
Studies in Variation, Contacts and Change in English
Studies in Variation, Contacts and Change in English
Christina Sanchez-Stockhammer
Friedrich-Alexander University Erlangen-Nürnberg
Empirical research on language is limited to the analysis of linguistic usage in the present and in the past. The unavailability of future linguistic performance makes it impossible to draw any certain conclusions regarding developments which lie ahead in time. It remains to be seen, however, whether all predictions are necessarily purely speculative: a growing body of empirical research on language variation and in statistics seems to suggest that linguistic change is subject to certain regularities, e.g. regarding the typical S-shaped growth curve observed in processes of change. At the same time, a multitude of disruptive factors may lead to unpredictable developments.
This introduction gives an overview of the current state of discussions on this issue and points out the main questions which are addressed in the various contributions.
The study of language usually pursues research questions that can be qualified as belonging into either of two categories:
This Saussurean (1916/1959: 79) dichotomy of synchronic and diachronic linguistic types of approach can be applied to any stage of any language (e.g. Old English or Middle High German). With regard to the present state of the English language, one finds synchronic descriptions of Present-Day English and diachronic descriptions of how Present-Day English has evolved.
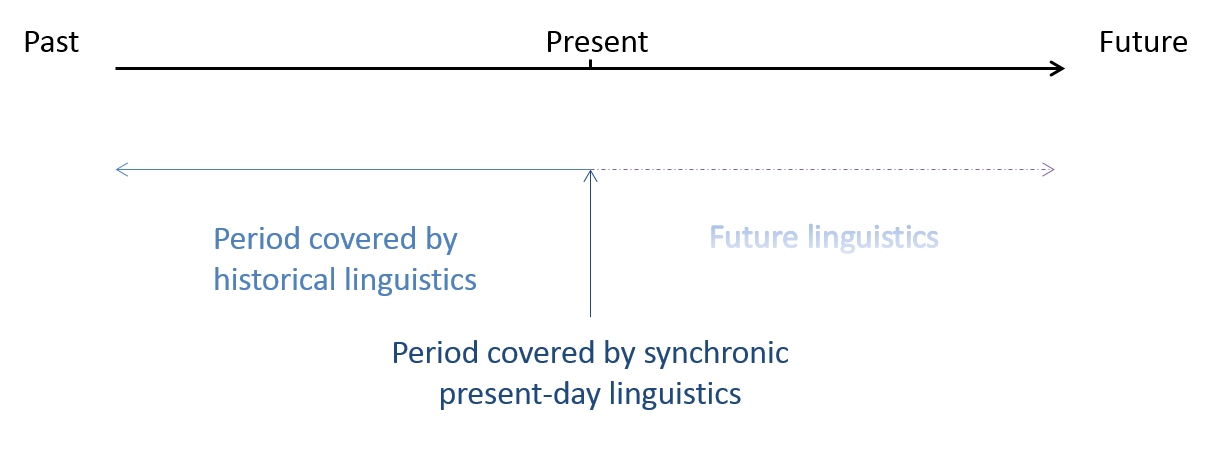
Figure 1. Possible synchronic and diachronic linguistic perspectives involving the present.
If we visualise time graphically as an arrow (as in Figure 1), present-day synchronic linguistics describes the present state of a language, and historical linguistics describes its past stages or developments in the past, i.e. the left hand side of the diagram. The right hand side of the diagram, by contrast, which represents the complementary perspective regarding linguistic change, namely the developments that still lie ahead, is rarely ever discussed in linguistic treatments of the English language (but cf. Section 4). The diachronic study of Present-Day English can thus be considered equivalent with historical studies of the language, whereas the discussion of future developments seems to occur most commonly in the form of subjective prescriptive laments by non-linguists about the deplorable present state of the language compared to an idealised past and caveats regarding the current trajectory of change (cf. also the discussion in Aitchison 1991). This current relative lack of discussion on possible future developments in the English language may be explained by the prevalent scepticism with regard to the predictability of future linguistic changes.
The common view is that it is not possible to make sensible predictions about future linguistic developments. The reasons for this are manifold. Szmrecsanyi (2014) argues that linguistic changes are part of culture and therefore similarly difficult to predict as other trends in society, Croft (2000: 2–3) assumes that language change is at least partly random, and Labov (1994: 10) characterises language change as “irrational, violent, and unpredictable”. Yet even if there should be laws of language change that apply regularly and even if we knew them, we could not be certain that their premisses are still going to be fulfilled in the future (Keller 1994: 75). Since similar words may undergo the same change at different times (cf. the case of can and may, which turned into modals at different speed), we need to conclude that even if we knew the starting date and direction of a change, we could not know in advance how long it would take (Bauer 1994: 24–25). Furthermore, it is difficult to determine whether ongoing variation in frequency distributions is the beginning of a full-fledged linguistic change or simply “an insignificant, temporary ‘blip’” (Graddol 1997: 19). Since “we lack the benefits of hindsight” and do not “have a clear idea about the goal of a development” (Mair 2009: 14), language users are more likely to prematurely “recognise” the start of a trend they expect, while “unexpected changes are likely to go unnoticed” (Graddol 1997: 19). Another problem is the fact that even trends that seem to develop steadily may change for reasons that are inconceivable at the moment of making a prediction. For instance, the emergence of computer-mediated communication and the ensuing primacy of typed writing has resulted in a decrease in the proportion of handwriting which was not to be expected in the early 20th century, and it may well be that the future holds communicative means that are not imaginable today. [1] Even if the more general question whether language change can be promoted by media is highly controversial, as is evidenced by Sayers’ (2014) focus article and the Debate suite of articles on the topic in the Journal of Sociolinguistics 18(2), it is relatively uncontroversial that linguistic change in the past has been affected by the occurrence of language-external “sudden and unique events” (Labov 1994: 21), such as political changes which resulted in “radical substitutions of one prestige norm for another, and consequent long-term effects on the language” (Labov 1994: 24). Since it is not possible to predict such disruptive factors (e.g. the 1066 Norman Conquest with its wide-reaching influence of French on English), they may potentially interfere with any prediction regarding linguistic change. [2] According to Zuraw (2003: 172), it is also difficult to determine which out of the variety of possible factors (such as variation caused by language/dialect contact or the frequencies of ambiguous constructions) were actually responsible for instances of language change. To many researchers, language is a complex system in which “complex interactions make prediction unreliable” (Graddol 1997: 21). Bauer’s (1994: 25) conclusion that “[d]iachronic linguistics is not a predictive science” is therefore highly understandable. To this can be added Jagger’s (1940: v) observation that
[s]cholars are naturally reluctant to commit themselves to statements which, being highly speculative, are open to criticism from many sides, and which in some unsuspected way time may utterly falsify.
However, one should not forget that our knowledge of the past is also to a certain extent speculative. For instance, Proto-Indo-European, which is a reconstructed language, may have been reconstructed incorrectly at least regarding certain aspects (Comrie 2003: 245). Since there are no sound recordings prior to the 19th century, the phonetic realisation of individual letters in Old or Middle English written texts also had to be reconstructed based on various types of evidence (cf. e.g. Hogg 1992: 67–71). [3] Also, the etymologies of individual lexemes sometimes differ between various sources (particularly where changes in both form and meaning are involved), which would seem to suggest that their reconstruction is error-prone at least to a certain extent, and the first known mention of any word (and thus its reconstructed age) only stands for as long as it is not superseded by the discovery of an even older document attesting to the word’s use. All these observations can be summed up in Labov’s (1994: 11) statement that “[h]istorical linguistics can […] be thought of as the art of making the best use of bad data”. However, while our assumptions about the history of the English language are only correct with a certain degree of likelihood, there seems to be a tendency to accept historical accounts of language as relatively factual. [4] This comparatively favourable attitude may be due to the fact that explanations in hindsight are likely to lead into the “I knew it would happen” trap described by Fischhoff & Beyth (1975). [5] As soon as diachronic linguistics assumes the opposite perspective, however, the uncertainty of the outcome is not veiled by such effects, which may deter the majority of researchers from pursuing this type of analysis. Nonetheless, the application of the diachronic approaches used for the study of the past to the discussion of potential future developments is justified – and the present volume intends to discuss whether it is possible to predict linguistic change on this basis.
Admittedly, the number of previous attempts at predicting the future of the English language is relatively small, but the proportion of eminent scholars who have been intrigued by this question and attempted to answer it is considerable.
Crystal (1995: 112) gives a brief overview of assumptions about the future of the English language from the 18th and 19th centuries, e.g. Jakob Grimm’s expectations regarding the global status of the English language or Noah Webster’s and Henry Sweet’s prediction that British, American and Australian English would soon develop into “mutually unintelligible languages”. Crystal (1995: 112) himself is rather sceptical regarding the issue and concludes that “[p]erhaps the only safe generalization to be made is that predictions about the future of English have a habit of being wrong”.
Quirk (1972: 68), by contrast, in an “exercise of enforced speculation”, makes a number of educated guesses about the shape and particularly the role of English twenty years ahead of the 1970 conference at which he delivered his original paper. He concludes: “I foresee a marked Europeanization of English, with large-scale borrowing of vocabulary”, with the intensity of the change depending on the relation of Great Britain to Europe.
Kortmann (2001) also discusses the question in detail in his paper “In the year 2525... Reflections on the future shape of English”. He states that “there is nothing daring in predicting an ever-increasing uniformity in the future” (Kortmann 2001: 102) and concludes with a number of predictions for future developments, which are based on current and previous changes in the English language. Among other things, he suggests that the progressive will become more pervasive, that the simple past will take over functions of the present perfect in British English (as in American English), that whom will be replaced with who, that the s-genitive will spread and that would will be used in conditionals (e.g. If he would come, we could leave.)
Mair (2013) speculates on the future of the English language from its perspective as a contact language in his eponymous paper. Since he evaluates the risk of predicting specific changes in the language higher than that of “extrapolating general socio-demographic trends” (Mair 2013: 315), his predictions for “a mobile and globalizing world” (Mair 2013: 317) are of the second kind, namely that
- there will be more and more diverse contact between English and other languages;
- there will be more and more diverse contact among varieties of English (standard and non-standard);
- the mediated performance (Coupland 2009) of vernaculars will be far more important as a site of language contact in the future. (Mair 2013: 317)
If we go back in time, one of the earliest longer discussions on the topic is Sélincourt’s (1928) fifty-page pamphlet Pomona or The Future of English. He states that “we know that the future will be linked mechanically with the present as the present is with the past”, but while he believes that “[t]here is basis [...] for a certain kind of scientific prediction“, he is more sceptical with regard to language (Sélincourt 1928: 8). Sélincourt (1928: 20) is of the opinion that English “is already spoken too generally for its good” and that “its expansion may yet prove its undoing”.
Yet another early book-length treatment of the topic is Jagger’s (1940) English in the Future. While the greatest proportion of the book is actually an account of the then present stage of the language and its historical evolution, it also entertains the idea that English will become more uniform in the future in “a fusion of English as now spoken in Britain and English as now spoken in America” due to the fact that American English has more speakers but that British English has “a greater general prestige” (Jagger 1940: 159). However, Jagger (1940: 174) believes that “the English of the future is going to be more American English than English English”. In the same vein, he expects that some American expressions “will be our own [= British English] very soon” (Jagger 1940: 81). According to Jagger (1940: 122), “[t]he most important event in the history of mankind during the last two centuries has been the growth and diffusion of the English tongue”, and he believes it likely to become “the universal tongue” (Jagger 1940: 193) in the future.
By comparison to these longer discussion of the topic, many other linguistic texts only make predictions about future developments in the English language in passing – e.g. Zipf (1965: 259–260), who predicts what he calls “the grand cycle in linguistic development”; i.e. that languages start out as analytic, then acquire inflection and then lose it again. Bochkarev, Solovyev & Wichmann (2014: 5) observe in passing that British English has recently become more similar to American English after an extended period during which its changes lagged behind one or two decades. They conclude: “Were we to try to predict the future, […] our bet would be that British English will cease to be conservative relative to American English” (Bochkarev, Solovyev & Wichmann 2014: 5).
The final chapter of Shay’s (2008) History of English also formulates predictions on a number of future developments in the English language. What makes this discussion of possible changes in the English language stand out is its inclusion of a number of sample texts written in what Future English might look like according to the author, e.g. Act 2, Scene 2 from Shakespeare’s Romeo and Juliet and the “nout frǝm dǝ ɔfǝ”, which states that “mi houp ju hæv ɛndӡɔi bʊk ǝv mi. dɛm hæv bi ǝ laiflɔŋ drim ǝv mi rait dɛm” (Shay 2008: 195). While Shay’s predictions are also based on currently observable processes in some varieties of English, many of his predictions are bolder than those found elsewhere – for instance, his expectation that the preterite form of verbs will be replaced by hæv + bare infinitive (Shay 2008: 192), or the orthographic system he proposes for an expected spelling reform, which partly uses IPA symbols (e.g. /ʃ/ for the current grapheme <sh>) and may therefore be considered relatively unlikely to gain common acceptance. [6]
Other samples of the English of the future are typically found in non-academic, borderline academic or literary texts: thus the online satirical linguistics journal SpecGram offers its readers an excerpt from Matthew 9:10–13 in “the dominant dialect of world English of the 22nd century”, in which present-day Jesus sat at meat in the house becomes Jesus was sittin ta eat n’t’house. Science fiction stories, which may be set in a more or less distant future, also need to represent their characters’ speech in some way or another and are thus forced to make predictions about the future of English (or, rarely, other languages; cf. Meyers 1980). Meyers (1980) gives examples from various science fiction novels in which the characters speak some future variety of English, e.g. Anthony Burgess’s A Clockwork Orange, in which the teenage slang Nadsat comprises loans from Russian. He concludes that the similarity of the language spoken in most science-fiction novels to Present-Day English is actually larger than the differences (Meyers 1980: 20), even if stylistic devices such as alternative spellings or verb-final sentence structures are used to convey a futuristic touch.
While these last instances might suggest that the predictability of linguistic change had better be relegated to the realm of science fiction, it is worthwhile considering the comparable case of bridges: bridges establish an enduring connection between entities that are apart and thus separate but at the same time still close enough to permit being linked. If entities are too distant from each other, they cannot be linked by a bridge but only by some means of transport, such as a ship or spaceship (if at all): thus a bridge between the Earth and the Moon is a highly unrealistic endeavour (e.g. due to the extremely long distance to cover, the lack of ground to base pillars on and the rotation of the heavenly bodies). However, if we look less far than the Moon, we can see several bridges on Earth whose construction was presumably also deemed impossible in the past, such as the Golden Gate Bridge in San Francisco, which has a main span of 1,280 metres and a total length of 2,737 metres. Construction of this longest suspension bridge in the world (from its completion in 1937 to 1964) had been delayed, since “there had been reasonable doubt as to whether it was even achievable, due to the strong currents and changing tides of the channel, as well as the commonly foggy, windy weather”. [7] [8] However, technological advances have long surpassed that feat of the past, and the impressive achievement of the Golden Gate Bridge is dwarfed by another modern suspension bridge, the 1998 Akashi Kaikyō Bridge in Japan, which has an impressive main span of 1,991 metres – that is, more than one and a half times the length of the Golden Gate Bridge.
The analogy to linguistic research is self-evident: in the past few decades, the technical opportunities for the empirical study of language have been increased beyond all expectations, too. As Sinclair put it in (1991: 1),
[t]hirty years ago when this research [i.e., corpus linguistics] started it was considered impossible to process texts of several million words in length. Twenty years ago it was considered marginally possible but lunatic. Ten years ago it was considered quite possible but still lunatic. Today it is very popular.
While the first corpora on the market still met with doubt regarding the degree to which they reflected linguistic usage, present-day corpora cover a large variety of different registers, and new corpora are continually being compiled: since 2013, for example, GloWbE, the Corpus of Global Web-Based English, has permitted the analysis of regional variation in English web pages. In 2009, a balanced corpus representing British English in the beginning of the 21st century, the BE06 Corpus, was added to the BROWN corpus family. With BLOB-1931 completed and BLOB-1901 “at an advanced stage of compilation”, the opportunity to observe recent change bordering on change in progress has thus increased dramatically. [9]
At the same time, corpus size has become ever larger: if GloWbE already comprises 1.9 billion words of mostly unedited electronic material, Google books contains as many as 361 billion words from edited books (Michel et al. 2011). The Google n-gram viewer provides appealing frequency charts of developments in any period between the years 1500 and 2000. Technological progress in general is likely to provide ever more suitable tools for the study of language and linguistic change, too. As a consequence, it is not completely excluded that it will be possible to achieve quantitative empirical results in future linguistic analyses that seem a long way off at present.
Even at the present, however, linguists can already draw on relatively sophisticated resources in order to analyse language empirically. Numerous studies research variation in linguistic usage and determine statistically under what conditions language users tend to choose one among the possible linguistic options over another.
To give just a few examples, Plag, Kunter & Lappe (2007) investigate stress assignment in noun-noun compounds and reach prediction accuracies of about 94% based on structural and semantic features and with constituent family as the most important determinant in their analogical model.
Szmrecsanyi and Hinrichs’s (2008) study of genitive variation considers seven major conditioning factors such as the animacy of the possessor or final sibilants in the possessor. Their use of binary logistic regression permits the correct prediction of the choice of S-genitive and OF-genitive in 70.4% to 88.8% of the cases in various corpora.
Gries (2003) uses discriminant analysis to explore what variables – such as the length of the direct object or the idiomaticity of the verb phrase – result in a preference for verb-particle-object ordering (e.g. in John picked up the book) vs. verb-object-particle ordering (e.g. in John picked the book up): all independent variables are entered into a single equation, and the strength with which they contribute to the selection of the variant is determined. The results based on multifactorial statistical techniques permit the prediction of “the subconscious choices of native speakers” with a predictive accuracy of 83.1% (Gries 2003: 166).
Studies such as these provide us with the means of making empirically grounded predictions regarding the linguistic behaviour of language users for one particular phenomenon in particular situations in the present state of the language. In these probabilistic accounts, the expectations for new test sets or situations are based on the algorithms’ performance in earlier tests. With the advent of a growing number of individual studies, our knowledge of the present and past stages of the English language becomes ever more detailed. Probabilistic variationist studies are of particular interest in the context of our overarching question whether it is possible to predict linguistic change, because variation is commonly recognised as the originator of linguistic change – which leads Guy (2011: 179) to characterise variation as “the synchronic face of change” and thus as the starting point for potential future developments in the English language to consider when attempting predictions.
Figure 2. Language through time.
Figure 2 exemplifies this graphically: if we represent language in all its many aspects as a two-dimensional vertical plane, then our knowledge about one particular phenomenon – such as particle placement – can be represented as a small area within that plane. (Of course, the scale is not accurate here.) If we now consider that language may change across time – which is represented as consecutive language planes following each other on the time arrow (actually, with an infinitely small distance between them), then it is theoretically possible to carry out studies on the same phenomenon at different times (e.g. for particle placement in the 17th, 18th, 19th, 20th and 21st century, or for sentence-initial and in Early Modern vs. Modern English registers, as is done by Dorgeloh 2004). The more individual research points there are, the more we know about the historical development of a particular phenomenon (which corresponds to the yellow arrow). [10] The same can be done for all phenomena of a language (exemplified by the colourful dots; e.g. comparison in adjectives, which corresponds to the orange points), and with each individual piece of empirical information at some time or another, our knowledge of a language and thus the basis from which we may extrapolate grows. A first step in this direction is the Language Change Database (LCD), which is currently being compiled at the University of Helsinki. Provided that we have some diachronic results, among which there is at least one relatively recent account, it may be possible to extrapolate from the findings about the present and the past and to make tentative predictions concerning future developments for particular phenomena, based on what we already know about linguistic change.
The study of linguistic change has always played an important role in linguistics. Particularly in its beginnings, the academic study of language mainly focused on historical developments and the earlier stages of the various languages under consideration. The neo-grammarians attempted to reconstruct language and to determine general principles governing linguistic change in the past (cf. e.g. Hickey 2003: 1). Recently, there has been growing interest in what Mair (2006: 11) calls modern historical linguistics: “the very recent history of English, that is, the two centuries since c. 1800, which is the time at which the history of English as told in classic treatments (for example, by Brunner, Jespersen or Visser) tends to peter out”. This is also the time which is crucial when it comes to the prediction of potential future changes in the language. Speculative as the enterprise of prediction may seem, the impressive body of previous research furnishes us firstly with a number of considerations regarding the nature of linguistic change and secondly with several observations that seem to apply relatively regularly when it comes to language change, and which one may base some educated guesses upon. [11]
In the very first place, there are a number of elaborate discussions of how and why languages change. For an overview of central approaches addressing the topic on a general level, cf. Schneider (1997). Labov has written extensively on the internal (1994), social (2001), cognitive and cultural (2010) principles which drive linguistic change. If we go back in time, Weinreich, Labov and Herzog (1968: 101–102) lay the foundations for much of the subsequent discussion of language change by identifying five issues that any theory of linguistic change (and thus also any prediction of future linguistic changes) needs to take into consideration: the constraints on changes, the stages intervening in transition, the associated changes and the effects of changes (e.g. on linguistic structure). Their most important question is why “changes in a structural feature take place in a particular language at a given time, but not in other languages with the same feature, or in the same language at other times” (Weinreich, Labov & Herzog 1968: 102). That linguistic change is “not a single event, but a high-level description of millions of individual interactions over time, with early interactions influencing later ones” (Zuraw 2003: 163), is also quite uncontroversial. So is the idea that living languages are usually in transition and therefore in a state of “orderly heterogeneity” (Weinreich, Labov & Herzog 1968: 100).
As for the generally applying principles, one which is widely accepted in the study of linguistic change (cf. Labov 1994: 22) is the so-called “Uniformitarian Axiom” (Lass 1980: 55), which states that “[n]othing (no event, sequence of events, constellation of properties, general law) that cannot for some good reason be the case in the present was ever true in the past” (Lass 1980: 55) and that processes which produce change in the present also applied in the past (Labov 1994: 21). For predictions, the uniformitarian principle is simply extrapolated to the future, which means that any general principles that hold true now are expected to apply to future linguistic stages.
As for the recurring patterns regarding linguistic change which predictions might focus on, the spread of innovations represents a central case. If linguistic change worked according to laypeople’s perspective, who usually assume “that what is happening now will simply continue” (Graddol 1997: 18), this could be graphed as a linear pattern, as in Figure 3.
Figure 3. Linear growth.
However, a common observation is that this is not how linguistic innovations spread. Instead, linguistic change is more aptly represented graphically as an exponential S-shaped growth curve (cf. e.g. Lass 1997: 140; Denison 2003: 56), which has, for instance, been observed in the historical separation of modal verbs from ordinary verbs or in the development of the use of the progressive (Aitchison 1991: 98–99).
Figure 4. The S-curve model of linguistic change.
The typical linguistic change thus fits into what Aitchison (1991: 83) calls “a slow-quick-quick-slow pattern” (but cf. Nevalainen for a critical discussion of that model). In the beginning, changes only affect few constructions (so that the curve is relatively flat). As soon as a critical mass has been affected, the change gathers momentum and has wide-reaching consequences (reflected by the steep part of the graph) before slowing down with regard to the last remaining constructions of the previous type (some of which may actually never change). An example for a development which is not yet complete would be the shift of short /æ/ to /ɑ:/ before /f/, /s/, /θ/, /m/_C and /n/_C, e.g. in class, sample and can’t, at the end of the 18th century in British English – but we still find /æ/ in the same phonological environment in classical, ample and cant in the early 21st century (Brinton & Arnovick 2006: 315–316, 397). With regard to the prediction of linguistic change, the observation of an S-shaped growth curve preceding the present time in an ongoing process of change means that the change is unlikely to speed up in the future, since most items in the language will have been affected by it already.
As for the speed of linguistic change, the analysis of lexical frequencies in the Google Books N-Gram Corpus suggests that the change rates in the English lexicon have been particularly high during politically turbulent times (such as the periods around the World Wars) and particularly low during politically stable periods, such as the Victorian era (Bochkarev, Solovyev & Wichmann 2014: 3–4).
In view of the observation that it is unusual for a language to borrow grammatical words such as personal pronouns (which is, however, the case with Scandinavian-origin they, their etc.; cf. Brinton & Arnovick 2006: 339), radical changes in that part of the lexicon are therefore relatively unlikely to occur in the future – or will at least require important external events and presumably an extended period of time.
While the vocabulary of a language such as English quickly adapts to new expressive requirements by the creation or borrowing of new words, diachronic research suggests that “grammar does not easily respond to changing fashions” and that it “typically takes several generations” to achieve grammatical change in a language (Kortmann 2001: 111). The reason why “there is more inertia, more continuity, than change”, is presumably the “need to be understood, both by peers and by the older generation, [which] applies a braking force on potential linguistic changes” (Hogg & Denison 2008: 39).
Another general observation is that
innovative features are not that radically novel in most instances – typically, changing features are not traits that were absolutely nonexistent in a language before, but rather it is inconspicuous older features, existing internal tendencies, properties that were there before but only under specific circumstances (Schneider 1997: 50),
which spread.
Sociolinguistic research has also yielded the result that linguistic change tends to start with younger speakers, with lower-class speakers, in spoken language and in informal language (Mair 2006: 29). It is more usual for linguistic changes to spread from spoken to written language rather than the other way round (Kortmann 2001: 100), and spoken forms are likely to enter the written language in the process of “colloquialization” (cf. Mair 1997). This can, for instance, be seen from the increased use of contractions in writing (Mair & Hundt 1997: 75).
With regard to geographical variation, Schneider’s (2007) Dynamic Model describes the development of all postcolonial Englishes all over the world as an analogous series of successive steps, starting with a stage of foundation, which is followed by periods of exonormative stabilisation, nativisation, endonormative stabilisation and finally differentiation. This regularly recurring pattern permits us to assign any postcolonial variety of English to a particular position on the evolutionary pathway and to make “educated guesses about its linguistic reality in future stages” (Szmrecsanyi 2014).
In spite of the relative confidence underlying predictions of this kind, these are still a long distance from what Weinreich, Labov and Herzog (1968: 99) consider the strong form of a theory of language change – after all, that “would predict, from a description of a language state at some moment in time, the course of development which that language would undergo within a specified period”. One may therefore still agree today with their conclusion that “[f]ew practising historians of language would be rash enough to claim that such a theory is possible” (Weinreich, Labov & Herzog 1968: 99).
At the same time, however, Weinreich, Labov and Herzog (1968: 99) do make a prediction of the negative type in their “more modest version” of a theory of language change, which formulates “constraints on the transition from one state of a language to an immediately succeeding state”. While such a modest theory of linguistic change does not predict “positively what will happen (except that the language will somehow change), such a theory would at least assert that some changes will not take place”, since they would violate “such formal principles as are postulated to be universal in human languages” (Weinreich, Labov & Herzog 1968: 100). [12] Even if one might be sceptical about what could constitute such universal principles, in the context of the question whether it is possible to predict linguistic change, it makes sense to explore the boundaries of linguistic change (i.e. unlikely future developments) which are set by the cognitive and physiological limitations of human speakers. [13]
Based on the assumption that any stage of any language needs to meet certain physiological and cognitive requirements, changes violating such constraints are less likely than other types of change – and sometimes even impossible (for instance, the biological foundations of language impose limitations on possible sounds; cf. Lenneberg 1967: 51). Lass (1980: 16–17) uses the term “boring universal” (which he credits to Geoff Pullum) to refer to linguistic changes that can be excluded a priori on physiological grounds: thus there are no languages making exclusive use of ingressive sounds (he jokes that “one did, but all the speakers died of anoxia”), and similarly, “no language has apico-uvular stops” (Lass 1980: 17) – the practical attempt at articulation explains why. Also, the openness and closeness of vowels is restricted by the physical qualities of the articulators (Labov 2001: 400). Very often, however, the limitations will not concern the articulatory extremes and be absolute but rather gradient, resulting in reduced likelihood of a potential change and thus a “statistical law” (Lass 1980: 18): for instance, combinations of nasals and obstruents in any language are likely to be homorganic because this reduces the articulatory effort, and we therefore “expect them to become homorganic if they aren’t already” (Lass 1980: 17). The same applies from the perspective of the listener: since maximally open front and back sounds are difficult to distinguish, linguistic changes which would emphasise this phonemic difference are relatively unlikely (Martinet 1952: 24). The non-existence of patterns across a large number of languages in typological research is thus indicative of the limits of potential language change (Kortmann 2001: 98). For instance, a change resulting in a language with more nasal than oral vowels does not conform “to the definition of possible language structure provided by present-day theory and typology” (Labov 1994: 17) and is therefore unlikely. While some constraints may be present in a large number of languages and thus reflect “universal tendencies of the language faculty”, other constraints may be “operative to greater or lesser degree in different languages” (Bod, Hay & Jannedy 2003: 7), which has direct implications regarding their likelihood to constrain potential linguistic changes in a particular language.
The cognition of their speakers also sets a limit to the shapes that natural languages may take. As Kiparsky (2008: 24) puts it, “properties of language change might be explained by the way language is acquired and structured in the mind”. Based on the assumption that “categories can be considered mental structures”, Winters (2010: 17–18) remarks that “the locus of language change lies within and across cognitive categories”. Compared to the physiological constraints, limitations on cognition and memory will tend to be even more of the gradual and less of the categorical type. For instance, linguistic changes resulting in a massive increase in very long compounds (such as holiday car sightseeing trip) are very unlikely, since these make high demands on processing, particularly in spoken language (cf. Schmid 2011: 205–206).
We may conclude from all of the above that some linguistic changes are indeed likelier than others – but as in any probabilistic model, this does not prevent some unlikely events from happening and some likely events from not happening. For instance, “grammars that seem to be functionally nonoptimal can persist for centuries” (Newmeyer 2003: 30). While general principles of language change might therefore provide the “favourable undercurrent, or perhaps prevailing wind, for changes now in progress”, it is possible that “enough social motivation or contrary linguistic pressures”, such as the efficient implementation of prescriptivism among language users, may result in movements in the opposite position, “just as a boat may tack into the wind” (Labov 2001: 499).
It is in full awareness of all of the above that the present volume attempts to discuss the question whether it is possible to predict linguistic change. The authors are not equipped with crystal balls but with corpora, statistical tests and critical minds. The volume assembles seven papers in total. The first two contributions (Nevalainen; Tagliamonte) focus on the general theoretical discussion of predictability in language change. They discuss the predictive potential of S-curve models of change (Nevalainen) and synchronic regional variation (Tagliamonte), among other things. The second half of the volume approaches the question whether it is possible to predict linguistic change by drawing on historical case studies on different levels of language; more specifically, phonology (Minkova) and syntax (Rütten on mood; Dorgeloh & Kunter on word order). The volume closes with a discussion of the potential influence of linguistic contact between native and non-native speakers of English on language change (MacKenzie).
More specifically, Nevalainen’s contribution “Descriptive adequacy of the S-curve model in diachronic studies of language change” discusses the modelling of variation across time. Her research on the Corpus of Early English Correspondence reveals an S-curve-like development in twelve out of fourteen cases under investigation (e.g. the subject form you replacing traditional ye), but periphrastic do reverts its change and thus develops in an inverted U-shaped curve. Interestingly, some reversals may even slightly revert again (e.g. the use of the form you was). While an expected S-curve does not call for an explanation, Nevalainen notes, a change reversal usually does – e.g. in the form of dialect contact or normative pressure. Nevalainen argues that real-time S-curves “can serve as a baseline against which individual, register and community variation can be identified and measured”.
In “Exploring the architecture of variable systems to predict language change”, Tagliamonte reviews three changes in progress (have got to, going to and be like) in order to answer the question whether it is possible to predict linguistic change, stressing the important role of context particularly in the beginning stages of a linguistic change. Even though Tagliamonte concludes that it is not possible to know precisely in advance what will change when, she expects an increase in predictive accuracy “given a longitudinal perspective, a known trajectory of constraints as well as attention to social, cultural and economic conditions”. Thus more conservative dialects are likely to follow the same steps in their development as more progressive dialects, so that the data from another region can be used to predict linguistic change at a specific place. Where studies in apparent time (and thus synchrony) mirror diachrony, the prediction that certain changes will go on seems more reasonable (e.g. the increase in have got in British dialects). Prescriptive tendencies may serve to explain differences that can be observed in specific registers or varieties (such as American English), e.g. with regard to the use of do periphrases or the development of have got. Tagliamonte also points out an important advantage of making predictions, namely that they permit to look for explanations when the actual results deviate from the predicted ones. Eventually, she calls for conducting more replications of existing studies, so as to catch language change in action and to improve predictability.
Minkova’s contribution “A U-turn and its consequences for the history of final schwa in English” represents a historical study as the background from which one might start to think about making predictions regarding future changes. Like Nevalainen, Minkova introduces a trajectory of change which does not represent an S-curve but a reversal of a statistically “perfect” change. She provides a very detailed discussion of the history of word-final schwa in English and analyses the possible reasons for the historical development of schwa-loss and its reinstatement in English – such as the influence of personal names with word-final schwa and the contact with languages like Latin, Spanish or Italian. Minkova argues that the reintegration of word-final schwa is irreversible and expects an extension rather than a reduction of its functions (such as the marking of personal names as female, e.g. in Georgia, which may possibly gain ground in recent word formations of the type artista or feminista).
In “For whom the bell tolls, or: why we predicted the death of the mandative subjunctive”, Rütten also discusses a phenomenon whose disappearance has been predicted, even frequently, in the past (but so far incorrectly), namely the mandative subjunctive. She argues that a very important aspect to consider in any prediction of linguistic change is what the alternatives to the phenomenon under consideration are, since this has direct implications for the results. For instance, it is very difficult to compare the various periods of English using the same potential triggering expressions for the mandative subjunctive as a context, because these are highly period-specific. As a consequence, one would be comparing very different systems at different times – a problem which can also be generalised to other phenomena of language change, and ultimately to the prediction of likely future developments.
Dorgeloh & Kunter’s paper “Modelling adjective phrase inversion as an instance of functional specialization in non-locative inversion” presents an empirical study on non-locative inversion following a fronted adjective phrase (e.g. in More significant is the finding that…) conducted on material from the 1820s to the 2000s from the COHA Corpus. Based on the preference of structures in the left periphery of clauses to connect to previous discourse or to express subjective contents, they expect to find an increase in this function over time in phrases consisting of one adjective with one premodifying general or degree adverb – which they do indeed. Dorgeloh and Kunter argue in favour of modelling linguistic change statistically, since this manages to represent the gradience of short-term developments. Their conclusion regarding the prediction of linguistic change in general is the importance of selecting a suitable scale for the classification.
According to MacKenzie’s “Will English as a lingua franca impact on native English?”, the variation found in English as a Lingua Franca (ELF) compared to English as a native language can either be explained by mistakes and imperfect acquisition or as instances of deliberate, simplifying choices. This involves features such as the use of the simple present (rather than the past perfect) to express duration, or the use of past time adverbials with the present perfect (rather than with the simple past). By comparison to previous stages of English, however, MacKenzie does not expect the same simplifying effect of non-native adult acquisition of English in the future because of widespread literacy and the omnipresence of the written standard variety. MacKenzie is highly sceptical regarding the amount of influence of non-native English on the native English of inner circle countries, since he believes the native speakers in those countries to be exposed relatively little to non-native language use. Where native speakers adopt non-native constructions, this is presumably because these constructions are regarded as more expressive or as having a certain attention-getting stylistic effect or for reasons of prestige.
Since all contributions in this volume – even those which are sceptical regarding the predictability of future linguistic change – assume that the English language is going to change in the future, one might argue that this constitutes a prediction on a very general level already. However, the expectation that it is an inherent feature of natural languages to change can be found so generally in the literature (e.g. in Keller 1994: 21; Rauch 1989: 376) that it is presumably relatively uncontested in linguistics and therefore not really newsworthy. Let us therefore consider what more specific predictions are made in the course of the present volume, based on the respective experts’ own empirical research:
The summaries and the list above indicate already that the individual contributions in this volume address a range of central questions regarding the predictability of future changes in the English language, such as what common methodological problems there are (e.g. Rütten), whether all changes follow an S-curve (e.g. Nevalainen), whether linguistic change is reversible (e.g. Minkova), how fine-grained predictions of linguistic change need to be in order to work best (e.g. Dorgeloh & Kunter), the future of which variety of English we are actually attempting to predict (e.g. MacKenzie) and how we can use present-day geographical variation in order to make educated guesses about future trajectories of change (e.g. Tagliamonte). This introduction has also addressed a number of issues, such as the question whether negative predictions (in which no changes in a particular feature are expected) are more likely to come true than positive predictions.
However, a number of questions remain, which could either only be touched upon in passing in the present volume or not at all, but which would merit to have more detailed discussion and research devoted to them:
With regard to this last question, most researchers will presumably agree that the language ten years from now can be considered Future English, but there may be disagreement concerning the state of the language in a year’s, a month’s or even a day’s time (even though all of these are technically Future English). This is due to the fact that even synchronic slices of time need to have a certain extension so as to make them analysable in practice. As a consequence, studies which predict the use of particular linguistic variants in specific Present-Day English situational contexts (cf. Gries 2003 etc. above) are actually predictions of future linguistic behaviour under the assumption that distributions will remain stable with reference to the not too distant past. [14] In parallel to weather forecasts, which can be stunningly precise for intervals of about one day, timed to the hour (cf. Wetter Online) and supported by radar films with simulations of moving clouds, one might wish to argue that it is possible to make plausible predictions for language, too – but only for a highly limited period of time.
This also raises the question whether predictions are more likely to be correct if they concern clearly delimited small-scale phenomena (such as the future development of one particular grammatical construction) or more general tendencies (such as the development of global English). While some researchers seem to argue in favour of the former (e.g. Dorgeloh & Kunter, this volume), others (e.g. Szmrecsanyi 2014) expect that more general tendencies will lend themselves better to prediction. Be that as it may, what they presumably would still all agree upon is that the prediction of the future of a specific language as a whole is practically impossible to achieve: thus Denison (2003: 67–68) explores the idea of conflating all linguistic changes into one big S-curve for the history of English but reaches the conclusion that this cannot be done plausibly. Not only would this require an immense amount of data on innumerable linguistic phenomena but it would also be error-prone due to the interaction between the various levels of language. The prediction of future stages of a language in the form of specific possible text samples is particularly problematic from a statistical point of view: since any text consists of individual linguistic entities (some lexical in the traditional sense, others combinations of words in the sense of prefabricated lexical units) which can be considered linked by means of linguistic principles (i.e. grammatical rules), any prediction of a specifically shaped future text makes implicit predictions about each of these variables in the sample. Since their statistical probabilities would need to be multiplied in order to compute their joint likelihood, this would result in minute probabilities of actual realisation. [15]
Furthermore, academic discussions attempting to predict future developments in the English language usually have two things in common: firstly, they do not make absolute but only probabilistic predictions, and secondly, these are based on the assumption that there are no massive disruptions to the currently observable trajectory of change. [16] As for the second characteristic, one may feel tempted to criticise the expectation that a development will go on if no change occurs as too obvious to merit the status of a prediction. However, the fact that an S-curve-shaped trajectory is expected (rather than the linear growth usually hypothesised by non-experts), combined with the specifics of the individual phenomenon (such as the competing alternative constructions) means that this statement is not completely tautological. In addition, even if the acting forces were natural laws, one would have to admit for the intrusion of additional forces: for instance, in physics, the law of gravitation makes it possible to predict that an object which is dropped on Earth will fall to the ground at a specific angle, because it is attracted by the mass of the planet – but the matter changes completely as soon as an additional force (such as wind) is applied from the side. Predicting something with 100% accuracy is thus impossible if the conditions change, even with natural laws – but predictions regarding future developments are likelier to come true if converging evidence suggests a similar trajectory of change (cf. also Kortmann 2001: 106).
To return to the first characteristic above, the fact that empirical linguistic studies can usually only yield probabilistic predictions of future variant distribution has very important epistemological implications (cf. Lass 1980: 19): since probabilistic laws cannot be falsified by individual counterexamples, we can never be sure, whenever such laws fail to apply in one specific case, whether this represents an exception to the rule or whether the rule as such is an incorrect model. As a consequence, Lass (1980: 20) considers probabilistic laws “non-empirical”, because “they can neither predict particular states of affairs (in the sense of singular spatio-temporal occurrences) nor counter-predict their opposites” – and “only a sequence of failures of some length deemed by investigators in a field to invalidate the generalization” will lead to their falsification (Lass 1980: 21).
Does this mean, then, that all probabilistic predictions are pointless? No, I would like to argue: according to Comrie (2003: 245), linguistics is in a particularly bad situation compared to a large number of other disciplines, “since our reconstructions are rarely subject to empirical verification”. The discussion of the plausibility and probability of potential future developments in language thus offers the opportunity for testing models of language use and language change which are unbiased by the retrospective knowledge of past events (and thus potentially more universally applicable), by comparing their predicted outcome with the state of the English language at some predefined time in the future. In addition, the formulation of predictions is not necessarily esoteric: building upon what was said above, humans subconsciously formulate expectations about what will happen in the more or less distant future all the time – e.g. when crossing a road or catching a ball and calculating its trajectory (cf. e.g. Gigerenzer 2007). The same can be expected to apply to the use of language in communication. Most of these live hypotheses are presumably based on the expectation that language use by an interlocutor a few seconds from now will be extremely similar to that at one’s own time of speaking. In the natural sciences, researchers also postulate beforehand what will happen when they carry out an experiment – which is comparable to predicting the future in a test tube.
To conclude, there are many problems facing the prediction of future linguistic changes, but also the more commonly accepted reconstruction of the past. In order to make educated guesses about potential developments in a specific language such as English, it is possible to build upon what we already know about its past, its present, linguistic change in general and the physiological and cognitive limitations of human language users. Even upon completion of this volume, there are still many open questions regarding the predictability of linguistic change which merit being discussed. Time will tell whether we have succeeded, in this volume, to build a bridge that will extend into the future of the English language.
I am very grateful to the eVARIENG editorial board for making it possible, with the publication of this volume, to conserve the memories of a workshop with great contributions, vivid discussions and splendid atmosphere at the 2014 ISLE 3 conference in Zurich. My compliments go to all the authors of the present volume, who were wonderfully cooperative within our relatively rigid publication schedule. I would also like to thank all our anonymous reviewers, who contributed their valuable expertise and time to this project. Last but not least, many thanks are due to Tanja Säily, and particularly Joe McVeigh, who skilfully edited the contributions for publication on the internet.
[1] For past predictions of future means of communication, cf. Jagger’s (1940: 157) assumption that “[t]he gramophone [sic] and the overseas telephone [...] may in time become two of the chief means of unifying speech”, which might be complemented by cheaper and improved “talking books”. Cf. also the second part of the “Back to the future” trilogy (1989), which predicted some trends (such as video calls and large flatscreens) correctly, while incorrectly predicting the omnipresence of fax machines and failing to predict the massive advent of smartphones (cf. Alba 2015; Curtis 2015). [Go back up]
[2] This is also supported by Bochkarev, Solovyev & Wichmann (2014: 4), who observe that “the presence of frequency changes can be provoked by major international historical events and, reversely, the potential for change is dampened by political stability”. [Go back up]
[3] See the entry for Sound Recording on Wikipedia. [Go back up]
[4] As Comrie (2003: 245) puts it, “it is never possible to reconstruct the past with absolute certainty; all that we can do is to do our best”. [Go back up]
[5] When subjects were asked to remember how probable they had estimated particular events would be in the then-future, they tended to reconstruct higher probabilities than the originally assigned ones. As soon as an event has happened, humans seem to have a tendency to accept the outcome as necessarily derived from the historical situation in hindsight. This postdictive perceived inevitability is called “creeping determinism” by Fischhoff & Beyth (1975: 2). [Go back up]
[6] Thus Shay (2008: 188) predicts the transformation of /θ/ into /t/ in initial and into /f/ in medial and final position based on current substitutions in Cockney and African-American Vernacular English. [Go back up]
[7] See the entries for the Golden Gate Bridge and lists of the longest bridges in the world on Wikipedia. [Go back up]
[8] See the history of the Golden Gate Bridge on the San Francisco Travel Secrets website. [Go back up]
[9] See the BLOB-1931 Corpus on CoRD. [Go back up]
[10] Note that this figure necessarily constitutes a simplification, in which the linear arrow is not meant to imply a linear development but simply to provide a connection between studies of the same linguistic phenomenon at different times. Also, if we consider the structuralist principle that the value of a linguistic construction depends on that of the other constructions within the same linguistic system (cf. Saussure 1916/1959: 114–115), the position of the dots would actually have to vary on each plane due to the differences in the system, but this was avoided for simplificatory reasons. [Go back up]
[11] Note that there have already been relatively successful computer simulations of linguistic evolution (i.e. change) – even if these could still be improved by taking into account interaction in “socio-cultural networks” (Frank & Gontier 2010: 44). [Go back up]
[12] In a similar vein, Lass (1980: 53) uses “the idealized Popperian notion that the ‘strength’ of a theory can partly be interpreted as its ability to ‘forbid’ states of affairs in nature” as the starting point for his methodological considerations, which “will prompt us to search for a constrained and constraining theory”. [Go back up]
[13] Kiparsky (2008: 25; 28–29) discusses different approaches (e.g. by Bloomfield and Jakobson) to what may be considered linguistic universals, such as the view that universal features do not need to be present in all languages but at least be generally available. [Go back up]
[14] I owe this argument to Donka Minkova in the discussion part of the ISLE 3 workshop in Zurich 2014. [Go back up]
[15] Cf. also Bod (2003: 18): “The product rule […] describes the probability that both A and B occur as a joint event in an experiment where events can have more than one outcome; and this probability is equal to the product of the probabilities of A and B (or in the general case, to the product of the probability of A and the conditional probability of B given A).” This last addition is important, since certain linguistic changes may increase or decrease the likelihood for other specific linguistic forms. [Go back up]
[16] For instance, Kortmann (2001: 98) bases his predictions on “the assumption that the English language is allowed to develop naturally” – by which he understands the exclusion of “massive and long-term contact with a foreign language spoken by socially equal or superior groups” and little influence from prescriptivism (Kortmann 2001: 99). [Go back up]
“A Bit of Golden Gate Bridge History” on San Francisco Travel Secrets: http://www.san-francisco-travel-secrets.com/golden-gate-bridge-history.html
Golden Gate Bridge entry on Wikipedia: http://en.wikipedia.org/wiki/Golden_Gate_Bridge
List of the Longest Bridges in the World on Wikipedia: http://en.wikipedia.org/wiki/List_of_longest_bridges_in_the_world
List of the Longest Suspension Bridge Spans on Wikipedia: http://en.wikipedia.org/wiki/List_of_longest_suspension_bridge_spans
Sound Recording entry on Wikipedia: http://en.wikipedia.org/wiki/Sound_recording
The Language Change Database: http://www.helsinki.fi/lcd/database.shtml
Wetter Online (in German): http://www.wetteronline.de
RegenRadar on Wetter Online: http://www.wetteronline.de/regenradar
Aitchison, Jean. 1991. Language Change: Progress or Decay? 2nd edn. Cambridge: Cambridge University Press.
Alba, Alejandro. 2015. “These are the 2015 predictions ‘Back to the Future 2’ got right, wrong”. New York Daily News, October 21, 2015. http://www.nydailynews.com/news/national/2015-predictions-back-future-2-wrong-article-1.2063197
Bauer, Laurie. 1994. Watching English Change: An Introduction to the Study of Linguistic Change in Standard Englishes in the Twentieth Century. London: Longman.
Bochkarev, Vladimir, Valery Solovyev & Søren Wichmann. 2014. “Universals versus historical contingencies in lexical evolution”. Journal of the Royal Society Interface 11: 20140841. doi:10.1098/rsif.2014.0841
Bod, Rens. 2003. “Introduction to elementary probability theory and formal stochastic language theory”. Probabilistic Linguistics, ed. by Rens Bod, Jennifer Hay & Stefanie Jannedy, 11–37. Cambridge, MA: MIT Press.
Bod, Rens, Jennifer Hay & Stefanie Jannedy. 2003. “Introduction”. Probabilistic Linguistics, ed. by Rens Bod, Jennifer Hay & Stefanie Jannedy, 3–10. Cambridge, MA: MIT Press.
Brinton, Laurel J. & Leslie K. Arnovick. 2006. The English Language: A Linguistic History. Oxford: Oxford University Press.
Comrie, Bernard. 2003. “Reconstruction, typology and reality”. Motives for Language Change, ed. by Raymond Hickey, 243–257. Cambridge: Cambridge University Press.
Coupland, Nikolas. 2009. “The mediated performance of vernaculars”. Journal of English Linguistics 37(3): 284–300.
Croft, William. 2000. Explaining Language Change: An Evolutionary Approach. Harlow: Longman.
Crystal, David. 1995. The Cambridge Encyclopedia of the English Language. Cambridge: Cambridge University Press.
Curtis, Sophie. 2015. “From hoverboards to self-tying shoes: 6 predictions that Back to the Future II got right”. The Telegraph, October 20, 2015. http://www.telegraph.co.uk/technology/news/11699199/From-hoverboards-to-self-tying-shoes-6-predictions-that-Back-to-the-Future-II-got-right.html
Denison, David. 2003. “Log(ist)ic and simplistic S-curves”. Motives for Language Change, ed. by Raymond Hickey, 54–70. Cambridge: Cambridge University Press.
Dorgeloh, Heidrun. 2004. “Conjunction in sentence and discourse: Sentence-initial and and discourse structure”. Journal of Pragmatics 36: 1761–1779.
Fischhoff, Baruch & Ruth Beyth. 1975. “‘I knew it would happen’: Remembered probabilities of once-future things”. Organizational Behavior and Human Performance 13: 1–16.
Frank, Roslyn M. & Nathalie Gontier. 2010. “On constructing a research model for historical cognitive linguistics (HCL): Some theoretical considerations”. Historical Cognitive Linguistics, ed. by Margret E. Winters, 31–69. Berlin: de Gruyter Mouton.
Gigerenzer, Gerd. 2007. Gut Feelings: The Intelligence of the Unconscious. London: Penguin.
Graddol, David. 1997. The Future of English? London: British Council.
Gries, Stefan Th. 2003. “Grammatical variation in English: A question of ‘structure vs. function’?” Determinants of Grammatical Variation in English, ed. by Günter Rohdenburg & Britta Mondorf, 155–173. Berlin: de Gruyter.
Guy, Gregory R. 2011. “Variation and change”. Analyzing Variation in English, ed. by Warren Maguire & April McMahon, 178–198. Cambridge: Cambridge University Press.
Hickey, Raymond. 2003. “Introduction”. Motives for Language Change, ed. by Raymond Hickey, 1–4. Cambridge: Cambridge University Press.
Hogg, Richard. 1992. “Phonology and morphology”. The Cambridge History of the English Language, Volume I, The Beginnings to 1066, ed. by Richard Hogg, 67–167. Cambridge: Cambridge University Press.
Hogg, Richard & David Denison. 2008. A History of the English Language. Cambridge: Cambridge University Press.
Jagger, Hubert J. 1940. English in the Future. London: Thomas Nelson.
Journal of Sociolinguistics 18(2). 2014. “Debate: Media and language change”. 213–286.
Keller, Rudi. 1994. On Language Change: The Invisible Hand in Language. London: Routledge.
Kiparsky, Paul. 2008. “Universals constrain change; change results in typological generalizations”. Linguistic Universals and Language Change, ed. by Jeff Good, 23–53. Oxford: Oxford University Press.
Kortmann, Bernd. 2001. “In the year 2525... Reflections on the future shape of English”. Anglistik 12: 97–114.
Labov, William. 1994. Principles of Linguistic Change. Volume 1: Internal Factors. Oxford: Blackwell.
Labov, William. 2001. Principles of Linguistic Change. Volume 2: Social Factors. Oxford: Blackwell.
Labov, William. 2010. Principles of Linguistic Change. Volume 3: Cognitive and Cultural Factors. Oxford: Wiley-Blackwell.
Lass, Roger. 1980. On Explaining Language Change. Cambridge: Cambridge University Press.
Lass, Roger. 1997. Historical Linguistics and Language Change. Cambridge: Cambridge University Press.
Lenneberg, Eric H. 1967. Biological Foundations of Language. New York: Wiley.
Mair, Christian. 1997. “Parallel corpora: A real-time approach to the study of language change in progress”. Corpus-Based Studies in English Papers from the 17th International Conference on English Language Research on Computerized Corpora (ICAME 17), Stockholm, May 15–19, 1996, ed. by Magnus Ljung, 195–208. Amsterdam: Rodopi.
Mair, Christian. 2006. “Grammatical change in 20th-century English”. Anglistik 17(2): 11–34.
Mair, Christian. 2009. Twentieth-Century English: History, Variation and Standardization. Cambridge: Cambridge University Press.
Mair, Christian. 2013. “Speculating on the future of English as a contact language”. English as a Contact Language, ed. by Daniel Schreier & Marianne Hundt, 314–328. Cambridge: Cambridge University Press.
Mair, Christian & Marianne Hundt. 1997. “The corpus-based approach to language change in progress”. Anglistentag 1996 Dresden: Proceedings, ed. by Uwe Böker & Hans Sauer, 71–82. Trier: wvt.
Martinet, André. 1952. “Function, structure, and sound change”. Word 8: 1–32.
Matthews, Peter. 2003. “On change in ‘E-language’”. Motives for Language Change, ed. by Raymond Hickey, 7–17. Cambridge: Cambridge University Press.
Meyers, Walter E. 1980. Aliens and Linguists: Language Study and Science Fiction. Athens: University of Georgia Press.
Michel, Jean-Baptiste et al. 2011. “Quantitative analysis of culture using millions of digitized books”. Science, 14 January, 2011: 176–182.
Newmeyer, Frederick J. 2003. “Formal and functional motivation for language change”. Motives for Language Change, ed. by Raymond Hickey, 18–36. Cambridge: Cambridge University Press.
Plag, Ingo, Gero Kunter & Sabine Lappe. 2007. “Testing hypotheses about compound stress assignment in English: A corpus-based investigation”. Corpus Linguistics and Linguistic Theory 3(2): 199–233.
Psammeticus Press. 2011. Book announcement for The Future English Bible. Speculative Grammarian CLX(4). http://specgram.com/CLX.4/10.pspress.feb.html
Quirk, Randolph. 1972. “English in twenty years”. The English Language and Images of Matter, ed. by Randolph Quirk, 68–76. London: Oxford University Press.
Rauch, Irmengard. 1989. “Language change in progress: Privacy and ‘firstness’”. The Semiotic Bridge: Trends from California, ed. by Irmengard Rauch & Gerald F. Carr, 375–384. Berlin: Mouton de Gruyter.
Saussure, Ferdinand de. 1916/1959. Course in General Linguistics. Transl. by Wade Baskin. New York: Philosophical Library.
Sayers, Dave. 2014. “The mediated innovation model: A framework for researching media influence in language change”. Journal of Sociolinguistics 18(2): 185–212.
Schmid, Hans-Jörg. 2011. English Morphology and Word-Formation: An Introduction. Berlin: Schmidt.
Schneider, Edgar W. 1997. “Language change: The state of the art”. Anglistentag 1996 Dresden: Proceedings, ed. by Uwe Böker & Hans Sauer, 49–60. Trier: wvt.
Schneider, Edgar W. 2007. Postcolonial English: Varieties around the World. Cambridge: Cambridge University Press.
Sélincourt, Basil de. 1928. Pomona or The Future of English. New York: E.P. Dutton. http://babel.hathitrust.org/cgi/pt?id=mdp.39015008020367;view=1up;seq=11;size=125
Shay, Scott. 2008. The History of English: A Linguistic Introduction. San Francisco: Wardja Press.
Sinclair, John. 1991. Corpus, Concordance, Collocation. Oxford: Oxford University Press.
Szmrecsanyi, Benedikt. 2014. “On the sorts of changes that linguists can(not) predict”. Paper presented at the 3rd Conference of the International Society for the Linguistics of English, University of Zurich, 24–27 August 2014.
Szmrecsanyi, Benedikt & Lars Hinrichs. 2008. “Probabilistic determinants of genitive variation in spoken and written English: A multivariate comparison across time, space, and genres”. The Dynamics of Linguistic Variation: Corpus Evidence on English Past and Present, ed. by Terttu Nevalainen, 291–309. Amsterdam: John Benjamins.
Weinreich, Uriel, William Labov & Marvin I. Herzog. 1968. “Empirical foundations for a theory of language change”. Directions for Historical Linguistics, ed. by Winfred P. Lehmann & Yakov Malkiel, 95–195. Austin: University of Texas Press.
Winters, Margret E. 2010. “Introduction: On the emergence of diachronic cognitive linguistics”. Historical Cognitive Linguistics, ed. by Margret E. Winters, 3–27. Berlin: de Gruyter Mouton.
Zipf, George Kingsley. 1965. The Psycho-Biology of Language: An Introduction to Dynamic Philology. Cambridge, MA: MIT Press.
Zuraw, Kie. 2003. “Probability in language change”. Probabilistic Linguistics, ed. by Rens Bod, Jennifer Hay & Stefanie Jannedy, 139–176. Cambridge, MA: MIT Press.
BE06 = The British English 2006 Corpus. 2008. Compiled by Paul Baker. Lancaster University. http://www.helsinki.fi/varieng/CoRD/corpora/BE06/
BLOB-1901 = Lancaster-1901 Corpus. In progress. Compiled by Nick Smith, Paul Rayson & Geoffrey Leech. Lancaster University.
BLOB-1931 = Lancaster-1931 Corpus. 2003–2006. Compiled by Geoffrey Leech, Paul Rayson & Nick Smith. Lancaster University. http://www.helsinki.fi/varieng/CoRD/corpora/BLOB-1931/
Brown = A Standard Corpus of Present-Day Edited American English, for Use with Digital Computers. 1964, 1971, 1979. Compiled by W. Nelson Francis & Henry Kucera. Brown University. http://www.helsinki.fi/varieng/CoRD/corpora/BROWN/
GloWBE = Corpus of Global Web-Based English: 1.9 Billion Words from Speakers in 20 Countries. 2013. Compiled by Mark Davies. http://corpus2.byu.edu/glowbe/

University of Helsinki