
Studies in Variation, Contacts and Change in English
Studies in Variation, Contacts and Change in English
Joe McVeigh
University of Helsinki
Although the genres of blogs and marketing have been studied, the sub-genres of monotopical blogs and email marketing have not received as much attention by scholars. An account of the ways that these sub-genres use language to meet their goals is needed to see whether they follow similar patterns of the larger genres that contain them. Since marketing has been seen as a dynamic genre that liberally borrows linguistic and rhetorical structures from other genres, a comparative analysis of marketing and blogging will show just how close these two genres really are. A close look at two similar sub-genres within marketing and blogging will also help define the expansive genres of which they are a part.
This article analyzes the linguistic properties of blog texts and marketing texts which share a topic and discourse community. That is, all of the texts analyzed are about labor and employment law in the United States and all of them are directed at lawyers. The only difference between them is that they have different goals depending on which genre they come from. For the blog texts, the goal is exposition, while the marketing texts are promotional. Drawing on previous corpus linguistics research, I wish to answer two related questions. First, I want to know how the two sub-genres differ in terms of their linguistic properties. Second, I want to see whether a comparison of the texts from the two sub-genres is really possible or whether it would be just like comparing apples to oranges.
Corpus linguistic methods are used to compare the lexico-grammatical properties of the texts from the two sub-genres at large. An analysis is then made of the texts which share the same micro-topic in labor and employment law (in this case, discrimination at the work place). The results show that texts from monotopical blogs and email marketing do not always divide easily based on either their genres or expectations from previous research.
Marketers create texts that they want people to read. Popular bloggers create texts that people read willingly. But what happens when a blog post and an advertisement share the same topic and are aimed at the same community? How then does the blogger's language compare to the marketer's? Is there a quantifiable difference between the two genres?
The corpus analyzed in this article contains blog and marketing texts and every text has the same general topic, which is labor and employment (L&E) law in the United States. A corpus linguistic analysis is made to give a general overview of their linguistic properties and to see how texts from the sub-corpora of marketing and blogs relate to each other. A similar analysis is then done on texts from each sub-corpus which focus on the micro-topic of discrimination in the workplace .
I hope to gain a better insight into how these marketing texts and blogs are written for their shared and well-defined community of labor and employment lawyers. I want to answer two questions:
In a general sense related to my first research question, the topic of this article is important because it offers benefits to both linguists and marketers. Herring and Paolillo (2006: 440) note that “weblogs deserve linguistic study, especially if language use differs in blogs compared to other genres”. The findings in the analysis section help to further define the sprawling nature of the blog genre, which can seem impenetrable to linguists venturing an description of it. But the analysis presented here not only describes a specific sub-genre of blogs, it can also be of future use to linguists studying similar monotopical blogs by offering a way to describe their linguistic properties. By monotopical, I mean author-controlled blogs with substantial linguistic content on one specific topic and with relatively little use of images and video. This is to differentiate them from the traditional notion of blogs as online diaries and from what are called single topic blogs, such as I Can Has Cheezburger and Awkward Family Photos (Kim 2009).
For the marketing aspect, researchers such as Kim (2007) have noted how advertising provides vast possibilities for linguists to study discourse strategies and the ways that language is used for persuasion. As a former copy writer, I know that my analysis can aid marketers in getting to know their genre better and, hopefully, in writing better marketing copy in the future. I believe that for anyone serious about marketing and/or linguistics, it is not enough to say that marketing is marketing and blogging is blogging, especially in cases where marketers and bloggers are discussing the same topic. What is needed instead is a comprehensive analysis of each genre to better understand the ways that they present their topics to their communities.
In a more specific sense, there is (to my knowledge) a gap in previous genre research in that it has not addressed the lexico-grammatical properties of texts on the same topic which are addressed to the same community, but which have very different goals. For the blogs, we can say their goal is mainly explanatory. They follow the model described by Blood (2002) where each post includes a link and commentary, although these monotopical L&E blogs in my corpus would perhaps be better described as commentary which sometimes includes links. The commentary, or each post in the blog which is not a quote from a legal case, is always meant to explain an area of L&E law. The marketing texts are inherently promotional. They exist to sell a product. The entire text, from the subject line of the email through to the link located at the end, serve to get readers to purchase the single product advertised in the text. But how are the differences in the texts reflective of these goals? And if these genres are related in terms of their topics and communities, should we not expect them to have influences on each other?
Since I used to work as a webinar producer for one of the marketing companies that I drew texts from for this article, I can state for a fact that the blogs in my corpus do have an influence on the marketing texts. [1] Webinar producers working with the L&E law topic were encouraged to find topics that would interest L&E lawyers by reading the L&E law blogs, precisely because the audience for the webinars is the same as it is for the blogs. On the other hand, Bhatia (2004: 84) has noted that the linguistic properties of advertising have invaded almost every other genre. So in my corpus, influence cuts both ways.
To avoid the problem of having to define genre or of having to (perhaps arbitrarily) group the texts into genres, I have decided to use a two-fold classification technique. First, the texts in each genre that I am analyzing share a purpose, which is an aspect that has been shown to be of primary importance when deciding which texts constitute a genre by Swales (1990) and Yates and Orlikowski (1992). Second, I have purposefully chosen texts which the active discourse community – the readers and writers – have already divided into genres.
I was fortunate in being able to avoid bias and circular reasoning on which blogs to include by referring to lists of L&E law blogs that were generated by the discourse community. Two separate organizations, LexisNexis and the American Bar Association (ABA) Journal release lists of the best L&E law blogs every year. [2] Most importantly, both the LexisNexis and ABA Journal lists of L&E law blogs are voted on by readers. I chose to include four blogs in my corpus: the top two blogs on the list published by the ABA Journal, which listed vote tallies for its blogs; the blog which was chosen as the “Top Labor & Employment Law Blog of 2011” by LexisNexis readers, and a blog which was featured on both lists (second on the LexisNexis list and third on the ABA list). The marketing texts were also classified by the discourse community. I chose to include texts from two companies, both of which placed their texts under appropriate headings on their sites, in this case ones which were clearly targeted to labor and employment lawyers: “Employment and ERISA” and “Employment”.
Before going on, some descriptions of the terminology that will be used in this article is necessary. The term webinar is a portmanteau of “web” and “seminar” and it basically refers to an online course where audience members view a presentation on their computers while listening to an instructor over the phone or internet. The technology involved allows a moderator to restrict sound from the audience during the presentation, so that only the instructor’s voice can be heard. It also allows the moderator to set up a one-on-one discussion between audience members and the instructor during a question and answer session. These Q&As can be live and heard by the rest of the audience. These events are sometimes also called web seminars, online seminars, web conferences, and audio conferences.
Email marketing is simply a form of advertising done through email. Brownlow (2013) says about email marketing that “In its broadest sense, the term covers every email you ever send to a customer, potential customer or public venue.” Brownlow then lists three types of email marketing, the first of which, direct email, is the only one relevant to this study. [3] Direct email, according to Brownlow (2013), “involves sending a promotional message in the form of an email.” This message is designed to sell a product or service and the text in the email can include various forms. The email will always have a hyperlink that will take readers to a webpage, called a “landing page”, where they will be able to purchase the product or service advertised in the email. For example, the marketing texts in my corpus, which are also marketing emails since that is how they are transmitted, include some (but not all) of the language that is on the landing page of the webinar that they are advertising. The extra language on the landing page, and my reasons for not including it, will be discussed below.
The blog texts in my corpus also need to be contextualized in order to understand what they are and where they come from. First, the blogs in my corpus all include the possibility for readers to comment and they all have hyperlinks in at least some of their texts. They are arranged in the reverse-chronological format that is so definitive of blogs (Blood 2003, Herring et al. 2004). Furthermore, they incorporate two types of blogs that Blood (2003) defines: they are (1) “written by professionals about their industry” and (2) they “link primarily to news about current events”. The blogs in my corpus are mainly of the first type, possibly because it is not always easy to link to a news article about a court case or a court’s ruling, but the authors do link to other sites wherever they deem it appropriate. Hyperlinking and commenting will not be discussed in this article because the focus is on the comparison of the lexico-grammatical nature of the blogs and marketing texts.
Perhaps the most important aspect of the blogs in my corpus is that they are all monotopical blogs. This really cannot be overstated. Every post from these blogs is about labor and employment law in the United States and only labor and employment law in the United States. They naturally incorporate other fields or social areas into their discussion (for example, baseball or literature), but their discussion is firmly focused on law. This is an important aspect of the blogs in my corpus not only because it defines them, but because it is an aspect that (to my knowledge) has been left mostly unaddressed by researchers. Whereas previous literature focuses on the “blogs at large” genre (Herring and Paolillo 2006, Myers 2010), this article can perhaps best be described as focusing on the monotopical blog sub-genre. Nevertheless, previous literature on blogs and online writing recognize the importance of contextualizing or locating them (Myers 2010, Barton and Lee 2013). The position of the monotopical L&E law blogs, the specific sub-genre that I am analyzing, is shown in Figure 1.
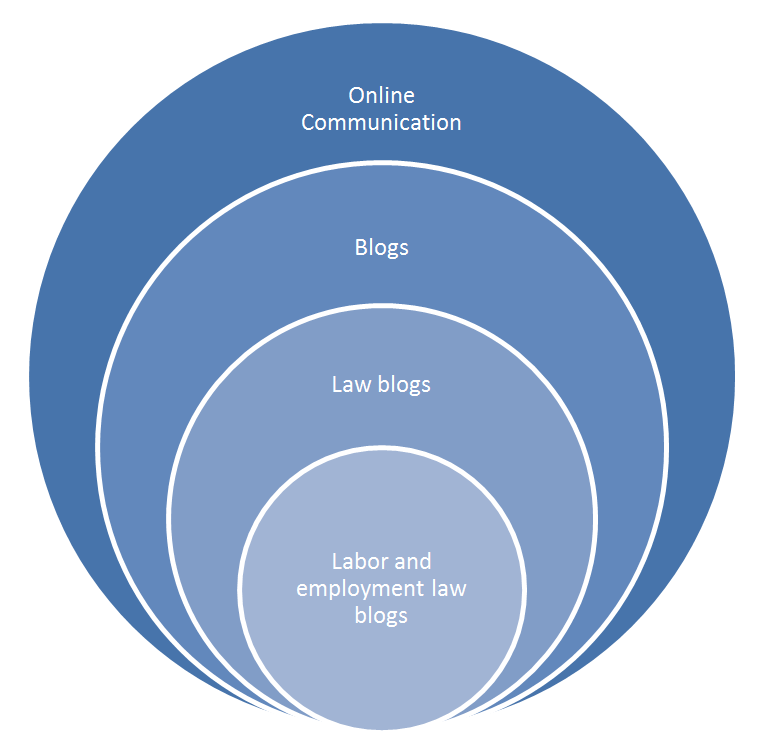
Figure 1. The position of the L&E law blogs as a sub-genre. The figure shows that L&E law blogs are a sub-genre of law blogs, which is a sub-genre of blogs, which is a genre in online communication.
In creating the corpus, I decided to focus on one year’s worth of texts for two reasons. First, although a calendar year may be arbitrary, it is relevant in the business world, especially when companies analyze their success and report their profits. Second, I reviewed the sources and recognized that a year’s worth of text from both the marketing companies and the blogs would be a sufficient amount of language to base a study upon. This is not to say that more texts would not be helpful (and that is certainly open for future research), just that drawing the line at one year seemed both logical and justified.
The texts in my marketing sub-corpus are drawn from two webinar firms, National Constitution Center Conferences (NCCC) and Strafford. NCCC was chosen because I used to be a webinar producer at that company so I am familiar with the meta-linguistic aspects of the texts, such as what goes into creating them and, how they are edited, and that they are influenced by the blogs and the other marketing texts. Strafford was chosen because it is one of NCCC’s biggest competitors and I know that the text and topics are monitored by the NCCC marketers. I also know that NCCC marketers believe that the Strafford marketers are watching their topics and texts, which would mean that the influence on the marketing texts works both ways, but I cannot say this for certain. There are eleven texts from NCCC and nineteen from Strafford. The texts constitute every webinar advertisement that was aimed directly at L&E lawyers from both companies in 2011, the same year that my blog posts are from. When I say that they were aimed directly at L&E lawyers, this means that each text was sent as an email, either in whole or in parts, at least once and that L&E lawyers made up the bulk of the email recipients. The companies know which email recipients are L&E lawyers based on such factors as previous attendance in an L&E law webinar, information provided when signing up to receive email alerts, and email lists that the companies may have purchased. Obviously, who exactly the emails were sent to is a company secret, and other types of lawyers would have also received the same marketing emails. But the emails were targeted so that more emails were sent to those who were more likely to purchase the webinar based on their job title, i.e. L&E lawyers. For each webinar, hundreds of thousands of emails were sent and, most importantly, the same marketing text was sent to everyone.
The construction of the NCCC marketing texts is represented in Figure 2. The first part of a L&E law webinar producer’s job is to research a field of business and come up with a topic for a webinar that they think L&E lawyers would purchase. After the topic for a webinar is approved by their supervisor, the producer writes copy for the marketing. The marketing copy goes through many revisions; since the marketing is done entirely through email, the language in the copy is pored over. For example, when submitting copy for the first time, webinar producers are required to write seven to ten phrases to appear as the email subject line. After that, it is not unusual to rewrite the marketing copy (the email body) three to four times. [4] The idea is to not only use language that would tell the customer what material will appear in the webinar, but to also use language that would encourage customers to feel the need to purchase the webinar, which is the style common to hard-sell advertisements (Kim 2007, Bhatia 2004). Sometimes this means using drastic warnings to scare the customer into thinking there might be legal ramifications if they do not make changes based on the information provided in the webinar and sometimes this simply means using hot button terminology, such as the names of recent court cases or updates to federal law.
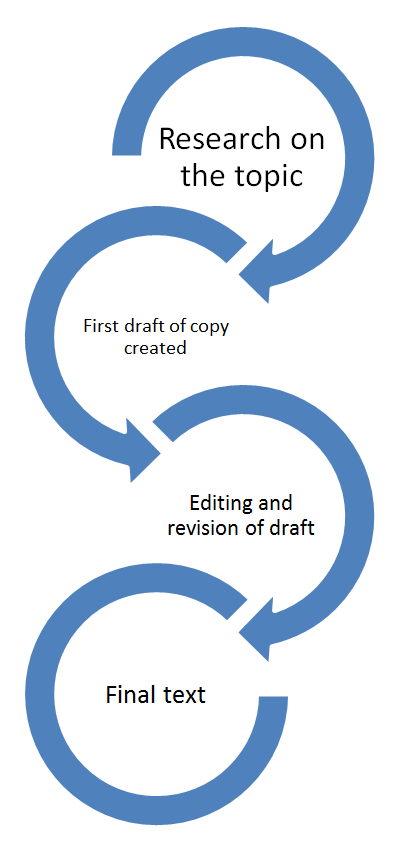
Figure 2. Creation process for the marketing texts.
Each marketing text in my sub-corpora (from both NCCC and Strafford) also includes a section that describes the speaker, who is a practicing lawyer that does not work at the company which markets the webinar. The marketing copy is influenced by the webinar speakers only to the extent that the webinar producer and speaker would agree on exactly what would be covered in the webinar. Webinar producers, who had done the initial research on the topic, were encouraged to find speakers who could both present the issues that the producer wanted covered and who were “celebrities” in their fields. In the case of L&E law, this often meant that the speaker worked for a big name law firm that L&E lawyers would recognize. Other than that, the marketing copy is left to the webinar producer and their supervisor(s). In terms of content, which obviously would be reflected in the copy, producers did not just allow the speaker to dictate what would be in the webinar. Usually, the producer simply told the speaker what to cover and the speaker agreed since both wanted to cover the pressing issues in the allotted time. This process is more straightforward than it seems. If the speaker does not agree to cover what the producer wants covered, another speaker is found. The benefit to the speaker is that they could be seen as an expert in the field and add the webinar presentation to their resume, two things which may lead to more speaking positions (and higher speaking fees) in the future. I can only speculate that a similar creation process occurs at Strafford, since the process described is rather ordinary.
The final aspect of the content to discuss is “CLE”, a term which is common in the marketing texts in my corpus. It stands for “continuing legal education” and it refers to the mandatory requirements of attorneys in the United States to maintain their license to practice law. The amount of CLE credits needed differs by state, but every lawyer is required to gain a certain number of CLE credits every year. It is important in this article because in almost every state, lawyers can receive CLE credits by attending webinars and the companies analyzed in this article offer CLE credits to lawyers who purchase and attend their webinars.
The texts in my blog sub-corpus come from four different blogs aimed at L&E lawyers. The blogs are Employment and the Law (E&theL), FMLA Insights (FMLAI), Screw You Guys, I’m Going Home (SYGIGH), and Work Matters (WM). Each blog is written by a practicing attorney and each is aimed at a national audience. I included every post from 2011 from each blog, with the exception of eight posts from FMLA Insights because they were written by a different author and I wanted to keep my data uniform. The exclusion of these texts will be discussed in further detail in the Methodology section below.
In order to give an idea of the size of the corpus, the number of texts and word counts of each blog and marketing text are in Table 1 below.
| Name | Number of texts | Word count (tokens) | Average word count per text |
|---|---|---|---|
| NCCC | 11 | 4,759 | 433 |
| Strafford | 19 | 9,431 | 496 |
| E & the L | 32 | 14,526 | 454 |
| FMLAI | 46 | 23,275 | 506 |
| SYGIGH | 64 | 28,398 | 444 |
| WM | 77 | 19,679 | 256 |
| Totals | 249 | 100,068 |
Table 1. General statistics for my corpus. The thick gray line divides the corpus between the marketing and blog genres.
In gathering the texts from marketing companies, I took only the language that was relevant to the marketing. For example, the pages for the marketing texts in my corpus had the same boilerplate sidebars and banners that most web pages have, full of information about the company and links that take users to different locations in the website . There is also an explanation of what a webinar is and instructions on how to register for one. Most importantly for the webinars aimed at lawyers, there is information on how attending the webinar can count as a CLE credit. I did not include any of this information since it was neither written by the marketers, nor would it have been in the emails sent to potential customers. Rather, the emails include a link that takes interested customers to the landing page set up exclusively for the webinar advertised in the email, which is also the page where I took the text for each webinar. On that page, customers can find a link to the page where they can register (and pay) for the webinar. The landing pages for both of the companies naturally vary a bit, but they follow this general structure. The most important thing to note here is that the marketing text for the webinars from both companies is placed front and center on their respective landing pages. Examples of webinar marketing landing pages from both companies, complete with the sidebars and banners, are in the Appendix.
I also excluded some other information from the marketing text I analyzed. First, I removed the price from the NCCC texts. Although price is an obvious factor involved in whether someone buys a product, it is not pertinent to this study, even though it is placed between the title and the marketing text body on the webpage. [5] Second, where NCCC placed the price of the webinar or recording between the title and marketing body, Strafford placed the phrases “Recording of a 90-minute CLE webinar/teleconference with Q&A” and “Conducted on Wednesday, September 21, 2011 Recorded event now available”. I removed each of these, which was the same across each marketing text (with the exception of differing dates), because, like the price for the NCCC marketing texts, it is not important for the linguistic analyses I will make and it would not have been included in the emails sent to potential customers. Another reason for excluding these phrases is to keep them from skewing the quantitative analysis of the texts. It would be easy in a close reading to glance over them and focus on the main body of the marketing text, but a corpus tool would not be able to do so. It therefore makes more sense to exclude them from the start.
I did not exclude the information about the speaker (or presenter) of the webinar since, unlike the price and general information about webinars that I did remove, the speaker bio works as marketing copy. From my experience as a webinar producer, I know that this text often comes from the speaker themselves and it is always in the form of a short biography. It may have been written by the speaker for the specific webinar, but for lawyers it is more likely to have been pulled directly from their personal website or their personal page on the website of the law firm where they work. Each time a speaker is chosen to present a webinar, they are asked to submit a short bio, unless they have spoken for the company before, in which case it is common to see the same bio appear in the marketing for each webinar that the speaker presents, perhaps with slight modifications. Although the text is not written by the webinar producers, it is often edited by them, usually to cut down the length. As previously mentioned, the speaker bio is a marketing text in itself, designed in this case to sell the webinar by selling the speaker, which could mean either name-dropping a well-known law firm or government agency that the potential customers would recognize, or by mentioning that the speaker has experience presenting the topic of the webinar.
For the blogs, I followed roughly the same process. After deciding which blogs I would draw the texts from, I took the title and body of every blog post that was published in 2011 on each blog. As there was on the webpages for the marketing texts, the blogs also had sidebars, banners, etc. that were excluded. I also did not include any comments because analyzing them is outside the scope of this article. Examples of the blog pages, complete with the sidebars and banners, can be found in the Appendix.
One common practice among blogs is to place publishing information between the title and the body of each post. The blogs in my corpus are no different and I removed this information, which for every blog post was either the author, the date the text was posted, or both. Three of the four blogs in my corpus have only one author, while the fourth, FMLA Insights, had two authors. I felt it was important to keep constant as many variables as possible in my analysis and so I only used posts from one of the authors of FMLA Insights. The author I used posted to the blog 46 times and posted every month of the year, compared with the author I excluded, who posted only eight times and only in the first four months of the year. [6] The only other language removed from the blog posts was text related to images, such as captions and alt-text, which is a kind of second caption that appears when readers hold their mouse pointers over an image, an aspect made possible by HTML. Some of the blog texts included images, but they will not be discussed here except for mentioning that each and every one of them was a stock photo or image.
I used AntConc (Anthony 2011) and the Constituent Likelihood Automatic Word-tagging System (CLAWS) tagset to analyze the corpus. The motivation of which linguistic properties to analyze comes from previous work by Biber and others. In an exhaustive analysis, Biber (1988) identified linguistic dimensions on which texts differed in comparison to each other. These dimensions were defined by the consistent co-occurrence of linguistic features (Biber 1988: 13). Adopting this approach, I analyzed and compared the frequencies of nouns and adjectives in the texts to the frequencies of verbs and adverbs. The reason this particular comparison is made in this article is because it should be indicative of a major feature in which texts differ, which is the relative formality of the texts in each of the sub-corpora. Biber and Conrad (2001: 6) say that genres “differ from one another by being more or less formal”. Heylighen and Dewaele (2002: 320) are more direct by saying “It is hard to avoid the conclusion that a dimension similar to [the relative formality of the text] appears as the most important and universal feature distinguishing styles, registers or genres in different languages” (italics original). [7] The previous studies are in agreement that the frequencies of nouns and adjectives should be higher in more formal texts, while the frequencies for verbs and adverbs should be higher in more informal texts. Moreover, what is important is the co-occurrence of these features, since as Biber (1988: 101) notes, the co-occurrence of linguistic features is indicative of texts which share communicative functions or goals. Since the texts in my corpus make up two different genres, i.e. two separate groups of texts with different sets of communicative functions or goals, we should see differences in the co-occurrence of linguistic features. Specifically, the frequencies of nouns and adjectives compared to the frequencies of verbs and adverbs should indicate which genre is relatively more formal. In performing such an analysis, we should expect to see a difference between the genres because, as Conrad and Biber (2001) have noted, “when analyses are based on the co-occurrence and alternation patterns for groups of linguistic features, important differences across registers are revealed”.
I will start with an analysis of the texts using corpus linguistic methods. This will give us a general overview of the linguistic properties of the texts before moving on to an analysis of the texts which focus on the same specific topic. As said before, the writers of the texts in my corpus have different goals, so we should expect their language to be different. But we can take the highly regarded nature of the blogs and (at the very least) the continued business of the webinar companies to say that in 2011 this is how the best L&E law blogs and webinar marketing companies discussed their topics with the same audience. For better clarity, and because they show conflicting results, I separated the noun and adjective analyses from the pronoun analyses.
Figure 3 shows the normalized frequencies (per one thousand words, ptw) of the mean, standard deviation, minimum, maximum, and range of noun use in each sub-corpus. These scores, Biber (1988: 180) says, “enable comparison of the mean scores for different sub-genres as well as consideration of the internal coherence of the sub-genre categories”. As can be easily seen, the two genres differ greatly in their use of nouns. While the mean frequencies for nouns in the blogs are around 300 or below, the means for the marketing sub-corpora are as high as 390 and 439. Biber (1988: 227) says that “a high nominal content in a text indicates a high (abstract) informational focus, as opposed to primarily interpersonal or narrative foci”. So we can say that in relation to each other, the marketing texts are more information oriented than the blogs, which is perhaps not surprising when we remember that the marketing texts have stricter length constraints and so they have to compact more information into fewer words in order to achieve their purpose of selling a webinar to the audience.
The higher noun frequencies of the marketing texts also show, according to Heylighen and Dewaele (2002), that the marketing texts are more formal than the blogs. They claim (2002: 308) that more formal language features a higher use of nouns, while more informal language has a higher frequency of verbs. The use of verbs in the corpus will be analyzed in the next section (5.2).
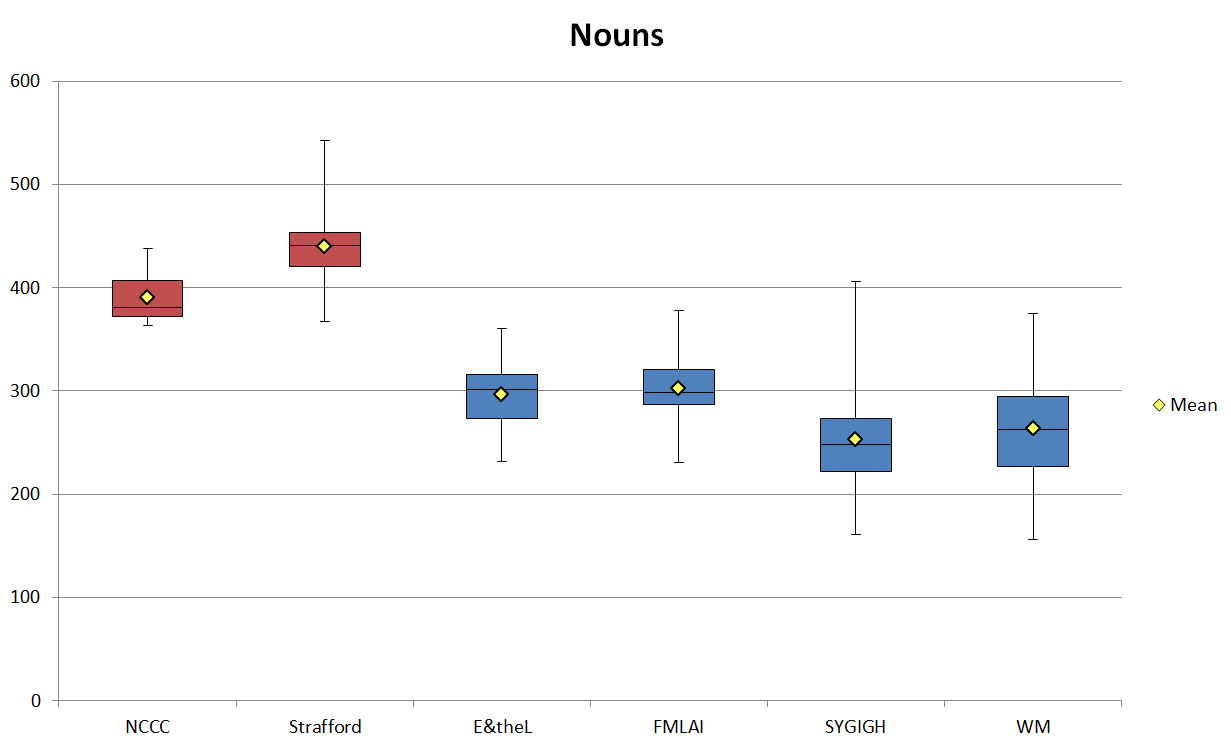
Figure 3. Normalized noun frequencies per thousand words (ptw) in the corpus.
| Nouns | NCCC | Strafford | E&theL | FMLAI | SYGIGH | WM |
|---|---|---|---|---|---|---|
| Count | 11 | 19 | 32 | 46 | 64 | 77 |
| Mean | 390.09 | 439.84 | 296.58 | 302.74 | 252.95 | 263.54 |
| SD | 22.81 | 36.26 | 31.97 | 30.11 | 46.92 | 50.80 |
| Min | 363.64 | 366.81 | 231.34 | 230.45 | 161.07 | 156.00 |
| Max | 438.03 | 542.80 | 360.52 | 377.95 | 406.25 | 375.00 |
| Range | 49.77 | 175.99 | 129.17 | 147.50 | 245.18 | 219.00 |
Heylighen and Dewaele (2002: 308) claim that as the frequency of nouns in a text increases, so will the frequency of adjectives, while on the other hand an increase in verbs will lead to an increase in adverbs. Figure 4 shows the normalized frequencies of adjectives in each sub-corpus and the numbers do indeed comply with Heylighen and Dewaele’s assertion. The mean adjective frequencies are nearly identical for the marketing sub-corpora (94.70 for NCCC and 92.47 for Strafford) and they range from 16 to 30 points higher than the blogs. The confirmation of the fact that an increase in nouns leads to an increase in adjectives is probably best shown in Figure 5, which is a scatter plot of the mean noun and adjective frequencies in the sub-corpora. It is also interesting to see that while the standard deviations of adjective frequency for each of the sub-corpora are relatively close, the ranges vary greatly, from FMLAI’s 117.22 and WM’s 112.97 to E&theL’s 60.12 and Strafford’s 60.49. This shows that the use of adjectives varies internally to a greater extent among the texts in the FMLAI and WM sub-corpora than it does for NCCC, Strafford, and E&theL, possibly because the lengths of the texts also vary to a greater extent.
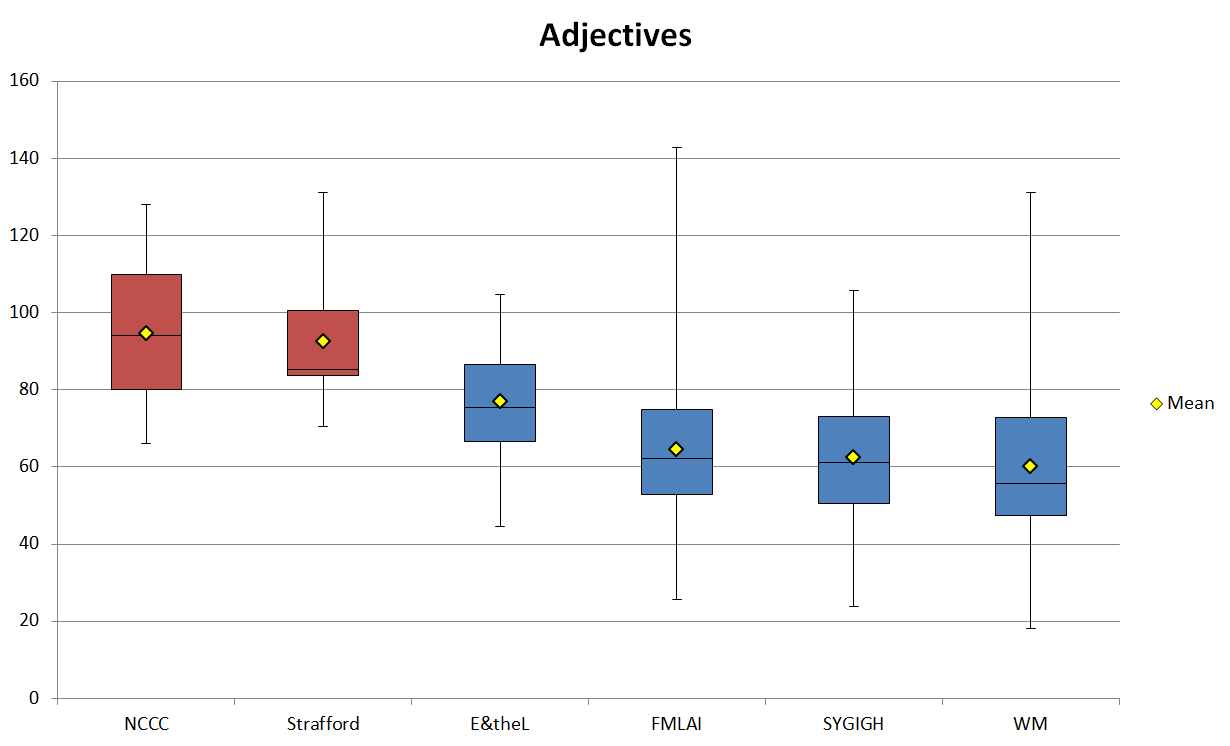
Figure 4. Normalized adjective frequencies (ptw) in the corpus.
| Adjectives | NCCC | Strafford | E&theL | FMLAI | SYGIGH | WM |
|---|---|---|---|---|---|---|
| Mean | 94.70 | 92.47 | 76.94 | 64.64 | 62.44 | 60.11 |
| SD | 18.79 | 15.77 | 15.02 | 21.02 | 18.93 | 22.68 |
| Min | 66.01 | 70.56 | 44.48 | 25.64 | 23.81 | 18.18 |
| Max | 128.15 | 131.05 | 104.60 | 142.86 | 105.84 | 131.15 |
| Range | 62.14 | 60.49 | 60.12 | 117.22 | 82.03 | 112.97 |
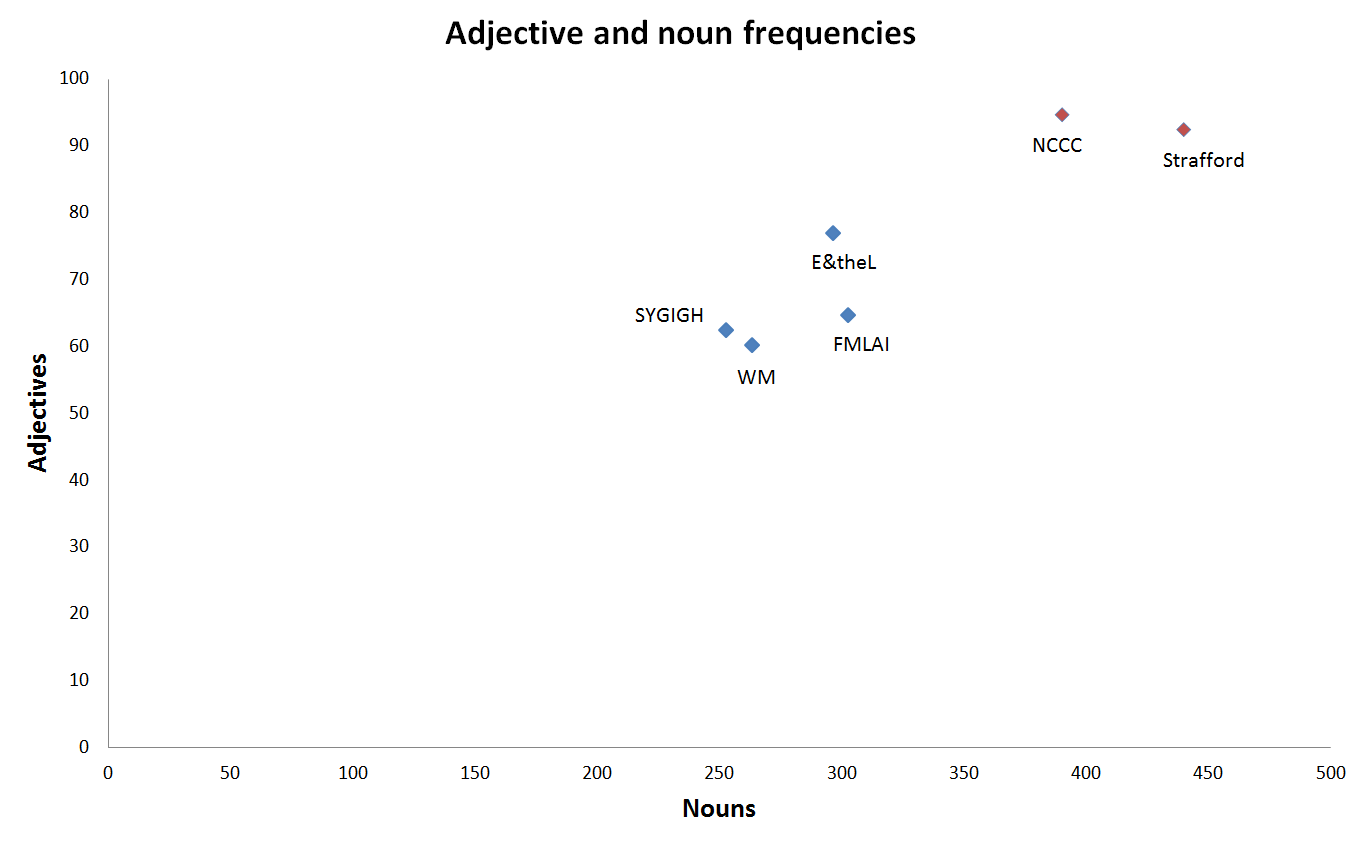
Figure 5. Scatter plot of the mean noun and adjective frequencies in the sub-corpora.
The next step then is to compare the use of verbs and adverbs in the sub-corpora. If we accept Heylighen and Dewaele’s claims, we should expect that the frequencies of verbs and adverbs will be lower in the marketing sub-corpora than the blog sub-corpora, since the use of nouns and adjectives was higher. Figure 6 shows the normalized frequencies (per one thousand words) of the mean, standard deviation, minimum, maximum, and range of verb use in each sub-corpus. It is easy to see that indeed the marketing texts use fewer verbs relative to the blog texts. Even beyond that, Strafford, the marketing sub-corpus which used more nouns compared to NCCC, uses fewer verbs, while the blog sub-corpora which had higher mean noun frequencies (E&theL and FMLAI) actually have lower mean verb frequencies, just as Heylighen and Dewaele led us to expect.
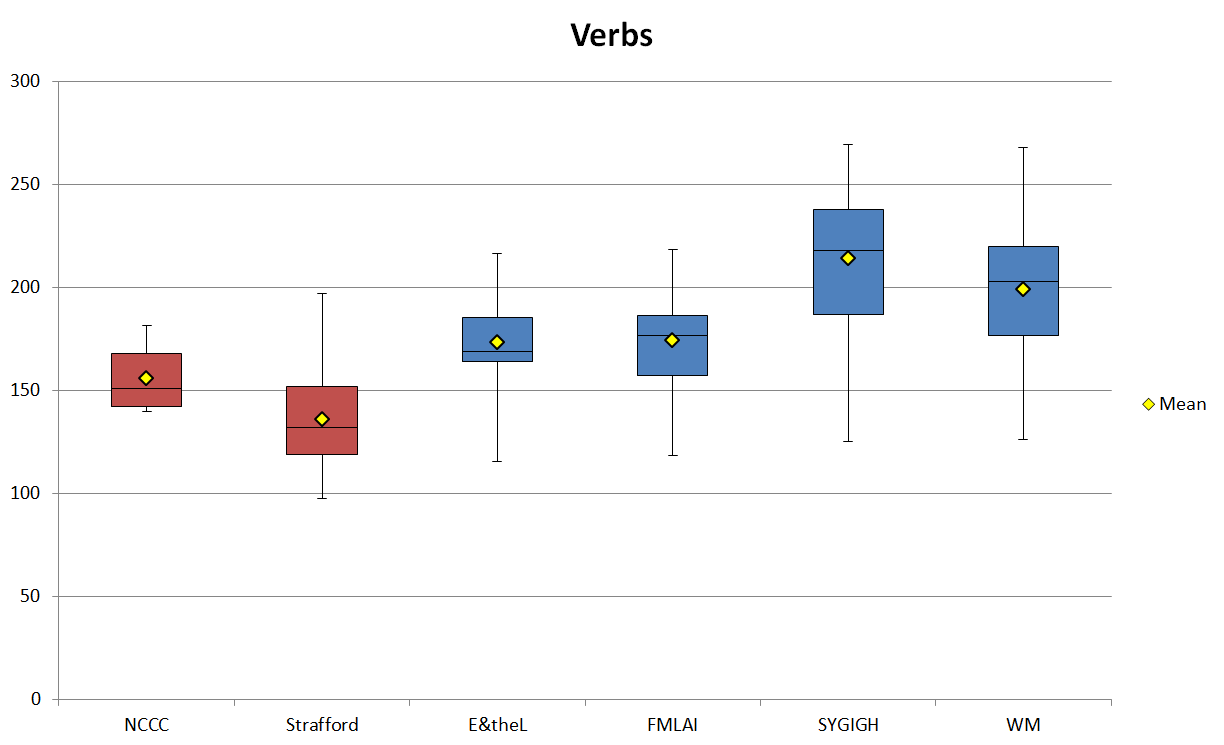
Figure 6. Normalized verb frequencies (ptw) in the corpus.
| Verbs | NCCC | Strafford | E&theL | FMLAI | SYGIGH | WM |
|---|---|---|---|---|---|---|
| Mean | 155.71 | 135.75 | 173.05 | 173.88 | 214.00 | 198.84 |
| SD | 15.03 | 22.79 | 19.16 | 20.20 | 31.92 | 28.49 |
| Min | 139.66 | 97.28 | 115.58 | 118.11 | 125.00 | 126.05 |
| Max | 181.52 | 196.72 | 216.37 | 218.11 | 269.44 | 267.80 |
| Range | 41.85 | 99.45 | 100.80 | 100.00 | 144.44 | 141.75 |
The adverb frequencies mimic this divide. Figure 7 shows the normalized frequencies for adverbs in each sub-corpus. Biber (1988: 224) writes that place and time adverbials “mark direct reference to the physical and temporal context of the text […] their distribution as marking situated, as opposed to abstract, textual content”. So the frequencies here bring us to the same conclusion that the analysis of nouns and adjectives did, i.e. that the marketing texts are more abstract and informational in relation to the blog texts, which are more informal and situated or contextual. This is perhaps because the marketing texts are sent to a wider audience and therefore may try to appeal to a wider variety of people, but I believe it is more likely due to blogs having a history of being more personal. Many early blogs functioned as online diaries and they have been shown to practice very particular ways of being personal with their audience (Blood 2003, Myers 2010).
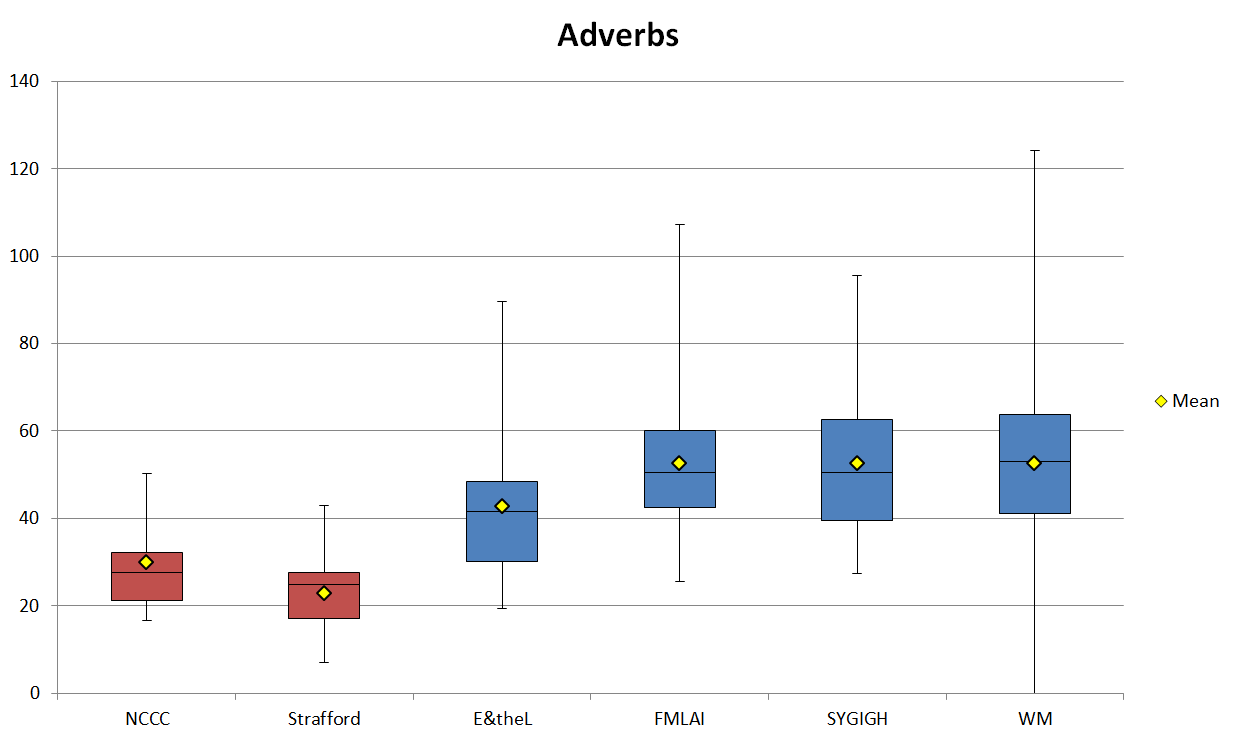
Figure 7. Normalized adverb frequencies (ptw) in the corpus.
| Adverbs | NCCC | Strafford | E&theL | FMLAI | SYGIGH | WM |
|---|---|---|---|---|---|---|
| Mean | 29.82 | 22.82 | 42.63 | 52.50 | 52.57 | 52.48 |
| SD | 10.73 | 9.11 | 16.18 | 14.69 | 15.36 | 19.88 |
| Min | 16.63 | 6.97 | 19.47 | 25.64 | 27.40 | 0.00 |
| Max | 50.28 | 43.03 | 89.55 | 107.32 | 95.65 | 124.03 |
| Range | 33.65 | 36.06 | 70.08 | 81.68 | 68.25 | 124.03 |
Referring to a study by Biber, Hudson (1994: 332) says that “The balance of common nouns to pronouns is already well-established as one of the most important variables on which genres vary”. Figure 8 below presents the normalized frequencies for all pronouns in each sub-corpus. The frequencies mirror the use of nouns, where a higher frequency of nouns in a sub-corpus correlates with a lower frequency of pronouns in that sub-corpus (in relation to the other sub-corpora).
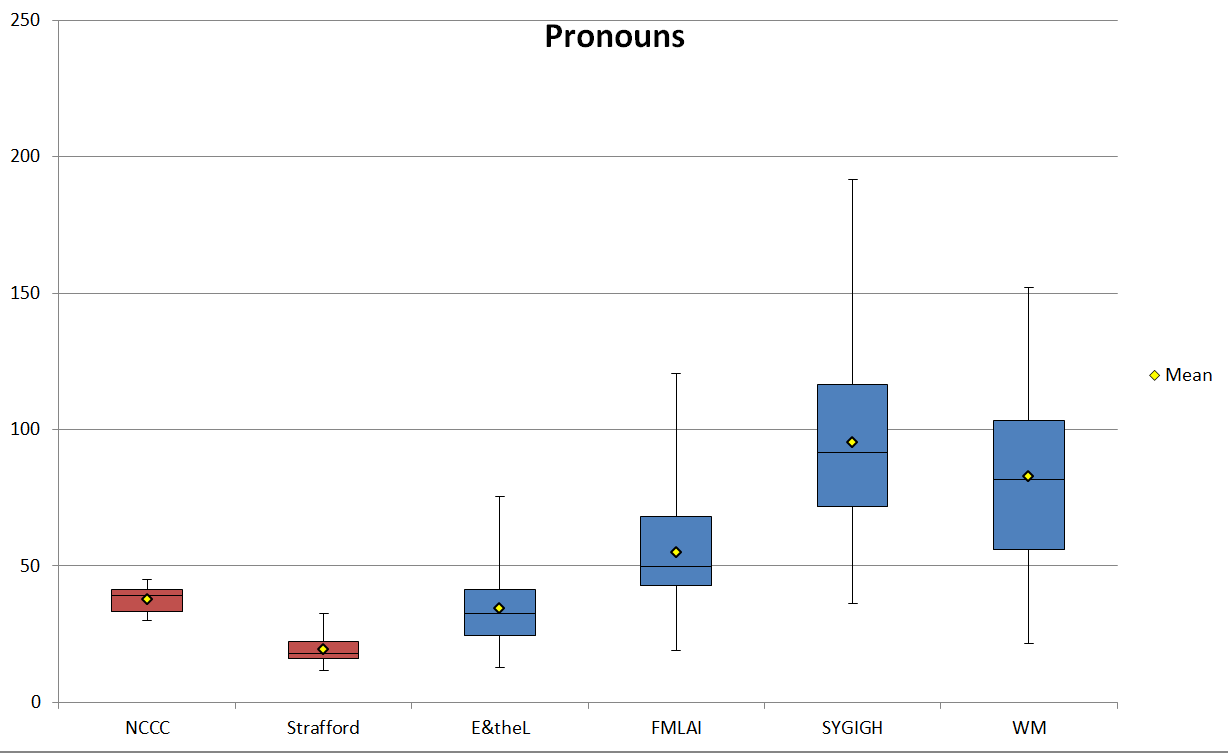
Figure 8. Normalized pronoun frequencies (ptw) in the corpus.
| Pronouns | NCCC | Strafford | E&theL | FMLAI | SYGIGH | WM |
|---|---|---|---|---|---|---|
| Mean | 37.76 | 19.24 | 34.51 | 54.92 | 95.30 | 82.89 |
| SD | 4.61 | 5.06 | 14.74 | 22.55 | 29.60 | 34.78 |
| Min | 30.00 | 11.63 | 12.88 | 18.94 | 36.11 | 21.74 |
| Max | 44.87 | 32.75 | 75.38 | 120.37 | 191.78 | 152.00 |
| Range | 14.87 | 21.12 | 62.50 | 101.43 | 155.67 | 130.26 |
A discussion of which exact pronouns are used is beyond the scope of this article, but Biber (1988: 225) has noted that studies which have grouped pronouns together as one class, such as this one, have found that a higher frequency in their use is indicative of “a less formal style” and a more “interpersonal focus”. So the pronoun frequencies show precisely what the other frequencies have, i.e. that the blogs are more informal in relation to the marketing texts. The only discrepancy, however, is very interesting in that the pronoun frequencies for E&theL show that it is much more similar to the marketing texts than the other blogs. The noun frequencies did not show this. This is not entirely unusual, however, since of the blog corpus, E&theL was the most similar to the marketing texts in three of the other categories already analyzed (adjectives, verbs, and adverbs). E&theL seems to be the most formal of the blogs, more drastically so when looking at the use of pronouns in the texts.
As noted above, the topic analysis will focus on discrimination in order to compare texts which share the exact same microtopic within the overarching topic of L&E law. In the marketing sub-corpus, there are two texts from NCCC and three from Strafford; in the blog sub-corpus, there are six texts from E&theL, thirteen from SYGIGH, and five from WM.
Figure 9 shows the normalized frequencies of nouns in the texts about discrimination from each sub-corpus. The frequencies and their relations to each other are similar to those that were found in the analysis of the entire corpus (section 5.1). Again we see that the blogs feature much fewer nouns than the marketing texts, where the maximum frequency of nouns in the blogs (WM: 355.56) is still 19 points lower than the minimum frequency of nouns in the marketing sub-corpora (NCCC: 374.41). In fact, with the exception of WM, the mean frequencies of nouns in the discrimination texts from each sub-corpus are all within eight points of their respective total mean noun frequencies. So when discussing the topic of discrimination in the workplace (or trying to sell a webinar that will discuss it), the marketing texts are far more abstract and information oriented than the blogs, which could be said to be more informal in comparison.
The other interesting aspect to note about these figures is the differences in ranges for the marketing texts and blogs. Whereas the marketing texts have much smaller ranges in noun frequencies, the blogs vary quite a bit, from 69.32 in WM to 133.61 in SYGIGH. This shows that the bloggers write with a freer style, another indication of their relative informality.
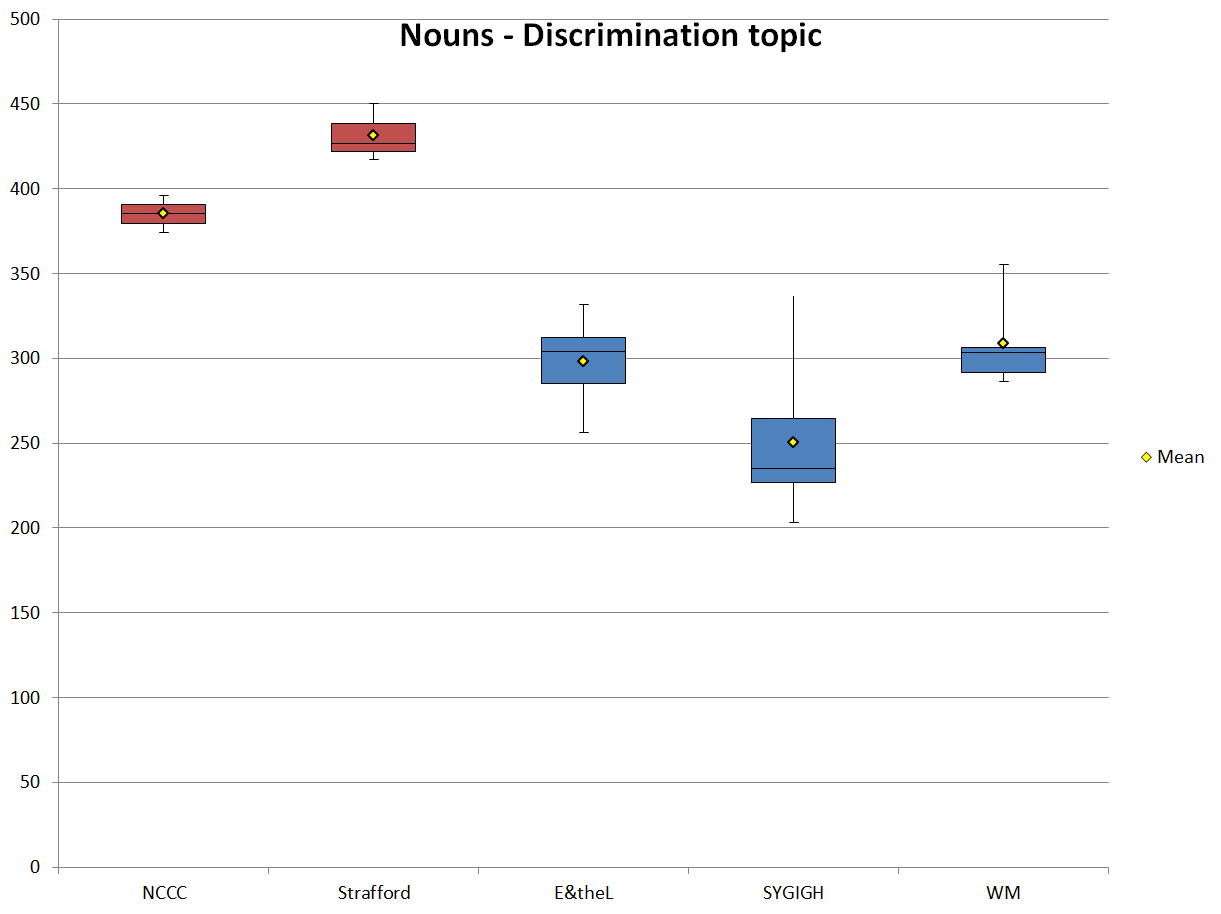
Figure 9. Normalized noun frequencies (ptw) of the texts that discuss discrimination.
| Nouns | NCCC | Strafford | E&theL | SYGIGH | WM |
|---|---|---|---|---|---|
| Count | 2 | 3 | 6 | 13 | 5 |
| Mean | 385.22 | 431.51 | 298.30 | 250.38 | 308.51 |
| SD | 10.82 | 13.95 | 24.31 | 34.87 | 24.64 |
| Min | 374.41 | 417.27 | 256.10 | 203.47 | 286.23 |
| Max | 396.04 | 450.45 | 331.95 | 337.08 | 355.56 |
| Range | 21.63 | 33.18 | 75.85 | 133.61 | 69.32 |
The frequencies of adjective use in the discrimination texts in each sub-corpus also follow the total frequencies found in the analysis of the entire corpus. Figure 10 is interesting not because it shows that the adjective frequencies follow the nouns frequencies (we should expect that), but because of the differences in ranges that it shows. While the marketing sub-corpus NCCC shows considerable range in adjective frequency, even greater than one of the blogs (E&theL), its range is much smaller than the two blogs with the highest ranges, SYGIGH and WM. The ranges of adjective frequencies of these two blogs also dwarf the range of Strafford. A comparison of the adjective frequencies again leads to the conclusion that the blogs are more informal and less information oriented than the marketing texts.
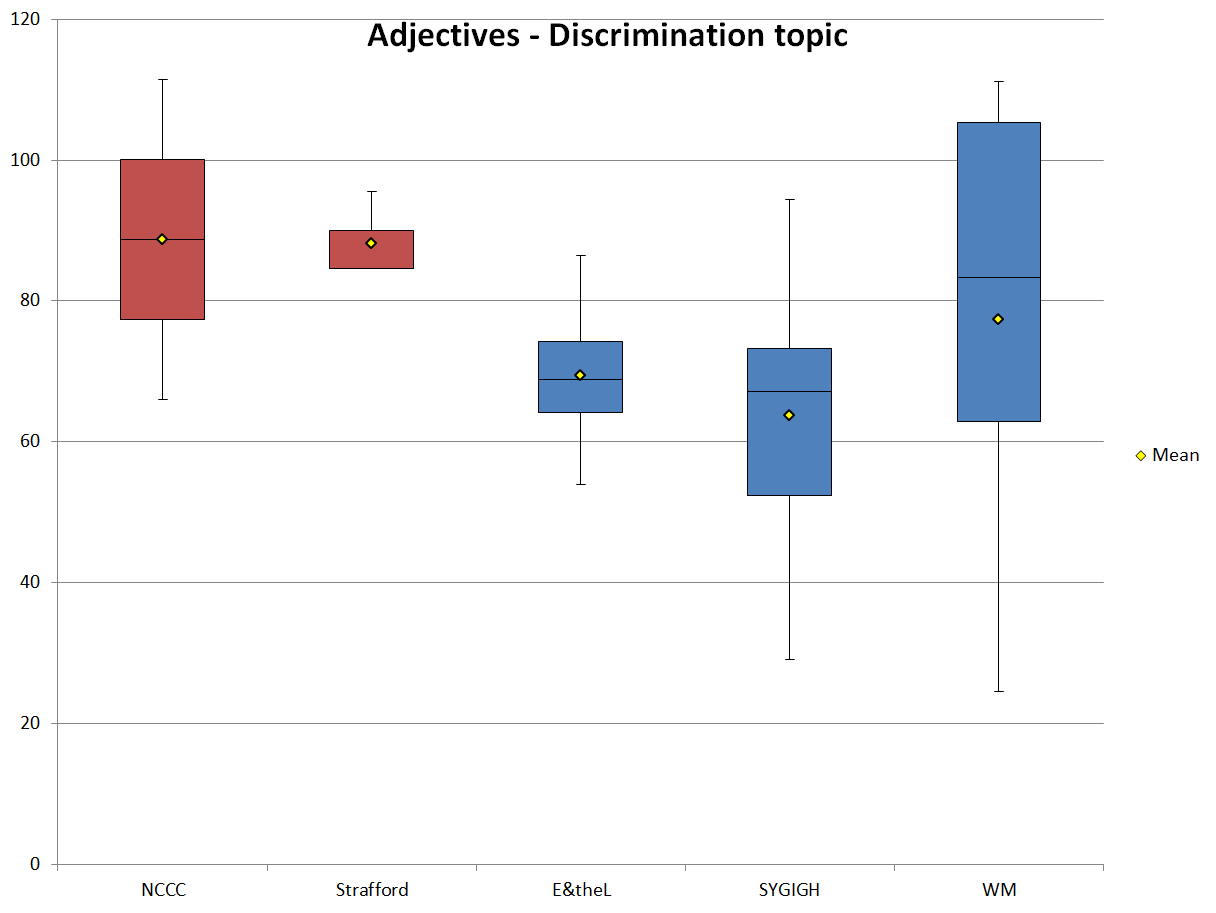
Figure 10. Normalized adjective frequencies (ptw) of the texts that discuss discrimination.
| Adjectives | NCCC | Strafford | E&theL | SYGIGH | WM |
|---|---|---|---|---|---|
| Mean | 88.69 | 88.19 | 69.43 | 63.70 | 77.42 |
| SD | 22.68 | 5.17 | 10.08 | 16.34 | 31.49 |
| Min | 66.01 | 84.53 | 53.94 | 29.07 | 24.49 |
| Max | 111.37 | 95.50 | 86.38 | 94.46 | 111.11 |
| Range | 45.37 | 10.96 | 32.44 | 65.39 | 86.62 |
While the analysis of nouns and adjectives in the texts on discrimination in the workplace showed that the marketing sub-corpora were more formal and informational than the blog sub-corpora, the frequencies for the verbs and adverbs are not as clear cut. Figure 11 shows the normalized verb frequencies for the discrimination texts in each sub-corpus. Here the differences in usage between the marketing and blog sub-corpora are not nearly as large as they were for the nouns. The difference in means between the blog sub-corpus WM and the marketing sub-corpus NCCC, for example, is less than three points, while the difference between the blog sub-corpus E&theL and NCCC is only ten points. These frequencies and the differences between them do not easily fit with the idea that the blogs are more informal than the marketing texts, at least not in terms of their use of verbs. It would be safer to say instead that based on these frequencies, the marketing sub-corpus NCCC and the blog sub-corpora E&theL and WM are relatively similar to each other and that they are less formal than the marketing sub-corpus Strafford and more formal than the blog sub-corpus SYGIGH.
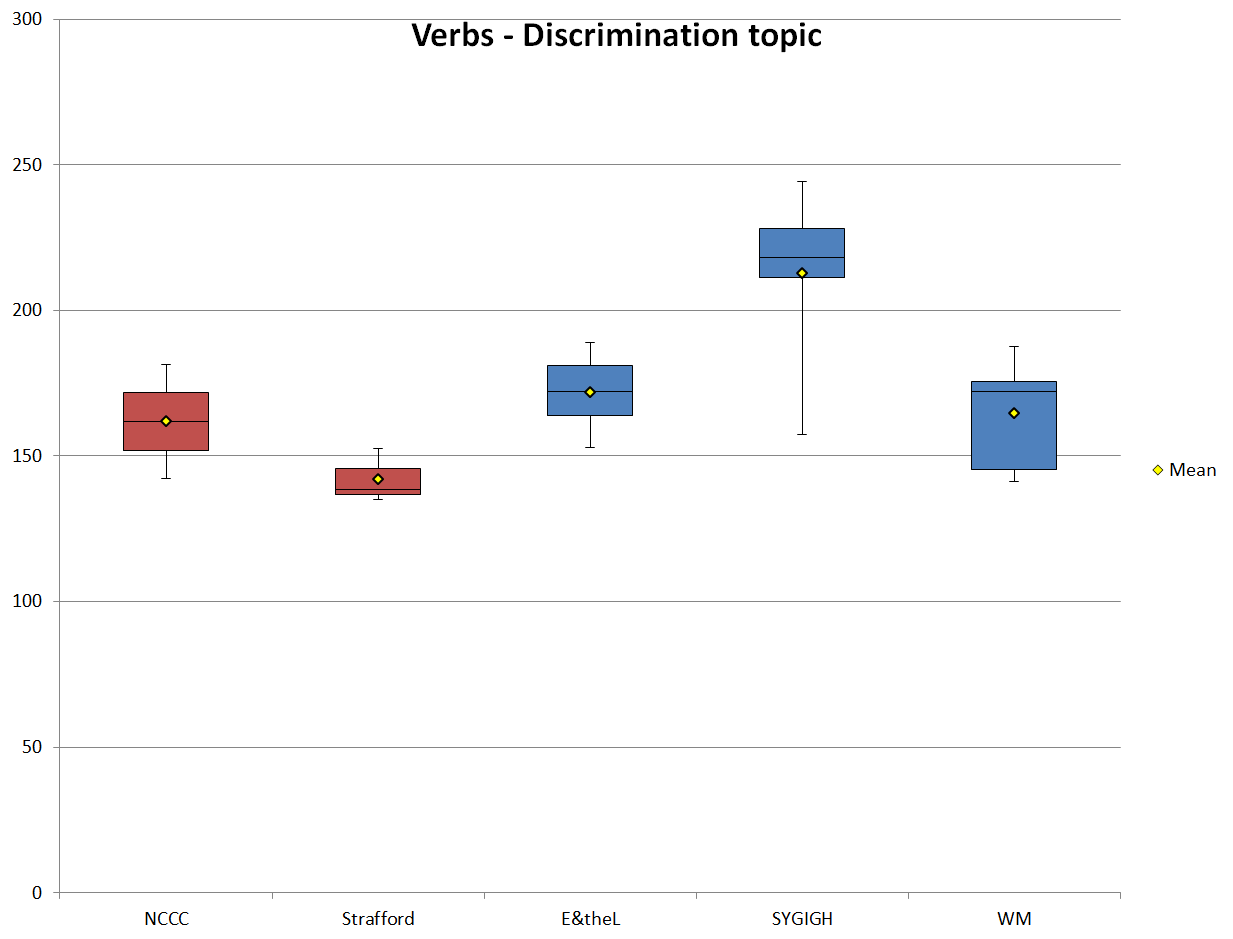
Figure 11. Normalized verb frequencies (ptw) of the texts that discuss discrimination.
| Verbs | NCCC | Strafford | E&theL | SYGIGH | WM |
|---|---|---|---|---|---|
| Mean | 161.85 | 142.07 | 171.90 | 212.77 | 164.43 |
| SD | 19.67 | 7.56 | 12.25 | 25.04 | 18.03 |
| Min | 142.18 | 135.14 | 152.82 | 157.30 | 141.30 |
| Max | 181.52 | 152.58 | 189.02 | 244.19 | 187.76 |
| Range | 39.34 | 17.44 | 36.20 | 86.88 | 46.45 |
The use of adverbs backs up this statement. Figure 12 shows the adverb frequencies for the discrimination texts for each sub-corpus. From the mean frequencies, we can see that NCCC, E&theL, and WM are relatively similar to each other, but different than both Strafford and SYGIGH. This is what we would expect from the analysis of verbs in the discrimination topic, but like that analysis, it is also in direct contrast to what we would expect from the analysis of nouns and adjectives in the discrimination topic. It is not so easy to divide the two genres based on formality. Rather, when we try to conclude the relative formality of these sub-corpora based on their use of nouns/adjectives and verbs/adverbs, we get conflicting results. Thus, I would argue that Heylighen and Dewaele’s (2002: 335) claim that formality “is the most fundamental and most universal dimension of stylistic variation” needs to be qualified. It does not seem to hold for genres or texts that share an audience and a microtopic. Their claim is not apparent here, at least not when the other analyses have shown a clear distinction between the genres. I would not be surprised if other comparisons between texts which share certain features such as topic and audience, but which come from different genres, showed similar results.
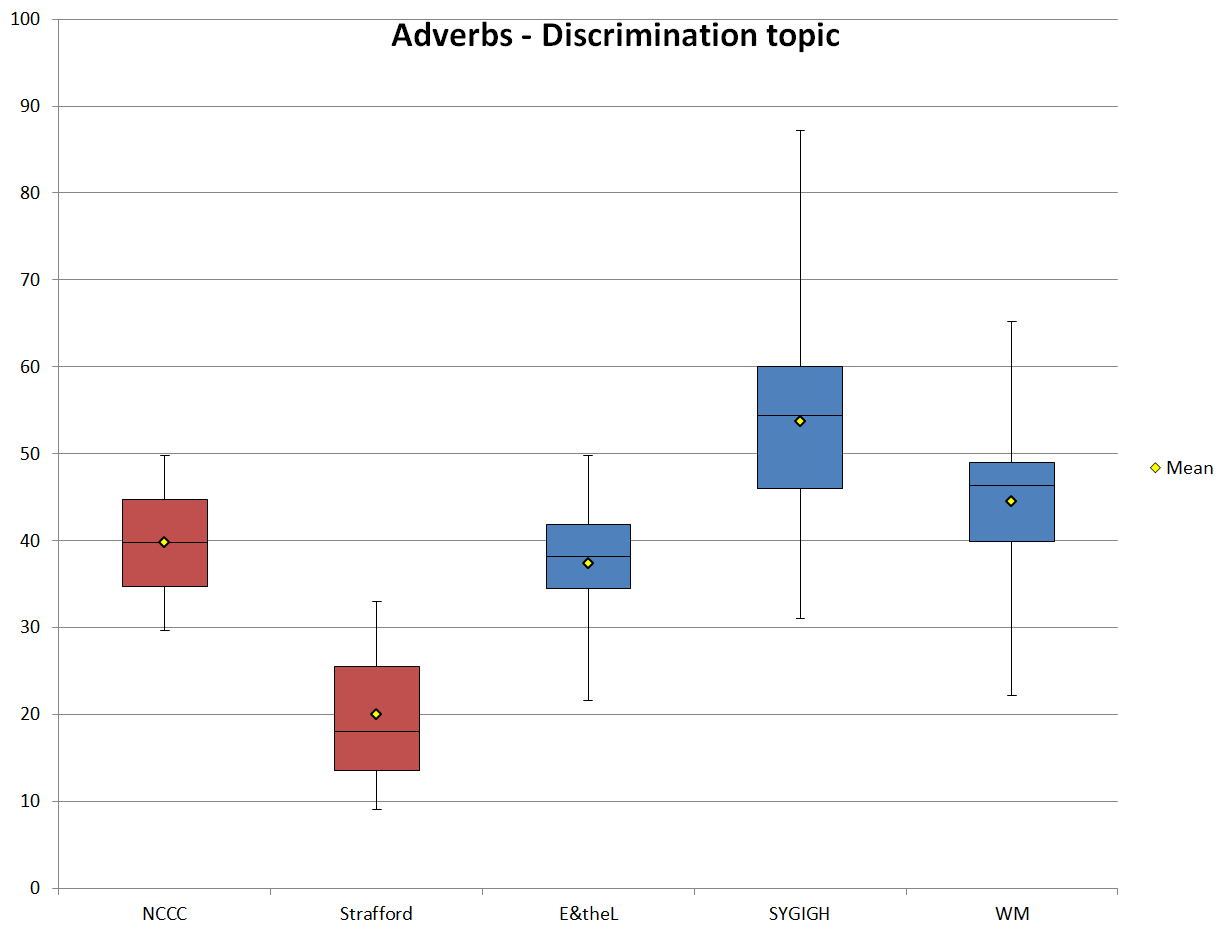
Figure 12. Normalized adverb frequencies (ptw) of the texts that discuss discrimination.
| Adverbs | NCCC | Strafford | E&theL | SYGIGH | WM |
|---|---|---|---|---|---|
| Mean | 39.73 | 19.99 | 37.35 | 53.65 | 44.52 |
| SD | 10.03 | 9.89 | 8.65 | 14.54 | 13.92 |
| Min | 29.70 | 9.01 | 21.59 | 31.09 | 22.22 |
| Max | 49.76 | 32.99 | 49.79 | 87.21 | 65.16 |
| Range | 20.06 | 23.98 | 28.20 | 56.12 | 42.94 |
The frequencies of pronoun usage in the discrimination texts are similar to the verb and adverb frequencies. Figure 13 shows the normalized pronoun frequencies and we can see that again the mean frequencies for NCCC, E&theL, and WM are similar. If a higher frequency of pronouns indicates “a less formal style” and a more “interpersonal focus” (Biber 1988: 225), then these three sub-corpora are somewhat less formal than the marketing sub-corpus Strafford and very much more formal than the blog sub-corpus SYGIGH. This is the same conclusion that was drawn from the verb and adverb frequencies and it is different than what the noun and adjective frequencies told us. The frequencies do, however, fit with Heylighen and Dewaele’s (2002: 308) assumption that in less formal texts, an increase in verb frequencies “will be reinforced by the fact that the more formal noun phrases [….] will tend to be left out completely or replaced by pronouns”.
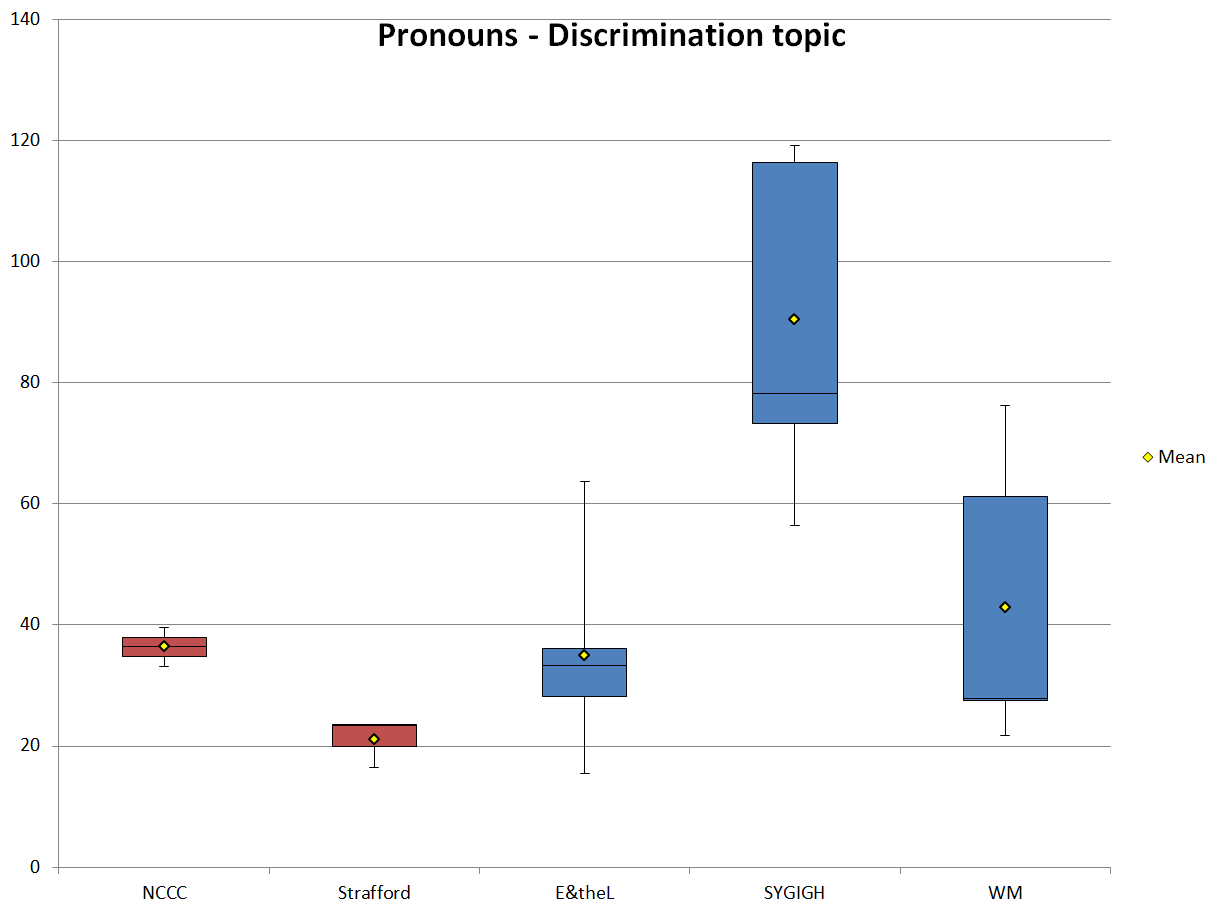
Figure 13. Normalized pronoun frequencies (ptw) of the texts that discuss discrimination.
| Pronouns | NCCC | Strafford | E&theL | SYGIGH | WM |
|---|---|---|---|---|---|
| Mean | 36.39 | 21.10 | 34.91 | 90.48 | 42.89 |
| SD | 3.21 | 3.26 | 14.64 | 22.43 | 21.70 |
| Min | 33.18 | 16.49 | 15.43 | 56.49 | 21.74 |
| Max | 39.60 | 23.42 | 63.67 | 119.08 | 76.16 |
| Range | 6.43 | 6.93 | 48.24 | 62.59 | 54.42 |
In terms of the relative formality of the sub-corpora then, we are left with, on the one hand, noun and adjective frequencies that make a clear divide between the genres and, on the other hand, verb and adverb frequencies, backed up by the pronoun frequencies, that group two of the blog sub-corpora (E&theL and WM) with one of the marketing sub-corpora (NCCC). The verb/adverb and pronoun frequencies further set this group off as being more formal than the other blog sub-corpus (SYGIGH) and less formal than the other marketing sub-corpus (Strafford).
The first result of this article is that the corpus linguistic analysis showed that dividing the texts on formality is not as straightforward or clear cut as it would seem to be. We saw that the overall comparison of the genres showed that the marketing texts displayed lexico-grammatical features that pointed to a more formal style than the blogs. The analysis of the discrimination topic, however, showed conflicting results. The division of the sub-corpora based on formality markers in the topic analysis was not between the blog and marketing genres, but rather between NCCC, E&theL, and WM on the one side and Strafford and SYGIGH on the other. I believe this shows the need to perform more precise analyses when using corpus linguistics and making claims.
Another aspect of my research that should be discussed is how the comparison of the corpus linguistic analysis to the genre analysis of the WM blog showed what the corpus annotation software missed. The lengthy genre analysis performed in my MA thesis (McVeigh 2013), which unfortunately had to be left out of this article, showed that although the WM texts were the most formal based on their lexico-grammatical properties analyzed, they still included very informal language, which was found in the close readings using genre analysis. [8] This is precisely the problem that Archer (2012) warned researchers about when she reiterated Sinclair’s (2004) concerns about corpus annotation schemes which are not sensitive to certain linguistic properties. Corpus linguists would be wise to remember Archer’s warning and always analyze their texts more closely to see if texts on specific topics follow the general properties of the corpus. In the case of the discrimination texts in the WM sub-corpus, claiming that they are more formal would be misleading. The close reading of the marketing texts also helped to further show how uniform they are in their structure. Every text includes the exact same sections and the exact same rhetorical moves forming in a straight line from top to bottom. They start with a title, then comes a summary of the webinar (the product being sold), then bullet points on the topic of the webinar, and finally each text ends with the speaker bio. This formulaic structure is followed across every text in the corpus. It partly explains why they would be more formal, since the bullet points would have to be noun heavy if they want to convey the maximum amount of information about the webinar, but it is also very interesting to notice in a genre that is by and large thought to be very dynamic and innovative.
My analysis showed that comparing marketing to blogging really is like comparing apples to oranges. The claim at the start of this paper, that marketing liberally borrows linguistic structures, was not proven from this comparative analysis, even though the marketing texts are heavily influenced by the blogs. Despite the many similarities of the subgenres in my corpus, such as the community of discourse and topic, their differing goals or purposes is enough to result in two relatively different sets of texts.
The analysis showed that it is obvious the marketers are not trying to make their texts look like the blog posts which are directed at the same audience. This is smart. No matter how much the blogs influence the marketers, or how much the marketers borrow from the blogs, they would do well to remember what the community expects from them and what the purposes of their texts are if they wish to create texts that will be valued by the community. For their part, linguists wishing to compare genres should prepare to see variation even at the microlevel of monotopical blogs and targeted email marketing texts.
The other benefit to marketers is that further research in this area can provide them with the information they need to write successful marketing in the future. Email marketers have recourse to certain ways of analyzing their copy, such as A|B testing, where a few small groups of people on a large email list are sent different messages selling the same product. The message which performs (or sells) the best, will then be used to market the product to the entire email list. For example, President Barack Obama’s election team successfully used A|B testing with their email list to raise money for his reelection campaign in 2012 (Green 2012). This type of analysis is insufficient, however, in that it can only tell marketers which text performed better. What they should be asking is why that text performed better and what its specific linguistic properties are so that they can mimic the successful style in their future copy writing.
On the linguistics side, there are some important areas that were not discussed in this article, but which are open for future research. The first of these is obviously the comments and hyperlinking aspects of the blogs, two aspects of the genre that previous researchers have deemed to be essential to its definition (Blood 2003, Myers 2010) and an area that linguists are showing an interest in (Kehoe & Gee 2012). Since the blogs here represent a sub-genre, research into these aspects of them could show whether they follow the larger blog genre, or whether there is an important and interesting variation between these two.
Another area that I plan to incorporate in future research is the software used in email marketing. These days it is easy to automatically append a recipient’s name to the email, or any other personal information that is known. This changes the emails slightly in that they can include personal details about the recipients and yet still be produced for the mass community. So from a sociolinguistics perspective, it would be interesting to see how this technology affects the interpretation of the marketing texts. Now that I have shown how the quantifiable structure of these texts, we can ask qualitative questions such as whether the community members feel a more personal connection with the emails when their name is automatically appended, therefore making the emails more informal? Or are these viewed as technological gimmicks, quickly picked up and brushed aside? If the community judges this automatic appending of their names to the emails to be insincere, it may serve to place the two at a greater distance from each other, which is exactly the opposite of what the technology is supposed to do. By adding more texts to the corpus which cover a greater period of time, a diachronic approach can be taken to show how the sub-genres have changed over time. The very existence of monotopical blogs shows how the larger blog genre has grown and shifted, so it would be informative to compare the results here to other types of email marketing to show the variation in the genre. Finally, my future research will focus on comparing the language of successful email marketing texts to less successful ones from the same company. I will be looking for patterns in the successful texts, while at the same time separating the subject lines from the email bodies since these are often treated as distinct entities in the creation of email marketing texts.
Finally, there are many more directions to go in both the corpus linguistic and genre analyses. This article looked at the relationship between nouns and verbs, and what that says about the formality of the text, but the corpus could be divided in many other ways. For example, the specific pronouns used in the different sub-corpora could be analyzed, as well as the way in which they cluster. Other possibilities for future research include a comparison of tense, the type-token ratio and the average word length in the sub-corpora. These areas of research would contribute to the analysis by helping to define the corpus better and by situating it in terms of the (sub)genres that it includes.
[1] “Webinars” are online seminars or learning courses offered to any sort of business professional. They will be explained in more detail below. [Go back up]
[2] The ABA Journal calls these “blawgs”, but I’ll refrain. [Go back up]
[3] The other types of email marketing are “retention email,” an informational text that usually takes the form of a newsletter, and “advertising in other people's emails.” [Go back up]
[4] Obviously, the amount of rewrites I performed may just show that I am a lousy copywriter. [Go back up]
[5] The issue of price is something that I plan to address in my doctoral dissertation, in which I will rank marketing texts based on their sales figures and then compare the linguistic properties of the more successful texts to the least successful ones. [Go back up]
[6] The law firm that these two authors work for actually started another law blog in 2011, with the author I excluded as its main author and one of the posts in my corpus is a promotion for this new blog. [Go back up]
[7] Heylighen and Dewaele use the term “contextuality” to refer to the informality of a text.[Go back up]
[8] Examples of this informal language are “Let’s play claim or no claim”, a subtitle which appeared in more than a couple posts, and “My take:”, which was used to introduce the blogger’s advice on the issue at hand. [Go back up]
Awkward Family Photos: http://awkwardfamilyphotos.com/
I Can Has Cheezburger: http://icanhas.cheezburger.com/
American Bar Association Journal. 2012. The 2011 ABA Journal Blawg 100. Available in archived form (cached 20 September 2012) at: http://web.archive.org/web/20120920090752/http://www.abajournal.com/blawg100
Anthony, Laurence. 2011. AntConc, freeware, build 3.2.4. Tokyo: Waseda University. http://www.laurenceanthony.net/software/antconc/
Archer, Dawn. 2012. “Corpus annotation: A welcome addition or an interpretation too far?” Outposts of Historical Corpus Linguistics: From the Helsinki Corpus to a Proliferation of Resources (Studies in Variation, Contacts and Change in English 10), ed. by Jukka Tyrkkö, Matti Kilpiö, Terttu Nevalainen & Matti Rissanen. Helsinki: VARIENG. http://www.helsinki.fi/varieng/series/volumes/10/archer/
Barton, David & Carmen Lee. 2013. Language Online: Investigating Digital Texts and Practices. New York: Routledge.
Bhatia, Vijay K. 2004. Worlds of Written Discourse: A Genre-Based View. New York: Continuum.
Biber, Douglas. 1988. Variation Across Speech and Writing. Cambridge: Cambridge University Press.
Biber, Douglas & Susan Conrad. 2001. “Introduction: Multi-dimensional analysis and the study of register variation”. Variation in English: Multi-Dimensional Studies, ed. by Susan Conrad & Douglas Biber, 1–13. London: Longman.
Blood, Rebecca. 2002. “Weblogs: A history and perspective”. We’ve Got Blog, ed. by Rodzvilla, John, 7–16. Cambridge, MA: Perseus.
Blood, Rebecca. 2003. “Weblogs and journalism: Do they connect?”. Nieman Reports 57(3). http://niemanreports.org/articles/weblogs-and-journalism-do-they-connect/
Brownlow, Mark. 2013. “What is email marketing?”. Email Marketing Reports. http://www.email-marketing-reports.com/intro.htm [archive.org]
Clark, Brian. 2012. “How to write magnetic headlines”. Copyblogger. http://www.copyblogger.com/magnetic-headlines/
CLAWS (The Constituent Likelihood Automatic Word-tagging System), software, CLAWS7 tagset. University Centre for Computer Corpus Research on Language: Lancaster University. http://ucrel.lancs.ac.uk/claws/
Conrad, Susan & Douglas Biber, eds. 2001. Variation in English: Multi-Dimensional Studies. London: Longman.
Green, Joshua. 2012. “The science behind those Obama campaign e-mails”. Bloomberg Businessweek. https://www.bloomberg.com/news/articles/2012-11-29/the-science-behind-those-obama-campaign-e-mails
Herring, Susan C., Lois Ann Scheidt, Sabrina Bonus & Elijah Wright. 2004. “Bridging the gap: A genre analysis of weblogs”. Proceedings of the 37th Hawaii International Conference on System Sciences, Track 4, Vol 4, doi:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.459.2930&rep=rep1&type=pdf
Herring, Susan C. & John C. Paolillo. 2006. “Gender and genre variation in weblogs”. Journal of Sociolinguistics 10(4): 439–459. doi:10.1111/j.1467-9841.2006.00287.x
Heylighen, Francis & Jean-Marc Dewaele. 2002. “Variation in the contextuality of language: An empirical measure”. Foundations of Science 7(3): 293–340. doi:10.1023/A:1019661126744
Hudson, Richard. 1994. “About 37% of word-tokens are nouns”. Language 70(2): 331–339. http://www.jstor.org/stable/415831
Kehoe, Andrew & Matt Gee. 2012. “Reader comments as an aboutness indicator in online texts: Introducing the Birmingham Blog Corpus”. Aspects of Corpus Linguistics: Compilation, Annotation, Analysis (Studies in Variation, Contacts and Change in English 12), ed. by Signe Oksefjell Ebeling, Jarle Ebeling, & Hilde Hasselgård. Helsinki: VARIENG. http://www.helsinki.fi/varieng/series/volumes/12/kehoe_gee/
Kim, Brad. 2009. “Single topic blogs”. Know Your Meme. http://knowyourmeme.com/memes/single-topic-blogs
Kim, Maria. 2007. “Discourse features and marketing strategy in American magazine advertising”. Texas Linguistic Forum 51 (Proceedings of the Fifteenth Annual Symposium About Language and Society, Austin, April 13–15, 2007): 95–102. http://salsa-tx.org/proceedings/2007/Kim.pdf
LexisNexis. 2011. “Announcing the LexisNexis labor & employment top blog 2011”. 1 October 2011. https://www.lexisnexis.com/legalnewsroom/labor-employment/b/top-blogs/archive/2011/10/01/announcing-the-lexisnexis-labor-amp-employment-top-blog-2011.aspx?Redirected=true
McGlaughlin, Flint, Daniel Burstein, Ashley Hanania, Paul Cheney, Luke Thorpe, Dave Garlock, Steven Beger, Jessica McGraw, Austin McCraw & Aimee Thompson. 2012. “Subject lines tested: How to write subject lines that double your clickthrough rate”. MarketingExperiments. http://www.marketingexperiments.com/website-optimization-transcripts/2012-07-24.pdf
McVeigh, Joseph. 2013. Apples and Oranges: A Comparative Analysis of Blogs and Marketing Texts Which Share an Audience. Unpublished Master’s thesis. University of Helsinki: Modern Languages Department.
Myers, Greg. 2010. The Discourse of Blogs and Wikis. London: Continuum.
Sinclair, John. 2004. Trust the Text: Language, Corpus and Discourse. London: Routledge.
Swales, John. 1990. Genre Analysis. Cambridge: Cambridge University Press.
Yates, Joanne & Wanda J. Orlikowski. 1992. “Genres of organizational communication: A structurational approach to studying communication and media”. Academy of Management Review 17(2): 299–326.
NCCC. 2011. National Constitution Center Conferences. http://www.constitutionconferences.com/18E/3CH
Strafford. 2011. Strafford Publication, Inc. http://www.straffordpub.com/employment-law-erisa [archive.org]
E&theL = Kasarjian, Ashley. 2011. Employment and the Law. https://employmentandthelaw.com
FMLAI = Nowak, Jeff. 2011. FMLA Insights. http://www.fmlainsights.com/
SYGIGH = Ballman, Donna. 2011. Screw You Guys, I'm Going Home. http://employeeatty.blogspot.com/
WM = Maslanka, Michael P. 2011. Work Matters. http://www.texaslawyer.typepad.com/work_matters/
Figure 14. The NCCC7 landing page. The language outside of the red box was not included in the corpus. URL for the landing page: http://www.constitutionconferences.com/1R4/0
Figure 15. The Strafford8 landing page. The language outside of the red box was not included in the corpus. URL for the landing page: http://www.straffordpub.com/products/when-the-eeoc-comes-knocking-2011-07-21
Figure 16. E&theL5 as it appears on the internet. The language outside of the red box was not included in the corpus. The URL for the page is: https://employmentandthelaw.com/2011/01/24/in-the-zone-retaliation-under-title-vii/.
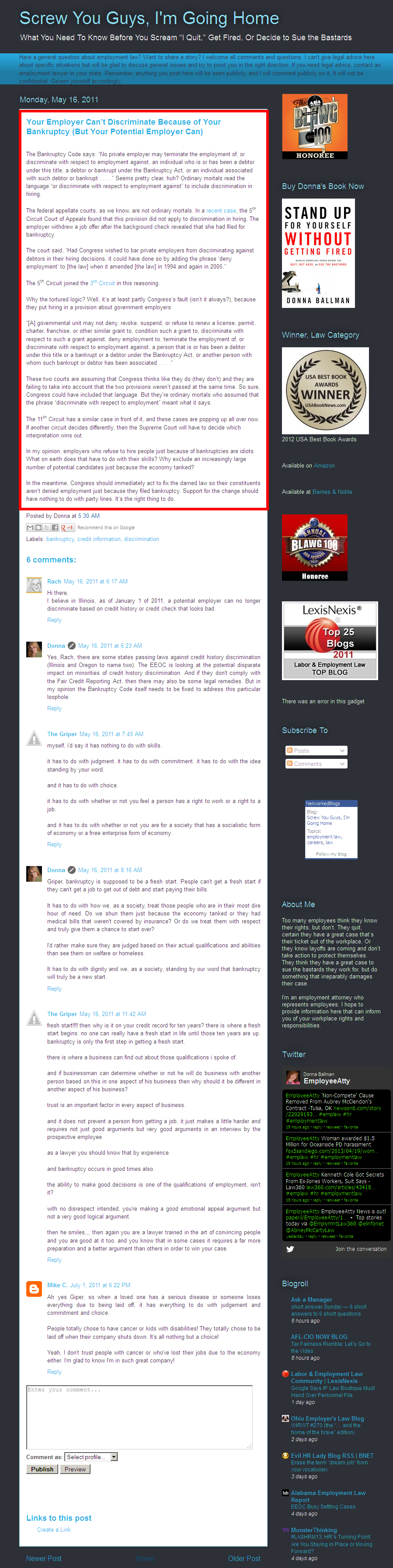
Figure 17. SYGIGH12 as it appears on the internet (the image is cut off at the end of the comments section, but the page continues down because the sidebar is so long). The language outside of the red box was not included in the corpus. The URL for the page is: http://employeeatty.blogspot.fi/2011/05/your-employer-cant-discriminate-because.html
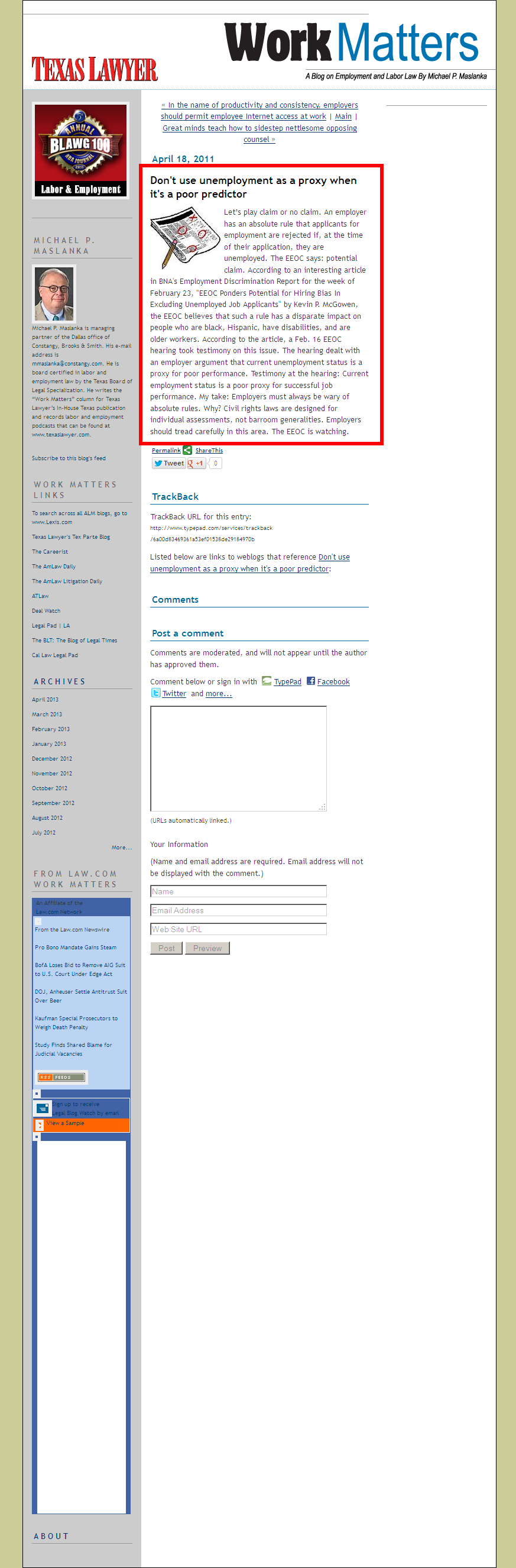
Figure 18. WM26 as it appears on the internet. The language outside of the red box was not included in the corpus. The URL for the page is: http://texaslawyer.typepad.com/work_matters/2011/04/dont-use-unemployment-as-a-proxy-when-its-a-poor-predictor.html.

University of Helsinki