
Studies in Variation, Contacts and Change in English
Studies in Variation, Contacts and Change in English
Jason Grafmiller
University of Birmingham
Variationist research seeks to identify and examine variation among factors that influence linguistic choices, i.e. alternate ways of saying ‘the same’ thing (Labov 1972: 188), and comparative variationists in particular focus on how the influence of those factors differs across varieties. The aim of this paper is to illustrate methods for visualizing effects of such factors and their cross-varietal patterns based on techniques already common in variationist analysis, e.g. logistic regression and random forests. Recent years have seen a rise in new methods for visually interpreting statistical models, however these methods have not been taken up much (yet) in linguistics research. As a way of encouraging wider use of visualization techniques in variationist studies, I present a few of these newer methods using a case study of the English genitive alternation across five genres of written American English. I show how different methods can be used to examine effects of linguistic factors – and their interactions – from the perspective of entire datasets as well as individual observations.
A central goal of comparative linguistics is to determine to what extent two or more varieties of a language are grammatically ‘similar’ (Montgomery 1997; Poplack & Tagliamonte 2001; Tagliamonte 2013). This paper examines methods for assessing the grammatical similarity between language varieties using analytical tools common to the variationist’s toolkit. Comparative variationist research investigates how language users’ grammatical choices depend on specific linguistic, social, and/or contextual constraints, and to what extent those constraints influence choices differently across varieties, communities, and even individuals.
The focus of this paper is on methods for visualizing effects of predictors and their interactions in statistical models commonly used for variationist analysis. Recent years have seen a considerable proliferation of techniques for visually interpreting various kinds of machine learning models (see e.g. Molnar 2021; Biecek & Burzykowski 2021), yet these techniques are still relatively under-used in linguistics. Using a case study of the English genitive alternation across five genres of written American English sampled from two time periods, I illustrate some of these techniques for visualizing results from two of the most widely used statistical procedures in comparative variationist analysis, namely generalized linear mixed models (GLMMs) and random forests (RFs). The latter method in particular has become increasingly popular in the last 10 years or so; however, the basic outputs of random forest and other so-called “black box” models, while useful in some respects, are rather limited in their capacity to help us understand complex predictor behaviors. Thus, the aim of this paper is to illustrate how visualization can be useful for interpreting statistical models such as random forests, which often do not provide direct measures of predictor effect size and direction. There is a growing body of techniques for examining effects of linguistic constraints, and especially differences in the effects of these constraints across varieties, registers, time periods, etc. – knowledge of such techniques is an invaluable addition to the quantitative linguist’s toolkit.
In the following sections, I briefly introduce data from a case study of the English genitive alternation, followed by a description of the statistical models used to model the choice of genitive construction. Section 4 discusses a number of techniques used for visualizing and interpreting model results, both from the perspective of the entire dataset as well as individual observations. Section 5 concludes.
The genitive alternation is one of the most extensively studied syntactic alternations in English. Most research has focused specifically on the binary alternation between the of genitive construction (1) and the Saxon ’s genitive construction (2) (see Rosenbach 2014 for review). [1]
| (1) | Not that Weeks had any reason to know the creative history of this fledgling writer […] <Frown:G35> |
| (2) | Not that Weeks had any reason to know this fledgling writer’s creative history […] |
While the genitive alternation has been extensively studied from synchronic and diachronic perspectives, there is relatively little research on the factors shaping its stylistic variation in English. As a sociolinguistic variable, this alternation appears to be well below the level of consciousness, and to exhibit little vernacular variation along the usual social dimensions, e.g. age, gender, socio-economic status, or region. Nonetheless, there is evidence for both recent change in the frequency of the s-genitive in some written genres (Hundt & Mair 1999), as well as the possible influence of stylistic effects on factors governing genitive choice, most notably possessor animacy (Grafmiller 2014). Thus a comparative examination of the factors influencing genitive variation across written registers/genres and time could prove insightful. At the same time, teasing apart the effects of the many factors known to influence genitive choice often requires the use of complex models, which present challenges for interpretation. Visualization of model predictions is one way to (at least partly) address some of these challenges.
Data for this case study comprise 5093 tokens of interchangeable English genitive constructions extracted from five genres of the Brown (1960s) and Frown (1990s) corpora of written U.S. English (Francis & Kučera 1979; Mair & Leech 2007). The genres included in the study are listed in Table 1 below (both corpora contain an equal number of texts per genre).
| Genre | N texts | Description |
|---|---|---|
| Press | 88 | Newspaper reporting including politics, sports, financial, and cultural reporting |
| Non-fiction (Belles-Lettres) | 150 | Aesthetic non-fiction, including essays, biographies, memoirs, etc. |
| Learned | 160 | Academic writing covering humanities, natural & social sciences, medicine, law, etc. |
| General Fiction | 58 | Novels and short stories of non-specific literary themes |
| Adventure Fiction | 58 | Novels and short stories, predominantly westerns and speculative fiction |
Table 1. Genres included in the present dataset from the combined Brown and Frown corpora.
Examples were collected and semi-automatically filtered to exclude non-interchangeable tokens following conventions set by previous work on these corpora (Garretson 2004; O’Connor et al. 2006; Hinrichs & Szmrecsanyi 2007). For further details see Grafmiller (2014).
In total, 5093 genitive tokens (s-genitives = 1992, 39%) were collected, and their distribution by genre and time is represented in Figure 1. Overall, the Press genre features the greatest proportion of s-genitives, and the data show a slight increase in s-genitive use over time across all genres, but most notably in Press writing.
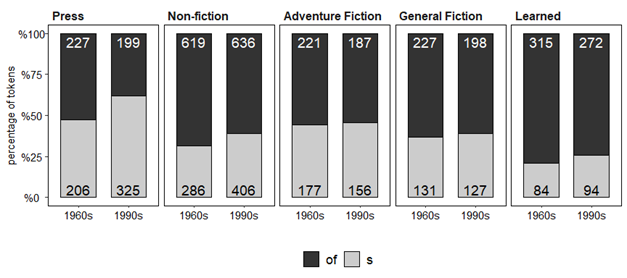
Figure 1. Distribution of genitive tokens (N = 5042) across the 5 genres in the 1960s and 1990s. Bar heights represent proportions of tokens and values in bars represent the number of observed tokens.
Factors influencing the choice between genitive variants are well known, and I focus here on those predictors that have been shown to have a reliable effect in the literature (see e.g. Rosenbach 2014). Following annotation procedures used in Grafmiller (2014: 476–479), each token in the dataset was semi-automatically annotated for the features listed in Table 2 (see Hinrichs & Szmrecsanyi 2007: 449–459; Heller et al. 2017b: 9–13 for similar approaches).
| Predictor | Levels | Description |
|---|---|---|
| possessor animacy | animate, collective, inanimate | s-genitive preference should follow the animacy scale: animate > collective > inanimate |
| possessor – possessum length | continuous | Length in words of the possessor minus length in words of the possessum. Values < 0 favor the s-genitive, values > 0 favor the of genitive |
| final sibilant | yes, no | Does the possessor NP end in a sibilant? 'Yes' should favor the of genitive |
| possessor np type | proper, common | Proper noun possessors should favor the s-genitive |
| possessor givenness | given, new | Is the possessor referred to in the preceding 100 words? (yes = given). Given possessors should favor the s-genitive |
| prototypical semantic relation | yes, no | Is the relation between possessor and possessum a prototypical genitive one? (yes = ownership, kinship, body part, part-whole; no = all others). Prototypical relations favor the s-genitive |
| structural persistence | yes, no | Was the most recent genitive in the 10 sentences preceding the token an s-genitive? 'Yes' should favor the s-genitive |
| genre | press, learned, non-fiction, general fiction, adventure fiction | Press texts favor the s-genitive compared to other genres |
| time | 1960s, 1990s | 1990s texts favor the s-genitive compared to 1960s texts |
| possessor thematicity | continuous | Frequency of the possessor head noun in its text (normalized per 2000 words). Higher thematicity favors the s-genitive |
| type-token ratio | continuous | Calculated over the 100 words immediately surrounding the token. Higher TTR favors the s-genitive |
Table 2. Predictors included in the genitive models.
For a typical comparative variationist study, the main research questions would be fairly straightforward: To what extent do (the effects of) the internal linguistic factors vary across time and genre, and how might we assess the relative (dis)similarity of the genitive alternation ‘grammars’ in these different times/genres? These questions can be investigated by means of statistical models, e.g. logistic regression models, but interpreting said models can be challenging when there are many predictors (potentially) interacting with one another. In the rest of this paper, I will examine how one might address these questions by visually exploring the results of statistical methods commonly used to model alternation phenomena of this kind.
One of the most common approaches to investigating variation across varieties – however they are defined – involves the single-model-with-interaction approach, in which the effects of all internal factors in different varieties are estimated within a single model (e.g. Bresnan & Hay 2008; Szmrecsanyi et al. 2017; Tagliamonte et al. 2016). In this approach, cross-varietal ‘interaction effects’ measure the degree to which the influence of internal factors varies across the varieties in question, and the researcher can directly test the extent to which the influence of a particular internal factor changes from variety A to B to C and so on.
The two most common modeling methods used in comparative variationist research are generalized linear regression models, specifically (mixed effects) logistic regression models (e.g. Bresnan & Hay 2008; Szmrecsanyi et al. 2017; Grafmiller & Szmrecsanyi 2018), and random forest models (e.g. Tagliamonte & Baayen 2012; Szmrecsanyi et al. 2016b; Heller et al. 2017a). Depending on the method, interactions to be examined must be prespecified by the researcher (as in regression models), or they may be detected by the modeling algorithm itself (as in random forest models). In this section, I illustrate how such methods can be used to examine cross-varietal patterns in internal linguistic constraints, and discuss their relative strengths and limitations for investigating large-scale datasets. All datasets, R code, and supplementary material for the present paper can be found at the Open Science Framework.
Regression modeling has been the workhorse analytical technique in variationist analysis since the development of variable rule analysis in the 1970s (Sankoff & Cedergren 1976), and over the past 15 years or so, generalized linear mixed models (GLMMs) have arguably become the standard approach (Bresnan et al. 2007; Johnson 2009). [2] For the GLMM analysis here, Bayesian mixed-effects models were fit using the brms package (Bürkner 2017), which provides an easy-to-use implementation of the Stan programming language (Carpenter et al. 2017) in R (R Core Team 2021). Bayesian methods offer practical advantages over traditional approaches, the most pertinent being the fact that Bayesian models will (almost) always converge and can be adapted to sparse data with appropriate adjustments to the priors (see below). [3]
All of the internal factors mentioned previously were included in the model. To examine the effects of these factors across genre and time, the model included all two-way (genre * predictor and time * predictor) and three-way interactions (genre * time * predictor) with time and genre for all internal predictors. No interactions between internal predictors were included. By-Text intercepts were included in the random effects structure to control for potential biases of individual authors. The model formula was as follows.
Type ~ (1 | Text) +
Genre * Time * (
Possessor_Animacy3 + Possessor_NP_Type + Final_Sibilant +
ProtoSemanticRelation + Possessor_Thematicity + TTR +
Possessor_Givenness + PersistenceBinary + Possr_Possm_Length_diff1)
Model inputs were standardized following Gelman et al. (2008), in which continuous predictors are centered around their means and scaled to have a standard deviation of 0.5, and binary predictors have sum contrasts with deviations of ±0.5 (see also Kimball et al. 2018). Standardizing in this way ensures that the main effects of continuous and categorical regression predictors are on similar scales, which makes it much simpler to specify their prior distributions. As Kimball et al. (2018) note, scaling by 0.5 means that interaction terms will automatically have smaller scales than main effects, and thus the model will tend to be more conservative in estimating interaction effects.
For the model priors, I use so-called regularizing prior distributions in order to minimize the probability of extreme coefficient estimates (McElreath 2020: 214–216). All regression models used normal priors with a mean of 0 and standard deviation of 1.5 (μ = 0, σ = 1.5) for the fixed terms and model intercepts (Ghosh et al. 2018; McElreath 2020). For the random effects, I used a half normal prior with a standard deviation of 2. Measures of overall performance of the full GLMM model show that it fits the data well: Concordance index C = .92; Brier score = .10; predictive accuracy = 85% (61% baseline).
Random forests and classification trees are a popular alternative to regression, as these methods can address some of the limitations of traditional regression models, most notably their ability to handle multicollinearity among predictors and overfitting (Baayen et al. 2013; Matsuki et al. 2016; Tagliamonte & Baayen 2012). But despite the advantages of the “tree and forest” approach, it remains something of an open question as to how reliably the methods can be used to investigate interaction effects (Boulesteix et al. 2015; Wright et al. 2016; Gries 2019). Random forests do not provide direct indices of predictor effects comparable to regression coefficients, so in order to examine predictor effects and their possible interactions, additional methods must be applied.
One of the most common methods involves the visual examination of large individual classification trees, as in Figure 2, which are often claimed to be good at representing interaction effects (see e.g. Bernaisch et al. 2014; Hundt 2018; Szmrecsanyi et al. 2016b).
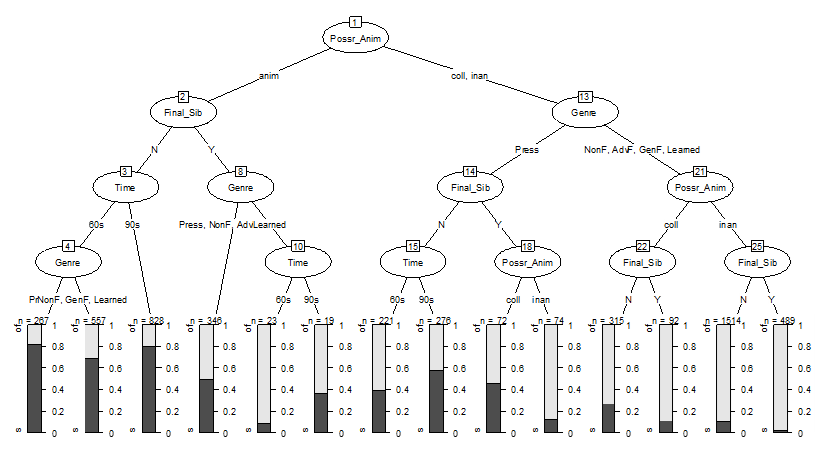
Figure 2. Conditional inference tree modeling the effect of time, genre, possessor animacy and final sibilant on genitive choice.
For illustration, I have simplified this tree model by including only four predictors (genre, time, possessor animacy, and final sibilant), and restricted the branching depth to four levels. Figure 2 does indeed suggest some potential cross-varietal interaction effects. For example, among genitives with non-animate possessors there is a considerably stronger tendency to avoid the s-genitive in genres other than Press (right branch descending from node 13), or when the genre is Press, but a final sibilant is present (node 18). There also appears to be an effect of time, particularly when the possessor is non-animate, lacks a final sibilant, and the token occurs in press texts (node 15), as well as when the possessor is animate, has a final sibilant, and the token occurs in academic texts (node 10). Note that Figure 2 suggests even more patterns of this kind, but it is hopefully clear from this example that large trees can truly push the limits of human interpretation.
The tree in Figure 2 shows a moderately complex case, but it is by no means exceptional, especially in corpus studies of grammatical alternations. However, even very simple trees can lead one astray, as the existence of branching does not itself provide conclusive evidence of an interaction effect (see Boulesteix et al. 2015: 343–344). Further, true interaction effects may not always be represented in the tree. In the latter case, there is the so-called exclusive or (XOR) problem, which “describes a situation where two variables show no main effect but a perfect interaction. In this case, because of the lack of a marginally detectable main effect, none of the variables may be selected in the first split of a classification tree, and the interaction may never be discovered” (Strobl et al. 2009: 341). That is to say, because the tree model only examines splits based on one predictor at a time, if no single predictor leads to a useful split in the data, no branches will be made in the tree. Whether such a scenario is likely to arise in real language data is of course hard to say (see Gries 2019 for an illustration of how the XOR problem works using simulated data), but the larger point is that when we don’t know the true relationship between a set of predictors and the outcome, we should be careful about how we interpret individual decision trees.
Nevertheless, even if we assume such XOR cases are rare, we are still faced with the fact that large trees are often extremely difficult to interpret – how does one meaningfully summarize the findings in Figure 2? [4] In the end, while large classification trees may look impressive, I would argue they are of limited use for understanding how individual (sets of) constraints impact language usage, which is what we are typically after. In Section 4, I discuss some newer methods for exploring individual predictor effects in random forest models which are becoming increasingly common in work on interpretable machine learning (Molnar 2021; Biecek & Burzykowski 2021).
But first, the models. To fit random forest models of the entire genitives dataset I used both cforest() and ranger() in the party and ranger packages, respectively. The former utilizes forests grown from conditional inference trees and was one of the earliest methods to be used in variationist linguistic research (e.g. Tagliamonte & Baayen 2012; Baayen et al. 2013); ranger, on the other hand, grows forests of standard classification and regression trees (as used in e.g. Deshors & Gries 2016; Heller et al. 2017a) but is computationally much faster than party. In practice, both methods tend to yield similar results (Gries 2019), and while party is useful for its conditional variable importance estimation method, the extremely fast implementation in ranger makes it more feasible for generating predictions and visualizing effects. For this paper, plots and calculations for the random forest were created in R with a ranger model and functions in the flashlight and DALEX packages (Mayer 2021; Biecek 2018). [5]
For GLMMs, results of individual predictor effects are reported in the summary tables that are standard outputs of modeling functions (e.g. glmer) in R. But especially for large models with many interactions, such tables are often unwieldy and difficult to interpret, and this is doubly so for non-linear effects (if they are included). For illustration, I provide a summary of all the fixed effects for the genitives GLMM (complete details can be found on the OSF repository). I would argue this table is of little practical use in understanding the effects of the linguistic constraints, or any interactions they might have with genre, time, or other linguistic predictors.
However, the information in the OSF repository can be simplified to focus only on those interactions whose effects are large and have sufficiently strong evidence, and I provide a visual representation of those effects in Figure 3. Here we have the posterior distributions of only those interactions whose 95% posterior uncertainty intervals did not include 0. Graphs of model outputs such as this one convey information much more effectively than tables, as the sizes of the effects, and their degree of uncertainty, can be read from the plot. Note, however, that direct comparisons among the coefficients requires appropriate scaling (cf. Section 3.1). We can see, for instance, that there are several large interaction effects of genre and possessor-possessum length, and of genre and possessor animacy. However for many, including myself, it still can take quite a bit of mental effort to interpret these interaction coefficients on the level of the linguistic phenomena themselves.
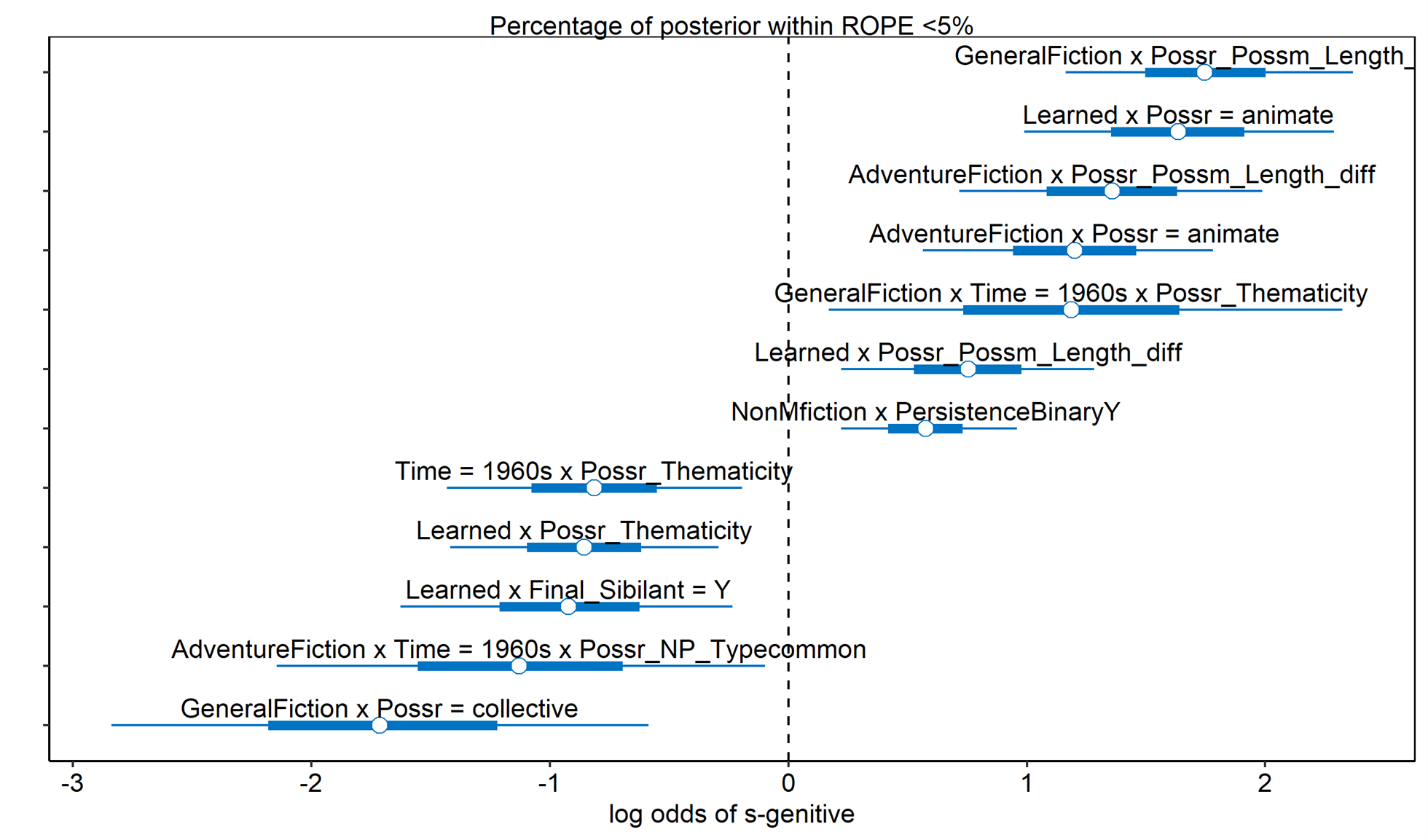
Figure 3. Posterior estimates of interaction coefficients from single generalized linear mixed model (thin lines = 90% HDI; thicker lines = 50% HDI). Only effects with 95% of the posterior HDI falling outside the Region of Practical Equivalence are shown.
The challenge for interpreting categorical predictors’ effects in regression models lies partly in understanding the contrasts between predictor levels that were evaluated by the model, and this challenge is compounded in the face of multiple interactions. Thus, while summary tables and coefficient plots undoubtedly provide important information, their usefulness for actual interpretation diminishes considerably when there are multiple 2- and 3-way interactions specified in the model. Thus, when it comes to interpreting complex interaction effects, visualization of our model predictions becomes invaluable.
To visualize predictor effects of a regression model we can use Conditional Effects (CE) plots. In a nutshell, conditional effects plots show how the predicted probability of the outcome changes as the values of a given predictor p change, while holding the other predictors at specific values. [6] In most regression model applications, continuous variables are held at their mean and categorical factors at their reference level. When no interactions are specified in the model, the predicted effects of the given predictor are assumed to hold across all values of the other predictors. However, when an interaction between, e.g., possessor animacy and time, is specified, the conditional effects plots show how the predicted probability of the outcome changes as the values of possessor animacy change, conditional on the values of time. The advantage of visualizing the conditional effects of interacting predictors is that the strength and direction of the interactions are much easier to understand, compared to a large table of coefficients. Moreover, 2- and 3-way interactions can be plotted from different perspectives to aid in interpreting the effects.
To illustrate, Figures 4 and 5 show a Conditional Effects plot of the 3-way interaction of possessor animacy * genre * time from two perspectives. These plots show the posterior estimates, with 50% and 90% uncertainty intervals, of the combined effects of these three predictors on the log odds scale (the colored points and bars). In addition to the effect estimates, I have also included the predicted log odds of the s-genitive for each observation in the dataset (the small black dots).
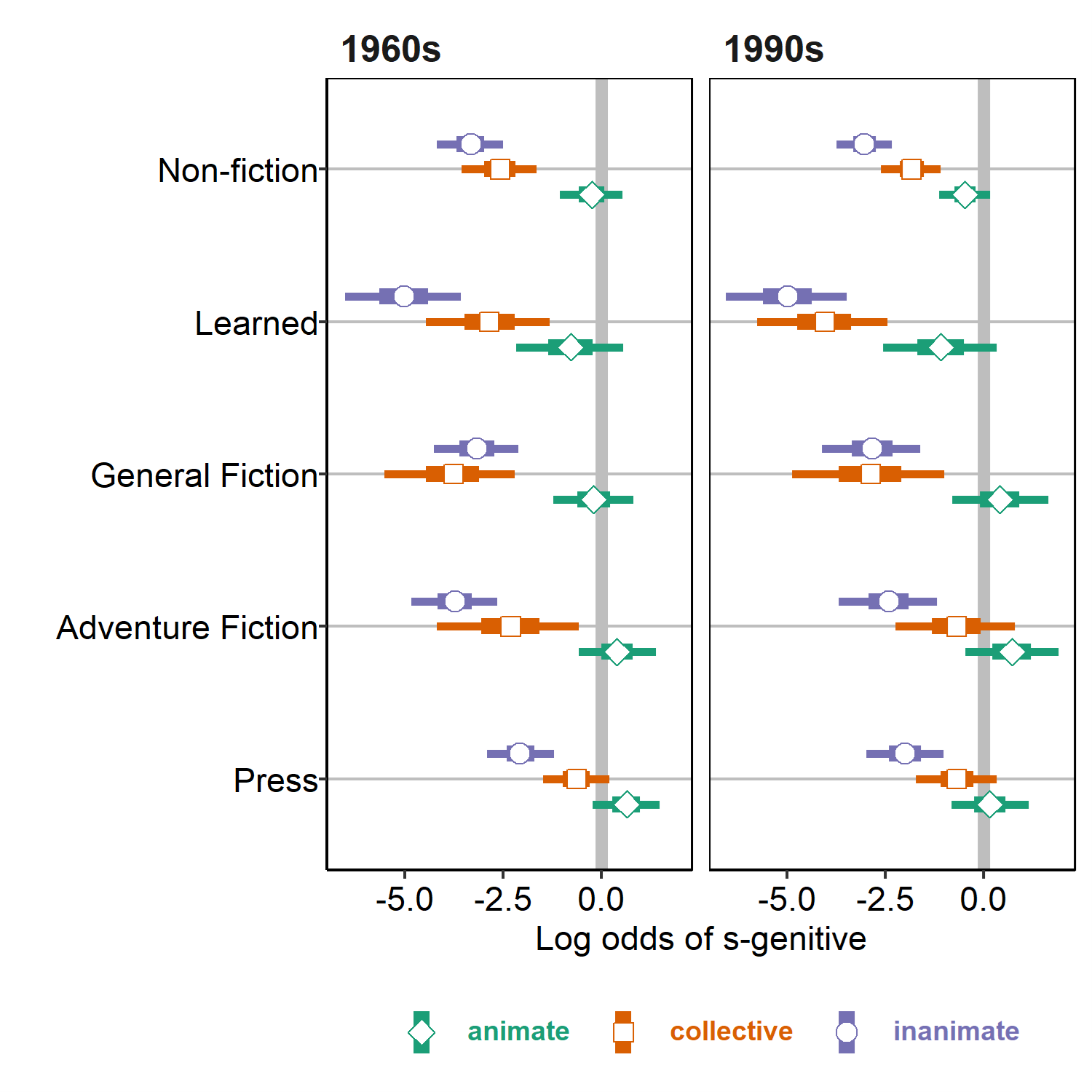
Figure 4. Conditional effects plots of interaction of possessor animacy and genre (grouped by time) in the generalized linear mixed model.
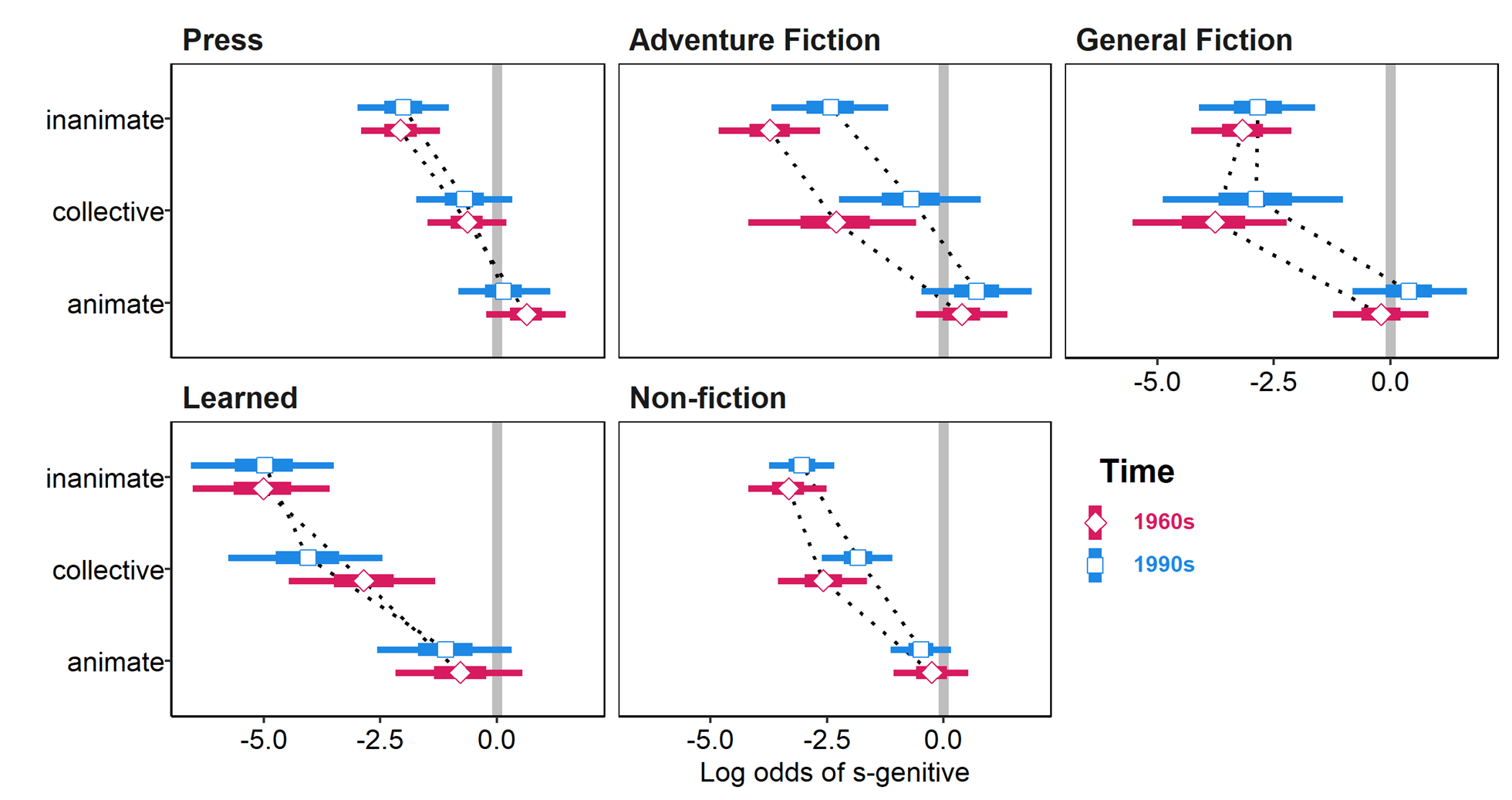
Figure 5. Conditional effects plots of interaction of possessor animacy and time (grouped by genre) in the generalized linear mixed model.
A few things are clear from these plots. First, we can see from Figure 4 that the s-genitive generally follows the expected patterns with respect to possessor animacy: it is most likely with animate possessors, followed by collective possessors and then inanimate possessors. This animacy trend is least pronounced in General Fiction texts, where the difference between collective and inanimate possessors is negligible. It is also clear that across all three animacy levels, Press texts (at the bottom) show the highest probability of an s-genitive of all the genres. At the other end of the plot (the top), we see that Learned texts show the lowest s-genitive probabilities of all genres for both inanimate and animate possessors. Figure 5 provides an alternative perspective where the effect of time across each of the genres and animacy levels is easier to see. From this plot we can see perhaps some very slight evidence of an overall increase in s-genitives for the Non-fiction and two fiction genres.
Another advantage of plots such as these, which show uncertainty intervals and data points, is that they provide information about the amount of data on which the model estimates are relying, and hence how confident we should be when interpreting those estimates. For example, collective possessors tend to be much more common in newspaper articles (29.4% of all tokens) than in other genres overall (8.6% on average), and this greater number of tokens surfaces in the narrower uncertainty bounds for collective entities in the Press genre. Note that the narrower intervals in Non-fiction are also a reflection of greater numbers, but in this case the reason is simply the overall larger number of tokens we find in this genre (more than twice as many as in any other genre).
Interactions with continuous predictors can also be visualized, as in the interaction effects of genre, time, and possessor-possessum length in Figure 6. The trend lines in these plots show considerable variation in the effect of relative length across genres and time. Again, negative possessor-possessum length values to the left reflect cases where the possessor is shorter than the possessum, and we would expect higher probability of the s-genitive in such contexts. The opposite holds true when possessor-possessum length is above 0 - the possessor is longer than the possessum, hence the likelihood of the s-genitive should decrease. All things considered, we expect the lines to trend downward.
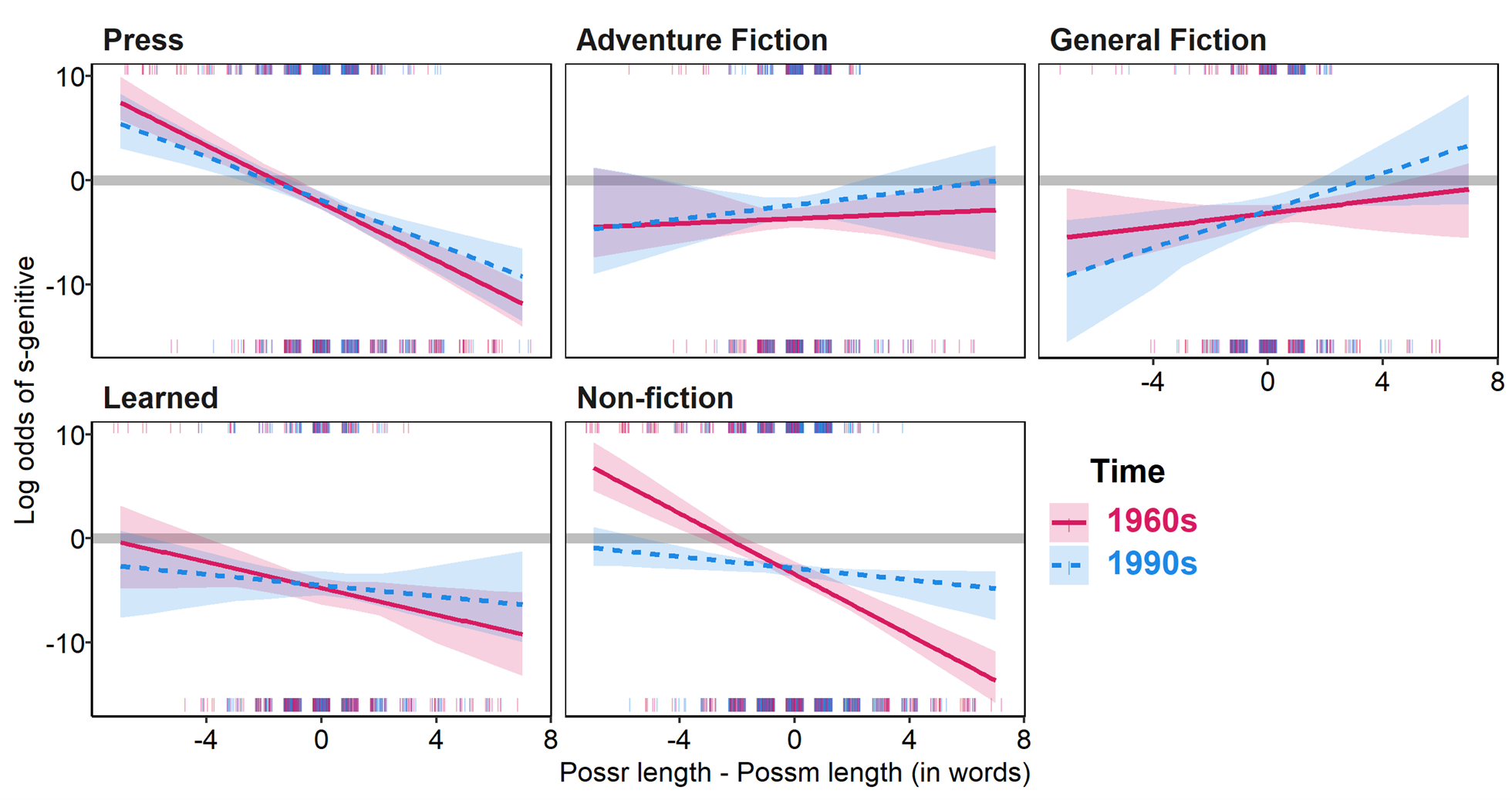
Figure 6. Conditional effects plots of interaction of time, genre, and possessor-possessum length (in words). Lines represent mean posterior predicted probabilities, and ribbons represent the 90% uncertainty intervals. Rug lines reflect individual observations (top = s-genitives; bottom = of genitives).
What we see is a very strong effect in the expected direction in Press texts, but at best fairly weak effects in the other genres. Indeed the fiction genres seem to show effects in the opposite direction in the 1990s data. One thing to note is that the uncertainty intervals for these genres – similar in spirit to confidence intervals in non-Bayesian models – are quite large at the extreme ranges, which strongly suggests that the evidence for these trends is weak. The sparse rug lines in these ranges, representing the individual observations in the data confirm this. We should therefore be careful about attributing much meaning to some of these patterns.
Nonetheless, the variability in the trends is puzzling. Take for example the two fiction genres, where Figure 6 suggests a strong effect in exactly the opposite direction from what we would expect. Extreme positive values should favor the of genitive, and indeed this is what the data suggest (Table 3). All relevant tokens are in fact of genitives, but the model reports a high probability of the s-genitive for these data. On the other hand, extreme negative values should favor the s-genitive, but it turns out that most of the data here show a preference for the of genitive as well (Table 4).
Genre |
1960s | 1990s | ||
|---|---|---|---|---|
| of | s | of | s | |
| Adventure Fiction | 18 | 0 | 11 | 0 |
| General Fiction | 17 | 0 | 13 | 0 |
Table 3. Tokens in 1990s General Fiction with Possessor-Possessum >= 3. These cases should be expected to heavily favor the *of* genitive.
Genre |
1960s | 1990s | ||
|---|---|---|---|---|
| of | s | of | s | |
| Adventure Fiction | 209 | 177 | 181 | 156 |
| General Fiction | 218 | 131 | 192 | 127 |
Table 4. Tokens in 1990s General Fiction with Possessor-Possessum <= -3. These cases should be expected to heavily favor the *s*-genitive.
What is going on here is not entirely clear. But one thing that is clear from the visualizations is that the model is not performing well, at least for predicting the effect of possessor-possessum length, and we should therefore be especially cautious. One explanation could be that this predictor’s effect is not in fact linear, as the model assumes, and/or that the data are not distributed evenly across the range of length values. Inappropriately forcing a linear relationship on non-linear data can lead to a poor model, and it may be that an alternative approach, e.g. an additive model, is more appropriate. Further inspection of the data, and the possible re-evaluation with a different model, would be the proper next step(s) here.
For the sake of space, I will not go through the rest of the predictors in the model, though the general procedure remains the same: we plot the effects from different perspectives and see what we find. With even these few examples, it is clear how visualization of predictor effects and interactions in this manner makes model interpretation considerably easier. As the case of the genre and possessor-possessum length shows, Conditional Effects plots are a useful means of visualizing predictor effects in ways that allows one to spot potential problems with the analysis, or identify subregions of the data in need of closer examination.
That said, it should be noted that Conditional Effects plots cannot directly uncover interaction effects themselves. For regression models, interactions must be pre-specified in the model formula, so interaction effects not considered in the initial model fitting cannot be examined post hoc. More importantly, GLMMs by definition assume that predictor effects are linear, and so Conditional Effects plots will not reveal any non-linearities. To explore non-linear effects, linguists have more recently been turning to other methods such as random forest models.
Summarising the effects of predictors from a random forest model is not easy because a random forest can contain many hundreds or even thousands of potentially very different trees. Nonetheless, we can make use of Partial Dependence (PD) plots (Friedman 2001) to give us insight into the structure of a model and interpretation of predictor effects. Partial dependence plots show the effect of a given predictor (or combination of predictors) on the probability of the outcome, and are thus conceptually similar to conditional effects plots. The partial dependence is estimated by examining the model predictions if all our observations had the same value for the predictor(s) in question. For example, if we are interested in the partial dependence of possessor animacy, we calculate three PD estimates, one each for animate, collective, and inanimate possessors. The PD estimate for “animate” is calculated by forcing each observation in the dataset to have an “animate” possessor, calculating the predicted s-genitive probability for that observation (while keeping all other predictors at their observed values), and then averaging over the predictions for all observations. [7] We do the same for the other levels of possessor animacy, and that gives us our partial dependence estimate for the effect of possessor animacy. [8]
One limitation of PD plots is that because they plot only the average effects, more heterogeneous patterns within the data can be obscured. One solution to this problem is to use Individual Conditional Expectation (ICE) plots (Goldstein et al. 2015). Rather than averaging over the data, ICE plots visualize the effect of manipulating a predictor’s values for each individual observation separately. The results can then be plotted to reveal how the behavior of a focal predictor (e.g. possessor animacy) might change across each observation individually. In essence, ICE plots are simply the ‘unaveraged’ equivalent of PD plots. By combining ICE and PD plots, we can visualize both how individual observations behave and the average effect of a predictor over the entire dataset. Additionally, these plots can be anchored (or centered) around specific values of the predictors, allowing us to plot the difference in the model predictions between a given reference value and other possible values.
To illustrate, Figure 7 shows an ICE plot, overlaid with a PD plot in yellow, for the effect of possessor animacy across time and genres, treating “inanimate” as the anchor value. With “inanimate” as the anchor for possessor animacy, the plot shows differences in s-genitive probability when comparing “inanimate” vs. “collective,” and “inanimate” vs. “animate” levels. Focusing on the average partial dependencies in yellow, it is clear that the random forest model does not detect any substantial qualitative differences in the average effect of animacy across genres or time periods, as evident in the roughly parallel PD lines. Nonetheless, we see that the effect is somewhat weaker in the Press genre compared to the others. Turning to the lines in black, we can see that there is some variability among individual observations, especially within the Press texts, where the model actually predicts that the s-genitive would be less likely if the possessor were animate than if it were collective. This is evident in the lines that fall to the left of the gray line for the animate condition. By plotting effects as changes in the model predictions across levels in this way, centered plots allow us to easily examine cross-varietal differences in the influence of (the levels of) an individual predictor – the “constraint hierarchy” in variationist sociolinguistic terms (Tagliamonte 2013).
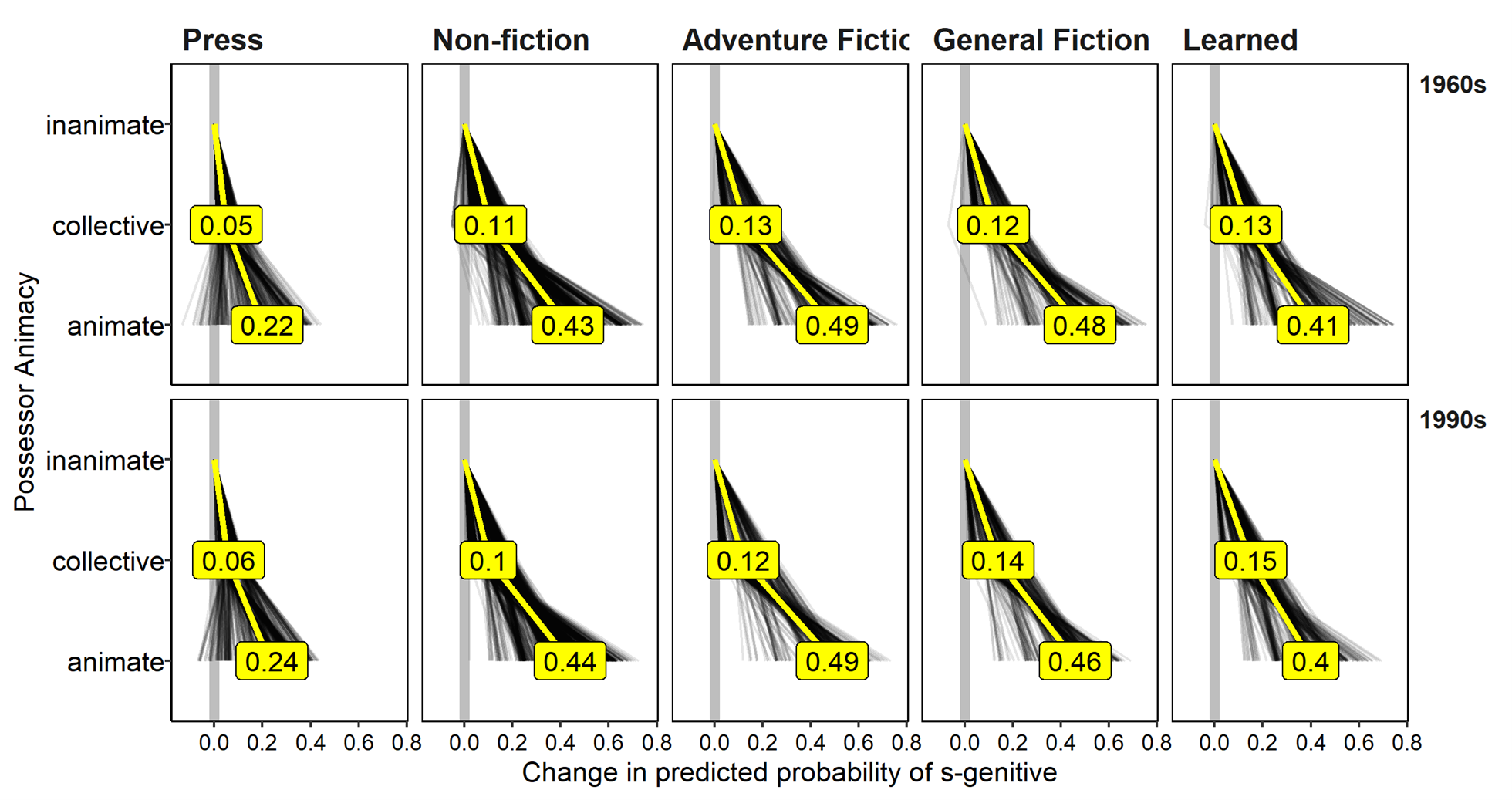
Figure 7. Centered Individual Conditional Expectation (ICE) estimates of s-genitive probability when comparing ’inanimate‘ vs. ’collective,’ and ‘inanimate’ vs. ‘animate’ possessors, grouped by time and genre. Mean probabilities by group (i.e. partial dependence estimates) are shown in yellow.
While centered plots can be helpful for comparing individual levels within a given predictor, it is also worth examining the uncentered plot in order to fully understand what is going on. For example, we can see from Figure 7 that the difference in s-genitive probability between tokens with animate and inanimate possessors is smaller in Press texts (~.22-.24) compared to other non-fiction texts (~.43-.44), but it is not clear from the plot whether this is because animate possessors are less likely to appear in s-genitives in Press writing, or whether it is because inanimate possessors are more likely to appear in s-genitives. Either scenario could explain the pattern in Figure 7. To settle this, we can look at the uncentered ICE plot in Figure 8. From this perspective, it seems clear that the latter is the case: inanimate possessors are much more likely to occur in the s-genitive in Press writing than in the other genres, while animate possessors are about equally likely in the s-genitive across all genres. We can also see more clearly in Figure 8 the overall effect of genre, where it is clear that on average, the s-genitive is much more likely in Press writing than in the other genres. This largely aligns with what we saw with the GLMM above.
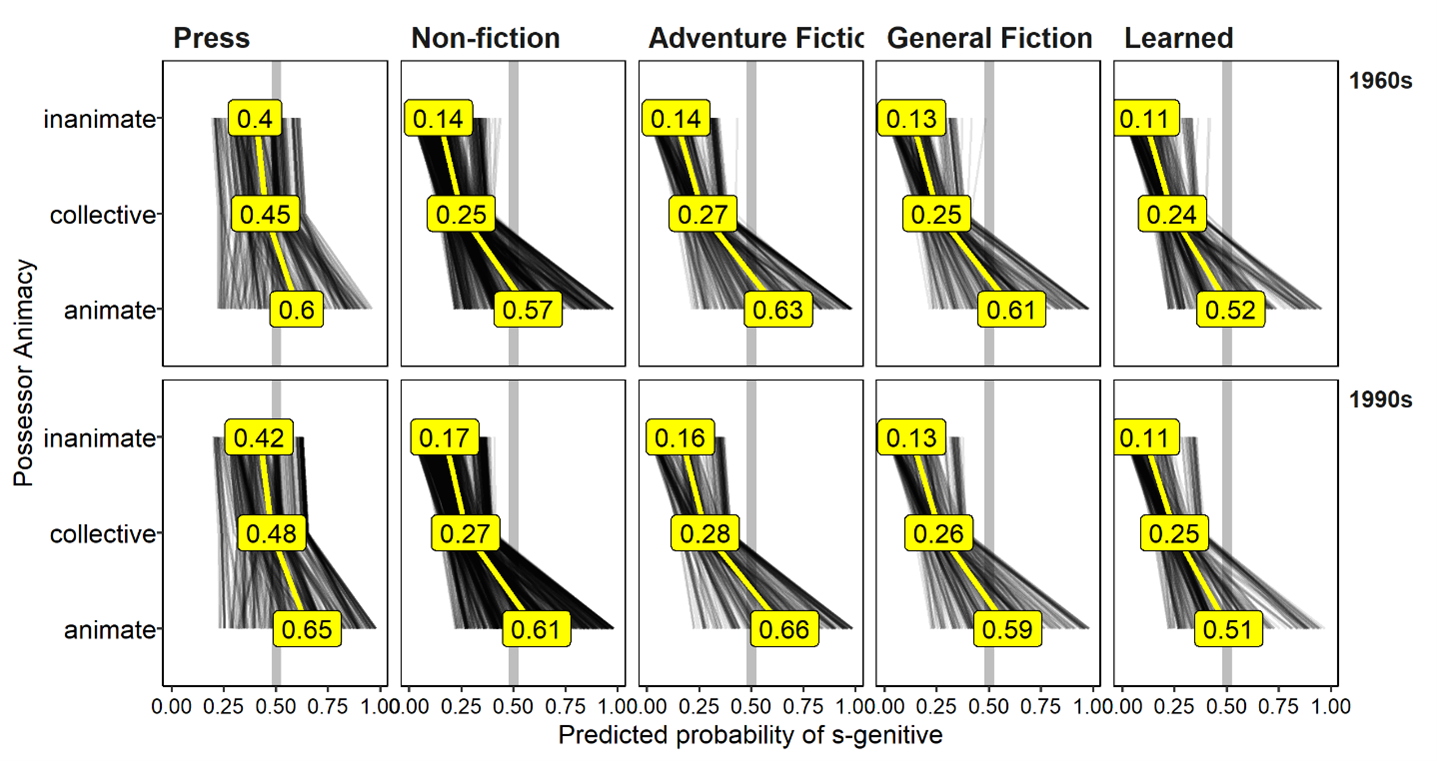
Figure 8. Individual Conditional Expectation (ICE) estimates of s-genitive probability grouped by possessor animacy, time and genre. Mean probabilities by group (i.e. partial dependence estimates) is shown in yellow.
Continuous predictors can be plotted in the same fashion. Figure 9 shows the effect of possessor-possessum length across time and genre. Again, compared to the GLMM estimates (Figure 6), the differences in the random forest model are not nearly as striking. There is a general negative trend, as predicted, but with a curious reversal between the values -1 and 1. These are tokens where the possessor is either one word shorter (Clinton’s tax record) or one word longer (his mother’s lap) than the possessum. There could be any number of reasons for this. For instance it could be that tokens with a length difference of 1 involve an inordinate proportion of animate possessors, or it could be that certain words, e.g. articles, contribute less to constituent ‘weight’ than others (many such tokens are of the form Det N’s N).
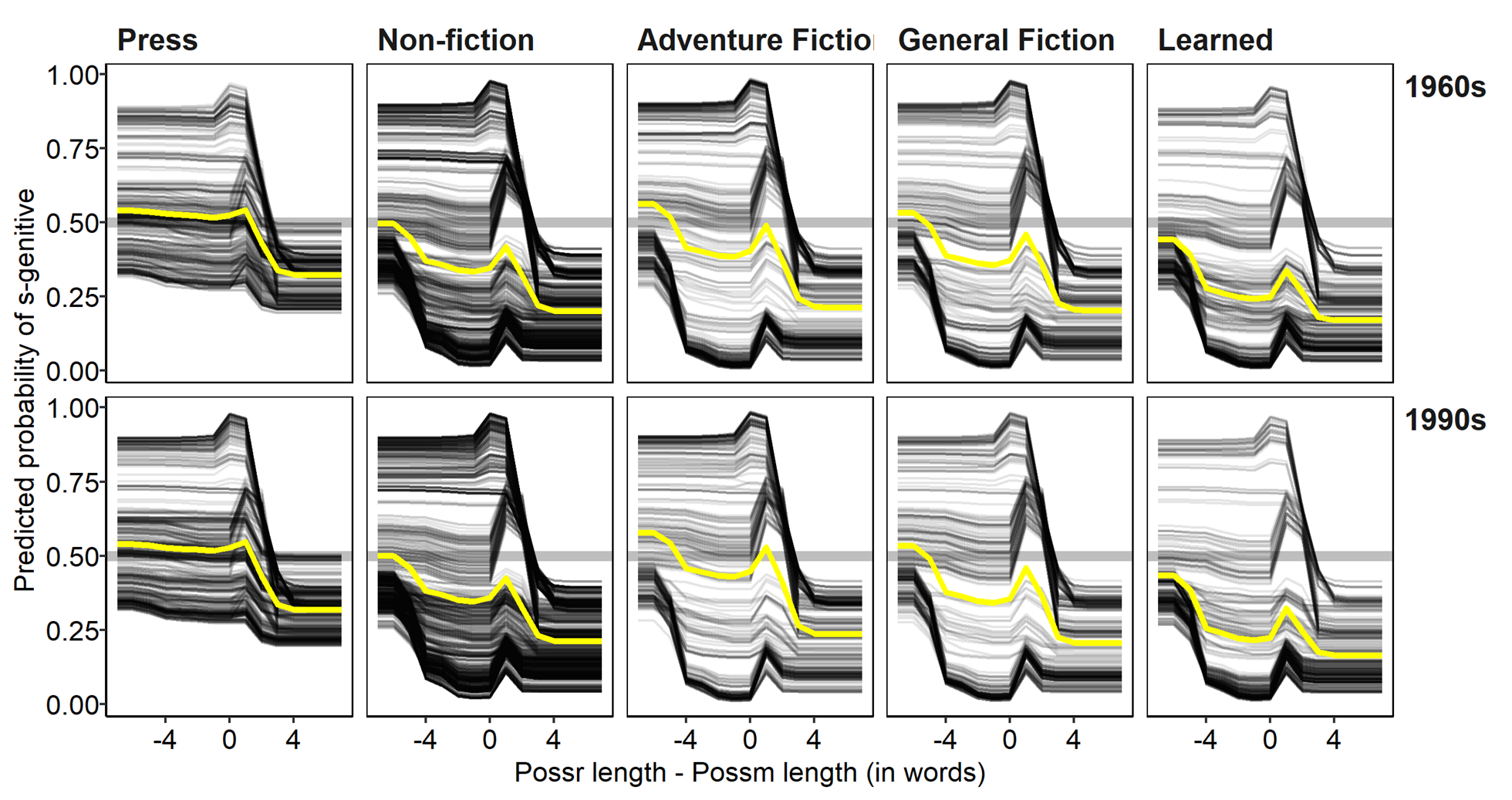
Figure 9. Individual Conditional Expectation (ICE) estimates of s-genitive probability by possessor-possessum length, grouped by time and genre. Mean probabilities by group (i.e. partial dependence estimates) are shown in yellow.
We can begin to explore these kinds of hypotheses by considering how these effects are distributed across other features, e.g. possessor animacy, as in Figure 10. From this it seems that most of the “action” in this effect occurs in different regions of the data for animate and inanimate possessors. It appears that among animate possessors, possessor-possessum length has the biggest impact when possessor-possessum length is between 1 and 4, i.e. when the possessor is 1 to 4 words longer than the possessum. On the other hand, it appears that among inanimate possessors, length only begins to make a big impact when the possessum is considerably longer than the possessor. In other words, if the possessor is inanimate, it takes a big difference in possessor-possessum length to increase the probability of the s-genitive by very much.
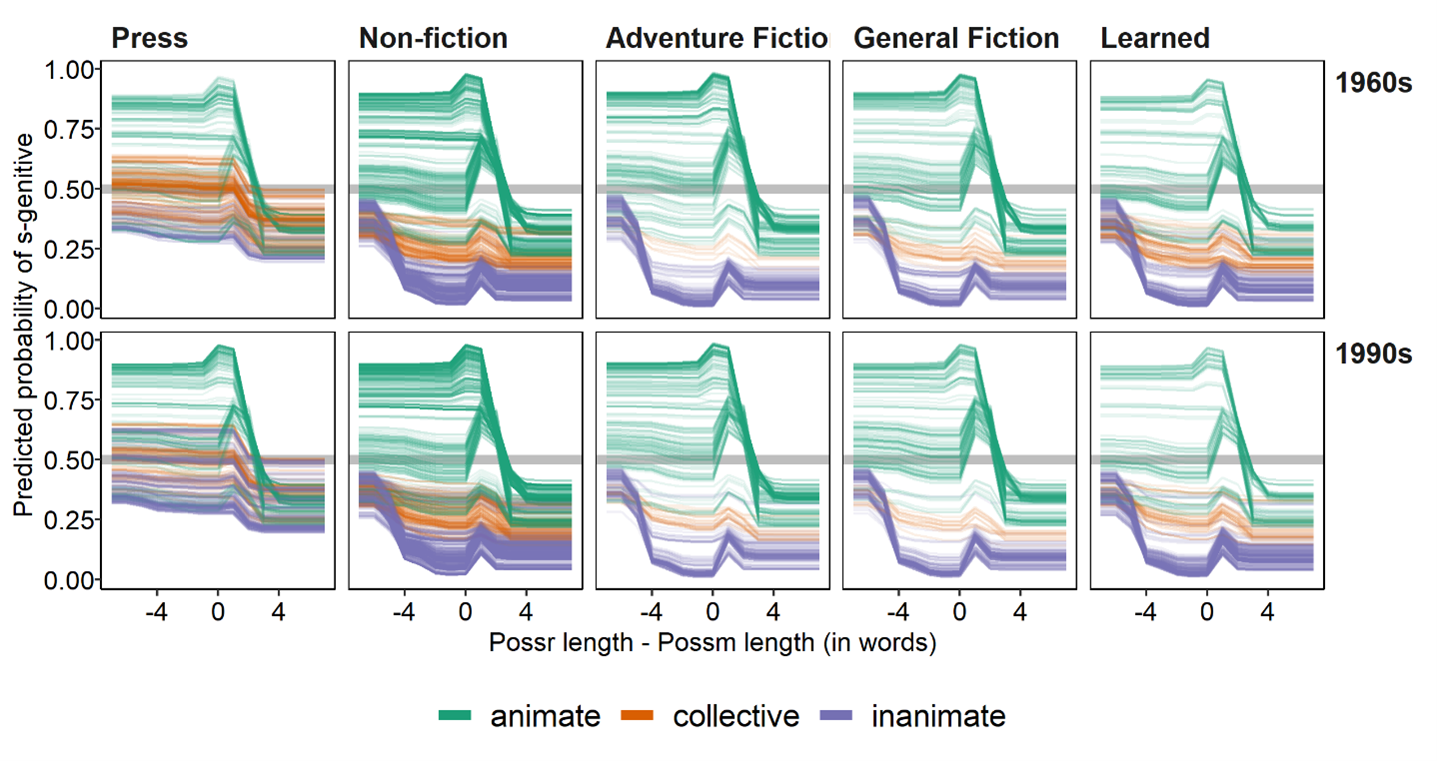
Figure 10. Individual Conditional Expectation (ICE) estimates of s-genitive probability by possessor-possessum length, grouped by time and genre, and possessor animacy.
There is of course much more to say about these methods, but the point here is that visualizing model results via ICE plots allows us to uncover patterns that cannot be seen with simple summary statistics, or with average effects estimates such as in conditional effect or partial dependence plots. In the next section we’ll see another method for investigating interaction effects.
One result that most studies using random forests report is a measure of predictor (a.k.a. variable, or feature) importance, which assesses the relative influence an individual predictor has on the model predictions. In essence, predictor importance scores reflect the degree to which the model accuracy deteriorates when that predictor is removed from the model. One limitation of these global scores however, is that they conflate information about a predictor’s direct (i.e. main) effect, and its effects through interaction(s) with other predictors. One potential solution is to explicitly add interaction terms to a model by creating separate predictors in the dataset representing the interactions to be considered. This approach seems quite effective in severe cases of XOR data (Gries 2019: 22–23); however, it is possible that in the presence of strong main effects, the importance of these added interaction terms can be spuriously inflated. [9]
Another potential strategy for investigating interaction effects is a method developed by Friedman & Popescu (2008), which measures the relative influence of interactions vs. main effects on the variation in a model’s prediction. In simplest terms, the approach compares the observed partial dependence of two (or more) predictors in the model to the partial dependence under the assumption that there are no interactions. In the latter case, the assumption is that when there are no interactions, the joint partial dependence of predictors A and B is simply equal to the sum of the partial dependences of A and B individually (see Molnar 2021: sec. 5.4). Large differences between the observed partial dependence and the ‘no-interaction’ partial dependence suggest that the two predictors’ effects are not independent. The resulting H statistic is used to represent the amount of variance in the difference between observed and no-interaction PD explained by the interaction. An H value of 0 for a predictor means there is no interaction (i.e. only a main effect), and an H value of 1 means that a predictor only has an effect via interactions with other predictors (i.e. there is no main effect).
One common use of this method involves the calculation of a total interaction score for each predictor, which tells us to what extent the effect of a given predictor can be attributed to its interaction with other predictors in the model. For example, Figure 11 shows the overall predictor importance together with the overall interaction strength for each predictor in the genitives random forest. We can see that Possessor Animacy is by far the most important predictor, and that roughly 1/4 of its effect (H = .27) on the s-genitive comes via its interaction with other predictors. We can also see that, of the two external predictors &ndash: genre and time – only genre has much of an effect at all, and it interacts to some degree with the internal predictors. The large impact of possessor np type is also somewhat surprising, but I will not examine it further here.
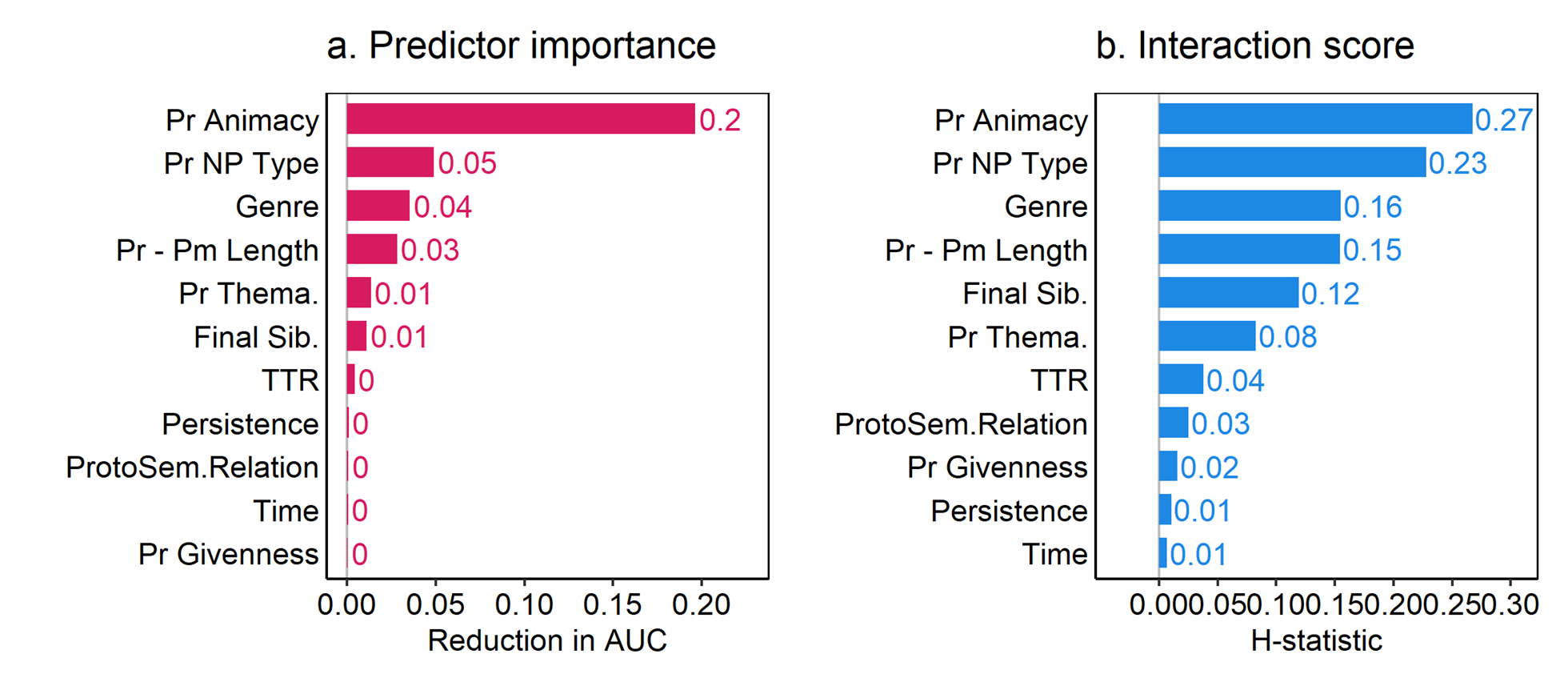
Figure 11. Overall predictor importance (reduction in area under the curve/Concordance C) and interaction strength (Friedman’s H) for each predictor with all other predictors for the random forest predicting the probability of the s-genitive.
The H statistic can also be used to examine interactions among specific predictors. Figure 12 shows all 2-way interactions with genre and with possessor animacy for the six internal predictors with the largest overall interaction strength. Here we can see that the biggest cross-genre interaction is with possessor animacy, followed by possessor-possessum length. At the same time, we can see that possessor animacy also interacts with possessor-possessum length (as suggested by Figure 10), and possessor np type.
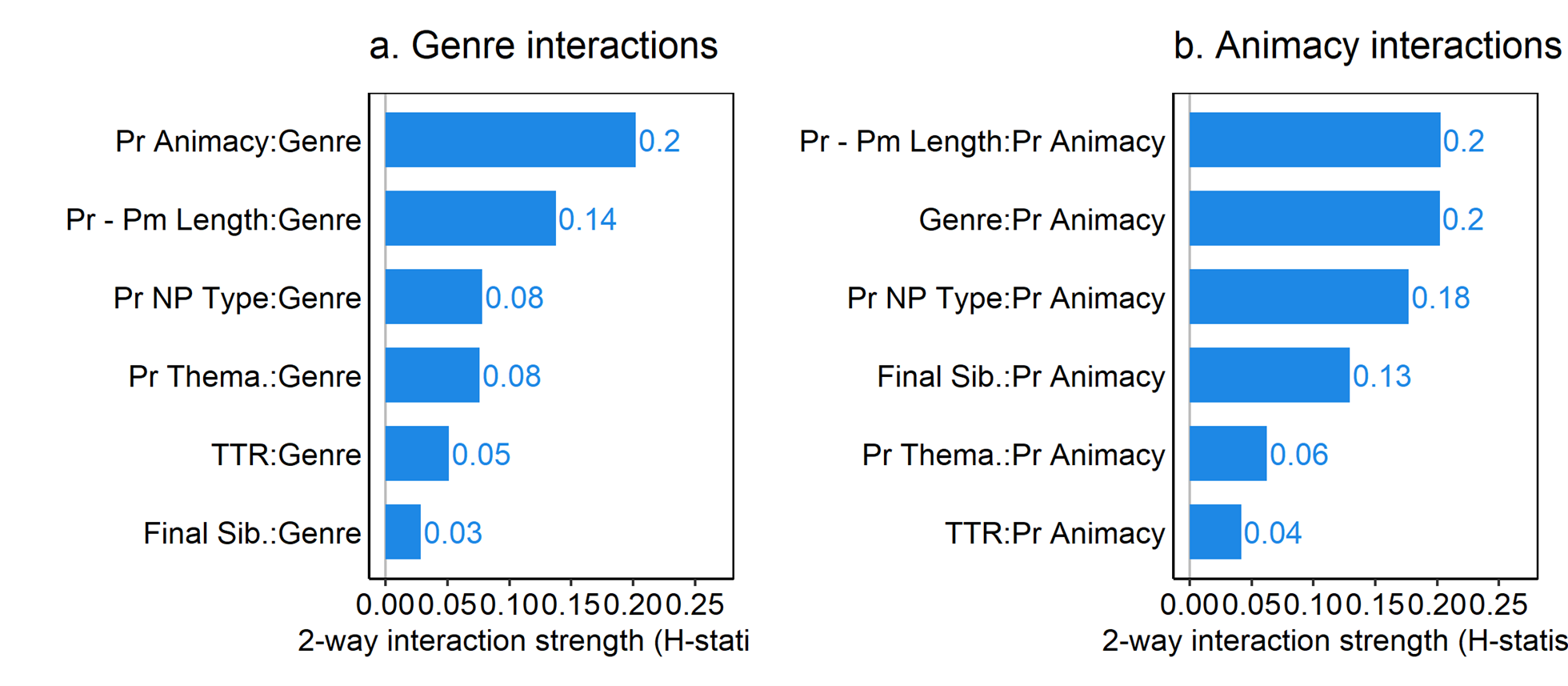
Figure 12. 2-way interaction strength (Friedman’s H-statistic) for genre with the 6 most important internal predictors for the random forest predicting the probability of the s-genitive.
One known disadvantage of this method is that it does not offer a test of whether a given interaction effect is significantly different from 0, which would be helpful for assessing whether a value of say, .1, is likely to be meaningful. It also suffers from some of the same limitations of partial dependence plots more generally, e.g. they consider combinations of predictors that are very unlikely. Nonetheless, as a method for detecting interaction effects, Friedman’s H offers a promising method for complementing standard measures of predictor importance.
The final technique to discuss is the (interaction) Breakdown plot, one of a number of recently developed methods for examining the effects of predictors on individual observations (Gosiewska & Biecek 2019). Breakdown plots are useful because they show how each predictor contributes to the model’s prediction for a specific observation in a way that is easy to understand. To illustrate, consider the example genitive token from the Press component of the Brown (1960s) Corpus in (3).
| (3) | Unfortunately, Brooks’ teammates were not in such festive mood as the Orioles expired before the seven-hit pitching of three Kansas City rookie hurlers. <Brown:A11> |
The corresponding breakdown plot for this token, based on the random forest model, is shown in Figure 13.
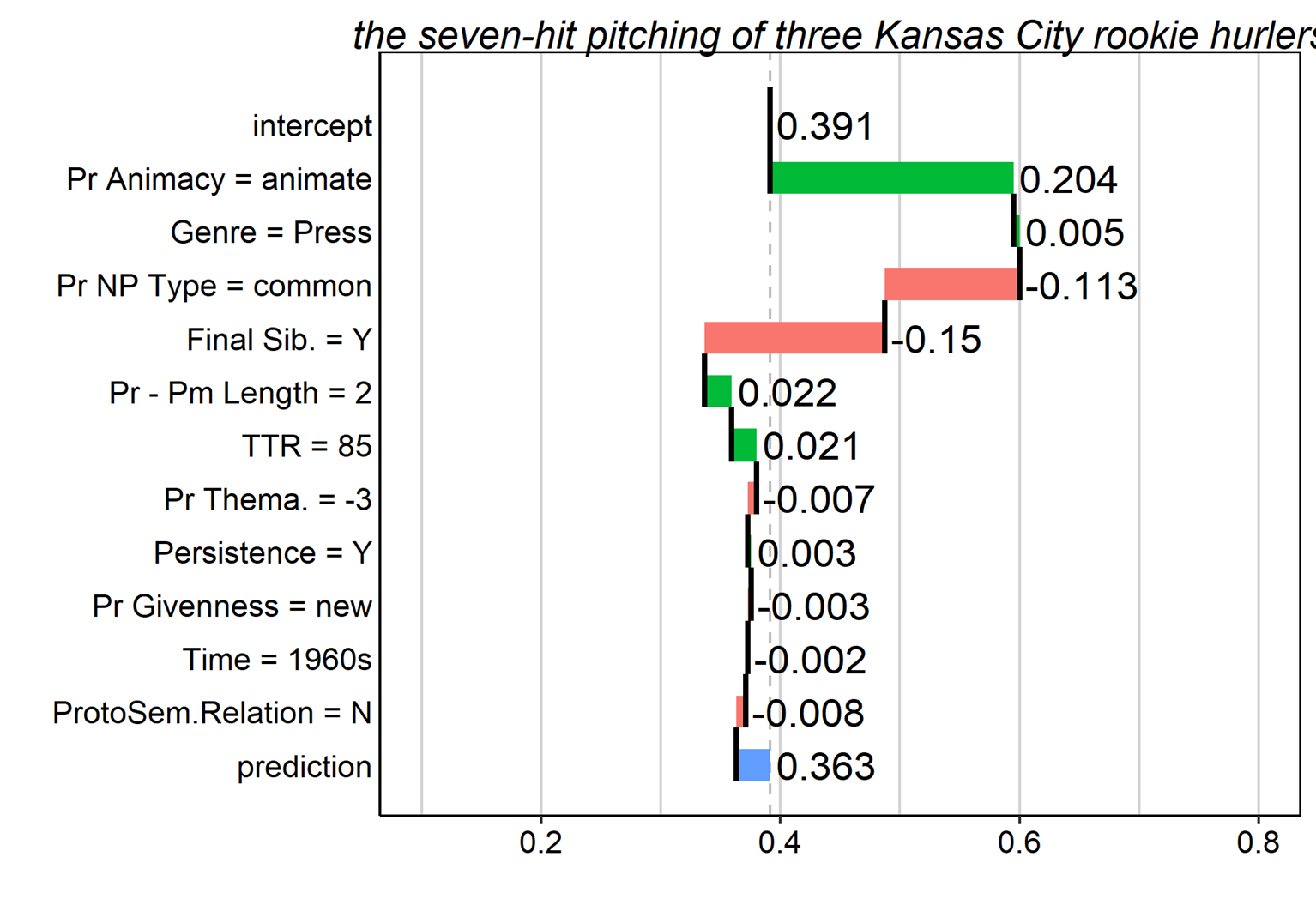
Figure 13. Breakdown plot for the genitive token ‘the seven-hit pitching of three Kansas City rookie hurlers.’ Contributions of predictor values are interpreted additively from the top to the bottom of the plot.
In essence, the breakdown plot shows the changes to the model’s prediction for this token as we successively consider the values of the token’s various features, starting at the top and working down to the final predicted probability. At the top of the plot is the model intercept, which represents the mean predicted probability of the s-genitive across all observations &NDASH; essentially the global proportion of s-genitives in the data (0.391). Moving down, the next row represents the adjustment to the predicted probability given that the possessor animacy value is ‘animate.’ The number to the side of the bar shows a positive value of 0.204, indicating how much the probability increases compared to the row above. Moving down to the next row, we see a smaller increase (+.005) due to the fact that the genre here is ‘Press.’ We proceed consecutively in this fashion working through the predictors until all have been considered. The final row shows the predicted probability of the outcome (s-genitive) for this token, here 0.363, and the bar reflects the difference between the baseline probability, and the final prediction taking into account all the predictors in the model.
The rankings of predictors in the breakdown plot is determined by the overall importance of that predictor to the model’s prediction for that token. In other words, for a given predictor with, e.g., genre = ‘Press,’ we calculate the difference between the prediction of the model when genre = ‘Press’ and the global prediction of the model. This is done for all predictors in the model, which are then ranked by decreasing importance. The contribution value in each row is determined by subtracting the model’s prediction given the set of values up to and including that row from the model’s prediction given only the set of values above that row. Thus, at each step going down, we see the model’s prediction having taken into account all the preceding feature values, but none of those below. Figure 14 shows a few more examples of what these look like for different tokens.
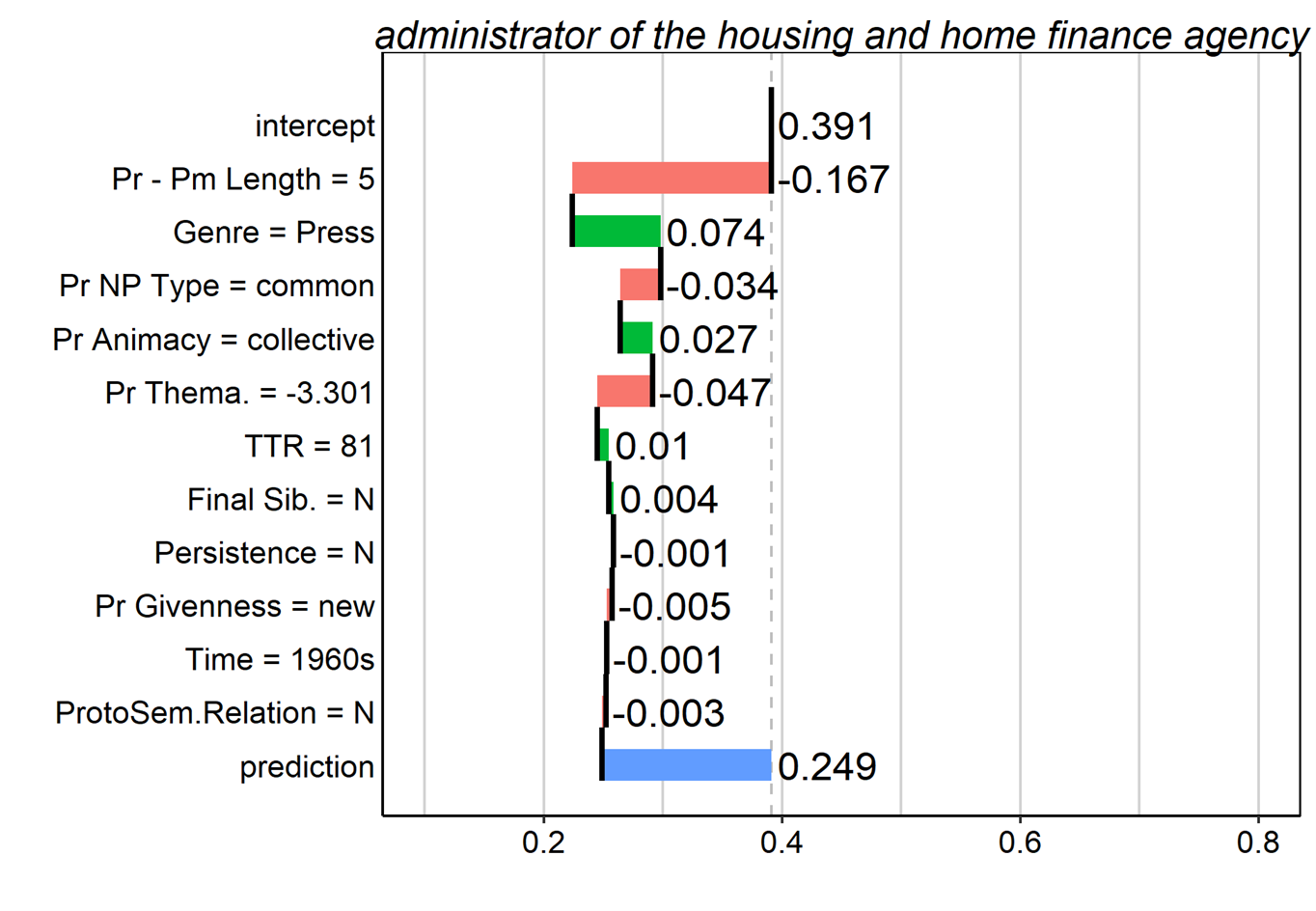
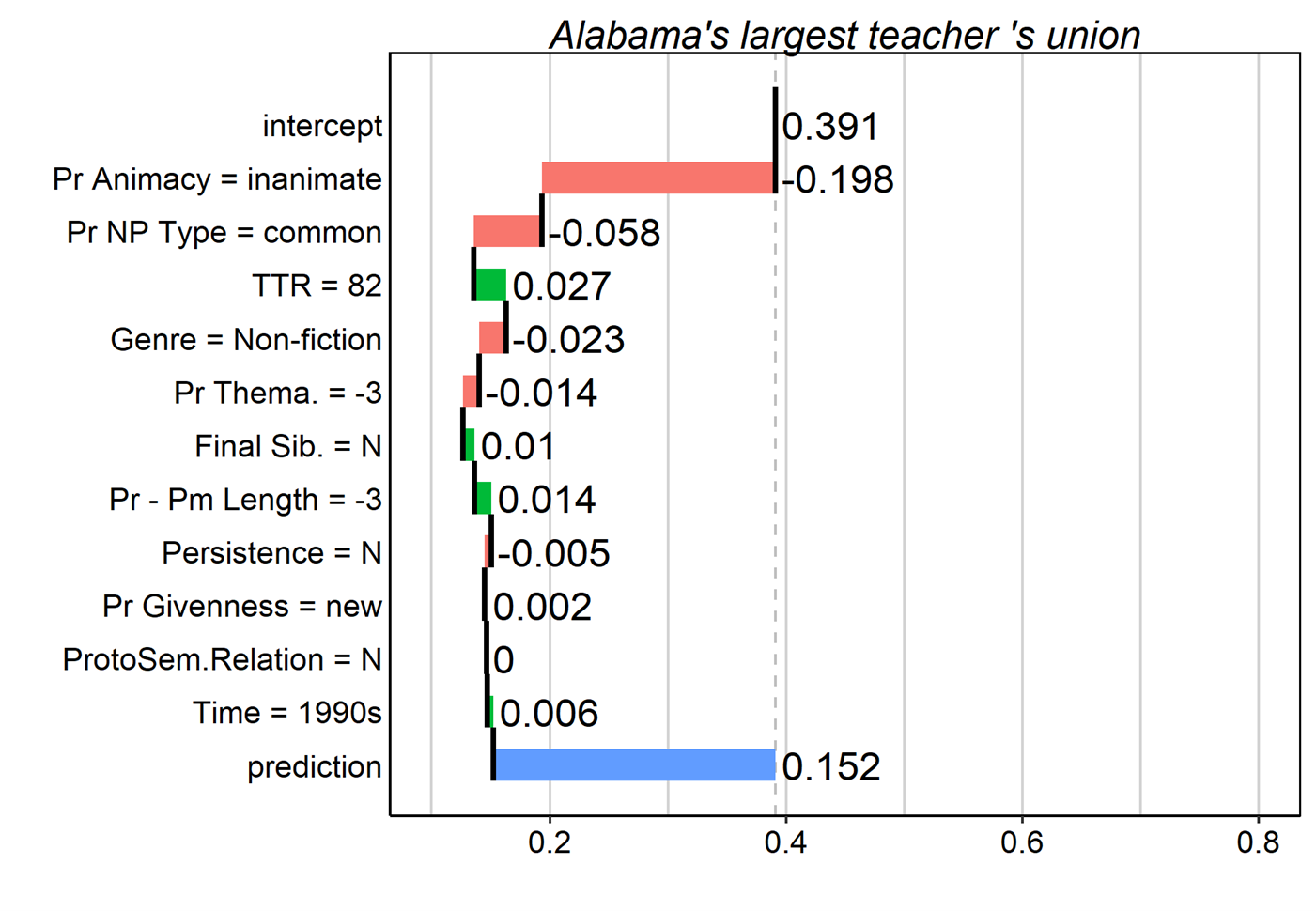
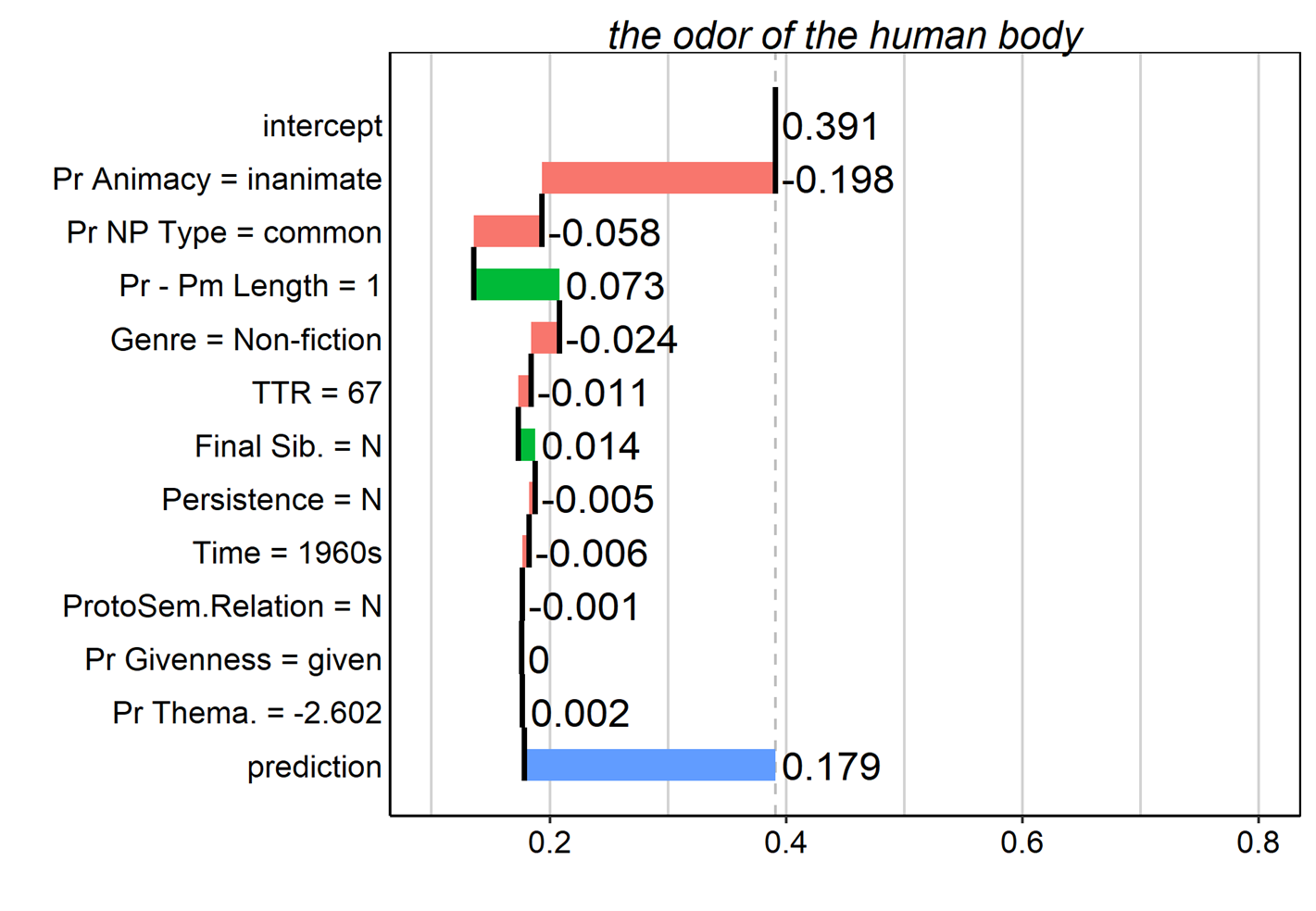
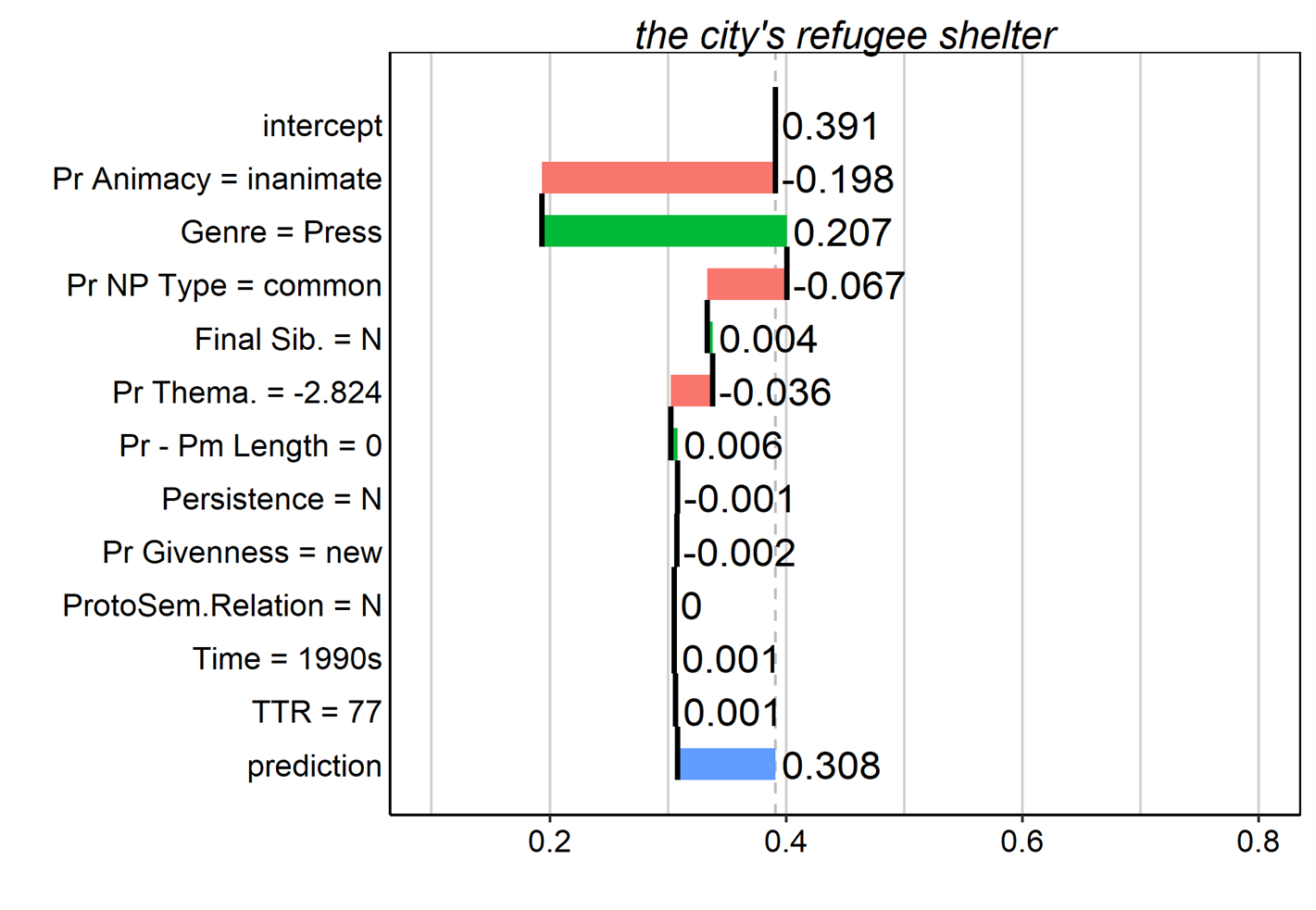
Figure 14. Breakdown plots for several tokens in the dataset. Contributions of predictor values are interpreted additively from the top to the bottom of the plot.
However, because breakdown plots show only the sequential additive contributions of each feature’s value to the model, these plots can be misleading for models that involve interactions. This is because when interactions are present, the contribution of a given predictor can change considerably – even reverse direction – depending on whether it is added before or after another predictor with which it interacts. Biecek & Burzykowski (2021) discuss a couple of remedies to this problem. One method involves the inclusion of pairwise interaction effects in the calculation of the predictor contributions. The method thus considers not only the independent contributions of two (or more) predictors, but also calculates the effect of their interaction. As a rule of thumb, the method considers an interaction to be important if its importance is greater than the individual importance of either of its two predictors (see Biecek & Burzykowski 2021, Chapter 7.3). The plots in Figures 13 and 14 exemplify so-called interaction breakdown plots, and it is clear from the lack of interaction terms that in all these cases, the breakdown plots suggest that there are no interactions of much importance. Whatever interactions there may be are relatively minor.
An alternative solution to the ordering problem involves calculating the contribution of each predictor using multiple random orderings, and then simply averaging across those orderings (Biecek & Burzykowski 2021, Chapter 8). This method relies heavily on the approach based on ‘Shapley values’ developed by Lundberg & Lee (2017). Figure 15 illustrates this method for the same token in (3), the seven-hit pitching of three Kansas City rookie hurlers. Here we can see that in this case, a final sibilant in the possessor, i.e. hurlers, plays an even bigger role than we might have thought. Also of note is the fact that the distribution of possessor-possessum length crosses 0, indicating that its contribution reverses direction across some of the different orderings. This is an indication of possible interactions with this predictor. The interaction breakdown plot above (Figure 13) did not indicate any strong interactions however, so we are probably safe here.
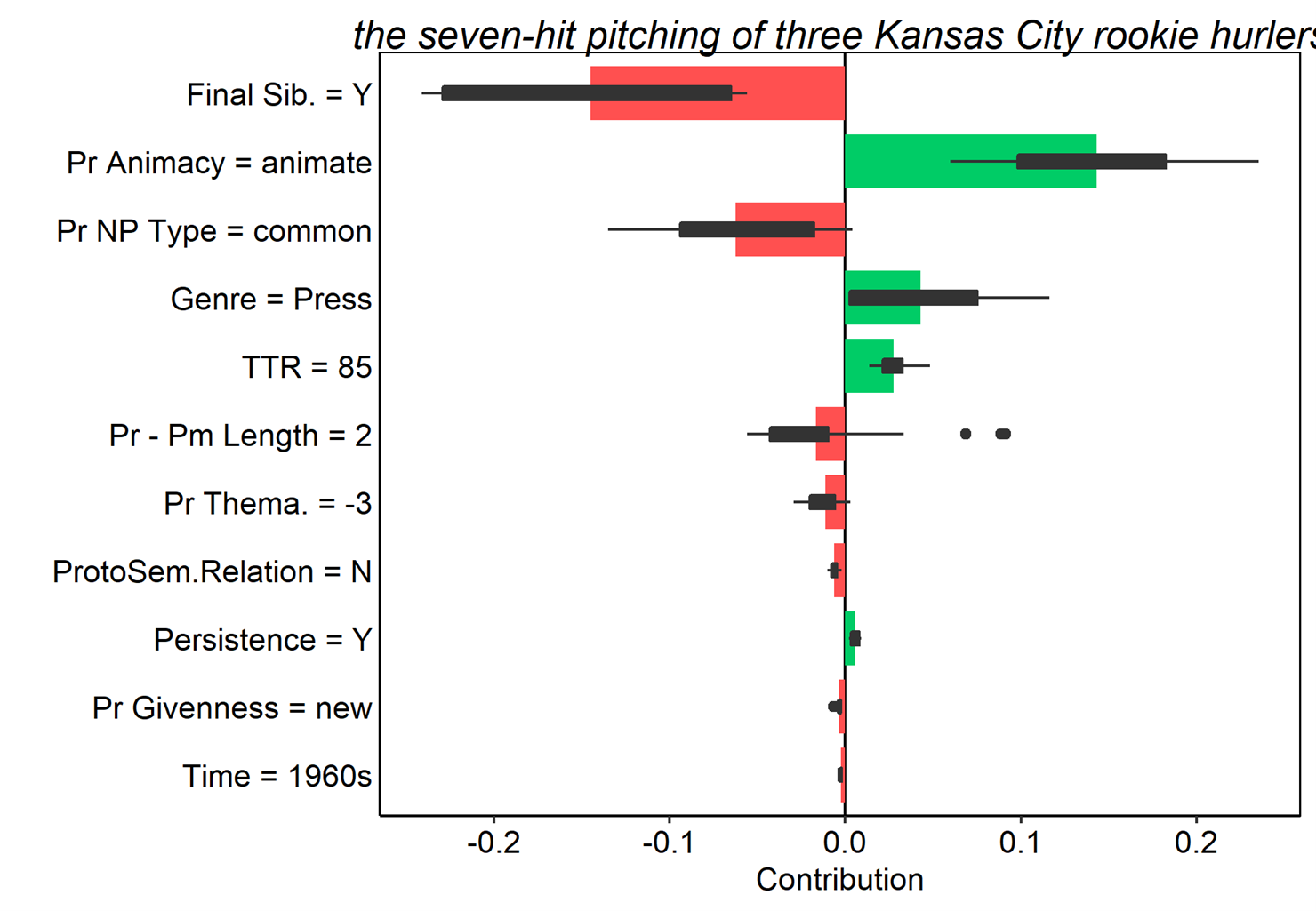
Figure 15. Average contributions to random forest model prediction for the s-genitive for 25 random orderings. Red and green bars present the mean contributions, and box plots summarize the distribution of contributions across the orderings.
One potential use for breakdown plots might be for understanding those cases where a model makes the wrong prediction. For example, the following examples of observed of-genitives were incorrectly predicted by the model to be s-genitives.
For each of these tokens, we can use breakdown plots to identify the predictors that contribute the most to the model’s prediction.
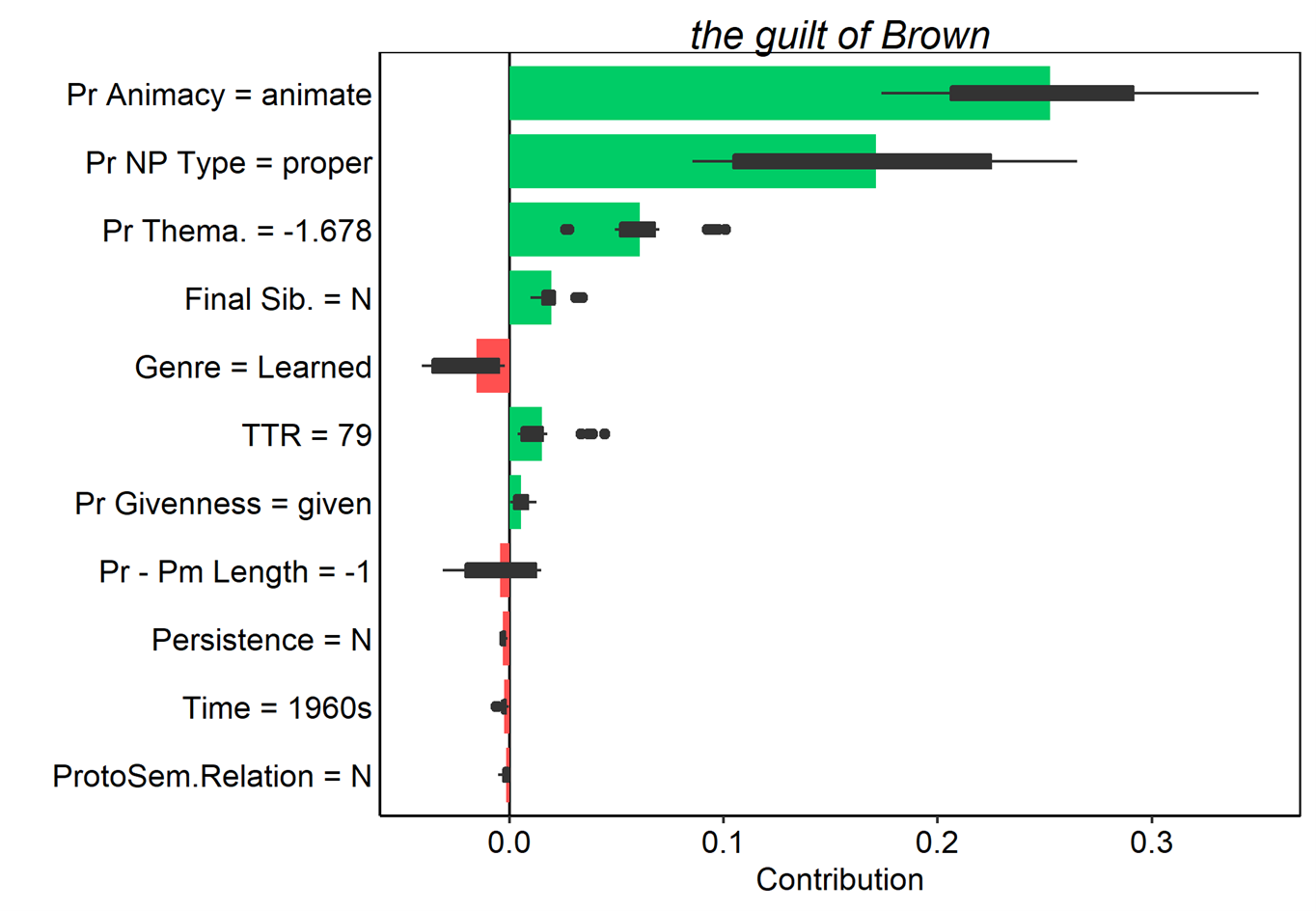
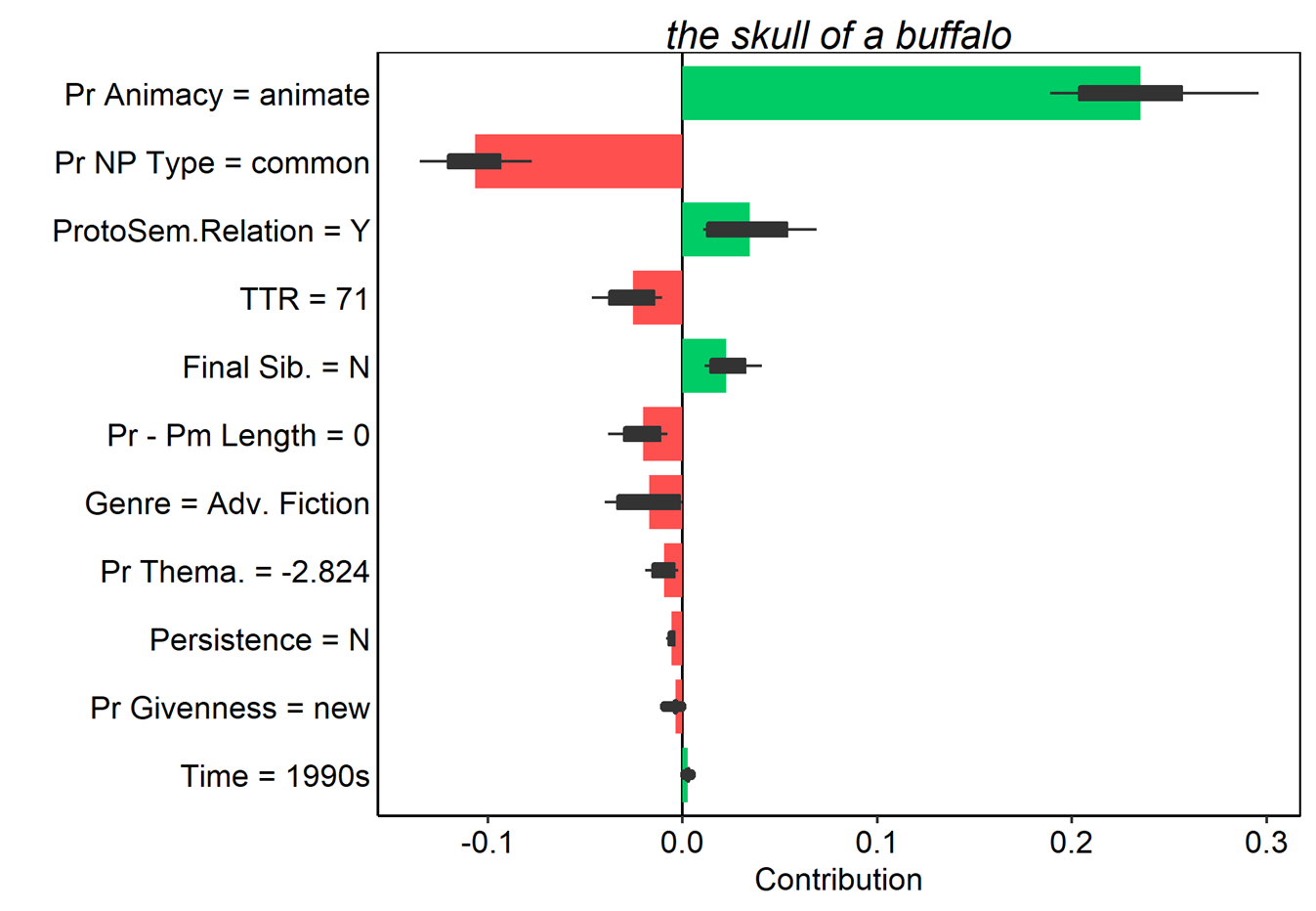
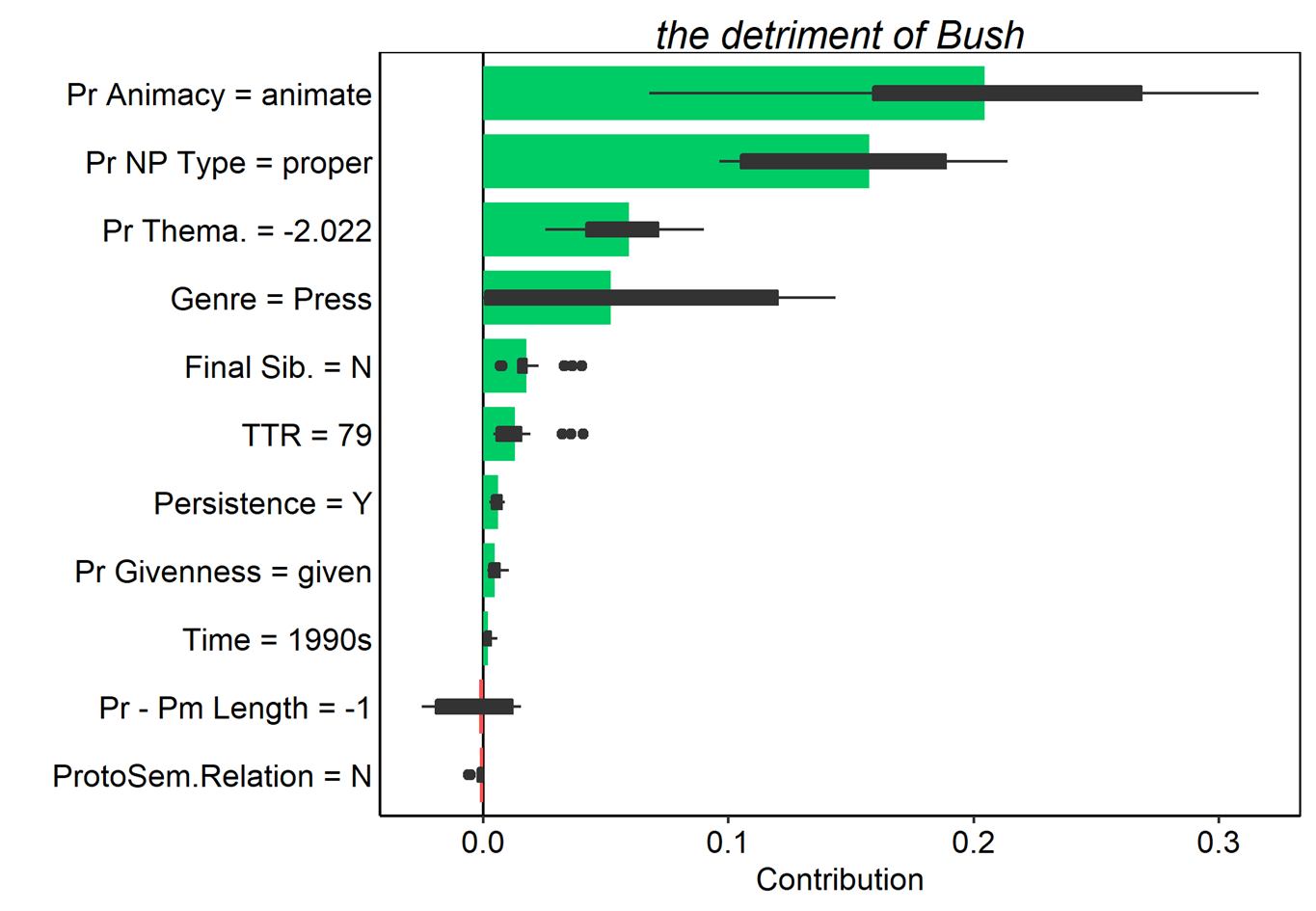
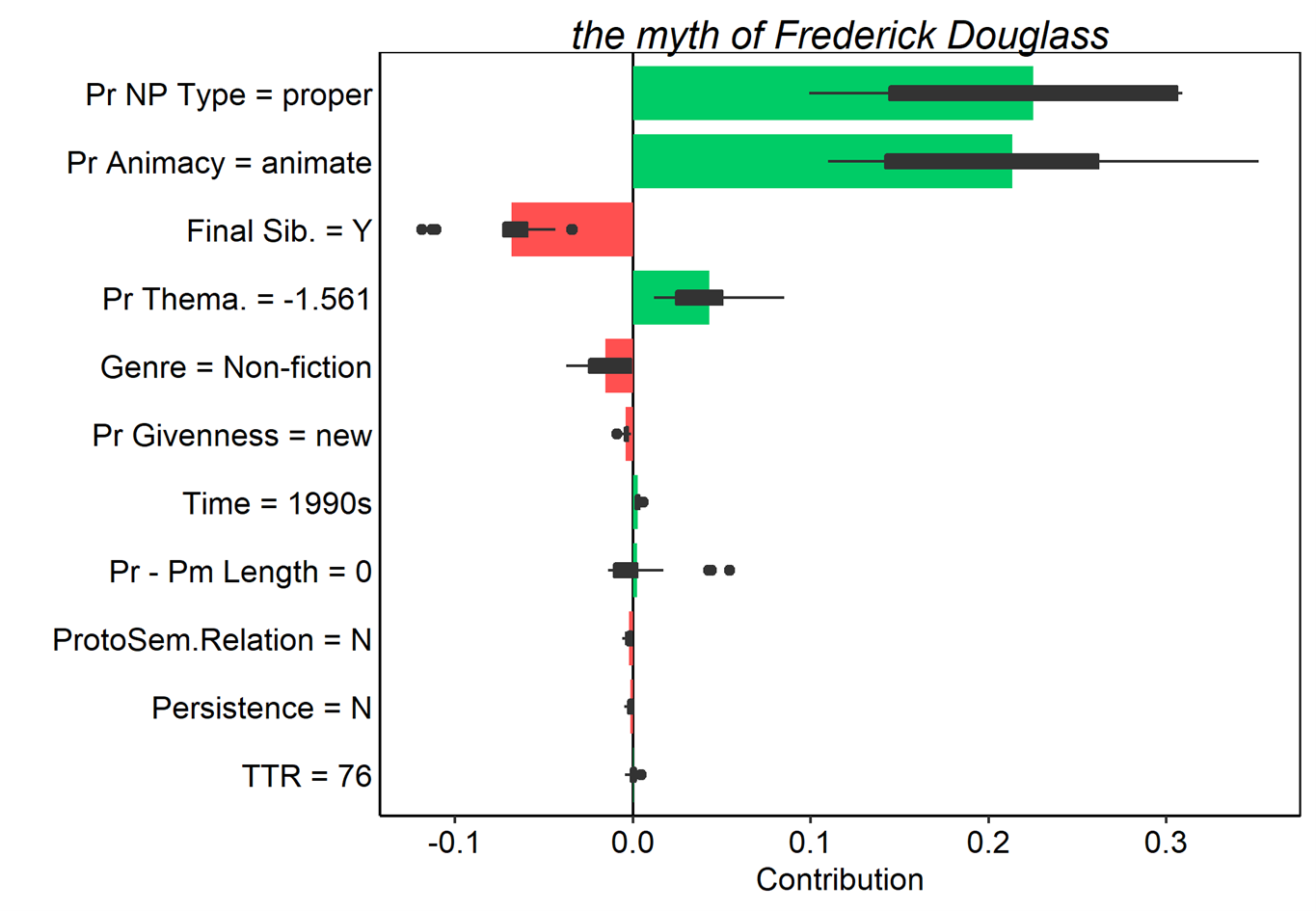
Figure 16. Average contributions to random forest model prediction for the s-genitive for 25 random orderings. Tokens here were all misclassified as s-genitives. Red and green bars present the mean contributions, and box plots summarize the distribution of contributions across the orderings.
Looking across these examples, it is clear that possessor animacy makes a considerable contribution the model’s error in every case, as does the NP type of the possessor. On the whole, animate, proper noun possessors heavily favour the s-genitive, so this is not too surprising. It is also apparent that several of these tokens involve highly thematic possessors, which again increase the s-genitive probability. Finally, the highly variable contribution of genre to the token in (6) is noteworthy, especially because it seems that this is in fact quoted speech, rather than a genuine written token.
We can also look at the converse cases, where actual s-genitives were misclassified as of-genitives.
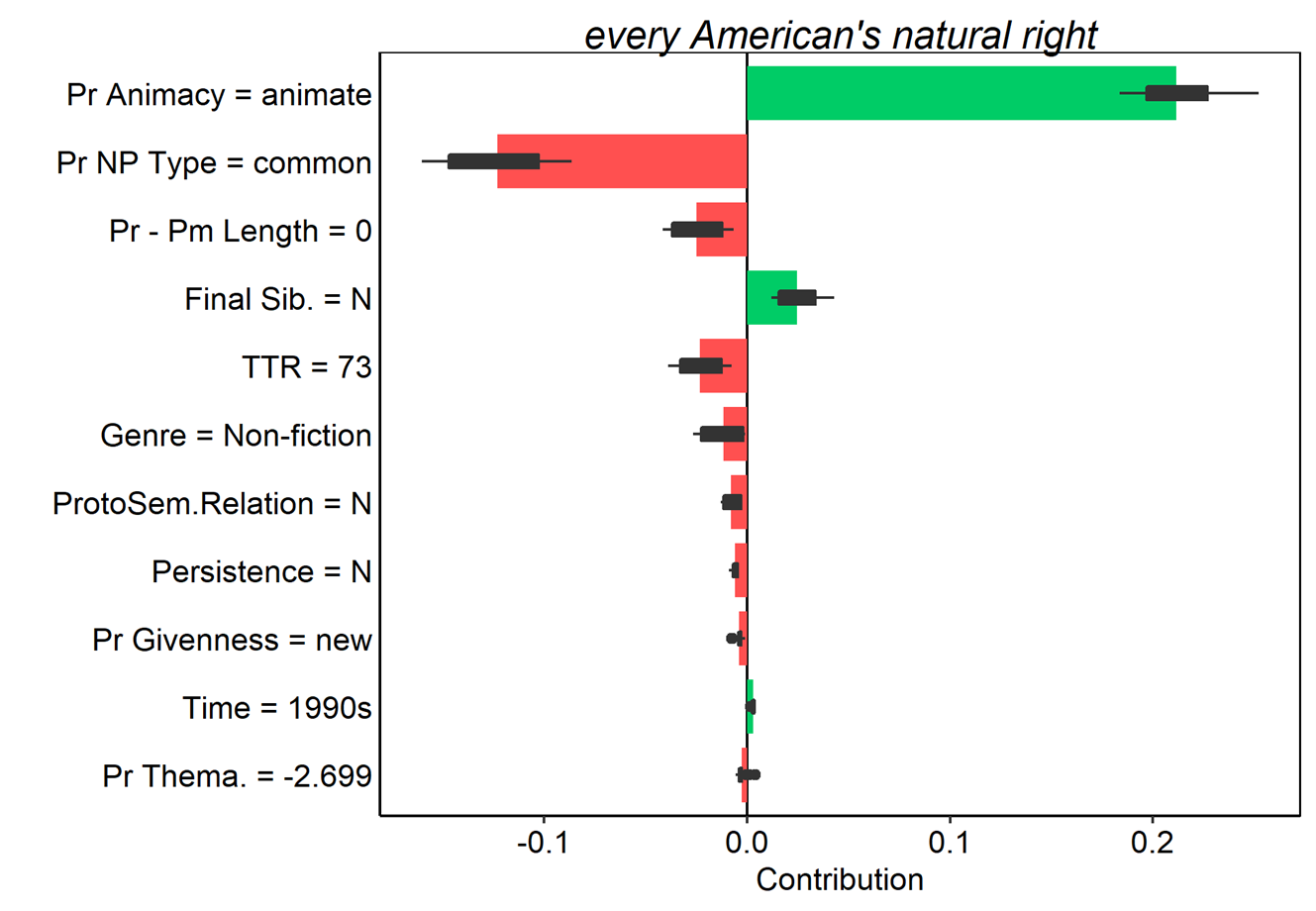
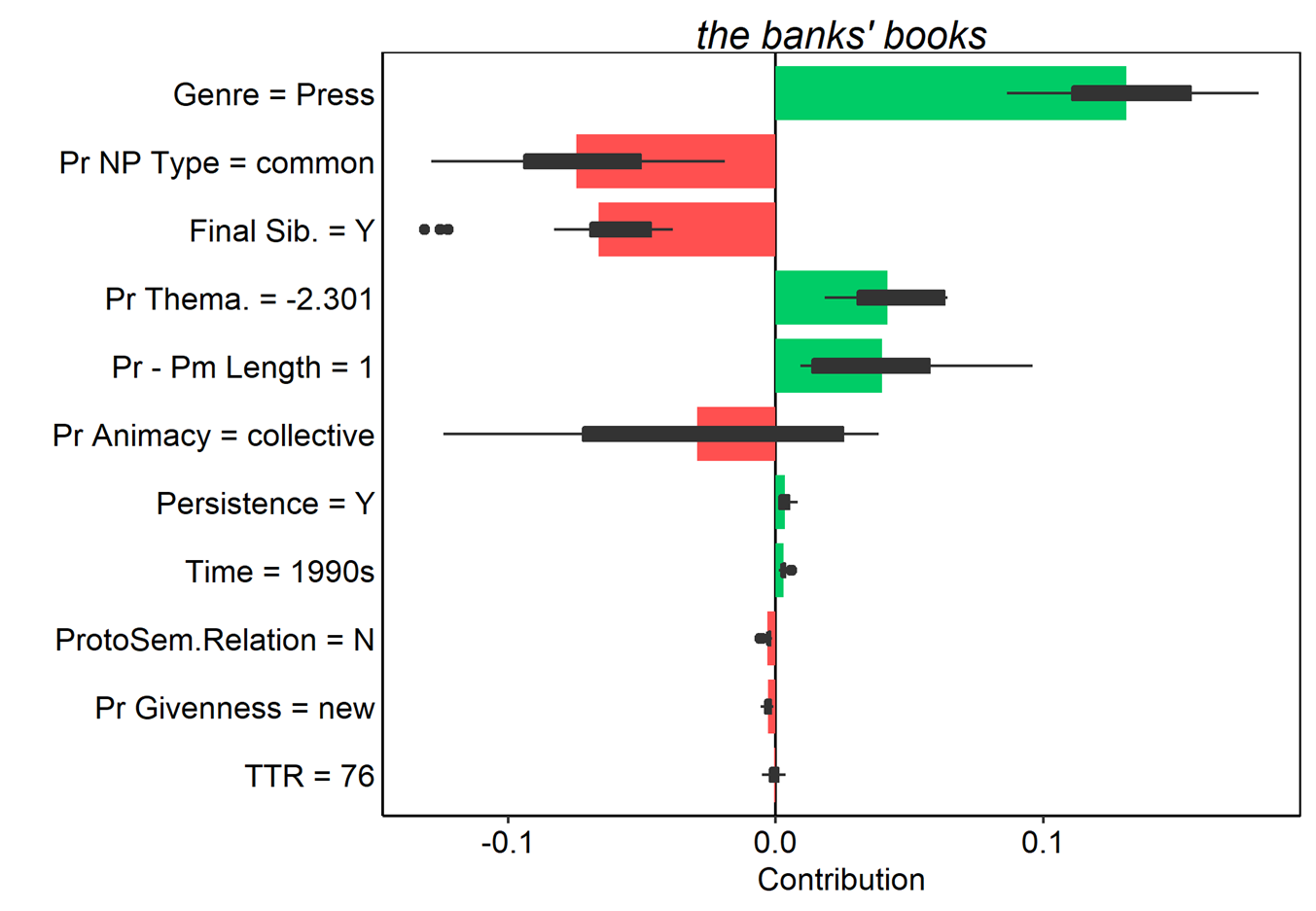
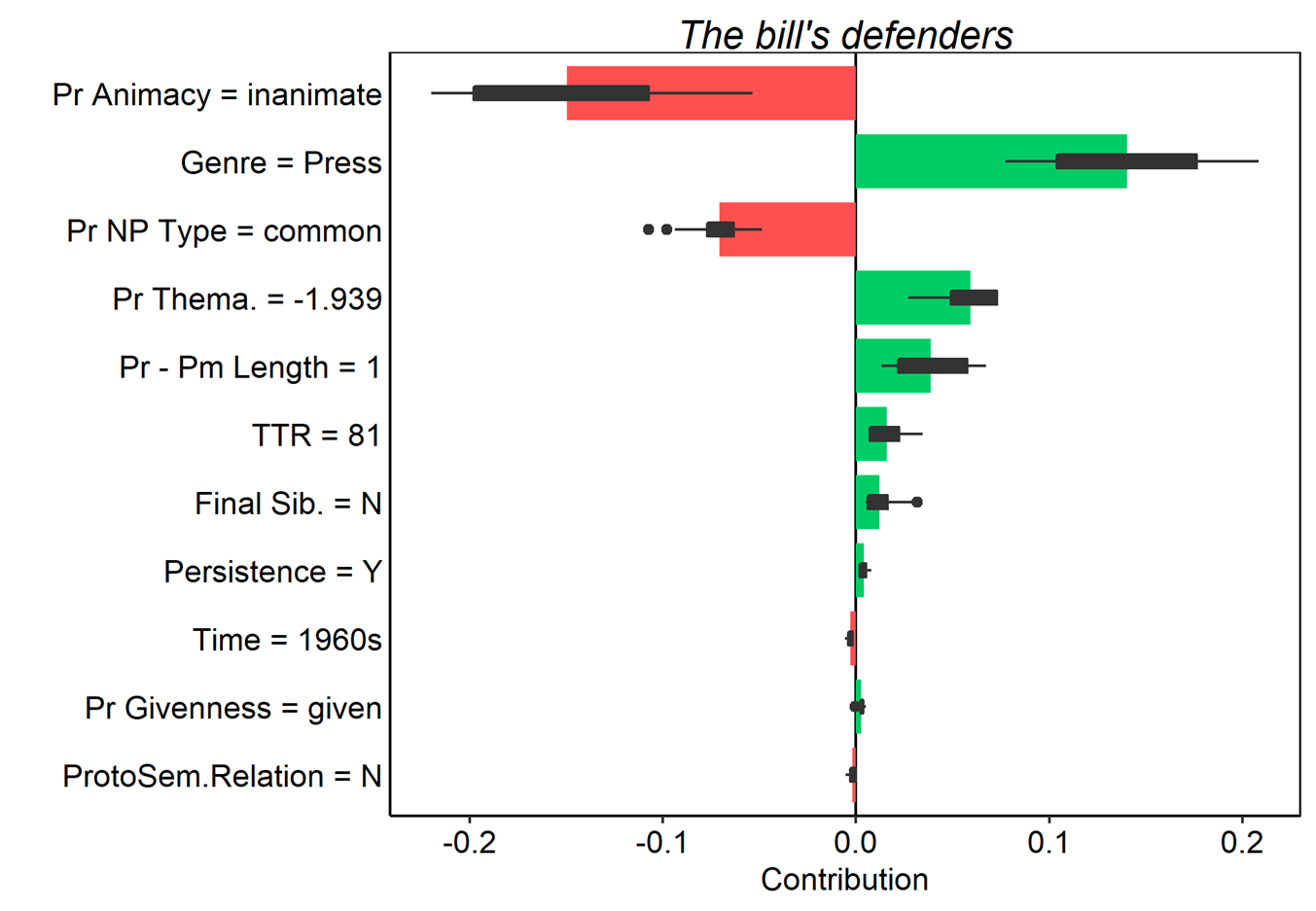
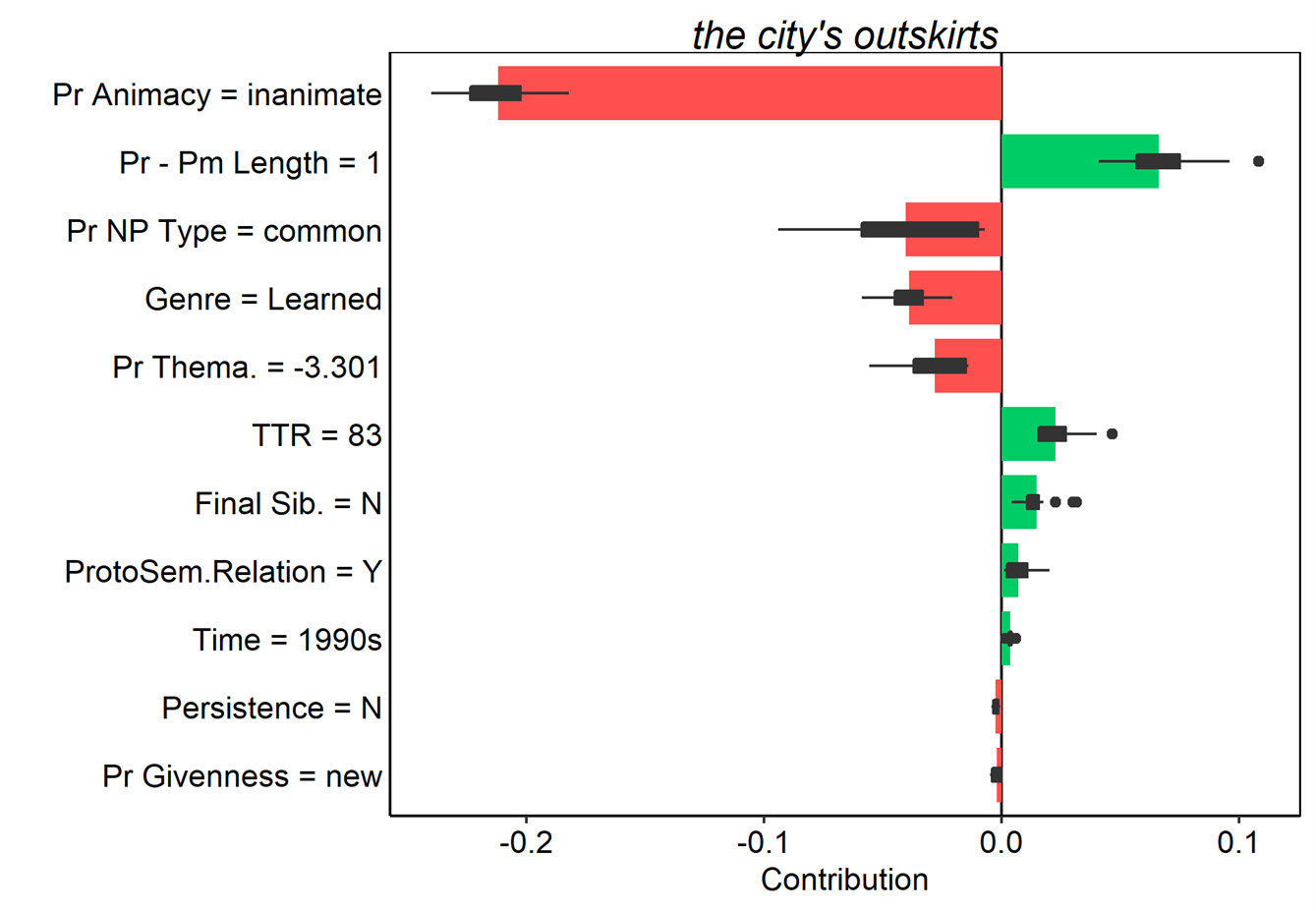
Figure 17. Average contributions to random forest model prediction for the s-genitive for 25 random orderings. Tokens here were all misclassified as of-genitives. Red and green bars present the mean contributions, and box plots summarize the distribution of contributions across the orderings.
In these examples it is a bit easier to see how the various features of each token pull the model’s predictions in different directions. possessor animacy still exerts a strong pull when the possessor is animate or inanimate; however, the token the banks’ books in (10) shows that when the possessor is a collective, the model is ambivalent. The example of every American’s natural right (upper left in Figure 17) also shows nicely how the cumulative influence of many weaker features favoring one outcome can outweigh even a very strong feature pulling in the opposite direction. Breakdown plots thus offer an elegant method for examining how individual observations are classified by a model, and how specific feature values contribute incrementally (as in standard breakdown plots) or cumulatively (as the Shapley value-based plots) to those classifications.
The present paper set out to provide a wider perspective on the value of, and possibilities for, visualizing predictive models in linguistic research. The growing availability of large amounts of data, as well as increased computing power and processing speed has greatly expanded the potential for statistical modeling of more and more complex phenomena. But as the saying goes, there’s no such thing as a free lunch, and as models become more complex, they also become harder for humans to interpret. Thus, one of my primary aims here has been to show how visualizations can be helpful, even necessary, for understanding complex statistical models. While conditional (partial) effects plots for regression models, decision trees, and predictor importance plots for random forests are common in variationist (corpus) studies, they are merely a small sample out of many possible strategies for exploring model results. The point of this paper is that it is possible to visualize the results of regression and random forest models (or truthfully any predictive model) from a number of different perspectives, many of which can be especially useful for investigating effects of models and procedures that do not provide direct measures of predictor effects. PD and ICE plots offer methods for examining individual predictor effects at the level of both the global dataset and across individual observations. ICE plots are particularly useful as they allow us to see heterogeneous patterns and outlying observations, which can be further explored in the existing (training) data or used to guide further data collection. At the same time, breakdown plots and Shapley values are useful for understanding the behavior of a model at the level of individual observations, which is something that is not always appreciated in variationist studies (Gries et al. 2020). Finally, there are now methods in development for exploring the importance of interaction effects in random forest and other “black box” models, which can partly address some of the concerns about such methods (e.g. Boulesteix et al. 2015; Gries 2019; Wright et al. 2016).
The field of interpretable machine learning has made considerable strides in recent years, and many techniques have been in development for addressing some (though certainly not all) of the challenges facing quantitative linguists. It is of course true that some of these techniques are themselves quite new, and have not been thoroughly tested, but then the same can be said of many approaches that have been suggested in the literature. Ultimately, no single approach is perfect, and results of any model must be considered carefully in light of one’s understanding of the data and phenomenon in question.
As a final note, I would like to digress a bit to take a broader (and perhaps bolder) perspective beyond the methods discussed above. I believe it is worth exploring the degree to which visualization of constraint effects in single models and mapping of more holistic patterns can provide complementary “jeweler’s eye” and “bird’s eye” perspectives in comparative variationist analysis. While the techniques discussed in this paper are capable of examining patterns with respect to individual linguistic constraints and/or observations, they offer limited insight into the relative degree of similarity across constraints in aggregate. What has been lacking is a more macroscopic perspective for comparing variable grammars in the spirit of Comprative Sociolinguistics (Tagliamonte 2013). In recent years, researchers have been exploring techniques for providing just such a holistic perspective on cross-varietal patterns. Two noteworthy examples include Variation-based Distance and Similarity Modeling (Grafmiller & Szmrecsanyi 2018; Szmrecsanyi et al. 2019), and Multifactorial Prediction and Deviation Analysis (Deshors & Gries 2020; Gries & Deshors 2014; Heller et al. 2017a). These methods are similar in that they set out to decompose complex models with many potential interactions into sets of simpler models of individual datasets, whose results can be compared and evaluated in systematic ways. There are important differences in these approaches, but what is most pertinent to the present paper is that they both provide methods for representing aggregate grammatical similarities among varieties (however they may be defined). Such methods are of obvious potential value to researchers in many subfields, but I believe they are a particularly promising direction for variationist linguists to pursue.
[1] There is ongoing debate regarding the full scope of this alternation, but I will not wade into these murky waters here (see Szmrecsanyi et al. 2016a for discussion). The aim of this paper is to illustrate methods for exploring similarities among variables and varieties within a variationist framework, and so for simplicity’s sake I focus on only this binary genitive alternation. [Go back up]
[2] More sophisticated regression approaches such as generalized additive models (GAMs) have recently been gaining traction (e.g. Wieling et al. 2014; Tamminga et al. 2016), but these come with their own complications, which I cannot address here. [Go back up]
[3] Gelman & Hill (2007) and Harrell (2015) offer excellent general introductions to regression modeling, and Nicenboim & Vasishth (2016) provide a concise introduction to Bayesian methods for linguistics. For a more comprehensive and highly accessible introduction to applied Bayesian modeling, see McElreath (2020). [Go back up]
[4] I invite readers to send suggestions to j.grafmiller@bham.ac.uk [Go back up]
[5] The visualization methods used here for random forests are ‘model agnostic,’ meaning they can in principle be used with many other packages and any kind of predictive models, including GLMMs. However, calculations for brms GLMMs and party random forests can be incredibly computationally demanding for large datasets and models, generating very large vectors and/or taking hours or even days to compute. I do not illustrate them here. [Go back up]
[6] These are also often referred to as ‘partial effects’ or ‘marginal effects’ plots. [Go back up]
[7] This is where partial dependence plots differ from conditional effects plots. The latter plots effects with the other predictors fixed at default values. [Go back up]
[8] Gries (2019: 25–26) suggests using weighted means derived from the frequency distributions of the combined predictor values in the observed data. This approach is appealing because it allows one to better adjust the model estimates based on the amount of available evidence (i.e. data), and it is surely an avenue worth exploring further. But there are additional complications to this, e.g. how to treat continuous predictors, and so to keep things simple I use the unweighted means here. [Go back up]
[9] I am not aware of any peer-reviewed study demonstrating this problem, but see O’Sullivan (2021) for an informal illustration of such a case. [Go back up]
Datasets, R code, and supplementary material for the present paper at OSF: https://osf.io/tkfnc/
Baayen, R. Harald, Anna Endresen, Laura A. Janda, Anastasia Makarova & Tore Nesset. 2013. “Making choices in Russian: Pros and cons of statistical methods for rival forms”. Russian Linguistics 37(3): 253–291. doi:10.1007/s11185-013-9118-6
Bernaisch, Tobias, Stefan Th. Gries & Joybrato Mukherjee. 2014. “The dative alternation in South Asian English(es): Modelling predictors and predicting prototypes”. English World-Wide 35: 7–31.
Biber, Douglas & Susan Conrad. 2009. Register, Genre, and Style (Cambridge Textbooks in Linguistics). Cambridge: Cambridge University Press.
Biecek, Przemyslaw. 2018. “DALEX: Explainers for complex predictive models in R”. Journal of Machine Learning Research 19(84): 1–5.
Biecek, Przemyslaw & Tomasz Burzykowski. 2021. Explanatory model analysis: Explore, Explain, and Examine Predictive Models (Chapman & Hall/CRC Data Science Series). First edition. Boca Raton: CRC Press.
Boulesteix, Anne-Laure, Silke Janitza, Alexander Hapfelmeier, Kristel Van Steen & Carolin Strobl. 2015. “Letter to the Editor: On the term ‘interaction’ and related phrases in the literature on Random Forests“. Briefings in Bioinformatics 16(2): 338–345. doi:f67gf3
Bresnan, Joan, Anna Cueni, Tatiana Nikitina & R. Harald Baayen. 2007. “Predicting the dative alternation”. Cognitive Foundations of Interpretation, ed. by G. Boume, I. Kraemer & J. Zwarts, 69–94. Amsterdam: Royal Netherlands Academy of Science.
Bresnan, Joan & Jennifer Hay. 2008. “Gradient grammar: An effect of animacy on the syntax of give in New Zealand and American English”. Lingua 118: 245–259. doi:10.1016/j.lingua.2007.02.007
Bürkner, Paul-Christian. 2017. “brms: An R package for Bayesian multilevel models using Stan”. Journal of Statistical Software 80(1). doi:gddxwp
Carpenter, Bob, Andrew Gelman, Matthew D. Hoffman, Daniel Lee, Ben Goodrich, Michael Betancourt, Marcus Brubaker, Jiqiang Guo, Peter Li & Allen Riddell. 2017. “Stan: A probabilistic programming language”. Journal of Statistical Software 76(1). doi:10.18637/jss.v076.i01
Deshors, Sandra C. & Stefan Th. Gries. 2016. “Profiling verb complementation constructions across New Englishes: A two-step random forests analysis of ing vs. to complements”. International Journal of Corpus Linguistics 21(2): 192–218. doi:10.1075/ijcl.21.2.03des
Deshors, Sandra C. & Stefan Th. Gries. 2020. “Mandative subjunctive versus should in world Englishes: A new take on an old alternation”. Corpora 15(2): 213–241. doi:10.3366/cor.2020.0195
Francis, W. Nelson & Henry Kučera. 1979. A Standard Corpus of Present-Day Edited American English, for Use with Digital Computers (Brown). Providence, RI: Brown University. https://varieng.helsinki.fi/CoRD/corpora/BROWN/
Friedman, Jerome H. 2001. “Greedy function approximation: A gradient boosting machine”. Annals of Statistics 29(5): 1189–1232. doi:10.1214/aos/1013203451
Friedman, Jerome H. & Bogdan E. Popescu. 2008. “Predictive learning via rule ensembles”. The Annals of Applied Statistics 2(3): 916–954. doi:10.1214/07-AOAS148
Garretson, Gregory. 2004. Coding Practices Used in the Project Optimality Typology of Determiner Phrases. http://npcorpus.bu.edu/documentation/BUNPCorpus_coding_practices.pdf
Gelman, Andrew & Jennifer Hill. 2007. Data Analysis Using Regression and Multilevel/Hierarchical Models. New York: Cambridge University Press.
Gelman, Andrew, Aleks Jakulin, Maria Grazia Pittau & Yu-Sung Su. 2008. “A weakly informative default prior distribution for logistic and other regression models”. The Annals of Applied Statistics 2(4): 1360–1383. doi:10.1214/08-AOAS191
Ghosh, Joyee, Yingbo Li & Robin Mitra. 2018. “On the use of Cauchy prior distributions for Bayesian logistic regression”. Bayesian Analysis 13(2): 359–383. doi:gdfv6g
Goldstein, Alex, Adam Kapelner, Justin Bleich & Emil Pitkin. 2015. “Peeking inside the black box: Visualizing statistical learning with plots of Individual Conditional Expectation”. Journal of Computational and Graphical Statistics 24(1): 44–65. doi:gffgnc
Gosiewska, Alicja & Przemyslaw Biecek. 2019. “Do not trust additive explanations”. arXiv:1903.11420 [cs, stat]. http://arxiv.org/abs/1903.11420
Grafmiller, Jason. 2014. “Variation in English genitives across modality and genres”. English Language and Linguistics 18(03): 471–496. doi:10.1017/S1360674314000136
Grafmiller, Jason & Benedikt Szmrecsanyi. 2018. “Mapping out particle placement in Englishes around the world: A study in comparative sociolinguistic analysis”. Language Variation and Change 30(3): 385–412. doi:gf4p2w
Gries, Stefan Th. 2019. “On classification trees and random forests in corpus linguistics: Some words of caution and suggestions for improvement”. Corpus Linguistics and Linguistic Theory 16(3): 617–647. doi:10.1515/cllt-2018-0078
Gries, Stefan Th., Santa Barbara, Justus Liebig & Sandra C. Deshors. 2020. “There’s more to alternations than the main diagonal of a 2 confusion matrix: Improvements of MuPDAR and other classificatory alternation studies”. ICAME Journal 44(1): 69–96. doi:10.2478/icame-2020-0003
Gries, Stefan Th. & Sandra C. Deshors. 2014. “Using regressions to explore deviations between corpus data and a standard/target: Two suggestions”. Corpora 9(1): 109–136. doi:10.3366/cor.2014.0053
Harrell, Frank E. 2015. Regression Modeling Strategies. Second edition. New York: Springer.
Heller, Benedikt, Tobias Bernaisch & Stefan Th. Gries. 2017a. “Empirical perspectives on two potential epicenters: The genitive alternation in Asian Englishes”. ICAME Journal 41(1): 111–144. doi:10.1515/icame-2017-0005
Heller, Benedikt, Benedikt Szmrecsanyi & Jason Grafmiller. 2017b. “Stability and fluidity in syntactic variation world-wide: The genitive alternation across varieties of English”. Journal of English Linguistics 45(1): 3–27. doi:10.1177/0075424216685405
Hinrichs, Lars & Benedikt Szmrecsanyi. 2007. “Recent changes in the function and frequency of standard English genitive constructions: A multivariate analysis of tagged corpora”. English Language and Linguistics 11(3): 437–474. doi:10.1017/S1360674307002341
Hundt, Marianne. 2018. “It is time that this (should) be studied across a broader range of Englishes”. Modeling World Englishes. Assessing the Interplay of Emancipation and Globalization of ESL Varieties, ed. by Sandra C. Deshors, 217–244. Amsterdam: John Benjamins.
Hundt, Marianne & Christian Mair. 1999. “‘Agile’ and ‘uptight’ genres: The corpus-based approach to language change in progress”. International Journal of Corpus Linguistics 4: 221–242.
Johnson, Daniel Ezra. 2009. “Getting off the GoldVarb standard: Introducing Rbrul for mixed-effects variable rule analysis”. Language and Linguistics Compass 3(1): 359–383. doi:10.1111/j.1749-818X.2008.00108.x
Kimball, Amelia E., Kailen Shantz, Christopher Eager & Joseph Roy. 2018. “Confronting quasi-separation in logistic mixed effects for linguistic data: A Bayesian approach”. Journal of Quantitative Linguistics 26(3): 1–25. doi:gfv3f7
Labov, William. 1972. Sociolinguistic Patterns. 10th pr. Philadelphia: University of Pennsylvania Press.
Lundberg, Scott M. & Su-In Lee. 2017. “A unified approach to interpreting model predictions”. 31st Conference on Neural Information Processing Systems, 10.
Mair, Christian & Geoffrey Leech. 2007. The Freiburg-Brown Corpus (‘Frown’) (POS-tagged version). Freiburg and Lancaster: Albert-Ludwigs-Universität. https://varieng.helsinki.fi/CoRD/corpora/FROWN/
Matsuki, Kazunaga, Victor Kuperman & Julie A. Van Dyke. 2016. “The Random Forests statistical technique: An examination of its value for the study of reading”. Scientific Studies of Reading 20(1): 20–33. doi:10.1080/10888438.2015.1107073
Mayer, Michael. 2021. “flashlight: Shed light on black box machine learning models”. R package version 0.7.5.
McElreath, Richard. 2020. Statistical Rethinking: A Bayesian Course with Examples in R and Stan (CRC Texts in Statistical Science). Second edition. Boca Raton: Taylor and Francis, CRC Press.
Molnar, Christoph. 2021. Interpretable Machine Learning. Leanpub.
Montgomery, Michael. 1997. “Making transatlantic connections between varieties of English: The case of plural verbal -s”. Journal of English Linguistics 25(2): 122–141. doi:10.1177/007542429702500206
Nicenboim, Bruno & Shravan Vasishth. 2016. “Statistical methods for linguistic research: Foundational ideas – part II”. Language and Linguistics Compass 10(11): 591–613. doi:gcpb49
O’Connor, M. Catherine, Joan Maling, Arto Anttila, Vivienne Fong, Gregory Garretson, Barbora Skarabela, Marjorie Hogan & Fred Karlsson. 2006. Boston University Noun Phrase Corpus. http://npcorpus.bu.edu
O’Sullivan, Conor. 2021. “Finding and visualising interactions”. Towards Data Science. https://towardsdatascience.com/finding-and-visualising-interactions-14d54a69da7c
Poplack, Shana & Sali Tagliamonte. 2001. African American English in the Diaspora (Language in Society 30). Malden, MA: Blackwell.
R Core Team (2021). R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing. https://www.R-project.org/.
Rosenbach, Anette. 2014. “English genitive variation – the state of the art”. English Language and Linguistics 18(2): 215–262. doi:10.1017/S1360674314000021
Sankoff, David & Henrietta J. Cedergren. 1976. “The dimensionality of grammatical variation”. Language 52: 163–178.
Strobl, Carolin, James Malley & Gerhard Tutz. 2009. “An introduction to recursive partitioning: Rationale, application, and characteristics of classification and regression trees, bagging, and random forests”. Psychological Methods 14(4): 323–348. doi:10.1037/a0016973
Szmrecsanyi, Benedikt, Douglas Biber, Jesse Egbert & Karlien Franco. 2016a. “Toward more accountability: Modeling ternary genitive variation in Late Modern English”. Language Variation and Change 28(1): 1–29. doi:10.1017/S0954394515000198
Szmrecsanyi, Benedikt, Jason Grafmiller, Benedikt Heller & Melanie Röthlisberger. 2016b. “Around the world in three alternations: Modeling syntactic variation in varieties of English”. English World-Wide 37(2): 109–137. doi:10.1075/eww.37.2.01szm
Szmrecsanyi, Benedikt, Jason Grafmiller, Joan Bresnan, Anette Rosenbach, Sali Tagliamonte & Simon Todd. 2017. “Spoken syntax in a comparative perspective: The dative and genitive alternation in varieties of English”. Glossa 2(1): 86. doi:10.5334/gjgl.310
Szmrecsanyi, Benedikt, Jason Grafmiller & Laura Rosseel. 2019. “Variation-based distance and similarity modeling: A case study in World Englishes”. Frontiers in Artificial Intelligence 2. doi:10.3389/frai.2019.00023
Tagliamonte, Sali. 2013. “Comparative Sociolinguistics”. Handbook of Language Variation and Change, ed. by J.K. Chambers & Natalie Schilling, 130–156. Second edition. Chichester: Wiley.
Tagliamonte, Sali A., Alexandra D’Arcy & Celeste Rodríguez Louro. 2016. “Outliers, impact, and rationalization in linguistic change”. Language 92(4): 824–849. doi:gdg6vt
Tagliamonte, Sali & Harald Baayen. 2012. “Models, forests and trees of York English: Was/were variation as a case study for statistical practice”. Language Variation and Change 24(2): 135–178. doi:10.1017/S0954394512000129
Tamminga, Meredith, Christopher Ahern & Aaron Ecay. 2016. “Generalized Additive Mixed Models for intraspeaker variation”. Linguistics Vanguard 2(s1). doi:10.1515/lingvan-2016-0030
Wieling, Martijn, Simonetta Montemagni, John Nerbonne & R. Harald Baayen. 2014. “Lexical differences between Tuscan dialects and standard Italian: Accounting for geographic and sociodemographic variation using generalized additive mixed modeling”. Language 90(3): 669–692.
Wright, Marvin N., Andreas Ziegler & Inke R. König. 2016. “Do little interactions get lost in dark random forests?” BMC Bioinformatics 17: article 145. doi:b5t7

University of Helsinki