Basic structure of the corpus
The structure is based on 10 decades and 6 domains (or registers). Each decade contains twelve texts, i.e. two texts from every domain. Corpus texts are accordingly identified by markers, which are derived from the domain structure and the chronological ordering. The text marker is combined of the initial letters of the domains (Rel, Pol, Ec, Sci, Law, Msc), the letter A or B to distinguish the two texts of the same domain, followed by the year of publication, yielding e.g. EcA1641, SciB1735.
Word counts by decade and domain
Table 1. The ten decades: word counts and percentages.
| 1640s |
1650s |
1660s |
1670s |
1680s |
1690s |
1700s |
1710s |
1720s |
1730s |
| 129,431 |
98,505 |
97,844 |
138,048 |
154,611 |
129,047 |
104,125 |
103,559 |
126,709 |
111,506 |
| 11% |
8% |
8% |
12% |
12% |
11% |
9% |
9% |
11% |
9% |
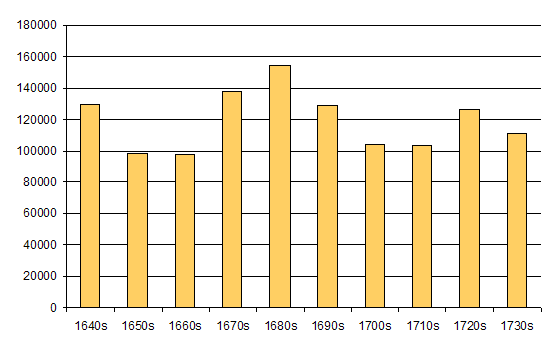
Figure 1. Lampeter Corpus word counts by decade.
Table 2. The six domains: word counts and percentages.
| Economy |
Law |
Miscellaneous |
Politics |
Religion |
Science |
| 178,110 |
209,742 |
169,019 |
208,228 |
206,338 |
221,948 |
| 15% |
18% |
14% |
17% |
17% |
19% |
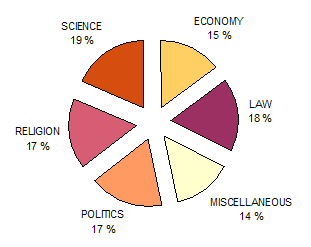
Figure 2. Percentage of words by domain in the Lampeter Corpus.
|
|
|
