
Studies in Variation, Contacts and Change in English
Studies in Variation, Contacts and Change in English
William Kretzschmar, University of Georgia
Steven Coats, University of Oulu
The relationship between word frequency and rank order, when considering the lexical types of a given text and their frequencies, was first noted and described by George Zipf; it was later interpreted by Mandelbrot in terms of fractal dimensionality. In this paper, we discuss some properties of rank-frequency profiles and demonstrate use of the ZipfExplorer tool, an online app for the visualization of shared lexis in two texts, to compare the lexical types in well-known novels. We demonstrate that the alpha parameter of a power law function as well as several other measures can be used to quantify the shared lexical diversity of two texts. In addition, visual examination of the A-curves of rank-frequency profiles can help to interpret similarities and differences between texts and corpora.
Corpus linguists understand that frequency lists of words or collocates in corpora all come out with nonlinear, Zipfian distributions. So, for example, the wordlist for the Brown Corpus starts with the at about 70,000 tokens, of at 36,000 tokens, and at 29,000 tokens, and on down the list where there is approximately an inverse relationship between rank and frequency, so that the word at rank two has about half the tokens of the top-ranked word, the word at rank three has about a third of the tokens of the top-ranked word, and so on. When you graph the frequency profile of such a list, you get an asymptotic hyperbolic curve – which we can call an A-curve, for short – like the one in Figure 1. Labels at the bottom of the figure do not show all of the words.
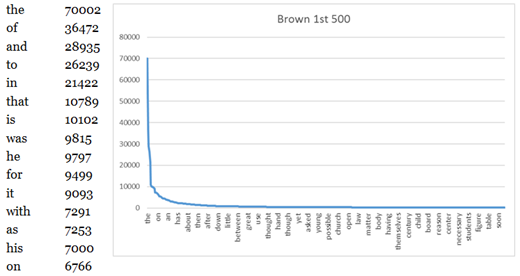
Figure 1. Brown Corpus wordlist (frequency on the y-axis and rank on the x-axis).
Every chart of a wordlist from a corpus or novel or any other text of any size, ordered by frequency, will have a small number of frequent forms on the left, a moderate number of fairly common forms near the bend, and a large number of rare forms in the long tail at right.
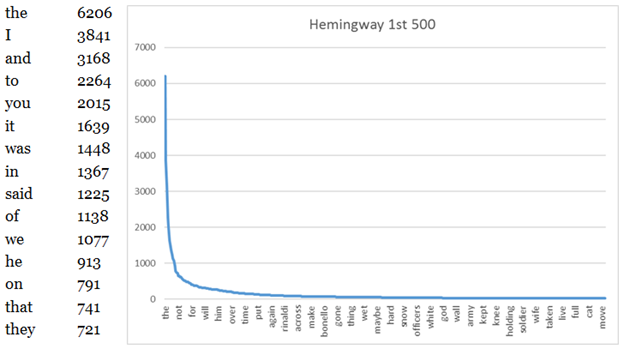
Figure 2. Hemingway A Farewell to Arms wordlist (frequency on the y-axis and rank on the x-axis).
Just to show the A-curve from a single work, Figure 2 illustrates the beginning of the wordlist and the chart from Hemingway’s novel A Farewell to Arms. Again, labels at the bottom of the figure do not show all of the words. The graph looks similar, even though the scale is different with numbers of tokens about a tenth the size of those from the Brown Corpus. We can also see that the top-ranked words on the list are different: the is at the top of both lists, but Hemingway has I and you near the top when Brown does not. This of course reflects what Biber called an "involved" (as opposed to "informational") register, appropriate for a novel (Biber et al. 1998: 135–171). From the point of view of making visualizations, however, the thing to see here is that the A-curves are similar in both data sets. This is a situation that calls for new methods of showing relationships in our data.
While some linguists will want to name such a distributional pattern after George Zipf, we should really be giving it a different name: fractal. Benoit Mandelbrot (1982) described fractals, beginning in the late 1970s, as mathematical formulae that show self-similarity at all scales. Self-similarity is not the same thing as self-identity; thus coastlines, in one of Mandelbrot’s famous passages, appear similar (but not identical) at any scale of observation. The formulae have been called “curves without tangents,” meaning that they are exotic to the mathematics of calculus, and they derive their behavior from exponents in the formulae which account for their dimensionality. Mandelbrot claimed that fractals applied widely in the natural world – as in the measurement of coastlines or the branching of ferns and trees – and human speech is another example (see Mandelbrot 1982: 344–347; Kretzschmar 2009, 2015). Mandelbrot offered a slightly different formula than Zipf for the frequency of a word in texts, where F, V, and D are parameters and D can be interpreted as a fractal dimension (see Kretzschmar 2009: 190–192 for more discussion). Visualizations clearly show this self-similarity, as in Figure 3 charting the A-curves for the Press and Fiction portions of the Brown Corpus (again, labels at the bottom of the figure do not show all of the words). We presented the A-curve for the first 500 words of the whole Brown Corpus in Figure 1; here the A-curves for the Press and Fiction sections of the corpus have smaller numbers of tokens from the lower level of scale.
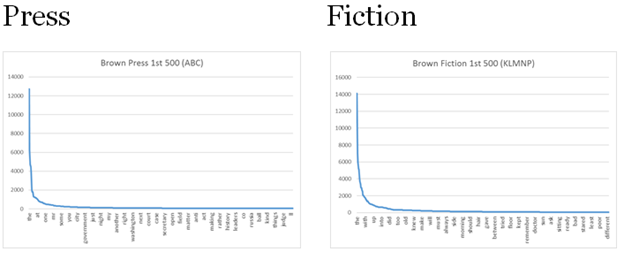
Figure 3. Brown Corpus Press and Fiction (frequency on the y-axis and rank on the x-axis).
We could continue even further down the scale to the individual 2000-word constituents of the Brown Corpus and see the same thing. At the smallest levels of scale in speech, say a single page of text or even a single paragraph, the A-curves get a bit more ragged but they are still present – again, self-similarity in the real world is not self-identity, just a recognizable pattern that is approximately the same. We can see the fractal nature of human speech the best with larger samples, but it is always there. Corpus linguists will be most interested in words, but the fractal structure also appears in measurements of pronunciation (Kretzschmar 2015: 180–192) and of grammatical constructions (Kretzschmar 2015: 73–104).
The fractal structure of language is a different way to talk about many problems corpus linguists have known about and tried to cope with. Our interest in sampling, i.e. knowing where we get our data to build corpora, is certainly the best practice as opposed to the NLP approach of “the more data the merrier no matter where it comes from” (see Kretzschmar 2015: 195–196). We need to be able to identify every scale for analysis, and not just trust that all speakers and writers have the same grammar. Fractal structure is a model that justifies the idea that "every text has its own grammar." Corpus linguists have also learned to use specialized statistics, like Mutual Information scores (the extent to which observed frequency of co-occurrence differs from expectation based on word frequencies), and now we know why: language data sets never have normally distributed rank/frequency profiles, and so we need to avoid statistical approaches that assume normality and prefer statistical approaches that do not require it. Since we always get the same frequency profile at every scale, the nonlinear A-curve, what we most need to do is to describe how the language at any scale compares to the language at another scale, not in the general pattern of the graph, but in the order of all of the elements on the curve. We can compare part to whole, as Press or Fiction to the whole Brown Corpus, or whole to whole, as Press compared to Fiction within the Brown Corpus, or as Hemingway’s Farewell to Arms with the Brown Corpus. In every such case, we will be interested in how words in one data set are higher or lower on the curve than they are in a different data set. In this way we can determine how any individual work differs from a reference baseline, whether that baseline consists of a general corpus like the Brown Corpus or some other text (whether spoken or written) or collection of texts.
The study of lexical type frequencies is often considered to have originated with George Zipf (1936, 1949) who noted that when the words of a text are ordered in decreasing frequency, the relationship between the frequency and the rank for a word of rank r can be expressed as fr = Cr-1, where C represents a constant. As already mentioned, Mandelbrot offered a somewhat different formula. In recent years, word frequency profiles and other heavy-tailed distributions in language datasets have attracted increasing interest; they have been considered in a theoretical perspective in terms of their statistical properties (Baayen 2001; Berubé et al. 2018; Clauset et al. 2009, Lü et al. 2010; Montemurro 2001; Newman 2005; Piantadosi 2014) and also modeled in various software packages (Alstott et al. 2014; Evert & Baroni 2007; Gillespie 2015). The statistical parameters of word frequency distributions play an important role in some natural language processing models, but word frequency distributions are not only interesting from a statistical perspective: With appropriate visualization, a Zipfian rank-frequency profile can give insight into the discourse of a particular text, particularly so in comparison to another text or a reference corpus, in terms of the rank position of individual lexemes and the overall shape of the profile in double-logarithmic space, which depends on parameters of the distribution and properties of the text under consideration. In a broader perspective, the visualization of word frequency distributions can serve to demonstrate properties of frequency distributions in general, making such visualizations useful from a pedagogical perspective.
Most commonly, and following Zipf (1936: 45–48; 1949: 25), word frequency distributions have been displayed in double logarithmic space, with frequency on the y-axis and rank on the x-axis, as in the top right quadrant of Figure 4, which shows four visualizations of the word frequency distribution for Mark Twain’s novel Huckleberry Finn. Each circle on the plot corresponds to a distinct word type.
Figure 4. Visualizations of word frequencies in Huckleberry Finn.
There are, however, other possible visualizations. In the top left quadrant, the distribution is shown in linear space. One can also plot the probability distribution not of the lexical types, but of the frequency ranks themselves (this plot, in the lower left quadrant of Figure 4, is sometimes referred to as the frequency spectrum or the degree distribution), by showing the proportion of word types with a given frequency value on the y-axis and the frequencies on the x-axis. A possible disadvantage of such a visualization is that its interpretation is somewhat less intuitive in terms of the interpretation of discourse compared to a Zipfian rank-frequency profile: instead of representing particular word types, the points on the plot represent the proportion of word types that have a given frequency. For example, approximately a third of the word types in Huckleberry Finn are hapax legomena, having a frequency of one, but it is not clear which word types these represent. The lower right-hand quadrant in Figure 4 shows the complementary cumulative distribution for the same data, or the cumulative probability that a word has a frequency equal or greater than x: This value is 1 for words of frequency 1, approximately .62 for words of frequency 2, and so on. The complementary cumulative distribution, which is a mirror image of the Zipf rank-frequency profile across a line extending from the lower left to the upper right of the plot, is also somewhat difficult to interpret in terms of discourse, as the points in the plot do not correspond to distinct word types. In general, however, it can be observed that more uniform distributions, for which word types have more equal frequencies, have flatter slopes in their double-logarithmic Zipf profiles, whereas more unequal distributions have steeper slopes.
If the goal of a visualization is not to analyze discourse, but rather to provide an impression of the overall lexical diversity of a text, another possibility would be to plot the Lorenz curve for the distribution (Figure 5). The Lorenz curve, which is most often used to show wealth and income distributions in a society, is summarized by the Gini coefficient, which ranges between zero (absolute equality) and one (absolute inequality). The x-axis in Figure 5 shows the cumulative proportion of word types in Huckleberry Finn, while the y-axis shows the cumulative proportion of word frequencies. A Lorenz curve along the yellow line would correspond to a Gini coefficient of zero, for a text in which all word types have the same frequency. Curves further away from the yellow line have a coefficient closer to one, with some words having high frequencies and many words occurring infrequently. Mathematically, the functions of the curves in Figures 4 and 5 can be derived from one another by straightforward transformations.
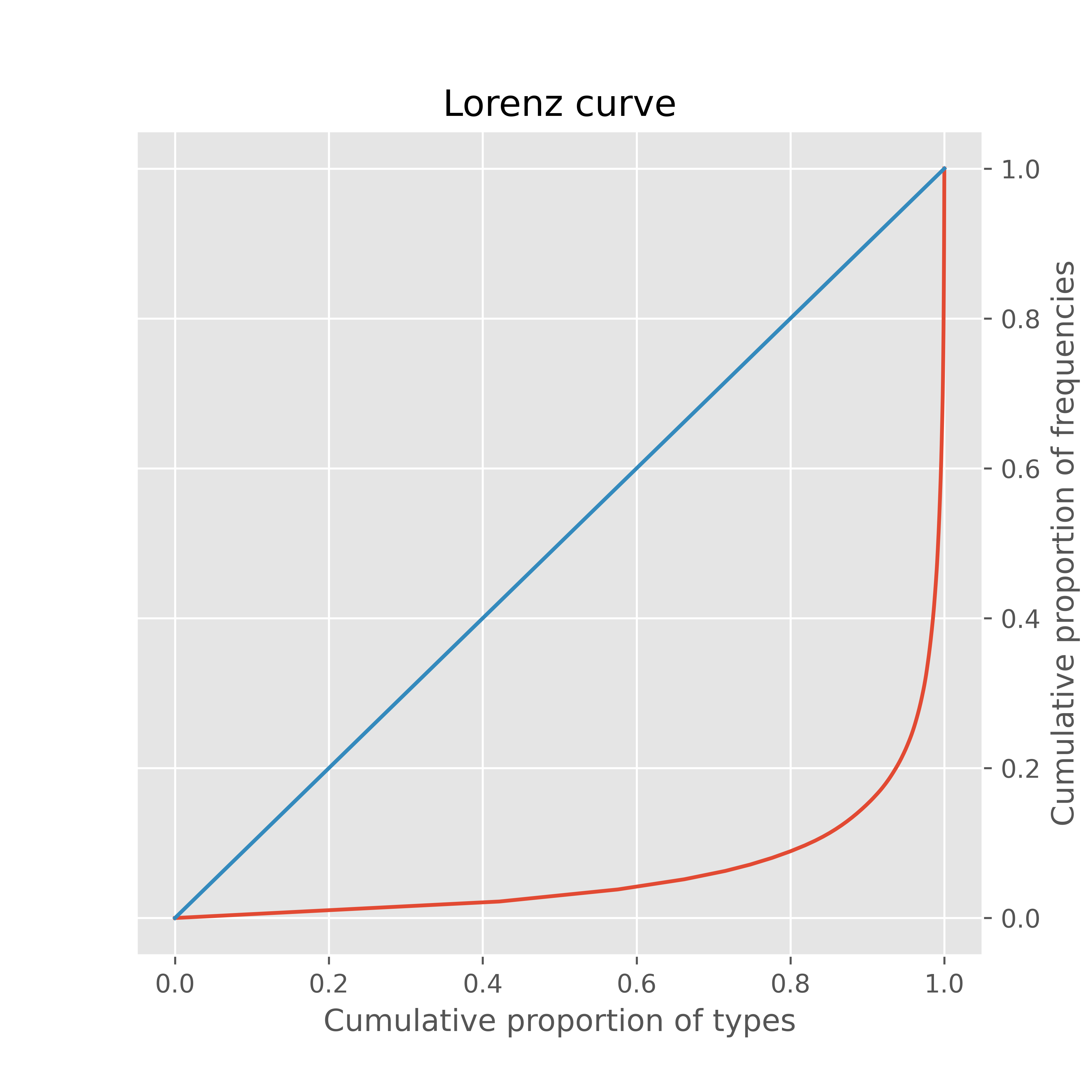
Figure 5. Lorenz curve for Huckleberry Finn.
For Huckleberry Finn (and for other natural language texts), word frequencies are unequally distributed: the Lorenz curve is far from the equality line, and the Gini coefficient is .87. As is the case with the frequency spectrum plot and the cumulative complementary distribution plot, the Lorenz curve, while showing the shape of the distribution, is difficult to interpret in terms of discourse properties for a text.
The ZipfExplorer tool provides a means for the side-by-side interactive visualization of frequency distributions of shared lexical types for two texts or corpora. By presenting the frequency information for shared word types (i.e. those types that occur at least once in both texts to be compared) in the form of Zipf rank-frequency profiles in linear and logarithmic space, as in the top two plots in Figure 4 above, the tool makes interpretations in terms of discourse differences possible, as well as giving insight into the ways in which lexical diversity measures for shared types and the shape of the Zipf plot can vary according to parameters such as text length, discourse overlap, and the exclusion of stopwords. The tool allows direct inspection of the frequencies of shared vocabulary, which is compared according to rank, absolute and relative frequency, difference in relative frequency, and log-likelihood score, a statistical measure of relative frequency (Dunning 1993; Rayson & Garside 2000).
Figure 6 shows the default view of the tool for William Blake’s Poems and Herman Melville’s Moby Dick with the rank-frequency profiles of the shared lexical types in linear space (above) and in double logarithmic space (below). On the plots, the relative frequency of shared types (per 10,000 word tokens) is on the y-axis and rank among the shared types on the x-axis. In addition, several measures of lexical diversity are displayed above the graphs: the type-token ratio, the Gini coefficient, the value of the alpha exponent parameter for the best-fit power law distribution according to the formula p(x) = Cx-𝛼, and the Shannon entropy (Shannon 1948), which has a maximum theoretical value of log2(n), for data consisting of n unique types. The tool uses the powerlaw package in Python (Alstott et al. 2014; see also Clauset et al. 2009; Newman 2005) to fit the empirical distribution to a discrete power law and calculate the best-fit alpha parameter for the fitted function. [1]
Circles on the plots represent individual lexemes, and hovering over a word shows its rank among the shared lexical types for the text, frequency, and relative frequency, as well as the log-likelihood measure and p-value for the type compared to the other text. Users can manipulate the plots with zoom, selection, and movement tools, situated above the right-hand plot.
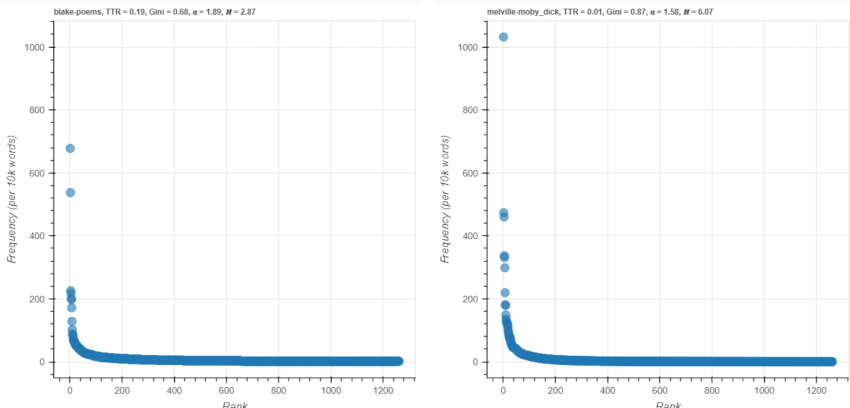
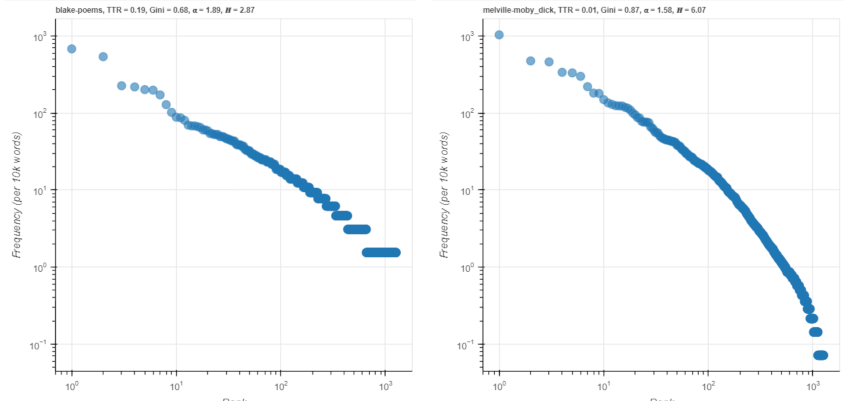
Figure 6. Default views of ZipfExplorer plots.
Selecting words on the plot with the Box Select tool or on the sortable tables below the plots highlights them. The tables show rank, word, frequency, relative frequency per 10,000 word tokens, difference in relative frequency compared to the other text, and log-likelihood score. To the right of the plots, users can select the texts to be compared, or upload their own texts (as .txt files) to the tool – uploaded texts are automatically tokenized and converted to frequency tables. Selecting the same text for both plots shows the frequency distribution and derived values for a single text. A ‘Remove most frequent words’ drop-down menu allows up to 200 of the most frequent words in English to be removed from the plots/tables, based on word frequencies in a corpus of English-language Project Gutenberg texts prepared by SketchEngine (Kilgarriff et al. 2014). Removing the most frequent words, which are typically function words bearing relatively little semantic information, can help to highlight content differences between the texts. Below the ‘Remove most frequent words’ drop-down, the total numbers of types and tokens in the original texts are displayed, as well as the lexical overlap, expressed as a percentage. For Blake’s Poems and Melville’s Moby Dick, 83% of word types in the former can be found in the latter, whereas only 7% of the latter can be found in the former. This is unsurprising, considering the larger number of types in Moby Dick. Because lexical diversity measures such as those shown above the rank-frequency plots depend on sample size (Baayen 2001; Kunegis & Preusse 2012; Bérubé et al. 2018), their values for the shared vocabulary tend to vary systematically, with shorter texts typically exhibiting smaller Gini coefficients and entropy values and larger type-token ratios and power-law alpha parameter values.
The data for the tool consist of several literary texts and a corpus of inaugural addresses of U.S. presidents from the Natural Language Processing Toolkit (Bird et al. 2019), additional texts scraped from Project Gutenberg, the Brown Corpus and its subsections (Francis & Kučera 1979), and the Freiburg-Brown Corpus of American English (Hundt et al. 1999). The HTML formatting of scraped Project Gutenberg texts was cleaned using a modified function from the GutenTag Python module (Brooke et al. 2015); texts were tokenized with the Spacy module (Honnibal & Johnson 2015).
In Figure 6, in which the shared vocabulary types of William Blake’s Poems and Melville’s Moby Dick are compared, other than the fact that the curves exhibit the characteristic nonlinear distribution associated with word frequencies, the relative frequencies of the types in the heads and in the long tails of the distributions, as well as the overall shapes of the curves, are not easily interpretable: long-tailed curves such as those shown on the plots can be best-fit to lognormal, power-law, or truncated power-law functions, among others. Switching the visualization to logarithmic scale, however, allows several additional insights into the shared lexis. The most frequent type in both texts is ‘the’, whose relative frequency is comparable, with values in the range 102–103. The approximately ten most frequent shared lexical types fall in this range for most of the text pairs in the data set. Both curves approximately correspond to a straight line in double-logarithmic space, although this is more true for Poems than for Moby Dick. The alpha parameters for the frequency spectra for the shared types are 1.89 for Poems and 1.58 for Moby Dick: the former value falls within a range typical for natural language texts, whereas the latter does not (Ferrer i Cancho 2005; Moreno-Sanchez et al. 2016). Because the vocabulary of Moby Dick has been constrained in the visualization – the frequencies for only 7% of its word types are shown – the shape of the Zipfian rank-frequency profile deviates substantially from a straight line with a slope of -1, especially for the long tail of low-frequency types. [2] Removing increasing numbers of the most frequent words from the shared lexis, by using the drop-down feature, additionally affects the shape of the rank-frequency profile, causing its slope to become shallower and the tail of the distribution to curve more steeply downward.
The plot for Moby Dick also shows distinct scaling regimes: The head of the plot has a somewhat shallower slope, whereas the mid-portion and the tail are steeper. For non-filtered rank-frequency profiles, it has been suggested that this plot shape may relate to underlying cognitive and communicative considerations: It has been proposed that a “kernel lexicon” of 300–1,500 words, which approximately corresponds to the vocabulary sizes of several pidgin languages, suffices for most communicative situations, and the usage profile of these words may differ from that of other words that a user knows (Ferrer i Cancho & Solé 2001). It has also been noted that when double-logarithmic rank-frequency profiles are filtered to only show words of particular grammatical classes, the shape of the distribution is affected: a two-regime profile is more characteristic for noun phrase elements than for verbal phrase elements (Piantadosi 2014). The increasing deviation from Zipf’s law as manifest in the shape of the rank-frequency profile when vocabulary is constrained in this manner by only showing those word types shared with another text and additionally removing frequent words makes this regime scaling difference more apparent.
If Blake’s Poems is replaced with the much longer Brown Corpus, the plot for Moby Dick again more closely approximates a straight line with a slope of -1, corresponding to Zipf’s law (Figure 7), while the plot for the Brown Corpus shows a marked downward curvature in the tail of the distribution in double-logarithmic space.
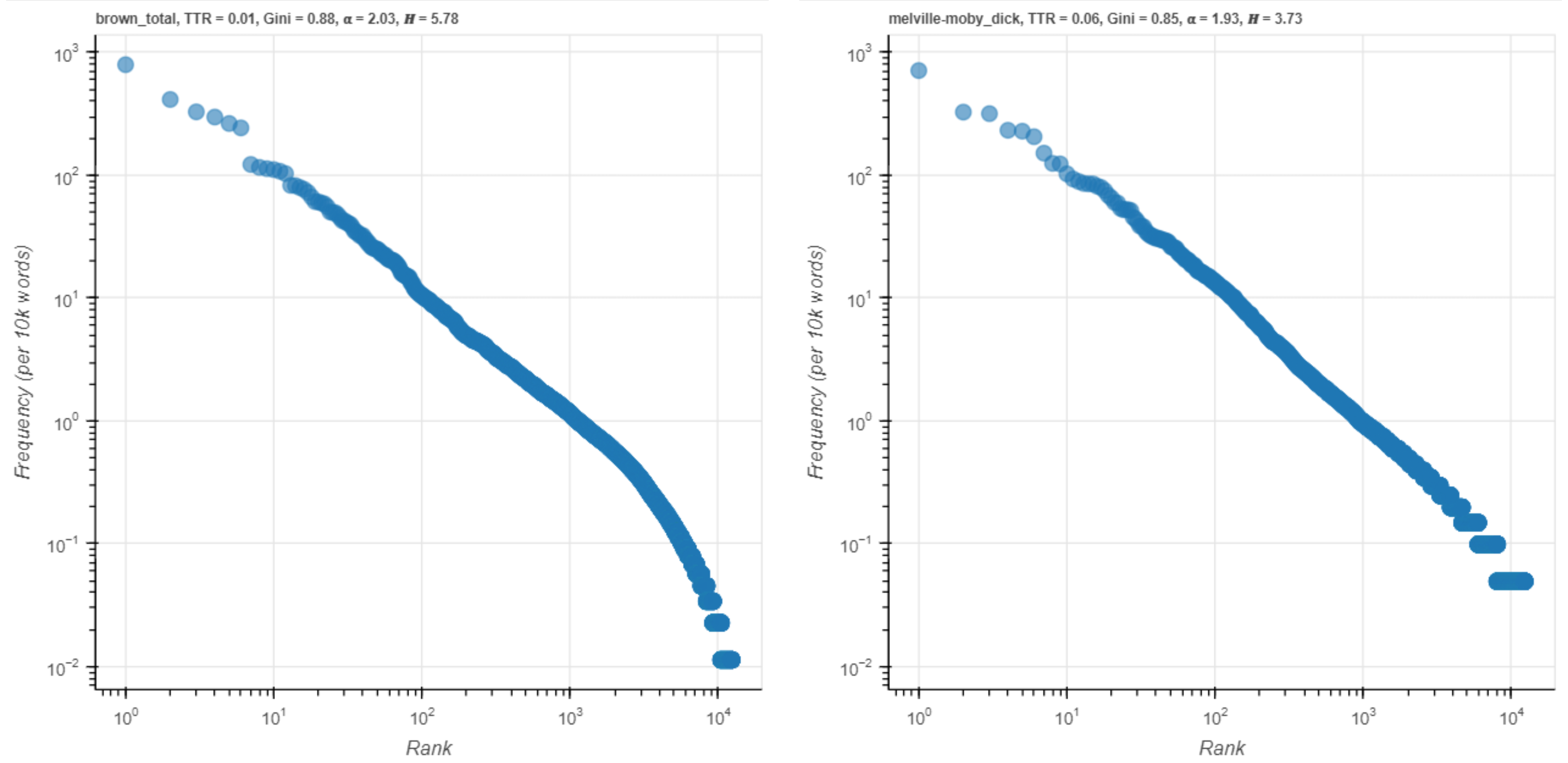
Figure 7. Rank-frequency profiles for vocabulary shared between the Brown corpus and Moby Dick.
The plots can be manipulated in various ways. Sorting word types in the tables below the plots by difference in relative frequency or by log-likelihood score after removing frequent words gives access to the lexemes that are most over- or underused in each of the texts, potentially shedding light on discourse differences. In Figure 8, a comparison of Poems and Moby Dick with the 200 most-frequent English words removed, ‘thee’, ‘sweet’, ‘weep’, and ‘joy’ are shown to be much more frequent in Poems; the types ‘sea’, ‘seemed’, ‘white’, and ‘round’ are much more frequent in Moby Dick. Holding the shift button down when sorting a field in the tables below the plots allows a second variable to be sorted.
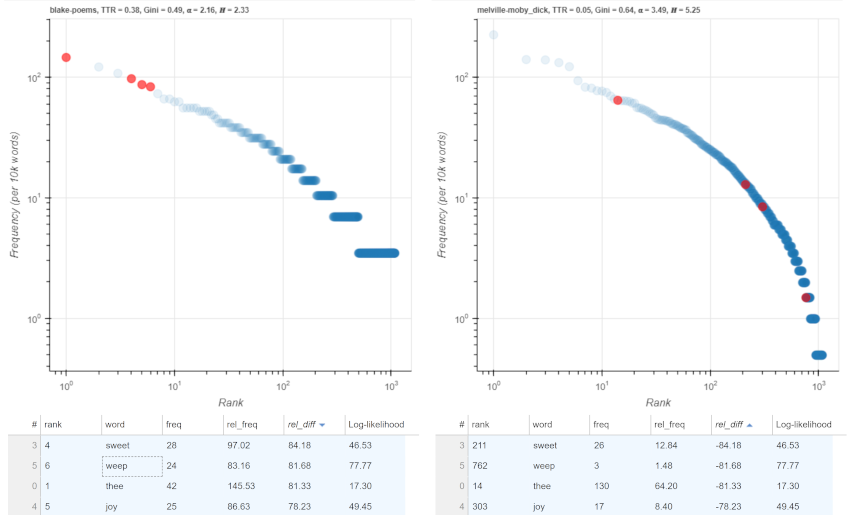
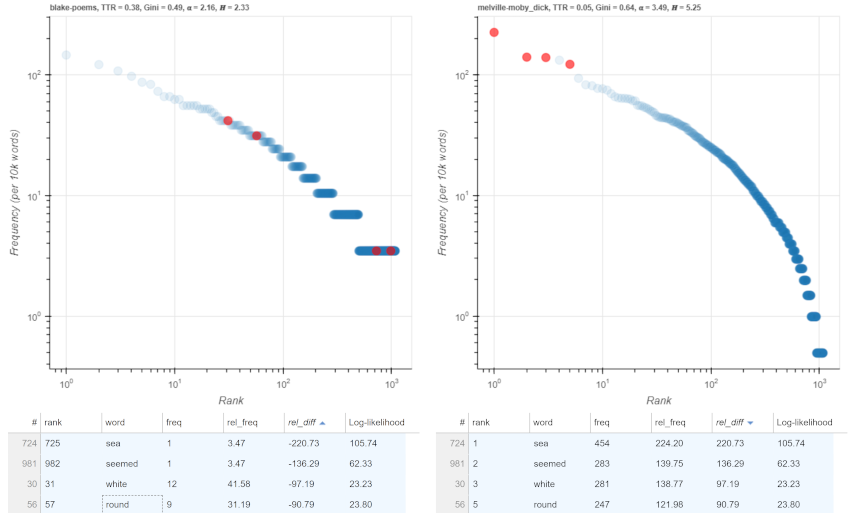
Figure 8. Types with largest relative frequency differences.
The ZipfExplorer tool was built using the Bokeh interactive visualization library in Python (Bokeh Development Team 2020). A number of platforms are available for the creation of interactive visualizations, such as Shiny in R (Chang et al. 2019), Plotly/Dash for R or Python (Sievert 2018), and D3 for Javascript (Bostock et al. 2011). Bokeh can simultaneously visualize multiple data sets and can be seamlessly integrated into a Python-based workflow for the processing and analysis of corpus and computational linguistics data using standard tools such as Jupyter notebooks and the Pandas module. The source code for the ZipfExplorer is publically available, and it is hoped that other researchers working with visualization techniques will make use of the code in order to highlight particular aspects of word frequency distributions.
To return to Hemingway, then, for an example of how to make visualizations, we will be looking for images that consist of two parts for the comparison. Figure 9 shows a list of fifty keywords that are more common in Hemingway’s novel (all further references refer just to the novel, not to Hemingway’s opus overall) than in the Brown Corpus, using the log-likelihood method as generated with the free program AntConc. We have removed single letters (except I) and evidence from contractions, so the numbered list goes up to 61 and not 50. I and you are on the list, as discussed above, along with various character names and words related to the story of ambulance drivers in rainy Italy.

Figure 9. Hemingway top 50 words (adjusted).
In Figure 10 we see the word darling as it appears in Hemingway and Brown in the ZipfExplorer tool. Darling is the 93th most frequent word in Hemingway but 2369th on the Brown list, with a high log-likelihood score to demonstrate keyness.
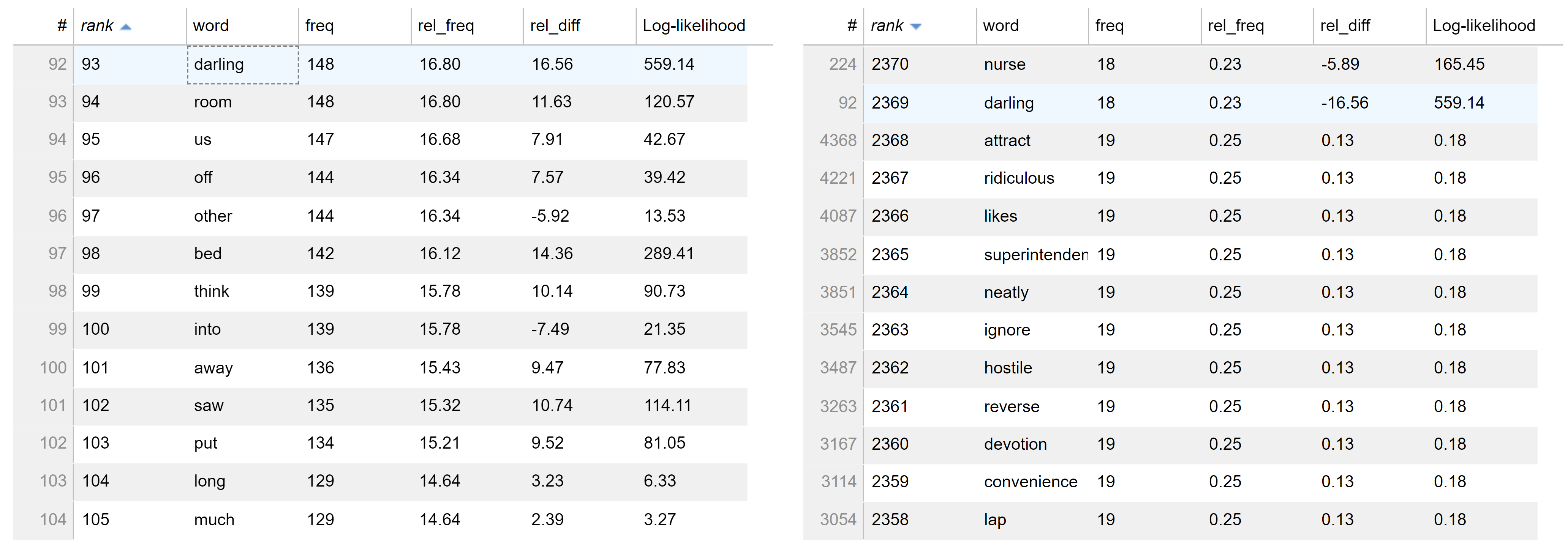
Figure 10. darling (Hemingway’s Farewell to Arms on left, Brown Corpus on right).
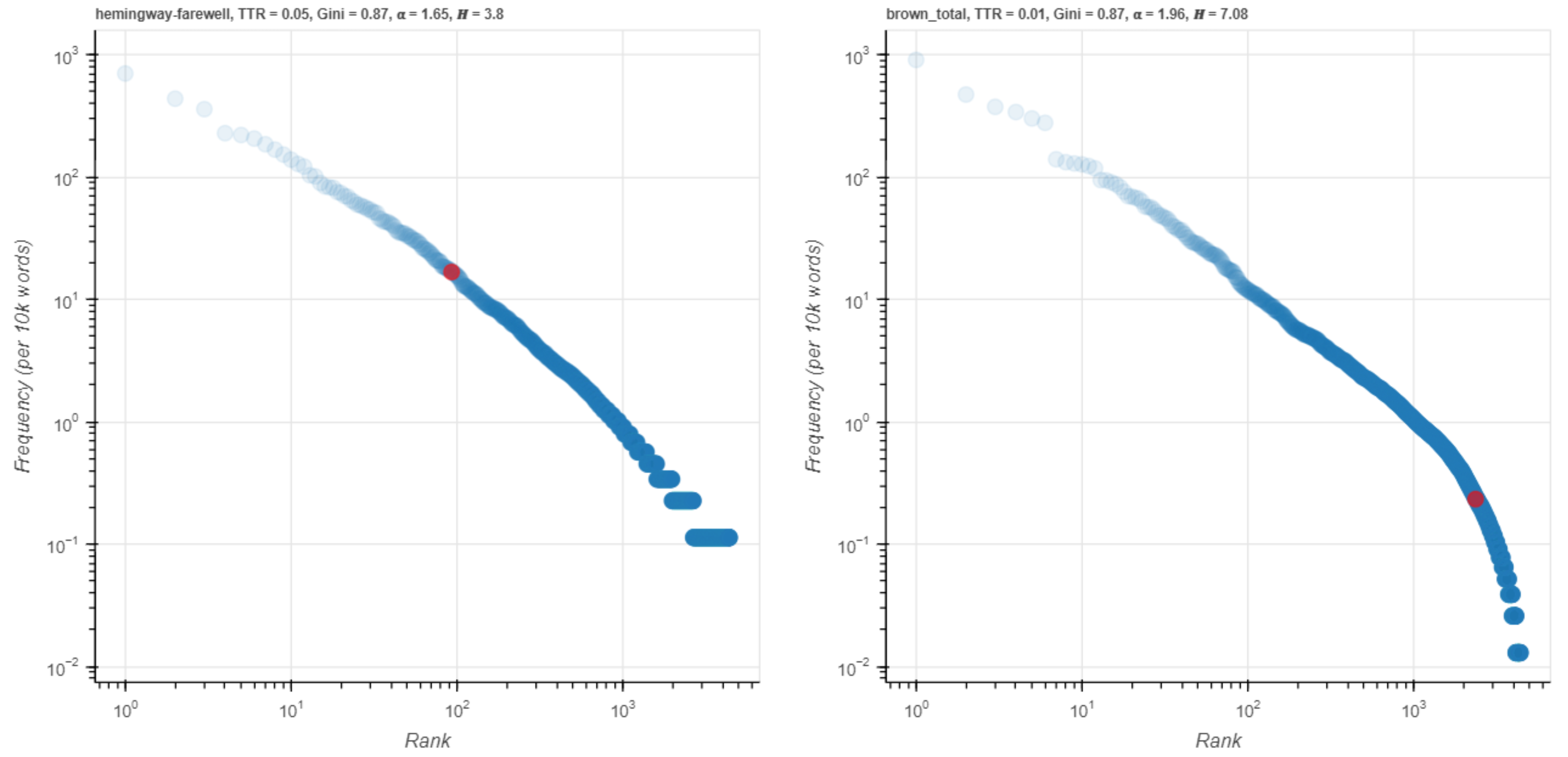
Figure 11. darling on a log scale.
The visualization in Figure 11 (made on a log scale, not an A-curve) clearly shows that the two red points are far distant from each other in rank, more than 1.5 orders of magnitude different. This is an effective way to demonstrate visually that darling is much more common in Hemingway.
Let’s look at a few more of these plots, now without showing the numbers, just the logarithmic plots. The word rain is a somewhat less common word in Hemingway and less frequent in Brown, with a log-likelihood score about half of the one for darling.
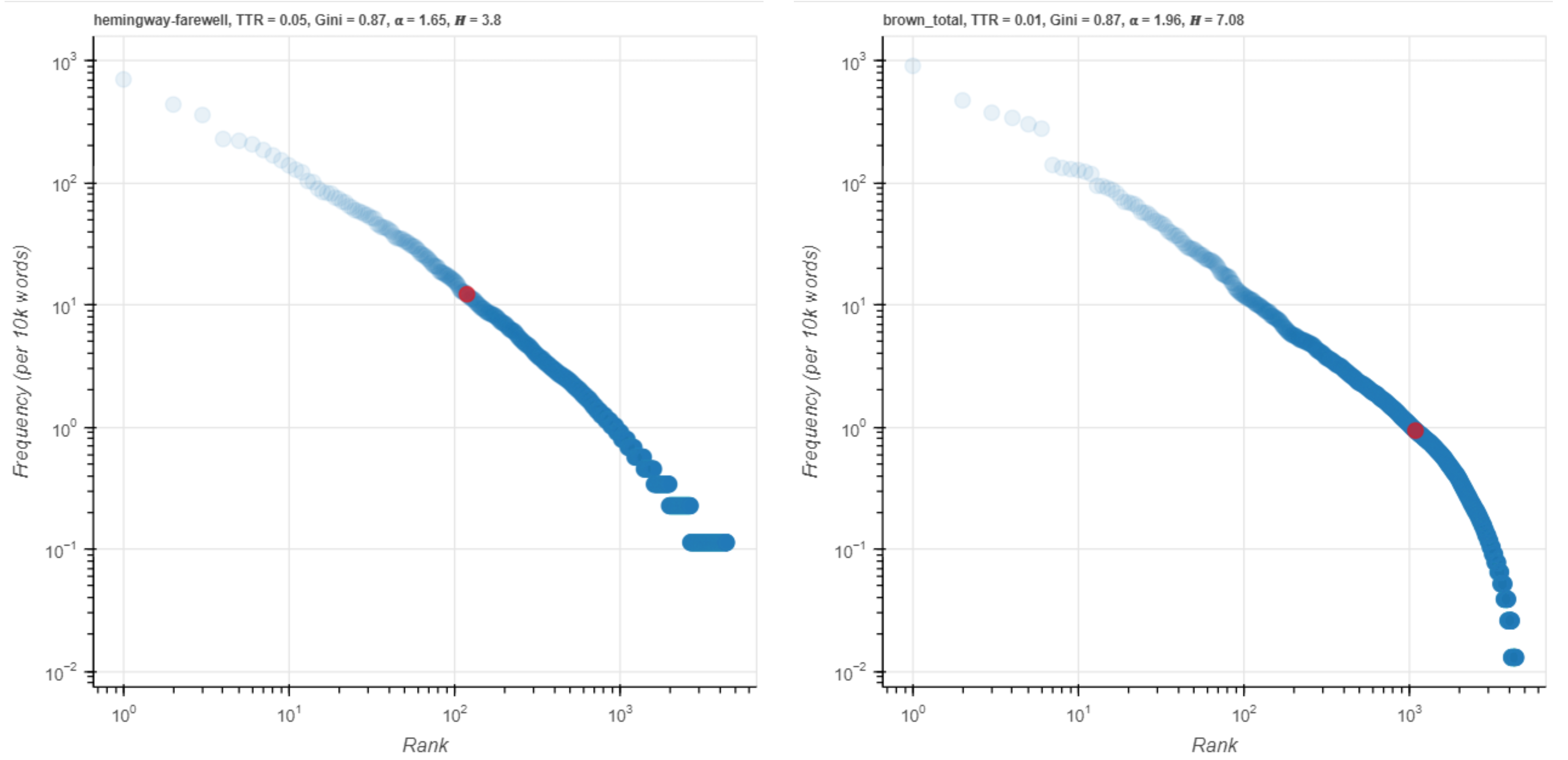
Figure 12. rain on a log scale.
In the visualization (Figure 12), we see that the two red points are about 1 order of magnitude different. The word nurse is still less common in Hemingway and less frequent in Brown, with a log-likelihood score slightly less than half the one for rain.
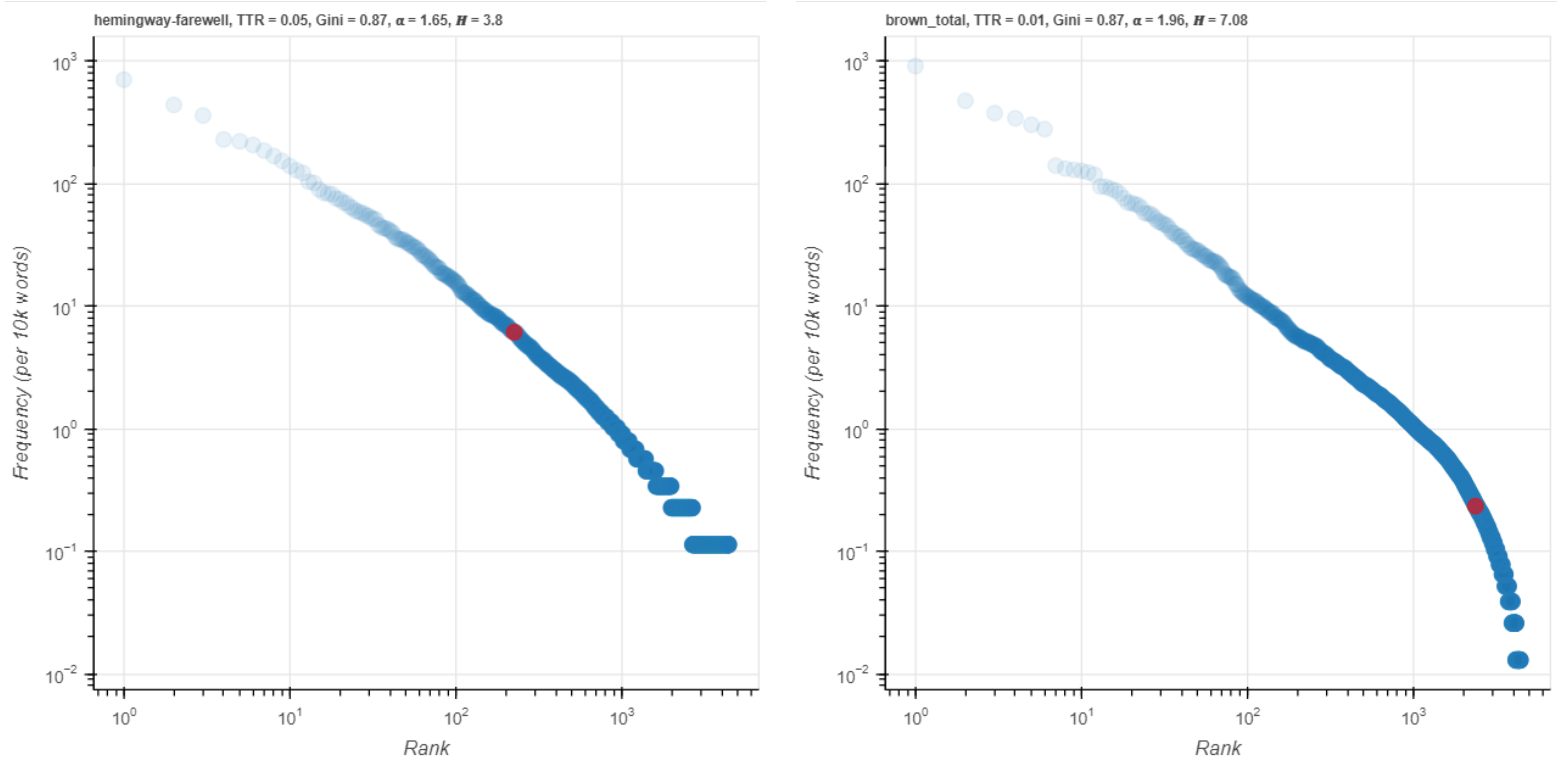
Figure 13. nurse on a log scale.
The visualization in Figure 13 shows that the two red points are about one order of magnitude different. So far, then, the visualization has matched the log-likelihood scores pretty well: darling is more of a Hemingway word than rain, which itself is more Hemingway than nurse. However, one more visualization shows that the numbers may not always be in step with the picture. The number four ranked keyword, said, has a much higher log-likelihood score than does darling: 1710 to 538, over three times larger.
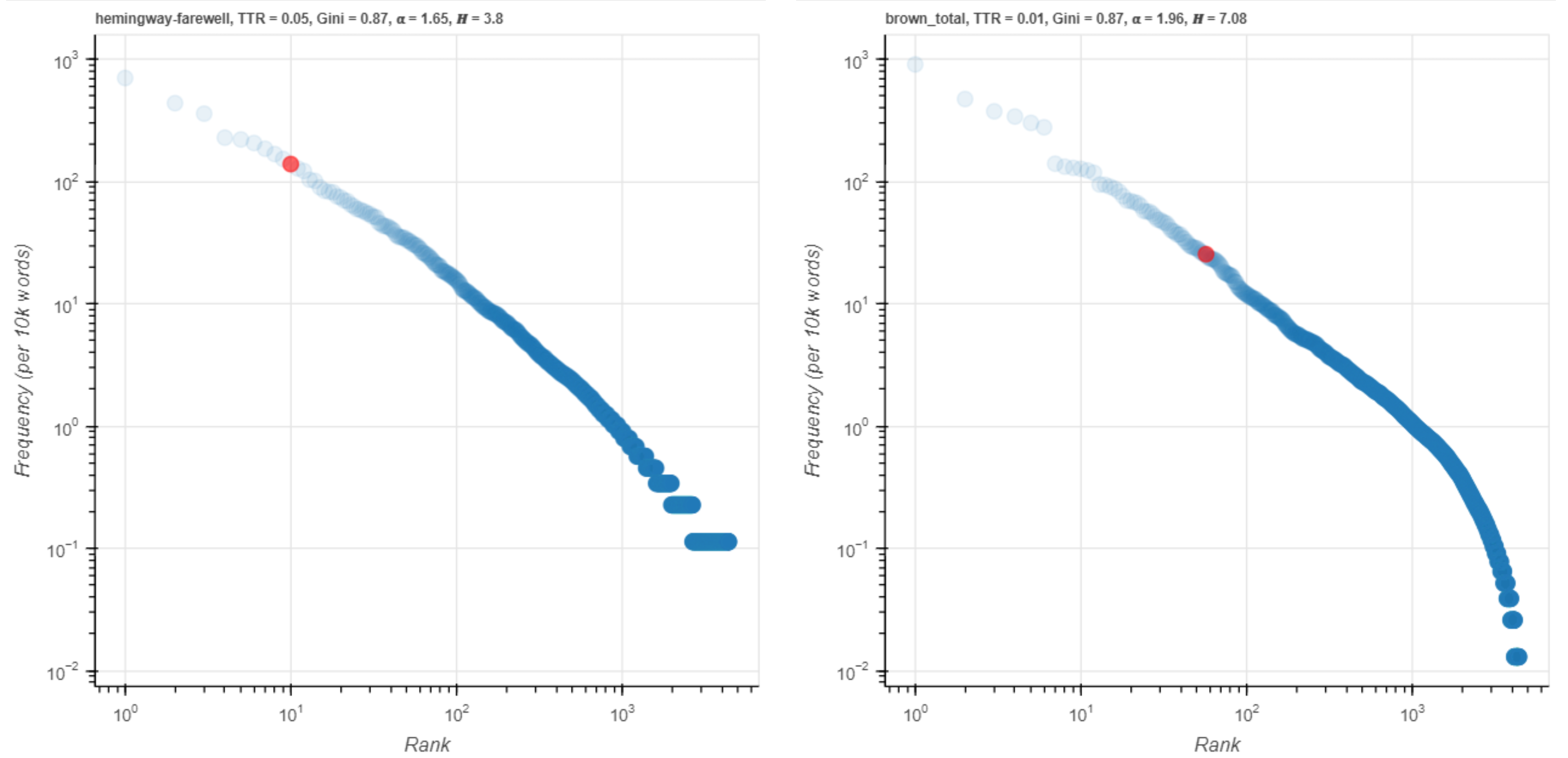
Figure 14. said on a log scale.
When we look at the visualization in Figure 14, though, the red points are less than one order of magnitude apart on the logarithmic scale, so that the difference looks more like the one for nurse than the one for darling. In this case, the very high frequency of said, way up at the top of the A-curve, appears to have influenced the log-likelihood score to make it appear that said is more different than it appears on the visualization. The same is true when we inspect two of the top keywords according to log-likelihood scores: I and you (Figures 15 and 16).
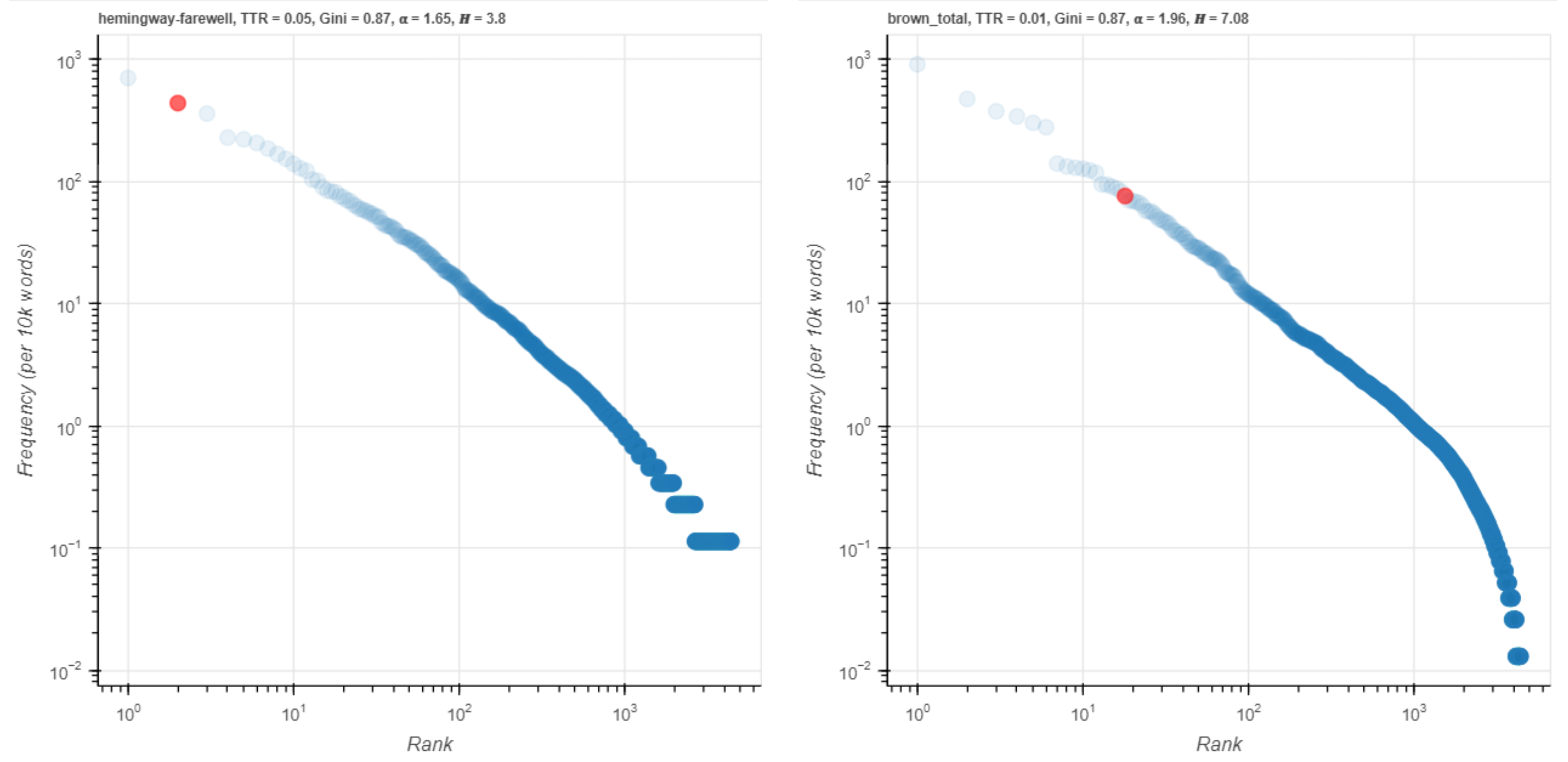
Figure 15. I on a log scale.
I is a very frequent word in both data sets, but it shows a rank difference of less than one order of magnitude on the log-scale plot.
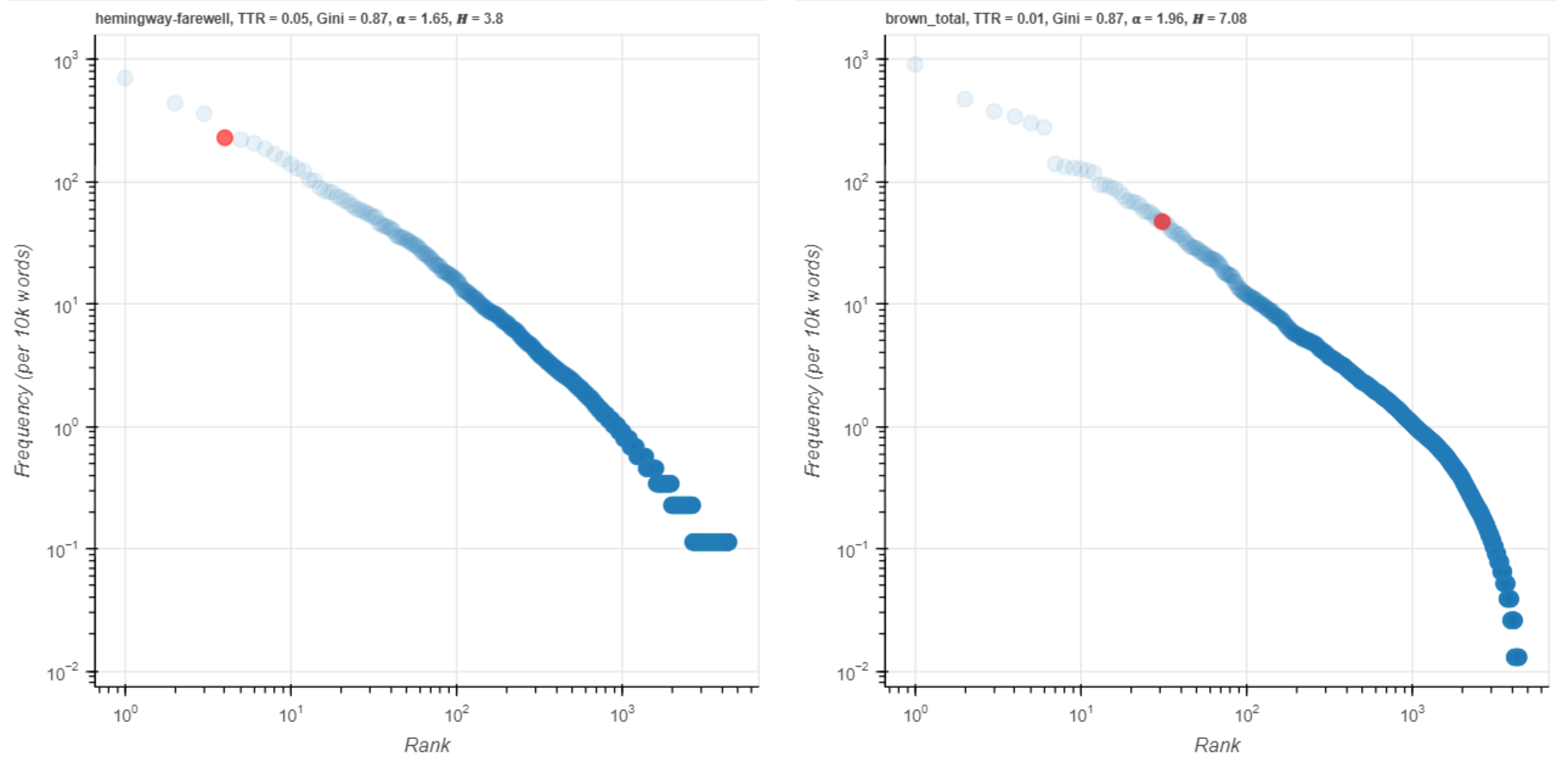
Figure 16. you on a log scale.
You is just the same, a very frequent word but with a difference of less than one order of magnitude on the log-scale plot. So, in these cases the visualization acts as a correction for the log-likelihood numbers.
The reason for this correction appears when we shift the visualization to the A-curve display of raw frequency data (Figure 17). The distributions for darling show the red point in the long tail of the curve in the Brown Corpus but in the steep upward part of the curve in A Farewell to Arms.
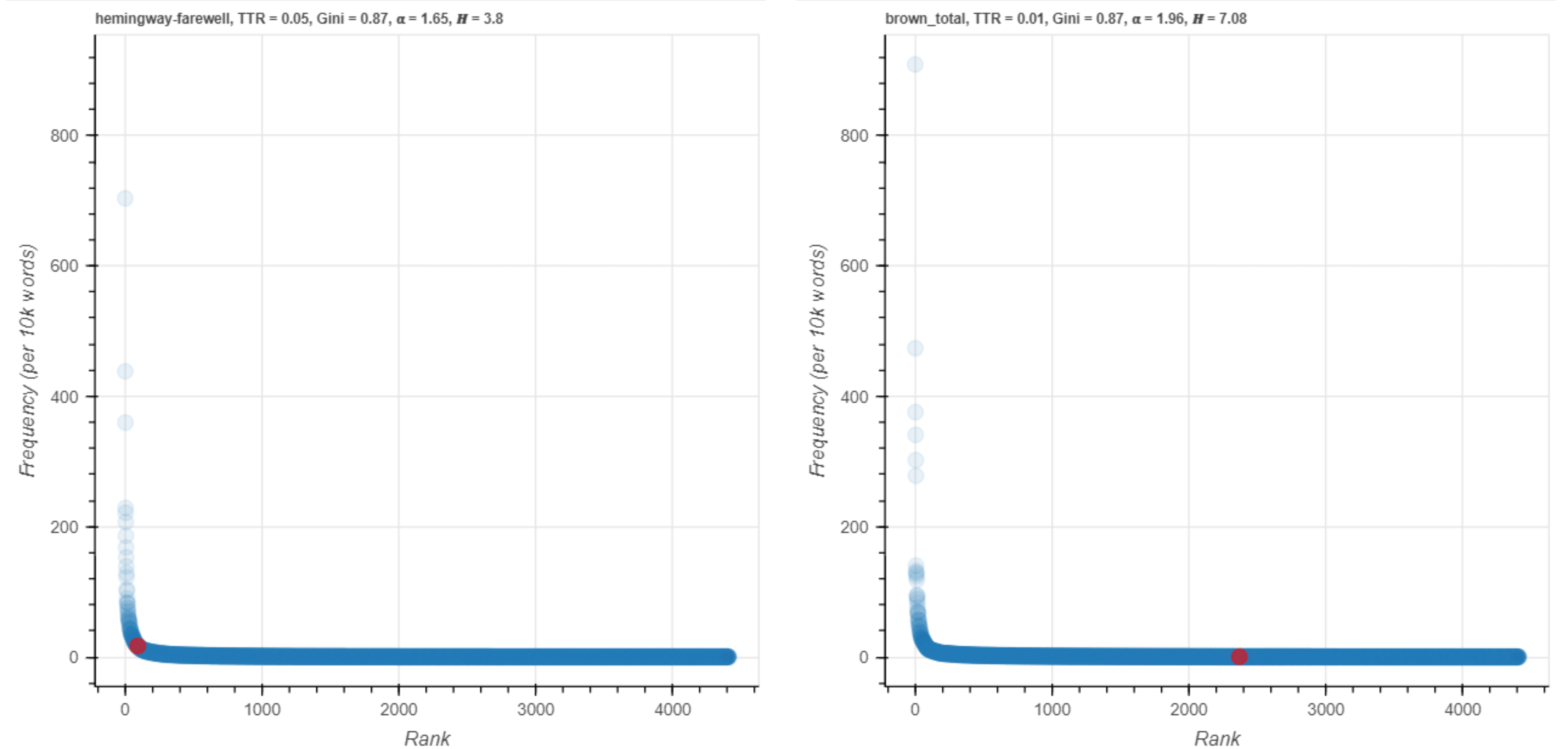
Figure 17. darling on an A-curve.
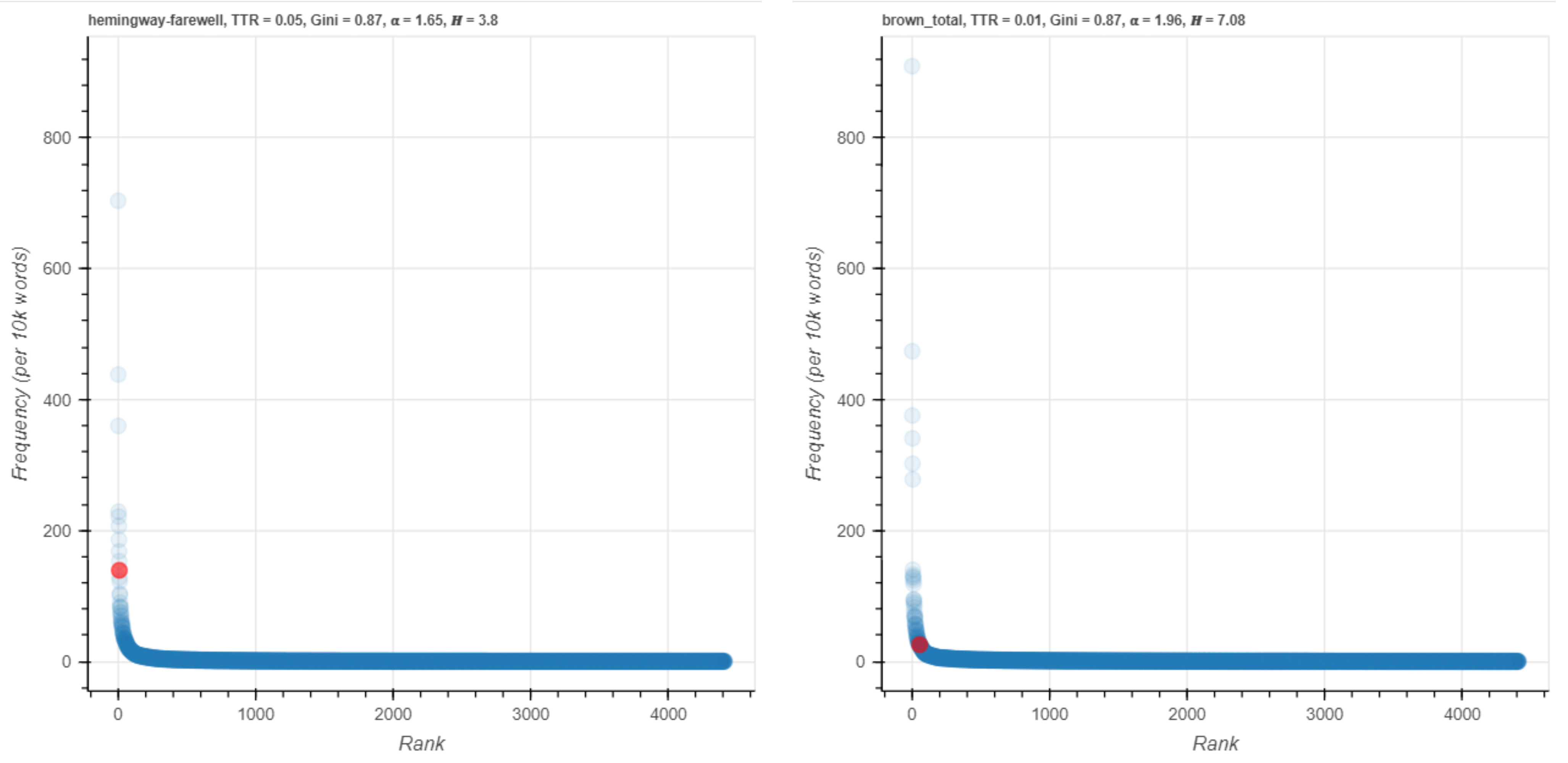
Figure 18. said on an A-curve.
The said distribution, on the other hand, does have a large frequency difference but the red points are both on the steep upward part of the curve (Figure 18). This difference, changing location on the section of the A-curve, might be thought to play a role in the importance of a word as an indicator of Hemingway’s special use of language in the novel. The visualizations for rain and nurse (Figure 19, Figure 20) can also be read in this way.
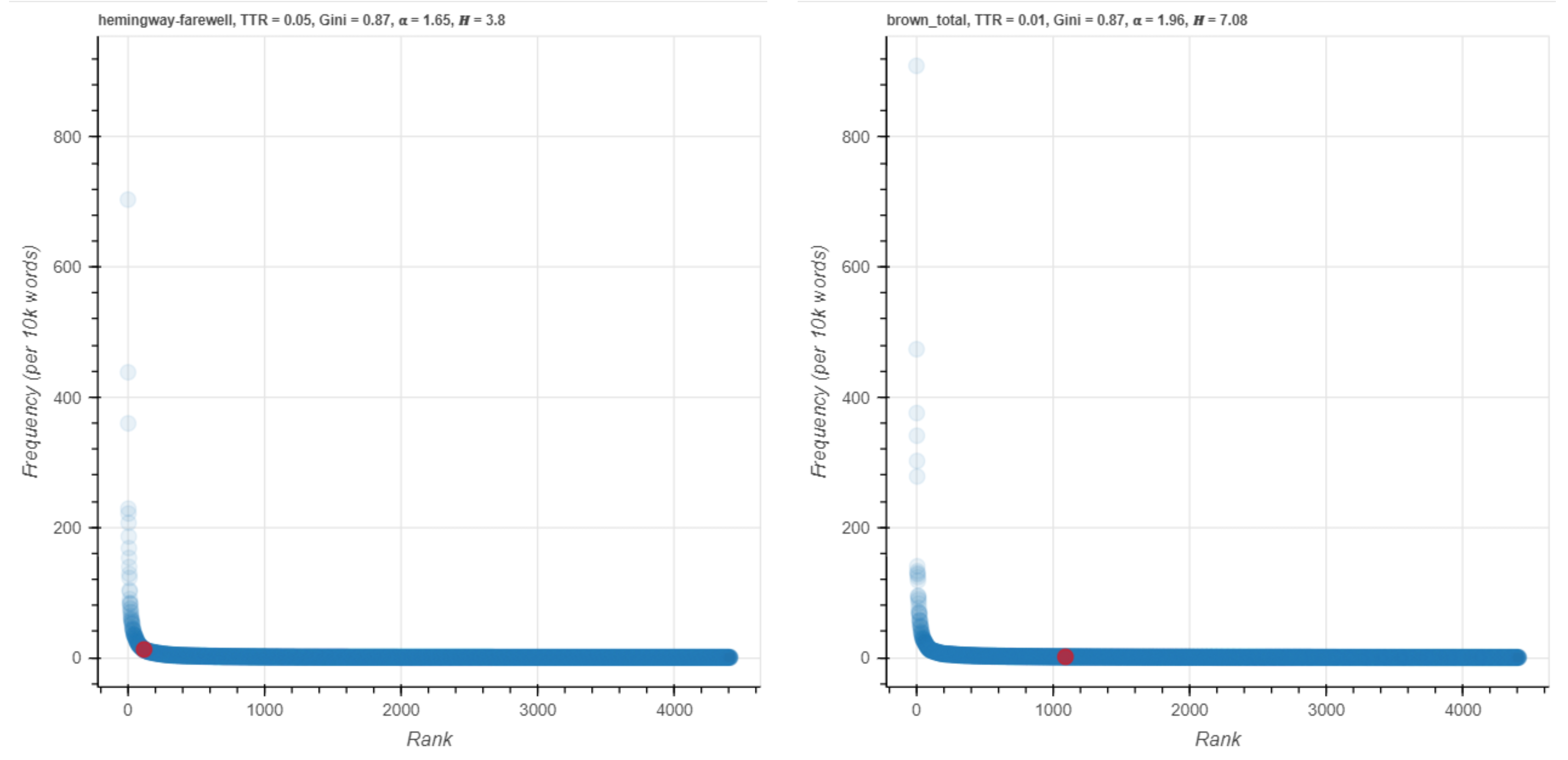
Figure 19. rain on an A-curve.
The red points for rain are in the tail of the curve in Brown but in the steep upward part in Hemingway.
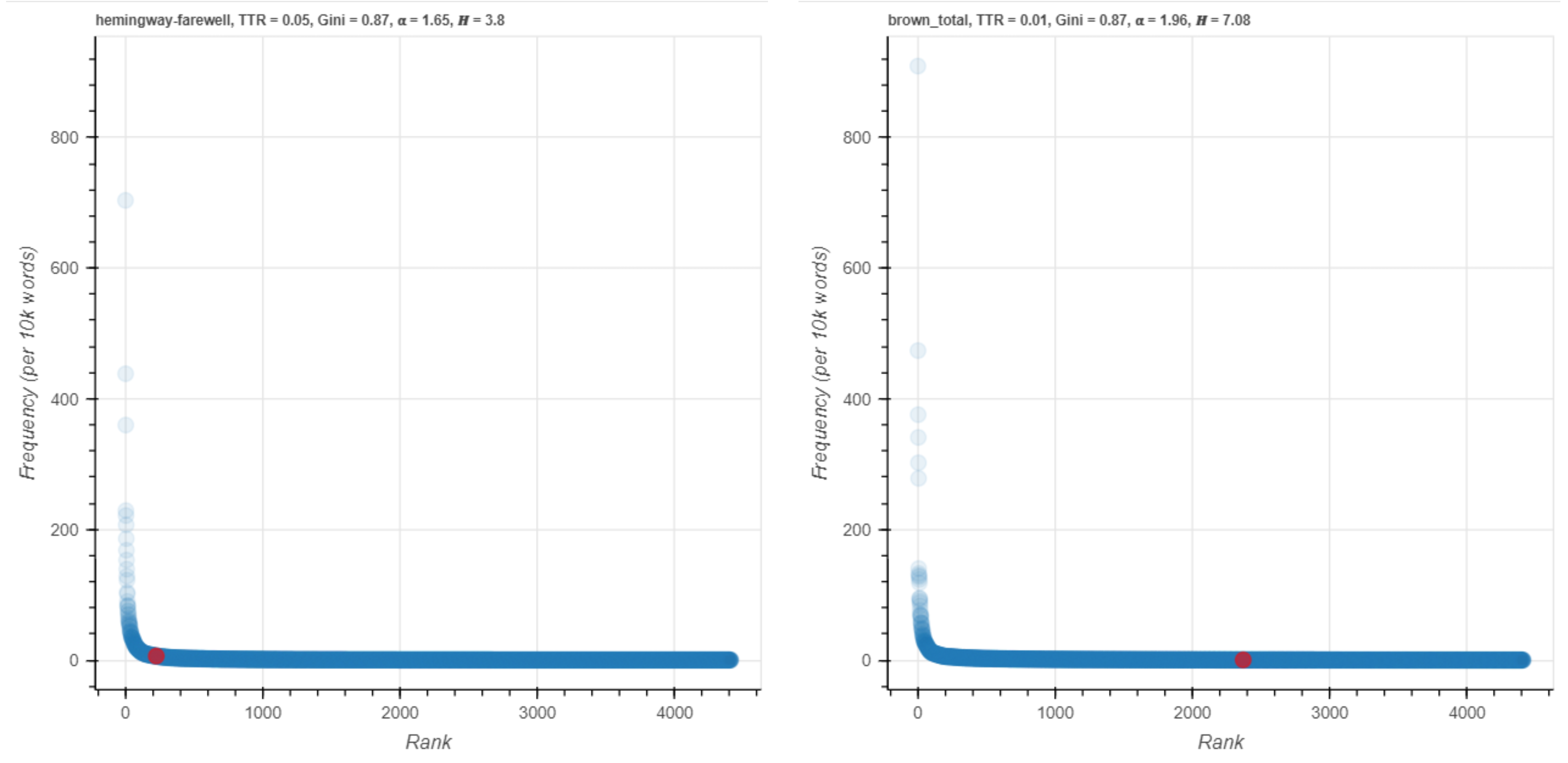
Figure 20. nurse on an A-curve.
The red points for nurse, further down the long tail in Brown, are closer to the cusp in Hemingway. In both cases we see the different status of the word, perhaps more subtle than the difference for darling but still present, resulting in the words appearing at different positions in the A-curves. This suggests that frequency alone may not be the whole story in the comparison of words between corpora.
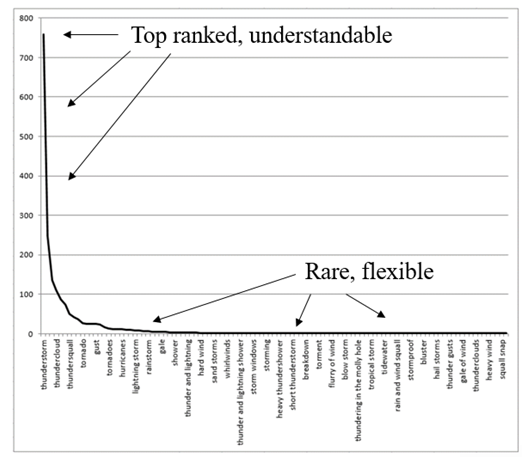
Figure 21. How we use the A-curve in language.
We might think of this change in location on the A-curve as corresponding to the psychological status of high frequency vs low frequency variants on the curve. High frequency words (Figure 21 shows different names for a thunderstorm in survey data from the Eastern US) are common, usual, and more understandable, while low frequency words are more flexible for use for special purposes or for personal identifiers. If a word changes its status from low frequency in a broad balanced corpus like Brown, to high frequency in Hemingway’s novel — to become one of his common, usual words in the novel — then we should pay attention and grant value to that fact. In practice, then, we can think of the A-curve as having three different regions. Top-ranked words are found in the long vertical ascender; there is also a long horizontal tail of rare words; and between them is the third region, the (relatively, depending on the data set) sharp curve that connects the ascender and the tail. There are no precise boundaries between the ascender, the cusp, and the tail, since these are regions on a curve, so the three categories will always allow some interpretation. If we notice in a comparison that a word is clearly in a different place in the ascender, or clearly in a different place in the tail, that is interesting but may not be perceptually relevant. However, if we can perceive from the visualization that a word occurs in different regions, say in the curve and the tail, or the ascender and the curve, then we can consider this to be evidence of an important change in the word’s status. Even moving from the beginning of the curve to the end of the curve is an important change in perceptual terms. A change between regions as we interpret them on the A-curves thus provides evidence of the importance of a word (or by extension a collocation or colligation) in the style of a novel, or of an author, or of a corpus defined in another way (say, women authors, or science fiction) in comparison to an appropriate reference corpus.
There are, of course, other ways of visualizing comparisons that allow differences at different scales to become evident.
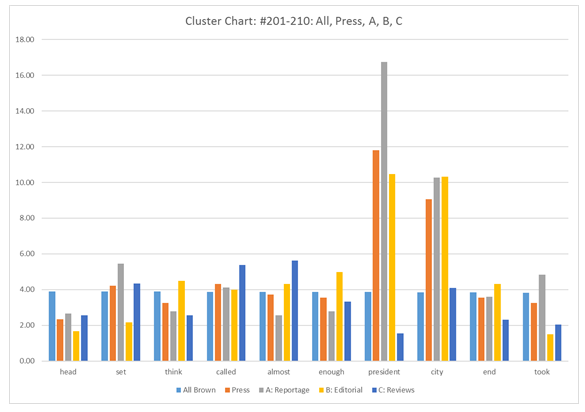
Figure 22. Clustered bar graph.
Figure 22 shows a clustered bar graph that shows ten words from the Brown Corpus, those from #201–210 on the wordlist. It shows the ten single words but each with a bar for the entire corpus, just the Press section, just the Reportage section, just the Editorial section, and just the Reviews section. It is clear to see that the frequencies of the words are not the same in the different sections. If we had plotted an A-curve for each word, we would see that each word occurs at a different place in the frequency order for each section. The first bar is about the same height for the words, since these are consecutive words by frequency in the corpus as a whole, but the other bars are quite variable. President and city, especially, have much higher frequencies in the Reportage and Editorial sections, as well as the Press section overall.
In order to make this kind of chart, one has to manipulate the data within Excel. The first step is to create an index number that accounts for the variable sizes of the corpora.
| Press | Tokens | Rate/10,000 |
|---|---|---|
| the | 12,729 | 647.42 |
| of | 6,201 | 315.39 |
| and | 4,715 | 239.81 |
| to | 4,477 | 227.71 |
| in | 3,857 | 196.17 |
| is | 1997 | 101.57 |
| for | 1,815 | 92.31 |
| that | 1,792 | 91.14 |
Table 1. Occurrence per 10,000 words (196,612 words in Press).
The one chosen in Table 1 is “occurrences per 10,000 words”: the raw counts of tokens just have to be divided by the total number of words in the corpus or section, by 10,000. So, if we divide the 196,612 words in the Press section by 10,000 we get 19.612, and if we divide the 12,729 occurrences of the by that number, we get 647.42. Once we carry out this data conversion on the numbers for the corpus as a whole and each subsection of it, we have comparable index figures. In fact, the visualizations in the ZipfExplorer tool are made with the “occurrences per 10,000” index, so we have already presented this in action.
To make a visualization in Excel, we next need to align the data sets. There are multiple ways to do this, but I have used the VLOOKUP function.
Basically, we make a data table with the full wordlist from your corpus, and also create columns for the wordlists from subsections of the corpus, each with its index number. We then use Excel references to bring a piece of data from a specific point elsewhere in the table to where you want it.
| All | Press | A | B | C | |
|---|---|---|---|---|---|
| head | 3.91 | 2.34 | 2.67 | 1.66 | 2.56 |
| set | 3.89 | 4.22 | 5.44 | 2.16 | 4.35 |
| think | 3.89 | 3.26 | 2.77 | 4.49 | 2.56 |
| called | 3.88 | 4.32 | 4.11 | 3.99 | 5.37 |
| almost | 3.87 | 3.71 | 2.57 | 4.32 | 5.63 |
| enough | 3.87 | 3.56 | 2.77 | 4.99 | 3.33 |
| president | 3.87 | 11.80 | 16.74 | 10.48 | 1.53 |
| city | 3.83 | 9.05 | 10.27 | 10.31 | 4.09 |
| end | 3.83 | 3.56 | 3.59 | 4.32 | 2.30 |
| took | 3.82 | 3.26 | 4.83 | 1.50 | 2.05 |
Table 2. Table of indices, # per 10,000.
The finished product looks something like Table 2. In order to create the clustered bar graph from it, all we have to do is highlight the desired data, and select Bar Graph from the Insert Chart menu.
Of course, the same data manipulation can make many other tables. Excel offers a number of different chart options.
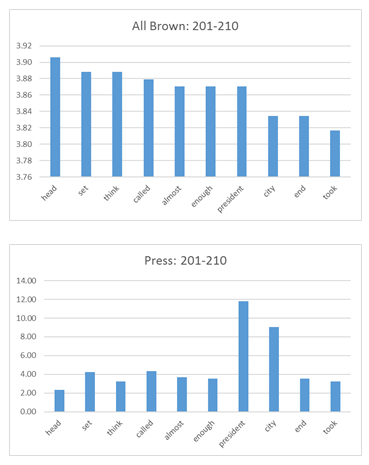
Figure 23. Paired graph in Excel.
Figure 23 is an example of a paired graph, made with the same words as the clustered bar graph. Each of these charts was made separately in Excel, then set next to each other so that the differences stand out. Pairing the simple graphs makes it easy to see differences in the frequency profile of the words: the ten words from the whole Brown Corpus wordlist are similar in height since they are consecutive entries, but the heights of the words in the Press graph are clearly different. One may prefer to use other Excel chart options, but the best practice will always be to make a comparison between a target data set and a reference data set, in order to show the frequency profile for more than a single data set.
At the end of the day, appropriate visualizations make for more effective exploration of data by concentrating on the real differences in usage in different samples. The important thing is to make a clear comparison of words at different scales in the fractal structure of language. While some linguists may be most interested in the mathematics of frequency distributions of words (or other features) in linguistic data sets, others may prefer to rely on visualizations in order to see how one corpus is different from another. We have shown that corpora and text types like novels all have nonlinear, A-curve frequency profiles for the words that they contain. We have related this observation to Mandelbrot’s idea of fractals, and especially to the fact that such frequency profiles are scale-free, that they show the same A-curve frequency profile at every level of scale. This means that we are entitled to observe differences in the location of individual words on the A-curves that we know will be present in different data sets, such as the words in the Brown Corpus vs. the words in a Hemingway novel. We then have discussed mathematics in association with the ZipfExplorer tool, and have shown that visualizations in logarithmic space and linear space can help us to understand differences in the location of individual words. Finally, we have offered examples of how such differences might appear in visualizations that can be created in the common spreadsheet, Excel. Since language is scale-free, comparisons are the natural way to examine how people use language, and the underlying self-similar structure of language facilitates that process.
[1] The alpha parameter is corresponds to the slope of the best-fit line through the frequency spectrum distribution in double logarithmic space, as in the lower left-hand corner of Figure 6. If the data is distributed according to a power law, the exponential parameter for the of the corresponding Zipf rank-frequency profile is 1\({α\over -1}\) (see Newman 2005; Adamic & Huberman 2002). Thus, for texts that follow “Zipf’s law”, with an exponential parameter of 1, the corresponding power-law alpha parameter is 2. [Go back up]
[2] This can be verified by examining the unfiltered rank-frequency profile for the text by selecting Moby Dick in both plots. [Go back up]
The ZipfExplorer tool: https://zipfexplorer.fly.dev
Source code for the ZipfExplorer is publically available at https://github.com/stcoats/zipf_explorer
Adamic, Lada & Bernardo A. Huberman. 2002. “Zipf’s law and the Internet”. Glottometrics 3: 143–150.
Alstott, Jeff, Ed Bullmore & Dietmar Plenz. 2014. “Powerlaw: A Python package for analysis of heavy-tailed distributions”. PLoS ONE 9(1): e85777. doi:10.1371/journal.pone.0085777
Baayen, R. Harald. 2001. Word Frequency Distributions. Dordrecht: Kluwer.
Bérubé, Nicolas, Maxime Sainte-Marie, Philippe Mongeon & Vincent Larivière. 2018. “Words by the tail: Assessing lexical diversity in scholarly titles using frequency-rank distribution tail fits”. PLoS One 13(7): e0197775. doi:10.1371/journal.pone.0197775
Biber, Douglas, Susan Conrad & Randi Reppen. 1998. Corpus Linguistics: Investigating Language Structure and Use. Cambridge: Cambridge University Press.
Bird, Steven, Edward Loper & Ewan Klein. 2019. Natural Language Processing with Python, updated for NLTK 3.0. https://www.nltk.org/book/
Bokeh Development Team. 2020. Bokeh: Python Library for Interactive Visualization. http://bokeh.org/
Bostock, Michael, Vadim Ogievetsky & Jeffrey Heer. 2011. “D3 data-driven documents”. IEEE Transactions on Visualization and Computer Graphics 17(12): 2301–2309. doi:10.1109/TVCG.2011.185
Brooke, Julian, Adam Hammond & Graeme Hirst. 2015. “GutenTag: An NLP-driven tool for digital humanities research in the Project Gutenberg corpus”. Proceedings of the 4th Workshop on Computational Literature for Literature (CLfL ’15), ed. by Anna Feldman, Anna Kazantseva, Stan Szpakowicz & Corina Koolen, 42–47. Stroudsburg, PA: Association for Computational Linguistics. doi:10.3115/v1/W15-0705
Chang, Winston, Joe Cheng, J.J. Allaire, Yihui Xie & Jonathan McPherson. 2019. Shiny: Web Application Framework for R. R package version 1.4.0. https://cran.r-project.org/web/packages/shiny/index.html.
Clauset, Aaron, Cosma Rohilla Shalizi & Matthew E.J. Newman. 2009. “Power-law distributions in empirical data”. SIAM Review 51(4): 661–703.
Dunning, Ted. 1993. “Accurate methods for the statistics of surprise and coincidence”. Computational Linguistics 19: 61–74.
Evert, Stefan & Marco Baroni. 2007. “zipfR: Word frequency distributions in R”. Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics, Posters and Demonstrations Sessions, 29–32. Stroudsburg, PA: Association for Computational Linguistics. https://dl.acm.org/doi/proceedings/10.5555/1557769
Ferrer i Cancho, Ramon. 2005. “The variation of Zipf’s law in human language”. European Physical Journal B 44: 249–257.
Ferrer i Cancho, Ramon & Richard V. Solé. 2001. “Two regimes in the frequency of words and the origins of complex lexicons: Zipf’s law revisited”. Journal of Quantitative Linguistics 8(3): 165–173.
Francis, W. Nelson & Henry Kučera. 1979. A Standard Corpus of Present-day Edited American English, For Use with Digital Computers. Providence, RI: Brown University.
Gillespie, Colin S. 2015. “Fitting heavy tailed distributions: The poweRlaw package”. Journal of Statistical Software 64(2): 1–16. doi:10.18637/jss.v064.i02
Honnibal, Matthew & Mark Johnson. 2015. “An improved non-monotonic transition system for dependency parsing”. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, ed. by Matthew Honnibal & Mark Johnson, 1373–1378. Stroudsburg, PA: Association for Computational Linguistics. doi:10.18653/v1/D15-1162
Hundt, Marianne, Andrea Sand & Paul Skandera. 1999. Manual of Information to Accompany The Freiburg – Brown Corpus of American English (‘Frown’). Freiburg, Germany: Department of English, Albert-Ludwigs-Universität Freiburg.
Kilgarriff, Adam, Vít Baisa, Jan Bušta, Miloš Jakubíček, Vojtěch Kovář, Jan Michelfeit, Pavel Rychlý & Vít Suchomel. 2014. “The Sketch Engine: Ten years on”. Lexicography 1: 7–36.
Kretzschmar, William A., Jr. 2009. The Linguistics of Speech. Cambridge: Cambridge University Press.
Kretzschmar, William A., Jr. 2015. Language and Complex Systems. Cambridge: Cambridge University Press.
Kunegis, Jérôme & Julia Preusse. 2012. “Fairness on the web: Alternatives to the Power Law”. Proceedings of WebSci 2012, June 22–24, 2012, 175–184. New York: ACM.
Lü, Linyuan, Zi-Ke Zhang & Tao Zhou. 2010. “Zipf’s law leads to heaps’ law: Analyzing their relation in finite-size systems”. PLoS One 5(12): e14139. doi:10.1371/journal.pone.0014139
Mandelbrot, Benoit. 1982. The Fractal Geometry of Nature. San Francisco: Freeman.
Montemurro, Marcelo A. 2001. “Beyond the Zipf-Mandelbrot law in quantitative linguistics”. Physica A: Statistical Mechanics and its Applications 300(3–4): 567–578.
Moreno-Sánchez, Isabel, Francesc Font-Clos & Álvaro Corral. 2016. “Large-scale analysis of Zipf’s law in English texts”. PLoS One 11(1): e0147073. doi:10.1371/journal.pone.0147073
Newman, Matthew E.J. 2005. “Power laws, Pareto distributions and Zipf’s law”. Contemporary Physics 46(5): 323–351.
Piantadosi, Steven T. 2014. “Zipf’s word frequency law in natural language: A critical review and future directions”. Psychonomic Bulletin & Review 21(5): 1112–1130. doi:10.3758/s13423-014-0585-6
Rayson, Paul & Roger Garside. 2000. “Comparing corpora using frequency profiling”. WCC ’00: Proceedings of the Workshop on Comparing Corpora, 1–6. New York: ACM. https://dl.acm.org/doi/10.5555/1604683.1604686
Shannon, Claude E. 1948. “A mathematical theory of communication”. Bell System Technical Journal 27: 379–423; 623–656.
Sievert, Carsten. 2018. Plotly for R. https://plotly-r.com
Zipf, George K. 1936. The Psycho-biology of Language. London: Routledge.
Zipf, George K. 1949. Human Behavior and the Principle of Least Effort: An Introduction to Human Ecology. Cambridge, MA: Addison-Wesley.

University of Helsinki