Basic structure
The main purpose of the corpus is to allow the study of publicly delivered speeches delivered by elected politicians or other individuals commenting on significant civil or societal issues in the political arena; several speeches by Malcolm X exemplify this latter type. So far speeches by unelected civic leaders are scarce.
Sampling
All texts in the corpus were downloaded from online speech repositories, with the name of the source repository retained inside mark-up. The texts were selected by students, who were instructed to collect up to five speeches each. The texts were stripped of noise and boilerplate, and basic header information was included. The samples were not selected to promote any particular political ideology, nor were they analysed linguistically prior to inclusion into the corpus.
Each speech is included in full. This allows for the study of rhetorical structure and specific discoursive events, such as the beginnings or ends of speeches. Some speeches include successive false starts or thank you's resulting from the speakers interacting with a cheering audience prior to commencing the actual speech. These have been retained, though some researchers may decide to omit them. Answers to possible questions by reported after the speech are not included, if available in the transcript.
Some specific contexts and mediums can be identified. The corpus contains eight radio addresses, three victory speeches, two conceccion speeches, and 11 inaugural addresses. As the corpus grows, these may become interesting opportunities for very specific subsections.
Time periods
The corpus covers slightly over 200 years. It is weighed heavily in favour of the last 50 years.The balance between American and British speeches is now relatively good, which allows reasonably robust contrastive analysis. The next installments of the corpus will focus on the 1980-2000 slot and then start adding to earlier time periods.
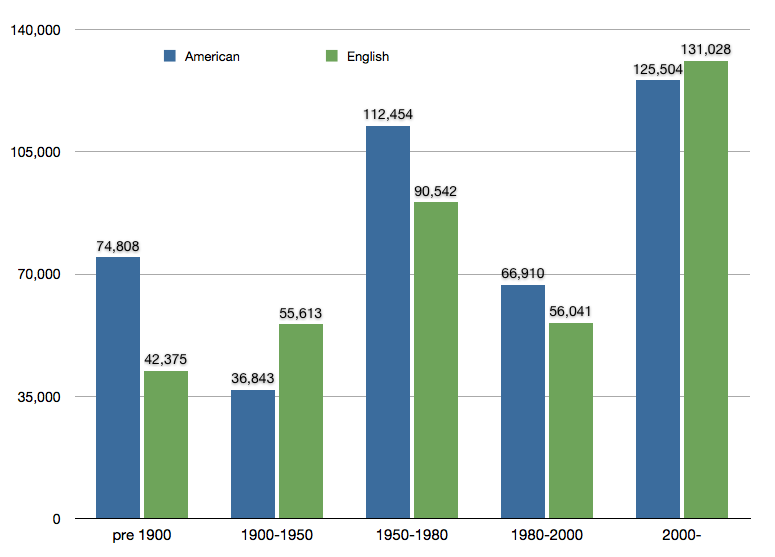
The speeches range in length from 243 words (a 1944 speech by Dwight D Eisenhower) to 14,000 (a 1860 speech by James Buchanan). Most speeches are around 2000-3000 words in length.
Nationality and gender
The nationalities of speakers are one of the major descriptors in the corpus. Although the corpus is too small at present to allow any major conclusion about the impact of nationality on the treatment of specific topics, some tentative remarks can be made about stylistic and discoursive features; for example, the frequency of references to God and to the speaker's own nation are significantly higher in American than in British speeches.
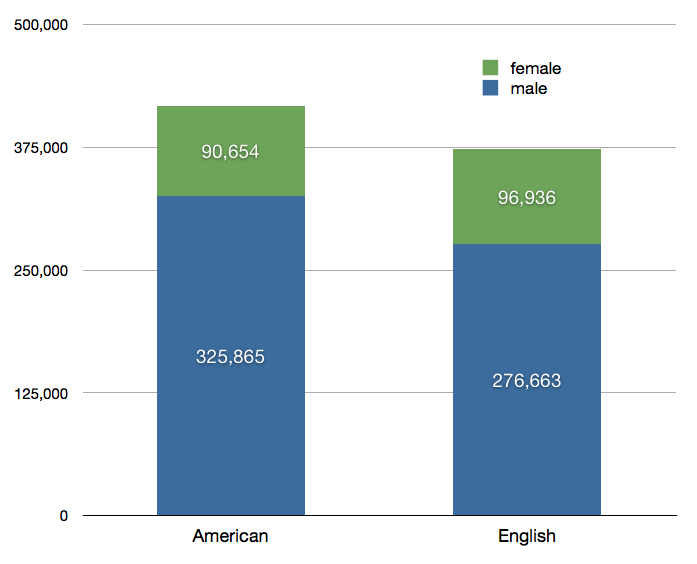
In addition to English and American, there is a small category 'other' which currently includes speakers from Canada, Ireland, and India. These are identified in the corpus according to nationality. As the size of the corpus increases, more fine-tuned detail will be added. There are longer-term plans to extend the corpus to include speeches translated into English.
In the last few installments, the balance between genders has greatly improved.
Annotation
At present the corpus has minimal annotation, consisting of a header with four descriptors. When the necessary time becomes available, the corpus will be converted to TEI Lite XML.
Datatable
The SCPS datatable can be accessed here. |
