Analyzing personal weblogs in Singapore English: the Wmatrix approach
Vincent B.Y. Ooi, Peter K.W. Tan & Andy K.L. Chiang
National University of Singapore
The blog, as a new text type, is a very recent and phenomenally successful online genre that is receiving worldwide attention. Of the many types of blogs (adventure, travel, political etc.) available, the personal weblog/journal has emerged as one that is arguably the most interesting. We therefore propose to test the hypothesis that the personal blogs of younger teens and maturing adults (such as undergraduates) in Singapore, different though by a few chronological years, will reveal their respective online identities/cultures. A further hypothesis is that, since on-going research shows that gender is a significant sociolinguistic variable, the linguistic styles of males and females in these two groups may also be sufficiently differentiating. In order to test these two hypotheses, two corpora representing Singaporean teenage and undergraduate personal blogs respectively are compiled for the study. For the corpus analysis, we propose to use an integrated corpus linguistic tool, Wmatrix, which affords word frequency profiles, lexico-grammatical patterning, part-of-speech annotation and semantic content analysis. As users of the software, we pose some challenges for future versions of Wmatrix to handle computer-mediated patterning and varieties of English (other than British and American) for the personal blog and other newer text types of online communication.
In recent years, the weblog (or 'blog') has become a newer and important text type to emerge on the World Wide Web and is considered a 'genre' (see Herring et al. 2004a). Incorporating multi-modalities - author's text, video, pictures, audio files, hypertextual links to other blogs - the blog has been gaining enormous popularity especially in the past few years. The electronic/computer keyboard has emerged as the central factor which mediates conventional speech and writing conventions, thus leading to the existence of computer-mediated communication (CMC). Thus, for the textual component, the blog can feature computer-mediated features (which are also found in instant messaging and online discourse). However, linguistic computing/corpus linguistic software nowadays is only beginning to grapple with such dynamics because standard computer corpora have so far been compiled using material from conventional / traditional print and speech material only.
Of the various types of blogs (political, adventure, historical etc.), the personal blog is perhaps the most linguistically interesting. Such a blog type is not necessarily a random or motley collection of opinions, feelings, and comments. Rather, because of the existence of 'blog rings' (see Section 2), it is not surprising to find that parameters such as age (teens or young adults), gender (males vs. females), level of formality (formal vs. informal) and CMC features are significant in revealing collective behaviour and help in the formation of distinctively virtual or online communities.
Conventionally, age ('aging') is a significant sociolinguistic variable, with its 'achievement of physical and social capacities and skills' (Eckhert 1997:151), and 'the answer to an inquiry about an individual's age is invariably given in chronological years, not in terms of family or institutional status, or in terms of physical maturation.' (Eckhert, p. 156). Would a similar finding hold for an online community such as Singapore's? Hence, the first hypothesis is that the personal blogs of teens and college undergraduates (as young adults) in Singapore would not only be indicative of their respective chronological ages but also be linguistically expressive, reflecting their respective maturity and social capacities. Gender certainly also is a significant sociolinguistic variable online (see Herring 2000), with males sometimes adopting an 'adversarial style even in cooperative exchanges, and females often appear to be aligned even when they disagree with one another.' There is also the suggestion that females and teens tend to create more personal blogs (or journals) than do males and adults (Herring et al. 2004a, 2004b).
Notwithstanding this last finding (that females outnumber males in personal journals/blogs), a corpus of personal blogs should reflect the participation of men and women equally (see Section 3) so that we can test the second hypothesis regarding the respective differentiation of males and females in their blogging styles.
In terms of quantitative analysis, we suggest applying the Wmatrix analysis and comparison software tool (Rayson 2003, 2005). Wmatrix is a leading corpus linguistic software which is currently best utilized for the analysis of standard written texts which do not have computer-mediated features. In applying Wmatrix, our objective should not be taken as one that seeks to highlight its weaknesses in handling CMC aspects but one which instead focuses on some of the future challenges and attendant issues for the compilation and analysis of such texts.
The blog type represents 'the latest genre of Internet communication to attain widespread popularity' (Herring et al. 2004a) and takes its place amongst an electronic netscape that includes online chatrooms (e.g. Crystal 2007, Crystal 2003, Ooi 2002), online personal ads (e.g. Ooi 2001a), instant messaging (e.g. Google Talk, Windows Live Messenger, and Yahoo! Messenger), and text messaging.
Blogs may be characterized as personal journals or online diaries that are publicly available on the World Wide Web (Huffaker and Calvert 2005), but sometimes the blog is password-protected for access by a group close to the blogger only. The Merriam-Webster Dictionary defines the blog as a web site 'that contains an online personal journal with reflections, comments, and often hyperlinks provided by the writer.' They represent a channel for bloggers to express their views on a particular theme (e.g. politics, travel, or adventure), indicate their mood for the day, link with other blogger friends, and comment on their friend's blogs, character, etc. Blogs have engendered various studies. For instance, while Herring et al. (2004a) discuss the structural analysis of blogs, Huffaker and Calvert (2005) focus on the issue of gender and stylistic differences across blogs written by male and female teenagers.
Some central motivations for personal blogs include the following: (i) personal "empowerment" for the blogger; (ii) letting out one's 'exhibitionistic tendencies'; (iii) an avenue for political and social comments by people disenchanted with mainstream media; (iv) 'confessional poetry', as a cathartic avenue for people who need to let out their personal ventings; (v) bonding with other bloggers. Bloggers read each others' entries and exchange opinions on a regular basis, thus facilitating a continuing dialogue. Besides having video and audio clips (including podcasts), blogs allow the owner to post relevant or current clips of articles from newspapers, magazines, other blogs, or simply include hypertextual links.
A blogger tends to be part of a 'blog ring', in which people in the rings are chosen in terms of the themes/topics/ethnicity or general interests that appeal to the blogger. [1] More than choosing a specific theme or interest, a blogger tends to find comfort in 'adding' (or 'being added to') friends and groups that he/she is comfortable with. For instance, in LiveJournal.com, a blogger has either 'friends' or 'mutual friends' pre-defined by him/her. A feature of this particular website is that it arranges for the latest 2-day blog entries (or 'updates') of the pre-defined friends to be visible to the blogger (as 'friend'). Correspondingly, each member of the blog ring will also be alerted to the latest blog entries (including digital photos and audio files) written by the blogger concerned. Thus, members of the blog ring stay connected to each other and can leave entries/comments for the friend who has posted an entry. This type of communication is 'asynchronous' (or non real-time) unlike, say, a chatroom which is much more real-time (or 'synchronous').
The 'invisible' bonds that exist between the members of the blog ring do mean some self-selection, e.g. if one does not identify with teenagers, he/she would not want to have such blogger friends. We may therefore postulate that members of a group ring tend to share at least one of the following: age, ethnicity, interests, or socio-economic background - each a marker of one's cultural identity. The hyperlinks on a blogger's page point to the people that he/she is interested in identifying with, i.e. typically friends who are of similar ages and interests. Thus, extending the dictum attributed to the linguist J.R. Firth that 'you shall know a word by the company it keeps', we may say that 'you shall know a blogger by the company (through the blog rings and hyperlinks) that he/she keeps'.
We now turn to the compilation of two Singapore English corpora of personal weblogs [2]: 100K words containing teenage blogs (henceforth, the T-corpus) and 100K words containing undergraduate blogs (henceforth, the U-corpus). Complementing Huffaker and Calvert's (2005) observation that nearly half of all blog entries comes from teens, another recent study finds that 91.9 percent of blogs are authored by persons between the ages of 13 and 29: 51.5% being teens (13 to 19 year-olds) and 39.6% being young adults (20 to 29 year-olds) (ClickZ Stats 2004). Thus, older and more mature bloggers would be much fewer and far in between and so, for the present study, we have excluded them from this collection.
Our expectation is that teenagers in Singapore would generally differ in their use of language from college undergraduates (typically 18 to 21 years for females, 21 to 24 years old for males who typically go to university after 2.5 years of national service). Early and mid-teens have different expressions of maturity from their older counterparts. Chan's (2006) study involving 300 blog postings from 100 local teenage personal blog websites from the ages of 13-19 shows that teen bloggers tend to share a common linguistic way of blogging. By analyzing such features as creative re-spellings, lexico-grammatical choices, and pragmatic particles, Chan concludes that the language of Singaporean teenagers online may be said to reflect a distinctive genre.
For the present paper, the sampling involves a more controlled size of 25 males and 25 females with an approximately 2000-word sample size from each blogger - for each of the T and U corpora. Two methods are used to search for relevant blogs. Firstly, the simpler but less reliable method is to use a blog search engine by keying in words such 'Singaporean teen blogs' or 'Singaporean undergrads'. However, this is a less productive method since most bloggers do not tend to explicitly say that they are 'Singaporean teen' or 'Singaporean undergrad'. A more effective, but laborious method, has been to find at least 1 Singaporean blog through personal contacts and social networks. Similar blogs are then found by clicking on the other blog addresses linked to that first blog. This process is then duplicated to find even more blogs. However, a challenging aspect of compiling a corpus of blogs is to identify the nationality, age, and gender of bloggers - since a number do not display their personal profile explicitly. Reading through the entries and tagboards is therefore a necessary prerequisite. A further specification for the Singaporean undergraduate blogs is the inclusion of bloggers who are Singaporeans and currently studying in one of the three local universities. Two or three blog entries comprising 2000 words are then randomly selected from each blog site. The textual content, excluding the hypermedia aspects, from the blogs can then be transferred to WordPad simply by a copy-and-paste method. While there is no intention to favour a particular blog site, many of the blogs happen to be hosted by Blogspot, followed by LiveJournal and WordPress.
In terms of ethical considerations, we choose to remove the names of bloggers in order not to compromise personal privacy. Of course, we can also never be really sure that the personal blog that we read is genuinely trustworthy. Neher and Sandin (2007:296-297) remind us that, while there are 'editors and editorial boards ensuring some checking of facts for print and broadcast media...we have no such assurances for ..privately produced blogs and bulletin boards.' The personal blog therefore retains its ambiguity as expressing an online identity that is either deeply serious or lightly entertaining.
A flavour of the respective contents of the T and U corpora is given in both Figures 1 and 2.
after todae i'm gonna become 17..
OFFICALLY 17 YRS OLD!!!!
yeah....
stop callin mi a small kid ya...
i'm not anymore!!
wahahax...
finally..
i've waited fer tis dae fer sooooo long..
i'm jux so excited!!! yes yes yes!!!
wahahax....
Figure 1. An extract from a blog entry from a 16-year old female blogger in Singapore.
my birthday today... somehow... i dunno.. there's no more thrill in the fact that it's your birthday anymore. it's just another passing day... it means another year has passed, and i'm a year older. i'm 22 this year... but ppl say i act like a 12 year old.
Figure 2. An extract from a blog entry from a 22-year old female blogger in Singapore.
A cursory examination of Figures 1 and 2 indicates that, while the older blogger would use the conventional spelling today, the younger one uses the creative re-spelling of todae. Similar newer forms include fer ('for'), tis ('this'), dae, and the addition/substitution of 'x' at the end of the word (wahahax, jux). The younger blogger seems to be more expressive, with more repetitive markers and exclamations (and yet shorter phrasing) that reflect her teenage enthusiasm.
Constraints of space do not permit a detailed treatment of the type of English that is found in Singapore, a multicultural and multilingual country. Singapore has a small population of 4.68 million, of which there are 979 males per 1000 females. The population comprises various ethnic groups, of which the largest are the Chinese (75%), Malays (14%), and Indians (9%) respectively. [3] With four official working languages (Malay, Chinese, English, and Tamil), the link language used is Singapore English. Singapore English (see Ooi 2001b), traditionally influenced by British English with some American English influence, may be subcategorized into Standard Singapore English and Colloquial Singapore English (the latter being more popularly known as Singlish). It is not uncommon to find Singlish used in such informal contexts as the personal blog and instant messaging; Singlish derives its grammar noticeably from various Chinese dialects (especially Hokkien) and Malay.
The Wmatrix program (Rayson 2003, Rayson 2005) is an online integrated corpus linguistic software environment in which texts can be loaded and analyzed for word frequency profiles and concordances, annotated in terms of part-of-speech (using the well-known CLAWS tagger, see Garside et al. 1997) and word-sense (semantic content and word sense tagger), and analyzed in terms of complex lexical frequency profiles that statistically compare them against standard corpora samplers (e.g. the British National Corpus 1-million word sampler). CLAWS is said to achieve 96-97% accuracy for standard written texts. The part-of-speech component uses categories such as 'N' for nouns, 'V' for verbs, 'J' for adjectives, 'R' for adverbs, and 'A' for articles and determiners.
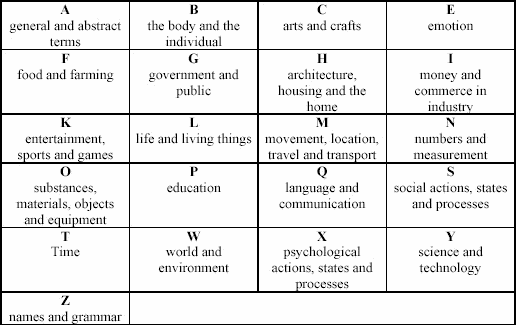
The semantic content component, named the UCREL Semantic Analysis System (or USAS), contains a multi-tier structure with 21 major discourse categories (see Figure 3):
These 21 categories are further refined and categorized. A particular refinement within the 'Z' category worth noting is that unmatched items (or those items not recognized by the system) are categorized as 'Z99'.
As mentioned in the preceding section, the Z99 category in Wmatrix contains unmatched items that present a challenge and further development to the Wmatrix lexicon, which currently has 54776 single words, and 18823 multi-word expressions (Rayson, personal communication).
These unmatched items may be divided into two general groups:
- Computer-mediated items that are likely to be shared between the major varieties of English, including the following:
- Emoticons and Discourse Markers: e.g. :) :X,*yummy*, ermmm, hahahaha, sheesh
- Abbreviations (also in SMS/texting language): e.g. Tmr, pple, bf, lol, wtf ("what the fuck")
- Creative re-spellings (also in SMS/texting language), e.g. Dun ("don't"), noe ("know"), urself, nid ("need"), oso ("also")
- Recent standard lexical terms, e.g. blog, chatroom
- 'Core' lexical items, e.g. Hokkien, mahjong, bitch/fucker
- New/Popular proper nouns, e.g. (Roger) Federer
- Informal English, e.g. prolly ("probably"), hafta ("have to")
- Computer-mediated and varietal terms that may be said to characterize online Singapore English particularly, including the following:
- Abbreviations: e.g. sgh (Singapore General Hospital), cny (Chinese New Year)
- Discourse particles: e.g. de, lah, leh, liao, sia
- Neologisms: e.g. freshies ("freshmen")
- Emoticons: e.g. =D (elation)
- Morphology, addition of [x] and [z]: e.g. lolx, frenz, lolz;
replacement of [k] with "x": e.g. sux ("sucks")
- Voiceless fricative: wif ("with"), haf ("have")
- y-replacement: e.g. lyk ("like")
- r-addition: e.g. gort (for "got")
- Abbreviations: e.g. ytd ("yesterday")
- Double letter addition for distinctiveness and emphasis: ii (for "I"), uu or euu (for "You"), moii ("moi", "my"), iish ("is")
A closer examination of each of the four sub-categories reveals the following top 10 unmatched lexical items respectively (in order of descending ranking; see Figure 4):
TeenFemaleBlogs |
TeenMaleBlogs |
FemaleUndergdBlogs |
MaleUndergdBlogs |
- haha
- dun
- im
- euu
- mie
- wat
- noe
- lor
- hhmmm
- miie
|
- haha
- lol
- blog
- wif
- im
- lah
- cuz
- haas
- wat
- dun
|
- haha
- smu
- im
- ive
- blog
- wat
- dun
- pple
- tink
- cny
|
- haha
- smu
- dun
- blog
- lah
- sem
- abt
- ntu
- alot
- internship
|
Figure 4. Top 10 unmatched items (excluding smileys) in the Z99 category, in order of descending ranking, for males and females in the T and U corpora.
It is remarkable that the top wordform for all four columns is the interjection/noun haha. Its function as the top marker indicates a projection of amusement or fun on the part of these young bloggers. The ludic (or playful) nature of language is brought out particularly in the female component of the T-corpus, with forms such as euu ("you"), mie and miie (both forms for "me"). Such double letter additions are perceived as 'cute' markers especially among teen female bloggers, who tend to signify their femininity by employing such visual cues. It is not as if local females need to stretch the pronunciation of such personal pronouns but this phenomenon is not exclusively done by female bloggers: the male component of the T-corpus has an instance of such a tendency (haas for "has"). Colloquial Singapore English is also evident in terms of the pragmatic particles lor ('self-evident' marker) and lah ('emphasis' marker) which are borrowed from Hokkien Chinese and Malay respectively. In the U sub-corpus, Singaporean undergrads are certainly more concerned with markers connected with their institutions ("smu"=Singapore Management University; "ntu"=Nanyang Technological University). The inability of the Wmatrix program to categorize such terms as blog and internship (in both the T and U corpora) means that its lexicon has not really been customized to handle newer Net features nor is it rich enough (for such a conventional term as 'internship'). However, the Wmatrix lexicon has now been updated to handle Middle English features, and has proven itself quite robust in handling conventional texts such as the British National Corpus sampler (see Piao et al. 2004, 2005). For the foreseeable future, the developers of Wmatrix will have to engage further with such computer-mediated features.
The online version of the Wmatrix software is currently able to analyze, at any one time, a dataset which is no larger than approximately 100 thousand words only. While this configuration fits in nicely with the testing of our two hypotheses (i.e. 100K teenage data vs. 100K undergraduate data, with further differentiation between males and females), it would not be possible to engage in the analysis of corpora above the stated limit (unless a special request is sent to the developers to process the data off-line). Again, for the foreseeable future, Wmatrix needs to be adapted to handle more data online.
A central feature of Wmatrix is the statistical profiling analysis of any corpus to be done in terms of a conventional baseline corpus to compare with, i.e. the corpus is compared with conventional speech or writing, represented by either the BNC Spoken or Written Sampler (i.e. in this case, it would be Educated/Standard British English). The BNC Sampler consists of one-fiftieth of the well-known British National Corpus of 100 million words, standing at 2 million words. It has an almost equal division between the spoken and written components, with 990704 and 1010690 words respectively. It contains a wide and balanced sampling of texts from the BNC to maintain the range of text types and their various proportions. [4]
Both Figures 5 and 6 show the top 10 lexical items of the T and U corpora ("O1") respectively, when compared with the spoken component of the BNC Sampler ("O2").
Item O1 %1 O2 %2 LL
haha 397 0.42 0 0.00 + 1938.86
den 340 0.36 1 0.00 + 1647.01
my 1079 1.15 2354 0.24 + 1424.02
u 332 0.35 181 0.02 + 988.31
= 183 0.20 0 0.00 + 893.73
im 156 0.17 5 0.00 + 718.22
dun 162 0.17 11 0.00 + 711.27
de 165 0.18 14 0.00 + 710.15
ii 145 0.15 0 0.00 + 708.15
me 834 0.89 2861 0.29 + 647.30
Figure 5. The top 10 lexical items of the T-corpus, compared with the BNC Spoken Sampler.
Item O1 %1 O2 %2 LL
my 1005 1.25 2354 0.24 + 1457.72
haha 165 0.20 0 0.00 + 851.43
2 104 0.13 1 0.00 + 525.52
to 2163 2.68 16611 1.69 + 364.04
me 595 0.74 2861 0.29 + 346.45
3 67 0.08 1 0.00 + 335.46
smu 65 0.08 0 0.00 + 335.41
am 162 0.20 281 0.03 + 298.46
1 59 0.07 2 0.00 + 287.16
nt 73 0.09 24 0.00 + 271.93
Figure 6. The top 10 lexical items of the U-corpus, compared with the BNC Spoken Sampler.
The statistical ranking is done in terms of the log-likelihood (LL) value, which shows the overuse (with the plus sign; or underuse, with the minus sign) of the first corpus (i.e. the blog corpus) against the reference corpus (i.e. the BNC Spoken Sampler). In Wmatrix, statistical significance begins with a LL value of approximately 7, since 6.63 is the cut-off for 99% confidence of significance (Rayson 2003, Rayson 2005). The preponderance of the personal pronoun my is not surprising in the personal blog, which by its nature reflects the concerns of 'me, myself, and I' (a popular phrase nowadays). Also, the T and U corpora diverge for the dyadic forms "I" and "you" which enjoy top rankings in a conventional spoken corpus: the corresponding online form for the second person pronoun "u" (in lower case) is among the top ten markers in Figure 5, compared with its non-appearance in Figure 6. In other words, we may argue that teens write in a more speech-like fashion compared with their college counterparts.
Also, in Figure 5, the wordform ii does not indicate the numeral "2", but is the 'cute marker' form for the first personal pronoun "I". Concomitantly, the numerals 2 and 1 are over-represented as phonological markers for "to" and "want" respectively.
On the other hand, if we benchmark the two corpora against the BNC Written Sampler, a different picture emerges (see Figures 7 and 8):
Item O1 %1 O2 %2 LL
i 3647 3.89 6904 0.71 + 5382.50
so 1097 1.17 1503 0.16 + 2064.66
haha 397 0.42 0 0.00 + 1928.14
my 1079 1.15 1914 0.20 + 1680.71
u 332 0.35 0 0.00 + 1612.45
den 340 0.36 20 0.00 + 1500.51
me 834 0.89 1438 0.15 + 1328.89
went 348 0.37 340 0.04 + 799.25
dun 162 0.17 2 0.00 + 765.56
im 156 0.17 1 0.00 + 745.73
Figure 7. The top 10 lexical items of the T-corpus, compared with the BNC Written Sampler.
Item O1 %1 O2 %2 LL
i 3118 3.87 6904 0.71 + 4680.56
my 1005 1.25 1914 0.20 + 1705.65
haha 165 0.20 0 0.00 + 846.91
me 595 0.74 1438 0.15 + 825.87
really 252 0.31 296 0.03 + 584.63
'm 252 0.31 375 0.04 + 508.49
so 477 0.59 1503 0.16 + 502.18
u 90 0.11 0 0.00 + 461.95
cos 75 0.09 0 0.00 + 384.96
n 96 0.12 31 0.00 + 356.54
Figure 8. The top 10 lexical items of the U-corpus, compared with the BNC Written Sampler.
Both Figures 7 and 8 show the personal pronoun "I" emerging as the top lexical item, considering that the most important reference in the blog tends to be the author herself/himself (with the popular phrasing of 'me, myself, and I' emerging among more egocentric bloggers). Of course, when compared with a written corpus, the dyadic speech items I and You (i.e. the CMC forms i and u) are over-represented. In addition, the relatively higher usage of the second personal pronoun (i.e. 'u') among teens in these few figures may indicate the more speech-like nature of the T-corpus. The preferred amusement/joviality marker "haha" coincidentally emerges as the 3rd top item and is rightly ranked by Wmatrix as an item not commonly found in standard formal writing or speech.
Turning to the part-of-speech annotation aspect, Figures 9 and 10 show the top ten part-of-speech items for the T and the U corpora (as compared with the BNC Written Sampler).
Item O1 %1 O2 %2 LL
ZZ1 2481 2.65 1698 0.18 + 6717.38
VV0 4910 5.24 11012 1.14 + 6206.67
NNU 2486 2.65 3580 0.37 + 4524.00
UH 1270 1.36 1278 0.13 + 2871.79
PPIO1 824 0.88 1373 0.14 + 1348.43
MC1 1070 1.14 2598 0.27 + 1247.81
FO 903 0.96 2050 0.21 + 1127.87
FU 291 0.31 277 0.03 + 677.39
RT 1141 1.22 4644 0.48 + 653.95
RG 953 1.02 3762 0.39 + 576.66
(ZZ1=singular letter, e.g. "A", "b"; VV0=base form of lexical verb; NNU=unit of measurement; UH=interjection; PPIO1=pronoun "me"; MC1=cardinal number "one"; FO=formula; FU=unclassified word; RT=adverb of time, e.g. "now", "tomorrow"; RG=degree adverb, e.g. "very", "so", "too")
Figure 9. A comparison of the top ten Wmatrix part-of-speech markers for the T-corpus with the BNC Written Sampler.
Item O1 %1 O2 %2 LL
ZZ1 1161 1.44 1698 0.18 + 2368.65
VV0 2538 3.15 11012 1.14 + 1717.11
PPIS1 1894 2.35 6898 0.71 + 1661.92
PPIO1 592 0.73 1373 0.14 + 853.17
RR 3706 4.60 25887 2.67 + 833.78
UH 537 0.67 1278 0.13 + 756.02
VBM 373 0.46 673 0.07 + 659.31
RG 769 0.95 3762 0.39 + 421.25
MC1 575 0.71 2598 0.27 + 363.50
PN1 508 0.63 2193 0.23 + 346.54
(ZZ1=singular letter, e.g. "A", "b"; VV0=base form of lexical verb; NNU=unit of measurement; UH=interjection; PPIS1= pronoun "I"; PPIO1=pronoun "me"; RR=general adverb; UH=interjection; VBM="am"; RG=degree adverb, e.g. "very", "so", "too"; MC1=cardinal number "one"; PN1=singular indefinite pronoun, e.g. "anyone", "everything", "nobody")
Figure 10. A comparison of the top ten Wmatrix part-of-speech markers for the U(undergrad) sub-corpus with the BNC Written Sampler.
Notwithstanding our reservations regarding the accuracy of the part-of-speech annotation (since CLAWS, the annotation program, has not been customized to handle computer-mediated features - see Ooi 2002), the results in Figures 9 and 10 are still quite interesting. On closer inspection (not available from the figures here), the top category "ZZ1" does show twice the number of singular items (such as "i" and "u") in the T-corpus because the teens tend to use lower-case more often than their undergraduate counterparts. Hence, while the U-corpus tends to have more overt categorization of the personal forms (i.e. PPIS1 for "I" and, PPIO1 for "me"), such forms are categorized as "ZZ1" in the T corpus (i.e. "i" stands for the first person singular pronoun "I").
Another category which ranks very high in the T-corpus is the "NNU" (unit of measurement) category (see Figure 11).
Word POS Frequency Relative
Frequency
euu NNU 89 0.00
ppl NNU 87 0.00
bt NNU 65 0.00
sch NNU 64 0.00
hhmmm. NNU 59 0.00
la. NNU 48 0.00
nvm NNU 41 0.00
hahaha. NNU 40 0.00
sec NNU 35 0.00
tmr NNU 32 0.00
nt NNU 32 0.00
gt NNU 31 0.00
mr NNU 31 0.00
lk NNU 29 0.00
lor. NNU 29 0.00
me. NNU 26 0.00
nvr NNU 25 0.00
lah. NNU 23 0.00
yr NNU 23 0.00
sia. NNU 23 0.00
hw NNU 20 0.00
tml NNU 19 0.00
slp NNU 19 0.00
thn NNU 18 0.00
cnt NNU 18 0.00
(euu = "you"; ppl = "people"; bt = "but"; sch = "school"; nvm = "never mind"; sec = "secondary"; tmr, tml = "tomorrow"; nt = "not"; gt = "got"; slp = "sleep"; nvr = "never"; mr = "mister"; lk = "look"; hw = "how"; thn = "then"; cnt = "can't"; la, lor, sia = pragmatic particles in Singlish/Colloquial Singapore English)
Figure 11. The top 25 "NNU", nominal units of measurement, in the T sub-corpus.
The T-corpus has more of these items wrongly categorized as "nominal units of measurement" because teens tend to abbreviate and turn 3-letter items into consonants. In turn, the program is mislead into thinking that these items are similar to true units of measurement such as "lbs", "cm.", and "ft." If anything, turns of phrasing such as nvm ("never mind"), and "http" (the URL address) should not be classified as "units of measurement". However, other abbreviated items such as "yr" ("year"), "wk" ("week") and "tml" ("tomorrow") should of course be classified as time measurement units.
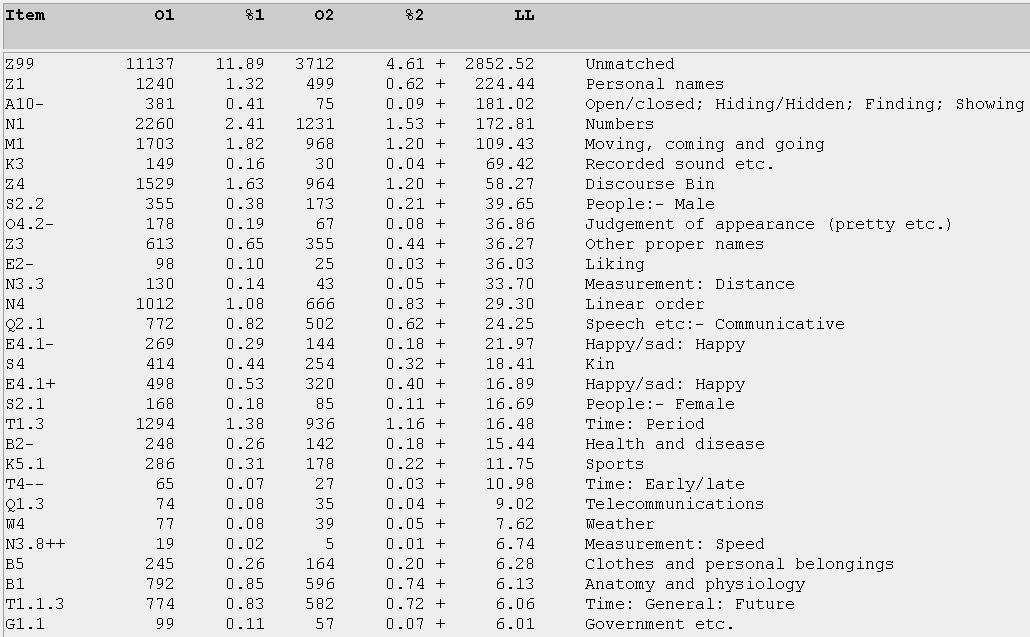
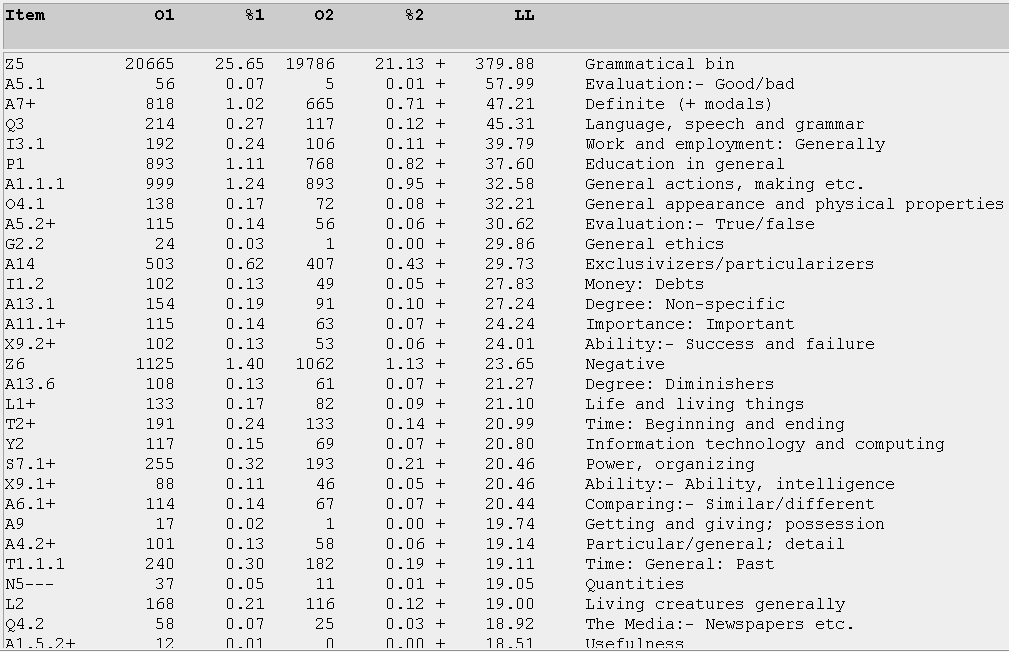
As mentioned in Section 5, the Wmatrix Corpus Tool contains a semantic tagger which can categorize information into 21 different categories; if it is unable to do so, it will relegate the information into a broad "Z99" category. Both Figures 12 and 13 show the T and U-corpora benchmarked against the BNC Written Sampler for such semantic information respectively:
Item LL Semantic Category
Z99 + 15737.42 Unmatched
Z8 + 2186.32 Pronouns etc.
Z4 + 1492.65 Discourse Bin
A13.3 + 597.81 Degree: Boosters
E4.1+ + 505.31 Happy/sad: Happy
M1 + 387.16 Moving, coming and going
P1 + 314.39 Education in general
N1 + 291.04 Numbers
A5.1+ + 291.02 Evaluation:- Good/bad
T1.3 + 224.36 Time: Period
Figure 12. The top 10 semantic categories for the T-corpus, compared with the BNC Written Sampler.
Item LL Semantic Category
Z8 + 2293.56 Pronouns etc.
Z99 + 652.65 Education in general
P1 + 652.65 Education in general
Z4 + 612.20 Discourse Bin
A13.3 + 467.53 Degree: Boosters
L1+ + 391.34 Life and living things
A14 + 233.27 Exclusivizers/particularizers
Z6 + 232.82 Negative
X2.1 + 229.52 Thought, belief
E4.1+ + 221.24 Happy/sad: Happy
Figure 13. The top 10 semantic categories for the U-corpus, compared with the BNC Written Sampler.
Both Figures 12 and 13 show the undergraduate bloggers being somehow more overtly concerned about their studies than the teen bloggers (3rd top for Education in the U-corpus; 7th in the T-corpus). On the other hand, the teen bloggers tend to use more adverbial degree boosters such as "very", "fantastically" and "incredibly" in their writing, reflecting our earlier observation that the teens tend to be more enthusiastic and use more speech-like patterns (since such boosters tend to be less peppered in formal writing and more exaggerated in speech). The boosters reflect an attempt to infuse degrees of personal enthusiasm (i.e. liking someone, and being happy/sad) into the blogs and thus make them livelier and more interesting to the reader. Compared with the BNC Written Sampler, the E4.1+ category (with the plus here indicating a positive turn) reflects an overuse of adjectives as "happy", having "fun", "laugh(ing)", and "celebrat(ing)" as compared with typical everyday writing. Again, the teenagers tend to project a public identity of being the more enthusiastically-inclined of the two groups, with the E4.1+ category ranked fifth in the T-corpus (compared with its 10th ranking in the U-corpus).
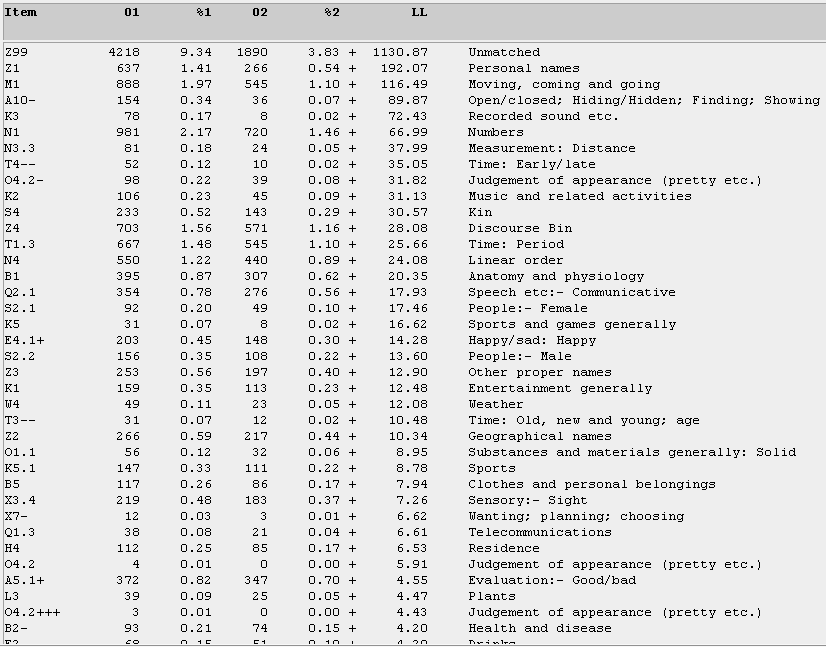
Since it may be argued that a comparison of Singapore blog English to the BNC Sampler is fundamentally somewhat of a mismatch and likely to yield skewed LL-scores and an over-representation of the Z99 category, Wmatrix also permits a more direct comparison between the T and U corpora (see Figure 14).
Item 01 %1 02 %2 LL
den 340 0.36 25 0.03 + 278.38
de 165 0.18 0 0.00 + 204.85
so 1097 1.17 477 0.59 + 166.60
ii 145 0.15 3 0.00 + 155.32
LOL 109 0.12 0 0.00 + 135.33
went 348 0.37 85 0.11 + 134.28
tat 105 0.11 0 0.00 + 130.36
then 500 0.53 167 0.21 + 127.64
le 133 0.14 8 0.01 + 116.02
u 332 0.35 90 0.11 + 113.59
euu 89 0.10 0 0.00 + 110.50
noe 84 0.09 0 0.00 + 104.29
mie 74 0.08 0 0.00 + 91.87
mii 73 0.08 0 0.00 + 90.63
bt 70 0.07 0 0.00 + 86.91
Figure 14. The top 15 frequency ranked items for the T-corpus (01) compared with the U-corpus (02).
In this wider window frame of the top 15 items, it is perhaps a truism to say that Singaporean teens are keen on differentiating themselves from other groups. The Singlish particles de and le (completive discourse particles) are complemented by other creative re-spellings, including the double letter addition ii (for the singular first person pronoun), den (for "then"), tat (for "that"), euu (for "you"), noe (for "know"), and mie/mii (for "me").
A closer examination of the double letter addition for the singular first person pronoun ii ("I") indicates that the Singaporean teen bloggers do not always adhere to the principle of economy in saving keystrokes (see Figure 15):
e told mie he ish nort full yet . so ii suggest to go pasar malam and buyy so
man ! ! iit 's like arhhhh ! ! denn ii was holding him like a small baby den
, 2007 hhmmm .. UPDATED ! ! whyy am ii alwaes liidat ? ? Am i having to high
lii gibb mie alort of attention when ii needed them ! There isnt anione who k
out rather than keep it in mie coss ii 'm very exhausted by everything ! ! S
nd Junjie ! ! KIAT WAH iish cute ! ! ii mean though ii 'm in a bad mood BUT h
IAT WAH iish cute ! ! ii mean though ii 'm in a bad mood BUT he manage to mak
UT he manage to makke miie laugh ! ! ii was laughing likke mad ! ! and also t
s CUTE ! ! realii berii CUTE ! ! yst ii was nort hapiie BUT when i saw her my
9 , 2007 SHAWN BULLY MIE ! ! he sae ii 'm nort good ! ! HUMPH ! ! shawn ! !
CHEE HOW cancelled it ! ! HOORAY ! ! ii did most of mii homeworks and i am ve
change mii English teacher ivv nort ii wil definitely fail mi ENGLISH ! done
Figure 15. Select concordance listing for ii (singular first personal pronoun), from the T-corpus.
It would be more economical, for instance, to key in the form im (for singular first person pronoun + copula) or even the conventional I'm - instead of ii'm. The need for distinctiveness in terms of an in-group identity and the perceived 'cuteness' factor would seem to take precedence over the idea of economizing on keyboard strokes.
This distinctiveness is seen again when we look at the overuse in the grammatical tags for the T corpus, when compared with the U corpus (see Figure 16).
Item 01 %1 02 %2 LL
NNU 2486 2.65 617 0.77 + 942.60
VV0 4910 5.24 2538 3.15 + 454.05
ZZ1 2481 2.65 1161 1.44 + 311.52
FO 903 0.96 311 0.39 + 219.20
UH 1270 1.36 537 0.67 + 206.04
FW 254 0.27 32 0.04 + 164.25
NN1 14404 15.38 10574 13.13 + 154.67
NPM1 184 0.20 23 0.03 + 119.50
NP1 1673 1.79 929 1.15 + 118.53
VVD 2757 2.94 1704 2.12 + 117.74
(e.g. NNU=unit of measurement; VV0=base form of lexical verb. For a full list of the tags, see The Claws 7 tagset)
Figure 16. The top 10 frequency ranked part-of-speech categories for the T-corpus (01) compared with the U-corpus (02).
Due to constraints of space, let us take a more detailed look at the top 2 categories only, i.e. NNU, and VVO. Further to what we have said regarding Figure 11, NNU wrongly categorizes forms favoured by teens as group identifying markers, e.g. euu ("you"), ppl ("people"), bt ("but"), sch ("school"), hhmmm (reservation/doubt marker), la (Singlish discoursal marker), nvm ("never mind"), hahaha (interjection/noun marker), and sec ("secondary") as units of measurement. For VVO, the top verbs include go, think, see, know, love, say, want, and get for the T-corpus.
A verb of 'doing' (or material process verb) such as go seems to characterize the teenage bloggers who tend to be constantly on the move (or at least, project an online identity of being so). Let us therefore take a closer look at this particular verb (see Figure 17):

Figure 17. Select concordance listing of the verb go, from the T-corpus. (Click to enlarge)
Figure 17 shows a prime instance of Colloquial Singapore English (or Singlish) in action. Examples include go walk walk (verb + reduplicative marker, meaning "take a walk"), go Popular (ellipsis, for "go to the Popular bookshop"), and go home liao (verb + object + Singlish completive discourse particle marker). We can see a parallel in the syntactic structures of such sentences as We faster go to the canteen and buy food and Long time never go to that coffee shop liao with their Chinese equivalents, i.e. wo men gan kuai qu shi tang mai tong xi (Mandarin Chinese) and jin ku mmm pat ke hege kopitiam liao (Hokkien Chinese) respectively. Chinese (especially Hokkien and Mandarin) is a major substrate influencing the syntactic pattern of Colloquial Singapore English.
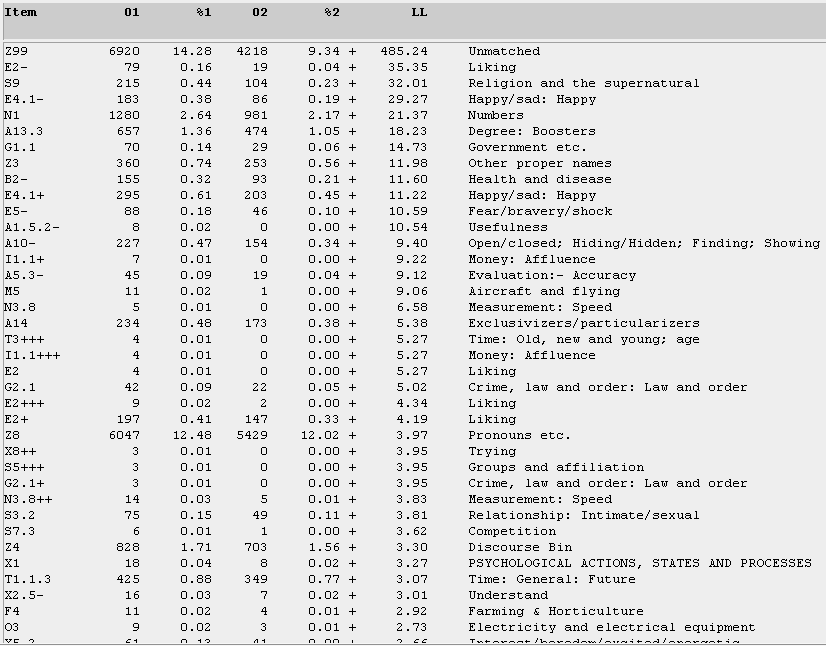
Our claim regarding the teenage bloggers appearing to be constantly on the move is borne out also in Figure 18.
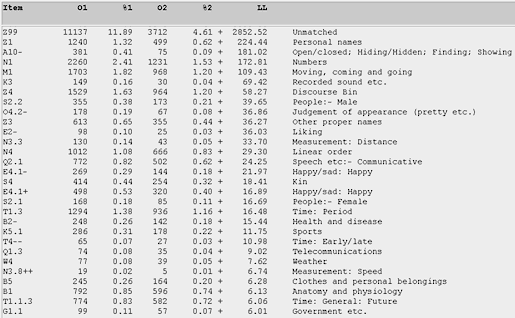
Figure 18. Comparing the overuse of various semantic categories for the T-corpus in relation to the U-corpus. (Click to enlarge)
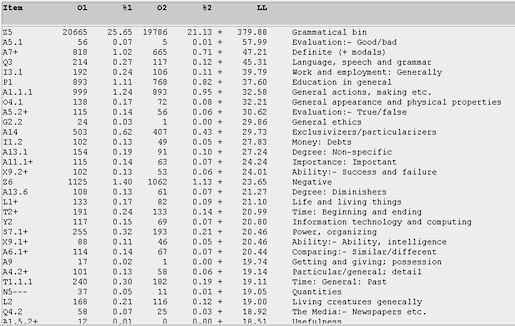
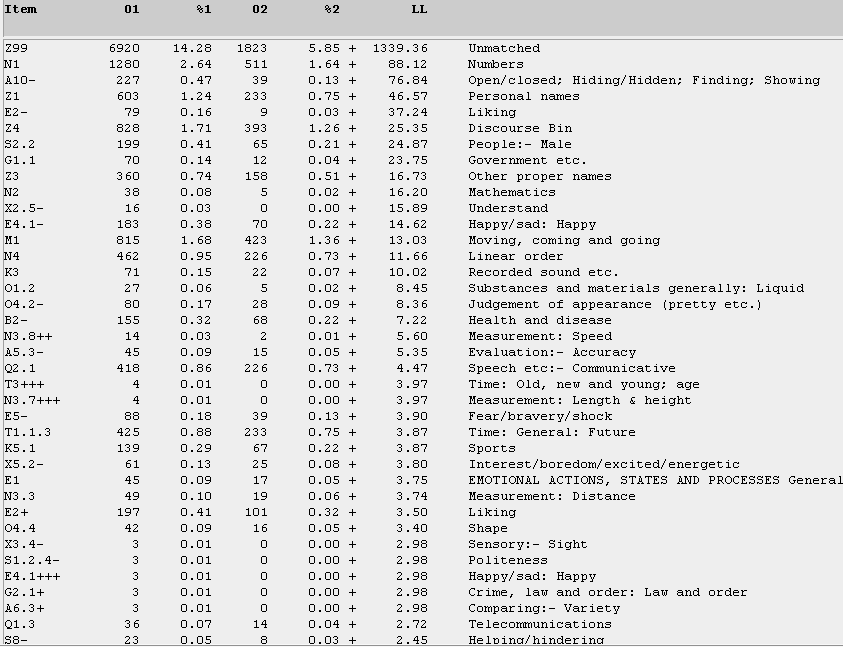
Figure 19. Comparing the overuse of various semantic categories for the U-corpus in relation to the T-corpus. (Click to enlarge)
Figure 18 indicates that the M1 category of "moving, coming and going" ranks quite highly (5th) among the teenage bloggers. If we take the corresponding view, i.e. for the U-bloggers (see Figure 19), this category does not appear within the first 30 occurrences. And, notwithstanding the significantly large "unmatched" (Z99) category, both Figures 18 and 19 give an essential semantic profiling of the various concerns, behaviour, and cultural identity of these two groups of bloggers. The overall picture that emerges is that Singaporean teens express an online identity of being 1) the more expressive ones in indicating varying moods in their blog entries 2) given more to venting about their feelings and emotions, and 3) on the move. The high proportion of unmatched items in the Z99 category (11137) for teens indicates that Wmatrix is less able to analyze such teen language, with their greater creative re-spellings, fewer standard lexical items, and a greater use of colloquial Singapore English. By comparison, Singaporean undergraduates seem to prefer less formal English syntax, possess better socio-cognitive skills, and are more outward-looking and mature. They display a greater concern with work, language, employment and other societal aspirations.
Let us now examine the second hypothesis in relation to the first hypothesis. In line with the claim that the male and female bloggers differ in terms of their meaning creation processes, let us look at the following comparisons (which are by no means exhaustive): (1) Male Teens vs. Female Teens, (2) Male Teens vs. Male Undergrads, (3) Female Teens vs. Male Teens, (4) Female Teens vs. Female Undergrads, (6) Male Undergrads vs. Female Undergrads, and (7) Female Undergrads vs. Male Undergrads.
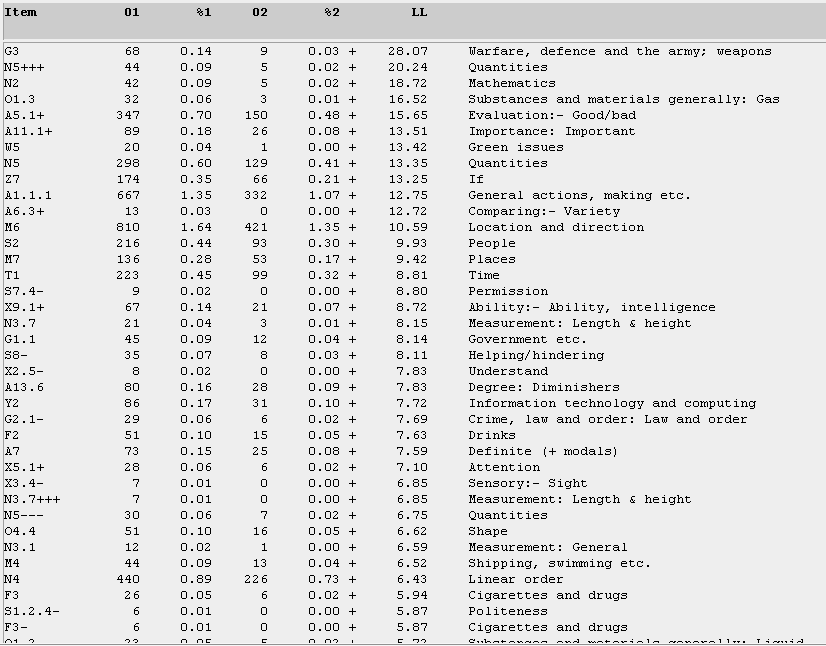
By examining Figure 20 (and the concordances and lists in greater detail), we see the preferred meaning creation processes of the male teen bloggers. For "location and direction", male teens use such markers as this, there, here, back, and where. Male teens are also significantly more interested than female teen bloggers in "sports and games", favouring items such as score and championships. Under "substances and materials", the male teens in this corpus somehow favour talking more about such items as china, ice, glass, crystals, plastic etc. For "Evaluation: good and bad", they also use markers such as well, good, ok, alright, super, and fine. And under "Music and related activities", the male teens talk more about such items and activities as songs, singing, guitar, band, drums, and percussion. Of course, a narrow interpretation of this marker is not that female teens are less interested in a topic such as music, but there is merely less of an overt and explicit mention in female teen blogs (but see Figure 25).
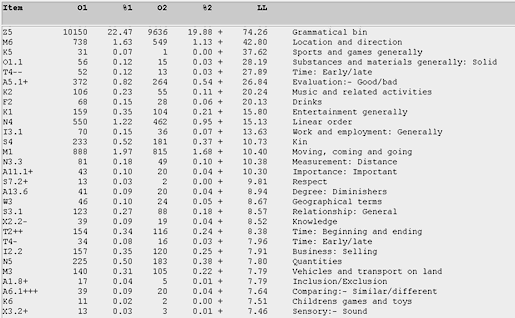
Figure 20. Log-likelihood comparison for the semantic categories among male teens, in relation to female teens, in the T-corpus. (Click to enlarge)
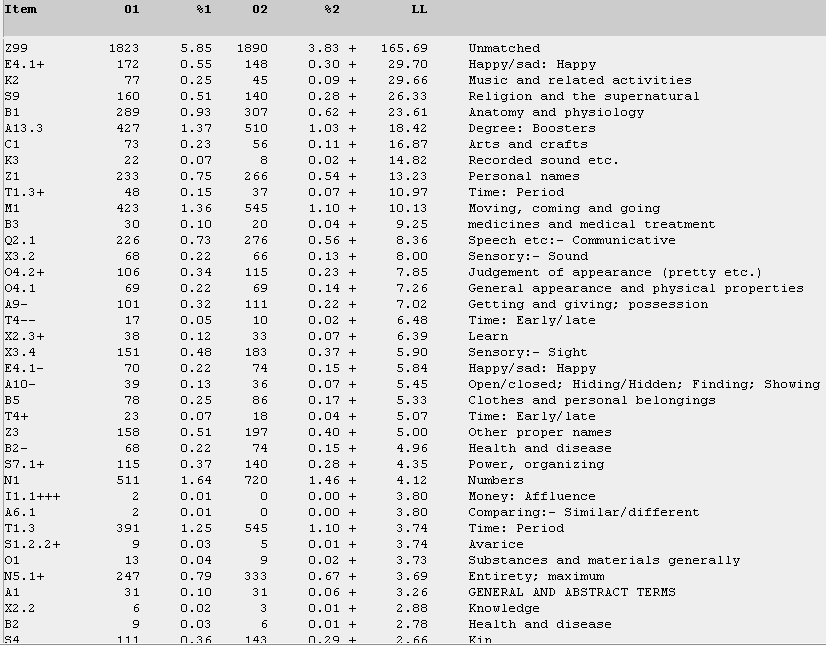
Next, Figure 21 shows how male teen bloggers compare with their male undergraduate counterparts. As mentioned before, the male teens tend to be more on the move, so to speak. Top verbs include went (200 times), go (149 times), reach (29), come (25), walk (19), came (17), and going (16). For A10- (the "Open/closed; Hiding/hidden" category), the male teens (like Harry Potter) seem to focus on negatively closed and hidden items such as secret, hide, and decipher. And in the "Judgement of Appearance" category (which is way above the same category having positive terms such as nicest and cutest), the male teens seem to be more negative than their male undergraduate counterparts in the use of terms such as ugly, dirty, and rotting.
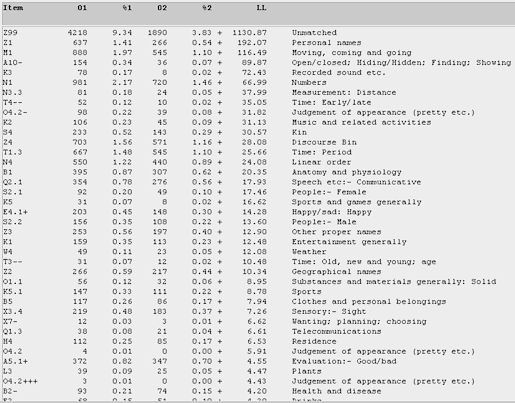
Figure 21. Log-likelihood comparison for the semantic categories among male teens in the T-corpus, in relation to male undergraduates in the U-corpus. (Click to enlarge)
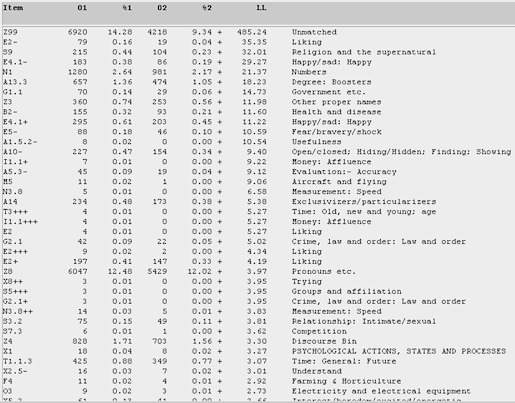
Figure 22. Log-likelihood comparison for the semantic categories among female teens, in relation to male teens, in the T-corpus. (Click to enlarge)
Figure 22 is similar to Figure 20, except that we focus on the concerns of female teen bloggers with reference to the male teens. From this perspective, the second top-ranked category of "Liking" (with the negative indication), reveals that female teens tend to express their hate, dislike, and turn-off more so than their male counterparts. The category of "Religion and the supernatural" is also accorded greater importance, with prominent terms such as God, ghost, Christmas, and magic. In the "Happy/sad" category, the females also tend to be a little more negative, with prominence given to terms such as miss, sad, cry, regret, suffer, pity, and jealous. But, while being negative, they are also able to express positive emotions such as fun, happy, laughing, smile, and playful more for the same category (E4.1+). Also, the highly ranked category of "Numbers" is to be interpreted in the context of what has been said earlier in this section: the top-occurring forms i (472 times) and ii (108 times) do not stand for any numeral but denote the single first person pronoun instead. The overall tendency to intensify matters among teens may be attributed largely to the female teens rather than their male counterparts (for the category of "Degree boosters"). Similarly, under "Health and Disease", female teens expressly blog about pain, hurt, sick, crazy, lame, mad, and scar.
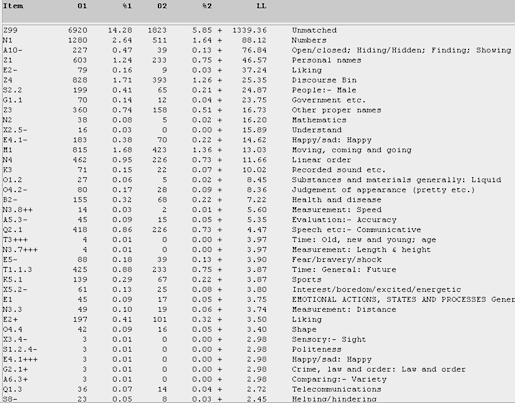
Figure 23. Log-likelihood comparison for the semantic categories among female teens in the T-corpus, in relation to female undergraduates in the U-corpus. (Click to enlarge)
From Figure 23, we see that female teens are more overtly expressive (in liking and hating) than their older female counterparts. The teens are also more prone to use 'cute markers' such as letter additions (hence, the higher ranking of the wrongly classified numerals "i" and "ii" to represent the singular first person pronoun in the "Numbers" category). Female undergraduates, being older and mature, feel less compelled to be overt about revealing people's names (under the "Personal names" category) as they are more discreet about expressing such terms as man, guys, and mr ("People: Male" category).
Finally, our comparison involves an examination of male and female undergraduates for their overtly expressed concerns (see Figures 24 and 25).
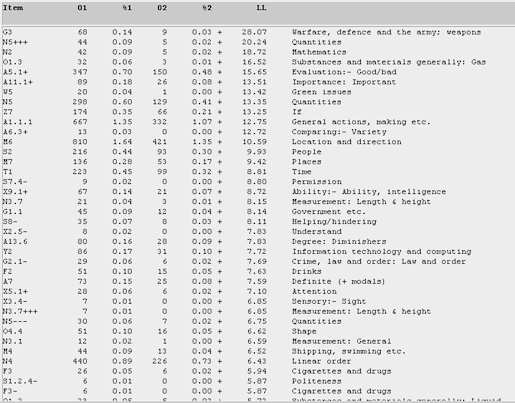
Figure 24. Log-likelihood comparison for the semantic categories among male undergraduates, in relation to female undergraduates in the U-corpus. (Click to enlarge)
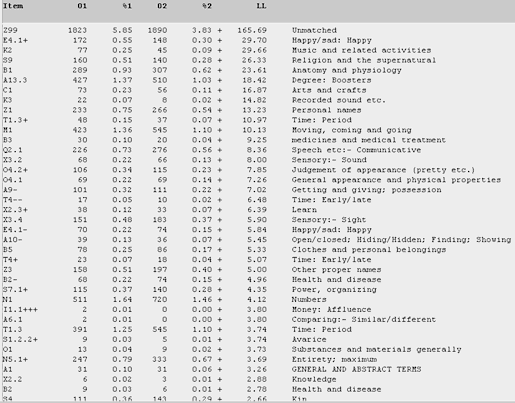
Figure 25. Log-likelihood comparison for the semantic categories among female undergraduates, in relation to male undergraduates in the U-corpus. (Click to enlarge)
Both Figures 24 and 25 do indicate a more mature profiling than their teen counterparts. Undergraduates are better-placed for discoursing on their societal roles and relationships. In this respect, Figure 24 provides evidence that male undergraduates, having done national service of approximately 2.5 years, tend to talk more than their female counterparts (who do not do national service) about this significant experience in their blogs - hence the top occurrence of the "Warfare, military and defence" category. Military terms mentioned include army, rocket, bomb, pistols, and soldiers. Conforming to the stereotype about males, these bloggers also give top mention, in the "Mathematical" category, to such terms as stats, count, statistical, calculations, and of course mathematical. They also talk about terms such as gas, smoke, nitrogen, methane and steam in the next ranked "Substances and materials" category. And, in the "Evaluation" category, the male bloggers tend to use more positive adjectival terms such as good, well, great, super, wonderful, decent, and fantastic than their female counterparts.
Figure 25 shows that the female undergraduate bloggers are not to be outdone by their male counterparts when projecting a positive online identity. The top rankings of more positive categories indicate the determination among female undergraduate bloggers to give verve and vitality to their blog entries. For instance, in the E4.1+ category, preferred terms include fun, happy, funny, happily, joy, hilarious, celebrate, laugh, and smile. And, unlike Figure 20 (which shows male teens discoursing about music more than female teens), female undergraduates tend to talk more overtly than their male counterparts regarding terms such as band, concert, piano, sing, choir, and music in the category "Music and related activities". And, like their female teen counterparts, the female undergraduates tend to rank categories such as "Religion and the supernatural" and "Degree: boosters" higher than the males. The "Anatomy and physiology" category does not imply some crazed reference to boyfriends and their physical attributes but instead to ranting on their tiredness, lack of sleep, etc. Since taking care of one's looks and body seems to be even more important to women at this age range, prominent terms suggested in this category include sleep, body, tired, eye, hair, face and skin, head and feet.
In this paper, the hypotheses that age and gender - as would the variety of English and its computer-mediated nature - are significant sociolinguistic variables for the personal blog have been centrally examined using the Wmatrix approach. Notwithstanding its original use to analyze conventional British (and American) English specifically, the robustness of Wmatrix can be seen in its linguistic content analysis (see Wilson 1993) of an online version of a non-Anglo variety, i.e. personal blogs of Singaporean teens and undergraduates that contain computer-mediated features. This systematic approach fosters a greater awareness of the 'creative acts' in Internet discourse (see Carter 2004) among Singaporean teens and undergraduates (as young adults). In turn, a close study of such creative linguistic patterns can lead to a deeper understanding of the various cultural identities at play (i.e. amongst teens and undergraduates, males and females, and between the two groups). As the Wmatrix software gets continually upgraded, we are confident that the developers of the software will ensure that Wmatrix adequately meets future challenges such as computer-mediated features and varieties of English other than British and American. Such a suggestion is also extended to other corpus linguistic software for handling newer text types, such as blogs and instant messaging.
[1] For instance, there is 'The Egyptian Blog Ring' (http://www.egybloggers.com/, accessed 29 Apr 2007), with a selection of three languages (Arabic, French, English) and its attendant categories of 'Art and Culture', 'Entertainment', 'Personal', 'Society', etc. [N.B. In 2008 this seems to have turned into an online casino site.]
[2] This corpus is part of a 7-million word database of electronic English resulting from a National University of Singapore (NUS) funded research project, E-English, E-Communication, and E-Communities in Southeast Asia: R-103-000-019-112. This project has also given rise to the NUS module "EL3216: Language and the Internet".
[3] Source. Department of Statistics: http://www.singstat.gov.sg/pubn/popn/population2007.pdf (accessed 1 Dec 2007). [http://www.singstat.gov.sg/publications/publications-and-papers/population-and-population-structure/population-trends]
[4] For this, and other general pointers and technical assistance, we are grateful to Paul Rayson - the principal developer of the Wmatrix software tool. We are also grateful to the anonymous reviewer for this paper, who has asked us not to compare Singaporean English blogs with the BNC Sampler (so much) because of the 'fundamental mismatch'.
Blog hosting services:
Corpora and related tools:
General information:
- Blog, in Wikipedia, The Free Encyclopedia, https://en.wikipedia.org/wiki/Blog
- Chinese dialects, in Wikipedia, The Free Encyclopedia, https://en.wikipedia.org/wiki/Varieties_of_Chinese
- ClickZ: The Blogosphere By the Numbers, https://www.clickz.com/the-blogosphere-by-the-numbers/65540/
- Computer-mediated communication, in Wikipedia, The Free Encyclopedia, https://en.wikipedia.org/wiki/Computer-mediated_communication
- Content analysis, https://www.ischool.utexas.edu/~palmquis/courses/content.html
- Definition of blog, in Merriam-Webster's Online Dictionary, http://www.merriam-webster.com/dictionary/blog
- J.R. Firth, in Wikipedia, The Free Encyclopedia, https://en.wikipedia.org/wiki/John_Rupert_Firth
- The Malay language, in Wikipedia, The Free Encyclopedia, http://en.wikipedia.org/wiki/Malay_language
- Singapore English, in Citizendium, The Citizens' Compendium, http://en.citizendium.org/wiki/Singlish
- Singlish, in Wikipedia, The Free Encyclopedia, https://en.wikipedia.org/wiki/Singlish
Carter, R. 2004. Language and Creativity: The Art of Common Talk. London: Routledge.
Chan, Y.H. 2006. CMC Features in English Personal Blogs by Singaporean Teens. Unpublished B.A. (Honours) thesis, National University of Singapore. [supervisor: Assoc Prof Vincent Ooi]
Crystal, D. 2003. The Cambridge Encyclopedia of the English Language (2nd edition). Cambridge: Cambridge University Press.
Crystal, D. 2007. Language and the Internet (2nd edition). Cambridge: Cambridge University Press.
Eckhert, P. 1997. "Age as a sociolinguistic variable". The Handbook of Sociolinguistics, ed. by F. Coulmas, 151-167. Oxford: Blackwell.
Garside, R., G. Leech & T. McEnery, eds. 1997. The Computational Analysis of English. London: Longman.
Herring, S.C. 2000. "Gender differences in CMC: Findings and implications". Computer Professionals for Social Responsibility Journal (formerly Computer Professionals for Social Responsibility Newsletter) 18(1). 29 Apr 2007. http://cpsr.org/issues/womenintech/herring/view?searchterm=herring
Herring, S., L. Scheidt, S. Bonus & E. Wright. 2004a. "Bridging the gap: a genre analysis of weblogs". Proceedings of the 37th Hawaii International Conference on System Sciences. 29 Apr 2007. https://www.researchgate.net/publication/261299701_Bridging_the_Gap_A_Genre_Analysis_of_Weblogs
Herring, S.C., I. Kouper, L.A. Scheidt & E. Wright. 2004b. "Women and children last: The discursive construction of weblogs". Into the Blogosphere: Rhetoric, Community, and Culture of Weblogs, ed. by L. Gurak, S. Antonijevic, L. Johnson, C. Ratliff & J. Reyman, University of Minnesota. 29 Apr 2007. http://conservancy.umn.edu/handle/11299/172825
Huffaker, D.A. & S.L. Calvert. 2005. "Gender, identity, and language use in teenage blogs". Journal of Computer-Mediated Communication 10(2), article 1. 29 Apr 2007. http://onlinelibrary.wiley.com/doi/10.1111/j.1083-6101.2005.tb00238.x/abstract
Neher, W.W. & P.J. Sandin. 2007. Communicating Ethically: Character, Duties, Consequences, and Relationships. Boston: Pearson Education.
Ooi, V.B.Y. 2001a. "Investigating and teaching genres using the World Wide Web". Small Corpus Studies and ELT: Theory and Practice, ed. by M. Ghadessy, A. Henry & R.L. Roseberry, 175-203. Amsterdam: John Benjamins.
Ooi, V.B.Y., ed. 2001b. Evolving Identities: The English Language in Singapore and Malaysia. Singapore: Times Academic Press.
Ooi, V.B.Y. 2002. "Aspects of computer-mediated communication for research in corpus linguistics". New Frontiers of Corpus Research, ed. by P. Peters, P. Collins & A. Smith, 91-104. New York: Rodopi.
Piao, S., D. Archer, O. Mudraya, P. Rayson, R. Garside, T. McEnery & A. Wilson. 2005. "A large semantic lexicon for corpus annotation". Proceedings of the Corpus Linguistics 2005 Conference, July 14-17, University of Birmingham, United Kingdom. 29 Apr 2007. http://eprints.lancs.ac.uk/12680/
Piao, S., P. Rayson, D. Archer & T. McEnery. 2004. "Evaluating lexical resources for a semantic tagger". Proceedings of the 4th International Conference on Language Resources and Evaluation (LREC 2004), 26-28 May 2004, Lisbon, Portugal, vol. II, 499-502.
Rayson, P. 2003. Matrix: A Statistical Method and Software Tool for Linguistic Analysis through Corpus Comparison. Ph.D. thesis, Lancaster University. 29 Apr 2007. http://ucrel.lancs.ac.uk/people/paul/publications/phd2003.pdf
Rayson, P. 2005. Wmatrix: A Web-based Corpus Processing Environment. Computing Department, Lancaster University. 29 Apr 2007. http://www.lancaster.ac.uk/staff/rayson/publications/icame01.pdf
Wilson, A. 1993. "Towards an integration of content analysis and discourse analysis: the automatic linkage of key relations in text". 29 Apr 2007. http://ucrel.lancs.ac.uk/papers/techpaper/vol3.pdf
|
|