
Studies in Variation, Contacts and Change in English
Studies in Variation, Contacts and Change in English
Ole Schützler
Leipzig University
This chapter starts from the premise that the ways in which corpus linguists conceptualise and visualise frequencies (and frequency differences) have not been sufficiently problematised and need to be addressed in a more principled way. A key aspect in this is the non-linearity of frequency differences and its consequences for data displays, with a focus on normalised text frequencies, frequency differences, and proportions (or percentages) in diachronic research. These issues are relevant because, ultimately, they may strongly affect how we interpret results in empirical, corpus-based research. The chapter proceeds from general and theoretical considerations – rooted, for instance, in principles of numerical processing – to their application in data scaling and visualization. Researchers are supported in making decisions on three counts: (i) How to transform absolute frequency values, (ii) which plot types to use, and (iii) how to label and annotate graphs in an accessible and transparent way. Different ways of scaling and displaying frequencies will be introduced and compared, in order to provide recommendations for more informative, easily (and flexibly) interpretable displays. For illustration, the chapter draws on datasets from the published literature and offers modified visualisations of their findings. To aid researchers in applying suggested solutions, annotated R scripts are made available online.
Measuring the frequencies of occurrence of linguistic phenomena is central to many, if not most, corpus-linguistic studies (Tognini-Bonelli 2010; Baker et al. 2006, s.v. “frequency”). The term frequency may denote absolute frequency – e.g. the raw counts of a phenomenon – and relative frequency, i.e. counts normalised relative to some reference value. In this contribution, only the latter is of interest. It is further subdivided into (i) text frequency and (ii) percentages. This distinction is not made by all corpus linguists (see, for example, Baker et al. 2006, s.v. “frequency”; McEnery & Hardie 2012: 50), since the two frequency measures differ only in the baselines that they use (total number of words vs. variable contexts). However, this paper does differentiate between the two concepts and approaches them with different visualisation strategies. For one, the distinction between text frequency and percentages (or proportions) is traditionally important in corpus linguistics: Text frequency is used for phenomena that (seemingly) have no obvious envelope of variation, while percentages describe the share of a variant relative to all contexts in which it can occur. [1] For another, even if the percentage (or proportion) scale and the text frequency scale (e.g. pmw) are quite closely related in theory, they behave rather differently in practice.
Rates of occurrence are typically measured per 1 million words (pmw; cf. Lindquist & Levin 2018: 42; Baker et al. 2006, s.v. “frequency”), but may also be calculated relative to any other denominator, or “base of normalisation” (McEnery & Hardie 2012: 49), e.g. per 10,000 words. A proportion p is calculated by dividing the raw frequency of one variant by the total count of all variants of a phenomenon or variable; percentages simply rescale proportions to values between zero and one hundred. These frequency measures are summarised by the following formulae, where f is the raw frequency of a phenomenon, w is the number of words in a corpus, p is a proportion, P is a percentage, the index i denotes one of several alternating forms, F is the total count of variable contexts in which these alternating forms may occur, and v is the total number of variants if an alternation is inspected.
Text frequency (pmw): $$f_{pmw} = {f \over w} \times 1,000,000$$
Relative frequency:
a) Proportions $$p_i = {f_i \over F}$$
b) Percentages: $$P_i = p_i \times 100$$
These different quantifications of frequency are in essence uncontroversial. However, what I propose in this contribution is that our perception and intuitive evaluation of frequencies, and particularly frequency differences, is less straightforward and deserves theoretical discussion. The aim is to arrive at more conscious, better-informed methodological decisions in frequency-based, corpus-linguistic research. Following some theoretical preliminaries in Section 2, the issues that are involved will be discussed from an explicitly graphical perspective: Which ways of visualising frequency values, differences and changes exist, what are their respective advantages and disadvantages, and how well do they correspond to general principles of numerical perception?
Thus, different ways of scaling and displaying frequencies will be introduced, compared and weighed against each other, aiming at the formulation of best practices for more informative, easily (and flexibly) interpretable displays. The main argument revolves around the issue of whether frequencies should be treated as linear, nonlinear or both. Other aspects that are treated in their relation to the main topic include (i) the appropriateness of different plot types (e.g. bar charts vs. dot plots/line plots) in combination with the suggested approaches and (ii) the use of transparent and informative tick mark labels for logarithmically scaled plots. For illustration, previously published linguistic studies will be re-visualised, and the original displays will be directly compared to alternative ones.
The chapter is structured as follows: Section 2 discusses some general principles underlying numerical perception, with a particular focus on linearity and nonlinearity. Sections 3–5 are similar in structure: They explain theoretical aspects of three approaches to frequency and demonstrate the effects of nonlinear scaling by taking a fresh look at linguistic studies from the literature. The three aspects covered are normalised text frequency (Section 3), frequency differences and ratios (Section 4), and proportions/percentages in diachronic research (Section 5). Finally, Section 6 provides a general discussion, concluding remarks and suggestions for best practices in future research. Data and scripts used in this chapter can be found online at OSF.
The inspection and comparison of the frequencies of linguistic phenomena depends on our sense of numerical perception: Numbers – and differences between numbers – trigger sensations that can be described as ‘large’, ‘small’, ‘larger’ or ‘smaller’, for instance. In this paper, it is assumed that the perception of frequencies and frequency differences is governed by the same principles as numerical perception more generally. In this context, an important cognitive principle is that the meaning of numerical values and distances is relative. Dehaene (2011: 65), for instance, says that
[…] the parameter that governs the ease with which we distinguish two numbers is not so much their absolute numerical distance, but their distance relative to their size. Subjectively speaking, the distance between 8 and 9 is not identical to that between 1 and 2.
Between members of both number pairs in the example, the absolute difference is Δ = 1. However, a smaller distance will be perceived between 8 and 9 than between 1 and 2. Dehaene (2011: 65) discusses what he calls our “mental ruler”, i.e. the facility we use to measure and evaluate numbers, as follows:
It tends to compress larger numbers into a smaller space. Our brain represents quantities in a fashion not unlike the logarithmic scale on a slide rule, where equal space is allocated to the interval between 1 and 2, between 2 and 4, or between 4 and 8.
Experimental studies have pointed to a “bias for small numbers”, i.e. a tendency to give greater weight to differences and distances between smaller numbers, or to apply “the mental compression of larger numbers” (Dehaene 2011: 65). [2] Even in the strictly categorical, logical process of deciding whether two numbers are the same or different, respondents take measurably longer to declare 8 and 9 to be different as compared to the pair 1 and 2 (Dehaene 2011: 67; cf. Moyer & Landauer 1967). Issues like these are related to the “scaling problem”, i.e. the question as to whether numerical values should be scaled in a linear or logarithmic fashion, or by using a power function (Dehaene 2003: 145). Historically, debates of this kind were important during the emergence of psychology as a scientific discipline, although in this context ‘a continuum of sensation’ (e.g. of loudness or duration) was of interest, not pure numbers (Dehaene 2003: 145).
The relationship between physical (and by extension: numerical) stimuli and their perception and representation in the mind is captured by the Weber-Fechner Law. As concisely paraphrased by Portugal & Svaiter (2011: 73–74; see also Varshney & Sun 2013: 28–29), Weber’s (1851) work lead Fechner (1860) to conclude “that the intensity of a sensation is proportional to the logarithm of the intensity of the stimulus”. In other words: If we start from different baseline values and change the absolute stimulus intensity by a constant factor, the perceived difference in the sensation will be the same each time. As Dehaene (2003) explains, and as detailed above, these findings were later extended to non-physical domains, like the perception of numbers (e.g. Shepard et al. 1975), which makes them relevant for the present chapter.
Varshney & Sun (2013: 28; see also Sun et al. 2012) also discuss the “compressed logarithmic mapping” of numbers. [3] From a more broadly information-theoretic perspective they explain that psychophysicists aim to describe the mapping of physical signals (stimuli) onto mental percepts and representations in a way that minimises the remaining error, or noise. To do so, they experimentally search for the best mathematical link between the two domains (cf. Laming 2011: 13). The Weber-Fechner Law may not be “precisely true in all sensory regimes”, and alternative quantifications exist (e.g. Stevens 1961), but the log approach has proven extremely useful (Varshney & Sun 2013: 30; also see Portugal & Svaiter 2011).
In summary, there appears to be strong agreement on the following three points: (i) There is ample evidence to suggest that the mapping of physical stimuli onto mental percepts and representations is nonlinear; (ii) this has been shown to apply not only to physical stimuli (e.g. weight, pressure, heat or loudness), but also to numbers and numerical differences; and (iii) while a single scale may not be optimal for all kinds of quantities, the logarithmic transformation has been found to provide a very good (and often the best) approximation of those relationships. It is assumed that, since frequencies are numbers, the above is of relevance for frequency-based corpus linguistics. Finally, apart from providing an arguably more realistic model of how we perceive and intuitively evaluate frequency values and differences in corpus linguistics, using log scales has advantages of a purely visual kind, which will feature in the following sections.
Mathematically, the logarithm of a given value is the power (or exponent) to which a certain fixed value b – called the ‘base’ – needs to be raised to obtain that value. Thus, the logarithm of 512 to the base b = 2 equals 8, because 28 = 512; we write: log2 (512) = 8. Likewise, the logarithm of 1,000 to the base b = 10 equals 3 (since 103 = 1,000) – we write: log10 (1,000) = 3. To effect a certain change in the logged value, the input value needs to change by a certain factor, not by an absolute increment. Three central properties of logarithms discussed by Tukey (1977: 93) are the following:
| (i) | For the relative size of logged values it does not matter which base is used (e.g. log2, log10, loge/ln), since “logarithms to different bases differ only by multiplicatory constants” (cf. Fox & Weisberg 2011: 127); |
| (ii) | the logarithm (to any base) of 1 is zero; and |
| (iii) | the logarithm of zero is not defined (in R it returns the value ‘−Inf ’, i.e. an infinitely small value). |
Using log transformation raises several questions, four of which are discussed here: (i) Which base should be used, (ii) how can we deal with zero frequencies, (iii) how can readers be supported in relating logged values to the original input, and (iv) what plot types are appropriate in combination with log-scaled values?
For visualisation purposes, the choice of base is irrelevant, since the relative magnitude of values on a log scale are always the same, in the same sense that it does not make a visual difference whether we use percentages (0–100) or proportions (0–1). The issue of zero frequencies needs to be addressed, however, since it is impossible to represent f = 0 on a standard log scale. Since frequencies of zero do occur in language data, we find various workarounds in the literature. Thus, Clark & Trousdale (2009: 38) add 1 to each input value, while Schützler (2015: 43) corrects all values of f = 0 to f = 1. Since both studies apply quantitative methods (correlation/regression), they somehow need to manipulate zeroes in such a way as to include them in their set of logged values. In this chapter, however, with its focus on visualisation, a different approach is suggested. We will call this the ‘threshold’ approach and offer an explanation in connection with Figure 1 below.
While logged data communicate the relative sizes of values, linking logged values to the original scores is a difficult mental task. [4] In this chapter it is therefore proposed to label tick marks in the plot with the original (non-logged) values. The spacing of tick marks on a log-scaled axis can follow a properly exponential series (e.g. 1, 2, 4, 8, 16, 32, …) or an approximately exponential series (e.g. 1, 2, 5, 10, 20, 50, …), as suggested by Dehaene (2011: 66; see illustrations below).
Bar plots are commonly used in (synchronic) corpus linguistics (cf. Sönning 2016 and references therein). [5] They work best if they show the origin of the scale (f = 0); for logged data they are therefore not ideal, since logx (0) is not defined. If f > 0 across the board, we can freely define the lower and upper boundaries in the plot – as explained above – and thus achieve a good resolution of values. Plots of this type thus have a ‘floating’ scale, since they do not have a lower bound. This kind of log-scaled plot is contrasted with a traditional bar plot in Figure 1. There are three categories, A, B and C, with frequency values of 30, 80 and 130 pmw, respectively.
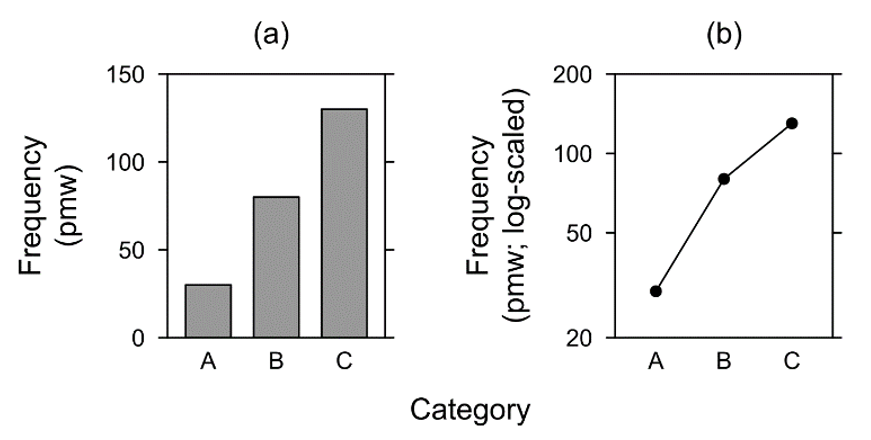
Figure 1. Text frequency: (a) Linearly-scaled bar plot, (b) floating log-scaled line plot, cut off at f = 20 pmw.
Figure 1a shows the regular increase by 50 pmw between categories A–C in a linear fashion. The origin of the scale (f = 0) is included, making the absolute magnitudes of values transparent. The plot in Figure 1b scales frequencies logarithmically but retains the original values as tick mark labels on the y-axis (also see Sönning, this volume) – the label of the y-axis makes explicit that we are looking not at log-frequency values, but at ‘normal’ values that are merely log-scaled. In contrast to Figure 1a, the visual distance between categories B and C is smaller than the one between categories A and B, since higher values are compressed. This plot has a ‘floating’ scale, since there is no point of origin (cf. Cleveland 1985: 81). If there was an additional category D, with fD = 0 pmw, we would plot this value in a shaded area below the value of 20 pmw, at some distance from the plotting region proper. Zeroes are thus shown as what they are (i.e. they are not manipulated onto the log scale), but at the same time it is made explicit that they are not part of the regular, log-scaled part of the figure. This is the threshold approach mentioned above; for an applied example see Figure 5b below. [6]
Before we proceed further, let us briefly comment on the appropriate use of axis and tick mark labels when showing transformed (e.g. log-scaled) values (see Wilke 2019: 17). If we decide to mark the original values along the y-axis, as we have done in Figure 1b, the axis label should refer to the original scale, i.e. “Frequency”. In general, the axis label should match the tick mark labels. Therefore, “Log frequency” would not have been appropriate here. Nevertheless, it is informative to add to the axis label information about the type of transformation used. The strategy we will adopt – and which we would recommend – is to add scaling details in parentheses, i.e. “Frequency (log-scaled)”.
Let us turn to a study by Rohdenburg & Schlüter (2009: 370–372) to illustrate the different approaches to synchronic investigations of text frequency. Their focus is on the frequencies of overly and plenty as premodifiers of adjectives and adverbs in American and British English (AmE; BrE) newspaper corpora. In both varieties, overly is more frequent than plenty, and both items are more frequent in AmE. The reader will be interested in three aspects:
| (i) | How frequent are the two items in the two varieties, |
| (ii) | how much more frequent than plenty is overly in each of them, and |
| (iii) | how much more frequent is each of the two items in AmE, compared to BrE? |
The discussion will move on directly to Figures 2b and 2c, while Figure 2a shows a plot resembling Rohdenburg & Schlüter’s (2009) original chart for comparison. [7]
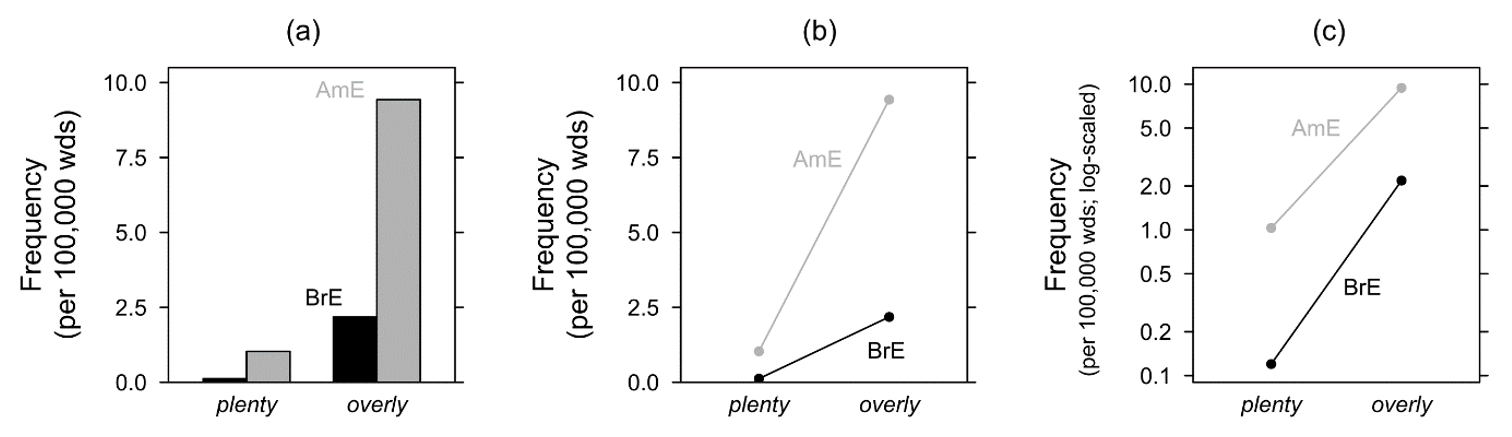
Figure 2. Premodifiers plenty and overly in BrE and AmE (based on Rohdenburg & Schlüter (2009: 372): (a) Linearly-scaled bar plot, (b) linearly-scaled line plot, (c) log-scaled line plot, ‘floating’, cut off at f = 0.9 per 100,000 wds.
The line plot in Figure 2b is based on exactly the same data as Figure 2a. It suggests the following conclusions: While overly is more frequent than plenty in both varieties, the steeper slope of the grey line indicates that, in absolute terms, this difference is greater in AmE. Secondly, for plenty, the frequency difference between varieties is rather small, while for overly it is substantial (compare the vertical space between black and grey dots). In the log-scaled plot of Figure 2c, a different picture emerges: In relative terms, the frequency difference between the two items is greater in BrE, and it is the frequency of plenty that differs more substantially between varieties. While both displays are based on the same data, panel (b) foregrounds absolute differences, and panel (c) communicates relative differences. The best advice may often be to graph both absolute and relative comparisons during data analysis. If the choice of a single perspective for data presentation and publication cannot be motivated, both can be shown and discussed.
Similar considerations apply to the plotting of text frequency in diachrony. Figure 3 is a schematic plot of the occurrence rate of two structures, A and B, across time. Again, we observe the compression of higher values and the expansion of lower values in the log-scaled plot in Figure 3b. For example, in Figure 3a, structure A seems to rise more steeply in frequency between periods 1 and 2 than structure B, while in the log-scaled representation their rates of change are quite similar. In the linear display, A appears to change at approximately the same rate between periods 1 and 2 and periods 3 and 4; in the log-scaled display, the rate of change is much slower in the later periods.
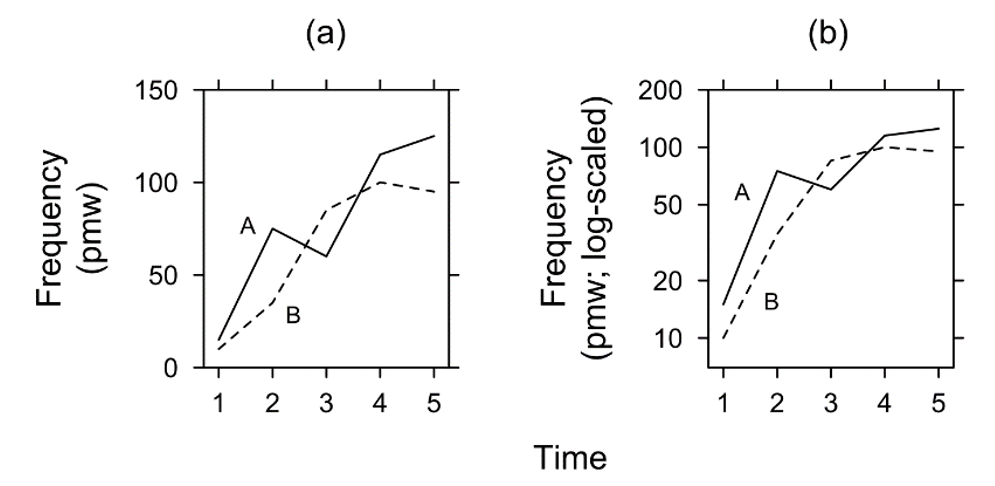
Figure 3. Text frequency in diachrony: (a) linear scaling and (b) log scaling, ‘floating’, cut off at f = 7 pmw.
Finally, B follows a roughly S-shaped course (cf. Section 6) between periods 1–4 in the linear display, while in the log-scaled display the curve is ballistic, with constantly decreasing rates of change in the vertical dimension. Whereas Figure 3a retains a point of origin at f = 0, Figure 3b is ‘floating’ in the sense discussed above: All frequencies are larger than zero and the lower bound of the y-axis is at f = 7. Looking at the trend across time from an absolute (Figure 3a) and a relative perspective (Figure 3b) leads to different linguistic interpretations about the propagation of these structures. Whichever of the two legitimate approaches we chose, we should state explicitly whether absolute or relative rates of change are under discussion.
To add linguistic context, let us turn to another example from the literature. Kranich (2010: 95, 107) investigates the text frequency of progressive verb forms in the ARCHER 2 corpus. She discusses her findings in terms of an S-curve and concludes that, while the slow beginning and the steeper rise in the middle are visible, the final stage – characterised by a flatter curve that levels off against some maximum – has not been reached. Figure 4a reproduces Kranich’s (2010: 107) plot, using normalized figures. [8]
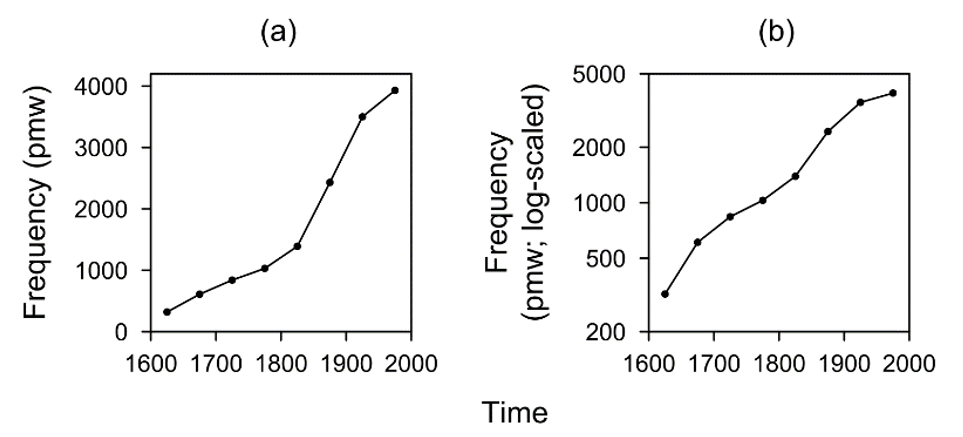
Figure 4. Diachronic changes in the frequencies of progressives (Kranich 2010: 95, 107): (a) linear scaling, (b) log-scaling, ‘floating’, cut off at f = 200 pmw.
Figure 4b represents the rate of occurrence on the log scale. The S-curve no longer materializes: Apart from minor variations, the rate of change is relatively constant. If we decide that ‘rate of change’ should be measured relative to some starting value, and if we rescale our frequency measurements accordingly, then the eye-catching S-curve pattern disappears. As an aside, finding S-curves in investigations of text frequency (like Kranich 2010) is intriguing: While we might expect such patterns on percentage or proportion scales (see Section 5), due to the upper and lower limits of such scales, they are more puzzling if the scale is practically unbounded at the upper end. One hypothesis would be that there exist relevant, unoperationalised baselines other than the size of the corpus (see Wallis & Mehl 2022). For example, if we measure progressives not per million words but relative to the number of all verb phrases, and if we further assume the density of verb phrases in texts to be relatively constant over time, this would also yield an S-curve that gives us a better idea as to the underlying mechanisms.
Another diachronic study that can illustrate the effects of scaling frequency logarithmically is Schützler (2018a: 109). The frequencies of four syntactic functions of the connective notwithstanding are traced through Late Modern and Present-day English in written AmE, using the Corpus of Historical American English (COHA; Davies 2010-): conjunct (1), subordinating conjunction (2), postposition (3) and preposition (4).
Figure 5 shows that the frequencies of all four construction types change over time. There are two issues with these particular data: (i) With the exception of the preposition, f = 0 at some point for all constructions, and (ii) frequencies are very unequal between construction types.
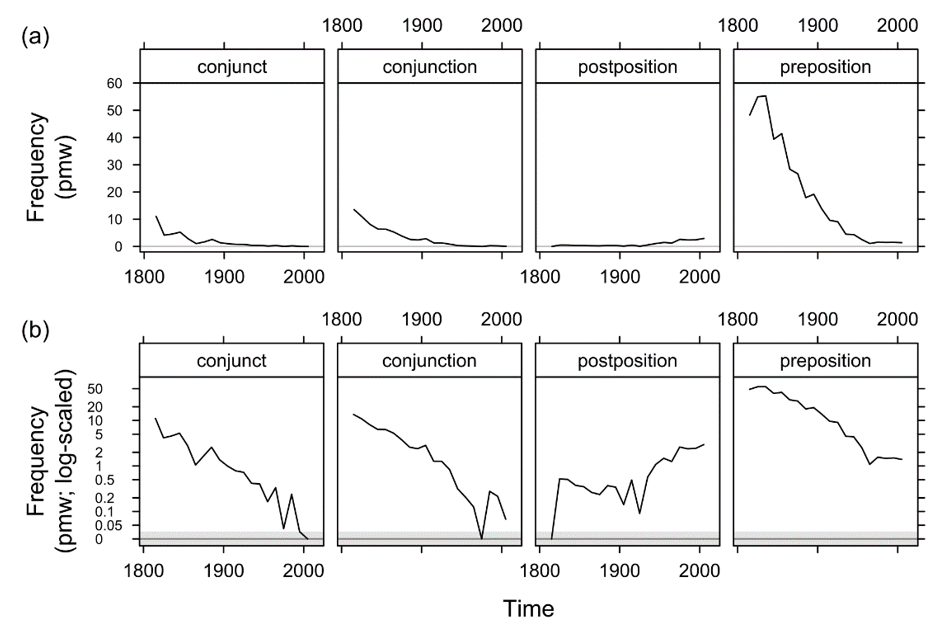
Figure 5. Diachronic changes in the frequency of notwithstanding (Schützler 2018a: 109): (a) linear scaling, (b) log-scaling, threshold at f = 0.036 pmw.
In Figure 5a, the first issue does not pose any problems, but the second one does: Resolution for the three less-frequent constructions is relatively poor, i.e. differences between low frequency values are hard to discern. In Figure 5b, the situation is reversed: Resolution is improved, but the occurrence of zero frequencies had to be dealt with by fixing a threshold at 0.036 pmw. [9] Minute frequency differences are now almost given too much weight – see for examples fluctuations in the late 20th century in panels 1 and 2 of Figure 5b, which suggest substantial and important variation if taken at face value. However, the absolute counts for notwithstanding as a conjunct or a conjunction are quite low in the period between the 1950s and the early 2000s. This is shown in Table 1, along with absolute frequencies for the other two constructions. One could argue that it is a matter of chance whether a phenomenon occurs once, twice, or not at all in a corpus. In Figure 5b, however, such small absolute differences are given enormous weight, due to the logarithmic scale. This must be regarded as a major weakness of log-scaled frequency displays.
| Time period | ||||||
|---|---|---|---|---|---|---|
| Construction | 1950s | 1960s | 1970s | 1980s | 1990s | 2000s |
| Conjunct | 4 | 8 | 1 | 6 | 1 | 0 |
| Conjunction | 5 | 3 | 0 | 7 | 6 | 2 |
| Postposition | 36 | 30 | 62 | 60 | 68 | 87 |
| Preposition | 62 | 26 | 37 | 37 | 42 | 41 |
Table 1. Absolute counts of notwithstanding-constructions in the late 20th century (COHA; Schützler 2018a)
To circumvent this issue, one might smooth the time series, e.g. using a simple moving average; one might permit the log scale to transition into a linear scale below some defined (low) value – an approach in fact used by Schützler (2018a); one might use a different transformation, e.g. a square-root scale; and one might in any case show an additional plot with normalised values that are scaled linearly. In sum, log scaling provides a better resolution of lower values if highly divergent frequencies need to be compared on the same scale, but it may also give undue importance to very small frequency differences at the lower end of the scale.
Frequencies can be compared in absolute terms and relative terms; the relevant quantities that are measured are differences and ratios, respectively. In Figure 1 above, for example, the absolute frequency difference between categories C (130 pmw) and B (80 pmw) is fC – fB = 50 pmw, while the frequency ratio is fC ÷ fB ≈ 1.6. That is, C is more frequent than B by a factor of 1.6. For reasons similar to those outlined for logged frequencies, I will argue that relative differences are in most corpus linguistic applications more meaningful, particularly if we inspect and compare frequency differences in rare and frequent phenomena at the same time: The absolute difference between 5 and 15 is the same as the one between 100 and 110, but the respective ratios are substantially different, at 3.0 and 1.1, respectively.
In applied work, the use of log ratios (rather than simple ratios; cf. Hardie 2014) yields two advantages: For one, they offer benefits in terms of resolution, which is crucial in data visualisation. For another, logged ratios create symmetry around the value that represents equality, while simple ratios do not. With log ratios, then, the magnitude of a difference does not depend on which value is divided by which. For example, in Figure 1, fC ÷ fB ≈ 1.6, as we have seen. In contrast, fB ÷ fC ≈ 0.6, a very different (smaller) value. The two values are not equidistant from 1. The respective log ratios are 0.21 and −0.21, respectively. Their unsigned values are the same, which is intuitively plausible since we simply changed the direction – but not the magnitude – of the effect, and they are centred around zero.
Unlike text frequencies and percentages (or proportions), differences are only sometimes discussed and visualised in corpus linguistics; ratios are even less commonly used (cf. Weisser 2016: 175–176). While seeing two frequencies vis-à-vis will give us some idea of the difference between them, directly measuring and plotting differences or ratios can be informative (see Sönning 2016 for examples). This section introduces three ways of expressing ‘difference’: (i) simple absolute differences, (ii) relative differences (or ratios) and (iii) log-scaled ratios (cf. Hardie 2014). These are illustrated in Figure 6 (based on Schützler 2018b), which visualises the frequencies of the conjunct though, as in the following sentences: John is already in his fifties. He looks much younger, though. Conjunct though is typically a feature of spoken, rather than written English (see Schützler 2020). Frequencies in the spoken and written parts of ten components of the International Corpus of English (ICE; Greenbaum 1996) are plotted in Figure 6a. The respective frequency differences, ratios and log-scaled ratios are shown in panels b–d.
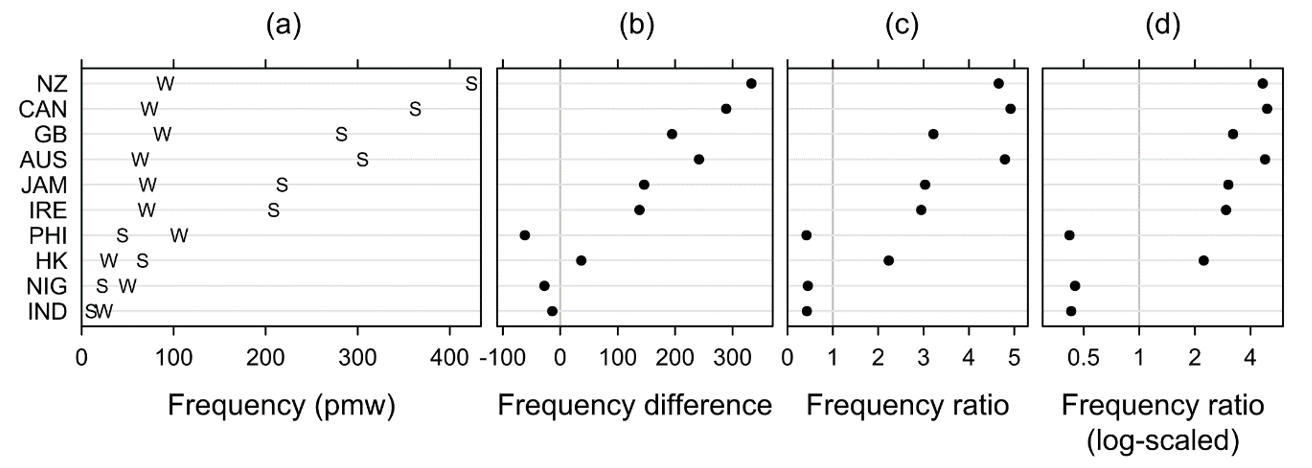
Figure 6. The conjunct though in spoken (S) and written (W) varieties of English: Frequencies (a), frequency differences (b), frequency ratios (c) and log-scaled frequency ratios (d).
It is plain to see in Figure 6a that, as expected, though is usually more frequent in spoken language, exceptions being Philippine, Nigerian and Indian English. [10] In Figure 6b, the difference fspoken − fwritten is plotted, and Figure 6c measures the frequency ratio fspoken / fwritten (cf. McEnery & Hardie 2012: 50) which is then arranged on a log scale in Figure 6d.
Absolute differences in frequency correlate strongly with the general frequency of a phenomenon. For example, in IndE the difference between frequencies – i.e. the divergence from zero in panel (b) – is lower than in any of the other varieties. When we inspect ratios in panel (c), however, we can see that relative differences are rather similar in IndE, NigE and PhilE, for example. We also observe that the frequency difference is greater in NZE than in CanE, while this ranking is inverted for frequency ratios. In short: Relative measures like ratios may lead to different conclusions in comparison to absolute measures, partly because they normalise for general differences in frequency. However, ratios still have the disadvantage that we get a rather different impression if numerator and denominator are exchanged. Thus, all the values to the right of the grey line in Figure 6c would be compressed into the narrow space between zero and one if the ratio was re-defined as fwritten / fspoken, and our perception of differences between varieties would change substantially. In contrast, if we use log-scaled ratios as in in Figure 6d, the relationships ‘twice as frequent’ and ‘half as frequent’ are visualised as equidistant (in different directions) from the neutral value (‘equally frequent’). Figure 6d uses the original ratios (not their logged values) to label tick marks on the y-axis, so that the reader can easily understand the real-word relationships between values. As a final illustration of the effect of this kind of plot, compare IndE and HKE in panels b–d of Figure 6: In panel (b), HKE seems to make a much greater difference between speech and writing concerning the frequency of though. This impression persists in panel (c), because the effect has different directions in both varieties. In panel (d), however, we can see that the relative difference between modes of production is rather similar in magnitude in both IndE and HKE, if of course differently signed.
The example in Figure 7 is based on the same data as Figure 2 (Rohdenburg & Schlüter 2009: 370–372), comparing the frequencies of overly and plenty as adjective or adverb premodifiers in BrE and AmE. In this case, the focus is not on the frequency values themselves, but on the differences between conditions. In Figure 7b, the absolute frequency difference between AmE and BrE is small for plenty (Δ = 0.91) compared to overly (Δ = 7.3). We arrive at different conclusions if ratios, not absolute differences, are measured. In Figure 7c, the ratio fAmE / fBrE is greater for plenty (R = 8.6) than for overly (R = 4.3).
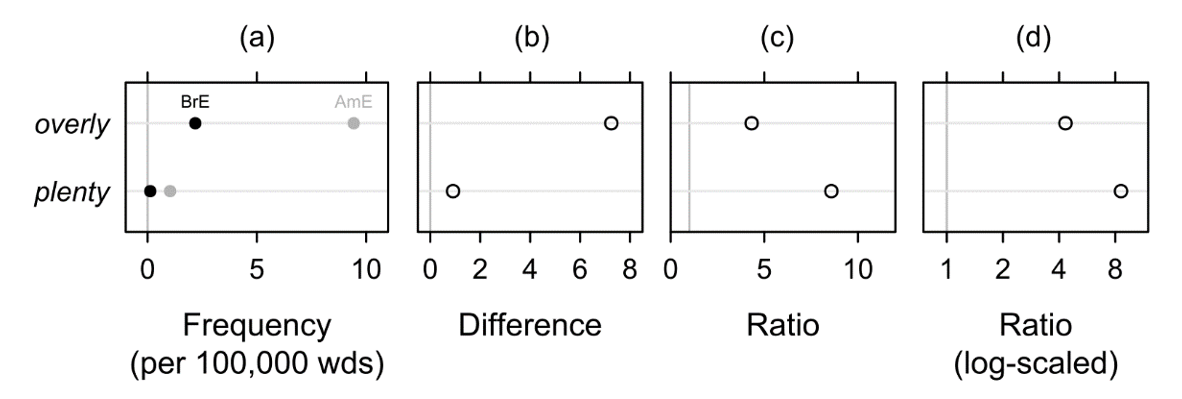
Figure 7. The premodifiers overly and plenty in BrE and AmE (based on Rohdenburg & Schlüter 2009: 370–372): Frequencies (a), differences (b), ratios (c) and log-scaled ratios (d).
Again, inverting numerator and denominator for the calculation of ratios in Figure 7c would confine both values to the narrow space of 0 < R < 1, to the left of the grey vertical line. This would not happen in Figure 7d: The values of R = 0.12 (the inversion of R = 8.6 for plenty) and R = 0.23 (the inversion of R = 4.3 for overly) would still be relocated to the left of the vertical line, but their distances from the grey vertical line at R = 1 would remain the same. This may not seem particularly important in this example, where both items are more frequent in AmE. However, if some of our phenomena are more frequent in BrE, log-scaled ratios are not only visually more informative but also avoid bias in one direction or the other. It remains a problem that ratios (and log ratios) can only be calculated if f ≠ 0 in both the numerator and the denominator. If one of these conditions is not met, we can use threshold values and treat the resulting log ratios as similarly exceptional as logged zero frequencies, as discussed in Section 3.
The main advantage of relative comparisons is that, compared to simple (absolute) differences, they are easier to process and have greater cognitive immediacy for the reader, a conclusion that rests on our acceptance of the general principles of numerical perception outlined in Section 2 above. At the same time, logged ratios facilitate comparisons of very large and very small relative differences in a single display. [11] At the very least, therefore, it is proposed that we show (log-scaled) ratios along with absolute differences.
Fox & Weisberg (2011: 133–134) characterise percentages and proportions as “restricted-range variables” that may be subject to “ceiling or floor effects”, i.e. a greater density or weight of values near the extremes, {0, 1} or {0, 100}, respectively. They further write that,
[b]ecause small changes in a proportion near 0 or 1 are much more important than small changes near 0.5, potentially useful transformations will spread out both large and small proportions relative to proportions near 0.5.
This notion is related to what was discussed in the context of logarithms in Section 3. However, with proportions or percentages, there is not only a lower bound to the scale but also an upper one, and this affects the kind of nonlinearity that is relevant here: An increase from 2% to 4% is equivalent to an increase from 96% to 98%, and both are considerably more substantial than an increase from 52% to 54%. The notion of the ceiling and floor effect (cf. Fox & Weisberg 2011) is more easily understood if we remember that a proportion or percentage measures the frequency of a category relative to one or more alternative categories: As the proportion of one variant changes from 98% to 99% (a small relative change), the share of alternative variants changes from 2% to 1% (a substantial relative change), and vice versa.
One transformation that “will spread out both large and small proportions relative to proportions near 0.5” (Fox & Weisberg 2011: 133) is the arcsine square-root transformation; another is the log-odds or logit transformation. The latter is adopted here: Although still rather abstract, it is intuitively at least somewhat more plausible (converting proportions to odds, then logging the odds), and it may be familiar from logistic regression analyses, where it serves as a link function (see Luke 2004: 53–54; Agresti & Finlay 2009: 484). Figure 8 shows the relationship between proportions/percentages and logits.
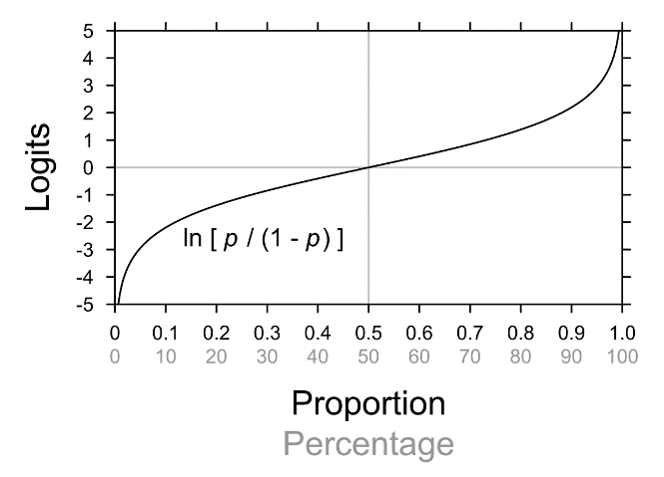
Figure 8. Logits as a function of proportions/percentages.
Beyond the frequencies themselves (be it text frequencies or percentages), rates of change are often of interest in sociolinguistics and in investigations of language variation and change more generally. In our discussion we will focus on such diachronic developments; applying the principles outlined below to percentages in synchrony is possible but generates less convincing results.
A central concept in the literature is the S-curve, as described, for example, by Osgood & Sebeok (1954: 155):
The process of change in the community would most probably be represented by an S-curve. The rate of change would probably be slow at first, appearing in the speech of innovators […], or more likely young children; become relatively rapid as these young people become the agents of differential reinforcement; and taper off as fewer and fewer older and more marginal individuals remain to continue the old forms.
Weinreich et al. (1968: 113) even speak of the S-curve pattern as “a lawful course” of change. Bailey (1973: 77) essentially echoes these views, but adds that the middle part of the curve with its more rapid rate of change begins when the novel variant appears in about 20% of the relevant contexts. Finally, Chambers (1992: 695) talks about critical thresholds both for the speeding up (at 20%) and the slowing down (at 80%) of the change:
The empirical basis underlying the S-curve is the sparsity of speakers caught in the middle three fifths, 20–80%, at any given time, in contrast to the clusters of speakers found at either end. These figures are taken to signify that speakers must sporadically acquire new pronunciations for about 20% of the available instances as the basis for generalizing a rule, and that, once the process becomes rule-governed, about 80% of the instances will be affected immediately, with some portion of the remaining instances […] resisting change and perhaps remaining as residue.
The S-curve as a general law describing patterns of change is propagated in innumerable publications (e.g. Labov 1994: 65–66; Denison 1999, 2003; Blythe & Croft 2012: 278 and further sources therein). Kroch (1989), however, presents a view diametrically opposed to the mainstream one and proposes the “constant rate hypothesis”. Kroch’s argument builds upon the logistic function (see Section 5 above): When proportions are converted into logits, the gradient of an S-curve becomes almost linear. He then proceeds to reanalyse four linguistic studies with this method, among them Ellegård’s (1953) investigation of the rise of do-support in Early Modern English.
As explained by Fox & Weisberg (2011: 133–134; see above), the logit-transform increases the weight of percentage changes near the two extremes (0% and 100%), at the same time decreasing the weight of changes near the centre of the scale. That is, the S-curve pattern may be a recurring pattern if we use a standard percentage scale, but it will be much reduced (or will not surface at all) on the logit scale. Figure 9 is a schematic illustration. It shows two diachronic frequency patterns through time: If we use a standard percentage scale as in Figure 9a, phenomenon A increases in frequency along a perfectly linear trajectory, while phenomenon B follows a typical S-curve. Both patterns start at 0% and reach 100%.
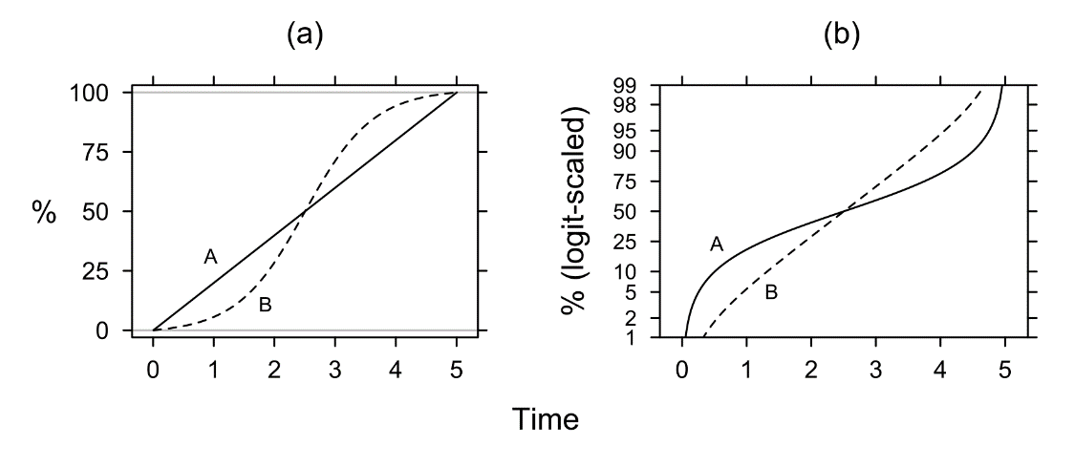
Figure 9. Percentages (a) and logit-scaled percentages (b) for diachronic research.
Using a logit-scaled percentage axis in Figure 9b, the constant rate of change of phenomenon A becomes distinctly ‘warped’: The rate of change is now evaluated to be much more rapid up to about 20% and above 80%. By contrast, phenomenon B no longer changes along an S-curve but has become quasi-linear. Particularly the pattern of phenomenon A in Figure 9b once again illustrates that logits are not defined for 0% and 100% (see Figure 8 above). For diachronic data, we can also place values of 0% and 100% outside the logit-scaled area and make their exceptional status explicit.
Like Kroch (1989), I will use the well-known study by Ellegård (1953) to illustrate how logit-scaled percentages put the traditional S-curve pattern in a different light. Ellegård investigates the rise of do-support in different constructions in English prose texts from the fifteenth to the early eighteenth century. Figure 10a reproduces Ellegård’s results, focusing on three of the five construction types he investigated. These patterns have been argued to constitute good representatives of S-curves, being characterised by a slow rate of increase at the beginning, some point of acceleration, and a more or less clearly defined final stabilisation phase (which had not been reached yet by negative declaratives in the early eighteenth century).
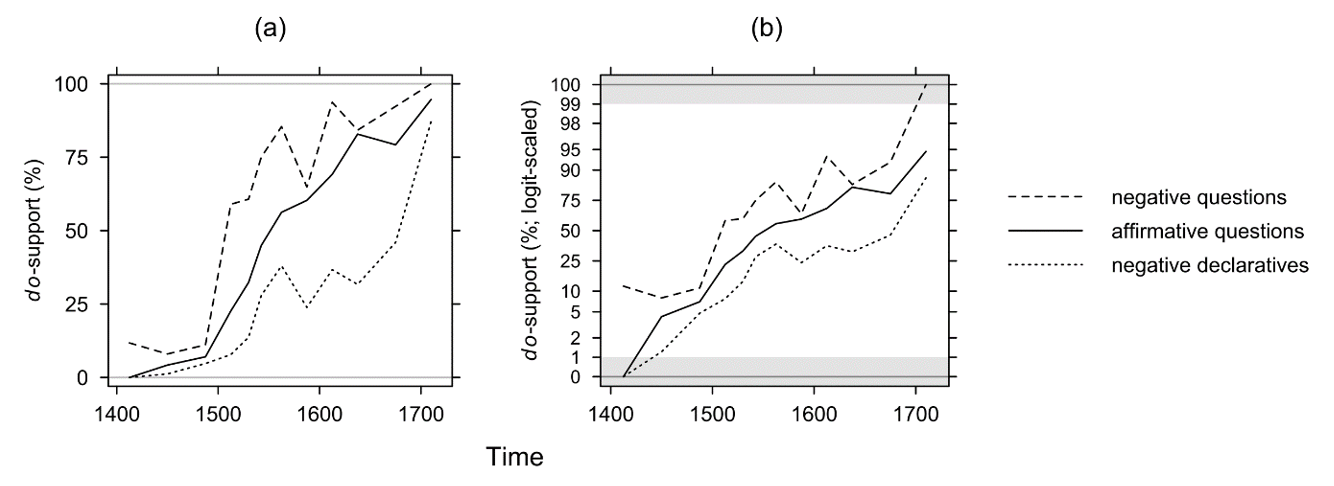
Figure 10. Changing percentages (a) and logit-scaled percentages (b) of do-support with different construction types (Ellegård 1953).
The logit-scaled plot in Figure 10b shows that, apart from the considerable irregularities typically found in descriptive corpus studies of this kind, the percentage of do-support in all three construction types increases relatively steadily over time. Furthermore, in contrast to Figure 10a, affirmative questions and negative declaratives are evaluated as being still relatively far from categorically using do-support, even though in absolute terms they reach levels of 95% and 87%, respectively.
Another study by Devitt (1989) investigates (among other things) the change from the preterite suffix <-it> (as in grantit and allowit) to the anglicised form <-ed> in different genres of sixteenth- and seventeenth-century Scots. Figure 11 reproduces her results for four of the five text types that are part of the study, omitting private records.
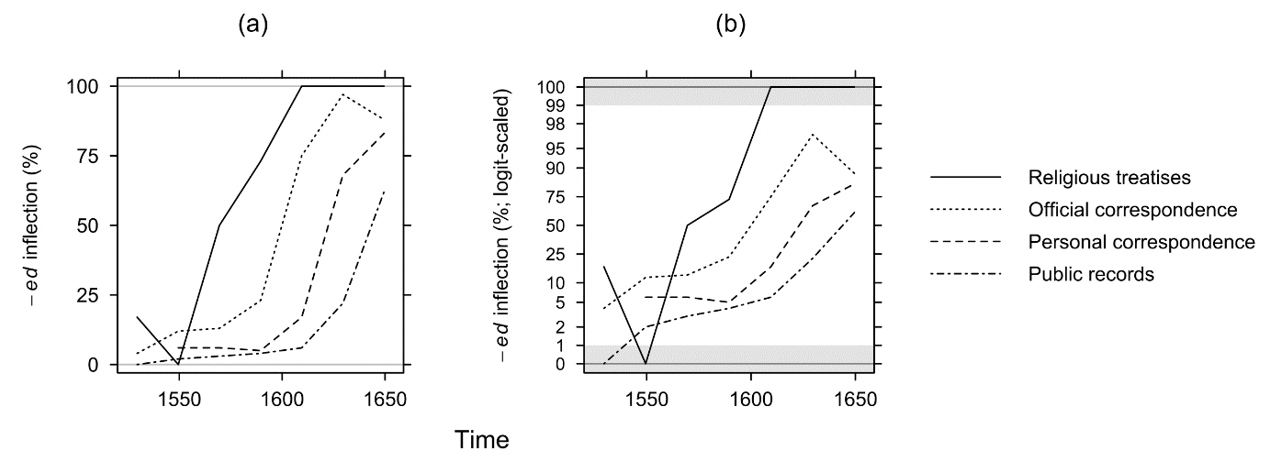
Figure 11. Percentages (a) and logit-scaled percentages (b) of anglicised past-tense inflection in Scots (Devitt 1989: 60, 97).
In her interpretation, Devitt (1989: 60) argues that, while the standardising southern variant <-ed> spreads in a clear S-curve in each genre, “the rapid middle stage occurs earlier in the more highly anglicized genres and later in the less anglicized genres”. This pattern can be seen in Figure 11a. Devitt concludes that “[t]he regularity of this pattern supports both the importance of the S-curve as a description of diffusion and the importance of genre as a crucial variable”. I would concur with the second statement, but not with the first: If percentages are shown in a logit-scaled display, which gives greater weight to the more extreme values near the poles of the scale (Figure 11b), the S-curve patterns disappear. The visualisation now suggests that the change starts earlier and progresses faster in religious treatises; the other genres are time-shifted, but rates of change are very similar between them. That is, the general interpretation does not change fundamentally, but it is perhaps not always helpful to actively look for S-curve patterns to emerge, as they may simply be an artefact of constrained scales, and the underlying processes may be relatively linear. Thus, for example, we should perhaps not over-interpret the fact that the genre of public records in Figure 11a still increases relatively steeply in absolute terms at the end of the period, while the other genres are beginning to stabilise.
This paper mainly revolved around the notion that numbers, and thus frequencies in corpus linguistics, are perceived in a nonlinear way, and that it is thus relative, not absolute values that count. The focus was on the consequences of this notion for the visualisation of corpus-based results. If researchers adopt this way of thinking, they face mainly three decisions: (i) How to transform absolute frequency values, (ii) which plot types to use, and (iii) how to label plots in an accessible and transparent way.
It was argued that logarithmic transformations of text frequency can provide the link between absolute frequencies and their evaluation; it was further suggested that it is more informative to compare frequencies by means of log-scaled ratios rather than absolute differences; finally, for proportions or percentages in diachronic research, the logit-transform was proposed. All such transformations have the effect of expanding certain parts of the underlying linear scales and compressing others. As soon as such nonlinear transformations are used, the traditional bar plot may be problematic, since it is best understood if it has a point of origin, and this point of origin is lost if values of zero are logged, or if proportions of {0, 1} undergo the logit-transform. As alternatives, dot plots or line plots were suggested. If, for example, in a given dataset f > 0 for all text frequencies or 0 < p < 1 for all proportions, the lower boundary of the plotting region can be freely chosen, resulting in what was called a “floating” display. If, on the other hand, there are values of f = 0 or p ∈ {0, 1}, those extreme values can be plotted as exceptional and categorically different by placing them in a highlighted (shaded) area outside the logarithmically- or logit-scaled plotting area.
While the positions of frequency values relative to each other will thus be based on their logged (or logit-transformed) values, the original, non-transformed values can be used to label the tick marks on the frequency axis. Readers will thus be able to relate to quantities they understand (e.g. occurrences pmw, or percentages), but the visual representation (i.e. the spacing) will still reflect the relative importance of values. Plots that use nonlinear scaling in combination with the original values will thus be intuitively easy to read. The terms ‘log-scaled’ and ‘logit-scaled’ were proposed in this chapter, and frequency axes were accordingly labelled as ‘Frequency (pmw; log-scaled)’ (rather than ‘Log-frequency’) and ‘% (logit-scaled)’ (rather than ‘Logits’).
It was shown that applying those principles results in plots that differ from traditional ones: For text frequencies, lower values (and differences between them) gain in importance – resolution at the lower end of the scale is improved, i.e. small differences near zero become clearly visible. Conversely, higher values are compressed, and large absolute differences in higher regions of the frequency space will be represented as less important. For percentages (and proportions), the process is slightly different as values both near 0% and 100% will be spaced more generously, while values in the central region around 50% will be compressed. This approach has serious consequences particularly for scenarios of language change and our interpretation of the patterns that we find in corpora. It was shown, for instance, that S-curve patterns may disappear from displays that represent relative differences among data points, since such patterns will appear as quasi-linear in a logit-scaled percentage space – see Kroch’s (1989) “constant rate hypothesis”. In the context of historical linguistics, Hilpert (2011: 51) says that “[i]f an item increases or decreases substantially in frequency, that signals a process of change in the language system [...]”. When, however, do we consider a change – or, for that matter, a general frequency difference – to be “substantial”? I would argue that relative measures (and plots using relative, nonlinear scaling) provide a better basis for assessments of this type than traditional, linearly-scaled ones, and that we should think more carefully about our general notion and definition of “rate”. Hilpert (2011) goes on to discuss the relationship between frequency on the one hand and mental chunking and processing on the other. Concerning these cognitive or psycholinguistic aspects it may be even more important to think about the true link between observed absolute frequencies and mental mapping, and it may be in this area that the mechanisms of numerical perception and processing outlined in Section 2 are particularly relevant. If we assume – as cognitive linguists tend to do – that language processing and the formation of our mental grammar are based on similar general principles as other domains (spatial, temporal, sensory or numerical processing), then we should let those other domains inform our linguistic research. This not only concerns descriptive approaches to language variation and change, but also functionally motivated accounts that draw upon the relationship of frequency and grammaticalization, for example (e.g. Krug 1998).
The approaches to the visualisation of frequency presented in this chapter are motivated by general, psycho-physical principles of human perception; they are relatively easy to implement; and they can be used in addition or as alternatives to traditional, linear plots. In many cases, using a nonlinear transformation of frequencies will have an effect on the interpretation of our results, which can be quite substantial. If there is no clear reason for using either linear or nonlinear plots, presenting both types of visualisation will therefore be the most informative and balanced approach – at the very least at the data analysis stage, but possibly also when presenting or publishing our findings. When thinking about the quantification and visualisation of their corpus data in future research, the arguments that were put forward in this contribution should help linguists to make informed decisions of this kind.
[1] See Wallis & Mehl (2022) for a critical discussion of the baseline issue in corpus linguistics. [Go back up]
[2] Experiments include the spontaneous judgment of distances between numbers, or the generation of random numbers in a specified number space, for example. [Go back up]
[3] According to them, the linear treatment of number scales is a learned habit, which, by implication, can be unlearned. [Go back up]
[4] For example, a calculator will be required to establish that log2 (f) = 1.3 corresponds to f = 2.46, log10 (f) = 2.1 corresponds to f = 126, and loge (f) = −1.5 corresponds to f = 0.22. [Go back up]
[5] Editorial note: Also see our survey in the first chapter. [Go back up]
[6] Our approach differs somewhat from what Cleveland (1985: 85-86) suggests, namely that scale breaks should always be “full scale breaks” (see Sönning, this volume), with no suggestion that data points beyond the scale break are connected to the rest. In any case, the scale break must be made explicit. [Go back up]
[7] For a discussion of the advantages of line plots compared to bar plots see Sönning (this volume). [Go back up]
[8] Somewhat surprisingly, Kranich uses raw frequencies, although the normalised numbers are available; however, the curve reproduced here is very similar to the original – the incipient third stage of the S-curve is even brought out more clearly using normalised frequency. [Go back up]
[9] The very low normalised frequencies arise because of the large size of COHA. [Go back up]
[10] While these exceptions should not be given too much weight since absolute frequencies in those three varieties are low, they serve as good examples in our methodological argument. [Go back up]
[11] An alternative approach would be to use simple differences based on logged frequency, since ’[t]he log of a ratio is the difference of the logs of numerator and denominator’ (Tukey 1977: 93); this, however, would entail using the more abstract logged values. [Go back up]
COHA = The Corpus of Historical American English. https://www.english-corpora.org/coha/
ICE = The International Corpus of English. https://www.ice-corpora.uzh.ch/en.html
OSF repository for data and scripts: https://osf.io/2e53v/
Agresti, Alan & Barbara Finlay. 2009. Statistical Methods for the Social Sciences. Upper Saddle River, NJ: Pearson Education.
Bailey, Charles-James N. 1973. Variation and Linguistic Theory. Washington, DC: Center for Applied Linguistics.
Baker, Paul, Andrew Hardie & Tony McEnery. 2006. A Glossary of Corpus Linguistics. Edinburgh: Edinburgh University Press.
Blythe, R.A. & William Croft. 2012. “S-curves and the mechanisms of propagation in language change”. Language 88(2): 269–304.
Chambers, J.K. 1992. “Dialect acquisition”. Language 68(4): 673–705.
Clark, Lynn & Graeme Trousdale. 2009. “Exploring the role of token frequency in phonological change: Evidence from TH-fronting in east-central Scotland”. English Language and Linguistics 13(1): 33–55.
Cleveland, William S. 1985. The Elements of Graphing Data. Monterey, CA: Wadsworth.
Davies, Mark. 2010–. The Corpus of Historical American English: 400 Million Words, 1810–2009. Available online at https://www.english-corpora.org/.
Dehaene, Stanislas. 2003. “The neural basis of the Weber-Fechner law: A logarithmic mental number line”. Trends in Cognitive Science 7(4): 145–147.
Dehaene, Stanislas. 2011. The Number Sense. Oxford: Oxford University Press.
Denison, David. 1999. “Slow, slow, quick, quick, slow: The dance of language change?” Woonderous Ænglissce, ed. by Ana Bringas López, Dolores González Álvarez, Javier Pérez Guerra, Esperanza Rama Martínez & Eduardo Varela Bravo, 51–64. Universidade de Vigo: Servicio de Publicacións.
Denison, David. 2003. “Log(ist)ic and simplistic S-curves”. Motives for Language Change, ed. by Raymond Hickey, 54–70. Cambridge: Cambridge University Press.
Devitt, Amy J. 1989. Standardizing Written English. Diffusion in the Case of Scotland 1520–1659. Cambridge: Cambridge University Press.
Ellegård, Alvar. 1953. The Auxiliary do: The Establishment and Regulation of its Use in English (Gothenburg Studies in English II). Stockholm: Almqvist & Wiksell.
Fechner, Gustav Th. 1860. Elemente der Psychophysik. Leipzig: Breitkopf & Härtel.
Fox, John & Sanford Weisberg. 2011. An R Companion to Applied Regression. Los Angeles: Sage.
Greenbaum, Sidney. 1996. “Introducing ICE”. Comparing English Worldwide. The International Corpus of English, ed. by Sidney Greenbaum, 3–12. Oxford: Clarendon Press.
Hardie, Andrew. 2014. “Log ratio – an informal introduction”. Blog post, ESRC Centre for Corpus Approaches to Social Science (CASS). http://cass.lancs.ac.uk/log-ratio-an-informal-introduction/
Hilpert, Martin. 2011. “Frequencies in diachronic corpora and knowledge of language”. The Changing English Language. Psycholinguistic Perspectives, ed. by Marianne Hundt, Sandra Mollin & Simone E. Pfenninger, 49–68. Cambridge: Cambridge University Press.
Kranich, Svenja. 2010. The Progressive in Modern English. A Corpus-based Study of Grammaticalization and Related Changes. Amsterdam: Rodopi.
Kroch, Anthony S. 1989. “Reflexes of grammar in patterns of language change”. Language Variation and Change 1: 199–244.
Krug, Manfred. 1998. “String frequency: A cognitive motivating factor in coalescence, language processing and linguistic change”. Journal of English Linguistics 26(4): 286–320.
Labov, William. 1994. Principles of Linguistic Change. Vol. 1: Internal Factors. Oxford: Blackwell.
Laming, Donald. 2011. “Fechner’s Law: Where does the log transform come from?” Fechner’s Legacy in Psychology: 150 Years of Elementary Psychophysics, ed. by Joshua A. Solomon, 7–23. Leiden/Boston: Brill.
Lindquist, Hans & Magnus Levin. 2018. Corpus Linguistics and the Description of English. Edinburgh: Edinburgh University Press.
Luke, Douglas A. 2004. Multilevel Modeling. Thousand Oaks, CA: Sage Publications.
McEnery, Tony & Andrew Hardie. 2012. Corpus Linguistics: Method, Theory and Practice. Cambridge: Cambridge University Press.
Moyer, Robert S. & Thomas K. Landauer. 1967. “Time required for judgements of numerical inequality”. Nature 215: 1519–1520.
Osgood, Charles E & Thomas A. Sebeok. 1954. Psycholinguistics – A Survey of Theory and Research Problems. Bloomington, IN: Indiana University Press.
Portugal, R.D. & Benar F. Svaiter. 2011. “Weber-Fechner Law and the optimality of the logarithmic scale”. Minds and Machines 21(1): 73–81.
Rohdenburg, Günter & Julia Schlüter. 2009. “New departures”. One Language, Two Grammars? Differences Between British and American English, ed. by Günter Rohdenburg & Julia Schlüter, 364–423. Cambridge: Cambridge University Press.
Schützler, Ole. 2015. A Sociophonetic Approach to Scottish Standard English. Amsterdam/Philadelphia: John Benjamins.
Schützler, Ole. 2018a. “Grammaticalization and information structure: Two perspectives on diachronic changes of notwithstanding in written American English”. English Language and Linguistics 22(1): 101–122.
Schützler, Ole. 2018b. Concessive Constructions in Varieties of English. Post-doctoral thesis, University of Bamberg.
Schützler, Ole. 2020. “Frequency changes and stylistic levelling of though in diachronic and synchronic varieties of English – linguistic democratisation?” Language Sciences 79: 101266.
Shepard, Roger N., Dan W. Kilpatric & James P. Cunningham. 1975. “The internal representation of numbers”. Cognitive Psychology 7(1): 82–138.
Sönning, Lukas. 2016. “The dot plot: A graphical tool for data analysis and presentation”. A Blend of MaLT. Selected Contributions from the Methods and Linguistic Theories Symposium 2015, ed. by Hanna Christ, Daniel Klenovšak, Lukas Sönning & Valentin Werner, 101–129. Bamberg: University of Bamberg Press.
Stevens, Stanley S. 1961. “To honor Fechner and repeal his law: A power function, not a log function, describes the operating characteristic of a sensory system”. Science 133(3446): 80–86.
Sun, John Z., Grace I. Wang, Vivek K. Goyal & Lav R. Varshney. 2012. “A framework for Bayesian optimality of psychophysical laws”. Journal of Mathematical Psychology 56(6): 495–501.
Tognini-Bonelli, Elena. 2010. “Theoretical overview of the evolution of corpus linguistics”. The Routledge Handbook of Corpus Linguistics, ed. by Anne O’Keefe & Michael McCarthy, 14–27. London/New York: Routledge.
Tukey, John W. 1977. Exploratory Data Analysis. Reading, MA: Addison-Wesley Publishing Company.
Varshney, Lav R. & John Z. Sun. 2013. “Why do we perceive logarithmically?” Significance 10(1): 28–31. doi:10.1111/j.1740-9713.2013.00636.x
Wallis, Sean & Seth Mehl. 2022. “Comparing baselines for corpus analysis: Research into the get-passive in speech and writing”. Data and Methods in Corpus Linguistics – Comparative Approaches, ed. by Ole Schützler & Julia Schlüter, 101–126. Cambridge: Cambridge University Press.
Weber, Ernst H. 1851. Die Lehre vom Tastsinne und Gemeingefühle auf Versuche gegründet. Braunschweig: Friedrich Vieweg & Sohn.
Weinreich, Uriel, William Labov & Marvin I. Herzog. 1968. “Empirical foundations for a theory of language change”. Directions for Historical Linguistics, ed. by W.P. Lehman & Yakov Malkiel, 95–188. Austin: University of Texas Press.
Weisser, Martin. 2016. Practical Corpus Linguistics: An Introduction to Corpus-based Language Analysis. Malden, MA: Wiley-Blackwell.
Wilke, Claus O. 2019. Fundamentals of Data Visualization: A Primer on Making Informative and Compelling Figures. Sebastopol, CA: O’Reilly.

University of Helsinki