Reader comments as an aboutness indicator in online texts: introducing the Birmingham Blog Corpus
Andrew Kehoe & Matt Gee
Research & Development Unit for English Studies, Birmingham City University
Abstract
This paper presents work based on the new Birmingham Blog Corpus: a 600 million word collection of blog posts and reader comments, available through the WebCorp Linguist’s Search Engine interface. We begin by describing the steps involved in building the corpus, including a discussion of the sources chosen for blog data, the ‘seeding’ techniques used, and the design decisions taken. We then go on to focus on textual ‘aboutness’ (Phillips 1985). Whereas in previous work we examined social tagging sites as an aboutness indicator (Kehoe & Gee 2011), in this paper we analyse the reader comments found at the bottom of posts in our blog corpus. Our aim is to determine whether free-text comments offer different insights into the reader perspective on aboutness than those offered by social tags, and whether comments present further linguistic challenges. Online comments are often associated with blogs but are found increasingly on web documents of all kinds, and we also examine the growing importance of reader comments on online news articles.
1. Background
‘Web 2.0’ is the term applied to the current generation of web technologies, which allow users to interact with online content and participate in its creation rather than treat the web as an information source to be read passively.
In previous work on textual aboutness (Kehoe & Gee 2011), we focussed on one aspect of this new participatory web, in the form of social tagging. Social tagging sites – sometimes known as folksonomies – allow users to assign keywords (‘tags’) to their favourite web pages to describe the content of the pages. In the first instance, this is a way of organising one’s favourite web pages, or bookmarks, in an accessible manner. There is also a collaborative aspect in that other users can search the collection by tag in order to find web pages that may be of interest. Folksonomies range from the specialist, including CiteULike, Connotea and BibSonomy for academic references, to the general purpose.
Using data from the general tagging site, Delicious, we examined the relationship between the textual content of a web page and the tags assigned to it by its readers. Knowing what a document is about is essential in the matching of online documents to user queries. Our aim was to ascertain whether social tagging data could be used to enhance the indexing and search of web-scale document collections by providing a new source of information on aboutness (Phillips 1985). We took as our starting point the traditional approach to document indexing in libraries, captured in the following quote from an early Information Science journal:
Every reader interprets a text according to his [sic] own knowledge and environment; every reader has his own idea of what ‘topic’ may be. The indexer’s task is to take as broad a view as possible of what others may ‘read into’ a text (Hutchins 1977: 2)
We suggested that social tagging offers access to the reader’s view of aboutness in a way which was previously possible only on a small scale through elicitation experiments. However, we illustrated that the so-called ‘folksonomies’ built up through the process of social tagging are rather ‘messy’, lacking the uniformity and standard vocabularies of traditional taxonomies. Our classification of the tags assigned to a single web page included topic-related words but also evaluative words (fantastic, useful, nifty, cool), mnemonics (toread, readmelater), and typos, amongst other less useful categories (Kehoe & Gee 2011).
As a result, we argued, the challenge for the indexer is now in attempting to find consensus amongst the jumble of tags surrounding a text and to extract those most indicative of textual aboutness. The quality and usefulness of tag data is affected by the common restriction to single word tags, and by the design of some tagging interfaces, which encourage users to select tags already applied by other users or to select tags directly from the text itself. In our linguistic analyses of tag data we sensed a general uncertainty amongst taggers as to the purpose of tagging as an activity.
In this paper, we turn to another aspect of Web 2.0, by conducting a corpus linguistic analysis of the comments found at the bottom of web documents, in which readers react to and discuss the text appearing immediately above. Online comments are often associated with blogs, and we begin by analysing this web document format. However, as we shall illustrate, comments are found increasingly on web documents of all kinds, and we consider newspaper articles in Section 5. Our aim is to determine whether free-text comments offer different insights into the reader perspective on aboutness than those offered by social tags, and whether comments present further linguistic challenges. In the following section, we introduce a new blog corpus designed with the analysis of reader comments in mind and describe some of the issues involved in building such as corpus.
2. The Birmingham Blog Corpus
2.1 The blog format
The popular view of blogs as online personal journals is captured in the BBC WebWise ‘Beginner’s guide to the internet’, which states that “Blogs have been around for about 10 years. The word stands for ‘web log’ and they’re effectively online diaries”. The definition of weblog in the online edition of the Oxford English Dictionary (OED) uses similar terms (our emphasis):
2. A frequently updated web site consisting of personal observations, excerpts from other sources, etc.,
typically run by a single person, and usually with hyperlinks to other sites; an online journal or diary. [1]
Researchers in the field have used a looser, less restricted definition. Herring et al. (2005: 142), for instance, refer to blogs as ‘frequently modified web pages in which dated entries are listed in reverse chronological sequence’. This is the definition we adopt in this paper, referring to the ‘dated entries’ as posts and to a particular collection of posts as a blog. We do not restrict ourselves to ‘online diaries’. In fact, the shift in the definition of the term (we)blog is something we address throughout this paper, by examining the content of blogs and the purposes to which they are put.
2.2 ‘Web corpora’
Since corpus linguists began to turn to the web as a source of linguistic data in the mid-1990s, the ‘web as corpus’ approaches they have adopted can be grouped in to three main categories. The first is the approach taken by us with the original WebCorp system, first developed in 1998 (Kehoe & Renouf 2002). WebCorp, and similar tools such as KWiCFinder, run ‘on top of’ existing commercial search engines like Google, adding search refinement and output formatting options specifically for linguistic study. This approach has been referred to as ‘web as corpus surrogate’ (Bernardini et al. 2006), reflecting the fact that the data set used is not a ‘corpus’ in the strictest sense but is often the next best thing available, particularly when searching for rare or emergent language use.
The second approach – ‘web as corpus shop’ (Bernardini et al. 2006) – uses the web as a source of data for the building of structured corpora, often with a specific research question in mind. In relation to this approach to the building of web corpora, Nesselhauf (2007: 287) draws a useful distinction between, on the one hand, ‘texts written for other media and later made available on the internet’ and, on the other, texts produced specifically for the internet.
Somewhat surprisingly given the growing influence of the web on society in general and on language in particular, there are relatively few large-scale, publicly-available corpora of the latter kind of text: what we would term ‘web-native’ text types. The structure of the Corpus of Contemporary American English (COCA; Davies, 2008-) exemplifies what we mean by this. Although all texts found in COCA were downloaded from the web using the ‘web as corpus shop’ approach, the written genres in the corpus are similar to those found in pre-web corpora: fiction, popular magazines, newspapers, academic journals. COCA is a contemporary corpus, and a ‘web corpus’ in a loose sense, but it does not contain recent, web-specific textual varieties such as blogs, message boards or other computer-mediated communication. This is for good reason: maintaining the genre balance across the years 1990-present would be impossible if web-specific genres were included, and the inclusion of a wider range of web texts would make it more difficult to limit the corpus to American English.
Turning to blogs as an example of a web-native text type, one of the few large-scale, publicly-available corpora is the Blog Authorship Corpus created by Bar-Ilan University, Israel (Schler et al. 2006). This contains 681,000 posts from over 19,000 blogs, downloaded from the hosting site Blogger.com in August 2004 and totalling 140 million words. [2] The work by Schler et al. focuses on the effects of age and gender on blogging practices, and this is reflected in the design of the corpus, with meta-data fields for gender and age, as well as occupation and astrological sign. Understandably given the emphasis on blog authorship in the work of Schler et al., reader comments are not included in the corpus.
There have been many ethnographic and socio-linguistic analyses of blog data, but most use small manually-collected datasets. A more recent large-scale source of blog data is the TREC Blog collection, released by the University of Glasgow. The Blogs08 dataset includes over 28 million posts from over 1 million blogs. However, the collection is designed for specific information retrieval tasks as part of the TREC conference, so is not publicly searchable and is expensive to purchase (over £700).
In our own work on the WebCorp Linguist’s Search Engine (WebCorpLSE) we have adopted the selective ‘web as corpus shop’ approach in the diachronic analysis of online versions of UK broadsheet newspaper articles (Kehoe & Gee 2009). We have also adopted a third approach to ‘web as corpus’, downloading web data on a vast scale in order to build a corpus so large that it becomes a microcosm of the web itself. During the WebCorpLSE project, we built a ‘mini web’ corpus containing 9.2 billion words of randomly crawled web texts in English (Kehoe & Gee 2007). We begin our discussion of blogs in the following section by examining the extent of blog data found in this random mini web.
2.3 Blog data in our existing web corpora
Taking the URLs of the 3 million documents in our WebCorpLSE mini web, we conducted a simple experiment by splitting each of the domain names into its constituent parts, excluding the www part. For instance, the document with the URL http://www.bbc.co.uk/news/business-14441453 is hosted on the domain http://www.bbc.co.uk, which would become bbc + co + uk (i.e. three URL components). The domain http://maps.google.com, on the other hand, would become maps + google + com. This approach deliberately mixes Top-Level Domains (TLDs; e.g. com, uk – the final part of a domain name), Second-Level Domains (SLDs, e.g. co.uk) and sub-domains (e.g. maps in http://maps.google.com). It should be noted that the frequency of TLDs and SLDs associated with non-English speaking countries will be limited by the fact that the mini web contains only texts in English.
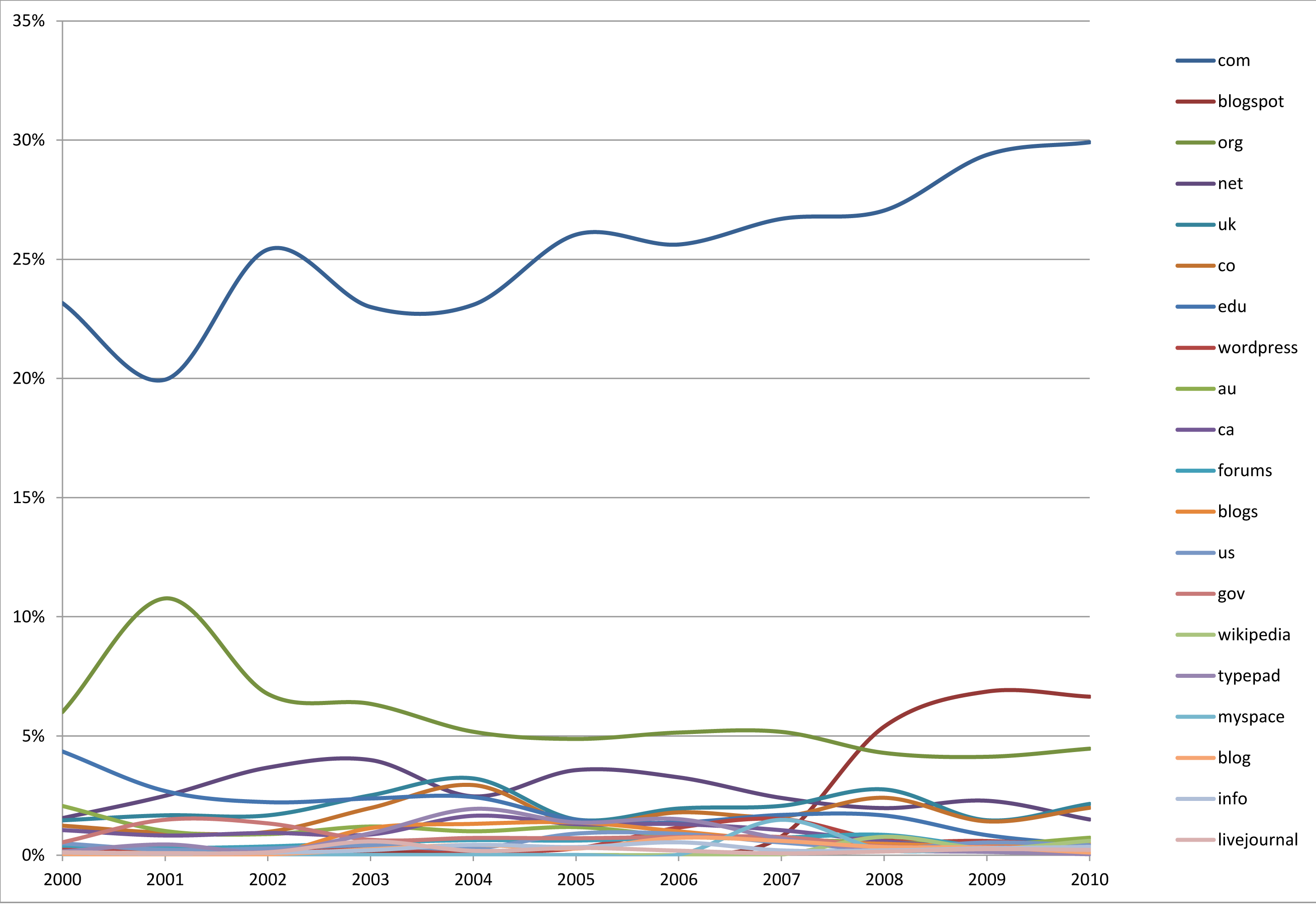
As the mini web was constructed diachronically, we are able to plot the frequency of each URL component on an annual basis. Figure 1 shows that com remains the most frequent URL component across the ten year period covered by the corpus, accounting for 30% of all components by 2010. This is not surprising given that com is the most frequently used TLD on the web as a whole. A simple way to confirm this is to run a site: query in Google, which shows the number of URLs in the whole Google index ending in a particular string. On August 8 2011, site:.com returned 25,270,000,000 results; .net: 7,560,000,000; .org: 4,170,000,000; .uk: 1,940,000,000; .edu: 297,000,000; and .gov: 196,000,000.
What is surprising in our analysis of URL components in the mini web corpus is that, by 2008, the component blogspot was the second most common, ranked higher than org, edu, net and gov, and higher than any country-specific TLD, including .uk. In fact, blogspot is also the second most frequent URL component in the mini web corpus when taken as a whole.
The component blogspot appears in URLs assigned to users of the Blogger blog publishing service, launched in 1999 and acquired by Google in 2003. [3] A blog hosted on Blogger will have a URL of the form http://healthygirlskitchen.blogspot.com or http://bicycledesign.blogspot.com. [4] What our experiment indicates is that, if our mini web can indeed be viewed as a microcosm of the web, there are now more blog posts hosted on Blogger than there are web pages from any single (English-speaking) country outside the US. Information from other sources would seem to support this finding: Blogger is the fifth most visited website worldwide according to the Alexa web traffic analysis service, and Google returns 1,390,000,000 results for a site:blogspot.com search; more than it returns for .edu and .gov. As shown in Figure 1, other blog hosting services Typepad, WordPress and LiveJournal also appear frequently as components of URLs in the mini web corpus. Furthermore, blogs and blog are frequently occurring components, appearing as sub-domains on a wide range of web hosts (Figure 2).
|
blogs.law.harvard.edu
blogs.smh.com.au
blogs.theage.com.au
blog.washingtonpost.com
blog.seattletimes.nwsource.com
blog.modishhandmade.com
blog.nj.com
blogs.zdnet.com
blogs.crikey.com.au
blog.inc.com
blogs.courant.com
blogs.suburbanchicagonews.com
blogs.salon.com
|
blogs.ittoolbox.com
blogs.reuters.com
blog.oregonlive.com
blog.getliberty.org
blogs.raincoast.com
blog.3g.co.uk
blogs.telegraph.co.uk
blogs.chron.com
blogs.guardian.co.uk
blogs.lib.sfu.ca
blogs.wsj.com
blogs.mysanantonio.com
blogs.abcnews.com
|
blogs.brisbanetimes.com.au
blog.generasian.ca
blogs.browardpalmbeach.com
blog.tenaday.co.in
blog.azcardinals.com
blog.iblamethepatriarchy.com
blogs.mirror.co.uk
blogs.thetimes.co.za
blogs.computerworld.com
blog.wellsfargo.com
blogs.cicerofd.org
blog.wired.com
blog.bigsnit.com
|
Figure 2. Examples of URLs in mini web corpus beginning blog(s)
These are organisations that host blogs on their own servers rather than on an external hosting site such as Blogger. As can be seen in Figure 2, the organisations include universities and newspapers in the US, UK, Australia and South Africa. We look more closely at newspaper blogs in Section 5.
Overall, our analysis of the mini web corpus has begun to illustrate the growing importance of blogs on the web in general. We built a large web corpus at random without prioritising blogs in any way yet found that this corpus was dominated by blog posts, particularly those hosted on the Blogger service. In fact, there are likely to be many more blog texts in the corpus which are not marked explicitly as blogs in their URLs, either in the host (blogspot, etc.) or in the sub-domain (blog/s). This would have led us to wonder whether our mini web were biased towards blog texts, were it not for the fact that the findings from the mini web have been seen to mirror those on the web as a whole, as indexed by Google.
Our focus when building the mini web corpus was on scale and breadth of coverage and, thus, we did not pay special attention to the structure of any particular web text type. However, after noting the dominance of the blog text type and wishing to examine this in more depth, we set about building a new blog-specific corpus, as detailed in the following section.
2.4 Building a blog corpus
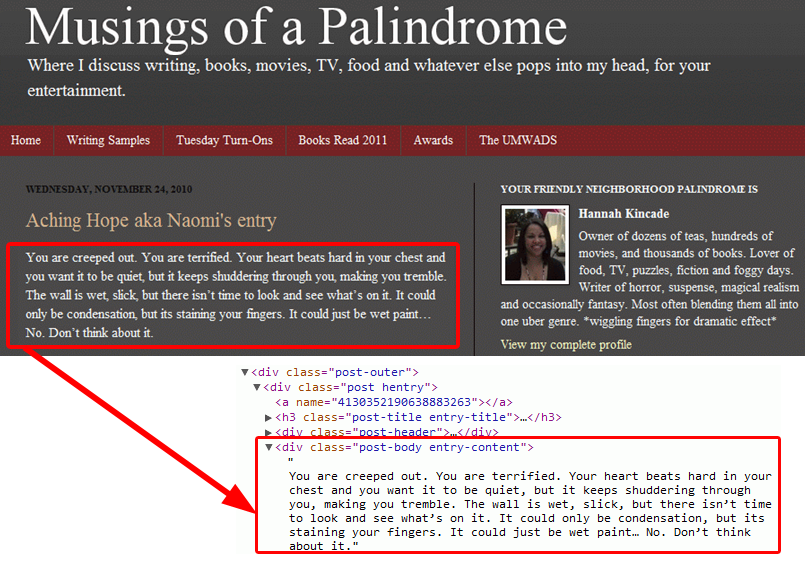
Our analysis of the mini web corpus had already suggested hosting sites such as Blogger (Blogspot) and WordPress as useful sources of blog data. The advantage of these sites from a corpus-building perspective is that they store data using a limited set of templates. Previously, in building our mini web, we had to devise algorithms to detect and extract the main body text on a web page, excluding the various ‘boilerplate’ – menus, advertisements, etc. – elsewhere on the page (Kehoe & Gee 2007). Although the many blogs hosted on Blogger may look very different and contain very different content, the underlying structure will always be very similar. This makes the development of software to extract body text from blogs much more straightforward. Figure 3 shows an extract of the document mark-up used in one of the Blogger templates, for the blog Musings of a Palindrome. As this illustrates, there is a particular code in the document template, or style-sheet, which helps us to identify the main body of the blog post. [5] Post titles and dates can also be identified and extracted in this way.
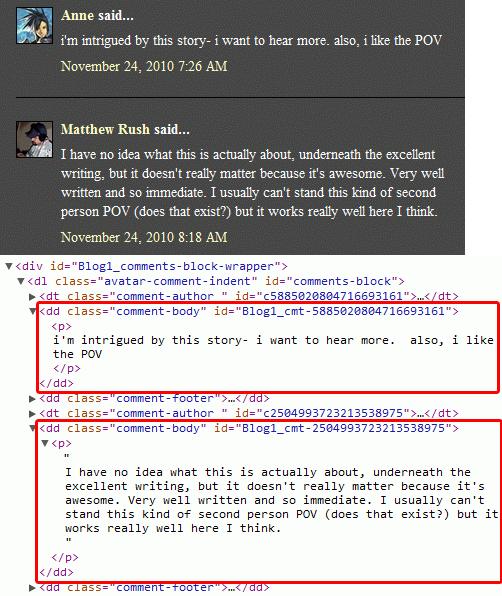
The formulaic structure of blogs hosted on Blogger and WordPress means that, in addition to the blog post itself, we are able to identify and extract the comments section at the bottom of each post, where readers respond to what the blogger has written above (Figure 4).
For the diachronic corpus linguist, another advantage of blogs is that they are inherently diachronic, in that posts are presented in reverse date order (most recent first) with the publication date included at the top of each post. Comments on each post are usually presented in date order (most recent last), with both the date and time included (as shown in Figure 4). In previous work, we demonstrated how difficult it is to extract reliable date information from web texts in general, how limited standard web search engines are when it comes to date-restricted queries, and how it is often necessary to resort to potentially unreliable copyright dates in the absence of any other dating information on web pages (Kehoe 2006). Blogs appear to buck this trend, perhaps as a result of their origins as online diaries, but perhaps also because the blog hosting companies increasingly see value in structured, searchable text archives with date information clearly recorded. Indeed, there are websites such as BlogPulse which track changes in word frequencies in blogs across time (Figure 5), and so-called ‘trending topics’ – actually just frequent words at a given point in time – are at the heart of the Twitter micro-blogging service.
The diachronic search tools available for blogs, while limited compared to those used routinely by corpus linguists, are an advance on those previously available on the web (cf. Kehoe & Gee 2009 on the limitations of the Google News ‘timeline’ interface). Although the focus of this paper is on reader comments and how our blog corpus has been designed to facilitate the study of these, the ability to search for lexical trends across time was also a major factor in our corpus design methodology.
In fact, we used the notion of ‘trend’, which is central to blog hosting and search sites, as a first step in the building of the Birmingham Blog Corpus. Both Blogger and WordPress provide lists of ‘trending’, or topical, blogs, known as ‘Blogs of Note’ on Blogger and ‘Freshly Pressed’ on WordPress. Using these lists to seed our crawl, we downloaded each post from each of the featured blogs. We then used the method described above to extract the main textual content from each post, as well as the reader comments associated with the post. During this text processing stage, we extracted all links to other Blogger or WordPress blogs, whether these links were in the body of a post, in a comment, or in a ‘blogroll’ (a list of other blogs recommended by the blog author – see Figure 6). New links were then added to the queue of blogs to crawl. In this way, we were able to widen our coverage beyond the initial ‘trending’ blogs list.
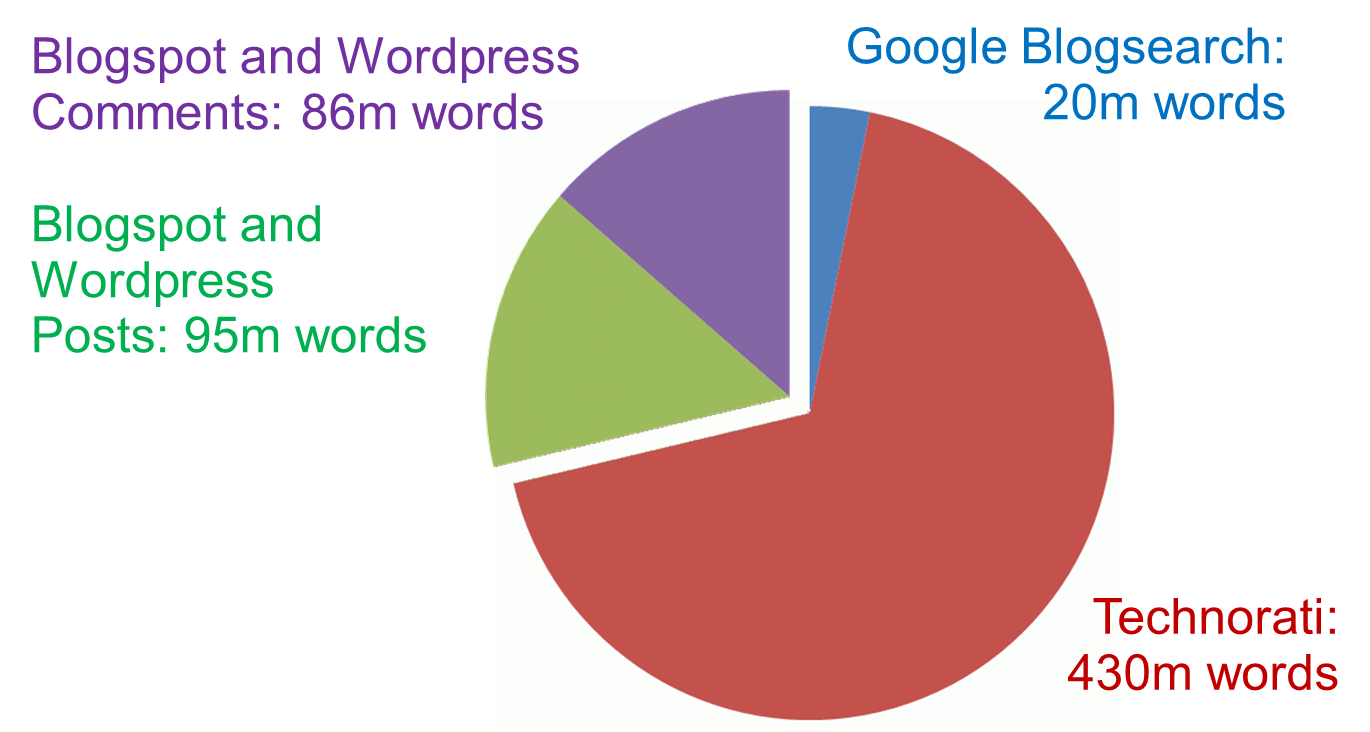
The crawling process ran for one month (December 2010). During this period, we were able to download and process 222,245 blog posts from Blogger and WordPress combined, totalling 95 million tokens. In addition, we downloaded all comments made on these blog posts, resulting in a further 86 million tokens, as shown in Figure 7. We go in to more detail about the relationship between a blog post and its comments in Section 3.
2.5 Other sub-corpora
As illustrated in Figure 7, the Blogger and WordPress posts and comments together form only one sub-section of the Birmingham Blog Corpus. This is the sub-corpus we shall focus on in this study of blog comments and their potential as an aboutness indicator. We outline the other sub-corpora briefly here.
The small Google Blog Search sub-corpus (20 million words) was compiled using the blog-specific search tool provided by Google. This operates in a similar way to a standard Google search but limits its results to sites identified as blogs. These are not restricted to blogs hosted on Google’s own Blogger service or other services such as WordPress. Any blog author can publish a site feed – a list of site updates, usually in RSS or Atom format – and submit this feed to Google. [6] By monitoring the feed, Google knows exactly when each blog has been updated and is able to update its own index automatically. In contrast to standard web pages, Google does not need to crawl blogs to discover new updates. This means that the Google blog index contains more up-to-date content than the standard Google web index, and it also means that the dating of texts in the blog index is much more accurate. As a result, linguists interested in the very latest coinages may find Google Blog Search of use.
At the time of our crawl, Google made available its own RSS feed of all new posts added to its blog index under a range of general topic categories: Politics, US, World, Business, Technology, Video Games, Science, Entertainment, Movies, Television, Sports and Top Stories. We used this information to build the Google Blog Search subsection of our blog corpus, recording Google’s topic labels in the process. At the time of writing, whilst Google still makes available RSS feeds for new blog posts matching a particular search term, the option to view an RSS feed of all new blog posts by topic has been removed.
Technorati is a web search engine and directory designed specifically for blog search. It ranks blogs by ‘authority’, with the rating for each blog determined by the number of other blogs linking to it (similar to the PageRank approach employed by Google for general web search). As in Google, blogs are assigned to general topic categories: Entertainment, Business, Sports, Politics, etc. We took the list of the 100 top ranked blogs and crawled each one in turn, downloading and processing all posts.
The blogs listed in Technorati and Google Blogs are not necessarily hosted on sites such as Blogger and WordPress and, thus, are in a wide variety of different formats. For this reason, we had to use more general processing tools and were unable to extract comments from the Google Blogs and Technorati sub-corpus. We focus on Blogger and WordPress in the remainder of this paper but believe that the other sub-corpora will be of use in other studies. The whole Birmingham Blog Corpus is freely available for searching and we plan to update the corpus at regular intervals if there is sufficient demand.
3. The Blogger & WordPress sub-corpus: an overview
Table 1 gives statistics for the Blogger & WordPress sub-corpus, relating to the length of blog posts and to the number and length of comments associated with each post.
| Total sub-corpus size (tokens): |
181,405,634 |
| Total size of post section (tokens): |
94,977,062 |
| Total size of comment section (tokens): |
86,428,572 |
| Number of posts: |
222,245 |
| Number of comments: |
2,253,855 |
| Number of posts with comments: |
173,386
(78%) |
| Avg. sentence length in posts (tokens): |
13.97 |
| Avg. sentence length in comments (tokens): |
8.28 |
| Avg. tokens per post: |
427.35 |
| Avg. tokens per set of comments: |
498.47 |
| Avg. tokens per individual comment: |
38.35 |
| Avg. comments per post (all posts): |
10.14 |
| Avg. comments per post (posts with comments only): |
13.00 |
Table 1. Blogger & WordPress sub-corpus statistics
It is striking that almost half of the sub-corpus is made up of comments. Related to this is the fact that 78% of the blog posts in the sub-corpus have at least one comment associated with them. As Table 1 shows, the average blog post has around 10 comments, and if we exclude posts with no comments at all the average rises to 13. Our findings differ from those of previous studies. Herring et al. (2005) surveyed 203 blogs and found the average number of comments per post to be 0.3. However, Herring et al. analysed only the most recent post on each of the blogs, excluding older posts from their calculation. As we go on to discuss in this paper, comments on a blog post tend to build up over time, as readers discover and comment on the post and as they react to the comments of other readers. By limiting their study to recent posts, Herring et al. limited the potential for comments to develop in this way.
Mishne & Glance (2006) found the average number of comments per post in their blog collection to be slightly higher, at 0.9. This was a larger-scale study of 36,044 blogs, and we believe the reason that the average reported by Mishne & Glance is still considerably lower than our own is that their system did not extract all comments accurately. They did not restrict their analysis to blogs on a particular hosting site such as Blogger or WordPress, meaning that comments were not in a standard format (cf. Section 2.4) and their reported accuracy rate for comment detection was only 70%. Only 15% of posts in the collection analysed by Mishne & Glance were found to have at least one comment associated with them, as compared with 78% in our collection. We believe that time may also be a factor in the discrepancies between our study and the studies by Herring et al. and by Mishne & Glance, which were carried out in 2005 and 2006 respectively. Technological innovations and the growth of hosting sites like Blogger may have served to allow commenting on a wider range of blogs. Indeed, Herring et al. found that only 43% of the blogs they surveyed in 2005 allowed commenting at all. Another possible reason for the discrepancy in the figures is that we began our crawl with popular blogs which, by definition, have a larger readership and thus greater potential for reader comment.
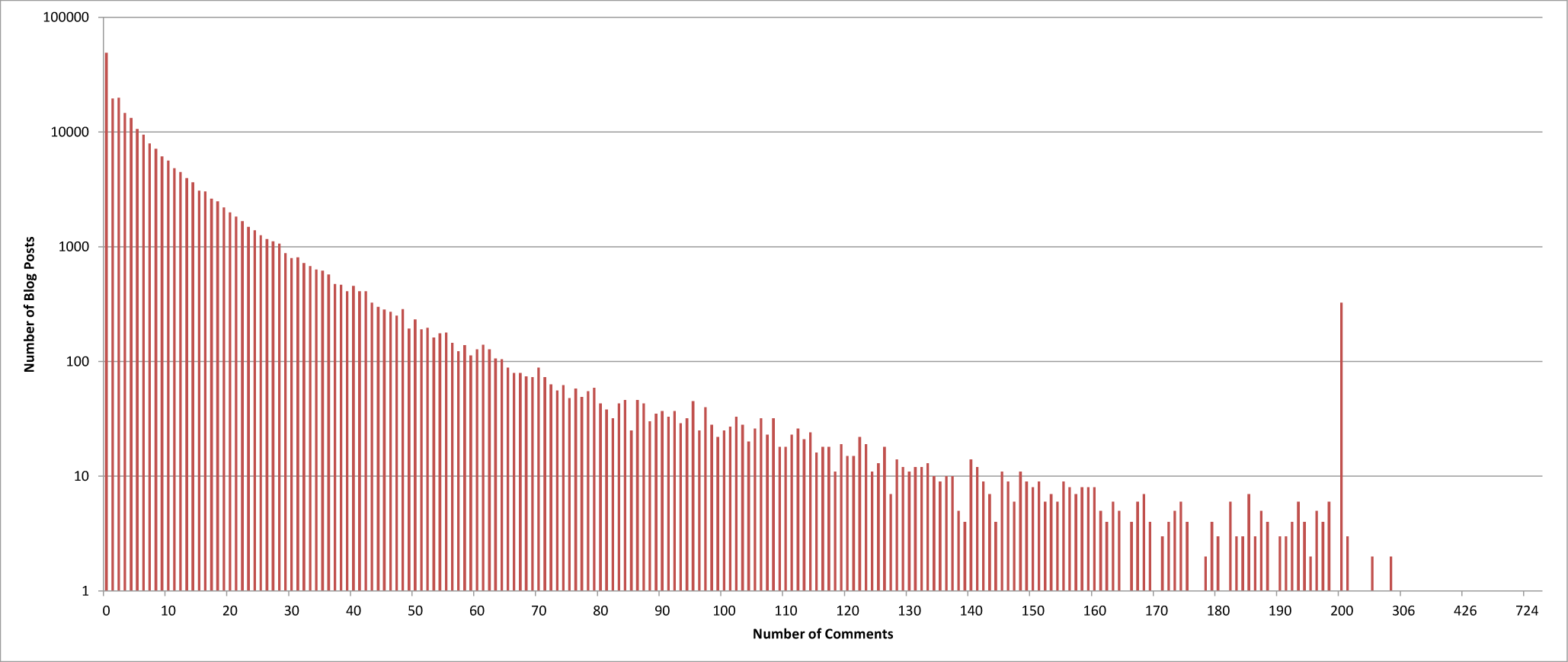
Another striking feature of Table 1 is that, on average, the set of comments associated with a single post in our corpus contains more tokens than the post itself (498.47 versus 427.35). Figure 8 shows the distribution of comments in more detail.
On the extreme left of this graph are the 22% of blog posts with no comments: 48,859 posts in total. It should be noted that a lack of comments cannot always be taken as an indication that a blog post is not comment-worthy. In some cases, the author may have disabled the comment feature, either for a particular post or for the entire blog. Of interest to us are the posts with comments, and we see in Figure 8 that the majority of posts have 1 or 2 comments. In fact, 73% of all posts have 10 or fewer comments, 88% have 20 or fewer, and 98% have 50 or fewer. The one anomaly in Figure 8 is the large number of posts with 200 comments (325). This happens because some blogs limit the maximum number of comments per post to 200, i.e. these posts would contain more than 200 comments were it not for the restriction. The Blogger and WordPress hosting services do not themselves impose a limit on the number of comments. [7] There are, in fact, 361 posts with 200 or more comments, the most commented upon post having 914. [8]
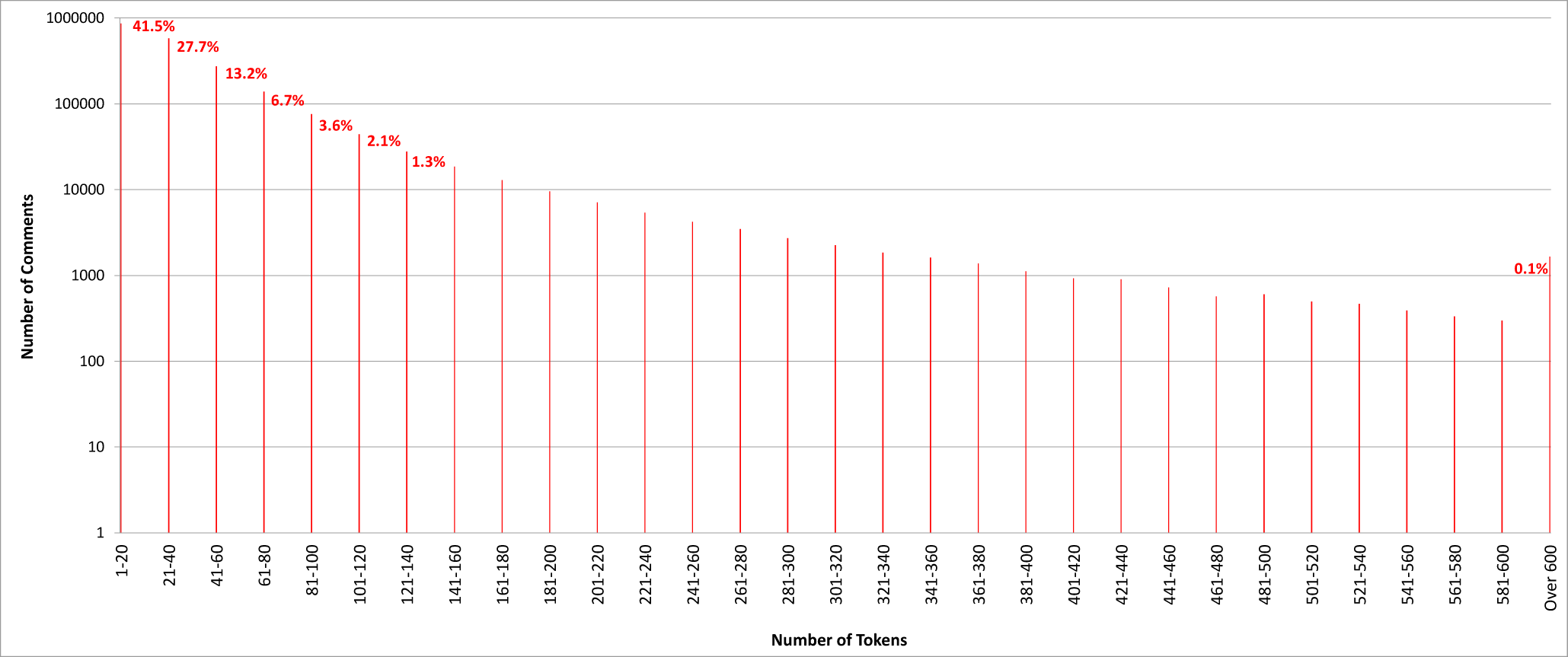
Turning to individual comments, Table 1 shows the average length to be 38.35 tokens, while Figure 9 plots the distribution of comment length. As this illustrates, the majority of comments (41.5%) are between 1 and 20 tokens in length, with a further 27.7% at between 21 and 40 tokens. Whilst the proportion is low (0.1%), there are a sizeable number of individual comments (1664) with more than 600 tokens. Most of the longer comments are, in fact, spam, as we discuss in Section 4.3.
We have shown that the average post in our Blogger & WordPress sub-corpus has 10.14 comments associated with it, each of 38.35 tokens in length. Given these relatively small numbers, one may question whether the consideration of comments could possibly improve information retrieval to any worthwhile extent. However, we have already illustrated (Kehoe & Gee 2011) that the consideration of reader-assigned ‘tags’ – in effect, single word comments – can aid document indexing by sharpening the aboutness picture which emerges through analysis of the tagged document alone. Furthermore, previous studies of blog data have shown that even a small number of comments can have a significant impact on search and retrieval. Potthast (2009: 725) found that ‘10 comments are sufficient to reach a considerable similarity between a document and its comments [...]. 100-500 comments contain a measurable commenter contribution that is not contained in the original document’. Similarly, the aforementioned study by Mishne & Glance (2006) found that ‘comments often add new terms to the content of the post, terms which assist in retrieving it given a query’.
The studies by Potthast and Mishne & Glance both adopted a macro-level approach to aboutness, using statistical measures to compare the comments with the post. Mishne & Glance focussed on recall, examining the increase in the number of blog posts matching a particular query when the comments associated with each post are taken into account. Precision – whether a post is actually a good match for the query – was not felt to be as important, the argument being that, unlike standard search engines, blog search tools tend to order results by date rather than by relevance. By contrast, in the following section we adopt a micro-level approach, focussing on the lexical content of blog comments and the relationship between post and comments in aboutness terms.
4. Case study: aboutness indicators
In this section, we work through a specific case study to illustrate how comments could be used to improve document indexing on the web. The example is taken from ‘Lorelle on WordPress’, a blog acting as a guide to the WordPress hosting service and to blogging in general. The particular post we shall examine is from April 10 2006 and is entitled ‘What do you do when someone steals your content?’ (Figure 10). We refer to this as the ‘Content Theft’ post in the remainder of the paper. With 4985 tokens in the body of the post, this is a long text by web standards. As we have reported elsewhere (Kehoe & Gee 2007), only 3.73% of pages in our mini web corpus contain more than 2000 tokens.
4.1 Key words: a text-internal aboutness indicator
As a first step in the study of aboutness, we turn to text-internal indicators and the widely used ‘key words’ approach, as popularised by WordSmith Tools (Scott 1996). Table 2 shows the results of a comparison between the Content Theft post and all posts in the Blogger/WordPress sub-corpus, using the log-likelihood statistic (Dunning 1993). We do not consider comments at this stage. The words that emerge from this comparison as indicative of the aboutness of the Content Theft post are words relating to copyright, Intellectual Property, and suitable action to take against those who steal content from a blog or other website. These words do not come as a surprise when we know already what the text is about, but they indicate that a relatively simple calculation can be helpful in the automatic indexing and classification of texts.
| Word |
‘Theft’ Freq |
Corpus Freq |
L-L |
| copyright |
99 |
2646 |
1,080.36 |
| content |
74 |
6,246 |
639.70 |
| theft |
40 |
621 |
478.87 |
| desist |
27 |
102 |
394.63 |
| cease |
27 |
805 |
288.85 |
| infringement |
15 |
128 |
196.77 |
| wordpress |
21 |
1545 |
187.24 |
| plugin |
16 |
455 |
172.66 |
| stolen |
19 |
1,658 |
163.00 |
| dmca |
10 |
26 |
152.64 |
| information |
30 |
16,501 |
148.79 |
| copyrights |
9 |
84 |
116.54 |
| contact |
20 |
8,323 |
110.03 |
| copyrighted |
9 |
186 |
102.74 |
| advertisers |
9 |
254 |
97.25 |
| material |
17 |
6,697 |
95.35 |
| steals |
9 |
324 |
92.95 |
| owner |
14 |
3,899 |
88.03 |
| intellectual |
12 |
2066 |
86.82 |
| thief |
10 |
877 |
85.69 |
Table 2. Top 20 key words in Content Theft post compared with all posts (log-likelihood)
4.2 Social tags as an aboutness indicator
As we noted in Section 1, we have previously explored the use as a text-external aboutness indicator of tags assigned in the Delicious ‘folksonomy’. If we turn to the Delicious entry for the Content Theft post, we find that it has been assigned 380 unique tags by 1067 Delicious users since April 2006 – the same month the post was published. The top 30 tags are shown in Figure 11.
In our study of social tagging as an aboutness indicator, we classified tags into nine general groups (Kehoe & Gee 2011). One of these groups was made up of cases where taggers are apparently attempting to categorise a web text according to its general topic or purpose, and there are several examples in Figure 11: webdesign, resources, howto, tips, reference, advice, tutorial, articles. There are also 25 instances of the mnemonic tag toread, which we found to be well established in the tagging lexicon. However, with these few exceptions, the top externally-assigned tags are remarkably similar to the top text-internal key words shown in Table 2. That is to say that the Delicious users who have tagged this blog post have done so largely by using words which appear relatively frequently in the text. In this instance, then, social tagging appears to offer few advantages as an aboutness indicator.
4.3 Comments as an aboutness indicator
With 276 comments, the Content Theft example is the twenty-fifth most commented upon post in our corpus. In addition to the 4,985 tokens of text in the body of the post, there are over 26,000 tokens in the associated comments. We processed all 276 comments, comparing the words therein with the words in the Content Theft post itself. A stop-word filter was applied and all words were converted to lower-case. From this comparison emerged a list of over 100 potential aboutness indicators appearing in the comments but not in the post (Table 3). We then took the further step of comparing these words with the words used to tag the Content Theft post in the Delicious folksonomy. This revealed that only five of the aboutness indicators extracted from the comments also appeared as tags (shown in red in Table 3).
|
acceptable
acknowledging
acknowledgment
advice
allow
allowed
allowing
allows
attorney
attribute
attributed
attribution
authorised
authorities
authority
authorize
bandwidth
battle
battles
battling
borrowed
breach
cite
cited
citing
complain
complaints
|
consent
consented
copy-pasting
copying
copying-and-pasting
copyrightable
copyrighting
copywrite
creator
creators
credited
crediting
credits
crime
distribute
distribution
distributor
distributors
duplicate
duplicating
encrypt
enforceable
guidelines
hotlink
hotlinked
imprisonment
infringer
|
infringers
infringing
legalese
legality
legally
legislative
legitimate
license
licenses
litigation
non-commercial
paste
pasted
pasting
patent
patented
patents
piracy
pirates
plagiarism
plagiarist
plagiarize
plagiarizes
plagiarizing
reposting
reprint
reproduce
|
reproduction
republished
republishing
restrict
restricted
restrictions
rightful
righting
ripped
ripping
robbing
scraped
scraper
scrapers
scraping
spoofed
unacceptable
unethical
vandalism
verbatim
violated
violates
|
Table 3. Aboutness-indicating words appearing in Content Theft comments but not the post itself
This analysis has demonstrated the potential of comments as an aboutness indicator, going beyond the information that can be extracted from the post itself and beyond the information offered by topic-related tags assigned by readers in the Delicious folksonomy. However, a degree of manual intervention was required to extract the words shown in Table 3 as there are many other words found in the comments section which do not appear in the post but which are unrelated to the topic of the post. One way of down-weighting these is to compare the set of comments associated with a particular blog post with all comments in the Blogger & WordPress sub-corpus (86 million tokens of comments). Table 4 shows the output from such a comparison, again using the log-likelihood measure. The words that have been up-weighted here are those which are relatively frequent in the comments associated with the Content Theft post in relation to the comments associated with all other posts in the sub-corpus.
| Word |
‘Content Theft’
Comment freq |
All
Comment freq |
L-L |
| attorney |
9 |
352 |
61.65 |
| advice |
26 |
11,112 |
60.53 |
| copying |
10 |
657 |
58.39 |
| legally |
8 |
422 |
50.13 |
| vandalism |
5 |
63 |
45.24 |
| plagiarist |
3 |
20 |
30.75 |
| duplicate |
5 |
348 |
28.63 |
| scraper |
3 |
30 |
28.46 |
| credited |
4 |
175 |
26.52 |
| copyrightable |
2 |
7 |
22.84 |
| paste |
6 |
1,156 |
22.65 |
| copyrighting |
2 |
8 |
22.37 |
| scrapers |
2 |
10 |
21.56 |
| republishing |
2 |
15 |
20.06 |
| rightful |
3 |
138 |
19.60 |
| plagiarize |
2 |
32 |
17.17 |
| crediting |
2 |
38 |
16.51 |
| republished |
2 |
39 |
16.41 |
| ripping |
3 |
306 |
14.96 |
| license |
4 |
893 |
14.00 |
Table 4. Top 20 key words in Content Theft comments compared with all comments
Taken individually, the words in Table 4 are of limited use in determining the aboutness of this particular blog post. However, we would argue that, taken as a set and used to supplement the text-internal aboutness indicators found in the post, the aboutness words extracted from the comments help to refine the aboutness profile for the post.
Furthermore, our detailed analyses of the lexical content of comments reveal that our techniques could be applied to the opposite problem: that of determining which comments are unrelated to the original post, either because they are off-topic or because they are topic-free. By topic-free comments, we mean comments which are purely evaluative, responding to the original post with phrases such as ‘Thank you for writing this. Very informative’ or simply ‘Cool post’ (both taken from the comment thread on the Content Theft post). The same statistical approach can be used in reverse to down-weight such comments (Table 5). The vast majority of words in this table are evaluative. Even words which occur frequently in the Content Theft comments (really, good, great, like) are down-weighted because they appear so frequently in comments in general.
Word |
‘Content Theft’
Comment freq |
All
Comment freq |
L-L |
| better |
9 |
71673 |
-9.83 |
| enjoyed |
1 |
27107 |
-10.36 |
| totally |
1 |
27454 |
-10.55 |
| loved |
2 |
37782 |
-12.11 |
| sharing |
3 |
45780 |
-12.77 |
| agree |
2 |
41660 |
-14.09 |
| books |
2 |
45983 |
-16.34 |
| really |
27 |
178700 |
-17.26 |
| back |
13 |
112318 |
-17.46 |
| awesome |
1 |
40436 |
-17.72 |
| story |
3 |
56396 |
-18.02 |
| amazing |
2 |
53067 |
-20.10 |
| good |
25 |
181215 |
-21.08 |
| great |
26 |
194110 |
-23.84 |
| fun |
2 |
74095 |
-31.64 |
| lovely |
1 |
72435 |
-36.13 |
| wonderful |
3 |
95701 |
-38.90 |
| like |
48 |
368069 |
-47.39 |
| love |
4 |
362030 |
-201.51 |
Table 5: Down-weighted words in Content Theft comments compared with all comments
By off-topic comments we refer mainly to spam. There are various automated software ‘bots’ designed to post spam comments in response to blog posts, often including a link to a website that the spammer is attempting to publicise. Running our own WordPress blog for our eMargin project, we are aware that each new post can generate up to a dozen spam comments. For higher-traffic blogs, the number of spam comments is undoubtedly much higher. However, blog hosting sites such as WordPress provide moderation tools so that comments do not appear until they have been checked by the blog author. Our experience analysing comments in our blog corpus has been that spam comments are not a major issue. We would suggest that this is either because spam attempts have been blocked by the blog author using the moderation tools or because our analysis of lexis across the whole set of comments associated with a post cancels out those individual spam comments which do manage to evade moderation. Where we have seen examples of spam comments in our blog corpus, these are usually very long sequences of unrelated sentences. In one extreme case a single comment contains 71,253 tokens. [9] Evidently, the blog authors have not employed the available moderation tools in such cases.
Not all off-topic comments are spam. We have noted in our studies of the blog corpus that, in longer comment threads, the topic will often shift subtly as new comments are added and new contributors take the discussion in different directions. It is beyond the scope of the current paper but we would like to explore this new diachronic aspect of aboutness in more depth, looking in particular at the role of the original author of the post in responding to reader comments. The design of the Birmingham Blog Corpus facilitates such analysis.
5. Beyond the Birmingham Blog Corpus
Any study based on a web corpus will face questions about the linguistic quality of the texts and the validity of conclusions drawn through the study of them. Some may offer the fact that the average online comment in our study is relatively short (38.35 tokens) with short sentences (8.28 tokens) as evidence of the poor linguistic quality of comments in general. Whilst there are undoubtedly many short, topic-free comments in our corpus, and whilst spam is always an issue in any web collection, we would argue that comments offer new possibilities for linguistic study. As we have pointed out in our discussion of spam comments, the problems are reduced if the commenting process is moderated, either by the original author of the post or by a third party.
Figure 2 gave an indication that blog-specific sections are now to be found on a wide range of newspaper websites, including the UK Telegraph, Guardian and Mirror, and the US Wall Street Journal and Washington Post. In fact, an increasing number of news websites are allowing readers to comment not simply on posts in the blog-specific section of the site but on all sections of the site, including ‘traditional’ news articles. Most news sites moderate reader comments, either through a process of pre-moderation, where comments require approval by editorial staff before they appear, or post-moderation, where comments appear immediately but are removed if found to breach the site rules. Some sites allow readers to vote on the comments left by other readers, thus providing an additional layer of filtering for spam or offensive comments. Hermida & Thurman (2008) provide a useful overview of comment facilities on UK newspaper websites.
We felt that news websites, with their larger audiences and stricter policing of reader contributions, may offer a different perspective on comments than that offered by our blog corpus. One of our existing sub-corpora in WebCorpLSE is of UK broadsheet newspapers, and part of this is made up of texts downloaded from The Guardian website, covering the period 2000-present. We had previously focussed on the main body of the article, ignoring the comment section at the bottom, but we have recently revisited the Guardian articles in our corpus and discovered that the commenting option was first enabled on the Guardian website in March 2006 with the launch of the Comment is Free section. This section allows non-journalists to write about issues in the news in the form of a blog post, and was described in the following way by the editor in its launch week:
Many of the conventions ingrained by 16 years as an editor on the print version of the Guardian have been turned on their head. Instead of rejecting all but a tiny number of pieces [...] we’ve invited several hundred people to blog as and when they want on any subject they choose and at any length. Instead of tight copy-editing - back and forth to writers, asking them to elaborate arguments, change introductions, and cut copy to fit - we’re checking mainly just for libel. [10]
This shift in policy has implications for all linguists who work with newspaper texts on the assumption that these will have been tightly edited in accordance with strict a house style. The launch of Comment is Free was an early step in the integration of so-called ‘user-generated content’ within newspaper websites. The following week, The Guardian began to allow reader comments on news articles across their website, and Hermida & Thurman (2008: 6) report that six UK newspaper sites were allowing reader comments of this type by November 2006.
Although we did not previously include reader comments in our newspaper corpus, we have recently re-accessed the URLs associated with all Guardian articles published since March 2006 and downloaded the associated comments. Of the 528,729 articles, 116,880 (22%) had at least one comment. This is higher than the 15% reported in the study of blog comments by Mishne & Glance (2006) but lower than the 78% in our own blog study. However, the reason that 78% of Guardian articles are without comments is that commenting is not allowed on these articles, as explained in the FAQ document:
In general we want to open comments up on our material wherever possible, but time and attention is finite (particularly in moderation resource) and we’ve learned from experience that some subjects and types of article attract less constructive or engaging debate than others. [...] Comments will generally not be open on content which is sensitive for legal reasons (e.g. where there’s a high risk of libel or contempt), or editorial reasons (could include: announcements of deaths, breaking news, stories about particularly divisive or emotional issues). In addition, where a number of threads are already open on a specific topic or story, we try to keep commenting to a single thread, to make it easier for people to find and follow the unfolding conversation.
The experiences outlined here are in line with the findings of Mishne & Glance (2006), who examined disputative comments in their blog corpus and found that posts about politics and religion generated the most heated debates.
We can look in more detail at the distribution of comments across those articles which do have at least one comment (Table 6). The largest proportion of articles in our Guardian corpus have between 41 and 50 comments, but the distribution would seem to suggest that there was once a limit of 50 comments per articles. [11] The average number of comments per article is 25.73 – more than twice the average in our blog corpus. The average comment length is 92.6 tokens – almost three times as long as the average blog comment. This is even more significant given that the strict Guardian moderation process means that there will be very few, if any, very long spam comments to inflate the average length. There is, then, scope for further analysis of comments in the newspaper corpus, in aboutness research and in wider linguistic study.
Number of
comments |
% of
articles |
| 1-10 |
34.7 |
| 11-20 |
14.1 |
| 21-30 |
9.1 |
| 31-40 |
6.8 |
| 41-50 |
35.2 |
| Over 50 |
0.1 |
Table 6. Number of comments per article on those Guardian articles with comments
6. Conclusion
In this paper, we have introduced the Birmingham Blog Corpus and illustrated one possible use for the reader comments associated with the blog posts in the corpus. In using comments as an aboutness indicator, we have been able to broaden the view of ‘what others may “read into” a text’ (Hutchins 1977: 2), going beyond what is possible through examination of the text alone or examination of the single-word tags associated with the text in folksonomies such as Delicious. Our case study demonstrated that, when analysing a text of almost 5000 tokens which had been assigned 380 unique tags in Delicious, there were still over 100 aboutness-indicating words in the comments section which did not appear either in the text or in the tags. We suggested a preliminary ranking of these aboutness words, taking into account the lexis used most frequently in comments in general. Further research is required to analyse the relationship between comment words and post words in more depth. The consideration of comments may be particularly useful in the indexing of short blog posts containing few words or blog posts which contain only a hyperlink, image or video, with no words in the body of the post at all.
This paper has also examined the growth of blogs in recent years and their increasing importance on the web as a whole. In their 2005 paper, Herring et al. predicted that
the purposes to which weblog software will be put and the conventions that will arise around them will become so diverse in the future that it will no longer be meaningful to speak of weblogs as a single genre. Rather [...] weblogs will become a ‘medium’, or in our term, a socio-technical format, whose convenience and general utility support a variety of uses. (2005: 164)
We would argue that this broadening of the definition of ‘blog’ is now almost complete. The uses to which the blog format is put go far beyond the ‘online journal or diary’ role suggested by the OED definition. We have highlighted the dominance of blogs in our WebCorpLSE ‘mini web’ sub-corpus, a randomly-crawled slice of the web, and have shown that the blog format is now being employed on a wide range of websites. In particular, we have explored the increasing role of blogs on newspaper websites, in terms of both blog-specific sub-sections and blog-like commenting features extending to traditional news articles.
In the past, blogs, as a particular genre or text-type, were of interest only in specific sub-fields of linguistic study. Now, we would concur with Herring et al. (2005) in saying that ‘blog’ is simply a particular kind of webpage format, which can contain almost any textual content. For this reason, we hope that the Birmingham Blog Corpus is of interest to linguists working across the discipline.
Sources
Web 2.0 definition: http://www.oreilly.com/pub/a//web2/archive/what-is-web-20.html.
CiteULike homepage: http://www.citeulike.org.
Connotea homepage: http://www.connotea.org/.
BibSonomy homepage: http://www.bibsonomy.org/.
Delicious homepage: https://del.icio.us.
BBC WebWise ‘Beginner’s guide to the internet’: http://www.bbc.co.uk/webwise/guides/how-to-get-a-blog [archive.org].
WebCorp homepage: http://www.webcorp.org.uk/.
KWiCFinder homepage: http://www.kwicfinder.com/KWiCFinder.html.
Blog Authorship Corpus: http://u.cs.biu.ac.il/~koppel/BlogCorpus.htm.
TREC Blog collection: http://ir.dcs.gla.ac.uk/wiki/TREC-BLOG.
WebCorp Linguist’s Search Engine (WebCorpLSE): http://www.webcorp.org.uk/lse.
Blogger blog publishing service: https://www.blogger.com. ‘Blogs of Note’ page: http://blogsofnote.blogspot.com/.
Alexa web traffic analysis service: http://www.alexa.com/siteinfo/blogger.com.
Typepad homepage: http://www.typepad.com/.
WordPress homepage: https://wordpress.com. ‘Freshly Pressed’ page: http://wordpress.com/#!/fresh/.
LiveJournal homepage: http://www.livejournal.com/.
BlogPulse homepage: http://nmincite.com/.
Birmingham Blog Corpus: http://www.webcorp.org.uk/blogs.
The blog-specific search tool provided by Google: http://www.google.com/blogsearch [archive.org].
Technorati homepage: http://technorati.com.
‘What do you do when someone steals your content?’ post URL: https://lorelle.wordpress.com/2006/04/10/what-do-you-do-when-someone-steals-your-content/.
WordPress blog for our eMargin project: http://emargin.bcu.ac.uk/blog/.
The Guardian website: https://www.theguardian.com/uk. Comment is Free section: https://www.theguardian.com/us/commentisfree. FAQ document: https://www.theguardian.com/community-faqs.
Notes
[1] The first definition of the noun weblog relates to the earlier (and unrelated) ‘file storing a detailed record of requests handled (and sometimes also errors generated) by a web server’.
[2] Schler et al. (2006) state that the corpus contains 295,526,889 words. However, the publicly-available version contains fewer words: ‘over 140 million’ according to the corpus web page at http://u.cs.biu.ac.il/~koppel/BlogCorpus.htm; 138,393,571 according to our WebCorpLSE tokeniser.
[3] Soon to be renamed ‘Google Blogs’ at the time of writing.
[4] Thus, all URLs containing the component ‘blogspot’ will also contain the component ‘com’.
[5] In this case, the code is the DIV style “post-body entry-content”. Through iterative refinement, we developed a series of rules to account for the variations in the different Blogger and WordPress templates.
[6] As explained at http://support.google.com/blogsearch/?hl=en.
[7] Google did once impose a limit of 500 comments per post but there is now no limit: http://support.google.com/blogger/bin/answer.py?hl=en&answer=42348 [archive.org].
[8] https://margaretandhelen.com/2010/11/24/thanksgiving-letter-to-the-family-2010/
[9] A comment on the post at http://gingajoy.blogspot.com/2008/01/yea-verily-what-i-have-learned-living.html. A Google search reveals that this same spam comment appears on over 12,000 other blog posts.
[10] https://www.theguardian.com/commentisfree/2006/mar/18/editorsweek
[11] The FAQ document does not mention any limit on the number of comments but does state that comment threads are closed ‘automatically after a particular period (this time limit is dependent on the section of the site: some conversations go on longer than others)’.
References
Bernardini, S., M. Baroni & S. Evert. 2006. “A WaCky Introduction”. Wacky! Working papers on the Web as Corpus, ed. by Marco M. Baroni & S. Bernardini. Bologna: GEDIT, 9–40. http://wackybook.sslmit.unibo.it/pdfs/bernardini.pdf
Davies, M. 2008–. The Corpus of Contemporary American English: 425 million words, 1990-present. http://corpus.byu.edu/coca/
Dunning, T. 1993. “Accurate methods for the statistics of surprise and coincidence”. Computational Linguistics 19(1): 61–74.
Hermida, A. & N. Thurman. 2008. “A clash of cultures: the integration of user-generated content within professional journalistic frameworks at British newspaper websites”. Journalism Practice 2(3): 343–356. http://opendepot.org/147/1/hermida_thurman_JP_2_3.pdf
Herring, S., L.A. Scheidt, E. Wright & S. Bonus. 2005. “Weblogs as a bridging genre”. Information Technology & People 18(2): 142–171. http://www.oed.com.libproxy.helsinki.fi/view/Entry/256743?redirected
Hutchins, W.J. 1977. “On the problem of ‘aboutness’ in document analysis”. Journal of Informatics, April 1977, 1(1): 17–35. http://www.hutchinsweb.me.uk/JInformatics-1977.pdf
Kehoe, A. 2006. “Diachronic linguistic analysis on the web with WebCorp”. The Changing Face of Corpus Linguistics, ed. by A. Renouf & A. Kehoe. Amsterdam: Rodopi, 297–307. http://rdues.bcu.ac.uk/publ/AJK_Diachronic_WebCorp_DRAFT.pdf
Kehoe, A. & M. Gee. 2007. “New corpora from the web: making web text more ‘text-like’”. Towards Multimedia in Corpus Studies, ed. by P. Pahta, I. Taavitsainen, T. Nevalainen & J. Tyrkkö. (Studies in Variation, Contacts and Change in English 2). Helsinki: Research Unit for Variation, Contacts, and Change in English. http://www.helsinki.fi/varieng/series/volumes/02/kehoe_gee/
Kehoe, A. & M. Gee. 2009. “Weaving Web data into a diachronic corpus patchwork”. Corpus Linguistics: Refinements & Reassessments, ed. by A. Renouf & A. Kehoe. Amsterdam: Rodopi, 255–279. http://rdues.bcu.ac.uk/publ/Kehoe_Gee-Diachronic_Corpus_Patchwork-DRAFT.pdf
Kehoe, A. & M. Gee. 2011. “Social Tagging: A new perspective on textual ‘aboutness’”. Methodological and Historical Dimensions of Corpus Linguistics, ed. by P. Rayson, S. Hoffmann & G. Leech. (Studies in Variation, Contacts and Change in English Volume 6). Helsinki: Research Unit for Variation, Contacts, and Change in English. http://www.helsinki.fi/varieng/journal/volumes/06/kehoe_gee/
Kehoe, A. & A. Renouf. 2002. “WebCorp: Applying the Web to Linguistics and Linguistics to the Web”. Proceedings of WWW 2002, Honolulu, Hawaii. Electronic publication. http://wwwconference.org/proceedings/www2002/poster/67/index.html
Mishne, G. & N. Glance. 2006. “Leave a Reply: An Analysis of Weblog Comments”. Third Annual Workshop on the Weblogging Ecosystem (WWW 2006). http://leonidzhukov.net/hse/2011/seminar/papers/www2006-blogcomments.pdf
Nesselhauf, N. 2007. “Diachronic analysis with the internet? Will and shall in ARCHER and in a corpus of e-texts from the web”. Corpus Linguistics and the Web, ed. by M. Hundt, N. Nesselhauf & C. Biewer. Amsterdam & New York: Rodopi, 287–305.
Phillips, M. 1985. Aspects of Text Structure: An Investigation of the Lexical Organization of Text. Amsterdam: North-Holland.
Potthast, M. 2009. “Measuring the Descriptiveness of Web Comments”. Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval. New York: ACM. http://www.uni-weimar.de/medien/webis/publications/papers/potthast_2009a.pdf
Schler, J., M. Koppel, S. Argamon & J. Pennebaker 2006. “Effects of Age and Gender on Blogging“. AAAI Spring Symposium on Computational Approaches for Analyzing Weblogs, April 2006, Stanford, CA. http://www.aaai.org/Papers/Symposia/Spring/2006/SS-06-03/SS06-03-039.pdf
Scott, M. 1996. WordSmith Tools. Oxford: OUP. http://www.lexically.net/wordsmith/
“weblog, n.”. OED Online. September 2012. Oxford University Press. http://www.oed.com.libproxy.helsinki.fi/view/Entry/256743?redirected (accessed November 19, 2012).
|