Basic structure
The composition of the corpus, like those of Brown and LOB, is as follows:
- The corpus consists of 500 text samples
- Each of the text samples consists of 2000 words, or a little more (ending at the first sentence break after the 2000th word)
- The text samples are grouped into 15 genre categories:
Table 1. Text genres in The BLOB-1931 Corpus.
Subcorpora |
Genre categories |
No. of texts |
Press |
A. press reports |
44 |
B. press editorial |
27 |
C. press reviews |
17 |
General prose |
D. religion |
17 |
E. skills, trades, hobbies |
38 |
F. popular lore |
44 |
G. biography and essays |
77 |
H. miscellaneous |
30 |
Learned, Academic |
J. learned |
80 |
Fiction |
K. general fiction |
29 |
L. adventure fiction |
24 |
M. science fiction |
6 |
N. mystery fiction |
29 |
P. romance and love story |
29 |
R. humour |
9 |
- Most genre categories are subdivided into sub-genre sections. For example, category J is subdivided into Natural Sciences, Medicine, Mathematics, Social and Behavioural Sciences, Political Science/Law/Education, Humanities, and Technology/Engineering. See the LOB Corpus manual (Johansson et al. 1978) for a detailed breakdown within each text category.
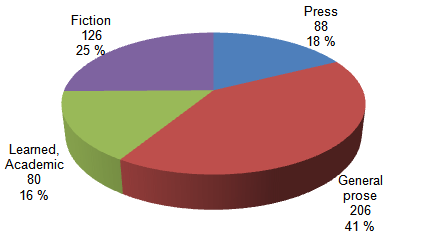
Figure 1. Number of texts in B-LOB subcorpora.
Sampling
As in the case of the LOB Corpus, the sampling frame was set by two bibliographical compilations for the years 1928-1934: the British National Bibliography Cumulative Index (for non-periodical publications), and Willings Press Guide (for periodical publications – but see the qualifications in the next paragraph).
Given the numbers and categories of texts in the above table, the selection of texts followed the principle that comparability with LOB and F-LOB was the most important criterion of choice: thus if possible, samples from periodicals were chosen from the same periodical publication sampled in 1961 and 1991. The original selection of periodicals in LOB was based on random sampling from Willings Press Guide, 1961 edition. In this respect comparability with LOB/F-LOB overrides the concern for representativeness in 1928-34 – for discussion see Leech and Smith (2005).
The second most important criterion was that there should be no influence of the compilers’ personal judgement in the selection of texts. Hence random sampling was used where possible. However, the difficulty of finding texts published in the 1928-34 period fitting the genre categories and subcategories was such that a further principle sometimes obtained: that the first text found matching the criteria of selection be accepted for inclusion in the corpus. This was particularly the case with categories (e.g. M science fiction) where only a small number of texts matching the genre could be found in the 1928-34 period.
The ideal sampling frame would have been one in which all publications came from the same year, 1931, such that LOB (1961) would be equidistant in time between F-LOB and BLOB-1931. However, in practice it would have been impossible to obtain texts from one single year, and the period 1931±3 was chosen as a reasonable though less-than-ideal solution.
Regarding the selection of pages for sampling, as far as possible we used random or pseudo-random methods (e.g. a random number generator) to determine the page at which to start sampling. However, sometimes practical constraints prevented fully random sampling: for example, we avoided pages in which the contents appeared to deviate from the genre category of the LOB and F-LOB corpora (even though the publication title might remain unchanged), and pages that were difficult to photocopy or scan (e.g. those in the middle of tightly bound newspapers).
|
