
Studies in Variation, Contacts and Change in English
Studies in Variation, Contacts and Change in English
Martin Weisser
Guangdong University of Foreign Studies
Recent years have seen a renewed interest in the compilation of next-generation or new ICE sub-corpora, possibly also including new genres or data. And because, today, corpus compilation via the web has become a much more convenient method than the traditional sampling employed in creating the original ICE corpora, it makes sense to try and compile as much of the materials as possible for new or updated written ICE materials from online sources. This article introduces ICEweb 2, a new and considerably advanced version of a tool designed to collect written data for such purposes, as well as to process and analyse them in similar ways to those offered by most concordance packages, thus, at least to some extent, obviating the need to switch between tools.
Over the last few years, a growing interest in compiling next-generation ICE corpora, or new sub-corpora to complement the original data, has arisen (cf. Nelson 2017). In particular, as Nelson points out, “ICE corpora are frequently criticized for being too small, at just one million words each [so that i]t is natural, therefore, that researchers should call for ever-larger corpora, in the expectation that more data is likely to be better data” (2017: 368). And although he goes on to point out that “[t]he equation is not quite as simple as that” (2017), there is probably no doubt that having additional data of equal quality may enhance the representativeness and usefulness of the ICE corpora, as well as increasing the likelihood that new, rarer, local phenomena may be uncovered, or that perhaps developmental trends may be identified by comparing the original data with updated materials.
Such new sets of data may possibly also include purely web-based genres, or data from Outer Circle varieties, i.e. the “Expanding Circle” (EC), since, as Edwards (2017: 404) quite rightly states, “[b]y restricting itself to Inner and Outer Circle countries, the ICE reinforces the exclusion of EC Englishes as a potential site of dynamic English use and change”. Thus, in order to avoid this issue, it clearly becomes a necessity to widen the scope of corpora of English as an International Language to allow us to gain better insights into the global development of the language and how this development may in turn potentially affect the Inner and Outer Circle varieties in a kind of ‘washback effect’.
Hence, as corpus compilation via the web now has become much easier and probably also much more convenient than using the traditional sampling employed in creating the original ICE corpora, it would seem to make sense to try and compile as many materials as possible for these new or additional materials from online sources. However, when compiling corpora off the web, there are a number of highly important issues one needs to bear in mind in selecting the right method for the right purpose, as I shall try to illustrate in the next section.
As the point of this article is not to introduce new and ground-breaking algorithms for harvesting the web automatically, though, but to present an integrated tool that enables corpus linguists to collect new ICE or other web data conveniently and compile them into high-quality materials, I shall avoid an in-depth discussion of many technical details.
Today, creating web corpora has become easier than ever, with web interfaces like the Sketch Engine even allowing users to compile their own corpora semi-automatically using a modified version of the BootCaT (Bootstrapping Corpora and Terms from the Web; Baroni & Bernardini 2004) approach. Yet, such a more or less automated approach carries with it a number of advantages and disadvantages; on the one hand, it now becomes very easy and convenient to generate masses of corpus data very quickly by filling in a few boxes and with just a few mouse clicks, but, on the other, there’s a relative lack of control over the results produced by using such methods. In other words, the user/corpus compiler has to have a high degree of ‘blind faith’ in the underlying technology, in particular the software’s ability to identify and remove duplicates, as well as to exclude so-called boilerplate content, i.e. content that is mainly there for navigational or advertising purposes. Using a tool for such types of web crawling may also not allow the user to have any say in which particular web engine is being queried in order to create a list of web pages from their respective URLs (Uniform Resource Locators), therefore potentially introducing a bias caused by the web engine’s policies or technology. Furthermore, more or less unsupervised crawling will almost definitely cause issues of representativeness. The main reason for this is that the seed terms – i.e. search terms that help to identify the target domain – used to identify potentially relevant pages alone cannot tell us anything about whether the pages we find through them ultimately mirror the actual genre we’re trying to represent in our corpus data. Instead, they may only represent a particular topic that might be discussed across a variety of different genres. After all, as Biber and Kurjian point out, “[w]ith most standard corpora […], register categories are readily identifiable and can therefore be used in linguistic studies. However, research based on the web lacks this essential background information.” (Biber & Kurjian 2007: 111). Hence, in order to identify whether a particular web page is to be included in a sub-corpus for a specific genre/category, one does at the very least have to cursorily inspect that page. For an in-depth discussion of problems like these in crawling the web for data, see Schäfer and Bildhauer (2013) or Gatto (2014).
Provided that the right seed terms have been selected, the automated approach may be very useful for producing large ad-hoc corpora in specialised and clearly identifiable domains. This is especially true for extracting domain-specific terminology and phraseology. However, a different approach might be more appropriate when we try to produce smaller, more qualitatively oriented corpora, and representativeness and genre issues need to be controlled more precisely. This approach essentially consists in the following, sometimes cyclical, steps:
Hundt et al. refer to this strategy as using the “‘Web for corpus building’” (2007: 2), and, despite certain issues described there (Hundt et al. 2007: 3) and in other publications (cf. again Schäfer & Bildhauer 2013, or Gatto 2014), this method represents a useful way of generating high-quality corpus data via visual inspection, and would thus seem more appropriate for creating smaller-scale corpora constructed according to the principles and categories originally employed in the compilation of the ICE corpora.
The original version of ICEweb – which was created in 2008, but not released until 2013 – was rather different from version 2, especially because it was more or less designed to cater for a set of categories only vaguely related to the existing ICE categories. In other words, while the idea of creating comparable corpora for different countries where English was one of the major languages used was definitely part of the design scheme, many of the categories envisaged in the design, which was suggested to me by a colleague, did not overlap with existing ICE categories. In order to create a corpus structure, ICEweb1 offered two different options, one where a more complex predefined structure containing various sub-folders was created when a country was set up, and one where a simpler structure for general links, containing only one folder named ‘genLinks’, was created. The complex structure consisted of a set of main category folders, each with a set of sub-category folders, with all category names in lowercase:
In addition, this structure also contained the folder for general links. Although, of course, it would have theoretically been possible to create a ‘proper ICE structure’ for a country using the setup mechanism for creating a ‘simple’ structure, this could only have been done with considerable effort, i.e. by renaming the ‘genLinks’ folder and creating additional sub-folders reflecting the original ICE categories. And even if the tool was nicely colourful (see Figure 1), it also had a few other disadvantages in terms of its design.
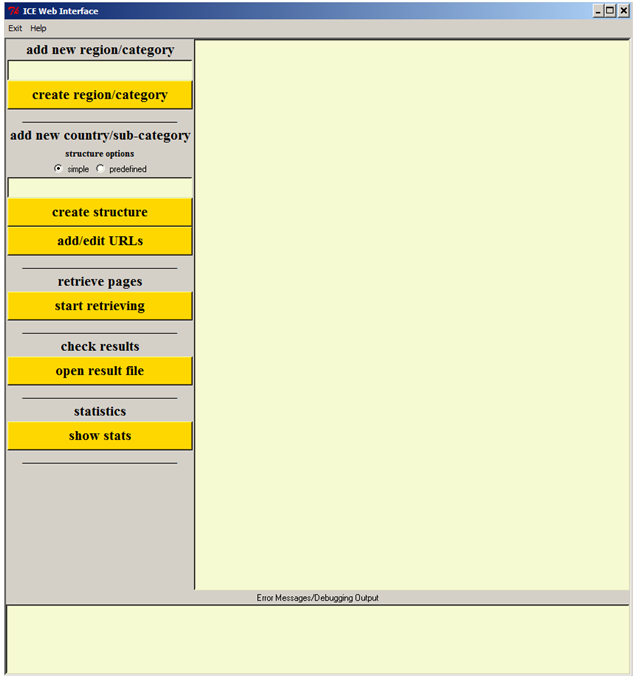
Figure 1. ICEweb version 1.
For one thing, adding new regions or countries already required multiple steps and destination target selections, forcing the user to go through multiple dialogues. Regarding interaction with a web browser, there was also no support for seeding or controlling the browser from within the tool at all. In order to conduct any searches, this required the user to open the browser separately, select a search engine, navigate to the relevant page, and formulate the query manually from scratch. All this had to be done without any assistance in specifying language and domain options to restrict this search. Apart from this, the latter are steps many users unfamiliar with the search syntax of the respective search engines would not have been able to perform without any prior training.
Adding or editing the web addresses again involved making a target folder selection to start the built-in web address (URL; Uniform Resource Locator) editor. In addition, once all URLs to be downloaded had been specified, and the download process started, the user had no control over the ensuing data processing options and steps; all files were – server permitting – downloaded, automatically converted to text, and tokenised.
Last, but not least, the statistics that the tool was able to produce were limited to reporting the number of types, tokens, and the type/token ratio. This, despite the fact that all of these pieces of information could at least be reported in- or excluding function words, nevertheless was not really very informative or as useful as one would expect from a tool providing basic descriptive statistics.
Hence, even if the tool allowed users to download web pages for corpus building and at the very least alleviated them of having to produce the raw text files for their corpus without any manual intervention, the general usefulness of the tool, especially for work with the real ICE categories, unfortunately remained rather limited.
Having myself primarily worked with spoken ICE data since writing the original version of ICEweb, in 2017, when John Kirk and Gerry Nelson conducted a survey about how the ICE corpora could be suitably updated, my interest in written ICE data was rekindled. At that point, I had already started developing my own plans to carry out automated speech-act analysis on written ICE data, and devised ideas on how to modify and adapt the original data format to facilitate this. This particular format is similar to the new format I had recommended for spoken data in Weisser 2017, and designed to replace the original, nowadays outdated, original SGML-compliant format described in Nelson (1991, 1996). At this point, the next logical step was to develop a better way to collect such data online by tapping into the larger variety of public and private texts available there, as well as taking advantage of the fact that some of the original HTML markup may be highly useful in identifying structural elements, such as headings or paragraphs, etc., that would make it possible to create data in the newly envisaged format more easily.
ICEweb 2 (henceforth simply ICEweb) is now a tool that makes it easy for the user to create new sub-corpora based on the ICE criteria by providing a convenient way of selecting ICE locations and categories, and automatically creating the relevant data structures. However, the existing categories can also easily be extended to new genres via the same mechanisms.
In addition, the new version of ICEweb also provides assistance in constructing and running queries through a number of different search engines to create lists of suitable web page addresses for the user to inspect. Any potential bias introduced by using only a single search engine (cf. Section 1.1) can hence largely be avoided by compiling lists produced through results from these different engines.
Pages identified in this way can then be downloaded fully automatically, storing the original URL and other meta information, and cleaned up inside the tool, prior to converting them to plain text and/or a dedicated form of XML designed for later pragmatic annotation. Unlike in the original version, though, both conversion processes do not occur automatically, but are user-initiated, so that only the format that is actually relevant to the user needs to be generated as and when necessary. For most users, this is most likely going to be the raw text format, though, which all corpus linguists will be familiar with.
Apart from providing means for downloading, cataloguing, and converting data in order to produce a specific sub-corpus, ICEweb now also contains facilities for PoS tagging, concordancing, and n-gram analysis, including adjustable frequency norming, turning it into an all-round tool for working with new ICE data.
Along with these new features, and at least partly to accommodate them, the interface design has also changed to a tabbed form, similar to the one in AntConc (Anthony 2018). This design allows the user to focus better on particular tasks to be carried out within the different corpus compilation and analysis phases.
In summary, ICEweb now sports the following enhancements:
In the following sections, I will describe the usage and advantages of ICEweb as a corpus-building and analysis tool in more detail, and providing suitable illustrations.
The first step in creating a sub-corpus in ICEweb consists in choosing a region – usually a continent –, followed by country and ICE category, from the dropdown lists shown at the top of Figure 2.
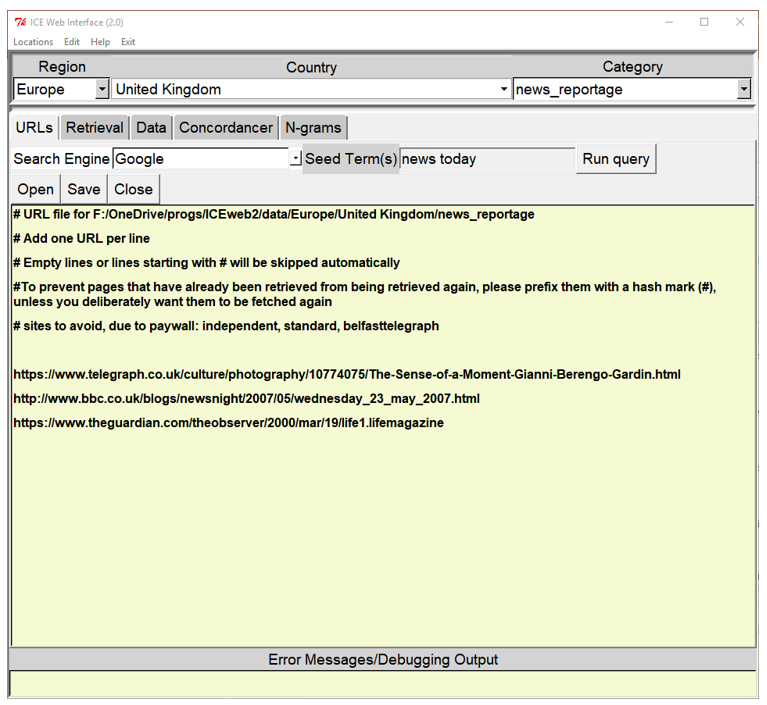
Figure 2. ICEweb URL collection options.
In our example, the ‘Region’ is set to ‘Europe’, the country/location to ‘United Kingdom’, and the ICE category to ‘news_reportage’. The underscore between the words in the category name is there to facilitate the processing on the computer because spaces may represent issues in handling file or folder names.
Selecting a country – as yet invisibly to the user – also sets the restriction for the domain to be searched, based on its country code, once the search engine is activated later. All that is left to do then is to select ‘Locations → Edit/add URLs’, and a new file to collect URLs to download will be created and opened automatically in the URL editor in preparation for the data collection. Once a location has been selected in this way, and (remains) chosen via the respective dropdown options, or set in the configuration file, it serves as the basic corpus configuration for all ensuing corpus-related actions, such as downloads, data conversion steps, as well as the analysis options.
The second step in collecting data in ICEweb is to ensure that the ‘URLs’ tab is selected. As the name implies, this tab essentially contains all the necessary functionality for managing the web data to be downloaded and later compiled into the relevant sub-corpus.
To get started on the search process, the user can select a preferred search engine from another dropdown list immediately below the ‘URLs’ tab, choosing between Google, DuckDuckGo, and Bing. As pointed out earlier, being able to select different search engines may help prevent the bias introduced by a single search engine, but of course also makes it possible to use alternative resources in countries where specific engines may be blocked. A default for this option can also be changed/set in the configuration file in order to prevent the user from having to make this choice repeatedly.
In the next step, the user needs to enter a set of suitable seed terms into the relevant box. These ought to identify the potential target domain as closely as possible, so, in the above example, I chose the terms news and today because they are likely to produce links to web pages containing up-to-date news items. As I tried to point out earlier, though, not all seed terms will automatically make it possible to narrow down the results to the relevant genre/category, so these should in most cases only be seen as a suitable starting point to begin the identification process for suitable pages in the first place.
Clicking on the ‘Run query’ button will then launch the user’s default browser, automatically opening the page for the selected search engine, insert the seed terms into the search box, and, depending on the search engine’s (security) settings, possibly even start the search automatically. However, even if the search doesn’t start automatically, the user only needs to press the ‘Enter’ key to start it because, usually, the search box will automatically be activated. In addition to priming the search engine with the seed terms, though, ICEweb also uses the country information related to the user’s choice to restrict the search domain to the relevant country, automatically adding the relevant search parameter into the search box after the seed terms, along with the official ‘country code’ representing the location. In the same way, the language of the web pages to be identified is also set to English, as can be seen in Figures 3–5 that reflect the results from the respective search engines.
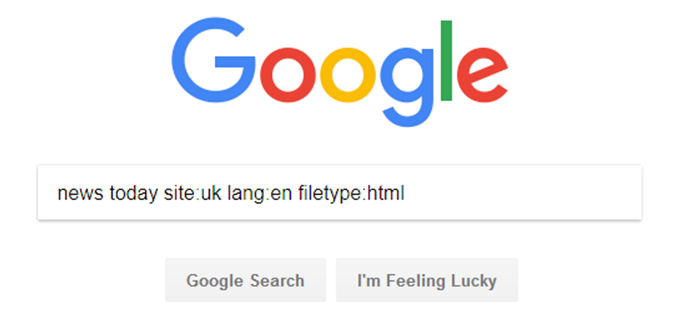
Figure 3. The Google® search page, primed.
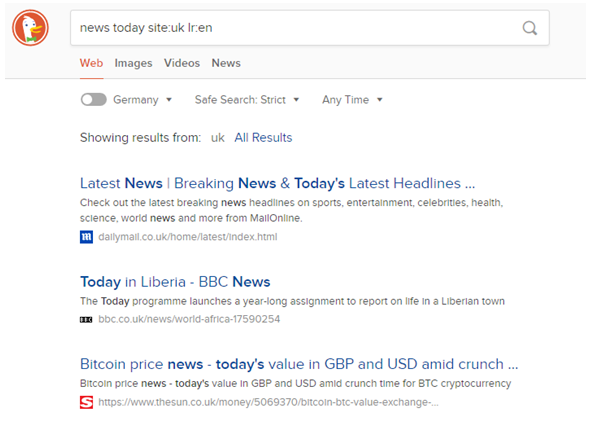
Figure 4. The DuckDuckGo® search page with automatic query results.
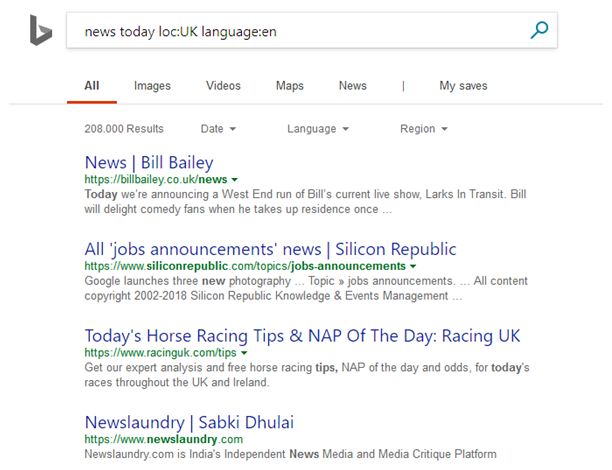
Figure 5. The Bing® search page with automatic query results.
Once the results of the web search have been displayed, it now becomes possible to inspect and identify relevant pages that are of suitable length and content, ideally by opening them in new tabs. The latter is usually achieved by clicking on a search engine link using the right mouse button and choosing the relevant option. Doing so makes it easier to return to the original results page of the search engine, as the user simply needs to close the new tab, rather than reload any previous results.
Note, though, that even though the search parameters may have been restricted, not all of the pages an engine identifies may be suitable examples in the first instance, due to categorisation errors made by the search engine. This can, for instance, quite easily be seen in the last example from Figure 5. Here, actually not a news page from the UK has been found, but instead one from India, which should, of course, be excluded from the collection process. This example again underscores the advantage of the interactive selection process over a completely automated collection of URLs, as trusting the domain classification provided by the search engine blindly makes it easy to miss such an error, which could, in the worst case, affect the research results by suggesting that specific features from the wrong variety have found their way into another.
When the user identifies a suitable page, the URL can be copied directly from the web browser and pasted into the URL editor, where each URL needs to appear on a single line. Once enough URLs have been collected, the URL file can be saved via the relevant button.
While the main function of the resulting URL file is to allow ICEweb to download the relevant pages in the retrieval process described below, it also provides a commenting mechanism that can be used in two different ways. The most basic form is to allow the user to add general comments to the file by prefixing lines with a hash mark (or “pound symbol”, to use the American term). Figure 2 provides an illustration of this, where some pieces of meta and usage information were automatically inserted by ICEweb when the file was created, but I also added an additional comment after realising that some of the news sites did not allow their pages to be downloaded automatically, as they were hidden behind a so-called ‘paywall’ that forces users to pay for any content they wanted to download. Such comments may be particularly helpful in creating the documentation for the corpus later and at least partially justifying the choices made. In addition, they can prevent the user from inadvertently trying to download from such paywall sites later again if the corpus is to be expanded further, perhaps after a considerable period of time, and when this particular issue may since have been forgotten about.
The second function of the commenting mechanism also comes into play whenever it may be necessary to add content to the corpus later, either if the data collected originally are not sufficient to make up for the desired sub-corpus size, or if the collection process cannot be completed in one go and needs to be resumed later. Here, commenting the URLs out makes it possible to prevent pages from being downloaded again – unless explicitly desired, perhaps in order to get the latest versions –, as all lines that start with a comment symbol are excluded from any processing.
Retrieving the URLs collected in the URL document is rather straightforward; all the user needs to do is activate the ‘Retrieval’ tab and click on the ‘Get web pages’ button. Provided that the right parameters for location and category type are still selected, and the list of URLs to download has been created previously, ICEweb will now automatically attempt to retrieve the relevant web pages. In the process, it will also report the base target folder for the category, the URL that it is currently attempting to download from, as well as download success or failure for each of these URLs, as can be seen in Figure 6.
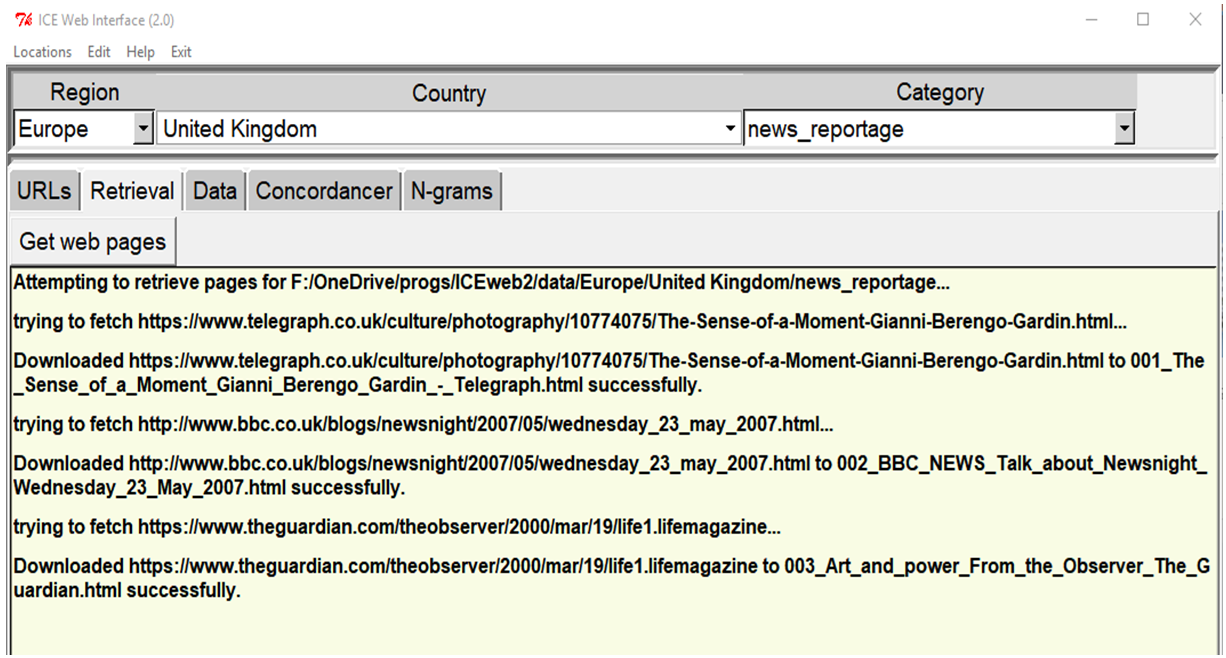
Figure 6. Illustration of the HTML retrieval process.
In addition to downloading and storing as many web pages as possible – as raw HTML, without images, scripts, etc. – in an automatically created sub-folder named ‘html’, ICEweb also either creates or appends to a CSV file in the main category folder. For each web page downloaded successfully, this tab-delimited file stores the original title and URL, a local filename, and the download time. The file can easily be viewed in an editor or spreadsheet application, and not only serves as a basis for creating the documentation for the corpus, but also makes it possible to later return to the original web sites for verification purposes, provided, of course, that these have not been deleted or moved in the meantime.
Storing only raw HTML in a sense also already creates a derived form of the data, so that the likelihood of infringing any copyright is already diminished to some extent through the potential format change alone. However, as the copyright status of web pages at least for some countries remains unclear, the user still needs to use their own discretion in determining whether the resulting corpus data can be distributed in a suitable form. If in doubt, it might be best to try and contact the owners/creators of specific web pages directly, which is frequently possible if the web pages contain a ‘mailto’ link.
Once the HTML data has been successfully downloaded into the ‘html’ sub-folder, it can be converted into one of three different formats. To achieve this, all that is necessary is to switch to the ‘Data’ tab, and click the relevant button, either ‘HTML→txt’, ‘HTML→XML’, or ‘Tag text’ (see Figure 7).
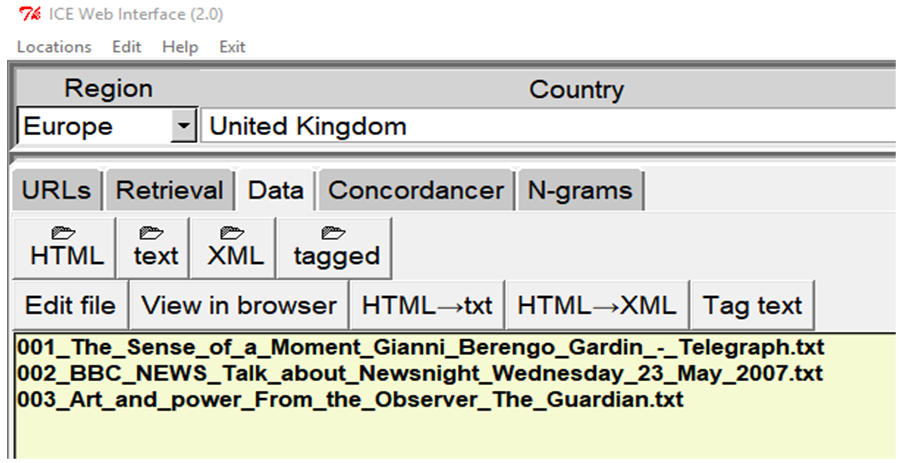
Figure 7. Working with data.
Out of these three formats, the one that most corpus users will be maximally familiar with is raw text. In this format, all the HTML-related markup has simply been stripped from the original web page, and a certain amount of ‘conservative’ boilerplate removal – mainly based on coding for navigational elements and to some extent also the length of HTML units – has been carried out in order to safely remove as much as possible of the textual material that may be irrelevant for the user/corpus. This boilerplate removal process may not represent the ‘state-of-the-art’ techniques employed in computational linguistics, but the approach chosen here is designed to prevent the user from inadvertently losing any useful text, and the basic assumption is that the user will edit and further clean up the resulting text, as described in the next section, prior to including it in a corpus, anyway. The text files resulting from the conversion process are stored in another sub-folder named ‘text’.
Conversion to XML will create a relatively simple form of XML, where the conversion process takes advantage of the original HTML coding in order to identify different types of units, such as headings or paragraphs, and encode them accordingly. This format is still somewhat experimental, and primarily designed to later be used for analysis within the Text Annotation and Analysis Tool (TART; cf. Weisser 2015), whose development, however, has unfortunately been delayed and is not likely to be completed very soon. The automatic conversion process currently makes no attempts at identifying units below the paragraph, such as sentences, due to the fact that any segmentation based on punctuation marks may be somewhat inaccurate (cf. Mikheev 2003) and especially also because the ‘sentences’ that could potentially be identified in this way may represent more than one functional unit in terms of speech-act realisations. Such a segmentation into genuine functional units can of course be done manually, but as ICEweb currently offers no options for adding pre-defined XML tags to the data within the editor to facilitate this process, it may be better to use another tool, such as my Simple Corpus Tool, for this kind of editing. The ability to manually annotate the data further in this way will probably be included in a later version of the tool, though.
One definite advantage of having this type of segmentation into functional units would be that later analyses, such as those for n-grams, would not be carried out across unit boundaries and thus become more accurate. A simple work-around to achieve this, short of adding the XML, would be to at least break the paragraphs into such functional units without labelling them, simply by adding line breaks between them, so that each unit appears on a separate line, as all analyses in ICEweb (see Sections 3.4.3 and 3.4.4) are carried out on a line-basis.
The final format option is that of tagged text, where the built-in tagger module may be used to add POS information to the raw text, and stored in the ‘tagged’ sub-folder. This option, which depends on the prior conversion to text, i.e. the existence of data in the ‘text’ sub-folder, later enables the user to work with morpho-syntactically enriched data in the analysis modes.
There are, however, two caveats here: a) that the tagging facility is based on a relatively simple probabilistic tagging module, the Lingua::EN::Tagger (Coburn 2003), which is bound to produce a higher error-rate than e.g. the TreeTagger (Schmid 1994) or Stanford POS Tagger (Toutanova et al. 2003), and b) that the tagset used, as in the other two taggers just mentioned, is the PENN Treebank one, which, with only 48 POS categories, is rather coarse-grained and may not lend itself to many types of grammatical analyses, although it should be sufficient for more syntax-oriented research, such as parsing. If the resulting data is meant to be used for research that requires a higher degree of accuracy, I would definitely recommend to a) manually post-correct the tagging output thoroughly and b) to additionally run it through my Tagging Optimiser (Weisser 2018), which is designed to correct certain errors produced by probabilistic freeware taggers, and also enhances the tagset by nearly doubling it to 94 tags and increasing its readability, thereby making it more suitable for grammatical analyses. Future versions of ICEweb will probably include this optimisation as a built-in option.
Files of any of the four categories (‘HTML’, ‘text’, ‘XML’, ‘tagged’) can be listed via the relevant folder button indicated through the folder image above the category name (see again Figure 7). Clicking the relevant button then makes it possible to either view or edit the files in the built-in editor, as well as open and view the corresponding HTML file in the default browser (see Figure 8) for comparison.
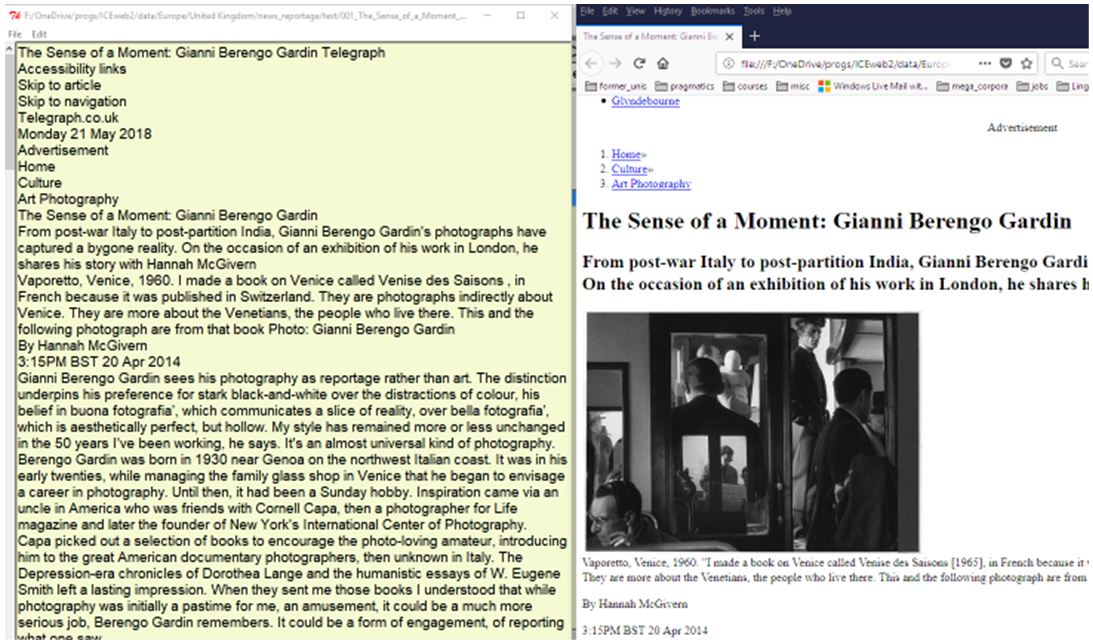
Figure 8. Viewing/editing text and corresponding HTML side-by-side.
This feature allows the user to view or edit files in the different formats, at the same time being able to compare the extracted text or XML files directly to the original HTML files in order to conduct any potential post-editing that may be necessary. As no conversion process is ever 100% fool-proof, and the boilerplate removal may either not have removed all irrelevant content, or, in rarer cases, removed something that may be useful text, interacting with the data in this way ultimately makes it possible to create a cleaner, and hence more useful, corpus. I would therefore absolutely recommend this as one of the essential steps in the overall corpus compilation process that always ought to be conducted prior to carrying out any analyses on the corpus data.
Apart from providing these facilities for compiling web-based corpora, ICEweb already also includes useful features that enable the user to carry out some of the most common types of corpus-linguistic analysis that would otherwise require the user to resort to external analysis programs, such as AntConc (Anthony 2018). For all these types of analysis, it is possible to set the default target folder to either ‘text’, ‘xml’, or ‘tagged’, depending on the analysis need/purpose.
Even if, nowadays, some corpus linguists may claim that “[i]n essence, corpus linguistics is a quantitative methodology” (Brezina 2018: 3; my emphasis), concordancing, a highly qualitative form of analysis, is still one of the most common and useful forms of corpus investigation. Through the initial interaction with the data in the download or editing process, or based on features discussed in the literature on World Englishes, users may already have certain ideas about items to investigate. This is why the first analysis option ICEweb provides is to create concordances from the corpus data collected. To do so, one first needs to switch to the ‘Concordancer’ tab, which also activates the target folder selection option, as well as the ‘context-sensitive’ run button that triggers either form of analysis, both of which are hidden for all but the analysis modes. These options can be seen at the top of Figure 9.
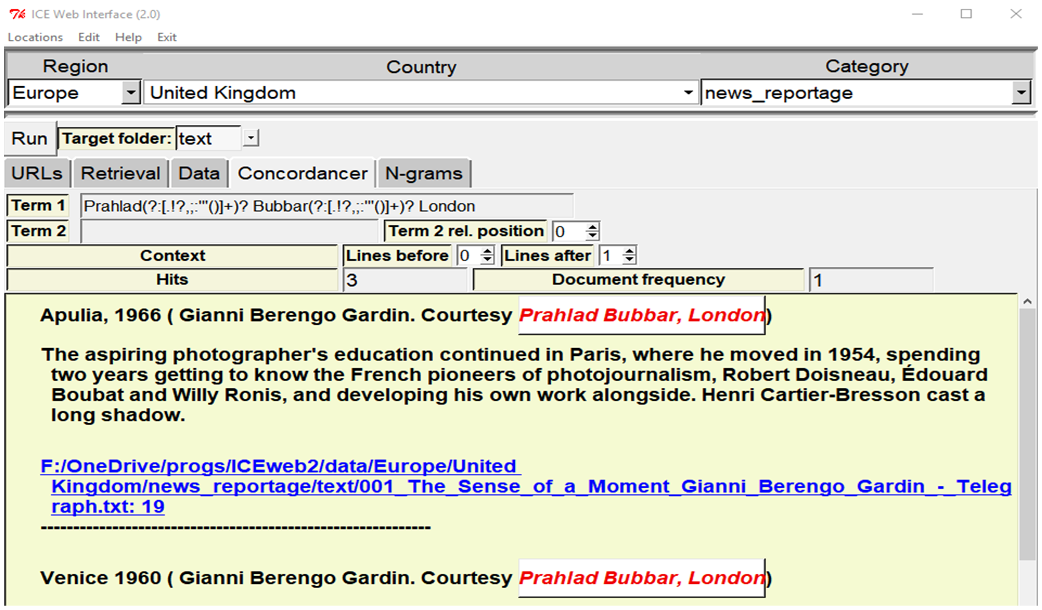
Figure 9. Illustration of the Concordancer analysis module.
One thing to note when working with the built-in concordancer is that, unlike most other concordancers that treat the text as a continuous stream of text – i.e. are stream based – and ignore all line breaks, the concordancer in ICEweb is line-based. In other words, it finds search terms and initially displays them within the context of whatever line of text, delimited by minimally one line break, they are found on. In practice, this may make little difference to the user, other than being a somewhat unusual format that is different from the more common KWIC one, and that the context may either be rather longer or shorter than one has come to expect from a concordance display. The reason for this difference is that the concordance module was originally designed to work with textual data where each functional unit of text – or what is commonly perceived as a ‘sentence’ and generally marked up as a text unit (cf. Nelson 1996: 37) in the original ICE markup scheme – appears on a line where it is separated from XML annotation that describes different features of it. For more on this format, which I call ‘Simple XML’, see Weisser (2016: Chapter 11).
However, apart from the immediate context on whatever line either of the two possible search terms is found, there is also an option to adjust the context of the surrounding lines displayed around the first search term to n-many lines before and/or after. This makes it possible to understand the discourse context better or view any surrounding annotations/text, and also to view search terms and surrounding annotations or vice versa, especially since it’s equally possible to define the relative (line) position of the second term. This feature would, for instance, allow the user to look for headings followed by specific text in the next paragraph, provided one is working with XML-annotated data.
As can be seen in Figure 9, the concordance results are displayed with the hit highlighted through a box with white background and red italicised text (yellow for the second search term, not displayed in this example). Similarly to other concordancers, the hit is also hyperlinked to allow it to be viewed in full file context, with the hyperlink showing the full file path and line number displayed beneath the results. What is different from most other concordancers, though, is that the hyperlinks open the built-in editor, so that the example can not only be viewed, but also edited, for instance to add further annotation.
The search itself is based on (full Perl) regular expressions (see Weisser 2016: Chapter 6 for an introduction), making it always case sensitive by default, and allows for the specification of relatively complex(-looking) search terms. This can again be seen in Figure 9. The exact significance of some of the regular expression features shown in the example will be explained in the next section.
Apart from the results themselves, the number of hits is also displayed, along with its ‘Document frequency’, i.e. dispersion.
For both the concordance and analysis modules, the results can be saved by highlighting them in the results window via Ctrl + a, copying them via Ctrl + c, and then pasting them into any text editor or word processor from which they can be saved. This is one of the reasons why the information contained in the hyperlinks is relatively detailed, as otherwise the information about the file the hit was found in and its position would be lost. Future versions may again offer more convenient methods for storing the output, including the search term(s), number of hits and dispersion, which are not saved when copying and pasting from the results window unless one manually selects and copies them as well.
The second analysis option ICEweb offers is to produce word frequency or n-gram lists from the target files, where, unlike in AntConc, the former are simply treated as lists of n-grams where the n is set to one, in other words producing unigrams, rather than having separate tabs for what is essentially the same type of variable frequency list. Producing such lists may be important for investigating frequency distributions, e.g. the over- or underuse of certain vocabulary items, or for identifying formulaic expressions or (lexico-)grammatical structures that may be unique to a variety.
To produce one of these lists, it is first necessary to activate the ‘N-grams’ tab, possibly select the target folder again, and adjust the required analysis parameters. Figure 10 shows an example of a tri-gram analysis on the raw text.
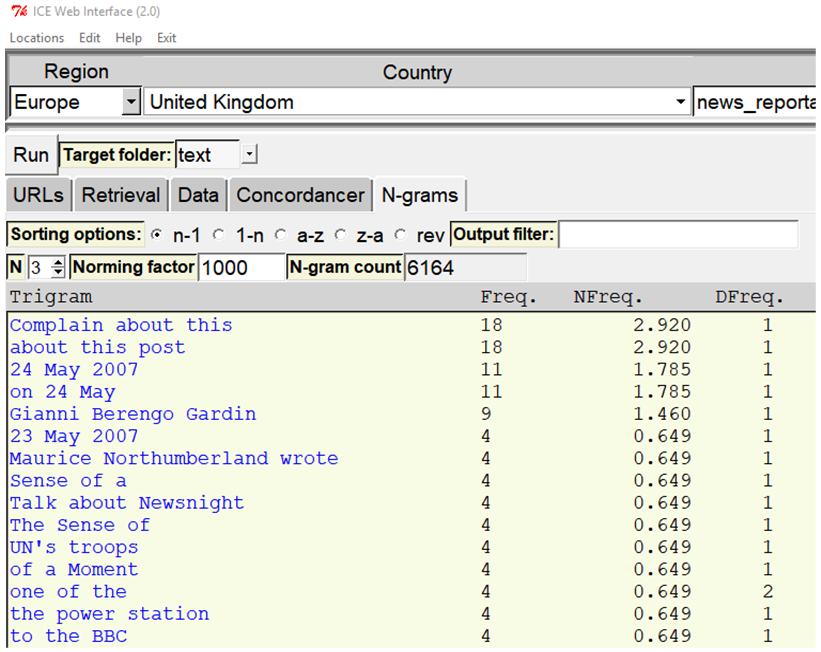
Figure 10. Word frequency/n-gram analysis illustration.
The n-gram analysis module reports the number of words/n-grams identified, and displays these along with their raw (‘Freq.’), normed (‘NFreq.’), and document frequency (‘DFreq.’). Normed frequencies are calculated based on a freely adjustable norming factor, with the initial default set to 1,000, so as to avoid excessive interpolation (see Weisser 2016: 175 for issues related to inappropriate frequency norming), as the documents analysed are likely to be relatively small. Another difference to AntConc here is that n-grams are always fixed in their length, rather than allowing for n to encompass a range.
As is customary for most tools that produce such lists, the output can be sorted in various ways to provide different views of the data for different purposes. The current options are to sort by descending frequency (‘n-1’), ascending frequency (‘1-n’), alphabetical – strictly speaking ‘asciibetical’, where capital letters appear before small ones – order (‘a-z’), reverse alphabetical (‘z-a’), as well as reverse sorted (‘rev’) frequency, where words/n-grams are sorted according to their endings. The latter option either lends itself to morphological or topic analysis.
Prior to n-gram generation, the input is cleaned of all potential ‘punctuation’, including round brackets and double quotation marks. The words/n-grams in the results are hyperlinked to activate the ‘Concordancer’ tab and prime the first search term, so that they can be further investigated through concordancing conveniently. In order to ensure that all n-grams can be found again, any ‘punctuation’ that has previously been deleted is automatically re-interpolated into the regular expression in the search box. This explains why the pattern for the concordance search term depicted in Figure 9 is slightly more complex than simply looking for the n-gram that it was primed from. As pointed out earlier, working with data where the text has been broken down into functional units makes the n-gram analysis more reliable because n-grams that span across multiple units are rarely of interest.
In addition to the more general options for setting the length of n-grams and sorting the output, ICEweb also contains a special feature. The analysis output for this module is filterable via a regular expression to list only output that fulfils certain pattern criteria. Thus, when e.g. investigating words or n-grams starting with Proper names, or sentence-initial structures, putting the regular expression ‘^[A-Z]’ in the box for ‘Output filter’ prior to running the analysis will restrict the output displayed – though not the total word/n-gram count – to only words or n-grams that start with a proper name or appear sentence-initially, as shown in Figure 11. This feature, however, may not only be useful in anchoring n-grams in this way, but also in creating clusters around specific search terms in order to investigate phraseological variability or patterns.
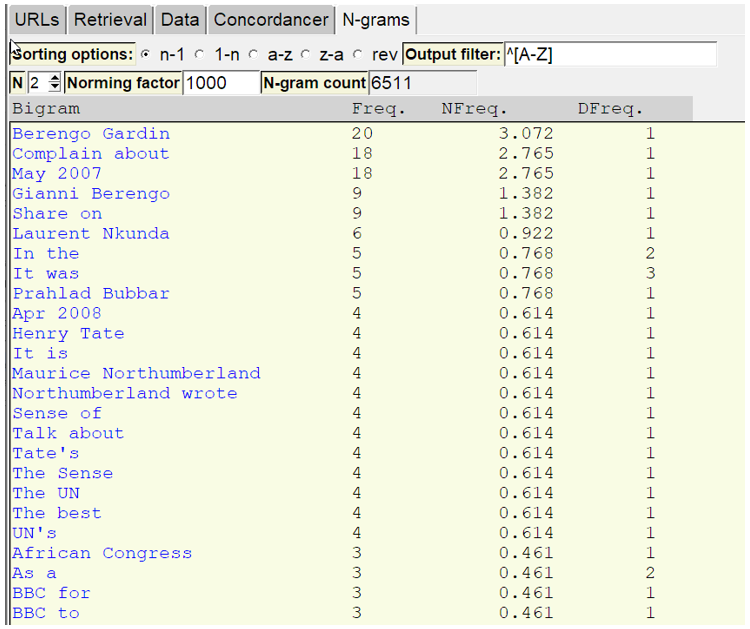
Figure 11. Filtered n-gram output.
If corpus data for multiple countries and/or sub-categories exists, ICEweb, due to its simple setup, makes it very easy to compare these sets of data. Essentially all that is required for investigating the same features across (sub-)corpora is to switch the target location and/or category and run the same analysis again.
For instance, it would become a very simple task to investigate the acceptability of the conventionally stigmatised use of initial co-ordinating conjunctions through use of the regular expression pattern ‘^[ABO](r|nd|ut)\b’ – or the more readable, but less efficient, ‘^(And|But|Or)\b’ –, or that of the British or American spelling variants through ‘[Cc]olou?r’, in either the concordance or n-gram module, and keeping a record of the number of occurrences and dispersion.
For somewhat more complex tasks, it may of course be necessary to create more comprehensive listings in this way and then annotate them in some form to cater for different features, or to even import n-gram lists into a spreadsheet application like Excel or a statistic package like R.
However, an obvious note of caution is in order at this point. As easy as a tool like ICEweb might make it to procure web-based data, turn it into a corpus, and carry out even perhaps seemingly complex types of analysis, the validity of any such analysis of course ultimately depends on the nature and representativeness of the data collected by the user. In many cases, especially if the amount of data collected is still relatively small, it may be advisable to perhaps take such results only as an initial starting point and to compare them to (hopefully) equivalent data from a much larger corpus, such as the GloWbE corpus (Davies 2013). Once the validity of the task has been ascertained, or at least corroborated, in this way, one can then go back to collecting more data.
Although ICEweb is designed for working primarily with web data, it may of course not be possible to find suitable data – or enough of it – online for all categories. In this case, it is still perfectly possible to ‘import’ data collected in some other way in order to create a unified corpus. All one would then need to do is locate (or create) the relevant sub-folder(s) in the ICEweb data folder and create a folder ‘text’ within it where the relevant data can be copied. Any XML versions – along with the relevant folder – would of course need to be created manually. This could probably be done most easily using the Simple Corpus Tool mentioned earlier, which allows the user to create new XML files based on a user-defined structure, insert the contents of text files into these, as well as define one’s own XML tags and attributes and insert those into the XML documents.
Any raw text data could of course simply be tagged and edited using ICEweb’s built-in facilities in order to create POS-tagged versions for analysis.
As already pointed out earlier, ICEweb also offers a number of useful configuration options, controlled via its easily editable configuration file. These are designed to either facilitate daily work with a corpus or to add new options to the tool. In terms of the latter, it is easily possible to add multiple new region or category options quickly, even without having to use the regular mechanism for doing so via the menus or dropdown lists. They can simply be added in the configuration files, and, when a new URL file is generated for them, the relevant folders will also automatically be created.
The other type of options enables the user to set various types of default startup options, such as which search engine to use as a default, how many lines of prior or following context the concordancer should display, which norming factor to use for n-grams, or which tab of the tool should be activated at startup, depending on which stage in the corpus compilation, editing, or analysis process has been reached.
All configurable options are also suitably commented regarding the format they take, so that it is very difficult to actually make a mistake in editing them, short of actually deleting them altogether, and the configuration file itself can be edited from within the tool.
In this paper, I have introduced and described version 2 of ICEweb, a tool designed to facilitate creating, or adding data to, ICE corpora by downloading data from the Web, and also providing some basic means of analysing them. Apart from describing the functionality and advantages of the tool, I have also tried to point out some of its potential usages and added a few notes of caution as and when necessary in order to remind readers that creating clean and usable corpora still requires a considerable amount of diligence and manual effort to ensure quality and representativeness, even if ICEweb ought to simplify the compilation process considerably.
The extensible nature of the tool of course also makes it usable for other web-based corpus acquisition projects, ranging from classroom applications, via small student projects, to compiling potentially much larger corpora for more advanced research purposes.
Future versions of ICEweb will probably also contain further enhancements, such as the ability to use proxy configurations for classroom work in order to ensure that all students get the same search results, more extensive sorting options that will hopefully integrate the dispersion measures better, etc. Furthermore, as the Perl/Tk toolkit used to create the user interface is at times somewhat ‘clunky’, especially when selecting or unselecting text, later versions, which will probably be written in Python and PyQt, will hopefully eliminate some of the slight technical usability issues that are still present.
Sketch Engine: https://auth.sketchengine.eu/
Anthony, Laurence. 2018. AntConc (Version 3.5.7) [Computer software]. Tokyo: Waseda University. https://www.laurenceanthony.net/software.html
Baroni, Marco & Silvia Bernardini. 2004. “BootCaT: Bootstrapping corpora and terms from the web”. Proceedings of the Fourth International Conference on Language Resources and Evaluation (LREC’04), ed. by Maria Teresa Lino, Maria Francisca Xavier, Fátima Ferreira, Rute Costa, Raquel Silva et al., 1313–1316. Paris: ELRA. http://www.lrec-conf.org/proceedings/lrec2004/pdf/509.pdf
Biber, Douglas & Jerry Kurjian. 2007. “Towards a taxonomy of web registers and text types: A multidimensional analysis”. Corpus Linguistics and the Web, ed. by Marianne Hundt, Nadja Nesselhauf & Carolin Biewer, 109–131. Amsterdam: Rodopi.
Brezina, Vaclav. 2018. Statistics in Corpus Linguistics: A Practical Guide. Cambridge: Cambridge University Press.
Coburn, Aaron. 2003. “Lingua::EN::Tagger”. Perl Software Module. https://metacpan.org/pod/Lingua::EN::Tagger
Davies, Mark. 2013. Corpus of Global Web-Based English: 1.9 Billion Words from Speakers in 20 Countries (GloWbE). https://corpus.byu.edu/glowbe/
Edwards, Alison. 2017. “ICE age 3: The expanding circle”. World Englishes 36(3): 404–426. doi:10.1111/weng.12279
Gatto, Maristella. 2014. Web as Corpus: Theory and Practice. London: Bloomsbury.
Hundt, Marianne, Nadja Nesselhauf & Carolin Biewer. 2007. “Corpus linguistics and the web”. Corpus Linguistics and the Web, ed. by Marianne Hundt, Nadja Nesselhauf & Carolin Biewer, 1–5. Amsterdam: Rodopi.
Mikheev, Andrei. 2003. “Text segmentation”. The Oxford Handbook of Computational Linguistics, ed. by Ruslan Mitkov, 209–221. Oxford: Oxford University Press.
Nelson, Gerald. 1991. Manual for Written Texts. London: Survey of English Usage.
Nelson, Gerald. 1996. “Markup systems”. Comparing English World-Wide: The International Corpus of English, ed. by Sidney Greenbaum, 36–53. Oxford: Clarendon.
Nelson, Gerald. 2017. “The ICE project and world Englishes”. World Englishes, 36(3): 367–370. doi:10.1111/weng.12276
Schäfer, Roland & Felix Bildhauer. 2013. Web Corpus Construction. San Rafael, CA: Morgan & Claypool Publishers.
Schmid, Helmut. 1994. “Probabilistic part-of-speech tagging using decision trees”. Paper presented at International Conference on New Methods in Language Processing, Manchester, UK.
Toutanova, Kristina, Dan Klein, Christopher Manning & Yoram Singer. 2003. “Feature-rich part-of-speech tagging with a cyclic dependency network”. Proceedings of HLT-NAACL 2003, 252–259. https://www.aclweb.org/anthology/N03-1033
Weisser, Martin. 2015. The Simple Corpus Tool (Version 1.5) [Computer software]. http://martinweisser.org/ling_soft.html#viewer
Weisser, Martin. 2016. Practical Corpus Linguistics: An Introduction to Corpus-based Language Analysis. Malden, MA & Oxford: Wiley-Blackwell.
Weisser, Martin. 2017. “Annotating the ICE corpora pragmatically – preliminary issues & steps”. ICAME Journal 41: 181–214.
Weisser, Martin. 2018. “Automatically enhancing tagging accuracy and readability for common freeware taggers”. Proceedings of Asia Pacific Corpus Linguistics Conference 2018, 502–505. Takamatsu, Japan.
