BNC Dependency Bank 1.0
Hans Martin Lehmann & Gerold Schneider
University of Zürich
Abstract
In this paper we present the first release version of our dependency bank for the British National Corpus. We describe the process of annotating the corpus with syntactic information, discuss the resulting dependency annotation and outline a database storage model for the annotation. We then present a web-based interface to the syntactically annotated data and provide an overview of its functionality. The use of fully automatically parsed data without massive manual intervention is far from unproblematic, given the limited accuracy of state of the art parsers. We discuss the problems inherent to automatic annotation and present strategies for coping with them. The purpose of this project is to give general linguists access to the wealth of syntactic and distributional information present in a large corpus like the British National Corpus.
1. Introduction
The large-scale use of syntactically annotated material for the purpose of general descriptive linguistics is a fairly recent development. Only with robust parsers like Pro3Gres (Schneider 2008) annotating a 100 million word corpus has become feasible at all. The dependency bank presented here is the result of several iterative development cycles in which the syntactic annotation has been used in linguistic analyses, evaluated and then revised in the light of the results. So far we have made use of dependency bank data in the study of syntax-lexis interactions in the active-passive alternation (Lehmann and Schneider 2009), in verb attached PP structures (Lehmann and Schneider 2011) and the dative shift alternation (Lehmann and Schneider 2012a). For more information about the dependency bank project and access to various online resources see this website as well as Lehmann and Schneider (2012b).
2. Annotation
In this section we describe the process of (re-)annotating the British National Corpus, taking the release version of the BNC XML as a starting point and resulting in a syntactically annotated dependency database. The British National Corpus is released in XML format with segmentation at sentence and word level. In terms of linguistic annotation it contains information like word-class and lemma. The headers also encode a wealth of contextual information concerning medium, domain, text type, age of speaker etc. For the purpose of automatic annotation we ignore all linguistic information and discard segmentation at the word-level. We decided to keep segmentation at the sentence level, which enables us to provide standard references to the original corpus. We also conserve contextual attributes at utterance and text level. In the present annotation chain we make use of the LT-TTT2 annotation framework. After tokenization, LT-TTT2 uses the maximum entropy tagger C&C (Curran and Clark 2003) for word-class annotation, morpha for lemmatization and its own chunker (Grover and Tobin 2006) for the identification of verb group chunks and base NP chunks.
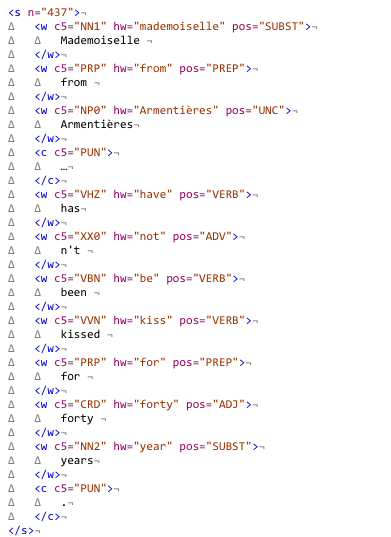
Let us consider the annotation of an s-unit found in the BNC (BNC:H0F:437). In a first step the original is stripped of linguistic annotation and segmentation at word-level, as illustrated in Figure 1. Contextual annotation is stored outside the text pipeline.
The orthographically normalized s-unit is then fed into the LT-TTT2 pipeline, which adds segmentation at word-level, lemma and part of speech tags and groups w-units into chunks (vg, ng, pg) in a next step. LT-TTT2 also provides detailed information for verb groups, for which tense, voice, aspect, modality and negation are indicated. The result is illustrated in Figure 2.
In turn, Pro3Gres, the dependency parser, then takes the tagged and chunked data as input. As many other tools developed in computational linguistics Pro3Gres builds on the PENN Treebank tag-set. Pro3Gres numbers the chunks created by LT-TTT2 and then performs its main task of providing dependency relations that hold between the chunks. A graphic representation of the parsed output can be seen in figure 3.
To linguists accustomed to constituency based syntactic representations, dependency based structures may look unfamiliar. Dependency Grammar (Tesnière 1959) focuses on grammatical relations, on government, on valency relations (e.g. Helbig 1992) and thus expresses the verb’s central valency relations like subject and object. From the verb, the concept of valency was then extended to other word classes like relational nouns or adjectives and also to adjuncts in addition to complements.
According to Tesnière, dependency relations hold between nuclei. The concept of nucleus roughly corresponds to noun and verb chunks (e.g. Abney 1995). Accordingly, the dependency relations that we produce generally have their origin in the main verb and establish links to noun chunks as a first step. These relations are what we refer to as major relation types. Their interpretation and the linguistic motivation is straightforward.
However, in order to obtain fully connected parses, also secondary nuclei like prepositions, complementizers and conjunctions need to be connected. It is far from obvious how this should be achieved in a linguistically meaningful way. Accordingly, many different approaches have been suggested. See Schneider (2008) for a discussion. In our approach, we attach complementizers to the verb in the subordinate clause and prepositions to the nouns in the PP. While these decisions can be seen as arbitrary, they mirror the original view taken by Dependency Grammar that governors should be content words and not functional categories. We refer to these relations as minor relations. In addition, relations inside a chunk, for example the relation between an NP head noun and its determiner, can also be described as dependency relations. We omit chunk internal relations in graphical representations and treat them as minor relations.
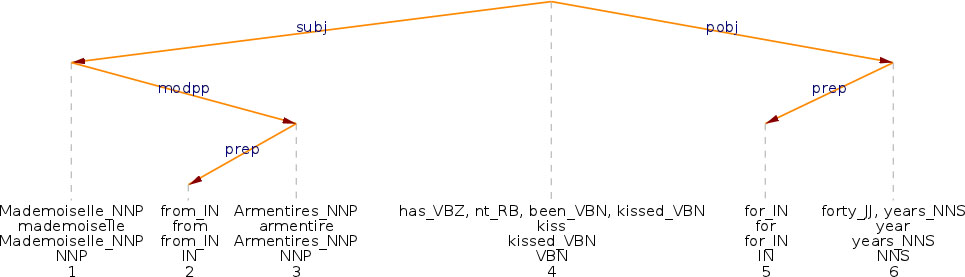
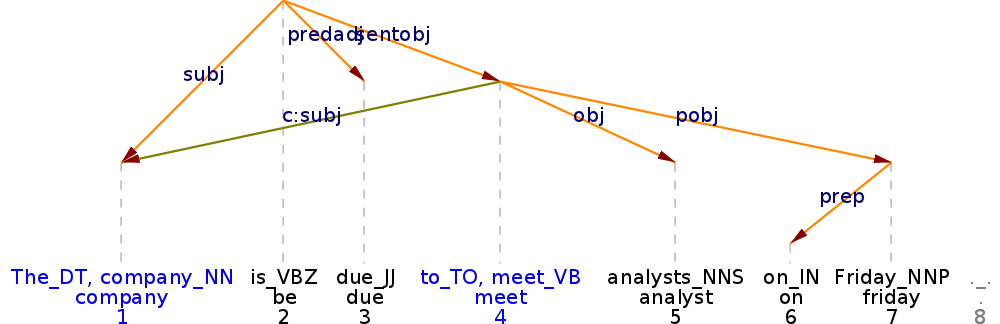
Generally, dependency grammar does not know empty categories. We represent long-distance dependencies with so-called secondary or indirect dependencies. For example, in the have-to construction in Figure 4, company is marked both as the overt subject of is and as the implicit subject of the subordinate clause that is headed by the verb meet. In Figure 5, we can see an indirect relation between meet and film-makers, expressing the ‘object’ role of film-makers in the subordinated relative clause. Such indirect links are not compatible with classic tree-structure, but related to traces of movements in GB (Government and Binding), or re-entrancy in HPSG (Head-Driven Phrase Structure Grammar). As a consequence we refer to the resulting structures as graphs.
In cases where the parser cannot assemble a connected dependency graph for an s-unit, it will report several fragments. These fragments are linked via a support relation labeled bridge.
Table 1 provides an overview of the dependency labels assigned by Pro3Gres. For technical reasons the parser distinguishes dependency relations that hold between chunks and relations that are chunk internal. In cases such as the auxiliary dependency there is a chunk internal relation labeled aux1, as in have met, and a chunk external relation labeled aux, as in the have you met where we see auxiliary-subject inversion and the chunker will not include have in the verb chunk. In the dependency bank we can group Pro3Gres labels to provide general linguists with conceptually unified labels.
| Pro3Gres labels |
BNC DB labels |
Example (Head - Dependent) |
| subj |
Subject |
He sleeps |
| obj |
Object |
She sees it |
| obj2 |
Second Object |
He gave her flowers |
| adj |
Nominal Adjuncts |
Shares rose Friday |
| modpp |
PP Attached to Noun |
draft of paper |
| pobj |
PP Attached to Verb |
slept in bed |
| iobj2 |
PP Attached to Verb as
Complement (subset of pobj) |
gave it to John |
| predadj |
Predicative Adjective |
This is great |
| prep |
Preposition |
to the house |
| vpart1 vpart |
Verbal Particle all |
hand in paper |
| pos1 pos |
Saxon Genitive all |
Peter’s car |
| sentobj |
Subordinate Clause |
She says that they are |
| compl |
Complementizer |
that they are |
| modrel |
Finite Relative Clause |
reports which said |
| modpart |
Reduced Relative Clause |
reports written then |
| modpart modrel |
Relative Clause |
[both of the above] |
| appos |
Apposition |
Mr. Miller, the chairman, |
| adv |
Adverb |
eat often |
| adjective |
Postposed Adjective |
the president elect |
| detmod1 |
Determiner |
the house |
| ncmod1 nchunk |
Noun Modification all |
the large house |
| aux1 aux |
Auxiliary all |
we have seen it |
| conj |
Conjunction |
Peter and Paul / Peter and Paul |
| passive |
Passive |
will be eaten |
| bridge |
Bridge |
[connects partial structures] |
| vpart |
Verbal Particle ci |
[ci or ce depends on chunker] |
| vpart1 |
Verbal Particle ce |
[ci or ce depends on chunker] |
| ncmod1 |
Noun Modification ci |
[ci or ce depends on chunker] |
| nchunk |
Noun Modification ce |
[ci or ce depends on chunker] |
| aux1 |
Auxiliary ci |
you have eaten |
| aux |
Auxiliary ce |
have you eaten |
| pos1 |
Saxon Genitive ci |
[ci or ce depends on chunker] |
| pos |
Saxon Genitive ce |
[ci or ce depends on chunker] |
Table 1. Dependency Relations in the BNC Dependency Bank
The dependency representation of Pro3Gres is very close to and can be mapped to the dependency parsing standard evaluation set GREVAL (Carroll et al. 2003) and the Stanford scheme (Haverinen et al. 2008).
Processing of the whole BNC corpus with the current version of our annotation pipeline (t6571) results in 78,361,274 chunks and 91,279,082 major and minor dependency relations. For instance, the annotated corpus contains 10,152,711 subj-relations and 5,916.106 obj-relations. The most frequent dependency is ncmod1 with 12,795,396 occurrences, which annotates chunk internal modification of nominal chunks. Working with such a large amount of data poses many problems. For smaller projects, it is possible to work directly with the Prolog output of the parser. However, with data sets like the parsed BNC this turned out not to be a viable option. In order to cope with large data sets, we make use of a relational database. We use MySQL, a relational SQL database system, for structured storage and analysis of the annotated data. The annotated material is represented in a set of four tables.
A general annotation table with one record per s-unit, where we store the different levels of annotation, the raw parser output, pointers to the source of the s-unit as well as keys for the association of meta-data. A table containing one record per dependency relation indicating the label, direction, direct or indirect attachment as well as the lemmas of the head and the dependent for every dependency relation. Additional information for each chunk is available in a third database. In addition to the lemma, it provides word-form, word-class and additional features like tense, voice, aspect, number and the presence of modals or negation. We also store information about the number and type of dependency relations that lead to, or originate in, the node. The fourth database contains meta-data, such as spoken or written, region, speaker age, word-frequencies etc.
The present setup permits direct querying of the annotated data via SQL queries. Complex queries as the ones used to extract result sets for the dative-shift alternation (cf. Lehmann and Schneider 2012a) can take several days to complete. However, an astonishingly large subset of queries performs fast enough for an interactive system.
3. BNC Dependency Bank
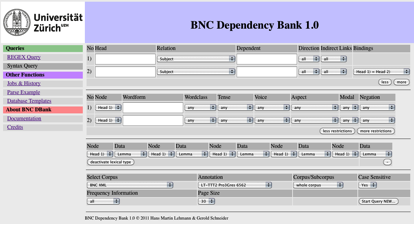
In this section we present the BNC Dependency Bank, an online interface for querying the dependency database described above. The web-based interface and the paging mechanism have a common ancestry with earlier projects like BNCweb (Lehmann et al. 2000) and ZEN Online (Lehmann et al. 2006), from which the BNC Dependency Bank also inherits the regular expression search functionality. The query mechanism that generates the result sets from the dependency database is an entirely new component written in SQL and Perl.
Figure 6 shows the new interface to the BNC Dependency Bank. The input page for syntactic queries consists of three parts. In the top section, a set of connected dependency relations is specified. The second section is optional and permits the specification of restrictions for individual chunks/nodes specified in the first section. The third section does not influence the result of the search itself. It optionally instructs the system to store a type specification during the search, which can be used to produce a frequency analysis of the result set.
3.1 Dependency Queries
Dependency queries are specified as a set of connected dependency relations. For each dependency relation, the relation label has to be specified. See table 1 for a list of relations. Alternatively, it is possible to specify the lemma of the head and the dependent of the relation. If more than one relation is specified, the way in which dependency relations are connected must be specified. Let us consider the verb give with a subject and a direct object and a prepositional object with the preposition to.
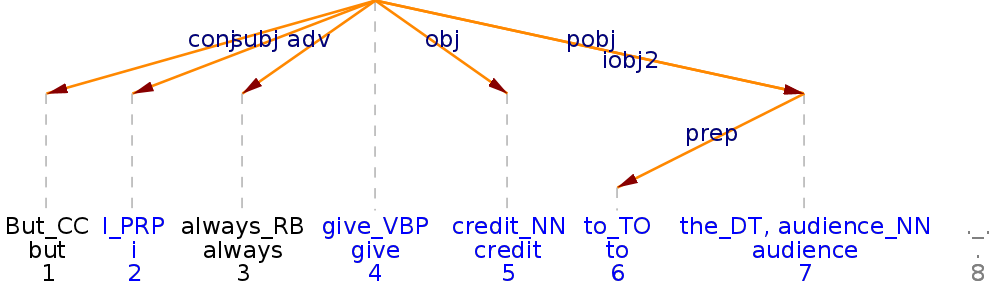
Figure 7 shows a dependency query with an example of a retrieved instance (BNC:C9K:1532). The query specifies three major dependencies of the verb give, i.e. subj, obj and pobj, an oblique NP (PP) attached to the verb. Typical for dependency syntax, the preposition is specified via a minor dependency of the nominal head of the oblique NP. The column direction specifically requires the subject to be left attached and the object and the oblique NP to be right attached. All the major relations are specified as direct, excluding long distance dependencies. The column labeled bindings is important as it permits the preposition dependency to originate not in the head but in the dependent of the previous dependency. We also make use of the head field by specifying the lemma of the head of the subject dependency and via the binding also the heads of the obj and pobj dependencies. Finally, we specify the lemma of the dependent of the prep dependency as to. In Figure 7, we can observe that the arch from give to audience is both labeled popj and iobj2. In fact, these are the labels of two separate dependency relations linking give and audience. While pobj only specifies audience as the head of an oblique NP attached to the verb give, iobj2 marks the noun group headed by audience as a complement of give. The query illustrated above results in a result set of 7,169 instances for the whole BNC.
3.2 Restricting Queries
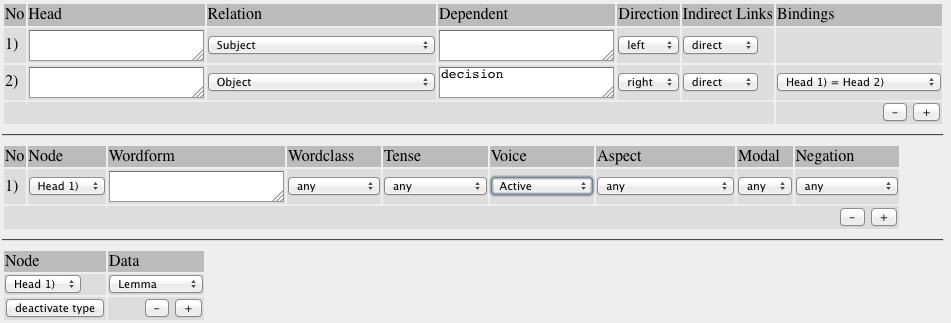
In the dependency specification above, we can directly specify the lemma for nodes in the dependency structure. In the restrictions section we can set further restrictions for every head or dependent node defined in the dependency specification.
The restrictions illustrated in Figure 8 require the head of the first dependency, the verb give, to be in the present perfect and also specify the presence of negation. The dependent of the second dependency is restricted by the tag NNS, i.e. general noun in the plural. These restrictions reduce the set of found instances from 7169 to the two instances shown.
3.3 Specifying Types
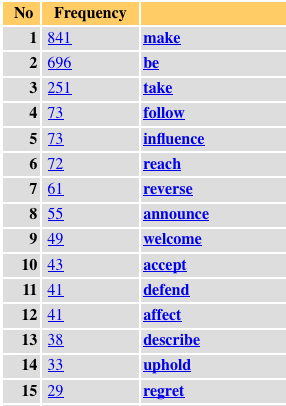
Unlike setting restrictions, the specification of a type does not have any influence on the number of instances found by the query. The specification of a type instructs the system to store a type specification with every instance found. This makes it possible to generate frequency breakdowns for the specified type. In Figure 9, we see a dependency query specifying a verb with a subject dependency and an object dependency with decision as head of dependent. The construction is restricted to the active voice. The query contains a type specification for the lemma of the head of dependency one. Running a frequency list command on the result set of the query produces the frequency breakdown shown in Figure 10, left column. Here we see that the most frequent verb in the construction is make, followed by the copula be, take, follow, influence etc. We make, take, follow decisions. In comparison, the right hand column shows a corresponding frequency breakdown for a query specifying decision as subject of passive verbs. We can see that, unlike make, take in combination with decision clearly favors the passive construction.
Figure 10. List of finite verbs taking decision as object in the written BNC
3.4 Contextual information
As mentioned above, contextual information is also stored in our relational database. In fact, every single utterance can be associated with information about the whole text such as medium, date of publication, domain as well as information concerning the individual utterance like the demographic details of the speaker. In combination with the contextual information we also store the basic word frequencies derived from the PENN-tokenized form of the corpus. Word-frequencies in our interface will be higher than frequencies derived from CLAWS-tokenization due to the use of multi-word entities (MWE).
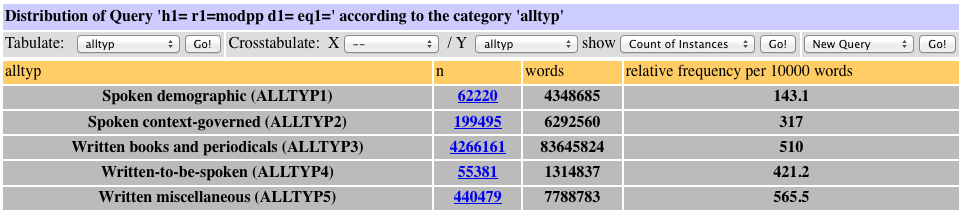
In our web-interface, the result sets produced by a dependency syntax query or a regular expression query can be tabulated and cross-tabulated with this information. A query for all noun-attached oblique NPs (PPs), as in the student of English, results in over 5 million results for the whole BNC. Figure 11 shows a tabulation of the 5 million instances according to the type (alltyp) category. In terms of relative frequency, we can observe a cline from the spoken demographic component to the written miscellaneous material with the context governed component and the written to be spoken material taking intermediate positions.
Queries may result in a fairly large proportion of unwanted instances. Cross-tabulating such unedited result sets with contextual data will thus be only of limited, explorative interest. In many cases, manual annotation in terms of excluding unwanted instances but also in terms of additional categorization is needed for meaningful results. The BNC Dependency Bank offers downloadable database templates for this purpose. The templates contain all contextual information and can also be used to calculate word-counts for arbitrary combinations of contextual categories.
4. A Word of Caution
The web-based interface puts a lot of power into the hands of the user. It provides easy access to native-like constructions, which can be used by linguists for illustrative purposes and by teachers in exercises as well as for exemplifying specific constructions. However, besides the new and exciting possibilities demonstrated above, there is also a huge potential for jumping to wrong conclusions.
The automatic annotation can result in observational gaps. For instance, a search for all verbs that can occur in a double object construction, will not find instances like cry me a river, because the parser only permits a closed set of verbs to take double objects, i.e. the parser as an observational instrument will prevent us from observing other verbs in double object constructions. Even if that parser rule is adapted to allow any verb to take two objects (cf. Lehmann and Schneider 2012a), constructions like e-mail him a picture will not be found, if the lexicon of the tagger only lists e-mail as a noun and thus does not provide the necessary verb reading for the parser. Of course we can amend the lexicon of the tagger in the case of e-mail. The problem, however, remains, as there is no systematic way of finding such observational gaps. To expect and account for these problems, the user of the database would need intimate knowledge of the rule-based grammar used by the parser in the first case and detailed knowledge of the lexicon used by the tagger in the second case.
Another problem is posed by the fact that — from the perspective of descriptive linguistics — state-of-the-art parsers are far from perfect. This certainly also holds for Pro3Gres. Table 2 shows evaluations of recall and precision for several sets of data and different versions of the annotation chain. What becomes immediately visible is that Pro3Gres misses about 15 % of all subjects and of the subjects reported more than 10% are false positives. Moreover, the results for other major dependencies are even less accurate.
| GREval |
Subject |
Object |
Noun-PP |
Verb-PP |
sub.clause |
| Precision |
92% |
89% |
74% |
72% |
74% |
| Recall |
81% |
84% |
65% |
85% |
62% |
| GENIA |
Subject |
Object |
Noun-PP |
Verb-PP |
sub.clause |
| Precicion |
90% |
| 93% |
85% |
82% |
| Recall |
87% |
91% |
82% |
84% |
|
| BNC World |
Subject |
Object |
Noun-PP |
Verb-PP |
sub.clause |
| Precision |
86% |
87% |
|
89% |
|
| Recall |
83% |
88% |
|
70% |
|
| BNC LT-TT2 |
Subject |
Object |
Noun-PP |
Verb-PP |
sub.clause |
| Precision |
89% |
75% |
75% |
83% |
73% |
| Recall |
86% |
83% |
77% |
69% |
63% |
Table 2. Evaluation of Pro3Gres parser on random subsets of several corpora
GREval (Carroll et al. 2003) is a manually annotated evaluation corpus of 500 sentences from the Susanne corpus. GENIA contains 100 manually annotated random sentences from the biomedical domain (Kim et al. 2003). We have manually annotated 100 sentences from two different pipelines of our system. BNC LT-TTT2 contains 100 random sentences from the LT-TTT2 pipeline used in this paper. BNC World contains 100 different random sentences from an earlier pipeline that is based on a different tagger and a different chunker. The evaluation differences between the two different BNC pipelines are partly random fluctuations as we have used a different 100 random sentence test set. Error sources include attachment errors but also tagging, chunking and lemmatization errors.
These general figures for precision and recall cannot be directly applied to specific queries. Complex queries will rely on a combination of several dependency types and it is generally not possible to derive the accuracy from the figures provided above. For descriptive purposes, the main problem lies with recall, given that low precision can be coped with by manually excluding unwanted instances (false positives). Without alternative discovery procedures, missing instances will simply not be visible in the query results. In the dependency bank, we provide two methods for estimating the recall of specific linguistic phenomena.
Our online interface offers the possibility of parsing individual sample sentences on the fly. Any sample input can be annotated as if it had been included in the corpus. A collection of sample sentences gleaned from grammars and articles as well as experimentation with constructed input can be used to expose problems with specific constructions. In our opinion, this functionality of the interface is more valuable than the most detailed description of the various annotation schemes, as the user can directly inspect the system’s performance.
In addition to dependency queries, the BNC Dependency Bank provides regular expression searches on tagged and untagged versions of the corpus. Regular expression searches tend to result in high recall at the expense of precision (e.g. Lehmann 1997: 192). Annotated and un-annotated flat-file versions of all sentences can be searched via regular expression queries. The flat-file data and the parsed data are aligned at s-unit level. From the result display of such a regex query the user has direct access to the dependency annotation of the s-unit containing the retrieved instance and can see whether it would have been reported by a dependency query. Regular expression queries for assessing recall may be formulated as complex patterns based on word-class tagging or as simple and complex lexical patterns that may result in high recall for a lexical sub-set of instances. Such a two-pronged approach offers a second strategy for identifying problems with recall of dependency queries. If carried out in a systematic way, this results in figures for recall that take the regular expression search as baseline. Besides the options provided by the interface, there remains the classic strategy of so-called manual retrieval or ocular scan for identifying problems with recall. Manual retrieval, however, is only a viable option for phenomena with a reasonable relative frequency.
5. Conclusion
In this paper we have given an overview of the process of annotating the BNC with the help of a dependency parser. We have presented the BNC dependency bank as a new resource for descriptive linguists. We have outlined the functionality provided by our web-based interface to the BNC Dependency Bank. We have also discussed potential pitfalls and traps for the unwary and strategies for dealing with the problems inherent to our approach based on automatic annotation.
There are many different directions in which we plan to further develop the dependency bank framework. An interesting option to explore is the improvement of the parser with the help of its own output. The very accessibility of the data may be used to revise, adapt and improve the parser, Pro3Gres, in iterative development cycles. There are many possible additions to the functionality of the web-based interface. Currently, we offer only frequency-based analyses of specified types. We envisage a system that permits a more sophisticated approach based on various measures of surprise. Also the cross-tabulations of contextual information and the specified types appear to be an interesting possible feature. Last but not least the framework can be used for the annotation of other corpora. With the complete linguistic annotation added by the framework itself, we find ideal conditions for comparing the BNC with other corpora and additional sources of linguistic data.
Sources
Dependency bank project: http://www.es.uzh.ch/en/Subsites/Projects/dbank.html.
LT-TTT2 annotation framework: http://www.ltg.ed.ac.uk/software/lt-ttt2/.
C&C maximum entropy tagger: http://svn.ask.it.usyd.edu.au/trac/candc/ [archive.org].
morpha: http://users.sussex.ac.uk/~johnca/morph.html.
References
Abney, Steven. 1995. “Chunks and dependencies: Bringing processing evidence to bear on syntax”. Computational Linguistics and the Foundations of Linguistic Theory, ed. by Jennifer Cole, Georgia Green & Jerry Morgan. CSLI: 145–164.
Carroll, John, Guido Minnen & Edward Briscoe. 2003. “Parser evaluation: using a grammatical relation annotation scheme”. Treebanks: Building and Using Parsed Corpora., ed. by Anne Abeillé. Dordrecht: Kluwer: 299–316.
Curran, James R. & Stephen Clark. 2003. “Investigating GIS and Smoothing for Maximum Entropy Taggers”. Proceedings of the 11th Meeting of the European Chapter of the Association for Computational Linguistics (EACL-03). Budapest, Hungary. 91–98.
Grover, Claire & Richard Tobin. 2006. “Rule-Based Chunking and Reusability”. Proceedings of the Fifth International Conference on Language Resources and Evaluation (LREC 2006), Genoa, Italy. 873–878.
Haverinen, Katri, Filip Ginter, Sampo Pyysalo & Tapio Salakoski. 2008. “Accurate conversion of dependency parses: targeting the Stanford scheme”. Proceedings of Third International Symposium on Semantic Mining in Biomedicine (SMBM 2008), Turku, Finland. 133–136.
Helbig, Gerhard. 1992. Probleme der Valenz- und Kasustheorie. Konzepte der Sprach- und Literaturwissenschaft. Tübingen: Niemeyer.
Kim, J.D., T. Ohta, Y. Tateisi & J. Tsujii. 2003. “GENIA corpus – a semantically annotated corpus for bio-textmining”. Bioinformatics 19(1): 180–182.
Lehmann, Hans Martin. 1997. “Automatic Retrieval of Zero Elements in a Computerised Corpus”. Corpus-based Studies in English. Papers from the Seventeenth International Conference on English Language Research on Computerized Corpora, ed. by Magnus Ljung. Amsterdam: Rodopi. 179–194.
Lehmann, Hans Martin, Caren auf dem Keller & Beni Ruef. 2006. “ZEN Corpus 1.0”. Corpus-based Studies of Diachronic English, ed. by Roberta Facchinetti & Matti Rissanen. Bern: Peter Lang. 135–155.
Lehmann, Hans Martin & Gerold Schneider. 2009. “Parser-based analysis of syntax-lexis interactions”. Corpora: pragmatics and discourse papers from the 29th International Conference on English Language Research on Computerized Corpora (ICAME 29), Ascona, Switzerland, 14-18 May 2008, ed. by Andreas H. Jucker, D. Daniel Schreier & Marianne Hundt. Amsterdam: Rodopi. 477–502.
Lehmann, Hans Martin & Gerold Schneider. 2011. “A large-scale investigation of verb-attached prepositional phrases”. Methodological and Historical Dimensions of Corpus Linguistics, ed. by Sebastian Hoffmann, Paul Rayson & Geoffrey Leech. (Studies in Variation, Contacts and Change in English 6). Helsinki: Research Unit for Variation, Contacts, and Change in English. http://www.helsinki.fi/varieng/series/volumes/06/.
Lehmann, Hans Martin & Gerold Schneider. 2012a. “Syntactic variation and lexical preference in the dative-shift alternation”. Corpus Linguistics and Variation in English. Theory and Description, ed. by Joybrato Mukherjee & Magnus Huber. Amsterdam: Rodopi. 65–76.
Lehmann, Hans Martin & Gerold Schneider. 2012b. “Dependency bank”. LREC 2012 Conference Workshop ‘Challenges in the Management of Large Corpora’, Istanbul, Turkey, 22 May 2012 – 22 May 2012. 23–28 http://dx.doi.org/10.5167/uzh-63508.
Lehmann, Hans Martin, Peter Schneider & Sebastian Hoffmann. 2000. “BNCweb”. Corpora Galore. Analyses and Techniques in Describing English, ed. by John Kirk. Amsterdam & Atlanta: Rodopi. 259–266 http://www.brill.com/products/book/corpora-galore-0.
Schneider, Gerold. 2008. Hybrid Long-Distance Functional Dependency Parsing. Doctoral Thesis, Institute of Computational Linguistics, University of Zurich. http://dx.doi.org/10.5167/uzh-7188.
Tesnière, Lucien. 1959. Eléments de syntaxe structurale. Paris: C. Klincksieck.
|