Basic structure
The Diachronic Corpus of Present Day Spoken English is sampled from ICE-GB and from the London-Lund Corpus. ICE-GB texts are 2,000 words each while the LLC contains 5,000-word texts. To achieve a balanced sample, it was necessary to take proportionately fewer texts from the LLC.
The texts were sampled into the following categories as follows:
Table 1. DCPSE text categories and statistics.
|
number of words |
Text category |
ICE |
LLC |
target |
actual |
A. |
Face-to-face conversations, formal |
20 |
8 |
80,000 |
90,775 |
B. |
Face-to-face conversations, informal |
90 |
36 |
360,000 |
403,844 |
C. |
Telephone conversations (mostly informal) |
10 |
4 |
40,000 |
47,242 |
D. |
Broadcast discussions (disparates/equals) |
20 |
8 |
80,000 |
89,157 |
E. |
Broadcast interviews (disparates/equals) |
10 |
4 |
40,000 |
43,046 |
F. |
Spontaneous commentary |
23 |
9 |
91,000 |
95,381 |
G. |
Parliamentary language |
5 |
2 |
20,000 |
21,083 |
H. |
Legal cross-examination |
2 |
1 |
9,000 |
9,658 |
I. |
Assorted spontaneous (unscripted) speech |
5 |
2 |
20,000 |
21,675 |
J. |
Prepared speech (mostly monologue) |
15 |
6 |
60,000 |
63,575 |
Total |
200 |
80 |
800,000 |
885,436 |
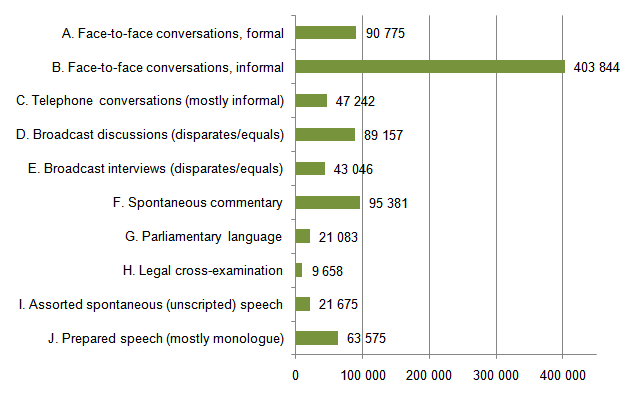
Figure 1. Word counts per text category in DCPSE.
Only c. 130,000 words are found in corpus texts with one speaker, the remainder are conversations or multi-speaker presentations.
DCPSE text codes are given the prefix "DI-" (for ICE-GB) or "DL-" (for LLC), the letter code A-J (above), followed by an index number. Thus,
DI-B07 is the seventh text in the ICE-GB (1990s) sourced informal face-to-face conversations.
The sociolinguistic variable Source corpus stores the source corpus (ICE-GB or LLC) for every text.
|
|
|
