
Studies in Variation, Contacts and Change in English
Studies in Variation, Contacts and Change in English
Hermann Moisl
Vice President, International Quantitative Linguistics Association
The first step in analysis of data, linguistic or otherwise, is often graphical visualization with the aim of identifying latent structure, awareness of which can be used in hypothesis formulation. Where the data dimensionality is three or less, the standard visualization method is to plot the values for each data object relative to one, two, or three axes, where each axis represents a variable. As dimensionality grows beyond three, however, visualization becomes increasingly difficult and, for dimensionalities in the hundreds or thousands, even widely-used methods like parallel coordinate plots become intractable. General solutions for visualization of high-dimensional data are indirect; the present discussion describes two such solutions, both of which are based on the fundamental ideas that data have a shape in n-dimensional space, where n is the dimensionality of the data, and that this shape can be projected into two or three dimensional space for graphical display with, in general, tolerable loss of information. The first of these is Principal Component Analysis, which is very widely used but ignores any nonlinearity in the data manifold, and the second is the Self-Organizing Map, which preserves the topology of and thereby any nonlinearity in the manifold. The discussion is in two main parts. The first part introduces mathematical concepts relevant to data representation, and the second describes the selected visualization methods using these concepts.
Data are an interpretation of some domain of interest in the natural world for the purpose of scientific study, and a description of the domain in terms of that conceptualization. The interpretation consists of a set of variables which constitute the conceptual template whereby the researcher has chosen to understand the domain, and the description is the values assigned to the variables relative to the domain; a human population of n individuals can be interpreted in terms of the variables ‘age’ and ‘height’, for example, and these are assigned observed values for each individual. The number of chosen variables is referred to as the dimensionality of the data.
The first step in analysis of data, linguistic or otherwise, is often graphical visualization with the aim of identifying latent structure, awareness of which can be used in hypothesis formulation. Where the data dimensionality is 3 or less, the standard visualization method is to plot the values for each data object relative to one, two, or three axes, where each axis represents a variable. As dimensionality grows beyond 3, however, visualization becomes increasingly difficult and, for dimensionalities in the hundreds or thousands, even widely-used methods like parallel coordinate plots become intractable (Theus 2007). General solutions for visualization of high-dimensional data are indirect; the present discussion describes two such solutions, both of which are based on the fundamental idea that data have a shape in an n-dimensional space, where n is the dimensionality of the data.
The discussion is in two main parts. The first part introduces several mathematical concepts relevant to data representation, and the second describes the selected visualization methods using these concepts.
The following concepts are fundamental to work in data visualization and in data analysis more generally.
A vector is a sequence of n numbers each of which is indexed by its position in the sequence. Figure 1 shows n = 6 real-valued numbers, where the first number v(1) is 2.5, the second v(2) is 5.1, and so on.
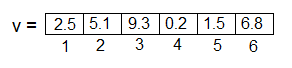
Figure 1. A vector.
A matrix is a table of vectors. Table 1 shows a small matrix abstracted from the Diachronic Electronic Corpus of Tyneside English (DECTE), an English dialect corpus, consisting of m = 6 rows of n = 12 variables; the leftmost column contains labels corresponding to DECTE speakers and the topmost row consists of phonetic variable labels, and neither is part of the matrix proper.
| Ə1 | Ə2 | o: | Ə3 | ī | eī | n | a:1 | a:2 | aī | r | w | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| tlsg01 | 3 | 1 | 55 | 101 | 33 | 26 | 193 | 64 | 1 | 8 | 54 | 96 |
| tlsg02 | 8 | 0 | 11 | 82 | 31 | 44 | 205 | 54 | 64 | 8 | 83 | 88 |
| tlsg03 | 4 | 1 | 52 | 109 | 38 | 25 | 193 | 60 | 15 | 3 | 59 | 101 |
| tlsg04 | 15 | 0 | 12 | 75 | 21 | 23 | 186 | 57 | 6 | 12 | 32 | 97 |
| tlsg05 | 14 | 6 | 45 | 70 | 49 | 0 | 188 | 40 | 0 | 45 | 72 | 79 |
| tlsg06 | 5 | 0 | 40 | 70 | 32 | 22 | 183 | 46 | 0 | 2 | 37 | 117 |
Table 1. A matrix abstracted from the Diachronic Electronic Corpus of Tyneside English.
In colloquial usage, the word ‘space’ denotes a fundamental aspect of how humans understand their world: that we live our lives in a three-dimensional space, that there are directions in that space, that distances along those directions can be measured, that relative distances between and among objects in the space can be compared, that objects in the space themselves have size and shape which can be measured and described. The earliest geometries were attempts to define these intuitive notions of space, direction, distance, size, and shape in terms of abstract principles which could, on the one hand, be applied to scientific understanding of physical reality, and on the other to practical problems like construction and navigation. Since the nineteenth century alternative geometries have continued to be developed without reference to their utility as descriptions of physical reality, and as part of this development ‘space’ has come to have an entirely abstract meaning which has nothing obvious to do with the one rooted in our intuitions about physical reality. A space under this construal is a mathematical set on which one or more mathematical structures are defined, and is thus a mathematical object rather than a humanly-perceived physical phenomenon (Lee 2010). The present discussion uses ‘space’ in the abstract sense; the physical meaning is often useful as a metaphor for conceptualizing the abstract one, though it can easily lead one astray.
Vectors have a geometrical interpretation (Strang 2016).
This is exemplified in Figure 2. In the left-hand plot the vector location is reached by moving 0.8 rightwards along the horizontal axis and from there 0.9 upwards parallel to the vertical axis. Interpretation of the right-hand plot is less straightforward because it attempts to show three dimensions on a two-dimensional surface by adding a further axis at 45 degrees to represent the third dimension, with a visually puzzling result. As before, move 0.8 along the horizontal axis and 0.9 along the vertical one, but then, from that location, follow the axis shown at 45 degrees for 0.7 to arrive at the location shown. This visual positional ambiguity is a problem that pervades attempts at three-dimensional graphical visualization generally: the vector’s position obeys the law of perspective on the two-dimensional surface and can for that reason be confusing.
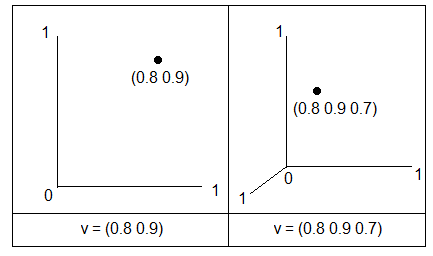
Figure 2. Two and three dimensional vector spaces.
It is possible to have more than one vector in a vector space. For a matrix with m rows, there will be m points in the space, and those m points define a shape in the space. That shape is a manifold (Strang 2016). For example, Figure 3 shows a manifold in 2-dimensional space:
Figure 3. A manifold in two-dimensional space.
The concept of manifolds applies not only to two and three-dimensional spaces but also to arbitrary dimensionality n; for n > 3 manifolds are referred to as hypercurves, hyperplanes, and hypersurfaces, as appropriate. Hyper-object shapes cannot be directly visualized or even conceptualized except by analogy with two and three dimensional ones, but as mathematical objects they are unproblematical.
The concepts of vector, matrix, vector space, and manifold are standardly used across the sciences to represent and interpret data. For a domain of interest containing m objects such as historical texts or dialect speakers, each vector represents a single text or speaker, each text or speaker is described in terms of one or more variables, and each variable is represented by a different vector component. Table 1 above shows a matrix in which the rows, labelled tlsgxxx, represent speakers, the columns represent phonetic segments, and the values represent the number of times that a speaker uses any given segment in the corpus from which the matrix was abstracted.
The collection of 12-dimensional speaker-vectors constitutes the data. Geometrically, those data exist in a 12-dimensional vector space and constitute a data manifold. The manifold is the shape of the data in that 12-dimensional space, and the aim is to visualize that shape in a 2 or 3-dimensional one.
In natural processes there is a fundamental distinction between linear and nonlinear behavior. Linear processes have a constant proportionality between cause and effect. If a ball is kicked x hard and it goes y distance, then a 2x kick will appear to make it go 2y, a 3x kick 3y, and so on. Nonlinearity is the breakdown of such proportionality. In the case of our ball, the linear relationship increasingly breaks down as it is kicked harder and harder. Air and rolling resistance become significant factors, so that for, say, 5x it only goes 4.9y, for 6x 5.7y, and again so on until eventually it bursts and goes hardly any distance at all. This is nonlinear behaviour: the breakdown of strict proportionality between cause and effect. Such nonlinear effects pervade the natural world and give rise to a wide variety of complex and often unexpected – including chaotic – behaviours (Bertuglia & Vaio 2005).
The linearity of a natural process is reflected in data describing that process by the curvature in the data manifold: for a linear process the manifold will be a straight line or a flat plane, and for a nonlinear one the manifold is curved in proportion to the type and degree of nonlinearity in the process. The manifold in Figure 3 is linear; Figure 4 shows a nonlinear one.

Figure 4. A nonlinear data manifold.
The problem that nonlinearity poses for visualization of high-dimensional multivariate data manifolds is that the most commonly-used visualization methods assume linearity, and when applied to nonlinear manifolds they can give misleading results in proportion to the degree of nonlinearity.
The above intuitive account of manifold nonlinearity is sufficient for present purposes, but for the mathematically-inclined it may be useful to state the technical definition of nonlinearity intended here. A data matrix M is linear when the functional relationships between all its variables, that is, the values in its columns, conform to the mathematical definition of linearity. A linear function f is one that satisfies the following properties, where x and y are variables and a is a constant (Lay 2010):
A function which does not satisfy these two properties is nonlinear, and so is a data matrix in which the functional relationships between two or more of its columns are nonlinear.
The discussion in this section is in five parts: the first part outlines the corpus-derived data used for exemplification, the second introduces the idea of projection from high to low dimensional spaces, the third describes Principal Component Analysis, a linear projection method, the fourth describes a nonlinear projection method, the Self Organizing Map, and the fifth compares results obtained from application of the two methods to the corpus data.
The visualization methods described in what follows will need to be exemplified with reference to specific data. The data matrix used for this purpose is abstracted from a collection of Old English, Middle English, and Early Modern English texts listed in Table 2, which were chosen because their chronological distribution is well established. The aim is to show how the selected methods for visualization of high-dimensional data can identify that distribution.
| Old English | Middle English | Early Modern English |
|---|---|---|
| Exodus | Sawles Warde | King James Bible |
| Phoenix | Henryson, Testament of Cressid | Campion, Poesie |
| Juliana | The Owl and the Nightingale | Milton, Paradise Lost |
| Elene | Malory, Morte d’Arthur | Bacon, Atlantis |
| Andreas | Gawain and the Green Knight | More, Richard III |
| Genesis | Morte Arthure | Shakespeare, Hamlet |
| Beowulf | King Horn | Jonson, Alchemist |
| Alliterative Morte Arthure | ||
| Bevis of Hampton | ||
| Chaucer, Troilus | ||
| Langland, Piers Plowman | ||
| York Plays | ||
| Cursor Mundi |
Table 2. The corpus.
All the above texts were downloaded from online digital collections:
Spelling is used as the basis for inference of the relative chronology of the above texts on the grounds that it reflects the phonetic, phonological, and morphological development of English over time. The variables used to represent spelling in the texts are letter pairs: for ‘the cat sat’, the first letter pair is (<t,h>), the second (<h,e>), the third (<e, space>), and so on. All distinct pairs across the entire text collection were identified, and the number of times each occurs in each text was counted and assembled in a matrix, henceforth M. A fragment of M is shown in Table 3, where the rows are the texts and the columns the letter-pair variables. Note that it is very high-dimensional, and cannot be graphically represented directly.
| 1. <space h> | 2. <hw> | 3. <wæ> | ... | 841. <jm> | |
|---|---|---|---|---|---|
| Exodus | 338 | 35 | 94 | ... | 0 |
| Sawles Warde | 629 | 52 | 0 | ... | 0 |
| ... | ... | ... | ... | ... | ... |
| Cursor Mundi | 15219 | 20 | 0 | ... | 0 |
Table 3. Fragment of the data matrix M.
Before applying visualization methods to M, a problem that often arises when working with multi-text corpora must be dealt with: variation in text length. Why this can be a problem is easy enough to see. If the data are based on frequency of some textual feature such as words or, as here, letter pairs, then for whatever feature one is counting it is in general probable that a relatively longer text will contain more instances of it than a shorter one - a novel inevitably contains more instances of <the> than a typical email, for example. If frequency vector profiles for varying-length texts are constructed, then the profiles for longer texts can generally be expected to have larger frequency values than the profiles for shorter ones, and when visualization methods are applied to a collection of such vectors the results will be distorted by these disparities of magnitude. The texts listed in Table 2 vary substantially in length, and so our data matrix M poses this problem.
The solution is to transform or ‘normalize’ the values in the data matrix so as to mitigate or eliminate the effect of text length variation. Various normalization methods exist; for discussion and references see (Moisl 2015: Ch. 3). The one used here on account of its intuitive simplicity is normalization by mean document length. Restricting the discussion to M, this involves transformation of its row vectors in relation to the mean number of pairs per text across all texts in the corpus, as in Equation 1.
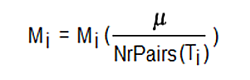
Equation 1. Mean document length normalization.
Mi is the i’th matrix row (for i = 1…the number of texts / number of matrix rows), Ti is the i’th text, NrPairs(Ti) is the number of letter pairs in Ti, and µ is the mean number of letter pairs per text across all the texts in the corpus, which is calculated as in Equation 2.
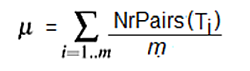
Equation 2. Mean number of letter pairs.
Here m is the number of texts in the corpus / number of matrix rows and the Σ term with subscript stands for summation over all m rows.
In words, first calculate the mean number of letter pairs per text across all texts in the corpus by adding the number of pairs in each of the texts and then dividing by the number of texts. This quantity µ is then used to transform the matrix so as to compensate for the variation in text length: for each row Mi multiply every value in Mi by the ratio of µ to the total number of pairs in text Ti: if Ti is larger than µ then multiplication by the ratio will decrease the values in Mi in proportion to how much larger Ti is than µ; if Ti is smaller than µ then multiplication by the ratio will increase the values in Mi in proportion to how much smaller Ti is than µ; and if Ti and µ are equal then the ratio is 1 and there will be no change.
M was normalized as above, and the fragment of the normalized version M' shown in Table 4 is the one to which the visualization methods described in the next section are applied. The numerical quantities are now real-valued and no longer represent observed frequencies on account of the normalization procedure; note how the large observed disparities between the relatively short Exodus and the relatively long Cursor Mundi in column 1 of M have been brought much closer together in M' by the procedure.
| 1. <space h> | 2. <hw> | 3. <wæ> | ... | 841. <jm> | |
|---|---|---|---|---|---|
| Exodus | 2728.55 | 282.54 | 758.82 | ... | 0 |
| Sawles Warde | 3824.59 | 316.18 | 0 | ... | 0 |
| ... | ... | ... | ... | ... | ... |
| Cursor Mundi | 3005.92 | 3.95 | 0 | ... | 0 |
Table 4. Fragment of M' derived from M by mean document length normalization.
The selection of variables in any given application is at the discretion of the researcher, and it is possible that the selection will be suboptimal in the sense that there is redundancy among the variables, that is, that they overlap with one another to greater or lesser degrees in terms of what they represent in the research domain. Where there is such redundancy, dimensionality reduction can be achieved by eliminating the repetition of information which redundancy implies, and more specifically by replacing the researcher-selected variables with a smaller set of new, non-redundant variables. Slightly more formally, given an n-dimensional data matrix, dimensionality reduction by variable redefinition assumes that the data can be described, with tolerable loss of information, by a manifold in a vector space whose dimensionality is lower than that of the data, and proposes ways of identifying that manifold.
For example, data for a study of student performance at university might include variables like personality type, degree of motivation, score on intelligence tests, scholastic record, family background, class, ethnicity, age, and health. For some of these there is self-evident redundancy: between personality type and motivation, say, or between scholastic record and family background, where support for learning at home is reflected in performance in school. For others the redundancy is less obvious or controversial, as between class, ethnicity, and score on intelligence tests. The researcher-defined variables personality type, motivation, scholastic record, and score on intelligence tests might be replaced by a ‘general intelligence’ variable based on similarity of variability among these variables in the data, and family background, class, ethnicity, age, and health with a ‘social profile’ one, thereby reducing data dimensionality from nine to two. Conceptually, such a reduction can be understood as projection of the data manifold in high-dimensional space into a lower-dimensional one. In Figure 5, for example, a three-dimensional manifold is projected into a two-dimensional space. The two-dimensional projection has lost some information - the volume of the sphere - but retains the essential circularity of the manifold.
Figure 5. Projection from three to two-dimensional physical space.
Clearly, if there is little or no redundancy in the user-defined variables there is little or no point to variable redefinition. The first step must, therefore, be to determine the level of redundancy in the data of interest to see whether variable extraction is worth undertaking; for details on how to do this see (Moisl 2015: Ch. 3).
The theoretical basis for projection is the concept of intrinsic dimension. We have seen that an m x n matrix defines a manifold in n-dimensional space. In such a space, it is possible to have manifolds whose shape can be described in k dimensions, where k < n. Figure 6a shows, for example, a three dimensional matrix and the corresponding plot in three dimensional space. The data in 6a describe a straight line in three dimensional space. That line can also be described in two dimensions, as in 6b, and in fact can be described in only one dimension, its length 10.69, that is, by its distance from 0 on the real-number line, as in 6c. In general, a straight line can be described in one dimension, two dimensions, three dimensions, or any number of dimensions one likes. Essentially, though, it is a one-dimensional object; its intrinsic dimension is 1. In other words, the minimum number of dimensions required to describe a line is 1; higher-dimensional descriptions are possible but unnecessary.
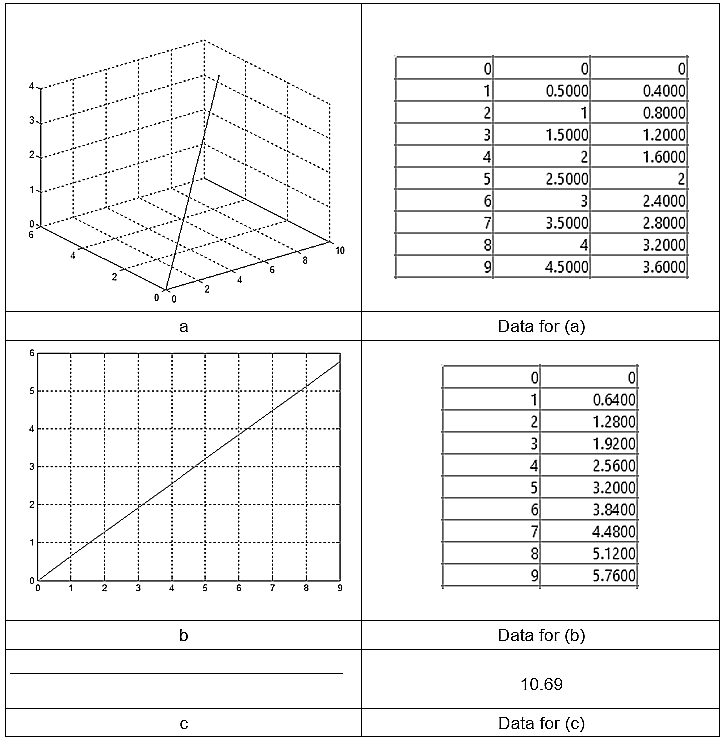
Figure 6. A line in 3, 2, and 1-dimensional spaces.
Another example is a plane in three-dimensional space, shown in Figure 7a. This plane can be redescribed in two-dimensional space, as in Figure 7b, and again in any number of dimensions one likes. Clearly, however, it cannot be described in one dimension; the intrinsic dimension of a plane is 2.
Figure 7. A plane in 3 and 2-dimensional spaces.
Similarly, the intrinsic dimension of a cube is 3, in that the minimum dimensionality data set that can describe it is the three x, y and z coordinates of the points that comprise it. A cube can of course, exist not only in 3 dimensional space but also in four, ten, twenty, and n-dimensional spaces, in which case it would be a k-dimensional manifold of intrinsic dimension k = 3 embedded in n-dimensional space, where k < n and n is the embedding dimensionality. For discussion of intrinsic dimension see Jain & Dubes (1988: Ch. 2.6), Camastra (2003), Verleysen (2003), Lee & Verleysen (2007: Ch. 3).
The concept of intrinsic dimension is straightforwardly relevant to dimensionality reduction. The informational content of data is conceptualized as a k-dimensional manifold in the n-dimensional space defined by the data variables. Where k = n, that is, where the intrinsic dimension of the data corresponds to the number of data variables, no dimensionality reduction is possible without significant loss of information. Where, however, there is redundancy between and among variables in a data matrix, it is possible to represent this information using a smaller number of variables, thus reducing the dimensionality of the data. In such a case, the aim of dimensionality reduction of data is to discover its intrinsic dimensionality k, for k < n, and to redescribe its informational content in terms of those k dimensions.
Unfortunately, it is not usually obvious what the intrinsic dimension of given data is, and there is currently no known general solution for finding k. Reviews of existing methods are found in Lee & Verleysen (2007) and Camastra (2003). Existing dimensionality reduction methods require the researcher to approximate k using a variety of criteria; the remainder of this section describes one linear and one nonlinear method.
The standard method for dimensionality reduction via variable redefinition is Principal Component Analysis (PCA). PCA is based on the idea that most of the global variance of data with n variables can be expressed by a smaller number k < n of newly-defined variables. These k new variables are found using the shape of the manifold in the original n-dimensional space. The mathematics of how PCA works are too complex for detailed exposition here; for the technicalities see the standard accounts by Jolliffe (2002) and Jackson (2003) and, more briefly, Bishop (1995: 310 ff.), Everitt & Dunn (2001: 48 ff.), Tabachnick & Fidell (2007: Ch. 13), Izenman (2008: Ch. 7), Moisl (2015: Ch. 3). Instead, an intuitive graphical explanation is given.
Because real-world objects can be distinguished from one another by the degree to which they differ, the data variables used to describe those objects are useful in proportion to how well they describe that variability. In reducing dimensionality, therefore, a reasonable strategy is to attempt to preserve variability, and that means retaining as much of the variance of the original data in the reduced-dimensionality representation as possible. Redundancy, on the other hand, is just repeated variability, and it can be eliminated from data without loss of information. PCA reduces dimensionality by eliminating the redundancy while preserving most of the variance in data.
Given an n-dimensional data matrix containing some degree of redundancy, PCA replaces the n variables with a smaller set of k uncorrelated variables called principal components which retain most of the variance in the original variables, thereby reducing the dimensionality of the data with only a relatively small loss of information. It does this by projecting the n-dimensional data reduction into a k-dimensional vector space, where k < n and closer than n to the data’s intrinsic dimensionality. This is a two-step process: the first step identifies the reduced-dimensionality space, and the second projects the original data into it. Figure 8 shows a small two-dimensional data matrix and the corresponding manifold in the vector space, both in relation to two axes representing v1 and v2. Vectors v1 and v2 both have a substantial degree of variance, as shown both by the standard deviation and the scatter plot, and the coefficient of determination shows that they are highly redundant in that they share 90 percent of their variance.
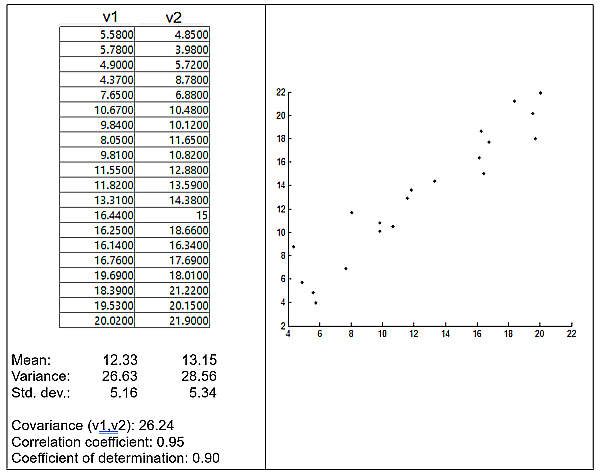
Figure 8. Two-dimensional matrix with high redundancy between variables.
The aim is to reduce the dimensionality of this data from 2 to 1 by eliminating the redundancy and retaining most of the data variance. The first step is to centre the data on 0 by subtracting their respective means from v1 and v2. This restates the data in terms of different axes but does not alter either the variable variances or their covariance. The mean-centred variables and corresponding plot are shown in Figure 9.
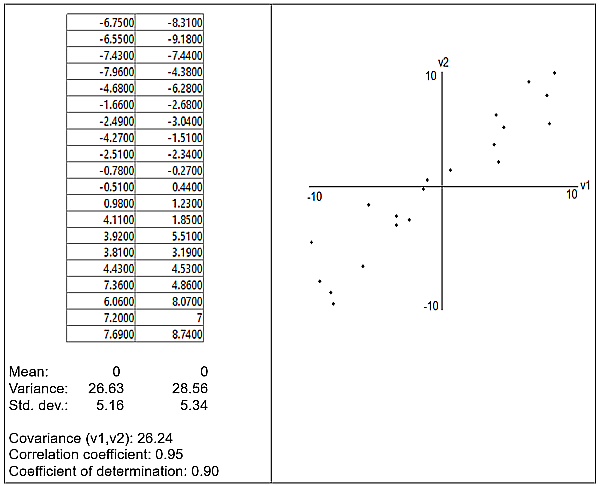
Figure 9. Mean-centred version of the matrix in Figure 8.
The axes are now rotated about the origin so that one or the other of them – in this case the horizontal one – becomes the line of best fit to the data distribution, as shown in Figure 10; the line of best fit is the one that minimizes the sum of squared distances between itself and each of the data points. This again changes the axes, and the variable values are again adjusted relative to them.
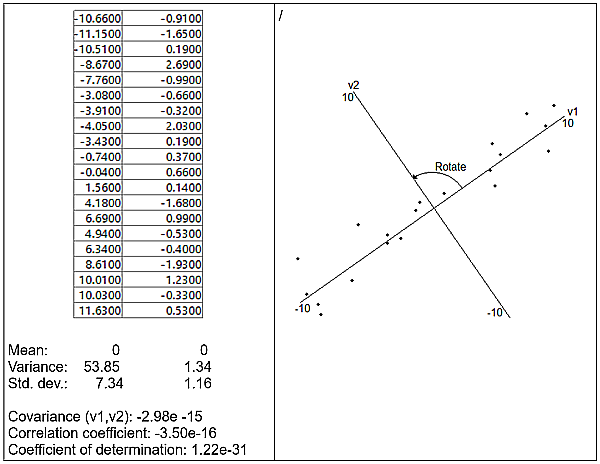
Figure 10. Axes of Figure 9 rotated so that v1 becomes the line of best fit to the data distribution.
Note that:
The main direction of variability in Figure 10 can be visually identified; the line of best fit drawn through the manifold in that direction is the first new variable w1, and it captures most of the variance in the manifold. A second line of best fit is now drawn at right angles to the first to capture the remaining variance. This is the second new variable w2. We now have two new variables in addition to the two original ones. What about dimensionality reduction? It’s clear that w1 captures almost all the variance in the manifold and w2 very little, and one might conclude that w2 can simply be omitted with minimal loss of information. Doing so reduces the dimensionality of the original data from 2 to 1.
This idea extends to any dimensionality. Using it, PCA is a general method for dimensionality reduction of n-dimensional data, where n is any integer. The first variable represents the largest direction of variability in the data manifold, the second variable represents the second-largest direction of variability in the manifold, the third represents the third-largest direction, and so on; the first two or three variables can be visualized by scatter plotting, and that visualization will represent the most important directions of variability in the original data.
Applying this to the example data, PCA was applied to the full normalized 841-dimensional data matrix M', yielding a new matrix M'' containing 841 new variables. The variances of these new variables are plotted in descending order of magnitude in Figure 11. To see the distribution in Figure 11a more clearly, the twelve highest-variance variables are shown in 11b.
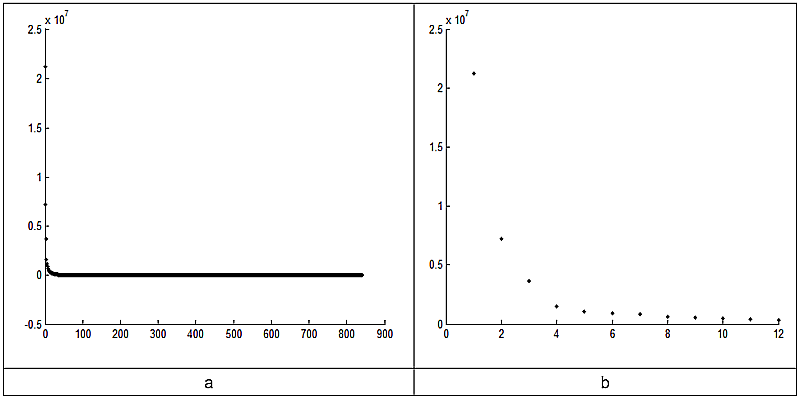
Figure 11. Variances of the variables from PCA-generated M''.
Almost all the variability is in the first 4 variables. In fact, the first two variables contain 69% of the variability. These latter are plotted together with associated text-labels in Figure 13. The result is a visualization of the 841-dimensional manifold in 2-dimensional space. Examination of this visualization will attest to the reliability of PCA relative to what is known of the texts: the spatial distribution of the texts is consonant with their independently-known chronological structure.

Figure 12. Scatter-plot of the two highest-variance PCA-generated variables.
PCA is a linear projection method. It ignores any curvature in the high-dimensional data manifold being reduced, and can thereby introduce distortions into visualization results in proportion to the degree of nonlinearity in the manifold. This is the essence of the problem that topological mapping addresses.
Topology is an aspect of contemporary mathematics that grew out of the vector space geometry we have been using so far in the discussion. Its objects of study are manifolds, but these are studied as spaces in their own right, topological spaces, without reference to any embedding vector space and associated coordinate system. In Figure 13a the locations of the points constituting the manifold in the three-dimensional vector space are specifed relative to the three axes by three-dimensional vectors; in Figure 13b there are no axes, and so no way of locating the points relative to them.

Figure 13. A manifold in three-dimensional vector space and as a topological space.
Topology replaces the concept of vector space and associated coordinate system with relative nearness of points to one another in the manifold, as in Figure 14.
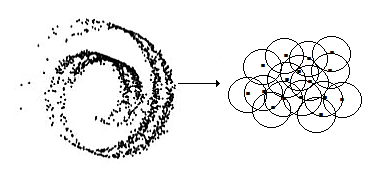
Figure 14. Relative proximity of points in a manifold.
Relative nearness of points is determined by a function which, for any given point p in the manifold, returns the set of all points within some specified proximity e to p. The set of all points in proximity e to p constitute the neighbourhof of p.In this way, manifolds of arbitrary shape, whether linear or nonlinear, can be conceptualized as a patchwork of overlapping neighbourhoods.
A widely-used topological mapping method is the Self-Organizing Map (SOM). The SOM is an artificial neural network that was originally invented to model a particular kind of biological brain organization, but that can also be and often has been used without reference to neurobiology as a way of visualizing high-dimensional data manifolds by projecting and displaying them in low-dimensional space.
A good intuition for how the SOM works can be gained by looking at the biological brain structure it was originally intended to model: sensory input systems (Kohonen 2001, Chs. 2 and 4; Van Hulle 2000). The receptors in biological sensory systems generate very high dimensional signals which are carried by nerve pathways to the brain. The retina of the human eye, for example, contains on the order of 108 photoreceptor neurons each of which can generate a signal in selective response to light frequency, and the number of pathways connecting the retina to the brain is on the order of 106 (Hubel & Wiesel 2005). At any time t, a specific visual stimulus vt to the eye generates a pattern of retinal activation at which is transmitted via the nerve pathways to the part of the brain specialized for processing of visual input, the visual cortex, which transmits a transformed version of vt to the rest of the brain for further processing.
It is the response of the visual cortex to retinal stimulation which is of primary interest here. The visual cortex is essentially a two-dimensional region of neurons whose response to stimulation is spatially selective: any given retinal activation at sent to it stimulates not the whole two-dimensional cortical surface but only a relatively small region of it, and activations at+1, at+2... similar to at stimulate adjacent regions. Similar stimuli in very high-dimensional input space are thereby projected to spatially adjacent locations on a two-dimensional output surface. Figure 15 is a graphical representation of what a highly simplified physical model of a visual input system might look like.
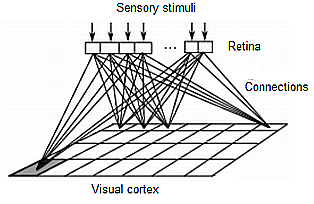
Figure 15. A highly-simplified model of the biological visual system.
Only a very few retinal and cortical neurons are shown. Also, only a few connections between retina and cortex are represented to convey an idea of the pattern of connectivity without cluttering the diagram; each of the cells of the retina is connected to each of the cells in the visual cortex so that if the retina had, say, 10 cells there would be 10×(7×4) = 280 connections, where (7×4) are the dimensions of the cortex.
For manifold projection a SOM works as follows, assuming an m x n data matrix D is given. For each row vector Di (for i = 1...m) repeat these two steps:
Once all the vectors have been presented there is a pattern of activations on the surface, and this pattern is the two-dimensional projection of the n-dimensional data matrix D.
In biological systems, evolution combined with individual experience of a structured environment determines the pattern of connectivity and cortical response characteristics which implement the mapping from high-dimensional sensory inputs to a two-dimensional representation in the brain. An artificially constructed model of such a system does not have the benefit of aeons of selective adaptation, however, and the mapping must somehow be specified. Like other artificial neural network architectures, the SOM specifies the mapping by learning them from the regularities in the input data. The learning mechanism is too complex for detailed description here, but in outline it works as follows. Each of the connections from the input to the two-dimensional surface can vary in terms of how strongly the input activations it receives are transmitted to the surface; SOM learning tries to find a pattern of connection strength variation across all the connections such that similar high-dimensional input vectors are mapped to spatially-adjacent regions on the surface. Given a set of input vectors, SOM learning is a dynamic process that unfolds in discrete time steps t1, t2...tp, where p is the number of time steps required to learn the desired mapping. At each time step ti, a data vector Dj is selected, usually randomly, as input to the SOM, and the connection strengths are modified in a way that is sensitive to the pattern of numerical values in Dj. At the start of the learning process the magnitude of modifications to the connections is typically quite large, but as the SOM learns via the modification process the magnitude decreases and ultimately approaches 0, at which point learning is stopped at the p’th time step.
The SOM’s representation of high dimensional data in a low-dimensional space is a two-step process. The SOM is first trained using the vectors comprising the given data, as above. Once training is complete all the data vectors are input once again in succession, this time without training. The aim now is not to learn but to generate the two-dimensional representation of the data on the two-dimensional surface. Each successive input vector activates the cell in the surface with which training has associated it together with neighbouring cells to an incrementally diminishing degree. When all the data vectors have been input, there is a pattern of activations on the surface, and that pattern is the representation of the input manifold in two-dimensional space.
Note that, because the SOM preserves the neighbourhood relations of the high-dimensional input manifold in the two-dimensional output space, it follows any curvature in the data manifold and is thus a nonlinear projection method.
The standard work on the SOM is Kohonen (2001). Shorter accounts are Lee & Verleysen (2007: Ch. 5), Izenman (2008: Ch. 12.5), Xu & Wunsch (2009: Ch. 5.3.3), and Moisl (2015: Ch.4); collections of work on the SOM are in Oja and Kaski (1999) and Allinson et al. (2001). For overviews of applications of the SOM to data analysis see Kohonen (2001: Ch. 7) and Vesanto & Alhoniemi (2000).
How is nonlinearity relevant to data abstracted from natural language? In general, nonlinearity in the human brain arises on account of latency and saturation effects in individual neurons and neuronal assemblies, which, together with extensive fedback, makes the brain a nonlinear dynamical system that exhibits highly complex physical behaviour (Freeman 2000a, 2000b; Stam 2006), and output from that system will at least potentially be nonlinear. For example, as a speaker matures from childhood, do all aspects of phonetic or phonological usage develop proportionately at the same rate? If not, data abstracted from that development will be nonlinear.
To exemplify topological mapping, our normalized 841-dimensional data matrix M' was used to train a SOM, and the result is shown in Figure 16.
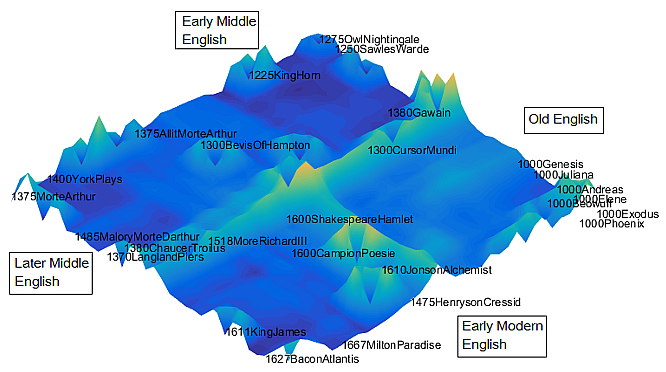
Figure 16. SOM projection of the data matrix M.
The map is here visualized using the U-matrix method (Ultsch 2003; discussed in Moisl 2015: Ch.4) as a landscape in which units of relatively high activation are shown as peaks and those with relatively low activation as troughs, with colour-coding from deep blue to yellow. The texts are assigned to four regions corresponding to their independently known chronological distribution. Note that the text labels are ‘anchored’ on the left so that, for example, the vector corresponding to Cursor Mundi is at ‘1300’ on the map.
Numerous developments of the basic SOM described above have been proposed to address specific limitations – see Kaski (1997), Vesanto (1999, 2000), Kohonen (2001: Ch. 5) Lee & Verleysen (2007: 142f.), Xu & Wunsch (2009: Ch. 5.3.4).
The PCA and SOM results are broadly compatible in separating the texts into four groups corresponding to what is independently known of their chronological distribution, though PCA shows the later Middle English and Early Modern English ones as a continuum whereas the SOM distinguishes them clearly. There are also differences of detail. PCA puts Gawain and the Green Knight decisively with the Early Middle English texts while the SOM places it midway between Early Middle and Old English, for example.
Which analysis should be preferred, that is, which reflects the similarity structure of the vectors which represent the texts more accurately? On the one hand, we know that PCA ignores any data nonlinearity and loses some of its variance as part of its dimensionality reduction, both of which potentially affect the accuracy of the two-dimensional representation to some degree. On the other, the SOM neither ignores nonlinearity nor loses variance, and for those reasons is more accurate in principle. In practice, however, there are factors which can affect its accuracy (Moisl 2015: 178–80).
The moral is that, like related methods such as multidimensional scaling and hierarchical cluster analysis, neither PCA nor SOM can on its own be relied on to generate optimal visualizations of any given data. For reliable insight into the structure of data, several visualization methods should be applied and consensus among them identified.
Two dimensionality reduction methods have been presented, both of them with a clear applicability to data visualization in linguistics. One of them, PCA, is long-established and widely used across the range of science and engineering disciplines. The other, the SOM, is well known in data processing disciplines such as information retrieval and data mining but relatively little known in linguistics. The presentation has involved reference to mathematical concepts, but no apology is made for this: understanding of how fundamentally mathematical methods work is, in the present view, essential to their responsible use.
Two final comments are ventured. One is that engagement with nonlinear methods for visualization of high-dimensional data offers an interesting and potentially very useful enhancement to the collection of mainly linear ones currently in use among linguists. The other is to stress the importance of something all too briefly touched on in the course of the foregoing discussion: understanding of how data chatacteristics such as nonlinearity, variation in document length, and differences in variable scaling affect the reliability of visualization methods, and ways of transforming data to mitigate or eliminate their effects.
Corpus of Middle English Prose and Verse. https://quod.lib.umich.edu/c/cme/
DECTE = The Diachronic Electronic Corpus of Tyneside English. https://research.ncl.ac.uk/decte/index.htm
Early English Books Online. https://quod.lib.umich.edu/e/eebogroup/
Internet Sacred Text Archive. https://www.sacred-texts.com/neu/ascp/
Allinson, Nigel, Hujun Yin, Lesley Allinson & Jon Slack. 2001. Advances in Self-Organising Maps. Berlin: Springer.
Bertuglia, Cristoforo Sergio & Franco Vaio. 2005. Nonlinearity, Chaos, and Complexity: The Dynamics of Natural and Social Systems. Oxford: Oxford University Press.
Bishop, Christopher M. 1995. Neural Networks for Pattern Recognition. Oxford: Clarendon Press.
Camastra, Francesco. 2003. “Data dimensionality estimation methods: A survey”. Pattern Recognition 36(12): 2945–2954. doi:10.1016/S0031-3203(03)00176-6
Everitt, Brian S. & Graham Dunn. 2001. Applied Multivariate Data Analysis, 2nd ed. London: Arnold.
Freeman, Walter J. 2000a. How Brains Make up their Minds, 2nd ed. London: Weidenfeld and Nicholson.
Freeman, Walter J. 2000b. Neurodynamics. Berlin: Springer.
Hubel, David H. & Torsten N. Wiesel. 2005. Brain and Visual Perception. Oxford: Oxford University Press.
Izenman, Alan J. 2008. Modern Multivariate Statistical Techniques. Regression, Classification and Manifold Learning. Berlin: Springer.
Jackson, J. Edward. 2003. A User’s Guide to Principal Components. Hoboken NJ : Wiley-Interscience.
Jolliffe, Ian T. 2002. Principal Component Analysis, 2nd ed. Berlin: Springer.
Jain, Anil K. & Richard C. Dubes. 1988. Algorithms for Clustering Data. London: Prentice Hall.
Kaski, Samuel. 1997. Data Exploration Using Self-organizing Maps (Mathematics, Computing, and Management in Engineering Series 82). Helsinki: Acta Polytechnica Scandinavica.
Kohonen, Teuvo. 2001. Self-Organizing Maps, 3rd ed. Berlin: Springer.
Lay, David. 2010. Linear Algebra and its Applications, 4th ed. London: Pearson.
Lee, John M. 2010. Introduction to Topological Manifolds, 2nd ed. Berlin: Springer.
Lee, John M. & Michel Verleysen. 2007. Nonlinear Dimensionality Reduction. Berlin: Springer.
Moisl, Hermann. 2015. Cluster Analysis for Corpus Linguistics. Berlin: de Gruyter.
Oja, Erkki & Samuel Kaski. 1999. Kohonen Maps. London: Elsevier.
Stam, Cornelius J. 2006. Nonlinear Brain Dynamics. Hauppauge, NY: Nova Science Publishers.
Strang, Gilbert. 2016. Introduction to Linear Algebra, 5th ed. Cambridge: Wellesley-Cambridge Press.
Tabachnick, Barbara G. & Linda S. Fidell. 2007. Using Multivariate Statistics. London: Pearson Education.
Tabak, John. 2011. Geometry: The Language of Space and Form, revised edition. New York: Chelsea House Publishers.
Theus, Martin. 2007. “High-dimensional data visualization”. Handbook of Data Visualization, ed. by Chun-houh Chen, Wolfgang Härdle & Antony Unwin, 151–178. Berlin: Springer.
Ultsch, Alfred. 2003. “Maps for visualization of high-dimensional data spaces”. Proceedings of the Workshop on Self Organizing Maps, WSOM03, 225–230.
Van Hulle, Marc M. 2000. Faithful Representations and Topographic Maps. Hoboken, NJ: John Wiley and Sons.
Verleysen, Michel. 2003. “Learning high-dimensional data”. Limitations and Future Trends in Neural Computation, ed. by S. Ablameyko, L. Goras, M. Gori & V. Piuri, 141–162. Amsterdam: IOS Press.
Vesanto, Juha. 1999. “SOM-based data visualization methods”. Intelligent Data Analysis 3: 111–126.
Vesanto, Juha. 2000. Using SOM in Data Mining. Helsinki: Helsinki University of Technology, Department of Computer Science and Engineering.
Vesanto, Juha & Esa Alhoniemi. 2000. “Clustering of the self-organizing map”. IEEE Transactions on Neural Networks 11(3): 586–600. doi:10.1109/72.846731
Xu, Rui & Donald C. Wunsch. 2009. Clustering. London: Wiley.

University of Helsinki