
Studies in Variation, Contacts and Change in English
Studies in Variation, Contacts and Change in English
Alexander Lakaw
Linnaeus University
English collective nouns and their agreement patterns have received a great deal of attention in corpus linguistics. Previous synchronic research has found evidence of variability within and across the varieties of English (e.g., Levin 2001, Depraetere 2003, Hundt 2006). This diachronic study compares the agreement patterns with collective nouns in American and British English (henceforth AmE and BrE respectively) and draws evidence from the Corpus of Historical American English (COHA), the Old Bailey Corpus (OBC) and the Corpus of Late Modern English Texts (CLMET). The study covers the time span 1810–1909 and includes the agreement patterns of a range of collective nouns from six semantic domains: (1) EMPLOYEES (e.g., crew), (2) FAMILY (e.g., couple), (3) MILITARY (e.g., army), (4) POLITICS (e.g., government), (5) PUBLIC ORDER (e.g., police) and (6) SOCIETY (e.g., generation).
The results show an overall increase of singular agreement in both varieties. Moreover, the findings suggest that verbal and pronominal agreement patterns behave differently in that the latter is more likely to be of the plural kind, and that variation between singular and plural agreement exists even amongst the semantic categories. The incipient change in AmE towards the singular is visible in the 19th-century material. The expected leading role of AmE in this change (cf. Collins 2015: 29) could not be confirmed. Instead, AmE displays signs of a kick-down development (Hundt 2009a: 33) in which BrE shows a greater tendency for the singular in the 19th century, but is overtaken by AmE at a later point in time.
This study investigates agreement patterns of collective nouns in 19th-century American and British English (henceforth AmE and BrE respectively). This group, here defined as nouns referring to at least two human beings, can trigger singular or plural verbal and pronominal agreement (cf. Quirk et al. 1985: 316). As discussed below, various scholars have focused on the synchronic patterns of agreement, but much less is known about variable diachronic agreement patterns (as exemplified by (1) and (2) below).
| (1) | Again, it will not do to say that the army has gone into winter quarters, for the very reverse is the fact; (COHA (AmE), 1864) |
In (1) the verb has agrees with the singular form of the subject army (henceforth singular agreement), whereas in (2), the plural form have is used with a morphologically singular noun (plural agreement). Various language internal factors might play a role in agreement. According to Corbett (2006: 155), the semantic, or notional, property of a collective noun can result in plural agreement in which a verb or pronoun does not agree with the subject in grammatical number but with its semantic property to stress “the personal individuality within the group” (cf. also Quirk et al. 1985: 316). However, in a synchronic study on verbal agreement with collective nouns, Depraetere (2003) questions the assumption “that the verb form is semantically or pragmatically motivated, i.e. that there is always a contextual element that induces the use of either a singular or a plural verb” (2003: 124).
Other synchronic corpus-based studies provide evidence for differences between AmE and BrE regarding agreement patterns with collective nouns. These studies indicate that AmE favours singular agreement more strongly than BrE (Levin 2001: 36f, Hundt 2009b: 208) and that these differences can be explained by lexical specifications and dialectal variation (Bock et al. 2006: 101). Another factor influencing the form of agreement is Corbett’s Agreement Hierarchy (2006: 206), in which elements which usually are positioned further away from the collective noun (e.g., pronouns) are more likely to form notional, or plural, agreement than elements which are usually positioned closer to the noun (e.g., verbs). Indeed, studies on agreement with collective nouns show that verbal and pronominal agreement tend to behave differently. For instance, the likelihood of plural pronominal agreement increases with the distance in words between the pronoun and the collective noun antecedent (e.g., Levin 2001: 91).
The present diachronic study fills a research gap in several ways. In his account on Late Modern English syntax, Denison (1998: 99) points out that “[c]ollective nouns are notoriously troublesome as to number, and there has been much fluctuation over time.” It is this fluctuation over time which is of particular interest in this investigation. Other research has called for further studies of this phenomenon with “a more in-depth examination of usage and a classification of collectives” (Depraetere 2003: 124). Levin (2006: 341) adds that “further studies of other corpora with other time depths and other nouns are needed to chart this particular area of language variation and change.” Therefore, this investigation focuses on collective nouns which are well represented in the studies mentioned above (e.g., government, army, society) and such that have not been studied intensively before (e.g., cavalry, patrol, watch) (see Section 2 below). Furthermore, to the best of my knowledge, this study is the first to consult large historical corpora in the study of agreement with collective nouns.
The diachronic development of agreement patterns of collective nouns is an understudied phenomenon; the only major studies were carried out before the availability of electronic corpora, concentrating on BrE (e.g., Liedtke 1910, Dekeyser 1975). Only a few more recent studies apply a comparative diachronic approach (e.g., Hundt 2009a, Collins 2015). As an illustration, when comparing Australian English (AusE) with the two major varieties BrE and AmE, Collins suggests that “the increasing popularity of singular concord is more plausibly interpreted as an American-led revival, rather than a survival, of the older latent pattern” (Collins 2015: 29). Hundt (2009a: 30) points out that “[i]t may even be the case that we are dealing with a parallel long-term development rather than differential change in the two national varieties of English.” Since the ARCHER corpus, which was used for both of these corpus-based studies, contains a small data set, testing the findings by means of accessing bigger corpora is necessary.
For AmE, this study makes use of the Corpus of Historical American English (COHA; Davies 2010–). The study tests whether the development of the agreement patterns with collective nouns in 19th-century AmE is different to that of BrE, and which variety can be determined to be in the lead with regard to a possible change. Regarding BrE, an objective is to put the results of older small-scale investigations (especially Dekeyser 1975) to the test by using large data collections. In order to obtain comparable results to the study of the AmE material, and for reasons further discussed below, the results for BrE have been drawn from two corpora, the Old Bailey Corpus (OBC; Huber et al. 2012) and the extended version of the Corpus of Late Modern English Texts (CLMET; De Smet 2006). A discussion of the material and methods follows in Section 2. The results will be presented in Section 3.
This section is divided into three subsections, and it first turns to a presentation of the corpus material in Section 2.1. In Section 2.2 the nouns and their raw frequencies are discussed briefly, while the last Section 2.3 gives detailed information about the data retrieval method used.
Table 1 presents the corpora consulted for each variety and some basic statistics.
| Variety | Corpus | Time span investigated | Size of subcorpora investigated (in million words) |
|---|---|---|---|
| AmE | Corpus of Historical American English | 1810–1909 | 155 |
BrE |
The Old Bailey Corpus | 1810–1909 | 8 |
| Corpus of Late Modern English Texts | 1810–1909 | 10 |
Table 1. Overview of the corpora used
The largest of the corpora used is COHA, a diachronic multi-genre corpus with AmE texts, covering a time-span of 200 years. Its total size exceeds 400 million words. The majority of the texts are fiction, but the non-fiction genres are well represented as well. Finding a historical BrE corpus with a size comparable to the AmE equivalent turned out to be difficult. The Hansard corpus, currently being the only available historical BrE corpus that matches COHA in size, proved to be unsuitable for research of the present type. According to Ryx (2014: 457) the older material in Hansard has been edited and adapted to certain stylistic norms before publication. [1] Hence, this study makes use of two smaller diachronic BrE corpora. They are the extended version of the CLMET, a 15-million-word diachronic corpus, containing mainly fiction (covering the time span from 1710 to 1920), and the OBC, a corpus containing 14 million words of transcriptions of spoken data, taken from the historical proceedings of London’s central criminal court from the years 1720 to 1913.
The corpora used in this investigation give access to a large diachronic data set, but their choice reveals two limitations. First of all, the difference in size results in the fact that the subcorpus for AmE is almost ten times larger than the two BrE subcorpora combined (i.e. 155 vs. 18 million words). However, despite the big difference in size, both subcorpora yielded a sound number of pertinent attestations (further discussed below). Furthermore, the lack of sufficiently large BrE corpora also results in an uneven distribution across genres between the two varieties. As discussed above, the BrE corpora contain mainly fiction material and transcriptions of speech. Spoken data are not at all present in COHA, which otherwise is the most diversified corpus with regards to genre, given that it contains material from fiction, magazines, non-fiction literature and newspapers (the latter only being available from the 1860s onwards). Considering these differences, there is only partial comparability between the corpora. The majority of the AmE and BrE material is fiction or fiction-like. In Biber’s (1988: 168) terms, fiction (the genre constituting the majority in both COHA and the CLMET) is very close to the oral mode of expression, which in this study is represented by the speech-like data from the OBC. This guarantees the comparability in terms of genre, at least to some extent. However, due to the presence of non-fiction material in the AmE corpus (and its absence in the BrE corpora), a more in-depth analysis of genre differences is beyond the scope of this study.
Since COHA’s earliest material dates back to 1810, the investigation of the BrE corpora (i.e. OBC and CLMET) was limited to the same starting-point. Similarly, the BrE corpora determine the cut-off point of the investigation, as they do not extend beyond the early decades of the 20th century. For those reasons, this investigation examines the time span from 1810 to 1909. It covers most of the 19th century, enabling comparisons with the other diachronic studies available. Extending the study into the 20th century would have been preferable, but is not possible at the current time, due to the lack of diachronic BrE corpora that contain material from especially the first half of the 20th century.
Table 2 below shows the 20 collective nouns in the present study, their raw token data for both varieties and the frequency per million words (pmw) for the subtotals and the combined totals. With regard to the choice of collective nouns, the objective was to find several semantically related collective nouns, and to group them into different semantic categories. The choice of nouns is largely based on the previous studies by Hundt (2006) and Dekeyser (1975), but it has been modified to include both high-frequency (e.g., government, army) and low-frequency nouns (e.g., cavalry, infantry, watch). The study operates under the assumption that lexical characteristics of collective nouns might influence the agreement patterns as suggested by, e.g., Levin (2006: 339) and Bock et al. (2006: 103). With that in mind, it can be assumed that semantically related nouns show similarities in their verbal and pronominal agreement pattern. Hence, the 20 collective nouns were grouped into six different semantic categories.
| Instances of agreement (frequency pmw) | ||||
|---|---|---|---|---|
| Semantic category | Collective noun | AmE | BrE | Total |
| EMPLOYEE | cast | 32 | 1 | 33 |
| crew | 501 | 71 | 572 | |
| staff | 112 | 14 | 126 | |
| subtotal | 645 (4.15) | 86 (4.78) | 731 | |
| FAMILY | clan | 78 | 1 | 79 |
| couple | 553 | 43 | 596 | |
| family | 293 | 309 | 602 | |
| subtotal | 924 (5.96) | 353 (19.61) | 1,277 | |
| MILITARY | army | 405 | 201 | 606 |
| navy | 322 | 64 | 386 | |
| cavalry | 494 | 27 | 521 | |
| infantry | 272 | 28 | 300 | |
| subtotal | 1,493 (9.63) | 320 (17.78) | 1,813 | |
| POLITICS | cabinet | 129 | 26 | 155 |
| committee | 430 | 192 | 622 | |
| government | 360 | 249 | 609 | |
| subtotal | 919 (5.93) | 467 (25.94) | 1,386 | |
| PUBLIC ORDER | patrol | 43 | 21 | 64 |
| police | 334 | 249 | 583 | |
| watch | 37 | 4 | 41 | |
| subtotal | 414 (2.67) | 274 (15.22) | 688 | |
| SOCIETY | class | 155 | 95 | 250 |
| club | 169 | 28 | 197 | |
| generation | 270 | 52 | 322 | |
| society | 152 | 198 | 350 | |
| subtotal | 746 (4.81) | 373 (20.72) | 1,119 | |
| TOTAL | 5,141 (33.17) | 1,873 (104.05) | 7,014 | |
Table 2. The frequency of collective nouns grouped into semantic categories and the occurrences of agreement
Some comments have to be made on the frequency of the tokens investigated. The total number of tokens with collective meaning and which occurred with verbal or pronominal agreement is 7,014 (AmE: 5,141; BrE: 1,873). Compared to other studies mentioned before, this number is substantially higher; Dekeyser (1975) on BrE and Collins (2015) on AusE found 1,410 and 1,197 tokens respectively, whereas Hundt’s (2009a) material for the 19th century adds up to 107 tokens (AmE 58; BrE 49). As for the normalized frequencies in Table 2, it is noticeable that relevant tokens are about three to four times more frequent in the BrE material than in AmE. These differences in frequency can most likely be explained by the rather unilateral composition of the BrE corpora, being genre-specific (i.e. fiction and spoken data, see above), whereas the AmE corpus is a multi-genre corpus with a more balanced share of fiction and non-fiction material.
Even with regard to the semantic categories, Table 2 above displays some frequency-related differences between the two sets of corpora, which can partially be explained by the unequal sizes of the corpora. Within the semantic categories some collective nouns are rare in both varieties (i.e., cast, patrol and watch, and to some extent even clan), whereas other nouns are frequent in the AmE but infrequent in the BrE material (e.g., cavalry, infantry, staff). Furthermore, only in two of the six semantic categories is the most frequent collective noun the same in both AmE and BrE (i.e. crew in EMPLOYEE and police in PUBLIC ORDER). In the remaining categories, the most frequent collective noun differs in the two sets of corpora. These differences can again be explained by the uneven genre representation in the corpora (as discussed above). Therefore, the findings are not compared on the lexeme level. Instead, the semantic categories will be in focus and comments on the individual lexemes will be made whenever necessary. The results for the semantic categories will be discussed in Section 3.2.
All corpora were searched for the different collective nouns to retrieve them as key words in context. However, due to the different nature of the corpora, two different procedures were applied. Since the BrE corpora CLMET and OBC were available in an off-line format, they were searched by means of the concordance tool WordSmith6 (Scott 2012). COHA was accessed and searched via the web interface provided by the BYU (http://corpus.byu.edu/coha/). Furthermore, it must be noted that whenever a collective noun had a frequent equivalent form in a different word class (usually being a verb, e.g., cast, couple, watch, etc.) the search was further defined with a POS tag for noun to filter out instances tagged as verbs. [2] The raw results were manually scanned to exclude incorrectly tagged items.
Due to the smaller size of the BrE corpora, no restrictions were made and all tokens were investigated. The same procedure was applied for the low-frequency nouns in COHA (e.g., clan, patrol, staff). However, given the large number of tokens for some nouns in the AmE material, the following restriction was made: whenever a collective noun yielded more than 500 tokens in a decade, a randomised sample of 250 instances was investigated. This method evolved in a pilot study, in which low-frequency nouns yielded instances with agreement in less than 10% of all tokens in each decade, whereas the share of instances with agreement for the more frequent nouns was exceeding 10% in most decades. To be able to account for the underrepresentation of tokens with agreement for the less frequent items, and to prevent a too strong overrepresentation of high-frequent items in the data, the number of high-frequency tokens had to be limited, and 250 randomised tokens per decade yielded a suitable number of tokens with agreement to investigate.
The units of analysis are solely singular and plural verbal (e.g., (3a+b)) and pronominal (cf. (4a+b)) agreement, which were counted manually after a qualitative analysis of each concordance line.
| (3a) | It seemed certain, then, the old Staff so long doomed has finally been dissolved, in these hours. (CLMET, 1837) |
| (4a) | IN THE end, the committee found itself nonplused as to what to do about the situation. (COHA, 1894) |
Furthermore, it is important to highlight that different meanings of the nouns had to be accounted for, because not all collective nouns are monosemous. Especially for the PUBLIC ORDER category this was labour-intensive, as the nouns patrol, police and watch were frequently used to denote specific officers of a patrol-, watch-, or police-unit:
| (6) | This, now, was too savage; and when Mr. Virginius got the other gentleman by the throat, I looked round for the police, to see if he would part them… (COHA, 1854) |
Examples (5) and (6) exemplify non-collective uses of these nouns involving the third-person pronoun he. These occur frequently in both the AmE and BrE corpora, but they are not very common in present-day English. Such instances were not counted in the present study. Sometimes when these nouns take plural agreement, context shows that there are in fact multiple officers involved (as in (7) below).
Such instances were not counted, either, because it can be questioned whether plural agreement is triggered by the collective use of the noun. Instead, the explanation that police here denotes several police officers, further referred to with each, is more plausible. Hence, even instances with plural agreement can refer to non-collective uses of the nouns in question.
Furthermore, contrary to Levin (2001), agreement with relative pronouns was not counted, since relative pronouns do not directly mark number in the English language (Corbett 2000: 190). Finally, instances like (8) below, in which the collective noun is preceded or followed by an of-adjunct, were not included, since this is a topic of its own which is currently being studied by other researchers (Fernández Pena 2017 (this volume)).
| (8) | Probably he had his staff of newspaper correspondents, and saw to it that they sounded his praises through their organs. (COHA, 1875) |
It should be noted that verbal and pronominal agreement were frequently found in one concordance line, referring to one and the same collective noun, as in (9) below.
| (9) | Our Government relate, in such communications, that they have a bill before them for the repeal of their embargo, as recommended by Congress… (COHA, 1839) |
Such instances were counted as one instance of verbal and one pronominal agreement, as they are two different types of agreement. This circumstance results sometimes in mixed agreement, which stands for the occurrence of a singular verb and a plural pronoun with reference to the same collective noun (Hundt 2009b: 210). Contrary to Hundt’s (2009b) approach, mixed agreement is not regarded as a specific form of agreement but a combination of singular and plural agreement and will therefore be counted as singular and plural instances respectively. This method is based on Bock et al.’s (1999: 343) conclusion that verbal and pronominal agreement are outcomes of two different processes of language production, and it was also applied in other studies, e.g., Bauer (1994) and Levin (2001). The mixed agreement within the sentence boundary in (10) below was for example counted as one instance of singular verbal agreement and one instance of plural pronominal agreement.
| (10) | If your committee is looking for a good, genuine animal they will do well to see this. (OBC, 1907) |
The extract in (11) above exemplifies mixed agreement across sentence boundaries. Such instances were included in the study, since “pronouns are quite likely to occur at a greater distance [and p]ronominal concord may even run across sentence boundaries” (Hundt 2009b: 209).
This result section will begin with a discussion of the specific semantic category of PUBLIC ORDER, for reasons further discussed below in Section 3.1. The following Section 3.2 presents a comparison of the agreement patterns of the remaining semantic groups of nouns, followed by detailed descriptions of the results for both verbal and pronominal agreement patterns in Section 3.3. Lastly, the overall findings of this investigation will be compared with other diachronic studies in Section 3.4. Unless stated otherwise, the statistical significances mentioned below are based on chi-square tests (at a 0.01 significance level) of the combined results per language variety investigated. [3]
Before we turn to the results, the semantic category of PUBLIC ORDER needs to be discussed in more detail. It is characterised by an overrepresentation of the noun police, covering the vast majority of the tokens in this group (cf. Table 2 above). This is not unexpected, given the low frequency of the other two nouns in that group, i.e. watch and patrol. The following discussion, therefore, refers mainly to the specific collective noun police, even though Figure 1 below shows the results for the entire semantic category.
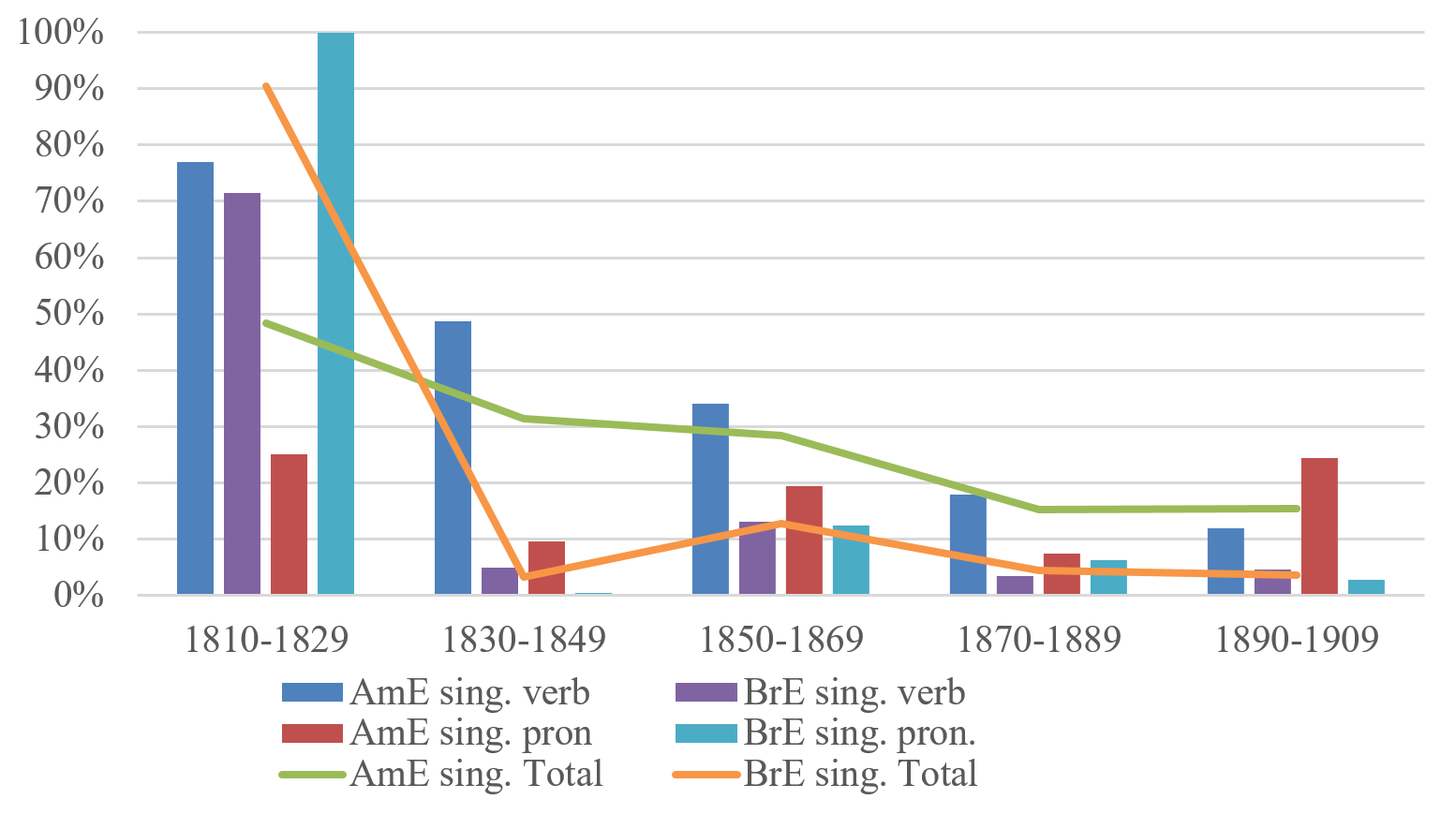
Figure 1. Singular agreement of PUBLIC ORDER in 19th-century AmE and BrE
Figure 1 presents the share of singular agreement in AmE and BrE throughout the time span pooled into 20-year periods. [4] With reference to the green and orange lines in the figure, we can see a general trend in both varieties towards plural agreement. In comparison to the other semantic categories (as discussed below), the rapid decline of the singular in both varieties is unexpected. The change is completed until the end of the 19th century, as the share of singular verbal agreement in both AmE and BrE is low. A more fine-grained analysis (Lakaw forthcoming b) reveals that it is very likely that the noun police had developed into a plurale tantum already by the middle of the 19th century, due to changes to the working habits of the contemporary police officers (Reppetto 2010: 22), implemented between 1850s and 1870s. From then on, “[t]he public experienced not ‘the’ cop on the beat, but ‘the cops’” (Thale 2004: 1053). It can be argued that this shift in perception resulted in a change of agreement from singular to plural, as the police from then on is being conceptualised as something that invariably involves more than one person.
Several qualities of the noun police make me question its status as a collective noun. It was frequently used in a non-collective sense as a synonym for “police officer” (a use that was not found for the other nouns investigated here, and which still exists in some present-day dialects). [5] [6] Furthermore, for reasons discussed above, variation in agreement with police was on a rapid decline and had almost disappeared by the latter decades of the 19th century. It is today described (or even prescribed) as an “unmarked plural noun” (Quirk et al. 1985: 303), taking only plural agreement (e.g., Biber et al. 1999: 289); hence, police does not adhere to the definition of collective nouns used in this study. As a consequence, the results presented in the following sections exclude the PUBLIC ORDER findings, since police represents the majority of the data in this semantic group.
Before we turn to the results for the remaining categories, a brief note on the method to group the nouns into semantic categories: it needs to be highlighted that the development of agreement within the semantic categories is homogenous for most groups in both the AmE and BrE material, as the agreement patterns of the individual nouns within a group are similar to each other and to the overall trend of the semantic category in general. [7] Only the semantic category EMPLOYEE shows some deviating trends of the nouns belonging to this group, which most likely can be explained by the low-frequency of the nouns cast and staff, resulting in an overrepresentation of crew in this group.
Figure 2 below presents the share of singular agreement for the remaining semantic categories in AmE over time (pooled into 20-year periods). The graphs contain the combined findings for verbal and pronominal agreement.
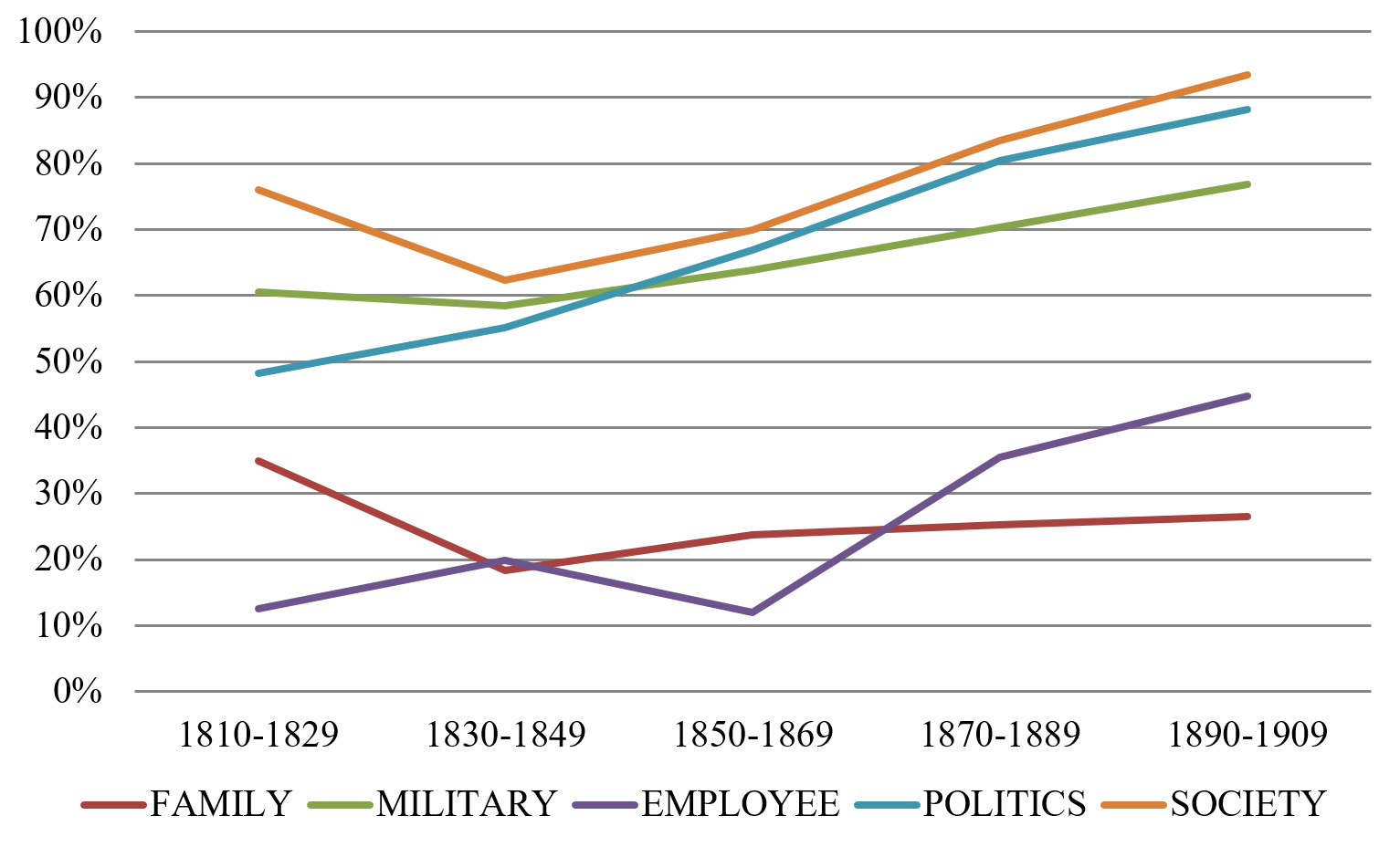
Figure 2. Singular agreement in 19th-century AmE
The overall development in AmE can be summarised as follows: the data show a steady increase of the singular for most semantic categories, but the different semantic categories vary in the starting point of that development. Some of the categories had a majority share of singular agreement already in the beginning of the 19th century (i.e., SOCIETY, POLITICS and MILITARY), whereas others have more variable patterns with a higher share of plural throughout the time period (i.e., FAMILY and EMPLOYEE).
The results for the semantic categories in the BrE variety are presented in Figure 3.
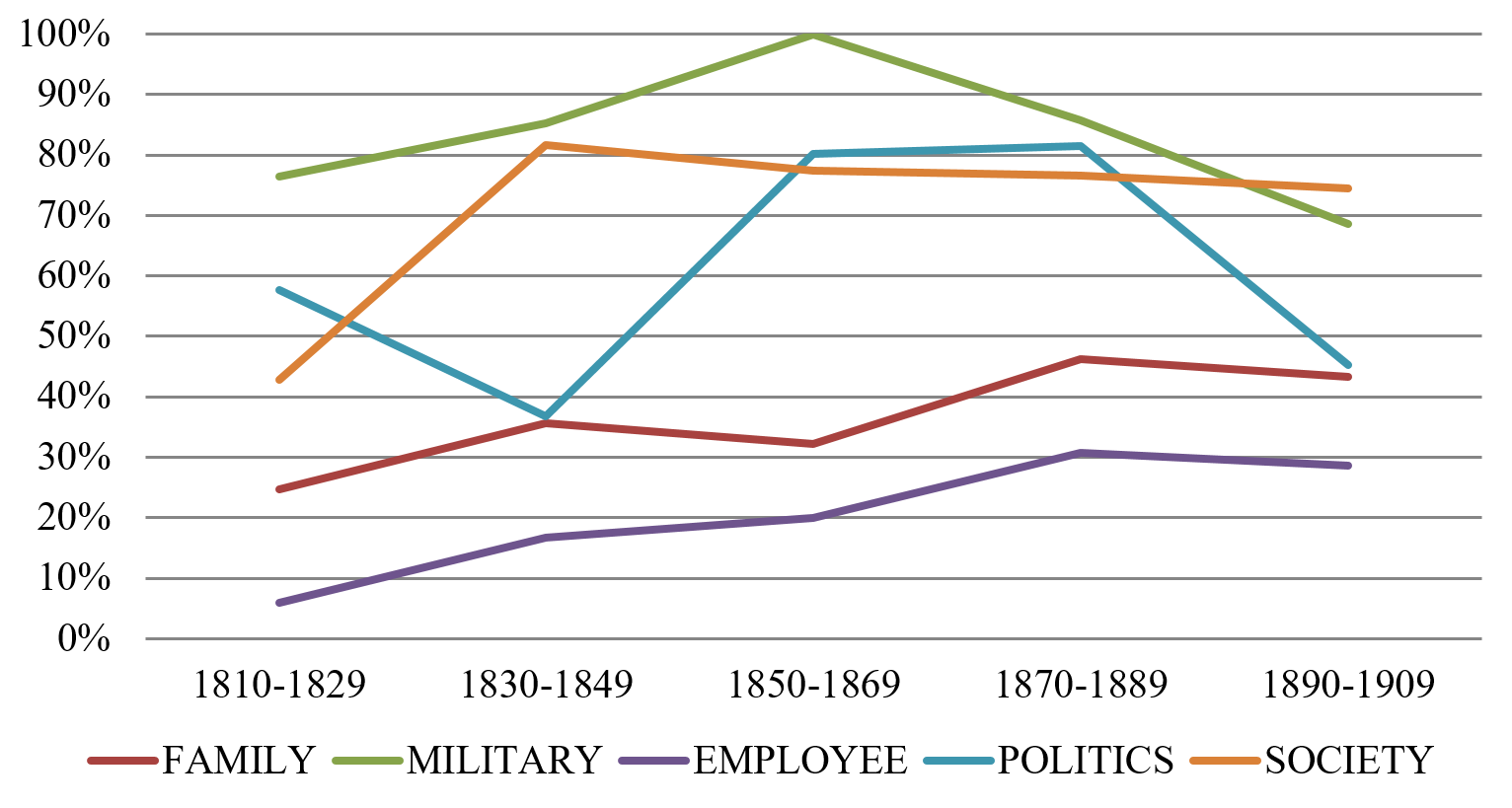
Figure 3. Singular agreement in 19th-century BrE
There is considerably more fluctuation in the BrE material in Figure 3 than in the AmE data in Figure 2, suggesting a higher rate of variability within the formation of agreement with collective nouns in this variety in the 19th century. This confirms the findings of the studies with a focus on present-day English (e.g., Levin 2001, Hundt 2009b, Bock et al. 2006), showing that agreement with collective nouns is more variable in present-day BrE than in AmE, which prefers singular agreement. However, on the level of the semantic categories themselves, some developments found in the present study do not support the present-day tendencies mentioned above. Regarding the MILITARY category, for instance, BrE has a higher share of singular agreement than AmE. Furthermore, where AmE showed a clear tendency of an increase of singular agreement for most semantic categories, the BrE material reveals groups where the opposite seems to be the case. The categories MILITARY and POLITICS, after having gone through an increase in the beginning of the 19th century, show a decline of the singular towards the end of the investigated period, of which only the decline of the singular in POLITICS in the last two 20-year periods is statistically significant (chi-square value: 16.24, p < 0.01). Other semantic categories show a similar development as in AmE, e.g., EMPLOYEE and FAMILY with a slight (but not statistically significant) increase of the singular even though plural agreement dominates throughout the 100-year period.
Figure 4 presents the total share of singular agreement (verbs and pronouns combined) in the AmE and BrE data. The results for all semantic categories (i.e. FAMILY, EMPLOYEE, MILITARY, POLITICS and SOCIETY) were pooled together.
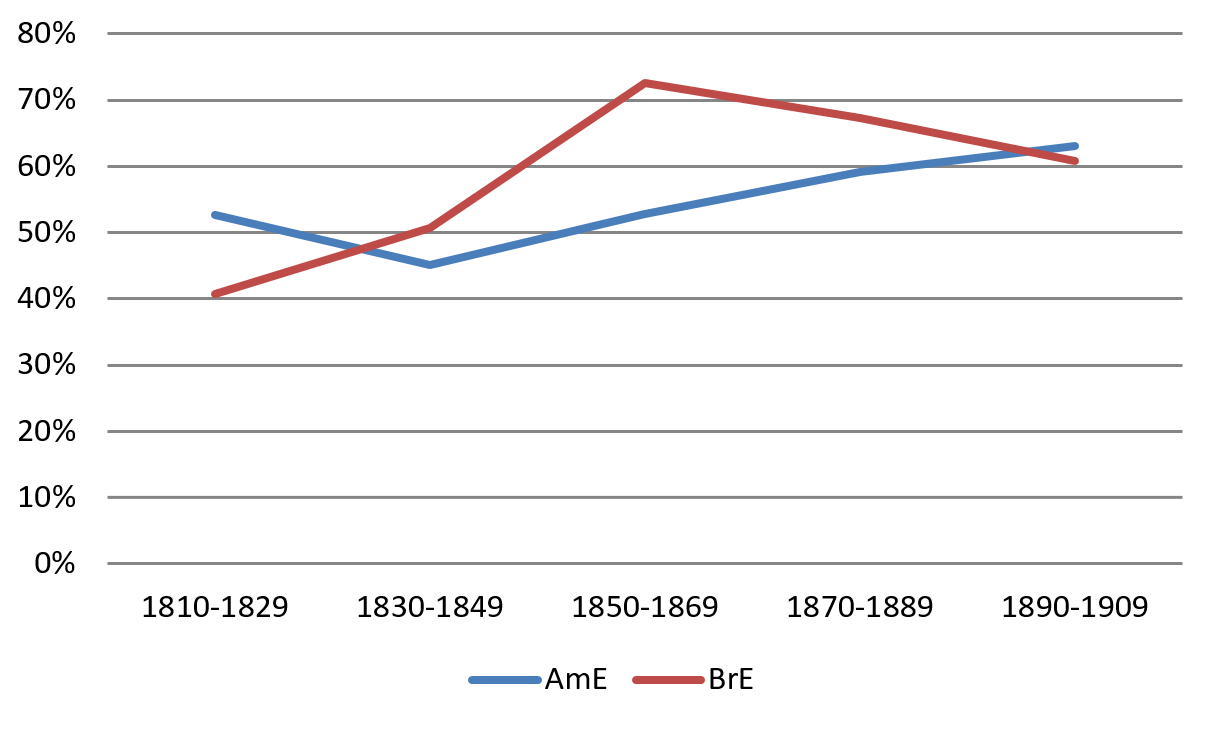
Figure 4. Development of singular agreement in 19th-century AmE and BrE
When comparing the total values for the years 1890–1909 in Figure 4 above, the conclusion might be drawn that AmE overtook BrE in the development of singular agreement with collective nouns in this period. However, drawing this conclusion would be too far-fetched. It seems more reasonable that the slight, not statistically significant decrease of singular agreement in BrE in the very same time period is due to an increased likelihood of large but insignificant fluctuations caused by the lack of tokens in the British corpora used for this study (discussed in Section 2). In the period from 1900 to 1909, for instance, only 100 tokens of collective nouns with singular or plural agreement could be found. The MILITARY domain, for instance, is only represented by two instances of plural pronominal agreement. When comparing these numbers to the AmE data set, which exceeds 500 tokens for the same decade, it becomes clear that there are certain limitations in the corpus material.
These limitations in mind, the rest of this section will present the results until 1899. This solution enables comparisons with the findings from Dekeyser’s (1975) and Collins’ (2015) studies on collective noun agreement in the 19th century (further discussed in Section 3.4). Figure 5 below displays the overall development of singular agreement in 19th-century American and British English. Since we are dealing with a long-term diachronic development and for ease of comparison with Dekeyser (1975) and Collins (2015), the figure visualises the findings for 1810–1849 and 1850–1899.
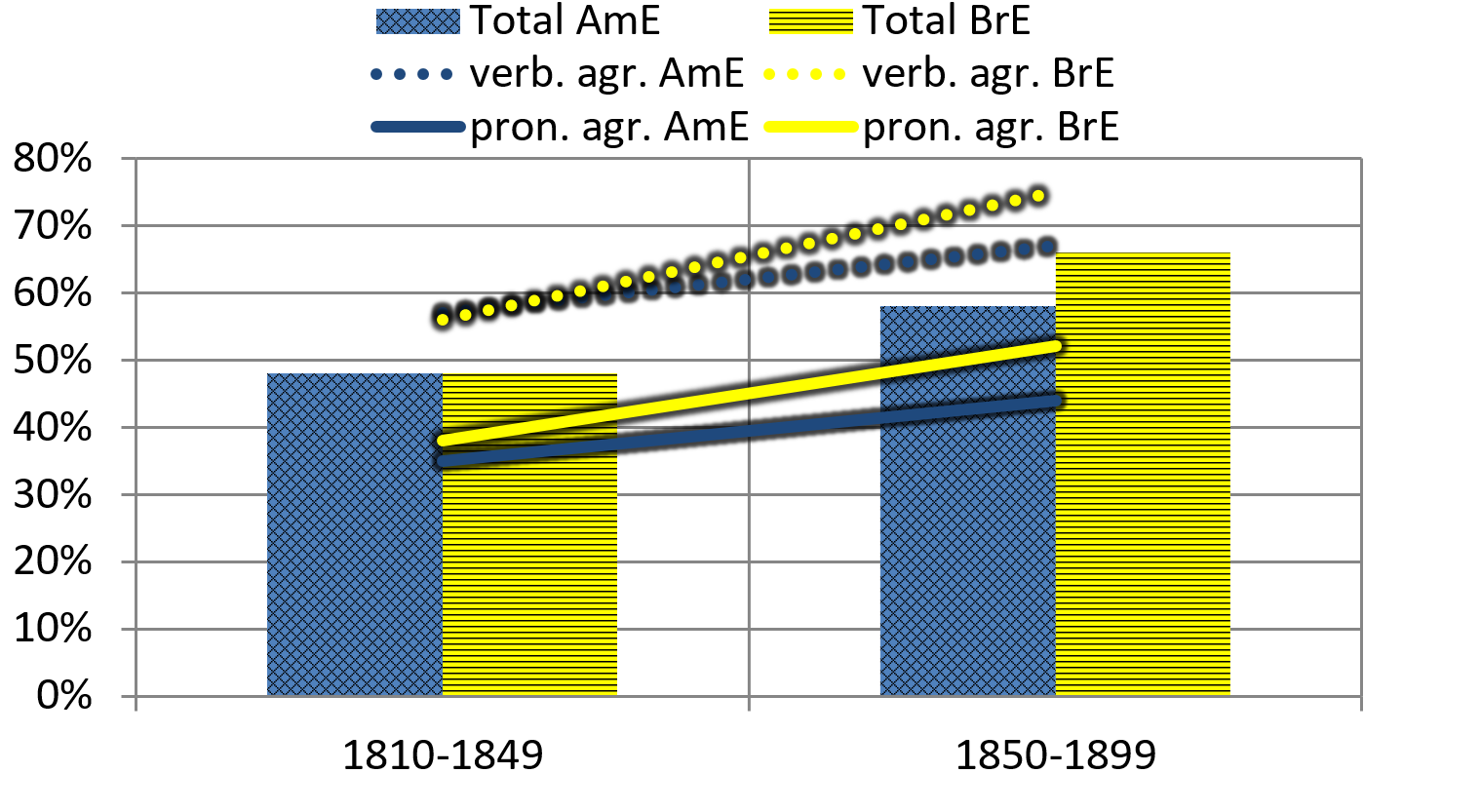
Figure 5. Singular agreement in AmE and BrE from 1810–1899
The blue and yellow bars to the left show that both AmE and BrE start out at a similar share of singular agreement of around 48% (verbs and pronouns combined). This indicates that in both varieties, the plural was at least used as frequently as the singular, if not being the dominant form of agreement for collective nouns in the 1st half of the century. Furthermore, a significant (chi-square value: AmE: 33.74; BrE: 49.19, p < 0.01) rise of the singular was found for both varieties, and in both of them the singular becomes the preferred choice in the 2nd half of the 19th century. A Mantel-Haenszel chi-square test (henceforth MH test) was used to test the statistical significance of the different patterns observed in the AmE and BrE data for the 1st and the 2nd half of the 19th century. [8] The result is that the developments in both varieties are significant (p < 0.01), with odds ratio scores of 1.36 for AmE and 2.1 for BrE respectively. The odds ratio for BrE is greater than for AmE, which means that the former variety shows a greater effect size, indicating a statistically stronger development towards the singular than AmE.
The development towards singular agreement found in the present study has resulted in the almost exclusive preference for singular verbal agreement in present-day AmE, as is reported in studies on synchronic material (Levin 2001: 36f, Hundt 2009b: 208). In the 19th century data, however, the almost exclusive preference for singular verbal agreement found in present-day AmE is not confirmed. Instead, singular agreement is less frequent in AmE in the latter half of the century when compared to BrE (chi-square value: 38.74, p < 0.01), especially with regard to verbal agreement (dotted lines). The finding that BrE had a higher share of singular than AmE, even at the end of the 19th century, diverges from the observations of the synchronic studies on agreement with collective nouns.
Previous studies have found evidence for Corbett’s (2006: 206) Agreement Hierarchy (e.g., Levin 2001: 108), stating that elements which usually are positioned further away from the collective noun are more likely to trigger plural agreement than elements which are usually positioned closer to it. This provides the need for a deeper analysis of the two types of agreement independently of each other. With regards to verbal agreement (dotted lines in Figure 5), Figure 6 visualises the results per semantic category.
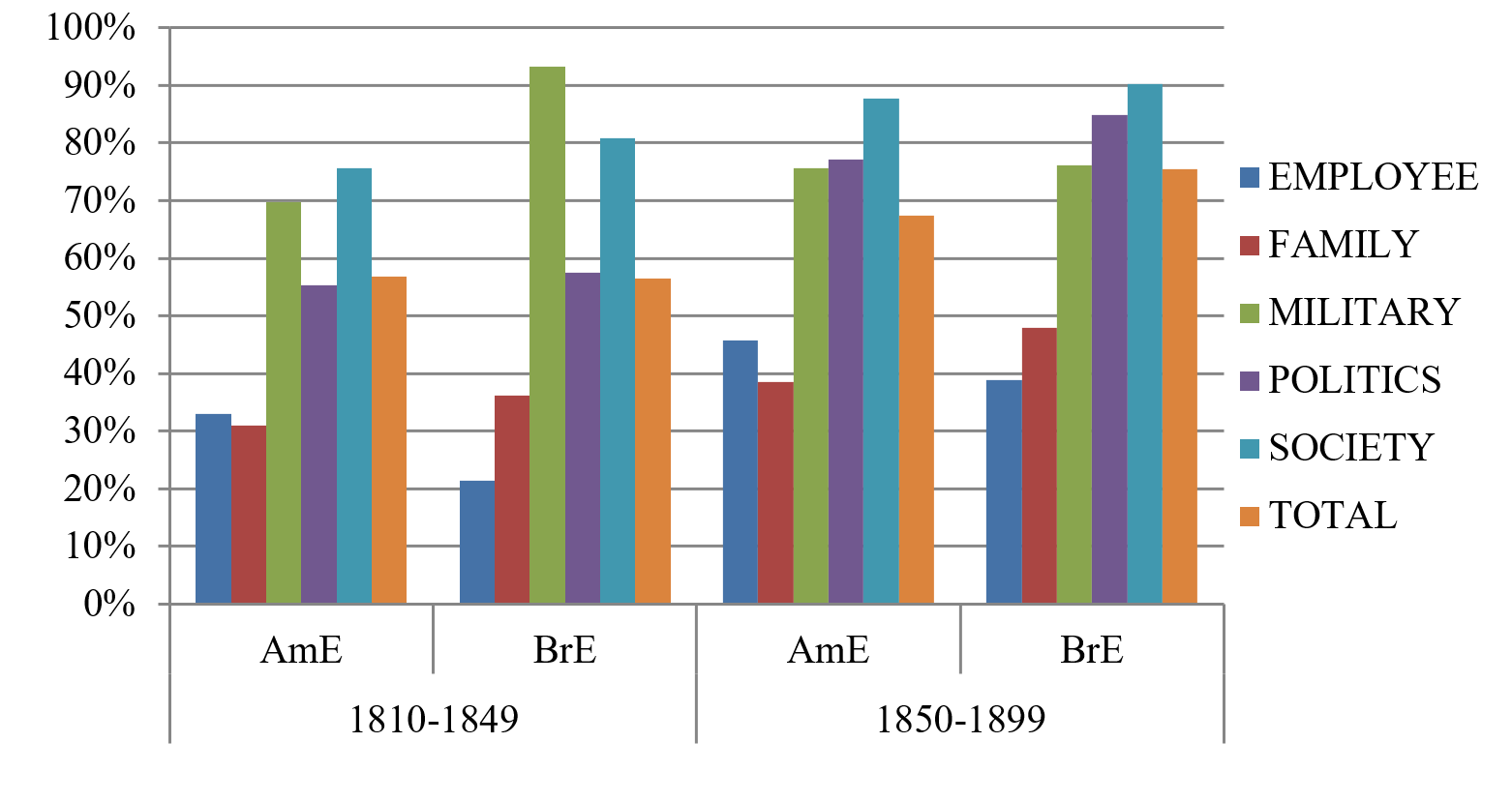
Figure 6. Singular verbal agreement per semantic category
Almost all semantic categories were found to have undergone similar developments in AmE and BrE, as they move towards a higher share of singular agreement by the second half of the 19th century, indicating a general shift towards singular verbal agreement in both varieties. [9] Only the development of MILITARY nouns in BrE goes against this trend; in the first half of the 19th century, they had the highest share of singular verbal agreement of all nouns in the two varieties with over 90%, and the number decreases (not significantly) by about 10% in the second half of the century, making plural verbal agreement as in (12) below more common.
| (12) | But the Nile was falling rapidly, and the army were soon in danger of being stranded (CLMET, 1899) |
In AmE, there was more variation with nouns from this category from the beginning, even though singular verbal agreement was more frequent throughout the century. Instead, SOCIETY was the category with the highest share of singular verbal agreement throughout the period. Plural verbal agreement with nouns from this category, as in (13) and (14) below, were rare in both AmE and BrE.
| (13) | Really the society were under considerable obligations to him in that last business (CLMET, 1821) |
The similarities between the semantic categories across the varieties are striking. For instance, FAMILY and EMPLOYEE have the lowest share of singular agreement over time in both AmE and BrE, which makes plural verbal agreement common in both varieties throughout the century, as in (15) and (16).
Semantic and lexical qualities of the nouns in these two categories might be involved here. Still, the rise of singular verbal agreement can be found in both varieties, which means that they follow the general trend but lag behind the other categories at the end of the 19th century.
EMPLOYEE is the only category with a higher share of singular verbal agreement in the AmE material when compared to BrE throughout the investigated time span, even though the plural is the more frequent variant form ((17) and (18) below).
Note that especially in (18), plural agreement is unexpected, since the adjective whole suggests unity and the triggering of singular agreement would be more likely (cf., Levin 2001: 124). This speaks for a very strong relationship between plural verbal agreement and the nouns from the EMPLOYEE category investigated.
We now turn to the pronominal agreement patterns, presented in Figure 7 below.
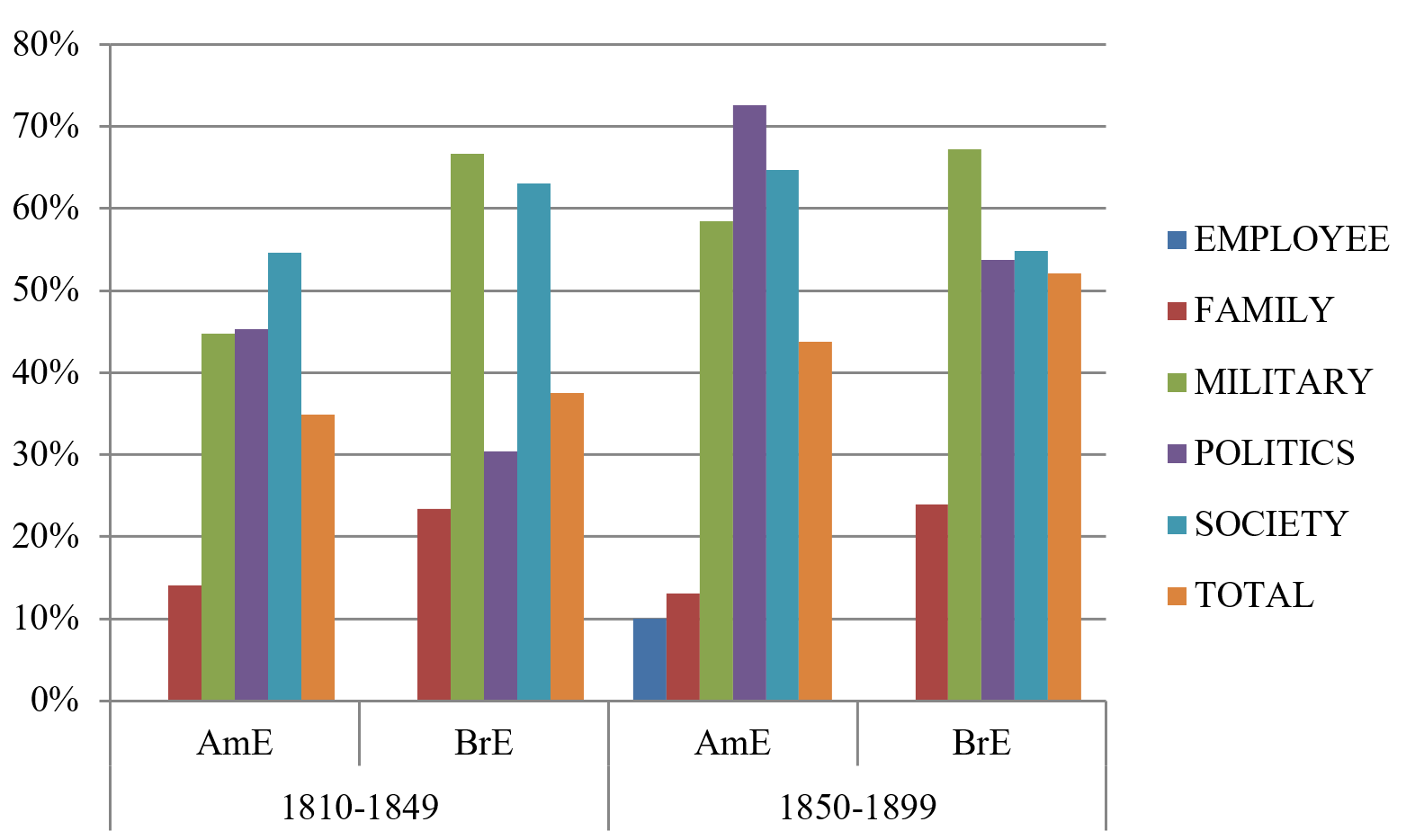
Figure 7. Singular pronominal agreement per semantic category
Similarly to the verbal agreement, the (orange) total bars display a slight rise of the singular in the 19th century (which is significant (chi-square value: AmE 11.92; BrE 14.41, p < 0.01) for both varieties), despite the fact that singular pronominal agreement is by no means the preferred choice in both varieties by the end of the century. [10] Only in BrE, singular pronominal agreement accounts for a marginal majority in the second half of the 19th century with a share of 52%. According to Hundt (2009a: 28), the increased likelihood of plural pronominal agreement is related to the general preference of pronominal agreement to be of the notional kind with a “focus on the individual within the group”. This is supported by Corbett’s Agreement Hierarchy (2006: 206), to which the mean distances between the collective nouns and their anaphoric pronouns in the present study differ in accordance with: AmE singular pronouns are on average 5.18 words away from the collective noun whereas plurals appear on average after 5.93 words. The same tendency was observed for the BrE variety (i.e., 6.44 words for singular and 6.85 for plural pronouns).
On the level of the semantic categories it can be noted that the two categories which show a preference for plural verbal agreement (i.e. EMPLOYEE and FAMILY) also display the same tendency with regard to pronominal agreement. Singular pronominal agreement was almost non-existent for EMPLOYEE nouns in the 19th century; only few instances could be found in the AmE material of the latter decades of the investigated period, e.g., (19). The plural is the major variant throughout, e.g., (20).
| (20) | The landlord who amply pays his staff and enforces their efficiency without tips will have an element of attraction... (COHA, 1885) |
Furthermore, the development of singular pronominal agreement in the POLITICS category is noteworthy. In both varieties, the singular increases with more than 20% towards the second half of the 19th century, making POLITICS the semantic category with the strongest increase of singular pronominal agreement in AmE and BrE. The corpus data show that expressions such as (21) and (22), which are atypical from a present-day AmE perspective, were more common in the beginning of the 19th century than towards the end.
| (22) | and the Cabinet feeling that they have not the support which every Ministry ought to enjoy (COHA, 1874) |
In the BrE variety, it is the MILITARY category that combines with singular pronouns more frequently than all the other nouns. Figure 7 above illustrates that the nouns army, cavalry, infantry and navy are the most advanced group of nouns in BrE in their preference for singular pronominal agreement, as exemplified by (23) and (24) below.
| (23) | The great army, however, still advanced majestically, pressing the cavalry back before it (CLMET, 1899) |
Sections 3.2 and 3.3 have discussed the different developments which singular verbal and pronominal agreement underwent in AmE and BrE of the 19th century. The results show that there are differences in the share of the singular in both varieties, but not in the general trend of development towards the singular over time. The findings of the present study show that the share of singular agreement in AmE is lower than in BrE, which contradicts the synchronic studies. How the results discussed conform to the other diachronic studies on collective noun agreement is discussed in the following section.
This section compares the results presented above with other studies investigating diachronic agreement with collective nouns, i.e. Dekeyser (1975) on BrE and Collins (2015) on AusE. To make the results of all three investigations comparable, the distribution of singular agreement (both verbal and pronominal agreement combined) of each study was calculated for the two 50-year periods in the 19th century. This practise follows the method of presenting the results in Dekeyser (1975) and Collins (2015). Hence, Figure 8 shows the development of agreement with collective nouns in three English varieties for the periods 1810–1849 and 1850–1899.
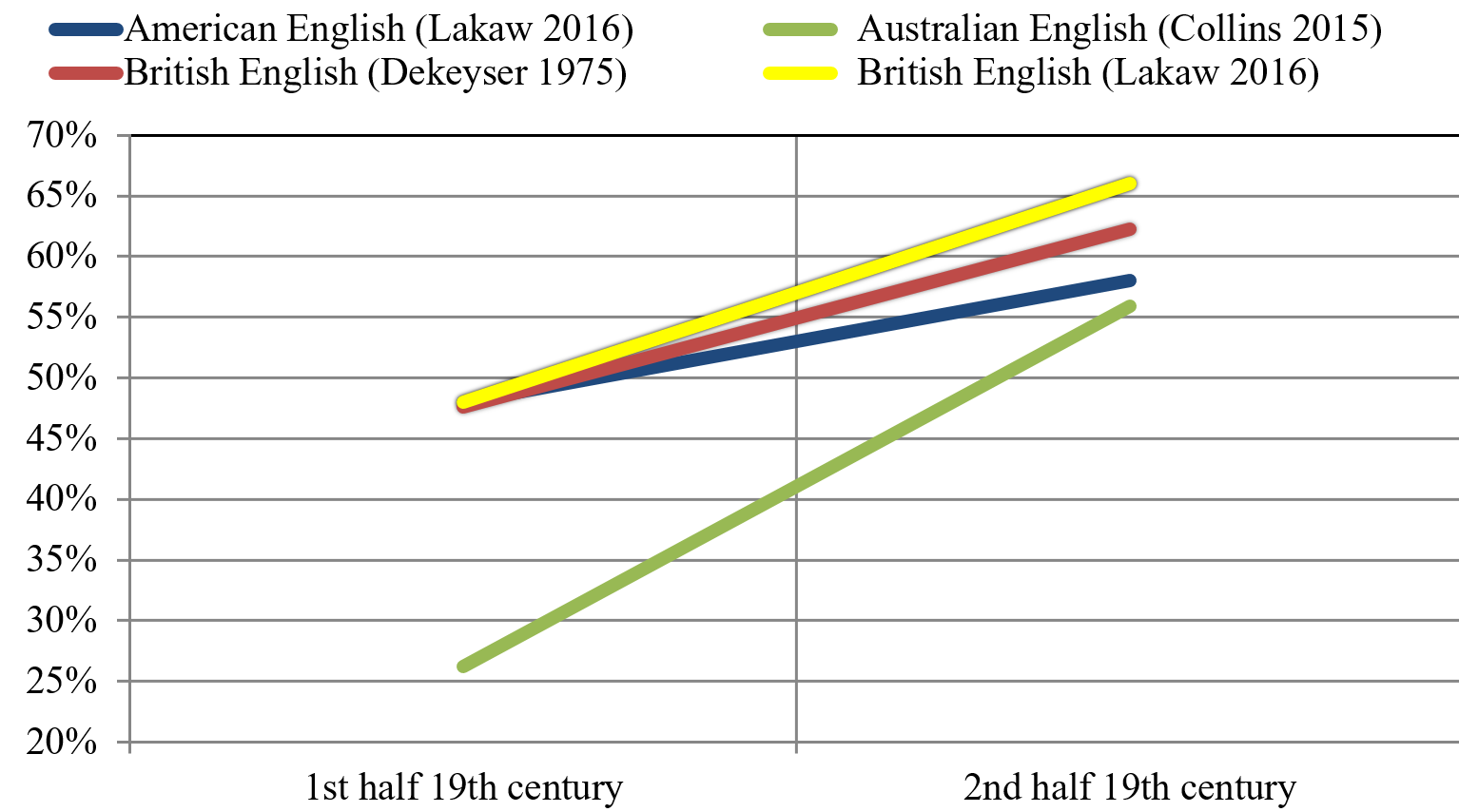
Figure 8. Rise of singular agreement with collective nouns in the 19th century
Note that the data sets in these studies are slightly different; as mentioned, Dekeyser’s (1975) study was conducted before digital corpora were available, and Collins (2015) makes use of small corpora. Moreover, the number of collective nouns is different. Dekeyser looked at an individually composed set of nouns, and Collins concentrated on Hundt’s (2009b: 211) list of collectives, whereas the set of nouns in this study is the smallest of the three, especially after the exclusion of the PUBLIC ORDER category. However, the results of the present study are drawn from substantially larger corpora compared to the other two investigations.
Figure 8 shows that in all three varieties, the plural is the preferred choice in the first half of the 19th century. In the second half, this changed considerably: Dekeyser (1975: 51) concludes that in 19th-century BrE there is “a significant diachronic shifting from plural to singular, not only for the sample at large, but also for its constituent parts.” Indeed, the present study supports Dekeyser’s findings, providing evidence that BrE preferred plural at first, but that the singular became the preferred choice in the second half of the century. The increase is substantial (18%), resulting in the highest rate of singular agreement of the three varieties. Furthermore, the present study gives quantitative evidence from large diachronic corpora, showing that the share of singular agreement in BrE is even larger in the latter half of the 19th century than Dekeyser (1975) observed. The comparative data show that AmE starts out at the same share of singular agreement and only records a rise of about 10%. AmE therefore shows a lower share of singular than BrE. Contrary to Collins’ (2015: 29) observations, this result indicates that AmE does not lead the change, but is lagging behind. The data reported here suggest that AmE exemplifies a colonial lag (as does AusE), as it shows signs of change in the same direction as BrE, but is more conservative. An alternative explanation is that AmE shows signs of a kick-down development, as defined by Hundt (2009a: 33), in which it starts out as lagging behind, but, as synchronic studies (e.g., Bauer 1994, Levin 2001 & 2006, Hundt 2009a) show, AmE has overtaken BrE at some point and the singular now is the dominant variant. Hence, a change in agreement patterns with collective nouns in AmE must have occurred, but the turning point for that change is not in the 19th century, which suggests that it must be detectable in the 20th century. Put together, these results indicate that, for the 19th century, expressions such as (25) and (26)[11] below were far more common in AmE than could be expected from a purely synchronic perspective.
| (26) | Thus our government have introduced and are acting upon a new principle, which would have made the hair of Grotius stand on end (COHA, 1860) |
This study has investigated the agreement patterns of collective nouns in 19th-century AmE and BrE using large diachronic corpora (i.e. COHA, OBC and CLMET). The results show that collective nouns from different semantic categories (i.e. EMPLOYEE, FAMILY, MILITARY, POLITICS, PUBLIC ORDER and SOCIETY) exhibit some similarities in the development towards singular agreement over time. Especially with regard to verbal agreement, most categories and the nouns therein display an increase of singular verbal agreement over the time span and across the varieties. However, this pattern is far from uniform, as for instance EMPLOYEE and FAMILY nouns still prefer plural verbal agreement in both AmE and BrE in the 19th century. Even the pronominal agreement patterns develop towards the singular over time, but they are more variable as many semantic categories favour plural agreement, some of which were even found to develop against the rising share of singular agreement (e.g., FAMILY in AmE as well as MILITARY and POLITICS in BrE).
An investigation of the change from an inter-varietal perspective suggests that AmE is lagging behind BrE in the development towards singular in the 19th century. The data used here show that the cross-over point at which AmE becomes the more advanced variety could not be located in the 19th century. However, judging by the results of present-day synchronic studies, it can be assumed that it must have happened in the early 20th century. For those reasons, the development of singular agreement with collective nouns in AmE can be interpreted as a kick-down development (Hundt 2009a: 33), as it is initially lagging behind BrE, but gains momentum in the 20th century to overtake BrE in the primary preference of singular agreement.
The big corpus approach applied in this study lead to the discovery of broad patterns of variability in the agreement patterns of collective nouns in 19th-century AmE and BrE, a discovery which in turn highlights the importance of more research on the possibly underlying language-internal and language-external factors. Such language internal factors could be, for example, the distance between the collective noun and the verb or pronoun and genre differences. A language-external factor that could play a role is, for instance, prescriptivism. Furthermore, the need for further investigation into other varieties of English by means of accessing large corpora to ensure better comparability from an inter-varietal perspective needs to be highlighted. Despite the apparent need for further investigation into this matter, this study has illustrated a diachronic shift in the agreement patterns of collective nouns from the plural being the preferred choice initially towards a majority share of singular agreement in 19th-century AmE and BrE, in which the latter variety appears to be leading the change. Given the almost absolute preference for singular agreement in present-day material of AmE (cf. Section 1), this finding is striking.
Further studies are planned with a special focus on extending the scope of the investigation of the AmE variety into the 20th century to provide quantitative data establishing the point of divergence.
[1] For more information see Mollin (2007) and Lakaw (forthcoming a). [Go back up]
[2] For more information on the POS tagging of COHA, see Davies (2012: 125). [Go back up]
[3] Furthermore, unless stated otherwise, the chi-square tests used in this study compare the raw tokens for singular or plural verbal or pronominal agreement (or a combination of the two types of agreement) over time, and not across the language variety. [Go back up]
[4] For this and all the other figures in this article it was decided against including the absolute token numbers to minimize complexity. For the absolute token numbers consult the Appendix. [Go back up]
[5] Note again that these instances were not counted as singular agreement in the present study. [Go back up]
[6] The OED (s.v. police, noun, 5a) only refers to this sense with plural agreement, hence with reference to several police officers. See discussion on (7) under Section 2.3. [Go back up]
[7] See the Appendix for the absolute numbers and the proportional shares of singular and plural agreement for each noun and category over the investigated time-span. [Go back up]
[8] This test is used in the present study because it is the most suitable statistical method for the data analysed here. It compares odds ratios (effect size measure) of two 2x2 contingency tables (i.e. the relationship between singular and plural agreement in the two different time bins, calculated for both the AmE and BrE data). The tool used for the calculations can be found in the Sources section or by clicking here. [Go back up]
[9] In AmE, the development of singular verbal agreement is statistically significant (p < 0.01) for the semantic groups POLITICS, SOCIETY as well as the totals. In BrE, this is only the case for POLITICS and the totals. A MH test across the varieties revealed a statistical significance of p < 0.01 for POLITICS and SOCIETY, as well as the total results. The differences of singular agreement in the 1st and the 2nd half of the 19th century in AmE and BrE are statistically significant at p < 0.05. [Go back up]
[10] In AmE, the categories MILITARY, POLITICS (p < 0.01) and EMPLOYEE (at p < 0.05) show statistically significant changes in singular pronominal agreement over the two halves of the century. In BrE, only POLITICS shows a statistically significant development. A MH test revealed statistically significant differences for all groups across the varieties (except for FAMILY and SOCIETY) at p < 0.01 (FAMILY: p < 0.05). Even the compared total developments in AmE and BrE are significantly different at p < 0.01. [Go back up]
[11] Bibliographic details and co-text reveal that these two examples are describing American contexts. [Go back up]
COHA = The Corpus of Historical American English: 400 million words, 1810–2009. 2010–. Compiled by Mark Davies. Available online at http://corpus.byu.edu/coha/
CLMET = The Corpus of Late Modern English Texts (Extended Version). 2006. Compiled by Hendrik De Smet. Department of Linguistics, University of Leuven.
Mantel-Haenszel chi-square test for stratified 2 by 2 tables: http://epitools.ausvet.com.au/content.php?page=mantel_haenszel
OBC = The Old Bailey Corpus. Spoken English in the 18th and 19th centuries. Version 1.0, 2013-06-04. 2012. Compiled by Huber, Magnus, Magnus Nissel, Patrick Maiwald, & Bianca Widlitzki. Accessed via http://www1.uni-giessen.de/oldbaileycorpus/
WordSmith Tools version 6. 2012. Mike Scott. Stroud: Lexical Analysis Software.
Bauer, Laurie. 1994. Watching English change. London: Longman.
Biber, Douglas. 1988. Variation across speech and writing. Cambridge: Cambridge University Press.
Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad & Edward Finegan. 1999. Longman grammar of spoken and written English. Harlow: Longman.
Bock, Kathryn, Janet Nicol & J. Cooper Cutting. 1999. “The ties that bind: creating number agreement in speech”. Journal of Memory and Language 40: 330–346. doi:10.1006/jmla.1998.2616
Bock, Kathryn, Sally Butterfield, Anne Cutler, J. Cooper Cutting, Kathleen M. Eberhard & Karin R. Humphreys. 2006. “Number agreement in British and American English: Disagreeing to agree collectively”. Language 82(1): 64–113. doi:10.1353/lan.2006.0011
Collins, Peter. 2015. “Diachronic variation in the grammar of Australian English”. Grammatical Change in English World-Wide, ed. by Peter Collins, 15–42. Amsterdam: John Benjamins. doi:10.1075/scl.67.02col
Corbett, Greville G. 2000. Number. Cambridge: Cambridge University Press.
Corbett, Greville G. 2006. Agreement. Cambridge: Cambridge University Press.
Davies, Mark. 2012. “Expanding Horizons in Historical Linguistics with the 400 million word Corpus of Historical American English”. Corpora 7: 121–57. doi:10.3366/cor.2012.0024
Dekeyser, Xavier. 1975. Number and case relations in 19th century British English: a comparative study of grammar and usage. Antwerp: Bibliotheca linguistica.
Denison, David. 1998. “Syntax”. The Cambridge history of the English language: 1776–1997, Vol. 4, ed. by Suzanne Romaine, 92–329. Cambridge: Cambridge University Press.
Depraetere, Ilse. 2003. “On verbal concord with collective nouns in British English”. English Language and Linguistics 7(1): 85–127. doi:10.1017/S1360674303211047
Fernández-Pena, Yolanda. 2017. “‘These points stated, a number of problems remain’: A corpus-based analysis of the idiomatisation of collective noun-based constructions”. Exploring Recent Diachrony: Corpus Studies of Lexicogrammar and Language Practices in Late Modern English (Studies in Variation, Contacts and Change in English 18), ed. by Sebastian Hoffmann, Andrea Sand & Sabine Arndt-Lappe. Helsinki: VARIENG.
Hundt, Marianne. 2006. “‘The committee has/have decided…’. On concord patterns with collective nouns in inner- and outer-circle varieties of English”. Journal of English Linguistics 34(3): 206–232. doi:10.1177/0075424206293056
Hundt, Marianne. 2009a. “Colonial lag, colonial innovation, or simply language change?” One Language, Two Grammars, ed. by Günter Rohdenburg & Julia Schlüter, 13–37. Cambridge: Cambridge University Press.
Hundt, Marianne. 2009b. “Concord with collective nouns in Australian and New Zealand English”. Comparative Studies in Australian and New Zealand English: Grammar and beyond, ed. by Pam Peters, Peter Collins & Adam Smith, 207–224. Amsterdam/Philadelphia: John Benjamins. doi:10.1075/veaw.g39.12hun
Lakaw, Alexander. Forthcoming a. The Hansard hazard revisited. Manuscript in preparation.
Lakaw, Alexander. Forthcoming b. Here come the police, here they come. Manuscript in preparation.
Levin, Magnus. 2001. Agreement with Collective Nouns in English. Stockholm: Almquist and Wiksell.
Levin, Magnus. 2006. “Collective nouns and language change”. English Language and Linguistics 10(2): 321–43. doi:10.1017/S1360674306001948
Liedtke, Ernst. 1910. Die numerale Auffassung der Kollektiva im Laufe der englischen Sprachgeschichte. Königsberg.
Mollin, Sandra. 2007. “The Hansard hazard: Gauging the accuracy of British parliamentary transcripts”. Corpora 2(2): 187–210. doi:10.3366/cor.2007.2.2.187
OED. 2017. Oxford English Dictionary online. Oxford: Oxford University Press. www.oed.com.
Quirk, Randolph, Sidney Greenbaum, Geoffrey Leech & Jan Svartvik. 1985. A Comprehensive Grammar of the English Language. London: Longman.
Reppetto, Thomas A. 2010. American Police: A History, 1845–1945. New York: Enigma Books.
Ryx, Kathryn. 2014. “‘Whatever Passed in Parliament Ought to be Communicated to the Public’: Reporting the Proceedings of the Reformed Commons, 1833–50”. Parliamentary History, Vol. 33, pt. 3: 453–474. doi:10.1111/1750-0206.12106
Thale, Christopher. 2004. “Assigned to Patrol: Neighborhoods, Police, and Changing Deployment Practices in New York City before 1930”. Journal of Social History, 37 (4): 1037–1064. doi:10.1353/jsh.2004.0070
Below are the full tables of the absolute numbers per decade, absolute numbers pooled 2 decades, absolute numbers pooled 50 years, and absolute numbers PUBLIC ORDER. To download the Excel spreadsheet (.xlsx), click here.
