Basic structure
(Source: the ICAME London-Lund Corpus manual page.)
The complete London-Lund Corpus (LLC:c) consists of 100 spoken texts of British English: the original corpus of 87 texts (LLC:o, the spoken part of the Survey of English Usage corpus) and a supplement of 13 texts (LLC:s). For basic information on all the texts, including text category (eg
conversation), year of recording (eg 1984), speaker category (eg female undergraduate) and speaker age (eg c. 20), see here.
Text types
The texts comprise both dialogue and monologue. Within dialogue we distinguish conversation in private from public discussion. The most common type of conversation is face-to-face, which occurs when the participants can see each other and can observe each other's reactions. Technology allows for private conversation by telephone when the participants are not in the same place. 'Public discussion' is dialogue that is heard by an audience that does not participate in the dialogue; it includes interviews and panel discussions that have been broadcast. All the telephone conversations and many of the face-to-face conversations were recorded surreptitiously, which means that (at the time of recording) one or more of the participants did not know that their conversation was being preserved. These surreptitiously recorded conversations represent spoken English at its most natural. All the surreptitiously recorded face-to-face conversations with one exception (S.3.7, recorded in 1984) have been published in Svartvik & Quirk (1980).
Within monologue we distinguish spontaneous from prepared. Spontaneous monologue, which is nearest to conversation in being relatively unplanned, includes running commentaries on sport events and state occasions, demonstrations of experiments, and speeches in parliamentary debates. Prepared monologue, on the other hand, is closest to written English but retains some spontaneity in not being read from a script and therefore allowing for improvisation. Typical prepared monologues in the corpus are sermons, lectures, addresses by lawyers and a judge in court, and political speeches. A special type of prepared monologue is represented by the text of dictated letters, where the speech is intended to be written down.
Table 1. Word counts by text type in the London-Lund Corpus.
|
Text type |
No of texts |
Word count |
S.1-S.3 |
Spontaneous, surreptitiously recorded conversations between intimates and distants |
35 |
175,000 |
S.4 |
Conversations between intimates and equals |
7 |
35,000 |
S.5 |
Non-surreptitious public and private conversations |
13 |
65,000 |
S.6 |
Non-surreptitious conversations between disparates |
9 |
45,000 |
S.7 |
Surreptitious telephone conversations between personal friends |
3 |
15,000 |
S.8 |
Surreptitious telephone conversations between business associates |
4 |
20,000 |
S.9 |
Surreptitious telephone conversations between disparates |
5 |
25,000 |
S.10 |
Spontaneous commentary |
11 |
55,000 |
S.11 |
Spontaneous oration |
6 |
30,000 |
S.12 |
Prepared but unscripted oration |
7 |
35,000 |
|
Total |
100 |
500,000 |
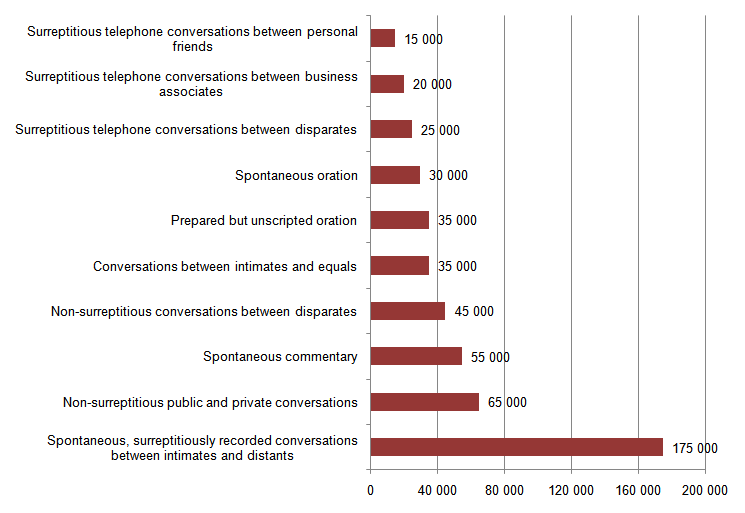
Figure 1. Word counts by text type in the LLC.
Within the written SEU corpus, 17 texts were recorded from spoken deliveries of written material, such as news broadcasts, plays, and scripted speeches. These are not included in LLC:c, though in the computerized version they have been transcribed in the same way as the spoken texts.
Transcription
The spoken corpus of the Survey of English Usage has been transcribed with a sophisticated marking of prosodic and paralinguistic features. All the SEU texts, written as well as spoken, have been analysed grammatically. The grammatical analysis and the prosodic/paralinguistic analysis are represented in the Survey files by typed slips (6x4 inches). Each slip contains 17 lines, including 4 lines of overlap between that slip and the adjacent ones before and after. For each grammatical, prosodic and paralinguistic feature there is one slip that is marked for that item. The Survey collects 65 grammatical features, over 400 specified words or phrases, and about 100 prosodic and paralinguistic features.
We must distinguish the full prosodic and paralinguistic transcription in the SEU corpus from the reduced transcription in LLC:c and in the computerized 17 texts that were read aloud from written material.
The basic prosodic features marked in the full transcription are
- tone unit boundaries,
- the location of the nucleus (ie the peak of greatest prominence in a tone unit),
- the direction of the nuclear tone,
- varying lengths of pauses, and
- varying degrees of stress.
Other features comprise
- varying degrees of loudness and tempo (eg allegro, clipped, drawled),
- modifications in voice quality (pitch range, rhythmicality and tension), and
- paralinguistic features such as whisper and creak.
Indications are given of overlap in the utterances of speakers. The full transcription and the grammatical analysis are available only on the slips at the Survey of English Usage at University College London.
The reduced transcription of the computerized LLC:c corpus and the 17 computerized texts of written English read aloud retains the basic prosodic features of the full transcription but omits all paralinguistic features and certain indications of pitch and stress. It retains the following features:
- tone units (including the subdivision where necessary into subordinate tone units),
- onsets (the first prominent syllable in a tone unit),
- location of nuclei,
- direction of nuclear tones (falls, rises, levels, fall-rises, etc),
- boosters (ie relative pitch levels),
- two degrees of pause (brief and unit pauses alone or in combination) and
- two degrees of stress (normal and heavy).
Also indicated are
- speaker identity,
- simultaneous talk,
- contextual comment ('laughs', 'coughs', 'telephone rings', etc) and
- incomprehensible words (ie where it is uncertain what is said in the recording).
For explanations of the prosodic and paralinguistic system we refer to Crystal 1969. Researchers may obtain from the Survey of English Usage a guide to the full SEU transcription and an account of differences between the full and the reduced transcriptions. |
|
