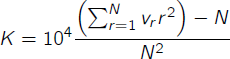This paper explores verb-attached PPs as adjuncts or parts of verbal frames with the help of a large-scale valency-database generated from the output of a dependency parser. Our investigation is based on more than 240 million words of American and British English. We combine measures of surprise with measures of lexical diversity in order to study fixedness of various types. We also use these measures to explore the cline from verbal complement to adjunct and test statistical measures of surprise as a means of distinguishing complements from adjuncts. We calculate measures of surprise and variability for verb-preposition, verb-object-PP and other combinations in order to identify and locate verbal idioms.
1. Introduction
In this paper we present a parser based analysis of verb-attached prepositional phrases. We investigate fixedness and idiomaticity of verb-attached PP structures and explore the cline from verbal idioms to verbal frames to adverbials based on measures of association and measures of variation. Specifically, we do this by observing the combinations of lexical items found in the verb-attached prepositional phrase structures located in the syntactic analysis produced by the parser.
Syntactically annotated data offers the unique possibility of selecting syntactic structures in abstraction from lexis. The use of large-scale automatic annotation with syntactic information has only recently become possible. Van Noord and Bouma (2009) find that:
Knowledge-based parsers are now accurate, fast and robust enough to be used to obtain syntactic annotations for very large corpora fully automatically. We argued that such parsed corpora are an interesting new resource for linguists. (van Noord & Bouma 2009: 37)
In Lehmann and Schneider (2009), we have investigated subject-verb-object structures. However, prepositional phrase attachment is a more problematic area in terms of parser performance. In addition to presenting new data on verb-attached prepositional phrases, we also test fully automatically parsed data for its potential in an area where parser performance must be regarded as problematic.
In section 2 we discuss the measures of surprise and variability used for ranking lexical types. In section 3 we introduce the data analysed and discuss the process of annotation. Section 4 documents the extraction of verb-attached PPs from the annotated material. Section 5 presents the results achieved by the application of the measures of surprise and variability introduced in section 2 to the structures extracted in section 4. In section 6 we discuss our results and our methodological approach.
2. Theoretical background
Collocations and idiomaticity are prime examples of areas of gradience and of grammar and lexis in co-operation. The concepts of collocation, fixedness, idiomaticity and non-compositionality are often described as closely related. For example, Fernando (1996) states:
[W]hile habitual co-occurrence produces idiomatic expressions, both canonical and non-canonical, only those expressions which become conventionally fixed in a specific order and lexical form, or have a restricted set of variants, acquire the status of idioms. (Fernando 1996: 31)
In this view, idioms are a subset of collocation and the touchstone for idiomaticity is typically non-compositionality (see e.g. Fernando & Flavell 1981: 17). Non-compositionality is difficult to measure in an automatic, corpus-based approach, but non-compositionality has a strong impact on fixedness in the following two ways: First, on the paradigmatic axis, non-compositional expressions have very limited lexical choice: the expression kick the bucket cannot be rephrased using synonyms, e.g. kick the bin or hit the bucket. Limited lexical choice often leads to a strong association between the elements forming an idiom, which can be easily detected by collocation measures (which we treat in section 2.1). Second, on the syntagmatic axis, syntactic variability is restricted. Idiomatic expressions have high fixedness (which we treat in section 2.2). The phrase kick a bucket is as unusual as kick the large bucket, only very few modifications such as kick the proverbial bucket are usually found in large text collections. The close connection between compositionality and fixedness has e.g. been demonstrated by Gibbs and Nayak (1989) who have shown that native speakers judge non-compositional idioms as less syntactically flexible than partly compositional idioms. We therefore use fixedness and co-occurrence measures as proxies to non-compositionality.
Non-compositionality, which we discuss section 2.1, and fixedness, which we discuss in section 2.2, are often used as the key features for describing idiomaticity, see e.g. Wulff (2008). Modifiability, i.e. the opposite of fixedness, expresses how far the idiom components can be modified by adjectives, determiners etc. Syntactic flexibility, finally, expresses the availability of syntactic alternation operations. Our parser-based approach also offers interesting possibilities for the investigation of syntactic flexibility. Left-attached PPs offer a possibility for identifying PPs attached as adjuncts. Moreover, the active-passive alternation is a relevant phenomenon. Passive constructions will also result in a majority of PPs attached as adjuncts – with the exception of ditransitive constructions. In our present approach, however, we mainly focus on non-compositionality and modifiability.
In section 2.3, we motivate the association measure and the statistical significance test that we use. In section 2.4 we present our parser-based approach.
2.1 Non-compositionality and collocation
Non-compositionality is difficult to measure with corpus-based approaches. According to Wulff (2008), there are two approaches: substitution-based approaches and similarity-based approaches. Substitution-based approaches measure compositionality by means of substitutability: given a potential collocation containing the word W, how likely is it that the word W′ which is a synonym of W, can appear instead of W? Large synonym dictionaries can be used to generate and test W′. In contrast, similarity-based approaches measure associations between the words in a potential collocation, using association measures known from collocation detection. Wulff (2008) considers three recent substitution-based methods (Lin 1999, Schone & Jurafsky 2001, McCarthy et al. 2003) and one ‘classical’ similarity-based method (Berry-Rogghe 1974) for her research on idiom detection. Although the substitution-based method intuitively seems like a better proxy to non-compositionality than the similarity-based method, Wulff (2008) finds the similarity-based approach by Berry-Rogghe’s R (1974) more suitable for the task. Similarity-based approaches measure collocation strengths. For our investigation, we use Observed over Expected (O/E) as collocation measure, which we discuss in section 2.3. While we do not investigate non-compositionality in our investigation, it is important to motivate our use of collocation strength measures in order to detect non-compositional collocations.
2.2 Modifiability, TTR and Yule’s K
Modifiability expresses how far the idiom components can be modified by adjectives, determiners etc. Completely fixed collocations, in which no participant is ever modified, or always modified by the same word, are extremely rare (see e.g. Barlow 2000). We thus need a measure that expresses the lexical variation among the modifiers, including null-modifiers as tokens of absent modification. We have split modification into nominal modification (adjectives, non-head nouns) and determiner-modification (articles).
Looking at triples like take into consideration, we can take stock of all the determiners and modifiers that accompany the description noun consideration. A frequently considered possibility for measuring the variability of such slots is the ratio of types per tokens. Type-token ratio (TTR) is a popular measure for expressing lexical variation. Low and high TTRs imply a low respectively high level of lexical diversity.
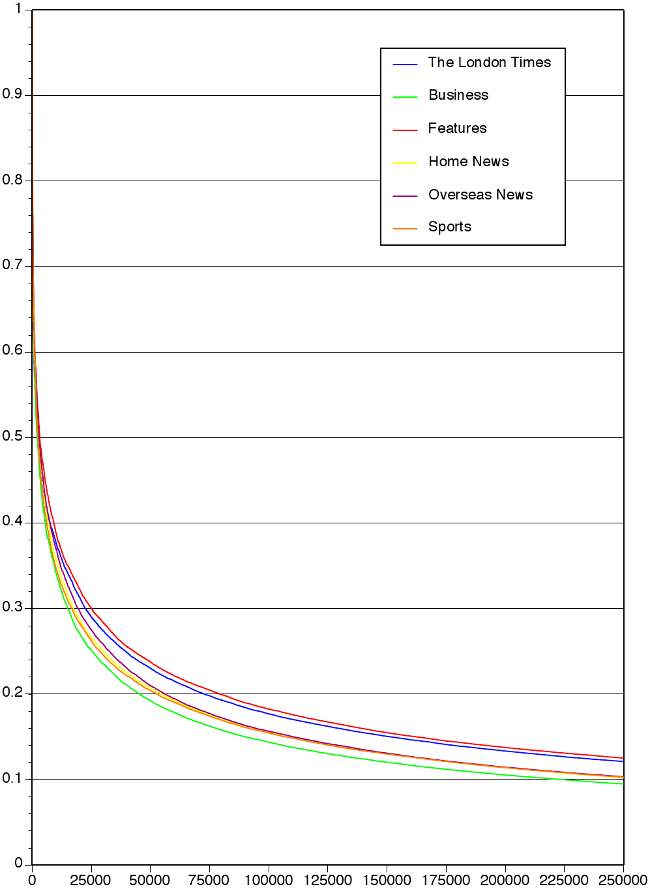
Although TTR is a useful measure for variability on texts of equal length, it has a major disadvantage: it is dependent on the number of tokens observed: any text of 5 words will almost certainly have TTR = 1, any text of 1000 words almost certainly a TTR that is considerably lower. We expect a curve that, in relation to text length, increasingly flattens out but never stops falling slightly, even for extremely large texts. Figure 1 shows TTRs in The [London] Times Corpus for the whole paper and its sub-sections plotted from word 1 to word 250,000. We can observe a steep fall from the first tokens observed. It is thus obvious that comparing TTRs at different token counts is not possible. Such a comparison, however, is certainly desirable, given the difference in lexical diversity observable between the different sections.
Figure 1. Type-token ratios in The [London] Times.
It would thus be necessary to compare texts of equal length or lists containing the same number of tokens. This is not always possible, and if one does so, one discards much information and thus increases data sparseness to the level of the common denominator. When comparing the TTR of different texts, this is the length of the shortest text in the comparison. There are many applications in which the effect is even more serious. Let us look at the example of an application investigating the contexts of word-word combinations, where the TTR of the context words that are found can serve as a variability measure (we will in fact do so in section 5). The rarest word-word combinations in such a comparison are hapax legomena, i.e. word-word combinations that occur only once. Discarding all but one occurrence for each combination would be the common denominator, but at the same time this would entail giving up measuring frequencies of occurrence and variation, which would precisely be the purpose of the exercise. Using a more pragmatic approach, one could set a threshold and use this as denominator (e.g. only keep 10 occurrences, and only of word-word combinations that occur at least 10 times), but if one sets a high threshold all relatively rare combinations are completely discarded, and if one sets a low threshold only a small random sample of the frequently occurring combinations can be considered.
However, there are size-independent measures of variability, for example Yule’s K (Yule 1944). The theoretical background is mathematically complex, Malvern et. al (2004) offer a good introduction. Yule’s K is formulated as follows:
where vr is the number of types which occur r times in a text of length N. K yields values between 0 and 10,000 (or between 0 and 1 if the initial multiplication by 104 is omitted), 0 for maximal lexical diversity (i.e. each type occurs only once) and 10,000 for no diversity at all (i.e. a long text, only consisting of one repeated type). We have opted to use Yule’s K as a measure of diversity because of its proven independence on token counts.
2.3 O/E and statistical measures
We use O/E as a collocation measure. O/E expresses the frequency of an observed event O divided by its expected frequency E. E calculates a homogenous distribution of words, for example in our investigation of VPN triplets, independent probabilities of drawing V from an urn containing all the verbs, P from an urn containing all the prepositions, and N from an urn containing all the nouns that we have observed in VPN structures. In other words, E simulates a situation of completely random lexical combinations in the observed verb- preposition-description noun syntagma. O/E expresses how many times more frequent a VPN triplet occurs than in random lexical combination, and thus serves as an association measure. Associations may of course both be semantic (selectional restrictions) or idiomatic in nature.
Our choice of O/E is based on the following reasons. First, it has a clear probabilistic definition and is directly related to information-theoretic measures of surprise such as mutual information. Second, it is a measure of surprise, which means that also rare, very sparse collocations can be detected. In window-based approaches (see section 4), the vast majority of the top-ranked O/E entries are garbage. Approaches based on parsed corpora provide considerably cleaner data (see e.g. Seretan & Wehrli 2006), as we discuss in section 2.4. Third, it is a simple and straightforward probabilistic measure that is easy to interpret.
As a probabilistic measure of surprise, O/E does not express statistical significance. As such it has no bias towards frequent items. In contrast, it will inevitably result in high values for rare combinations of rare items. In order to eliminate random noise introduced by tagging, chunking and parsing errors, we employ a significance test. We measure the statistical significance of observations with the t-score test. Of course, statistical significance can be tested with a large range of significance tests: Berry-Rogghe (1974) used the z-score, Wulff (2008) uses the Fisher Yates exact test. We use the t-score. The t-score test is frequently used. Evert (2009) describes it as a version of the z-score that heuristically corrects its disadvantage.
2.4 Large-scale syntactic parsing
Most approaches to collocations and fixedness in language are based on the use of observation windows or of regular expression patterns applied to large corpora with flat, i.e. non-hierarchical, part-of-speech annotation. However, syntactic analysis has been recognised as a prerequisite for accurately describing the syntax-lexis interface:
Ideally, in order to identify lexical relations in a corpus one would need to first parse it to verify that the words are used in a single phrase structure. However, in practice, free-style texts contain a great deal of nonstandard features over which automatic parsers would fail. This fact is being seriously challenged by current research (…), and might not be true in the near future” (Smadja 1993, 151)
Although parsing technology has progressed since, the currently available corpora which are manually analysed for syntactic structure, for example ICE-GB (Nelson et al. 2002) and the Penn Treebank (Marcus et al. 1993), are too small for infrequent word-word interactions, and automatic parsers have, until recently, not been robust enough to analyse large corpora. This partly explains why most approaches have been based on observation windows or part-of-speech sequences applied to corpora without hierarchical syntactic annotation. We give an evaluation of Pro3Gres, the parser that we use, in section 3.
To summarise, we have explained in section 2.1 why collocation and fixedness is a good proxy to non-compositionality. We have motivated our variability measure Yule’s K in section 2.2, and our use of O/E collocation measure and the t-score significance test in section 2.3. In section 2.4, we have motivated our use of a parser.
3. Data and annotation
The automatic detection of collocations requires large amounts of text. In the case of our investigation this requirement is even more stringent. Classic collocation analysis observes two elements, a node and a collocate, within a pre-defined span of observation. Our approach restricts observations syntactically, which results in a sub-set of all the verb tokens, namely those for which the parser reports that they have a PP attached. In addition we investigate patterns of three or four elements, which requires considerably more data than classic approaches involving only node and collocate, because tokens are triplets or quadruplets in our data, not only doublets as in node-collocate approaches.
For the present study we chose the written section of the BNC World Edition (90 million words), The Boston Globe (BOGL, 37,450,270 words) and The [London] Times (TLND, 36,545,704 words). This selection may seem somewhat eclectic. The most stringent criterion for the selection is size. Corpora containing fewer than 15 million words turned out to be too small for our purpose, as we will see in section 6. BOGL and TLND consist of the editorial content published in 1999. The Newspapers were chosen in the hope of finding differences between American and British English. Although the newspapers also contain what we might tentatively call international newspaper English, there is a large proportion of the material produced by regional writers that can be attributed to the regional varieties. A comparison between the BNC and a 90-million-words American National Corpus would certainly have been preferable. However, such a corpus is not available yet.
The three corpora were tagged for word-class, chunked and parsed with Pro3Gres, a dependency parser (Schneider 2008). See Lehmann and Schneider (2009) for a more detailed description of the annotation process.
Window-based approaches inevitably pick up a high number of irrelevant co-occurrences. They operate n words to the right and/or to the left of a selected node and do not take into account syntactic structures. Parsing methods incur fewer errors than surface-based approaches, but they are not free from errors. We now provide a short evaluation of the parser, showing the rate of remaining errors that one needs to expect. We present four partial evaluations of the parser on written text material: First, we give an evaluation on the standard 500 sentence evaluation corpus GREVAL (Carroll et al. 2003). Second, we give an evaluation of its performance on 100 random sentences from the written part of the BNC. Third, we give an evaluation of American newspaper English, using 100 random sentences from the LA Times. Performance of the Pro3Gres parser on selected relations – subject, object, PP-attachment to verb and PP-attachment to noun is given in Table 1. The last evaluation is provided for the verb-PP-attachment relation only, which is at the core of our application in this article.
Table 1. Performance of the Pro3Gres parser.
Subject
Object
Noun-PP
Verb-PP
Performance on GREVAL
Precision
92%
89%
74%
72%
Recall
81%
84%
66%
84%
Performance on BNC
Precision
86%
87%
89%
Recall
83%
88%
70%
Performance on LA Times
Precision
80%
Recall
74%
For more detailed evaluations, including a complete mapping to the relation set used in GREVAL and a comparison to several other syntactic parsers, refer to Schneider (2008). An independent evaluation mapping Pro3Gres output to the Stanford dependency scheme has been conducted in Haverinen et al. (2008), confirming that the parser reaches state-of-the-art performance.
Parsing performance on PP-attachment is considerably lower than on subject and object. This is partly due to the fact that inter-annotator agreement is lower and ambiguity is much higher. Collins and Brooks (1995) report that inter-annotator agreement for a verb/noun attachment ambiguous PP is 93.2%, if the decision is based on only the potential attachment site (verb/noun), the preposition and the description noun – which is all the information that the parser has to take the decision – inter-annotator agreement is 88.2%. The figure of 88.2% thus marks the upper bound: no automatic procedure can ever be expected to perform better. Attachment ambiguity is particularly high if several PPs form a sequence.
Due to the difficulty of the PP-attachment disambiguation task, we opted to use an underspecified representation: the parser only decides on the attachment. The question whether the attached PP is a complement or an adjunct, and the question if the word introducing the PP is a preposition or a verbal particle is left underspecified. This approach has two advantages: first, parser performance remains relatively high, as only one decision (i.e. which attachment) needs to be taken, and second, the area of gradience between complement and adjunct can be explored. As this is an area of gradience, postulating prototype categories and having to discuss innumerable borderline cases may be a less promising approach than exploring the gradience based on a corpus-driven method.
4. Retrieval
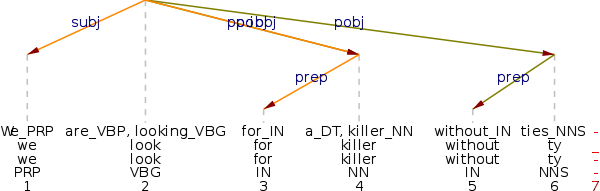
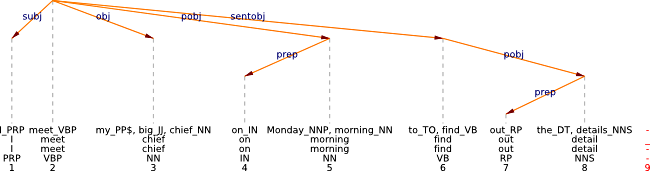
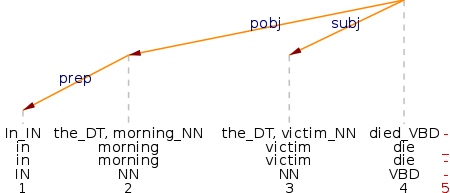
In our approach we use syntactic annotation for selecting verb-attached prepositional phrases, as we have discussed in section 2.4. The retrieval strategy selects prepositional verbs, as in (1), phrasal verbs as in (2) and adverbials as in (3). While (1)–(3) show right-attached PPs, we observe an instance of a left attached PP in (4). The pro3gres parser treats the head of the noun phrase found in the PP as head of the whole PP with the preposition as a dependent. Henceforth we refer to the head of the noun phrase in the attached prepositional phrase with the term description noun.
(1)
BNC:K95:3448
(2)
(3)
(4)
BNC:HXE:1888
The retrieval process reports a list of verb-PP combination tokens. In the case of (1) to (4), it extracts the triplets look for killer in (1), give up work in (2), meet on morning (3) and die in morning (4). The process also reports look without tie in (1), since without tie is erroneously attached to the verb, and it correctly omits the PP on his farm in (2), being analyzed as a post modification of work. Note that the basic unit of observation is the verb-attached PP token and not the individual verb. As a consequence the same verb will be included as many times as an attached PP is present.
Due to the enormous size of the result sets and the obvious structural heterogeneity we decided to treat verb-PPs with direct objects separately from those without. This results in two data sets. The first set contains verb-preposition-description noun triplets (1,129,643 tokens), henceforth referred to as VPN. The second set contains verb-object-preposition-description noun 4-tuples (987,276 tokens), henceforth referred to as VOPN. These two databases with over 2 million verb-PP tokens form the basis of our investigation.
5. Results
In this section, we present the results of running collocation calculations on the VPN and VOPN databases. Taking the VPN and VOPN lists of tokens as a basis, our algorithm produces a list of types ranked according to O/E, our measure of surprise, and filtered based on the t-score and Yule’s K. Types are based on the lemma, i.e. the base-form of the verb. As mentioned above, we also exclude left-attached PPs and passive constructions from our analysis.
We first present data from the written part of the BNC. In section 5.1 we focus on VPN triplets, i.e. the syntactic configuration of a verb attaching a PP, without a direct object. In section 5.2 we focus on VOPN 4-tuples, i.e. the syntactic configuration of a verb attaching a direct object and a PP. In section 5.3 we also present data from the other corpora to complement the BNC data.
5.1 VPN triplets in the written BNC
The written part of the BNC contains 90 million words. Our dependency-based retrieval strategy reports 5,156,281 VPN triple tokens resulting in 1,129,643 VPN triple types. Compared to all combinations of verbs, prepositions, and description nouns observed in verb-attached PP structures, only one in a million possible VPN combinations actually occurs. The distribution is highly Zipfian: the most frequent triple occurs over 2,000 times, while 896,963 types (about 80%) are hapax legomena, i.e. they occur only once.
The most frequent VPN triplets are listed in Table 2.
Table 2. VPN triplets ordered by frequency f(VPN) in BNC written. (Full table.)
The majority of the highly frequent triplets are not collocations. The top of the list is dominated by PPs attached to the verb be, the most frequent verb. Attached PPs include lexicalized expressions like of course. However, we also observe frames like think about sth and fairly fixed combinations like take into account or fall in love. Raw frequency is not generally a useful measure of surprise.
In Table 3 we can observe the same VPN triplets ordered by the collocation measure O/E. We have set a high t-score threshold in order to suppress rare, statistically insignificant co-occurrences.
Table 3. VPN triplets ordered by O/E filtered by t-score in BNC-W written. (Full table.)
The top 1,000 or so list entries mainly contain strong collocations, selectional restrictions and a few systematic tagging, chunking or parsing errors. There is a cline from non-compositional collocations like pale into insignificance, pluck up courage and let off steam to verbal frames like stub out cigarette, plug into socket and blow out candle. The triple dump of waste arises from a tagging error, dump is often mis-tagged as verb. The cryptic triple contain within begins is caused by annotation garbage in file CA5 of the original BNC. Given the ranking criterion O/E, we observe considerably lower frequencies than in Table 2. The amount of non-collocations stays low in the first 1,000 or so entries. For example the collocation take into account which we have seen in Table 2 appears in position 249.
Idiomatic expressions are typically more fixed than compositional, selectionally restricted expressions, which also appear highly ranked in Table 3. In order to focus on idioms, i.e. largely non-compositional collocations, we use a filter that only reports collocations with low determiner and modification variability. We measure variability with Yule’s K, as we have discussed in section 2.2. The settings for the results displayed in Table 4 are otherwise identical to those in Table 3. Column 8 displays the few modifiers, column 9 the few determiners that are used.
Table 4. VPN triplets ordered by O/E, with low variability, filtered by t-score, in BNC-W written. (Full table.)
While the list still contains some compositional expressions which are hardly ever modified, for example summarise(d) in appendix A or infect(ed) with HIV, the density of idioms like burst into tear(s), roar with laughter and start from scratch has increased. A linguist filtering such lists can easily compile idiom dictionaries.
To observe VPN triplets with high variability, we use a filter that only reports collocations with high determiner or modification variability for the description noun, based on Yule’s K. The settings for the results, which are displayed in Table 5, are otherwise identical to those in Table 3. Column 8 displays the modifiers, column 9 the determiners that are used. This table is dominated by non-idiomatic collocations, by verbal frames. One of the most frequent things people do with sockets is that they plug in cables.
Table 5. VPN triplets ordered by O/E, with high variability, filtered by t-score, in BNC-W written. (Full table.)
So far, we have focused on VPN triples in which V, P, and N are all fixed. While this yields many idioms, there are many fixed expressions, notably phrasal verbs, in which the N slot is highly variable. Berry-Rogghe (1974) suggested a method to detect phrasal and prepositional verbs by comparing the association strength between V and P to the association strength between P and N. If the association between V and P is relatively high, while the strength between P and N is relatively low, this can be used as an indicator for distinguishing phrasal and prepositional verbs.
For this purpose we calculate frequencies for VPX and XPN combinations, leaving either the verb or the description noun underspecified. We calculate O/E for the VPX and XPN combinations separately. We then divide O/E of VP by O/E of PN to obtain a complement indicator.
Tables 6 and 7 are ordered by this complement indicator. Table 6 lists VPN triplets in descending order, which results in complement structures being top ranked. Table 7 lists them in ascending order, which will prefer adjunct structures. In Table 6, we observe a high proportion of prepositional verb frames. Deal with sth/one, consist of sth and depend on sth exemplify the case of prepositional verbs, whereas carry out sth and set up sth are phrasal verbs. The top of Table 7, in contrast, shows those VPN triples that contain PPs functioning as verb adjuncts.
Table 6. Association between verb and preposition, compared to the association between preposition and description noun, ordered by descending comp index (comp index = O/E(VP) / O/E(PN)), filtered by t-score in BNC-W written. (Full table.)
Table 7. Association between verb and preposition compared to the association between preposition and description noun, ordered by ascending comp index (comp index = O/E(VP) / O/E(PN)), filtered by t-score in BNC-W written. (Full table.)
So far we have looked at the variability of the verb and the description noun slot. In Table 8 we keep the verb and description noun slot constant and investigate variability of the preposition slot. For every verb description noun type we calculate Yule’s K for the prepositions occurring in VXN frames. Table 8 shows VXN frames ordered by O/E for the co-occurrence of VN types observed with more than one preposition type.
Table 8. VXN tuples, prepositions are left variable, ordered by O/E (VN), filtered by t-score in BNC-W written. (Full table.)
Table 8 shows verb – description noun frames that take more than one preposition. As every single preposition that occurs is recorded, even single parsing errors leave strong footprints in this list, reporting prepositions that arise from parsing and tagging errors. For example, the majority of entries of the preposition of are due to tagging errors: in rest of laurel and gasp of breath the superordinate noun is mis-tagged as verb. A closer analysis, however, shows interesting cases, like die from/of a disease, sigh with/in relief or fill in/out/up a questionnaire, where there is variation in the choice of preposition without great semantic consequences. In contrast to these, roll up/down sleeve or rain on/during parade display a semantic shift. It is interesting to see that some semantically opaque idioms also offer prepositional variability, for example jump on/aboard bandwagon and rest on/upon laurel.
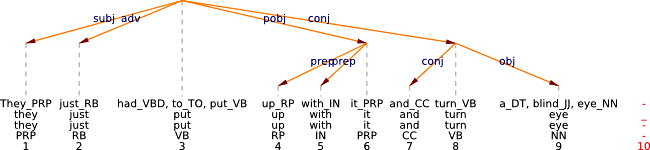
In our underspecified approach, in which P also includes verbal participles, there are also cases in which description nouns attach two prepositions, particularly phrasal-prepositional verbs, as in sentence (5).
(5)
Table 9 lists significant VPPN tuples, ordered by O/E. The list contains phrasal-prepositional verbs like live up to and phrasal verbs that are often modified by a particular PP, such as stay on at school. The phrasal-prepositional verb come up with of example sentence (5) appears at position 37.
Table 9. Double Preposition VPPN tuples ordered by O/E, filtered by t-score in BNC-W written. (Full table.)
5.2 VOPN 4-tuples in the BNC
In the previous section, we focused on PPs that are attached to a verb that has no object. There are also many idiomatic expressions and collocations that involve both an object and a PP. We investigate them in this section.
Our dependency-based retrieval strategy reports 987,276 VOPN triple tokens resulting in 887,328 VOPN triple types. Compared to the free combination of all verbs, objects, prepositions, and description nouns observed in verb-attached PP structures, only one in a billion possible VPN combinations actually occurs. The distribution is highly Zipfian: the most frequent triple occurs 192 times, while 837, 551 types (above 90%) are hapax legomena.
Table 10. VOPN 4-tuples ordered by O/E, filtered by t-score in BNC-W written. (Full table.)
Table 10 lists VOPN 4-tuples, ordered by O/E. The list contains many prototypical idioms, e.g. send shiver down spine, kill bird with stone and keep head above water. It also contains many types caused by selectional restrictions like tap esc for escape and put arm around shoulder. As PP-attachment is highly ambiguous, particularly between attaching to V or to O, there are also many attachment-errors in the list, e.g. ask secretary for (foreign) affairs, where for foreign affairs should be attached to secretary, not to ask and thus not reported at all.
While Table 10 reports collocations with fixed VOPN types, some VOPN collocations allow considerable variability in the description noun slot. Table 11 lists VOPX structures with the N slot left variable. Here O/E is calculated for the VOP-triple. The results are ordered by O/E (VOP).
Table 11. VOPX triples, description nouns are left variable, ordered by O/E (VOP), filtered by t-score in BNC-W written. (Full table.)
In Table 11, the collocations slam/shut/close door behind something or someone are even ranked above send shiver down spine. The list hardly contains parsing errors and lists many idioms, e.g. poke fun at, cast shadow over and shed light on. Some genre-dependent compositional collocations, e.g. melt butter in (from cooking recipes) and commit offence under (from news) also appear prominently.
Table 12 covers the same VOPX structures found in Table 11. In addition we use Yule’s K for the description nouns found in the variable slot X in VOPX. Table 12 filters the results from Table 11 with the additional requirement of high variability for the description noun.
Table 12. VOPX triples, description nouns are left variable, ordered by O/E (VOP), filter for high variability in X, filtered by t-score in BNC-W written. (Full table.)
In Table 12 we see verb frames with fixed object, as in cock a snook at sone. The chosen ranking by O/E allows for the detection of very rare combinations. Figure 2 shows the 12 instances of cock a snook at sone on which the first result in Table 12 is based.
O/E is a measure of surprise that favours infrequent items. By contrast, t-score favours frequent items, as – other things being equal – more frequent items are observed with a higher degree of certainty, i.e. statistical significance. If results are ordered by t-score, frequent events are thus ranked higher. This also delivers interesting results. Frequent VOPX structures, ordered by t-score, are shown in Table 13.
Table 13. VOPX triples, description nouns are left variable, ordered by t-score (VOP), filtered by t-score in BNC-W written. (Full table.)
In Table 14 we keep the verb, preposition and description noun slot constant and investigate variability of the object slot. For every VOPN type we calculate Yule’s K for the objects occurring in VXPN. Table 14 shows VXPN frames ordered by O/E for the co-occurrence of VNP types observed with more than one object type.
Table 14. VXPN triples: object slot left variable, ordered by O/E (VPN), filtered by t-score in BNC-W written. (Full table.)
The list mainly contains verbal frames, and few idioms, for example let sth/one off the hook. Most of the idioms are partly compositional, for example bring sth/one into disrepute and engage sth/one in conversation.
5.3 Comparing TLND and BOGL
The 20 top ranked VOPN tuples from TLND on the left and BOGL on the right are shown in Table 15. We manually annotated collocations that are idioms (with +++). We immediately notice that there are considerably more idioms in TLND than in BOGL. In the 50 top ranked VOPN collocations, there are sixteen idioms in TLND, whereas in BOGL there are only two. Also further down in the lists, the same tendency can be observed. While parameters such as genre mix may have an influence on results, we think that the difference is striking, and intend to conduct further research. One explanation may be that American English with its history of contact situations may have a tendency to show fewer idioms.
Table 15. 20 top-ranked VOPN collocations from TLND on the left and BOGL on the right, ordered by O/E, filtered by t-score, manually annotated for idiomaticity. (Full table.)
6. Discussion
Statistical tests used in collocation analysis are mostly discussed as a means of ranking collocations. The tests are then heuristically judged to be “better” if they produce more collocations at the top of the ranked list. It is obvious that the choice of test heavily depends on what linguists expect to find at the top of the ranking.
Collocation tools like BNCweb (cf. Lehmann et al. 2000) use a frequency based cut-off for excluding combinations that occur below a user-specified frequency. In our approach we have decided to separate the task of producing ranked lists of types into two distinct sub-tasks. First, listing only observations that are statistically significant. Second, ranking according to a measure of surprise. The combination of O/E as a ranking criterion and t-score, as a statistical cut-off, results in fairly clean listings. Given the parser’s precision of about 80%, we would expect 20% of false positives, but this does not translate into our list of co-occurrence types. Most errors produced by the parser are not systematic in the sense of consistently reporting the same type of false positive. The majority of parsing errors are caused by failures elsewhere in the grammar and such errors do not result in repeated patterns, but in white noise, which is filtered out by the statistical cut-off to a large degree. Due to the characteristic that unsystematic errors are filtered out, we find our parser-based approach particularly suitable to the task of collocation and idiom detection. With the benefit of hindsight we will consider using a less heuristic test than t-score and plan to use z-score as cut-off in future work.
Our use of O/E as a measure of surprise has proven extremely useful in experimentally exploring an appropriate level of significance for excluding noise. Due to the fact that O/E prefers low frequency combinations, the rarest items allowed by a specific statistic cut-off turn up near the top of our lists. O/E is certainly also useful in a typological undertaking in which rare new items are the goal of the investigation. For other purposes like lexicography, more traditional rankings based on log-likelihood or mutual information may turn out to be more appropriate and would certainly have produced cleaner lists in our experiments.
Given the level of noise introduced by the annotation process and the Zipfian nature of the distribution of types, we found that corpora of smaller size do not yield interesting results with the present methodology. With a series of smaller test-samples we have observed patterns to emerge above the noise level only at 15-30 million words, depending on the phenomenon. The 90 million words of BNC written permits us to investigate rare patterns of up to four elements. For example, VOPN patterns in which all four elements are fixed, like throw caution to wind (26 instances) but also VOPN patterns with variable slots, like cock a snook at someone, which occurred only 12 times.
In this paper, we have used syntactic annotation to select only verb-PP structures and the heads involved. This is radically different from more traditional, window-based approaches (e.g. Hoffmann & Lehmann 2000). In addition to the low performance of window-based approaches, they also entail methodological problems for measuring association, for example by means of O/E. Our approach based on parsed data provides considerably cleaner data even at low levels of frequency. Even the majority of reported nonce occurrences are parsed correctly, and the vast majority of top-ranked O/E entries are true positives.
Window-based approaches to syntax-lexis interaction (e.g. Stubbs 1995) take into account all content words present in the vicinity of each other (inside the observation window), irrespective of their syntactic function, and irrespective whether they are syntactically connected at all. As a consequence such non-hierarchical approaches are forced to base the expected value (E, null-hypothesis) on the assumption of a corpus in which the words appear in random order. As Evert (2008) points out such a null-hypothesis is not unproblematic.
[T]he null hypothesis of independence is extremely unrealistic. Words are never combined at random in natural language, being subject to a variety of syntactic, semantic and lexical restrictions. For a large corpus, even a small deviation from the null hypothesis may lead to highly significant rejection and inflated association scores calculated by significance measures. Effect-size measures are also subject to this problem and will produce inflated scores, e.g. for two rare words that always occur near each other (such as déjà and vu). A possible solution would be to specify a more realistic null hypothesis that takes some of the restrictions on word combinatorics into account, but research along these lines is still at a very early stage.
For these reasons, we avoid a null hypothesis (E) based on a random shuffling of words. Instead, we base our expectation on a random shuffling of the heads actually observed in the verb-preposition-description noun structures. This offers a more realistic expectation, by taking the syntactic restrictions on word combinatorics into account. The observed lexical verb-preposition-description noun preferences inside a fixed structure allow us to investigate selectional preferences and native-like selection (Pawley & Syder 1983).
Our approach has the advantage of focusing on the construction under examination; for example verb-PP relations ignoring frequent lexical items found outside this specific construction, which would skew our results otherwise. As a consequence we do not measure the surprise of finding a specific lexical item in the observed verb-PP construction in general (cf. Stefanowitsch & Gries 2003). In contrast, our measure of surprise expresses the surprise of finding a specific combination on the background of all elements found in the observed construction.
We may have presented our syntax-based approach as an alternative to the classic approach. However, there certainly is the possibility of using the overall frequency of the elements in the whole corpus to formulate a more traditional null-hypothesis and even combine the resulting measures of surprise.
7. Conclusion
In this paper, we have presented a corpus- and parser-driven investigation of verb-attached PPs. We have shown different distributional properties of idioms, complements and adjuncts. We have introduced tools for ranking and filtering co-occurrence types. Our approach based on parsed data provides astonishingly clean data at low levels of frequency. Even the majority of reported nonce occurrences are parsed correctly, and the vast majority of top-ranked O/E entries are true positives.
The data acquired and described in this paper can serve as a base for a variety of future work. We envisage investigations of prepositional verb-frames resulting in lexicon entries containing detailed information on combinatorial preferences. An appropriate ranking method could be used for extracting prototypical patterns for teaching English as a foreign language. Another possible application is the use of distributional properties for an automatic sub-classification of the verb-attached PPs. Finally, it would also be interesting to see if the parser performance in the area of complement vs. adjunct could be improved with the distributional patterns extracted from its own output.
References
Barlow, Michael. 2000. “Usage, Blends, and Grammar”. Usage-Based Models of Language, ed. by Michael Barlow & Suzsanne Kemmer, 315-45. Stanford, CA: Center for the Study of Language and Information (CSLI).
Berry-Rogghe, Godelieve L. M. 1974. “Automatic identification of phrasal verbs”. Computers in the Humanities,ed. by John Lawrence Mitchell, 16-26. Edinburgh: Edinburgh University Press.
Carroll, John, Guido Minnen & Edward Briscoe. 2003. “Parser evaluation: using a grammatical relation annotation scheme”. Treebanks: Building and Using Parsed Corpora, ed. by Anne Abeillé, 299-316. Dordrecht: Kluwer.
Collins, Michael & James Brooks. 1995. “Prepositional attachment through a backed-off model”. Proceedings of the Third Workshop on Very Large Corpora, Cambridge, MA, ed. by David Yarowsky and Kenneth Church, 27-38. Association for Computational Linguistics (ACL). http://aclweb.org/anthology/W95-0103.
Evert, Stefan. 2008. “Corpora and collocations”. Corpus Linguistics. An International Handbook, ed. by Anke Lüdeling and Merja Kytö, 1212–1248 . Berlin: Mouton de Gruyter.
Fernando, Chitra. 1996. Idioms and Idiomaticity. Oxford: Oxford University Press.
Fernando, Chitra & Roger Flavell. 1981. On Idiom: Critical Views and Perspectives (Exeter Linguistic Studies 5). Exeter: University of Exeter.
Gibbs, Raymond W. & Nandini Nayak. 1989. “Psycholinguistic studies on the syntactic behavior of idioms”. Cognitive Psychology 21(1): 100-138.
Haverinen, Katri, Filip Ginter, Sampo Pyysalo & Tapio Salakoski. 2008. “Accurate conversion of dependency parses: targeting the Stanford scheme”. Proceedings of Third International Symposium on Semantic Mining in Biomedicine (SMBM 2008), Turku, Finland, ed. by Tapio Salakoksi, Dietrich Rebholz-Schuhmann & Samp Pyysalo, 133-136. Turku: Turku Centre for Computer Science (TUCS). http://www.doria.fi/bitstream/handle/10024/42045/GEN51_SMBM_Proceedings.digi.pdf.
Hoffmann, Sebastian & Hans Martin Lehmann. 2000. “Collocational Evidence from the British National Corpus”. Corpora Galore. Analyses and Techniques in Describing English, ed. by John Kirk, 17-32. Amsterdam/Atlanta: Rodopi.
Lehmann, Hans Martin & Gerold Schneider. 2009. “Parser-Based Analysis of Syntax-Lexis Interaction”. Corpora: Pragmatics and discourse : papers from the 29th International conference on English language research on computerized corpora (ICAME 29), Ascona, Switzerland, 14-18 May 2008 (Language and computers 68), Ed. by Andreas H. Jucker, Daniel Schreier & Marianne Hundt, . 477-502. Amsterdam: Rodopi.
Lehmann, Hans Martin, Peter Schneider & Sebastian Hoffmann. 2000. “BNCweb”. Corpora Galore. Analyses and Techniques in Describing English, ed. by John Kirk, 259-266. Amsterdam/Atlanta: Rodopi.
Lin, Dekang. 1999. “Automatic identification of noncompositional phrases”. Proceedings of the 37th Annual Meeting of the ACL, College Park, USA, ed. by Steven Bird, 317-324. Association for Computational Linguistics (ACL). http://www.aclweb.org/anthology/P/P99/P99-1041.pdf.
Malvern, David D., Brian J. Richards, Ngoni Chipere & Pilar Durán. 2004. Lexical Diversity and Language Development, Houndmills, UK: Palgrave MacMillan.
Marcus, Mitch, Beatrice Santorini & Mary Ann Marcinkiewicz. 1993. “Building a large annotated corpus of English: the Penn Treebank”. Computational Linguistics 19: 313-330. http://dl.acm.org/citation.cfm?id=972475.
Nelson, Gerald, Sean Wallis & Bas Aarts. (2002). Exploring Natural Language: Working with the British component of the International Corpus of English. Amsterdam: Benjamins.
Pawley, Andrew & Frances Hodgetts Syder. 1983. “Two Puzzles for Linguistic Theory: Native-like selection and native-like fluency”. Language and Communication, ed. by Jack C. Richards & Richard W. Schmidt, 191-226. London: Longman.
McCarthy, Diana, Bill Keller & John Carroll. 2003. “Detecting a continuum of compositionality in phrasal verbs”. Proceedings of the ACL Workshop on Multiword Expressions: Analysis, Acquisition, and Treatment. ed. by Francis Bond, Anna Korhonen, Diana McCarthy & Aline Villavicencio, 73-80. Association for Computational Linguistics (ACL). http://www.aclweb.org/anthology/W/W03/W03-1810.pdf.
van Noord, Gertjan & Gosse Bouma. 2009. “Parsed Corpora for Linguistics”. In Proceedings of the EACL 2009 Workshop on the Interaction between Linguistics and Computational Linguistics: Virtuous, Vicious or Vacuous?, Athens, Greece, ed. by Timothy Baldwin Valia Kordoni, 33-39. Association for Computational Linguistics (ACL). http://www.aclweb.org/anthology/W/W09/W09-0107.pdf.
Schone, Patrick & Dan Jurafsky. 2001. “Is knowledge-free induction of multiword unit dictionary headwords a solved problem?” Proceedings of the 6th Conference on Empirical Methods in Natural Language Processing, Carnegie Mellon University, Pittsburgh, Pennsylvania, ed. by Lillian Lee & Donna Harman, 100-108. Association for Computational Linguistics (ACL). http://www.aclweb.org/anthology/W/W01/W01-0513.pdf.
Seretan, Violeta & Eric Wehrli. 2006. “Accurate collocation extraction using a multilingual parser”. Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics, pages 953–960, Sydney, Australia, July. Association for Computational Linguistics. http://www.aclweb.org/anthology/P/P06/P06-1120.pdf.
Stefanowitsch, Anatol & Stefan Th. Gries. 2003. Collostructions: investigating the interaction of words and constructions. International Journal of Corpus Linguistics 8(2): 209-243.
Stubbs, Michael. 1995. Collocations and semantic profiles: on the cause of the trouble with quantitative studies. Functions of Language 2(1): 23-55.
Wulff, Stefanie. 2008. Rethinking Idiomaticity. Research in Corpus and Discourse. London: Continuum. ISBN 978-1847064202
Yule, George U. 1944. The statistical study of literary vocabulary. Cambridge: Cambridge University Press.