
Studies in Variation, Contacts and Change in English
Studies in Variation, Contacts and Change in English
Jane Winters
School of Advanced Study, University of London
One of the key characteristics of big data for the humanities is its complexity, whether we are dealing with the text of digitised nineteenth-century newspapers or the vast quantities of born-digital data generated by social media platforms such as Twitter. It has been produced over different periods of time, using different and often undocumented methods; at best it may be only partially structured; and on occasion we may not even know precisely what it looks like. How can humanities researchers develop theoretical and methodological frameworks for dealing with such complex material? What tools and skills do we need to help us to work effectively with big data? How can we analyse data at scale, while retaining an understanding of the people and stories which are woven into its fabric? What, ultimately, can the humanities in general, and history in particular, bring to big data research? This article addresses some of these questions, focusing on two very different types of data: parliamentary proceedings in the UK, the Netherlands and Canada (from c.1800 to the present day); and the archive of UK web space from 1996 to 2013. Both offer fascinating insights into language, politics, culture and society, but both also present challenges, some of which we are only just beginning to identify, let alone to solve. It is vital that scholars work together to tackle these questions, or contemporary decisions about how we describe, publish and preserve big data may hamper the humanities researchers of the future.
As evidenced by numerous conferences, nascent research centres and funding calls, there is increasing interest among arts and humanities researchers in working with big data. But what precisely do we mean by big data when we are talking about the humanities, and is it in fact a particularly useful term? The Arts and Humanities Research Council (AHRC) in the UK notes that:
In research terms, big data comprises information resources which are so large that they exceed the capacity of commonly used software and other tools, so that users have perforce to develop new approaches and methodologies to analyse them. [1]
The first example given is that of the Large Hadron Collider, which apparently produces 15 petabytes of data annually (that is, 15 million gigabytes). Obviously, the humanities cannot offer anything on this scale, but digitisation and aggregation are moving us in that general direction. I am co-director of a project called Connected Histories, which brings together 25 major sources for the study of British history from the early modern period to the nineteenth century using a single federated search. One of the largest sources to be added was the collection of ‘British Newspapers, 1600–1900’ from the British Library, and its inclusion was an object lesson in some of the very basic problems that researchers and research projects can encounter. In order to index and mark-up the OCRed text, it had to be physically transferred from hard drives supplied by the British Library to servers at the University of Sheffield. We had not really considered the logistics of all this, but simply moving the data – before any analytical work could be undertaken – took weeks rather than days. The whole experience highlighted the demands that large-scale digital humanities projects can place on institutional computing services and infrastructure, as well as the importance of working closely and building good relations with those responsible for their management.
Of course, some big data has been made freely available by organisations which are able to call on resources that most universities can only dream of – notably Google Books and the HathiTrust digital library. The former already contains more than 25 million volumes, comprising many billions of words, readily accessible using the now ubiquitous Ngram Viewer. Indeed, the entire corpus is available to download if, as Google notes, you have the bandwidth and space. Given this, why do humanities researchers need to worry about handling big data themselves? I think the answer to this is twofold. First, there is the ‘black box’ problem. The Ngram Viewer produces deceptively simple results, but do we really know what it is showing us? Some of this is simply due diligence – it takes a bit of investigation, for example, to find that the downloadable data only features Ngrams that appear more than 40 times across the corpus. [2] This will, no doubt, capture most words – but certainly not all. The problem is more fundamental than this, though – and for me it boils down to whether this decontextualised macro-level view actually tells us anything particularly meaningful at all. Humanities big data is messy and unpredictable – ultimately I think this rather than scale is its distinguishing factor – and complexity is masked by a smooth curve on a graph. How, for example, does an Ngram Viewer handle changes in printing technology, type of paper and variation of fonts over a 200-year period? It is useless to think of consistency in this context. Given these problems, can visualisation at this very broad level ever be anything other than indicative, or suggestive of possible avenues of research, rather than offering genuinely new insights?
The second, related reason for humanities researchers to get directly involved in developing the tools and methods for big data research is simply to ensure that our voices are heard. We need to influence the questions that are asked, and the development of the data structures and tools that are required to begin to answer them. If a database developed by a team of historians might fail to anticipate the research questions a linguist brings to a particular source or collection of sources, this is magnified at the intersection of the humanities and the sciences. Conversations across disciplines are challenging, but the rewards are potentially great. [3] There are growing opportunities to work with technologists, information scientists and others to bring humanities concerns to approaches generated by the hard sciences, and vice versa. If we fail to take advantage of them, we run the risk that our sources – our data – will be misrepresented and we will effectively be deskilled.
This has recently come on to the agenda for historians in particular with the publication of the History Manifesto by Jo Guldi and David Armitage (Guldi & Armitage 2015). It argues for historians ‘to speak truth to power’, which broadly means a return to the longue durée and a shift to big data to answer what the authors describe as the major questions facing us in the early twenty-first century. The book is explicitly designed to provoke debate, and that it most certainly has done. Some of this discussion, while acknowledging the value of calls for historians to move into the public space, has been rather negative. But the most interesting responses have called for a more nuanced approach – there is value to be had from using digital tools to interrogate big data, but as Tim Hitchcock has argued persuasively there remains a place for “beautiful histories of small things” (Hitchcock 2014). In my view, this is precisely what the humanities bring to the table when we are thinking about and working with big data – close and distant reading are not mutually exclusive, and we can study the big picture and the long term without losing sight of the individual, the small business or the village. The best way to achieve this is by placing humanities research questions at the heart of the process, rather than by allowing the technology solely to determine what those questions might be. New tools and methods can, of course, be suggestive of new directions, but perhaps more valuably they can shed different light on old questions – and allow those questions to be explored and to evolve in ways which would previously have been impossible.
Over the past 18 months I have been involved with a number of big data projects, ranging from the thirteenth to the twenty-first century, and researcher engagement is central to all of them. I will discuss two of them in this article. The first, Big UK Domain Data for the Arts and Humanities (BUDDAH), is a collaboration with the British Library, the Oxford Internet Institute and Aarhus University in Denmark. [4] The archived web is an increasingly important resource for humanities researchers, but we do not yet have either the expertise or the tools to work with it effectively. Both the data itself and the process of collection are poorly understood, and it is possible only to draw the broadest of conclusions using current analytical tools. We have been working with a dataset derived from the crawl of the UK domain undertaken by the Internet Archive between 1996 and April 2013, which totals approximately 65 terabytes, and using it to develop a theoretical and methodological framework within which to study UK web space in particular, but also web archives more broadly. This dataset is big enough, but the scale of the problem facing both archival organisations and researchers is clear when you look at the first full domain crawl undertaken by the British Library in 2013. The crawl started with 3.86 million seed websites, and this initial list led to the capture of 1.9 billion URLs (web pages, documents, images, sound files, and so on). The process took 70 days, and generated 30.84 terabytes of data – that is, almost half as much again as for the previous 17.5 years (Webber 2014). [5] With at least one full domain crawl scheduled to be undertaken annually in the UK, we are soon going to be dealing with very big data indeed.
At the moment the challenges posed by this data mean that it is rarely used – even by those who know that it exists – and we were keen both to demonstrate its value for humanities researchers and to build a community that would advocate for its significance. To this end, we awarded bursaries to 10 researchers from a number of different disciplines, who came up with a varied range of research projects focusing on the archived web as a primary source – from analysing disability action groups online to studying the Ministry of Defence’s recruitment strategy, from examining discourse about heritage to looking at Beat literature in the contemporary imagination. As they refined their research questions, they worked alongside technical developers at the British Library to co-design a new interface and tools which, as far as possible, would allow them to do what they wanted to do. [6]
The ‘Shine’ interface that was developed during this collaboration provides access to one of the largest full-text indexes of web archive files in the world. The coverage of the Internet Archive in the US is much greater, of course, but at the time of writing access still primarily relies on knowing and searching for a particular URL. [7] This is severely limiting for researchers, as you can only find something if you know that it previously existed, and serendipitous discovery is effectively curtailed.
At the moment, the focus is still very much on searching, and I think it is fair to say that this has highlighted some problems with the way in which researchers think about building queries. [8] To illustrate the difficulty, Richard Deswarte, who was interested in tracing Euro-scepticism online, soon hit up against the problem that ‘UKIP’ was the name of an internet service provider as well as the acronym used for the UK Independence Party (Deswarte 2015). Another researcher, Gareth Millward, was forced to reduce the number of charities that he included in his case study because the tendency for disability organisations to rebrand themselves with names such as Scope or Mind made it impossible to generate meaningful results (Millward 2015). A reliance on algorithmically ranked search results designed to narrow down rather than to expose the scope of a collection is a clear problem when we are dealing with big data. Some of these difficulties can, of course, be ironed out, through training, through experience, and through the interface itself. For example, proximity searching is now explicitly available in the ‘Shine’ advanced search, date ranges can be applied, file formats can be excluded, and website and page titles can be factored in. Perhaps most useful is the option to restrict searching to particular domain suffixes, so that a search for “David Cameron”, for example, produces 1.25 million results, but limiting this to parliament.uk results in only 6,295. You still cannot be sure that all of these are references to former UK prime minister David Cameron, but it is a much more manageable dataset with which to work.
More difficult to deal with are the problems inherent in the data. The archival unit is the web page, and moreover one which appears in a solely national context. It goes without saying that the web is both international and networked. Deswarte, for example, could study how Euro-scepticism manifests itself in the UK web domain, but could not easily trace responses within the European Union (and incidentally, no one currently has formal responsibility for archiving the .eu domain). He could look at the links between websites opposed to greater European integration, but only provided that they end with .uk. Then there is the fact that a web page consists of multiple elements, which at the moment cannot be isolated or disaggregated. This is currently a real hindrance to both proximity searching and large-scale analysis – advertising tickers, for example, were common at the turn of the century, and frequently bear no relation to the content of the web page with which they have been captured. A rolling news item about a fire in the Channel Tunnel, for instance, might form part of multiple captures of the Yorkshire Post website. [9] Similarly, a post code which appears in the footer of a page may be the address of a hosting company rather than of the business or individual with which the page is concerned, so geo-location becomes problematic. And so on.
Then there is the way in which the data itself has been collected. Fundamentally, we do not really know what it looks like. It is, of course, unstructured, but there are other unique issues to be addressed. While the British Library’s on-going full domain crawl is as comprehensive as it is possible to be, this is not the case with the dataset derived from the Internet Archive. It started from a small seed list of websites and took time to acquire the full range of URLs which it now contains. In addition, the rate of data collection has not been consistent over time – there are peaks and troughs which it is relatively easy to identify for a single website, but not necessarily at scale. Taking the website of the Institute of Historical Research as an example, you can see superficially what is going on. The site as a whole has been captured 198 times between 27 December 1996 and 14 September 2014, but only three times in 1998, 24 times in 2003, three times in 2007, and so on. The three captures in 2007 were all within the space of four weeks, so any changes during the rest of that year are not reflected in the archive. This pattern will not be consistent across websites or national domains, and the reasons for the disparities are not documented. So while a researcher may know that these differences exist, it is very difficult systematically to allow for them.
As if this was not enough, there are undocumented variations in the depth to which particular sites are crawled. Some may be captured in their entirety, either consistently or only on occasion; others may have been crawled to just one or two navigational levels. Sometimes multimedia content will have been archived effectively; at other times images, advertisements etc. may be missing, or partially captured. [10] The patchiness of the data collection introduces another issue, which is that the researcher may be presented with a version of a web page that never actually existed. The Internet Archive, from which our data was drawn, makes use of the Memento ‘Time Travel for the Web’ protocol. This searches across various web archives to find prior versions of a particular page instance, or memento. It then reconstructs the page, drawing from multiple mementos to create the best possible representation of the page as it existed at a particular point in time. A snapshot of the British Library home page on 20 July 2009, for example, is reconstructed using fourteen mementos, from four different archives, covering a period of four months. This is the nearest we can get to knowing what that page looked like at that particular point in time, but it was not viewed by any human being in 2009.
Finally, further complexity is added by the problem of duplication. Websites are crawled irrespective of whether they have changed since the last time they were captured, and this results in multiple duplicates in the archive. For the BUDDAH project we tried to make allowances for this, and removed identical instances of web pages from the dataset. However, this is something of a blunt tool. A page with a dynamically changing date field, for example, but otherwise unaltered content, will still appear multiple times. This particular problem is not confined to web archives – anyone who has worked with newspapers will be aware of the problem of multiple editions and the re-use of articles by different newspapers – but the combination of uncertainties posed by web archives is perhaps uniquely challenging.
Lack of awareness of the problems can seriously distort research, particularly in disciplines such as history where quantitative skills training has been largely absent in recent decades. To take one example, the Ngram in Figure 1 compares absolute numbers of references in the archive to malaria, tuberculosis and Ebola. Taken at face value, it seems to illustrate a significant increase in mentions of all terms, rising more or less to a peak in 2010, with some interesting looking dips in previous years. But in fact this is what any Ngram based on absolute numbers will look like – there is not very much data in the archive at the start of the period so the curve will always be upwards; there are always periods of reduced data collection which will cause dips in the graph at the same points. The results are essentially meaningless. A graph showing the relative number of mentions compared to the archive as a whole reveals a very different picture. From 1999 onwards, malaria clearly predominates as a term, and there is an interesting peak in references to Ebola the following year (Figure 2). This kind of visualisation can be enormously useful as a route in to complex data, but it is no substitute for understanding the data in the first place.
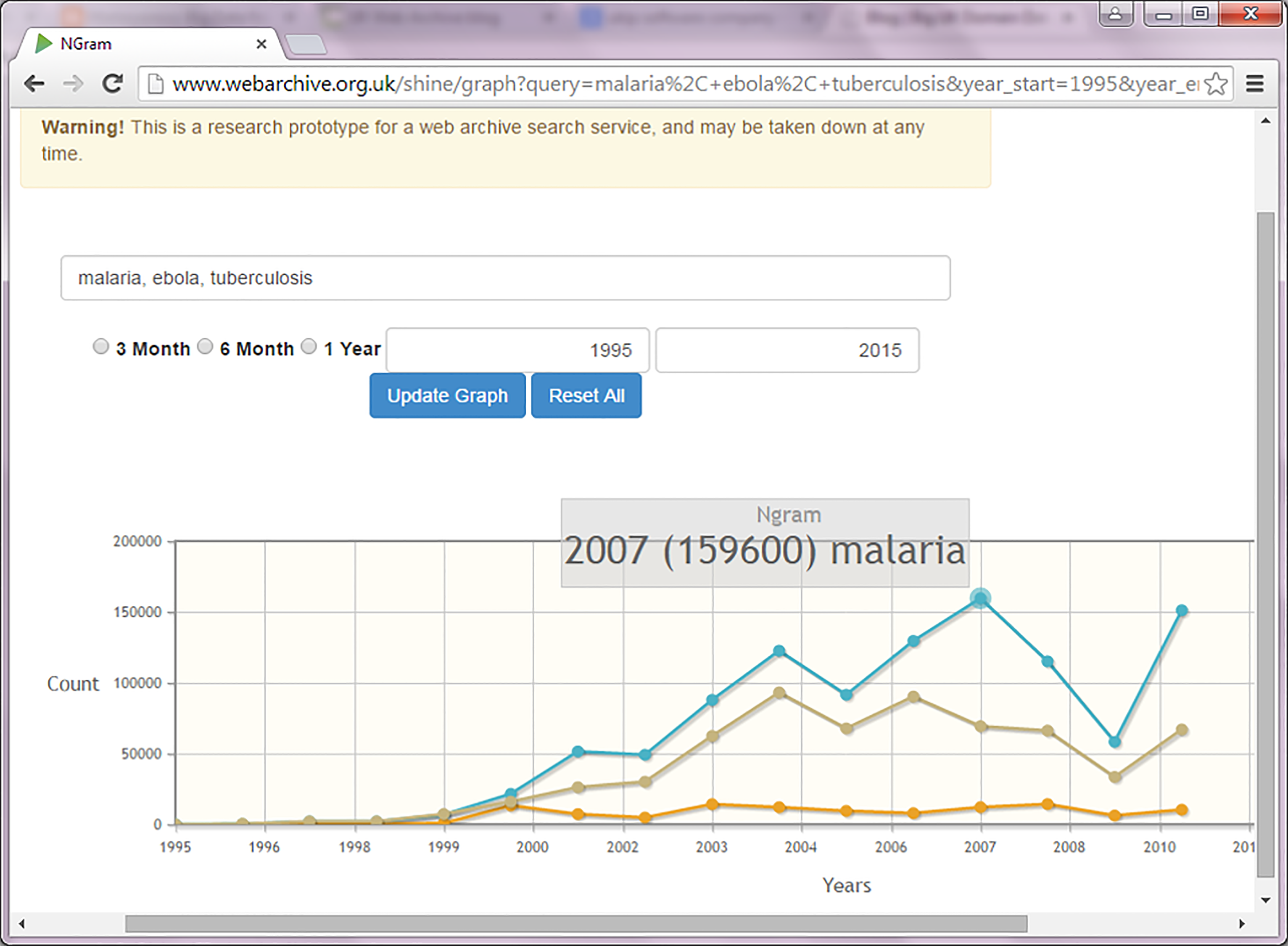
Figure 1. Absolute numbers of references to ‘malaria’, ‘tuberculosis’ and ‘Ebola’ (Shine dataset, 1996–2013).
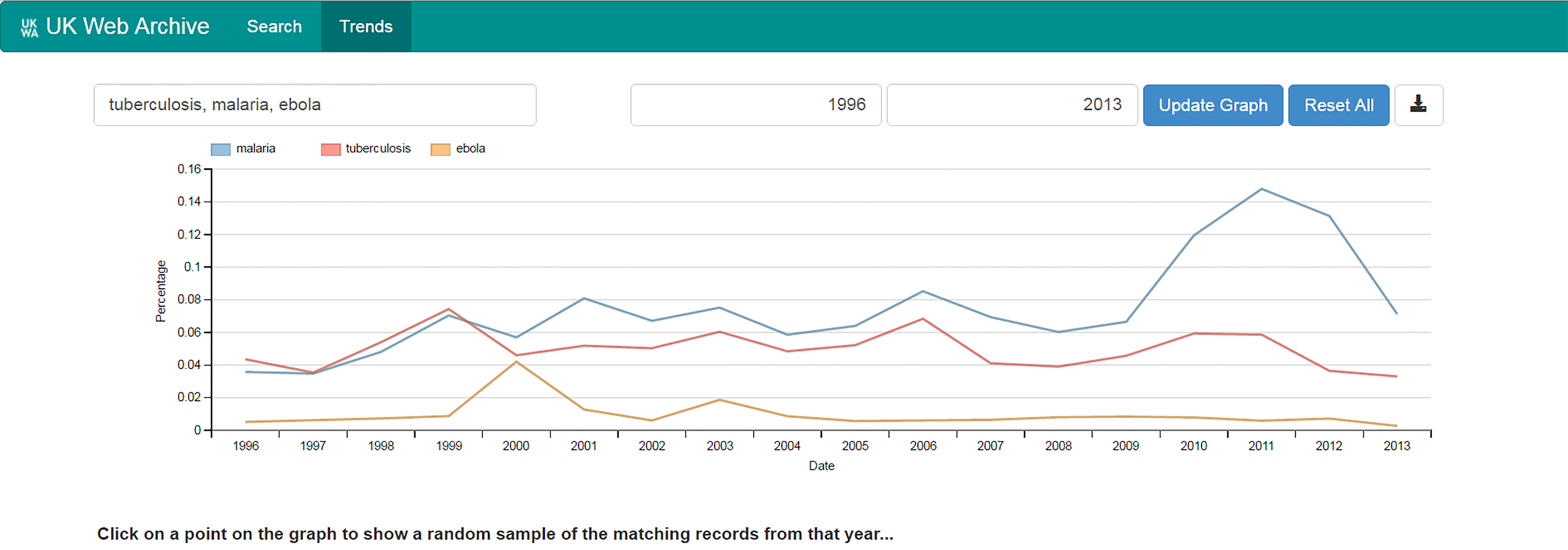
Figure 2. Relative numbers of references to ‘malaria, ‘tuberculosis’ and ‘Ebola’ (Shine dataset, 1996–2013).
Once you begin to understand the data, however, visualisation can be extremely effective. The Oxford Internet Institute, for example, has used information about links contained in the dataset to map UK central government online. It is possible to see immediately which government departments are well connected, which are relatively isolated, and the degree of reciprocity in the linkages between them. Similarly, a series of graphs produced by the British Library, drawing on a representative sample of the larger archive, reveals the waning importance of universities in the UK domain. In 1996, the ac.uk domain accounts for 39% of all links captured in the dataset, but by 2008, this figure has declined to just 1%. Neither of these visualisations allows us to understand why something is happening, but they do reveal information which can only be detected at scale. The question of how much importance we ascribe to a link – fundamentally what it means – is, of course, much more complex and will vary depending on a huge range of criteria.
To date, and necessarily, much of the activity around the archived web has focused on the logistics of harvesting, storing and making available in some form this enormous and growing dataset. We are now just starting to explore it as a primary source, and we will undoubtedly begin to acquire the necessary skills and methodologies. The importance of doing so is obvious. Web and related social media archives will be the big data which it is impossible for humanities researchers to avoid. To take just two examples, first, what would the history of the 2014 referendum on Scottish independence from the UK look like if researchers only had access to official documents and mainstream media? The eventual closeness of the vote would seem inexplicable without an understanding of how campaigning and debate played out online. Second, another of the project bursary-holders, Rowan Aust, has been studying what goes missing online when large institutions respond to reputational crisis. She has been comparing references to the posthumously disgraced media figure Jimmy Savile on the live BBC website with those in the web archive to see how much content has been removed, from where, and according to what strategy – or indeed none. It is a fascinating insight into several spheres of contemporary life, and an investigation which could not otherwise have been carried out (Aust 2015). All of these questions are brought sharply into focus by a 2014 study which found that 70% of the URLs within the Harvard Law Review, and more significantly 50% of those within United States Supreme Court opinions, no longer link to the originally cited information (Zittrain, Albert & Lessig 2014). The material has disappeared from the live web, but remains within the web archive. There is a clear imperative to get to grips with this data if we are to understand our own recent past. And digital humanists are precisely the people to do this.
I will turn now to my second project, Digging into Linked Parliamentary Data (DILIPAD). [11] This is another international collaboration, involving researchers in the universities of Toronto, Amsterdam and Oxford, King’s College London and the History of Parliament Trust. It is also notably interdisciplinary, with historians, political scientists, computational linguists and information scientists working together to analyse parliamentary proceedings from three countries. Parliamentary records form a unique longitudinal dataset about human behaviour: they can span hundreds of years, with periodical (often daily or weekly) accounts published according to a stable procedure. The nearly verbatim character of much of the transcription, albeit within certain conventions, also renders it closer to the spoken word than other sources with similar chronological coverage. [12] The digitised parliamentary collections of the UK (known as Hansard) and The Netherlands both cover almost 200 years, and are complete and published in machine-readable format. The digitised records of the Canadian parliament (also called Hansard) back to Confederation in 1867 are gradually becoming available.
This all sounds great, and it is worth acknowledging here the significance of the UK Parliament’s decision not just to invest in the digitisation of Hansard, but to make it available for re-use, with an API, under an Open Government Licence. However, the digitisation of all of this material has been shaped by the paradigm of print – the proceedings are offered simply as digital versions of the original debate transcripts. Consequently, while it is more or less easy to find out, in individual cases, what is said, who says it, to whom and why, it is virtually impossible to undertake complex, large-scale analysis of data about members of parliament, governments, parties, debate topics, and so on; and in particular to compare slices of data over time and across different nation-states.
The UK team have been working on UK Hansard, so it is that element of the project that I will discuss here. Our first step was to enhance the data in ways which would allow us to undertake much more sophisticated analysis. A pilot project developed an XML schema, Parliamentary Markup Language (or PML), which encompasses the key elements of the parliamentary record – people, bills, acts, items of business, debates, divisions, sessions and so on (Gartner 2012). [13] These different components can then be joined together, so that a particular speech in Parliament is linked to information about the speaker, to the session in which it occurred, and to any resulting legislation. As I mentioned, compared to, say, nineteenth-century newspapers, parliamentary proceedings are relatively structured – but not all parliamentary proceedings are equal. The Dutch material, for example, has a clear order of business for debates. A member from each party is allowed to speak from a central lectern, and there is a very well-defined process for interruptions, which are also identified as such. This is very different from the relative free-for-all of Prime Minister’s Questions for example. There is structure present in the UK proceedings, but it is much harder to unpick. We are, however, beginning to identify character strings in the data which will help to reveal patterns of discourse within the overarching debate structure, and ultimately this should help us to establish whether something is a speech, an interruption or a question.
There are other complications too. In the nineteenth century party affiliations, if present at all, were much more fluid than they are today. MPs frequently represented multiple constituencies in the course of their political careers, and constituency boundaries have also changed over time. Finally, while it is relatively easy to identify MPs when they are speaking, it is much more of a challenge to do so when they are being referred to by another speaker – whether as “the Minister’s right honourable friend”, “the Secretary of State” or “the Member for Southwark and Bermondsey”.
MPs have been identified in the proceedings using string matching and then associated with their unique PML ID. This is the information associated with the ID for Ellen Wilkinson, the only female Labour MP in the 1924 Parliament, who subsequently played a leading role in the Jarrow March against unemployment and poverty in 1936 (Figure 3):
<mads>
<authority>
<name type="personal" valueURI="http://liparm.ac.uk/id/person/person/wilkinsonellen1891-1947">
<namePart type="family">Wilkinson</namePart>
<namePart type="given">Ellen</namePart>
<namePart type="given">Cicely</namePart>
<namePart type="termsOfAddress">Miss</namePart>
<namePart type="date">1891-1947</namePart>
</name>
</authority>
<variant type="other" otherType="firstNameUsed">
<name>
<namePart type="given">Ellen</namePart>
</name>
</variant>
<identifier type="Rush Individual ID">9234</identifier>
<extension>
<affil_group><affiliation><rushID>9234</rushID><partyID>5</partyID><partyName>Communist Party</partyName><name type="party" regURI="http://liparm.ac.uk/id/party/communist-party" /><connection>member</connection><dates></dates><notes>founder member</notes></affiliation><affiliation><rushID>9234</rushID><partyID>1</partyID><partyName>Labour Party</partyName><name type="party" regURI="http://liparm.ac.uk/id/party/labour-party" /><connection>member</connection><dates></dates><notes>NEC member 1927-1929, 1937-1947; Party Chairman 1944.</notes></affiliation></affil_group>
<dateOfBirth>1891-10-08</dateOfBirth>
<dateOfDeath>1947-02-06</dateOfDeath>
<constituency valueURI="http://liparm.ac.uk/id/unit/constituency/middlesbrougheast1918-1974" dateOfElection="1924-10-29" dateOfExit="1931-10-27">Middlesbrough East</constituency>
<constituency valueURI="http://liparm.ac.uk/id/unit/constituency/jarrow1885-current" dateOfElection="1935-11-14" dateOfExit="1947-02-06">Jarrow</constituency>
<gender><genderTerm>female</genderTerm></gender></extension>
</mads>
Figure 3. PML information associated with the Labour MP Ellen Wilkinson.
So we have the standard biographical details (family and given names, term of address, dates of birth and death), but also information about the two constituencies which she represented – Middlesbrough East and Jarrow – along with dates of election and exit for both. Just as an aside, when we get to the most recent parliaments, there are a handful of MPs who do not make public their date of birth, whether for reasons of data security or personal vanity is unclear. [14]
We were concerned from the outset that PML should be extensible to parliamentary systems not based on Westminster, so there are, for example, very general categories such as Proceedings Object Types, Functions, Legislative Stages and so on, which can also be expanded as necessary. All of this data is freely downloadable from the School of Advanced Study’s institutional repository, SAS-Space, for both Westminster and Stormont in Northern Ireland. None of this may seem particularly ground-breaking, but it made it possible for the first time automatically to identify the gender and party affiliation of every speaker in Hansard.
This preliminary work was vitally important, and revealed the potential of adding greater structure to Hansard and to other parliamentary proceedings. The PML version of Hansard will remain available for research and analysis, and the schema may be applied by anyone with an appropriate dataset. However, within the DILIPAD project we were dealing with multiple datasets and multiple existing schema. The most advanced of these, PM, was devised by the Political Mashup project at the University of Amsterdam and had already been applied both to the Dutch proceedings and to more recent Hansard data published by TheyWorkForYou. Consequently, it was decided to use this schema rather than PML when unifying the three sets of proceedings featured in the project, so that they could be searched through the same interface.
With the post-1935 data in the UK, Canada and the Netherlands marked up in PM, a number of new research questions are possible. Two case studies were originally proposed for the project, one considering left/right ideological polarisation and the other migration. In the former case, for example, it might be possible to assess whether more extreme and entrenched positions are apparent in the months leading up to a general election; if language varies depending on whether or not an individual MP is in the party of government or in opposition; or whether the perks and benefits of executive positions encourage party leaders and officers of state to temper their ideological convictions in the interests of holding on to power or appealing to voters. The range of questions that can be asked in relation to migration is equally rich. Immigration, and opposition to it, have been a feature of political debate throughout the nineteenth and twentieth centuries, but the ways in which it has been discussed have differed according to diverse local, national and international factors. The Netherlands and the UK gained and lost large empires during this period, while Canada was first a colony and then experienced decolonisation and independence. It will be possible to investigate whether the frequency of discussion of immigration in the three national legislatures corresponds with actual increases in the rate of immigration, or whether other factors such as reporting and perception are at work. We will also be able to study how the framing of immigration has changed over time, encompassing scientific racism, economic considerations, both positive and negative, and crime and security concerns. And with speakers’ party affiliations securely identified, how does discussion vary between parties, and does the rhetoric shift, for example, if the overall left/right balance in Parliament changes?
These were the two major research questions we identified at the outset, but the more we work with the data the more the possibilities expand. For example, now that we have assigned gender to all speakers, we can analyse whether in the UK the admission of female MPs after 1919 affected the language of debate, or whether women are more likely to be interrupted in debate than men. Issues around the representation of women and women’s issues in the UK Parliament since 1945 have been explored by two members of the project, Blaxill and Beelen, with some particularly suggestive findings for the Thatcher administration and the period post-1997 which saw an influx of female MPs under the first Blair government (Blaxill & Beelen 2016). [15] Similarly, for much of the twentieth century a time stamp has been included for individual debates, allowing us to look at whether the nature of discussion is affected by, for example, late evening sessions (Figure 4). Does argument become more confrontational as speakers become tired, for instance? There is a gender issue here too. It has long been posited that one of the reasons why many women are put off from pursuing a career in politics is the unsociability of the hours, particularly for those with childcare responsibilities. Is this in fact reflected in levels of attendance and participation in late-night debates?
<stage-direction pm:id="uk.proc.d.1935-12-05.33.1.4">
<p pm:id="uk.proc.d.1935-12-05.33.1.4.1">4.3 p.m.</p>
</stage-direction>
<speech pm:speaker="Mr. DALTON" pm:party="Lab" pm:role="mp" pm:member-ref="uk.m.17126" pm:id="uk.proc.d.1935-12-05.33.1.5" dp:time="16:03:00" pm:party-ref="uk.p.Lab">
<p pm:id="uk.proc.d.1935-12-05.33.1.5.1">Yesterday's Debate turned largely on questions of domestic policy. To-day something more is due to be said about the foreign policy of His Majesty's Government both as revealed, and as not revealed, by the Gracious Speech. We are all very glad to see the Foreign Secretary here. We hope that he is better, and we hope that when he returns from his holiday he will be completely fit again.</p></speech>
Figure 4. An example of a time stamp recorded in UK Hansard (highlighted in red).
A beta interface has been developed allowing full-text searching of the three sets of proceedings post-1935, which also allows some basic visualisation. [16] For example, a search for ‘nuclear weapons’ reveals that Labour MPs on the left have used the term considerably more than the Conservatives on the right, that the recently deceased Denis Healey is just ahead of Margaret Thatcher, and that backbenchers and Opposition MPs are far more likely to have spoken about nuclear weapons than those in government. Peaks of activity occur in 1960 and 1987, and while the Labour party is concerned with proliferation, defence and deterrence, the Conservatives are much more likely to focus on manufacture, capability and tactics. At the time of writing, nuclear weapons are again in the spotlight, with a debate over the renewal of the UK’s Trident nuclear submarines likely to be held some time in 2016, and the Labour party bitterly divided over the issue. Searching for Trident in Hansard reveals four distinct categories of entry: the metaphor of the trident, often in association with the figure of Britannia; references to various naval vessels named Trident; mentions of the Hawker Siddeley Trident aircraft, used by the state-owned British European Airways Corporation (BEA); and finally the Trident nuclear programme announced in 1980. Limiting results to the period from 1980 to 2005 reveals more or less equality of mentions between the Conservative and Labour parties (1,925 as opposed to 1,909), but the top three speakers are all Labour MPs opposed to the programme – Bob Cryer (113), Denzil Davies (95) and the current leader of the Labour party, Jeremy Corbyn (92). On a lighter note, MPs in the Netherlands have referenced Hamlet’s famous “To be or not to be” soliloquy no fewer than 149 times – compared to just 29 in UK Hansard. [17] Shakespeare by contrast has been mentioned 1,296 times – ranging from Conservative Michael Gove showing off his knowledge of Sonnet 116, to the Liberal Democrat Robert Maclennan expressing shock at the Royal Shakespeare Company closing its residency at the Barbican for four months, to a Conservative MP in 1956 stating something which would sound very familiar today: “for the next 20 years it will be much more important to understand and to be able to quote scientific formulae than to be able to quote and understand Shakespeare”.
There are only so many questions that we can explore within a two-year project, but we hope that others will be able to build on this work and take it further. One of the key outputs of the project will be a joint dataset covering all three jurisdictions, made available as XML proceedings and as RDF triples linked to DBpedia. Our project would not have been possible without the generosity of others in making their data open, well-documented and re-usable, and we now have the opportunity to do the same. DILIPAD will thus complement other major resources for parliamentary research, like the Hansard Corpus developed at the University of Glasgow.
This is inevitably a very quick overview of two quite different projects, involving different configurations of expertise and varying levels of complexity. They are linked by collaboration and interdisciplinarity, but also by scale and complexity. It is only possible to ask research questions of this kind at scale – and working with big data requires the application of a range of digital methods and tools, some of which have not yet been fully developed. And that is why this is such an important moment for humanities researchers to get involved, and to inform approaches to big data research – before other people make the decisions for us and we find ourselves on the outside looking in, without the appropriate skills to intervene. Whether we are dealing with digitised texts such as newspapers or born digital data such as emails, web archives and social media, we have important questions to ask and important ideas – and concerns – to contribute. We can also learn from our colleagues in the sciences and together develop genuinely innovative approaches which generate new insights.
This is not to say that collaboration of this kind is without challenges. We should not overlook the fact that, for the majority of humanities researchers, this is a very new way of working. Most research is collaborative, even if not explicitly conceived as such – it involves not just researchers, but archivists, peer reviewers, publishers. Working with big data, however, requires a more fundamental accommodation to different approaches, to different understandings about research outputs, to different career imperatives. For both the BUDDAH and DILIPAD projects, it was essential that the research questions were interesting and significant for each of the partners, whether historians, archivists or computer scientists. This is very difficult to achieve unless projects are co-designed from the outset, and the requirements of all parties taken into consideration. Collaboration and interdisciplinarity should not be afterthoughts – simply bolted on to a project as a means to secure funding – but lie at the heart of the research process. They also require ongoing dialogue, and the development of shared vocabularies which acknowledge but help to negotiate disciplinary differences. Finally, collaboration requires compromise. For humanities researchers, this might be accepting that not everything can be checked, but that an algorithm is producing results that are good enough to work with; for computer scientists, it might be coming to terms with a historian’s concern to move beyond abstraction and dig in to the messy data that humans have always produced and will continue to generate in ever larger quantities. Learning from different approaches, and being exposed to different tools and technologies, are enormously rewarding aspects of working in collaboration to explore big data – and the challenges are well worth trying to overcome.
[1] This definition, and the following information about the Large Hadron Collider, formed part of the guidance for applicants to the ‘Digital transformations in the arts and humanities: big data research’ call for proposals, 2013. [Go back up]
[2] Information about the corpus, how it was constructed and how to download it is available on the Ngram Viewer page. [Go back up]
[3] This is, of course, a question of enormous significance for the digital humanities. It has been debated by, to name just a few, Moretti (2013), Svensson (2012), Svensson & Goldberg (2015) and Manovich (2015); and most recently in the new companion edited by Schreibman, Siemens & Unsworth (2016). Digital humanities networks and associations are also important forums in which these discussions are pursued, including, for example, the European Association for Digital Humanities (EADH), the Association of Digital Humanities Organisations (ADHO) and the Digital Research Infrastructure for the Arts and Humanities (DARIAH). [Go back up]
[4] Project reference AH/L009854/1. The project team consisted of Jonathan Blaney, Niels Brügger, Josh Cowls, Helen Hockx-Yu, Andrew Jackson, Eric Meyer, Ralph Schroeder, Jason Webber, Peter Webster and Jane Winters. [Go back up]
[5] The development of the UK Web Archive is being documented on a British Library blog which will prove invaluable for researchers using this data. [Go back up]
[6] The researchers awarded bursaries by the project were: Rowan Aust, Rona Cran, Richard Deswarte, Saskia Huc-Hepher, Alison Kay, Gareth Millward, Marta Musso, Harry Raffal, Lorna Richardson and Helen Taylor. The case studies that they produced are available on the project website. [Go back up]
[7] Since this article was written, a beta version of the Wayback Machine has been launched which supports full-text searching of the home pages of archived websites. None of the research that was undertaken for the Big UK Domain Archive for the Arts and Humanities project would have been possible without the pioneering work undertaken by the Internet Archive, and their generosity in making data available for analysis. [Go back up]
[8] This is not, of course, the only problem of approaching big data through search. For example, lack of knowledge about how datasets have been constructed, compounded by the frequent lack of documentation, can lead researchers to make assumptions which are not ultimately borne out, or to impose unwarranted new structures on the data. I owe this point to one of the anonymous reviewers for this series. [Go back up]
[9] I am grateful to Richard Deswarte for pointing me towards this example. [Go back up]
[10] Some of these issues are discussed in Leetaru (2015). It is very important that these questions are explored, but the arguments can tend to obscure, problems notwithstanding, the value of the work undertaken by the Internet Archive and other archiving institutions. [Go back up]
[11] The project team consists of Kaspar von Beelen, Jonathan Blaney, Luke Blaxill, Chris Cochrane, Richard Gartner, Graeme Hirst, Jaap Kamps, Maarten Marx, Nona Naderi, Paul Seaward, Martin Steer and Jane Winters. [Go back up]
[12] It should be emphasised that, however closely they might mirror the tone of particular debates and particular speakers, parliamentary proceedings are not recorded speech. [Go back up]
[13] The Principal Investigator on the Linking Parliamentary Records through Metadata project was Richard Gartner. The project was a collaboration between King’s College London, the History of Parliament Trust, the Institute of Historical Research, the National Library of Wales and Queen's University, Belfast. [Go back up]
[14] For more recent MPs, IDs have also been included from the Public Whip website, which allows members of the public to see how individual MPs have voted. [Go back up]
[15] Beelen and Blaxill’s analysis suggests, for example, that the Conservative party under Margaret Thatcher may have been wrongly “sidelined” in the debate about feminised language in parliament, while “the Blair landslide in 1997 may have dulled, rather than magnified, the effect of gender in the language of parliamentary debates”. [Go back up]
[16] The three sets of proceedings can currently only be searched separately, and a user would be required to translate his or her search term into the language(s) of the particular proceedings. Proceedings for Belgium, Denmark, Norway and Sweden are also available, along with data from the European Parliament. [Go back up]
[17] I am grateful to Maarten Marx for this suggestion. [Go back up]
BUDDAH = Big UK Domain Data for the Arts and Humanities: https://buddah.projects.history.ac.uk/
British Newspapers, 1600–1900: http://www.connectedhistories.org/resource.aspx?sr=bu
Connected Histories: http://www.connectedhistories.org/
DILIPAD = Digging into Linked Parliamentary Data: https://dilipad.history.ac.uk/
‘Digital transformations in the arts and humanities: big data research’ call for proposals: http://www.ahrc.ac.uk/documents/calls/digital-transformations-in-the-arts-and-humanities-big-data-research-call-for-proposals/
Google Books: https://books.google.co.uk/
Google Books Ngram Viewer: https://books.google.com/ngrams
Google Books Ngram Viewer supporting information: http://storage.googleapis.com/books/ngrams/books/datasetsv2.html
Hansard 1803–2005: http://hansard.millbanksystems.com/
Hansard Corpus: British Parliament, 1803–2005: https://www.hansard-corpus.org/
HathiTrust Digital Library: https://www.hathitrust.org/
Interactive Map of UK Central Government Online: http://oxfordinternetinstitute.github.io/InteractiveVis/network/?config=config_ukgov.json
Internet Archive: https://archive.org/
LIPARM: Linking Parliamentary Records through Metadata: http://sas-space.sas.ac.uk/4315/
Parliament Debate Search: http://search.politicalmashup.nl/
Shine: https://www.webarchive.org.uk/shine
The Public Whip: http://www.publicwhip.org.uk/
TheyWorkForYou: https://www.theyworkforyou.com/
Time Travel for the Web: http://timetravel.mementoweb.org/
UK Web Archive blog: http://britishlibrary.typepad.co.uk/webarchive/
Visualisation of Links, by Domain Suffix, from the Jisc UK Web Domain Dataset (1996–2010): http://www.webarchive.org.uk/ukwa/visualisation/ukwa.ds.2/linkage
Aust, Rowan. 2015. “Online reactions to institutional crises: BBC Online and the aftermath of Jimmy Savile”. Web Archives as Big Data. http://sas-space.sas.ac.uk/6100/
Blaxill, Luke & Kaspar von Beelen. 2016. “A feminized language of democracy? The representation of women at Westminster since 1945”. Journal of Twentieth Century British History 27: 412-449. doi:10.1093/tcbh/hww028
Deswarte, Richard. 2015. “A case study of the use of web archives for historical research, focusing on British Euroscepticism”. Web Archives as Big Data. http://sas-space.sas.ac.uk/6103/
Gartner, Richard. 2012. “The LIPARM project: A new approach to parliamentary metadata”. Ariadne 70. http://www.ariadne.ac.uk/issue70/gartner/
Guldi, Jo & David Armitage. 2015. The History Manifesto. Cambridge: Cambridge University Press. http://historymanifesto.cambridge.org/read. doi:10.1017/9781139923880
Hitchcock, Tim. 2014. “Big data, small data and meaning”. Historyonics. http://historyonics.blogspot.co.uk/2014/11/big-data-small-data-and-meaning_9.html
Leetaru, Kalev. 2015. “How much of the internet does the Wayback Machine really archive?” Forbes. https://www.forbes.com/sites/kalevleetaru/2015/11/16/how-much-of-the-internet-does-the-wayback-machine-really-archive/
Manovich, Lev. 2015. “The science of culture? Social computing, digital humanities and cultural analytics”. http://manovich.net/index.php/projects/cultural-analytics-social-computing/
Millward, Gareth. 2015. “Digital barriers and the accessible web: disabled people, information and the internet”. Web Archives as Big Data. http://sas-space.sas.ac.uk/6104/
Moretti, Franco. 2013. Distant Reading: the Formation of an Unorthodox Literary Critic. New York: Verso Books.
Schreibman, Susan, Ray Siemens & John Unsworth. 2016. A New Companion to Digital Humanities. 2nd edn. Oxford: Wiley-Blackwell.
Svensson, Patrik. 2012. “Envisioning the digital humanities”. Digital Humanities Quarterly 6(1). http://www.digitalhumanities.org/dhq/vol/6/1/000112/000112.html
Svensson, Patrik & David Theo Goldberg. 2015. Between Humanities and the Digital. Cambridge, MA: MIT Press.
Webber, Jason. 2014. “How big is the UK web?”. UK Web Archive blog. http://britishlibrary.typepad.co.uk/webarchive/2014/06/how-big-is-the-uk-web.html
Zittrain, Jonathan, Kendra Albert & Lawrence Lessig. 2014. “Perma: Scoping and addressing the problem of link and reference rot in legal citations: How to make legal scholarship more permanent”. Harvard Law Review Forum 127(4): 176–199. http://harvardlawreview.org/2014/03/perma-scoping-and-addressing-the-problem-of-link-and-reference-rot-in-legal-citations/
