Technical information
More detailed information is provided in the User Manual available via the corpus online interface.
Format
The APU corpus exists in different versions to suit different users and uses:
- digitised images in .PDF format
- transliteration in .XML format with TEI Lite mark-up and metadata, without linguistic tagging
- transliteration in .TXT format, plain text and original spelling
- .TXT format, plain text and normalised spelling
- .TXT format with part-of-speech tagging (CLAWS7)
- .TXT format with semantic tagging (USAS)
Editorial conventions
Transliterations of the school scripts retain the original spelling, including orthographic and grammatical deviations from written Standard English, as well as the original punctuation (or lack thereof); these deviations are displayed as such in the online interface, and the appropriate XML tag has been added in order to display the normalised form. Abbreviations have been retained in their short form as written in the original script; the expanded form has been coded in the XML version. Text alignment, lineation and paragraph indentation have been preserved.
File extent
The Perl-script used to count ‘words’ was kindly produced by Prof. David Denison (University of Manchester). The word count is an accurate word count of the actual text; that is, of everything in the file which is not enclosed in <…> brackets used for XML tags. Hyphenated words are counted as one item, as are all items other than punctuation surrounded by white space. Note that word counts have been calculated from the version with original spelling, deviations included. In the “School Scripts” component, the Rule scripts tend to be shorter than the Story scripts. In the “Basal Reader” component the length of the samples varies considerably.
Lines are counted from the first line with running text to the last line with running text, including intermediate blank lines. This applies to both components of the corpus. Counts have been calculated with the XML editor oXygen from the XML version.
Online interface
The APU corpus is freely available online from the corpus website. Access will be granted to interested users upon receipt of the APU User Agreement, whereby they will agree formally to the conditions of use.
The following documents are available to registered users via the APU online interface:
- Common to all files: XML tagset (TEI P5), POS tagset (CLAWS7), Semantic tagset (USAS).
- For each individual file: frequency list of words in .TXT file (original and normalised); frequency list of POS tags; frequency list of words and POS tags; frequency list of semantic tags; frequency list of words and semantic tags; word counts per file.
Two layouts have been built in the web-based application: Browse and Search. It is also possible to download the search hits into a CSV file.
For the Browse layout, users can explore the school scripts/basal readers in running text with original spelling and XML tags by the side of the digitised PDF image, of the text with part-of-speech tagging, or of the text with semantic tagging.
For the Search layout, users can search the corpus data and the metadata. Users can search by text, by XML tag, by POS tag, or by semantic tag. The search hits are displayed in KWIC concordance format; they can be viewed and downloaded with approximately 600 characters left and right. It is also possible to show/hide POS tags or semantic tags in the expanded view.
The User’s Corner is an optional tool for users to document their work with APU, in form of academic publication, teaching materials or any other type of research and/or educational resources. Copyrights of any materials uploaded rest with the author(s).
Selection of images from the online corpus

Figure 1. Format: .PDF digitised image.
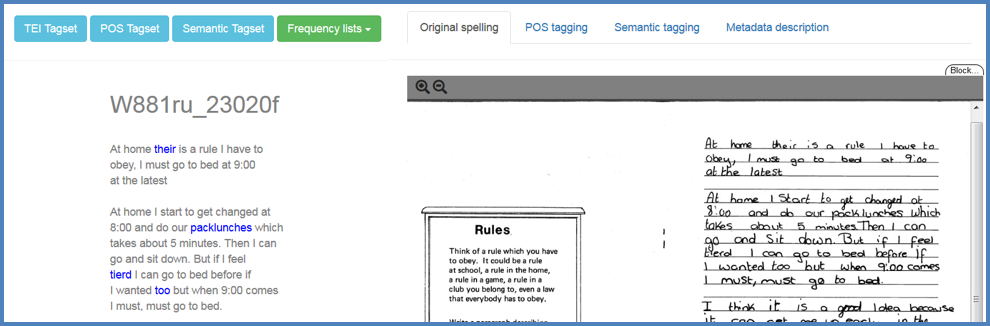
Figure 2. Text with original spelling side by side PDF image.

Figure 3. Browse tool.
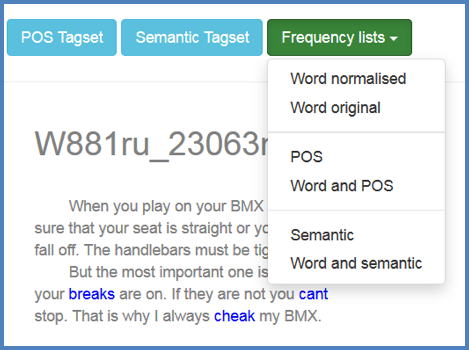
Figure 4. Browse tool: Frequency lists drop-down menu.
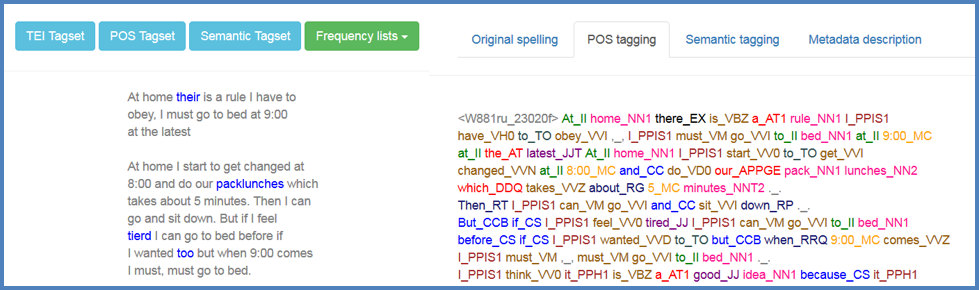
Figure 5. Text with original spelling side by side text with POS tagging.
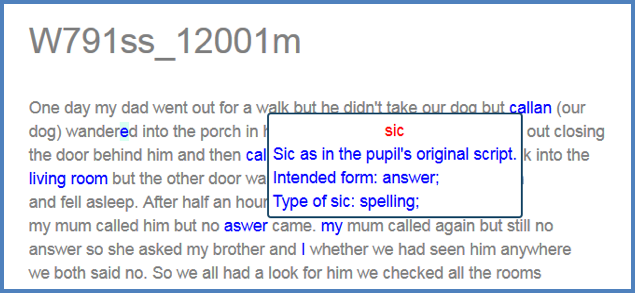
Figure 6. Pop-up bubbles with XML tag description.

Figure 7. School Scripts: abbreviations expanded.


Figure 8. Anonymised School Scripts: PDF image (top) and display online (bottom).
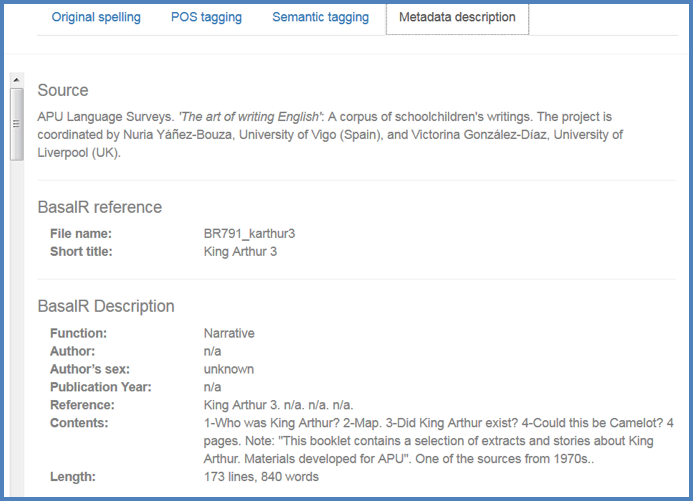
Figure 9. Metadata: Basal Readers.
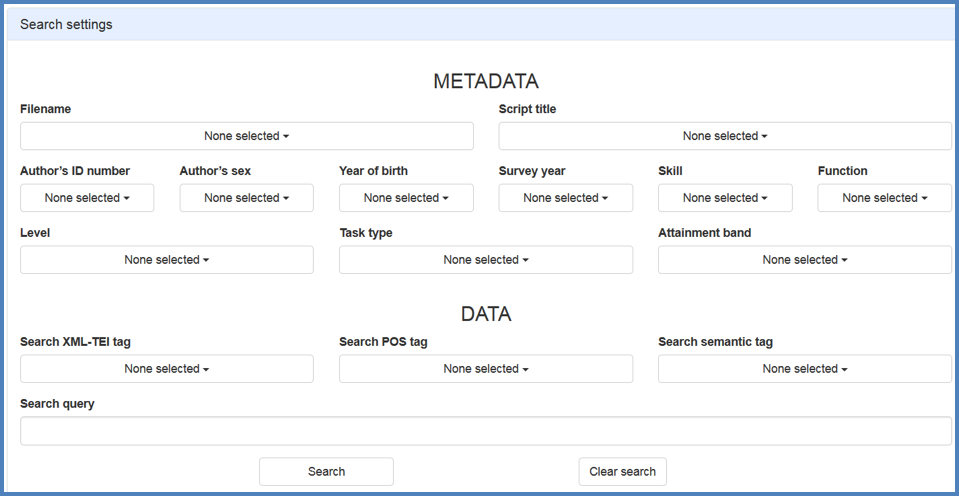
Figure 10. Search tool: School Scripts.
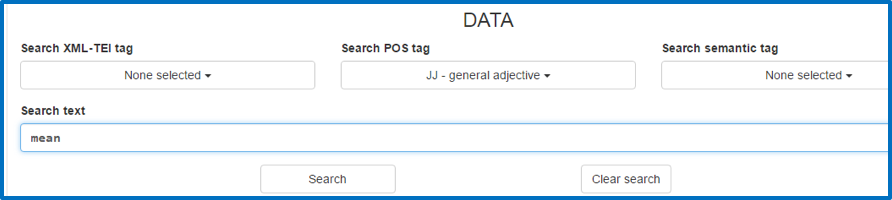
Figure 11. Search text: mean tagged as adjective.
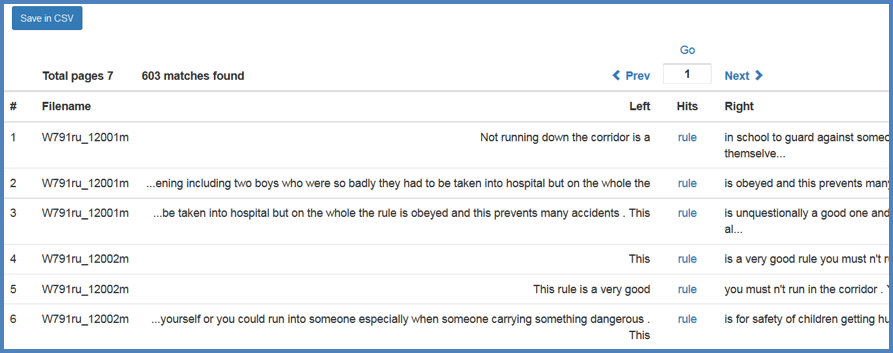
Figure 12. Search results display for “rule”.

Figure 13. Download search results: select fields.
|
