Basic structure
(Source: the ELFA project home page, http://www.helsinki.fi/englanti/elfa/elfacorpus.html)
The speech events in the corpus include both monologic events, such as
lectures and presentations (33% of data), and dialogic/polylogic events,
such as seminars, thesis defences, and conference discussions, which have
been given an emphasis in the data (67%).
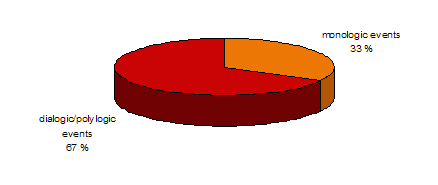
Figure 1. Monologues and dialogues in ELFA.
Figure 2. Event categories in ELFA.
As for the disciplinary domains, the ELFA Corpus is composed of social
sciences (29% of the recorded data), technology (19%), humanities (17%),
natural sciences (13%), medicine (10%), behavioural sciences (7%), and
economics and administration (5%).
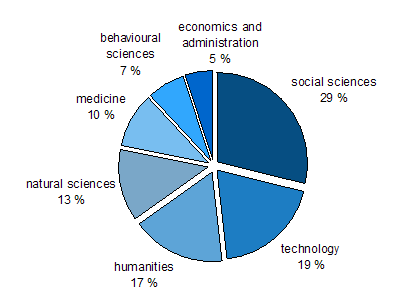
Figure 3. Disciplinary domains represented in ELFA.
First language backgrounds of the speakers
Also the speakers in ELFA represent a wide range of first language
backgrounds as the data comprises approximately 650 speakers with 51
different first languages ranging from African languages (e.g. Akan,
Dagbani, Igbo, Kikuyu, Somali, Swahili), to Asian (e.g. Arabic, Bengali,
Chinese, Hindi, Japanese, Persian, Turkish, Uzbek), and European languages
(e.g. Czech, Danish, Dutch, French, German, Italian, Lithuanian, Polish,
Portuguese, Russian, Romanian, Swedish etc.). The percentage of speech by
native English speakers is 5%. Also, considering that the recordings were
made in Finnish speaking universities, the percentage of speech by Finnish
mother tongue speakers is relatively low at 28.5%.
As a general principle, all data in the corpus is authentic in the sense
that it is not elicited for research purposes but occurs naturally. It
consists of complete speech events, i.e. complete individual sessions.
Native speakers of English are excluded when possible, but if they are
present in groups, this is coded. Sessions with speakers who all share an L1
are not included, neither are English language courses.
|
