
Studies in Variation, Contacts and Change in English
Studies in Variation, Contacts and Change in English
Exploring the characterisation of social ranks in Early Modern English comediesUrsula Lutzky AbstractThis study explores the representation of two groups of social ranks in the Early Modern English period. It draws on a corpus of drama comedy samples to discover differences and similarities in the depiction of the upper and lower ranks in the period from 1500 to 1760 by carrying out a keyword analysis. For this purpose, the speech turns of all upper and lower rank characters were extracted separately from the sociopragmatically annotated Drama Corpus to serve as the target subcorpus and reference subcorpus, needed to create the wordlists for the keyword analysis. Comparing the speech of these two social ranks reveals linguistic features that are characteristic of their language use in the constructed text type of drama comedy and allows insights into the stylistic representation of characters from these groups. This article therefore illustrates the interplay of stylistics and sociopragmatics in the study of historical data of a fictional nature and discusses findings pertaining to the interactive nature of characters’ language use (e.g. terms of address and proper nouns), to the typical focus of their interactions (e.g. discussing topics of love vs. lack) and to specific pragmatic means of situating them in a specific social rank (e.g. the discourse marker forsooth). 1. IntroductionStudying language in use in the history of English entails that scholars mainly have to rely on data that is available in written form, especially for the earlier periods. As much of the speech related data from past periods is of a fictional or reconstructed kind, the analysis of certain pragmatic features will therefore also reveal insights into stylistic effects and characterisation. At the same time, it allows us to take glimpses at sociolinguistic representations in previous periods by studying participants’ gender, age or rank, leading to cross-disciplinary approaches. This article discusses the language use of characters forming part of the upper and lower ranks in a corpus of Early Modern English (EModE) comedies. In particular, it sets out to explore which linguistic forms are ‘key’ in the upper ranks’ turns, as compared to the lower ranks, and to thereby show which forms are characteristic of their constructed language use. The analysis is based on the sociopragmatically annotated Drama Corpus which builds on the drama sections of A Corpus of English Dialogues, 1560–1760, the Sociopragmatic Corpus and the Penn-Helsinki Parsed Corpus of Early Modern English. This corpus is annotated for the sociopragmatic variable of social rank and includes drama comedy samples by a range of different authors from the period 1500 to 1760. The study will combine a predominantly quantitative approach with a qualitative perspective in that the statistical keyword analysis will be complemented by taking a closer look at individual examples in their specific contexts of attestation. Due to the fictional nature of the data, the results will primarily reflect a particular perception or dramatic representation of the language of those in positions of high or low social and linguistic influence. The aim is to identify the linguistic features that are especially characteristic of a social level in EModE drama comedy to gain insights into their use in characterisation and into statistically significant differences in style. 2. Stylistics meets sociopragmaticsThis article is embedded in two approaches to the study of linguistics, stylistics and historical sociopragmatics, and it engages with them through the application of a corpus linguistic methodology in the analysis of historical data from the EModE period, a methodology which has been increasingly used for studies in pragmatics and stylistics in recent years (see e.g. Biber 2011, Jucker et al. 2009, Romero-Trillo 2008). Historical pragmatics, which celebrated its twentieth anniversary in 2015 (see Taavitsainen and Jucker 2015), has been extensively concerned with the study of representations of or approximations to the spoken language of the past. While spoken interactions are not directly available for historical periods, they can be studied in recorded or reconstructed (e.g. trial proceedings, witness depositions) and constructed form (e.g. plays, prose fiction). At the same time, it has been acknowledged that these historical texts, while providing clues about the spoken language use of the past, also “warrant a pragmatic analysis in their own right” (Jucker 2006: 329). In particular in the case of fictional data, such as drama, this is where the study of pragmatics meets the study of stylistics. The discipline of stylistics generally focuses on the discussion of foregrounding and deviation from a linguistic norm and their contribution to creating a certain stylistic effect in literary texts. This is related to the fact that “[s]tyle is always defined by differences against the average or some other measure” (Lindquist 2009: 66). Although stylistics therefore differs from corpus linguistics, which is usually more interested in repeated and typical linguistic features, approaches of studying literary texts using a corpus linguistic methodology have received increased attention through the development of the subdiscipline of corpus stylistics (see e.g. Mahlberg 2007a). Many studies in corpus stylistics have applied a corpus-driven methodology where “the linguistic constructs themselves emerge from analysis of a corpus” (Biber 2009: 276). That is to say that the data are approached from an impartial perspective, without looking for specific pre-selected constructions; instead tools are employed that, for instance, allow for significantly frequent words or clusters of words to be identified. This has in particular been done through the use of keyness analysis, where a specific text or a collection of texts is compared to a reference corpus. Thus, Fischer-Starke (2009) studied keywords and frequent phrases in Jane Austen’s novel Pride and Prejudice, Mahlberg and McIntyre (2011) explored keywords and key semantic domains in Ian Fleming’s Casino Royale, Mahlberg (2007b) discussed word clusters and key word clusters in novels by Charles Dickens, and McIntyre (2012) extracted prototypical characteristics of blockbuster movie dialogue through a study of keywords and key semantic domains. Concerning the EModE period, Culpeper (2002, 2009) carried out a keyness analysis of Shakespeare’s play Romeo and Juliet in which he compared each main character’s speech to that of all other five main characters combined, resulting in a character-specific set of keywords (and in Culpeper (2009) also in key parts-of-speech and key semantic domains). While Culpeper’s keyword study is similar to the present one in its temporal and genre focus, in this study I compare two broad social groups of fictional characters to each other using a variety of play samples, rather than studying individual characters from one specific play. As my analysis will therefore include the dimension of social rank and take the sociohistorical context into account in the attribution of characters to certain social status levels (see section 3 for the methodology), this study takes a sociopragmatic approach. According to Culpeper (2010: 76), sociopragmatics “concerns itself with any interaction between specific aspects of social context and particular language use that leads to pragmatic meanings”. As a method within the framework of sociopragmatics, Archer and Culpeper (2009: 287) introduced the approach of sociophilology which takes context as its starting point and describes “how historical contexts, including the co-text, genre, social situation and/or culture, shape the functions and forms of language taking place within them”. To illustrate this approach, Archer and Culpeper (2009) studied social dyads in Early Modern trial proceedings and play texts from the period 1640–1760. For the drama comedy samples, they looked in particular at the interaction between masters and mistresses and their male and female servants, amounting to a total of 4485 words in their corpus, to identify forms that are statistically characteristic of these social role dyads. As a consequence of choosing to study these specific constellations relating not only to the social rank of characters but also their gender and social role, the output of their keyness analysis pertains to the specific local context in which they interact, showing for example that imperative verbs appear with statistically significant frequencies when masters and mistresses talk to male servants. The present study takes a less restrictive approach in comparison; it covers a longer time span and compares two broad social groups to discover differences in their language use within the context of EModE drama comedy. It therefore does not proceed to the level of interactional detail discussed by Archer and Culpeper (2009) but aims to gain results on a more general level using a considerably larger amount of data. 3. MethodologyThis study draws on data from the Drama Corpus comprising twenty-four drama comedy samples from the period 1500–1760. The advantage of using this corpus for the present research is that it is sociopragmatically annotated on a turn-by-turn level, with tags indicating the social status and gender of both the speaker and addressee. The Drama Corpus is based on and follows the design of the Sociopragmatic Corpus (1640–1760) (the SPC; see e.g. Archer and Culpeper 2003 or Archer 2005), which was expanded through the inclusion and tagging of drama comedy samples from the Penn-Helsinki Parsed Corpus of Early Modern English (the PPCEME), and sub-periods one and two of A Corpus of English Dialogues, 1560–1760 (the CED). Its size amounts to a total of 242,561 words and it is, as its name implies, restricted to a single constructed and dialogic text type. In addition to its fictional nature and the suitability of this data for studies in stylistics, drama is also regarded as a “speech-related” (see e.g. Archer and Culpeper 2003: 43; Culpeper and Kytö 2010: 23) or “speech-based” (Biber et al. 1998: 210) text type that is useful for the study of historical forms of the English language more generally. The sociopragmatic XML tagging of the Drama Corpus follows the conventions of the SPC. Thus, each speaker turn is marked off by an opening and a closing XML tag providing a speaker and addressee identification and information about their social status and gender, as illustrated by example (1). Changes in addressee within a single turn are indicated by the insertion of a new opening and closing tag.
This sociopragmatic annotation was used to extract the total number of words spoken by the upper and lower ranks and therefore facilitated compiling the two sub-corpora needed for the following keyword analysis. The XML tags illustrated in example (1) and used throughout the Drama Corpus reflect the social status classification developed for the SPC (see e.g. Archer and Culpeper 2003: 53), comprising six status levels numbered 0 to 5, with 0 equating to the highest rank:
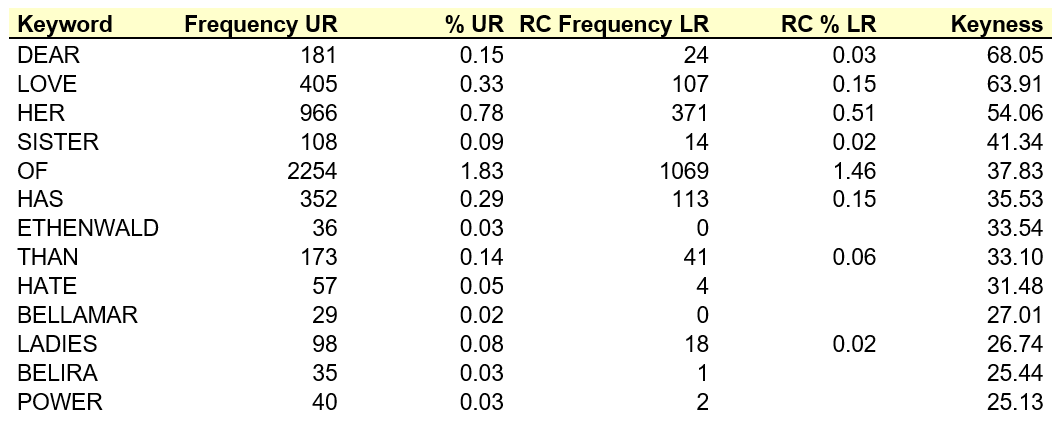
For the purposes of this study, I divided characters into two overarching categories: the upper ranks, corresponding to status levels 0 and 1, and the lower ranks, corresponding to all remaining social levels. This was done in order to enable the comparison between the upper and lower ranks without going into more fine-grained detail, and corresponds to other social status classifications used in historical linguistic research of the period in question (cf. e.g. Nevalainen and Raumolin-Brunberg 2003). Combining the speech of characters accordingly resulted in a total number of 123,148 words spoken by the nobility and gentry (171 characters) and 73,034 words by all lower rank speakers (204 characters). [1] Thus, the data show that despite there being more lower class characters, it is the upper classes that talk more in the play texts. Speech turns per social rank were extracted with the help of Scott Piao’s MLCT and form the basis of this study aiming to arrive at a list of characteristic features per social status and to discover how their (constructed) style of speech differs in EModE drama comedy. This will be done through an analysis of keywords which, in corpus linguistics, are defined as “items of unusual frequency in comparison with a reference corpus of some suitable kind” (Scott and Tribble 2006: 55). Keyness in this sense therefore goes beyond the general use of the word to describe specific entities as having social, cultural or political significance (cf. e.g. Williams 1988 [1976]) and describes a textual quality. In other words, keyness is “[w]hat the text ‘boils down to’ … once we have steamed off the verbiage, the adornment, the blah blah blah” (Scott and Tribble 2006: 56). The concept of keywords is based on two premises. The first one is repetition, which means that a word which appears repeatedly in a target text or corpus is more likely to be key than words which are not repeated frequently. The second premise is a reference corpus, against which to compare the target corpus. A word-list of the original corpus, i.e. a list of all the words occurring in the corpus sorted by frequency, is compared against the wordlist of the reference corpus to discover “which words occur statistically more often in wordlist A when compared with wordlist B and vice versa” (Baker 2006: 125). Keywords are therefore based on the underlying notion of statistically-based “outstandingness” (Scott 1997: 236) in a word’s attestation in one corpus when compared to another. Concerning historical linguistic data, keyword analysis requires “a corpus that contains texts with normalised spellings” (Kytö 2010: 55; see also Baron et al. 2009). While the corpus used in this study is characterised by considerable spelling variation, described by Culpeper (2002: 14) as “perhaps the greatest obstacle in the statistical manipulation of historical texts”, the software tool VARD 2 was used to normalise the relevant files containing speech by the upper and lower ranks, based on the guidelines suggested by Archer et al. (2015) for normalising EModE corpora. These two groups of files will serve as the respective target and reference corpora in the following keyword analysis. This is in line with Culpeper (2009: 34, see also 2002), who claims that “a set of data which has no relationship whatsoever with the data to be examined is unlikely to reveal interesting results regarding the stylistic characteristics of the data”, and entails that the analysis will reveal keywords reflecting distinctive features of characters’ style. 4. AnalysisThe following discussion will focus on the positive keywords of both the upper and lower ranks, i.e. words that are key because they are unusually frequent in their speech. [2] In the keyword analysis a minimum frequency of 5 was determined as a cut-off point to avoid one-off or localised occurrences and the p-value was set at 0.000001 for the log-likelihood statistical test in WordSmith. Previous research on keywords (see in particular Scott and Tribble 2006) allidayintroduced different types or categories of keywords: proper nouns, keywords indicating the aboutness of a text, i.e. its propositional content, and style indicators, including primarily closed class and high-frequency words. Culpeper (2009: 39) suggests slightly different but corresponding categories, mainly to avoid the separation of aboutness and style, and speaks of keywords with a functional emphasis that is ideational, textual or interpersonal (cf. Halliday 1970: 140ff., 1979: 59ff.). In any case, a keyword analysis highlights the most statistically significant differences on a lexical level between two corpora, revealing “important concepts in a text (in relation to other texts)” (Baker 2004: 347), which can then be interpreted for their stylistic significance. Table 1 provides the positive keywords of the upper ranks in the Drama Corpus when compared to the lower ranks. From left to right, the columns list the keywords, their frequency in the upper rank target corpus as well as their percentage in this corpus, their frequency in the lower rank reference corpus, plus percentages, and their log-likelihood keyness value.
Table 1. Positive keywords upper social ranks. As Table 1 shows, among the positive keywords of upper rank speech one finds three names of characters: Ethenwald (A Knack to Know a Knave, Anonymous, 1594), Bellamar (Chit-Chat, Thomas Killigrew, 1719), and Belira (The Lost Lover, Mary Manley, 1696), with only the latter occurring once in the speech of the lower ranks (see column RC Frequency LR). This conforms to McIntyre’s (2012: 412) observation that “[p]roper nouns are often featured in keyword lists simply as a result of their not being present in the reference corpus”. With regard to the current data, the names Ethenwald and Bellamar, members of the nobility and gentry respectively, are not attested in the speech of the lower ranks at all, despite the fact that the plays in which they appear comprise both upper and lower rank characters. In dialogic text types of a fictional kind, such as drama, the appearance of a character name in a keyword list is a sign that they are either directly addressed (term of address) or talked about (term of reference) significantly more frequently than the other characters in the corpus; equally, in the case of this study, the absence of that name in the reference corpus indicates that this use is restricted to the upper ranks. Taking a closer look at the proper noun with the highest keyness value, the name Ethenwald from A Knacke to Knowe a Knaue (1594) appears 36 times in the speech of the upper ranks in the Drama Corpus. Examining the individual occurrences in more detail, one discovers that the name is used as a direct form of address and as a term of reference to an equal extent, both with 18 attestations in the data. The character who uses the name most frequently is King Edgar of England (20 tokens, 55%) and this relates to the plot of the play: Ethenwald, the Earl of Cornwall, woos Alfrida in the King’s name. However, Ethenwald falls in love with Alfrida, marries her himself, and has the King meet the kitchen maid dressed up as Alfrida during the royal visit to protect his wife. The King, outraged by this ploy, therefore engages in frequent references to and direct addresses of Ethenwald, the main protagonist at the centre of the action, to finally forgive and pardon him at the end of the play. In addition to proper nouns, Table 1 comprises further forms of address, including dear, sister, and ladies, all of which appear in both subcorpora but are significantly more frequent in the upper ranks’ speech. These are used when directly addressing someone, as in the following examples for sister, with the first example showing the collocation of the top keyword dear with sister: [3]
At the same time, they are also used as terms of reference when talking about another character, for instance someone’s sister:
When studying the distribution of the different uses of the forms, one discovers that both sister (66%) and dear (83%, both in its adjectival and nominal uses) primarily appear in noun phrases functioning as forms of address, rather than as forms of reference (sister 34%, dear 10%; note that dear is also attested with other functions in 7% of its attestations, e.g. the dear pleasure of). Ladies, on the other hand, shows a different distribution and is used as a term of reference in more than three quarters of its attestations. All three of these terms are characteristic of the upper ranks’ speech, expressing affection or polite regard for addressees or other characters in the corpus of EModE plays. The second most significant keyword after dear, love, equally has affectionate connotations. Appearing with a raw frequency of 405 attestations and a density of 0.33 in upper rank speech, this form has the second highest keyness factor. An analysis of its individual occurrences reveals that in almost 70% of its attestations, the form love is used as a noun, with about 7% of its uses forming part of a name (e.g. Lady Young-Love) or appearing as forms of address or reference (e.g. my Love). Given its high keyness value, one can thus note that the upper ranks’ discourse mainly revolves around the theme of love and the act of loving (30% of verbal attestations). This relates to the observation that in keyword lists “content words directly indicate the propositional content of texts” (Stubbs 2010: 25), especially when they are semantically related, as is the case for love, hate and power listed in Table 1, which would classify as ‘aboutness’ keywords (see Scott and Tribble 2006). Contrary to love and power, hate is however used primarily as a verb (91% of its attestations), thus putting the emphasis on the expressive speech act. In addition to the verbal uses of love and hate, Table 1 also lists has as a positive keyword in upper rank speech in the Drama Corpus. Its density in their speech turns is almost twice as high as in the lower ranks’ sub corpus. When looking at the total number of its attestations, it turns out that 56% of its examples are uses of has as an auxiliary verb in a present perfect construction, which “was well established” in EModE (Nevalainen 2006: 94), with the remaining 44% having a primarily possessive meaning. Thus has features quite prominently in constructions of upper rank characters narrating what has happened or what someone else has done or said. While this functional distribution is not dissimilar from the lower ranks, where indeed 61% of all attestations of has form part of present perfect constructions, the fact that it appears as a keyword for the upper ranks entails that it occurs more often than expected in their speech when compared to the lower ranks. The remaining keywords listed in Table 1, her, of and than, are function keywords, which means that they stem from closed word classes. While function keywords have often been ignored in stylistic analyses, which mainly focus on the open word classes, Culpeper (2002: 17–18) makes a claim for scrutinising grammatical keywords as they may be indicators of style as well. Concerning the present study, one can note that two of the three function keywords in Table 1, her and of, appear within the top five of the positive keywords identified for the upper ranks, having a particularly high keyness value. The third person singular pronoun her is used in reference to a female character that can be identified as a ‘third party’, i.e. not including the speaker or the addressee of an utterance (cf. Quirk et al. 1985: 6.6). It is thus linked to the forms sister, ladies and Belira, all of which are also used when referring to females. As the third most statistically significant keyword overall in the speech of the upper ranks and given the attestation of other female reference terms in the keyword list, one conclusion to be drawn is that upper rank characters talk about female characters to a significant extent. This can be seen in comparison to female characters being allowed less floor time in the context of the Drama Corpus, with the total number of words spoken by female characters amounting to less than half (44%) of the speech volume of male characters (see Lutzky 2013). When studying the functions of the keyword her, one finds that it is used as a modifier in a noun phrase in 47% of its attestations, with examples referring to her beauty, her eyes, her face, her father, her fortune or her husband. The remaining 53% of attestations function as noun phrases in their own right, mainly referring anaphorically to a previously mentioned noun phrase (e.g. Your violence and temper is too much for her; I will marry her). Thus, in addition to the proper nouns, terms of address and reference, as well as the content nouns discussed above, her is indicative of a nominal style. In fact, the same can be said with reference to the preposition of and than in both its conjunctive and prepositional uses, which show that the upper ranks have a tendency to contrast two entities, concepts or people with each other in this comparative construction (e.g. he had a little more wickedness than the rest of his neighbours; a fortune better worth than all your fathers lands; more power over you than beauty). Overall, the positive keywords of the upper ranks therefore provide a clear indication of a more nominal style, while the top keyword dear as well as the attestation of terms of address bear witness to an interactive component to their speech. At the same time, one also notices differences to the positive keywords of the lower rank characters given in Table 2, where the top keyword and only pronoun occurring in the list is the form ye.
Table 2. Positive keywords lower social ranks. While the upper ranks’ speech included the third person singular pronoun her as the third most significant keyword, the number one keyword in the lower ranks’ speech is the second person plural pronoun ye. In terms of key-pronouns, the two social groups thus differ from each other: while a third person pronoun that is descriptive in nature and serves to identify or refer to a female character is used to a statistically significant extent by the upper ranks, the lower ranks have a second person pronoun that is used in direct address of characters as their top keyword, pointing towards a less narrative and more interactive style. However, it is important to note here that the attestations of lower rank ye are largely restricted to three EModE plays: Menaecmi by Warner (1595), Gammer Gurton’s Needle by Stevenson (1553–63), and Roister Doister by Udall (1552–53), with only 5% of all attestations appearing in other play samples included in the corpus (cf. also Mitchell 1971, cited in Busse 1998, who found the amount of ye attestations to vary considerably between individual dramatists). In these three plays, ye is primarily used when addressing a single person (88%) while its use as a plural pronoun is comparatively smaller (12%), which means that its original plural function is considerably reduced. Concerning the case in which it is used, 79% of its attestations appear in the original nominative with the remaining 21% illustrating its use in the object case; these numbers are identical to Mitchell’s findings (1971: 86f., cited in Busse 1998: 95) in an investigation of Early Modern English drama, while Busse (1998: 94) found the percentage of ye with a subject function to be slightly more reduced, amounting to 72% compared to 28% for the object function, in Shakespearean drama. Contrary to drama, Nevalainen and Raumolin-Brunberg (2003: 141f.) note that both the lower and the upper ranks had almost fully replaced the subject pronoun ye by you in their letter data by 1560–1599, highlighting the difference in pronoun development and usage in different genres in the EModE period. In the Drama Corpus, the majority of attestations of ye stem from the sixteenth century and from three specific comedies that have an increased number of lower rank characters compared to other plays in the corpus. The fact that it is a keyword in the lower ranks’ speech contrasts with Walker (2007: 268f.), who studied the use of ye in relation to you in Warner’s Menaecmi, using a more fine-grained social status classification and not carrying out a keyword analysis; she came to the conclusion that ye “does not seem to be influenced by the rank (or sex, or age) of the speaker or addressee” (Walker 2007: 268), but that the choice of you or ye was influenced by sentence type, with ye being favoured in questions and imperatives. At the same time, the present findings provide a comparison to Busse (1998), who found ye to be primarily attested in Shakespearean histories and tragedies, even claiming that the form was of limited relevance to comedies, and who found it attested at extreme positions of the social scale, being used either by the highest ranks or social outsiders. According to Busse (1998: 108–110), this distribution can be explained with regard to the marked nature of ye, which predominated in higher literary registers and was already in Shakespeare’s time considered archaic, possibly being used to situate the plot in previous time frames. The results of the current study show that ye seems to have had slightly different functions in comedies, where it is key in the more colloquial dialogue of the lower ranks. However, as in tragedies and histories, the reasons for the increased use of ye in their speech could be linked to the archaic nature of the form. In plays in which ye clusters, such as Gammer Gurton’s Needle, it may have formed part of the “literary dialect based on archaic, southern, rural forms of English” (Hope 2010: 116), sometimes referred to as ‘stage Kentish’, and contributed to the characterisation of lower class characters as lagging behind with regard to a linguistic innovation, i.e. the introduction of you in subject case (cf. Nevalainen and Raumolin-Brunberg 2003, who show that the change was initially led by the upper ranks in letter data). The list of lower rank keywords (Table 2) furthermore comprises a considerable number of characters’ names. While proper nouns also form part of the upper ranks’ keyword list, it is noticeable that the number of names is four times higher for the lower ranks. Furthermore, one can note that the characters’ names stem from four plays only, all of which were published before 1640. Thus, the names Gammer, Hodge, Diccon, Dame Chat, Gib (the cat) and Cock are all taken from the play Gammer Gurton’s Needle by Stevenson (1553–63), Tibet, Annot and Margerie are from Roister Doister by Udall (1552–53), Menechmus and Erotium from Menaecmi by Warner (1595) and Ursula from Jonson’s Bartholomew Fair (1639). None of these names are used by the upper ranks as Table 2 indicates and it should be pointed out that with regard to the first two plays by Udall and Stevenson, this is due to the fact that they only comprise characters from the lower ranks. When studying each character name individually, a few notable points emerge. The character Ursula in Jonson’s Bartholomew Fair is not one of the main characters of the play but her name comes up as a positive keyword in the speech of the lower rank characters. While this is, on the one hand, related to the fact that her name is not mentioned by any of the upper rank characters, on the other hand, it also attributes a certain significance to her character who is central in terms of the dramatic space of the fair, where she roasts and sells pigs at her booth. The situation is slightly different for the play Menaecmi, where the plot revolves around the twin brothers Menechmus the Citizen and Menechmus the Traveller being reunited and mistaken for each other by the other characters, even by the Citizen’s lover Erotium. Consequently, almost half of all attestations of the name Menechmus are attempts at identifying him (e.g. your name is Menechmus?, are you Menechmus?, This is Menechmus). On the other hand, the reason why the three maids’ names from Roister Doister appear in the keyword list pertains mainly to their repeated use in a song (see e.g. the line Sew Tibet, knit Annot, spin Margerie), which also includes the keyword Trilla. In Gammer Gurton’s Needle almost all characters’ names are keywords; as the sample chosen from this play is of comparable length to the remaining samples, this play stands out in comparison to the others by showing an unexpectedly frequent attestation of character names as both terms of address and reference. Given that actors at the time did not receive the complete play text but the roll of text was divided into individual parts and each actor would only get their own part (see e.g. Palfrey and Stern 2007), these uses will have helped to facilitate dramatic interactions and fulfilled discourse structuring as well as coherence functions. Thus one explanation could be that the high number of character names from Gammer Gurton’s Needle in Table 2 is linked to the fact that it is the earliest play included in the corpus, where these means could have been more extensively relied upon compared to later plays; however, an idiosyncratic explanation cannot be ruled out and further research would be needed to confirm this. In addition to these proper nouns, terms of address or reference form part of the positive keywords of the lower ranks: sir, worship, boy, knave, and master. The forms Gammer and Dame are not included here as they collocate tightly with the names (Gammer) Gurton and (Dame) Chat, two characters in the play Gammer Gurton’s Needle. When studying the remaining terms with regard to their use in the corpus, it turns out that both boy (58%) and knave (64%) are used more frequently as terms of reference, i.e. when talking about another character, as illustrated by the following examples.
On the other hand, the form master functions as a term of address (49%) and reference (51%) to an almost equal extent, while the forms worship (85%) and sir (94%) are predominantly used with an address function, as in these examples from the corpus:
Contrary to the upper ranks’ keywords, where polite terms featured to a statistically significant extent when addressing or referring to members of the same social class (cf. sister, ladies), among the lower ranks’ keywords one finds a mixture of more and less polite forms. Thus, the keywords with the highest keyness values, sir, master and worship, are indications of frequent and polite interactions with or references to the higher ranks, whereas knave and boy, i.e. a male servant, pertain to the lower level and may potentially have impolite connotations. The keywords of the lower ranks furthermore comprise the content words needle, cloak, stolen, lack and (partly) cock. As the proper nouns discussed above, these words mainly relate to particular plays: Gammer Gurton’s Needle, for example, focuses on Gammer Gurton having lost her needle but accusing Dame Chat of having stolen it, in addition to having previously accused her of having stolen her cock. [4] Likewise, Warner’s Menaecmi tells the story of Menechmus having given his lover Erotium one of his wife’s cloaks but then wanting it back to return it to his wife. While not all of these content word attestations are restricted to these two plays, the majority of them are. Overall, they are therefore more indicative of features pertaining to particular play texts rather than the corpus as a whole and do not specifically point towards a more general difference in style. Finally, the adverb forsooth, meaning ‘in truth, truly’, forms part of the lower ranks’ list of positive keywords given in Table 2. Forsooth is “an emphasizer which became highly frequent at the beginning of Middle English” (Lenker 2008: 245), and was often attested in interactive dialogue at the time, being especially frequent in drama in the EModE period (cf. Bromhead 2009: 117, Lenker 2008: 258). In the present EModE data, which is exclusively dialogic in nature, forsooth appears primarily in short statements, in reply to a previous request for information (interrogative) or action (mainly imperative), which is in line with Lenker’s (2008) findings for ME, where it mainly appeared in direct speech answers to questions (cf. also Bromhead 2009: 104). These uses are illustrated in examples (2) and (3). Example (2) shows the gentlewoman Mistress Arthur in conversation with her maid, who intensifies her positive response (I as in aye/ay, see OED s.v. aye | ay, int. (and adv.) and n.) through the use of forsooth. Likewise, in example (3), the servant Quickly addresses the servant Simple, both of them forming part of the lowest ranks, to inquire about his master’s looks and when her description of his master’s appearance does not match his actual looks, forsooth adds emphasis to Simple’s negative response. It should be added, however, that the majority of the examples are used with an upward direction, that is to say by a character of lower social rank addressing someone of higher social descent; in this context forsooth serves the function of confirming that a particular task has been done or will be done shortly or of confirming or denying specific pieces of information.
The association of forsooth with the lower classes has already been discussed in previous research (see e.g. Tucker 1962, Salmon 1987, Lenker 2003). Bromhead (2009: 108f.) links this to the “‘culture of honour’ which characterized the practice of truth telling in 16th and 17th [century] England”, where the lower classes were considered to be unreliable and therefore in greater need of justifying the truth of their statements. With regard to drama, Lenker (2010: 122f.) in fact mentions that forsooth, as a feature of lower class speech, is “used for such a depiction of characters in Early Modern English plays”. The present study, which comes to a similar conclusion, adds to this observation by providing statistical evidence for this claim. It shows that forsooth is indeed a keyword of the lower social ranks when comparing their speech to the upper ranks in EModE drama comedy, which implies that it may have been used deliberately as a stylistic feature to define certain characters as forming part of the lower social ranks. 5. Summary and conclusionThe keyword analysis of upper and lower rank language use in EModE drama comedy has uncovered stylistic similarities and differences with regard to the types of words that are statistically significant in the speech of characters from these different social backgrounds. Thus, the analysis has revealed that proper nouns form part of both positive keyword lists, which may be due to their absence from the respective reference corpus. At the same time, their presence in the keyword list is a sign that these characters are either directly addressed (term of address) or talked about (term of reference) significantly more frequently than the other characters in the corpus, which, as was shown above, may relate to the plot of a play (e.g. Ethenwald from A Knacke to Knowe a Knaue, 1594, or Menechmus from Warner’s Menaecmi, 1595) or the significance of a character to a specific dramatic space (e.g. Ursula from Jonson’s Bartholomew Fair, 1639). Additionally, the fact that the number of proper noun keywords is four times higher for the lower than the upper ranks may pertain to an effort of facilitating dramatic interactions and fulfilling discourse structuring as well as coherence functions especially in earlier plays which have a higher density of lower class characters. In addition to proper nouns, both subcorpora comprise further terms of address and reference. For the upper ranks, they include forms that convey affection or polite regard for addressees or other characters, such as dear, sister, and ladies. For the lower ranks, on the other hand, they represent a mixture of forms, some of which are signs of frequent interactions with the upper ranks (e.g. worship, sir), whereas others are mainly references to the lower levels, which may have impolite connotations depending on their context of use (e.g. knave, boy). The content keywords of the two rank groups differ with regard to their scope. Thus, the lower ranks’ content keywords are of a more specific nature, relating to the plot of certain plays, including the words needle, cock, cloak, or stolen (cf. Gammer Gurton’s Needle, Menaecmi). While these words are more indicative of features pertaining to particular play texts, the upper ranks’ content keywords point towards a more universal difference in ‘aboutness’. This is due to the fact that their content keywords are more general in nature and give an indication of the themes characterising their discourse: love, hate and power. Function or closed class keywords are not as prominent statistically speaking as open class keywords and they appear more frequently among the upper ranks, with her and of appearing within the top five of their positive keywords. Additionally, the difference in pronoun keywords indicates a difference in style between the upper and lower ranks, with a more descriptive and narrative style on the one hand and a more interactive style on the other. Her is the third most prominent keyword in the speech of the upper ranks and suggests that upper rank characters talk about female characters to a significant extent (see also sister or ladies). In lower class speech, ye is the top keyword and it is mainly attested when addressing a single person in the nominative, clustering in particular in three sixteenth century plays. This study therefore indicates that the speaker’s and addressee’s rank seems to have influenced the use of ye, which contrasts with Walker’s (2007: 268f.) conclusion, claiming that it was mainly sentence type that was decisive in this case. The stylistic function of ye in this context could be linked to the archaic nature of the form (see also Busse 1998 who mainly found it attested in Shakespearean histories and tragedies). In the early plays of the Drama Corpus in particular, it may have represented an archaic, rural variety, also referred to as ‘stage Kentish’, characterising lower class characters as using the traditional form in subject function. Finally, the emphasizer forsooth was found to be a positive keyword of the lower ranks. This study was therefore able to provide additional evidence for previous findings (cf. e.g. Bromhead 2009, Lenker 2003, 2010, Salmon 1987, Tucker 1962), showing that forsooth is in fact statistically significant in the speech of the lower ranks when compared to the upper ranks in EModE drama comedy. Contrary to ye, the majority of attestations show an upward direction of use, which is to say that forsooth is used by a character of lower social rank when addressing someone of higher social descent. It is in this context that forsooth may have been used deliberately as a stylistic means defining characters of lower social descent. The present study has thus provided an insight into ways in which EModE drama comedy projects its own sociohistorical context (cf. Culpeper 2010: 86) and uncovered the characteristic features and stylistic aspects that qualify the upper and lower ranks against this background. It has revealed lexical and grammatical patterns of language use typical of two groups of social rank and discussed their contribution to style in the genre of drama comedy. In particular, the keywords obtained in this study include pragmatic and politeness features, such as terms of address or reference, discourse markers and pronouns, which contribute to defining interpersonal relationships between characters. Future research in the field could expand on these findings by comparing different subperiods of the Drama Corpus to each other, as there may be a diachronic development that has not been made explicit by the current analysis. Additionally, one could move from single keywords to key clusters, key parts-of-speech or key semantic domains to gain further insights into the differences in language use by the two groups of fictional characters. Notes[1] In order to have drama comedy samples of comparable sizes, for the PPCEME the number of files per play was reduced to align the total number of words per sample to the CED and SPC. The chosen files were: MiddletH, Middlet P2, StevensonH, StevensonP2, UdallH, UdallP2, and VanbrP2. [Go back up] [2] Negative keywords, while generated by WordSmith for the current analysis, will not be discussed here. This is mainly due to the similarity of the negative keywords for one social rank, i.e. words that are unusually underused by them, to the other rank’s positive keywords. [Go back up] [3] Corpus annotation and coding were removed from all of the following examples to enhance readability. [Go back up] [4] Note that cock is used both to refer to the animal as well as Gammer Gurton’s servant, with a few attestations appearing in the construction by cock. [Go back up] SourcesCED = A Corpus of English Dialogues, 1560–1760. 2006. Compiled under the supervision of Merja Kytö (Uppsala University) and Jonathan Culpeper (Lancaster University). http://www.helsinki.fi/varieng/CoRD/corpora/CED/ MLCT = Multilingual Corpus Toolkit. Copyright Scott Piao. https://sites.google.com/site/scottpiaosite/software/mlct PPCEME = Kroch, Anthony, Beatrice Santorini & Lauren Delfs. 2004. Penn-Helsinki Parsed Corpus of Early Modern English. http://www.helsinki.fi/varieng/CoRD/corpora/PPCEME/ and http://www.ling.upenn.edu/hist-corpora/ SPC = Sociopragmatic Corpus. 2007. Annotated under the supervision of Jonathan Culpeper (Lancaster University). A Derivative of A Corpus of English Dialogues 1560–1760, Compiled under the supervision of Merja Kytö (Uppsala University) and Jonathan Culpeper (Lancaster University). VARD 2 = Variant Detector 2. Copyright Alistair Baron. http://ucrel.lancs.ac.uk/vard/about/ Wordsmith: Scott, Mike. 2012. WordSmith Tools version 6. Stroud: Lexical Analysis Software. http://www.lexically.net/wordsmith/ ReferencesArcher, Dawn. 2005. Questions and Answers in the English Courtroom (1640–1760). A Sociopragmatic Analysis. Amsterdam: John Benjamins. Archer, Dawn & Jonathan Culpeper. 2003. “Sociopragmatic annotation: New directions and possibilities in historical corpus linguistics”. Corpus Linguistics by the Lune: A Festschrift for Geoffrey Leech, ed. by Andrew Wilson, Paul Rayson & Tony McEnery, 37–58. Frankfurt am Main: Peter Lang. Archer, Dawn & Jonathan Culpeper. 2009. “Identifying key sociophilological usage in plays and trial proceedings (1640–1760). An empirical approach via corpus annotation”. Journal of Historical Pragmatics 10(2): 286–309. doi:10.1075/jhp.10.2.07arc Archer, Dawn, Merja Kytö, Alistair Baron & Paul Rayson. 2015. “Guidelines for normalising Early Modern English corpora: Decisions and justifications”. ICAME Journal 39: 5–24. doi:10.1515/icame-2015-0001 “aye | ay, int. (and adv.) and n.” OED Online. September 2015. Oxford University Press. http://www.oed.com/view/Entry/14090 Baker, Paul. 2004. “Querying keywords. Questions of difference, frequency, and sense in keyword analysis”. Journal of English Linguistics 32(4): 346–359. doi:10.1177/0075424204269894 Baker, Paul. 2006. Using Corpora in Discourse Analysis. London: Continuum. Baron, Alistair, Paul Rayson & Dawn Archer. 2009. “Word frequency and key word statistics in historical corpus linguistics”. Anglistik: International Journal of English Studies 20(1): 41–67. Biber, Douglas. 2009. “A corpus-driven approach to formulaic language in English. Multi-word patterns in speech and writing”. International Journal of Corpus Linguistics 14(3): 275–311. doi:10.1075/ijcl.14.3.08bib Biber, Douglas. 2011. “Corpus linguistics and the study of literature. Back to the future?”. Scientific Study of Literature 1(1): 15–23. doi:10.1075/ssol.1.1.02bib Biber, Douglas, Susan Conrad & Randi Reppen. 1998. Corpus Linguistics. Investigating Structure and Use. Cambridge: Cambridge University Press. Bromhead, Helen. 2009. The Reign of Truth and Faith. Epistemic Expressions in 16th and 17th Century English. Berlin: Mouton de Gruyter. Busse, Ulrich. 1998. “Stand, sir, and throw us that you have about ye. Zur Grammatik und Pragmatik des Anredepronomens ‘ye’ in Shakespeares Drama”. Betrachtungen zum Wort: Lexik im Spannungsfeld von Syntax, Semantik und Pragmatik, ed. by Eberhard Klein & Stefan J. Schierholz, 85–115. Tübingen: Stauffenburg. Culpeper, Jonathan. 2002. “Computers, language and characterisation: An analysis of six characters in Romeo and Juliet”. Conversation in Life and in Literature: Papers from the ASLA Symposium (Association Suedoise de Linguistique Appliquée (ASLA) 15), ed. by Ulla Melander-Marttala, Carin Östman & Merja Kytö, 11–30. Universitetstryckeriet: Uppsala. Culpeper, Jonathan. 2009. “Keyness. Words, parts-of-speech and semantic categories in the character-talk of Shakespeare’s Romeo and Juliet”. International Journal of Corpus Linguistics 14(1): 29–59. doi:10.1075/ijcl.14.1.03cul Culpeper, Jonathan. 2010. “Historical sociopragmatics”. Historical Pragmatics, ed. by Andreas H. Jucker & Irma Taavitsainen, 69–94. Berlin: Mouton de Gruyter. Culpeper, Jonathan & Merja Kytö. 2010. Early Modern English Dialogues. Spoken Interaction as Writing. Cambridge: Cambridge University Press. Fischer-Starcke, Bettina. 2009. “Keywords and frequent phrases of Jane Austen’s Pride and Prejudice. A corpus-stylistic analysis”. International Journal of Corpus Linguistics 14(4): 492–523. doi:10.1075/ijcl.14.4.03fis Halliday, M. A. K. 1970. “Language structure and language function”. New Horizons in Linguistics, ed. by John Lyons, 140–165. Harmondsworth: Penguin Books. Halliday, M. A. K. 1979. “Modes of meaning and modes of expression: Types of grammatical structure, and their determination by different semantic functions”. Function and Context in Linguistic Analysis. A Festschrift for William Haas, ed. by D. J. Allerton, Edward Carney & David Holdcroft, 57–79. Cambridge: Cambridge University Press. Hope, Jonathan. 2010. Shakespeare and Language: Reason, Eloquence and Artifice in the Renaissance. London: Methuen Drama. Jucker, Andreas H. 2006. “Historical pragmatics”. Encyclopedia of Language and Linguistics. Volume 5, ed. by Keith Brown et al., 329–331. Amsterdam: Elsevier. Jucker, Andreas H., Daniel Schreier and Marianne Hundt. 2009. “Corpus linguistics, pragmatics and discourse”. Corpora: Pragmatics and Discourse. Papers from the 29th International Conference on English Language Research on Computerized Corpora (ICAME 29), ed. by Andreas H. Jucker, Daniel Schreier & Marianne Hundt, 3–9. Amsterdam: Rodopi. Kytö, Merja. 2010. “Data in historical pragmatics”. Historical Pragmatics, ed. by Andreas H. Jucker & Irma Taavitsainen, 33–67. Berlin: Walter de Gruyter. Lenker, Ursula. 2003. “Forsooth, a source: Metalinguistic thought in early English”. Bookmarks from the Past. Studies in Early English Language and Literature in Honour of Helmut Gneuss, ed. by Lucia Kornexl & Ursula Lenker, 262–288. Frankfurt am Main: Peter Lang. Lenker, Ursula. 2008. “Booster prefixes in Old English – an alternative view of the roots of ME forsooth”. English Language and Linguistics 12(2): 245–265. doi:10.1017/S136067430800261X Lenker, Ursula. 2010. Argument and Rhetoric: Adverbial Connectors in the History of English. Berlin: Walter de Gruyter. Lindquist, Hans. 2009. Corpus Linguistics and the Description of English. Edinburgh: Edinburgh University Press. Lutzky, Ursula. 2013. “Early Modern English discourse markers – a feature of female speech?”. Historical Perspectives on Forms of English Dialogue, ed. by Gabriella Mazzon & Luisanna Fodde, 80–98. Naples: Franco Angeli Editore. Mahlberg, Michaela. 2007a. “Corpus stylistics: Bridging the gap between linguistic and literary studies”. Text, Discourse and Corpora. Theory and Analysis, ed. by Michael Hoey, Michaela Mahlberg, Michael Stubbs & Wolfgang Teubert, 219–246. London: Continuum. Mahlberg, Michaela. 2007b. “Clusters, key clusters and local textual functions in Dickens”. Corpora 2(1): 1–31. doi:10.3366/cor.2007.2.1.1 Mahlberg, Michaela & Dan McIntyre. 2011. “A case for corpus stylistics. Ian Fleming’s Casino Royale”. English Text Construction 4(2): 204–227. doi:10.1075/etc.4.2.03mah McIntyre, Dan. 2012. “Prototypical characteristics of blockbuster movie dialogue: A corpus stylistic analysis”. Texas Studies in Literature and Language 54(3): 402–425. Mitchell, E. R. 1971. Pronouns of Address in English, 1580–1780. A Study of Form Changes as Reflected in British Drama. Ph.D. dissertation, A & M University, Texas. Nevalainen, Terttu. 2006. An Introduction to Early Modern English. Edinburgh: Edinburgh University Press. Nevalainen, Terttu & Helena Raumolin-Brunberg. 2003. Historical Sociolinguistics: Language Change in Tudor and Stuart English. London: Longman. Palfrey, Simon & Tiffany Stern. 2007. Shakespeare in Parts. Oxford: Oxford University Press. Quirk, Randolph, Sidney Greenbaum, Geoffrey Leech & Jan Svartvik. 1985. A Comprehensive Grammar of the English Language. London: Longman. Romero-Trillo, Jesús. 2008. “Introduction: Pragmatics and corpus linguistics – a mutualistic entente”. Pragmatics and Corpus Linguistics. A Mutualistic Entente, ed. by Jesús Romero-Trillo, 1–10. Berlin: Mouton de Gruyter. Salmon, Vivian. 1987. “Elizabethan colloquial English in the Falstaff plays”. A Reader in the Language of Shakespearean Drama, ed. by Vivian Salmon & Edwina Burness, 37–70. Amsterdam: John Benjamins. Scott, Mike. 1997. “PC analysis of key words – and key key words”. System 25(2): 233–245. doi:10.1016/S0346-251X(97)00011-0 Scott, Mike & Christopher Tribble. 2006. Textual Patterns. Key Words and Corpus Analysis in Language Education. Amsterdam: John Benjamins. Stubbs, Michael. 2010. “Three concepts of keyword”. Keyness in Texts, ed. by Marina Bondi & Mike Scott, 21–42. Amsterdam: John Benjamins. Taavitsainen, Irma & Andreas H. Jucker. 2015. “Twenty years of historical pragmatics. Origins, developments and changing thought styles”. Journal of Historical Pragmatics 16(1): 1–24. doi:10.1075/jhp.16.1.01taa Tucker, Susie. 1962. “Forsooth, Madam”. Notes and Queries 9(1): 15–16. Walker, Terry. 2007. Thou and You in Early Modern English Dialogues. Amsterdam: John Benjamins. Williams, Raymond. 1988 [1976]. Keywords: A Vocabulary of Culture and Society. Revised and expanded edition. London: Fontana Press. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

{kind=link}
{kind=link}