Basic structure
(Adapted from the corpus website)
The basic architecture and interface of the COCA corpus is similar to other large corpora that I have placed online, including my interface to the 100 million word British National Corpus (British, 1980s–1993), the 100 million word TIME Corpus of Contemporary American English (1923–2006), the NEH-funded 100 million word Corpus del Español (1200s–1900s), and the 45 million word NEH-funded Corpus do Português (1300s–1900s).
Genre distribution
The corpus contains more than 520 million words of text and is equally divided among spoken language, fiction, popular magazines, newspapers, and academic texts. It includes 20 million words each year from 1990–2015 and the corpus is also updated once or twice a year (the most recent texts are from December 2015). Because of its design, it is perhaps the only corpus of English that is suitable for looking at current, ongoing changes in the language.
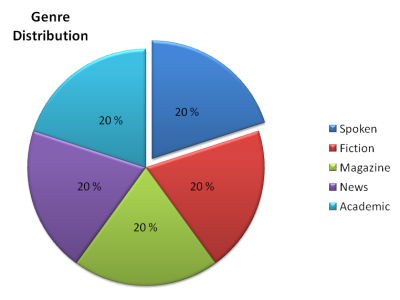
Each genre is further divided into subgenres which can be searched individually and comparatively using the online corpus interface.
Timeline
COCA is a monitor corpus, which means that new texts are added each year and the corpus can be used for the study of diachronic change. The timeline is divided by default into five sections: 1990–1994, 1995–1999, 2000–2004, 2005–2009, 2010–2015. The corpus interface provides convenient illustrated views of frequency distributions over the timeline, making it easy to see diachronic changes.

|
