Background
A brief history of ARCHER
Versions
ARCHER (A Representative Corpus of Historical English Registers) is a multi-genre historical corpus of British and American English covering the period 1600–1999. The corpus has been designed as a tool for the analysis of language change and variation in a range of written and speech-based registers of English, setting the target sampling at 10 texts of approximately 2,000 words per genre and variety in each 50-year period.
ARCHER was originally constructed by Douglas Biber and Edward Finegan in the early 1990s at the universities of Northern Arizona and Southern California. Since 2000 it has been managed as an ongoing project by a consortium of participants at various universities in the US and in Europe. Since December 2008 it has been coordinated from Manchester (UK) and the consortium currently includes participants at fourteen universities in seven countries. (See below.)
The corpus exists in four major versions: ARCHER 1 (1992–93), ARCHER 2 (2004–05), ARCHER 3.1 (2006) and ARCHER 3.2 (2013).
The earliest version of ARCHER, henceforth referred to as ARCHER 1, was compiled in the period 1990-1993 by Douglas Biber and Edward Finegan at the universities of Northern Arizona and Southern California. It contained ten major genre categories grouped in fifty-year periods from 1650 to 1990. ARCHER 1 consisted of 1,037 files and ca. 1.7 million words, as described by Biber et al. (1994a, 1994b) and Biber & Finegan (1997: 255–7). Appendix I displays the data of a later, slightly different version of ARCHER 1 as held at Manchester in 2005 (e.g. more words, fewer texts, one single genre for fiction dialogue and fiction narrative).
The second version of the corpus, known as ARCHER 2, started in 2000 when the ARCHER consortium was founded with Uppsala, Helsinki and Freiburg. ARCHER 2 was completed at the University of Helsinki in 2004 under the supervision of Merja Kytö (now at Uppsala). New texts were compiled primarily with a view to filling the gaps in the coverage of the American variety. It comprised ARCHER 1 in its entirety plus ca.394,000 words from 92 new American texts and 20 British texts, adding up to 1,074 files and ca. 2.3 million words altogether. The major innovations were the addition of early drama and early prose in the period 1600–49, and the addition of American advertising covering the periods from 1750 to 1990; with advertising, the total number of registers increased to eleven. Appendix II displays the distribution of the new data in this version.
The version resulting from the third phase of the project is known as ARCHER 3.1. The phase began in 2004 under the co-ordination of Heidelberg with Marianne Hundt (now at Zurich) and Nadja Nesselhauf. ARCHER 3.1 was completed in summer 2006 and comprised ca. 1.8 million words from a total of 955 files – ca. 1.2 million words from 674 British files and over half a million words from 281 American files, as shown in Appendix III. Amongst other values, it incorporated a partial clean-up and correction of many files and deletion of duplicate files; word counts were consistently calculated with a Perl script; it introduced a new labelling system for filenames and a suggested protocol for future compilation of texts. See more details about this version in the section ARCHER 3.1.
The fourth version of the corpus is known as ARCHER 3.2 (2013) and has been co-ordinated from Manchester by David Denison and Nuria Yáñez-Bouza since 2008. This new version has improved in size (more than doubled), text type coverage (four more genres), regional coverage (especially the American variety) and mark-up (now TEI/xml-conformant and soon with new POS-tagging). Textual accuracy and consistency in the provision of bibliographic information has also been improved. Altogether, ARCHER 3.2 adds up to ca. 3.3 million words and 1,710 files; that is ca. 2 million words in 1,075 files of British English and ca. 1.3 million words in 635 files of American English, as shown in Appendix IV below. Appendix V displays the distribution of the new data only. See more details about this version in the section ARCHER 3.2 below.
We are currently working towards ARCHER 3.3. The phase 2014–2016 is co-ordinated from Manchester by David Denison and Nuria Yáñez-Bouza.
Appendices
The links below will open a PDF file with the breakdown of the number of words and files by version, variety, period and genre. The image that follows the links offers a visual summary. See also the ARCHER poster based on the poster presented at ICAME 32 (2011) by Nuria Yáñez-Bouza and now updated to October 2013 (PDF). For a more detail account, see Yáñez-Bouza (2011).
Appendix I. ARCHER-1 number of files and words in each category (PDF)
NB. This table displays the data according to the version held at Manchester in 2005
Appendix II. ARCHER-2 number of new files and words in each category (PDF)
Appendix III. ARCHER 3.1 number of files and words in each category (PDF)
Appendix IV. ARCHER 3.2 number of files and words in each category (PDF)
Appendix V. ARCHER 3.2 number of new and restored files and words in each category (PDF)
Appendix VI. ARCHER poster (updated in October 2013, PDF)
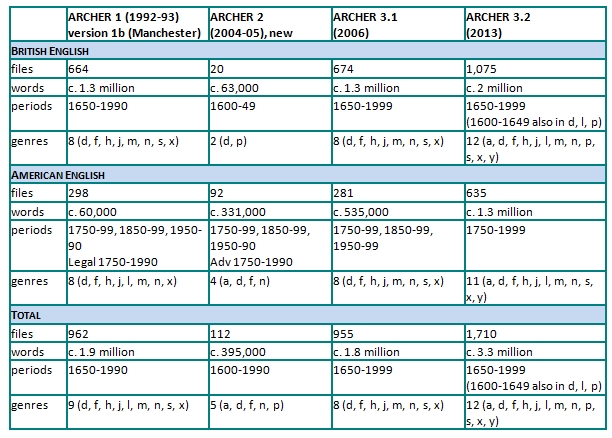
Image 1. Versions
Funding
Members of the ARCHER consortium would like to thank the various institutions which have financially or otherwise supported the development of ARCHER over the years.
References and bibliography
How to cite ARCHER
Publications making use of ARCHER shall include a reference to the name of the corpus, the years of compilation, and the compiler team. A suitable bibliographic listing is as follows (with ‘x’ replaced as appropriate):
ARCHER-X = A Representative Corpus of Historical English Registers version X. 1990–1993/2002/2007/2010/2013/2016. Originally compiled under the supervision of Douglas Biber and Edward Finegan at Northern Arizona University and University of Southern California; modified and expanded by subsequent members of a consortium of universities. Current member universities are Bamberg, Freiburg, Heidelberg, Helsinki, Lancaster, Leicester, Manchester, Michigan, Northern Arizona, Santiago de Compostela, Southern California, Trier, Uppsala, Zurich. Examples of usage taken from ARCHER were obtained under the terms of the ARCHER User Agreement.
We recommend that individual citations from ARCHER should include the text identifier (filename), e.g. “1722grah_s3b”. The ARCHER version used should be acknowledged with the citation or globally in the bibliography. For examples retrieved at the consortium departments this will be ARCHER 3.2 / 3.1 / 2 / 1, as appropriate; for examples retrieved from the online versions it will be ARCHER 3.2 (Lancaster) or ARCHER 3.2 (Zurich), as appropriate.
Reference works on ARCHER
ARCHER website. http://www.manchester.ac.uk/archer.
Biber, Douglas, Edward Finegan & Dwight Atkinson. 1994. ARCHER and its challenges: Compiling and exploring A Representative Corpus of Historical English Registers. In Udo Fries, Peter Schneider & Gunnel Tottie (eds.), Creating and using English language corpora. Papers from the 14th International Conference on English Language Research on Computerized Corpora, Zurich 1993, 1–13. Amsterdam: Rodopi.
Biber, Douglas, Edward Finegan, Dwight Atkinson, Ann Beck, Dennis Burges & Jene Burges. 1994. The design and analysis of the ARCHER corpus: A progress report [A Representative Corpus of Historical English Registers]. In Merja Kytö, Matti Rissanen & Susan Wright (eds.), Corpora across the centuries: Proceedings of the First International Colloquium on English Diachronic Corpora, St Catharine's College Cambridge, 25-27 March 1993 (Language and Computers. Studies in Practical Linguistics 11), 3–6. Amsterdam & Atlanta: Rodopi.
Hardie, Andrew. 2012. CQPweb - combining power, flexibility and usability in a corpus analysis tool. International Journal of Corpus Linguistics 17.3, 380-–409. [This paper is not on ARCHER, but it is the standard reference for the web search tool used by ARCHER online]
López-Couso, María José & Belén Méndez-Naya. 2012. Compiling British English legal texts: A contribution to ARCHER. In Nila Vázquez González (ed.) Creation and use of historical English corpora in Spain, 1–15. Newcastle upon Tyne: Cambridge Scholars Publishing.
Yáñez-Bouza, Nuria. 2011a. ARCHER past and present (1990–2010). ICAME Journal 35, 205-236.
Yáñez-Bouza, Nuria. 2011b. ARCHER past and present (1990–2011). Poster presented at the 32nd Conference of the International Computer Archive of Modern and Medieval English (ICAME 32), Oslo, 1-5 June 2011.Poster. Now updated to October 2013.
Yáñez-Bouza, Nuria. 2012. Diaries and/vs journals in ARCHER. Paper presented at the ARCHER symposium, 30 March 2012. The University of Manchester, Manchester.
Yáñez-Bouza, Nuria. ms, 2013. ‘Have you ever written a diary or a journal?’ Modes of diurnal narrative and register variation.
Bibliography
For a list of publications that have made use of ARCHER at one of the participating departments, please visit the Publications page on the project website.
Please keep us informed of research publications, presentations and projects which have made use of ARCHER. Send details in an email to archer@manchester.ac.uk with the subject header 'ARCHER publications'.
|
