
Studies in Variation, Contacts and Change in English
Studies in Variation, Contacts and Change in English
Jefrey Lijffijt, IDLab, Department of Electronics and Information Systems, Ghent University – imec
Terttu Nevalainen, VARIENG, Department of Modern Languages, University of Helsinki
Human communicative practices are organized in terms of genres, and people are highly skilled at recognizing genre differences. In text corpora, genres are typically defined on the basis of text-external features, such as medium, function and format. We show that the core genres of face-to-face conversation, prose fiction, broadsheet newspapers, and academic prose can also be reliably recognized based on a small set of text-internal (linguistic) surface features. Using a 40-million-word subset of the British National Corpus, we study select text-internal surface features that capture language complexity. It is shown that externally-defined genres differ substantially from each other, and that, using pairs of surface features, such as counts of nouns and pronouns, or of average word lengths and type/token ratios, it is possible to recognize those highly productive genres with a high degree (> 90%) of accuracy. Furthermore, our model can be used to get a quick overview of the structure a corpus, which is very useful when exploring big and diverse corpora. It is also possible to detect errors in the genre annotation of the BNC and develop software for detecting genre differences. By applying it to the Lancaster–Oslo/Bergen Corpus of British English, we also demonstrate that the model generalizes well across corpora of different sizes. Not unexpectedly, native speakers are still found to outperform the model, especially when very short text samples are analysed. [1]
Genres play a central role in language production and recognition. Humans are highly skilled at recognizing major genres: adult speakers can readily distinguish newspaper reports from academic journal articles and do not confuse either of them, for example, with fiction. Although fiction may contain dialogue, it is seldom mistaken for genuine face-to-face conversation – the most common kind of human interaction (Biber et al. 1999: 15–17). What is more, tests show that human genre recognition is often almost instantaneous (McCarthy et al. 2009).
Human genre-detection ability is based on exposure to both the formal and functional properties of texts. Substantial advances have also been made in training computers to recognize and describe genres, as shown, e.g., by Karlgren & Cutting (1994) and Kessler, Nunberg & Schütze (1998), who used the Brown University Corpus of American English. The more recent studies on genre classification and description have extended to web pages, for example, in Meyer zu Eissen & Stein (2004), Mehler, Sharoff & Santini (2010), and Biber & Egbert (2016).
The work on corpora has typically been based on a variety of textual features (twenty in Karlgren & Cutting 1994) or bundles of classifiers, which correlate with various structural, lexical, character-level, and statistically derived cues (fifty-five altogether in Kessler, Nunberg & Schütze 1998). The trend in more recent studies has been to base the statistical analyses performed on a large number of textual features and other cues, including features that relate to the appearance of the document (c. 150 linguistic features in Biber & Egbert 2016, for example; for surveys, see Meyer zu Eissen & Stein 2004, Petrenz & Webber 2011: 388–389, and Santini, Mehler & Sharoff 2010: 3–23).
In this paper we move in the other direction by minimizing the number of linguistic features that are needed to reliably identify a number of central categories or, in terms of Lee (2001: 51, 57–58), super-genres for analysing the British National Corpus (BNC). Our genre selection matches that presented, for example, by Biber et al. (1999: 15–40) and consists of face-to-face conversation, prose fiction, broadsheet newspapers, and academic prose. We discuss genre distinctions in corpus linguistics in more detail in Section 2.
Our aim is to provide both corpus linguists and computational linguists with a solid frame of reference for exploring established core genres and their variation in corpora over time and the medium of communication. Accompanied by visualizations, it can offer a quick overview of the high-level structure and diversity of a text corpus. We also believe that this framework can serve as a useful point of departure for more fine-grained linguistic analyses and computational applications.
Using a machine-learning algorithm, we construct a simple model for the recognition of the four core genres in the BNC (Section 4). We show that using a small set of features that are easily retrievable from plain (unannotated) text, it is possible to recognize these highly productive genres with a high degree of accuracy, and the visual presentation of the model makes it easy to interpret (4.1). We also find that several texts that appear as outliers in the model constructed on the BNC are indeed errors in the genre classification of the corpus (4.2). We validate the model on the Lancaster–Oslo/Bergen Corpus (LOB), which comes with a similar genre annotation, but has been compiled earlier and completely independently (4.3). Finally, we compare the model with the recognition performance of human labellers using minimally short text samples (4.4). The theoretical and practical implications of our findings are discussed in Section 5 with a brief conclusion in Section 6.
There is a rich literature on genres, ranging from the long tradition in literary scholarship (e.g. Fowler 1982) to recent work on discourse studies and digital communication (e.g. Wang 2009, Heyd 2016). The bases of text categorization vary greatly, and so does the terminology used. [2] Halliday (1978: 31–35) introduces the situational components of registers, which in later work on systemic-functional grammar are culturally contextualized by genres (Halliday & Hasan 1985: 108). By contrast, Werlich (1983) presents a cognitively based text typology (text grammar), and Faigley & Meyer (1983) outline a similar but rhetorically motivated approach to text types. Nevalainen (1992) adopts a prosodically-oriented approach to study discourse types in spoken interaction. Biber distinguishes the concept of genre (1988: 65–71), and later register (1995: 6–18), from text type in his inductive, quantitative research into the linguistic dimensions of discourse variation. Lee (2001) views genre as a hierarchically organized prototype concept in corpus design, and Leech (2007) contrasts externally defined genres and linguistically determined text types. Most genre studies address similar issues, including formal vs. functional approaches, repertoires, taxonomies, networks, and levels of granularity (Heyd 2016: 92–99). The focus of our discussion is genre as a superordinate, language-externally defined concept in corpus linguistics.
Corpus linguists typically base their analyses on the corpus compilers’ classifications of texts. As mentioned above, the vocabulary used with reference to these compiler categories varies greatly, but typically includes the terms genre, register,and text type. These labels are used to refer to both written and spoken texts. Unlike corpus linguists, who can rely on structured corpora, web-page analysts do not have the benefit of hand-classified texts but have to straddle the textual and medium-specific, e.g. hypertextual, properties of the web. However, categories such as mode of production and medium of communication are also becoming increasingly relevant in corpus work as corpora begin to integrate textual analysis with video analysis, for example (see McEnery & Hardie 2012: 4–5).
The specifics of text classification and labelling partly depend on the granularity (e.g. Leech 2007: 140) or, in Hallidayan terms, delicacy of the analysis, i.e. “the scale of differentiation, or depth of detail” (Halliday 1961: 272, Halliday & Hasan 1985: 108). Some genre analysts have approached this issue by adopting a prototype perspective. Following this tradition, Lee (2001: 48) discusses distinctions between superordinate, basic-level and subordinate levels of genre conceptualization, which he also adopts in his categorization of the BNC data. For example, the notion of “literature” would count as a superordinate or super-genre category for basic-level genre distinctions such as Novel, Poem and Drama, while Western, Romance and Adventure would represent sub-genres of Novels. Basic-level genres, he explains, “are characterized as having the maximal clustering of humanly-relevant properties (attributes), and are thus distinguishable from superordinate and subordinate terms”; super-genres, in turn, “operate in terms of prototypes or fuzzy boundaries: some are better members than others, but all are valid to some degree” (Lee 2001: 48).
In view of the diversity of approaches, the text classifications of traditional corpora can present problems for their theoretical and practical applications. Kessler, Nunberg & Schütze (1998: 33) note that (sub)genres such as “Popular Lore” in the Brown Corpus, for example, hardly constitute a natural class. Santini, Mehler & Sharoff (2010: 14) point out the roundabout ways in which the genres in the British National Corpus (BNC) were defined in terms of medium, domain, and target audience before David Lee (2001) developed a system of seventy genre tags for the BNC documents based on these distinctions. Most of these genres are easy to grasp, but they also reflect the compilation history of the corpus and contain labels such as “popular lore” and “miscellaneous spoken genres” (see Lee 2001, Appendix B).
Lee’s (2001) definitions and annotation of the BNC genres draw on those developed for earlier corpora, such as the Lancaster–Oslo/Bergen Corpus and the London–Lund Corpus. Since we are analysing texts drawn from the BNC, annotated by Lee, we shall adopt Lee’s terminology. Our study uses his classification to retrieve a set of tried and tested, higher-level genres: face-to-face conversation, prose fiction, broadsheet newspapers, and academic prose. These four categories are also used to illustrate linguistic variation in the comprehensive Longman Grammar of Spoken and Written English (LGSWE). Referring to them by the term register, the authors note that “[t]he four registers described throughout the LGSWE are important benchmarks, spanning much of the range of register variation in English” (Biber et al. 1999: 17). They are “both important, highly productive varieties of the language” and “different enough from one another to represent a wide range of variation” (Biber et al. 1999: 15–16).
Of the four core genres of interest to us, broadsheet newspapers would probably have undergone the most change in recent years. They of course continue to be available in print format, but their online editions often provide new kinds of functionalities such as reader comments. Research nevertheless suggests that editorial content can be clearly distinguished from user-generated communication and that the latter is usually monitored for content and language (Fitzmaurice 2011, Landert 2014). Landert (2014) also emphasizes the continuity of user-generated content, which has a long tradition in letters-to-the editor columns although, as Fitzmaurice (2011) shows, online reader posts need not adhere to conventional discourse practices.
Although the bulk of the BNC data come from the late 20th century, we would argue, following Hoffmann et al. (2008: 45–46), that in most respects the corpus represents present-day English. They note that the vocabulary of English has of course been greatly enriched due to the dramatic rise of Internet usage but that changes in areas such as morphology and grammar are remarkably fewer and much slower, most of them taking hundreds of years to progress. [3] Recent lexical innovations are not our concern in this study because, as described in Section 3, we focus on structural properties of texts, analysing word and sentence length, type/token ratios and relations between part-of-speech categories. Such basic text analytic measures can be observed and analysed in any set of written texts that come with the required markup.
Leech (2007) considers two approaches to corpus balance, proportionality being one of them. Accordingly, in a balanced corpus “the size of its subcorpora (representing particular genres or registers) is proportional to the relative frequency of occurrence of those genres in the language’s textual universe as a whole” (Leech 2007: 136). The alternative approach that he considers prioritizes a maximally heterogeneous corpus in linguistic terms and is based on “a quantitative INTERNAL analysis of genres according to their linguistic characteristics” (Leech 2007: 140, original emphasis). Both approaches have their problems, of (sub)genre conceptualization and their proportional representation in the first case, and of delicacy of the linguistic analysis in the second. Neither approach has so far been fully implemented in corpus building. [4]
Biber (1993), for one, rejects proportionality and opts for the second alternative: he proposes that in corpus design representativeness should be measured by the degree of internal linguistic variation within a corpus. A corpus is representative if it captures the full range of linguistic variability of a language (Biber 1993: 247–248). Corpora of face-to-face conversation, for example, would not be considered representative in this sense, although everyday conversation constitutes the most common kind of human interaction.
This view reflects the conceptual and terminological distinction that Biber (e.g. 1988: 65–71) makes between genre or register and text type. Genres/registers consist of situationally defined varieties that are “readily distinguished by mature speakers of a language; for example … novels, newspaper articles, editorials, academic articles, public speeches, radio broadcasts, and everyday conversations”, while text types are text categories “defined in strictly linguistic terms” (Biber 1995: 9–10). In his seminal work (1988), Biber analyses 67 linguistic features based on a survey of earlier research and, adopting a multi-dimensional approach, arrives at half a dozen text types that the genres in the analysed corpora are characterized by (e.g. “Involved vs. informational production”, “Narrative vs. non-narrative concerns” and “Explicit vs. situation-dependent reference”). Lee (2001: 40) suggests a separation of genre and text type similar to Biber’s, but goes on to note that it “still remains to be seen if stable and valid dimensions of (internal) variation, which can serve as useful criteria for text typology, can be found”. [5]
In practice compromises need to be made. To illustrate variation in English grammar, Biber et al. (1999) used the same core category selection as we did in this study. Analysing the Longman Spoken and Written Corpus of English (LSWE Corpus), they argued that “the grammatical features typically rise or fall consistently … across these four registers, reflecting the influence of these situational characteristics” (Biber et al. 1999: 17). The LSWE Corpus is characterized as both large and balanced in that it includes some five million words of each of the four core register categories with their major subregisters, a balanced corpus in general being defined as one that represents highly productive varieties of the language by “appropriately balanced amounts of text, while covering the widest possible range of variation within their sampling frame” (Biber et al. 1999: 27–28). The authors add that the British National Corpus is exceptional in being both fairly balanced and very large. Originally collected by Longman, the 4-million-word conversational subcorpus that is part of the LSWE Corpus in fact comes from the BNC (Biber et al. 1999: 28).
Our data come from the four genres of conversation, fiction, newspaper and academic prose in the BNC (Burnard 2007). As the genre classification in the BNC is quite fine-grained (Lee 2001), we selected only the subgenres that are prototypical representatives of these genres: demographically sampled conversations (N = 151), prose fiction (N = 431), broadsheet newspaper texts (N = 337), and academic prose (N = 505; see Appendix 1). Together, these texts cover some 40% of the 100-million-word corpus. Table 1 presents these core genres and their subgenres in more detail (drawn from Table 37 in Burnard 2007).
| Classification | Number of texts | W-units | % |
|---|---|---|---|
| Conversation | |||
| S conv | 153 | 4,233,955 | 4.30 |
| Academic prose | |||
| W ac:humanities arts | 87 | 3,358,167 | 3.41 |
| W ac:medicine | 24 | 1,435,608 | 1.45 |
| W ac:nat science | 43 | 1,122,939 | 1.14 |
| W ac:polit law edu | 186 | 4,703,304 | 4.78 |
| W ac:soc science | 142 | 4,785,423 | 4.8 |
| W ac:tech engin | 23 | 692,141 | 0.70 |
| Total | 16,097,582 | 16.28 | |
| Fiction | |||
| W fict prose | 431 | 16,033,647 | 16.30 |
| Newspaper | |||
| W newsp brdsht nat: arts | 51 | 352,137 | 0.35 |
| W newsp brdsht nat: commerce | 44 | 430,075 | 0.43 |
| W newsp brdsht nat: editorial | 12 | 102,718 | 0.10 |
| W newsp brdsht nat: misc | 95 | 1,040,943 | 1.05 |
| W newsp brdsht nat: report | 49 | 668,613 | 0.67 |
| W newsp brdsht nat: science | 29 | 65,880 | 0.06 |
| W newsp brdsht nat: social | 36 | 82,605 | 0.08 |
| W newsp brdsht nat: sports | 24 | 300,033 | 0.30 |
| Total | 2,983,712 | 3.04 |
Table 1. Core genres and their subgenres included in the study, their word counts (w-units) and relative frequencies (%) in the BNC.
Our data selection follows the approaches to genre balance discussed by Leech (2007: 144) within the limits of the sampling constraints of the BNC. Our selection reflects the scales of representativeness, balance and comparability that were attainable by the corpus compilers. Hence academic prose, for example, is proportionally overrepresented compared to broadsheet newspapers. We will compare and contrast the four highly productive core genres by using a small set of linguistic features to find whether they can provide useful criteria for a basic core text typology (cf. Lee 2001: 40–41). If they do, we suggest that these features can serve as indicators of prototypical genre differences both within and across corpora.
Figure 1 presents our approach in a nutshell. It is possible to provide descriptions of genres at any level of linguistic detail (dark blue arrow) and this is what most corpus linguists have been interested in doing. Informed by past work, we wish to explore the extent to which it is possible to go from language back to genres and identify superordinate genres using a small set of linguistic features (light blue arrow). These features will be discussed next.
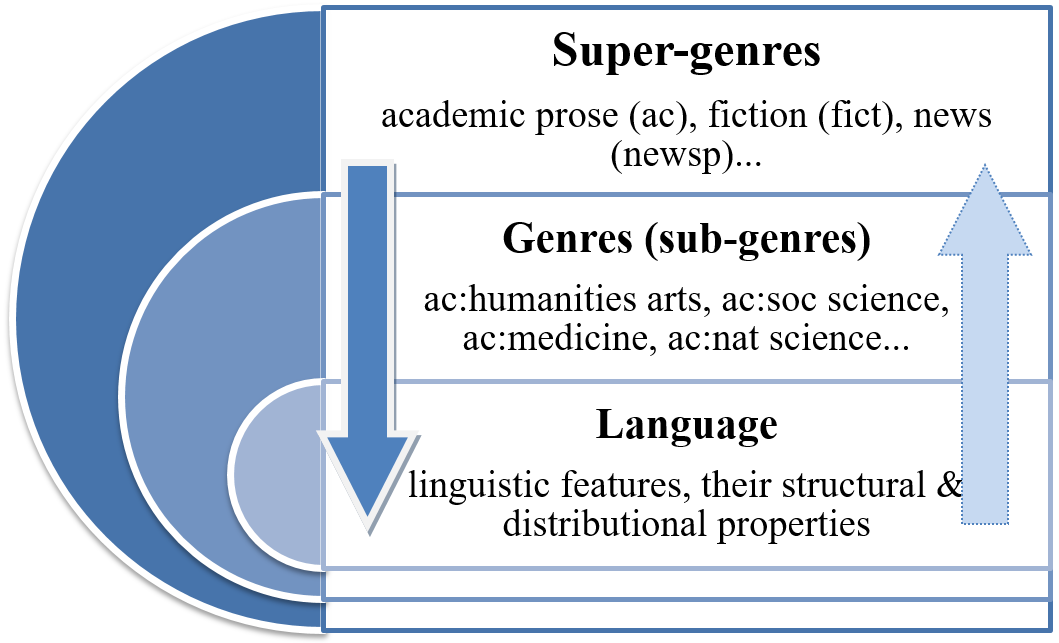
Figure 1. Linguistic analysis of super-genres: top-down (dark-blue arrow) and bottom-up (light-blue arrow) approaches.
The linguistic features we analysed are the relative frequency of nouns (NR) and pronouns (PR), average word length (AWL), average sentence length (ASL), type/token ratio (TTR), which is the relative frequency of distinct lexical elements in the text, and hapax legomenon ratio (HLR), which is the relative frequency of lexical elements that appear only once. We hypothesize that these features can capture some prototypical aspects of the complexity of a text and are thus capable of separating core genres.
This hypothesis is supported by earlier research, based on different approaches and carried out with different applications in mind. For example, the textual dimensions in Biber (1988: 104–114, and his later work) include counts for several parts-of-speech categories, ASL, and TTR; experimentation in text visualization by Siirtola et al. (2014: 420–422) includes AWL, ASL, and TTR; word lengths, in particular, have been related to information density in a number of studies (e.g. Piantadosi, Tily & Gibson 2011), as have noun and pronoun frequencies (Argamon et al. 2003); Säily et al. (2011), for example, analyse noun and pronoun frequencies to study language stability over time in a historical corpus. It is well known that both TTR and HLR strongly correlate with the length of a text. To remove this bias, we compute them using a sliding window of 250 words and afterwards averaging the value over all windows. See Appendix 2 for further details on these features.
We use the C4.5 decision-tree learning algorithm (Quinlan 1993) to find boundaries between the genres. A decision tree is a set of rules such as ‘if AWL is larger than a, then the sample belongs to the newspaper genre, else the sample belongs to academic prose’. The rules can be nested, such that, in the previous example, instead of a class (e.g., newspaper) there would be another rule, i.e., another ‘if … then … else …’ statement. The C4.5 algorithm is straightforward in the sense that it iteratively adds rules, each based on only a single variable, in a greedy fashion. Thus, at the top level, there is only one rule, and each rule presents a boundary between two classes. Because the rules are added in a greedy fashion, the algorithm is not guaranteed to give a globally optimal solution. We use the implementation in the statistics toolbox of Matlab, but implementations are readily available for other statistical software programs, such as R.
A decision tree can, like most machine learning methods, model any data set with perfect accuracy. However, such a model is likely to generalize very poorly to unseen data; data that was not provided to the method at the learning stage. To address this problem, machine learning methods employ regularization as part of the learning procedure, which balances the complexity of the produced model against the accuracy of the model (Hastie, Tibshirani & Friedman 2009). Simpler models are typically less accurate. In decision trees, the regularization takes the form that one typically requires any leaf node (i.e., end-point in the nested tree) to cover at least 30 samples. This prevents the model from over-fitting, i.e., the rules becoming overly specific.
For efficiency of the learning process, decision trees are restricted to use only one feature and threshold in every node in the tree. That means only axis-parallel splits are possible and, hence, every leaf node corresponds to a hypercube in the data space. If the boundaries between classes are not axis-parallel, this will lead to a suboptimal model. To potentially improve the accuracy of the solution, the algorithm is given two input features and also their cross-terms: feature1 +/- c * feature2, where c is a scaling constant chosen such that the range of the variables is equivalent. Adding the cross-terms allows for genre boundaries based on the interaction between the features. Equating the range of the two variables ensures that class separation boundaries in the decision tree have a 45º angle (see, e.g., Figure 3). As a measure of performance we use classification accuracy, which is defined as the number of samples correctly classified over the total number of samples.
Figures 2 and 3 show that the four genres can be distinguished accurately by using either NR and PR or AWL and TTR. The scaling factor c for PR and NR (Figure 2) is 1.88, and 7.98 for AWL and TTR (Figure 3). The classification accuracy, computed using n-fold cross-validation, is 92.5% for NR and PR, and 91.6% for AWL and TTR. The latter combination is especially attractive to use in practice, because neither feature requires part-of-speech information and both can be computed straightforwardly from plain text. As the correlations between NR, PR and AWL are very high (NR–PR -0.91, NR–AWL 0.86, PR–AWL -0.94), Figure 2 encodes partly the same information as Figure 3. See Table 2 in Appendix 3 for the classification accuracy for all pairs of the variables.

Figure 2. Scatter plot of relative frequency of nouns versus relative frequency of pronouns for the BNC texts.

Figure 3. Scatter plot of average word length versus type/token ratio for the BNC texts.
The dotted lines in Figures 2 and 3 correspond to decision boundaries, and each region separated by the boundaries corresponds to a genre. Conversation can be recognized both by short words and considerable repetition and by few nouns and many pronouns. Prose fiction contains less repetition and longer words, more nouns and fewer pronouns. Newspaper and academic texts have even fewer pronouns as well as longer words. Newspaper texts differ from academic texts in having higher information density: shorter words and greater lexical variation, on the one hand, and more nouns and slightly more pronouns, on the other.
These linguistic profiles reflect the communicative contexts in which the four core genres are produced. Face-to-face conversations are conducted in informal situations under online processing constraints. As the interlocutors are actively involved in negotiating the topics and managing the flow of talk, the resulting language is marked by frequent pronoun use and more lexical repetition than in the other genres. In contrast, the most economical way of transmitting information is aimed at by newspaper journalists, who have only limited space at their disposal and need to edit their texts accordingly. A tendency towards greater information density has been detected in English newspapers, which are characterized by an increasingly heavy nominal style over time (e.g., Szmrecsanyi & Hinrichs 2008).
Fiction and academic writing share some features with conversation and journalese, respectively. As a print genre, fiction is carefully planned and has more varied lexical information than conversation, but also contains dialogue, imitating face-to-face interaction. Like newspaper articles, academic writing focuses on information transmission but ensures clarity by a higher degree of repetition. The frequent use of technical terminology borrowed from Latin and French (Culpeper & Clapham 1996) is reflected in the greater word length found in newspapers but especially in academic texts.
It is not our intent to argue that this model is a new state-of-the-art in automatic genre classification. A non-linear model such as a Support Vector Machine or Deep Neural Network, combined with a rich set of features (n-gram counts, other part-of-speech frequencies, and maybe other features) would undoubtedly be more accurate. However, the constructed model would, due to the high dimensionality, not be interpretable. We feel that Figures 2 and 3 show clearly that, for these pairs of features, the model is close to optimal. Visually, the class boundaries are where they should be, there are very few mistakes, and as we argue in the next section, some of these misclassifications are in fact errors in the annotation. Finally, in Section 4.3 we show that the model generalizes well to other corpora.
The measures employed here can also be used to find outliers with respect to genre annotation. For example, text G3J, annotated in the corpus as fiction, has AWL = 4.61, TTR = 0.472; it is actually a law text on alcohol licensing. A text classified in the corpus as conversation with NR = 0.270 and PR = 0.069 is a quiz on television watched by four friends; there is no interaction and almost all speech is by the scripted television host. Another example is a text annotated in the corpus as fiction with AWL = 4.12 and TTR = 0.414: it is a short book to teach children their first words.
Incidentally, for our paper, NR is 0.292, PR is 0.016, AWL is 5.17, and TTR is 0.597, all features that clearly classify this paper as academic prose.
To eliminate any potential bias in corpus design or annotation, we validated this study by using the Lancaster–Oslo/Bergen Corpus of British English (The LOB Corpus 1999). The corpus contains 1 million words in 500 texts, divided into 15 (sub-)genres. As there is no transcribed speech in the corpus, we analysed only three genres from the LOB Corpus: fiction (N = 117), newspaper (N = 88), and academic prose (N = 80). Using the four-genre model trained on the BNC, the classification accuracy is 83.5% using NR and PR, and 82.1% using AWL and TTR. To compare: the n-fold cross-validation accuracy with training on the LOB corpus (and only three genres) leads to 85.6% and 81.8% accuracy, respectively.
As the model trained on the BNC performs very similarly to the model trained on the LOB Corpus, we conclude that the model is very robust and generalizes well. This is also confirmed by the visualization of the BNC model on the LOB Corpus given in Figures 4 and 5. Still, the classification accuracy on the LOB is considerably lower than on the BNC: 83.5% and 82.1% on LOB, as opposed to 92.5% and 91.6% on BNC, for NR-PR and AWL-TTR, respectively. There are a number of possible reasons for this difference, besides the LOB data coming from only three genres. For example, the genre annotation schemes of the corpora may not be fully compatible, the definitions of what constitutes a word may differ, and part-of-speech tagging may be based on different tag sets, or they may have been implemented differently in the two corpora. [6] The performance difference is likely to be a result of a combination of these factors.

Figure 4. Scatter plot of relative frequency of nouns versus relative frequency of pronouns for the LOB texts.

Figure 5. Scatter plot of average word length versus type/token ratio for the LOB texts.
Humans are able to identify the genre of a text even from a short sample. We also tested the above features for 50 words from the beginning of all texts – in which case no sliding window was used to compute the TTR and HLR and the model was retrained because the value ranges and variation between texts within each genre is larger for each of the features. The accuracy was 61.8% using NR-PR and 62.8% using AWL-TTR. By comparison, human respondents can classify single sentences into the genres of narrative, history, and science with 83.4% accuracy (McCarthy et al. 2009). This drop in classification accuracy compared to using full texts and to the capabilities of human experts suggests that humans use more fine-grained information to identify genres. But it is worth bearing in mind that, as McCarthy et al. (2009: 50) note, they cannot be sure the research they presented could suitably distinguish topic from genre. This content issue is avoided by the classification method we have proposed.
The good overall fit of our classification model has a bearing on the theoretical discussion of the correlation between genre and text type. At the practical level, our findings provide baseline evidence for various corpus linguistic studies as well as computational applications that can improve the search efficiency of digital materials such as web pages.
In this paper we have shown that the core genres we identified using Lee’s genre classification are in fact highly consistent with respect to certain text-internal features, and thus that this culturally-motivated division of texts into genres is not arbitrary. The point is strengthened by the fact that some of the outlier texts we detected proved misclassified. Our overall results support an argument in favour of a hierarchical organization of genres with a good match between genre and text type at the superordinate category level. More varied and fine-grained distinctions would naturally need to be made to analyse their sub-generic text-type characteristics (e.g. Biber et al. 1999: 17, Biber & Gray 2013).
Since the four core genres we have studied are expected to cover much of the range of variation in English (Biber et al. 1999: 25), our simple model of classification can provide useful higher-level points of reference for diachronic, contrastive, and comparative corpus linguistic studies. For example, studies on the colloquialization and economization of genres could benefit from basic exploratory indicators suggesting linguistic shifts in the language’s textual universe across time and space (Hundt & Mair 1999, Szmrecsanyi & Hinrichs 2008, Nevalainen 2013: 42–43).
More specifically, a classification model such as the one we have presented could be used to explore corpus comparability and representativeness, which often becomes an issue, for example, when matching datasets are being analysed. This is the case even with resources such as the chronological extensions of the Brown family of corpora, designed to be maximally comparable. Discussing this difficulty, Leech notes that:
While it makes sense to achieve success in both representativeness and comparability, there is a sense in which these two goals conflict: an attempt to achieve greater comparability may actually impede representativity and vice versa. (Leech 2007: 142)
The problem becomes increasingly acute with historical corpora, both single-genre and multi-genre collections, which cover a long time span. Our model could be applied to tracing basic aspects of genre evolution over time and hence prove useful in assessing the degree of diachronic comparability of existing historical corpora (Lijffijt, Säily & Nevalainen 2012). Diachronic studies based on materials that have part-of-speech annotation would benefit most from the classification model, and further applications can be found in work on social and stylistic variation (Säily, Nevalainen & Siirtola 2011). Other potential uses of the model we have proposed include the analysis of historical text corpora and databases such as the massive ECCO-TCP and EEBO-TCP collections and any smaller, more specialized corpora derived from them that come with genre or content-related metadata. [7]
Similarly, we hope that practical computational applications could refer to this model in their search for easy-to-implement structural analyses (cf. Mehler, Sharoff & Santini 2010). One such application is provided by Text Variation Explorer (TVE), an interactive text visualization tool for comparing texts, which implements three of the linguistic measures studied here, i.e., average word length (AWL), type/token ratio (TTR) and hapax legomenon ratio (HLR). In addition, the application makes it possible to explore, for example, pronoun frequencies by inputting a word list that contains the relevant word forms and submitting it to a principal component analysis (PCA; see Siirtola et al. 2014). Besides user-generated word-lists, TVE features window size and text overlap sliders, which allow rapid exploration of the effect of these settings on AWL, TTR and HLR by updating their respective line graphs according to the changes made in the slider values. [8]
We conclude that by counting nouns and pronouns in a text and using a simple classification model, we are able to distinguish between four core genres of English texts. An alternative solution that is straightforward to compute even for plain text is to count word lengths and vocabulary size. By doing a cross-corpus validation, we have also shown that the results can generalize well over corpora. However, we do observe that the accuracy decays if the texts analysed are very short and that human experts can be expected to perform significantly better at that task.
[1] This work was supported by the Academy of Finland (projects 129300, 276349, 293009), the Finnish Centre of Excellence for Algorithmic Data Analysis Research (ALGODAN), the Finnish Centre of Excellence for the Study of Variation, Contacts and Change in English (VARIENG), and Jefrey Lijffijt is supported by a FWO [Pegasus]2 Marie Skłodowska-Curie Fellowship (FWO and European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No 665501). [Go back up]
[2] Genre and related concepts are widely used in both theoretical and applied fields across the humanities. Recent surveys of genre analysis include, e.g., Bawarshi & Reiff (2010) and (in Finnish) Heikkinen et al. (2012), which comprises over 800 pages. [Go back up]
[3] To meet the practical need to gain access to linguistic variability in corpus research, McEnery & Hardie (2012: 8) advocate complementary use of corpora and suggest how the lexical information offered by the BNC, for example, could be supplemented by using the Web as corpus (with certain reservations). [Go back up]
[4] A rare example of the application of the principle of proportionality is the Corpus of Early Modern English Medical Texts (EMEMT). The compilers specify: “[t]he distribution of texts with regard to the different categories and time periods reflects the combined effects of perceived significance and availability of texts”, thus paying attention to “the degree of coverage not only over time but also across different fields of medicine”. See the corpus entry at CoRD, and further Taavitsainen & Pahta (2010). [Go back up]
[5] Lee (2001: 40) notes that the internal and external approaches need not necessarily produce complementary results as texts that represent the same genre according to external criteria could be classified as belonging to different text types or more abstract linguistic dimensions on the basis of their linguistic characteristics. [Go back up]
[6] For the annotation of the BNC, see its entry in CoRD and the explanation about tagging on the BNC website. For details of the LOB, see the annotation section of its entry in CoRD and the references therein. [Go back up]
[7] The ECCO-TCP and EEBO-TCP collections and some smaller corpora based on them are available for download in normalized spelling versions from the Visualizing English Print (VEP) project home page. [Go back up]
[8] A tutorial is available from Text Variation Explorer website. An updated version of the application, TVE2, is being designed in the STRATAS project, part of the Academy of Finland Digital Humanities programme. [Go back up]
Download the code used for this article in a .zip file.
BNC = The British National Corpus. 2007. Version 3 (BNC XML Edition). Distributed by Oxford University Computing Services on behalf of the BNC Consortium. http://www.natcorp.ox.ac.uk/, http://www.helsinki.fi/varieng/CoRD/corpora/BNC/
CoRD entry for Corpus of Early Modern English Medical Texts (EMEMT): http://www.helsinki.fi/varieng/CoRD/corpora/CEEM/EMEMTcategories.html
Linguistic Annotation of Texts (“tagging”) page on the BNC website: http://www.natcorp.ox.ac.uk/corpus/creating.xml?ID=annotation
LOB = The LOB Corpus. 1999. POS-tagged version (1981–1986), compiled by Geoffrey Leech, Stig Johansson, Roger Garside and Knut Hofland. Distributed by the International Computer Archive of Modern and Medieval English. http://icame.uib.no/newcd.htm, http://www.helsinki.fi/varieng/CoRD/corpora/LOB/annotation.html
The STRATAS project: https://www.helsinki.fi/en/researchgroups/varieng/interfacing-structured-and-unstructured-data-in-sociolinguistic-research-on-language-change-stratas
TVE = Text Variation Explorer. 2012. Harri Siirtola. University of Tampere. http://www.uta.fi/sis/tauchi/virg/projects/dammoc/tve.html
Visualizing English Print (VEP) project home page: http://graphics.cs.wisc.edu/WP/vep/vep-tcp-collection/
Argamon, Shlomo, Moshe Koppel, Jonathan Fine & Anat Rachel Shimoni. 2003. “Gender, genre, and writing style in formal written texts”. Text 23(3): 321–346.
Bawarshi, Anis S. & Mary Jo Reiff. 2010. Genre: An Introduction to History, Theory, Research, and Pedagogy. Anderson, SC: Parlor Press.
Biber, Douglas. 1988. Variation Across Speech and Writing. Cambridge: Cambridge University Press.
Biber, Douglas. 1993. “Representativeness in corpus design”. Literary and Linguistic Computing 8(4): 243–257. doi:10.1093/llc/8.4.243
Biber, Douglas. 1995. Dimensions of Register Variation: A Cross-linguistic Comparison. Cambridge: Cambridge University Press.
Biber, Douglas & Jesse Egbert. 2016. “Using grammatical features for automatic register identification in an unrestricted corpus of documents from the open web”. Journal of Research Design and Statistics in Linguistics and Communication Science 2(1): 3–36. doi:10.1558/jrds.v2i1.27637
Biber, Douglas & Bethany Gray. 2013. “Being specific about historical change: The influence of sub-register”. Journal of English Linguistics 41(2): 104–134.
Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad & Edward Finegan. 1999. The Longman Grammar of Spoken and Written English. London: Longman.
Burnard, Lou, ed. 2007. Reference Guide for the British National Corpus (XML Edition). Published for the British National Corpus Consortium by the Research Technologies Service at Oxford University Computing Services. http://www.natcorp.ox.ac.uk/docs/URG/
Culpeper, Jonathan & Phoebe Clapham. 1996. “The borrowing of Classical and Romance words into English: A study based on the electronic Oxford English Dictionary”. International Journal of Corpus Linguistics 1(2): 199–18.
Faigley, Lester & Paul Meyer. 1983. “Rhetorical theory and readers’ classifications of text types”. Text – Interdisciplinary Journal for the Study of Discourse 3(4): 305–325. doi:10.1515/text.1.1983.3.4.305
Fitzmaurice, Susan. 2011. “Talking politics across transnational space: Researching linguistic practices in the Zimbabwe Diaspora”. How to Deal with Data: Problems and Approaches to the Investigation of the English Language over Time and Space (Studies in Variation, Contacts and Change in English 7), ed. by Terttu Nevalainen & Susan Fitzmaurice. Helsinki: VARIENG. http://www.helsinki.fi/varieng/series/volumes/07/fitzmaurice/
Fowler, Alastair. 1982. Kinds of Literature: An Introduction to the Theory of Genres and Modes. Oxford: Oxford University Press.
Halliday, M.A.K. 1961. “Categories of the theory of grammar”. Word 17(3): 241–292.
Halliday, M.A.K. 1978. Language as Social Semiotic: The Social Interpretation of Language and Meaning. London: Edward Arnold.
Halliday, M.A.K. & Ruqaiya Hasan. 1985. Language, Context and Text: Aspects of Language in a Social-Semiotic Perspective. Oxford: Oxford University Press.
Hastie, Trevor, Robert Tibshirani & Jerome Friedman. 2009. The Elements of Statistical Learning. New York: Springer-Verlag New York.
Heikkinen, Vesa, Eero Voutilainen, Petri Lauerma, Ulla Tiililä & Mikko Lounela, eds. 2012. Genreanalyysi – tekstilajitutkimuksen käsikirja (Publications of the Research Institute for the Languages of Finland 169). Helsinki: Gaudeamus.
Heyd, Theresa. 2016. “Digital genres and processes of remediation”. The Routledge Handbook of Language and Digital Communication, ed. by Alexandra Georgakopoulou & Tereza Spilioti, 87–102. London & New York: Routledge.
Hoffmann, Sebastian, Stefan Evert, Nicholas Smith, David Lee & Ylva Berglund Prytz. 2008. Corpus Linguistics with BNCweb – A Practical Guide. Frankfurt am Main: Peter Lang.
Hundt, Marianne & Christian Mair. 1999. “‘Agile’ and ‘uptight’ genres: The corpus-based approach to language change in progress”. International Journal of Corpus Linguistics 4(2): 221–242.
Karlgren, Jussi & Douglas Cutting. 1994. “Recognizing text genres with simple metrics using discriminant analysis”. COLING ’94: Proceedings of the 15th Conference on Computational linguistics, Volume 2, ed. by Makoto Nagao & Yorick Wilks, 1071–1075. Stroudsburg: ACL.
Kessler, Brett, Geoffrey Nunberg & Hinrich Schütze. 1998. “Automatic detection of text genre”. ACL ’98: Proceedings of the 35th Annual Meeting of the Association for Computational Linguistics and Eighth Conference of the European Chapter of the Association for Computational Linguistics, ed. by P.R. Cohen & W. Wahlster, 32–38. Stroudsburg: ACL.
Landert, Daniela. 2014. “Blurring the boundaries of mass media communication? Interaction and user-generated content on online news sites”. Texts and Discourses of New Media (Studies in Variation, Contacts and Change in English 15), ed. by Jukka Tyrkkö & Sirpa Leppänen. Helsinki: VARIENG. http://www.helsinki.fi/varieng/series/volumes/15/landert/
Lee, David Y.W. 2001. “Genres, registers, text types, domains and styles: Clarifying the concepts and navigating a path through the BNC jungle”. Language Learning & Technology 5(3): 37–72.
Leech, Geoffrey. 2007. “New resources, or just better old ones? The Holy Grail of representativeness”. Corpus Linguistics and the Web, ed. by Marianne Hundt, Nadja Nesselhauf & Carolin Biewer, 133–149. Amsterdam: Rodopi.
Lijffijt, Jefrey, Tanja Säily & Terttu Nevalainen. 2012. “CEECing the baseline: Lexical stability and significant change in a historical corpus”. Outposts of Historical Corpus Linguistics: From the Helsinki Corpus to a Proliferation of Resources (Studies in Variation, Contacts and Change in English 10), ed. by Jukka Tyrkkö, Matti Kilpiö, Terttu Nevalainen & Matti Rissanen. Helsinki: VARIENG. http://www.helsinki.fi/varieng/series/volumes/10/lijffijt_saily_nevalainen/
McCarthy, Philip M., John C. Myers, Stephen W. Briner, Arthur C. Graesser & Danielle S. McNamara. 2009. “A psychological and computational study of sub-sentential genre recognition”. Journal for Language Technology and Computational Linguistics 24(1): 23–55.
McEnery, Tony & Andrew Hardie. 2012. Corpus Linguistics: Method, Theory and Practice. Cambridge: Cambridge University Press.
Mehler, Alexander, Serge Sharoff & Marina Santini, eds. 2010. Genres on the Web: Computational Models and Empirical Studies. Dordrecht, Heidelberg, London & New York: Springer.
Meyer zu Eissen, Sven & Benno Stein. 2004. “Genre classification of web pages: User study and feasibility analysis”. KI-2004: Advances in AI (Lecture Notes in Artificial Intelligence 3228), ed. by S. Biundo, T. Frühwirth & G. Palm, 256–269. Berlin: Springer.
Nevalainen, Terttu. 1992. “Intonation and discourse type”. Text – Interdisciplinary Journal for the Study of Discourse 12(3): 397–428. doi:10.1515/text.1.1992.12.3.397
Nevalainen, Terttu. 2013. “English historical corpora in transition: From new tools to legacy corpora? New Methods in Historical Corpora (Corpus Linguistics and Interdisciplinary Perspectives on Language 3), ed. by Paul Bennett, Martin Durrell, Silke Scheible & Richard J. Whitt, 37–53. Tübingen: Narr Verlag.
Petrenz, Philipp & Bonnie Webber. 2011. “Stable classification of text genres”. Computational Linguistics 37(2): 385–393.
Piantadosi, Steven T., Harry Tily & Edward Gibson. 2011. “Word lengths are optimized for efficient communication”. Proceedings of the National Academy of Sciences 108(9): 3526–3529.
Quinlan, J. Ross. 1993. C4.5: Programs for Machine Learning. San Francisco: Morgan Kaufmann Publishers.
Säily, Tanja, Terttu Nevalainen & Harri Siirtola. 2011. “Variation in noun and pronoun frequencies in a sociohistorical corpus of English”. Literary and Linguistic Computing 26(2): 167–188.
Santini, Marina, Alexander Mehler & Serge Sharoff. 2010. “Riding the rough waves of genre on the web”. Genres on the Web: Computational Models and Empirical Studies, ed. by Alexander Mehler, Serge Sharoff & Marina Santini, 3–30. Dordrecht, Heidelberg, London & New York: Springer.
Siirtola, Harri, Tanja Säily, Terttu Nevalainen & Kari-Jouko Räihä. 2014. “Text Variation Explorer: Towards interactive visualization tools for corpus linguistics”. International Journal of Corpus Linguistics 19(3): 417–429.
Szmrecsanyi, Benedikt & Lars Hinrichs. 2008. “Probabilistic determinants of genitive variation in spoken and written English: A multivariate comparison across time, space, and genres”. The Dynamics of Linguistic Variation: Corpus Evidence on English Past and Present, ed. by Terttu Nevalainen, Irma Taavitsainen, Päivi Pahta & Minna Korhonen, 291–309. Amsterdam: Benjamins.
Taavitsainen, Irma & Päivi Pahta, eds. 2010. Corpus of Early Modern English Medical Texts: Corpus Description and Studies. Amsterdam: Benjamins.
Wang, Sungsoon. 2009. “Text types and dynamism of genres”. Discourse, of Course: An Overview of Research in Discourse Studies, ed. by Jan Renkema, 81–92. Amsterdam & Philadephia: John Benjamins.
Werlich, Egon. 1983. A Text Grammar of English. 2nd ed. Heidelberg: Quelle & Meyer.
The four genres contain the following texts from the BNC:
| Conversation is built up from all texts in the class “S_conv”. |
| Prose fiction contains all texts listed in “W_fict_prose”. |
| Newspaper contains all texts in categories starting with “W_newsp_brdsht”. |
| Academic prose contains all texts in categories starting with “W_ac”. |
The four genres contain the following texts from the LOB Corpus:
| Conversation is empty. |
| Fictional prose contains all texts in categories K–P. |
| Newspaper contains all texts in categories A–C. |
| Academic prose contains all texts in category J. |
We excluded all texts shorter than 250 words, because the type/token ratio computation we use is not defined for shorter texts.
We initially considered the following six features in our analysis:
| Noun ratio (NR) | Pronoun ratio (PR) | Average word length (AWL) | Average sentence length (ASL) | Type/token ratio (TTR) | Hapax legomenon ratio (HLR) | |
|---|---|---|---|---|---|---|
| NR | 77.2% | |||||
| PR | 92.5% | 73.2% | ||||
| AWL | 87.2% | 83.8% | 78.0% | |||
| ASL | 86.6% | 85.3% | 86.1% | 80.9% | ||
| TTR | 88.7% | 92.3% | 91.6% | 90.5% | 66.9% | |
| HLR | 86.2% | 88.6% | 91.4% | 90.0% | 74.4% | 60.3% |
Table 2. Classification accuracy for pairs of features using n-fold cross-validation. On the diagonal are the classification accuracies for single features.
