Basic structure
YCCQA has been compiled using material downloaded from http://answers.yahoo.com/. The site offers an environment in which users post questions and answers. Several features of the site make it interesting as a basis for a contrastive corpus. The site has 'national' daughter sites, including one for the UK & Ireland, for France, for Germany and for Spain. Consequently, the site offers language material in a constant genre produced under virtually identical circumstances within an almost identical user-interface but in different national languages.
For the current version of YCCQA, language material, consisting of questions and the accompanying answers, has been extracted for English (UK & Ireland), French (France), German (Germany) and Spanish (Spain).
All the material collected has been posted by users between 2006 and 2009.
While the language material is written, it is characteristically highly informal and spontaneous. The style is mostly unmonitored and is often a written rendering of non-standard spoken language.
The question-answer format is, in one sense, a very specific genre. At the same time, it subsumes many other genres, as questions range over a great variety of topics (science, health, relations, travel, pets,…) and incorporate many different text types as a result (including scientific writing, poetry, jokes, recipes,…).
Contrary to other contrastive corpora, the corpus does not contain parallel translated texts. All texts are untranslated originals. As a result, the subcomponents of the corpus can be used independently as language-specific corpora of informal internet writing.
In its current form, YCCQA contains about 90,000 questions with accompanying answers, together about 29 million words of text. These are divided over the different languages as follows:
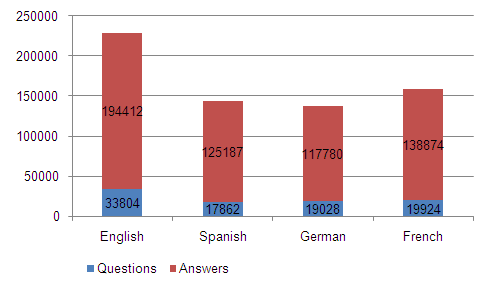
Figure 1. Questions and answers by language.
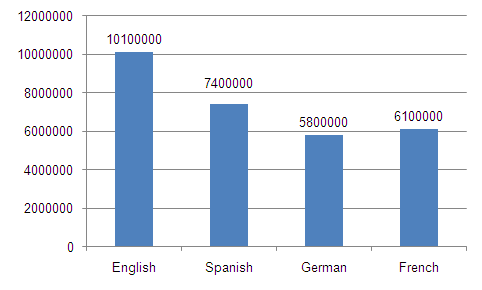
Figure 2. Word counts by language.
Sampling of questions and answers from the Yahoo site has been as random as possible. As a result, the same broad topic categories are covered by the language-specific corpora, but they are not represented with comparable amounts of text, as different question topics enjoy different degrees of popularity among national populations (predictably, certain clichés are confirmed in amounts of topical coverage, such as 'The French love cooking' or 'The English love dogs').
There are some further points it is good to be aware of when using the corpus:
1. Correct spelling is not a major concern to many internet users (even though the Yahoo site itself points out spelling mistakes and urges users to correct them). The result is that searching the corpus may require some more creative searching strategies than one is generally used to.
2. There is no guarantee that all text comes from native speakers or from speakers resident in the nation represented by a specific sub-corpus. In as far as native-speaker provenance of the text can be established, however, the problem seems relatively small.
3. The corpus may contain rude and insulting texts. Fortunately, these are a minority.
|
