Contacts and variability in international Englishes: Compiling and using the Corpus of English in Finland
Mikko Laitinen, Research Unit for Variation, Contacts and Change in English, University of Helsinki
Abstract
The past few decades have witnessed a substantial spread of English as the language of international communication. One of the consequences of this growth of English world-wide is that there is a need to develop new corpora that make it possible to describe these expanded uses of English. To illustrate the expansion of English, this article first presents an overview of the linguistic situation of present-day Finland, a country in which English has for long been used as a foreign language with no institutional status. The various uses of English in Finland are illustrated drawing from the results of the recent large-scale survey of English in Finland, carried out at the Research Unit for Variation, Contacts and Change in English (VARIENG). These survey results provide useful background information for an on-going corpus compilation process of the Corpus of English in Finland. The article then presents the results of three case studies that explore morphological and grammatical variability in this material.
1. Introduction
The book of abstracts of the ICAME30 conference offers a good overview of the materials used in English corpus linguistics today. [1] It shows that roughly half the studies at the conference on present-day Englishes made use of corpora of native varieties (such as the British National Corpus, the International Corpus of English-Great Britain (ICE-GB), etc.), and approximately one fifth, including the papers in the workshops, drew data from learner corpora (the various sister corpora of the International Corpus of Learner English). About ten per cent used the English as a Second Language corpora (the various siblings of the ICE). Some relied on parallel corpora, whereas some did not specify their material. In view of the on-going spread of English as the language for international communication, the absence of lingua franca corpora in this conference is unexpected.
My objective in this article is to suggest that English corpus linguistics could move forward by taking into account the global spread of English more than it does today. It is clear that the number of English speakers has been on the increase (McArthur 2002, Crystal 2006, Graddol 2006), and a growing number of people, in Europe and in many other parts of the world, are non-native speakers of English but are no longer learners in a school setting nor do they use an institutionalized second-language variety of English. Instead they use it as regular resource in a variety of settings (Taavitsainen & Pahta 2003, 2008, Louhiala-Salminen, Charles & Kankaanranta 2005), and this highlights the need for new corpora of the international Englishes used a lingua franca. Ideally, such new corpora would supplement the set of corpora mentioned above and the existing English as a lingua franca corpora, such as the VOICE (Seidlhofer 2005) and ELFA (Mauranen 2003).
According to Traugott (2008), the global spread offers English linguistics interesting prospects, ranging from documenting the newest international Englishes at early stages to the study of patterns of variability in language contact and advanced acquisition. However, corpora today do not necessarily represent the emerging Englishes, and there is a need to develop new corpora that reflect the macro-level trend and the globalization of the language today. A good illustration is Mesthrie and Bhatt’s (2008: 221) projection of the spread of English to new populations, and its hypothetical path from a foreign language (EFL) to the first language (L1) in a country.
EFL > 1st FL > ESL > 2nd L1 > a high variety > L1.
The intervening stages on this path from EFL to ESL to L1 include English first becoming the predominant foreign language in a country (1st FL stage), then parts of the population adopting English as their L1, and finally English being as the most prestigious L1 (high variety). Even though the path is theoretical, it illustrates how communities may be dynamic, and how the role of a language may develop over time. Our corpora, however, do not necessarily capture this dynamism.
The article focuses on a nation-state that has recently seen an increase in use of English, and introduces a corpus that documents the English used in Finland. This country is undergoing a transition in which English is used as a regular resource by many (Leppänen & Nikula 2007, Taavitsainen & Pahta 2008). To provide empirical evidence supporting this claim, section 2 presents select results of the national survey on English in Finland, carried out by a group of researchers of the Research Unit for Variation, Contacts and Change in English (VARIENG) in 2007.
Section 3 introduces the new corpus in compilation at VARIENG, the Corpus of English in Finland (FIN-CE), and section 4 presents three case studies on variability in international Englishes as the outcome of contact and acquisition. The first study in section 4.1 examines Finnish informants’ uses of variants that distinguish British (Br.E) and American English (Am.E) (i.e. variability that might be recognized by speakers). In sections 4.2 and 4.3 the corpus is used to search for forms that are undergoing changes in native Present-day Englishes (Leech 2003, Mair 2006, Mair & Leech 2006, Leech, Hundt, Mair & Smith 2009) (i.e. variability that is most likely below the level of linguistic awareness and is therefore not recognized).
The objective of this study is to introduce a corpus project documenting one form of present-day international English that is not represented in the stock of corpora used at the ICAME 30 conference.
2. Globalization of English and the case of present-day Finland
Broadening the scope of English in Europe has meant that it has become the widely-used common language in many contexts, one of which is Finland (McArthur 2002: 156-162). This bilingual nation with its national languages Finnish and Swedish has witnessed such development in the late 20th century. A few years ago, a group of VARIENG members at the University of Jyväskylä pooled together with Statistics Finland to conduct a survey on the uses of English in Finland. The survey results from nearly 1,500 respondents [2] provide evidence of the new sociolinguistic situation in the country (Leppänen et al. 2009, 2011): Nearly two-thirds of the respondents report that English is important for them personally, and half of those in working life use it at least weekly. Around one in four in larger cities writes e-mails in English at least weekly, or roughly the same proportion of those with higher education use the language with their colleagues or customers regularly. Taking into account the fact that it has no official status in Finland, these proportions are high. McArthur (2002: 312), for instance, estimates that roughly 4% of the population in India, where English is one of the official languages, used English regularly in the early 1990s, and predicts the proportion today to be around 10-20%. [3]
More important than comparisons with other countries is the fact that English in Finland is in many instances paired with the native languages. In addition, there is a growing multilingual community of immigrants in the country. [4] English has a semi-official position in administration, business, and education (Leppänen & Nikula 2007, Taavitsainen & Pahta 2003, 2008), and it is often difficult to obtain employment in the civil service with no knowledge of English, and many companies operating globally or in pan-Nordic contexts have chosen it as their corporate language (Louhiala-Salminen et al. 2005, Virkkula 2008). In schools it is the most popular foreign/second language, as nearly every pupil (99.3%) in compulsory education studied English in 2008 (Statistics Finland 2009). [5]
This bi- and multilingual situation is not restricted to the elite echelons of the society but permeates into nearly all levels of it. For instance, roughly one-third of those in office work or customer service use English regularly at work. Equally important, however, is the fact that English seems not to be replacing the national languages, and is not used for intra-ethnic communication but is primarily reserved for cross-cultural communication.
The new sociolinguistic situation and scope of speakers of English in Finland highlight the fact that it would be insufficient to focus only on learners in corpus compilation. For a corpus linguist, the new situation provides not only an opportunity to build a corpus of the newest international Englishes, but also to explore variability in new contact-induced uses of English in Europe. Such studies might lead to rethinking the established views on language contact and the new Englishes. A case in point is the view on contact, pidgins, creoles and metropolitanization (Trudgill 2002). The evidence in such research is predominantly, to my knowledge, drawn from colonial and post-colonial contexts and could be complemented with evidence from other cultural and geographic contexts. Similarly, Schneider’s (2003: 234, 2007) dynamic model of New Englishes deals with “developmental phenomena characteristics of the early phases of colonial and postcolonial histories”. One fundamental difference with the Nordic context is the lack of colonial ties and the non-existence of colonizers. A study of international Englishes emerging in EFL contexts might make it possible to compare differences and similarities between these new contexts and the institutionalized ESL uses.
Following Bruthiaux’s (2003: 168) arguments against the so-called “Me too!” attitudes in the new Englishes debate, my aim is not to establish “Finnish English”, but to describe what takes place in contact, and to study how speakers of international Englishes might shape the language. However, before descriptions can be carried out, proper corpus material is needed. The next section suggests how new corpora of international uses require novel ways of charting and collecting data, and it is not necessarily possible to rely on old, often canonized, ways of compiling corpora.
3. The Corpus of English in Finland
The FIN-CE is an electronic collection that contains written and spoken English produced by present-day Finns (Laitinen 2010). The aim of this project is to enable the investigation of one form of international English and facilitate the study of English as a contact-induced language within one nation. Even though the corpus is a synchronic resource, its primary uses are in diachronic observations of variability in the English used by Finns. The English produced by Finns is one synchronic stage on the diachronic continuum of varieties, and the corpus should make it possible to track the quantitative distribution of variants from the native varieties to the newly-emerging international Englishes. In particular, the objective is to enable the study on how new speakers shape the various morpho-syntactic structures in the language. The informants’ backgrounds in the compilation are controlled, and this small and tidy corpus, therefore, provides an opportunity to explore variability as a result of informants’ language backgrounds (cf. Ringbom 2007: 41-53).
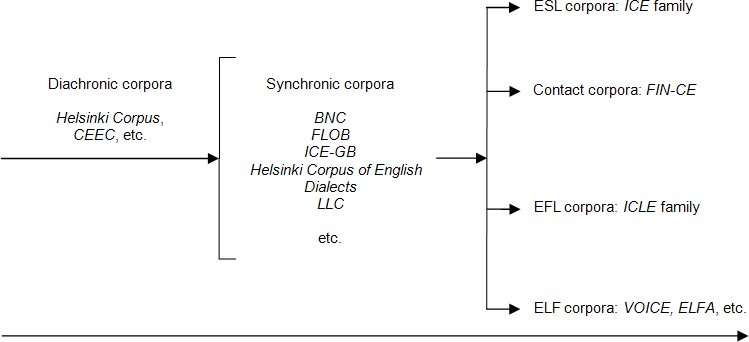
Figure 1, visualizing the FIN-CE with a set of corpora, shows how this new contact corpus reflects the recent rise of English as a medium for international communication (cf. section 2). The corpus makes it possible to investigate what takes place when individuals in a traditionally EFL country turn to English in their daily activities. The factor distinguishing the FIN-CE from other lingua franca corpora is its focus on a large, but geographically-bounded community whose members form a population of native speakers in this community (Patrick 2004).
The material collection for the FIN-CE requires the development of new ways for finding suitable material. This fact relates, in particular, to charting the various domains of uses of English that is done by making use of the survey of English results mentioned in section 2 above. To illustrate this, the survey results make it obvious that student writing and essays, the typical material source in collecting learner corpora (Granger 2003), represent only a small part of its uses in Finland in the early 21st century. Even though English is studied by practically every student at school, the survey shows that only 20% of the total population use it in the school setting alone (i.e. the younger generation who are pupils and students). A much higher share uses it in their free time activities (nearly 40%) or at work (over 40%). Similarly, extracts from printed texts, such as English-language newspapers or novels, which form a large part of the contents in the ICE family of corpora (cf. http://ice-corpora.net/ice/design.htm), have to be replaced by other forms of writing, since such material in Finland tends to be edited by native-speakers.
The following principles are used in compiling the FIN-CE:
- The population represented consists of non-native speakers who are inhabitants of Finland. This target population includes Finnish (c. 91%) and Swedish-speaking Finns (c. 6%), as they form the two largest language groups in Finland (Statistics Finland 2009). The other groups (the Sami languages, Russian, Estonian, etc.) are too small for corpus sampling (< 1%).
- The language variety sampled is predominantly monolingual English produced by the target population, but as the informants are non-native speakers of English, a certain degree of language mixing is tolerated. I aim to capture in the corpus the language used and the Finnish speakers of English during the period of 2005–2015, which corresponds to the first wave of globalization and economic and cultural integration at both the European and global levels (Leppänen & Nikula 2007). The survey results make it obvious that the FIN-CE should contain material from both the spoken and written media. Of those Finns who use English in their leisure time, a little less than half do so in writing at least occasionally, and a slightly higher proportion turns to spoken expression (Leppänen et al. 2009, 2011).
- The compilation process minimizes native-speaker intervention by excluding sources such as English language newspapers published in Finland whose language may be checked by native-speaker editors. One obvious source of such written material is the Internet and the new media texts, such as weblogs, Internet Relay Chat (IRC) texts, and electronic mail messages. Some of these, the weblogs in particular, form the core of the written component of the FIN-CE, since they offer an easily accessible material source, which represents one of the most common forms of written English production in the country in the early 21st century.
- On the basis of the survey results, the compilation of the FIN-CE collects material from five domains that include both public and private speech events. They are: (a) New media texts, (b) Traditional media texts and speech events, (c) Commercial speech events, (d) Education, and (e) Organized thematic discussions. The main principle is that the informant must use English as a contact resource without which it would not be possible to carry out the speech event. An example is a native Finnish/Swedish-speaking teacher in an English-language degree program lecturing in a Finnish institution of higher education. Alternatively, it might include a Finnish blogger aiming at reaching a larger audience and writing in English (see below).
- The corpus size, once finished, should be large enough to make it suitable for quantitative investigations of at least high-frequency grammatical items. The projected size of the FIN-CE is 1 million running words. It is compiled by emphasizing material quality, meaning that the informants must be identifiable to belong to the sampling frame of native Finns, and every effort is being done to gather necessary socio-demographic information from the informants.
The results presented here are based on the material of 144,251 words from the written New Media domain of the FIN-CE. As of the time of writing, it consists of weblog material from informants who have identified themselves online as Finns but write in English, and who have returned a background survey form sent to them in Finnish. [6] The sample used here contains material from 48 blogs from 49 informants. [7] The average sample size from one informant is nearly 3,000 words. An ideal case is an informant who introduces herself in the blog:
I’m 28-yrs old, and from Finland. I love reading fanfiction - especially BTVS and Dark Angel. And I love creating websites and graphics. I’d write also fanfiction myself, but English isn’t my first language - not even second one. I have lots of story ideas and I try to write them down. (informant W-NB09-31, written in 2007)
In addition to the information above, the data source contained the contact details, and the writer was kind enough to return the background survey.
4. Grammatical variability in international Englishes
My case studies explore the emergence of locally characteristic patterns of variation in international Englishes as represented in the FIN-CE. Instead of focusing on non-standard forms (e.g. Kortmann & Schneider, eds. 2004), or possible discrepancies in language acquisition, special attention is paid to quantitative differences of forms that belong to the common core of various varieties of English (Mukherjee & Gries 2009). In section 4.1, I study the possible norm of reference for Finnish speakers and compare the FIN-CE material with data from Br.E and Am.E. Sections 4.2 and 4.3 take a diachronic perspective and explore to what extent Finnish informants mirror some of the on-going grammatical changes in native varieties of English.
4.1 Morphological variable distinguishing Am.E and Br.E
The first case deals with a simple morphological variable in the indefinite pronouns of personal reference. The indefinites in Present-day English consist of four groups of compound quantifiers and nominals (-one/-body):
| -one |
-body |
everyone |
everybody |
someone |
somebody |
anyone |
anybody |
no one (no-one) |
nobody |
The two nominal variants in the four types are commonly thought to be in free variation. Biber et al. (1999: 351-353), however, show that the -body forms are more common in spoken uses, whereas the -one indefinites are preferred in written registers (see also Svartvik & Lindquist 1997). In addition, Biber et al. (1999: 352) suggest that Am.E contains more -body forms than Br.E, whose speakers prefer -one indefinites, but this is not supported by the FLOB/FROWN results shown in Table 1 below.
The distribution of the two forms in the FIN-CE (Table 1) shows that Finnish speakers prefer the indefinites of -one. Fewer than 20% of the indefinites appear in -body, and the distribution in FIN-CE is statistically highly significant (p < .001). Table 1 also shows the distribution of the two indefinites in the FLOB/FROWN pair, and the variant distribution in the three corpora is nearly equal. Considering that the material in the three corpora consists of written material, this distribution is expected.
Table 1. Distribution of -one and -body indefinites in three corpora.
|
-one |
% |
-body |
% |
Total |
FIN-CE |
170 |
82 |
38 |
18 |
208 |
FLOB |
564 |
76 |
179 |
24 |
743 |
FROWN |
689 |
76 |
217 |
24 |
906 |
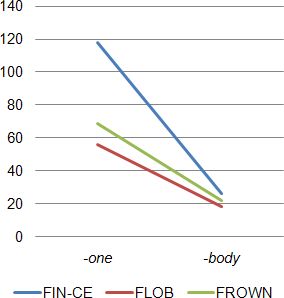
Table 2 and Figure 2 display the normalized frequencies (per 100,000 words) of the indefinites, which should indicate whether the overall frequencies of the indefinites are different in the three datasets.
Table 2. Normalized frequencies of compound indefinites in three corpora.
|
-one |
-body |
Total |
FIN-CE |
118 |
26 |
144 |
FLOB |
56 |
18 |
74 |
FROWN |
69 |
22 |
91 |
The normalized total in the FIN-CE is considerably higher than the frequencies in the native corpora. However, while the frequencies of -body are nearly equal in the three corpora, the 118 instances of -one indefinites per 100,000 words in the FIN-CE are considerably higher than the respective figures in the FLOB/FROWN data. Two explanations might be possible here. A simple one could claim that Finnish informants overuse -one in written texts as a result of possible interference of their L1s, which seems unlikely considering the distribution in Table 1. An alternative explanation is related to text types. The FIN-CE material used here consists of written weblogs, whereas the two native corpora contain material from fifteen text categories, ranging from press to science, adventure and romance. It could be that weblogs as a text type are such that they favor a higher overall concentration of indefinites, which here appear more in -one than in -body, than the range of text types represented in the FLOB/FROWN.
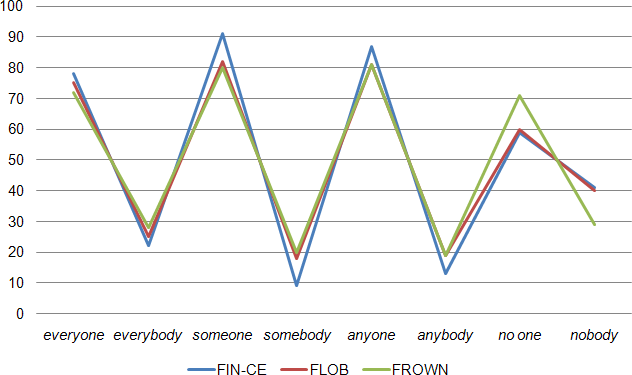
To explore the question further, I will next look into the distribution of the two nominal variants, -one and -body, with the quantifiers. If the working hypothesis of text type as a deciding factor is correct, the distributions between -one and -body with the four determiners should be nearly equal in the three corpora. Table 3 and Figure 3 show the percentages of -one and -body indefinites.
Table 3. Frequencies of the four indefinite pronouns in the three corpora (with absolute frequencies in brackets).
|
FIN-CE |
FLOB |
FROWN |
|
one |
body |
one |
body |
one |
body |
every |
78 (46) |
22 (13) |
75 (114) |
25 (37) |
72 (178) |
28 (70) |
some |
91 (71) |
9 (7) |
82 (199) |
18 (43) |
80 (228) |
20 (57) |
any |
87 (34) |
13 (5) |
81 (155) |
19 (36) |
81 (142) |
19 (33) |
no |
59 (19) |
41 (13) |
60 (96) |
40 (63) |
71 (141) |
29 (57) |
As can be seen, the distribution of -one and -body in the FIN-CE and the FLOB/FROWN differs only with the syntagmatic variants of some and any, in which Finns tend to use more -one forms than what is observed in the two other corpora. The difference with some is statistically significant between the FIN-CE and FROWN (p < .05), but not with FLOB. However, the distribution is highly similar with every in the three corpora. Furthermore, the FIN-CE and FLOB are alike in the negative indefinites so that roughly 40% appear in -body, whereas the proportion is much lower in FROWN.
These results seem not to point to deviations that would be indicative of insufficient language acquisition, but it is rather the case that the differences in Tables 1 and 2 above are illustrative of text type variation, in which FLOB/FROWN show averages of a range of text types, whereas the FIN-CE illustrates the distribution in one type, namely weblogs.
My next evidence concerns possible semantic differences in the nominal variants -one and -body, suggested by Bolinger (1976). In a corpus-based follow-up to Bolinger’s observation, Svartvik and Lindquist (1997) examine collocations of indefinites to determine whether the -one set could be inclined to express closeness and individualization whereas the -body set would be more general in its meanings. Their observation of relativizers that/who, supporting semantic differences, is that the -one set tends to be followed by who more frequently than -body that prefers that relatives.
Table 4 displays the absolute frequencies of two relativizers following the -one and -body indefinites in the FIN-CE. The frequencies are low, but the tendency seems to be clear. It shows that only the -one indefinites are followed by relative clauses, most typically who, illustrated in examples (1)–(4).
Table 4. Relative post-collocates of -one and -body in the FIN-CE.
|
who |
that/which |
one |
13 |
1 |
body |
0 |
0 |
Is an erotic dancer or a silicon princess really a challenging enough target for a powerful politician? Shouldn’t you choose someone who is way more influential than that? (informant W-NB09-19, 2008)
Well I’ve only done jogging, cruising around in da VOLVOe and talking my heart out with my girl Jeannie. Hey, one can’t expect someone who’s always working on saturdays to know how to spend a saturday wisely (W-NB09-40, 2008)
Have a freaking amazing and FUN weekend :) And respect for everyone who dares to brake [sic.] the norm! (W-NB09-33, 2008)
Who is this man? I think he is a criminal who is sentenced to death. He lives the last hours of his life before his death. He is telling his last thoughts to anyone who listens. And that is you. (W-NB09-18, 2009)
The -body indefinites, on the other hand, are not followed with relative clauses, but tend to be used to express less individualized meanings. A good illustration is (5) in which the writer, discussing innovations in IT, first refers to a specific though unknown solution X created by a person, and this reference is made apparent by the use of -one. [8] The focus then shifts to the possibility that the original solution X might not work. This time, the generalized, hypothetical prediction takes place using somebody.
Part of what is done has no real relevance to the problem at hand. The procedures just happen that way as a result of accidents being replicated and accidentally frozen behavior, just because someone happened to originally do it that way. Somebody may finally realize that some parts of procedures are not bringing any value and improve, but that seems to take ages. (W-NB09-23, 2007)
In sum, the distribution of the compound indefinites shows that the Finnish informants in written texts tend to favor the -one forms heavily (over 80%), conforming to the tendency of using -one over -body in written registers in particular. The normalized frequencies show, however, that the FIN-CE contains considerably more -one forms than the two native corpora. The Finnish informants, who use English as non-native resource, seem to be able to distinguish the fine semantic and functional differences between the compounds, as illustrated with the relative post-collocates shown in Table 4 above.
4.2 Non-finite verbal complementation
I will now move on to take a dynamic perspective to variability in contact and study how contact-induced uses in Finland compare with some on-going grammatical changes in native varieties. The results should allow the uncovering of locally characteristic patterns of variability.
Unlike the simple morphological variants in the previous section, the variable here is a more complex one. It deals with verbal complement types in which the variants are to-infinitives or ing-clauses (cf. Rudanko 2006, Egan 2008). Biber et al. (1999: 757-759) point out that the variants, when used with aspectual verbs like begin/start, are interchangeable, forming a variable. They suggest subtle semantic differences in the variants so that speakers might express more hypothetical meanings with to-clauses than with the corresponding gerunds.
Mair’s (2006: 127-130) study of complementation of begin shows how the infinitival complements heavily dominate in Br.E and Am.E. Only about 10% of the complements in Br.E are gerunds, and the proportion in Am.E is slightly higher. A diachronic examination of begin/start complements reveals a small increase in gerundial complements with begin in Am.E in the late 20th century, whereas no changes are attested in Br.E, except in newspaper style. The complements with start, according to Mair (2006: 129-130), occur primarily in gerunds partly because its semantic change to a verb of inception took place in the 18th century when gerunds became more frequent, and because its antonym stop only accepts gerunds. The following illustrations from the Brown quartet of corpora illustrate the variable.
Readers will begin to see the results this week in our… (FROWN B08: 23)
Bypassing the plodding police, he and his friend Scott begin investigating Tom’s fellow faculty… (FROWN C13: 61)
The significant feature of this exciting win was that Badie only really started to make ground after being taken to the outside (FLOB A08: 5)
The 42-year-old fisherman went to help brother Franz when his vessel Lagan Lomea started taking in water eight miles out to sea. (FLOB A36:22)
What follows is a comparison of the frequencies in the FIN-CE with Mair’s (2006: 127-130) figures that illustrate changes in the native varieties and serve to show how the FIN-CE results compare with these changes.
In the Brown family, the verb begin is more frequent than start, but it is extremely rare in the FIN-CE. There are only six instances of begin followed by the two variants, equally split between the gerund (10) and infinitive (11).
It’s another uptempo one - we decided somewhere down the line to start with the faster songs and move on to the slow ones later. We began working on the song a few weeks back (W-NB09-32, 2005)
I just finalized a paper about strategic conversations. Before I began to write, I didn’t have any difficulties to recognize or define a strategic conversation. (W-NB09-35, 2008)
The contexts in the examples are highly similar as the verbal constructions describe an event in question that has truly begun to happen, typically expressed through gerundial structures (Biber et al. 1999: 759).
The informants in the FIN-CE opt for start over begin. Table 5 below displays both the absolute and normalized figures (per 100,000 words) for the two complement forms of start. Both complement variants are in use by Finns, and the gerunds are preferred over the infinitives, illustrated in (12) to (15). The difference is not statistically significant at the 5% level.
So the SIVs had to draw short-term finance from their parent banks as soon as their commercial paper market started to dry up. The same commercial and investment banks that previously parceled loans into (W-NB09-36, 2008)
I never spent much time thinking about the choices I made. I never regreted anything. When you get older, you start to question yourself. Is this really what I want? (W-NB09-33, 2009)
That was not here, so that crucial ingredient was missing and it showed. Because of that I started looking at other things, like how annoying it is that the only word Ranger seems to know is babe (W-NB09-43, 2009)
It’s uncomfortable and slightly scary: you start falling asleep, and your breathing gets shallower and shallower, and then you wake up…Then once you got your oxygen, you start getting sleepier again, and the process is repeated. (W-NB09-39, 2008)
Breaking down the frequencies according to verb tenses shows that nearly all (40/48) instances of start followed by to-infinitives occur with the controlling verb in the simple past or present perfect. The ing-gerundial complements, on the other hand, are more evenly distributed, and the majority (46/69) are in present tense, and the rest in present or past perfect. Moreover, the ing-gerunds tend to occur in contexts in which there is a semi-modal preceding the controlling verb, illustrated in (16). Such contexts, though not extremely frequent (8/69), clearly favor gerundial complements.
Long term, I want to start keeping my bodyfat between 15 and 18% so that I could easily be reasonable competitive at a meet, real or virtual, without having to diet extensively. (W-NB09-37, 2006)
The differences between the frequencies in the FIN-CE and FLOB/FROWN are not statistically significant, but the normalized figures of the complements of start in the FIN-CE are considerably higher than in FLOB/FROWN.
Table 5. Frequencies of the start complements in the three corpora.
| |
Absolute |
Normalized |
| |
to |
ing |
to |
ing |
FIN-CE |
48 |
69 |
33 |
48 |
FLOB |
49 |
59 |
5 |
6 |
FROWN |
59 |
110 |
6 |
11 |
These figures indicate register differences between the weblog material and the text types in FLOB/FROWN. The differences in the normalized figures show how the textual composition of the three corpora is different. The FIN-CE contains new media texts in which the Finnish informants nearly always use start as the verb of inception, not begin, as is illustrated above. The native corpora, however, contain published written texts from a range of text types in which begin is more frequent than start, as reported in Mair (2006: 128; 130).
The results show both similarities and differences between the FIN-CE and the native varieties. The differences are visible in the limited selection of the controlling verb, as the informants clearly choose start but not begin. There are few signs of simplification in the forms of complementation in the FIN-CE, as the complement variant distributions with start in the data do not differ from the native corpora at statistically significant levels. These results provide indications that when variant forms in native varieties of English are undergoing changes, speakers of international Englishes (at least in the material used here) tend to conform to and mirror these changes. It should be pointed out that the evidence at this stage is drawn from a relatively small corpus material, and the results ought to be considered as tendencies.
4.3 For+NP+to-infinitive
The third grammatical structure to be discussed here does not have an explicit variable, but instead consists of a single post-predicate complement structure. It consists of the preposition for plus a noun phrase subject that is followed by an infinitival clause, illustrated in (17) below.
In this technological age, there is a tendency for people to forget that humans are mammals (F-LOB E33: 7)
Similarly to the topic in section 4.2, the use of the for+NP+to-infinitive is closely related to the increase of nonfinite clauses during the last few centuries (Denison 1998: 256-257). It has been amply discussed in previous literature (Jespersen 1909[1965]: 299-315, Visser 1972: 957-958, Biber et al. 1999: 698ff).
In his discussion on the diachronic development of the for-structure, Mair (2006) demonstrates the functional spread of this construction in Present-day English and shows how it is well-represented in all subordinate classes. Some of its most remarkable developments in the twentieth century are its uses as objects to transitive verbs and as complements to nouns, as in (17). Using the OED and the Brown quartet of corpora as his material, Mair (2006: 124-5) illustrates how its frequencies have differed considerably during the last three centuries. Its frequencies in native varieties (c. 300 per million words) are not results of a linear increase, but contain considerable fluctuation. Overall the structure is slightly more frequent in Br.E than in Am.E.
The questions answered here include to what extent the Finnish informants in the FIN-CE have adopted the construction in their written uses (i.e. whether they mirror this increase in nonfinite clauses), and what, if any, the quantitative differences are between the FIN-CE and FLOB/FROWN. The construction is more complex than the simple morphological variable discussed in section 4.1 or the verbal complementation with two variants considered in section 4.2.
Table 6 shows the absolute and normalized figures (per 100,000 words) of the for+NP+to-infinitive-structure in the FIN-CE and compares them with Mair’s (2006: 124) results from the FLOB/FROWN.
Table 6. Frequencies for the for+NP+to-infinitive in the three corpora.
|
Absolute |
Normalized |
FIN-CE |
61 |
42 |
FLOB |
334 |
33 |
FROWN |
275 |
28 |
This illustrates that the Finnish informants use the construction in slightly higher frequencies than native writers. The figures are statistically significant between FIN-CE/FROWN (p < .005), but not between FIN-CE/FLOB, suggesting some differences in the samples drawn from non-native and native Englishes. The following examples illustrate the uses of this grammatical construction in the FIN-CE.
…all those hard times made us even stronger and now that we’ve taken our time and waited for the inspiration to take over again (W-NB09-33, 2009)
Some have fled to Warhammer Online, some to Age of Conan, some to Guild Wars, some to Perfect World, and now people are waiting for Aion to come out so they can jump on that wagon. (W-NB09-42, 2009)
This is just critical for me to enjoy an online game. My time has to go toward something (W-NB09-30, 2008)
In (18) and (19), the construction functions as an object in the complex clause, which is the most frequent function of the for-structure in the FIN-CE, whereas in (20) it is used as a complement to an adjective, a much rarer use in the corpus. In Mair’s (2006: 124) material, the most common uses in both Br.E and Am.E varieties appear in extraposed subjects, noun complements, direct objects, and adverbials.
The second most frequent uses in the FIN-CE are those in which the structure occurs in the object function. These uses often take place in contexts in which the for+NP+to-infinitive appears with prepositional verbs, such as hope in (21), or speech act verbs, for example ask, in (22).
So, my plans for the summer that’s just starting? I’ll be working and fixing that home of mine little by little and in the meantime I’ll keep on working and hoping for my workout plan to start working. (W-NB09-40, 2009)
What can one possibly say other than oooh la-la!!! When she approached me in order to ask for my opinion on how to accessorize her evening outfit, my imagination immediately took off. (W-NB09-08, 2009)
The third most frequent uses in the FIN-CE occur as adverbial functions, illustrated in (23)–(24). [9]
Walking up a hill along a bendy road in the middle of a forest not far from home. There were no street lights, just snow reflecting enough for me to see where I was going. (W-NB09-19, 2008)
EP is practical place to locate some second class politicians for retirement or out to not make any mess in national policy. (W-NB09-12, 2009)
The for+NP+to-infinitive structure also functions as an extraposed subject in the FIN-CE, illustrated in (25)–(26).
Don’t people do this?? I’m sorry but it’s hard for me to buy into the idea that people would be so dumb as not to get such fundamental issues on their own. (W-NB09-03, 2009)
Design, especially in its more strategic forms, is supposed to make things more effective and efficient e.g. in the use of materials by establishing more effective processes and reducing the need for raw materials. Is it possible for the designer to justify a higher price for a product (W-NB09-21, 2009)
These structures also occur as noun complements, illustrated in (27) below. These functions closely resemble the functions of a relative clause, (28)–(29).
Furthermore, large corporations that usually dominate the markets cut down on investments in order to cut down on expenses to keep the companies solvent and this gives excellent possibilities for startups to take market share. (W-NB09-09, 2009)
Valerna, from the city of angels, dropped 3 new tracks for us to listen to and enjoy. It’s electro, but get a small taste of hip-hop at times. And a small odour of dance. (W-NB09-02, 2009)
So, I offered to lend her a set of jewellery for her to wear at the party. I would have liked nothing better than to be able to go there myself but since that was out of the question, I thought it would be lovely if at least my jewellery could attend! (W-NB09-08, 2009)
Similarly, in (29), the indirect object in the main clause is co-referential with the notional subject in the non-finite for-clause that functions as a relative is paraphrased as ‘jewellery that she could wear at the party’.
There is one functional category that is found only once in the FIN-CE material. It is the for-structure used as a subject complement, as seen in (30) in which the clausal SV seems to be ellipted to avoid repetition.
A building is not only walls, a floor and a roof… a building is for the future, for people to spend time together, for laughter, for tears… we carry on our shoulders the responsibility to build…(W-NB09-05, 2008)
Those for+NP+to-infinitive structures that are found by Mair (2006: 124) but not present in the FIN-CE include its uses as subject clauses, and as extraposed object in complex transitive constructions.
The results presented here make it clear that the for-structure is in use in the international English material of the FIN-CE, and these results support the conclusion in section 4.2 above that speakers of international English mirror these current grammatical changes.
5. Conclusions
This article set out by suggesting that the on-going growth of international Englishes might require English corpus linguistics in the early 21st century to rethink its established division of corpora. I suggested above that there is a need to reconsider the existing stock of data used in the field, and that the rise of international Englishes is a change that should be taken into account by those working in corpus-based descriptions of English. It is essential that new corpora, which match the global spread of the language, are developed. This means making use of new material sources and finding solutions in compiling corpora that represent the newest forms of English today. These new data sources can then be used to describe grammatical variability in international Englishes.
This article has presented a corpus currently being compiled at the Research Unit for Variation, Contacts, and Change in English (VARIENG), a joint research venture of the Universities of Helsinki and Jyväskylä. The Corpus of English in Finland (FIN-CE) adds a new resource to the large set of English corpora available today. It represents the uses of English in Finland, where English has been used as a foreign language but which is making a transition towards second language uses in many contexts. This transition is a result of increased contacts between the speakers of domestic languages in the country and English, and it is clearly reflected in the results of a national survey on the uses of and functions of English in Finland, carried out at VARIENG (Leppänen et al. 2009, 2011). The survey shows there to be a considerable proportion of the population who resort to English as a regular linguistic resource. Similarly, there exist a number of speech events that take place in English in this traditionally EFL nation, and the FIN-CE is aimed at collecting a representative sample of these contact-induced uses of English.
The three case studies presented describe quantitative differences of forms and structures between the English used by present-day Finns and the standardized varieties of British and American English in the Brown family of corpora. These investigations focus on variability in some of the core features of English grammar today. The results were heterogeneous, showing that speakers of international Englishes occasionally simplified structures but were occasionally quantitatively more advanced in some on-going grammatical changes of English.
Notes
[1] My overview includes full papers, pre-conference workshops, work-in-progress reports, and posters. It is solely based on the book of abstracts and is intended to be suggestive, as there are corpora available that were not used as material at ICAME30 (cf. the corpus of CNN transcripts in Hoffmann 2007).
[2] The respondents were picked by stratified sampling in the Statistics Finland database of the 15–79-year old citizens of the country.
[3] The actual numbers of speakers of English in India are naturally much higher than in Finland.
[4] The largest linguistic minorities are speakers of Russian, Estonian, English, Somali, Sami languages, and Arabic in that order (Statistics Finland 2009).
[5] The corresponding figures for Swedish are 92%, German 12%, French 6%, Russian c. 1%.
[6] The background information form, in addition to a set of standard socio-demographic questions, asks the informants to grant permission for their material to be included in a corpus and used for research purposes. Contacting the writers takes place after the material had been collected.
[7] One of the blogs had two writers, each contributing identifiable entries.
[8] For more on the semantics of the compound indefinite pronouns, see Laitinen (2007: 128-132).
[9] Many of the instances are difficult to categorize, as alternative readings exist, so that (23) could also function as adjective complement, and (24) as a noun complement (cf. similar questions discussed by Mair 2006: 121).
Electronic references
BNC = British National Corpus. http://www.natcorp.ox.ac.uk/.
The Brown corpora:
FROWN = The Freiburg-Brown corpus of American English. http://www.helsinki.fi/varieng/CoRD/corpora/FROWN/index.html.
FLOB = The Freiburg–LOB Corpus of British English. http://www.helsinki.fi/varieng/CoRD/corpora/FLOB/index.html.
ELFA = English as a Lingua Franca in Academic Settings. http://www.helsinki.fi/englanti/elfa/.
ICE-GB = International Corpus of English – the British component. http://www.ucl.ac.uk/english-usage/projects/ice-gb/.
ICLE = International Corpus of Learner English. http://www.uclouvain.be/en-cecl-icle.html.
VOICE = Vienna–Oxford International Corpus of English. http://www.univie.ac.at/voice/.
References
Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad & Edward Finegan. 1999. Longman Grammar of Spoken and Written English. London: Longman.
Bolinger, Dwight. 1976. “The in-group: one and its compounds”. The Second Lacus Forum, 1975, ed. by Peter A. Reich, 229-237. Columbia: Hornbeam Press.
Bruthiaux, Paul. 2003. “Squaring the circles: Issues in modeling English worldwide”. International Journal of Applied Linguistics 13(2): 159-178.
Crystal, David. 2006. “English worldwide”. A History of the English Language, ed. by Richard Hogg & David Denison, 420-439. Cambridge: Cambridge University Press.
Denison, David. 1998. “Syntax”. The Cambridge History of the English Language, Vol. 4, 1776–1997, ed. by Suzanne Romaine, 92-329. Cambridge: Cambridge University Press.
Egan, Thomas. 2008. Non-Finite Complementation: A Usage-Based Study of Infinitive and -ing Clauses in English. Amsterdam and New York: Rodopi.
Graddol, David 2006. English Next. London: The British Council.
Granger Sylviane. 2003. “The International Corpus of Learner English: A new resource for foreign language learning and teaching and second language acquisition research”. TESOL Quarterly 37(3): 538-546.
Hoffmann, Sebastian. 2007. “From webpage to mega-corpus: The CNN transcripts”. Corpus Linguistics and the Web, ed. by Marianne Hundt, Nadja Nesselhauf & Carolin Biewer, 69-86. Amsterdam and New York: Rodopi.
Jespersen, Otto. 1909[1965]. A Modern English Grammar on Historical Principles. Part V. Syntax (Fourth Volume). London: George Allen & Unwin.
Kortmann, Bernd & Edgar W. Schneider, eds. 2004. A Handbook of Varieties of English. Volume 2: Morphology and Syntax. Berlin: Mouton de Gruyter.
Laitinen, Mikko. 2007. Agreement Patterns in English. Diachronic Corpus Studies on Common-Number Pronouns. Helsinki: Société Néophilologique.
Laitinen, Mikko. 2010. “Describing ‘orderly differentiation’: Compiling the Corpus of English in Finland. English Today 26(1): 26-33.
Leech, Geoffrey. 2003. “Modality on the move: The English modal auxiliaries 1961–1992”. Modality in Contemporary English, ed. by Roberta Facchinetti, Manfred Krug & Frank Palmer, 223-240. Berlin: Mouton.
Leech, Geoffrey, Marianne Hundt, Christian Mair & Nicholas Smith. 2009. Change in Contemporary English. A Grammatical Study. (Studies in English Language). Cambridge: Cambridge University Press.
Leppänen, Sirpa & Tarja Nikula. 2007. “Diverse uses of English in Finnish Society: Discourse-pragmatic insights into media, educational and business contexts”. Multilingua 26, 333-380.
Leppänen, Sirpa, Anne Pitkänen-Huhta, Tarja Nikula, Samu Kytölä, Timo Törmäkangas, Kari Nissinen, Leila Kääntä, Tiina Virkkula, Mikko Laitinen, Päivi Pahta, Heidi Koskela, Salla Lähdesmäki & Henna Jousmäki. 2009. Suomalaisten asenteet englantia kohtaan: Kansallisen kyselytutkimuksen tulokset. [The Attitudes of Finns towards English. Results from a National Survey.] Jyväskylä: Studies in the Humanities.
Leppänen, Sirpa, Anne Pitkänen-Huhta, Tarja Nikula, Samu Kytölä, Timo Törmäkangas, Kari Nissinen, Leila Kääntä, Tiina Räisänen, Mikko Laitinen, Päivi Pahta, Heidi Koskela, Salla Lähdesmäki & Henna Jousmäki. 2011. National Survey on the English Language in Finland: Uses, meanings and attitudes. (= Studies in Variation, Contacts and Change in English, 5). http://www.helsinki.fi/varieng/series/volumes/05/
Louhiala-Salminen, Leena, Mirjaliisa Charles & Anne Kankaanranta. 2005. “English as a lingua franca in Nordic corporate mergers: Two case companies”. English for Specific Purposes 24: 401-421.
Mair, Christian. 2006. Twentieth Century English. History, Variation and Standardization. Cambridge: Cambridge University Press.
Mair, Christian & Geoffrey Leech. “2006. Current change in English syntax”. The Handbook of English Linguistics, ed. by Bas Aarts & April McMahon, 318-342. Oxford: Blackwell.
Mauranen, A. 2003. “Academic English as Lingua Franca – a corpus approach”. TESOL Quarterly 37: 513-27.
McArthur, Tom. 2002. The Oxford Guide to World English. Oxford: Oxford University Press.
Mesthrie, Rajend & Rakesh M. Bhatt. 2008. World Englishes: The Study of New Linguistic Varieties. Cambridge: Cambridge University Press.
Mukherjee, Joybrato & Stefan Th. Gries. 2009. “Collostructional nativisation in New Englishes. Verb-construction association in the International Corpus of English”. English World-Wide 30(1): 27-51.
Patrick, Peter L. 2004. “The speech community”. The Handbook of Language Variation and Change, ed. by Jack (J.K.) Chambers, Peter Trudgill & Natalie Schilling-Estes, 573-597. London: Blackwell.
Ringbom, Håkan. 2007. Cross-linguistic Similarity in Foreign Language Learning. (= Second Language Acquisition, 21). Clevedon: Multilingual Matters.
Rudanko, Juhani. 2006. “Watching English grammar change: A case study on complement selection in British and American English”. English Language and Linguistics 10(1): 31-48.
Schneider, Edgar W. 2003. “The dynamics of new Englishes: From identity construction to dialect birth”. Language 79(2): 232-281.
Schneider, Edgar. 2007. Postcolonial English: Varieties around the World. Cambridge: Cambridge University Press.
Seidlhofer, Barbara. 2005. “English as a Lingua Franca”. ELT Journal 59: 339-341.
Statistics Finland 2009. 25 Nov 2009. http://www.stat.fi/til/ava/2008/02/ava_2008_02_2009-05-25_tie_002_en.html.
Svartvik, Jan & Hans Lindquist. 1997. “One and body language”. From Ælfric to the New York Times. Studies in English Corpus Linguistics, ed. by Udo Fries, Viviane Müller & Peter Schneider, 11-20. Amsterdam/Atlanta: Rodopi.
Taavitsainen, Irma & Päivi Pahta. 2003. “English in Finland: Globalisation, language awareness and questions of identity”. English Today 19(4): 3-15.
Taavitsainen, Irma & Päivi Pahta. 2008. “From global language use to local meanings: English in Finnish public discourse”. English Today 24(3): 25-38.
Traugott, Elizabeth. 2008. “The state of English language studies: A linguistic perspective”. English Now. Selected Papers from the 20th IAUPE Conference in Lund 2007, Marianne Thormählen, 199-225. Lund: Lund University.
Trudgill, Peter. 2002. Sociolinguistic Variation and Change. Edinburgh: Edinburgh University Press.
Virkkula, Tiina. 2008. “Työntekijöiden kokemuksia englannista yritysmaailman yhteisenä kielenä [Professionals’ views on English as the shared language in business world]”. Kolmas kotimainen. Lähikuvia englannin käytöstä Suomessa [The third domestic language. Case studies on the use of English in Finland.], ed. by Sirpa Leppänen, Tarja Nikula & Leila Kääntä, 382-420. Helsinki: SKS.
Visser, Fredericus Th. 1972. An Historical Syntax of the English Language. Part II. Syntactical Units with one Verb. Leiden: E.J. Brill.
|