.
Sources
Sub-periods in the Helsinki Corpus of English Texts: http://www.helsinki.fi/varieng/CoRD/corpora/HelsinkiCorpus/period.html
Dictionary of Old English project: http://www.helsinki.fi/varieng/CoRD/corpora/DOEC/index.html
Parameter codes in the Helsinki Corpus: http://www.helsinki.fi/varieng/CoRD/corpora/HelsinkiCorpus/parameters.html
Later versions of the Helsinki Corpus:
XML version: http://www.helsinki.fi/varieng/CoRD/corpora/HelsinkiCorpus/HC_XML.html
The Penn-Helsinki Parsed Corpus of Early Modern English (PPCEME) http://www.helsinki.fi/varieng/CoRD/corpora/PPCEME/
Penn-Helsinki Parsed Corpus of Middle English, second edition (PPCEME2): http://www.helsinki.fi/varieng/CoRD/corpora/PPCME2/
Dialects in the Old and Middle English sections of the Helsinki Corpus: http://www.helsinki.fi/varieng/CoRD/corpora/HelsinkiCorpus/dialect.html
Sociolinguistic information in the late Middle and Early Modern English subsections: http://www.helsinki.fi/varieng/CoRD/corpora/HelsinkiCorpus/sociolinguistic.html
Genres in the Helsinki Corpus: http://www.helsinki.fi/varieng/CoRD/corpora/HelsinkiCorpus/genres.html
Text categories in the Helsinki Corpus: http://www.helsinki.fi/varieng/CoRD/corpora/HelsinkiCorpus/textcategories.html
Helsinki Corpus on the University of Bergen ICAME CD-ROM: http://clu.uni.no/icame/
Helsinki Corpus on the Oxford Text Archive: http://ota.ox.ac.uk/
Middle English section of the Helsinki Corpus: http://www.helsinki.fi/varieng/CoRD/corpora/HelsinkiCorpus/meintro.html
Linguistic Atlas of Late Medieval English: http://www.helsinki.fi/varieng/CoRD/corpora/LAEME/background.html
Description of CEEC: http://www.helsinki.fi/varieng/CoRD/corpora/CEEC/index.html
Text Encoding Initiative (TEI): http://www.tei-c.org/index.xml
TEI P5 Guidelines: http://www.tei-c.org/Guidelines/P5/
Helsinki Corpus of Older Scots: http://www.helsinki.fi/varieng/CoRD/corpora/HCOS/
Corpus of Early English Medical Writing: http://www.helsinki.fi/varieng/CoRD/corpora/CEEM/
References
Corpus Resource Database (CoRD). Helsinki: Research Unit for Variation, Contacts and Change in English. http://www.helsinki.fi/varieng/CoRD/
Rissanen, Matti. 1989. “Three problems connected with the use of diachronic corpora”. ICAME Journal 13: 16–19. http://clu.uni.no/icame/
Rissanen, Matti, Merja Kytö & Minna Palander, eds. 1993. Early English in the Computer Age: Explorations through the Helsinki Corpus. Berlin: Mouton.
Rissanen, Matti, Merja Kytö & Kirsi Heikkonen, eds. 1997a. English in Transition: Corpus-Based Studies in Linguistic Variation and Genre Styles (Topics in English Linguistics 23). Berlin: Mouton.
Rissanen, Matti, Merja Kytö & Kirsi Heikkonen, eds. 1997b. Grammaticalization at Work: Studies of Long-Term Developments in English (Topics in English Linguistics 24). Berlin: Mouton.
Rissanen, Matti. 2012. “Corpora and the study of English historical syntax:” English Corpus Linguistics: Crossing Paths, ed. by Merja Kytö, 197–220. Amsterdam & New York: Rodopi.
TEI Consortium, eds. TEI P5: Guidelines for Electronic Text Encoding and Interchange. Version 2.3.0. Last modified 2013-01-17. TEI Consortium. http://www.tei-c.org/Guidelines/P5/
|