Parameters
and annotation
Each text is preceded by a text header which contains the text ID as well as information on the dialect area, county and location where the conversation took place (i.e. where the speaker came from), the available sociolinguistic information, and the date of the interview. The reason for adding a separate tag for 'recording decade' and 'decade of birth' is that, in various cases, the exact recording date of the interview and/or year of birth of the speaker is not known. Information is given where available; otherwise, the value is empty.
The figure below shows the beginning of an interview with two informants from Swarland, Northumberland, in 1974.
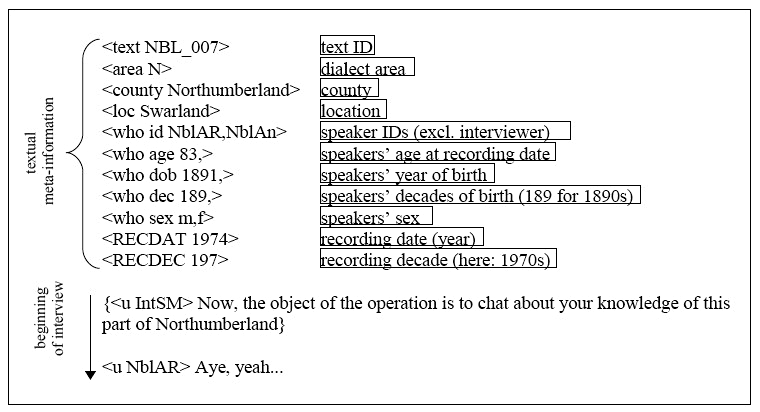
Figure 1. Header and first lines of a FRED-S interview
The sound files and transcripts in FRED are not aligned, nor POS-tagged or syntactically parsed.
FRED is an orthographically transcribed corpus. The decision in favour of orthographic transcripts was made for a number of reasons, the most important being the research group's predominant interest in morphosyntactic features. A consistent markup was applied to both the texts transcribed at Freiburg University and pre-existing transcripts from other sources. Please consult the FRED and FRED-S manuals for a detailed description of the text format, bracket types, text headers, tags and general orthographic transcription guidelines, and the rendering of nonstandard pronunciations. |
