Basic structure
The corpus is an indispensable and unique collection of continuous free dialect speech. It helps us ascertain
the real frequencies of certain features that have traditionally been considered typical of dialects. It
further enables us to consider the spread and contexts of these features. Furthermore, synchronic study of dialectal variation
might suggest distinctions that are not distinguishable from the somewhat fragmentary historical data.
The recordings were made in the 1970s and the 1980s by Finnish postgraduates, advised in this work by Professor Harold Orton and
other Leeds scholars. The fieldwork done in the 1970s was supervised by Tauno F. Mustanoja at the University of Helsinki. The aim was
to create a computer corpus consisting of enough continuous speech to provide material for the study of dialectal morphosyntax and
thus to supplement the Leeds Survey of English Dialects, which focuses mainly on phonological and lexical data.
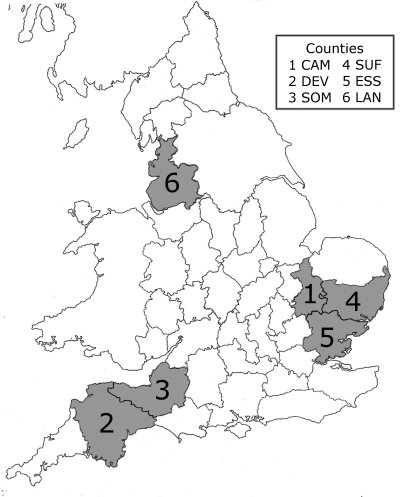
Map 1. Map of regions visited by the fieldworkers.
Table 1. Geographical regions covered in the corpus.
The number in the brackets denotes the number of secondary informants (primary informant =
sole speaker in a session or speaker of more than 500 words; secondary speaker = speaker
with less than 500 words in a session with more than one informant).
| Region (rural) |
No of villages |
No of informants |
| CAMBRIDGESHIRE |
26 |
38 (+ 6) |
| DEVON |
9 |
33 (+ 8) |
| ISLE OF ELY |
20 |
52 (+ 6) |
| SOMERSET |
15 |
24 (+ 5) |
| SUFFOLK |
16 |
47 (+ 4) |
| Region (urban) |
|
|
| ESSEX |
3 |
6 (+ 1) |
| LANCASHIRE |
3 |
6 (+ 1) |
| Total |
92 |
206 (+ 31) |
Recorded material
The fieldworkers found their informants, both men and women, with the help of locals. The fieldworkers went from
village to village on foot, by bicycle or by bus, carrying equipment weighing an average of 15 kilograms. The whole package included
the recorder itself, a bag of reels, a microphone, batteries, power outlet adapters, correction tape, cables, fuse, etc. (Figure 1).

Figure 1. Recording equipment. (Click to enlarge.)

Figure 2. Fieldworker's early transcription notes. (Click to enlarge.)
Some 210 hours of these recordings are now stored in digital form. The majority of the recordings have
been transcribed by the fieldworkers themselves. Most of the recorded material has been donated to the English Department of the Helsinki University.
Working the corpus material into a computer corpus was an idea introduced by Professor Ossi
Ihalainen in the 1980s. The project was integrated into VARIENG in 2000, under the coordination of
Kirsti Peitsara. The texts have been transcribed orthographically, with only minor changes to show
dialectal pronunciation. The nearly one-million-word corpus today includes speech from 237
informants recorded in 92 localities in six counties.
Sociolinguistic coverage
At the time of the interview in the 1970s and 1980s most of the male and female rural
informants were retired and in their mid 70s or older, having thus received their education
during the first decade of the 20th century. The Essex and Lancashire urban corpora, collected
in the late 1980s, differ from the above in giving three-generation two-sex samples, with informants
ranging from 19 to 70 years.
Most of the subcorpora have a high proportion of males as primary informants; the Devon corpus
has no females as primary speakers, and female speech covers circa one fifth in the Cambridgeshire,
Isle of Ely and Suffolk corpora. This reflects the traditional idea of males as best preservers of
genuine dialect, which was inherited from the SED model. An exception is made by the Essex and
Lancashire subcorpora, in which the proportion of female speech is considerably greater, owing to the
sociolinguistic theories being introduced to dialectology.
Table 2. Subcorpora word counts. Total WC indicates the number
of words in the entire corpus, including interviewers' speech, preface text and prosodic expressions.
Stripped WC is the number of words spoken by the informant only.
| Region (rural) |
Total WC/WordCruncher |
Stripped WC |
| CAMBRIDGESHIRE |
239206 |
190462 |
| DEVON |
87022 |
73350 |
| ISLE OF ELY |
140037 |
136944 |
| SOMERSET |
168211 |
132471 |
| SUFFOLK |
253270 |
218627 |
| Region (urban) |
|
|
| ESSEX |
58394 |
45930 |
| LANCASHIRE |
62501 |
48365 |
| Total |
1008641 |
846149 |
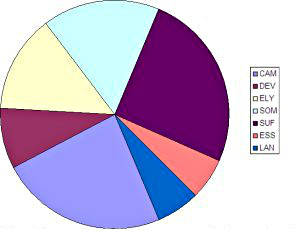
Figure 3. Relative proportions of the seven regions by word count.
|


{kind=link}