Exploiting salience and fuzzy matching in evaluating term candidates in comparable corpora
Magnar Brekke, Dept. of Professional and Intercultural Communication, NHH
Abstract
This paper reports on an ongoing experiment to develop a methodology for capturing term candidates in comparable corpora by exploiting their textual salience or significance in evaluating the statistical likelihood of a given vocabulary unit turning up in a specific text. For this experiment the specific texts were selected from the KB-N English Corpus of Comparable Text, one American, one British/European, both from the subdomain of taxation and representing the genre of regulation. Visual inspection of parallel frequency lists sorted by salience ratio revealed a limited but significant lexical overlap as well as interesting divergences. By moving from exact matching to “fuzzy” matching and combining captured items into fuzzy groups of lexically related but morphologically divergent forms the degree of terminological correspondence between the two comparable texts was seen to increase considerably, strengthening the case for a given term candidate or even bringing an otherwise unnoticed term candidate above the salience threshold. Implementation of the approach tested and described here would significantly increase the amount of text that can be brought within the scope of automatic term capture.
1. Introduction
The current state of Natural Language Processing (NLP) research reflects major strides in the automatic processing of large text corpora for the purpose of mining specialist knowledge residing in professional text, particularly in definable terminological units (see e.g. Castellvi et al. 2001). Automatic term capture from parallel text is largely in place, and KB-N (KnowledgeBank of Norway), a concept-oriented knowledge-bank for economic-administrative domains, has developed software and methods for trawling English-Norwegian parallel text for term candidates with reasonable success. Nevertheless, the supply of parallel text is rather limited, especially when a lesser spoken language like Norwegian is the other member of a language pair. If the approach could be extended to also handle comparable corpora, the text supply would be dramatically improved in comparison. This presupposes a technique for screening documents for inclusion in a comparable corpus which would allow the investigator to identify a significant number of term candidates.
2. Background: Term extraction from parallel text
Specific techniques proposed for automatic term extraction turn out to be highly sensitive to typological differences between languages. Thus the strategies available for English differ markedly from those relevant for Romance languages, or for those of Germanic stock, including Norwegian. Øvsthus et al. (2005) is the first published work indicating that this language has been tackled with reasonable success, using a heuristic three-pronged approach which exploits linguistic, lexical, as well as statistical techniques applied to a very large corpus, see Table 1.
Table 1. Norwegian term candidate extraction.
| 1. Linguistic Filter |
a) regular expressions
(adj. in positive form)* + noun (minus genitive form), adj +“og/eller” + adj + noun, noun + “-” + “og/eller” + noun |
b) general vocabulary trap (cumulative stop-list of non-focal adj) |
| 2. Named Entity Recognizer |
| Evaluates output of linguistic filter according to specific criteria |
| 3. Statistical Significance (“Weirdness”) Ratio |
Text occurrence ratio of given text checked against occurrence ratio in major general language corpus:
Frq. of W in t/No. of tokens in t
divided by
Frq. of W in C/No. of tokens in C
(If occurrence of W in C is zero, formula returns “Infinite”) |
Table 1 offers a fairly straightforward identification of complex NPs (1a) followed by cumulative list of stopwords (1b) which filters out the more obvious general language NPs, while an algorithm for named entity recognition (item 2, from an independent project called Nomen Nescio) prevents the exclusion of obviously desirable items. At this point the lexical properties of a massive and independently existing language resource is brought to bear on the task at hand: a list of word occurrence ratios (item 3) drawn from Hofland’s cumulative Norwegian Newspaper Corpus of general Norwegian news text (currently well beyond 1.2 billion words) is accessed and compared with the ratios generated from the new text, and a significance ratio is calculated for items exceeding a set threshold level (currently set at 60).
The end result of this filtering process is a list of “recommended” term candidates presented to the human expert for validation before final inclusion into the term bank. Critics may object that such human intervention constitutes a significant bottleneck which slows down processing and reduces the efficiency of the system by several orders of magnitude. The objection is valid – but this efficiency would come at a considerable cost, since fully automatic entry of term candidates into the term base would quickly clog the system with linguistic and conceptual debris which could only be eliminated through hugely complicated and expensive procedures (if at all).
It has been our philosophy that the superior capabilities of computer-based language processing are best exploited when harnessed to the professional knowledge of a human expert, such that each partner handles the tasks it is best equipped for handling: the computer performing speed-of-light indexing, harvesting and sophisticated pattern matching, and the person exercising professional skills and competence in refining raw data into validated knowledge prior to the inclusion of the output in the term bank.
The general approach to bilingual term extraction from parallel text outlined here (and further described in Brekke et al. 2006, Brekke et al. 2008) has been implemented as a standard semi-automatic procedure. KB-N’s term capture is based on carefully aligned (cf. Hofland 1996) and POS-tagged (cf. Hagen et al. 2000) parallel text in Norwegian and English. It has two parts: (a) semi-automatic term extraction from Norwegian text, and (b) the linking of a given Norwegian term candidate to its presumed English equivalent.
In the suite of computer-assisted working procedures developed through the KB-N project we consider our semi-automatic bilingual terminology matching technique for term capture the jewel in the crown. This method for term extraction from parallel texts represents our point of departure for an experimental extension into term extraction from comparable text. Can this knowledge engineering platform be extended to embrace the massive quantities of comparable text that lie beyond the realm of strictly parallel text, but without sacrificing the quality of results?
3. Term extraction from comparable text
3.1 Texts selected
To investigate the possibilities of term candidate extraction from monolingual texts we selected two obvious candidates for comparable text: Financial Accounting Standard (FAS) No. 109: Accounting for Income Taxes, the American equivalent to the British/European International Accounting Standard (IAS) No. 12: Income Tax, IAS-12. FAS is a much longer text than IAS but the two are fully comparable in terms of genre, text type and target audience, cf. Table 2.
Table 2. Essential statistics of the two texts compared.
|
|
FAS |
IAS |
a |
running words |
46 674 |
11 448 |
b |
unique content words |
1792 |
729 |
c |
S/GR>60 |
227 |
158 |
d |
inf! (→ SL term) |
59 |
18 |
e |
unique inf! |
33 |
7 |
f |
shared inf! |
11 |
g |
inf! termsets S/GR>60 |
18 |
As indicated by the official titles of the two texts they both fall within the same subdomain (income tax) and represent the same genre (official standard for professional work) and text type (expository), thus fulfilling the essential requirements for being considered comparable texts in view of the purpose for which they are being used in this experiment.
As a consequence of the increasing globalization of financial markets and even more so the major accounting fraud scandals following in its wake (suffice it to mention the fall of Enron and the demise of Anderson), great efforts go into the harmonization of general accounting regulations. The convergence seen so far makes it a reasonable hypothesis that the terminology used in these documents will show significant overlap. Can our methodological approach corroborate this?
Our choice of corpus exploration toolbox has been System Quirk (SQ) (Ahmad & Rogers 2001), providing a flexible suite of tools for standard corpus measures and functions. Textual salience or significance of a given lexical unit is calculated on the basis of its observed vs. expected frequencies in a given text, where the word count compiled from a commercially available learners’ corpus of English (henceforth referred to as “the general word list”) forms the basis for assigning expected frequencies. We will here follow SQ in assigning a specific “weirdness ratio” to each item occurring in the text being scrutinized with markedly higher frequencies than would be predicted by the corpus underlying the general word list. The label inf! is reserved for items not occurring in the general word list.
Setting out the bare statistical facts of our text selection, rows a and b of Table 2 show that while FAS is about four times longer than IAS, it contains less than 2.5 times more unique content words than FAS, confirming the general observation that the incremental curve representing content words in a text levels off with increasing text volume. Row c represents the following observation: In a comparison of word occurrences between a special language text (S) and a general language text (G), FAS contains 227 items occurring with higher frequency than expected, while IAS contains 158 such items above the threshold weirdness ratio of 60 (cf. formula given in item 3 of Table 1).
Among those given in c, row d picks out the inf! items, i.e. all items occurring in the special texts but totally absent from the general word list. This significantly boosts their likelihood of representing special terminology. FAS contains 59 inf! items, of those, 33 are not in IAS, while IAS has 18 inf! items, of those, 7 are not found in FAS (as indicated in row e).
Before turning our attention to rows f and g it would be instructive to look at specific items picked out by the procedures just described. The samples from the FAS weirdness list given in Tables 3a and 3b are very small and carry no statistical significance in isolation; they do, however, provide interesting glimpses of the sort of lexical substance that turns up.
Table 3a. Vocabulary at top of list.
| Freq |
Match |
SLR |
SL/GLR |
160 |
deductible |
0.0034 |
inf! |
117 |
carryforward |
0.0025 |
inf! |
105 |
carryforwards |
0.0022 |
inf! |
46 |
pretax |
0.0010 |
inf! |
36 |
carryback |
0.0008 |
inf! |
Table 3a are the items with the highest weirdness score (as reflected in their inf! label). they are also absent from the general word list which constitutes the standard of comparison. Tax consultants would have no problem recognizing such items as belonging to their specialist language. Now on to the other end of the spectrum:
Table 3b. Vocabulary near cut-off point (60).
| Freq |
Match |
SLR |
SL/GLR |
28 |
expenses |
0.0006 |
60.4255 |
20 |
illustrates |
0.0004 |
60.3073 |
3 |
amends |
0.0001 |
60.0331 |
86 |
benefits |
0.0018 |
58.2475 |
3 |
lenders |
0.0001 |
55.0304 |
2 |
allocations |
0.0000 |
55.0304 |
Table 3b displays the items straddling the weirdness ratio of 60, understood as occurring in the text being examined about 60 times over their expected frequency in a general language text. The specialist relevance of these items seems more variable, justifying our choice of 60 as a not unreasonable threshold level.
However, the most interesting aspect of Table 2 is not where FAS and IAS differ (more on that later), but where they overlap. As shown in row f, 11 inf! items are shared between our two comparable texts. This rather modest number represents exact matches, but if we extend the scope to that of lexically related fuzzy term sets, there are as many as 18 such overlapping related term sets (row g). Much of the remainder of this paper will be taken up with discussing and exploring the implications of extending our comparable corpus search from exact matches to fuzzy lexical sets. But first we need to outline the experimental design.
3.2 Experimental set-up
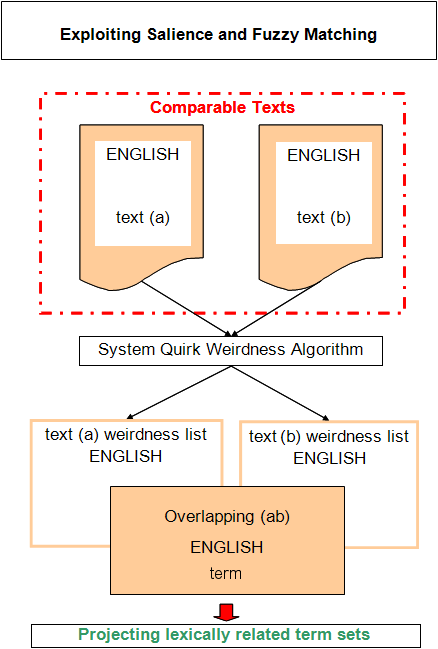
The flow chart in Figure 1 indicates the overall layout for testing the general hypothesis that texts sharing subdomain, genre, text type and audience orientation will have a significant terminological overlap.
Figure 1 indicates the stages of attempted monolingual term capture utilizing salience statistics for identifying term candidates in comparable texts in the manner just described and illustrated.
Submitting the FAS and the IAS texts to System Quirk’s weirdness algorithms produces the two lists already mentioned in row c in Table 2 with 227 and 158 items, respectively. These are items which in the KB-N context would be prime English term candidates. The two parallel lists were scrutinized for correspondences, and for each inf! item a search was extended into each list for lexically relevant items above a weirdness ratio of 60. Items representing corresponding lexical material but with morphology different from the inf! item were grouped with it into lexically related but morphologically fuzzy term sets.
3.3 Projecting related term sets
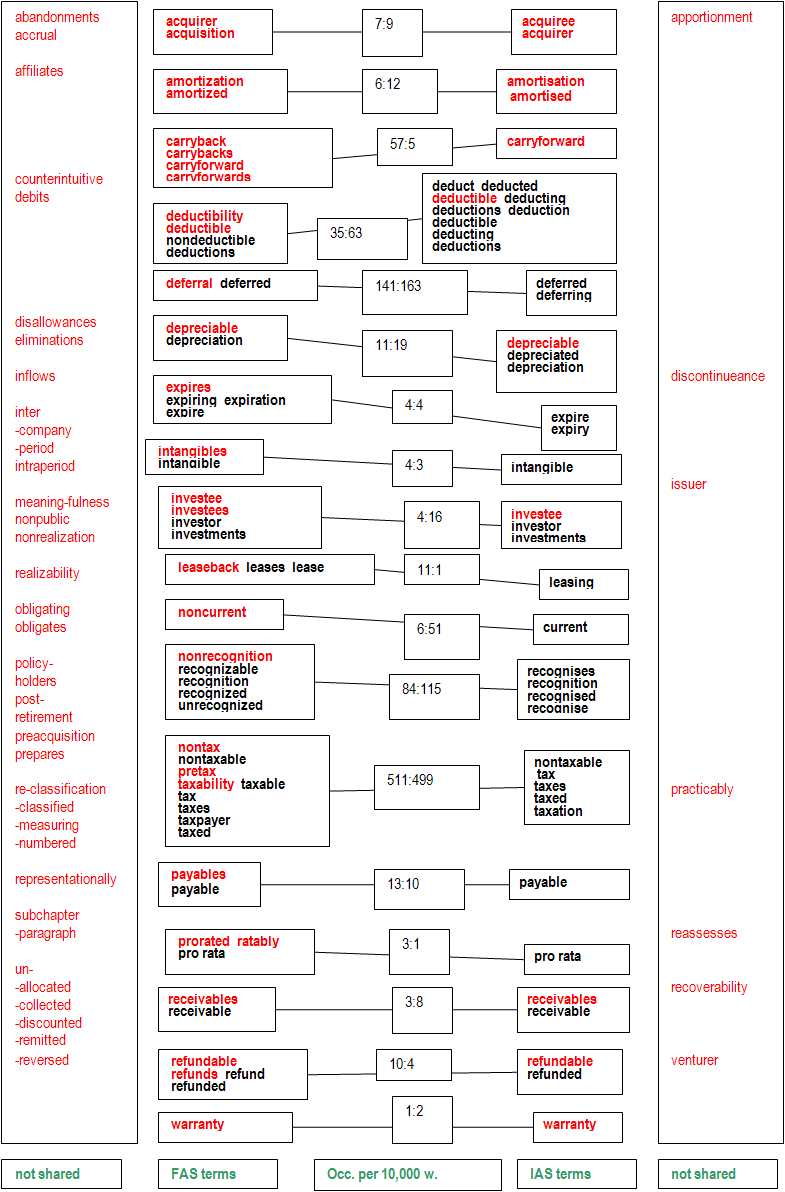
Figure 2 contains a detailed specification of the 18 term sets emerging from a scrutiny of the parallel FAS/IAS weirdness lists. Items shown in red are inf! items, i.e. “high-likelihood-terms”. The tall boxes to the left and right contain inf! items not shared by the two texts, while the central complex column shows the linked term sets, with the respective occurrence ratio normalized per 10,000 words of all members of a given term set, in one or the other text, entered in boxes down the middle.
The leftmost box in Figure 2, containing the 33 (American) FAS-terms which occur neither in System Quirk’s general word list nor in the comparable (British/European) IAS document (above the threshold level); these items clearly bring out the special domain basis for the document. They range from reasonably domain-focused items like abandonments, accrual, debits, inflows, realizability, preacquisition and unallocated (many of these are bona fide Accounting terms) to more refractive items like affiliates, counterintuitive, meaningfulness, subchapter, and unremitted (which do not per se suggest Accounting and will turn up across several domains, often gravitating toward the general pole of the general vs. specific continuum.
The rightmost box in Figure 2 displays the seven (British/European) IAS-terms not found in System Quirk’s general word list nor in the (American) IAS document, all except practicably belonging in a clear Accounting context. What this quick overview has shown is that in the application of the proposed lexical overlap method the non-shared items, although quantitatively marginal and of little value in identifying comparable texts, are likely to represent significant terms and should not be discarded out of hand.
That brings us to a closer consideration of the central area of Figure 2, an uneven column of paired fuzzy lexical sets, FAS-items to the left, IAS-items to the right, linked in each case via a box giving the (normalized) number of items contained in each respective set. To give a few examples of the results represented here: Top left we encounter the FAS-term acquirer, which also occurs in the IAS document (top right), and the FAS-term acquisition, which does not; but IAS has the item aquiree. All four appear in red, reflecting their inf!-status, i.e. they are absent from the general language lists and thus tentatively marked for term-hood. So, in this case, restricting our search to exact matches yields one shared term; while counting all tokens in the wider fuzzy set yields 7 and 9, a total of 16 items.
Further, the FAS inf! item nonrecognition about the center of Figure 2 does not have an exact match in IAS, but the fuzzy set of all the lexically related term items in IAS taken together indicates an occurrence of 115 items per 10,000 words, as well as to 84 per 10,000 words in FAS, a total of 199 relevant tokens of a term type which would have gone unnoticed (no shared inf! term) by the exact matching method. As a final example, notice warranty at the bottom of Figure 2, a straightforward exact match with balanced albeit marginal incidence.
Fuzzy matching of lexically related term sets has added, as we have just seen, an important dimension to our search for methods for capturing term candidates in comparable texts: inf! items reflecting only exact matches will miss a great deal of the relevant substance, unless they can be supplemented by lexically related material organized in fuzzy term sets. Table 4 rearranges our data to bring out the significance of this observation, showing the quantitative effect of allowing fuzzy matching of lexical sets.
Table 4. Effect of allowing fuzzy matching of lexical sets.
| Exact matches |
Fuzzy matches |
+types |
FAS-tokens |
IAS-tokens |
Total tokens |
carryforward |
CARRY* |
4 |
57 |
5 |
62 |
deductible |
DEDUCT* |
11 |
35 |
63 |
98 |
depreciable |
DEPREC* |
3 |
11 |
19 |
30 |
refundable |
REFUND* |
4 |
10 |
4 |
14 |
acquirer |
ACQUIR* |
2 |
7 |
9 |
16 |
amortiz/sation
amortiz/sed |
AMORT* |
0 |
6 |
12 |
18 |
investee |
INVEST* |
5 |
4 |
16 |
20 |
receivable/s |
RECEIVABLE* |
0 |
3 |
8 |
11 |
warranty |
WARRANTY |
0 |
1 |
2 |
3 |
10 exact matches |
Fuzzy items added |
29 |
134 |
138 |
272 |
|
|
|
|
|
|
0 |
TAX* |
14 |
511 |
499 |
1010 |
0 |
DEFER* |
4 |
141 |
163 |
304 |
0 |
RECOGNI* |
9 |
84 |
115 |
199 |
|
|
27 |
736 |
777 |
1513 |
|
|
|
|
|
|
0 |
PAYABLE* |
3 |
13 |
10 |
23 |
0 |
LEAS* |
4 |
11 |
1 |
12 |
0 |
CURRENT |
2 |
6 |
51 |
57 |
0 |
EXPIR* |
5 |
4 |
4 |
8 |
0 |
INTANGIBLE* |
3 |
4 |
3 |
7 |
0 |
PRO-RAT* |
4 |
3 |
1 |
4 |
|
New fuzzy items captured |
48 |
777 |
847 |
1624 |
|
Total from 18 fuzzy
lexical groups |
77 |
911 |
985 |
1896 |
Table 4 has six columns; the first column on the left lists the inf!-items where FAS and IAS match exactly, a total of ten matches. As shown in column 2 the list is almost doubled by allowing fuzzy searches for the same stems in the two documents. This adds 29 types (column 3) of term candidates (1/3 of which expand the DEDUCT* stem) as well as 134 FAS tokens (column 4) and 138 IAS tokens (column 5), a total of 272 tokens (column 6) with considerable overlap in the two lists. All in all we find this a significant increase in harvested term candidates, although not impressive relative to a corpus size of almost 60.000 running words. FAS and IAS seem fairly well balanced with one exception: carryforward and its lexical relatives have very high incidence in FAS, quite low in IAS.
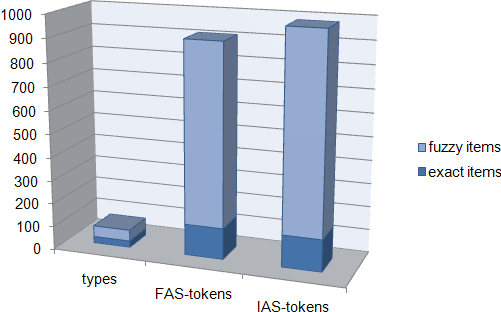
The lower half of Table 4 reflects the much higher yield which can be had from this field when fuzzy searches are allowed beyond inf!-items identified by exact matching, i.e. admitting items also occurring in the general word list but with a weirdness ratio above 60. Adjusting the settings of our pattern matching radar to also respond to such matches, nine new fuzzy lexical sets are picked up below its former range, harvesting 48 new types, 777 new FAS tokens and 847 new IAS tokens, a total of 1624 tokens (but again with considerable overlap), boosting the number of tokens eligible for term candidacy by a factor of about 6.
While all of the items in Table 4 added by fuzzy matching would ring familiar to any trained accountant and be missed if absent from a list of central Accounting terminology, there are three that stand out: TAX*, DEFER* and RECOGNI*, between the three of them representing 80% of the total of added tokens. None of them showed up by exact matching of inf! items, a particular surprise in two major documents expressly focused on taxation.
The experimental study reported here admittedly involves only a modest corpus sample of approximately 60,000 words, but the tabulated results hold out a considerable promise of similarly boosting the supply of term candidates found in any major comparable text sample of relevant type. Translating the numerical detail of Table 4 into a suitable graphic representation like Figure 3 provides a striking illustration of the gain that can be achieved.
The results displayed above go a long way toward corroborating our claim that vast new textual areas could be opened up for automatic term capture to the extent that fuzzy matching can be efficiently implemented and included in a corpus exploration toolbox.
4. The larger picture
The KB-N KnowledgeBank in its current phase is somewhat lacking in volume of captured and coded text from the relevant domains, since we have given quality priority over quantity. Holdings of English-Norwegian parallel text total just under half a million words in each language, while each subcorpus of monolingual comparable text is slightly over half a million. Consideration of text for inclusion in the corpus requires careful scrutiny of stylistic quality, lexical representativity as well as conceptual substance, and, in the case of parallel texts, the professional quality and equivalence of the target text must be assessed. The acquisition of comparable text will be speeded up considerably when the experimental method tested and described in this paper has been made operational. So far, so good. What are the limitations?
A serious hindrance to the efficient establishment of domain-specific archives of relevant electronic text has emerged from the legal agencies guarding the intellectual property rights of major publishing houses. Communication regarding permissions has proved extremely laborious, not just because some copyright holders refuse to respond to our formal requests but because those that do, often fail to comprehend the nature of our interest in their texts. For many languages this problem constitutes a major obstacle in most efforts to establish representative public language bank, archives of suitable linguistic resources necessary for documentation and research.
The volume of term records currently held in the KB-N KnowledgeBank (about 8,500), on the other hand, is quite respectable in four subdomains of major importance (Accounting being one of these, with about 1,200 records), a situation attributable not only to the continuous development and refinement of automatic term extraction, but in large measure also to the efficiency of the custom made tools for human-machine interaction which have been created to speed up the work flow in the KB-N project.
KB-N is designed to be a web-enabled resource available for systematic terminology look-up and usage documentation. Search for a given term in the term bank will retrieve essential data types relating to meaning, cross-language equivalence or usage etc. For any given special domain included KB-N will constitute a conceptual/terminological clearing house, a precise control system for the conceptual underpinnings of the relevant domain knowledge and their terminological and textual manifestations, in one or more languages.
We consider automatic term extraction the computationally most interesting achievement of the KB-N project, in exploiting the empirical value of linguistic resources (acquired for quite different purposes) in developing precise algorithms for automatically generated term candidate lists. This operation constitutes a significant link between the text bank and the term bank and exploits human-machine interaction to combine text-embedded domain knowledge with human expertise in a form which can be utilized in e.g. e-learning, machine translation, human translation, and knowledge management.
Nevertheless, the lack of major headway hitherto being made in applying automatic term extraction beyond parallel corpora, and the so far largely untapped resources encapsulated in huge repositories of comparable text, constitute a major challenge for the natural language processing community. The tentative results described above are taken as encouragements in our continued efforts to refine the use of salience measures supplemented by fuzzy sets of lexically related term candidates in achieving significant term capture on the basis of comparable corpora.
Acknowledgments
KB-N has been developed in the context of KUNSTI funded by the Norwegian Research Council (Brekke 2004). The written presentation of this paper has benefitted from valuable comments from the editors.
Sources
Nomen Nescio – Named Entity Recognition for Norwegian, Swedish and Danish (2001–2005). http://g3.spraakdata.gu.se/nn/.
Norwegian Newspaper Corpus. http://clu.uni.no/avis/.
System Quirk Language Engineering Workbench. http://www.computing.surrey.ac.uk/SystemQ/.
References
Ahmad, Kurshid & Margaret Rogers. 2001. “Corpus linguistics and terminology extraction”. Handbook of terminology management, vol. 2, ed. by Kurshid Ahmad, Sue Ellen Wright, Gerhard Budin & Margaret Rogers, 725-760. Philadelphia: Benjamins.
Brekke, Magnar. 2004. KB-N: “Computerized extraction, representation and dissemination of special terminology”, ed. by Rute Costa, Lotte Weilgaard, Raquel Silva & Pierre Auger. Workshop on Computational and Computer-assisted Terminology, IV LREC 2004, Lisbon.
Brekke, Magnar, Marita Kristiansen, Kai Innselset & Kari Øvsthus. 2006. “KB-N: Automatic Term Extraction from Knowledge Bank of Economics”. Poster presentation, Language Resource and Evaluation Conference (V LREC), Genova.
Brekke, Magnar, Marita Kristiansen, Kai Innselset & Kari Øvsthus. 2008. “Heuristics for term extraction from parallel and comparable text: The KB-N legacy”. Poster presentation, Language Resource and Evaluation Conference (LREC), Marrakech, May 2008. http://www.lrec-conf.org/proceedings/lrec2008/.
Castellvi, Maria Theresa Cabre, Rosa Estopa Bagot & Jordi Vivaldi Palatresi. 2001. “Automatic term detection: a review of current systems”. Recent advances in computational terminology, ed. by Didier Bourigault, Christian Jaquemin & Marie-Claude L'Homme, 53-87. Philadelphia: Benjamins.
Hagen Kristin, Janne Bondi Johannessen & Anders Nøklestad. 2000. “A constraint-based tagger for Norwegian”. 17th Scandinavian Conference of Linguistics, Odense Working Papers in Language and Communication, No. 19, vol I, ed. by Carl-Erik Lindberg & Steffen Nordahl Lund. Odense: University of Southern Denmark.
Hofland, Knut. 1996. “A program for aligning English and Norwegian sentences”. Research in Humanities Computing, ed. by Susan Hockey & Nancy Ide, 165-178. Oxford: Oxford University Press.
Øvsthus, Kari, Magnar Brekke & Kai Innselset. 2005. “Developing automatic term extraction: Automatic domain specific term extraction for Norwegian Terminology and Content Development”. Proceedings of the 7th International Conference on Terminology and Knowledge Engineering (TKE 2005). Copenhagen: Association for Terminology and Knowledge Transfer (GTW).
|