ARCHER 3.2
Structure
Makeup
ARCHER is a multi-genre historical corpus of British and American English. In ARCHER 3.2 the British variety ranges continuously from 1650 to 1999 in all except two genres, and three genres start in the 1600-49 period. The American variety starts in 1750. Altogether it contains ca. 3.3 million words in 1,710 text files, distributed as ca. 2 million words in 1,075 British files and ca. 1.3 million words in 635 American files, as shown in Appendix I.
The structure of ARCHER 3.2 is as follows:
- Twelve genres: a = advertising, d = drama, f = fiction, h = sermons, j = journals, l = legal, m = medicine, n = news, p = early prose, s = science, x = letters, y = diaries
- Eight periods: 1 = 1600-49, 2 = 1650-99, 3 = 1700-49, 4 = 1750-99, 5 = 1800-49, 6 = 1850-99, 7 = 1900-49, 8 = 1950-99
- Two varieties: b = British, a = American
Notes:
- One of the new features of the ARCHER 3.2 version is the split of the former single genre journals-diaries into two separate genres, journals (j) and diaries (y), under the supervision of Nuria Yáñez-Bouza at Manchester. Following the original design of the corpus, the defining criterion for the classification of the materials in ARCHER 3.2 is topic and purpose of the text: diaries record private matters, domestic affairs, everyday activities and routines; journals report on a journey or a task associated with travel (including sea travel and war campaigns) and with political matters. In ARCHER 3.2 there are 122 diaries and 122 journals, of which 105 are travel journals and 17 are political journals. (See further Yáñez-Bouza ms, 2013.)
- ‘Early prose’ (p) is a special genre classification which currently includes fiction and non‑fiction texts.
- The other new genres are advertising (a) and legal texts (l). These result partly from restoring materials from version 2 and partly from the compilation of new materials. (See the illustrative table in the section Distribution of work below.)
- Some new letters included in version 3.2 are from writers who are not published authors.
- Period 1 (1600–49) is only available in three genres, namely drama, legal texts, early prose. (We plan to expand the diachronic coverage in other genres in forthcoming versions.)
The distribution of British and American English texts classified by genre and period is displayed below and can be downloaded in PDF format here and in spreadsheet form here. The distribution of words and files in the new material only can be viewed here (PDF file).
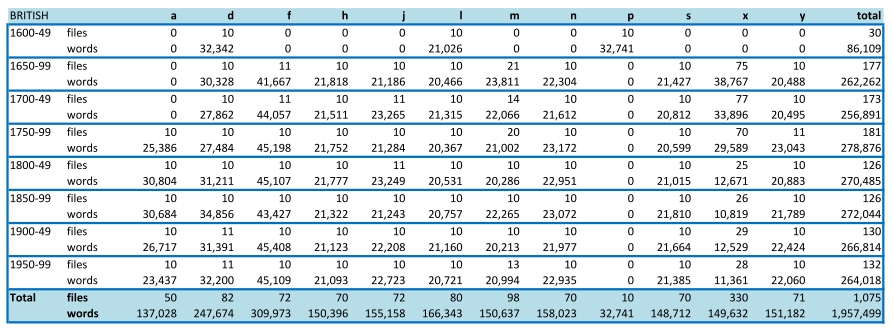
Image 2. British
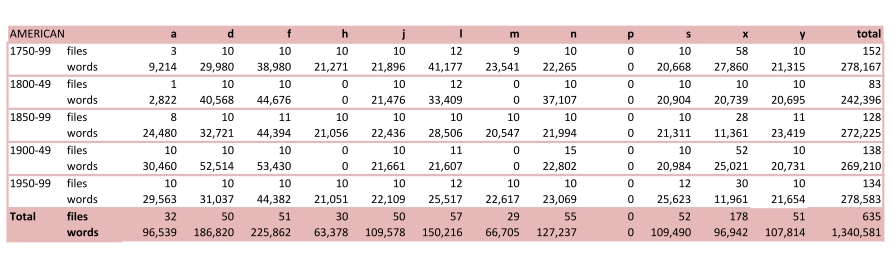
Image 3. American
The image below offers a graphic comparison of the distribution of words and files in ARCHER 3.2 (2013) and ARCHER 3.1 (2006), and the poster offers a summary of the development of ARCHER throughout its different versions (based on the poster presented by Nuria Yáñez-Bouza at ICAME 32 and now updated to October 2013).
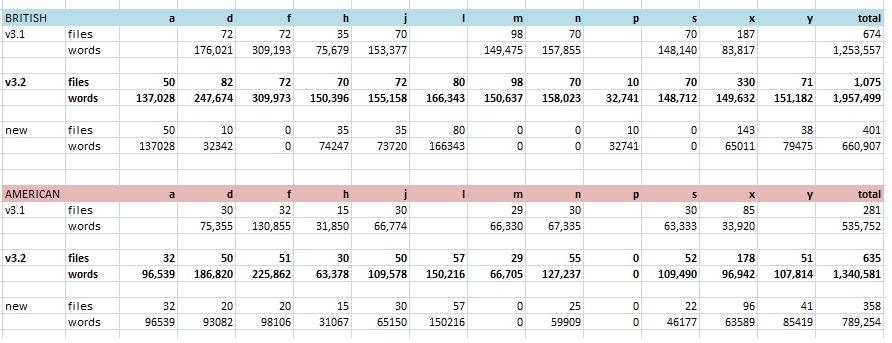
Image 4. Archer 3.1. - 3.2.
Archer poster here.
File names
All filenames in ARCHER 3.2, old and new, follow the formula nnnnabcd_gpv with 8+underscore+3 characters, always in lower case, where
- nnnn = year
- abcd = author abbreviation
- g = genre (a = advertising, d = drama, f = fiction, h = sermons, j = journals, l = legal, m = medicine, n = news, p = early prose, s = science, x = letters, y = diaries)
- p = period (1 = 1600–49, 2 = 1650–99, 3 = 1700–49, 4 = 1750–99, 5 = 1800–49, 6 = 1850–99, 7 = 1900–49, 8 = 1950–99)
- v = variety (b = British, a = American)
For example, the file 1653osbn_x2b is a text written in 1653 by Dorothy Osborne, is a letter (x), belongs to the period 1650-99 (2), and is British (b).
The table below displays the correspondence between the extensions representing period and variety in ARCHER 3.2 and ARCHER 3.1 in comparison with the earlier versions ARCHER 1 and ARCHER 2.
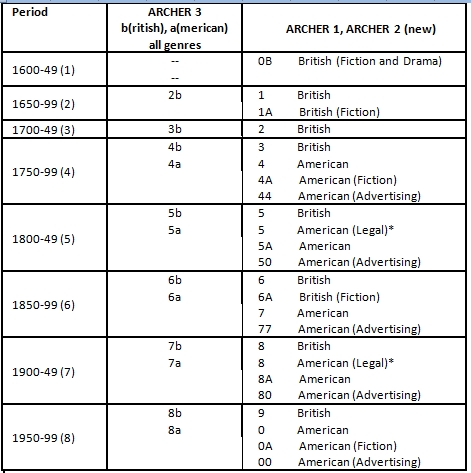
Image 5. Extensions
In ARCHER 3.2, when the precise year of the sample text is unknown the formula is completed with x or xx (e.g. nnnxabcd_gpv or nnxxabcd_gpv), and the value of p in the extension will tell us the subperiod to which it belongs; for instance, the file 17xxarch_h4b is a sermon (h) of unknown date (17xx) but written within period 4 (1750–99).
The author abbreviation (abcd) usually consists of the first four letters of the surname, padded out with hyphens if too short (e.g. 1697pix-_d2b for Mary Pix).
Anonymous files may be abbreviated with ‘anon’ (e.g. 1735anon_m3b) or with a shortened form from the title (e.g. 1653merc_n2b from the newspaper Mercurius Politicus). When there is more than one author or more than one excerpt in the same file, the abbreviation is usually taken from the first author/excerpt, e.g. 1985dupo_m8a is a scientific text written by William D. Dupont and David L. Page.
The same author should always have the same four-character abbreviation across sample texts, genres and periods (e.g. 1730fiel_d3b and 1743fiel_f3b for Henry Fielding’s drama and fiction samples, respectively). However, when there is more than one sample from the same year the fourth character becomes a numeral, as in 1666cavn_x2b and 1666cav2_f2b for Mary Cavendish’s letter and fiction samples respectively. Note, however, that the reverse implication does not hold: the abbreviation ‘hart’, for instance, represents numerous different authors, e.g. Bret Harte in 1894hart_x6a, H. Hart in 1872hart_j6b, Anonymous in 1957hart_l8a.
A complete file list with mapping to filenames used in ARCHER 1, ARCHER 2 and ARCHER 3.1 is provided in the ARCHER database, available on request to Nuria Yáñez-Bouza.
Spelling and punctuation
All dashes appear as a double hyphen surrounded by a space at each side -- like this -- unless at start or end of line. This clearly differentiates punctuation from the hyphen. Hyphens do not appear as the last character of any line: the second element is taken back from the next line and the whole thing made into either a single unbroken word or a hyphenated word.
Character encoding in the XML version is Unicode (UTF-8), while the text version is encoded in Latin-1. The exceptions in the XML version are the ampersand (&), apostrophe and single quotes ('), double quotes (") and angle brackets (<>). All accented letters, pound signs and other symbols display as that character in both XML and text versions. A list of non-ASCII characters that appear in ARCHER is available from the Documentation page on the ARCHER website.
ARCHER is essentially an original-spelling corpus, albeit the spelling of published editions. All versions share the same text and bibliographic and non-linguistic mark-up, but future online versions at Lancaster and at Zurich will differ in their linguistic mark-up.
Word counts
The word count provided in the TEI-header is an accurate word count of the actual text – that is, of everything in the file which is not enclosed in <…> brackets. That means that no header material is counted, nor the comments from the compilers now enclosed also in XML-tags. It also means that stage directions and speaker names – used in some drama and fiction texts – are not counted. Hyphenated words are counted as one item, as are all items other than punctuation surrounded by white space.
A typical word count per individual text is 2,000–2,500 words: although short by modern corpus standards, it is close to the existing average in ARCHER and so will not make new genres unbalanced. The exceptions to this word limit are fiction (with some texts reaching over 5,000 words), letters (with texts as small as 108 words) and British medical prose (with approximately sixty per cent of the texts below 1,800 words). If a particular file contains two or more excerpts, the total word count is provided in the header; in some cases word counts for individual excerpts are also given.
The Perl script used to count ‘words’ was produced by Sebastian Hoffmann (2013) and a full list of every ‘word’ in the corpus and its frequency is available from the Documentation page on the ARCHER website. Tables displaying the total distribution of British and American English texts and words classified by genre and period are available for download here and in spreadsheet form here; the word counts refer to the XML and plain text versions.
The online version uses the program CQPweb. It will soon be provided with part-of-speech tags in the CLAWS-6 tagset. The tagging process requires the text to be tokenized (in the same way as the British National Corpus in BNCweb), which means inter alia that each piece of punctuation counts as a token, while forms like don’t and he’ll are presented as do n’t and he ’ll and each counted accordingly as two words. Even the untagged version will have some tokenisation. The word counts in CQPweb are therefore different from those described above, typically coming in around 15% higher. However, the tokenized word counts are those appropriate for the statistics available in CQPweb.
Headers
All headers in the XML version contain the four major TEI elements: file description (including the current filename in the form nnnnabcd_gpv and full bibliographic information on the source text and edition used), encoding description (including any specific notes by the ARCHER compiler), profile description (with a description of non-bibliographic aspects), and revision history. Other annotations in the TEI-header may relate to footnotes and the use of italics; for instance ‘Footnotes in the original omitted’ or ‘Italics ignored, except for stress and contrast’. We have attempted to mark speakers in fiction and characters in drama consistently. Bibliographic information has been revised, enlarged and regularised.
A shortened header with filename, word count and source edition will be provided in the text file version.
Two samples of TEI-headers are given below: from a nineteenth-century American journal and from a twentieth-century British letter.
Sample I: American journal, file 1805clar_j5a
<?xml version="1.0" encoding="UTF-8"?>
<teiHeader>
<fileDesc>
<titleStmt>
<idno type="filename">1805clar_j5a</idno>
<author>Clark, William</author>
<sex value="1">male</sex>
</titleStmt>
<sourceStmt>
<date>1805</date>
<title type="sub">Chapter 19: Downstream Toward the Coast.</title>
<bibl>The Journals of the Lewis and Clark. American Studies at the University of Virginia (1997-98).</bibl>
<p>http://xroads.virginia.edu/~HYPER/JOURNALS/lewis6.html#chpt19</p>
</sourceStmt>
<publicationStmt>
<authority>ARCHER consortium</authority>
<availability status="restricted">
<p>Users must agree to the access conditions stated in the User Agreement Form.</p>
<p>ARCHER shall be used only for non-profit research and for no other purpose whatsoever. Apart from the data (examples) drawn from the corpus, the ARCHER 3.2 corpus files may not be reproduced in part or in whole in any format whatsoever, including, but not limited to, electronic disk copies, network copies, or paper copies. The "data (examples)" herein refers to the extracts of text illustrative of the research question studied, drawn from the corpus files. The material drawn from ARCHER, whether printed, in electronic, or any other form, is intended for the said registered user only and may not be distributed, or transferred to a third party.</p>
</availability>
<date>2013</date>
</publicationStmt>
<editionStmt>
<respStmt>
<resp key="editor">original editor</resp>
</respStmt>
</editionStmt>
<extent>
<measure quantity="2248" unit="words" />
</extent>
</fileDesc>
<encodingDesc>
<samplingDecl>
<respStmt>
<resp key="compiler">Bamberg</resp>
</respStmt>
<notesStmt>
<note>
<p>Original italics retained if for emphasis or marking foreign expressions or indicating direct speech; any others ignored.</p>
</note>
</notesStmt>
</samplingDecl>
<editorialDecl>
<hyphenation>
<p>A double hyphen is used to represent the punctuation mark dash, with one space to left and right -- like this -- unless at start or end of line.</p>
</hyphenation>
</editorialDecl>
<classDecl>
<taxonomy type="Genre">
<category xml:id="g_j">
<catDesc>Journal</catDesc>
</category>
</taxonomy>
<taxonomy type="Period">
<category xml:id="p_5">
<catDesc>1800-1849</catDesc>
</category>
</taxonomy>
<taxonomy type="Variety">
<category xml:id="v_a">
<catDesc>American</catDesc>
</category>
</taxonomy>
<taxonomy type="Version">
<category xml:id="v3_2">
<catDesc>ARCHER 3.2 (2013)</catDesc>
</category>
</taxonomy>
</classDecl>
</encodingDesc>
<profileDesc>
<langUsage>
<language ident="en-US">American English</language>
</langUsage>
<textClass>
<catRef target="#j #5 #a" />
</textClass>
</profileDesc>
<revisionDesc>
<change n="3_2">Filename in v3_2 is 1805clar_j5a</change>
</revisionDesc>
</teiHeader>
Sample II: British letter, file 1950nicl_x8b
<?xml version="1.0" encoding="UTF-8"?>
<teiHeader>
<fileDesc>
<titleStmt>
<idno type="filename">1950nicl_x8b</idno>
<author>Nicolson, Harold</author>
<sex value="1">male</sex>
</titleStmt>
<sourceStmt>
<date>1950</date>
<title type="sub">To Vita Sackville-West, wife.</title>
<bibl>Harold Nicolson: The later years, 1945-1962. Volume III of diaries and letters. 1968. Nigel Nicolson (ed.). New York: Atheneum. pp. 188-189.</bibl>
</sourceStmt>
<publicationStmt>
<authority>ARCHER consortium</authority>
<availability status="restricted">
<p>Users must agree to the access conditions stated in the User Agreement Form.</p>
<p>ARCHER shall be used only for non-profit research and for no other purpose whatsoever. Apart from the data (examples) drawn from the corpus, the ARCHER 3.2 corpus files may not be reproduced in part or in whole in any format whatsoever, including, but not limited to, electronic disk copies, network copies, or paper copies. The "data (examples)" herein refers to the extracts of text illustrative of the research question studied, drawn from the corpus files. The material drawn from ARCHER, whether printed, in electronic, or any other form, is intended for the said registered user only and may not be distributed, or transferred to a third party.</p>
</availability>
<date>2013</date>
</publicationStmt>
<editionStmt>
<respStmt>
<resp key="editor">original editor</resp>
</respStmt>
</editionStmt>
<extent>
<measure quantity="473" unit="words" />
</extent>
</fileDesc>
<encodingDesc>
<samplingDecl>
<respStmt>
<resp key="compiler">NAU&USC</resp>
</respStmt>
</samplingDecl>
<editorialDecl>
<hyphenation>
<p>A double hyphen is used to represent the punctuation mark dash, with one space to left and right -- like this -- unless at start or end of line.</p>
</hyphenation>
</editorialDecl>
<classDecl>
<taxonomy type="Genre">
<category xml:id="g_x">
<catDesc>Letters</catDesc>
</category>
</taxonomy>
<taxonomy type="Period">
<category xml:id="p_8">
<catDesc>1950-1999</catDesc>
</category>
</taxonomy>
<taxonomy type="Variety">
<category xml:id="v_b">
<catDesc>British</catDesc>
</category>
</taxonomy>
<taxonomy type="Version">
<category xml:id="v1">
<catDesc>ARCHER 1 (1992-93)</catDesc>
</category>
</taxonomy>
<taxonomy type="Version">
<category xml:id="v2">
<catDesc>ARCHER 2 (2004-05)</catDesc>
</category>
</taxonomy>
<taxonomy type="Version">
<category xml:id="v3_1">
<catDesc>ARCHER 3.1 (2006)</catDesc>
</category>
</taxonomy>
<taxonomy type="Version">
<category xml:id="v3_2">
<catDesc>ARCHER 3.2 (2013)</catDesc>
</category>
</taxonomy>
</classDecl>
</encodingDesc>
<profileDesc>
<langUsage>
<language ident="en-GB">British English</language>
</langUsage>
<textClass>
<catRef target="#x #8 #b" />
</textClass>
<particDesc>
<listPerson>
<person xml:id="Sackville-West, Vita" role="Addressee">
<persName>Sackville-West, Vita</persName>
<sex value="2">female</sex>
</person>
</listPerson>
</particDesc>
</profileDesc>
<revisionDesc>
<change n="1_2">Filename in v1 and v2 is 1950Nicl.X9</change>
<change n="3_1">Filename in v3_1 is 1950nicl.x8b</change>
<change n="3_2">Filename in v3_2 is 1950nicl_x8b</change>
</revisionDesc>
</teiHeader>
|
|
