
Studies in Variation, Contacts and Change in English
Studies in Variation, Contacts and Change in English
Marie-Louise Brunner, Trier University of Applied Sciences
Stefan Diemer, Trier University of Applied Sciences
Selina Schmidt, Birmingham City University
Spoken computer-mediated communication (CMC) presents a complex challenge for corpus creation. While big-data approaches work well with written data, rich conversation corpora pose major problems at the recording, transcribing, annotation and querying stages (Diemer, Brunner & Schmidt 2016). Many features of spoken and especially audio-visual corpora are not covered by current transcription standards (Nelson 2008). They may be a matter of debate (e.g. gestures and gaze, Adolphs & Carter 2013) and raise organizational issues. This article presents examples of rich data from CASE, the Corpus of Academic Spoken English (forthcoming), compiled at Saarland University, Germany. CASE consists of Skype conversations between speakers of English as a Lingua Franca (ELF). CASE data allows research on a wide range of linguistic features of informal spoken academic CMC discourse. Its multimodal nature illustrates both benefits and challenges of rich data, particularly during transcription and annotation. The article presents the organisation and transcription scheme developed for CASE. CASE is designed with multiple layers, including a discourse-oriented basic layer, as well as XML, orthographic, and part-of-speech-tagged layers. The paper discusses the challenges and limitations of transcription and annotation in view of the audiovisual corpus data, especially with regard to paralinguistic (e.g. laughter) and non-verbal (e.g. gestures) discourse features. We illustrate the advantages of the proposed organisation and transcription scheme with regard to the multimodal data set in the context of several quantitative and qualitative case studies.
Rich data has many benefits but also poses challenges to the researcher. In a corpus context we conceive of rich data as including information beyond the scope of a traditional collection of written data. This means the inclusion of, for example, audio or video components (and as a consequence the integration of paralinguistic features such as laughter, and the integration of non-verbal features, such as gestures or background noise), but also the ensuing procedural and organisational issues. This paper discusses the inclusion and the role of rich data in spoken CMC (computer-mediated communication) corpora using Skype conversations from CASE, the Corpus of Academic Spoken English (forthcoming, see also the project website). The article comments on organisational aspects, such as the presentation of rich language data in layers, and potential research directions. In addition, the paper provides case studies on the importance and the treatment of paralinguistic and non-verbal features, discussing selected issues (and possible solutions), especially regarding their role in the meaning-making process as these aspects of rich data have not yet been explored in great detail in previous studies and transcription guidelines.
The paper is organized as follows: After a brief description of CASE, its background, setting, and its compilation process in Section 1, Section 2 describes how rich data is managed in the corpus, focusing on general issues of audio-visual data (Section 2.1), the layered corpus structure (Section 2.2) and the transcription and compilation process (Section 2.3). Section 3 focuses on paralinguistic transcription features and provides a case study on laughter, in particular, discussing the detailed laughter transcription used in CASE and its advantages in comparison to other transcription systems (Section 3.1). This is illustrated by a qualitative and quantitative study of laughter in the corpus (Section 3.2). Section 4 focuses on non-verbal transcription features, discussing the theoretical implications of multimodal data (Section 4.1). This is followed by exemplary quantitative and qualitative analyses of gestures in CASE (Section 4.2). The final Section 5 sums up the key issues in the management of multimodal data and its benefits for context analyses in CASE.
CASE is currently being compiled at Trier University of Applied Sciences and its partner institutions. The corpus focuses on advanced academic L2 use of English in an international setting. As of October 2017, CASE consists of more than 200 hours of conversations (which translates to an extrapolated total of roughly 2 million words) between university students from Germany, Bulgaria, Italy, Spain, Finland, Sweden, Belgium and France. For comparison purposes, conversations between native and non-native speakers as well as between native-speakers only are currently being compiled with partners from the UK and the US.
Conversations are identified by a unique ID consisting of:
Abbreviations used in the examples of this article are: FL (Forlì, Italy), HE (Helsinki, Finland), LV (Louvain, Belgium), SB (Saarbrücken, Germany), SF (Sofia, Bulgaria), ST (Santiago de Compostela, Spain).
The language use documented in CASE can be categorized as English as a Lingua Franca (ELF). Seidlhofer (2011: 10) considers ELF to be “any use of English among speakers of different first languages for whom English is the communicative medium of choice”, implicitly including ENL speakers. Mauranen (2012: 6) suggests that in ELF, “spontaneous norms arise […] [and] are negotiated internally”, the only authority being “communicative efficiency” while Widdowson (2015: 371) argues that ELF users “both naturally and instinctively put the linguistic resources at their disposal to pragmatic use and so act on their communicative capability”. Successful communication is thus the key objective, whereas the imitation of native speaker varieties does not play a central role (Hülmbauer 2013: 50–51; Jenkins 2015: 45). In fact, Jenkins (2015: 45) points out that in ELF, “differences from native English that achieve this [successful intercultural communication] are regarded not as deficiencies but as evidence of linguistic adaptability and creativity”. Mauranen (2012) makes a similar argument, characterizing ELF as a set of strategies aimed at achieving mutual and situated comprehension. Speakers of ELF use, for example, features such as morphological and syntactical variation, approximations of standard forms, explicitness and metadiscourse, repetition (e.g. Björkman 2009, Mauranen 2012), code-switching (e.g. Cogo 2009, Klimpfinger 2009, Pennycook 2010, Vettorel 2014), as well as transfer, and lexical and idiomatic language innovations (e.g. Pitzl 2009, Brunner, Diemer & Schmidt 2016).
CASE conversations are recorded via the medium Skype, which constitutes a distinct new approach to corpus compilation. CASE is, to our knowledge the first corpus of Skype conversations to date and research on Skype as an oral, synchronous and usually dialogic (i.e. one-to-one, Herring 2007) discourse type (although more than two conversation partners are possible) is not very extensive. More research exists on video-conferencing as a predecessor of Skype. Fish et al. (1993: 50f.) state that the combination of video and audio channels imitate the features of face-to-face interactions, facilitating informal communication. According to Isaacs & Tang (1994), additional benefits of an audio-visual video connection are visual backchannels, non-verbal responses and non-verbal response forecasting, gesture-based support of descriptions, non-verbal expression of attitudes, and a better pause management. These features contribute to a “markedly richer, subtler, and easier [communication] than […] telephone interactions” (67) and are very useful in conflict situations to avoid misinterpretations. However, Tang & Isaacs (1993: 193f.) find that issues with the audio channel such as “delays, echoes, [and] incomprehensible audio quality” pose a substantial threat to successful interpersonal interactions. As Olson & Olson (2000: 173) observe “distance still matters”. Despite the benefits of international video and telephone communication and even though CMC facilitates intercultural communication regardless of national boundaries (Gong 2005: 1), the intercultural context itself can pose considerable problems for successful communication. Research that analyzes aspects such as paralinguistic and non-verbal meaning-making strategies in an ELF context, particularly via Skype, is as yet scarce. This makes CASE an indispensable and versatile research tool.
CASE guidelines require conversations to last at least 30 minutes, resulting in recordings between 30 and 200 minutes to reduce the effects of participants’ awareness of being recorded since, as Adolphs & Carter (2013: 148) point out, the longer the conversations the more natural they become. The video data is recorded using a side-by-side configuration, about 30% are audio only (in cases of low bandwidth). Each conversation was attributed a topic prompt from a loosely academic background to facilitate the conversation initiation in a first contact situation, for example “course of studies and job prospects”, “life as a university student”, “pros and cons of online learning”, and “cultures and traditions” (see Sources for a complete list). Usually, the topic prompts then quickly lead to conversations developing in a natural way so that the topics that were actually covered by participants go beyond just the proposed topic, including for example participants’ research interests, personal background, general small talk, the project itself, technical difficulties or meta topics (i.e. external factors from interlocutors’ surroundings intruding) (see Brunner 2015; Diemer, Brunner & Schmidt 2016), reflecting a natural conversation setting.
While the Skype recordings took place in an informal setting, i.e. a setting of the participants’ choice outside the university (not in a language lab, usually at home), the general context of the conversations can still be considered to be academic. Several elements contribute to establishing a generally academic context, and although they do not in and of themselves constitute such a context, they can be considered to be sufficient in combination with each other:
In contrast to established corpora of spoken academic language such as MICASE (2002), ELFA (2008) or the academic/educational parts of VOICE (2013), which mostly consist of seminar discussions, lectures, seminar and conference presentations, academic defenses, and other formal and official university settings, CASE can be located at the informal end of the academic language spectrum. Following Laitinen’s (2015) taxonomy of academic spoken and written discourse, CASE could be interpreted as falling into the same category (informal spoken academic) as, for example, informal talks between supervisors and students (outside advisory sessions), informal talk during academic breaks, talk at social academic settings (e.g. receptions), and team talk.
Paul Thompson’s statement that spoken corpora are “notoriously difficult to work with” (Thompson 2005, no pages) is as true today as ten years ago, and despite advances in technology, Diemer et al. (2016) point out that the complexity of spoken data cannot be fully captured in a written corpus setting. Spoken corpora such as the International Corpus of English (ICE, Nelson 2008), the Vienna Oxford International Corpus of English (VOICE 2013), the English as a Lingua Franca in Academic Settings project (ELFA 2008), or LINDSEI, the Louvain International Database of Spoken English Interlanguage (2010), have developed various ways of transcribing spoken features, including e.g. overlap, pauses, prosody, voice shift, non-verbal utterances, selected context, etc. These corpora all use different frameworks and illustrate that the main difficulty of spoken data transcription seems to be the selection (and transcription method) of potential features to be transcribed, as the researchers do not know which features might be important in a particular research context, only a selection can be transcribed, and those only with a certain degree of simplification.
The transcription of audio-visual CMC data adds another level of complexity by introducing yet more features. While much research has been focusing on written CMC, spoken conversations in a CMC setting, e.g. Skype, have not received similar attention due to the complexities introduced by the medium itself (see also Diemer, Brunner & Schmidt 2016), such as supporting gestures, non-verbal backchannels, references to the speaker’s physical environment, etc.
A corpus containing audio-visual data thus needs to include more complex transcription features, since meaning-producing aspects might get lost when using the usual transcription or annotation framework. CASE compilation procedure aims at including as much of the original data as possible (suitably anonymized) to allow research in a wide range of fields. For all transcription features, Edwards’ three principles for spoken corpus compilation (Edwards 1993) should remain valid. Edwards requires the established categories to be discriminable, exhaustive and contrastive. The mark-up should be systematic and predictable so that multiple transcribers can work on the data while ensuring consistency (and retrievability). Finally, the transcripts that are produced should be easily and intuitively readable. Because corpora of rich data are impossible to transcribe fully, transcribers have to be selective and decide on a finite number of features to transcribe.
A layered corpus organization has been proposed by Sauer & Lüdeling (2016) and Diemer, Brunner & Schmidt (2016) in order to facilitate the analysis of distinct elements, based on the original data. Rather than integrating orthographic, prosodic and phonetic transcription, as Thompson (2005) suggests, CASE is organized in several aligned layers (explained below) which are treated as separate but parallel files. The final interface will allow users to switch between these at need, permitting researchers in different fields to focus on features relevant to their area of interest. Additional layers can easily be added, creating an open-ended, expandable corpus.
The CASE design also includes sociolinguistic metadata. Participants complete anonymized questionnaires detailing key sociolinguistic indicators such as age range, gender, nationality, native and other languages. We also collect information that is important for the language background, such as time spent learning English, periods spent in English-speaking countries, variety of English spoken, as well as information on the use of English at university, at work, and at home. This data is attributed to the anonymized participant recordings, allowing correlation of sociolinguistic factors and language use.
In the rich data context of CASE, it is essential that the original data remains accessible as part of the corpus structure and aligned with all other features, so as to allow later analysis of features that at the moment cannot be considered and, of course, to re-analyze and refine earlier transcriptions. The video and/or audio component of the corpus is filtered in order to preserve anonymity while at the same time allowing the analysis of visual, prosodic, and paralinguistic features at need. After testing various alternatives, CASE is able to satisfy the requirement for anonymization by using the “Find Edges” filter in Adobe Premiere Pro. The filter ensures anonymity, prevents reconstruction of the filtered data and preserves facial cues and gestures, as well as the physical background of the recording (for further information and an example see also the CASE project post on the Red Hen Lab website, and the CASE project website). CASE anonymization guidelines and rules for informed consent conform to Boise State University, USA, and Saarland University, Germany, ethical guidelines for academic research.
At the moment, there are four main transcription layers in CASE (see also examples 1 to 4):
| SB02: | hello. |
| SF02: | hello there. |
| SB02: | ((laughs)) well .. it's: working, (that's good then), [that's] good news isn't it. |
| SF02: | [((hehe))] yes. I'm glad you .. you can uh you: managed to install it as well. |
| SB02: | yeah everything worked out .. q-uh: quite nicely, |
Example 1. CASE transcription layer (CASE 01SB02SF02).
| SB02: | hello |
| SF02: | hello there |
| SB02: | well it's working that's good then that's good news isn't it |
| SF02: | yes I'm glad you you can uh you managed to install it as well |
| SB02: | yeah everything worked out uh quite nicely |
Example 2. Orthographic layer (CASE 01SB02SF02).
<transcript file=“01SB02SF02.rtf”>
<body>
<utterance speaker="SB02”>hello<fall/></utterance>
<utterance speaker="SF02”>hello there<fall/></utterance>
<utterance speaker="SB02”><paraling desc="laughs"/>well<pause length=".."/>it's<long length=":”>working<level/><unclear>that's good then</unclear><level/>
<overlap>that's</overlap>good news isn't it<fall/></utterance>
<utterance speaker="SF02”><overlap><paraling desc="hehe"/></overlap>yes<fall/>I'm glad you<pause length=".."/>you can<hesitation>uh</hesitation>you<long length=":"/> managed to install it as well<fall/></utterance>
<utterance speaker="SB02”>yeah everything worked out<pause length=".."/>q<cutoff/><hesitation>uh</hesitation><long length=":"/>quite nicely<level/></utterance></body></transcript>
Example 3. XML layer (CASE 01SB02SF02).
| SB02: | hello_ITJ |
| SF02: | hello_ITJ there_AV0 |
| SB02: | well_AV0 it_PNP 's_VBZ working_VVG that_DT0 's_VBZ good_AJ0 then_AV0 that_DT0 's_VBZ good_AJ0 news_NN1 is_VBZ n't_XX0 it_PNP |
| SF02: | yes_ITJ I_PNP 'm_VBB glad_AJ0 you_PNP you_PNP can_VVB uh_ITJ you_PNP managed_VVD to_TO0 install_VVI it_PNP as_AV0 well_AV0 |
| SB02: | yeah_ITJ everything_PNI worked_VVD out_AVP uh_ITJ quite_SENT nicely_AV0 |
Example 4. POS-tagged layer (CASE 01SB02SF02).
The CASE transcription layer is the basic layer produced by manual transcription of the video data (see an in-detail description of features in 2.3). CASE transcription conventions include spoken language features beyond the words, such as prosodic, paralinguistic and non-verbal features. A conversion tool developed by Matt Gee (RDUES, Birmingham City University 2014) provides the XML layer, a version of the annotated CASE transcription encapsulating the original information in a machine-readable form. The tool also allows the removal of these elements, extracting a purely orthographic layer. This is then part-of-speech tagged with the CLAWS POS tagger (UCREL, Lancaster University). CLAWS is estimated to achieve an overall 96–97% accuracy (CLAWS website, UCREL), though accuracy with CASE data can be expected to be lower due to unresolved items such as cut-offs, code-switches, or non-standard terms, syntax or pronunciations.
The layer organisation provides several advantages. The corpus can be expanded at need without changing the basic structure or interfering with the transcript (for example by adding a more detailed gesture transcription layer). Corrections of selected features or additions need not influence the full corpus, and the layer structure provides an uncluttered view of selected features, making each layer easier to read. At the same time, features can be combined at need, for example by using the aligned video with the CASE transcript layer to focus on verbal and non-verbal backchanneling signals. Researchers from different disciplines can focus on the layers that provide them with the information relevant for their own work (e.g. a researcher interested in lexis may look at the orthographic layer without having to deal with additional annotation features, a discourse analyst at the CASE transcription layer, etc.). The various layers thus provide a differentiated resource for analyzing spoken CMC data.
After determining the basic scope of a layered corpus design, the issue of how to mark and annotate the features selected for transcription has to be resolved. Adolphs & Carter (2013) are faced with similar problems in the annotation of their data and caution that any annotation procedure needs to ensure “that recognizable patterns are consistently coded with reference to an agreed and replicable coding scheme. If this is not applied throughout the corpus, any searches for patterns will inevitably fail as they rely on the recurrence of consistent representations of linguistic phenomena” (Adolphs & Carter 2013: 155). CASE uses Dressler & Kreuz’s (2000) synthetic transcription conventions which were created using a best-practice approach, analyzing a corpus of 25 studies using different transcription conventions, among others Sacks, Schegloff & Jefferson (1974), Biber (1992), and Gumperz & Field (1995), with the main purpose of creating a model system that uses tags that are easily transcribable, retrievable, and readable. These conventions were then further developed by Norrick et al. (2013), e.g. dividing utterances into intonation units and turns (cf. Chafe 1982, 1994), and then modified for the particular conditions of spoken CMC in an international context (Schmidt et al. 2014). Dressler & Kreuz’s recommendations are essentially a simplified and selectively supplemented version of Sacks, Schegloff & Jefferson (1974). They are based on a standard typeset and use, as far as possible, intuitive symbols such as the question mark to indicate a rising pitch. The result is still essentially an orthographic transcription, but with further transcription elements being added. This has several advantages: the annotation is easily convertible during mark-up as needed, the transcript remains easy and intuitive to read, and there is no additional idiosyncratic typeset. The scheme thus fulfils Edwards’ (1993: 5–6) requirements of discrimination, readability and predictability. For reasons of objectivity, it aims to be as descriptive as possible, leaving room for interpretation. The CASE transcription conventions are available online. In the following paragraphs, the different elements of the CASE transcription layer are described in detail. As transcription is still ongoing, the examples in this article are based on preliminary versions of the transcripts.
Basic spoken language features: CASE transcription conventions generally follow British English spelling and orthography, differentiate between various types of hesitation markers and response tokens, and regulate the transcription of non-standard features (by requesting that contractions and characteristic pronunciation patterns with existing standardised spelling, such as gonna, wanna, gotta etc. are transcribed accordingly). They also include additional information beyond the orthographic transcript that may be relevant within the conversational context. On a basic level, this includes typical spoken language features such as overlap ([…]), cut-offs (-), and liaisons (_) and also instances where the utterance is latched onto the previous one (=), which are illustrated by example 5, as well as instances where the utterance remains unclear (marked by opening and closing brackets).
| LV20: | biology. or well sciences. but o:h, so I- I was just like yeah “let’s go for LANGUAGES”= |
| SB145: | =yea:h great. |
| LV20: | a:nd_I could only choose u:hm between, Dutch <English> and Spanish. I didn’t like Dutch. so- I mean not- {looks up} .. yeah Dutch is like F-Flemish. |
| SB145: | [yeah]. |
| LV20: | [and] German is German. |
Prosody: As part of the CASE transcription layer, selected prosodic features are annotated. These include intonation and pitch, volume, speed, and pauses. Intonation is only marked at the end of each intonation unit, where it occurs in a prominent position with immediate relevance to the conversation organisation. Individual and isolated pitch shifts are not transcribed within the intonation unit, but the transcription scheme marks general shifts in voice (occurring for example when voicing another person) with quotation marks (“ ”). Higher volume and particularly stressed words and syllables are marked with CAPITAL letters, whispering or lower volume with °whisper°. Passages that are quicker (>quick<) or slower (<slow>) than the surrounding discourse, as well as pauses (.. indicating less than 0.5 sec, … indicating 0.5–1.0 sec, longer pauses are timed) are also transcribed. An illustration of prosodic feature annotation can be found in example 6.
| ST04: | ... an:d some day they_w- went to- my house to dinner, (1.1) and we prepared four tortillas. and one of them u:h we: >didn't (a)te it<, ... and one of the English, ... (-girls) uh said "well tomorrow I have a party at my home", .. "can I borrow thi:s tortilla for my:", ... "my mates English mates" and I [(she said that)] <that he prepared the m- the tortilla but>, |
Features indicative of the CASE setting: The CASE annotation scheme also contains features that are typical within the particular context of the corpus, mainly the multilingual background of the participants and the CMC environment. The most noticeable features for the multilingual context are code-switching and non-standard pronunciation. Code-switching (see examples 9, 10 and 11 in Section 3.2) is marked with the respective language and duration indicated in double brackets after the code-switch, e.g. ((German (1.5))). Non-standard pronunciation is transcribed in problematic cases that might lead to confusion or misunderstandings, such as “thought” pronounced as “/t/ought” (/ / indicating the phonemic transcription of what is actually said, here the realization of the grapheme <th> as /t/), which may be interpreted as the past tense of teach, i.e. “taught”. These may lead to a clarification sequence, as in example 7, which would be difficult to interpret without the annotation of the actual pronunciation as the cause for the confusion would not be clear. The CMC setting is evident in interruptions of recordings and in echo (transcribed as “€€€”), i.e. when one speaker’s utterance is picked up by the speaker’s microphone at the other end, resulting in a second, slightly delayed echoing of the utterance, which may influence the conversation, as in example 8.
| SF06: | uh ..well, … what was the theme ((/t/eme))? |
| SB03: | hm? oh .. uhm .. the theme, I think (it’s) why are you studying English. right? |
| SF13: | uh, .. so where are you located in a dorm or something or, |
| SB14: | .. in a what i-? €€€ |
| SF13: | i- in a DORM? |
Example 8. Echo in CASE (CASE 02SB14SF13).
Paralinguistic and non-verbal elements: We consider paralinguistic and non-verbal elements to be an essential part of rich corpus data, as full understanding of all utterances is not always possible without further contextual clarifications. Taking such features into account when analyzing rich language data (e.g. video data) can contribute to expanding our knowledge of meaning-making mechanisms and practices. Paralinguistic features such as coughing, sighing, and especially laughter are transcribed as far as possible as they influence the course of the conversation (see also Section 3). Salient, that is meaning-supporting or meaning-creating, non-verbal behavior, such as gestures, facial expressions, and gaze, as well as additional information regarding participants’ physical surroundings, e.g. background noise, roommates intruding, etc., are currently transcribed in a descriptive manner (see Section 4).
A special case of paralinguistic transcription features as part of rich audio-visual data is laughter. It is by far the most frequently occurring type of all annotated features, but also the most complex in our data, which makes it an excellent feature to use in a case study regarding paralanguage in CASE. Laughter fulfils various functions in the conversations and it is an essential element of meaning construction, like other paralinguistic and non-verbal features (see 2.3). Laughter functions can roughly be grouped into Stewart’s (1997) three main functional domains: metalinguistic (e.g. emphasizing (Thonus 2008), backchanneling (Yngve 1970), and topic-ending (Holt 2010)), evaluative (e.g. agreement and alignment, cf. Glenn 1995, Partington 2006, Baynham 2011, Warner-Garcia 2014), and joking (cf. Partington 2006). All these functions ultimately relate to the social, interactional effect laughter has (cf. Gervais & Wilson 2005, Warner-Garcia 2014). Managing relationships, i.e. rapport management (Cassell et al. 2007, Spencer-Oatey & Franklin 2009) is important between the interlocutors. Laughter can help to establish harmony and achieve a polite, respectful interaction, in which speakers “position themselves as amiable and agreeable” (Warner-Garcia 2014: 177).
Due to the complex nature of conversational laughter, it seems to be one of the most difficult features to transcribe. Trouvain (2003) comments on the imprecision in the terminology of laughter, as well as the multitude and, simultaneously, the vagueness of laughter definitions and descriptions resulting from this complexity. The question of how precisely laughter should be represented in a transcript thus needs to be considered and discussed in detail before a particular transcription method is adopted. In existing spoken language corpora, laughter is usually included in the transcript, although transcriptions differ substantially. When deciding on using one laughter transcription over another, similarly tried and tested one, researchers need to take the purpose and aim of the corpus, as well as possible research fields into consideration, as with all elements of transcription. CASE was designed to be a useful tool not only for purely corpus linguistic approaches, but also for discourse analytical purposes (especially if they are corpus-based and aim to include quantitative elements), requiring detailed contextual information about the speech event, i.e. paralanguage and non-verbal elements. Even though every transcription is only a “partial record” (Cook 1995) of the actual event, CASE aims to be as detailed as possible while still remaining machine-readable for corpus analysis.
To date, Jefferson’s (1979, 1984, 2004) approach to the transcription of laughter is one of the most detailed. However, even though it tries to represent the actual instance of laughter as closely as possible, this system cannot be used in machine-readable corpora, as there would be an uncountable number of laughter variants in the data. “HA HA HA” in upper-case spelling for loud laughter, “ahh ha::ha::ha::” for a normal laugh burst (the colon as a sign of prolonging of the prior sound), “heh heh heh” for a chuckling sound, and “ehh ye(h)hhmh’hmh’hmh”, also chuckling, are just four realizations of her transcription conventions on laughter.
Several corpora try to avoid the problem of irretrievability by using special signs that are unique in the corpus and are thus easily searchable while still aiming to represent the laughter instance as closely as possible. The Santa Barbara Corpus (SBC 2000–2005) as well as VOICE and ELFA, for example, use @-signs to indicate laughter in their transcripts, each @-sign corresponding to an individual laugh pulse; in the SBC, genuine, voiced laughter includes vowels “@e@e@e@a@a@a”, while chuckling is portrayed as “@@@@@@” (VOICE and ELFA conventions do not differentiate between the two types). “Laughed speech” (Trouvain 2001: 3) is displayed in boldface and underlined (in VOICE/ELFA start and end points are marked). After finding that the perception of the vowel quality of laugh bursts is very subjective, Chafe (2007) omits vowels in his proposal for laughter transcription. He distinguishes between individual pulses, transcribing inhalation (v), exhalation (^), as well as chuckled (^ m ^ m ^ m) versus standard laughter (^ ^ ^ ^ v), where the characteristic final inhalation usually audibly ends the laugh sequence (Jefferson et al. 1987: 155f).
Dressler & Kreuz (2000) try to standardize the transcription of laughter, reducing variability and making laughter instances (as a whole, as opposed to single laugh pulses) more easily readable as well as quantitatively analyzable (the laugh pulses transcribed as repeated @ or ^ signs make counting instances of laughter difficult since the researcher would be counting single pulses rather than the whole laughter instance when searching @ or ^). They transcribe laughter as part of paralinguistic behavior, marking each instance as a whole, for example “((laugh))”. There are corpora that already use this system, e.g. SPICE-Ireland, which transcribes laughter as <&> laughter </&> (<&> indicating “non-linguistic behaviour” in ICE, cf. Kallen & Kirk 2012). This approach focuses more on the functional aspect of laughter in the context of the conversation, not aiming at representing the laughter instances as individual occurrences. However, reducing all different instances of laughter to one transcription feature might lead to an oversimplification of its functional purposes, since, as mentioned earlier in this section, laughter is a highly complex conversational feature with many different functions.
CASE transcription conventions try to preserve the best of both approaches, limiting the transcription to a fixed taxonomy of laughter types (based on descriptive and external factors) to ensure readability and retrievability for quantitative analysis, but at the same time preserving variability of different laughter instances to maintain functional complexity for qualitative analyses.
The taxonomy used for the transcription of laughter in CASE merely describes the laughter form, but leaves the analysis of its function to the researcher’s interpretation (Schmidt et al. 2014, Schmidt 2015).
The following laughter sounds are differentiated in CASE:
| ((LAUGHS)) | loud laughter (louder than surrounding discourse) | |
| ((laughs)) | laugh pulse sequence | |
| ((laughing)) | laughing while speaking | |
| ((chuckles)) | chuckling, softer than laughter | |
| ((chuckling)) | chuckling while speaking | |
| ((hehe)) | short chuckling, two pulses | |
| ((thh)) | aspirated minimum laughter starting with alveolar plosive sound | |
| ((ehh)) | monosyllabic laugh pulse | |
| ((heh)) | initially aspirated monosyllabic laugh pulse |
Table 1. Laughter taxonomy in CASE.
In analogy to Jefferson (1979, 1984, 2004), Chafe (2007), as well as the SBC transcription conventions, we differentiate between normal laughter, louder laughter, chuckling, and laughed speech, and expand on this taxonomy with several additional types, namely chuckling while speaking, as well as four types of minimal laughter: ((hehe)), ((heh)), ((ehh)), ((thh)).
The different short forms were introduced as a reaction to a test with multiple transcribers who expressed their dissatisfaction with only using ((chuckles)) for one- or two-pulsed chuckling. After collecting all laughter instances found in the sampled data, these four shorter forms were agreed on as adequate approximations to all encountered forms.
Being able to distinguish between these different types of laughter in the corpus offers the possibility of retrieving them more easily, as well as of analysing and interpreting the conversations in more detail. A practical application of our taxonomy in context is given in example 9.
| SB49: | u:hm, I think it's like u:hm … like, yeah typical stereotype Sauerkraut ((German (1.2))),_((ehh)) |
| FL33: | ah, okay. €€€ |
| SB49: | uhm, Knödel ((German (0.8))), .. I don't know if there is a word in English for that? [((chuckles))] |
| FL33: | [((LAUGHS))] (...) |
| FL33: | I'm sorry for this conversation like half an hour talking about food, and I haven't eaten yet. |
| SB49: | ((ehh)) |
| FL33: | ((ehh)) |
| SB49: | I think we don't have to talk the whole time about food, [it's just], |
| FL33: | [no no]. |
| SB49: | to start the conversation ((laughing)). |
| FL33: | yeah of course but still I'm like mhm I'm hungry ((laughing)). |
Example 9. Laughter types in context (CASE 07SB49FL33).
The short exchange about stereotypical German food in example 9 exemplifies the use of four of the nine types of laughter in CASE. After introducing the German term “Sauerkraut”, classifying it as a “typical stereotype”, the German student uses minimal laughter “((ehh))”, which might be interpreted as slightly ironic, as she is in the process of perpetuating the stereotype herself. After the following code-switch (“Knödel”, potato dumpling), she admits to not knowing the English equivalent and chuckles to downplay the slightly embarrassing moment. This prompts loud laughter by the Italian conversation partner. Both instances of laughter contribute to mitigating this increasingly delicate point of the conversation by laughing it off.
Two functions of reciprocal laughter can be observed in example 9: mitigation and positioning an utterance as non-serious (cf. Warner-Garcia 2014). The Italian participant’s complaint about not having eaten yet is reciprocated by a mitigating, very short chuckled pulse “((ehh))”. By backchanneling in this subtle way, the German interlocutor does not have to decide on whether the complaint was meant to be taken in a serious way or rather jokingly. This ambiguity is reduced when the Italian speaker echoes the ((ehh)), reframing the situation as being more non-serious; although the German speaker still feels the need to clarify the ambiguous situation, responding with “I think we don't have to talk the whole time about food”, which is supported by the Italian speaker’s “no no”. The following reciprocal laughed speech reinforces the non-serious frame of the original situation, with the German speaker further relativising the issue and the Italian speaker elaborating the joke.
To demonstrate the potential for quantitative analysis with the laughter types transcribed in CASE, laughter was correlated with code-switches in a subcorpus of 20 conversations from CASE, BabyCASE (forthcoming). [1] BabyCASE consists of 775 minutes (13 hours) of Skype conversations, totaling roughly 115,000 words in the annotated version. It is composed of 20 conversations with a total of 39 different speakers (one German speaker conducts two talks) from four corpus components: CASE SB-SF (German and Bulgarian L1 speakers), SB-FL (German and Italian), SB-ST (German and Spanish), SB-HE (German and Finnish). The duration of the talks is between 30 and 45 minutes; various topic prompts are represented. The data represents the rich data of CASE, with 10 hours of video and 3 hours of audio recordings.
The potential co-occurrence of laughter and code-switching was found through a data-driven analysis of the context of code-switching as a key feature of ELF (cf. Cogo 2009, Klimpfinger 2009). As speakers “draw attention to […] code-switches by repetition, hesitation, intonational highlighting, explicit metalinguistic commentary, etc […]” (Poplack 1988: 230), and as it is often flagged as a marked choice (Myers-Scotton 1989: 343f), we investigated a range of potentially co-occurring discourse features, such as pauses, hesitation and discourse markers, as well as paralinguistic and nonverbal features, which have also been shown to occur in contexts where the conversation is slowed down and re-negotiated, for example in transition zones between conversation segments (cf. Brunner 2015). Laughter was found to be particularly salient in this context.
Tables 2 and 3 show the distribution of laughter in close proximity (five preceding and five following intonation units) of the 107 code-switches found in BabyCASE. [2] Table 2 indicates that more than half the code-switches in BabyCASE co-occur with laughter, and there is, as Table 3 shows, no particular preference as to its position before or after the code-switch. As shown in Table 4, laughter (in general) is significantly more frequent (p < .01) in the context of code-switching compared to the whole corpus (BabyCASE); in particular, genuine laughter, i.e. ((laughs)) and ((laughing)), is significantly overrepresented while chuckling is underrepresented.
| Code-switching and contextual laughter in BabyCASE | n | % of total |
|---|---|---|
| Contextual laughter (5 preceding or following intonation units) | 60 | 56.07% |
| No contextual laughter | 47 | 43.12% |
| Code-switches total | 107 | 100.00% |
Table 2. Code-switching and contextual laughter in BabyCASE.
| Position of contextual laughter in BabyCASE | n | % of total |
|---|---|---|
| Contextual laughter (5 preceding intonation units) | 20 | 33.33% |
| Contextual laughter (5 following intonation units) | 24 | 40.00% |
| Contextual laughter (5 preceding AND 5 following intonation units) | 16 | 26.67% |
| Code-switches with contextual laughter | 60 | 100.00% |
Table 3. Position of contextual laughter in BabyCASE.
| Feature | n | Significance value (*<.05; **<.01; ***<.001) |
Overrepresented (+) / underrepresented (-) |
|---|---|---|---|
| Laughter (all types) | 1985 | ** (p ≤ .0056) | + |
| ((laughs)) ((laughing)) | 912 | *** (p ≤ .00000005) | + |
| ((chuckles)) ((chuckling)) | 368 | * (p ≤ .0369) | - |
| ((ehh)) | 282 | (p ≤ .4235) | - |
| ((thh)) | 117 | (p ≤ .6124) | - |
| ((heh)) ((hehe)) | 306 | (p ≤ .7410) | - |
Table 4. Significance values of contextual laughter with code-switching in BabyCASE.
The laughter documented in this case study is not only motivated by humorous contexts, but also to reduce situational awkwardness (cf. Chafe 2007) and create rapport (Schmidt 2015, Spencer-Oatey 2002). It may be used as a means of mitigating a delicate situation, in this case switching into another language when the language of choice in this particular context is English, and the interlocutor might not understand what is said. This potentially problematic situation may be defused by means of laughter (Jefferson et al. 1987: 172) by indicating non-seriousness (Chafe 2007), as example 10 shows:
| HE03: | yeah. yeah ... it's really doesn't cost anything. |
| SB106: | an apple and an Ei ((German (0.4))). ((laughs)) |
| HE03: | ((laughs)) yeah. yeah. that's fun. |
In example 10, SB106 and HE03 talk about prizes of plane tickets and how cheap they can be. The German speaker then transfers a German idiom directly into English, and in the second half code-switches into German (“Ei” meaning “egg”, the idiom refers to the fact that it costs very little, only an ‘apple and an egg’). As this seems to be a rather strange phrasing when directly transferred into English, and the additional code-switching contributes to the unusualness of the phrase (the Finnish participant here probably being fully aware of the meaning as HE03 speaks some German), both seem to laugh at the absurdity and to release some of the situational awkwardness.
| SB73: | okay how is it called that day? |
| ST14: | (1.3) uhm dia das letras galegas ((Galician (1.3))). |
| SB73: | “okay”, ((laughs)) |
| ST14: | [((ehh)) not] gonna try right? ((hehe)) |
| SB73: | [°it's- a- a-°] no no no. [((laughs))] |
| ST14: | [((laughs))] |
Example 11 shows an instance of code-switching that leads to laughter based on the supposed ‘unpronounceability’ of the term (see also Brunner et al. 2016), i.e. a general feeling that a short sequence in a foreign language is difficult to pronounce / reproduce. In this case, the German student does not speak Galician and does not seem to be able to reproduce the term “dia das letras galegas” after hearing it only once. The ironic acknowledgement of this is indicated by the following voice shift on “okay” and the laugh.
As the examples illustrate, laughter is an essential factor in rapport management. Particularly in first contact encounters between previously unacquainted people (as in CASE), establishing a relationship first may be more important than the actual content of the interaction. Conversations between unacquainted people, especially if they include more than just small talk (Coupland 2000), are prone to develop diverging stances (Du Bois 2007). In these situations, laughter serves to reframe situations as non-serious, playful, or unproblematic, generally having a positive effect on the communicative setting, putting the partners at ease with each other.
Scollon & LeVine (2004: 1f.) point out that “language in use […] is always and inevitably constructed across multiple modes of communication, including speech and gesture not just in spoken language but through such ‘contextual’ phenomena as the use of the physical spaces in which we carry out our discursive actions […]”. As a consequence, we consider the multimodal video elements in our data to be an important and indeed essential element of meaning construction. We concur with Kress (2011: 46), who states that “[m]ultimodality, first and foremost, refuses the idea of the ‘priority’ of the linguistic modes; it regards them as partial means of making meaning”. Non-verbal elements thus further enhance our understanding of meaning creation in discourse.
A major problem in managing multimodal data is the fact that the researcher’s perspective remains incomplete. Bezemer & Jewitt (2010: 194) point out that “[m]ultimodality is an eclectic approach”, arguing that researchers always are faced with a dilemma: “Too much attention to many different modes may take away from understanding the meanings of a particular mode; too much attention to one single mode and one runs the risk of ‘tying things down’ to just one of the many ways in which people make meaning.” A possible solution for this dilemma is making sure that both corpus data and corpus architecture allow the expansion and shifting of focus, providing the possibility of studying various factors either independently or in concert. As far as the general scope of multimodal analysis is concerned, we concur with Adolphs & Carter (2013: 144) who include “gestures which exist in and complement spoken discourse” or, to use their shorthand term, ‘non-verbal communication’ (NVC). They come to the conclusion that NVC “is used between participants […] as a key tool for managing discourse patterning and discourse structure” (145). Corpus compilers and annotators have to perform the difficult balancing act of preserving and documenting non-verbal features as far as possible in the transcriptions while at the same time focusing only on those features that can be shown to be relevant in their concrete discourse context.
The CASE annotation scheme tries to refrain, as far as possible, from interpreting during annotation in order to make the transcripts as objective as possible, leaving it to the researchers to draw their own conclusions. The transcription of the data presents challenges at various levels. Apart from the features described above, there are aspects of the speech event that remain untranscribed. At this point, there is no separate layer for gestures in CASE, but selected instances of non-verbal behaviour are included as part of the basic CASE transcription layer (using curly brackets, e.g. {shrugs}). The unique video component of CASE can be used to supplement the transcript for a more exhaustive multimodal interpretation, for example in the context of qualitative analysis (see examples 12 to 14), and further serves as basis for the development of a concise annotation scheme for non-verbal elements.
BabyCASE (forthcoming) contains 764 instances of transcribed non-verbal behaviour. We find features such as nodding, waving, head-shaking, smiling, looking away from the screen, leaning forward/backward, air quotes, mimicking, and other hand gestures, as well as background noise, among others. Here are some selected recurring gestures in context:
Nods (283 instances in BabyCASE) most frequently co-occurs with “yeah” (110), “mhm” (47), “right” (16), and “okay” (17) (within three preceding and following words), i.e. in more than two thirds of the contexts (67%), indicating (and emphasizing) support and agreement.
Shakes head (45 instances) does not only indicate (and underline) negation (co-occurring with no, verbal negation, not, also with questions, in 32 instances), but also despair (“it’s so fucking difficult to get in there”); awe (“London is a great city”); uncertainty (“in England or something like that”); self-correction (“for getting a teacher […] (1.7) for becoming a teacher?”); lack of alternatives/resignation (“everybody else just has to deal with some chocolate” as a gift); signaling lack of understanding (“what what one?”); and word search.
Shrugs (24) is used, for example, in cases of uncertainty (“I don’t know why”); to indicate normalcy (“I think it’s pretty much, like any other country in the world nowadays?”); to mark a lack of knowledge (“I’m missing the word?”); lack of alternatives/resignation (“that’s what it is”); acceptance (“{shrugs} right” as a response to the description of an unusual combination of subjects at university), to indicate a lack of preferences (“you want to go first or should I? […] Go ahead {shrugs}”); exasperation/frustration (“it doesn’t make sense, why is the table female?”); disapproval (“the topic is not, ((hehe)) {shrugs}”).
Points (13) is used to indicate objects in the physical surroundings; to refer to oneself or the interlocutor; to signal general direction (“the north part of the city”); and for metaphorical pointing (“I can see the end already”).
Makes air quotes (10) are used when the English term is unknown (e.g. with code-switching or approximations), but also for vague or unexplained terms (“Christmas stuff”); imprecise/generalizing terms (“Catholic” country); to distance oneself (Catholics “believe”); and to signal irony (being able to watch a lecture “again and again”).
Imitates (7) are used to represent particular activities, such as putting eggs in a bowl, limping, or whipping, and to indicate shapes, such as the shape of a tortilla.
Waves (6) is used for leave-taking in BabyCASE, sometimes reciprocally.
We also find instances of leans forward (3), e.g. indicating engagement at the beginning of the conversation (“How are you {leans forward}”), and leans backward (4), e.g. to signal a possible closing point of the opening, or a topic (“that’s cool {leans backward} ((clears throat))”).
Quantitative analyses provide first insights into the interplay between gestures and spoken discourse and can point to tendencies regarding co-occurring words and, by extension, possible functions of gestures in conversations. They have to be supplemented by a more detailed (qualitative) context analysis of the individual occurrences to give a more comprehensive view of the dynamic nature of communication and the meaning-making processes involved.
A qualitative analysis of gestures in context (examples 12 to 14) shows the additional information in detail that the CASE transcription scheme can provide and illustrates the added benefit of a multimodal (video) corpus.
In example 12, the German participant (SB27, on the left) and her Italian conversation partner (FL25, on the right) talk about the books they own but have not yet had a chance to read. Even just focusing on the visual level and disregarding, for the moment, aspects of speech and paralinguistic features, we can see several interesting features in this example.
| 1 | SB27: | I have so much books here? |
| 2 | .. that I .. bought, | |
| 3 | but .. I can’t read them. ((hehe)) | |
| 4 | FL25: | look, {shifts camera to show bookshelf} {points to bookshelf} |
| 5 | I mean [..] we have dictionaries, | |
| 6 | SB27: | [((ehh))] |
| 7 | FL25: | yes .. dictionaries, |
| 8 | but ther- but there are also books there somewhere, {makes brushing-away gesture; arm still extended to back} | |
| 9 | uhm? | |
| 10 | and I have SO many books to read {grasps head with hands} it’s just, | |
| 11 | .. SO: FRUstrating, | |
| 12 | because I like to read them all at the same time, | |
| 13 | and it’s, […] |
|
| 14 | so frustrating, {makes fists} | |
| 15 | a:h. | |
| 16 | SB27: | ((ehh)) |
Example 12. “Books” (CASE 03SB27FL25).
The video shows that on line 1, FL25 leans her head a little closer and starts nodding while SB27 explains, indicating engagement and providing a backchanneling signal to “maintain the flow of the discourse” (Adolphs & Carter 2013: 161) and to indicate her engagement with the interlocutor. In line 3, SB27 shakes her head to emphasize her negative statement, “but .. I can’t read them”. The first transcribed series of gestures occurs in line 4. FL25 shifts her stance by leaning back and out of the screen so the bookshelf in the background is no longer obscured, indicating awareness of her conversation partner’s field of view. This shift of orientation is accompanied by the invitation “look” while FL25 moves her laptop computer so that the camera “points” to the bookshelf (“{shifts camera to show bookshelf}”), forcing a shift of perspective also for SB27, who responds with a (backchanneling) “((ehh))”, signaling understanding and marking agreement and engagement – all non-verbally. This is then immediately followed by FL25 extending her right hand to point at the bookshelf and the books in it (see Figure 1).
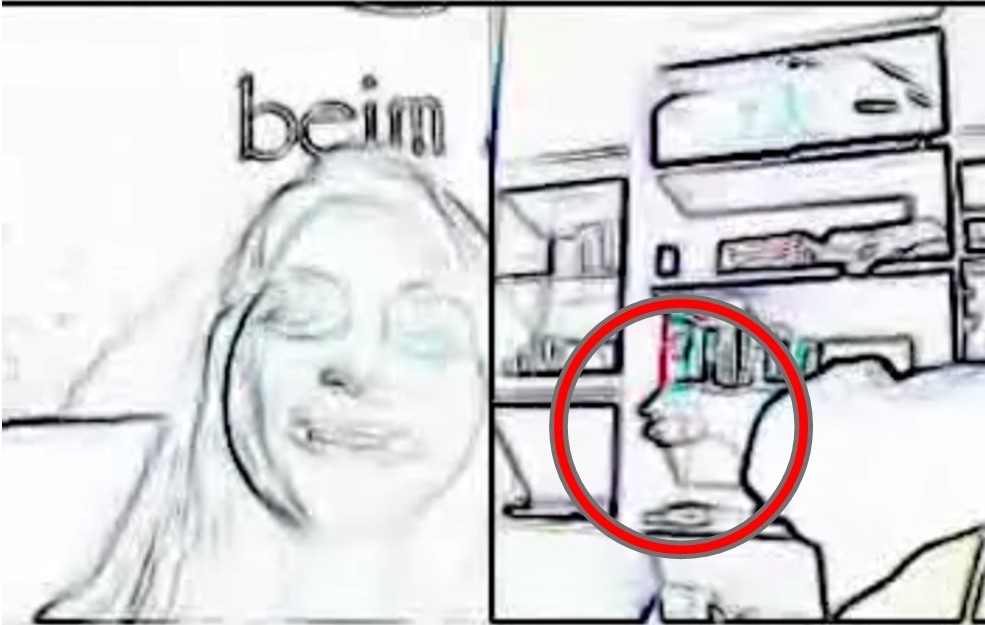
Figure 1. Pointing gesture (CASE 03SB27FL25).
Enfield et al. (2007: 1738f.) comment on what they call B-point (big in form) and S-point (small in form) pointing gestures and argue that in the extensive, “big” variant (which we see here), the speech component is supportive or elaborative. An elaborative function explains the sequence of invitation and gesture and additionally illustrates that gesture and speech are often used in concert. This sequence shows how even the basic {non-verbal feature} annotation adopted in the CASE layer facilitates the interpretation of the verbal sequence and is a necessary element of the transcription of audio-visual data, without which key aspects of meaning may be lost.
To further illustrate potential loss of meaning, consider the rest of the sequence: The pointing gesture is refined in lines 4 and 5 as FL25 indicates the dictionary section and then verbalizes: “dictionaries”. On the verbal level, there is no indication that she is using the actual object she is verbally identifying, and it would be difficult to understand the full meaning of the sequence just listening to the audio recording. The pointing gesture is then transformed into a brushing-away gesture in line 8, indicating distance which is verbally supported by the deictic expression “there somewhere” (l. 8), while simultaneously moving the camera to perform a searching movement and shift focus to the new section on the bookshelf. The speaker then reverts to the original orientation towards her conversation partner, signaling that the sequence is at an end. SB27 maintains her smile throughout the sequence, which functions as an engaged response token, contributing to the notion of the interlocutors’ generally positive attitudes towards each other and facilitating FL25’s continuation of her turn. In lines 10 to 14, FL25 uses a series of gestures to indicate frustration in a playful manner. This is indicated by her voice, which shows exaggerated pitch and stress pattern: “and I have SO many books to read”. Her mock frustration is summed up by the non-lexical “a:h”, with its exaggerated intonation pattern suggesting playful hyperbole. The words are accompanied by two gestures, FL25 first grasps her head several times with both hands (l. 10–12) punctuating the verbal emphasis “SO many books to read” and “SO: FRUstrating”. She then shortly puts her hands down but raises them again and makes fists on the second “so frustrating” (l. 14), then releasing them, raising her open hands on “a:h” (l. 15). SB27 responds with minimal laughter “((ehh))” as a backchannel, indicating engagement, agreement and information receipt, which together also serves to conclude FL25’s turn.
| 1 | ST07: | [so] °ho-°, |
| 2 | my .. m:, | |
| 3 | I would like to know, | |
| 4 | .. how is a, | |
| 5 | .. German pretzel? ((ehh)) | |
| 6 | SB57: | (1.3) uhm so, {lifts hands; palms up} |
| 7 | (1.4) uh[m:], | |
| 8 | ST07: | [for ins]tance, |
| 9 | .. ho- .. how it is made? | |
| 10 | ... is it uh .. uh .. how can I say, | |
| 11 | is it uhm ... more like a biscuit? | |
| 12 | ... is it more like a bread? | |
| 13 | SB57: | (2.2) it's uh .. hm .. hm, |
| 14 | I'd say it's actually more like .. m:, | |
| 15 | (2.0) <uh> ... hm, | |
| 16 | (1.5) also ((German (0.3))) .. uhm uh, | |
| 17 | I know that, | |
| 18 | uhm: pretzels are made by, | |
| 19 | .. being dipped into .. kind of an acid? {imitates dipping} | |
| 20 | ST07: | ... mhm= |
| 21 | SB57: | =that's why they have these, |
| 22 | .. brown .. crust things, {imitates shape of pretzel crust} | |
| 23 | ST07: | ... yes, |
| 24 | SB57: | .. and there is salt on them, {imitates sprinkling salt} |
| 25 | ST07: | ... mhm, {nods} |
| 26 | SB57: | .. and they are usually .. like (2.0), {imitates shape of pretzel with index fingers} {imitates tying knot repeatedly} |
| 27 | .. they have a knot in them, | |
| 28 | like the- .. they have [this eight .. eight] kind of shape. {imitates shape of eight with index fingers} | |
| 29 | ST07: | [okay okay] {nods} |
| 30 | SB57: | .. so, |
| 31 | ST07: | [m:], |
| 32 | SB57: | [are] are these the pretzels you have too? |
Example 13. “Pretzels” (CASE 07SB57ST07).
In example 13, the German participant SB57 (on the right) and his Spanish counterpart ST07 discuss pretzels, a stereotypical German food item. Several multimodal features can be observed here. The German speaker starts the sequence with his head propped on his hands, a gesture that indicates a passive but receptive, listening stance. SB57 reacts by signaling his lack of understanding or possibly also his indecision as to how to answer such a general question by pauses and hesitation markers, but also by a hand gesture, raising both hands, palms facing upwards. In reaction to this multimodal signal (and overlapping the last hesitation marker), ST07 appends her question with “[for ins]tance, .. ho- .. how it is made?” – and further specifies this request for information as to its manufacture. After short reflection indicated by a false start, numerous pauses, a code-switch with a German discourse marker “also”, SB57 ends his listening stance and spreads his hands, preparing for a series of gestures illustrating the complex manufacturing process that he verbally lays out: visualizing the dipping in “acid” (actually, lye), tracing an imaginary crust, sprinkling equally imaginary salt and then attempting (in several attempts) to trace the exterior shape with his index fingers and then tying the pretzel’s middle knot several times to emphasize this distinct feature. The gesture is more complex than his attempt at verbalizing “they are usually .. like (2.0)” (l. 26) which is at first not completed verbally but with a gesture illustrating the shape during the two second pause, then he follows up with “they have a knot in them” (l. 27) and “[this eight, eight] kind of shape” (l. 28) which he again illustrates with hand gestures that are repeated until the end of the sequence, emphasizing its relevance. Throughout ST07 indicates her attentive listening by verbal means (confirmation backchannels “yes”, “mhm”, and “okay”) and by two pronounced nods in lines 25 and 29–31. This example again shows the complex interplay between the various modes and illustrates both the importance and the complexity of our rich data.
| 1 | SB47: | yeah we’re always in the kitchen drinking and [watching], |
| 2 | FL21: | [yeah ((laughing)) ()] |
| 3 | SB47: | [{roommates shout in the background}] |
| 4 | [OH .. YEAH?] | |
| 5 | .. YEAH? {looks to roommates & nods} | |
| 6 | they are protesting but it is reality. | |
| 7 | FL21: | [((laughing))], |
| 8 | SB47: | [they are also] like, |
| 9 | always like, | |
| 10 | uh, | |
| 11 | here. {shows bottle of beer & points repeatedly to bottle of beer} | |
| 12 | beer? | |
| 13 | WE NEED BEER and, | |
| 14 | wine, ((laughs)) {shows glass of wine} {roommate clinks it with another glass} | |
| 15 | EVERY time, ((laughs)) |
Example 14. “Beer” (CASE 03SB47FL21).
In example 14, the German participant, SB47 (on the right), interacts with her roommates off-screen verbally and shifts her orientation towards them before reverting her orientation towards FL21 (l. 4 and 5). She then leans towards the camera, shifting her physical stance and aligning herself with FL21 instead of the roommates, emphasizing her claim “they are protesting but it is reality”. (l. 6). FL21 responds with backchanneling laughter, nodding, head movements and stance shifting to indicate continuing emotional engagement and understanding. SB47 additionally uses objects as a topic focus, such as a bottle of beer, raising it to the camera (in lines 11 and 12), emphasized by the pointing gesture (l. 11) and the words “here” and “beer”. She is then handed a glass of wine by her roommate off-screen, which she holds towards the camera and verbalizes “wine”, (l. 14). Altogether, this example illustrates a sequence of events that would be totally lost in an audio version of the same conversation.
CASE provides researchers with the possibility to work with gesture data both qualitatively and, through its easily retrievable transcription scheme for non-verbal behavior, also quantitatively, contributing to a more complete view of the speech event and providing valuable information regarding the correlation and interdependencies of non-verbal features and language in the context of a rich data corpus. On the basis of our findings from this preliminary study, we have since developed a comprehensive taxonomy of non-verbal elements, including gesture, which is available on the project website and which provides a systematic transcription scheme, facilitating retrieval for quantitative and qualitative analyses.
In this article several issues arising from using rich, multimodal data, such as Skype conversations, for corpus compilation were discussed. Examples from CASE illustrate both the complexity of multimodal data, and the challenges involved in compiling such a corpus. Rich data corpora require a different approach than traditional written language corpora, both in organisation and compilation, as well as in transcription and annotation.
A layered corpus design provides a very good option for organizing a multimodal corpus. The layer structure allows a separate annotation and analysis of selected features such as lexis, part-of-speech information, or paralanguage/non-verbal elements, but also makes a synthetic view regarding several different annotation levels possible. Researchers can concentrate on the layers that are relevant for their own work and make use of different layers for different research purposes. A crucial advantage of a layer design is its extensibility – additional layers can be added at need or when warranted due to the complexity of a feature.
Since it is not possible for transcribers to capture all facets of multimodal data across different modes, great care needs to be taken to preserve as much of the original setting as possible during corpus compilation, for example by adding video data (in an anonymized format) as part of the corpus. The inclusion of selected spoken language, paralinguistic and non-verbal features also in the transcription provides additional situational information and a more complete representation of the speech event. At the same time, readability and consistency need to be preserved in the transcription.
Two case studies (on laughter and gestures) were used to illustrate the benefits of including paralinguistic and non-verbal elements in the transcription of multimodal corpora. Though largely unexplored as part of spoken corpora, such multimodal elements are often indispensable for understanding the complexities involved in the negotiation of meaning. Integrating them as part of a large corpus is a challenge that has to be overcome in order to fully explore the potential of rich data. At the same time, the transcription scheme has to find a balance between accuracy and ease of use. Qualitative and quantitative sample analyses of the interaction between verbal discourse and paralinguistic/non-verbal elements have shown how the CASE transcription scheme allows a differentiated view on a rich multimodal CMC data source (i.e. Skype conversations) that has not yet been explored in any other corpora.
CASE has great potential and can be used for various purposes, in various research areas, and by using various approaches such as corpus linguistics, discourse analysis, or even conversation analysis, or combinations thereof. CASE, like other ELF corpora, allows research regarding different aspects of language use in ELF, for example analyzing the particularities of code-switching, lexical innovation and transfer, syntactic variation, regularization, discourse explicitness, identity negotiation, conversation organization, etc., some of which can be analyzed quantitatively, others only qualitatively. CASE is also a useful data source for investigating the distribution of ELF features found in other ELF contexts as it is based on data from an as yet uncharted medium. The added advantage of previously unexplored spoken CMC data and their realizations in the CASE transcription conventions open up further research areas. Researchers can not only analyze how the medium Skype influences conversations, but also how multimodal aspects of an interaction interact with the verbal aspects, contributing to a better understanding of meaning-making processes that go beyond mere words and include other means of producing meaning in language. Paralanguage and gesture in particular, as shown in Sections 3 and 4, are especially fruitful for context analyses and may reveal unexpected correlations, such as the co-occurrence of laughter and code-switching (see Section 3). Conversely, a lack of expected correlations can serve as a starting point for more in-depth analyses on the functionalities of these multimodal features in discourse. Shrugs, for example, does not always occur in contexts of uncertainty or knowledge deficiencies, but also in many other contexts (see Section 4).
In conclusion, we hope that the suggestions for the management of rich data presented here can contribute to providing a suitable framework for treatment of other rich data corpora, particularly in a computer-mediated environment. At the same time, the selected sample studies on CASE data illustrate not only that the procedure and transcription scheme presented here is suitable for the analysis of rich corpus data, but also that the rich data in CASE has the potential to increase our understanding of conversational processes as a complex interplay between verbal, non-verbal and paralinguistic factors.
[1] Numbers may still vary, as they are based on the preliminary first version of the CASE transcripts, pending final proofreading. [Go back up]
[2] The number of documented code-switches is different from the one provided in Brunner et al. (2016), as we have since refined and expanded our definition of code-switching, including in particular names other than proper names, and considering pronunciation as an attribution factor. [Go back up]
BabyCASE = Corpus of Academic Spoken English – 20 conversation subcorpus. Forthcoming. Stefan Diemer, Marie-Louise Brunner, Caroline Collet & Selina Schmidt. Birkenfeld: Trier University of Applied Sciences.
CASE = Corpus of Academic Spoken English. Forthcoming. Stefan Diemer; Marie-Louise Brunner; Caroline Collet; and Selina Schmidt. Birkenfeld: Trier University of Applied Sciences (coordination) / Saarbrücken: Saarland University / Sofia: St Kliment Ohridski University / Forlì: University of Bologna-Forlì / Santiago: University of Santiago de Compostela / Helsinki: Helsinki University & Hanken School of Economics / Birmingham: Birmingham City University / Växjö: Linnaeus University / Lyon: Université Lumière Lyon 2 / Louvain-la-Neuve: Université catholique de Louvain. http://umwelt-campus.de/case
CASE project website: http://www.umwelt-campus.de/case
CASE: Description of conversation topics: https://www.umwelt-campus.de/ucb/index.php?id=11349
CASE transcription conventions and samples: http://www.umwelt-campus.de/case-conventions
CASE taxonomy of non-verbal elements: http://www.umwelt-campus.de/case-conventions
CLAWS part-of-speech tagger for English. UCREL (University Centre for Computer Corpus Research on Language), Lancaster University. http://ucrel.lancs.ac.uk/claws/
ELFA = The Corpus of English as a Lingua Franca in Academic Settings. 2008. Director: Anna Mauranen. University of Helsinki. http://www.helsinki.fi/elfa/elfacorpus
LINDSEI = Louvain International Database of Spoken English Interlanguage. 2010. Project director: Sylviane Granger. Louvain-la-Neuve: Université catholique de Louvain. https://uclouvain.be/en/research-institutes/ilc/cecl/lindsei.html
MICASE = The Michigan Corpus of Academic Spoken English. 2002. R. C. Simpson, S. L. Briggs, J. Ovens & J. M. Swales; project leader: Ute Römer. Ann Arbor, MI: The Regents of the University of Michigan. https://quod.lib.umich.edu/m/micase/
Red Hen Lab: Anonymizing Audiovisual Data: https://sites.google.com/site/distributedlittleredhen/home/the-cognitive-core-research-topics-in-red-hen/the-barnyard/-anonymizing-audiovisual-data
SBC = Santa Barbara corpus of spoken American English, Parts 1–4. 2000–2005. Compiled by John W. Du Bois et al. Philadelphia: Linguistic Data Consortium.
VOICE = The Vienna-Oxford International Corpus of English (version 2.0 XML). 2013. Director: B. Seidlhofer. University of Vienna. https://www.univie.ac.at/voice/
Adolphs, Svenja & Ronald Carter. 2013. Spoken Corpus Linguistics – From Monomodal to Multimodal. London: Routledge.
Baynham, Mike. 2011. “Stance, positioning, and alignment in narratives of professional experience”. Language in Society 40(1): 63–74. doi:10.1017/S0047404510000898
Bezemer, Jeff & Carey Jewitt. 2010. “Multimodal analysis: Key issues”. Research Methods in Linguistics, ed. by Lia Litosseliti, 180–197. London: Continuum.
Biber, Douglas. 1992. “On the complexity of discourse complexity: A multidimensional analysis”. Discourse Processes 15: 133–163.
Björkman, Beyza. 2009. “From code to discourse in spoken ELF”. English as a Lingua Franca: Studies and Findings, ed. by Anna Mauranen & Elina Ranta, 225–251. Newcastle: Cambridge Scholars Press.
Brunner, Marie-Louise. 2015. Negotiating Conversation Starts in the Corpus of Academic Spoken English. MA thesis, Saarland University.
Brunner, Marie-Louise, Stefan Diemer & Selina Schmidt. 2016. “It’s always different when you look something from the inside” – Linguistic innovation in a corpus of ELF Skype conversations. International Journal of Learner Corpus Research 2(2), Special issue: Linguistic Innovations: Rethinking linguistic creativity in non-native Englishes, ed. by Sandra C. Deshors, Sandra Götz & Samantha Laporte, 321–348. Amsterdam: Benjamins. doi:10.1075/ijlcr.2.2.09bru
Cassell, Justine, Alastair J. Gill & Paul A. Tepper. 2007. “Coordination in conversation and rapport”. Proceedings of the Workshop on Embodied Language Processing, ed. by Justine Cassell & Dirk Heylen, 41–50. Stroudsburg: Association for Computational Linguistics.
Chafe, Wallace. 1982. “Integration and involvement in speaking, writing, and oral literature”. Spoken and Written Language: Exploring Orality and Literacy, ed. by Deborah Tannen, 35–53. Norwood, NJ: Ablex.
Chafe, Wallace. 1994. Discourse, Consciousness, and Time: The Flow and Displacement of Conscious Experience in Speaking and Writing. Chicago: The University of Chicago Press.
Chafe, Wallace. 2007. The Importance of Not Being Earnest: The Feeling Behind Laughter and Humor. Amsterdam: Benjamins.
Cogo, Alessia. 2009. “Accommodating difference in ELF conversation”. English as a Lingua Franca: Studies and Findings, ed. by Anna Mauranen & Elina Ranta, 254–273. Newcastle: Cambridge Scholars Press.
Cook, Guy. 1995. “Theoretical issues: Transcribing the untranscribable”. Spoken English on Computer, ed. by Geoffrey Leech, Greg Myers & Jenny Thomas, 35–53. Harlow: Longman.
Coupland, Justine. 2000. Small Talk. Harlow: Longman.
Diemer, Stefan, Marie-Louise Brunner & Selina Schmidt. 2016. “Compiling computer-mediated spoken language corpora: Key issues and recommendations”. International Journal of Corpus Linguistics 21(3): 349–373. doi:10.1075/ijcl.21.3.03die
Dressler, Richard A. & Roger J. Kreuz. 2000. “Transcribing oral discourse: A survey and a model system”. Discourse Processes 29(1): 25–36. doi:10.1207/S15326950dp2901_2
Du Bois, John W. 2007. “The stance triangle”. Stancetaking in Discourse, ed. by Robert Englebretson, 139–182. Amsterdam: Benjamins.
Edwards, Jane A. 1993. “Principles and contrasting systems of discourse transcription”. Talking Data: Transcription and Coding in Discourse Research, ed. by Jane A. Edwards & Martin D. Lampert, 3–32. Hillsdale, NJ: Lawrence Erlbaum Associates.
Enfield, Nick J., Sotaro Kita & Jan Peter De Ruiter. 2007. “Primary and secondary pragmatic functions of pointing gestures”. Journal of Pragmatics 39(10): 1722–1741.
Fish, Robert S., Robert E. Kraut, Robert W. Root & Ronald E. Rice. 1993. “Video as a technology for informal communication”. Communications of the ACM 36(1): 48–61.
Gee, Matt. 2014. CASE XML Conversion Tool. http://rdues.bcu.ac.uk/case
Gervais, Matthew & David Sloan Wilson. 2005. “The evolution and functions of laughter and humor: A synthetic approach”. The Quarterly Review of Biology 80(4): 395–430. doi:10.1086/498281
Glenn, Phillip. 1995. “Laughing at and laughing with: Negotiating participant alignments through conversational laughter”. Situated Order: Studies in the Social Organization of Talk and Embodied Activities, ed. by Paul ten Have & George Psathas, 43–56. Lanham, MD: University Press of America.
Gong, Wengao. 2005. “English in computer-mediated environments: A neglected dimension in large English corpus compilation”. Proceedings of Corpus Linguistics Conference Series 1(1). http://www.birmingham.ac.uk/Documents/college-artslaw/corpus/conference-archives/2005-journal/Compilingacorpus/englishincomputer.pdf
Gumperz, John J. & Margaret Field. 1995. “Children’s discourse and inferential practices in cooperative learning”. Discourse Processes 19: 133–147.
Herring, Susan C. 2007. “A faceted classification scheme for computer-mediated discourse”. Language@Internet 4(1). http://nbn-resolving.de/urn:nbn:de:0009-7-7611
Holt, Elizabeth. 2010. “The last laugh: Shared laughter and topic termination”. Journal of Pragmatics 42(6): 1513–1525. doi:10.1016/j.pragma.2010.01.011
Hülmbauer, Cornelia. 2013. “From within and without: The virtual and the plurilingual in ELF”. Journal of English as a Lingua Franca 2(1): 47–73.
Isaacs, Ellen A. & John C. Tang. 1994. “What video can and cannot do for collaboration: A case study”. Multimedia Systems 2: 63–73.
Jefferson, Gail. 1979. “A technique for inviting laughter and its subsequent acceptance declination”. Everyday Language: Studies in Ethnomethodology, ed. by George Psathas, 79–96. New York: Halsted.
Jefferson, Gail. 1984. “On the organization of laughter in talk about troubles”. Structures of Social Action: Studies in Conversation Analysis, ed. by Max Atkinson & John Heritage, 346–369. Cambridge: Cambridge University.
Jefferson, Gail. 2004. “Glossary of transcript symbols with an introduction”. Conversation Analysis: Studies from the First Generation, ed. by Gene H. Lerner, 13–23. Philadelphia: Benjamins.
Jefferson, Gail, Harvey Sacks & Emanuel A. Schegloff. 1987. “Notes on laughter in the pursuit of intimacy”. Talk and Social Organization, ed. by Graham Button & John R.E. Lee, 152–205. Clevedon: Multilingual Matters.
Jenkins, Jennifer. 2015. Global Englishes. A Resource Book for Students, 3rd edition. London & New York: Routledge.
Kallen, Jeffrey L. & John M. Kirk. 2012. SPICE-Ireland. A User's Guide. Belfast: Cló Ollscoil na Banríona.
Klimpfinger, Theresa. 2009. “‘She’s mixing the two languages together’ – Forms and functions of code-switching in English as a lingua franca”. English as a Lingua Franca: Studies and Findings, ed. by Anna Mauranen & Elina Ranta, 348–372. Newcastle: Cambridge Scholars Press.
Kress, Gunther. 2011. “Multimodal discourse analysis”. The Routledge Handbook of Discourse Analysis, ed. by James Paul Gee & Michael Handford, 35–50. London: Routledge.
Laitinen, Mikko. 2015. “From diachrony to typology: Testing typological profiling on advanced non-native data”. Paper presented at Changing English 2015: Integrating Cognitive, Social & Typological Perspectives, 8–10 June, 2015, Helsinki.
Mauranen, Anna. 2012. Exploring ELF: Academic English Shaped by Non-native Speakers. Cambridge: Cambridge University Press.
Myers-Scotton, Carol. 1989. “Codeswitching with English: Types of switching, types of communities”. World Englishes 8(3): 333–346.
Nelson, Gerald. 2008. ICE Mark-up Manual for Spoken Texts. http://ice-corpora.net/ice/manuals.htm
Norrick, Neal et al. 2013. Transcription conventions. Saarbrücken: Saarland University. http://www.uni-saarland.de/fileadmin/user_upload/Professoren/fr43_Engling/downloads/trans_conv.pdf
Olson, Gary M. & Judith S. Olson. 2000. “Distance matters”. Human-Computer Interaction 15(2–3): 139–178.
Partington, Alan. 2006. The Linguistics of Laughter: A Corpus-Assisted Study of Laughter-Talk. New York: Routledge.
Pennycook, Alastair. 2010. Language as a Local Practice. Oxford: Routledge.
Pitzl, Marie-Luise. 2009. “We should not wake up any dogs. Idiom and metaphor in ELF”. English as a Lingua Franca: Studies and Findings, ed. by Anna Mauranen & Elina Ranta, 298–322. Newcastle: Cambridge Scholars Press.
Poplack, Shana. 1988. “Contrasting patterns of code-switching in two communities”. Codeswitching: Anthropological and Sociolinguistic Perspectives (Contributions to the Sociology of Language 48), ed. by M. Heller, 215–244. Berlin: de Gruyter.
Sacks, Howard, Emanuel A. Schegloff & Gail Jefferson. 1974. “A simplest systematics for the organization of turn-taking for conversation”. Language 50: 696–735.
Sauer, Simon & Anke Lüdeling. 2016. “Flexible multi-layer spoken dialogue corpora”. International Journal of Corpus Linguistics 21(3): 421–440. Amsterdam: Benjamins.
Schmidt, Selina. 2015. Laughter in Computer-mediated Communication: A Means of Creating Rapport in First-contact Situations. MA thesis, Saarland University.
Schmidt, Selina, Marie-Louise Brunner & Stefan Diemer. 2014. CASE: Corpus of Academic Spoken English: Transcription Conventions. Birkenfeld: Trier University of Applied Sciences. http://www.umwelt-campus.de/case-conventions
Scollon, Ron & Philip LeVine. 2004. “Multimodal discourse analysis as the confluence of discourse and technology”. Discourse and Technology: Multimodal Discourse Analysis, ed. by Philip LeVine & Ron Scollon, 1–6. Georgetown: Georgetown University Press.
Seidlhofer, Barbara. 2011. Understanding English as a Lingua Franca. Oxford: Oxford University Press.
Spencer-Oatey, Helen. 2002. “Managing rapport in talk: Using rapport sensitive incidents to explore the motivational concerns underlying the management of relations”. Journal of Pragmatics 34(5): 529–545. doi:10.1016/S0378-2166(01)00039-X
Spencer-Oatey, Helen & Peter Franklin. 2009. Intercultural Interaction: A Multidisciplinary Approach to Intercultural Communication. Basingstoke: Palgrave Macmillan UK.
Stewart, Stuart. 1997. “The many faces of conversational laughter”. Paper presented at the 9th Annual Meeting of the Conference on Linguistics and Literature, Denton, TX, 7–9 February 1997. https://eric.ed.gov/?id=ED404859
Tang, John C. & Ellen Isaacs. 1993. “Why do users like video? Studies of multimedia-supported collaboration”. Computer Supported Cooperative Work: The Journal of Collaborative Computing 1: 163–196.
Thompson, Paul. 2005. “Spoken language corpora”. Developing Linguistic Corpora: A Guide to Good Practice, ed. by Martin Wynne, 59–70. Oxford: Oxbow Books. http://ota.ox.ac.uk/documents/creating/dlc/chapter5.htm
Thonus, Terese. 2008. “Acquaintanceship, familiarity, and coordinated laughter in writing tutorials”. Linguistics and Education 19(4): 333–350. doi:10.1016/j.linged.2008.06.006
Trouvain, Jürgen. 2001. “Phonetic aspects of ‘speech-laughs’”. Oralité et Gestualité: Actes du colloque ORAGE, Aix-en-Provence, 634–639. Paris: L’Harmattan.
Trouvain, Jürgen. 2003. “Segmenting phonetic units in laughter”. Proceedings of the 15th International Congress of Phonetic Sciences (ICPhS), ed. by Maria-Josep Solé, Daniel Recasens & Joaquin Romero, 2793–2796. Barcelona: Universitat Autònoma de Barcelona.
Vettorel, Paola. 2014. ELF in Wider Networking: Blogging Practices. Berlin: De Gruyter Mouton.
Warner-Garcia, Shawn. 2014. “Laughing when nothing’s funny: The pragmatic use of coping laughter in the negotiation of conversational disagreement”. Pragmatics 24(1): 157–180. doi:10.1075/prag.24.1.07war
Widdowson, Henry G. 2015. “ELF and the pragmatics of language variation”. Journal of English as a Lingua Franca 4(2): 359–372.
Yngve, Victor. 1970. “On getting a word in edgewise”. Papers from the Sixth Regional Meeting of the Chicago Linguistic Society, ed. by Mary Ann Campbell, 567–577. Chicago: University of Chicago.
